### What changes were proposed in this pull request?
Use the new framework to resolve the SHOW TBLPROPERTIES command. This PR along with #27243 should update all the existing V2 commands with `UnresolvedV2Relation`.
### Why are the changes needed?
This is a part of effort to make the relation lookup behavior consistent: [SPARK-2990](https://issues.apache.org/jira/browse/SPARK-29900).
### Does this PR introduce any user-facing change?
Yes `SHOW TBLPROPERTIES temp_view` now fails with `AnalysisException` will be thrown with a message `temp_view is a temp view not table`. Previously, it was returning empty row.
### How was this patch tested?
Existing tests
Closes#26921 from imback82/consistnet_v2command.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
TableCatalog reserves some properties, e,g `provider`, `location` for internal usage. Some of them are static once create, some of them need specific syntax to modify. Instead of using `OPTIONS (k='v')` or TBLPROPERTIES (k='v'), if k is a reserved TableCatalog property, we should use its specific syntax to add/modify/delete it. e.g. `provider` is a reserved property, we should use the `USING` clause to specify it, and should not allow `ALTER TABLE ... UNSET TBLPROPERTIES('provider')` to delete it. Also, there are two paths for v1/v2 catalog tables to resolve these properties, e.g. the v1 session catalog tables will only use the `USING` clause to decide `provider` but v2 tables will also lookup OPTION/TBLPROPERTIES(although there is a bug prohibit it).
Additionally, 'path' is not reserved but holds special meaning for `LOCATION` and it is used in `CREATE/REPLACE TABLE`'s `OPTIONS` sub-clause. Now for the session catalog tables, the `path` is case-insensitive, but for the non-session catalog tables, it is case-sensitive, we should make it both case insensitive for disambiguation.
### Why are the changes needed?
prevent reserved properties from being modified unexpectedly
unify the property resolution for v1/v2.
fix some bugs.
### Does this PR introduce any user-facing change?
yes
1 . `location` and `provider` (case sensitive) cannot be used in `CREATE/REPLACE TABLE ... OPTIONS/TBLPROPETIES` and `ALTER TABLE ... SET TBLPROPERTIES (...)`, if legacy on, they will be ignored to let the command success without having side effects
3. Once `path` in `CREATE/REPLACE TABLE ... OPTIONS` is case insensitive for v1 but sensitive for v2, but now we change it case insensitive for both kinds of tables, then v2 tables will also fail if `LOCATION` and `OPTIONS('PaTh' ='abc')` are both specified or will pick `PaTh`'s value as table location if `LOCATION` is missing.
4. Now we will detect if there are two different case `path` keys or more in `CREATE/REPLACE TABLE ... OPTIONS`, once it is a kind of unexpected last-win policy for v1, and v2 is case sensitive.
### How was this patch tested?
add ut
Closes#27197 from yaooqinn/SPARK-30507.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Now users can add directories from sql CLI as well using ADD FILE command and setting spark.sql.addDirectory.recursive to true.
### Why are the changes needed?
In SPARK-4687, support was added for adding directories as resources. But sql users cannot use that feature from CLI.
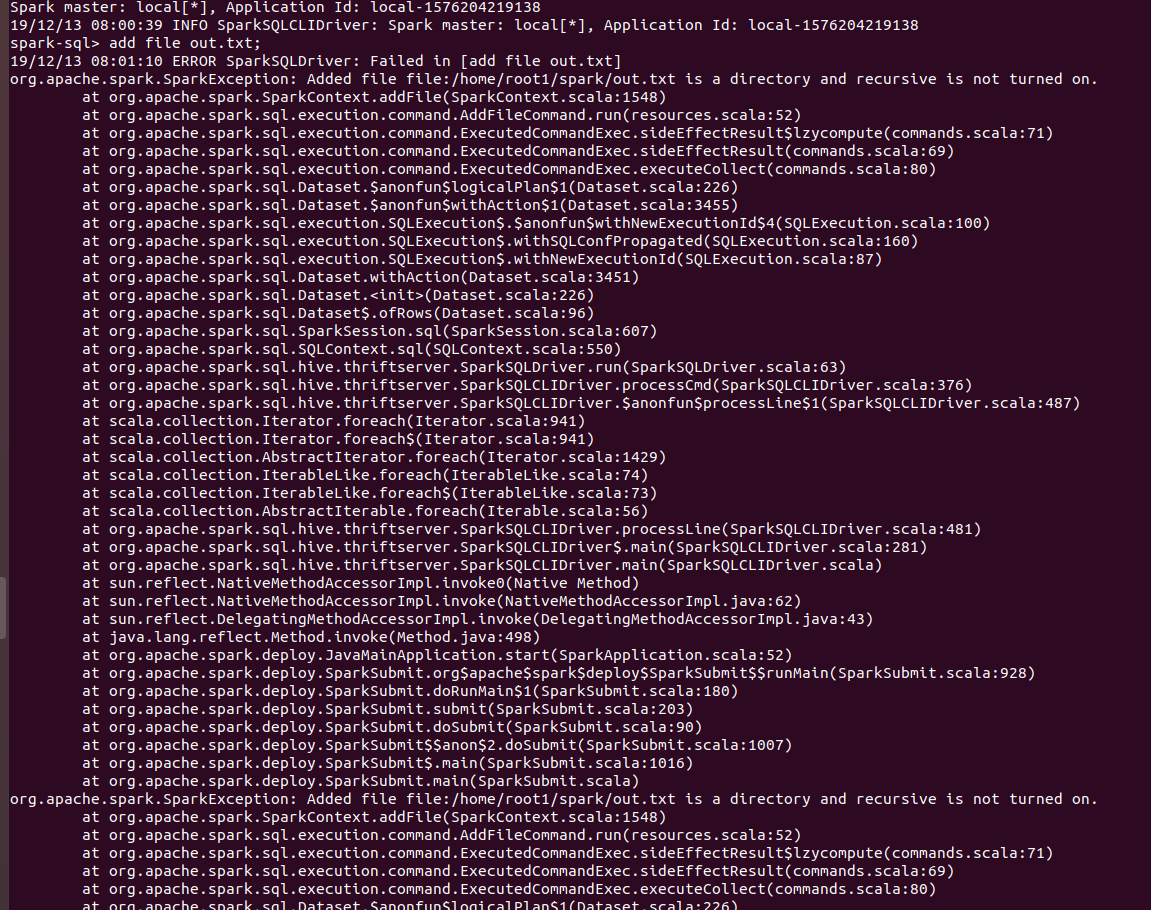
`ADD FILE /path/to/folder` gives the following error:
`org.apache.spark.SparkException: Added file /path/to/folder is a directory and recursive is not turned on.`
Users need to turn on `recursive` for adding directories. Thus a configuration was required which will allow users to turn on `recursive`.
Also Hive allow users to add directories from their shell.
### Does this PR introduce any user-facing change?
Yes. Users can set recursive using `spark.sql.addDirectory.recursive`.
### How was this patch tested?
Manually.
Will add test cases soon.
SPARK SCREENSHOTS
When `spark.sql.addDirectory.recursive` is not turned on.
After setting `spark.sql.addDirectory.recursive` to true.

HIVE SCREENSHOT

`RELEASE_NOTES.txt` is text file while `dummy` is a directory.
Closes#26863 from iRakson/SPARK-30234.
Lead-authored-by: root1 <raksonrakesh@gmail.com>
Co-authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Currently, COMMENT and LOCATION are reserved properties for Datasource v2 namespaces. They can be set via specific clauses and via properties. And the ones specified in clauses take precede of properties. Since they are reserved, which means they are not able to visit directly. They should be used in COMMENT/LOCATION clauses ONLY.
### Why are the changes needed?
make reserved properties be reserved.
### Does this PR introduce any user-facing change?
yes, 'location', 'comment' are not allowed use in db properties
### How was this patch tested?
UNIT tests.
Closes#26806 from yaooqinn/SPARK-30183.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change config name from `spark.sql.legacy.typeCoercion.datetimeToString` to `spark.sql.legacy.typeCoercion.datetimeToString.enabled`.
### Why are the changes needed?
To follow the other boolean conf naming convention.
### Does this PR introduce any user-facing change?
No, it's newly added in Spark 3.0.
### How was this patch tested?
Pass Jenkins
Closes#27065 from Ngone51/SPARK-27638-FOLLOWUP.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Create temporary or permanent function it should throw AnalysisException if the resource is not found. Need to keep behavior consistent across permanent and temporary functions.
## How was this patch tested?
Added UT and also tested manually
**Before Fix**
If the UDF resource is not present then on creation of temporary function it throws AnalysisException where as for permanent function it does not throw. Permanent funtcion throws AnalysisException only after select operation is performed.
**After Fix**
For temporary and permanent function check for the resource, if the UDF resource is not found then throw AnalysisException

Closes#25399 from sandeep-katta/funcIssue.
Authored-by: sandeep katta <sandeep.katta2007@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Update the Spark SQL document menu and join strategy hints.
### Why are the changes needed?
- Several new changes in the Spark SQL document didn't change the menu-sql.yaml correspondingly.
- Update the demo code for join strategy hints.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Document change only.
Closes#26917 from xuanyuanking/SPARK-30278.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
accuracyExpression can accept Long which may cause overflow error.
accuracyExpression can accept fractions which are implicitly floored.
accuracyExpression can accept null which is implicitly changed to 0.
percentageExpression can accept null but cause MatchError.
percentageExpression can accept ArrayType(_, nullable=true) in which the nulls are implicitly changed to zeros.
##### cases
```sql
select percentile_approx(10.0, 0.5, 2147483648); -- overflow and fail
select percentile_approx(10.0, 0.5, 4294967297); -- overflow but success
select percentile_approx(10.0, 0.5, null); -- null cast to 0
select percentile_approx(10.0, 0.5, 1.2); -- 1.2 cast to 1
select percentile_approx(10.0, null, 1); -- scala.MatchError
select percentile_approx(10.0, array(0.2, 0.4, null), 1); -- null cast to zero.
```
##### behavior before
```sql
+select percentile_approx(10.0, 0.5, 2147483648)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, CAST(0.5BD AS DOUBLE), CAST(2147483648L AS INT))' due to data type mismatch: The accuracy provided must be a positive integer literal (current value = -2147483648); line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 4294967297)
+10.0
+
+select percentile_approx(10.0, 0.5, null)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, CAST(0.5BD AS DOUBLE), CAST(NULL AS INT))' due to data type mismatch: The accuracy provided must be a positive integer literal (current value = 0); line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 1.2)
+10.0
+
+select percentile_approx(10.0, null, 1)
+scala.MatchError
+null
+
+
+select percentile_approx(10.0, array(0.2, 0.4, null), 1)
+[10.0,10.0,10.0]
```
##### behavior after
```sql
+select percentile_approx(10.0, 0.5, 2147483648)
+10.0
+
+select percentile_approx(10.0, 0.5, 4294967297)
+10.0
+
+select percentile_approx(10.0, 0.5, null)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, 0.5BD, NULL)' due to data type mismatch: argument 3 requires integral type, however, 'NULL' is of null type.; line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 1.2)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, 0.5BD, 1.2BD)' due to data type mismatch: argument 3 requires integral type, however, '1.2BD' is of decimal(2,1) type.; line 1 pos 7
+
+select percentile_approx(10.0, null, 1)
+java.lang.IllegalArgumentException
+The value of percentage must be be between 0.0 and 1.0, but got null
+
+select percentile_approx(10.0, array(0.2, 0.4, null), 1)
+java.lang.IllegalArgumentException
+Each value of the percentage array must be be between 0.0 and 1.0, but got [0.2,0.4,null]
```
### Why are the changes needed?
bug fix
### Does this PR introduce any user-facing change?
yes, fix some improper usages of percentile_approx as cases list above
### How was this patch tested?
add ut
Closes#26905 from yaooqinn/SPARK-30266.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to update the SQL migration guide and clarify semantic of string conversion to typed `TIMESTAMP` and `DATE` literals.
### Why are the changes needed?
This is a follow-up of the PR https://github.com/apache/spark/pull/23541 which changed the behavior of `TIMESTAMP`/`DATE` literals, and can impact on results of user's queries.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
It should be checked by jenkins build.
Closes#26985 from MaxGekk/timestamp-date-constructors-followup.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Fixed typo in `docs` directory and in other directories
1. Find typo in `docs` and apply fixes to files in all directories
2. Fix `the the` -> `the`
### Why are the changes needed?
Better readability of documents
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
No test needed
Closes#26976 from kiszk/typo_20191221.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR update document for make Hive 2.3 dependency by default.
### Why are the changes needed?
The documentation is incorrect.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#26919 from wangyum/SPARK-30280.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
add a migration guide for date_add and date_sub to indicates their behavior change. It a followup for #26412
### Why are the changes needed?
add a migration guide
### Does this PR introduce any user-facing change?
yes, doc change
### How was this patch tested?
no
Closes#26932 from yaooqinn/SPARK-29774-f.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When `spark.shuffle.useOldFetchProtocol` is enabled then switching off the direct disk reading of host-local shuffle blocks and falling back to remote block fetching (and this way avoiding the `GetLocalDirsForExecutors` block transfer message which is introduced from Spark 3.0.0).
### Why are the changes needed?
In `[SPARK-27651][Core] Avoid the network when shuffle blocks are fetched from the same host` a new block transfer message is introduced, `GetLocalDirsForExecutors`. This new message could be sent to the external shuffle service and as it is not supported by the previous version of external shuffle service it should be avoided when `spark.shuffle.useOldFetchProtocol` is true.
In the migration guide I changed the exception type as `org.apache.spark.network.shuffle.protocol.BlockTransferMessage.Decoder#fromByteBuffer`
throws a IllegalArgumentException with the given text and uses the message type which is just a simple number (byte). I have checked and this is true for version 2.4.4 too.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
This specific case (considering one extra boolean to switch off host local disk reading feature) is not tested but existing tests were run.
Closes#26869 from attilapiros/SPARK-30235.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
In the PR, I propose new implementation of `fromDayTimeString` which strictly parses strings in day-time formats to intervals. New implementation accepts only strings that match to a pattern defined by the `from` and `to`. Here is the mapping of user's bounds and patterns:
- `[+|-]D+ H[H]:m[m]:s[s][.SSSSSSSSS]` for **DAY TO SECOND**
- `[+|-]D+ H[H]:m[m]` for **DAY TO MINUTE**
- `[+|-]D+ H[H]` for **DAY TO HOUR**
- `[+|-]H[H]:m[m]s[s][.SSSSSSSSS]` for **HOUR TO SECOND**
- `[+|-]H[H]:m[m]` for **HOUR TO MINUTE**
- `[+|-]m[m]:s[s][.SSSSSSSSS]` for **MINUTE TO SECOND**
Closes#26327Closes#26358
### Why are the changes needed?
- Improve user experience with Spark SQL, and respect to the bound specified by users.
- Behave the same as other broadly used DBMS - Oracle and MySQL.
### Does this PR introduce any user-facing change?
Yes, before:
```sql
spark-sql> SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE;
interval 1 weeks 3 days 11 hours 12 minutes
```
After:
```sql
spark-sql> SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE;
Error in query:
requirement failed: Interval string must match day-time format of '^(?<sign>[+|-])?(?<hour>\d{1,2}):(?<minute>\d{1,2})$': 10 11:12:13.123(line 1, pos 16)
== SQL ==
SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE
----------------^^^
```
### How was this patch tested?
- Added tests to `IntervalUtilsSuite`
- By `ExpressionParserSuite`
- Updated `literals.sql`
Closes#26473 from MaxGekk/strict-from-daytime-string.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Now, we trim the string when casting string value to those `canCast` types values, e.g. int, double, decimal, interval, date, timestamps, except for boolean.
This behavior makes type cast and coercion inconsistency in Spark.
Not fitting ANSI SQL standard either.
```
If TD is boolean, then
Case:
a) If SD is character string, then SV is replaced by
TRIM ( BOTH ' ' FROM VE )
Case:
i) If the rules for literal in Subclause 5.3, “literal”, can be applied to SV to determine a valid
value of the data type TD, then let TV be that value.
ii) Otherwise, an exception condition is raised: data exception — invalid character value for cast.
b) If SD is boolean, then TV is SV
```
In this pull request, we trim all the whitespaces from both ends of the string before converting it to a bool value. This behavior is as same as others, but a bit different from sql standard, which trim only spaces.
### Why are the changes needed?
Type cast/coercion consistency
### Does this PR introduce any user-facing change?
yes, string with whitespaces in both ends will be trimmed before converted to booleans.
e.g. `select cast('\t true' as boolean)` results `true` now, before this pr it's `null`
### How was this patch tested?
add unit tests
Closes#26776 from yaooqinn/SPARK-30147.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In this PR, we propose to use the value of `spark.sql.source.default` as the provider for `CREATE TABLE` syntax instead of `hive` in Spark 3.0.
And to help the migration, we introduce a legacy conf `spark.sql.legacy.respectHiveDefaultProvider.enabled` and set its default to `false`.
### Why are the changes needed?
1. Currently, `CREATE TABLE` syntax use hive provider to create table while `DataFrameWriter.saveAsTable` API using the value of `spark.sql.source.default` as a provider to create table. It would be better to make them consistent.
2. User may gets confused in some cases. For example:
```
CREATE TABLE t1 (c1 INT) USING PARQUET;
CREATE TABLE t2 (c1 INT);
```
In these two DDLs, use may think that `t2` should also use parquet as default provider since Spark always advertise parquet as the default format. However, it's hive in this case.
On the other hand, if we omit the USING clause in a CTAS statement, we do pick parquet by default if `spark.sql.hive.convertCATS=true`:
```
CREATE TABLE t3 USING PARQUET AS SELECT 1 AS VALUE;
CREATE TABLE t4 AS SELECT 1 AS VALUE;
```
And these two cases together can be really confusing.
3. Now, Spark SQL is very independent and popular. We do not need to be fully consistent with Hive's behavior.
### Does this PR introduce any user-facing change?
Yes, before this PR, using `CREATE TABLE` syntax will use hive provider. But now, it use the value of `spark.sql.source.default` as its provider.
### How was this patch tested?
Added tests in `DDLParserSuite` and `HiveDDlSuite`.
Closes#26736 from Ngone51/dev-create-table-using-parquet-by-default.
Lead-authored-by: wuyi <yi.wu@databricks.com>
Co-authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
`UnaryPositive` only accepts numeric and interval as we defined, but what we do for this in `AstBuider.visitArithmeticUnary` is just bypassing it.
This should not be omitted for the type checking requirement.
### Why are the changes needed?
bug fix, you can find a pre-discussion here https://github.com/apache/spark/pull/26578#discussion_r347350398
### Does this PR introduce any user-facing change?
yes, +non-numeric-or-interval is now invalid.
```
-- !query 14
select +date '1900-01-01'
-- !query 14 schema
struct<DATE '1900-01-01':date>
-- !query 14 output
1900-01-01
-- !query 15
select +timestamp '1900-01-01'
-- !query 15 schema
struct<TIMESTAMP '1900-01-01 00:00:00':timestamp>
-- !query 15 output
1900-01-01 00:00:00
-- !query 16
select +map(1, 2)
-- !query 16 schema
struct<map(1, 2):map<int,int>>
-- !query 16 output
{1:2}
-- !query 17
select +array(1,2)
-- !query 17 schema
struct<array(1, 2):array<int>>
-- !query 17 output
[1,2]
-- !query 18
select -'1'
-- !query 18 schema
struct<(- CAST(1 AS DOUBLE)):double>
-- !query 18 output
-1.0
-- !query 19
select -X'1'
-- !query 19 schema
struct<>
-- !query 19 output
org.apache.spark.sql.AnalysisException
cannot resolve '(- X'01')' due to data type mismatch: argument 1 requires (numeric or interval) type, however, 'X'01'' is of binary type.; line 1 pos 7
-- !query 20
select +X'1'
-- !query 20 schema
struct<X'01':binary>
-- !query 20 output
```
### How was this patch tested?
add ut check
Closes#26716 from yaooqinn/SPARK-30083.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
add `.enabled` postfix to `spark.sql.analyzer.failAmbiguousSelfJoin`.
### Why are the changes needed?
to follow the existing naming style
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
not needed
Closes#26694 from cloud-fan/conf.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In SPARK-29421 (#26097) , we can specify a different table provider for `CREATE TABLE LIKE` via `USING provider`.
Hive support `STORED AS` new file format syntax:
```sql
CREATE TABLE tbl(a int) STORED AS TEXTFILE;
CREATE TABLE tbl2 LIKE tbl STORED AS PARQUET;
```
For Hive compatibility, we should also support `STORED AS` in `CREATE TABLE LIKE`.
### Why are the changes needed?
See https://github.com/apache/spark/pull/26097#issue-327424759
### Does this PR introduce any user-facing change?
Add a new syntax based on current CTL:
CREATE TABLE tbl2 LIKE tbl [STORED AS hiveFormat];
### How was this patch tested?
Add UTs.
Closes#26466 from LantaoJin/SPARK-29839.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For a literal number with an exponent(e.g. 1e-45, 1E2), we'd parse it to Double by default rather than Decimal. And user could still use `spark.sql.legacy.exponentLiteralToDecimal.enabled=true` to fall back to previous behavior.
### Why are the changes needed?
According to ANSI standard of SQL, we see that the (part of) definition of `literal` :
```
<approximate numeric literal> ::=
<mantissa> E <exponent>
```
which indicates that a literal number with an exponent should be approximate numeric(e.g. Double) rather than exact numeric(e.g. Decimal).
And when we test Presto, we found that Presto also conforms to this standard:
```
presto:default> select typeof(1E2);
_col0
--------
double
(1 row)
```
```
presto:default> select typeof(1.2);
_col0
--------------
decimal(2,1)
(1 row)
```
We also find that, actually, literals like `1E2` are parsed as Double before Spark2.1, but changed to Decimal after #14828 due to *The difference between the two confuses most users* as it said. But we also see support(from DB2 test) of original behavior at #14828 (comment).
Although, we also see that PostgreSQL has its own implementation:
```
postgres=# select pg_typeof(1E2);
pg_typeof
-----------
numeric
(1 row)
postgres=# select pg_typeof(1.2);
pg_typeof
-----------
numeric
(1 row)
```
We still think that Spark should also conform to this standard while considering SQL standard and Spark own history and majority DBMS and also user experience.
### Does this PR introduce any user-facing change?
Yes.
For `1E2`, before this PR:
```
scala> spark.sql("select 1E2")
res0: org.apache.spark.sql.DataFrame = [1E+2: decimal(1,-2)]
```
After this PR:
```
scala> spark.sql("select 1E2")
res0: org.apache.spark.sql.DataFrame = [100.0: double]
```
And for `1E-45`, before this PR:
```
org.apache.spark.sql.catalyst.parser.ParseException:
decimal can only support precision up to 38
== SQL ==
select 1E-45
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parse(ParseDriver.scala:131)
at org.apache.spark.sql.execution.SparkSqlParser.parse(SparkSqlParser.scala:48)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parsePlan(ParseDriver.scala:76)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:605)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:605)
... 47 elided
```
after this PR:
```
scala> spark.sql("select 1E-45");
res1: org.apache.spark.sql.DataFrame = [1.0E-45: double]
```
And before this PR, user may feel super weird to see that `select 1e40` works but `select 1e-40 fails`. And now, both of them work well.
### How was this patch tested?
updated `literals.sql.out` and `ansi/literals.sql.out`
Closes#26595 from Ngone51/SPARK-29956.
Authored-by: wuyi <ngone_5451@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
[HIVE-12063](https://issues.apache.org/jira/browse/HIVE-12063) improved pad decimal numbers with trailing zeros to the scale of the column. The following description is copied from the description of HIVE-12063.
> HIVE-7373 was to address the problems of trimming tailing zeros by Hive, which caused many problems including treating 0.0, 0.00 and so on as 0, which has different precision/scale. Please refer to HIVE-7373 description. However, HIVE-7373 was reverted by HIVE-8745 while the underlying problems remained. HIVE-11835 was resolved recently to address one of the problems, where 0.0, 0.00, and so on cannot be read into decimal(1,1).
However, HIVE-11835 didn't address the problem of showing as 0 in query result for any decimal values such as 0.0, 0.00, etc. This causes confusion as 0 and 0.0 have different precision/scale than 0.
The proposal here is to pad zeros for query result to the type's scale. This not only removes the confusion described above, but also aligns with many other DBs. Internal decimal number representation doesn't change, however.
**Spark SQL**:
```sql
// bin/spark-sql
spark-sql> select cast(1 as decimal(38, 18));
1
spark-sql>
// bin/beeline
0: jdbc:hive2://localhost:10000/default> select cast(1 as decimal(38, 18));
+----------------------------+--+
| CAST(1 AS DECIMAL(38,18)) |
+----------------------------+--+
| 1.000000000000000000 |
+----------------------------+--+
// bin/spark-shell
scala> spark.sql("select cast(1 as decimal(38, 18))").show(false)
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
|1.000000000000000000 |
+-------------------------+
// bin/pyspark
>>> spark.sql("select cast(1 as decimal(38, 18))").show()
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
// bin/sparkR
> showDF(sql("SELECT cast(1 as decimal(38, 18))"))
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
```
**PostgreSQL**:
```sql
postgres=# select cast(1 as decimal(38, 18));
numeric
----------------------
1.000000000000000000
(1 row)
```
**Presto**:
```sql
presto> select cast(1 as decimal(38, 18));
_col0
----------------------
1.000000000000000000
(1 row)
```
## How was this patch tested?
unit tests and manual test:
```sql
spark-sql> select cast(1 as decimal(38, 18));
1.000000000000000000
```
Spark SQL Upgrading Guide:

Closes#26697 from wangyum/SPARK-28461.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
[HIVE-12063](https://issues.apache.org/jira/browse/HIVE-12063) improved pad decimal numbers with trailing zeros to the scale of the column. The following description is copied from the description of HIVE-12063.
> HIVE-7373 was to address the problems of trimming tailing zeros by Hive, which caused many problems including treating 0.0, 0.00 and so on as 0, which has different precision/scale. Please refer to HIVE-7373 description. However, HIVE-7373 was reverted by HIVE-8745 while the underlying problems remained. HIVE-11835 was resolved recently to address one of the problems, where 0.0, 0.00, and so on cannot be read into decimal(1,1).
However, HIVE-11835 didn't address the problem of showing as 0 in query result for any decimal values such as 0.0, 0.00, etc. This causes confusion as 0 and 0.0 have different precision/scale than 0.
The proposal here is to pad zeros for query result to the type's scale. This not only removes the confusion described above, but also aligns with many other DBs. Internal decimal number representation doesn't change, however.
**Spark SQL**:
```sql
// bin/spark-sql
spark-sql> select cast(1 as decimal(38, 18));
1
spark-sql>
// bin/beeline
0: jdbc:hive2://localhost:10000/default> select cast(1 as decimal(38, 18));
+----------------------------+--+
| CAST(1 AS DECIMAL(38,18)) |
+----------------------------+--+
| 1.000000000000000000 |
+----------------------------+--+
// bin/spark-shell
scala> spark.sql("select cast(1 as decimal(38, 18))").show(false)
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
|1.000000000000000000 |
+-------------------------+
// bin/pyspark
>>> spark.sql("select cast(1 as decimal(38, 18))").show()
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
// bin/sparkR
> showDF(sql("SELECT cast(1 as decimal(38, 18))"))
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
```
**PostgreSQL**:
```sql
postgres=# select cast(1 as decimal(38, 18));
numeric
----------------------
1.000000000000000000
(1 row)
```
**Presto**:
```sql
presto> select cast(1 as decimal(38, 18));
_col0
----------------------
1.000000000000000000
(1 row)
```
## How was this patch tested?
unit tests and manual test:
```sql
spark-sql> select cast(1 as decimal(38, 18));
1.000000000000000000
```
Spark SQL Upgrading Guide:

Closes#25214 from wangyum/SPARK-28461.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
A java like string trim method trims all whitespaces that less or equal than 0x20. currently, our UTF8String handle the space =0x20 ONLY. This is not suitable for many cases in Spark, like trim for interval strings, date, timestamps, PostgreSQL like cast string to boolean.
### Why are the changes needed?
improve the white spaces handling in UTF8String, also with some bugs fixed
### Does this PR introduce any user-facing change?
yes,
string with `control character` at either end can be convert to date/timestamp and interval now
### How was this patch tested?
add ut
Closes#26626 from yaooqinn/SPARK-29986.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Modify `UTF8String.toInt/toLong` to support trim spaces for both sides before converting it to byte/short/int/long.
With this kind of "cheap" trim can help improve performance for casting string to integrals. The idea is from https://github.com/apache/spark/pull/24872#issuecomment-556917834
### Why are the changes needed?
make the behavior consistent.
### Does this PR introduce any user-facing change?
yes, cast string to an integral type, and binary comparison between string and integrals will trim spaces first. their behavior will be consistent with float and double.
### How was this patch tested?
1. add ut.
2. benchmark tests
the benchmark is modified based on https://github.com/apache/spark/pull/24872#issuecomment-503827016
```scala
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.execution.benchmark
import org.apache.spark.benchmark.Benchmark
/**
* Benchmark trim the string when casting string type to Boolean/Numeric types.
* To run this benchmark:
* {{{
* 1. without sbt:
* bin/spark-submit --class <this class> --jars <spark core test jar> <spark sql test jar>
* 2. build/sbt "sql/test:runMain <this class>"
* 3. generate result: SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain <this class>"
* Results will be written to "benchmarks/CastBenchmark-results.txt".
* }}}
*/
object CastBenchmark extends SqlBasedBenchmark {
This conversation was marked as resolved by yaooqinn
override def runBenchmarkSuite(mainArgs: Array[String]): Unit = {
val title = "Cast String to Integral"
runBenchmark(title) {
withTempPath { dir =>
val N = 500L << 14
val df = spark.range(N)
val types = Seq("int", "long")
(1 to 5).by(2).foreach { i =>
df.selectExpr(s"concat(id, '${" " * i}') as str")
.write.mode("overwrite").parquet(dir + i.toString)
}
val benchmark = new Benchmark(title, N, minNumIters = 5, output = output)
Seq(true, false).foreach { trim =>
types.foreach { t =>
val str = if (trim) "trim(str)" else "str"
val expr = s"cast($str as $t) as c_$t"
(1 to 5).by(2).foreach { i =>
benchmark.addCase(expr + s" - with $i spaces") { _ =>
spark.read.parquet(dir + i.toString).selectExpr(expr).collect()
}
}
}
}
benchmark.run()
}
}
}
}
```
#### benchmark result.
normal trim v.s. trim in toInt/toLong
```java
================================================================================================
Cast String to Integral
================================================================================================
Java HotSpot(TM) 64-Bit Server VM 1.8.0_231-b11 on Mac OS X 10.15.1
Intel(R) Core(TM) i5-5287U CPU 2.90GHz
Cast String to Integral: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
cast(trim(str) as int) as c_int - with 1 spaces 10220 12994 1337 0.8 1247.5 1.0X
cast(trim(str) as int) as c_int - with 3 spaces 4763 8356 357 1.7 581.4 2.1X
cast(trim(str) as int) as c_int - with 5 spaces 4791 8042 NaN 1.7 584.9 2.1X
cast(trim(str) as long) as c_long - with 1 spaces 4014 6755 NaN 2.0 490.0 2.5X
cast(trim(str) as long) as c_long - with 3 spaces 4737 6938 NaN 1.7 578.2 2.2X
cast(trim(str) as long) as c_long - with 5 spaces 4478 6919 1404 1.8 546.6 2.3X
cast(str as int) as c_int - with 1 spaces 4443 6222 NaN 1.8 542.3 2.3X
cast(str as int) as c_int - with 3 spaces 3659 3842 170 2.2 446.7 2.8X
cast(str as int) as c_int - with 5 spaces 4372 7996 NaN 1.9 533.7 2.3X
cast(str as long) as c_long - with 1 spaces 3866 5838 NaN 2.1 471.9 2.6X
cast(str as long) as c_long - with 3 spaces 3793 5449 NaN 2.2 463.0 2.7X
cast(str as long) as c_long - with 5 spaces 4947 5961 1198 1.7 603.9 2.1X
```
Closes#26622 from yaooqinn/cheapstringtrim.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
remove the leading "interval" in `CalendarInterval.toString`.
### Why are the changes needed?
Although it's allowed to have "interval" prefix when casting string to int, it's not recommended.
This is also consistent with pgsql:
```
cloud0fan=# select interval '1' day;
interval
----------
1 day
(1 row)
```
### Does this PR introduce any user-facing change?
yes, when display a dataframe with interval type column, the result is different.
### How was this patch tested?
updated tests.
Closes#26401 from cloud-fan/interval.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
During creation of array, if CreateArray does not gets any children to set data type for array, it will create an array of null type .
### Why are the changes needed?
When empty array is created, it should be declared as array<null>.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Tested manually
Closes#26324 from amanomer/29462.
Authored-by: Aman Omer <amanomer1996@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
re-arrange the parser rules to make it clear that multiple unit TO unit statement like `SELECT INTERVAL '1-1' YEAR TO MONTH '2-2' YEAR TO MONTH` is not allowed.
### Why are the changes needed?
This is definitely an accident that we support such a weird syntax in the past. It's not supported by any other DBs and I can't think of any use case of it. Also no test covers this syntax in the current codebase.
### Does this PR introduce any user-facing change?
Yes, and a migration guide item is added.
### How was this patch tested?
new tests.
Closes#26285 from cloud-fan/syntax.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes the incorrect `EqualNullSafe` symbol in `sql-migration-guide.md`.
### Why are the changes needed?
Fix documentation error.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#26163 from wangyum/EqualNullSafe-symbol.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
When inserting a value into a column with the different data type, Spark performs type coercion. Currently, we support 3 policies for the store assignment rules: ANSI, legacy and strict, which can be set via the option "spark.sql.storeAssignmentPolicy":
1. ANSI: Spark performs the type coercion as per ANSI SQL. In practice, the behavior is mostly the same as PostgreSQL. It disallows certain unreasonable type conversions such as converting `string` to `int` and `double` to `boolean`. It will throw a runtime exception if the value is out-of-range(overflow).
2. Legacy: Spark allows the type coercion as long as it is a valid `Cast`, which is very loose. E.g., converting either `string` to `int` or `double` to `boolean` is allowed. It is the current behavior in Spark 2.x for compatibility with Hive. When inserting an out-of-range value to a integral field, the low-order bits of the value is inserted(the same as Java/Scala numeric type casting). For example, if 257 is inserted to a field of Byte type, the result is 1.
3. Strict: Spark doesn't allow any possible precision loss or data truncation in store assignment, e.g., converting either `double` to `int` or `decimal` to `double` is allowed. The rules are originally for Dataset encoder. As far as I know, no mainstream DBMS is using this policy by default.
Currently, the V1 data source uses "Legacy" policy by default, while V2 uses "Strict". This proposal is to use "ANSI" policy by default for both V1 and V2 in Spark 3.0.
### Why are the changes needed?
Following the ANSI SQL standard is most reasonable among the 3 policies.
### Does this PR introduce any user-facing change?
Yes.
The default store assignment policy is ANSI for both V1 and V2 data sources.
### How was this patch tested?
Unit test
Closes#26107 from gengliangwang/ansiPolicyAsDefault.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
The commit 4e6d31f570 changed default behavior of `size()` for the `NULL` input. In this PR, I propose to update the SQL migration guide.
### Why are the changes needed?
To inform users about new behavior of the `size()` function for the `NULL` input.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#26066 from MaxGekk/size-null-migration-guide.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Updated the SQL migration guide regarding to recently supported special date and timestamp values, see https://github.com/apache/spark/pull/25716 and https://github.com/apache/spark/pull/25708.
Closes#25834
### Why are the changes needed?
To let users know about new feature in Spark 3.0.
### Does this PR introduce any user-facing change?
No
Closes#25948 from MaxGekk/special-values-migration-guide.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Currently, there is no migration section for PySpark, SparkCore and Structured Streaming.
It is difficult for users to know what to do when they upgrade.
This PR proposes to create create a "Migration Guide" tap at Spark documentation.


This page will contain migration guides for Spark SQL, PySpark, SparkR, MLlib, Structured Streaming and Core. Basically it is a refactoring.
There are some new information added, which I will leave a comment inlined for easier review.
1. **MLlib**
Merge [ml-guide.html#migration-guide](https://spark.apache.org/docs/latest/ml-guide.html#migration-guide) and [ml-migration-guides.html](https://spark.apache.org/docs/latest/ml-migration-guides.html)
```
'docs/ml-guide.md'
↓ Merge new/old migration guides
'docs/ml-migration-guide.md'
```
2. **PySpark**
Extract PySpark specific items from https://spark.apache.org/docs/latest/sql-migration-guide-upgrade.html
```
'docs/sql-migration-guide-upgrade.md'
↓ Extract PySpark specific items
'docs/pyspark-migration-guide.md'
```
3. **SparkR**
Move [sparkr.html#migration-guide](https://spark.apache.org/docs/latest/sparkr.html#migration-guide) into a separate file, and extract from [sql-migration-guide-upgrade.html](https://spark.apache.org/docs/latest/sql-migration-guide-upgrade.html)
```
'docs/sparkr.md' 'docs/sql-migration-guide-upgrade.md'
Move migration guide section ↘ ↙ Extract SparkR specific items
docs/sparkr-migration-guide.md
```
4. **Core**
Newly created at `'docs/core-migration-guide.md'`. I skimmed resolved JIRAs at 3.0.0 and found some items to note.
5. **Structured Streaming**
Newly created at `'docs/ss-migration-guide.md'`. I skimmed resolved JIRAs at 3.0.0 and found some items to note.
6. **SQL**
Merged [sql-migration-guide-upgrade.html](https://spark.apache.org/docs/latest/sql-migration-guide-upgrade.html) and [sql-migration-guide-hive-compatibility.html](https://spark.apache.org/docs/latest/sql-migration-guide-hive-compatibility.html)
```
'docs/sql-migration-guide-hive-compatibility.md' 'docs/sql-migration-guide-upgrade.md'
Move Hive compatibility section ↘ ↙ Left over after filtering PySpark and SparkR items
'docs/sql-migration-guide.md'
```
### Why are the changes needed?
In order for users in production to effectively migrate to higher versions, and detect behaviour or breaking changes before upgrading and/or migrating.
### Does this PR introduce any user-facing change?
Yes, this changes Spark's documentation at https://spark.apache.org/docs/latest/index.html.
### How was this patch tested?
Manually build the doc. This can be verified as below:
```bash
cd docs
SKIP_API=1 jekyll build
open _site/index.html
```
Closes#25757 from HyukjinKwon/migration-doc.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Add AL2 license to metadata of all .md files.
This seemed to be the tidiest way as it will get ignored by .md renderers and other tools. Attempts to write them as markdown comments revealed that there is no such standard thing.
## How was this patch tested?
Doc build
Closes#24243 from srowen/SPARK-26918.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
1. Split the main page of sql-programming-guide into 7 parts:
- Getting Started
- Data Sources
- Performance Turing
- Distributed SQL Engine
- PySpark Usage Guide for Pandas with Apache Arrow
- Migration Guide
- Reference
2. Add left menu for sql-programming-guide, keep first level index for each part in the menu.

## How was this patch tested?
Local test with jekyll build/serve.
Closes#22746 from xuanyuanking/SPARK-24499.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}