Just-in-Time Data Structures
Oliver Kennedy
okennedy@buffalo.edu
 |
 |
 |
 |
 |
| Saurav Singhi | Darshana Balakrishnan | Hank Lin | Ankur Upadhyay | Lukasz Ziarek |
| (PhD In Progress) | (MS In Progress) | (BS 2017) | (MS 2014) | (Prof @ UB) |
With support from NSF Awards IIS-1617586 and CNS-1629791

What is best in life?
(for organizing your data)
API
Insert $\lt key, value\gt$
Query for $key \in [low, high)$
Available Structures
Binary Tree, Linked List, Sorted Array

You guessed wrong!
(unless you didn't)
Other Tradeoffs
- Support for Threads
- Lookup vs Full Scan vs Range Scan
- Optimal Update Size
Interactive Analytics
- User Opens CSV File
- User Poses Query as File Loads
- Lots More Queries
- User Adds More Data
Even in a single session, there may be more than one "optimal" data structure.
State of the Art

 ➔
➔

- Jack of All Trads Datastructures (e.g., B+ Tree, LSM Tree)
- Keep re-building structures for different workloads(e.g., DROP INDEX ➔ LOAD TABLE ➔ CREATE INDEX)
- Bespoke data structures(e.g., KD+R*++#N-Tree; Author et.al. SIGMOD 2023)
No way to gracefully transition between different tradeoffs.
- What does it mean for a data structure to be halfway between a Binary Tree and a Linked List?
- How would we access and manipulate such a data structure?
- When and how should a data structure transition?
- How do we automatically generate bespoke data-structures?
Incremental Structure Transitions
- A Universal Instance Language
- Realizing Universal Data Structures
- Just-In-Time Data Structure Optimization
- Optimization Policy Discovery
Logical Content
↑
Physical Structure
A Bag of $\lt Key \rightarrow Value \gt$ Pairs
↑
One Physical Realization of the Bag
Primitives
- A Key ($\mathbb K$)Any ordered set
- A Record ($\mathbb R$)A key/value pair
- A Pointer ($\mathbb P$)Logically a bag of records
Grammar
\begin{align} \mathbb P :=\; &|\;Sng(\mathbb R) \\ &|\uplus(\mathbb P, \mathbb P) \\ &|\;BT_{\mathbb K}(\mathbb P, \mathbb P) \\ &|\;Array_N(\mathbb R \ldots \mathbb R) \\ &|\;Sorted_N(\mathbb R \ldots \mathbb R) \end{align}
Singleton
| Visual: |  |
| UIL: | $Sng(x: \mathbb R)$ |
| Logical: | $\{ x \}$ |
Union Node
| Visual: |  |
| UIL: | $\uplus(a: \mathbb P, b: \mathbb P)$ |
| Logical: | $a \uplus b$ |
Combining Primitives: Linked List
| Visual: |  |
| UIL: | \begin{align}LL :=\;&|\;U(Sng(x: \mathbb R), a: LL)\\&|\;Sng(x)\end{align} |
| Logical: | $\{ x \} \uplus a$ or $\{ x \}$ |
Many existing data structures can be expressed as syntactic restrictions on this grammar.
Extension 1: Semantic Constraints
| Visual: |  |
| UIL: | $BT_{k: \mathbb K}(a: \mathbb P, b: \mathbb P)$ |
| Logical: | $a \uplus b$ |
| Constraint: | $\forall r \in a: r.key \lt K$ $\forall r \in b: r.key \geq K$ |
Nodes can define syntactic constraints over the logical contents of descendents.
Combining Primitives: Binary Tree
\begin{align} BinTree :=\;&|\;BT_{k: \mathbb K}(a: BinTree, b: BinTree)\\&|\;Sng(x: \mathbb R) \end{align}Extension 2: Repetition
| Visual: |  |
| UIL: | $Array_{N : \mathbb N}(x_1: \mathbb R, \ldots, x_N: \mathbb R)$ |
| Logical: | $\{ x_1, \ldots, x_N \}$ |
Can repeat structures for efficiency (e.g., B+Tree vs BinTree)
Combining Extensions
| Visual: |  |
| UIL: | $Sorted_{N : \mathbb N}(x_1: \mathbb R, \ldots, x_N: \mathbb R)$ |
| Logical: | $\{ x_1, \ldots, x_N \}$ |
| Constraint: | $\forall i \lt j: x_i.key \leq x_j.key$ |
Example
$\uplus(Sng(1), $ $\uplus(Array_2(2,4,7), $ $BT_6($ $Sorted_2(3, 5)$ $, Sng(6))$ $)$ $)$
Incremental Structure Transitions
- A Universal Instance Language
- Realizing Universal Data Structures
- Just-In-Time Data Structure Optimization
- Optimization Policy Discovery
Universal Data Structures
- Physiological Morphisms
- Queries
- Updates
- Purely Physical Morphisms
- Optimization
Example: Range Queries
$Q_{\ell,h} : \mathbb P \mapsto \mathbb P$Return tuples in $[\ell,h)$
Insert
$$Insert_{\mathbb P}: \mathbb P \rightarrow \mathbb P$$Do the least work possible (optimize later)
Incremental Structure Transitions
- A Universal Instance Language
- Realizing Universal Data Structures
- Just-In-Time Data Structure Optimization
- Optimization Policy Discovery
Core Idea: Physical layout as a compiler optimization problem.
Example: Organize A Hybrid Data Structure
 ➔
➔ ➔
➔
Rewrites
A pattern/replacement pair.
- Crack-Array
- Sort-Array
- Sort-Merge
- Pushdown-Array
- Pushdown-BT
- Pushdown-Sorted
- ...
Events
A trigger for applying a rewrite.
- Before-Scan
- After-Scan
- Before-Visit
- After-Visit
- Before-Insert
- After-Insert
- Idle-Tick
Policies (Take 1)
A set of Rewrite/Event pairs.
- Cracker (Implements [Idreos et.al.-CIDR 2007])
- Adaptive Merge (Implements [Graefe/Kano-EDBT 2010])
- Swap (Heuristic Hybrid: Switch after 2000 events)
- Transition (Heuristic Hybrid: Gradient from 1-3k events)
The Entire Transition Policy
package jitd;
import java.util.*;
public class TransitionMode extends Mode {
int stepsTotal;
int stepsTaken = 0;
Random rand = new Random();
Mode source, target;
public TransitionMode(Mode source, Mode target, int steps)
{
this.stepsTotal = steps;
this.source = source;
this.target = target;
}
public Mode pick()
{
stepsTaken++;
if(rand.nextInt(stepsTotal) < stepsTaken){
return target;
} else {
return source;
}
}
public KeyValueIterator scan(Driver driver, long low, long high)
{
return pick().scan(driver, low, high);
}
public void insert(Driver driver, Cog values)
{
pick().insert(driver, values);
}
public void idle(Driver driver)
{
pick().idle(driver);
}
}
(40 lines of java)
Cracker Policy

(incrementally improving performance)
Adaptive Merge Policy

(first read: 33s; bimodal: merge vs already merged)
Swap Policy
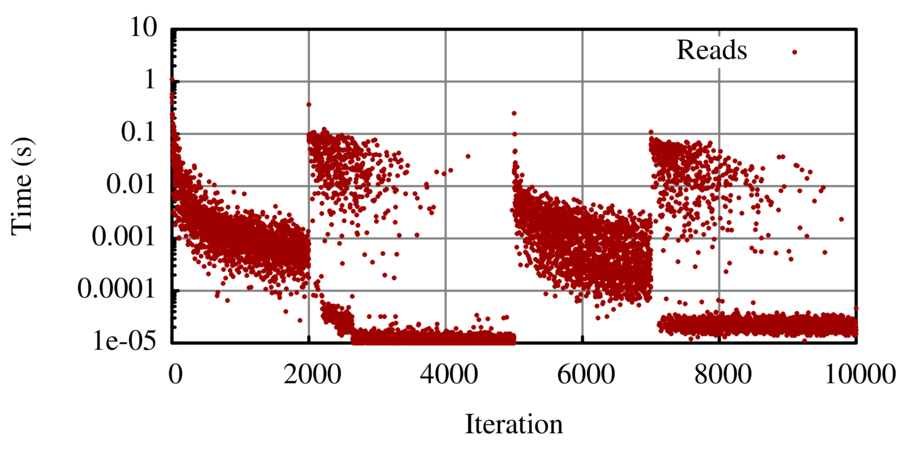
(can arbitrarilly switch to a different policy)
Transition Policy
(can have two policies running simultaneously in parallel)
Universal data structures allow us to
hybridize policies "for free".
Policies (Take 2)
Core Idea: Physical layout as a just-in-time compiler optimization problem.
Just-in-Time Data Structures

A background thread incrementally optimizes the data structure.
Continuous availability while performance improves.
Optimizer Work Loop
- Which rewrite to apply?
- On what to apply it?
A priority queue keeps track of available rewrite patterns
Example: A Load-Time Availabile Index
Input: An Unsorted Array
- Crack-in-Two (a.k.a. Radix-Partition)
- Fast ($O(N)$), but only small improvement
- ... but can be recursively improved
- Sort
- Slow ($O(N\cdot \log(N))$), but big improvement
Crack
\begin{align} Array_N(x_1, \ldots, x_N) \rightarrow BT_{x_j.key}(\;\;&Array_{|Y|}(y_1, \ldots, y_{|Y|}), \\&Array_{|Z|}(z_1, \ldots, z_{|Z|})\;\;) \end{align}where $j \in [1, N]$, $Y = \{x_i | x_i.key \lt x_j\}$, $Z = \{x_i | x_i.key \geq x_j\}$
Sort
$$Array_N(x_1, \ldots, x_N) \rightarrow Sorted_N(x_{f(1)}, \ldots, x_{f(N)})$$where $f : [N] \rightarrow [N]$ and $x_{f(i)} \leq x_{f(i+1)}$
Crack
Deqeue: 1x Array
Enqueue: 2x Array
Sort
Deqeue: 1x Array
Enqueue: 1x Sorted Array

Option 1: Crack($Array_8(1 \ldots 8)$)
Option 2: Sort($Array_8(1 \ldots 8)$)

Option 1: Crack($Array_4(1 \ldots 4)$)
Option 2: Sort($Array_4(1 \ldots 4)$)
Option 3: Crack($Array_4(5 \ldots 8)$)
Option 4: Sort($Array_4(5 \ldots 8)$)

Option 1: Crack($Array_4(1 \ldots 4)$)
Option 2: Sort($Array_4(1 \ldots 4)$)
Incremental Structure Transitions
- A Universal Instance Language
- Realizing Universal Data Structures
- Just-In-Time Data Structure Optimization
- Optimization Policy Discovery
How to prioritize rewrites?
Cost Model
| $Array_N$: | $(300 \cdot N)$ ns to scan for 1 record |
| $Sorted_N$: | $(175 \cdot \log N)$ ns to scan for 1 record |
| $BT$: | Negligible |
Measure, then compute expected utility of static states.
Utility
- Throughput
- (Negative) Latency
- Time spent with latency below 300ms
Heuristic: Sort Below Threshold Size

Deriving Policies
- Start with a heuristic and optimize parameters.
- e.g., Pick a threshold to sort at.
- Model the expected cumulative utility of each candidate rewrite
- e.g., Priority queue of Array nodes remaining.
Just-in-Time Data Structures
- The Universal Instance Language can describe the intermediate state of a data structure in transition.
- UIL + localized rewrite rules can emulate the behaviors of existing data structures and be hybridized.
- Simulation + Cost-Analysis can be used to derive policies to drive direct rewrites.
Questions?