Embracing uncertainty with
Joint work with:
PhD Students: Ying Yang, Will Spoth, Aaron Huber, Poonam Kumari, Jon Logan
BS Students: Lisa Lu, Jacob P. Verghese
Alums: Arindam Nandi, Niccoló Meneghetti (HPE/Vertica), Vinayak Karuppasamy (Bloomberg)
Collabs: Ronny Fehling (Airbus), Zhen-Hua Liu (Oracle), Dieter Gawlick (Oracle), Beda Hammerschmidt (Oracle),
Boris Glavic (IIT), Wolfgang Gatterbauer (CMU), Juliana Freire (NYU), Heiko Mueller (NYU), Moises Sudit (UB-ISE)
A Big Data Fairy Tale
Meet Alice

Alice has a Store
→
Alice's store collects sales data

Alice wants to use her sales data to run a promotion

So Alice loads up her sales data in her trusty database/hadoop/spark/etc... server.
+ ?
... asks her question ...
+ ? →

... and basks in the limitless possibilities of big data.
Why is this a fairy tale?
It's never this easy...
CSV Import
Run a SELECT on a raw CSV File
- File may not have column headers
- CSV does not provide "types"
- Lines may be missing fields
- Fields may be mistyped (typo, missing comma)
- Comment text can be inlined into the file
State of the art: External Table Defn + "Manually" edit CSV
Merge Two Datasets
UNION two data sources
- Schema matching
- Deduplication
- Format alignment (GIS coordinates, $ vs €)
- Precision alignment (State vs County)
State of the art: Manually map schema
JSON Shredding
Run a SELECT on JSON or a Doc Store
- Separating fields and record sets:
(e.g.,{ A: "Bob", B: "Alice" }) - Missing fields (Records with no 'address')
- Type alignment (Records with 'address' as an array)
- Schema matching$^2$
State of the art: DataGuide, Wrangler, etc...
Data Cleaning is Hard!
State of the Art

Alice spends weeks cleaning her data before using it.
Newer State of the Art

Curation is hard!
- Structured models (RelDBs) force curation during loading.
- Problem: All curation costs are upfront.
- Unstructured models (NoSQL) force curation into queries.
- Problem: Complexity/redundancy blowup in queries.
Make structure, curation effort On-Demand
Let the database make guesses!
In the name of Codd,
thou shalt not give the user a wrong answer.
... but what if we did?
What would it take for that to be ok?
Industry says...
My phone is guessing, but is letting me know that it did

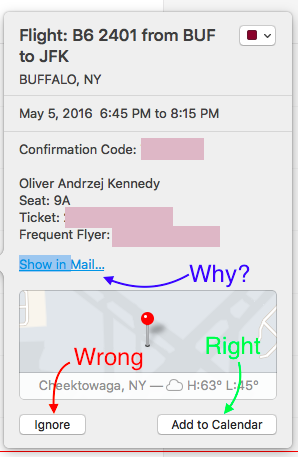
Easy interactions to accept, reject, or explain uncertainty
Easy access to: Provenance, Alternatives, and Confidence
Communication
- Why is my data uncertain?
- How bad is it?
- What can I do about it?
What if a database did the same?
- A: Standard SQL.
- B: Annotated Output.
- C: Subway Diagram.
- D: Result Explanations.
 Demo
Demo
Mimir
- Lenses: Generic, best-guess data curation operators.
- Explanations: How certain is my data?
- Provenance: What issues still need to be fixed?
Lenses
Here's a problem with my data. Fix it.
- What type is this column? (majority vote)
- How do the columns of these relations line up? (pick your favorite schema matching paper)
- How do I query heterogeneous JSON objects? (see above)
- What should these missing values be? (learning-based interpolation)
Lenses introduce uncertainty
The User's View
SELECT NAME, DEPARTMENT FROM PRODUCTS;
| Name | Department |
|---|---|
| Apple 6s, White | Phone |
| Dell, Intel 4 core | Computer |
| HP, AMD 2 core | Computer |
| ... | ... |
Simple UI: Highlight values that are based on guesses.
SELECT NAME, DEPARTMENT FROM PRODUCTS;
| Name | Department |
|---|---|
| Apple 6s, White | Phone |
| Dell, Intel 4 core | Computer |
| HP, AMD 2 core | Computer |
| ... | ... |
Allow users to EXPLAIN uncertain outputs
Explanations include reasons given in English
Explanations
- Mark uncertain data and results.
- Upon request, provide more detail:
- Why is my data uncertain? (provenance)
- How bad is it? (confidence, entropy, bounds)
- What are other possibile answers? (samples)
- What can I do to fix it? (repairs)
Available Lenses
- Missing Value Repair (using Wekka)
- Schema Matching (merging datasets)
- Type Inference (for CSV import)
- Entity Extraction (for JSON import)
- Functional-Dependency Repair
Entity Extraction
{
"grad":{"students":[
{name:"Alice",deg:"PhD",credits:"10"},
{name:"Bob",deg:"MS"}, ...]},
"undergrad":{"students":[
{name:"Carol"},
{name:"Dave",deg:"U"}, ...]}
}
Entity Extraction

Entity Extraction Lens
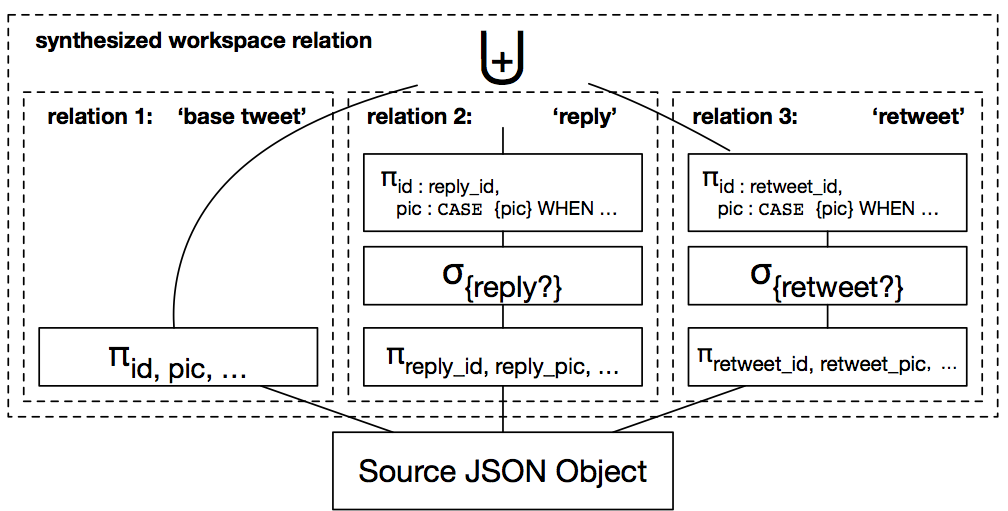
Shared Workspaces

Other Efforts in Progress
- Priority: Aggregate Queries
- Data Descriptors (DataGuides++)
- User-Interface Studies
- Prioritization of HITL Tasks
- Editable Query Results (Vizier)
- On-Demand Data Curation makes data exploration easier.
- "Best-Guess" results streamline analytics.
... if the DB communicates the resulting uncertainty.
Questions?
Backup Slides
Mimir is a DB Overlay
Mimir virtualizes uncertainty
How?
Labeled Nulls
$Var(\ldots)$ constructs new variables
- $Var('X')$ constructs a new variable $X$
- $Var('X', 1)$ constructs a new variable $X_{1}$
- $Var('X', ROWID)$ evaluates $ROWID$ and then constructs a new variable $X_{ROWID}$
Lazy Evaluation
Variables can't be evaluated until they are bound.
So, we allow arbitrary expressions to represent data.
- $X$ is a legitimate data value.
- $X+1$ is a legitimate data value.
- $1+1$ is a legitimate data value, but can be reduced to $2$.
A lazy value without variables is deterministic
Mimir SQL allows the $Var()$ operator to inlined
SELECT A, VAR('X', B)+2 AS C FROM R;
| A | B |
|---|---|
| 1 | 2 |
| 3 | 4 |
| 5 | 6 |
| A | C |
|---|---|
| 1 | $X_2+2$ |
| 3 | $X_4+2$ |
| 5 | $X_6+2$ |
Selects on $Var()$ need to be deferred too...
SELECT A FROM R WHERE VAR('X', B) > 2;
| A | B |
|---|---|
| 1 | 2 |
| 3 | 4 |
| 5 | 6 |
| A | $\phi$ |
|---|---|
| 1 | $X_2>2$ |
| 3 | $X_4>2$ |
| 5 | $X_6>2$ |
When evaluating the table, rows where $\phi = \bot$ are dropped.
C-Tables
- Original Formulation [Imielinski, Lipski 1981]
- PC-Tables [Green, Tannen 2006]
- Systems
- Orchestra [Green, Karvounarakis, Taylor, Biton, Ives, Tannen 2007]
- MayBMS [Huang, Antova, Koch, Olteanu 2009]
- Pip [Kennedy, Koch 2009]
- Sprout [Fink, Hogue, Olteanu, Rath 2011]
- Generalized PC-Tables [Kennedy, Koch 2009]
Labeled nulls capture a lens' uncertainty
CREATE LENS PRODUCTS
AS SELECT * FROM PRODUCTS_RAW
USING DOMAIN_REPAIR(DEPARTMENT NOT NULL);
is (almost) the same as the query...
CREATE VIEW PRODUCTS
AS SELECT ID, NAME, ...,
CASE WHEN DEPARTMENT IS NOT NULL THEN DEPARTMENT
ELSE VAR('PRODUCTS.DEPARTMENT', ROWID)
END AS DEPARTMENT
FROM PRODUCTS_RAW;
| ID | Name | ... | Department |
|---|---|---|---|
| 123 | Apple 6s, White | ... | Phone |
| 34234 | Dell, Intel 4 core | ... | Computer |
| 34235 | HP, AMD 2 core | ... | $Prod.Dept_3$ |
| ... | ... | ... | ... |
CREATE LENS PRODUCTS
AS SELECT * FROM PRODUCTS_RAW
USING DOMAIN_REPAIR(DEPARTMENT NOT NULL);
Behind the scenes, a lens also creates a model...
SELECT * FROM PRODUCTS_RAW;

An estimator for $PRODUCTS.DEPARTMENT_{ROWID}$
... but databases don't support labeled nulls
Labeled Nulls Percolate Up
SELECT A, VAR('X', B)+2 AS C FROM R;
Mimir dispatches this query to the DB:
SELECT A, B FROM R;
And for each row of the result, evaluates:
SELECT A, VAR('X', B)+2 AS C FROM RESULT;
Generating Explanations
All uncertainty comes from labeled nulls in the expressions that Mimir evaluates for each row of the output.
- Why is the data uncertain?
- All relevant lenses referenced in
VAR('X', B)+2. - How uncertain?
- Estimate by sampling from
VAR('X', B). - How do I fix it?
- Each lens fixes one well-defined type of error.
Lazy evaluation can cause problems
SELECT R.A, S.C FROM R, S WHERE VAR('X', R.B) = S.B;
Mimir dispatches this query to the DB:
SELECT R.A, S.C, R.B AS TEMP_1, S.B AS TEMP_2 FROM R, S;
And for each row of the result, evaluates:
SELECT A, C FROM RESULT WHERE VAR('X', TEMP_1) = TEMP_2;
UDFs allow the DB to interpret labeled nulls
SELECT R.A, S.C FROM R, S
WHERE S.B = MIMIR_VG_BESTGUESS('VARIABLE_X', R.B);
... but we lose the ability to explain outputs
Provenance Recovers Explanations
SELECT R.A, S.C FROM R, S WHERE VAR('X', R.B) = S.B;
Mimir dispatches this query to the DB:
SELECT R.A, S.C,
R.ROWID AS ID_1, S.ROWID AS ID_2
WHERE S.B = MIMIR_VG_BESTGUESS('VARIABLE_X', R.B);
Then to explain, Mimir dispatches the query:
SELECT R.A, S.C, R.B AS TEMP_1, S.B AS TEMP_2
WHERE R.ROWID = ID_1 AND S.ROWID = ID_2
Performance
PDBench: TPC-H Data, but add random FK violations.
- Query 1: ~TPC-H Q3; 3-way FK Join with Predicates
- Query 2: ~TPC-H Q6; Table Scan with Predicates.
- Query 3: ~TPC-H Q7; 5-way Star Join with Predicates.
- Partition:
- Separate query fragments compute 'certain' results and one or more classes of uncertain results.
- TupleBundle:
- Compute and summarize 10 sampled results in parallel
- Inline:
- UDFs dynamically inject best guess values into the query.
| Strategy | Q1 | Q2 | Q3 |
|---|---|---|---|
| Inline | 85.5s | 676.6s | 103.3s |
| TupleBundle | 8.2s | 55.2s | 9.8s |
| Partition | >1hr | 739.7s | >1hr |
Presentation
Participants were shown a table of 3 products with 3 ratings (e.g., Amazon, Best Buy, Walmart) each
Part 1: The randomly generated ratings were biased to encourage a predictable, but mildly ambiguous ordering of the three products.
Part 2: We used the same randomization, but this time we marked several of the values as uncertain:
| Red Text | value |
| Red Background | value |
| Asterisk | $value*$ |
| Tolerance | $value \pm tolerance$ |
| Range | $low – high$ |
Probability of Agreement With Elicited Order

Part 3: We asked participants to verbalize their thought process and tagged specific exclamations in the transcripts.

CONTEXT-DOMAIN: The participant relied on the 0-5 range of reviews to infer an uncertain ratingCONTEXT-ROW: The participant used other reviews for the same product to infer an uncertain ratingUNCERTAINTY-IGNORED: The participant explicitly disregarded an uncertain ratingUNCERTAINTY-IRRELEVANT: The participant didn't need the uncertain value.Part 3: We asked participants to verbalize their thought process and tagged specific exclamations in the transcripts.
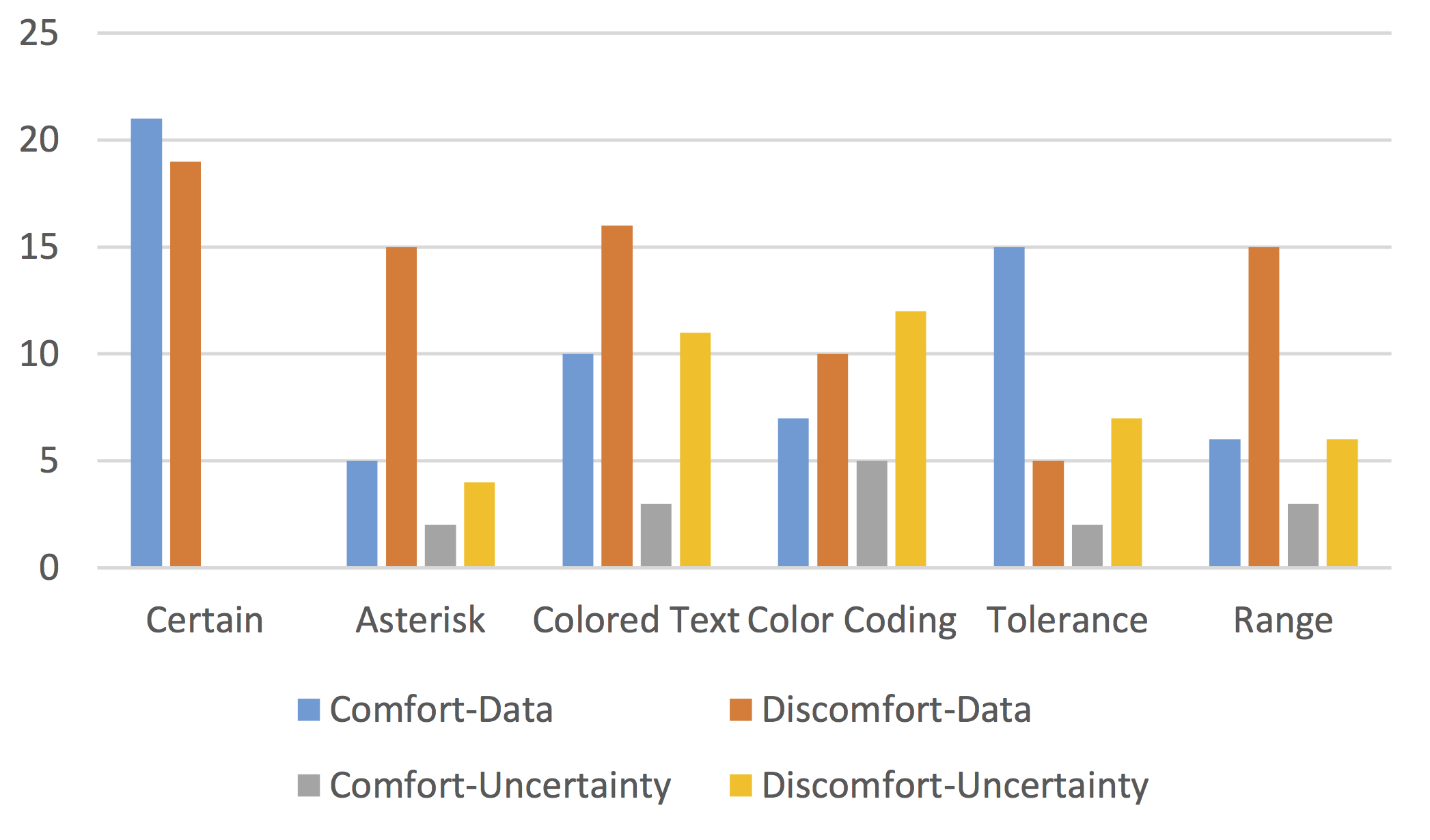
[DIS]COMFORT-*: The participant expressed a positive or negative emotional response.*-DATA: The emotional response pertained to the data itself.*-UNCERTAINTY: The emotional response pertained to the uncertain values or representation.Selection (Filtering)
SELECT NAME FROM PRODUCTS
WHERE DEPARTMENT='PHONE'
AND ( VENDOR='APPLE'
OR PLATFORM='ANDROID' )
Row-level uncertainty is a boolean formula $\phi$.
For this query, $\phi$ can be as complex as: $$DEPT_{ROWID}='P\ldots' \wedge \left( VEND_{ROWID}='Ap\ldots' \vee PLAT_{ROWID} = 'An\ldots' \right)$$
Too many variables! Which is the most important?
What is important?
Data Cleaning
Which variables are important?
The ones that keep us from knowing everything
$$D_{ROWID}='P' \wedge \left( V_{ROWID}='Ap' \vee PLAT_{ROWID} = 'An' \right)$$
$$A \wedge (B \vee C)$$
Naive Approach
Consider a game between a database and an impartial oracle.
- The DB picks a variable $v$ in $\phi$ and pays a cost $c_v$.
- The Oracle reveals the truth value of $v$.
- The DB updates $\phi$ accordingly and repeats until $\phi$ is deterministic.
Naive Algorithm: Pick all variables!
Less Naive Algorithm: Minimize $E\left[\sum c_v\right]$.
Exponential Time Bad!
The Value of What We Don't Know
$$\phi = A \wedge (B \vee C)$$
- Generate Samples for $A$, $B$, $C$
- Estimate $p(\phi)$
- Compute $H[\phi] = -\log\left(p(\phi) \cdot (1-p(\phi))\right)$
Entropy is intuitive:
$H = 1$ means we know nothing,
$H = 0$ means we know everything.
Information Gain
$$\mathcal I_{A \leftarrow \top} (\phi) = H\left[\phi\right] - H\left[\phi(A \leftarrow \top)\right]$$
Information gain of $v$: The reduction in entropy from knowing the truth value of a variable $v$.
Expected Information Gain
$$\mathcal I_{A} (\phi) = \left(p(A)\cdot \mathcal I_{A\leftarrow \top}(\phi)\right) + \left(p(\neg A)\cdot \mathcal I_{A\leftarrow \bot}(\phi)\right)$$
Expected information gain of $v$: The probability-weighted average of the information gain for $v$ and $\neg v$.
The Cost of Perfect Information
Combine Information Gain and Cost
$$f(\mathcal I_{A}(\phi), c_A)$$
For example: $EG2(\mathcal I_{A}(\phi), c_A) = \frac{2^{\mathcal I_{A}(\phi)} - 1}{c_A}$
Greedy Algorithm: Minimize $f(\mathcal I_{A}(\phi), c_A)$ at each step
Experimental Data
- Start with a large dataset.
- Delete random fields (~50%).
Experimental Queries
Simulate an analyst trying to manually explore correlations.
- Train a tree-classifier on the base data.
- Convert the decision tree to a query for all rows where the tree predicts a specific value.
Cost vs Entropy: Credit Data
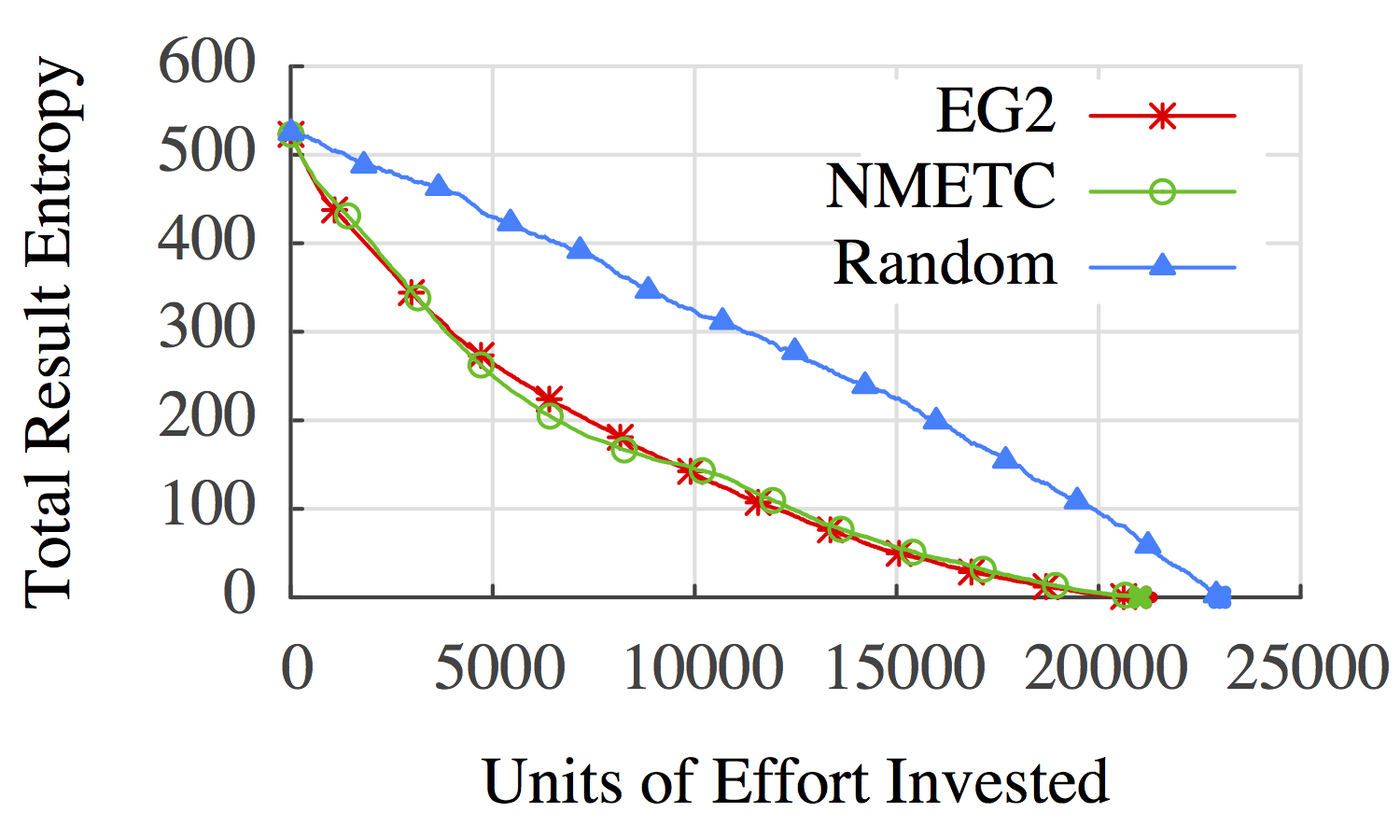
EG2: Greedy Cost/Value Ordering
NMETC: Naive Minimal Expected Total Cost
Random: Completely Random Order
Cost vs Entropy: Product Data

EG2: Greedy Cost/Value Ordering
NMETC: Naive Minimal Expected Total Cost
Random: Completely Random Order