### What changes were proposed in this pull request?
1, add field `storageLevel` in `PeriodicRDDCheckpointer`
2, for ml.GBT/ml.RF set storageLevel=`StorageLevel.MEMORY_AND_DISK`
### Why are the changes needed?
Intermediate RDDs in ML are cached with storageLevel=StorageLevel.MEMORY_AND_DISK.
PeriodicRDDCheckpointer & PeriodicGraphCheckpointer now store RDD with storageLevel=StorageLevel.MEMORY_ONLY, it maybe nice to set the storageLevel of checkpointer.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
existing testsuites
Closes#27189 from zhengruifeng/checkpointer_storage.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
For decimal values between -1.0 and 1.0, it should has same precision and scale in `Decimal`, in order to make it be consistent with `DecimalType`.
### Why are the changes needed?
Currently, for values between -1.0 and 1.0, precision and scale is inconsistent between `Decimal` and `DecimalType`. For example, for numbers like 0.3, it will have (precision, scale) as (2, 1) in `Decimal`, but (1, 1) in `DecimalType`:
```
scala> Literal(new BigDecimal("0.3")).dataType.asInstanceOf[DecimalType].precision
res3: Int = 1
scala> Literal(new BigDecimal("0.3")).value.asInstanceOf[Decimal].precision
res4: Int = 2
```
We should make `Decimal` be consistent with `DecimalType`. And, here, we change it to only count precision digits after dot for values between -1.0 and 1.0 as other DBMS does, like hive:
```
hive> create table testrel as select 0.3;
hive> describe testrel;
OK
_c0 decimal(1,1)
```
This could bring larger scale for values between -1.0 and 1.0.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Updated existed tests.
Closes#27217 from Ngone51/set-decimal-from-javadecimal.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Use the new framework to resolve the DESCRIBE TABLE command.
The v1 DESCRIBE TABLE command supports both table and view. Checked with Hive and Presto, they don't have DESCRIBE TABLE syntax but only DESCRIBE, which supports both table and view:
1. https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-DescribeTable/View/MaterializedView/Column
2. https://prestodb.io/docs/current/sql/describe.html
We should make it clear that DESCRIBE support both table and view, by renaming the command to `DescribeRelation`.
This PR also tunes the framework a little bit to support the case that a command accepts both table and view.
### Why are the changes needed?
This is a part of effort to make the relation lookup behavior consistent: SPARK-29900.
Note that I make a separate PR here instead of #26921, as I need to update the framework to support a new use case: accept both table and view.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing tests
Closes#27187 from cloud-fan/describe.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
This PR intends to improve partition pruning for nondeterministic expressions in Hive tables:
Before this PR:
```
scala> sql("""create table test(id int) partitioned by (dt string)""")
scala> sql("""select * from test where dt='20190101' and rand() < 0.5""").explain()
== Physical Plan ==
*(1) Filter ((isnotnull(dt#19) AND (dt#19 = 20190101)) AND (rand(6515336563966543616) < 0.5))
+- Scan hive default.test [id#18, dt#19], HiveTableRelation `default`.`test`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#18], [dt#19], Statistics(sizeInBytes=8.0 EiB)
```
After this PR:
```
== Physical Plan ==
*(1) Filter (rand(-9163956883277176328) < 0.5)
+- Scan hive default.test [id#0, dt#1], HiveTableRelation `default`.`test`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#0], [dt#1], Statistics(sizeInBytes=8.0 EiB), [isnotnull(dt#1), (dt#1 = 20190101)]
```
This PR is the rework of #24118.
### Why are the changes needed?
For better performance.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Unit tests added.
Closes#27219 from maropu/SPARK-26736.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Spark SQL Kafka consumer connector considers delegation token usage even if the user configures `sasl.jaas.config` manually.
In this PR I've added `spark.security.credentials.kafka.enabled` and cluster configuration check to the condition.
### Why are the changes needed?
Now it's not possible to configure `sasl.jaas.config` manually.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing + additional unit tests.
Closes#27191 from gaborgsomogyi/SPARK-30495.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
This patch addresses adding event filter to handle SQL related events. This patch is next task of SPARK-29779 (#27085), please refer the description of PR #27085 to see overall rationalization of this patch.
Below functionalities will be addressed in later parts:
* integrate compaction into FsHistoryProvider
* documentation about new configuration
### Why are the changes needed?
One of major goal of SPARK-28594 is to prevent the event logs to become too huge, and SPARK-29779 achieves the goal. We've got another approach in prior, but the old approach required models in both KVStore and live entities to guarantee compatibility, while they're not designed to do so.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added UTs.
Closes#27164 from HeartSaVioR/SPARK-30479.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
Removal of following `Param` fields:
- `factorSize`
- `fitLinear`
- `miniBatchFraction`
- `initStd`
- `solver`
from `FMClassifier` and `FMRegressor`
### Why are the changes needed?
This `Param` members are already provided by `_FactorizationMachinesParams`
0f3d744c3f/python/pyspark/ml/regression.py (L2303-L2318)
which is mixed into `FMRegressor`:
0f3d744c3f/python/pyspark/ml/regression.py (L2350)
and `FMClassifier`:
0f3d744c3f/python/pyspark/ml/classification.py (L2793)
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manual testing.
Closes#27205 from zero323/SPARK-30378-FOLLOWUP.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR adjusts `_to_java` and `_from_java` of `OneVsRest` and `OneVsRestModel` to preserve `weightCol`.
### Why are the changes needed?
Currently both `Params` don't preserve `weightCol` `Params` when data is saved / loaded:
```python
from pyspark.ml.classification import LogisticRegression, OneVsRest, OneVsRestModel
from pyspark.ml.linalg import DenseVector
df = spark.createDataFrame([(0, 1, DenseVector([1.0, 0.0])), (0, 1, DenseVector([1.0, 0.0]))], ("label", "w", "features"))
ovr = OneVsRest(classifier=LogisticRegression()).setWeightCol("w")
ovrm = ovr.fit(df)
ovr.getWeightCol()
## 'w'
ovrm.getWeightCol()
## 'w'
ovr.write().overwrite().save("/tmp/ovr")
ovr_ = OneVsRest.load("/tmp/ovr")
ovr_.getWeightCol()
## KeyError
## ...
## KeyError: Param(parent='OneVsRest_5145d56b6bd1', name='weightCol', doc='weight column name. ...)
ovrm.write().overwrite().save("/tmp/ovrm")
ovrm_ = OneVsRestModel.load("/tmp/ovrm")
ovrm_ .getWeightCol()
## KeyError
## ...
## KeyError: Param(parent='OneVsRestModel_598c6d900fad', name='weightCol', doc='weight column name ...
```
### Does this PR introduce any user-facing change?
After this PR is merged, loaded objects will have `weightCol` `Param` set.
### How was this patch tested?
- Manual testing.
- Extension of existing persistence tests.
Closes#27190 from zero323/SPARK-30504.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This pr intends to fix wrong aggregated values in `GROUPING SETS` when there are duplicated grouping sets in a query (e.g., `GROUPING SETS ((k1),(k1))`).
For example;
```
scala> spark.table("t").show()
+---+---+---+
| k1| k2| v|
+---+---+---+
| 0| 0| 3|
+---+---+---+
scala> sql("""select grouping_id(), k1, k2, sum(v) from t group by grouping sets ((k1),(k1,k2),(k2,k1),(k1,k2))""").show()
+-------------+---+----+------+
|grouping_id()| k1| k2|sum(v)|
+-------------+---+----+------+
| 0| 0| 0| 9| <---- wrong aggregate value and the correct answer is `3`
| 1| 0|null| 3|
+-------------+---+----+------+
// PostgreSQL case
postgres=# select k1, k2, sum(v) from t group by grouping sets ((k1),(k1,k2),(k2,k1),(k1,k2));
k1 | k2 | sum
----+------+-----
0 | 0 | 3
0 | 0 | 3
0 | 0 | 3
0 | NULL | 3
(4 rows)
// Hive case
hive> select GROUPING__ID, k1, k2, sum(v) from t group by k1, k2 grouping sets ((k1),(k1,k2),(k2,k1),(k1,k2));
1 0 NULL 3
0 0 0 3
```
[MS SQL Server has the same behaviour with PostgreSQL](https://github.com/apache/spark/pull/26961#issuecomment-573638442). This pr follows the behaviour of PostgreSQL/SQL server; it adds one more virtual attribute in `Expand` for avoiding wrongly grouping rows with the same grouping ID.
### Why are the changes needed?
To fix bugs.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
The existing tests.
Closes#26961 from maropu/SPARK-29708.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
The changes in the rule `SimplifyBinaryComparison` from https://github.com/apache/spark/pull/27008 could bring performance regression in the optimizer when there are a large set of filter conditions.
We need to improve the implementation and reduce the time complexity.
### Why are the changes needed?
Need to fix the potential performance regression in the optimizer.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing unit tests.
Also run a micor benchmark in `BinaryComparisonSimplificationSuite`
```
object Optimize extends RuleExecutor[LogicalPlan] {
val batches =
Batch("Constant Folding", FixedPoint(50),
SimplifyBinaryComparison) :: Nil
}
test("benchmark") {
val a = Symbol("a")
val condition = (1 to 500).map(i => EqualTo(a, a)).reduceLeft(And)
val finalCondition = And(condition, IsNotNull(a))
val plan = nullableRelation.where(finalCondition).analyze
val start = System.nanoTime()
Optimize.execute(plan)
println((System.nanoTime() - start) /1000000)
}
```
Before the changes: 2507ms
After the changes: 3ms
Closes#27212 from gengliangwang/SimplifyBinaryComparison.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Updated `docs/sql-data-sources-avro.md`, and added a few sentences about already deprecated in code Avro option `ignoreExtension`.
<img width="968" alt="Screen Shot 2020-01-15 at 10 24 14" src="https://user-images.githubusercontent.com/1580697/72413684-64d1c780-3781-11ea-948a-d3cccf4c72df.png">
Closes#27174
### Why are the changes needed?
To make users doc consistent to the code where `ignoreExtension` has been already deprecated, see 3663dbe541/external/avro/src/main/scala/org/apache/spark/sql/avro/AvroUtils.scala (L46-L47)
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
by building docs
Closes#27194 from MaxGekk/avro-doc-deprecation-ignoreExtension.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to remove the `header` option in the `Avro source v2: support partition pruning` test.
### Why are the changes needed?
The option is not supported by Avro, and may misleading readers.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By `AvroSuite`.
Closes#27203 from MaxGekk/avro-suite-remove-header-option.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to check the `ignoreExtensionKey` option in the case insensitive map of `AvroOption`.
### Why are the changes needed?
The map `options` passed to `AvroUtils.inferSchema` contains all keys in the lower cases in fact. Actually, the map is converted from a `CaseInsensitiveStringMap`. Consequently, the check 3663dbe541/external/avro/src/main/scala/org/apache/spark/sql/avro/AvroUtils.scala (L45) always return `false`, and the deprecation log warning is never printed.
### Does this PR introduce any user-facing change?
Yes, after the changes the log warning is printed once.
### How was this patch tested?
Added new test to `AvroSuite` which checks existence of log warning.
Closes#27200 from MaxGekk/avro-fix-ignoreExtension-contains.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Currently for Monitoring Spark application SQL information is not available from REST but only via UI. REST provides only applications,jobs,stages,environment. This Jira is targeted to provide a REST API so that SQL level information can be found
A single SQL query can result into multiple jobs. So for end user who is using STS or spark-sql, the intended highest level of probe is the SQL which he has executed. This information can be seen from SQL tab. Attaching a sample.

But same information he cannot access using the REST API exposed by spark and he always have to rely on jobs API which may be difficult. So i intend to expose the information seen in SQL tab in UI via REST API
Mainly:
Id : Long - execution id of the sql
status : String - possible values COMPLETED/RUNNING/FAILED
description : String - executed SQL string
planDescription : String - Plan representation
metrics : Seq[Metrics] - `Metrics` contain `metricName: String, metricValue: String`
submissionTime : String - formatted `Date` time of SQL submission
duration : Long - total run time in milliseconds
runningJobIds : Seq[Int] - sequence of running job ids
failedJobIds : Seq[Int] - sequence of failed job ids
successJobIds : Seq[Int] - sequence of success job ids
* To fetch sql executions: /sql?details=boolean&offset=integer&length=integer
* To fetch single execution: /sql/{executionID}?details=boolean
| parameter | type | remarks |
| ------------- |:-------------:| -----|
| details | boolean | Optional. Set true to get plan description and metrics information, defaults to false |
| offset | integer | Optional. offset to fetch the executions, defaults to 0 |
| length | integer | Optional. total number of executions to be fetched, defaults to 20 |
### Why are the changes needed?
To support users query SQL information via REST API
### Does this PR introduce any user-facing change?
Yes. It provides a new monitoring URL for SQL
### How was this patch tested?
Tested manually


Closes#24076 from ajithme/restapi.
Lead-authored-by: Ajith <ajith2489@gmail.com>
Co-authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
1, change `convertToBaggedRDDSamplingWithReplacement` to attach instance weights
2, make RF supports weights
### Why are the changes needed?
`weightCol` is already exposed, while RF has not support weights.
### Does this PR introduce any user-facing change?
Yes, new setters
### How was this patch tested?
added testsuites
Closes#27097 from zhengruifeng/rf_support_weight.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
* Annotate UserDefinedAggregateFunction as deprecated by SPARK-27296
* Update user doc examples to reflect new ability to register typed Aggregator[IN, BUF, OUT] as an untyped aggregating UDF
### Why are the changes needed?
UserDefinedAggregateFunction is being deprecated
### Does this PR introduce any user-facing change?
Changes are to user documentation, and deprecation annotations.
### How was this patch tested?
Testing was via package build to verify doc generation, deprecation warnings, and successful example compilation.
Closes#27193 from erikerlandson/spark-30423.
Authored-by: Erik Erlandson <eerlands@redhat.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Skew Join is common and can severely downgrade performance of queries, especially those with joins. This PR aim to optimization the skew join based on the runtime Map output statistics by adding "OptimizeSkewedPartitions" rule. And The details design doc is [here](https://docs.google.com/document/d/1NkXN-ck8jUOS0COz3f8LUW5xzF8j9HFjoZXWGGX2HAg/edit). Currently we can support "Inner, Cross, LeftSemi, LeftAnti, LeftOuter, RightOuter" join type.
### Why are the changes needed?
To optimize the skewed partition in runtime based on AQE
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
UT
Closes#26434 from JkSelf/skewedPartitionBasedSize.
Lead-authored-by: jiake <ke.a.jia@intel.com>
Co-authored-by: Wenchen Fan <wenchen@databricks.com>
Co-authored-by: JiaKe <ke.a.jia@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
There are some parity issues between python and scala
### Why are the changes needed?
keep parity between python and scala
### Does this PR introduce any user-facing change?
Yes
### How was this patch tested?
existing tests
Closes#27196 from huaxingao/spark-30498.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### **What changes were proposed in this pull request?**
Fix task status inconsistent in `executorLost` which caused by `markPartitionCompleted`
### **Why are the changes needed?**
The inconsistent will cause app hung up.
The bugs occurs in the corer case as follows:
1. The stage occurs during stage retry, scheduler will resubmit a new stage with unfinished tasks.
2. Those unfinished tasks in origin stage finished and the same task on the new retry stage hasn't finished, it will mark the task partition on the current retry stage as succesuful in TSM `successful` array variable.
3. The executor crashed when it is running tasks which have succeeded by origin stage, it cause TSM run `executorLost` to rescheduler the task on the executor, and it will change the partition's running status in `copiesRunning` twice to -1.
4. 'dequeueTaskFromList' will use `copiesRunning` equal 0 as reschedule basis when rescheduler tasks, and now it is -1, can't to reschedule, and the app will hung forever.
### **Does this PR introduce any user-facing change?**
No
### **How was this patch tested?**
Closes#26975 from seayoun/fix_stageRetry_executorCrash_cause_problems.
Authored-by: yu <you@example.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
If spark.sql.ansi.enabled is set,
throw exception when cast to any numeric type do not follow the ANSI SQL standards.
### Why are the changes needed?
ANSI SQL standards do not allow invalid strings to get casted into numeric types and throw exception for that. Currently spark sql gives NULL in such cases.
Before:
`select cast('str' as decimal) => NULL`
After :
`select cast('str' as decimal) => invalid input syntax for type numeric: str`
These results are after setting `spark.sql.ansi.enabled=true`
### Does this PR introduce any user-facing change?
Yes. Now when ansi mode is on users will get arithmetic exception for invalid strings.
### How was this patch tested?
Unit Tests Added.
Closes#26933 from iRakson/castDecimalANSI.
Lead-authored-by: root1 <raksonrakesh@gmail.com>
Co-authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to define a sub-class of `AppenderSkeleton` in `SparkFunSuite` and reuse it from other tests. The class stores incoming `LoggingEvent` in an array which is available to tests for future analysis of logged events.
### Why are the changes needed?
This eliminates code duplication in tests.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By existing test suites - `CSVSuite`, `OptimizerLoggingSuite`, `JoinHintSuite`, `CodeGenerationSuite` and `SQLConfSuite`.
Closes#27166 from MaxGekk/dedup-appender-skeleton.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to remove already deprecated SQL configs:
- `spark.sql.variable.substitute.depth` deprecated in Spark 2.1
- `spark.sql.parquet.int64AsTimestampMillis` deprecated in Spark 2.3
Also I moved `removedSQLConfigs` closer to `deprecatedSQLConfigs`. This will allow to have references to other config entries.
### Why are the changes needed?
To improve code maintainability.
### Does this PR introduce any user-facing change?
Yes.
### How was this patch tested?
By existing test suites `ParquetQuerySuite` and `SQLConfSuite`.
Closes#27169 from MaxGekk/remove-deprecated-conf-2.4.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Updated the doc for ADD FILE and LIST FILE
### Why are the changes needed?
Due to changes made in #26863 , it is necessary to update ADD FILE and LIST FILE doc.
### Does this PR introduce any user-facing change?
Yeah. Document updated.
### How was this patch tested?
Manually
Closes#27188 from iRakson/SPARK-30234_FOLLOWUP.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Fix all the failed tests when enable AQE.
### Why are the changes needed?
Run more tests with AQE to catch bugs, and make it easier to enable AQE by default in the future.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing unit tests
Closes#26813 from JkSelf/enableAQEDefault.
Authored-by: jiake <ke.a.jia@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
add weight support in BisectingKMeans
### Why are the changes needed?
BisectingKMeans should support instance weighting
### Does this PR introduce any user-facing change?
Yes. BisectingKMeans.setWeight
### How was this patch tested?
Unit test
Closes#27035 from huaxingao/spark_30351.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Make Regressors extend abstract class Regressor:
```AFTSurvivalRegression extends Estimator => extends Regressor```
```DecisionTreeRegressor extends Predictor => extends Regressor```
```FMRegressor extends Predictor => extends Regressor```
```GBTRegressor extends Predictor => extends Regressor```
```RandomForestRegressor extends Predictor => extends Regressor```
We will not make ```IsotonicRegression``` extend ```Regressor``` because it is tricky to handle both DoubleType and VectorType.
### Why are the changes needed?
Make class hierarchy consistent for all Regressors
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
existing tests
Closes#27168 from huaxingao/spark-30377.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Removal of `OneVsRestModel.setClassifier`, `OneVsRestModel.setLabelCol` and `OneVsRestModel.setWeightCol` methods.
### Why are the changes needed?
Aforementioned methods shouldn't by included by [SPARK-29093](https://issues.apache.org/jira/browse/SPARK-29093), as they're not present in Scala `OneVsRestModel` and have no practical application.
### Does this PR introduce any user-facing change?
Not beyond scope of SPARK-29093].
### How was this patch tested?
Existing tests.
CC huaxingao zhengruifeng
Closes#27181 from zero323/SPARK-30493.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
This PR proposes to increase the memory in `WorkerMemoryTest.test_memory_limit` in order to make the test pass with PyPy.
The test is currently failed only in PyPy as below in some PRs unexpectedly:
```
Current mem limits: 18446744073709551615 of max 18446744073709551615
Setting mem limits to 1048576 of max 1048576
RPython traceback:
File "pypy_module_pypyjit_interp_jit.c", line 289, in portal_5
File "pypy_interpreter_pyopcode.c", line 3468, in handle_bytecode__AccessDirect_None
File "pypy_interpreter_pyopcode.c", line 5558, in dispatch_bytecode__AccessDirect_None
out of memory: couldn't allocate the next arena
ERROR
```
It seems related to how PyPy allocates the memory and GC works PyPy-specifically. There seems nothing wrong in this configuration implementation itself in PySpark side.
I roughly tested in higher PyPy versions on Ubuntu (PyPy v7.3.0) and this test seems passing fine so I suspect this might be an issue in old PyPy behaviours.
The change only increases the limit so it would not affect actual memory allocations. It just needs to test if the limit is properly set in worker sides. For clarification, the memory is unlimited in the machine if not set.
### Why are the changes needed?
To make the tests pass and unblock other PRs.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manually and Jenkins should test it out.
Closes#27186 from HyukjinKwon/SPARK-30480.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This patch documents the configuration for the Kafka producer pool, newly revised via SPARK-21869 (#26845)
### Why are the changes needed?
The explanation of new Kafka producer pool configuration is missing, whereas the doc has Kafka
consumer pool configuration.
### Does this PR introduce any user-facing change?
Yes. This is a documentation change.

### How was this patch tested?
N/A
Closes#27146 from HeartSaVioR/SPARK-21869-FOLLOWUP.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a follow-up for https://github.com/apache/spark/pull/25248 .
### Why are the changes needed?
The new behavior cannot access the existing table which is created by old behavior.
This PR provides a way to avoid new behavior for the existing users.
### Does this PR introduce any user-facing change?
Yes. This will fix the broken behavior on the existing tables.
### How was this patch tested?
Pass the Jenkins and manually run JDBC integration test.
```
build/mvn install -DskipTests
build/mvn -Pdocker-integration-tests -pl :spark-docker-integration-tests_2.12 test
```
Closes#27184 from dongjoon-hyun/SPARK-28152-CONF.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add cache for Like and RLike when pattern is not static
### Why are the changes needed?
When pattern is not static, we should avoid compile pattern every time if some pattern is same.
Here is perf numbers, include 3 test groups and use `range` to make it easy.
```
// ---------------------
// 10,000 rows and 10 partitions
val df1 = spark.range(0, 10000, 1, 10).withColumnRenamed("id", "id1")
val df2 = spark.range(0, 10000, 1, 10).withColumnRenamed("id", "id2")
val start = System.currentTimeMillis
df1.join(df2).where("id2 like id1").count()
// before 16939
// after 6352
println(System.currentTimeMillis - start)
// ---------------------
// 10,000 rows and 100 partitions
val df1 = spark.range(0, 10000, 1, 100).withColumnRenamed("id", "id1")
val df2 = spark.range(0, 10000, 1, 100).withColumnRenamed("id", "id2")
val start = System.currentTimeMillis
df1.join(df2).where("id2 like id1").count()
// before 11070
// after 4680
println(System.currentTimeMillis - start)
// ---------------------
// 20,000 rows and 10 partitions
val df1 = spark.range(0, 20000, 1, 10).withColumnRenamed("id", "id1")
val df2 = spark.range(0, 20000, 1, 10).withColumnRenamed("id", "id2")
val start = System.currentTimeMillis
df1.join(df2).where("id2 like id1").count()
// before 66962
// after 29934
println(System.currentTimeMillis - start)
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Closes#26875 from ulysses-you/SPARK-30245.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1, del `NodeIdCache`, and use `PeriodicRDDCheckpointer` instead;
2, reuse broadcasted `Splits` in the whole training;
### Why are the changes needed?
1, The functionality of `NodeIdCache` and `PeriodicRDDCheckpointer` are highly similar, and the update process of nodeIds is simple; One goal of "Generalize PeriodicGraphCheckpointer for RDDs" in SPARK-5561 is to use checkpointer in RandomForest;
2, only need to broadcast `Splits` once;
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing testsuites
Closes#27145 from zhengruifeng/del_NodeIdCache.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
This PR removes a dangling test result, `JSONBenchmark-jdk11-results.txt`.
This causes a case-sensitive issue on Mac.
```
$ git clone https://gitbox.apache.org/repos/asf/spark.git spark-gitbox
Cloning into 'spark-gitbox'...
remote: Counting objects: 671717, done.
remote: Compressing objects: 100% (258021/258021), done.
remote: Total 671717 (delta 329181), reused 560390 (delta 228097)
Receiving objects: 100% (671717/671717), 149.69 MiB | 950.00 KiB/s, done.
Resolving deltas: 100% (329181/329181), done.
Updating files: 100% (16090/16090), done.
warning: the following paths have collided (e.g. case-sensitive paths
on a case-insensitive filesystem) and only one from the same
colliding group is in the working tree:
'sql/core/benchmarks/JSONBenchmark-jdk11-results.txt'
'sql/core/benchmarks/JsonBenchmark-jdk11-results.txt'
```
### Why are the changes needed?
Previously, since the file name didn't match with `object JSONBenchmark`, it made a confusion when we ran the benchmark. So, 4e0e4e51c4 renamed `JSONBenchmark` to `JsonBenchmark`. However, at the same time frame, https://github.com/apache/spark/pull/26003 regenerated this file.
Recently, https://github.com/apache/spark/pull/27078 regenerates the results with the correct file name, `JsonBenchmark-jdk11-results.txt`. So, we can remove the old one.
### Does this PR introduce any user-facing change?
No. This is a test result.
### How was this patch tested?
Manually check the following correctly generated files in the master. And, check this PR removes the dangling one.
- https://github.com/apache/spark/blob/master/sql/core/benchmarks/JsonBenchmark-results.txt
- https://github.com/apache/spark/blob/master/sql/core/benchmarks/JsonBenchmark-jdk11-results.txtCloses#27180 from dongjoon-hyun/SPARK-REMOVE.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to replace `.collect()`, `.count()` and `.foreach(_ => ())` in SQL benchmarks and use the `NoOp` datasource. I added an implicit class to `SqlBasedBenchmark` with the `.noop()` method. It can be used in benchmark like: `ds.noop()`. The last one is unfolded to `ds.write.format("noop").mode(Overwrite).save()`.
### Why are the changes needed?
To avoid additional overhead that `collect()` (and other actions) has. For example, `.collect()` has to convert values according to external types and pull data to the driver. This can hide actual performance regressions or improvements of benchmarked operations.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Re-run all modified benchmarks using Amazon EC2.
| Item | Description |
| ---- | ----|
| Region | us-west-2 (Oregon) |
| Instance | r3.xlarge (spot instance) |
| AMI | ami-06f2f779464715dc5 (ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20190722.1) |
| Java | OpenJDK8/10 |
- Run `TPCDSQueryBenchmark` using instructions from the PR #26049
```
# `spark-tpcds-datagen` needs this. (JDK8)
$ git clone https://github.com/apache/spark.git -b branch-2.4 --depth 1 spark-2.4
$ export SPARK_HOME=$PWD
$ ./build/mvn clean package -DskipTests
# Generate data. (JDK8)
$ git clone gitgithub.com:maropu/spark-tpcds-datagen.git
$ cd spark-tpcds-datagen/
$ build/mvn clean package
$ mkdir -p /data/tpcds
$ ./bin/dsdgen --output-location /data/tpcds/s1 // This need `Spark 2.4`
```
- Other benchmarks ran by the script:
```
#!/usr/bin/env python3
import os
from sparktestsupport.shellutils import run_cmd
benchmarks = [
['sql/test', 'org.apache.spark.sql.execution.benchmark.AggregateBenchmark'],
['avro/test', 'org.apache.spark.sql.execution.benchmark.AvroReadBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.BloomFilterBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.DataSourceReadBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.DateTimeBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.ExtractBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.FilterPushdownBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.InExpressionBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.IntervalBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.JoinBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.MakeDateTimeBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.MiscBenchmark'],
['hive/test', 'org.apache.spark.sql.execution.benchmark.ObjectHashAggregateExecBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.OrcNestedSchemaPruningBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.OrcV2NestedSchemaPruningBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.ParquetNestedSchemaPruningBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.RangeBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.UDFBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.WideSchemaBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.benchmark.WideTableBenchmark'],
['hive/test', 'org.apache.spark.sql.hive.orc.OrcReadBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.datasources.csv.CSVBenchmark'],
['sql/test', 'org.apache.spark.sql.execution.datasources.json.JsonBenchmark']
]
print('Set SPARK_GENERATE_BENCHMARK_FILES=1')
os.environ['SPARK_GENERATE_BENCHMARK_FILES'] = '1'
for b in benchmarks:
print("Run benchmark: %s" % b[1])
run_cmd(['build/sbt', '%s:runMain %s' % (b[0], b[1])])
```
Closes#27078 from MaxGekk/noop-in-benchmarks.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Defines a new subclass of UDF: `UserDefinedAggregator`. Also allows `Aggregator` to be registered as a udf. Under the hood, the implementation is based on the internal `TypedImperativeAggregate` class that spark's predefined aggregators make use of. The effect is that custom user defined aggregators are now serialized only on partition boundaries instead of being serialized and deserialized at each input row.
The two new modes of using `Aggregator` are as follows:
```scala
val agg: Aggregator[IN, BUF, OUT] = // typed aggregator
val udaf1 = UserDefinedAggregator(agg)
val udaf2 = spark.udf.register("agg", agg)
```
## How was this patch tested?
Unit testing has been added that corresponds to the testing suites for `UserDefinedAggregateFunction`. Additionally, unit tests explicitly count the number of aggregator ser/de cycles to ensure that it is governed only by the number of data partitions.
To evaluate the performance impact, I did two comparisons.
The code and REPL results are recorded on [this gist](https://gist.github.com/erikerlandson/b0e106a4dbaf7f80b4f4f3a21f05f892)
To characterize its behavior I benchmarked both a relatively simple aggregator and then an aggregator with a complex structure (a t-digest).
### performance
The following compares the new `Aggregator` based aggregation against UDAF. In this scenario, the new aggregation is about 100x faster. The difference in performance impact depends on the complexity of the aggregator. For very simple aggregators (e.g. implementing 'sum', etc), the performance impact is more like 25-30%.
```scala
scala> import scala.util.Random._, org.apache.spark.sql.Row, org.apache.spark.tdigest._
import scala.util.Random._
import org.apache.spark.sql.Row
import org.apache.spark.tdigest._
scala> val data = sc.parallelize(Vector.fill(50000){(nextInt(2), nextGaussian, nextGaussian.toFloat)}, 5).toDF("cat", "x1", "x2")
data: org.apache.spark.sql.DataFrame = [cat: int, x1: double ... 1 more field]
scala> val udaf = TDigestUDAF(0.5, 0)
udaf: org.apache.spark.tdigest.TDigestUDAF = TDigestUDAF(0.5,0)
scala> val bs = Benchmark.sample(10) { data.agg(udaf($"x1"), udaf($"x2")).first }
bs: Array[(Double, org.apache.spark.sql.Row)] = Array((16.523,[TDigestSQL(TDigest(0.5,0,130,TDigestMap(-4.9171836327285225 -> (1.0, 1.0), -3.9615949140987685 -> (1.0, 2.0), -3.792874086327091 -> (0.7500781537109753, 2.7500781537109753), -3.720534874164185 -> (1.796754196108008, 4.546832349818983), -3.702105588052377 -> (0.4531676501810167, 5.0), -3.665883591332569 -> (2.3434687534153142, 7.343468753415314), -3.649982231368131 -> (0.6565312465846858, 8.0), -3.5914188829817744 -> (4.0, 12.0), -3.530472305581248 -> (4.0, 16.0), -3.4060489584449467 -> (2.9372251939818383, 18.93722519398184), -3.3000694035428486 -> (8.12412890252889, 27.061354096510726), -3.2250016655261877 -> (8.30564453211017, 35.3669986286209), -3.180537395623448 -> (6.001782561137285, 41.3687811...
scala> bs.map(_._1)
res0: Array[Double] = Array(16.523, 17.138, 17.863, 17.801, 17.769, 17.786, 17.744, 17.8, 17.939, 17.854)
scala> val agg = TDigestAggregator(0.5, 0)
agg: org.apache.spark.tdigest.TDigestAggregator = TDigestAggregator(0.5,0)
scala> val udaa = spark.udf.register("tdigest", agg)
udaa: org.apache.spark.sql.expressions.UserDefinedAggregator[Double,org.apache.spark.tdigest.TDigestSQL,org.apache.spark.tdigest.TDigestSQL] = UserDefinedAggregator(TDigestAggregator(0.5,0),None,true,true)
scala> val bs = Benchmark.sample(10) { data.agg(udaa($"x1"), udaa($"x2")).first }
bs: Array[(Double, org.apache.spark.sql.Row)] = Array((0.313,[TDigestSQL(TDigest(0.5,0,130,TDigestMap(-4.9171836327285225 -> (1.0, 1.0), -3.9615949140987685 -> (1.0, 2.0), -3.792874086327091 -> (0.7500781537109753, 2.7500781537109753), -3.720534874164185 -> (1.796754196108008, 4.546832349818983), -3.702105588052377 -> (0.4531676501810167, 5.0), -3.665883591332569 -> (2.3434687534153142, 7.343468753415314), -3.649982231368131 -> (0.6565312465846858, 8.0), -3.5914188829817744 -> (4.0, 12.0), -3.530472305581248 -> (4.0, 16.0), -3.4060489584449467 -> (2.9372251939818383, 18.93722519398184), -3.3000694035428486 -> (8.12412890252889, 27.061354096510726), -3.2250016655261877 -> (8.30564453211017, 35.3669986286209), -3.180537395623448 -> (6.001782561137285, 41.36878118...
scala> bs.map(_._1)
res1: Array[Double] = Array(0.313, 0.193, 0.175, 0.185, 0.174, 0.176, 0.16, 0.186, 0.171, 0.179)
scala>
```
Closes#25024 from erikerlandson/spark-27296.
Authored-by: Erik Erlandson <eerlands@redhat.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Now Spark can propagate constraint during sql optimization when `spark.sql.constraintPropagation.enabled` is true, then `where c = 1` will convert to `where c = 1 and c is not null`. We also can use constraint in `SimplifyBinaryComparison`.
`SimplifyBinaryComparison` will simplify expression which is not nullable and semanticEquals. And we also can simplify if one expression is infered `IsNotNull`.
### Why are the changes needed?
Simplify SQL.
```
create table test (c1 string);
explain extended select c1 from test where c1 = c1 limit 10;
-- before
GlobalLimit 10
+- LocalLimit 10
+- Filter (isnotnull(c1#20) AND (c1#20 = c1#20))
+- Relation[c1#20]
-- after
GlobalLimit 10
+- LocalLimit 10
+- Filter (isnotnull(c1#20)
+- Relation[c1#20]
explain extended select c1 from test where c1 > c1 limit 10;
-- before
GlobalLimit 10
+- LocalLimit 10
+- Filter (isnotnull(c1#20) && (c1#20 > c1#20))
+- Relation[c1#20]
-- after
LocalRelation <empty>, [c1#20]
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Add UT.
Closes#27008 from ulysses-you/SPARK-30353.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The Executor Computing Time in Time Line of Stage Page will be right
### Why are the changes needed?
The Executor Computing Time in Time Line of Stage Page is Wrong. It includes the Scheduler Delay Time, while the Proportion excludes the Scheduler Delay
<img width="1467" alt="Snipaste_2020-01-08_19-04-33" src="https://user-images.githubusercontent.com/3488126/71976714-f2795880-3251-11ea-869a-43ca6e0cf96a.png">
The right executor computing time is 1ms, but the number in UI is 3ms(include 2ms scheduler delay); the proportion is right.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manual
Closes#27135 from sddyljsx/SPARK-30458.
Lead-authored-by: Neal Song <neal_song@126.com>
Co-authored-by: neal_song <neal_song@126.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
update the doc of momery package
### Why are the changes needed?
From Spark 2.0, the storage memory also uses off heap memory. We update the doc here.

### Does this PR introduce any user-facing change?
No
### How was this patch tested?
No Tests Needed
Closes#27160 from sddyljsx/SPARK-30478.
Lead-authored-by: Neal Song <neal_song@126.com>
Co-authored-by: neal_song <neal_song@126.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
A small fix to the Maven build file under the `assembly` module by switch "dir" attribute to "file".
### Why are the changes needed?
To make the `<delete>` task properly delete an existing zip file.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Ran a build with the change and confirmed that a corrupted zip file was replaced with the correct one.
Closes#27171 from jeff303/SPARK-30489.
Authored-by: Jeff Evans <jeffrey.wayne.evans@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Removing the sorting of PySpark SQL Row fields that were previously sorted by name alphabetically for Python versions 3.6 and above. Field order will now match that as entered. Rows will be used like tuples and are applied to schema by position. For Python versions < 3.6, the order of kwargs is not guaranteed and therefore will be sorted automatically as in previous versions of Spark.
### Why are the changes needed?
This caused inconsistent behavior in that local Rows could be applied to a schema by matching names, but once serialized the Row could only be used by position and the fields were possibly in a different order.
### Does this PR introduce any user-facing change?
Yes, Row fields are no longer sorted alphabetically but will be in the order entered. For Python < 3.6 `kwargs` can not guarantee the order as entered, so `Row`s will be automatically sorted.
An environment variable "PYSPARK_ROW_FIELD_SORTING_ENABLED" can be set that will override construction of `Row` to maintain compatibility with Spark 2.x.
### How was this patch tested?
Existing tests are run with PYSPARK_ROW_FIELD_SORTING_ENABLED=true and added new test with unsorted fields for Python 3.6+
Closes#26496 from BryanCutler/pyspark-remove-Row-sorting-SPARK-29748.
Authored-by: Bryan Cutler <cutlerb@gmail.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
### What changes were proposed in this pull request?
This patch proposes to preserve existing permission/acls of paths when truncate table/partition.
### Why are the changes needed?
When Spark SQL truncates table, it deletes the paths of table/partitions, then re-create new ones. If permission/acls were set on the paths, the existing permission/acls will be deleted.
We should preserve the permission/acls if possible.
### Does this PR introduce any user-facing change?
Yes. When truncate table/partition, Spark will keep permission/acls of paths.
### How was this patch tested?
Unit test.
Manual test:
1. Create a table.
2. Manually change it permission/acl
3. Truncate table
4. Check permission/acl
```scala
val df = Seq(1, 2, 3).toDF
df.write.mode("overwrite").saveAsTable("test.test_truncate_table")
val testTable = spark.table("test.test_truncate_table")
testTable.show()
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
+-----+
// hdfs dfs -setfacl ...
// hdfs dfs -getfacl ...
sql("truncate table test.test_truncate_table")
// hdfs dfs -getfacl ...
val testTable2 = spark.table("test.test_truncate_table")
testTable2.show()
+-----+
|value|
+-----+
+-----+
```
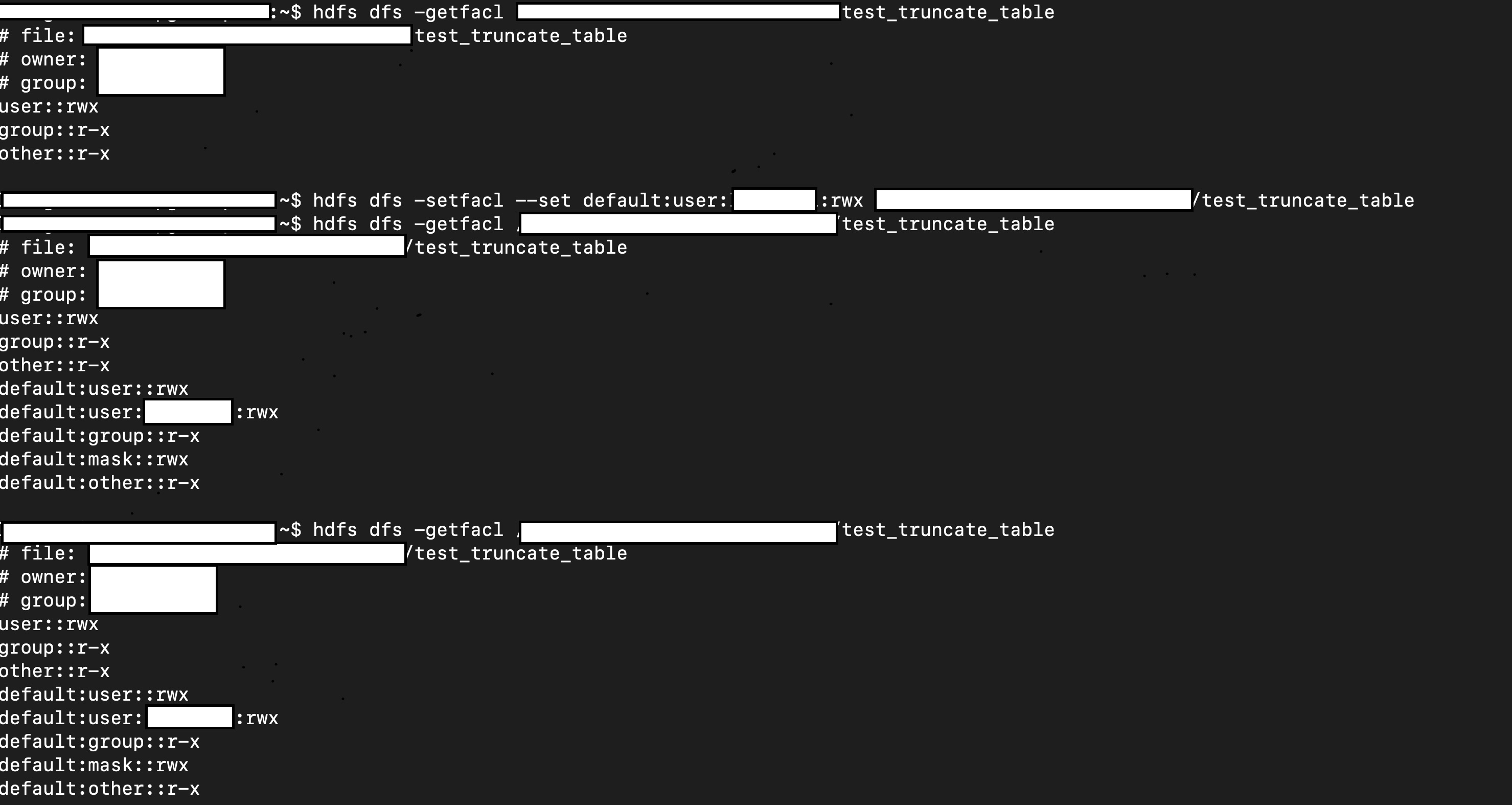
Closes#26956 from viirya/truncate-table-permission.
Lead-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Co-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch proposes to compact old event log files when end users enable rolling event log, and clean up these files after compaction.
Here the "compaction" really mean is filtering out listener events for finished/removed things - like jobs which take most of space for event log file except SQL related events. To achieve this, compactor does two phases reading: 1) tracking the live jobs (and more to add) 2) filtering events via leveraging the information about live things and rewriting to the "compacted" file.
This approach retains the ability of compatibility on event log file and adds the possibility of reducing the overall size of event logs. There's a downside here as well: executor metrics for tasks would be inaccurate, as compactor will filter out the task events which job is finished, but I don't feel it as a blocker.
Please note that SPARK-29779 leaves below functionalities for future JIRA issue as the patch for SPARK-29779 is too huge and we decided to break down:
* apply filter in SQL events
* integrate compaction into FsHistoryProvider
* documentation about new configuration
### Why are the changes needed?
One of major goal of SPARK-28594 is to prevent the event logs to become too huge, and SPARK-29779 achieves the goal. We've got another approach in prior, but the old approach required models in both KVStore and live entities to guarantee compatibility, while they're not designed to do so.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added UTs.
Closes#27085 from HeartSaVioR/SPARK-29779-part1.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
Currently data columns are displayed in one line for show create table command, when the table has many columns (to make things even worse, columns may have long names or comments), the displayed result is really hard to read.
To improve readability, we print each column in a separate line. Note that other systems like Hive/MySQL also display in this way.
Also, for data columns, table properties and options, we put the right parenthesis to the end of the last column/property/option, instead of occupying a separate line.
### Why are the changes needed?
for better readability
### Does this PR introduce any user-facing change?
before the change:
```
spark-sql> show create table test_table;
CREATE TABLE `test_table` (`col1` INT COMMENT 'This is comment for column 1', `col2` STRING COMMENT 'This is comment for column 2', `col3` DOUBLE COMMENT 'This is comment for column 3')
USING parquet
OPTIONS (
`bar` '2',
`foo` '1'
)
TBLPROPERTIES (
'a' = 'x',
'b' = 'y'
)
```
after the change:
```
spark-sql> show create table test_table;
CREATE TABLE `test_table` (
`col1` INT COMMENT 'This is comment for column 1',
`col2` STRING COMMENT 'This is comment for column 2',
`col3` DOUBLE COMMENT 'This is comment for column 3')
USING parquet
OPTIONS (
`bar` '2',
`foo` '1')
TBLPROPERTIES (
'a' = 'x',
'b' = 'y')
```
### How was this patch tested?
modified existing tests
Closes#27147 from wzhfy/multi_line_columns.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This pr intends to skip the unnecessary checks that most aggregate quries don't need in RewriteDistinctAggregates.
### Why are the changes needed?
For minor optimization.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#26997 from maropu/OptDistinctAggRewrite.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}