## What changes were proposed in this pull request?
This patch adds the DataFrames API to the multivariate summarizer (mean, variance, etc.). In addition to all the features of MultivariateOnlineSummarizer, it also allows the user to select a subset of the metrics.
## How was this patch tested?
Testcases added.
## Performance
Resolve several performance issues in #17419, further optimization pending on SQL team's work. One of the SQL layer performance issue related to these feature has been resolved in #18712, thanks liancheng and cloud-fan
### Performance data
(test on my laptop, use 2 partitions. tries out = 20, warm up = 10)
The unit of test results is records/milliseconds (higher is better)
Vector size/records number | 1/10000000 | 10/1000000 | 100/1000000 | 1000/100000 | 10000/10000
----|------|----|---|----|----
Dataframe | 15149 | 7441 | 2118 | 224 | 21
RDD from Dataframe | 4992 | 4440 | 2328 | 320 | 33
raw RDD | 53931 | 20683 | 3966 | 528 | 53
Author: WeichenXu <WeichenXu123@outlook.com>
Closes#18798 from WeichenXu123/SPARK-19634-dataframe-summarizer.
Proposed changes:
* Clarify the type error that `Column.substr()` gives.
Test plan:
* Tested this manually.
* Test code:
```python
from pyspark.sql.functions import col, lit
spark.createDataFrame([['nick']], schema=['name']).select(col('name').substr(0, lit(1)))
```
* Before:
```
TypeError: Can not mix the type
```
* After:
```
TypeError: startPos and length must be the same type. Got <class 'int'> and
<class 'pyspark.sql.column.Column'>, respectively.
```
Author: Nicholas Chammas <nicholas.chammas@gmail.com>
Closes#18926 from nchammas/SPARK-21712-substr-type-error.
## What changes were proposed in this pull request?
The method name `asNonNullabe` should be `asNonNullable`.
## How was this patch tested?
N/A
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#18952 from jiangxb1987/typo.
This version fixes a few issues in the import order checker; it provides
better error messages, and detects more improper ordering (thus the need
to change a lot of files in this patch). The main fix is that it correctly
complains about the order of packages vs. classes.
As part of the above, I moved some "SparkSession" import in ML examples
inside the "$example on$" blocks; that didn't seem consistent across
different source files to start with, and avoids having to add more on/off blocks
around specific imports.
The new scalastyle also seems to have a better header detector, so a few
license headers had to be updated to match the expected indentation.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18943 from vanzin/SPARK-21731.
Currently the launcher handle does not monitor the child spark-submit
process it launches; this means that if the child exits with an error,
the handle's state will never change, and an application will not know
that the application has failed.
This change adds code to monitor the child process, and changes the
handle state appropriately when the child process exits.
Tested with added unit tests.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18877 from vanzin/SPARK-17742.
## What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/15900 , to fix one more bug:
When table schema is empty and need to be inferred at runtime, we should not resolve parent plans before the schema has been inferred, or the parent plans will be resolved against an empty schema and may get wrong result for something like `select *`
The fix logic is: introduce `UnresolvedCatalogRelation` as a placeholder. Then we replace it with `LogicalRelation` or `HiveTableRelation` during analysis, so that it's guaranteed that we won't resolve parent plans until the schema has been inferred.
## How was this patch tested?
regression test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#18907 from cloud-fan/bug.
## What changes were proposed in this pull request?
This is a follow-up PR that moves the test case in PR-18920 (https://github.com/apache/spark/pull/18920) to DataFrameAggregateSuit.
## How was this patch tested?
unit test
Author: donnyzone <wellfengzhu@gmail.com>
Closes#18946 from DonnyZone/branch-19471-followingPR.
## What changes were proposed in this pull request?
This PR changes the codes to lazily init hive metastore client so that we can create SparkSession without talking to the hive metastore sever.
It's pretty helpful when you set a hive metastore server but it's down. You can still start the Spark shell to debug.
## How was this patch tested?
The new unit test.
Author: Shixiong Zhu <shixiong@databricks.com>
Closes#18944 from zsxwing/hive-lazy-init.
## What changes were proposed in this pull request?
This PR adds `since` annotation in documentation so that this can be rendered as below:
<img width="290" alt="2017-08-14 6 54 26" src="https://user-images.githubusercontent.com/6477701/29267050-034c1f64-8122-11e7-862b-7dfc38e292bf.png">
## How was this patch tested?
Manually checked the documentation by `cd sql && ./create-docs.sh`.
Also, Jenkins tests are required.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18939 from HyukjinKwon/add-sinces-date-functions.
## What changes were proposed in this pull request?
We put staging path to delete into the deleteOnExit cache of `FileSystem` in case of the path can't be successfully removed. But when we successfully remove the path, we don't remove it from the cache. We should do it to avoid continuing grow the cache size.
## How was this patch tested?
Added a test.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#18934 from viirya/SPARK-21721.
## What changes were proposed in this pull request?
Directly writing a snapshot file may generate a partial file. This PR changes it to write to a temp file then rename to the target file.
## How was this patch tested?
Jenkins.
Author: Shixiong Zhu <shixiong@databricks.com>
Closes#18928 from zsxwing/SPARK-21696.
## What changes were proposed in this pull request?
Recently, we have also encountered such NPE issues in our production environment as described in:
https://issues.apache.org/jira/browse/SPARK-19471
This issue can be reproduced by the following examples:
` val df = spark.createDataFrame(Seq(("1", 1), ("1", 2), ("2", 3), ("2", 4))).toDF("x", "y")
//HashAggregate, SQLConf.WHOLESTAGE_CODEGEN_ENABLED.key=false
df.groupBy("x").agg(rand(),sum("y")).show()
//ObjectHashAggregate, SQLConf.WHOLESTAGE_CODEGEN_ENABLED.key=false
df.groupBy("x").agg(rand(),collect_list("y")).show()
//SortAggregate, SQLConf.WHOLESTAGE_CODEGEN_ENABLED.key=false &&SQLConf.USE_OBJECT_HASH_AGG.key=false
df.groupBy("x").agg(rand(),collect_list("y")).show()`
`
This PR is based on PR-16820(https://github.com/apache/spark/pull/16820) with test cases for all aggregation paths. We want to push it forward.
> When AggregationIterator generates result projection, it does not call the initialize method of the Projection class. This will cause a runtime NullPointerException when the projection involves nondeterministic expressions.
## How was this patch tested?
unit test
verified in production environment
Author: donnyzone <wellfengzhu@gmail.com>
Closes#18920 from DonnyZone/Branch-spark-19471.
## What changes were proposed in this pull request?
At present, in test("broadcasted hash outer join operator selection") case, set the testData2 to _CACHE TABLE_, but no _uncache table_ testData2. It can make people confused.
In addition, in the joinsuite test cases, clear the cache table of work by SharedSQLContext _spark.sharedState.cacheManager.clearCache_ to do, so we do not need to uncache table
let's fix it. thanks.
## How was this patch tested?
Existing test cases.
Author: caoxuewen <cao.xuewen@zte.com.cn>
Closes#18914 from heary-cao/uncache_table.
## What changes were proposed in this pull request?
JIRA issue: https://issues.apache.org/jira/browse/SPARK-21658
Add default None for value in `na.replace` since `Dataframe.replace` and `DataframeNaFunctions.replace` are alias.
The default values are the same now.
```
>>> df = sqlContext.createDataFrame([('Alice', 10, 80.0)])
>>> df.replace({"Alice": "a"}).first()
Row(_1=u'a', _2=10, _3=80.0)
>>> df.na.replace({"Alice": "a"}).first()
Row(_1=u'a', _2=10, _3=80.0)
```
## How was this patch tested?
Existing tests.
cc viirya
Author: byakuinss <grace.chinhanyu@gmail.com>
Closes#18895 from byakuinss/SPARK-21658.
## What changes were proposed in this pull request?
Fix the race condition when serializing TaskDescriptions and adding jars by keeping the set of jars and files for a TaskSet constant across the lifetime of the TaskSet. Otherwise TaskDescription serialization can produce an invalid serialization when new file/jars are added concurrently as the TaskDescription is serialized.
## How was this patch tested?
Additional unit test ensures jars/files contained in the TaskDescription remain constant throughout the lifetime of the TaskSet.
Author: Andrew Ash <andrew@andrewash.com>
Closes#18913 from ash211/SPARK-21563.
## What changes were proposed in this pull request?
Several links on the worker page do not work correctly with the proxy because:
1) They don't acknowledge the proxy
2) They use relative paths (unlike the Application Page which uses full paths)
This patch fixes that. It also fixes a mistake in the proxy's Location header parsing which caused it to incorrectly handle redirects.
## How was this patch tested?
I checked the validity of every link with the proxy on and off.
Author: Anderson Osagie <osagie@gmail.com>
Closes#18915 from aosagie/fix/proxy-links.
## What changes were proposed in this pull request?
While discovering optimization rules and their test coverage, I did not find any tests for `CheckCartesianProducts` in the Catalyst folder. So, I decided to create a new test suite. Once I finished, I found a test in `JoinSuite` for this functionality so feel free to discard this change if it does not make much sense. The proposed test suite covers a few additional use cases.
Author: aokolnychyi <anton.okolnychyi@sap.com>
Closes#18909 from aokolnychyi/check-cartesian-join-tests.
## What changes were proposed in this pull request?
Update sbt version to 0.13.16. I think this is a useful stepping stone to getting to sbt 1.0.0.
## How was this patch tested?
Existing Build.
Author: pj.fanning <pj.fanning@workday.com>
Closes#18921 from pjfanning/SPARK-21709.
## What changes were proposed in this pull request?
Implemented a Python-only persistence framework for pipelines containing stages that cannot be saved using Java.
## How was this patch tested?
Created a custom Python-only UnaryTransformer, included it in a Pipeline, and saved/loaded the pipeline. The loaded pipeline was compared against the original using _compare_pipelines() in tests.py.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18888 from ajaysaini725/PythonPipelines.
## What changes were proposed in this pull request?
This is trivial, but bugged me. We should download software over HTTPS.
And we can use RAT 0.12 while at it to pick up bug fixes.
## How was this patch tested?
N/A
Author: Sean Owen <sowen@cloudera.com>
Closes#18927 from srowen/Rat012.
Fixes --packages flag for the stand-alone case in cluster mode. Adds to the driver classpath the jars that are resolved via ivy along with any other jars passed to `spark.jars`. Jars not resolved by ivy are downloaded explicitly to a tmp folder on the driver node. Similar code is available in SparkSubmit so we refactored part of it to use it at the DriverWrapper class which is responsible for launching driver in standalone cluster mode.
Note: In stand-alone mode `spark.jars` contains the user jar so it can be fetched later on at the executor side.
Manually by submitting a driver in cluster mode within a standalone cluster and checking if dependencies were resolved at the driver side.
Author: Stavros Kontopoulos <st.kontopoulos@gmail.com>
Closes#18630 from skonto/fix_packages_stand_alone_cluster.
## What changes were proposed in this pull request?
Jira : https://issues.apache.org/jira/browse/SPARK-19122
`leftKeys` and `rightKeys` in `SortMergeJoinExec` are altered based on the ordering of join keys in the child's `outputPartitioning`. This is done everytime `requiredChildDistribution` is invoked during query planning.
## How was this patch tested?
- Added new test case
- Existing tests
Author: Tejas Patil <tejasp@fb.com>
Closes#16985 from tejasapatil/SPARK-19122_join_order_shuffle.
## What changes were proposed in this pull request?
[SPARK-21595](https://issues.apache.org/jira/browse/SPARK-21595) reported that there is excessive spilling to disk due to default spill threshold for `ExternalAppendOnlyUnsafeRowArray` being quite small for WINDOW operator. Old behaviour of WINDOW operator (pre https://github.com/apache/spark/pull/16909) would hold data in an array for first 4096 records post which it would switch to `UnsafeExternalSorter` and start spilling to disk after reaching `spark.shuffle.spill.numElementsForceSpillThreshold` (or earlier if there was paucity of memory due to excessive consumers).
Currently the (switch from in-memory to `UnsafeExternalSorter`) and (`UnsafeExternalSorter` spilling to disk) for `ExternalAppendOnlyUnsafeRowArray` is controlled by a single threshold. This PR aims to separate that to have more granular control.
## How was this patch tested?
Added unit tests
Author: Tejas Patil <tejasp@fb.com>
Closes#18843 from tejasapatil/SPARK-21595.
Add an option to the JDBC data source to initialize the environment of the remote database session
## What changes were proposed in this pull request?
This proposes an option to the JDBC datasource, tentatively called " sessionInitStatement" to implement the functionality of session initialization present for example in the Sqoop connector for Oracle (see https://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html#_oraoop_oracle_session_initialization_statements ) . After each database session is opened to the remote DB, and before starting to read data, this option executes a custom SQL statement (or a PL/SQL block in the case of Oracle).
See also https://issues.apache.org/jira/browse/SPARK-21519
## How was this patch tested?
Manually tested using Spark SQL data source and Oracle JDBC
Author: LucaCanali <luca.canali@cern.ch>
Closes#18724 from LucaCanali/JDBC_datasource_sessionInitStatement.
## What changes were proposed in this pull request?
1. In Spark Web UI, the Details for Stage Page don't have a navigation bar at the bottom. When we drop down to the bottom, it is better for us to see a navi bar right there to go wherever we what.
2. Executor ID is not equivalent to Host, it may be better to separate them, and then we can group the tasks by Hosts .
## How was this patch tested?
manually test

Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Kent Yao <yaooqinn@hotmail.com>
Closes#18893 from yaooqinn/SPARK-21675.
## What changes were proposed in this pull request?
This patch removes the unused SessionCatalog.getTableMetadataOption and ExternalCatalog. getTableOption.
## How was this patch tested?
Removed the test case.
Author: Reynold Xin <rxin@databricks.com>
Closes#18912 from rxin/remove-getTableOption.
## What changes were proposed in this pull request?
When train RF model, there are many warning messages like this:
> WARN RandomForest: Tree learning is using approximately 268492800 bytes per iteration, which exceeds requested limit maxMemoryUsage=268435456. This allows splitting 2622 nodes in this iteration.
This warning message is unnecessary and the data is not accurate.
Actually, if all the nodes cannot split in one iteration, it will show this warning. For most of the case, all the nodes cannot split just in one iteration, so for most of the case, it will show this warning for each iteration.
## How was this patch tested?
The existing UT
Author: Peng Meng <peng.meng@intel.com>
Closes#18868 from mpjlu/fixRFwarning.
## What changes were proposed in this pull request?
This patch introduces an internal interface for tracking metrics and/or statistics on data on the fly, as it is being written to disk during a `FileFormatWriter` job and partially reimplements SPARK-20703 in terms of it.
The interface basically consists of 3 traits:
- `WriteTaskStats`: just a tag for classes that represent statistics collected during a `WriteTask`
The only constraint it adds is that the class should be `Serializable`, as instances of it will be collected on the driver from all executors at the end of the `WriteJob`.
- `WriteTaskStatsTracker`: a trait for classes that can actually compute statistics based on tuples that are processed by a given `WriteTask` and eventually produce a `WriteTaskStats` instance.
- `WriteJobStatsTracker`: a trait for classes that act as containers of `Serializable` state that's necessary for instantiating `WriteTaskStatsTracker` on executors and finally process the resulting collection of `WriteTaskStats`, once they're gathered back on the driver.
Potential future use of this interface is e.g. CBO stats maintenance during `INSERT INTO table ... ` operations.
## How was this patch tested?
Existing tests for SPARK-20703 exercise the new code: `hive/SQLMetricsSuite`, `sql/JavaDataFrameReaderWriterSuite`, etc.
Author: Adrian Ionescu <adrian@databricks.com>
Closes#18884 from adrian-ionescu/write-stats-tracker-api.
## What changes were proposed in this pull request?
Currently `df.na.replace("*", Map[String, String]("NULL" -> null))` will produce exception.
This PR enables passing null/None as value in the replacement map in DataFrame.replace().
Note that the replacement map keys and values should still be the same type, while the values can have a mix of null/None and that type.
This PR enables following operations for example:
`df.na.replace("*", Map[String, String]("NULL" -> null))`(scala)
`df.na.replace("*", Map[Any, Any](60 -> null, 70 -> 80))`(scala)
`df.na.replace('Alice', None)`(python)
`df.na.replace([10, 20])`(python, replacing with None is by default)
One use case could be: I want to replace all the empty strings with null/None because they were incorrectly generated and then drop all null/None data
`df.na.replace("*", Map("" -> null)).na.drop()`(scala)
`df.replace(u'', None).dropna()`(python)
## How was this patch tested?
Scala unit test.
Python doctest and unit test.
Author: bravo-zhang <mzhang1230@gmail.com>
Closes#18820 from bravo-zhang/spark-14932.
## What changes were proposed in this pull request?
This modification increases the timeout for `serveIterator` (which is not dynamically configurable). This fixes timeout issues in pyspark when using `collect` and similar functions, in cases where Python may take more than a couple seconds to connect.
See https://issues.apache.org/jira/browse/SPARK-21551
## How was this patch tested?
Ran the tests.
cc rxin
Author: peay <peay@protonmail.com>
Closes#18752 from peay/spark-21551.
## What changes were proposed in this pull request?
Push filter predicates through EventTimeWatermark if they're deterministic and do not reference the watermarked attribute. (This is similar but not identical to the logic for pushing through UnaryNode.)
## How was this patch tested?
unit tests
Author: Jose Torres <joseph-torres@databricks.com>
Closes#18790 from joseph-torres/SPARK-21587.
## What changes were proposed in this pull request?
This PR is to add the spark version info in the table metadata. When creating the table, this value is assigned. It can help users find which version of Spark was used to create the table.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#18709 from gatorsmile/addVersion.
## What changes were proposed in this pull request?
This pr updated `lz4-java` to the latest (v1.4.0) and removed custom `LZ4BlockInputStream`. We currently use custom `LZ4BlockInputStream` to read concatenated byte stream in shuffle. But, this functionality has been implemented in the latest lz4-java (https://github.com/lz4/lz4-java/pull/105). So, we might update the latest to remove the custom `LZ4BlockInputStream`.
Major diffs between the latest release and v1.3.0 in the master are as follows (62f7547abb...6d4693f562);
- fixed NPE in XXHashFactory similarly
- Don't place resources in default package to support shading
- Fixes ByteBuffer methods failing to apply arrayOffset() for array-backed
- Try to load lz4-java from java.library.path, then fallback to bundled
- Add ppc64le binary
- Add s390x JNI binding
- Add basic LZ4 Frame v1.5.0 support
- enable aarch64 support for lz4-java
- Allow unsafeInstance() for ppc64le archiecture
- Add unsafeInstance support for AArch64
- Support 64-bit JNI build on Solaris
- Avoid over-allocating a buffer
- Allow EndMark to be incompressible for LZ4FrameInputStream.
- Concat byte stream
## How was this patch tested?
Existing tests.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#18883 from maropu/SPARK-21276.
## What changes were proposed in this pull request?
Resources in Core - SparkSubmitArguments.scala, Spark-launcher - AbstractCommandBuilder.java, resource-managers- YARN - Client.scala are released
## How was this patch tested?
No new test cases added, Unit test have been passed
Author: vinodkc <vinod.kc.in@gmail.com>
Closes#18880 from vinodkc/br_fixresouceleak.
Signed-off-by: 10087686 <wang.jiaochunzte.com.cn>
## What changes were proposed in this pull request?
After Unit tests end,there should be call masterTracker.stop() to free resource;
(Please fill in changes proposed in this fix)
## How was this patch tested?
Run Unit tests;
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: 10087686 <wang.jiaochun@zte.com.cn>
Closes#18867 from wangjiaochun/mapout.
## What changes were proposed in this pull request?
Update breeze to 0.13.1 for an emergency bugfix in strong wolfe line search
https://github.com/scalanlp/breeze/pull/651
## How was this patch tested?
N/A
Author: WeichenXu <WeichenXu123@outlook.com>
Closes#18797 from WeichenXu123/update-breeze.
## What changes were proposed in this pull request?
Currently, each application and each worker creates their own proxy servlet. Each proxy servlet is backed by its own HTTP client and a relatively large number of selector threads. This is excessive but was fixed (to an extent) by https://github.com/apache/spark/pull/18437.
However, a single HTTP client (backed by a single selector thread) should be enough to handle all proxy requests. This PR creates a single proxy servlet no matter how many applications and workers there are.
## How was this patch tested?
.
The unit tests for rewriting proxied locations and headers were updated. I then spun up a 100 node cluster to ensure that proxy'ing worked correctly
jiangxb1987 Please let me know if there's anything else I can do to help push this thru. Thanks!
Author: Anderson Osagie <osagie@gmail.com>
Closes#18499 from aosagie/fix/minimize-proxy-threads.
The executor tab on Spark UI page shows task as completed when an executor process that is running that task is killed using the kill command.
Added the case ExecutorLostFailure which was previously not there, thus, the default case would be executed in which case, task would be marked as completed. This case will consider all those cases where executor connection to Spark Driver was lost due to killing the executor process, network connection etc.
## How was this patch tested?
Manually Tested the fix by observing the UI change before and after.
Before:
<img width="1398" alt="screen shot-before" src="https://user-images.githubusercontent.com/22228190/28482929-571c9cea-6e30-11e7-93dd-728de5cdea95.png">
After:
<img width="1385" alt="screen shot-after" src="https://user-images.githubusercontent.com/22228190/28482964-8649f5ee-6e30-11e7-91bd-2eb2089c61cc.png">
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: pgandhi <pgandhi@yahoo-inc.com>
Author: pgandhi999 <parthkgandhi9@gmail.com>
Closes#18707 from pgandhi999/master.
## What changes were proposed in this pull request?
Window rangeBetween() API should allow literal boundary, that means, the window range frame can calculate frame of double/date/timestamp.
Example of the use case can be:
```
SELECT
val_timestamp,
cate,
avg(val_timestamp) OVER(PARTITION BY cate ORDER BY val_timestamp RANGE BETWEEN CURRENT ROW AND interval 23 days 4 hours FOLLOWING)
FROM testData
```
This PR refactors the Window `rangeBetween` and `rowsBetween` API, while the legacy user code should still be valid.
## How was this patch tested?
Add new test cases both in `DataFrameWindowFunctionsSuite` and in `window.sql`.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#18814 from jiangxb1987/literal-boundary.
## What changes were proposed in this pull request?
When I was investigating a flaky test, I realized that many places don't check the return value of `HDFSMetadataLog.get(batchId: Long): Option[T]`. When a batch is supposed to be there, the caller just ignores None rather than throwing an error. If some bug causes a query doesn't generate a batch metadata file, this behavior will hide it and allow the query continuing to run and finally delete metadata logs and make it hard to debug.
This PR ensures that places calling HDFSMetadataLog.get always check the return value.
## How was this patch tested?
Jenkins
Author: Shixiong Zhu <shixiong@databricks.com>
Closes#18799 from zsxwing/SPARK-21596.
## What changes were proposed in this pull request?
Taking over https://github.com/apache/spark/pull/18789 ; Closes#18789
Update Jackson to 2.6.7 uniformly, and some components to 2.6.7.1, to get some fixes and prep for Scala 2.12
## How was this patch tested?
Existing tests
Author: Sean Owen <sowen@cloudera.com>
Closes#18881 from srowen/SPARK-20433.
This change adds an in-memory implementation of KVStore that can be
used by the live UI.
The implementation is not fully optimized, neither for speed nor
space, but should be fast enough for using in the listener bus.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18395 from vanzin/SPARK-20655.
## What changes were proposed in this pull request?
This PR proposes to use https://rversions.r-pkg.org/r-release-win instead of https://rversions.r-pkg.org/r-release to check R's version for Windows correctly.
We met a syncing problem with Windows release (see #15709) before. To cut this short, it was ...
- 3.3.2 release was released but not for Windows for few hours.
- `https://rversions.r-pkg.org/r-release` returns the latest as 3.3.2 and the download link for 3.3.1 becomes `windows/base/old` by our script
- 3.3.2 release for WIndows yet
- 3.3.1 is still not in `windows/base/old` but `windows/base` as the latest
- Failed to download with `windows/base/old` link and builds were broken
I believe this problem is not only what we met. Please see 01ce943929 and also this `r-release-win` API came out between 3.3.1 and 3.3.2 (assuming to deal with this issue), please see `https://github.com/metacran/rversions.app/issues/2`.
Using this API will prevent the problem although it looks quite rare assuming from the commit logs in https://github.com/metacran/rversions.app/commits/master. After 3.3.2, both `r-release-win` and `r-release` are being updated together.
## How was this patch tested?
AppVeyor tests.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18859 from HyukjinKwon/use-reliable-link.
## What changes were proposed in this pull request?
If we create a type alias for a type workable with Dataset, the type alias doesn't work with Dataset.
A reproducible case looks like:
object C {
type TwoInt = (Int, Int)
def tupleTypeAlias: TwoInt = (1, 1)
}
Seq(1).toDS().map(_ => ("", C.tupleTypeAlias))
It throws an exception like:
type T1 is not a class
scala.ScalaReflectionException: type T1 is not a class
at scala.reflect.api.Symbols$SymbolApi$class.asClass(Symbols.scala:275)
...
This patch accesses the dealias of type in many places in `ScalaReflection` to fix it.
## How was this patch tested?
Added test case.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#18813 from viirya/SPARK-21567.
## What changes were proposed in this pull request?
This commit adds a new argument for IllegalArgumentException message. This recent commit added the argument:
[dcac1d57f0)
## How was this patch tested?
Unit test have been passed
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Marcos P. Sanchez <mpenate@stratio.com>
Closes#18862 from mpenate/feature/exception-errorifexists.
## What changes were proposed in this pull request?
PySpark GLR ```model.summary``` should return a printable representation by calling Scala ```toString```.
## How was this patch tested?
```
from pyspark.ml.regression import GeneralizedLinearRegression
dataset = spark.read.format("libsvm").load("data/mllib/sample_linear_regression_data.txt")
glr = GeneralizedLinearRegression(family="gaussian", link="identity", maxIter=10, regParam=0.3)
model = glr.fit(dataset)
model.summary
```
Before this PR:

After this PR:
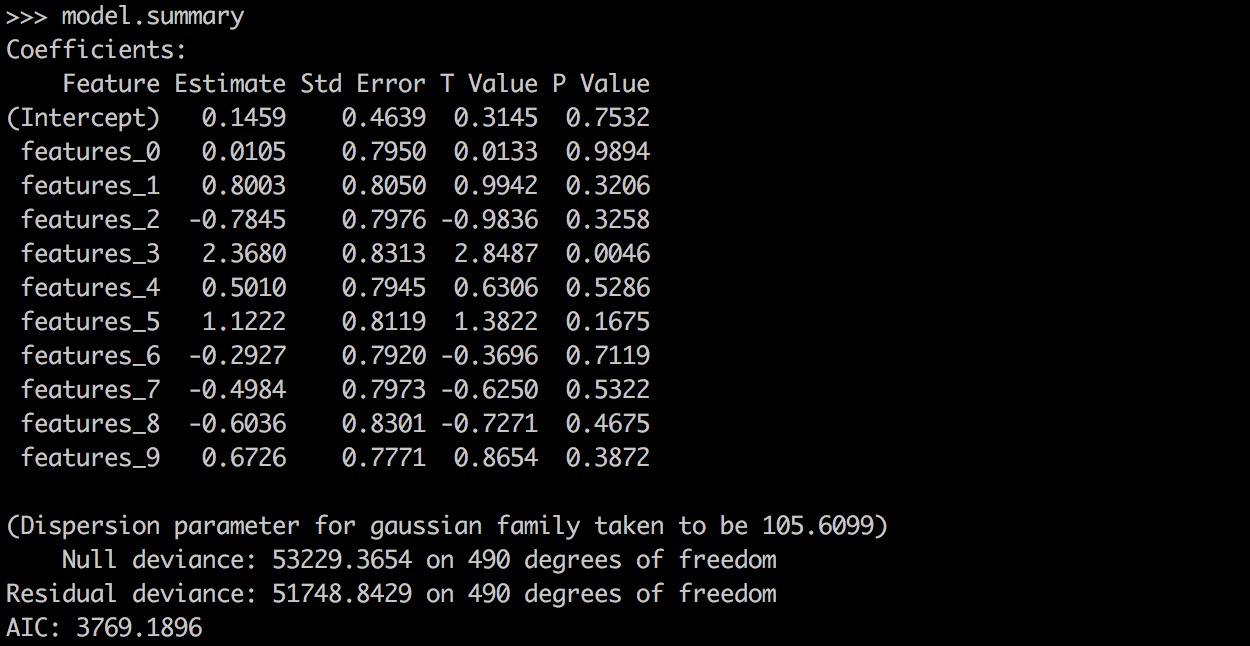
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18870 from yanboliang/spark-19270.
## What changes were proposed in this pull request?
Added DefaultParamsWriteable, DefaultParamsReadable, DefaultParamsWriter, and DefaultParamsReader to Python to support Python-only persistence of Json-serializable parameters.
## How was this patch tested?
Instantiated an estimator with Json-serializable parameters (ex. LogisticRegression), saved it using the added helper functions, and loaded it back, and compared it to the original instance to make sure it is the same. This test was both done in the Python REPL and implemented in the unit tests.
Note to reviewers: there are a few excess comments that I left in the code for clarity but will remove before the code is merged to master.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18742 from ajaysaini725/PythonPersistenceHelperFunctions.
### What changes were proposed in this pull request?
```SQL
CREATE TABLE mytesttable1
USING org.apache.spark.sql.jdbc
OPTIONS (
url 'jdbc:mysql://${jdbcHostname}:${jdbcPort}/${jdbcDatabase}?user=${jdbcUsername}&password=${jdbcPassword}',
dbtable 'mytesttable1',
paritionColumn 'state_id',
lowerBound '0',
upperBound '52',
numPartitions '53',
fetchSize '10000'
)
```
The above option name `paritionColumn` is wrong. That mean, users did not provide the value for `partitionColumn`. In such case, users hit a confusing error.
```
AssertionError: assertion failed
java.lang.AssertionError: assertion failed
at scala.Predef$.assert(Predef.scala:156)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:39)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:312)
```
### How was this patch tested?
Added a test case
Author: gatorsmile <gatorsmile@gmail.com>
Closes#18864 from gatorsmile/jdbcPartCol.
## What changes were proposed in this pull request?
Propagate metadata in attribute replacement during streaming execution. This is necessary for EventTimeWatermarks consuming replaced attributes.
## How was this patch tested?
new unit test, which was verified to fail before the fix
Author: Jose Torres <joseph-torres@databricks.com>
Closes#18840 from joseph-torres/SPARK-21565.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}