[SPARK-29431][WEBUI] Improve Web UI / Sql tab visualization with cached dataframes
### What changes were proposed in this pull request? With this pull request I want to improve the Web UI / SQL tab visualization. The principal problem that I find is when you have a cache in your plan, the SQL visualization don’t show any information about the part of the plan that has been cached. Before the change 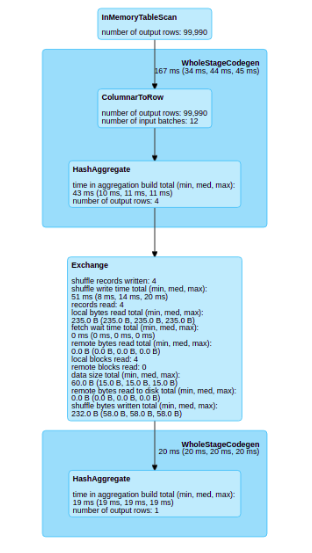 After the change  ### Why are the changes needed? When we have a SQL plan with cached dataframes we lose the graphical information of this dataframe in the sql tab ### Does this PR introduce any user-facing change? Yes, in the sql tab ### How was this patch tested? Unit testing and manual tests throught spark shell Closes #26082 from planga82/feature/SPARK-29431_SQL_Cache_webUI. Lead-authored-by: Pablo Langa <soypab@gmail.com> Co-authored-by: Gengliang Wang <gengliang.wang@databricks.com> Co-authored-by: Unknown <soypab@gmail.com> Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
{kind=link}
{kind=link}
This commit is contained in:
parent
271eb26c02
commit
e4db3b5b17
|
|
@ -19,6 +19,7 @@ package org.apache.spark.sql.execution
|
|||
|
||||
import org.apache.spark.annotation.DeveloperApi
|
||||
import org.apache.spark.sql.execution.adaptive.{AdaptiveSparkPlanExec, QueryStageExec}
|
||||
import org.apache.spark.sql.execution.columnar.InMemoryTableScanExec
|
||||
import org.apache.spark.sql.execution.exchange.ReusedExchangeExec
|
||||
import org.apache.spark.sql.execution.metric.SQLMetricInfo
|
||||
import org.apache.spark.sql.internal.SQLConf
|
||||
|
|
@ -56,6 +57,7 @@ private[execution] object SparkPlanInfo {
|
|||
case ReusedSubqueryExec(child) => child :: Nil
|
||||
case a: AdaptiveSparkPlanExec => a.executedPlan :: Nil
|
||||
case stage: QueryStageExec => stage.plan :: Nil
|
||||
case inMemTab: InMemoryTableScanExec => inMemTab.relation.cachedPlan :: Nil
|
||||
case _ => plan.children ++ plan.subqueries
|
||||
}
|
||||
val metrics = plan.metrics.toSeq.map { case (key, metric) =>
|
||||
|
|
|
|||
|
|
@ -0,0 +1,44 @@
|
|||
/*
|
||||
* Licensed to the Apache Software Foundation (ASF) under one or more
|
||||
* contributor license agreements. See the NOTICE file distributed with
|
||||
* this work for additional information regarding copyright ownership.
|
||||
* The ASF licenses this file to You under the Apache License, Version 2.0
|
||||
* (the "License"); you may not use this file except in compliance with
|
||||
* the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
package org.apache.spark.sql.execution.ui
|
||||
|
||||
import org.apache.spark.sql.execution.SparkPlanInfo
|
||||
import org.apache.spark.sql.test.SharedSparkSession
|
||||
|
||||
class SparkPlanInfoSuite extends SharedSparkSession{
|
||||
|
||||
import testImplicits._
|
||||
|
||||
def vaidateSparkPlanInfo(sparkPlanInfo: SparkPlanInfo): Unit = {
|
||||
sparkPlanInfo.nodeName match {
|
||||
case "InMemoryTableScan" => assert(sparkPlanInfo.children.length == 1)
|
||||
case _ => sparkPlanInfo.children.foreach(vaidateSparkPlanInfo)
|
||||
}
|
||||
}
|
||||
|
||||
test("SparkPlanInfo creation from SparkPlan with InMemoryTableScan node") {
|
||||
val dfWithCache = Seq(
|
||||
(1, 1),
|
||||
(2, 2)
|
||||
).toDF().filter("_1 > 1").cache().repartition(10)
|
||||
|
||||
val planInfoResult = SparkPlanInfo.fromSparkPlan(dfWithCache.queryExecution.executedPlan)
|
||||
|
||||
vaidateSparkPlanInfo(planInfoResult)
|
||||
}
|
||||
}
|
||||
Loading…
Reference in a new issue