## What changes were proposed in this pull request?
This PR proposes to replace `REL_12_BETA1` to `REL_12_BETA2` which is latest.
## How was this patch tested?
Manually checked each link and checked via `git grep -r REL_12_BETA1` as well.
Closes#25105 from HyukjinKwon/SPARK-28342.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
The new adaptive execution framework introduced configuration `spark.sql.runtime.reoptimization.enabled`. We now rename it back to `spark.sql.adaptive.enabled` as the umbrella configuration for adaptive execution.
## How was this patch tested?
Existing tests.
Closes#25102 from carsonwang/renameAE.
Authored-by: Carson Wang <carson.wang@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR adds some tests converted from `pgSQL/aggregates_part1.sql'` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
This PR also contains two minor fixes:
1. Change name of Scala UDF from `UDF:name(...)` to `name(...)` to be consistent with Python'
2. Fix Scala UDF at `IntegratedUDFTestUtils.scala ` to handle `null` in strings.
<details><summary>Diff comparing to 'pgSQL/aggregates_part1.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/pgSQL/aggregates_part1.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-aggregates_part1.sql.out
index 51ca1d55869..124fdd6416e 100644
--- a/sql/core/src/test/resources/sql-tests/results/pgSQL/aggregates_part1.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-aggregates_part1.sql.out
-3,7 +3,7
-- !query 0
-SELECT avg(four) AS avg_1 FROM onek
+SELECT avg(udf(four)) AS avg_1 FROM onek
-- !query 0 schema
struct<avg_1:double>
-- !query 0 output
-11,15 +11,15 struct<avg_1:double>
-- !query 1
-SELECT avg(a) AS avg_32 FROM aggtest WHERE a < 100
+SELECT udf(avg(a)) AS avg_32 FROM aggtest WHERE a < 100
-- !query 1 schema
-struct<avg_32:double>
+struct<avg_32:string>
-- !query 1 output
32.666666666666664
-- !query 2
-select CAST(avg(b) AS Decimal(10,3)) AS avg_107_943 FROM aggtest
+select CAST(avg(udf(b)) AS Decimal(10,3)) AS avg_107_943 FROM aggtest
-- !query 2 schema
struct<avg_107_943:decimal(10,3)>
-- !query 2 output
-27,285 +27,286 struct<avg_107_943:decimal(10,3)>
-- !query 3
-SELECT sum(four) AS sum_1500 FROM onek
+SELECT sum(udf(four)) AS sum_1500 FROM onek
-- !query 3 schema
-struct<sum_1500:bigint>
+struct<sum_1500:double>
-- !query 3 output
-1500
+1500.0
-- !query 4
-SELECT sum(a) AS sum_198 FROM aggtest
+SELECT udf(sum(a)) AS sum_198 FROM aggtest
-- !query 4 schema
-struct<sum_198:bigint>
+struct<sum_198:string>
-- !query 4 output
198
-- !query 5
-SELECT sum(b) AS avg_431_773 FROM aggtest
+SELECT udf(udf(sum(b))) AS avg_431_773 FROM aggtest
-- !query 5 schema
-struct<avg_431_773:double>
+struct<avg_431_773:string>
-- !query 5 output
431.77260909229517
-- !query 6
-SELECT max(four) AS max_3 FROM onek
+SELECT udf(max(four)) AS max_3 FROM onek
-- !query 6 schema
-struct<max_3:int>
+struct<max_3:string>
-- !query 6 output
3
-- !query 7
-SELECT max(a) AS max_100 FROM aggtest
+SELECT max(udf(a)) AS max_100 FROM aggtest
-- !query 7 schema
-struct<max_100:int>
+struct<max_100:string>
-- !query 7 output
-100
+56
-- !query 8
-SELECT max(aggtest.b) AS max_324_78 FROM aggtest
+SELECT CAST(udf(udf(max(aggtest.b))) AS int) AS max_324_78 FROM aggtest
-- !query 8 schema
-struct<max_324_78:float>
+struct<max_324_78:int>
-- !query 8 output
-324.78
+324
-- !query 9
-SELECT stddev_pop(b) FROM aggtest
+SELECT CAST(stddev_pop(udf(b)) AS int) FROM aggtest
-- !query 9 schema
-struct<stddev_pop(CAST(b AS DOUBLE)):double>
+struct<CAST(stddev_pop(CAST(udf(b) AS DOUBLE)) AS INT):int>
-- !query 9 output
-131.10703231895047
+131
-- !query 10
-SELECT stddev_samp(b) FROM aggtest
+SELECT udf(stddev_samp(b)) FROM aggtest
-- !query 10 schema
-struct<stddev_samp(CAST(b AS DOUBLE)):double>
+struct<udf(stddev_samp(cast(b as double))):string>
-- !query 10 output
151.38936080399804
-- !query 11
-SELECT var_pop(b) FROM aggtest
+SELECT CAST(var_pop(udf(b)) as int) FROM aggtest
-- !query 11 schema
-struct<var_pop(CAST(b AS DOUBLE)):double>
+struct<CAST(var_pop(CAST(udf(b) AS DOUBLE)) AS INT):int>
-- !query 11 output
-17189.053923482323
+17189
-- !query 12
-SELECT var_samp(b) FROM aggtest
+SELECT udf(var_samp(b)) FROM aggtest
-- !query 12 schema
-struct<var_samp(CAST(b AS DOUBLE)):double>
+struct<udf(var_samp(cast(b as double))):string>
-- !query 12 output
22918.738564643096
-- !query 13
-SELECT stddev_pop(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT udf(stddev_pop(CAST(b AS Decimal(38,0)))) FROM aggtest
-- !query 13 schema
-struct<stddev_pop(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<udf(stddev_pop(cast(cast(b as decimal(38,0)) as double))):string>
-- !query 13 output
131.18117242958306
-- !query 14
-SELECT stddev_samp(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT stddev_samp(CAST(udf(b) AS Decimal(38,0))) FROM aggtest
-- !query 14 schema
-struct<stddev_samp(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<stddev_samp(CAST(CAST(udf(b) AS DECIMAL(38,0)) AS DOUBLE)):double>
-- !query 14 output
151.47497042966097
-- !query 15
-SELECT var_pop(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT udf(var_pop(CAST(b AS Decimal(38,0)))) FROM aggtest
-- !query 15 schema
-struct<var_pop(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<udf(var_pop(cast(cast(b as decimal(38,0)) as double))):string>
-- !query 15 output
17208.5
-- !query 16
-SELECT var_samp(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT var_samp(udf(CAST(b AS Decimal(38,0)))) FROM aggtest
-- !query 16 schema
-struct<var_samp(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<var_samp(CAST(udf(cast(b as decimal(38,0))) AS DOUBLE)):double>
-- !query 16 output
22944.666666666668
-- !query 17
-SELECT var_pop(1.0), var_samp(2.0)
+SELECT udf(var_pop(1.0)), var_samp(udf(2.0))
-- !query 17 schema
-struct<var_pop(CAST(1.0 AS DOUBLE)):double,var_samp(CAST(2.0 AS DOUBLE)):double>
+struct<udf(var_pop(cast(1.0 as double))):string,var_samp(CAST(udf(2.0) AS DOUBLE)):double>
-- !query 17 output
0.0 NaN
-- !query 18
-SELECT stddev_pop(CAST(3.0 AS Decimal(38,0))), stddev_samp(CAST(4.0 AS Decimal(38,0)))
+SELECT stddev_pop(udf(CAST(3.0 AS Decimal(38,0)))), stddev_samp(CAST(udf(4.0) AS Decimal(38,0)))
-- !query 18 schema
-struct<stddev_pop(CAST(CAST(3.0 AS DECIMAL(38,0)) AS DOUBLE)):double,stddev_samp(CAST(CAST(4.0 AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<stddev_pop(CAST(udf(cast(3.0 as decimal(38,0))) AS DOUBLE)):double,stddev_samp(CAST(CAST(udf(4.0) AS DECIMAL(38,0)) AS DOUBLE)):double>
-- !query 18 output
0.0 NaN
-- !query 19
-select sum(CAST(null AS int)) from range(1,4)
+select sum(udf(CAST(null AS int))) from range(1,4)
-- !query 19 schema
-struct<sum(CAST(NULL AS INT)):bigint>
+struct<sum(CAST(udf(cast(null as int)) AS DOUBLE)):double>
-- !query 19 output
NULL
-- !query 20
-select sum(CAST(null AS long)) from range(1,4)
+select sum(udf(CAST(null AS long))) from range(1,4)
-- !query 20 schema
-struct<sum(CAST(NULL AS BIGINT)):bigint>
+struct<sum(CAST(udf(cast(null as bigint)) AS DOUBLE)):double>
-- !query 20 output
NULL
-- !query 21
-select sum(CAST(null AS Decimal(38,0))) from range(1,4)
+select sum(udf(CAST(null AS Decimal(38,0)))) from range(1,4)
-- !query 21 schema
-struct<sum(CAST(NULL AS DECIMAL(38,0))):decimal(38,0)>
+struct<sum(CAST(udf(cast(null as decimal(38,0))) AS DOUBLE)):double>
-- !query 21 output
NULL
-- !query 22
-select sum(CAST(null AS DOUBLE)) from range(1,4)
+select sum(udf(CAST(null AS DOUBLE))) from range(1,4)
-- !query 22 schema
-struct<sum(CAST(NULL AS DOUBLE)):double>
+struct<sum(CAST(udf(cast(null as double)) AS DOUBLE)):double>
-- !query 22 output
NULL
-- !query 23
-select avg(CAST(null AS int)) from range(1,4)
+select avg(udf(CAST(null AS int))) from range(1,4)
-- !query 23 schema
-struct<avg(CAST(NULL AS INT)):double>
+struct<avg(CAST(udf(cast(null as int)) AS DOUBLE)):double>
-- !query 23 output
NULL
-- !query 24
-select avg(CAST(null AS long)) from range(1,4)
+select avg(udf(CAST(null AS long))) from range(1,4)
-- !query 24 schema
-struct<avg(CAST(NULL AS BIGINT)):double>
+struct<avg(CAST(udf(cast(null as bigint)) AS DOUBLE)):double>
-- !query 24 output
NULL
-- !query 25
-select avg(CAST(null AS Decimal(38,0))) from range(1,4)
+select avg(udf(CAST(null AS Decimal(38,0)))) from range(1,4)
-- !query 25 schema
-struct<avg(CAST(NULL AS DECIMAL(38,0))):decimal(38,4)>
+struct<avg(CAST(udf(cast(null as decimal(38,0))) AS DOUBLE)):double>
-- !query 25 output
NULL
-- !query 26
-select avg(CAST(null AS DOUBLE)) from range(1,4)
+select avg(udf(CAST(null AS DOUBLE))) from range(1,4)
-- !query 26 schema
-struct<avg(CAST(NULL AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(null as double)) AS DOUBLE)):double>
-- !query 26 output
NULL
-- !query 27
-select sum(CAST('NaN' AS DOUBLE)) from range(1,4)
+select sum(CAST(udf('NaN') AS DOUBLE)) from range(1,4)
-- !query 27 schema
-struct<sum(CAST(NaN AS DOUBLE)):double>
+struct<sum(CAST(udf(NaN) AS DOUBLE)):double>
-- !query 27 output
NaN
-- !query 28
-select avg(CAST('NaN' AS DOUBLE)) from range(1,4)
+select avg(CAST(udf('NaN') AS DOUBLE)) from range(1,4)
-- !query 28 schema
-struct<avg(CAST(NaN AS DOUBLE)):double>
+struct<avg(CAST(udf(NaN) AS DOUBLE)):double>
-- !query 28 output
NaN
-- !query 29
SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
-FROM (VALUES (CAST('1' AS DOUBLE)), (CAST('Infinity' AS DOUBLE))) v(x)
+FROM (VALUES (CAST(udf('1') AS DOUBLE)), (CAST(udf('Infinity') AS DOUBLE))) v(x)
-- !query 29 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<>
-- !query 29 output
-Infinity NaN
+org.apache.spark.sql.AnalysisException
+cannot evaluate expression CAST(udf(1) AS DOUBLE) in inline table definition; line 2 pos 14
-- !query 30
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('Infinity'), ('1')) v(x)
-- !query 30 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 30 output
Infinity NaN
-- !query 31
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('Infinity'), ('Infinity')) v(x)
-- !query 31 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 31 output
Infinity NaN
-- !query 32
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('-Infinity'), ('Infinity')) v(x)
-- !query 32 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 32 output
NaN NaN
-- !query 33
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(udf(CAST(x AS DOUBLE))), udf(var_pop(CAST(x AS DOUBLE)))
FROM (VALUES (100000003), (100000004), (100000006), (100000007)) v(x)
-- !query 33 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(x as double)) AS DOUBLE)):double,udf(var_pop(cast(x as double))):string>
-- !query 33 output
1.00000005E8 2.5
-- !query 34
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(udf(CAST(x AS DOUBLE))), udf(var_pop(CAST(x AS DOUBLE)))
FROM (VALUES (7000000000005), (7000000000007)) v(x)
-- !query 34 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(x as double)) AS DOUBLE)):double,udf(var_pop(cast(x as double))):string>
-- !query 34 output
7.000000000006E12 1.0
-- !query 35
-SELECT covar_pop(b, a), covar_samp(b, a) FROM aggtest
+SELECT CAST(udf(covar_pop(b, udf(a))) AS int), CAST(covar_samp(udf(b), a) as int) FROM aggtest
-- !query 35 schema
-struct<covar_pop(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double,covar_samp(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double>
+struct<CAST(udf(covar_pop(cast(b as double), cast(udf(a) as double))) AS INT):int,CAST(covar_samp(CAST(udf(b) AS DOUBLE), CAST(a AS DOUBLE)) AS INT):int>
-- !query 35 output
-653.6289553875104 871.5052738500139
+653 871
-- !query 36
-SELECT corr(b, a) FROM aggtest
+SELECT corr(b, udf(a)) FROM aggtest
-- !query 36 schema
-struct<corr(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double>
+struct<corr(CAST(b AS DOUBLE), CAST(udf(a) AS DOUBLE)):double>
-- !query 36 output
0.1396345165178734
-- !query 37
-SELECT count(four) AS cnt_1000 FROM onek
+SELECT count(udf(four)) AS cnt_1000 FROM onek
-- !query 37 schema
struct<cnt_1000:bigint>
-- !query 37 output
-313,36 +314,36 struct<cnt_1000:bigint>
-- !query 38
-SELECT count(DISTINCT four) AS cnt_4 FROM onek
+SELECT udf(count(DISTINCT four)) AS cnt_4 FROM onek
-- !query 38 schema
-struct<cnt_4:bigint>
+struct<cnt_4:string>
-- !query 38 output
4
-- !query 39
-select ten, count(*), sum(four) from onek
+select ten, udf(count(*)), sum(udf(four)) from onek
group by ten order by ten
-- !query 39 schema
-struct<ten:int,count(1):bigint,sum(four):bigint>
+struct<ten:int,udf(count(1)):string,sum(CAST(udf(four) AS DOUBLE)):double>
-- !query 39 output
-0 100 100
-1 100 200
-2 100 100
-3 100 200
-4 100 100
-5 100 200
-6 100 100
-7 100 200
-8 100 100
-9 100 200
+0 100 100.0
+1 100 200.0
+2 100 100.0
+3 100 200.0
+4 100 100.0
+5 100 200.0
+6 100 100.0
+7 100 200.0
+8 100 100.0
+9 100 200.0
-- !query 40
-select ten, count(four), sum(DISTINCT four) from onek
+select ten, count(udf(four)), udf(sum(DISTINCT four)) from onek
group by ten order by ten
-- !query 40 schema
-struct<ten:int,count(four):bigint,sum(DISTINCT four):bigint>
+struct<ten:int,count(udf(four)):bigint,udf(sum(distinct cast(four as bigint))):string>
-- !query 40 output
0 100 2
1 100 4
-357,11 +358,11 struct<ten:int,count(four):bigint,sum(DISTINCT four):bigint>
-- !query 41
-select ten, sum(distinct four) from onek a
+select ten, udf(sum(distinct four)) from onek a
group by ten
-having exists (select 1 from onek b where sum(distinct a.four) = b.four)
+having exists (select 1 from onek b where udf(sum(distinct a.four)) = b.four)
-- !query 41 schema
-struct<ten:int,sum(DISTINCT four):bigint>
+struct<ten:int,udf(sum(distinct cast(four as bigint))):string>
-- !query 41 output
0 2
2 2
-374,23 +375,23 struct<ten:int,sum(DISTINCT four):bigint>
select ten, sum(distinct four) from onek a
group by ten
having exists (select 1 from onek b
- where sum(distinct a.four + b.four) = b.four)
+ where sum(distinct a.four + b.four) = udf(b.four))
-- !query 42 schema
struct<>
-- !query 42 output
org.apache.spark.sql.AnalysisException
Aggregate/Window/Generate expressions are not valid in where clause of the query.
-Expression in where clause: [(sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT)) = CAST(b.`four` AS BIGINT))]
+Expression in where clause: [(sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT)) = CAST(udf(four) AS BIGINT))]
Invalid expressions: [sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT))];
-- !query 43
select
- (select max((select i.unique2 from tenk1 i where i.unique1 = o.unique1)))
+ (select udf(max((select i.unique2 from tenk1 i where i.unique1 = o.unique1))))
from tenk1 o
-- !query 43 schema
struct<>
-- !query 43 output
org.apache.spark.sql.AnalysisException
-cannot resolve '`o.unique1`' given input columns: [i.even, i.fivethous, i.four, i.hundred, i.odd, i.string4, i.stringu1, i.stringu2, i.ten, i.tenthous, i.thousand, i.twenty, i.two, i.twothousand, i.unique1, i.unique2]; line 2 pos 63
+cannot resolve '`o.unique1`' given input columns: [i.even, i.fivethous, i.four, i.hundred, i.odd, i.string4, i.stringu1, i.stringu2, i.ten, i.tenthous, i.thousand, i.twenty, i.two, i.twothousand, i.unique1, i.unique2]; line 2 pos 67
```
</p>
</details>
Note that, currently, `IntegratedUDFTestUtils.scala`'s UDFs only return strings. There are some differences between those UDFs (Scala, Pandas and Python):
- Python's string representation of floats can make the tests flaky. (See https://docs.python.org/3/tutorial/floatingpoint.html). To work around this, I had to `CAST(... as int)`.
- There are string representation differences between `Inf` `-Inf` <> `Infinity` `-Infinity` and `nan` <> `NaN`
- Maybe we should add other type versions of UDFs if this makes adding tests difficult.
Note that one issue found - [SPARK-28291](https://issues.apache.org/jira/browse/SPARK-28291). The test was commented for now.
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25069 from HyukjinKwon/SPARK-28270.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Fix `stringToDate()` for the formats `yyyy` and `yyyy-[m]m` that assumes there are no additional chars after the last components `yyyy` and `[m]m`. In the PR, I propose to check that entire input was consumed for the formats.
After the fix, the input `1999 08 01` will be invalid because it matches to the pattern `yyyy` but the strings contains additional chars ` 08 01`.
Since Spark 1.6.3 ~ 2.4.3, the behavior is the same.
```
spark-sql> SELECT CAST('1999 08 01' AS DATE);
1999-01-01
```
This PR makes it return NULL like Hive.
```
spark-sql> SELECT CAST('1999 08 01' AS DATE);
NULL
```
## How was this patch tested?
Added new checks to `DateTimeUtilsSuite` for the `1999 08 01` and `1999 08` inputs.
Closes#25097 from MaxGekk/spark-28015-invalid-date-format.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This fixes a problem where it is possible to create a v2 table using the default catalog that cannot be loaded with the session catalog. A session catalog should be used when the v1 catalog is responsible for tables with no catalog in the table identifier.
* Adds a v2 catalog implementation that delegates to the analyzer's SessionCatalog
* Uses the v2 session catalog for CTAS and CreateTable when the provider is a v2 provider and no v2 catalog is in the table identifier
* Updates catalog lookup to always provide the default if it is set for consistent behavior
## How was this patch tested?
* Adds a new test suite for the v2 session catalog that validates the TableCatalog API
* Adds test cases in PlanResolutionSuite to validate the v2 session catalog is used
* Adds test suite for LookupCatalog with a default catalog
Closes#24768 from rdblue/SPARK-27919-add-v2-session-catalog.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The interval conversion behavior is same with the PostgreSQL.
https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/interval.sql#L180-L203
## How was this patch tested?
UT.
Closes#25000 from lipzhu/SPARK-28107.
Lead-authored-by: Zhu, Lipeng <lipzhu@ebay.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Lipeng Zhu <lipzhu@icloud.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds some tests converted from having.sql to test UDFs following the combination guide in [SPARK-27921](url)
<details><summary>Diff comparing to 'having.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/having.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-having.sql.out
index d87ee52216..7cea2e5128 100644
--- a/sql/core/src/test/resources/sql-tests/results/having.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-having.sql.out
-16,34 +16,34 struct<>
-- !query 1
-SELECT k, sum(v) FROM hav GROUP BY k HAVING sum(v) > 2
+SELECT udf(k) AS k, udf(sum(v)) FROM hav GROUP BY k HAVING udf(sum(v)) > 2
-- !query 1 schema
-struct<k:string,sum(v):bigint>
+struct<k:string,udf(sum(cast(v as bigint))):string>
-- !query 1 output
one 6
three 3
-- !query 2
-SELECT count(k) FROM hav GROUP BY v + 1 HAVING v + 1 = 2
+SELECT udf(count(udf(k))) FROM hav GROUP BY v + 1 HAVING v + 1 = udf(2)
-- !query 2 schema
-struct<count(k):bigint>
+struct<udf(count(udf(k))):string>
-- !query 2 output
1
-- !query 3
-SELECT MIN(t.v) FROM (SELECT * FROM hav WHERE v > 0) t HAVING(COUNT(1) > 0)
+SELECT udf(MIN(t.v)) FROM (SELECT * FROM hav WHERE v > 0) t HAVING(udf(COUNT(udf(1))) > 0)
-- !query 3 schema
-struct<min(v):int>
+struct<udf(min(v)):string>
-- !query 3 output
1
-- !query 4
-SELECT a + b FROM VALUES (1L, 2), (3L, 4) AS T(a, b) GROUP BY a + b HAVING a + b > 1
+SELECT udf(a + b) FROM VALUES (1L, 2), (3L, 4) AS T(a, b) GROUP BY a + b HAVING a + b > udf(1)
-- !query 4 schema
-struct<(a + CAST(b AS BIGINT)):bigint>
+struct<udf((a + cast(b as bigint))):string>
-- !query 4 output
3
7
```
</p>
</details>
## How was this patch tested?
Tested as guided in SPARK-27921.
Closes#25093 from huaxingao/spark-28281.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from `natural-join.sql` to test UDFs following the combination guide in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
<details><summary>Diff results comparing to `natural-join.sql`</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.
sql.out
index 43f2f9a..53ef177 100644
--- a/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out
-27,7 +27,7 struct<>
-- !query 2
-SELECT * FROM nt1 natural join nt2 where k = "one"
+SELECT * FROM nt1 natural join nt2 where udf(k) = "one"
-- !query 2 schema
struct<k:string,v1:int,v2:int>
-- !query 2 output
-36,7 +36,7 one 1 5
-- !query 3
-SELECT * FROM nt1 natural left join nt2 order by v1, v2
+SELECT * FROM nt1 natural left join nt2 where k <> udf("") order by v1, v2
-- !query 3 schema
diff --git a/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.
sql.out
index 43f2f9a..53ef177 100644
--- a/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out
-27,7 +27,7 struct<>
-- !query 2
-SELECT * FROM nt1 natural join nt2 where k = "one"
+SELECT * FROM nt1 natural join nt2 where udf(k) = "one"
-- !query 2 schema
struct<k:string,v1:int,v2:int>
-- !query 2 output
-36,7 +36,7 one 1 5
-- !query 3
-SELECT * FROM nt1 natural left join nt2 order by v1, v2
+SELECT * FROM nt1 natural left join nt2 where k <> udf("") order by v1, v2
-- !query 3 schema
struct<k:string,v1:int,v2:int>
```
</p>
</details>
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25088 from manuzhang/SPARK-27922.
Authored-by: manu.zhang <manu.zhang@vipshop.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Add python api support and JavaSparkContext support for resources(). I needed the JavaSparkContext support for it to properly translate into python with the py4j stuff.
## How was this patch tested?
Unit tests added and manually tested in local cluster mode and on yarn.
Closes#25087 from tgravescs/SPARK-28234-python.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
There is a bug in `ExtractPythonUDFs` that produces wrong result attributes. It causes a failure when using `PythonUDF`s among multiple child plans, e.g., join. An example is using `PythonUDF`s in join condition.
```python
>>> left = spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2, a1=2, a2=2)])
>>> right = spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=1, b1=3, b2=1)])
>>> f = udf(lambda a: a, IntegerType())
>>> df = left.join(right, [f("a") == f("b"), left.a1 == right.b1])
>>> df.collect()
19/07/10 12:20:49 ERROR Executor: Exception in task 5.0 in stage 0.0 (TID 5)
java.lang.ArrayIndexOutOfBoundsException: 1
at org.apache.spark.sql.catalyst.expressions.GenericInternalRow.genericGet(rows.scala:201)
at org.apache.spark.sql.catalyst.expressions.BaseGenericInternalRow.getAs(rows.scala:35)
at org.apache.spark.sql.catalyst.expressions.BaseGenericInternalRow.isNullAt(rows.scala:36)
at org.apache.spark.sql.catalyst.expressions.BaseGenericInternalRow.isNullAt$(rows.scala:36)
at org.apache.spark.sql.catalyst.expressions.GenericInternalRow.isNullAt(rows.scala:195)
at org.apache.spark.sql.catalyst.expressions.JoinedRow.isNullAt(JoinedRow.scala:70)
...
```
## How was this patch tested?
Added test.
Closes#25091 from viirya/SPARK-28323.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
## What changes were proposed in this pull request?
`DirectKafkaStreamSuite.offset recovery from kafka` commits offsets to Kafka with `Consumer.commitAsync` API (and then reads it back). Since this API is asynchronous it may send notifications late(or not at all). The actual test makes the assumption if the data sent and collected then the offset must be committed as well. This is not true.
In this PR I've made the following modifications:
* Wait for async offset commit before context stopped
* Added commit succeed log to see whether it arrived at all
* Using `ConcurrentHashMap` for committed offsets because 2 threads are using the variable (`JobGenerator` and `ScalaTest...`)
## How was this patch tested?
Existing unit test in a loop + jenkins runs.
Closes#25100 from gaborgsomogyi/SPARK-28335.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
`SslContextFactory` is deprecated at Jetty 9.4 and we are using `9.4.18.v20190429`. This PR aims to replace it with `SslContextFactory.Server`.
- https://www.eclipse.org/jetty/javadoc/9.4.19.v20190610/org/eclipse/jetty/util/ssl/SslContextFactory.html
- https://www.eclipse.org/jetty/javadoc/9.3.24.v20180605/org/eclipse/jetty/util/ssl/SslContextFactory.html
```
[WARNING] /Users/dhyun/APACHE/spark/core/src/main/scala/org/apache/spark/SSLOptions.scala:71:
constructor SslContextFactory in class SslContextFactory is deprecated:
see corresponding Javadoc for more information.
[WARNING] val sslContextFactory = new SslContextFactory()
[WARNING] ^
```
## How was this patch tested?
Pass the Jenkins with the existing tests.
Closes#25067 from dongjoon-hyun/SPARK-28290.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Up to now, Apache Spark maintains the given event log directory by **time** policy, `spark.history.fs.cleaner.maxAge`. However, there are two issues.
1. Some file system has a limitation on the maximum number of files in a single directory. For example, HDFS `dfs.namenode.fs-limits.max-directory-items` is 1024 * 1024 by default.
https://hadoop.apache.org/docs/r3.2.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
2. Spark is sometimes unable to to clean up some old log files due to permission issues (mainly, security policy).
To handle both (1) and (2), this PR aims to support an additional policy configuration for the maximum number of files in the event log directory, `spark.history.fs.cleaner.maxNum`. Spark will try to keep the number of files in the event log directory according to this policy.
## How was this patch tested?
Pass the Jenkins with a newly added test case.
Closes#25072 from dongjoon-hyun/SPARK-28294.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
In both cases, the input `DataFrame` schema must contain only the information that's required for the matrix object, so a vector column in the case of `RowMatrix` and long and vector columns for `IndexedRowMatrix`.
## How was this patch tested?
Unit tests that verify:
- `RowMatrix` and `IndexedRowMatrix` can be created from `DataFrame`s
- If the schema does not match expectations, we throw an `IllegalArgumentException`
Please review https://spark.apache.org/contributing.html before opening a pull request.
Closes#24953 from henrydavidge/row-matrix-df.
Authored-by: Henry D <henrydavidge@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
When using SparkLauncher to submit applications **concurrently** with multiple threads under **Windows**, some apps would show that "The process cannot access the file because it is being used by another process" and remains in LOST state at the end. The issue can be reproduced by this [demo](https://issues.apache.org/jira/secure/attachment/12973920/Main.scala).
After digging into the code, I find that, Windows cmd `%RANDOM%` would return the same number if we call it instantly(e.g. < 500ms) after last call. As a result, SparkLauncher would get same output file(spark-class-launcher-output-%RANDOM%.txt) for apps. Then, the following app would hit the issue when it tries to write the same file which has already been opened for writing by another app.
We should make sure to generate unique output file for SparkLauncher on Windows to avoid this issue.
## How was this patch tested?
Tested manually on Windows.
Closes#25076 from Ngone51/SPARK-28302.
Authored-by: wuyi <ngone_5451@163.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Looks `devtools` 2.1.0 is released and then our AppVeyor users the latest one.
The problem is, they added `testthat` 2.1.1+ as its dependency - https://github.com/r-lib/devtools/blob/master/DESCRIPTION#L35
Usually it should remove and reinstall it properly when we install other packages; however, seems it's being failed in AppVeyor due to the previous installation for an unknown reason.
```
[00:01:41] > devtools::install_version('testthat', version = '1.0.2', repos='https://cloud.r-project.org/')
[00:01:44] Downloading package from url: https://cloud.r-project.org//src/contrib/Archive/testthat/testthat_1.0.2.tar.gz
...
[00:02:25] WARNING: moving package to final location failed, copying instead
[00:02:25] Warning in file.copy(instdir, dirname(final_instdir), recursive = TRUE, :
[00:02:25] problem copying c:\RLibrary\00LOCK-testthat\00new\testthat\libs\i386\testthat.dll to c:\RLibrary\testthat\libs\i386\testthat.dll: Permission denied
[00:02:25] ** testing if installed package can be loaded from final location
[00:02:25] *** arch - i386
[00:02:26] Error: package or namespace load failed for 'testthat' in FUN(X[[i]], ...):
[00:02:26] no such symbol find_label_ in package c:/RLibrary/testthat/libs/i386/testthat.dll
[00:02:26] Error: loading failed
[00:02:26] Execution halted
[00:02:26] *** arch - x64
[00:02:26] ERROR: loading failed for 'i386'
[00:02:26] * removing 'c:/RLibrary/testthat'
[00:02:26] * restoring previous 'c:/RLibrary/testthat'
[00:02:26] Warning in file.copy(lp, dirname(pkgdir), recursive = TRUE, copy.date = TRUE) :
[00:02:26] problem copying c:\RLibrary\00LOCK-testthat\testthat\libs\i386\testthat.dll to c:\RLibrary\testthat\libs\i386\testthat.dll: Permission denied
[00:02:26] Warning message:
[00:02:26] In i.p(...) :
[00:02:26] installation of package 'C:/Users/appveyor/AppData/Local/Temp/1/RtmpIx25hi/remotes5743d4a9b1/testthat' had non-zero exit status
```
See https://ci.appveyor.com/project/ApacheSoftwareFoundation/spark/builds/25818746
Our SparkR testbed requires `testthat` 1.0.2 at most for the current status and `devtools` was installed at SPARK-22817 to pin the `testthat` version to 1.0.2
Therefore, this PR works around the current issue by directly installing from the archive instead, and don't use `devtools`.
```R
R -e "install.packages('https://cloud.r-project.org/src/contrib/Archive/testthat/testthat_1.0.2.tar.gz', repos=NULL, type='source')"
```
## How was this patch tested?
AppVeyor will test.
Closes#25081 from HyukjinKwon/SPARK-28309.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This is a followup of the discussion in https://github.com/apache/spark/pull/24675#discussion_r286786053
`QueryPlan#references` is an important property. The `ColumnPrunning` rule relies on it.
Some query plan nodes have `Seq[Attribute]` parameter, which is used as its output attributes. For example, leaf nodes, `Generate`, `MapPartitionsInPandas`, etc. These nodes override `producedAttributes` to make `missingInputs` correct.
However, these nodes also need to override `references` to make column pruning work. This PR proposes to exclude `producedAttributes` from the default implementation of `QueryPlan#references`, so that we don't need to override `references` in all these nodes.
Note that, technically we can remove `producedAttributes` and always ask query plan nodes to override `references`. But I do find the code can be simpler with `producedAttributes` in some places, where there is a base class for some specific query plan nodes.
## How was this patch tested?
existing tests
Closes#25052 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR reverts the partial bug fix in `ShuffleBlockFetcherIterator` which was introduced by https://github.com/apache/spark/pull/23638 .
The reasons:
1. It's a potential bug. After fixing `PipelinedRDD` in #23638 , the original problem was resolved.
2. The fix is incomplete according to [the discussion](https://github.com/apache/spark/pull/23638#discussion_r251869084)
We should fix the potential bug completely later.
## How was this patch tested?
existing tests
Closes#25049 from cloud-fan/revert.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from `pgSQL/case.sql'` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
This PR also contains two minor fixes:
1. Change name of Scala UDF from `UDF:name(...)` to `name(...)` to be consistent with Python'
2. Fix Scala UDF at `IntegratedUDFTestUtils.scala ` to handle `null` in strings.
<details><summary>Diff comparing to 'pgSQL/case.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/pgSQL/case.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-case.sql.out
index fa078d16d6d..55bef64338f 100644
--- a/sql/core/src/test/resources/sql-tests/results/pgSQL/case.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-case.sql.out
-115,7 +115,7 struct<>
-- !query 13
SELECT '3' AS `One`,
CASE
- WHEN 1 < 2 THEN 3
+ WHEN CAST(udf(1 < 2) AS boolean) THEN 3
END AS `Simple WHEN`
-- !query 13 schema
struct<One:string,Simple WHEN:int>
-126,10 +126,10 struct<One:string,Simple WHEN:int>
-- !query 14
SELECT '<NULL>' AS `One`,
CASE
- WHEN 1 > 2 THEN 3
+ WHEN 1 > 2 THEN udf(3)
END AS `Simple default`
-- !query 14 schema
-struct<One:string,Simple default:int>
+struct<One:string,Simple default:string>
-- !query 14 output
<NULL> NULL
-137,17 +137,17 struct<One:string,Simple default:int>
-- !query 15
SELECT '3' AS `One`,
CASE
- WHEN 1 < 2 THEN 3
- ELSE 4
+ WHEN udf(1) < 2 THEN udf(3)
+ ELSE udf(4)
END AS `Simple ELSE`
-- !query 15 schema
-struct<One:string,Simple ELSE:int>
+struct<One:string,Simple ELSE:string>
-- !query 15 output
3 3
-- !query 16
-SELECT '4' AS `One`,
+SELECT udf('4') AS `One`,
CASE
WHEN 1 > 2 THEN 3
ELSE 4
-159,10 +159,10 struct<One:string,ELSE default:int>
-- !query 17
-SELECT '6' AS `One`,
+SELECT udf('6') AS `One`,
CASE
- WHEN 1 > 2 THEN 3
- WHEN 4 < 5 THEN 6
+ WHEN CAST(udf(1 > 2) AS boolean) THEN 3
+ WHEN udf(4) < 5 THEN 6
ELSE 7
END AS `Two WHEN with default`
-- !query 17 schema
-173,7 +173,7 struct<One:string,Two WHEN with default:int>
-- !query 18
SELECT '7' AS `None`,
- CASE WHEN rand() < 0 THEN 1
+ CASE WHEN rand() < udf(0) THEN 1
END AS `NULL on no matches`
-- !query 18 schema
struct<None:string,NULL on no matches:int>
-182,36 +182,36 struct<None:string,NULL on no matches:int>
-- !query 19
-SELECT CASE WHEN 1=0 THEN 1/0 WHEN 1=1 THEN 1 ELSE 2/0 END
+SELECT CASE WHEN CAST(udf(1=0) AS boolean) THEN 1/0 WHEN 1=1 THEN 1 ELSE 2/0 END
-- !query 19 schema
-struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
+struct<CASE WHEN CAST(udf((1 = 0)) AS BOOLEAN) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
-- !query 19 output
1.0
-- !query 20
-SELECT CASE 1 WHEN 0 THEN 1/0 WHEN 1 THEN 1 ELSE 2/0 END
+SELECT CASE 1 WHEN 0 THEN 1/udf(0) WHEN 1 THEN 1 ELSE 2/0 END
-- !query 20 schema
-struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
+struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(CAST(udf(0) AS DOUBLE) AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
-- !query 20 output
1.0
-- !query 21
-SELECT CASE WHEN i > 100 THEN 1/0 ELSE 0 END FROM case_tbl
+SELECT CASE WHEN i > 100 THEN udf(1/0) ELSE udf(0) END FROM case_tbl
-- !query 21 schema
-struct<CASE WHEN (i > 100) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) ELSE CAST(0 AS DOUBLE) END:double>
+struct<CASE WHEN (i > 100) THEN udf((cast(1 as double) / cast(0 as double))) ELSE udf(0) END:string>
-- !query 21 output
-0.0
-0.0
-0.0
-0.0
+0
+0
+0
+0
-- !query 22
-SELECT CASE 'a' WHEN 'a' THEN 1 ELSE 2 END
+SELECT CASE 'a' WHEN 'a' THEN udf(1) ELSE udf(2) END
-- !query 22 schema
-struct<CASE WHEN (a = a) THEN 1 ELSE 2 END:int>
+struct<CASE WHEN (a = a) THEN udf(1) ELSE udf(2) END:string>
-- !query 22 output
1
-283,7 +283,7 big
-- !query 27
-SELECT * FROM CASE_TBL WHERE COALESCE(f,i) = 4
+SELECT * FROM CASE_TBL WHERE udf(COALESCE(f,i)) = 4
-- !query 27 schema
struct<i:int,f:double>
-- !query 27 output
-291,7 +291,7 struct<i:int,f:double>
-- !query 28
-SELECT * FROM CASE_TBL WHERE NULLIF(f,i) = 2
+SELECT * FROM CASE_TBL WHERE udf(NULLIF(f,i)) = 2
-- !query 28 schema
struct<i:int,f:double>
-- !query 28 output
-299,10 +299,10 struct<i:int,f:double>
-- !query 29
-SELECT COALESCE(a.f, b.i, b.j)
+SELECT udf(COALESCE(a.f, b.i, b.j))
FROM CASE_TBL a, CASE2_TBL b
-- !query 29 schema
-struct<coalesce(f, CAST(i AS DOUBLE), CAST(j AS DOUBLE)):double>
+struct<udf(coalesce(f, cast(i as double), cast(j as double))):string>
-- !query 29 output
-30.3
-30.3
-332,8 +332,8 struct<coalesce(f, CAST(i AS DOUBLE), CAST(j AS DOUBLE)):double>
-- !query 30
SELECT *
- FROM CASE_TBL a, CASE2_TBL b
- WHERE COALESCE(a.f, b.i, b.j) = 2
+ FROM CASE_TBL a, CASE2_TBL b
+ WHERE udf(COALESCE(a.f, b.i, b.j)) = 2
-- !query 30 schema
struct<i:int,f:double,i:int,j:int>
-- !query 30 output
-342,7 +342,7 struct<i:int,f:double,i:int,j:int>
-- !query 31
-SELECT '' AS Five, NULLIF(a.i,b.i) AS `NULLIF(a.i,b.i)`,
+SELECT udf('') AS Five, NULLIF(a.i,b.i) AS `NULLIF(a.i,b.i)`,
NULLIF(b.i, 4) AS `NULLIF(b.i,4)`
FROM CASE_TBL a, CASE2_TBL b
-- !query 31 schema
-377,7 +377,7 struct<Five:string,NULLIF(a.i,b.i):int,NULLIF(b.i,4):int>
-- !query 32
SELECT '' AS `Two`, *
FROM CASE_TBL a, CASE2_TBL b
- WHERE COALESCE(f,b.i) = 2
+ WHERE CAST(udf(COALESCE(f,b.i) = 2) AS boolean)
-- !query 32 schema
struct<Two:string,i:int,f:double,i:int,j:int>
-- !query 32 output
-388,15 +388,15 struct<Two:string,i:int,f:double,i:int,j:int>
-- !query 33
SELECT CASE
(CASE vol('bar')
- WHEN 'foo' THEN 'it was foo!'
- WHEN vol(null) THEN 'null input'
+ WHEN udf('foo') THEN 'it was foo!'
+ WHEN udf(vol(null)) THEN 'null input'
WHEN 'bar' THEN 'it was bar!' END
)
- WHEN 'it was foo!' THEN 'foo recognized'
- WHEN 'it was bar!' THEN 'bar recognized'
- ELSE 'unrecognized' END
+ WHEN udf('it was foo!') THEN 'foo recognized'
+ WHEN 'it was bar!' THEN udf('bar recognized')
+ ELSE 'unrecognized' END AS col
-- !query 33 schema
-struct<CASE WHEN (CASE WHEN (UDF:vol(bar) = foo) THEN it was foo! WHEN (UDF:vol(bar) = UDF:vol(null)) THEN null input WHEN (UDF:vol(bar) = bar) THEN it was bar! END = it was foo!) THEN foo recognized WHEN (CASE WHEN (UDF:vol(bar) = foo) THEN it was foo! WHEN (UDF:vol(bar) = UDF:vol(null)) THEN null input WHEN (UDF:vol(bar) = bar) THEN it was bar! END = it was bar!) THEN bar recognized ELSE unrecognized END:string>
+struct<col:string>
-- !query 33 output
bar recognized
```
</p>
</details>
https://github.com/apache/spark/pull/25069 contains the same minor fixes as it's required to write the tests.
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25070 from HyukjinKwon/SPARK-28273.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The sub-second part of the interval should be padded before parsing. Currently, Spark gives a correct value only when there is 9 digits below `.`.
```
spark-sql> select interval '0 0:0:0.123456789' day to second;
interval 123 milliseconds 456 microseconds
spark-sql> select interval '0 0:0:0.12345678' day to second;
interval 12 milliseconds 345 microseconds
spark-sql> select interval '0 0:0:0.1234' day to second;
interval 1 microseconds
```
## How was this patch tested?
Pass the Jenkins with the fixed test cases.
Closes#25079 from dongjoon-hyun/SPARK-28308.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Make the transform natively in ml framework to avoid extra conversion.
There are many TODOs in current ml module, like `// TODO: Make the transformer natively in ml framework to avoid extra conversion.` in ChiSqSelector.
This PR is to make ml algs no longer need to convert ml-vector to mllib-vector in transforms.
Including: LDA/ChiSqSelector/ElementwiseProduct/HashingTF/IDF/Normalizer/PCA/StandardScaler.
## How was this patch tested?
existing testsuites
Closes#24963 from zhengruifeng/to_ml_vector.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In Dataset drop(col: Column) method, the `equals` comparison method was used instead of `semanticEquals`, which caused the problem of abnormal case-sensitivity behavior. When attributes of LogicalPlan are checked for equality, `semanticEquals` should be used instead.
A similar PR I referred to: https://github.com/apache/spark/pull/22713 created by mgaido91
## How was this patch tested?
- Added new unit test case in DataFrameSuite
- ./build/sbt "testOnly org.apache.spark.sql.*"
- The python code from ticket reporter at https://issues.apache.org/jira/browse/SPARK-28189Closes#25055 from Tonix517/SPARK-28189.
Authored-by: Tony Zhang <tony.zhang@uber.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Mainly change logs:
### Version 3.0.13:
- Support for JDK 9/10 in Full Compiler
- The syntax elements that can have modifiers now all have sets of "is...()" methods that check for each modifier. Some also have methods "getAccess()" and/or "getAnnotations()".
- Implement "type annotations" (JLS8 9.7.4)
- Implemented parsing (but not compilation) of "modular compilation units" (JLS11 7.3).
- Replaced all "assert...Uncookable(..., Pattern messageRegex)" and "assert...Uncookable(..., String messageInfix)" method pairs with a single "assert...Uncookable(..., String messageRegex)" method.
Minor refactoring: Allowed modifiers are now checked in the Parser, not in Java.*. This saves a lot of THROWS clauses.
- Parse Type inference syntax: Type inference for generic instance creation implemented, test cases added.
- Parse MethodReference, ClassInstanceCreationReference and ArrayCreationReference
### Version 3.0.12
- Fixed: Operator "&" not defined on types "java.lang.Long" and "int"
- Major bug in JavaSourceClassLoader: When loading the second and following classes, CUs were compiled again, leading to an inconsistent class hierarchy.
- Fixed: Java 9 added "Override public final CharBuffer CharBuffer.rewind() { ..." -- leads easily to a java.lang.NoSuchMethodError
- Changed all occurences of the words "Java bytecode" to "JVM bytecode" to make clearer that the generated bytecode is for the JVMS and not suitable for, e.g. DALVIK.
http://janino-compiler.github.io/janino/changelog.html
## How was this patch tested?
Existing test
Closes#25021 from wangyum/SPARK-28221.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
We changed our non-standard syntax for `trim` function in #24902 from `TRIM(trimStr, str)` to `TRIM(str, trimStr)` to be compatible with other databases. This pr update the migration guide.
I checked various databases(PostgreSQL, Teradata, Vertica, Oracle, DB2, SQL Server 2019, MySQL, Hive, Presto) and it seems that only PostgreSQL and Presto support this non-standard syntax.
**PostgreSQL**:
```sql
postgres=# select substr(version(), 0, 16), trim('yxTomxx', 'x');
substr | btrim
-----------------+-------
PostgreSQL 11.3 | yxTom
(1 row)
```
**Presto**:
```sql
presto> select trim('yxTomxx', 'x');
_col0
-------
yxTom
(1 row)
```
## How was this patch tested?
manual tests
Closes#24948 from wangyum/SPARK-28093-FOLLOW-UP-DOCS.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds some more WITH test cases as a follow-up to https://github.com/apache/spark/pull/24842
## How was this patch tested?
Add new UTs.
Closes#24949 from peter-toth/SPARK-28002-follow-up.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
- Currently, `ExpressionEncoder` does not handle bigdecimal overflow. Round-tripping overflowing java/scala BigDecimal/BigInteger returns null.
- The serializer encode java/scala BigDecimal to to sql Decimal, which still has the underlying data to the former.
- When writing out to UnsafeRow, `changePrecision` will be false and row has null value.
24e1e41648/sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/codegen/UnsafeRowWriter.java (L202-L206)
- In [SPARK-23179](https://github.com/apache/spark/pull/20350), an option to throw exception on decimal overflow was introduced.
- This PR adds the option in `ExpressionEncoder` to throw when detecting overflowing BigDecimal/BigInteger before its corresponding Decimal gets written to Row. This gives a consistent behavior between decimal arithmetic on sql expression (DecimalPrecision), and getting decimal from dataframe (RowEncoder)
Thanks to mgaido91 for the very first PR `SPARK-23179` and follow-up discussion on this change.
Thanks to JoshRosen for working with me on this.
## How was this patch tested?
added unit tests
Closes#25016 from mickjermsurawong-stripe/SPARK-28200.
Authored-by: Mick Jermsurawong <mickjermsurawong@stripe.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
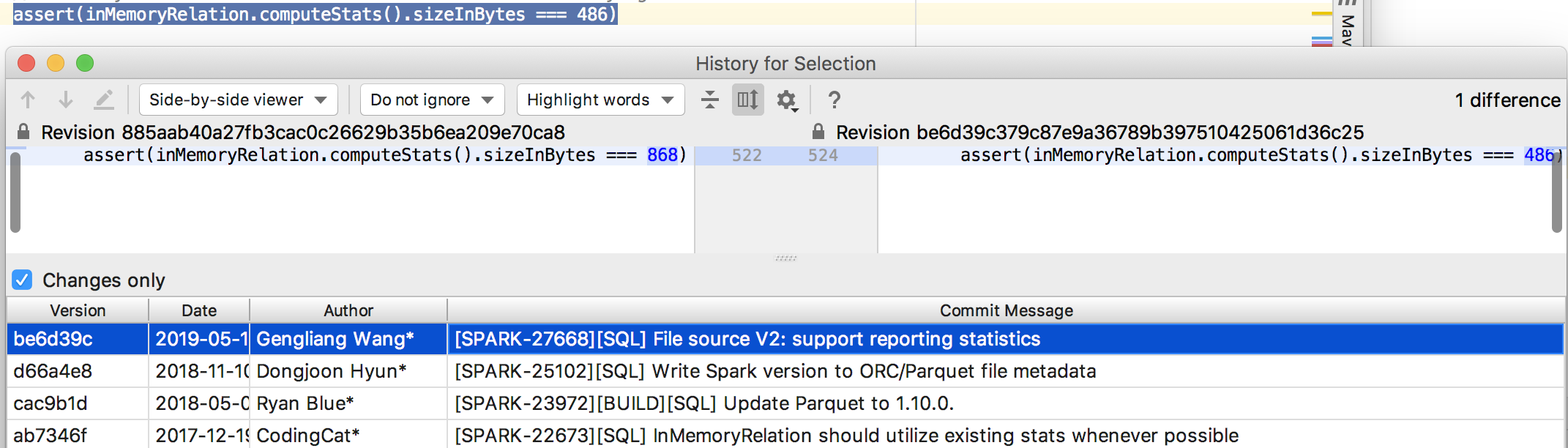
## What changes were proposed in this pull request?
Migrate Avro to File source V2.
## How was this patch tested?
Unit test
Closes#25017 from gengliangwang/avroV2.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr upgrades Postgres docker image for integration tests.
## How was this patch tested?
manual tests:
```
./build/mvn install -DskipTests
./build/mvn test -Pdocker-integration-tests -pl :spark-docker-integration-tests_2.12
```
Closes#25050 from wangyum/SPARK-28248.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR proposes to rename `mapPartitionsInPandas` to `mapInPandas` with a separate evaluation type .
Had an offline discussion with rxin, mengxr and cloud-fan
The reason is basically:
1. `SCALAR_ITER` doesn't make sense with `mapPartitionsInPandas`.
2. It cannot share the same Pandas UDF, for instance, at `select` and `mapPartitionsInPandas` unlike `GROUPED_AGG` because iterator's return type is different.
3. `mapPartitionsInPandas` -> `mapInPandas` - see https://github.com/apache/spark/pull/25044#issuecomment-508298552 and https://github.com/apache/spark/pull/25044#issuecomment-508299764
Renaming `SCALAR_ITER` as `MAP_ITER` is abandoned due to 2. reason.
For `XXX_ITER`, it might have to have a different interface in the future if we happen to add other versions of them. But this is an orthogonal topic with `mapPartitionsInPandas`.
## How was this patch tested?
Existing tests should cover.
Closes#25044 from HyukjinKwon/SPARK-28198.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Before this PR inserting into a non-existing table returned a weird error message:
```
sql("INSERT INTO test VALUES (1)").show
org.apache.spark.sql.AnalysisException: unresolved operator 'InsertIntoTable 'UnresolvedRelation [test], false, false;;
'InsertIntoTable 'UnresolvedRelation [test], false, false
+- LocalRelation [col1#4]
```
after this PR the error message becomes:
```
org.apache.spark.sql.AnalysisException: Table not found: test;;
'InsertIntoTable 'UnresolvedRelation [test], false, false
+- LocalRelation [col1#0]
```
## How was this patch tested?
Added a new UT.
Closes#25054 from peter-toth/SPARK-28251.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds support of `WITH` clause within a subquery so this query becomes valid:
```
SELECT max(c) FROM (
WITH t AS (SELECT 1 AS c)
SELECT * FROM t
)
```
## How was this patch tested?
Added new UTs.
Closes#24831 from peter-toth/SPARK-19799-2.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This is to implement a ReduceNumShufflePartitions rule in the new adaptive execution framework introduced in #24706. This rule is used to adjust the post shuffle partitions based on the map output statistics.
## How was this patch tested?
Added ReduceNumShufflePartitionsSuite
Closes#24978 from carsonwang/reduceNumShufflePartitions.
Authored-by: Carson Wang <carson.wang@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This patch adds missing UT which tests the changed behavior of original patch #24942.
## How was this patch tested?
Newly added UT.
Closes#24999 from HeartSaVioR/SPARK-28142-FOLLOWUP.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr add calculate local directory size to `SQLTestUtils`.
We can avoid these changes after this pr:
## How was this patch tested?
Existing test
Closes#25014 from wangyum/SPARK-28216.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
`requestHeaderSize` is added in https://github.com/apache/spark/pull/23090 and applies to Spark + History server UI as well. Without debug log it's hard to find out on which side what configuration is used.
In this PR I've added a log message which prints out the value.
## How was this patch tested?
Manually checked log files.
Closes#25045 from gaborgsomogyi/SPARK-26118.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR makes the predicate pushdown logic in catalyst optimizer more efficient by unifying two existing rules `PushdownPredicates` and `PushPredicateThroughJoin`. Previously pushing down a predicate for queries such as `Filter(Join(Join(Join)))` requires n steps. This patch essentially reduces this to a single pass.
To make this actually work, we need to unify a few rules such as `CombineFilters`, `PushDownPredicate` and `PushDownPrdicateThroughJoin`. Otherwise cases such as `Filter(Join(Filter(Join)))` still requires several passes to fully push down predicates. This unification is done by composing several partial functions, which makes a minimal code change and can reuse existing UTs.
Results show that this optimization can improve the catalyst optimization time by 16.5%. For queries with more joins, the performance is even better. E.g., for TPC-DS q64, the performance boost is 49.2%.
## How was this patch tested?
Existing UTs + new a UT for the new rule.
Closes#24956 from yeshengm/fixed-point-opt.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This pr add `PLACING` to `ansiNonReserved` and add `overlay` and `placing` to `TableIdentifierParserSuite`.
## How was this patch tested?
N/A
Closes#25013 from wangyum/SPARK-28077.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}