Adaptive Indexing
Adaptive Merge & Generalized Cracking
CSE 662 - September 15
To Index or Not
You've got an initially unsorted collection of records indexed by a key. You need to run range queries over it:
| Scan Type | Prep Cost | Query Cost |
|---|---|---|
| Linear Scan | None | Expensive |
| Index Scan | "Very" Expensive | Cheap |
| Cracker Scan | None | Decreasing |
Can we do better?
Cracker Index
- Partition on each range bound like quicksort
- A full range query partitions twice
- Save boundaries for future queries
Adaptive Indexing
How else can we re-use query work?
Adaptive Merge Trees
- Observation 1: Sorting a list is $O(N \cdot \log(N))$
- Observation 2: Sorting $k$ partitions is $O(N \cdot \log(\frac{N}{k}))$
Pick $k$ so that $\frac{N}{k}$ is a constant, and your startup work is linear!
Adaptive Merge Trees
A little more upfront work, faster responses
Adaptive Merge Trees
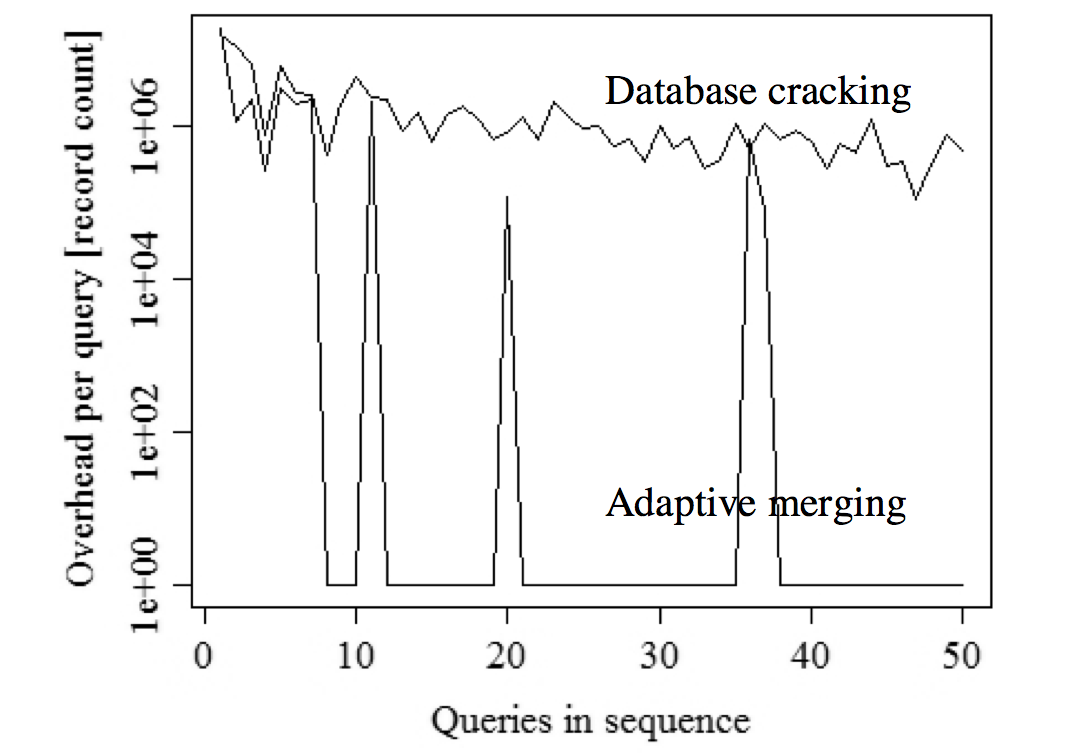
Much faster congergence!
In Practice...
- A factor of $O(\log(N))$ improvement is not huge
- "Merging" requires a huge amount of bookkeeping
- but... that fast convergence is nice!
Why do we get fast convergence?
Mixing Cracking and Merging
- Start with partitioned data
- Extract goal data from each partition independently
- Crack each partition independently
- Sort each partition independently then merge
- Radix "sort" each partition then crack
- Merge cracked regions
- Postprocess merged data
- "Crack" the merged data if needed
- Sort the merged data
- Radix partition the merged data
Crack + Crack

Crack+Crack vs Radix+Radix


Hybrid Algorithms
