[SPARK-24484][MLLIB] Power Iteration Clustering is giving incorrect clustering results when there are mutiple leading eigen values.
## What changes were proposed in this pull request?  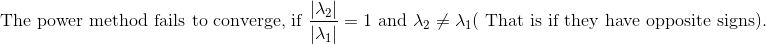 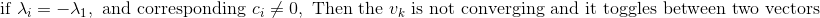 **Method to determine if the top eigen values has same magnitude but opposite signs** The vector is written as a linear combination of the eigen vectors at iteration k.  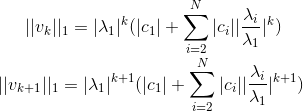    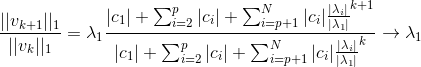   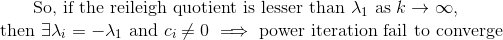  **So, we need to check if the reileigh coefficient at the convergence is lesser than the norm of the estimated eigen vector before normalizing** (Please fill in changes proposed in this fix) Added a UT Please review http://spark.apache.org/contributing.html before opening a pull request. Closes #21627 from shahidki31/picConvergence. Authored-by: Shahid <shahidki31@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
{kind=link}
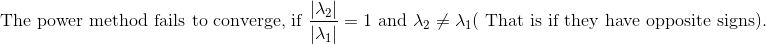{kind=link}
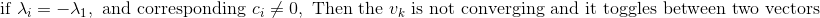{kind=link}
{kind=link}
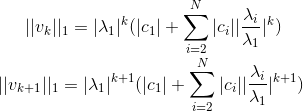{kind=link}
{kind=link}
{kind=link}
{kind=link}
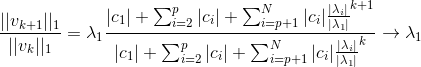{kind=link}
{kind=link}
{kind=link}
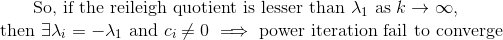{kind=link}
{kind=link}
This commit is contained in:
parent
9d2a11554b
commit
0d35f9ea3a
|
|
@ -378,6 +378,27 @@ object PowerIterationClustering extends Logging {
|
|||
logInfo(s"$msgPrefix: delta = $delta.")
|
||||
diffDelta = math.abs(delta - prevDelta)
|
||||
logInfo(s"$msgPrefix: diff(delta) = $diffDelta.")
|
||||
|
||||
if (math.abs(diffDelta) < tol) {
|
||||
/**
|
||||
* Power Iteration fails to converge if absolute value of top 2 eigen values are equal,
|
||||
* but with opposite sign. The resultant vector flip-flops between two vectors.
|
||||
* We should give an exception, if we detect the failure of the convergence of the
|
||||
* power iteration
|
||||
*/
|
||||
|
||||
// Rayleigh quotient = x^tAx / x^tx
|
||||
val xTAx = curG.joinVertices(v) {
|
||||
case (_, x, y) => x * y
|
||||
}.vertices.values.sum()
|
||||
val xTx = curG.vertices.mapValues(x => x * x).values.sum()
|
||||
val rayleigh = xTAx / xTx
|
||||
|
||||
if (math.abs(norm - math.abs(rayleigh)) > tol) {
|
||||
logWarning(s"Power Iteration fail to converge. delta = ${delta}," +
|
||||
s" difference delta = ${diffDelta} and norm = ${norm}")
|
||||
}
|
||||
}
|
||||
// update v
|
||||
curG = Graph(VertexRDD(v1), g.edges)
|
||||
prevDelta = delta
|
||||
|
|
|
|||
|
|
@ -184,6 +184,74 @@ class PowerIterationClusteringSuite extends SparkFunSuite
|
|||
assert(localAssignments === localAssignments2)
|
||||
}
|
||||
|
||||
test("power iteration clustering gives incorrect results due to failed to converge") {
|
||||
/*
|
||||
Graph:
|
||||
1
|
||||
/
|
||||
/
|
||||
0 2 -- 3
|
||||
*/
|
||||
val data1 = spark.createDataFrame(Seq(
|
||||
(0, 1),
|
||||
(2, 3)
|
||||
)).toDF("src", "dst")
|
||||
|
||||
val assignments1 = new PowerIterationClustering()
|
||||
.setInitMode("random")
|
||||
.setK(2)
|
||||
.assignClusters(data1)
|
||||
.select("id", "cluster")
|
||||
.as[(Long, Int)]
|
||||
.collect()
|
||||
val predictions1 = Array.fill(2)(mutable.Set.empty[Long])
|
||||
assignments1.foreach {
|
||||
case (id, cluster) => predictions1(cluster) += id
|
||||
}
|
||||
assert(Set(predictions1(0).size, predictions1(1).size) !== Set(2, 2))
|
||||
|
||||
|
||||
/*
|
||||
Graph:
|
||||
1
|
||||
/
|
||||
/
|
||||
0 - - 2 3 -- 4
|
||||
*/
|
||||
val data2 = spark.createDataFrame(Seq(
|
||||
(0, 1),
|
||||
(0, 2),
|
||||
(3, 4)
|
||||
)).toDF("src", "dst")
|
||||
|
||||
var assignments2 = new PowerIterationClustering()
|
||||
.setInitMode("random")
|
||||
.setK(2)
|
||||
.assignClusters(data2)
|
||||
.select("id", "cluster")
|
||||
.as[(Long, Int)]
|
||||
.collect()
|
||||
val predictions2 = Array.fill(2)(mutable.Set.empty[Long])
|
||||
assignments2.foreach {
|
||||
case (id, cluster) => predictions2(cluster) += id
|
||||
}
|
||||
assert(Set(predictions2(0).size, predictions2(1).size) !== Set(2, 3))
|
||||
|
||||
|
||||
var assignments3 = new PowerIterationClustering()
|
||||
.setInitMode("degree")
|
||||
.setK(2)
|
||||
.assignClusters(data2)
|
||||
.select("id", "cluster")
|
||||
.as[(Long, Int)]
|
||||
.collect()
|
||||
val predictions3 = Array.fill(2)(mutable.Set.empty[Long])
|
||||
assignments3.foreach {
|
||||
case (id, cluster) => predictions3(cluster) += id
|
||||
}
|
||||
assert(Set(predictions3(0).size, predictions3(1).size) !== Set(2, 3))
|
||||
}
|
||||
|
||||
test("read/write") {
|
||||
val t = new PowerIterationClustering()
|
||||
.setK(4)
|
||||
|
|
|
|||
Loading…
Reference in a new issue