## What changes were proposed in this pull request?
This improves the expression description for commonly used aggregate functions such as Max, Min, Count, etc.
## How was this patch tested?
Verified the function description manually from the shell.
Closes#23756 from dilipbiswal/dkb_expr_description_aggregate.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Run Spark-Sql job use transform features(`ScriptTransformationExec`) with config `spark.speculation = true`, sometimes job fails and we found many Executor Dead through `Executor Tab`, through analysis log and code we found :
`ScriptTransformationExec` start a new thread(`ScriptTransformationWriterThread`), the new thread is very likely to throw `TaskKilledException`(from iter.map.foreach part) when speculation is on, this exception will captured by `SparkUncaughtExceptionHandler` which registered during Executor start, `SparkUncaughtExceptionHandler` will call `System.exit (SparkExitCode.UNCAUGHT_EXCEPTION)` to shutdown `Executor`, this is unexpected.
We should not kill the executor just because `ScriptTransformationWriterThread` fails. log the error(not only `TaskKilledException`) instead of throwing it is enough, Exception already pass to `ScriptTransformationExec` and handle by `TaskRunner`.
## How was this patch tested?
Register `TestUncaughtExceptionHandler` to test case in `ScriptTransformationSuite`, then assert there is no Uncaught Exception handled.
Before this patch "script transformation should not swallow errors from upstream operators (no serde)" and "script transformation should not swallow errors from upstream operators (with serde)" throwing `IllegalArgumentException` and handle by `TestUncaughtExceptionHandler` .
Closes#22149 from LuciferYang/fix-transformation-task-kill.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Implements the solution proposed in [SPARK-26696](https://issues.apache.org/jira/browse/SPARK-26696), a minor refactoring that allows frameworks to perform advanced type-preserving dataset transformations without carrying `Encoder` implicits from user code.
The change allows
```scala
def foo[A](ds: Dataset[A]): Dataset[A] =
ds.toDF().as[A](ds.encoder)
```
instead of
```scala
def foo[A: Encoder](ds: Dataset[A]): Dataset[A] =
ds.toDF().as[A](implicitly[Encoder[A]])
```
## How was this patch tested?
This patch was tested with an automated test that was later removed as it was deemed unnecessary per the discussion in this PR.
Closes#23620 from ssimeonov/ss_SPARK-26696.
Authored-by: Simeon Simeonov <sim@fastignite.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In the PR, I propose to covert underlying types of timestamp/date columns to strings, and store the converted values as column statistics. This makes statistics for timestamp/date columns independent from system time zone while saving and retrieving such statistics.
I bumped versions of stored statistics from 1 to 2 since the PR changes the format.
## How was this patch tested?
The changes were tested by `StatisticsCollectionSuite` and by `StatisticsSuite`.
Closes#23662 from MaxGekk/column-stats-time-date.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This patch makes hardcoded configs in "mesos" module to use ConfigEntry, avoiding issues on mistake like SPARK-26082.
Please note that there're some changes on type while migrating to ConfigEntry: specifically "comma-separated list on a string" becomes "sequence of strings". While SparkConf smoothly handles on the change (comma-separated list on a string is still supported so backward compatible), there're some methods in utility class (`mesos` package private) to depend on the type change, so this patch also modifies the method signature for them a bit.
## How was this patch tested?
Existing tests.
Closes#23743 from HeartSaVioR/SPARK-26843.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
- The benchmark of `XORShiftRandom.nextInt` vis-a-vis `java.util.Random.nextInt` is moved from the `XORShiftRandom` object to `XORShiftRandomBenchmark`.
- Added benchmarks for `nextLong`, `nextDouble` and `nextGaussian` that are used in Spark as well.
- Added a separate benchmark for `XORShiftRandom.hashSeed`.
Closes#23752 from MaxGekk/xorshiftrandom-benchmark.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
Follow the [official document](https://docs.python.org/2/library/argparse.html#upgrading-optparse-code) to upgrade the deprecated module 'optparse' to 'argparse'.
## What changes were proposed in this pull request?
This PR proposes to replace 'optparse' module with 'argparse' module.
## How was this patch tested?
Follow the [previous testing](7e3eb3cd20), manually tested and negative tests were also done. My [test results](https://gist.github.com/cchung100m/1661e7df6e8b66940a6e52a20861f61d)
Closes#23730 from cchung100m/solve_deprecated_module_optparse.
Authored-by: cchung100m <cchung100m@cs.ccu.edu.tw>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
#23744 added a UT to prevent a future regression. However, it breaks Scala-2.11 build. This fixes that.
## How was this patch tested?
Manual test with Scala-2.11 profile.
Closes#23755 from HeartSaVioR/SPARK-26082-FOLLOW-UP-V2.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Delegation token providers interface now has a parameter `fileSystems` but this is needed only for `HadoopFSDelegationTokenProvider`.
In this PR I've addressed this issue in the following way:
* Removed `fileSystems` parameter from `HadoopDelegationTokenProvider`
* Moved `YarnSparkHadoopUtil.hadoopFSsToAccess` into `HadoopFSDelegationTokenProvider`
* Moved `spark.yarn.stagingDir` into core
* Moved `spark.yarn.access.namenodes` into core and renamed to `spark.kerberos.access.namenodes`
* Moved `spark.yarn.access.hadoopFileSystems` into core and renamed to `spark.kerberos.access.hadoopFileSystems`
## How was this patch tested?
Existing unit tests.
Closes#23698 from gaborgsomogyi/SPARK-26766.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Not all users wants to keep temporary checkpoint directories. Additionally hard to restore from it.
In this PR I've added a force delete flag which is default `false`. Additionally not clear for users when temporary checkpoint directory deleted so added log messages to explain this a bit more.
## How was this patch tested?
Existing + additional unit tests.
Closes#23732 from gaborgsomogyi/SPARK-26389.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
add weightCol for python version of MulticlassClassificationEvaluator and MulticlassMetrics
## How was this patch tested?
add doc test
Closes#23157 from huaxingao/spark-26185.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Holden Karau <holden@pigscanfly.ca>
## What changes were proposed in this pull request?
I was trying out pyspark on a system with only a `python3` command but no `python` command and got this error:
```bash
/opt/spark/bin/pyspark: line 45: python: command not found
```
I also noticed the bash syntax for the IPython version check is wrong: `[[ ! $WORKS_WITH_IPYTHON ]]` always evaluates to false when `$WORKS_WITH_IPYTHON` is non-empty
This PR simply eliminates the Python version check for executor at driver side when using IPython.
## How was this patch tested?
I manually tested the `pyspark` launch script and bash syntax stuff
Closes#23736 from soxofaan/master.
Authored-by: Stefaan Lippens <soxofaan@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This patch adds UT on testing SPARK-26082 to avoid regression. While #23743 reduces the possibility to make a similar mistake, the needed lines of code for adding tests are not that huge, so I guess it might be worth to add them.
## How was this patch tested?
Newly added UTs. Test "supports setting fetcher cache" fails when #23743 is not applied and succeeds when #23743 is applied.
Closes#23744 from HeartSaVioR/SPARK-26082-add-unit-test.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
* change MesosClusterScheduler to use correct argument name for Mesos fetch cache (spark.mesos.fetchCache.enable -> spark.mesos.fetcherCache.enable)
## How was this patch tested?
Not sure this requires a test, since it's just a string change.
Closes#23734 from mwlon/SPARK-26082.
Authored-by: mwlon <mloncaric@hmc.edu>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
SPARK-23991 introduced a bug in `ReceivedBlockTracker#allocateBlocksToBatch`: when a queue with more than a few thousand blocks are in the queue, serializing the queue throws a StackOverflowError. This change just adds `dequeueAll` to the new `clone` operation on the queue so that the fix in 23991 is preserved but the serialized data comes from an ArrayBuffer which doesn't have the serialization problems that mutable.Queue has.
## How was this patch tested?
A unit test was added.
Closes#23716 from rlodge/SPARK-26734.
Authored-by: Ross Lodge <rlodge@concentricsky.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR consists of the `test` components of #23665 only, minus the associated patch from that PR.
It adds a new unit test to `JsonSuite` which verifies that the `count()` returned from a `DataFrame` loaded from JSON containing empty lines does not include those empty lines in the record count. The test runs `count` prior to otherwise reading data from the `DataFrame`, so as to catch future cases where a pre-parsing optimization might result in `count` results inconsistent with existing behavior.
This PR is intended to be deployed alongside #23667; `master` currently causes the test to fail, as described in [SPARK-26745](https://issues.apache.org/jira/browse/SPARK-26745).
## How was this patch tested?
Manual testing, existing `JsonSuite` unit tests.
Closes#23674 from sumitsu/json_emptyline_count_test.
Authored-by: Branden Smith <branden.smith@publicismedia.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
Merge both case statements, and remove unused variables that
are not set by the Scala code anymore.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#23655 from vanzin/SPARK-26733.
## What changes were proposed in this pull request?
Recently, when I was reading some code of `BlockManager.getBlockData`, I found that there are useless code that would never reach. The related codes is as below:
```
override def getBlockData(blockId: BlockId): ManagedBuffer = {
if (blockId.isShuffle) {
shuffleManager.shuffleBlockResolver.getBlockData(blockId.asInstanceOf[ShuffleBlockId])
} else {
getLocalBytes(blockId) match {
case Some(blockData) =>
new BlockManagerManagedBuffer(blockInfoManager, blockId, blockData, true)
case None =>
// If this block manager receives a request for a block that it doesn't have then it's
// likely that the master has outdated block statuses for this block. Therefore, we send
// an RPC so that this block is marked as being unavailable from this block manager.
reportBlockStatus(blockId, BlockStatus.empty)
throw new BlockNotFoundException(blockId.toString)
}
}
}
```
```
def getLocalBytes(blockId: BlockId): Option[BlockData] = {
logDebug(s"Getting local block $blockId as bytes")
// As an optimization for map output fetches, if the block is for a shuffle, return it
// without acquiring a lock; the disk store never deletes (recent) items so this should work
if (blockId.isShuffle) {
val shuffleBlockResolver = shuffleManager.shuffleBlockResolver
// TODO: This should gracefully handle case where local block is not available. Currently
// downstream code will throw an exception.
val buf = new ChunkedByteBuffer(
shuffleBlockResolver.getBlockData(blockId.asInstanceOf[ShuffleBlockId]).nioByteBuffer())
Some(new ByteBufferBlockData(buf, true))
} else {
blockInfoManager.lockForReading(blockId).map { info => doGetLocalBytes(blockId, info) }
}
}
```
the `blockId.isShuffle` is checked twice, but however it seems that in the method calling hierarchy of `BlockManager.getLocalBytes`, the another callsite of the `BlockManager.getLocalBytes` is at `TorrentBroadcast.readBlocks` where the blockId can never be a `ShuffleBlockId`.
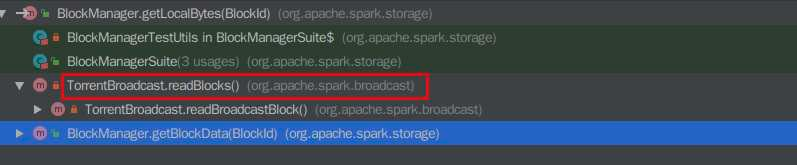
So I think we should remove these useless code for easy reading.
## How was this patch tested?
NA
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23693 from liupc/Remove-useless-code-in-BlockManager.
Authored-by: Liupengcheng <liupengcheng@xiaomi.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
How to reproduce
./build/mvn test -Dtest=org.apache.spark.network.RequestTimeoutIntegrationSuite,org.apache.spark.network.ChunkFetchIntegrationSuite -DwildcardSuites=None test
furtherRequestsDelay Test within RequestTimeoutIntegrationSuite was holding onto buffer references within worker threads. The test does close the server context but since the threads are global and there is sleep of 60 secs to fetch a specific chunk within this test, it grabs on it and waits for the client to consume but however the test is testing for a request timeout and it times out after 10 secs, so the workers are just waiting there for the buffer to be consumed by client as per my understanding.
This tends to happen if you dont have enough IO threads available on the specific system and also the order of the tests being run determines its flakyness like if ChunkFetchIntegrationSuite runs first then there is no issue. For example on mac with 8 threads these tests run fine but on my vm with 4 threads it fails. It matches the number of fetch calls in RequestTimeoutIntegrationSuite.
So do we really need it to be static?
I dont think this requires a global declaration as these threads are only required on the shuffle server end and on the client TransportContext initialization i.e the Client don't initialize these threads. The Shuffle Server initializes one TransportContext object. So, I think this is fine to be an instance variable and I see no harm.
## How was this patch tested?
Integration tests, manual tests
Closes#23700 from redsanket/SPARK-25692.
Authored-by: schintap <schintap@oath.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
**updateAndSyncNumExecutorsTarget** API should be called after **initializing** flag is unset
## How was this patch tested?
Added UT and also manually tested
After Fix
Closes#23697 from sandeep-katta/executorIssue.
Authored-by: sandeep-katta <sandeep.katta2007@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The java version here means versions of javac source, javac target, scalac target. They could be consolidated as a single version (currently 1.8)
| |javac|scalac |
|------|-----|---------|
|source|1.8 |2.12/2.11|
|target|1.8 |1.8 |
The current issues are as follows
* Maven build defines a single property (`java.version`) to specify java version while SBT build defines different properties for javac (`javacJVMVersion`) and scalac (`scalacJVMVersion`). SBT build should use a single property as Maven build does.
* Furthermore, it's better for SBT build to refer to `java.version` defined by Maven build. This is possible since we've already been using sbt-pom-reader.
## How was this patch tested?
Tested locally.
```
build/mvn clean compile
build/sbt clean compile
```
Closes#23724 from seancxmao/specify-java-version-once.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
- Covers latest minikube versions.
- keeps the older version support
Note: While I was facing disk pressure issues locally on machine, I noticed minikube status command would report that everything was working fine even if some kube-system pods were not up. I don't think the output is 100% reliable but it is good enough for most cases.
## How was this patch tested?
Run it against latest version of minikube (v0.32.0).
Author: Stavros Kontopoulos <stavros.kontopoulos@lightbend.com>
Closes#23520 from skonto/update-mini-backend.
## What changes were proposed in this pull request?
When we run in background and we get exception which is not HiveSQLException,
we may encounter memory leak since handleToOperation will not removed correctly.
The reason is below:
1. When calling operation.run() in HiveSessionImpl#executeStatementInternal we throw an exception which is not HiveSQLException
2. Then the opHandle generated by SparkSQLOperationManager will not be added into opHandleSet of HiveSessionImpl , and operationManager.closeOperation(opHandle) will not be called
3. When we close the session we will also call operationManager.closeOperation(opHandle),since we did not add this opHandle into the opHandleSet.
For the reasons above,the opHandled will always in SparkSQLOperationManager#handleToOperation,which will cause memory leak.
More details and a case has attached on https://issues.apache.org/jira/browse/SPARK-26751
This patch will always throw HiveSQLException when running in background
## How was this patch tested?
Exist UT
Closes#23673 from caneGuy/zhoukang/fix-hivesessionimpl-leak.
Authored-by: zhoukang <zhoukang199191@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In the PR, I propose to eliminate checking of parsed segments inside of the `stringToDate` and `stringToTimestamp` because such checking is already performed while constructing *java.time* classes, in particular inside of `LocalDate` and `LocalTime`. As a consequence of removing the explicit checks, the `isInvalidDate` method is not needed any more, and it was removed from `DateTimeUtils`.
## How was this patch tested?
This was tested by `DateExpressionsSuite`, `DateFunctionsSuite`, `DateTimeUtilsSuite` and `CastSuite`.
Closes#23717 from MaxGekk/datetimeutils-refactoring.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Update to Parquet Java 1.10.1.
## How was this patch tested?
Added a test from HyukjinKwon that validates the notEq case from SPARK-26677.
Closes#23704 from rdblue/SPARK-26677-fix-noteq-parquet-bug.
Lead-authored-by: Ryan Blue <blue@apache.org>
Co-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Co-authored-by: Ryan Blue <rdblue@users.noreply.github.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Collapsed notes about using Java 8 API for date/timestamp manipulations and Proleptic Gregorian calendar in the SQL migration guide.
Closes#23722 from MaxGekk/collapse-notes.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In this PR we've done two things:
1) updated the Spark's copy of cloudpickle to 0.6.1 (current stable)
The main reason Spark stayed with cloudpickle 0.4.x was that the default pickle protocol was changed in later versions.
2) started using pickle.HIGHEST_PROTOCOL for both Python 2 and Python 3 for serializers and broadcast
[Pyrolite](https://github.com/irmen/Pyrolite) has such Pickle protocol version support: reading: 0,1,2,3,4; writing: 2.
## How was this patch tested?
Jenkins tests.
Authors: Sloane Simmons, Boris Shminke
This contribution is original work of Sloane Simmons and Boris Shminke and they licensed it to the project under the project's open source license.
Closes#20691 from inpefess/pickle_protocol_4.
Lead-authored-by: Boris Shminke <boris@shminke.me>
Co-authored-by: singularperturbation <sloanes.k@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
When the job's partiton is zero, it will still get a jobid but not shown in ui. It's strange. This PR is to show this job in ui.
Example:
In bash:
mkdir -p /home/test/testdir
sc.textFile("/home/test/testdir")
Some logs:
```
19/01/24 17:26:19 INFO FileInputFormat: Total input paths to process : 0
19/01/24 17:26:19 INFO SparkContext: Starting job: collect at WordCount.scala:9
19/01/24 17:26:19 INFO DAGScheduler: Job 0 finished: collect at WordCount.scala:9, took 0.003735 s
```
## How was this patch tested?
UT
Closes#23637 from deshanxiao/spark-26714.
Authored-by: xiaodeshan <xiaodeshan@xiaomi.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Even if `spark.sql.hive.convertMetastoreParquet` is true, when writing to partitioned Hive metastore
Parquet tables, Spark SQL still can not use its own Parquet support instead of Hive SerDe.
Related code:
d53e11ffce/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveStrategies.scala (L198)
## How was this patch tested?
N/A
Closes#23671 from 10110346/parquetdoc.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Make .unpersist(), .destroy() non-blocking by default and adjust callers to request blocking only where important.
This also adds an optional blocking argument to Pyspark's RDD.unpersist(), which never had one.
## How was this patch tested?
Existing tests.
Closes#23685 from srowen/SPARK-26771.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Python version of https://github.com/apache/spark/pull/17654
## How was this patch tested?
Existing Python unit test
Closes#23676 from huaxingao/spark26754.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Right now, EventTimeStats.merge doesn't handle `zero.merge(zero)` correctly. This will make `avg` become `NaN`. And whatever gets merged with the result of `zero.merge(zero)`, `avg` will still be `NaN`. Then finally, we call `NaN.toLong` and get `0`, and the user will see the following incorrect report:
```
"eventTime" : {
"avg" : "1970-01-01T00:00:00.000Z",
"max" : "2019-01-31T12:57:00.000Z",
"min" : "2019-01-30T18:44:04.000Z",
"watermark" : "1970-01-01T00:00:00.000Z"
}
```
This issue was reported by liancheng .
This PR fixes the above issue.
## How was this patch tested?
The new unit tests.
Closes#23718 from zsxwing/merge-zero.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
Currently, spark would not release ShuffleBlockFetcherIterator until the whole task finished.In some conditions, it incurs memory leak.
An example is `rdd.repartition(m).coalesce(n, shuffle = false).save`, each `ShuffleBlockFetcherIterator` contains some metas about mapStatus(`blocksByAddress`) and each resultTask will keep n(max to shuffle partitions) shuffleBlockFetcherIterator and the memory would never released until the task completion, for they are referenced by the completion callbacks of TaskContext. In some case, it may take huge memory and incurs OOM.
Actually, We can release ShuffleBlockFetcherIterator as soon as it's consumed.
This PR is to resolve this problem.
## How was this patch tested?
unittest
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23438 from liupc/Fast-release-shuffleblockfetcheriterator.
Lead-authored-by: Liupengcheng <liupengcheng@xiaomi.com>
Co-authored-by: liupengcheng <liupengcheng@xiaomi.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
For types like Product, we've already add AssertNotNull when we construct serializer(see code below), so we could strip redundant AssertNotNull for those types.
```
val fieldValue = Invoke(
AssertNotNull(inputObject, walkedTypePath), fieldName, dataTypeFor(fieldType),
returnNullable = !fieldType.typeSymbol.asClass.isPrimitive)
```
## How was this patch tested?
Existed.
Closes#23651 from Ngone51/dev-strip-redundant-assertnotnull-for-ecnoder-serializer.
Authored-by: wuyi <ngone_5451@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
### Background
For the current status, the test script that generates coverage information was merged
into Spark, https://github.com/apache/spark/pull/20204
So, we can generate the coverage report and site by, for example:
```
run-tests-with-coverage --python-executables=python3 --modules=pyspark-sql
```
like `run-tests` script in `./python`.
### Proposed change
The next step is to host this coverage report via `github.io` automatically
by Jenkins (see https://spark-test.github.io/pyspark-coverage-site/).
This uses my testing account for Spark, spark-test, which is shared to Felix and Shivaram a long time ago for testing purpose including AppVeyor.
To cut this short, this PR targets to run the coverage in
[spark-master-test-sbt-hadoop-2.7](https://amplab.cs.berkeley.edu/jenkins/job/spark-master-test-sbt-hadoop-2.7/)
In the specific job, it will clone the page, and rebase the up-to-date PySpark test coverage from the latest commit. For instance as below:
```bash
# Clone PySpark coverage site.
git clone https://github.com/spark-test/pyspark-coverage-site.git
# Remove existing HTMLs.
rm -fr pyspark-coverage-site/*
# Copy generated coverage HTMLs.
cp -r .../python/test_coverage/htmlcov/* pyspark-coverage-site/
# Check out to a temporary branch.
git symbolic-ref HEAD refs/heads/latest_branch
# Add all the files.
git add -A
# Commit current HTMLs.
git commit -am "Coverage report at latest commit in Apache Spark"
# Delete the old branch.
git branch -D gh-pages
# Rename the temporary branch to master.
git branch -m gh-pages
# Finally, force update to our repository.
git push -f origin gh-pages
```
So, it is a one single up-to-date coverage can be shown in the `github-io` page. The commands above were manually tested.
### TODOs
- [x] Write a draft HyukjinKwon
- [x] `pip install coverage` to all python implementations (pypy, python2, python3) in Jenkins workers - shaneknapp
- [x] Set hidden `SPARK_TEST_KEY` for spark-test's password in Jenkins via Jenkins's feature
This should be set in both PR builder and `spark-master-test-sbt-hadoop-2.7` so that later other PRs can test and fix the bugs - shaneknapp
- [x] Set an environment variable that indicates `spark-master-test-sbt-hadoop-2.7` so that that specific build can report and update the coverage site - shaneknapp
- [x] Make PR builder's test passed HyukjinKwon
- [x] Fix flaky test related with coverage HyukjinKwon
- 6 consecutive passes out of 7 runs
This PR will be co-authored with me and shaneknapp
## How was this patch tested?
It will be tested via Jenkins.
Closes#23117 from HyukjinKwon/SPARK-7721.
Lead-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Co-authored-by: hyukjinkwon <gurwls223@apache.org>
Co-authored-by: shane knapp <incomplete@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
Error message falsely states standardization=True is causing a problem, even when standardization=False. The real issue is standardizeLabels=True, which is set automatically in LinearRegression and not currently available in the Public API.
## What changes were proposed in this pull request?
A simple change to an error message. More details here: https://jira.apache.org/jira/browse/SPARK-26787
## How was this patch tested?
This does not change any functionality.
Closes#23705 from bscan/bscan-errormsg-1.
Authored-by: bscan <brianjscannell@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Add python example for Power Iteration Clustering in spark.ml
## How was this patch tested?
Manually tested
Closes#22996 from huaxingao/spark-25997.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Metrics instance "mesos_cluster" exists in spark, but not mentioned in monitoring.md. This PR add it.
## How was this patch tested?
Manually test.
Closes#23691 from SongYadong/doc_mesos_metrics_inst.
Authored-by: SongYadong <song.yadong1@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Previously a "java.lang.UnsupportedOperationException: empty
collection" exception would be thrown due to using `reduce`, rather
than `fold` or similar that can tolerate empty RDDs.
This behaviour has existed for the Vertex RDDs since it was introduced
in b30e0ae035. It seems this behaviour
was inherited by the Edge RDDs via copy-paste in
ee29ef3800.
## How was this patch tested?
Two new unit tests.
Closes#23681 from huonw/empty-graphx.
Authored-by: Huon Wilson <Huon.Wilson@data61.csiro.au>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently ANTLR v4 versions used by Maven and SBT are slightly different. Maven uses `4.7.1` while SBT uses `4.7`.
* Maven(`pom.xml`): `<antlr4.version>4.7.1</antlr4.version>`
* SBT(`project/SparkBuild.scala`): `antlr4Version in Antlr4 := "4.7"`
We should make Maven and SBT use a single version. Furthermore we'd better specify antlr4 version in one place to avoid mismatch between Maven and SBT in the future.
This PR lets SBT use antlr4 version specified in Maven POM file, rather than specify its own antlr4 version. This is in the same as how `hadoop.version` is specified in `project/SparkBuild.scala`
## How was this patch tested?
Test locally.
After run `sbt compile`, Java files generated by ANTLR are located at:
```
sql/catalyst/target/scala-2.12/src_managed/main/antlr4/org/apache/spark/sql/catalyst/parser/*.java
```
These Java files have a comment at the head. We can see now SBT uses ANTLR `4.7.1`.
```
// Generated from .../spark/sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 by ANTLR 4.7.1
```
Closes#23713 from seancxmao/antlr4-version-consistent.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…not synchronized to the UI display
## What changes were proposed in this pull request?
The amount of memory used by the broadcast variable is not synchronized to the UI display.
I added the case for BroadcastBlockId and updated the memory usage.
## How was this patch tested?
We can test this patch with unit tests.
Closes#23649 from httfighter/SPARK-26726.
Lead-authored-by: 韩田田00222924 <han.tiantian@zte.com.cn>
Co-authored-by: han.tiantian@zte.com.cn <han.tiantian@zte.com.cn>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Create a framework for write path of File Source V2.
Also, migrate write path of ORC to V2.
Supported:
* Write to file as Dataframe
Not Supported:
* Partitioning, which is still under development in the data source V2 project.
* Bucketing, which is still under development in the data source V2 project.
* Catalog.
## How was this patch tested?
Unit test
Closes#23601 from gengliangwang/orc_write.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
This is a follow-up to PR:
https://github.com/apache/spark/pull/21632
## What changes were proposed in this pull request?
This PR tunes the tolerance used for deciding whether to add zero feature values to a value-count map (where the key is the feature value and the value is the weighted count of those feature values).
In the previous PR the tolerance scaled by the square of the unweighted number of samples, which is too aggressive for a large number of unweighted samples. Unfortunately using just "Utils.EPSILON * unweightedNumSamples" is not enough either, so I multiplied that by a factor tuned by the testing procedure below.
## How was this patch tested?
This involved manually running the sample weight tests for decision tree regressor to see whether the tolerance was large enough to exclude zero feature values.
Eg in SBT:
```
./build/sbt
> project mllib
> testOnly *DecisionTreeRegressorSuite -- -z "training with sample weights"
```
For validation, I added a print inside the if in the code below and validated that the tolerance was large enough so that we would not include zero features (which don't exist in that test):
```
val valueCountMap = if (weightedNumSamples - partNumSamples > tolerance) {
print("should not print this")
partValueCountMap + (0.0 -> (weightedNumSamples - partNumSamples))
} else {
partValueCountMap
}
```
Closes#23682 from imatiach-msft/ilmat/sample-weights-tol.
Authored-by: Ilya Matiach <ilmat@microsoft.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Add the R version of map_concat / map_from_entries / an option in months_between UDF to disable rounding-off
## How was this patch tested?
Add test in test_sparkSQL.R
Closes#21835 from huaxingao/spark-24779.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
A followup of https://github.com/apache/spark/pull/23388 .
`AggUtils.createAggregate` is not the right place to normalize the grouping expressions, as final aggregate is also created by it. The grouping expressions of final aggregate should be attributes which refer to the grouping expressions in partial aggregate.
This PR moves the normalization to the caller side of `AggUtils`.
## How was this patch tested?
existing tests
Closes#23692 from cloud-fan/follow.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR adds a note that explicitly `spark.executor.pyspark.memory` is dependent on resource module's behaviours at Python memory usage.
For instance, I at least see some difference at https://github.com/apache/spark/pull/21977#discussion_r251220966
## How was this patch tested?
Manually built the doc.
Closes#23664 from HyukjinKwon/note-resource-dependent.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In #23639, the API `supportDataType` is refactored. We should also remove the method `verifyWriteSchema` and `verifyReadSchema` in `DataSourceUtils`.
Since the error message use `FileFormat.toString` to specify the data source naming, this PR also overriding the `toString` method in `AvroFileFormat`.
## How was this patch tested?
Unit test.
Closes#23699 from gengliangwang/SPARK-26716-followup.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR reverts JSON count optimization part of #21909.
We cannot distinguish the cases below without parsing:
```
[{...}, {...}]
```
```
[]
```
```
{...}
```
```bash
# empty string
```
when we `count()`. One line (input: IN) can be, 0 record, 1 record and multiple records and this is dependent on each input.
See also https://github.com/apache/spark/pull/23665#discussion_r251276720.
## How was this patch tested?
Manually tested.
Closes#23667 from HyukjinKwon/revert-SPARK-24959.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}