[SPARK-26457] Show hadoop configurations in HistoryServer environment tab
## What changes were proposed in this pull request? I know that yarn provided all hadoop configurations. But I guess it may be fine that the historyserver unify all configuration in it. It will be convenient for us to debug some problems. ## How was this patch tested? 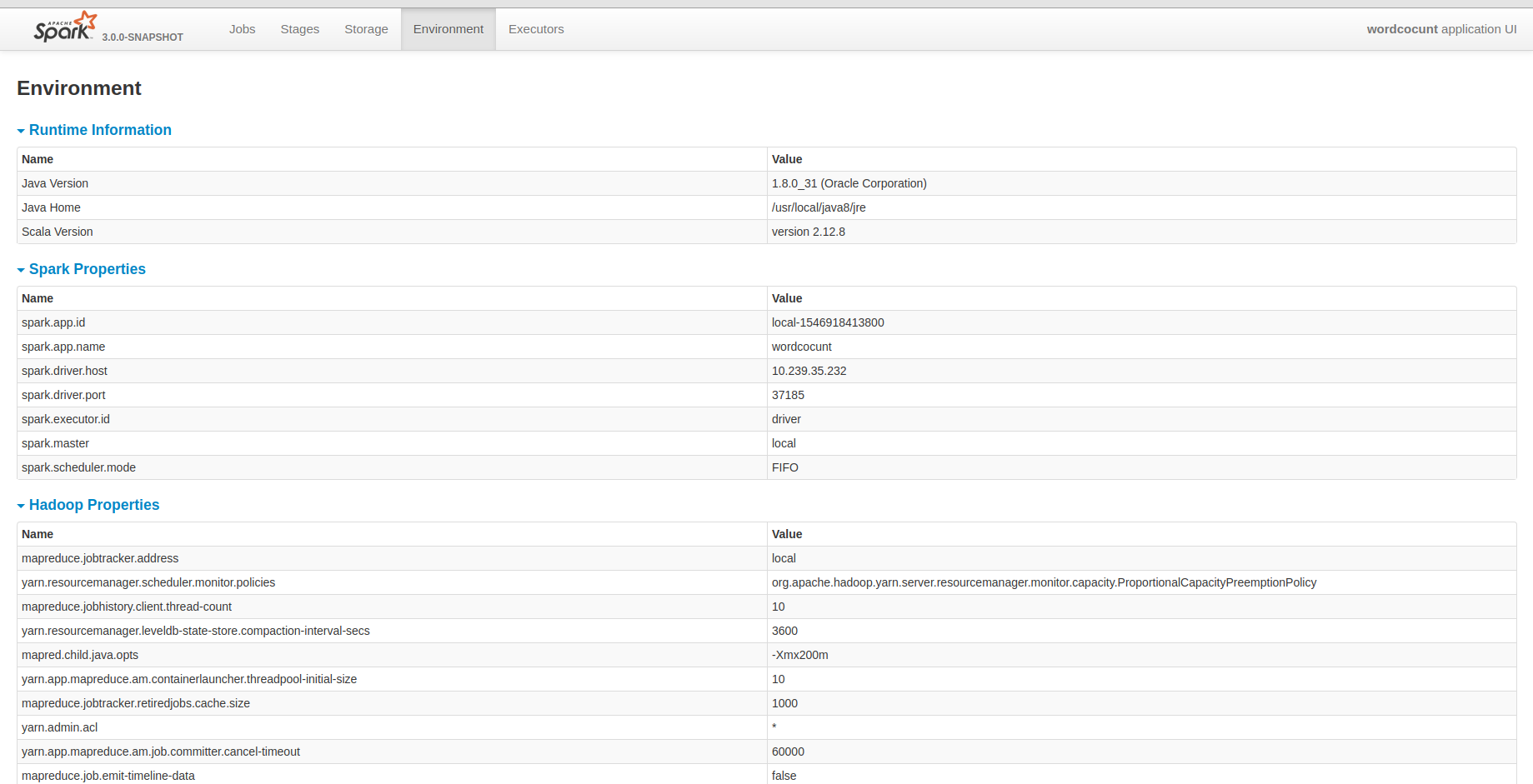 Closes #23486 from deshanxiao/spark-26457. Lead-authored-by: xiaodeshan <xiaodeshan@xiaomi.com> Co-authored-by: deshanxiao <42019462+deshanxiao@users.noreply.github.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
{kind=link}
This commit is contained in:
parent
4915cb3adf
commit
650b879de9
|
|
@ -63,6 +63,7 @@ $(function() {
|
|||
collapseTablePageLoad('collapse-aggregated-finishedDrivers','aggregated-finishedDrivers');
|
||||
collapseTablePageLoad('collapse-aggregated-runtimeInformation','aggregated-runtimeInformation');
|
||||
collapseTablePageLoad('collapse-aggregated-sparkProperties','aggregated-sparkProperties');
|
||||
collapseTablePageLoad('collapse-aggregated-hadoopProperties','aggregated-hadoopProperties');
|
||||
collapseTablePageLoad('collapse-aggregated-systemProperties','aggregated-systemProperties');
|
||||
collapseTablePageLoad('collapse-aggregated-classpathEntries','aggregated-classpathEntries');
|
||||
collapseTablePageLoad('collapse-aggregated-activeJobs','aggregated-activeJobs');
|
||||
|
|
|
|||
|
|
@ -2370,8 +2370,8 @@ class SparkContext(config: SparkConf) extends Logging {
|
|||
val schedulingMode = getSchedulingMode.toString
|
||||
val addedJarPaths = addedJars.keys.toSeq
|
||||
val addedFilePaths = addedFiles.keys.toSeq
|
||||
val environmentDetails = SparkEnv.environmentDetails(conf, schedulingMode, addedJarPaths,
|
||||
addedFilePaths)
|
||||
val environmentDetails = SparkEnv.environmentDetails(conf, hadoopConfiguration,
|
||||
schedulingMode, addedJarPaths, addedFilePaths)
|
||||
val environmentUpdate = SparkListenerEnvironmentUpdate(environmentDetails)
|
||||
listenerBus.post(environmentUpdate)
|
||||
}
|
||||
|
|
|
|||
|
|
@ -21,10 +21,12 @@ import java.io.File
|
|||
import java.net.Socket
|
||||
import java.util.Locale
|
||||
|
||||
import scala.collection.JavaConverters._
|
||||
import scala.collection.mutable
|
||||
import scala.util.Properties
|
||||
|
||||
import com.google.common.collect.MapMaker
|
||||
import org.apache.hadoop.conf.Configuration
|
||||
|
||||
import org.apache.spark.annotation.DeveloperApi
|
||||
import org.apache.spark.api.python.PythonWorkerFactory
|
||||
|
|
@ -400,6 +402,7 @@ object SparkEnv extends Logging {
|
|||
private[spark]
|
||||
def environmentDetails(
|
||||
conf: SparkConf,
|
||||
hadoopConf: Configuration,
|
||||
schedulingMode: String,
|
||||
addedJars: Seq[String],
|
||||
addedFiles: Seq[String]): Map[String, Seq[(String, String)]] = {
|
||||
|
|
@ -435,9 +438,13 @@ object SparkEnv extends Logging {
|
|||
val addedJarsAndFiles = (addedJars ++ addedFiles).map((_, "Added By User"))
|
||||
val classPaths = (addedJarsAndFiles ++ classPathEntries).sorted
|
||||
|
||||
// Add Hadoop properties, it will not ignore configs including in Spark. Some spark
|
||||
// conf starting with "spark.hadoop" may overwrite it.
|
||||
val hadoopProperties = hadoopConf.asScala.map(entry => (entry.getKey, entry.getValue)).toSeq
|
||||
Map[String, Seq[(String, String)]](
|
||||
"JVM Information" -> jvmInformation,
|
||||
"Spark Properties" -> sparkProperties,
|
||||
"Hadoop Properties" -> hadoopProperties,
|
||||
"System Properties" -> otherProperties,
|
||||
"Classpath Entries" -> classPaths)
|
||||
}
|
||||
|
|
|
|||
|
|
@ -147,6 +147,7 @@ private[spark] class AppStatusListener(
|
|||
val envInfo = new v1.ApplicationEnvironmentInfo(
|
||||
runtime,
|
||||
details.getOrElse("Spark Properties", Nil),
|
||||
details.getOrElse("Hadoop Properties", Nil),
|
||||
details.getOrElse("System Properties", Nil),
|
||||
details.getOrElse("Classpath Entries", Nil))
|
||||
|
||||
|
|
|
|||
|
|
@ -352,6 +352,7 @@ class VersionInfo private[spark](
|
|||
class ApplicationEnvironmentInfo private[spark] (
|
||||
val runtime: RuntimeInfo,
|
||||
val sparkProperties: Seq[(String, String)],
|
||||
val hadoopProperties: Seq[(String, String)],
|
||||
val systemProperties: Seq[(String, String)],
|
||||
val classpathEntries: Seq[(String, String)])
|
||||
|
||||
|
|
|
|||
|
|
@ -42,6 +42,8 @@ private[ui] class EnvironmentPage(
|
|||
propertyHeader, jvmRow, jvmInformation, fixedWidth = true)
|
||||
val sparkPropertiesTable = UIUtils.listingTable(propertyHeader, propertyRow,
|
||||
Utils.redact(conf, appEnv.sparkProperties.toSeq), fixedWidth = true)
|
||||
val hadoopPropertiesTable = UIUtils.listingTable(propertyHeader, propertyRow,
|
||||
Utils.redact(conf, appEnv.hadoopProperties.toSeq), fixedWidth = true)
|
||||
val systemPropertiesTable = UIUtils.listingTable(
|
||||
propertyHeader, propertyRow, appEnv.systemProperties, fixedWidth = true)
|
||||
val classpathEntriesTable = UIUtils.listingTable(
|
||||
|
|
@ -70,26 +72,37 @@ private[ui] class EnvironmentPage(
|
|||
<div class="aggregated-sparkProperties collapsible-table">
|
||||
{sparkPropertiesTable}
|
||||
</div>
|
||||
<span class="collapse-aggregated-hadoopProperties collapse-table"
|
||||
onClick="collapseTable('collapse-aggregated-hadoopProperties',
|
||||
'aggregated-hadoopProperties')">
|
||||
<h4>
|
||||
<span class="collapse-table-arrow arrow-closed"></span>
|
||||
<a>Hadoop Properties</a>
|
||||
</h4>
|
||||
</span>
|
||||
<div class="aggregated-hadoopProperties collapsible-table collapsed">
|
||||
{hadoopPropertiesTable}
|
||||
</div>
|
||||
<span class="collapse-aggregated-systemProperties collapse-table"
|
||||
onClick="collapseTable('collapse-aggregated-systemProperties',
|
||||
'aggregated-systemProperties')">
|
||||
<h4>
|
||||
<span class="collapse-table-arrow arrow-open"></span>
|
||||
<span class="collapse-table-arrow arrow-closed"></span>
|
||||
<a>System Properties</a>
|
||||
</h4>
|
||||
</span>
|
||||
<div class="aggregated-systemProperties collapsible-table">
|
||||
<div class="aggregated-systemProperties collapsible-table collapsed">
|
||||
{systemPropertiesTable}
|
||||
</div>
|
||||
<span class="collapse-aggregated-classpathEntries collapse-table"
|
||||
onClick="collapseTable('collapse-aggregated-classpathEntries',
|
||||
'aggregated-classpathEntries')">
|
||||
<h4>
|
||||
<span class="collapse-table-arrow arrow-open"></span>
|
||||
<span class="collapse-table-arrow arrow-closed"></span>
|
||||
<a>Classpath Entries</a>
|
||||
</h4>
|
||||
</span>
|
||||
<div class="aggregated-classpathEntries collapsible-table">
|
||||
<div class="aggregated-classpathEntries collapsible-table collapsed">
|
||||
{classpathEntriesTable}
|
||||
</div>
|
||||
</span>
|
||||
|
|
|
|||
|
|
@ -171,11 +171,13 @@ private[spark] object JsonProtocol {
|
|||
val environmentDetails = environmentUpdate.environmentDetails
|
||||
val jvmInformation = mapToJson(environmentDetails("JVM Information").toMap)
|
||||
val sparkProperties = mapToJson(environmentDetails("Spark Properties").toMap)
|
||||
val hadoopProperties = mapToJson(environmentDetails("Hadoop Properties").toMap)
|
||||
val systemProperties = mapToJson(environmentDetails("System Properties").toMap)
|
||||
val classpathEntries = mapToJson(environmentDetails("Classpath Entries").toMap)
|
||||
("Event" -> SPARK_LISTENER_EVENT_FORMATTED_CLASS_NAMES.environmentUpdate) ~
|
||||
("JVM Information" -> jvmInformation) ~
|
||||
("Spark Properties" -> sparkProperties) ~
|
||||
("Hadoop Properties" -> hadoopProperties) ~
|
||||
("System Properties" -> systemProperties) ~
|
||||
("Classpath Entries" -> classpathEntries)
|
||||
}
|
||||
|
|
@ -653,9 +655,13 @@ private[spark] object JsonProtocol {
|
|||
}
|
||||
|
||||
def environmentUpdateFromJson(json: JValue): SparkListenerEnvironmentUpdate = {
|
||||
// For compatible with previous event logs
|
||||
val hadoopProperties = jsonOption(json \ "Hadoop Properties").map(mapFromJson(_).toSeq)
|
||||
.getOrElse(Seq.empty)
|
||||
val environmentDetails = Map[String, Seq[(String, String)]](
|
||||
"JVM Information" -> mapFromJson(json \ "JVM Information").toSeq,
|
||||
"Spark Properties" -> mapFromJson(json \ "Spark Properties").toSeq,
|
||||
"Hadoop Properties" -> hadoopProperties,
|
||||
"System Properties" -> mapFromJson(json \ "System Properties").toSeq,
|
||||
"Classpath Entries" -> mapFromJson(json \ "Classpath Entries").toSeq)
|
||||
SparkListenerEnvironmentUpdate(environmentDetails)
|
||||
|
|
|
|||
|
|
@ -32,6 +32,11 @@
|
|||
[ "spark.app.id", "app-20161116163331-0000" ],
|
||||
[ "spark.task.maxFailures", "4" ]
|
||||
],
|
||||
"hadoopProperties" : [
|
||||
[ "mapreduce.jobtracker.address", "local" ],
|
||||
[ "yarn.resourcemanager.scheduler.monitor.policies", "org.apache.hadoop.yarn.server.resourcemanager.monitor.capacity.ProportionalCapacityPreemptionPolicy" ],
|
||||
[ "mapreduce.jobhistory.client.thread-count", "10" ]
|
||||
],
|
||||
"systemProperties" : [
|
||||
[ "java.io.tmpdir", "/var/folders/l4/d46wlzj16593f3d812vk49tw0000gp/T/" ],
|
||||
[ "line.separator", "\n" ],
|
||||
|
|
|
|||
File diff suppressed because one or more lines are too long
|
|
@ -624,6 +624,7 @@ class FsHistoryProviderSuite extends SparkFunSuite with BeforeAndAfter with Matc
|
|||
"test", Some("attempt1")),
|
||||
SparkListenerEnvironmentUpdate(Map(
|
||||
"Spark Properties" -> properties.toSeq,
|
||||
"Hadoop Properties" -> Seq.empty,
|
||||
"JVM Information" -> Seq.empty,
|
||||
"System Properties" -> Seq.empty,
|
||||
"Classpath Entries" -> Seq.empty
|
||||
|
|
@ -882,6 +883,7 @@ class FsHistoryProviderSuite extends SparkFunSuite with BeforeAndAfter with Matc
|
|||
SparkListenerApplicationStart("end-event-test", Some("end-event-test"), 1L, "test", None),
|
||||
SparkListenerEnvironmentUpdate(Map(
|
||||
"Spark Properties" -> Seq.empty,
|
||||
"Hadoop Properties" -> Seq.empty,
|
||||
"JVM Information" -> Seq.empty,
|
||||
"System Properties" -> Seq.empty,
|
||||
"Classpath Entries" -> Seq.empty
|
||||
|
|
|
|||
|
|
@ -108,8 +108,9 @@ class EventLoggingListenerSuite extends SparkFunSuite with LocalSparkContext wit
|
|||
val secretPassword = "secret_password"
|
||||
val conf = getLoggingConf(testDirPath, None)
|
||||
.set(key, secretPassword)
|
||||
val hadoopconf = SparkHadoopUtil.get.newConfiguration(new SparkConf())
|
||||
val eventLogger = new EventLoggingListener("test", None, testDirPath.toUri(), conf)
|
||||
val envDetails = SparkEnv.environmentDetails(conf, "FIFO", Seq.empty, Seq.empty)
|
||||
val envDetails = SparkEnv.environmentDetails(conf, hadoopconf, "FIFO", Seq.empty, Seq.empty)
|
||||
val event = SparkListenerEnvironmentUpdate(envDetails)
|
||||
val redactedProps = eventLogger.redactEvent(event).environmentDetails("Spark Properties").toMap
|
||||
assert(redactedProps(key) == "*********(redacted)")
|
||||
|
|
|
|||
|
|
@ -66,6 +66,7 @@ class JsonProtocolSuite extends SparkFunSuite {
|
|||
val environmentUpdate = SparkListenerEnvironmentUpdate(Map[String, Seq[(String, String)]](
|
||||
"JVM Information" -> Seq(("GC speed", "9999 objects/s"), ("Java home", "Land of coffee")),
|
||||
"Spark Properties" -> Seq(("Job throughput", "80000 jobs/s, regardless of job type")),
|
||||
"Hadoop Properties" -> Seq(("hadoop.tmp.dir", "/usr/local/hadoop/tmp")),
|
||||
"System Properties" -> Seq(("Username", "guest"), ("Password", "guest")),
|
||||
"Classpath Entries" -> Seq(("Super library", "/tmp/super_library"))
|
||||
))
|
||||
|
|
@ -1761,6 +1762,9 @@ private[spark] object JsonProtocolSuite extends Assertions {
|
|||
| "Spark Properties": {
|
||||
| "Job throughput": "80000 jobs/s, regardless of job type"
|
||||
| },
|
||||
| "Hadoop Properties": {
|
||||
| "hadoop.tmp.dir": "/usr/local/hadoop/tmp"
|
||||
| },
|
||||
| "System Properties": {
|
||||
| "Username": "guest",
|
||||
| "Password": "guest"
|
||||
|
|
|
|||
|
|
@ -227,6 +227,9 @@ object MimaExcludes {
|
|||
ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.SparkContext.setActiveContext"),
|
||||
ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.SparkContext.markPartiallyConstructed"),
|
||||
|
||||
// [SPARK-26457] Show hadoop configurations in HistoryServer environment tab
|
||||
ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.status.api.v1.ApplicationEnvironmentInfo.this"),
|
||||
|
||||
// Data Source V2 API changes
|
||||
(problem: Problem) => problem match {
|
||||
case MissingClassProblem(cls) =>
|
||||
|
|
|
|||
Loading…
Reference in a new issue