### What changes were proposed in this pull request?
- Create a new rule `ResolveStreamWrite` for all analysis logic for streaming write.
- Add corresponding logical plans `WriteToStreamStatement` and `WriteToStream`.
### Why are the changes needed?
Currently, the analysis logic for streaming write is mixed in StreamingQueryManager. If we create a specific analyzer rule and separated logical plans, it should be helpful for further extension.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#31842 from xuanyuanking/SPARK-34748.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes an incompatible behavior introduced by #31754.
The problem is that quoted name parts represented as a string are given to the constructor of `UnresolvedAttribute` which takes single string parameter, `sql` method invocation against the `UnresolvedAttrribute` returns different result than before.
One example is ``` UnresolvedAttribute("`a.b`").sql ```. This returned `a.b` before but it doesn't now.
See [this duscussion](https://github.com/apache/spark/pull/31754/files#r597181927) for more details.
### Why are the changes needed?
For compatibility.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New assertion.
Closes#31885 from sarutak/followup-SPARK-34636.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Improve `PropagateEmptyRelation` to support join with false condition. For example:
```sql
SELECT * FROM t1 LEFT JOIN t2 ON false
```
Before this pr:
```
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- BroadcastNestedLoopJoin BuildRight, LeftOuter, false
:- FileScan parquet default.t1[a#4L]
+- BroadcastExchange IdentityBroadcastMode, [id=#40]
+- FileScan parquet default.t2[b#5L]
```
After this pr:
```
== Physical Plan ==
*(1) Project [a#4L, null AS b#5L]
+- *(1) ColumnarToRow
+- FileScan parquet default.t1[a#4L]
```
### Why are the changes needed?
Avoid `BroadcastNestedLoopJoin` to improve query performance.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#31857 from wangyum/SPARK-28220.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
This patch proposes to fix a bug related to `NestedColumnAliasing`. The root cause is `Window` doesn't override `producedAttributes` so `NestedColumnAliasing` rule wrongly prune attributes produced by `Window`.
The master and branch-3.1 both have this issue.
### Why are the changes needed?
It is needed to fix a bug of nested column pruning.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test.
Closes#31897 from viirya/SPARK-34776.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
For all built-in datasources, prohibit saving of year-month and day-time intervals that were introduced by SPARK-27793. We plan to support saving of such types at the milestone 2, see SPARK-27790.
### Why are the changes needed?
To improve user experience with Spark SQL, and print nicer error message. Current error message might confuse users:
```
scala> Seq(java.time.Period.ofMonths(1)).toDF.write.mode("overwrite").json("/Users/maximgekk/tmp/123")
21/03/18 22:44:35 ERROR FileFormatWriter: Aborting job 8de402d7-ab69-4dc0-aa8e-14ef06bd2d6b.
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 1.0 failed 1 times, most recent failure: Lost task 0.0 in stage 1.0 (TID 1) (192.168.1.66 executor driver): org.apache.spark.SparkException: Task failed while writing rows.
at org.apache.spark.sql.errors.QueryExecutionErrors$.taskFailedWhileWritingRowsError(QueryExecutionErrors.scala:418)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:298)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$write$15(FileFormatWriter.scala:211)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:498)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1437)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:501)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.RuntimeException: Failed to convert value 1 (class of class java.lang.Integer}) with the type of YearMonthIntervalType to JSON.
at scala.sys.package$.error(package.scala:30)
at org.apache.spark.sql.catalyst.json.JacksonGenerator.$anonfun$makeWriter$23(JacksonGenerator.scala:179)
at org.apache.spark.sql.catalyst.json.JacksonGenerator.$anonfun$makeWriter$23$adapted(JacksonGenerator.scala:176)
```
### Does this PR introduce _any_ user-facing change?
Yes. After the changes, the example above:
```
scala> Seq(java.time.Period.ofMonths(1)).toDF.write.mode("overwrite").json("/Users/maximgekk/tmp/123")
org.apache.spark.sql.AnalysisException: Cannot save interval data type into external storage.
```
### How was this patch tested?
1. Checked nested intervals:
```
scala> spark.range(1).selectExpr("""struct(timestamp'2021-01-02 00:01:02' - timestamp'2021-01-01 00:00:00')""").write.mode("overwrite").parquet("/Users/maximgekk/tmp/123")
org.apache.spark.sql.AnalysisException: Cannot save interval data type into external storage.
scala> Seq(Seq(java.time.Period.ofMonths(1))).toDF.write.mode("overwrite").json("/Users/maximgekk/tmp/123")
org.apache.spark.sql.AnalysisException: Cannot save interval data type into external storage.
```
2. By running existing test suites:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *DataSourceV2DataFrameSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *DataSourceV2SQLSuite"
```
Closes#31884 from MaxGekk/ban-save-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
join condition 'a.attr == 'c.attr check the reference of these 2 objects which will always returns false. we need to use === instead
### Why are the changes needed?
Although this join condition always false doesn't break the test but it is not what we expected. We should fix it to avoid future confusing
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
UT
Closes#31890 from opensky142857/SPARK-34798.
Authored-by: Hongyi Zhang <hongyzhang@ebay.com>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
Change context classloader to Spark classloader at `RebaseDateTime.loadRebaseRecords`
### Why are the changes needed?
With custom `spark.sql.hive.metastore.version` and `spark.sql.hive.metastore.jars`.
Spark would use date formatter in `HiveShim` that convert `date` to `string`, if we set `spark.sql.legacy.timeParserPolicy=LEGACY` and the partition type is `date` the `RebaseDateTime` code will be invoked. At that moment, if `RebaseDateTime` is initialized the first time then context class loader is `IsolatedClientLoader`. Such error msg would throw:
```
java.lang.IllegalArgumentException: argument "src" is null
at com.fasterxml.jackson.databind.ObjectMapper._assertNotNull(ObjectMapper.java:4413)
at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:3157)
at com.fasterxml.jackson.module.scala.ScalaObjectMapper.readValue(ScalaObjectMapper.scala:187)
at com.fasterxml.jackson.module.scala.ScalaObjectMapper.readValue$(ScalaObjectMapper.scala:186)
at org.apache.spark.sql.catalyst.util.RebaseDateTime$$anon$1.readValue(RebaseDateTime.scala:267)
at org.apache.spark.sql.catalyst.util.RebaseDateTime$.loadRebaseRecords(RebaseDateTime.scala:269)
at org.apache.spark.sql.catalyst.util.RebaseDateTime$.<init>(RebaseDateTime.scala:291)
at org.apache.spark.sql.catalyst.util.RebaseDateTime$.<clinit>(RebaseDateTime.scala)
at org.apache.spark.sql.catalyst.util.DateTimeUtils$.toJavaDate(DateTimeUtils.scala:109)
at org.apache.spark.sql.catalyst.util.LegacyDateFormatter.format(DateFormatter.scala:95)
at org.apache.spark.sql.catalyst.util.LegacyDateFormatter.format$(DateFormatter.scala:94)
at org.apache.spark.sql.catalyst.util.LegacySimpleDateFormatter.format(DateFormatter.scala:138)
at org.apache.spark.sql.hive.client.Shim_v0_13$ExtractableLiteral$1$.unapply(HiveShim.scala:661)
at org.apache.spark.sql.hive.client.Shim_v0_13.convert$1(HiveShim.scala:785)
at org.apache.spark.sql.hive.client.Shim_v0_13.$anonfun$convertFilters$4(HiveShim.scala:826)
```
```
java.lang.NoClassDefFoundError: Could not initialize class org.apache.spark.sql.catalyst.util.RebaseDateTime$
at org.apache.spark.sql.catalyst.util.DateTimeUtils$.toJavaDate(DateTimeUtils.scala:109)
at org.apache.spark.sql.catalyst.util.LegacyDateFormatter.format(DateFormatter.scala:95)
at org.apache.spark.sql.catalyst.util.LegacyDateFormatter.format$(DateFormatter.scala:94)
at org.apache.spark.sql.catalyst.util.LegacySimpleDateFormatter.format(DateFormatter.scala:138)
at org.apache.spark.sql.hive.client.Shim_v0_13$ExtractableLiteral$1$.unapply(HiveShim.scala:661)
at org.apache.spark.sql.hive.client.Shim_v0_13.convert$1(HiveShim.scala:785)
at org.apache.spark.sql.hive.client.Shim_v0_13.$anonfun$convertFilters$4(HiveShim.scala:826)
at scala.collection.immutable.Stream.flatMap(Stream.scala:493)
at org.apache.spark.sql.hive.client.Shim_v0_13.convertFilters(HiveShim.scala:826)
at org.apache.spark.sql.hive.client.Shim_v0_13.getPartitionsByFilter(HiveShim.scala:848)
at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$getPartitionsByFilter$1(HiveClientImpl.scala:749)
at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$withHiveState$1(HiveClientImpl.scala:291)
at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:224)
at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:223)
at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:273)
at org.apache.spark.sql.hive.client.HiveClientImpl.getPartitionsByFilter(HiveClientImpl.scala:747)
at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$listPartitionsByFilter$1(HiveExternalCatalog.scala:1273)
```
The reproduce steps:
1. `spark.sql.hive.metastore.version` and `spark.sql.hive.metastore.jars`.
2. `CREATE TABLE t (c int) PARTITIONED BY (p date)`
3. `SET spark.sql.legacy.timeParserPolicy=LEGACY`
4. `SELECT * FROM t WHERE p='2021-01-01'`
### Does this PR introduce _any_ user-facing change?
Yes, bug fix.
### How was this patch tested?
pass `org.apache.spark.sql.catalyst.util.RebaseDateTimeSuite` and add new unit test to `HiveSparkSubmitSuite.scala`.
Closes#31864 from ulysses-you/SPARK-34772.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
Support `timestamp +/- day-time interval`. In the PR, I propose to extend the `TimeAdd` expression and support `DayTimeIntervalType` as the `interval` parameter. The expression invokes the new method `DateTimeUtils.timestampAddDayTime()` which splits the input day-time interval to `days` and `microsecond adjustment` of a day, and adds `days` (and the microseconds) to a local timestamp derived from the given timestamp at the given time zone. The resulted local timestamp is converted back to the offset in microseconds since the epoch.
Also I updated the rules that handle `CalendarIntervalType` and produce `TimeAdd` to take into account new type `DateTimeIntervalType` for the `interval` parameter of `TimeAdd`.
### Why are the changes needed?
To conform the ANSI SQL standard which requires to support such operation over timestamps and intervals:
<img width="811" alt="Screenshot 2021-03-12 at 11 36 14" src="https://user-images.githubusercontent.com/1580697/111081674-865d4900-8515-11eb-86c8-3538ecaf4804.png">
### Does this PR introduce _any_ user-facing change?
Should not since new intervals have not been released yet.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateTimeUtilsSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31855 from MaxGekk/timestamp-add-day-time-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to deduplicate the source table when there're conflicting attributes between the target table and the source table.
### Why are the changes needed?
When resolving the `UpdateAction`, which could reference attributes from both target and source tables, Spark should know clearly where the attribute comes from when there're conflicting attributes instead of picking up a random one.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added a unit test and updated existing tests.
Closes#31835 from Ngone51/dedup-MergeIntoTable.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Remove all SQLConf.get to conf if extends from SQLConfHelper
### Why are the changes needed?
Clean up code.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing unit tests.
Closes#31822 from leoluan2009/SPARK-34728.
Authored-by: Luan <luanxuedong2009@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR group exception messages in `/core/src/main/scala/org/apache/spark/sql/execution/datasources`.
### Why are the changes needed?
It will largely help with standardization of error messages and its maintenance.
### Does this PR introduce _any_ user-facing change?
No. Error messages remain unchanged.
### How was this patch tested?
No new tests - pass all original tests to make sure it doesn't break any existing behavior.
Closes#31757 from beliefer/SPARK-33602.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR simplifies `Analyzer.resolveLiteralFunction` to always create the `Alias`. The caller side will remove the `Alias` if it's not necessary.
### Why are the changes needed?
code simplification.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing tests
Closes#31844 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/31808 and simplifies its fix to one line (excluding comments).
### Why are the changes needed?
code simplification
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
N/A
Closes#31843 from cloud-fan/simplify.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR proposes to follow Univocity's input buffer.
### Why are the changes needed?
- Firstly, it's best to trust their judgement on the default values. Also 128 is too low.
- Default values arguably have more test coverage in Univocity.
- It will also fix https://github.com/uniVocity/univocity-parsers/issues/449
- ^ is a regression compared to Spark 2.4
### Does this PR introduce _any_ user-facing change?
No. In addition, It fixes a regression.
### How was this patch tested?
Manually tested, and added a unit test.
Closes#31858 from HyukjinKwon/SPARK-34768.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR updates `InMemoryCatalog.tableExists` to return false if database doesn't exist, instead of failing. The new behavior is consistent with `HiveExternalCatalog` which is used in production, so this bug mostly only affects tests.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
a new test
Closes#31860 from cloud-fan/catalog.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
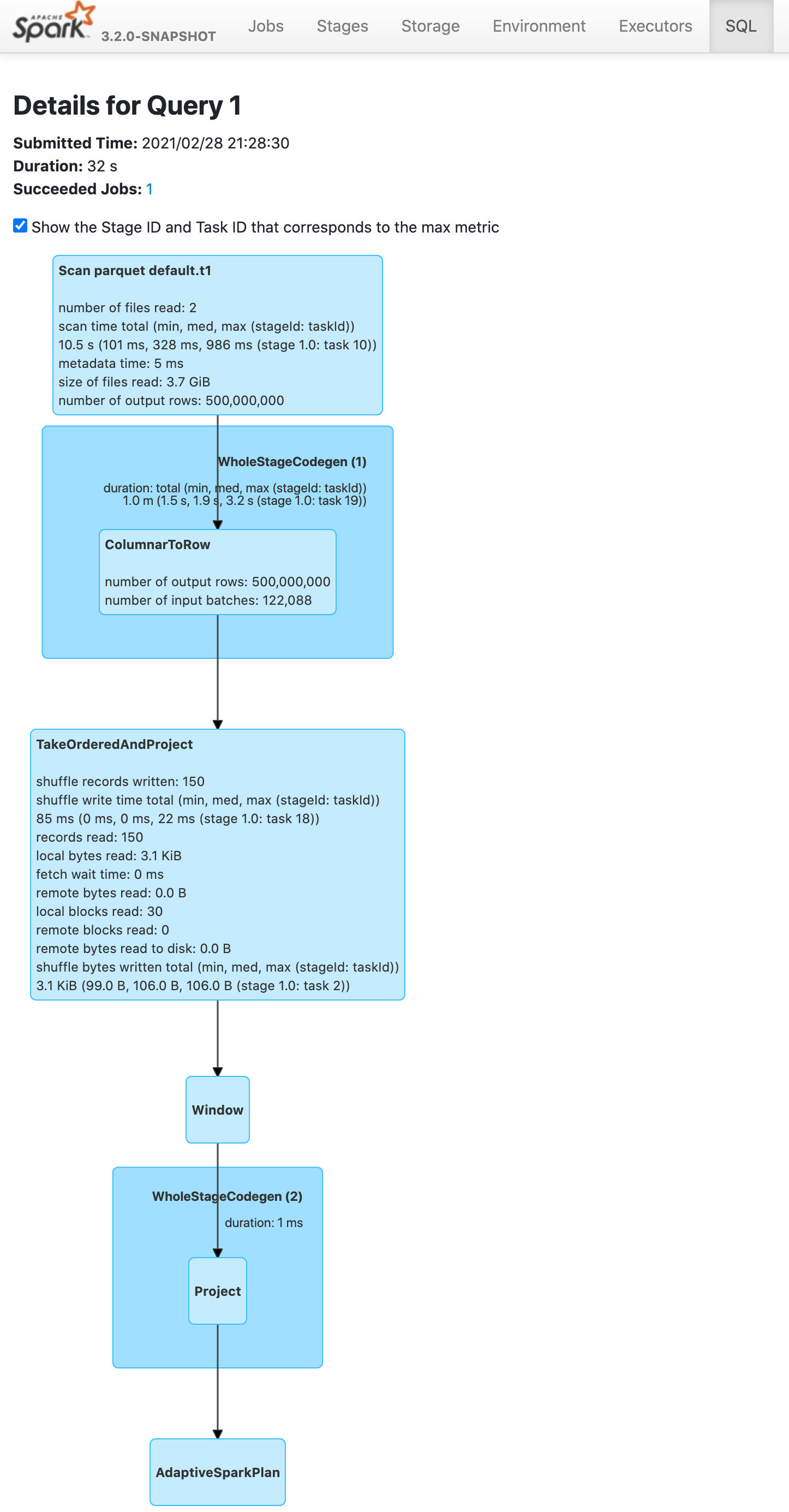
Push down limit through `Window` when the partitionSpec of all window functions is empty and the same order is used. This is a real case from production:

This pr support 2 cases:
1. All window functions have same orderSpec:
```sql
SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rn, RANK() OVER(ORDER BY a) AS rk FROM t1 LIMIT 5;
== Optimized Logical Plan ==
Window [row_number() windowspecdefinition(a#9L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rn#4, rank(a#9L) windowspecdefinition(a#9L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#5], [a#9L ASC NULLS FIRST]
+- GlobalLimit 5
+- LocalLimit 5
+- Sort [a#9L ASC NULLS FIRST], true
+- Relation default.t1[A#9L,B#10L,C#11L] parquet
```
2. There is a window function with a different orderSpec:
```sql
SELECT a, ROW_NUMBER() OVER(ORDER BY a) AS rn, RANK() OVER(ORDER BY b DESC) AS rk FROM t1 LIMIT 5;
== Optimized Logical Plan ==
Project [a#9L, rn#4, rk#5]
+- Window [rank(b#10L) windowspecdefinition(b#10L DESC NULLS LAST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#5], [b#10L DESC NULLS LAST]
+- GlobalLimit 5
+- LocalLimit 5
+- Sort [b#10L DESC NULLS LAST], true
+- Window [row_number() windowspecdefinition(a#9L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rn#4], [a#9L ASC NULLS FIRST]
+- Project [a#9L, b#10L]
+- Relation default.t1[A#9L,B#10L,C#11L] parquet
```
### Why are the changes needed?
Improve query performance.
```scala
spark.range(500000000L).selectExpr("id AS a", "id AS b").write.saveAsTable("t1")
spark.sql("SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rowId FROM t1 LIMIT 5").show
```
Before this pr | After this pr
-- | --
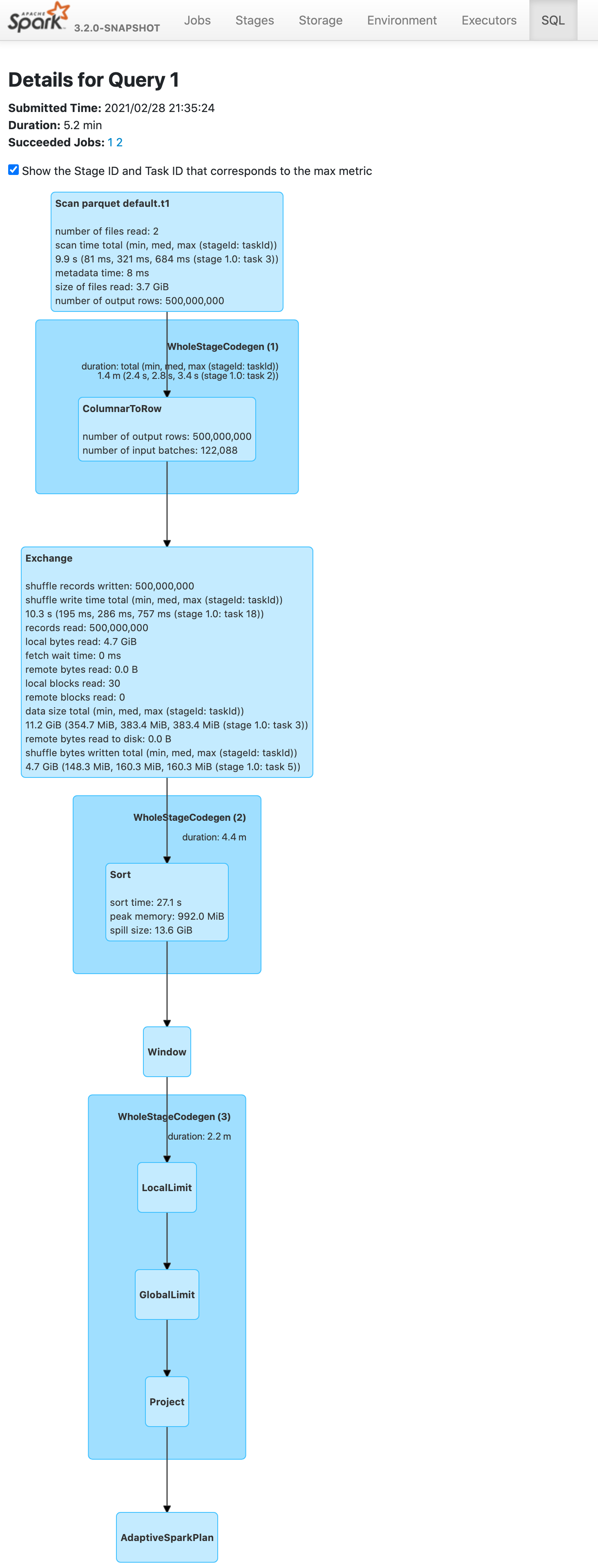 | 
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#31691 from wangyum/SPARK-34575.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For the following cases, ABS should throw exceptions since the results are out of the range of the result data types in ANSI mode.
```
SELECT abs(${Int.MinValue});
SELECT abs(${Long.MinValue});
```
### Why are the changes needed?
Better ANSI compliance
### Does this PR introduce _any_ user-facing change?
Yes, Abs throws an exception if input is out of range in ANSI mode
### How was this patch tested?
Unit test
Closes#31836 from gengliangwang/ansiAbs.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For DDL commands like DROP VIEW, they don't really need to resolve the view (parse and analyze the view SQL text), they just need to get the view metadata.
This PR fixes the rule `ResolveTempViews` to only resolve the temp view for `UnresolvedRelation`. This also fixes a bug for DROP VIEW, as previously it tried to resolve the view and failed to drop invalid views.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
new test
Closes#31853 from cloud-fan/view-resolve.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR removes one unused variable in `NewInstance.constructor`.
### Why are the changes needed?
This looks like a variable for debugging at the initial commit of SPARK-23584 .
- 1b08c4393c (diff-2a36e31684505fd22e2d12a864ce89fd350656d716a3f2d7789d2cdbe38e15fbR461)
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the CIs.
Closes#31838 from dongjoon-hyun/minor-object.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Support `timestamp +/- year-month interval`. In the PR, I propose to introduce new binary expression `TimestampAddYMInterval` similarly to `DateAddYMInterval`. It invokes new method `timestampAddMonths` from `DateTimeUtils` by passing a timestamp as an offset in microseconds since the epoch, amount of months from the giveb year-month interval, and the time zone ID in which the operation is performed. The `timestampAddMonths()` method converts the input microseconds to a local timestamp, adds months to it, and converts the results back to an instant in microseconds at the given time zone.
### Why are the changes needed?
To conform the ANSI SQL standard which requires to support such operation over timestamps and intervals:
<img width="811" alt="Screenshot 2021-03-12 at 11 36 14" src="https://user-images.githubusercontent.com/1580697/111081674-865d4900-8515-11eb-86c8-3538ecaf4804.png">
### Does this PR introduce _any_ user-facing change?
Should not since new intervals have not been released yet.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateTimeUtilsSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31832 from MaxGekk/timestamp-add-year-month-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR aims to make `ExpressionEncoderSuite` to use `deepEquals` instead of `equals` when `input` is `array of array`.
This comparison code itself was added by SPARK-11727 at Apache Spark 1.6.0.
### Why are the changes needed?
Currently, the interpreted mode fails for `array of array` because the following line is used.
```
Arrays.equals(b1.asInstanceOf[Array[AnyRef]], b2.asInstanceOf[Array[AnyRef]])
```
### Does this PR introduce _any_ user-facing change?
No. This is a test-only PR.
### How was this patch tested?
Pass the existing CIs.
Closes#31837 from dongjoon-hyun/SPARK-34743.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In `Analyzer.resolveExpression`, we have a parameter to decide if we should remove unnecessary `Alias` or not. This is over complicated and we can always remove unnecessary `Alias`.
This PR simplifies this part and removes the parameter.
### Why are the changes needed?
code cleanup
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing tests
Closes#31758 from cloud-fan/resolve.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to cast the input float to double in the `SecondsToTimestamp` expression in the same way as in the `Cast` expression.
### Why are the changes needed?
To have the same results from `CAST(<float> AS TIMESTAMP)` and from `TIMESTAMP_SECONDS`:
```sql
spark-sql> SELECT CAST(16777215.0f AS TIMESTAMP);
1970-07-14 07:20:15
spark-sql> SELECT TIMESTAMP_SECONDS(16777215.0f);
1970-07-14 07:20:14.951424
```
### Does this PR introduce _any_ user-facing change?
Yes. After the changes:
```sql
spark-sql> SELECT TIMESTAMP_SECONDS(16777215.0f);
1970-07-14 07:20:15
```
### How was this patch tested?
By running new test:
```
$ build/sbt "test:testOnly *DateExpressionsSuite"
```
Closes#31831 from MaxGekk/adjust-SecondsToTimestamp.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In non-ANSI mode, casting float to timestamp has different implementation for codegen on and off.
Codegen on:
1. Multiply float input by MICROS_PER_SECOND
2. Cast resulting float value to long
Codegen off:
1. CAST float input to double input
2. Multiply double input by MICROS_PER_SECOND
3. Cast resulting double value to long
In the PR, I propose to align to non-codegen code, and cast input float to double in codegen.
### Why are the changes needed?
This fixes the issue which is demonstrated by the code:
```sql
spark-sql> CREATE TEMP VIEW v1 AS SELECT 16777215.0f AS f;
spark-sql> SELECT * FROM v1;
1.6777215E7
spark-sql> SELECT CAST(f AS TIMESTAMP) FROM v1;
1970-07-14 07:20:15
spark-sql> CACHE TABLE v1;
spark-sql> SELECT * FROM v1;
1.6777215E7
spark-sql> SELECT CAST(f AS TIMESTAMP) FROM v1;
1970-07-14 07:20:14.951424
```
The result from the cached view **1970-07-14 07:20:14.951424** is different from un-cached view **1970-07-14 07:20:15**.
### Does this PR introduce _any_ user-facing change?
Yes. After the changes, the example above outputs the same timestamp for the cached view:
```sql
spark-sql> CACHE TABLE v1;
spark-sql> SELECT * FROM v1;
1.6777215E7
spark-sql> SELECT CAST(f AS TIMESTAMP) FROM v1;
1970-07-14 07:20:15
```
### How was this patch tested?
By running new test:
```
$ build/sbt "test:testOnly *CastSuite"
```
Closes#31819 from MaxGekk/fix-float-to-timestamp.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This patch proposes to fix incorrect parameter type for subexpression elimination under whole-stage.
### Why are the changes needed?
If the parameter is a byte array, the subexpression elimination under wholestage codegen will use incorrect parameter type and cause compile error. Although Spark can automatically fallback to interpreted mode, we should fix it.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually test with customer application. Unit test.
Closes#31814 from viirya/SPARK-34723.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Support `date +/- year-month interval`. In the PR, I propose to re-use existing code from the `AddMonths` expression, and extract it to the common base class `AddMonthsBase`. That base class is used in new expression `DateAddYMInterval` and in the existing one `AddMonths` (the `add_months` function).
### Why are the changes needed?
To conform the ANSI SQL standard which requires to support such operation over dates and intervals:
<img width="811" alt="Screenshot 2021-03-12 at 11 36 14" src="https://user-images.githubusercontent.com/1580697/110914390-5f412480-8327-11eb-9f8b-e92e73c0b9cd.png">
### Does this PR introduce _any_ user-facing change?
Should not since new intervals have not been released yet.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *ColumnExpressionSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
```
Closes#31812 from MaxGekk/date-add-year-month-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This bug was introduced by SPARK-23583 at Apache Spark 2.4.0.
This PR aims to use `getMethod` instead of `getDeclaredMethod`.
```scala
- obj.getClass.getDeclaredMethod(functionName, argClasses: _*)
+ obj.getClass.getMethod(functionName, argClasses: _*)
```
### Why are the changes needed?
`getDeclaredMethod` does not search the super class's method. To invoke `GenericArrayData.toIntArray`, we need to use `getMethod` because it's declared at the super class `ArrayData`.
```
[info] - encode/decode for array of int: [I74655d03 (interpreted path) *** FAILED *** (14 milliseconds)
[info] Exception thrown while decoding
[info] Converted: [0,1000000020,3,0,ffffff850000001f,4]
[info] Schema: value#680
[info] root
[info] -- value: array (nullable = true)
[info] |-- element: integer (containsNull = false)
[info]
[info]
[info] Encoder:
[info] class[value[0]: array<int>] (ExpressionEncoderSuite.scala:578)
[info] org.scalatest.exceptions.TestFailedException:
[info] at org.scalatest.Assertions.newAssertionFailedException(Assertions.scala:472)
[info] at org.scalatest.Assertions.newAssertionFailedException$(Assertions.scala:471)
[info] at org.scalatest.funsuite.AnyFunSuite.newAssertionFailedException(AnyFunSuite.scala:1563)
[info] at org.scalatest.Assertions.fail(Assertions.scala:949)
[info] at org.scalatest.Assertions.fail$(Assertions.scala:945)
[info] at org.scalatest.funsuite.AnyFunSuite.fail(AnyFunSuite.scala:1563)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.$anonfun$encodeDecodeTest$1(ExpressionEncoderSuite.scala:578)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.verifyNotLeakingReflectionObjects(ExpressionEncoderSuite.scala:656)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.$anonfun$testAndVerifyNotLeakingReflectionObjects$2(ExpressionEncoderSuite.scala:669)
[info] at org.apache.spark.sql.catalyst.plans.CodegenInterpretedPlanTest.$anonfun$test$4(PlanTest.scala:50)
[info] at org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf(SQLHelper.scala:54)
[info] at org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf$(SQLHelper.scala:38)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.withSQLConf(ExpressionEncoderSuite.scala:118)
[info] at org.apache.spark.sql.catalyst.plans.CodegenInterpretedPlanTest.$anonfun$test$3(PlanTest.scala:50)
...
[info] Cause: java.lang.RuntimeException: Error while decoding: java.lang.NoSuchMethodException: org.apache.spark.sql.catalyst.util.GenericArrayData.toIntArray()
[info] mapobjects(lambdavariable(MapObject, IntegerType, false, -1), assertnotnull(lambdavariable(MapObject, IntegerType, false, -1)), input[0, array<int>, true], None).toIntArray
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoder$Deserializer.apply(ExpressionEncoder.scala:186)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.$anonfun$encodeDecodeTest$1(ExpressionEncoderSuite.scala:576)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.verifyNotLeakingReflectionObjects(ExpressionEncoderSuite.scala:656)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.$anonfun$testAndVerifyNotLeakingReflectionObjects$2(ExpressionEncoderSuite.scala:669)
```
### Does this PR introduce _any_ user-facing change?
This causes a runtime exception when we use the interpreted mode.
### How was this patch tested?
Pass the modified unit test case.
Closes#31816 from dongjoon-hyun/SPARK-34724.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR fixes an issue that `sql` method in the following classes which take qualified names don't quote the qualified names properly.
* UnresolvedAttribute
* AttributeReference
* Alias
One instance caused by this issue is reported in SPARK-34626.
```
UnresolvedAttribute("a" :: "b" :: Nil).sql
`a.b` // expected: `a`.`b`
```
And other instances are like as follows.
```
UnresolvedAttribute("a`b"::"c.d"::Nil).sql
a`b.`c.d` // expected: `a``b`.`c.d`
AttributeReference("a.b", IntegerType)(qualifier = "c.d"::Nil).sql
c.d.`a.b` // expected: `c.d`.`a.b`
Alias(AttributeReference("a", IntegerType)(), "b.c")(qualifier = "d.e"::Nil).sql
`a` AS d.e.`b.c` // expected: `a` AS `d.e`.`b.c`
```
### Why are the changes needed?
This is a bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New test.
Closes#31754 from sarutak/fix-qualified-names.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to override the `typeName()` method in `YearMonthIntervalType` and `DayTimeIntervalType`, and assign them names according to the ANSI SQL standard:
<img width="836" alt="Screenshot 2021-03-11 at 17 29 04" src="https://user-images.githubusercontent.com/1580697/110802854-a54aa980-828f-11eb-956d-dd4fbf14aa72.png">
but keep the type name as singular according existing naming convention for other types.
### Why are the changes needed?
To improve Spark SQL user experience, and have readable types in error messages.
### Does this PR introduce _any_ user-facing change?
Should not since the types has not been released yet.
### How was this patch tested?
By running the modified tests:
```
$ build/sbt "test:testOnly *ExpressionTypeCheckingSuite"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z windowFrameCoercion.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z literals.sql"
```
Closes#31810 from MaxGekk/interval-types-name.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a bug caused by https://issues.apache.org/jira/browse/SPARK-31670 . We remove the `Alias` when resolving column references in grouping expressions, which breaks `ResolveCreateNamedStruct`
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
new tests
Closes#31808 from cloud-fan/bug.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to especially handle the amount of seconds `-9223372036855` in `IntervalUtils. durationToMicros()`. Starting from the amount (any durations with the second field < `-9223372036855`), input durations cannot fit to `Long` in the conversion to microseconds. For example, the amount of microseconds = `Long.MinValue = -9223372036854775808` can be represented in two forms:
1. seconds = -9223372036854, nanoAdjustment = -775808, or
2. seconds = -9223372036855, nanoAdjustment = +224192
And the method `Duration.ofSeconds()` produces the last form but such form causes overflow while converting `-9223372036855` seconds to microseconds.
In the PR, I propose to convert the second form to the first one if the second field of input duration is equal to `-9223372036855`.
### Why are the changes needed?
The changes fix the issue demonstrated by the code:
```scala
scala> durationToMicros(microsToDuration(Long.MinValue))
java.lang.ArithmeticException: long overflow
at java.lang.Math.multiplyExact(Math.java:892)
at org.apache.spark.sql.catalyst.util.IntervalUtils$.durationToMicros(IntervalUtils.scala:782)
... 49 elided
```
The `durationToMicros()` method cannot handle valid output of `microsToDuration()`.
### Does this PR introduce _any_ user-facing change?
Should not since new interval types has not been released yet.
### How was this patch tested?
By running new UT from `IntervalUtilsSuite`.
Closes#31799 from MaxGekk/fix-min-duration.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add `Not(In)` and `Not(InSet)` pattern when convert filter to metastore.
### Why are the changes needed?
`NOT IN` is a useful condition to prune partition, it would be better to support it.
Technically, we can convert `c not in(x,y)` to `c != x and c != y`, then push it to metastore.
Avoid metastore overflow and respect the config `spark.sql.hive.metastorePartitionPruningInSetThreshold`, `Not(InSet)` won't push to metastore if it's value exceeds the threshold.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Add test.
Closes#31646 from ulysses-you/SPARK-34538.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Extend the `Add`, `Subtract` and `UnaryMinus` expression to support `DayTimeIntervalType` and `YearMonthIntervalType` added by #31614.
Note: the expressions can throw the `overflow` exception independently from the SQL config `spark.sql.ansi.enabled`. In this way, the modified expressions always behave in the ANSI mode for the intervals.
### Why are the changes needed?
To conform to the ANSI SQL standard which defines `-/+` over intervals:
<img width="822" alt="Screenshot 2021-03-09 at 21 59 22" src="https://user-images.githubusercontent.com/1580697/110523128-bd50ea80-8122-11eb-9982-782da0088d27.png">
### Does this PR introduce _any_ user-facing change?
Should not since new types have not been released yet.
### How was this patch tested?
By running new tests in the test suites:
```
$ build/sbt "test:testOnly *ArithmeticExpressionSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31789 from MaxGekk/add-subtruct-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
SPARK-23596 added `CodegenInterpretedPlanTest` at Apache Spark 2.4.0 in a wrong way because `withSQLConf` depends on the execution time `SQLConf.get` instead of `test` function declaration time. So, the following code executes the test twice without controlling the `CodegenObjectFactoryMode`. This PR aims to fix it correct and introduce a new function `testFallback`.
```scala
trait CodegenInterpretedPlanTest extends PlanTest {
override protected def test(
testName: String,
testTags: Tag*)(testFun: => Any)(implicit pos: source.Position): Unit = {
val codegenMode = CodegenObjectFactoryMode.CODEGEN_ONLY.toString
val interpretedMode = CodegenObjectFactoryMode.NO_CODEGEN.toString
withSQLConf(SQLConf.CODEGEN_FACTORY_MODE.key -> codegenMode) {
super.test(testName + " (codegen path)", testTags: _*)(testFun)(pos)
}
withSQLConf(SQLConf.CODEGEN_FACTORY_MODE.key -> interpretedMode) {
super.test(testName + " (interpreted path)", testTags: _*)(testFun)(pos)
}
}
}
```
### Why are the changes needed?
1. We need to use like the following.
```scala
super.test(testName + " (codegen path)", testTags: _*)(
withSQLConf(SQLConf.CODEGEN_FACTORY_MODE.key -> codegenMode) { testFun })(pos)
super.test(testName + " (interpreted path)", testTags: _*)(
withSQLConf(SQLConf.CODEGEN_FACTORY_MODE.key -> interpretedMode) { testFun })(pos)
```
2. After we fix this behavior with the above code, several test cases including SPARK-34596 and SPARK-34607 fail because they didn't work at both `CODEGEN` and `INTERPRETED` mode. Those test cases only work at `FALLBACK` mode. So, inevitably, we need to introduce `testFallback`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the CIs.
Closes#31766 from dongjoon-hyun/SPARK-34596-SPARK-34607.
Lead-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR adds a default null ordering to public `SortDirection` to match the Catalyst behavior.
### Why are the changes needed?
The SQL standard does not define the default null ordering for a sort direction. That's why it is up to a query engine to assign one. We need to standardize this in our public connector expressions to avoid ambiguity. That's why I propose to match the behavior in our Catalyst expressions.
### Does this PR introduce _any_ user-facing change?
Yes, it affects unreleased connector expression API.
### How was this patch tested?
Existing tests.
Closes#31580 from aokolnychyi/spark-34457.
Authored-by: Anton Okolnychyi <aokolnychyi@apple.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes the following:
* `AlterViewAs.query` is currently analyzed in the physical operator `AlterViewAsCommand`, but it should be analyzed during the analysis phase.
* When `spark.sql.legacy.storeAnalyzedPlanForView` is set to true, store `TermporaryViewRelation` which wraps the analyzed plan, similar to #31273.
* Try to uncache the view you are altering.
### Why are the changes needed?
Analyzing a plan should be done in the analysis phase if possible.
Not uncaching the view (existing behavior) seems like a bug since the cache may not be used again.
### Does this PR introduce _any_ user-facing change?
Yes, now the view can be uncached if it's already cached.
### How was this patch tested?
Added new tests around uncaching.
The existing tests such as `SQLViewSuite` should cover the analysis changes.
Closes#31652 from imback82/alter_view_child.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR intends to remove unnecessary `SQLConf.withExistingConf` in `CastSuite`; since we've remove `ParVector ` in #31775, we no longer need to copy SQL configs into each thread env.
### Why are the changes needed?
Clean up the code.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Run the existing tests.
Closes#31785 from maropu/UpdateCastSuite.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add `DayTimeIntervalType` and `YearMonthIntervalType` to `DataTypeTestUtils.ordered`/`atomicTypes`, and implement values generation of those types in `LiteralGenerator`/`RandomDataGenerator`. In this way, the types will be tested automatically in:
1. ArithmeticExpressionSuite:
- "function least"
- "function greatest"
2. PredicateSuite
- "BinaryComparison consistency check"
- "AND, OR, EqualTo, EqualNullSafe consistency check"
3. ConditionalExpressionSuite
- "if"
4. RandomDataGeneratorSuite
- "Basic types"
5. CastSuite
- "null cast"
- "up-cast"
- "SPARK-27671: cast from nested null type in struct"
6. OrderingSuite
- "GenerateOrdering with DayTimeIntervalType"
- "GenerateOrdering with YearMonthIntervalType"
7. PredicateSuite
- "IN with different types"
8. UnsafeRowSuite
- "calling get(ordinal, datatype) on null columns"
9. SortSuite
- "sorting on YearMonthIntervalType ..."
- "sorting on DayTimeIntervalType ..."
### Why are the changes needed?
To improve test coverage.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the affected test suites.
Closes#31782 from MaxGekk/test-interval-as-atomic.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR updates UnresolvedTableValuedFunction's name to be a FunctionIdentifier instead of a string.
### Why are the changes needed?
To make UnresolvedTableValuedFunction consistent with UnresolvedFunction that uses FunctionIdentifier as the function name.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test.
Closes#31749 from allisonwang-db/spark-34627.
Authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
RewritePredicateSubquery Optimizer Rule must not update Filters without subqueries.
Following is one such example.
```
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.RewritePredicateSubquery ===
Project [a#0] Project [a#0]
!+- Filter (((a#0 > 1) OR (b#1 > 2)) AND ((c#2 > 1) AND (d#3 > 2))) +- Filter ((((a#0 > 1) OR (b#1 > 2)) AND (c#2 > 1)) AND (d#3 > 2))
+- LocalRelation <empty>, [a#0, b#1, c#2, d#3] +- LocalRelation <empty>, [a#0, b#1, c#2, d#3]
```
### Why are the changes needed?
minor change.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing UTs pass.
Closes#31712 from Swinky/rewritePredicateFix.
Authored-by: Swinky <mannswinky@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to extend Spark SQL API to accept [`java.time.Period`](https://docs.oracle.com/javase/8/docs/api/java/time/Period.html) as an external type of recently added new Catalyst type - `YearMonthIntervalType` (see #31614). The Java class `java.time.Period` has similar semantic to ANSI SQL year-month interval type, and it is the most suitable to be an external type for `YearMonthIntervalType`. In more details:
1. Added `PeriodConverter` which converts `java.time.Period` instances to/from internal representation of the Catalyst type `YearMonthIntervalType` (to `Int` type). The `PeriodConverter` object uses new methods of `IntervalUtils`:
- `periodToMonths()` converts the input period to the total length in months. If this period is too large to fit `Int`, the method throws the exception `ArithmeticException`. **Note:** _the input period has "days" precision, the method just ignores the days unit._
- `monthToPeriod()` obtains a `java.time.Period` representing a number of months.
2. Support new type `YearMonthIntervalType` in `RowEncoder` via the methods `createDeserializerForPeriod()` and `createSerializerForJavaPeriod()`.
3. Extended the Literal API to construct literals from `java.time.Period` instances.
### Why are the changes needed?
1. To allow users parallelization of `java.time.Period` collections, and construct year-month interval columns. Also to collect such columns back to the driver side.
2. This will allow to write tests in other sub-tasks of SPARK-27790.
### Does this PR introduce _any_ user-facing change?
The PR extends existing functionality. So, users can parallelize instances of the `java.time.Duration` class and collect them back:
```scala
scala> val ds = Seq(java.time.Period.ofYears(10).withMonths(2)).toDS
ds: org.apache.spark.sql.Dataset[java.time.Period] = [value: yearmonthinterval]
scala> ds.collect
res0: Array[java.time.Period] = Array(P10Y2M)
```
### How was this patch tested?
- Added a few tests to `CatalystTypeConvertersSuite` to check conversion from/to `java.time.Period`.
- Checking row encoding by new tests in `RowEncoderSuite`.
- Making literals of `YearMonthIntervalType` are tested in `LiteralExpressionSuite`.
- Check collecting by `DatasetSuite` and `JavaDatasetSuite`.
- New tests in `IntervalUtilsSuites` to check conversions `java.time.Period` <-> months.
Closes#31765 from MaxGekk/java-time-period.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When we do self join with transform in a CTE, spark will throw AnalysisException.
A simple way to reproduce is
```
create temporary view t as select * from values 0, 1, 2 as t(a);
WITH temp AS (
SELECT TRANSFORM(a) USING 'cat' AS (b string) FROM t
)
SELECT t1.b FROM temp t1 JOIN temp t2 ON t1.b = t2.b
```
before this patch, it throws
```
org.apache.spark.sql.AnalysisException: cannot resolve '`t1.b`' given input columns: [t1.b]; line 6 pos 41;
'Project ['t1.b]
+- 'Join Inner, ('t1.b = 't2.b)
:- SubqueryAlias t1
: +- SubqueryAlias temp
: +- ScriptTransformation [a#1], cat, [b#2], ScriptInputOutputSchema(List(),List(),Some(org.apache.hadoop.hive.serde2.DelimitedJSONSerDe),Some(org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe),List((field.delim, )),List((field.delim, )),Some(org.apache.hadoop.hive.ql.exec.TextRecordReader),Some(org.apache.hadoop.hive.ql.exec.TextRecordWriter),false)
: +- SubqueryAlias t
: +- Project [a#1]
: +- SubqueryAlias t
: +- LocalRelation [a#1]
+- SubqueryAlias t2
+- SubqueryAlias temp
+- ScriptTransformation [a#1], cat, [b#2], ScriptInputOutputSchema(List(),List(),Some(org.apache.hadoop.hive.serde2.DelimitedJSONSerDe),Some(org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe),List((field.delim, )),List((field.delim, )),Some(org.apache.hadoop.hive.ql.exec.TextRecordReader),Some(org.apache.hadoop.hive.ql.exec.TextRecordWriter),false)
+- SubqueryAlias t
+- Project [a#1]
+- SubqueryAlias t
+- LocalRelation [a#1]
```
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
Add a UT
Closes#31752 from WangGuangxin/selfjoin-with-transform.
Authored-by: wangguangxin.cn <wangguangxin.cn@bytedance.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This pr remove `GlobalLimit` operator if its child max rows not larger than limit number. For example:
```
val testRelation = LocalRelation.fromExternalRows(Seq("a".attr.int, "b".attr.int, "c".attr.int), 1.to(10).map(_ => Row(1, 2, 3)) )
val query = GlobalLimit(100, testRelation)
```
We can remove this `GlobalLimit`.
### Why are the changes needed?
Further optimize the query.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#31750 from wangyum/SPARK-34628.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Unify output of ShowCreateTableAsSerdeCommand and ShowCreateTableCommand
### Why are the changes needed?
Unify output of ShowCreateTableAsSerdeCommand and ShowCreateTableCommand
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Closes#31737 from AngersZhuuuu/SPARK-34621.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR intends to refactor the logic to resolve `__grouping_id` in the `Analyzer`; it moves the logic from `ResolveFunctions` to `ResolveReferences` (`resolveLiteralFunction`).
The original author of this PR is sqlwindspeaker (#30781).
Closes#30781.
### Why are the changes needed?
Code refactoring.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added tests in `AnalysisSuite`.
Closes#31751 from maropu/SPARK-22748.
Authored-by: suqilong <suqilong@qiyi.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
It's a bit confusing to see `resolveExpressionBottomUp` and `resolveExpressionTopDown`, which provide similar functionalities but with different tree traverse order. It turns out that the real difference between these 2 methods is: which attributes should the columns be resolved to? `resolveExpressionTopDown` resolves columns using output attributes of the plan children, `resolveExpressionBottomUp` resolves columns using output attributes of the plan itself.
This PR unifies `resolveExpressionBottomUp` and `resolveExpressionTopDown` and put the common logic in a new method, and let `resolveExpressionBottomUp` and `resolveExpressionTopDown` just call the new method. This PR also renames `resolveExpressionBottomUp` and `resolveExpressionTopDown` to make the difference clear.
### Why are the changes needed?
code cleanup
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing tests
Closes#31728 from cloud-fan/resolve.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
We have equality in `SqlBase.g4` for `RLIKE: 'RLIKE' | 'REGEXP';`
We seemed to miss adding` REGEXP` as a SQL function just like` RLIKE`
### Why are the changes needed?
symmetry and beauty
This is also a builtin function in Hive, we can reduce the migration pain for those users
### Does this PR introduce _any_ user-facing change?
yes new regexp function as an alias as rlike
### How was this patch tested?
new tests
Closes#31488 from yaooqinn/SPARK-34376.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR intends to fix a bug of `objects.NewInstance` if a user runs Spark on jdk8u and a given `cls` in `NewInstance` is a deeply-nested inner class, e.g.,.
```
object OuterLevelWithVeryVeryVeryLongClassName1 {
object OuterLevelWithVeryVeryVeryLongClassName2 {
object OuterLevelWithVeryVeryVeryLongClassName3 {
object OuterLevelWithVeryVeryVeryLongClassName4 {
object OuterLevelWithVeryVeryVeryLongClassName5 {
object OuterLevelWithVeryVeryVeryLongClassName6 {
object OuterLevelWithVeryVeryVeryLongClassName7 {
object OuterLevelWithVeryVeryVeryLongClassName8 {
object OuterLevelWithVeryVeryVeryLongClassName9 {
object OuterLevelWithVeryVeryVeryLongClassName10 {
object OuterLevelWithVeryVeryVeryLongClassName11 {
object OuterLevelWithVeryVeryVeryLongClassName12 {
object OuterLevelWithVeryVeryVeryLongClassName13 {
object OuterLevelWithVeryVeryVeryLongClassName14 {
object OuterLevelWithVeryVeryVeryLongClassName15 {
object OuterLevelWithVeryVeryVeryLongClassName16 {
object OuterLevelWithVeryVeryVeryLongClassName17 {
object OuterLevelWithVeryVeryVeryLongClassName18 {
object OuterLevelWithVeryVeryVeryLongClassName19 {
object OuterLevelWithVeryVeryVeryLongClassName20 {
case class MalformedNameExample2(x: Int)
}}}}}}}}}}}}}}}}}}}}
```
The root cause that Kris (rednaxelafx) investigated is as follows (Kudos to Kris);
The reason why the test case above is so convoluted is in the way Scala generates the class name for nested classes. In general, Scala generates a class name for a nested class by inserting the dollar-sign ( `$` ) in between each level of class nesting. The problem is that this format can concatenate into a very long string that goes beyond certain limits, so Scala will change the class name format beyond certain length threshold.
For the example above, we can see that the first two levels of class nesting have class names that look like this:
```
org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassName1$
org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassName1$OuterLevelWithVeryVeryVeryLongClassName2$
```
If we leave out the fact that Scala uses a dollar-sign ( `$` ) suffix for the class name of the companion object, `OuterLevelWithVeryVeryVeryLongClassName1`'s full name is a prefix (substring) of `OuterLevelWithVeryVeryVeryLongClassName2`.
But if we keep going deeper into the levels of nesting, you'll find names that look like:
```
org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$2a1321b953c615695d7442b2adb1$$$$ryVeryLongClassName8$OuterLevelWithVeryVeryVeryLongClassName9$OuterLevelWithVeryVeryVeryLongClassName10$
org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$2a1321b953c615695d7442b2adb1$$$$ryVeryLongClassName8$OuterLevelWithVeryVeryVeryLongClassName9$OuterLevelWithVeryVeryVeryLongClassName10$OuterLevelWithVeryVeryVeryLongClassName11$
org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$85f068777e7ecf112afcbe997d461b$$$$VeryLongClassName11$OuterLevelWithVeryVeryVeryLongClassName12$
org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$85f068777e7ecf112afcbe997d461b$$$$VeryLongClassName11$OuterLevelWithVeryVeryVeryLongClassName12$OuterLevelWithVeryVeryVeryLongClassName13$
org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$85f068777e7ecf112afcbe997d461b$$$$VeryLongClassName11$OuterLevelWithVeryVeryVeryLongClassName12$OuterLevelWithVeryVeryVeryLongClassName13$OuterLevelWithVeryVeryVeryLongClassName14$
org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$5f7ad51804cb1be53938ea804699fa$$$$VeryLongClassName14$OuterLevelWithVeryVeryVeryLongClassName15$
org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$5f7ad51804cb1be53938ea804699fa$$$$VeryLongClassName14$OuterLevelWithVeryVeryVeryLongClassName15$OuterLevelWithVeryVeryVeryLongClassName16$
org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$5f7ad51804cb1be53938ea804699fa$$$$VeryLongClassName14$OuterLevelWithVeryVeryVeryLongClassName15$OuterLevelWithVeryVeryVeryLongClassName16$OuterLevelWithVeryVeryVeryLongClassName17$
org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$69b54f16b1965a31e88968df1a58d8$$$$VeryLongClassName17$OuterLevelWithVeryVeryVeryLongClassName18$
org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$69b54f16b1965a31e88968df1a58d8$$$$VeryLongClassName17$OuterLevelWithVeryVeryVeryLongClassName18$OuterLevelWithVeryVeryVeryLongClassName19$
org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite$OuterLevelWithVeryVeryVeryLongClassNam$$$$69b54f16b1965a31e88968df1a58d8$$$$VeryLongClassName17$OuterLevelWithVeryVeryVeryLongClassName18$OuterLevelWithVeryVeryVeryLongClassName19$OuterLevelWithVeryVeryVeryLongClassName20$
```
with a hash code in the middle and various levels of nesting omitted.
The `java.lang.Class.isMemberClass` method is implemented in JDK8u as:
http://hg.openjdk.java.net/jdk8u/jdk8u/jdk/file/tip/src/share/classes/java/lang/Class.java#l1425
```
/**
* Returns {code true} if and only if the underlying class
* is a member class.
*
* return {code true} if and only if this class is a member class.
* since 1.5
*/
public boolean isMemberClass() {
return getSimpleBinaryName() != null && !isLocalOrAnonymousClass();
}
/**
* Returns the "simple binary name" of the underlying class, i.e.,
* the binary name without the leading enclosing class name.
* Returns {code null} if the underlying class is a top level
* class.
*/
private String getSimpleBinaryName() {
Class<?> enclosingClass = getEnclosingClass();
if (enclosingClass == null) // top level class
return null;
// Otherwise, strip the enclosing class' name
try {
return getName().substring(enclosingClass.getName().length());
} catch (IndexOutOfBoundsException ex) {
throw new InternalError("Malformed class name", ex);
}
}
```
and the problematic code is `getName().substring(enclosingClass.getName().length())` -- if a class's enclosing class's full name is *longer* than the nested class's full name, this logic would end up going out of bounds.
The bug has been fixed in JDK9 by https://bugs.java.com/bugdatabase/view_bug.do?bug_id=8057919 , but still exists in the latest JDK8u release. So from the Spark side we'd need to do something to avoid hitting this problem.
### Why are the changes needed?
Bugfix on jdk8u.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added tests.
Closes#31733 from maropu/SPARK-34607.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}