## What changes were proposed in this pull request?
Fair Scheduler can be built via one of the following options:
- By setting a `spark.scheduler.allocation.file` property,
- By setting `fairscheduler.xml` into classpath.
These options are checked **in order** and fair-scheduler is built via first found option. If invalid path is found, `FileNotFoundException` will be expected.
This PR aims unit test coverage of these use cases and a minor documentation change has been added for second option(`fairscheduler.xml` into classpath) to inform the users.
Also, this PR was related with #16813 and has been created separately to keep patch content as isolated and to help the reviewers.
## How was this patch tested?
Added new Unit Tests.
Author: erenavsarogullari <erenavsarogullari@gmail.com>
Closes#16992 from erenavsarogullari/SPARK-19662.
History Server Launch uses SparkClassCommandBuilder for launching the server. It is observed that SPARK_CLASSPATH has been removed and deprecated. For spark-submit this takes a different route and spark.driver.extraClasspath takes care of specifying additional jars in the classpath that were previously specified in the SPARK_CLASSPATH. Right now the only way specify the additional jars for launching daemons such as history server is using SPARK_DIST_CLASSPATH (https://spark.apache.org/docs/latest/hadoop-provided.html) but this I presume is a distribution classpath. It would be nice to have a similar config like spark.driver.extraClasspath for launching daemons similar to history server.
Added new environment variable SPARK_DAEMON_CLASSPATH to set classpath for launching daemons. Tested and verified for History Server and Standalone Mode.
## How was this patch tested?
Initially, history server start script would fail for the reason being that it could not find the required jars for launching the server in the java classpath. Same was true for running Master and Worker in standalone mode. By adding the environment variable SPARK_DAEMON_CLASSPATH to the java classpath, both the daemons(History Server, Standalone daemons) are starting up and running.
Author: pgandhi <pgandhi@yahoo-inc.com>
Author: pgandhi999 <parthkgandhi9@gmail.com>
Closes#19047 from pgandhi999/master.
## What changes were proposed in this pull request?
This PR proposes both:
- Add information about Javadoc, SQL docs and few more information in `docs/README.md` and a comment in `docs/_plugins/copy_api_dirs.rb` related with Javadoc.
- Adds some commands so that the script always runs the SQL docs build under `./sql` directory (for directly running `./sql/create-docs.sh` in the root directory).
## How was this patch tested?
Manual tests with `jekyll build` and `./sql/create-docs.sh` in the root directory.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19019 from HyukjinKwon/minor-doc-build.
JIRA ticket: https://issues.apache.org/jira/browse/SPARK-21694
## What changes were proposed in this pull request?
Spark already supports launching containers attached to a given CNI network by specifying it via the config `spark.mesos.network.name`.
This PR adds support to pass in network labels to CNI plugins via a new config option `spark.mesos.network.labels`. These network labels are key-value pairs that are set in the `NetworkInfo` of both the driver and executor tasks. More details in the related Mesos documentation: http://mesos.apache.org/documentation/latest/cni/#mesos-meta-data-to-cni-plugins
## How was this patch tested?
Unit tests, for both driver and executor tasks.
Manual integration test to submit a job with the `spark.mesos.network.labels` option, hit the mesos/state.json endpoint, and check that the labels are set in the driver and executor tasks.
ArtRand skonto
Author: Susan X. Huynh <xhuynh@mesosphere.com>
Closes#18910 from susanxhuynh/sh-mesos-cni-labels.
Right now the spark shuffle service has a cache for index files. It is based on a # of files cached (spark.shuffle.service.index.cache.entries). This can cause issues if people have a lot of reducers because the size of each entry can fluctuate based on the # of reducers.
We saw an issues with a job that had 170000 reducers and it caused NM with spark shuffle service to use 700-800MB or memory in NM by itself.
We should change this cache to be memory based and only allow a certain memory size used. When I say memory based I mean the cache should have a limit of say 100MB.
https://issues.apache.org/jira/browse/SPARK-21501
Manual Testing with 170000 reducers has been performed with cache loaded up to max 100MB default limit, with each shuffle index file of size 1.3MB. Eviction takes place as soon as the total cache size reaches the 100MB limit and the objects will be ready for garbage collection there by avoiding NM to crash. No notable difference in runtime has been observed.
Author: Sanket Chintapalli <schintap@yahoo-inc.com>
Closes#18940 from redsanket/SPARK-21501.
## What changes were proposed in this pull request?
This PR proposes to install `mkdocs` by `pip install` if missing in the path. Mainly to fix Jenkins's documentation build failure in `spark-master-docs`. See https://amplab.cs.berkeley.edu/jenkins/job/spark-master-docs/3580/console.
It also adds `mkdocs` as requirements in `docs/README.md`.
## How was this patch tested?
I manually ran `jekyll build` under `docs` directory after manually removing `mkdocs` via `pip uninstall mkdocs`.
Also, tested this in the same way but on CentOS Linux release 7.3.1611 (Core) where I built Spark few times but never built documentation before and `mkdocs` is not installed.
```
...
Moving back into docs dir.
Moving to SQL directory and building docs.
Missing mkdocs in your path, trying to install mkdocs for SQL documentation generation.
Collecting mkdocs
Downloading mkdocs-0.16.3-py2.py3-none-any.whl (1.2MB)
100% |████████████████████████████████| 1.2MB 574kB/s
Requirement already satisfied: PyYAML>=3.10 in /usr/lib64/python2.7/site-packages (from mkdocs)
Collecting livereload>=2.5.1 (from mkdocs)
Downloading livereload-2.5.1-py2-none-any.whl
Collecting tornado>=4.1 (from mkdocs)
Downloading tornado-4.5.1.tar.gz (483kB)
100% |████████████████████████████████| 491kB 1.4MB/s
Collecting Markdown>=2.3.1 (from mkdocs)
Downloading Markdown-2.6.9.tar.gz (271kB)
100% |████████████████████████████████| 276kB 2.4MB/s
Collecting click>=3.3 (from mkdocs)
Downloading click-6.7-py2.py3-none-any.whl (71kB)
100% |████████████████████████████████| 71kB 2.8MB/s
Requirement already satisfied: Jinja2>=2.7.1 in /usr/lib/python2.7/site-packages (from mkdocs)
Requirement already satisfied: six in /usr/lib/python2.7/site-packages (from livereload>=2.5.1->mkdocs)
Requirement already satisfied: backports.ssl_match_hostname in /usr/lib/python2.7/site-packages (from tornado>=4.1->mkdocs)
Collecting singledispatch (from tornado>=4.1->mkdocs)
Downloading singledispatch-3.4.0.3-py2.py3-none-any.whl
Collecting certifi (from tornado>=4.1->mkdocs)
Downloading certifi-2017.7.27.1-py2.py3-none-any.whl (349kB)
100% |████████████████████████████████| 358kB 2.1MB/s
Collecting backports_abc>=0.4 (from tornado>=4.1->mkdocs)
Downloading backports_abc-0.5-py2.py3-none-any.whl
Requirement already satisfied: MarkupSafe>=0.23 in /usr/lib/python2.7/site-packages (from Jinja2>=2.7.1->mkdocs)
Building wheels for collected packages: tornado, Markdown
Running setup.py bdist_wheel for tornado ... done
Stored in directory: /root/.cache/pip/wheels/84/83/cd/6a04602633457269d161344755e6766d24307189b7a67ff4b7
Running setup.py bdist_wheel for Markdown ... done
Stored in directory: /root/.cache/pip/wheels/bf/46/10/c93e17ae86ae3b3a919c7b39dad3b5ccf09aeb066419e5c1e5
Successfully built tornado Markdown
Installing collected packages: singledispatch, certifi, backports-abc, tornado, livereload, Markdown, click, mkdocs
Successfully installed Markdown-2.6.9 backports-abc-0.5 certifi-2017.7.27.1 click-6.7 livereload-2.5.1 mkdocs-0.16.3 singledispatch-3.4.0.3 tornado-4.5.1
Generating markdown files for SQL documentation.
Generating HTML files for SQL documentation.
INFO - Cleaning site directory
INFO - Building documentation to directory: .../spark/sql/site
Moving back into docs dir.
Making directory api/sql
cp -r ../sql/site/. api/sql
Source: .../spark/docs
Destination: .../spark/docs/_site
Generating...
done.
Auto-regeneration: disabled. Use --watch to enable.
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18984 from HyukjinKwon/sql-doc-mkdocs.
Add an option to the JDBC data source to initialize the environment of the remote database session
## What changes were proposed in this pull request?
This proposes an option to the JDBC datasource, tentatively called " sessionInitStatement" to implement the functionality of session initialization present for example in the Sqoop connector for Oracle (see https://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html#_oraoop_oracle_session_initialization_statements ) . After each database session is opened to the remote DB, and before starting to read data, this option executes a custom SQL statement (or a PL/SQL block in the case of Oracle).
See also https://issues.apache.org/jira/browse/SPARK-21519
## How was this patch tested?
Manually tested using Spark SQL data source and Oracle JDBC
Author: LucaCanali <luca.canali@cern.ch>
Closes#18724 from LucaCanali/JDBC_datasource_sessionInitStatement.
## What changes were proposed in this pull request?
This commit adds a new argument for IllegalArgumentException message. This recent commit added the argument:
[dcac1d57f0)
## How was this patch tested?
Unit test have been passed
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Marcos P. Sanchez <mpenate@stratio.com>
Closes#18862 from mpenate/feature/exception-errorifexists.
## What changes were proposed in this pull request?
Adds a sandbox link per driver in the dispatcher ui with minimal changes after a bug was fixed here:
https://issues.apache.org/jira/browse/MESOS-4992
The sandbox uri has the following format:
http://<proxy_uri>/#/slaves/\<agent-id\>/ frameworks/ \<scheduler-id\>/executors/\<driver-id\>/browse
For dc/os the proxy uri is <dc/os uri>/mesos. For the dc/os deployment scenario and to make things easier I introduced a new config property named `spark.mesos.proxy.baseURL` which should be passed to the dispatcher when launched using --conf. If no such configuration is detected then no sandbox uri is depicted, and there is an empty column with a header (this can be changed so nothing is shown).
Within dc/os the base url must be a property for the dispatcher that we should add in the future here:
9e7c909c3b/repo/packages/S/spark/26/config.json
It is not easy to detect in different environments what is that uri so user should pass it.
## How was this patch tested?
Tested with the mesos test suite here: https://github.com/typesafehub/mesos-spark-integration-tests.
Attached image shows the ui modification where the sandbox header is added.
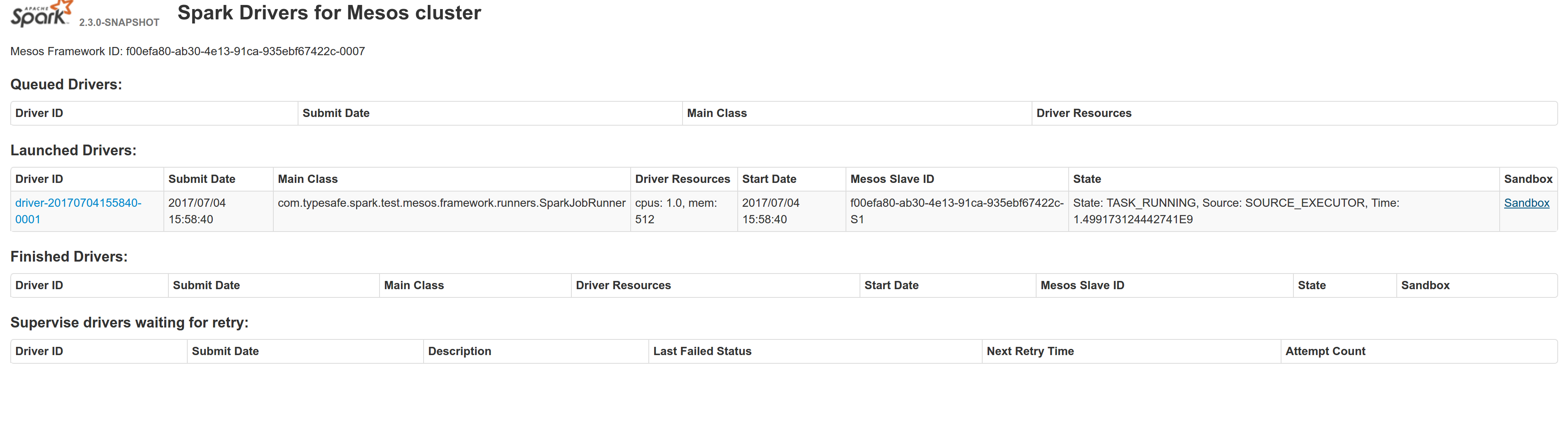
Tested the uri redirection the way it was suggested here:
https://issues.apache.org/jira/browse/MESOS-4992
Built mesos 1.4 from the master branch and started the mesos dispatcher with the command:
`./sbin/start-mesos-dispatcher.sh --conf spark.mesos.proxy.baseURL=http://localhost:5050 -m mesos://127.0.0.1:5050`
Run a spark example:
`./bin/spark-submit --class org.apache.spark.examples.SparkPi --master mesos://10.10.1.79:7078 --deploy-mode cluster --executor-memory 2G --total-executor-cores 2 http://<path>/spark-examples_2.11-2.1.1.jar 10`
Sandbox uri is shown at the bottom of the page:
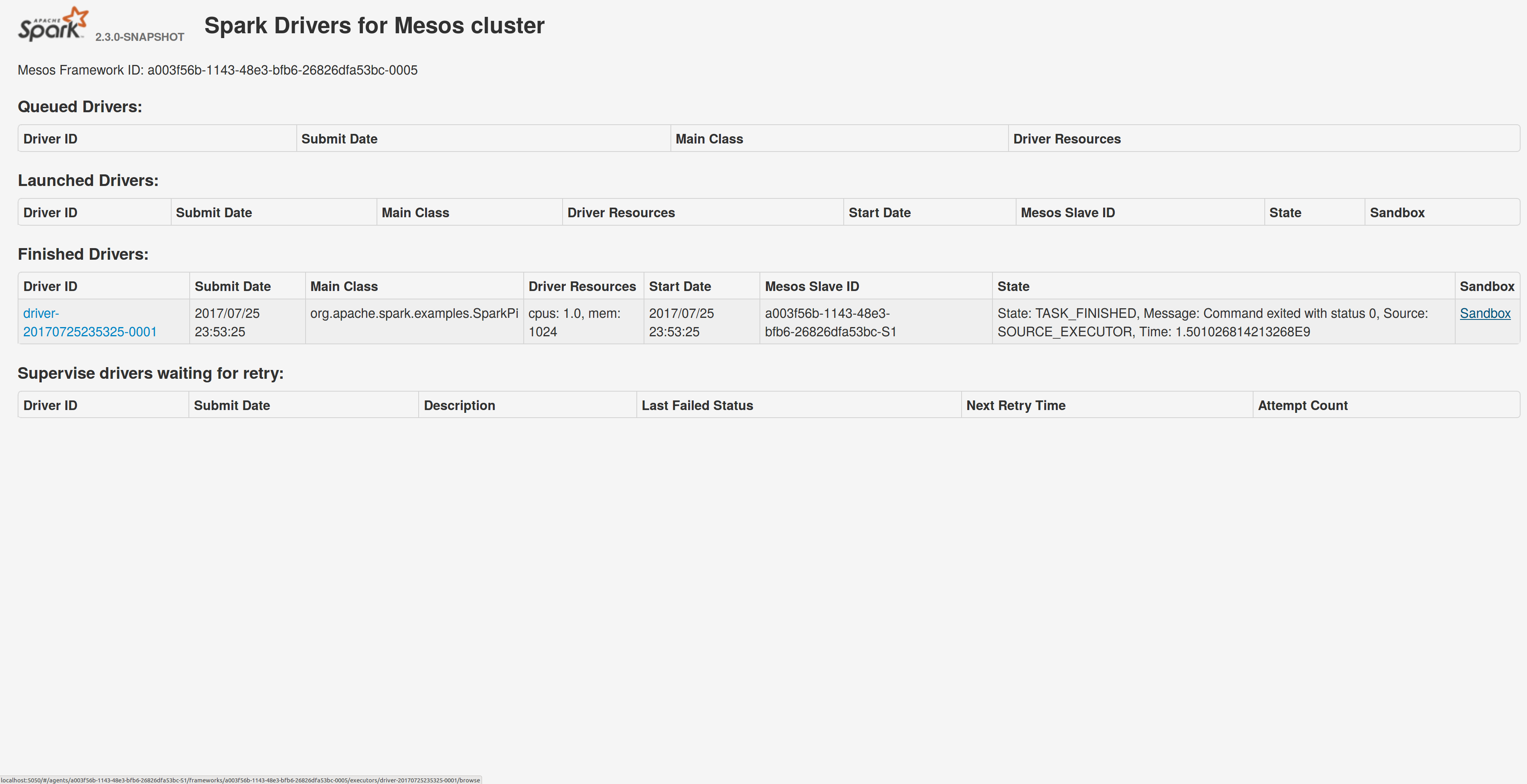
Redirection works as expected:
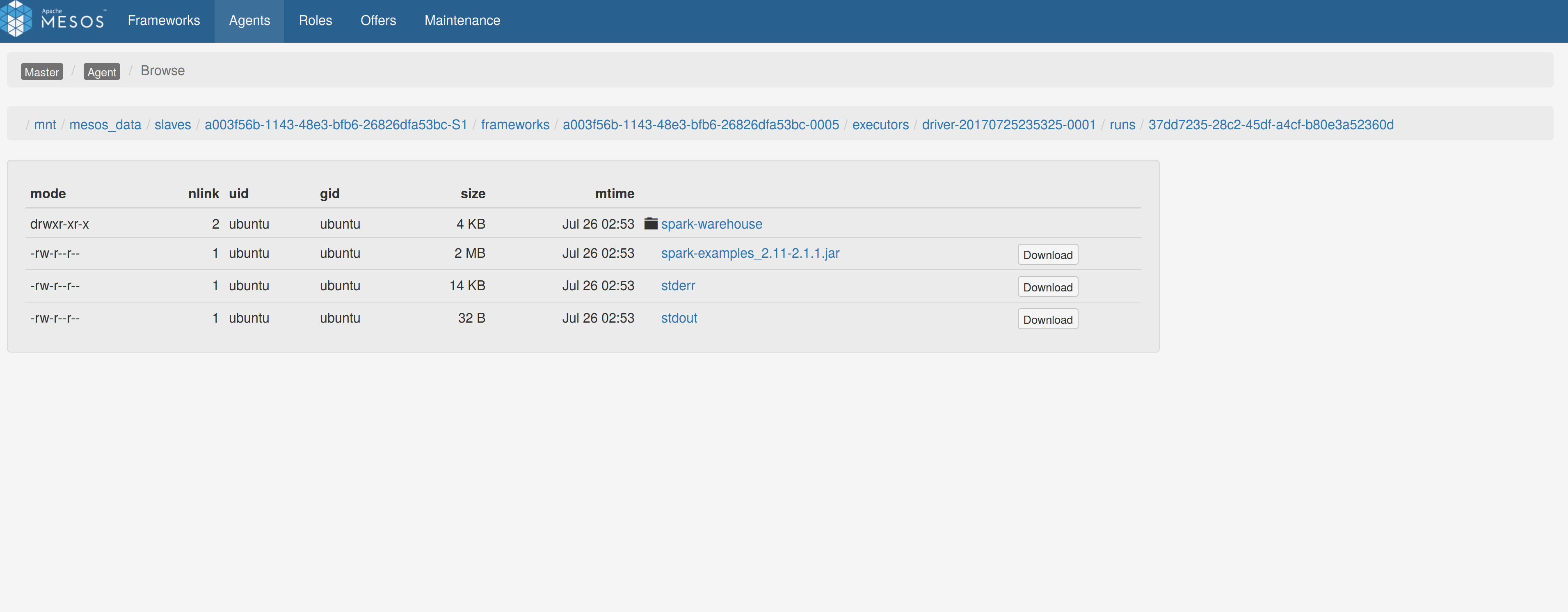
Author: Stavros Kontopoulos <st.kontopoulos@gmail.com>
Closes#18528 from skonto/adds_the_sandbox_uri.
## What changes were proposed in this pull request?
When we use `bin/spark-sql` command configuring `--conf spark.hadoop.foo=bar`, the `SparkSQLCliDriver` initializes an instance of hiveconf, it does not add `foo->bar` to it.
this pr gets `spark.hadoop.*` properties from sysProps to this hiveconf
## How was this patch tested?
UT
Author: hzyaoqin <hzyaoqin@corp.netease.com>
Author: Kent Yao <yaooqinn@hotmail.com>
Closes#18668 from yaooqinn/SPARK-21451.
## What changes were proposed in this pull request?
Add missing import and missing parentheses to invoke `SparkSession::text()`.
## How was this patch tested?
Built and the code for this application, ran jekyll locally per docs/README.md.
Author: Christiam Camacho <camacho@ncbi.nlm.nih.gov>
Closes#18795 from christiam/master.
## What changes were proposed in this pull request?
Fix 2 rendering errors on configuration doc page, due to SPARK-21243 and SPARK-15355.
## How was this patch tested?
Manually built and viewed docs with jekyll
Author: Sean Owen <sowen@cloudera.com>
Closes#18793 from srowen/SPARK-21593.
## What changes were proposed in this pull request?
This pr added documents about unsupported functions in Hive UDF/UDTF/UDAF.
This pr relates to #18768 and #18527.
## How was this patch tested?
N/A
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#18792 from maropu/HOTFIX-20170731.
In programming guide, `numTasks` is used in several places as arguments of Transformations. However, in code, `numPartitions` is used. In this fix, I replace `numTasks` with `numPartitions` in programming guide for consistency.
Author: Cheng Wang <chengwang0511@gmail.com>
Closes#18774 from polarke/replace-numtasks-with-numpartitions-in-doc.
## What changes were proposed in this pull request?
Update the description of `spark.shuffle.maxChunksBeingTransferred` to include that the new coming connections will be closed when the max is hit and client should have retry mechanism.
Author: jinxing <jinxing6042@126.com>
Closes#18735 from jinxing64/SPARK-21530.
## What changes were proposed in this pull request?
This generates a documentation for Spark SQL built-in functions.
One drawback is, this requires a proper build to generate built-in function list.
Once it is built, it only takes few seconds by `sql/create-docs.sh`.
Please see https://spark-test.github.io/sparksqldoc/ that I hosted to show the output documentation.
There are few more works to be done in order to make the documentation pretty, for example, separating `Arguments:` and `Examples:` but I guess this should be done within `ExpressionDescription` and `ExpressionInfo` rather than manually parsing it. I will fix these in a follow up.
This requires `pip install mkdocs` to generate HTMLs from markdown files.
## How was this patch tested?
Manually tested:
```
cd docs
jekyll build
```
,
```
cd docs
jekyll serve
```
and
```
cd sql
create-docs.sh
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18702 from HyukjinKwon/SPARK-21485.
## What changes were proposed in this pull request?
A shuffle service can serves blocks from multiple apps/tasks. Thus the shuffle service can suffers high memory usage when lots of shuffle-reads happen at the same time. In my cluster, OOM always happens on shuffle service. Analyzing heap dump, memory cost by Netty(ChannelOutboundBufferEntry) can be up to 2~3G. It might make sense to reject "open blocks" request when memory usage is high on shuffle service.
93dd0c518d and 85c6ce6193 tried to alleviate the memory pressure on shuffle service but cannot solve the root cause. This pr proposes to control currency of shuffle read.
## How was this patch tested?
Added unit test.
Author: jinxing <jinxing6042@126.com>
Closes#18388 from jinxing64/SPARK-21175.
I find a bug about 'quick start',and created a new issues,Sean Owen let
me to make a pull request, and I do
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Trueman <lizhaoch@users.noreply.github.com>
Author: lizhaoch <lizhaoc@163.com>
Closes#18722 from lizhaoch/master.
## What changes were proposed in this pull request?
The examples and docs for Spark-Kinesis integrations use the deprecated KinesisUtils. We should update the docs to use the KinesisInputDStream builder to create DStreams.
## How was this patch tested?
The patch primarily updates the documents. The patch will also need to make changes to the Spark-Kinesis examples. The examples need to be tested.
Author: Yash Sharma <ysharma@atlassian.com>
Closes#18071 from yssharma/ysharma/kinesis_docs.
## What changes were proposed in this pull request?
Update the Quickstart and RDD programming guides to mention pip.
## How was this patch tested?
Built docs locally.
Author: Holden Karau <holden@us.ibm.com>
Closes#18698 from holdenk/SPARK-21434-add-pyspark-pip-documentation.
## What changes were proposed in this pull request?
Minor change to kafka integration document for structured streaming.
## How was this patch tested?
N/A, doc change only.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#18550 from viirya/minor-ss-kafka-doc.
## What changes were proposed in this pull request?
After SPARK-12661, I guess we officially dropped Python 2.6 support. It looks there are few places missing this notes.
I grepped "Python 2.6" and "python 2.6" and the results were below:
```
./core/src/main/scala/org/apache/spark/api/python/SerDeUtil.scala: // Unpickle array.array generated by Python 2.6
./docs/index.md:Note that support for Java 7, Python 2.6 and old Hadoop versions before 2.6.5 were removed as of Spark 2.2.0.
./docs/rdd-programming-guide.md:Spark {{site.SPARK_VERSION}} works with Python 2.6+ or Python 3.4+. It can use the standard CPython interpreter,
./docs/rdd-programming-guide.md:Note that support for Python 2.6 is deprecated as of Spark 2.0.0, and may be removed in Spark 2.2.0.
./python/pyspark/context.py: warnings.warn("Support for Python 2.6 is deprecated as of Spark 2.0.0")
./python/pyspark/ml/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/mllib/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/serializers.py: # On Python 2.6, we can't write bytearrays to streams, so we need to convert them
./python/pyspark/sql/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/streaming/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/tests.py: # NOTE: dict is used instead of collections.Counter for Python 2.6
./python/pyspark/tests.py: # NOTE: dict is used instead of collections.Counter for Python 2.6
```
This PR only proposes to change visible changes as below:
```
./docs/rdd-programming-guide.md:Spark {{site.SPARK_VERSION}} works with Python 2.6+ or Python 3.4+. It can use the standard CPython interpreter,
./docs/rdd-programming-guide.md:Note that support for Python 2.6 is deprecated as of Spark 2.0.0, and may be removed in Spark 2.2.0.
./python/pyspark/context.py: warnings.warn("Support for Python 2.6 is deprecated as of Spark 2.0.0")
```
This one is already correct:
```
./docs/index.md:Note that support for Java 7, Python 2.6 and old Hadoop versions before 2.6.5 were removed as of Spark 2.2.0.
```
## How was this patch tested?
```bash
grep -r "Python 2.6" .
grep -r "python 2.6" .
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18682 from HyukjinKwon/minor-python.26.
## What changes were proposed in this pull request?
Current behavior: in Mesos cluster mode, the driver failover_timeout is set to zero. If the driver temporarily loses connectivity with the Mesos master, the framework will be torn down and all executors killed.
Proposed change: make the failover_timeout configurable via a new option, spark.mesos.driver.failoverTimeout. The default value is still zero.
Note: with non-zero failover_timeout, an explicit teardown is needed in some cases. This is captured in https://issues.apache.org/jira/browse/SPARK-21458
## How was this patch tested?
Added a unit test to make sure the config option is set while creating the scheduler driver.
Ran an integration test with mesosphere/spark showing that with a non-zero failover_timeout the Spark job finishes after a driver is disconnected from the master.
Author: Susan X. Huynh <xhuynh@mesosphere.com>
Closes#18674 from susanxhuynh/sh-mesos-failover-timeout.
## What changes were proposed in this pull request?
For configurations with external shuffle enabled, we have observed that if a very large no. of blocks are being fetched from a remote host, it puts the NM under extra pressure and can crash it. This change introduces a configuration `spark.reducer.maxBlocksInFlightPerAddress` , to limit the no. of map outputs being fetched from a given remote address. The changes applied here are applicable for both the scenarios - when external shuffle is enabled as well as disabled.
## How was this patch tested?
Ran the job with the default configuration which does not change the existing behavior and ran it with few configurations of lower values -10,20,50,100. The job ran fine and there is no change in the output. (I will update the metrics related to NM in some time.)
Author: Dhruve Ashar <dhruveashar@gmail.com>
Closes#18487 from dhruve/impr/SPARK-21243.
## What changes were proposed in this pull request?
Update internal references from programming-guide to rdd-programming-guide
See 5ddf243fd8 and https://github.com/apache/spark/pull/18485#issuecomment-314789751
Let's keep the redirector even if it's problematic to build, but not rely on it internally.
## How was this patch tested?
(Doc build)
Author: Sean Owen <sowen@cloudera.com>
Closes#18625 from srowen/SPARK-21267.2.
## What changes were proposed in this pull request?
- Remove Scala 2.10 build profiles and support
- Replace some 2.10 support in scripts with commented placeholders for 2.12 later
- Remove deprecated API calls from 2.10 support
- Remove usages of deprecated context bounds where possible
- Remove Scala 2.10 workarounds like ScalaReflectionLock
- Other minor Scala warning fixes
## How was this patch tested?
Existing tests
Author: Sean Owen <sowen@cloudera.com>
Closes#17150 from srowen/SPARK-19810.
## What changes were proposed in this pull request?
Since this document became obsolete, we had better remove this for Apache Spark 2.3.0. The original document is removed via SPARK-12735 on January 2016, and currently it's just redirection page. The only reference in Apache Spark website will go directly to the destination in https://github.com/apache/spark-website/pull/54.
## How was this patch tested?
N/A. This is a removal of documentation.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#18578 from dongjoon-hyun/SPARK-REMOVE-EC2.
## What changes were proposed in this pull request?
Spark provides several ways to set configurations, either from configuration file, or from `spark-submit` command line options, or programmatically through `SparkConf` class. It may confuses beginners why some configurations set through `SparkConf` cannot take affect. So here add some docs to address this problems and let beginners know how to correctly set configurations.
## How was this patch tested?
N/A
Author: jerryshao <sshao@hortonworks.com>
Closes#18552 from jerryshao/improve-doc.
## What changes were proposed in this pull request?
In current code, reducer can break the old shuffle service when `spark.reducer.maxReqSizeShuffleToMem` is enabled. Let's refine document.
Author: jinxing <jinxing6042@126.com>
Closes#18566 from jinxing64/SPARK-21343.
## What changes were proposed in this pull request?
Some link fixes for the documentation [Running Spark on Mesos](https://spark.apache.org/docs/latest/running-on-mesos.html):
* Updated Link to Mesos Frameworks (Projects built on top of Mesos)
* Update Link to Mesos binaries from Mesosphere (former link was redirected to dcos install page)
## How was this patch tested?
Documentation was built and changed page manually/visually inspected.
No code was changed, hence no dev tests.
Since these changes are rather trivial I did not open a new JIRA ticket.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Joachim Hereth <joachim.hereth@numberfour.eu>
Closes#18564 from daten-kieker/mesos_doc_fixes.
## What changes were proposed in this pull request?
SPARK-20979 added a new structured streaming source: Rate source. This patch adds the corresponding documentation to programming guide.
## How was this patch tested?
Tested by running jekyll locally.
Author: Prashant Sharma <prashant@apache.org>
Author: Prashant Sharma <prashsh1@in.ibm.com>
Closes#18562 from ScrapCodes/spark-21069/rate-source-docs.
## What changes were proposed in this pull request?
Few changes to the Structured Streaming documentation
- Clarify that the entire stream input table is not materialized
- Add information for Ganglia
- Add Kafka Sink to the main docs
- Removed a couple of leftover experimental tags
- Added more associated reading material and talk videos.
In addition, https://github.com/apache/spark/pull/16856 broke the link to the RDD programming guide in several places while renaming the page. This PR fixes those sameeragarwal cloud-fan.
- Added a redirection to avoid breaking internal and possible external links.
- Removed unnecessary redirection pages that were there since the separate scala, java, and python programming guides were merged together in 2013 or 2014.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#18485 from tdas/SPARK-21267.
Current "--jars (spark.jars)", "--files (spark.files)", "--py-files (spark.submit.pyFiles)" and "--archives (spark.yarn.dist.archives)" only support non-glob path. This is OK for most of the cases, but when user requires to add more jars, files into Spark, it is too verbose to list one by one. So here propose to add glob path support for resources.
Also improving the code of downloading resources.
## How was this patch tested?
UT added, also verified manually in local cluster.
Author: jerryshao <sshao@hortonworks.com>
Closes#18235 from jerryshao/SPARK-21012.
## What changes were proposed in this pull request?
This change adds a new configuration option `spark.scheduler.listenerbus.eventqueue.size` to the configuration docs to specify the capacity of the spark listener bus event queue. Default value is 10000.
This is doc PR for [SPARK-15703](https://issues.apache.org/jira/browse/SPARK-15703).
I added option to the `Scheduling` section, however it might be more related to `Spark UI` section.
## How was this patch tested?
Manually verified correct rendering of configuration option.
Author: sadikovi <ivan.sadikov@lincolnuni.ac.nz>
Author: Ivan Sadikov <ivan.sadikov@team.telstra.com>
Closes#18476 from sadikovi/SPARK-20858.
## What changes were proposed in this pull request?
Disable spark.reducer.maxReqSizeShuffleToMem because it breaks the old shuffle service.
Credits to wangyum
Closes#18466
## How was this patch tested?
Jenkins
Author: Shixiong Zhu <shixiong@databricks.com>
Author: Yuming Wang <wgyumg@gmail.com>
Closes#18467 from zsxwing/SPARK-21253.
## What changes were proposed in this pull request?
Currently we are running into an issue with Yarn work preserving enabled + external shuffle service.
In the work preserving enabled scenario, the failure of NM will not lead to the exit of executors, so executors can still accept and run the tasks. The problem here is when NM is failed, external shuffle service is actually inaccessible, so reduce tasks will always complain about the “Fetch failure”, and the failure of reduce stage will make the parent stage (map stage) rerun. The tricky thing here is Spark scheduler is not aware of the unavailability of external shuffle service, and will reschedule the map tasks on the executor where NM is failed, and again reduce stage will be failed with “Fetch failure”, and after 4 retries, the job is failed. This could also apply to other cluster manager with external shuffle service.
So here the main problem is that we should avoid assigning tasks to those bad executors (where shuffle service is unavailable). Current Spark's blacklist mechanism could blacklist executors/nodes by failure tasks, but it doesn't handle this specific fetch failure scenario. So here propose to improve the current application blacklist mechanism to handle fetch failure issue (especially with external shuffle service unavailable issue), to blacklist the executors/nodes where shuffle fetch is unavailable.
## How was this patch tested?
Unit test and small cluster verification.
Author: jerryshao <sshao@hortonworks.com>
Closes#17113 from jerryshao/SPARK-13669.
## What changes were proposed in this pull request?
Add lost `<tr>` tag for `configuration.md`.
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Closes#18372 from wangyum/docs-missing-tr.
## What changes were proposed in this pull request?
Currently the shuffle service registration timeout and retry has been hardcoded. This works well for small workloads but under heavy workload when the shuffle service is busy transferring large amount of data we see significant delay in responding to the registration request, as a result we often see the executors fail to register with the shuffle service, eventually failing the job. We need to make these two parameters configurable.
## How was this patch tested?
* Updated `BlockManagerSuite` to test registration timeout and max attempts configuration actually works.
cc sitalkedia
Author: Li Yichao <lyc@zhihu.com>
Closes#18092 from liyichao/SPARK-20640.
## What changes were proposed in this pull request?
The description for several options of File Source for structured streaming appeared in the File Sink description instead.
This pull request has two commits: The first includes changes to the version as it appeared in spark 2.1 and the second handled an additional option added for spark 2.2
## How was this patch tested?
Built the documentation by SKIP_API=1 jekyll build and visually inspected the structured streaming programming guide.
The original documentation was written by tdas and lw-lin
Author: assafmendelson <assaf.mendelson@gmail.com>
Closes#18342 from assafmendelson/spark-21123.
## What changes were proposed in this pull request?
Update Running R Tests dependence packages to:
```bash
R -e "install.packages(c('knitr', 'rmarkdown', 'testthat', 'e1071', 'survival'), repos='http://cran.us.r-project.org')"
```
## How was this patch tested?
manual tests
Author: Yuming Wang <wgyumg@gmail.com>
Closes#18271 from wangyum/building-spark.
## What changes were proposed in this pull request?
Move Hadoop delegation token code from `spark-yarn` to `spark-core`, so that other schedulers (such as Mesos), may use it. In order to avoid exposing Hadoop interfaces in spark-core, the new Hadoop delegation token classes are kept private. In order to provider backward compatiblity, and to allow YARN users to continue to load their own delegation token providers via Java service loading, the old YARN interfaces, as well as the client code that uses them, have been retained.
Summary:
- Move registered `yarn.security.ServiceCredentialProvider` classes from `spark-yarn` to `spark-core`. Moved them into a new, private hierarchy under `HadoopDelegationTokenProvider`. Client code in `HadoopDelegationTokenManager` now loads credentials from a whitelist of three providers (`HadoopFSDelegationTokenProvider`, `HiveDelegationTokenProvider`, `HBaseDelegationTokenProvider`), instead of service loading, which means that users are not able to implement their own delegation token providers, as they are in the `spark-yarn` module.
- The `yarn.security.ServiceCredentialProvider` interface has been kept for backwards compatibility, and to continue to allow YARN users to implement their own delegation token provider implementations. Client code in YARN now fetches tokens via the new `YARNHadoopDelegationTokenManager` class, which fetches tokens from the core providers through `HadoopDelegationTokenManager`, as well as service loads them from `yarn.security.ServiceCredentialProvider`.
Old Hierarchy:
```
yarn.security.ServiceCredentialProvider (service loaded)
HadoopFSCredentialProvider
HiveCredentialProvider
HBaseCredentialProvider
yarn.security.ConfigurableCredentialManager
```
New Hierarchy:
```
HadoopDelegationTokenManager
HadoopDelegationTokenProvider (not service loaded)
HadoopFSDelegationTokenProvider
HiveDelegationTokenProvider
HBaseDelegationTokenProvider
yarn.security.ServiceCredentialProvider (service loaded)
yarn.security.YARNHadoopDelegationTokenManager
```
## How was this patch tested?
unit tests
Author: Michael Gummelt <mgummelt@mesosphere.io>
Author: Dr. Stefan Schimanski <sttts@mesosphere.io>
Closes#17723 from mgummelt/SPARK-20434-refactor-kerberos.
## What changes were proposed in this pull request?
doc only change
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#18312 from felixcheung/sqljsonwholefiledoc.
## What changes were proposed in this pull request?
`df.groupBy.count()` should be `df.groupBy().count()` , otherwise there is an error :
ambiguous reference to overloaded definition, both method groupBy in class Dataset of type (col1: String, cols: String*) and method groupBy in class Dataset of type (cols: org.apache.spark.sql.Column*)
## How was this patch tested?
```scala
val df = spark.readStream.schema(...).json(...)
val dfCounts = df.groupBy().count()
```
Author: Ziyue Huang <zyhuang94@gmail.com>
Closes#18272 from ZiyueHuang/master.
## What changes were proposed in this pull request?
Add Mesos labels support to the Spark Dispatcher
## How was this patch tested?
unit tests
Author: Michael Gummelt <mgummelt@mesosphere.io>
Closes#18220 from mgummelt/SPARK-21000-dispatcher-labels.
## What changes were proposed in this pull request?
Add a new property `spark.streaming.kafka.consumer.cache.enabled` that allows users to enable or disable the cache for Kafka consumers. This property can be especially handy in cases where issues like SPARK-19185 get hit, for which there isn't a solution committed yet. By default, the cache is still on, so this change doesn't change any out-of-box behavior.
## How was this patch tested?
Running unit tests
Author: Mark Grover <mark@apache.org>
Author: Mark Grover <grover.markgrover@gmail.com>
Closes#18234 from markgrover/spark-19185.
## What changes were proposed in this pull request?
In our use case of launching Spark applications via REST APIs (Livy), there's no way for user to specify command line arguments, all Spark configurations are set through configurations map. For "--repositories" because there's no equivalent Spark configuration, so we cannot specify the custom repository through configuration.
So here propose to add "--repositories" equivalent configuration in Spark.
## How was this patch tested?
New UT added.
Author: jerryshao <sshao@hortonworks.com>
Closes#18201 from jerryshao/SPARK-20981.
## What changes were proposed in this pull request?
- Add Scala, Python and Java examples for `partitionBy`, `sortBy` and `bucketBy`.
- Add _Bucketing, Sorting and Partitioning_ section to SQL Programming Guide
- Remove bucketing from Unsupported Hive Functionalities.
## How was this patch tested?
Manual tests, docs build.
Author: zero323 <zero323@users.noreply.github.com>
Closes#17938 from zero323/DOCS-BUCKETING-AND-PARTITIONING.
Now that Structured Streaming has been out for several Spark release and has large production use cases, the `Experimental` label is no longer appropriate. I've left `InterfaceStability.Evolving` however, as I think we may make a few changes to the pluggable Source & Sink API in Spark 2.3.
Author: Michael Armbrust <michael@databricks.com>
Closes#18065 from marmbrus/streamingGA.
## What changes were proposed in this pull request?
1, add an example for sparkr `decisionTree`
2, document it in user guide
## How was this patch tested?
local submit
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#18067 from zhengruifeng/dt_example.
(Link to Jira: https://issues.apache.org/jira/browse/SPARK-20888)
## What changes were proposed in this pull request?
Document change of default setting of spark.sql.hive.caseSensitiveInferenceMode configuration key from NEVER_INFO to INFER_AND_SAVE in the Spark SQL 2.1 to 2.2 migration notes.
Author: Michael Allman <michael@videoamp.com>
Closes#18112 from mallman/spark-20888-document_infer_and_save.
## What changes were proposed in this pull request?
Currently the whole block is fetched into memory(off heap by default) when shuffle-read. A block is defined by (shuffleId, mapId, reduceId). Thus it can be large when skew situations. If OOM happens during shuffle read, job will be killed and users will be notified to "Consider boosting spark.yarn.executor.memoryOverhead". Adjusting parameter and allocating more memory can resolve the OOM. However the approach is not perfectly suitable for production environment, especially for data warehouse.
Using Spark SQL as data engine in warehouse, users hope to have a unified parameter(e.g. memory) but less resource wasted(resource is allocated but not used). The hope is strong especially when migrating data engine to Spark from another one(e.g. Hive). Tuning the parameter for thousands of SQLs one by one is very time consuming.
It's not always easy to predict skew situations, when happen, it make sense to fetch remote blocks to disk for shuffle-read, rather than kill the job because of OOM.
In this pr, I propose to fetch big blocks to disk(which is also mentioned in SPARK-3019):
1. Track average size and also the outliers(which are larger than 2*avgSize) in MapStatus;
2. Request memory from `MemoryManager` before fetch blocks and release the memory to `MemoryManager` when `ManagedBuffer` is released.
3. Fetch remote blocks to disk when failing acquiring memory from `MemoryManager`, otherwise fetch to memory.
This is an improvement for memory control when shuffle blocks and help to avoid OOM in scenarios like below:
1. Single huge block;
2. Sizes of many blocks are underestimated in `MapStatus` and the actual footprint of blocks is much larger than the estimated.
## How was this patch tested?
Added unit test in `MapStatusSuite` and `ShuffleBlockFetcherIteratorSuite`.
Author: jinxing <jinxing6042@126.com>
Closes#16989 from jinxing64/SPARK-19659.
## What changes were proposed in this pull request?
Currently, when number of reduces is above 2000, HighlyCompressedMapStatus is used to store size of blocks. in HighlyCompressedMapStatus, only average size is stored for non empty blocks. Which is not good for memory control when we shuffle blocks. It makes sense to store the accurate size of block when it's above threshold.
## How was this patch tested?
Added test in MapStatusSuite.
Author: jinxing <jinxing6042@126.com>
Closes#18031 from jinxing64/SPARK-20801.
Quick follow up to #17996 - forgot to add the HTML links to the relevant sections of the guide in the highlights list.
## How was this patch tested?
Built docs locally and tested links.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#18043 from MLnick/SPARK-20506-2.2-migration-guide-2.
Update ML guide for migration `2.1` -> `2.2` and the previous version migration guide section.
## How was this patch tested?
Build doc locally.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#17996 from MLnick/SPARK-20506-2.2-migration-guide.
## What changes were proposed in this pull request?
The changes were merged as part of - https://github.com/apache/spark/pull/17467.
The documentation was missed somewhere in the review iterations. Adding the documentation where it belongs.
## How was this patch tested?
Docs. Not tested.
cc budde , brkyvz
Author: Yash Sharma <ysharma@atlassian.com>
Closes#18028 from yssharma/ysharma/kinesis_retry_docs.
## What changes were proposed in this pull request?
Add docs and examples for ```ml.stat.Correlation``` and ```ml.stat.ChiSquareTest```.
## How was this patch tested?
Generate docs and run examples manually, successfully.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17994 from yanboliang/spark-20505.
## What changes were proposed in this pull request?
SPARK-13973 incorrectly removed the required PYSPARK_DRIVER_PYTHON_OPTS=notebook from documentation to use pyspark with Jupyter notebook. This patch corrects the documentation error.
## How was this patch tested?
Tested invocation locally with
```bash
PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS=notebook ./bin/pyspark
```
Author: Andrew Ray <ray.andrew@gmail.com>
Closes#18001 from aray/patch-1.
## What changes were proposed in this pull request?
Any Dataset/DataFrame batch query with the operation `withWatermark` does not execute because the batch planner does not have any rule to explicitly handle the EventTimeWatermark logical plan.
The right solution is to simply remove the plan node, as the watermark should not affect any batch query in any way.
Changes:
- In this PR, we add a new rule `EliminateEventTimeWatermark` to check if we need to ignore the event time watermark. We will ignore watermark in any batch query.
Depends upon:
- [SPARK-20672](https://issues.apache.org/jira/browse/SPARK-20672). We can not add this rule into analyzer directly, because streaming query will be copied to `triggerLogicalPlan ` in every trigger, and the rule will be applied to `triggerLogicalPlan` mistakenly.
Others:
- A typo fix in example.
## How was this patch tested?
add new unit test.
Author: uncleGen <hustyugm@gmail.com>
Closes#17896 from uncleGen/SPARK-20373.
## What changes were proposed in this pull request?
After SPARK-10997, client mode Netty RpcEnv doesn't require to start server, so port configurations are not used any more, here propose to remove these two configurations: "spark.executor.port" and "spark.am.port".
## How was this patch tested?
Existing UTs.
Author: jerryshao <sshao@hortonworks.com>
Closes#17866 from jerryshao/SPARK-20605.
## What changes were proposed in this pull request?
Add a new `spark-hadoop-cloud` module and maven profile to pull in object store support from `hadoop-openstack`, `hadoop-aws` and `hadoop-azure` (Hadoop 2.7+) JARs, along with their dependencies, fixing up the dependencies so that everything works, in particular Jackson.
It restores `s3n://` access to S3, adds its `s3a://` replacement, OpenStack `swift://` and azure `wasb://`.
There's a documentation page, `cloud_integration.md`, which covers the basic details of using Spark with object stores, referring the reader to the supplier's own documentation, with specific warnings on security and the possible mismatch between a store's behavior and that of a filesystem. In particular, users are advised be very cautious when trying to use an object store as the destination of data, and to consult the documentation of the storage supplier and the connector.
(this is the successor to #12004; I can't re-open it)
## How was this patch tested?
Downstream tests exist in [https://github.com/steveloughran/spark-cloud-examples/tree/master/cloud-examples](https://github.com/steveloughran/spark-cloud-examples/tree/master/cloud-examples)
Those verify that the dependencies are sufficient to allow downstream applications to work with s3a, azure wasb and swift storage connectors, and perform basic IO & dataframe operations thereon. All seems well.
Manually clean build & verify that assembly contains the relevant aws-* hadoop-* artifacts on Hadoop 2.6; azure on a hadoop-2.7 profile.
SBT build: `build/sbt -Phadoop-cloud -Phadoop-2.7 package`
maven build `mvn install -Phadoop-cloud -Phadoop-2.7`
This PR *does not* update `dev/deps/spark-deps-hadoop-2.7` or `dev/deps/spark-deps-hadoop-2.6`, because unless the hadoop-cloud profile is enabled, no extra JARs show up in the dependency list. The dependency check in Jenkins isn't setting the property, so the new JARs aren't visible.
Author: Steve Loughran <stevel@apache.org>
Author: Steve Loughran <stevel@hortonworks.com>
Closes#17834 from steveloughran/cloud/SPARK-7481-current.
## What changes were proposed in this pull request?
Add
- R vignettes
- R programming guide
- SS programming guide
- R example
Also disable spark.als in vignettes for now since it's failing (SPARK-20402)
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#17814 from felixcheung/rdocss.
Add PCA and SVD to PySpark's wrappers for `RowMatrix` and `IndexedRowMatrix` (SVD only).
Based on #7963, updated.
## How was this patch tested?
New doc tests and unit tests. Ran all examples locally.
Author: MechCoder <manojkumarsivaraj334@gmail.com>
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#17621 from MLnick/SPARK-6227-pyspark-svd-pca.
## What changes were proposed in this pull request?
Updating R Programming Guide
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#17816 from felixcheung/r22relnote.
## What changes were proposed in this pull request?
Currently, our project needs to be set to clean up the worker directory cleanup cycle is three days.
When I follow http://spark.apache.org/docs/latest/spark-standalone.html, configure the 'spark.worker.cleanup.appDataTtl' parameter, I configured to 3 * 24 * 3600.
When I start the spark service, the startup fails, and the worker log displays the error log as follows:
2017-04-28 15:02:03,306 INFO Utils: Successfully started service 'sparkWorker' on port 48728.
Exception in thread "main" java.lang.NumberFormatException: For input string: "3 * 24 * 3600"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Long.parseLong(Long.java:430)
at java.lang.Long.parseLong(Long.java:483)
at scala.collection.immutable.StringLike$class.toLong(StringLike.scala:276)
at scala.collection.immutable.StringOps.toLong(StringOps.scala:29)
at org.apache.spark.SparkConf$$anonfun$getLong$2.apply(SparkConf.scala:380)
at org.apache.spark.SparkConf$$anonfun$getLong$2.apply(SparkConf.scala:380)
at scala.Option.map(Option.scala:146)
at org.apache.spark.SparkConf.getLong(SparkConf.scala:380)
at org.apache.spark.deploy.worker.Worker.<init>(Worker.scala:100)
at org.apache.spark.deploy.worker.Worker$.startRpcEnvAndEndpoint(Worker.scala:730)
at org.apache.spark.deploy.worker.Worker$.main(Worker.scala:709)
at org.apache.spark.deploy.worker.Worker.main(Worker.scala)
**Because we put 7 * 24 * 3600 as a string, forced to convert to the dragon type, will lead to problems in the program.**
**So I think the default value of the current configuration should be a specific long value, rather than 7 * 24 * 3600,should be 604800. Because it would mislead users for similar configurations, resulting in spark start failure.**
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: 郭小龙 10207633 <guo.xiaolong1@zte.com.cn>
Author: guoxiaolong <guo.xiaolong1@zte.com.cn>
Author: guoxiaolongzte <guo.xiaolong1@zte.com.cn>
Closes#17798 from guoxiaolongzte/SPARK-20521.
## What changes were proposed in this pull request?
Add a new section for fpm
Add Example for FPGrowth in scala and Java
updated: Rewrite transform to be more compact.
## How was this patch tested?
local doc generation.
Author: Yuhao Yang <yuhao.yang@intel.com>
Closes#17130 from hhbyyh/fpmdoc.
## What changes were proposed in this pull request?
Add hyper link in the SparkR programming guide.
## How was this patch tested?
Build doc and manually check the doc link.
Author: wangmiao1981 <wm624@hotmail.com>
Closes#17805 from wangmiao1981/doc.
## What changes were proposed in this pull request?
add link to svmLinear in the SparkR programming document.
## How was this patch tested?
Build doc manually and click the link to the document. It looks good.
Author: wangmiao1981 <wm624@hotmail.com>
Closes#17797 from wangmiao1981/doc.
## What changes were proposed in this pull request?
Add `spark.fpGrowth` to SparkR programming guide.
## How was this patch tested?
Manual tests.
Author: zero323 <zero323@users.noreply.github.com>
Closes#17775 from zero323/SPARK-20208-FOLLOW-UP.
This change does a more thorough redaction of sensitive information from logs and UI
Add unit tests that ensure that no regressions happen that leak sensitive information to the logs.
The motivation for this change was appearance of password like so in `SparkListenerEnvironmentUpdate` in event logs under some JVM configurations:
`"sun.java.command":"org.apache.spark.deploy.SparkSubmit ... --conf spark.executorEnv.HADOOP_CREDSTORE_PASSWORD=secret_password ..."
`
Previously redaction logic was only checking if the key matched the secret regex pattern, it'd redact it's value. That worked for most cases. However, in the above case, the key (sun.java.command) doesn't tell much, so the value needs to be searched. This PR expands the check to check for values as well.
## How was this patch tested?
New unit tests added that ensure that no sensitive information is present in the event logs or the yarn logs. Old unit test in UtilsSuite was modified because the test was asserting that a non-sensitive property's value won't be redacted. However, the non-sensitive value had the literal "secret" in it which was causing it to redact. Simply updating the non-sensitive property's value to another arbitrary value (that didn't have "secret" in it) fixed it.
Author: Mark Grover <mark@apache.org>
Closes#17725 from markgrover/spark-20435.
## What changes were proposed in this pull request?
Simple documentation change to remove explicit vendor references.
## How was this patch tested?
NA
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: anabranch <bill@databricks.com>
Closes#17695 from anabranch/remove-vendor.
## What changes were proposed in this pull request?
- Add `rollup` and `cube` methods and corresponding generics.
- Add short description to the vignette.
## How was this patch tested?
- Existing unit tests.
- Additional unit tests covering new features.
- `check-cran.sh`.
Author: zero323 <zero323@users.noreply.github.com>
Closes#17728 from zero323/SPARK-20437.
## What changes were proposed in this pull request?
Pregel-based iterative algorithms with more than ~50 iterations begin to slow down and eventually fail with a StackOverflowError due to Spark's lack of support for long lineage chains.
This PR causes Pregel to checkpoint the graph periodically if the checkpoint directory is set.
This PR moves PeriodicGraphCheckpointer.scala from mllib to graphx, moves PeriodicRDDCheckpointer.scala, PeriodicCheckpointer.scala from mllib to core
## How was this patch tested?
unit tests, manual tests
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Author: ding <ding@localhost.localdomain>
Author: dding3 <ding.ding@intel.com>
Author: Michael Allman <michael@videoamp.com>
Closes#15125 from dding3/cp2_pregel.
## What changes were proposed in this pull request?
Just added the Maven `test`goal.
## How was this patch tested?
No test needed, just a trivial documentation fix.
Author: Armin Braun <me@obrown.io>
Closes#17756 from original-brownbear/SPARK-20455.
## What changes were proposed in this pull request?
Use the REST interface submits the spark job.
e.g.
curl -X POST http://10.43.183.120:6066/v1/submissions/create --header "Content-Type:application/json;charset=UTF-8" --data'{
"action": "CreateSubmissionRequest",
"appArgs": [
"myAppArgument"
],
"appResource": "/home/mr/gxl/test.jar",
"clientSparkVersion": "2.2.0",
"environmentVariables": {
"SPARK_ENV_LOADED": "1"
},
"mainClass": "cn.zte.HdfsTest",
"sparkProperties": {
"spark.jars": "/home/mr/gxl/test.jar",
**"spark.driver.supervise": "true",**
"spark.app.name": "HdfsTest",
"spark.eventLog.enabled": "false",
"spark.submit.deployMode": "cluster",
"spark.master": "spark://10.43.183.120:6066"
}
}'
**I hope that make sure that the driver is automatically restarted if it fails with non-zero exit code.
But I can not find the 'spark.driver.supervise' configuration parameter specification and default values from the spark official document.**
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: 郭小龙 10207633 <guo.xiaolong1@zte.com.cn>
Author: guoxiaolong <guo.xiaolong1@zte.com.cn>
Author: guoxiaolongzte <guo.xiaolong1@zte.com.cn>
Closes#17696 from guoxiaolongzte/SPARK-20401.
Hello
PR #10991 removed the built-in history view from Spark Standalone, so the history server is no longer useful to Yarn or Mesos only.
Author: Hervé <dud225@users.noreply.github.com>
Closes#17709 from dud225/patch-1.
## What changes were proposed in this pull request?
Typos at a couple of place in the docs.
## How was this patch tested?
build including docs
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: ymahajan <ymahajan@snappydata.io>
Closes#17690 from ymahajan/master.
## What changes were proposed in this pull request?
Note that you shouldn't manually add dependencies on org.apache.kafka artifacts
## How was this patch tested?
Doc only change, did jekyll build and looked at the page.
Author: cody koeninger <cody@koeninger.org>
Closes#17675 from koeninger/SPARK-20036.
## What changes were proposed in this pull request?
Allow passing in arbitrary parameters into docker when launching spark executors on mesos with docker containerizer tnachen
## How was this patch tested?
Manually built and tested with passed in parameter
Author: Ji Yan <jiyan@Jis-MacBook-Air.local>
Closes#17109 from yanji84/ji/allow_set_docker_user.
## What changes were proposed in this pull request?
This PR proposes corrections related to JSON APIs as below:
- Rendering links in Python documentation
- Replacing `RDD` to `Dataset` in programing guide
- Adding missing description about JSON Lines consistently in `DataFrameReader.json` in Python API
- De-duplicating little bit of `DataFrameReader.json` in Scala/Java API
## How was this patch tested?
Manually build the documentation via `jekyll build`. Corresponding snapstops will be left on the codes.
Note that currently there are Javadoc8 breaks in several places. These are proposed to be handled in https://github.com/apache/spark/pull/17477. So, this PR does not fix those.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#17602 from HyukjinKwon/minor-json-documentation.
## What changes were proposed in this pull request?
1. Omitted space between the sentences: `... on static data.The Spark SQL engine will ...` -> `... on static data. The Spark SQL engine will ...`
2. Omitted colon in Output Model section.
## How was this patch tested?
None.
Author: Lee Dongjin <dongjin@apache.org>
Closes#17564 from dongjinleekr/feature/fix-programming-guide.
## What changes were proposed in this pull request?
Since SPARK-18112 and SPARK-13446, Apache Spark starts to support reading Hive metastore 2.0 ~ 2.1.1. This updates the docs.
## How was this patch tested?
N/A
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#17612 from dongjoon-hyun/metastore.
## What changes were proposed in this pull request?
Add documentation for adding master url in multi host, port format for standalone cluster with high availability with zookeeper.
Referring documentation [Standby Masters with ZooKeeper](http://spark.apache.org/docs/latest/spark-standalone.html#standby-masters-with-zookeeper)
## How was this patch tested?
Documenting the functionality already present.
Author: MirrorZ <chandrika3437@gmail.com>
Closes#17584 from MirrorZ/master.
## What changes were proposed in this pull request?
1. '/applications/[app-id]/stages' in rest api.status should add description '?status=[active|complete|pending|failed] list only stages in the state.'
Now the lack of this description, resulting in the use of this api do not know the use of the status through the brush stage list.
2.'/applications/[app-id]/stages/[stage-id]' in REST API,remove redundant description ‘?status=[active|complete|pending|failed] list only stages in the state.’.
Because only one stage is determined based on stage-id.
code:
GET
def stageList(QueryParam("status") statuses: JList[StageStatus]): Seq[StageData] = {
val listener = ui.jobProgressListener
val stageAndStatus = AllStagesResource.stagesAndStatus(ui)
val adjStatuses = {
if (statuses.isEmpty()) {
Arrays.asList(StageStatus.values(): _*)
} else {
statuses
}
};
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: 郭小龙 10207633 <guo.xiaolong1@zte.com.cn>
Closes#17534 from guoxiaolongzte/SPARK-20218.
## What changes were proposed in this pull request?
Add spark.mesos.task.labels configuration option to add mesos key:value labels to the executor.
"k1:v1,k2:v2" as the format, colons separating key-value and commas to list out more than one.
Discussion of labels with mgummelt at #17404
## How was this patch tested?
Added unit tests to verify labels were added correctly, with incorrect labels being ignored and added a test to test the name of the executor.
Tested with: `./build/sbt -Pmesos mesos/test`
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Kalvin Chau <kalvin.chau@viasat.com>
Closes#17413 from kalvinnchau/mesos-labels.
## What changes were proposed in this pull request?
- Fixed bug in Java API not passing timeout conf to scala API
- Updated markdown docs
- Updated scala docs
- Added scala and Java example
## How was this patch tested?
Manually ran examples.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#17539 from tdas/SPARK-20224.
## What changes were proposed in this pull request?
Adding documentation to point to Kubernetes cluster scheduler being developed out-of-repo in https://github.com/apache-spark-on-k8s/spark
cc rxin srowen tnachen ash211 mccheah erikerlandson
## How was this patch tested?
Docs only change
Author: Anirudh Ramanathan <foxish@users.noreply.github.com>
Author: foxish <ramanathana@google.com>
Closes#17522 from foxish/upstream-doc.
…ucceeded|failed|unknown]
## What changes were proposed in this pull request?
'/applications/[app-id]/jobs' in rest api.status should be'[running|succeeded|failed|unknown]'.
now status is '[complete|succeeded|failed]'.
but '/applications/[app-id]/jobs?status=complete' the server return 'HTTP ERROR 404'.
Added '?status=running' and '?status=unknown'.
code :
public enum JobExecutionStatus {
RUNNING,
SUCCEEDED,
FAILED,
UNKNOWN;
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: guoxiaolongzte <guo.xiaolong1@zte.com.cn>
Closes#17507 from guoxiaolongzte/SPARK-20190.
## What changes were proposed in this pull request?
Add docs and examples for spark.ml.feature.Imputer. Currently scala and Java examples are included. Python example will be added after https://github.com/apache/spark/pull/17316
## How was this patch tested?
local doc generation and example execution
Author: Yuhao Yang <yuhao.yang@intel.com>
Closes#17324 from hhbyyh/imputerdoc.
# What changes were proposed in this pull request?
It seems there are several non-breaking spaces were inserted into several `.md`s and they look breaking rendering markdown files.
These are different. For example, this can be checked via `python` as below:
```python
>>> " "
'\xc2\xa0'
>>> " "
' '
```
_Note that it seems this PR description automatically replaces non-breaking spaces into normal spaces. Please open a `vi` and copy and paste it into `python` to verify this (do not copy the characters here)._
I checked the output below in Sapari and Chrome on Mac OS and, Internal Explorer on Windows 10.
**Before**


**After**


## How was this patch tested?
Manually checking.
These instances were found via
```
grep --include=*.scala --include=*.python --include=*.java --include=*.r --include=*.R --include=*.md --include=*.r -r -I " " .
```
in Mac OS.
It seems there are several instances more as below:
```
./docs/sql-programming-guide.md: │ ├── ...
./docs/sql-programming-guide.md: │ │
./docs/sql-programming-guide.md: │ ├── country=US
./docs/sql-programming-guide.md: │ │ └── data.parquet
./docs/sql-programming-guide.md: │ ├── country=CN
./docs/sql-programming-guide.md: │ │ └── data.parquet
./docs/sql-programming-guide.md: │ └── ...
./docs/sql-programming-guide.md: ├── ...
./docs/sql-programming-guide.md: │
./docs/sql-programming-guide.md: ├── country=US
./docs/sql-programming-guide.md: │ └── data.parquet
./docs/sql-programming-guide.md: ├── country=CN
./docs/sql-programming-guide.md: │ └── data.parquet
./docs/sql-programming-guide.md: └── ...
./sql/core/src/test/README.md:│ ├── *.avdl # Testing Avro IDL(s)
./sql/core/src/test/README.md:│ └── *.avpr # !! NO TOUCH !! Protocol files generated from Avro IDL(s)
./sql/core/src/test/README.md:│ ├── gen-avro.sh # Script used to generate Java code for Avro
./sql/core/src/test/README.md:│ └── gen-thrift.sh # Script used to generate Java code for Thrift
```
These seems generated via `tree` command which inserts non-breaking spaces. They do not look causing any problem for rendering within code blocks and I did not fix it to reduce the overhead to manually replace it when it is overwritten via `tree` command in the future.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#17517 from HyukjinKwon/non-breaking-space.
…anges.
## What changes were proposed in this pull request?
Document compression way little detail changes.
1.spark.eventLog.compress add 'Compression will use spark.io.compression.codec.'
2.spark.broadcast.compress add 'Compression will use spark.io.compression.codec.'
3,spark.rdd.compress add 'Compression will use spark.io.compression.codec.'
4.spark.io.compression.codec add 'event log describe'.
eg
Through the documents, I don't know what is compression mode about 'event log'.
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: 郭小龙 10207633 <guo.xiaolong1@zte.com.cn>
Closes#17498 from guoxiaolongzte/SPARK-20177.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}