## What changes were proposed in this pull request?
Bucketizer support multi-column in the python side
## How was this patch tested?
existing tests and added tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#19892 from zhengruifeng/20542_py.
## What changes were proposed in this pull request?
This syncs the ML Python API with Scala for differences found after the 2.3 QA audit.
## How was this patch tested?
NA
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#20354 from BryanCutler/pyspark-ml-doc-sync-23163.
## What changes were proposed in this pull request?
This PR proposes to actually run the doctests in `ml/image.py`.
## How was this patch tested?
doctests in `python/pyspark/ml/image.py`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20294 from HyukjinKwon/trigger-image.
## What changes were proposed in this pull request?
mark OneHotEncoder python API deprecated
## How was this patch tested?
N/A
Author: WeichenXu <weichen.xu@databricks.com>
Closes#20241 from WeichenXu123/mark_ohe_deprecated.
## What changes were proposed in this pull request?
OnehotEncoderEstimator python API.
## How was this patch tested?
doctest
Author: WeichenXu <weichen.xu@databricks.com>
Closes#20209 from WeichenXu123/ohe_py.
## What changes were proposed in this pull request?
Add a note to the `HasCheckpointInterval` parameter doc that clarifies that this setting is ignored when no checkpoint directory has been set on the spark context.
## How was this patch tested?
No tests necessary, just a doc update.
Author: sethah <shendrickson@cloudera.com>
Closes#20188 from sethah/als_checkpoint_doc.
Previously, `FeatureHasher` always treats numeric type columns as numbers and never as categorical features. It is quite common to have categorical features represented as numbers or codes in data sources.
In order to hash these features as categorical, users must first explicitly convert them to strings which is cumbersome.
Add a new param `categoricalCols` which specifies the numeric columns that should be treated as categorical features.
## How was this patch tested?
New unit tests.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#19991 from MLnick/hasher-num-cat.
(Please fill in changes proposed in this fix)
Python API for VectorSizeHint Transformer.
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
doc-tests.
Author: Bago Amirbekian <bago@databricks.com>
Closes#20112 from MrBago/vectorSizeHint-PythonAPI.
## What changes were proposed in this pull request?
Adding fitMultiple API to `Estimator` with default implementation. Also update have ml.tuning meta-estimators use this API.
## How was this patch tested?
Unit tests.
Author: Bago Amirbekian <bago@databricks.com>
Closes#20058 from MrBago/python-fitMultiple.
## What changes were proposed in this pull request?
Expose Python API for _LinearRegression_ with _huber_ loss.
## How was this patch tested?
Unit test.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#19994 from yanboliang/spark-22810.
## What changes were proposed in this pull request?
pyspark.ml.tests is missing a py4j import. I've added the import and fixed the test that uses it. This test was only failing when testing without Hive.
## How was this patch tested?
Existing tests.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Bago Amirbekian <bago@databricks.com>
Closes#19997 from MrBago/fix-ImageReaderTest2.
## What changes were proposed in this pull request?
Calling `ImageSchema.readImages` multiple times as below in PySpark shell:
```python
from pyspark.ml.image import ImageSchema
data_path = 'data/mllib/images/kittens'
_ = ImageSchema.readImages(data_path, recursive=True, dropImageFailures=True).collect()
_ = ImageSchema.readImages(data_path, recursive=True, dropImageFailures=True).collect()
```
throws an error as below:
```
...
org.datanucleus.exceptions.NucleusDataStoreException: Unable to open a test connection to the given database. JDBC url = jdbc:derby:;databaseName=metastore_db;create=true, username = APP. Terminating connection pool (set lazyInit to true if you expect to start your database after your app). Original Exception: ------
java.sql.SQLException: Failed to start database 'metastore_db' with class loader org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1742f639f, see the next exception for details.
...
at org.apache.derby.jdbc.AutoloadedDriver.connect(Unknown Source)
...
at org.apache.hadoop.hive.metastore.HiveMetaStore.newRetryingHMSHandler(HiveMetaStore.java:5762)
...
at org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:180)
...
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:195)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:195)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:195)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:97)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:194)
at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:100)
at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:88)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.externalCatalog(HiveSessionStateBuilder.scala:39)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog$lzycompute(HiveSessionStateBuilder.scala:54)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog(HiveSessionStateBuilder.scala:52)
at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anon$1.<init>(HiveSessionStateBuilder.scala:69)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.analyzer(HiveSessionStateBuilder.scala:69)
at org.apache.spark.sql.internal.BaseSessionStateBuilder$$anonfun$build$2.apply(BaseSessionStateBuilder.scala:293)
at org.apache.spark.sql.internal.BaseSessionStateBuilder$$anonfun$build$2.apply(BaseSessionStateBuilder.scala:293)
at org.apache.spark.sql.internal.SessionState.analyzer$lzycompute(SessionState.scala:79)
at org.apache.spark.sql.internal.SessionState.analyzer(SessionState.scala:79)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:70)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:68)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:51)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:70)
at org.apache.spark.sql.SparkSession.internalCreateDataFrame(SparkSession.scala:574)
at org.apache.spark.sql.SparkSession.createDataFrame(SparkSession.scala:593)
at org.apache.spark.sql.SparkSession.createDataFrame(SparkSession.scala:348)
at org.apache.spark.sql.SparkSession.createDataFrame(SparkSession.scala:348)
at org.apache.spark.ml.image.ImageSchema$$anonfun$readImages$2$$anonfun$apply$1.apply(ImageSchema.scala:253)
...
Caused by: ERROR XJ040: Failed to start database 'metastore_db' with class loader org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1742f639f, see the next exception for details.
at org.apache.derby.iapi.error.StandardException.newException(Unknown Source)
at org.apache.derby.impl.jdbc.SQLExceptionFactory.wrapArgsForTransportAcrossDRDA(Unknown Source)
... 121 more
Caused by: ERROR XSDB6: Another instance of Derby may have already booted the database /.../spark/metastore_db.
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/.../spark/python/pyspark/ml/image.py", line 190, in readImages
dropImageFailures, float(sampleRatio), seed)
File "/.../spark/python/lib/py4j-0.10.6-src.zip/py4j/java_gateway.py", line 1160, in __call__
File "/.../spark/python/pyspark/sql/utils.py", line 69, in deco
raise AnalysisException(s.split(': ', 1)[1], stackTrace)
pyspark.sql.utils.AnalysisException: u'java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient;'
```
Seems we better stick to `SparkSession.builder.getOrCreate()` like:
51620e288b/python/pyspark/sql/streaming.py (L329)dc5d34d8dc/python/pyspark/sql/column.py (L541)33d43bf1b6/python/pyspark/sql/readwriter.py (L105)
## How was this patch tested?
This was tested as below in PySpark shell:
```python
from pyspark.ml.image import ImageSchema
data_path = 'data/mllib/images/kittens'
_ = ImageSchema.readImages(data_path, recursive=True, dropImageFailures=True).collect()
_ = ImageSchema.readImages(data_path, recursive=True, dropImageFailures=True).collect()
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19845 from HyukjinKwon/SPARK-22651.
## What changes were proposed in this pull request?
Image test seems failed in Python 3.6.0 / NumPy 1.13.3. I manually tested as below:
```
======================================================================
ERROR: test_read_images (pyspark.ml.tests.ImageReaderTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/.../spark/python/pyspark/ml/tests.py", line 1831, in test_read_images
self.assertEqual(ImageSchema.toImage(array, origin=first_row[0]), first_row)
File "/.../spark/python/pyspark/ml/image.py", line 149, in toImage
data = bytearray(array.astype(dtype=np.uint8).ravel())
TypeError: only integer scalar arrays can be converted to a scalar index
----------------------------------------------------------------------
Ran 1 test in 7.606s
```
To be clear, I think the error seems from NumPy - 75b2d5d427/numpy/core/src/multiarray/number.c (L947)
For a smaller scope:
```python
>>> import numpy as np
>>> bytearray(np.array([1]).astype(dtype=np.uint8))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: only integer scalar arrays can be converted to a scalar index
```
In Python 2.7 / NumPy 1.13.1, it prints:
```
bytearray(b'\x01')
```
So, here, I simply worked around it by converting it to bytes as below:
```python
>>> bytearray(np.array([1]).astype(dtype=np.uint8).tobytes())
bytearray(b'\x01')
```
Also, while looking into it again, I realised few arguments could be quite confusing, for example, `Row` that needs some specific attributes and `numpy.ndarray`. I added few type checking and added some tests accordingly. So, it shows an error message as below:
```
TypeError: array argument should be numpy.ndarray; however, it got [<class 'str'>].
```
## How was this patch tested?
Manually tested with `./python/run-tests`.
And also:
```
PYSPARK_PYTHON=python3 SPARK_TESTING=1 bin/pyspark pyspark.ml.tests ImageReaderTest
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19835 from HyukjinKwon/SPARK-21866-followup.
## What changes were proposed in this pull request?
Adding spark image reader, an implementation of schema for representing images in spark DataFrames
The code is taken from the spark package located here:
(https://github.com/Microsoft/spark-images)
Please see the JIRA for more information (https://issues.apache.org/jira/browse/SPARK-21866)
Please see mailing list for SPIP vote and approval information:
(http://apache-spark-developers-list.1001551.n3.nabble.com/VOTE-SPIP-SPARK-21866-Image-support-in-Apache-Spark-td22510.html)
# Background and motivation
As Apache Spark is being used more and more in the industry, some new use cases are emerging for different data formats beyond the traditional SQL types or the numerical types (vectors and matrices). Deep Learning applications commonly deal with image processing. A number of projects add some Deep Learning capabilities to Spark (see list below), but they struggle to communicate with each other or with MLlib pipelines because there is no standard way to represent an image in Spark DataFrames. We propose to federate efforts for representing images in Spark by defining a representation that caters to the most common needs of users and library developers.
This SPIP proposes a specification to represent images in Spark DataFrames and Datasets (based on existing industrial standards), and an interface for loading sources of images. It is not meant to be a full-fledged image processing library, but rather the core description that other libraries and users can rely on. Several packages already offer various processing facilities for transforming images or doing more complex operations, and each has various design tradeoffs that make them better as standalone solutions.
This project is a joint collaboration between Microsoft and Databricks, which have been testing this design in two open source packages: MMLSpark and Deep Learning Pipelines.
The proposed image format is an in-memory, decompressed representation that targets low-level applications. It is significantly more liberal in memory usage than compressed image representations such as JPEG, PNG, etc., but it allows easy communication with popular image processing libraries and has no decoding overhead.
## How was this patch tested?
Unit tests in scala ImageSchemaSuite, unit tests in python
Author: Ilya Matiach <ilmat@microsoft.com>
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19439 from imatiach-msft/ilmat/spark-images.
## What changes were proposed in this pull request?
Add python api for VectorIndexerModel support handle unseen categories via handleInvalid.
## How was this patch tested?
doctest added.
Author: WeichenXu <weichen.xu@databricks.com>
Closes#19753 from WeichenXu123/vector_indexer_invalid_py.
## What changes were proposed in this pull request?
Add parallelism support for ML tuning in pyspark.
## How was this patch tested?
Test updated.
Author: WeichenXu <weichen.xu@databricks.com>
Closes#19122 from WeichenXu123/par-ml-tuning-py.
## What changes were proposed in this pull request?
This PR proposes to mark the existing warnings as `DeprecationWarning` and print out warnings for deprecated functions.
This could be actually useful for Spark app developers. I use (old) PyCharm and this IDE can detect this specific `DeprecationWarning` in some cases:
**Before**
<img src="https://user-images.githubusercontent.com/6477701/31762664-df68d9f8-b4f6-11e7-8773-f0468f70a2cc.png" height="45" />
**After**
<img src="https://user-images.githubusercontent.com/6477701/31762662-de4d6868-b4f6-11e7-98dc-3c8446a0c28a.png" height="70" />
For console usage, `DeprecationWarning` is usually disabled (see https://docs.python.org/2/library/warnings.html#warning-categories and https://docs.python.org/3/library/warnings.html#warning-categories):
```
>>> import warnings
>>> filter(lambda f: f[2] == DeprecationWarning, warnings.filters)
[('ignore', <_sre.SRE_Pattern object at 0x10ba58c00>, <type 'exceptions.DeprecationWarning'>, <_sre.SRE_Pattern object at 0x10bb04138>, 0), ('ignore', None, <type 'exceptions.DeprecationWarning'>, None, 0)]
```
so, it won't actually mess up the terminal much unless it is intended.
If this is intendedly enabled, it'd should as below:
```
>>> import warnings
>>> warnings.simplefilter('always', DeprecationWarning)
>>>
>>> from pyspark.sql import functions
>>> functions.approxCountDistinct("a")
.../spark/python/pyspark/sql/functions.py:232: DeprecationWarning: Deprecated in 2.1, use approx_count_distinct instead.
"Deprecated in 2.1, use approx_count_distinct instead.", DeprecationWarning)
...
```
These instances were found by:
```
cd python/pyspark
grep -r "Deprecated" .
grep -r "deprecated" .
grep -r "deprecate" .
```
## How was this patch tested?
Manually tested.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19535 from HyukjinKwon/deprecated-warning.
This PR adds methods `recommendForUserSubset` and `recommendForItemSubset` to `ALSModel`. These allow recommending for a specified set of user / item ids rather than for every user / item (as in the `recommendForAllX` methods).
The subset methods take a `DataFrame` as input, containing ids in the column specified by the param `userCol` or `itemCol`. The model will generate recommendations for each _unique_ id in this input dataframe.
## How was this patch tested?
New unit tests in `ALSSuite` and Python doctests in `ALS`. Ran updated examples locally.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#18748 from MLnick/als-recommend-df.
## What changes were proposed in this pull request?
Added Python interface for ClusteringEvaluator
## How was this patch tested?
Manual test, eg. the example Python code in the comments.
cc yanboliang
Author: Marco Gaido <mgaido@hortonworks.com>
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#19204 from mgaido91/SPARK-21981.
## What changes were proposed in this pull request?
Remove unnecessary default value setting for all evaluators, as we have set them in corresponding _HasXXX_ base classes.
## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#19262 from yanboliang/evaluation.
## What changes were proposed in this pull request?
#19197 fixed double caching for MLlib algorithms, but missed PySpark ```OneVsRest```, this PR fixed it.
## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#19220 from yanboliang/SPARK-18608.
## What changes were proposed in this pull request?
Added LogisticRegressionTrainingSummary for MultinomialLogisticRegression in Python API
## How was this patch tested?
Added unit test
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Ming Jiang <mjiang@fanatics.com>
Author: Ming Jiang <jmwdpk@gmail.com>
Author: jmwdpk <jmwdpk@gmail.com>
Closes#19185 from jmwdpk/SPARK-21854.
# What changes were proposed in this pull request?
Added tunable parallelism to the pyspark implementation of one vs. rest classification. Added a parallelism parameter to the Scala implementation of one vs. rest along with functionality for using the parameter to tune the level of parallelism.
I take this PR #18281 over because the original author is busy but we need merge this PR soon.
After this been merged, we can close#18281 .
## How was this patch tested?
Test suite added.
Author: Ajay Saini <ajays725@gmail.com>
Author: WeichenXu <weichen.xu@databricks.com>
Closes#19110 from WeichenXu123/spark-21027.
Probability and rawPrediction has been added to MultilayerPerceptronClassifier for Python
Add unit test.
Author: Chunsheng Ji <chunsheng.ji@gmail.com>
Closes#19172 from chunshengji/SPARK-21856.
https://issues.apache.org/jira/browse/SPARK-19866
## What changes were proposed in this pull request?
Add Python API for findSynonymsArray matching Scala API.
## How was this patch tested?
Manual test
`./python/run-tests --python-executables=python2.7 --modules=pyspark-ml`
Author: Xin Ren <iamshrek@126.com>
Author: Xin Ren <renxin.ubc@gmail.com>
Author: Xin Ren <keypointt@users.noreply.github.com>
Closes#17451 from keypointt/SPARK-19866.
## What changes were proposed in this pull request?
This PR proposes to support unicodes in Param methods in ML, other missed functions in DataFrame.
For example, this causes a `ValueError` in Python 2.x when param is a unicode string:
```python
>>> from pyspark.ml.classification import LogisticRegression
>>> lr = LogisticRegression()
>>> lr.hasParam("threshold")
True
>>> lr.hasParam(u"threshold")
Traceback (most recent call last):
...
raise TypeError("hasParam(): paramName must be a string")
TypeError: hasParam(): paramName must be a string
```
This PR is based on https://github.com/apache/spark/pull/13036
## How was this patch tested?
Unit tests in `python/pyspark/ml/tests.py` and `python/pyspark/sql/tests.py`.
Author: hyukjinkwon <gurwls223@gmail.com>
Author: sethah <seth.hendrickson16@gmail.com>
Closes#17096 from HyukjinKwon/SPARK-15243.
## What changes were proposed in this pull request?
Modify MLP model to inherit `ProbabilisticClassificationModel` and so that it can expose the probability column when transforming data.
## How was this patch tested?
Test added.
Author: WeichenXu <WeichenXu123@outlook.com>
Closes#17373 from WeichenXu123/expose_probability_in_mlp_model.
## What changes were proposed in this pull request?
Added call to copy values of Params from Estimator to Model after fit in PySpark ML. This will copy values for any params that are also defined in the Model. Since currently most Models do not define the same params from the Estimator, also added method to create new Params from looking at the Java object if they do not exist in the Python object. This is a temporary fix that can be removed once the PySpark models properly define the params themselves.
## How was this patch tested?
Refactored the `check_params` test to optionally check if the model params for Python and Java match and added this check to an existing fitted model that shares params between Estimator and Model.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#17849 from BryanCutler/pyspark-models-own-params-SPARK-10931.
Add Python API for `FeatureHasher` transformer.
## How was this patch tested?
New doc test.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#18970 from MLnick/SPARK-21468-pyspark-hasher.
## What changes were proposed in this pull request?
Implemented a Python-only persistence framework for pipelines containing stages that cannot be saved using Java.
## How was this patch tested?
Created a custom Python-only UnaryTransformer, included it in a Pipeline, and saved/loaded the pipeline. The loaded pipeline was compared against the original using _compare_pipelines() in tests.py.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18888 from ajaysaini725/PythonPipelines.
## What changes were proposed in this pull request?
Update breeze to 0.13.1 for an emergency bugfix in strong wolfe line search
https://github.com/scalanlp/breeze/pull/651
## How was this patch tested?
N/A
Author: WeichenXu <WeichenXu123@outlook.com>
Closes#18797 from WeichenXu123/update-breeze.
## What changes were proposed in this pull request?
PySpark GLR ```model.summary``` should return a printable representation by calling Scala ```toString```.
## How was this patch tested?
```
from pyspark.ml.regression import GeneralizedLinearRegression
dataset = spark.read.format("libsvm").load("data/mllib/sample_linear_regression_data.txt")
glr = GeneralizedLinearRegression(family="gaussian", link="identity", maxIter=10, regParam=0.3)
model = glr.fit(dataset)
model.summary
```
Before this PR:

After this PR:
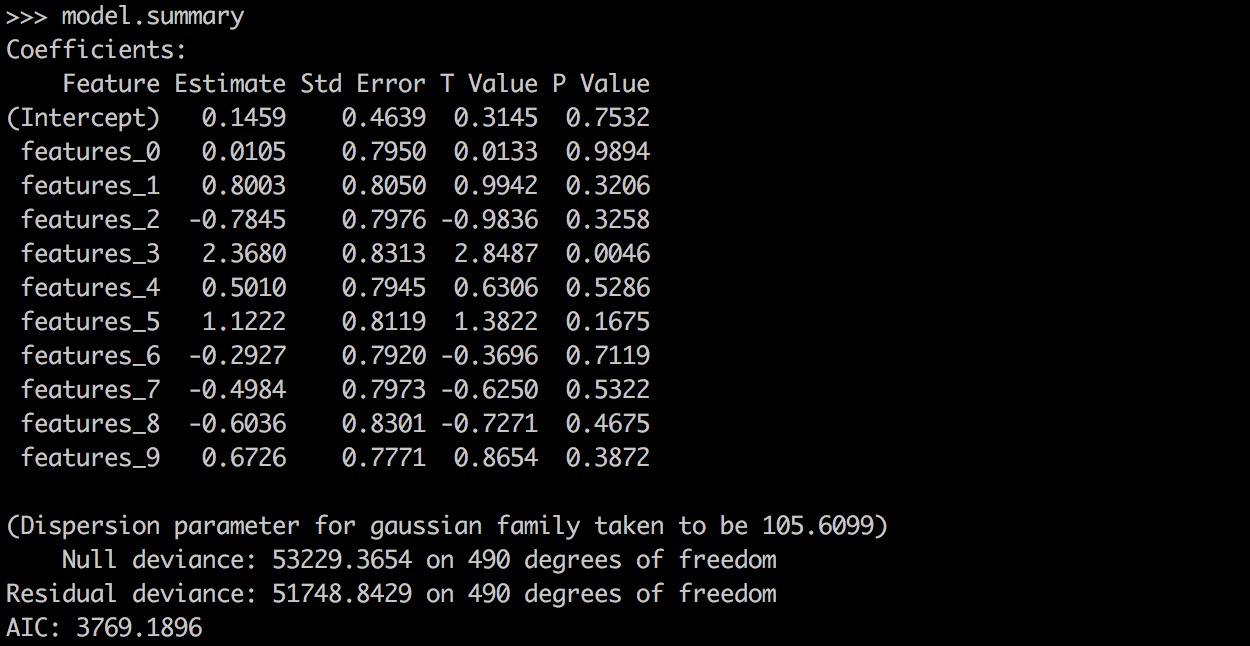
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18870 from yanboliang/spark-19270.
## What changes were proposed in this pull request?
Added DefaultParamsWriteable, DefaultParamsReadable, DefaultParamsWriter, and DefaultParamsReader to Python to support Python-only persistence of Json-serializable parameters.
## How was this patch tested?
Instantiated an estimator with Json-serializable parameters (ex. LogisticRegression), saved it using the added helper functions, and loaded it back, and compared it to the original instance to make sure it is the same. This test was both done in the Python REPL and implemented in the unit tests.
Note to reviewers: there are a few excess comments that I left in the code for clarity but will remove before the code is merged to master.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18742 from ajaysaini725/PythonPersistenceHelperFunctions.
## What changes were proposed in this pull request?
Implemented UnaryTransformer in Python.
## How was this patch tested?
This patch was tested by creating a MockUnaryTransformer class in the unit tests that extends UnaryTransformer and testing that the transform function produced correct output.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18746 from ajaysaini725/AddPythonUnaryTransformer.
## What changes were proposed in this pull request?
Python API for Constrained Logistic Regression based on #17922 , thanks for the original contribution from zero323 .
## How was this patch tested?
Unit tests.
Author: zero323 <zero323@users.noreply.github.com>
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18759 from yanboliang/SPARK-20601.
## What changes were proposed in this pull request?
GBTs inherit from HasStepSize & LInearSVC/Binarizer from HasThreshold
## How was this patch tested?
existing tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Author: Ruifeng Zheng <ruifengz@foxmail.com>
Closes#18612 from zhengruifeng/override_HasXXX.
## What changes were proposed in this pull request?
add `setWeightCol` method for OneVsRest.
`weightCol` is ignored if classifier doesn't inherit HasWeightCol trait.
## How was this patch tested?
+ [x] add an unit test.
Author: Yan Facai (颜发才) <facai.yan@gmail.com>
Closes#18554 from facaiy/BUG/oneVsRest_missing_weightCol.
## What changes were proposed in this pull request?
Added functionality for CrossValidator and TrainValidationSplit to persist nested estimators such as OneVsRest. Also added CrossValidator and TrainValidation split persistence to pyspark.
## How was this patch tested?
Performed both cross validation and train validation split with a one vs. rest estimator and tested read/write functionality of the estimator parameter maps required by these meta-algorithms.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18428 from ajaysaini725/MetaAlgorithmPersistNestedEstimators.
## What changes were proposed in this pull request?
```RFormula``` should handle invalid for both features and label column.
#18496 only handle invalid values in features column. This PR add handling invalid values for label column and test cases.
## How was this patch tested?
Add test cases.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18613 from yanboliang/spark-20307.
## What changes were proposed in this pull request?
1, HasHandleInvaild support override
2, Make QuantileDiscretizer/Bucketizer/StringIndexer/RFormula inherit from HasHandleInvalid
## How was this patch tested?
existing tests
[JIRA](https://issues.apache.org/jira/browse/SPARK-18619)
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#18582 from zhengruifeng/heritate_HasHandleInvalid.
## What changes were proposed in this pull request?
Add offset to PySpark in GLM as in #16699.
## How was this patch tested?
Python test
Author: actuaryzhang <actuaryzhang10@gmail.com>
Closes#18534 from actuaryzhang/pythonOffset.
## What changes were proposed in this pull request?
This PR is to maintain API parity with changes made in SPARK-17498 to support a new option
'keep' in StringIndexer to handle unseen labels or NULL values with PySpark.
Note: This is updated version of #17237 , the primary author of this PR is VinceShieh .
## How was this patch tested?
Unit tests.
Author: VinceShieh <vincent.xie@intel.com>
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18453 from yanboliang/spark-19852.
## What changes were proposed in this pull request?
1, make param support non-final with `finalFields` option
2, generate `HasSolver` with `finalFields = false`
3, override `solver` in LiR, GLR, and make MLPC inherit `HasSolver`
## How was this patch tested?
existing tests
Author: Ruifeng Zheng <ruifengz@foxmail.com>
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#16028 from zhengruifeng/param_non_final.
## What changes were proposed in this pull request?
LinearSVC should use its own threshold param, rather than the shared one, since it applies to rawPrediction instead of probability. This PR changes the param in the Scala, Python and R APIs.
## How was this patch tested?
New unit test to make sure the threshold can be set to any Double value.
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#18151 from jkbradley/ml-2.2-linearsvc-cleanup.
## What changes were proposed in this pull request?
PySpark supports stringIndexerOrderType in RFormula as in #17967.
## How was this patch tested?
docstring test
Author: actuaryzhang <actuaryzhang10@gmail.com>
Closes#18122 from actuaryzhang/PythonRFormula.
## What changes were proposed in this pull request?
Expose numPartitions (expert) param of PySpark FPGrowth.
## How was this patch tested?
+ [x] Pass all unit tests.
Author: Yan Facai (颜发才) <facai.yan@gmail.com>
Closes#18058 from facaiy/ENH/pyspark_fpg_add_num_partition.
## What changes were proposed in this pull request?
Follow-up for #17218, some minor fix for PySpark ```FPGrowth```.
## How was this patch tested?
Existing UT.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18089 from yanboliang/spark-19281.
## What changes were proposed in this pull request?
- Fix incorrect tests for `_check_thresholds`.
- Move test to `ParamTests`.
## How was this patch tested?
Unit tests.
Author: zero323 <zero323@users.noreply.github.com>
Closes#18085 from zero323/SPARK-20631-FOLLOW-UP.
## What changes were proposed in this pull request?
Add test cases for PR-18062
## How was this patch tested?
The existing UT
Author: Peng <peng.meng@intel.com>
Closes#18068 from mpjlu/moreTest.
Changes:
pyspark.ml Estimators can take either a list of param maps or a dict of params. This change allows the CrossValidator and TrainValidationSplit Estimators to pass through lists of param maps to the underlying estimators so that those estimators can handle parallelization when appropriate (eg distributed hyper parameter tuning).
Testing:
Existing unit tests.
Author: Bago Amirbekian <bago@databricks.com>
Closes#18077 from MrBago/delegate_params.
## What changes were proposed in this pull request?
SPARK-20097 exposed degreesOfFreedom in LinearRegressionSummary and numInstances in GeneralizedLinearRegressionSummary. Python API should be updated to reflect these changes.
## How was this patch tested?
The existing UT
Author: Peng <peng.meng@intel.com>
Closes#18062 from mpjlu/spark-20764.
## What changes were proposed in this pull request?
PySpark StringIndexer supports StringOrderType added in #17879.
Author: Wayne Zhang <actuaryzhang@uber.com>
Closes#17978 from actuaryzhang/PythonStringIndexer.
## What changes were proposed in this pull request?
Review new Scala APIs introduced in 2.2.
## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17934 from yanboliang/spark-20501.
## What changes were proposed in this pull request?
Before 2.2, MLlib keep to remove APIs deprecated in last feature/minor release. But from Spark 2.2, we decide to remove deprecated APIs in a major release, so we need to change corresponding annotations to tell users those will be removed in 3.0.
Meanwhile, this fixed bugs in ML documents. The original ML docs can't show deprecated annotations in ```MLWriter``` and ```MLReader``` related class, we correct it in this PR.
Before:

After:

## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17946 from yanboliang/spark-20707.
## What changes were proposed in this pull request?
- Replace `getParam` calls with `getOrDefault` calls.
- Fix exception message to avoid unintended `TypeError`.
- Add unit tests
## How was this patch tested?
New unit tests.
Author: zero323 <zero323@users.noreply.github.com>
Closes#17891 from zero323/SPARK-20631.
## What changes were proposed in this pull request?
Remove ML methods we deprecated in 2.1.
## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17867 from yanboliang/spark-20606.
Add Python API for `ALSModel` methods `recommendForAllUsers`, `recommendForAllItems`
## How was this patch tested?
New doc tests.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#17622 from MLnick/SPARK-20300-pyspark-recall.
## What changes were proposed in this pull request?
Some PySpark & SparkR tests run with tiny dataset and tiny ```maxIter```, which means they are not converged. I don’t think checking intermediate result during iteration make sense, and these intermediate result may vulnerable and not stable, so we should switch to check the converged result. We hit this issue at #17746 when we upgrade breeze to 0.13.1.
## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17757 from yanboliang/flaky-test.
## What changes were proposed in this pull request?
Upgrade breeze version to 0.13.1, which fixed some critical bugs of L-BFGS-B.
## How was this patch tested?
Existing unit tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17746 from yanboliang/spark-20449.
## What changes were proposed in this pull request?
The Dataframes-based support for the correlation statistics is added in #17108. This patch adds the Python interface for it.
## How was this patch tested?
Python unit test.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#17494 from viirya/correlation-python-api.
## What changes were proposed in this pull request?
`_convert_to_vector` converts a scipy sparse matrix to csc matrix for initializing `SparseVector`. However, it doesn't guarantee the converted csc matrix has sorted indices and so a failure happens when you do something like that:
from scipy.sparse import lil_matrix
lil = lil_matrix((4, 1))
lil[1, 0] = 1
lil[3, 0] = 2
_convert_to_vector(lil.todok())
File "/home/jenkins/workspace/python/pyspark/mllib/linalg/__init__.py", line 78, in _convert_to_vector
return SparseVector(l.shape[0], csc.indices, csc.data)
File "/home/jenkins/workspace/python/pyspark/mllib/linalg/__init__.py", line 556, in __init__
% (self.indices[i], self.indices[i + 1]))
TypeError: Indices 3 and 1 are not strictly increasing
A simple test can confirm that `dok_matrix.tocsc()` won't guarantee sorted indices:
>>> from scipy.sparse import lil_matrix
>>> lil = lil_matrix((4, 1))
>>> lil[1, 0] = 1
>>> lil[3, 0] = 2
>>> dok = lil.todok()
>>> csc = dok.tocsc()
>>> csc.has_sorted_indices
0
>>> csc.indices
array([3, 1], dtype=int32)
I checked the source codes of scipy. The only way to guarantee it is `csc_matrix.tocsr()` and `csr_matrix.tocsc()`.
## How was this patch tested?
Existing tests.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#17532 from viirya/make-sure-sorted-indices.
## What changes were proposed in this pull request?
A pyspark wrapper for spark.ml.stat.ChiSquareTest
## How was this patch tested?
unit tests
doctests
Author: Bago Amirbekian <bago@databricks.com>
Closes#17421 from MrBago/chiSquareTestWrapper.
## What changes were proposed in this pull request?
- Add `HasSupport` and `HasConfidence` `Params`.
- Add new module `pyspark.ml.fpm`.
- Add `FPGrowth` / `FPGrowthModel` wrappers.
- Provide tests for new features.
## How was this patch tested?
Unit tests.
Author: zero323 <zero323@users.noreply.github.com>
Closes#17218 from zero323/SPARK-19281.
Add Python wrapper for `Imputer` feature transformer.
## How was this patch tested?
New doc tests and tweak to PySpark ML `tests.py`
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#17316 from MLnick/SPARK-15040-pyspark-imputer.
## What changes were proposed in this pull request?
PySpark ```GeneralizedLinearRegression``` supports tweedie distribution.
## How was this patch tested?
Add unit tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17146 from yanboliang/spark-19806.
## What changes were proposed in this pull request?
The `keyword_only` decorator in PySpark is not thread-safe. It writes kwargs to a static class variable in the decorator, which is then retrieved later in the class method as `_input_kwargs`. If multiple threads are constructing the same class with different kwargs, it becomes a race condition to read from the static class variable before it's overwritten. See [SPARK-19348](https://issues.apache.org/jira/browse/SPARK-19348) for reproduction code.
This change will write the kwargs to a member variable so that multiple threads can operate on separate instances without the race condition. It does not protect against multiple threads operating on a single instance, but that is better left to the user to synchronize.
## How was this patch tested?
Added new unit tests for using the keyword_only decorator and a regression test that verifies `_input_kwargs` can be overwritten from different class instances.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#16782 from BryanCutler/pyspark-keyword_only-threadsafe-SPARK-19348.
## What changes were proposed in this pull request?
Updates the doc string to match up with the code
i.e. say dropLast instead of includeFirst
## How was this patch tested?
Not much, since it's a doc-like change. Will run unit tests via Jenkins job.
Author: Mark Grover <mark@apache.org>
Closes#17127 from markgrover/spark_19734.
## What changes were proposed in this pull request?
Remove `org.apache.spark.examples.` in
Add slash in one of the python doc.
## How was this patch tested?
Run examples using the commands in the comments.
Author: Yun Ni <yunn@uber.com>
Closes#17104 from Yunni/yunn_minor.
This PR adds a param to `ALS`/`ALSModel` to set the strategy used when encountering unknown users or items at prediction time in `transform`. This can occur in 2 scenarios: (a) production scoring, and (b) cross-validation & evaluation.
The current behavior returns `NaN` if a user/item is unknown. In scenario (b), this can easily occur when using `CrossValidator` or `TrainValidationSplit` since some users/items may only occur in the test set and not in the training set. In this case, the evaluator returns `NaN` for all metrics, making model selection impossible.
The new param, `coldStartStrategy`, defaults to `nan` (the current behavior). The other option supported initially is `drop`, which drops all rows with `NaN` predictions. This flag allows users to use `ALS` in cross-validation settings. It is made an `expertParam`. The param is made a string so that the set of strategies can be extended in future (some options are discussed in [SPARK-14489](https://issues.apache.org/jira/browse/SPARK-14489)).
## How was this patch tested?
New unit tests, and manual "before and after" tests for Scala & Python using MovieLens `ml-latest-small` as example data. Here, using `CrossValidator` or `TrainValidationSplit` with the default param setting results in metrics that are all `NaN`, while setting `coldStartStrategy` to `drop` results in valid metrics.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#12896 from MLnick/SPARK-14489-als-nan.
## What changes were proposed in this pull request?
Fixed the PySpark Params.copy method to behave like the Scala implementation. The main issue was that it did not account for the _defaultParamMap and merged it into the explicitly created param map.
## How was this patch tested?
Added new unit test to verify the copy method behaves correctly for copying uid, explicitly created params, and default params.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#16772 from BryanCutler/pyspark-ml-param_copy-Scala_sync-SPARK-14772.
## What changes were proposed in this pull request?
This pull request includes python API and examples for LSH. The API changes was based on yanboliang 's PR #15768 and resolved conflicts and API changes on the Scala API. The examples are consistent with Scala examples of MinHashLSH and BucketedRandomProjectionLSH.
## How was this patch tested?
API and examples are tested using spark-submit:
`bin/spark-submit examples/src/main/python/ml/min_hash_lsh.py`
`bin/spark-submit examples/src/main/python/ml/bucketed_random_projection_lsh.py`
User guide changes are generated and manually inspected:
`SKIP_API=1 jekyll build`
Author: Yun Ni <yunn@uber.com>
Author: Yanbo Liang <ybliang8@gmail.com>
Author: Yunni <Euler57721@gmail.com>
Closes#16715 from Yunni/spark-18080.
## What changes were proposed in this pull request?
This PR is to document the changes on QuantileDiscretizer in pyspark for PR:
https://github.com/apache/spark/pull/15428
## How was this patch tested?
No test needed
Signed-off-by: VinceShieh <vincent.xieintel.com>
Author: VinceShieh <vincent.xie@intel.com>
Closes#16922 from VinceShieh/spark-19590.
## What changes were proposed in this pull request?
Add missing `warnings` import.
## How was this patch tested?
Manual tests.
Author: zero323 <zero323@users.noreply.github.com>
Closes#16846 from zero323/SPARK-19506.
## What changes were proposed in this pull request?
Remove cyclic imports between `pyspark.ml.pipeline` and `pyspark.ml`.
## How was this patch tested?
Existing unit tests.
Author: zero323 <zero323@users.noreply.github.com>
Closes#16814 from zero323/SPARK-19467.
## What changes were proposed in this pull request?
Methods `numClasses` and `numFeatures` in LinearSVCModel are already usable by inheriting `JavaClassificationModel`
we should not explicitly add them.
## How was this patch tested?
existing tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#16727 from zhengruifeng/nits_in_linearSVC.
## What changes were proposed in this pull request?
* Removed Since tags in Python Params since they are inherited by other classes
* Fixed doc links for LinearSVC
## How was this patch tested?
* doc tests
* generating docs locally and checking manually
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#16723 from jkbradley/pyparam-fix-doc.
## What changes were proposed in this pull request?
Adding convenience function to Python `JavaWrapper` so that it is easy to create a Py4J JavaArray that is compatible with current class constructors that have a Scala `Array` as input so that it is not necessary to have a Java/Python friendly constructor. The function takes a Java class as input that is used by Py4J to create the Java array of the given class. As an example, `OneVsRest` has been updated to use this and the alternate constructor is removed.
## How was this patch tested?
Added unit tests for the new convenience function and updated `OneVsRest` doctests which use this to persist the model.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#14725 from BryanCutler/pyspark-new_java_array-CountVectorizer-SPARK-17161.
## What changes were proposed in this pull request?
Add Python API for the newly added LinearSVC algorithm.
## How was this patch tested?
Add new doc string test.
Author: wm624@hotmail.com <wm624@hotmail.com>
Closes#16694 from wangmiao1981/ser.
## What changes were proposed in this pull request?
add loglikelihood in GMM.summary
## How was this patch tested?
added tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Author: Ruifeng Zheng <ruifengz@foxmail.com>
Closes#12064 from zhengruifeng/gmm_metric.
## What changes were proposed in this pull request?
Add FDR test case in ml/feature/ChiSqSelectorSuite.
Improve some comments in the code.
This is a follow-up pr for #15212.
## How was this patch tested?
ut
Author: Peng, Meng <peng.meng@intel.com>
Closes#16434 from mpjlu/fdr_fwe_update.
## What changes were proposed in this pull request?
Copy `GaussianMixture` implementation from mllib to ml, then we can add new features to it.
I left mllib `GaussianMixture` untouched, unlike some other algorithms to wrap the ml implementation. For the following reasons:
- mllib `GaussianMixture` allows k == 1, but ml does not.
- mllib `GaussianMixture` supports setting initial model, but ml does not support currently. (We will definitely add this feature for ml in the future)
We can get around these issues to make mllib as a wrapper calling into ml, but I'd prefer to leave mllib untouched which can make ml clean.
Meanwhile, There is a big performance improvement for `GaussianMixture` in this PR. Since the covariance matrix of multivariate gaussian distribution is symmetric, we can only store the upper triangular part of the matrix and it will greatly reduce the shuffled data size. In my test, this change will reduce shuffled data size by about 50% and accelerate the job execution.
Before this PR:

After this PR:

## How was this patch tested?
Existing tests and added new tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#15413 from yanboliang/spark-17847.
## What changes were proposed in this pull request?
There are many locations in the Spark repo where the same word occurs consecutively. Sometimes they are appropriately placed, but many times they are not. This PR removes the inappropriately duplicated words.
## How was this patch tested?
N/A since only docs or comments were updated.
Author: Niranjan Padmanabhan <niranjan.padmanabhan@gmail.com>
Closes#16455 from neurons/np.structure_streaming_doc.
## What changes were proposed in this pull request?
Univariate feature selection works by selecting the best features based on univariate statistical tests.
FDR and FWE are a popular univariate statistical test for feature selection.
In 2005, the Benjamini and Hochberg paper on FDR was identified as one of the 25 most-cited statistical papers. The FDR uses the Benjamini-Hochberg procedure in this PR. https://en.wikipedia.org/wiki/False_discovery_rate.
In statistics, FWE is the probability of making one or more false discoveries, or type I errors, among all the hypotheses when performing multiple hypotheses tests.
https://en.wikipedia.org/wiki/Family-wise_error_rate
We add FDR and FWE methods for ChiSqSelector in this PR, like it is implemented in scikit-learn.
http://scikit-learn.org/stable/modules/feature_selection.html#univariate-feature-selection
## How was this patch tested?
ut will be added soon
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Author: Peng <peng.meng@intel.com>
Author: Peng, Meng <peng.meng@intel.com>
Closes#15212 from mpjlu/fdr_fwe.
## What changes were proposed in this pull request?
Updated Scala param and Python param to have quotes around the options making it easier for users to read.
## How was this patch tested?
Manually checked the docstrings
Author: krishnakalyan3 <krishnakalyan3@gmail.com>
Closes#16242 from krishnakalyan3/doc-string.
## What changes were proposed in this pull request?
In`JavaWrapper `'s destructor make Java Gateway dereference object in destructor, using `SparkContext._active_spark_context._gateway.detach`
Fixing the copying parameter bug, by moving the `copy` method from `JavaModel` to `JavaParams`
## How was this patch tested?
```scala
import random, string
from pyspark.ml.feature import StringIndexer
l = [(''.join(random.choice(string.ascii_uppercase) for _ in range(10)), ) for _ in range(int(7e5))] # 700000 random strings of 10 characters
df = spark.createDataFrame(l, ['string'])
for i in range(50):
indexer = StringIndexer(inputCol='string', outputCol='index')
indexer.fit(df)
```
* Before: would keep StringIndexer strong reference, causing GC issues and is halted midway
After: garbage collection works as the object is dereferenced, and computation completes
* Mem footprint tested using profiler
* Added a parameter copy related test which was failing before.
Author: Sandeep Singh <sandeep@techaddict.me>
Author: jkbradley <joseph.kurata.bradley@gmail.com>
Closes#15843 from techaddict/SPARK-18274.
## What changes were proposed in this pull request?
added the new handleInvalid param for these transformers to Python to maintain API parity.
## How was this patch tested?
existing tests
testing is done with new doctests
Author: Sandeep Singh <sandeep@techaddict.me>
Closes#15817 from techaddict/SPARK-18366.
## What changes were proposed in this pull request?
Add python api for KMeansSummary
## How was this patch tested?
unit test added
Author: Jeff Zhang <zjffdu@apache.org>
Closes#13557 from zjffdu/SPARK-15819.
## What changes were proposed in this pull request?
make a pass through the items marked as Experimental or DeveloperApi and see if any are stable enough to be unmarked. Also check for items marked final or sealed to see if they are stable enough to be opened up as APIs.
Some discussions in the jira: https://issues.apache.org/jira/browse/SPARK-18319
## How was this patch tested?
existing ut
Author: Yuhao <yuhao.yang@intel.com>
Author: Yuhao Yang <hhbyyh@gmail.com>
Closes#15972 from hhbyyh/experimental21.
## What changes were proposed in this pull request?
Remove deprecated methods for ML.
## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#15913 from yanboliang/spark-18481.
## What changes were proposed in this pull request?
Add model summary APIs for `GaussianMixtureModel` and `BisectingKMeansModel` in pyspark.
## How was this patch tested?
Unit tests.
Author: sethah <seth.hendrickson16@gmail.com>
Closes#15777 from sethah/pyspark_cluster_summaries.
## What changes were proposed in this pull request?
Gradient Boosted Tree in R.
With a few minor improvements to RandomForest in R.
Since this is relatively isolated I'd like to target this for branch-2.1
## How was this patch tested?
manual tests, unit tests
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#15746 from felixcheung/rgbt.
## What changes were proposed in this pull request?
Add missing 'subsamplingRate' of pyspark GBTClassifier
## How was this patch tested?
existing tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#15692 from zhengruifeng/gbt_subsamplingRate.
## What changes were proposed in this pull request?
- Renamed kbest to numTopFeatures
- Renamed alpha to fpr
- Added missing Since annotations
- Doc cleanups
## How was this patch tested?
Added new standardized unit tests for spark.ml.
Improved existing unit test coverage a bit.
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#15647 from jkbradley/chisqselector-follow-ups.
## What changes were proposed in this pull request?
Add subsmaplingRate to randomForestClassifier
Add varianceCol to randomForestRegressor
In Python
## How was this patch tested?
manual tests
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#15638 from felixcheung/pyrandomforest.
## What changes were proposed in this pull request?
This PR is an enhancement of PR with commit ID:57dc326bd00cf0a49da971e9c573c48ae28acaa2.
NaN is a special type of value which is commonly seen as invalid. But We find that there are certain cases where NaN are also valuable, thus need special handling. We provided user when dealing NaN values with 3 options, to either reserve an extra bucket for NaN values, or remove the NaN values, or report an error, by setting handleNaN "keep", "skip", or "error"(default) respectively.
'''Before:
val bucketizer: Bucketizer = new Bucketizer()
.setInputCol("feature")
.setOutputCol("result")
.setSplits(splits)
'''After:
val bucketizer: Bucketizer = new Bucketizer()
.setInputCol("feature")
.setOutputCol("result")
.setSplits(splits)
.setHandleNaN("keep")
## How was this patch tested?
Tests added in QuantileDiscretizerSuite, BucketizerSuite and DataFrameStatSuite
Signed-off-by: VinceShieh <vincent.xieintel.com>
Author: VinceShieh <vincent.xie@intel.com>
Author: Vincent Xie <vincent.xie@intel.com>
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#15428 from VinceShieh/spark-17219_followup.
## What changes were proposed in this pull request?
For feature selection method ChiSquareSelector, it is based on the ChiSquareTestResult.statistic (ChiSqure value) to select the features. It select the features with the largest ChiSqure value. But the Degree of Freedom (df) of ChiSqure value is different in Statistics.chiSqTest(RDD), and for different df, you cannot base on ChiSqure value to select features.
So we change statistic to pValue for SelectKBest and SelectPercentile
## How was this patch tested?
change existing test
Author: Peng <peng.meng@intel.com>
Closes#15444 from mpjlu/chisqure-bug.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}