### What changes were proposed in this pull request?
Add optional `allowMissingColumns` argument to SparkR `unionByName`.
### Why are the changes needed?
Feature parity.
### Does this PR introduce _any_ user-facing change?
`unionByName` supports `allowMissingColumns`.
### How was this patch tested?
Existing unit tests. New unit tests targeting this feature.
Closes#29813 from zero323/SPARK-32799.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR:
- rephrases some wordings in installation guide to avoid using the terms that can be potentially ambiguous such as "different favors"
- documents extra dependency installation `pip install pyspark[sql]`
- uses the link that corresponds to the released version. e.g.) https://spark.apache.org/docs/latest/building-spark.html vs https://spark.apache.org/docs/3.0.0/building-spark.html
- adds some more details
I built it on Read the Docs to make it easier to review: https://hyukjin-spark.readthedocs.io/en/stable/getting_started/install.html
### Why are the changes needed?
To improve installation guide.
### Does this PR introduce _any_ user-facing change?
Yes, it updates the user-facing installation guide.
### How was this patch tested?
Manually built the doc and tested.
Closes#29779 from HyukjinKwon/SPARK-32180.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Only calculate the executorRunTime when taskStartTimeNs > 0. Otherwise, set executorRunTime to 0.
### Why are the changes needed?
bug fix.
It's possible that a task be killed (e.g., by another successful attempt) before it reaches "taskStartTimeNs = System.nanoTime()". In this case, taskStartTimeNs is still 0 since it hasn't been really initialized. And we will get the wrong executorRunTime by calculating System.nanoTime() - taskStartTimeNs.
### Does this PR introduce _any_ user-facing change?
Yes, users will see the correct executorRunTime.
### How was this patch tested?
Pass existing tests.
Closes#29789 from Ngone51/fix-SPARK-32898.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a follow-up PR to https://github.com/apache/spark/pull/29771 and just adds a new test case.
### Why are the changes needed?
To have better test coverage.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New UT.
Closes#29802 from peter-toth/SPARK-32635-fix-foldable-propagation-followup.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
After https://github.com/apache/spark/pull/29660 and https://github.com/apache/spark/pull/29689 there are 13 remaining failed cases of sql core module with Scala 2.13.
The reason for the remaining failed cases is the optimization result of `CostBasedJoinReorder` maybe different with same input in Scala 2.12 and Scala 2.13 if there are more than one same cost candidate plans.
In this pr give a way to make the optimization result deterministic as much as possible to pass all remaining failed cases of `sql/core` module in Scala 2.13, the main change of this pr as follow:
- Change to use `LinkedHashMap` instead of `Map` to store `foundPlans` in `JoinReorderDP.search` method to ensure same iteration order with same insert order because iteration order of `Map` behave differently under Scala 2.12 and 2.13
- Fixed `StarJoinCostBasedReorderSuite` affected by the above change
- Regenerate golden files affected by the above change.
### Why are the changes needed?
We need to support a Scala 2.13 build.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Scala 2.12: Pass the Jenkins or GitHub Action
- Scala 2.13: All tests passed.
Do the following:
```
dev/change-scala-version.sh 2.13
mvn clean install -DskipTests -pl sql/core -Pscala-2.13 -am
mvn test -pl sql/core -Pscala-2.13
```
**Before**
```
Tests: succeeded 8485, failed 13, canceled 1, ignored 52, pending 0
*** 13 TESTS FAILED ***
```
**After**
```
Tests: succeeded 8498, failed 0, canceled 1, ignored 52, pending 0
All tests passed.
```
Closes#29711 from LuciferYang/SPARK-32808-3.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This pr fix all 14 failed cases in `external/avro` module in Scala 2.13, the main change of this pr as follow:
- Manual call `toSeq` in `AvroDeserializer#newWriter` and `SchemaConverters#toSqlTypeHelper` method because the object type for case match is `ArrayBuffer` not `Seq` in Scala 2.13
- Specified `Seq` to `s.c.Seq` when we call `Row.get(i).asInstanceOf[Seq]` because the data maybe `mutable.ArraySeq` but `Seq` is `immutable.Seq` in Scala 2.13
### Why are the changes needed?
We need to support a Scala 2.13 build.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Scala 2.12: Pass the Jenkins or GitHub Action
- Scala 2.13: Pass 2.13 Build GitHub Action and do the following:
```
dev/change-scala-version.sh 2.13
mvn clean install -DskipTests -pl external/avro -Pscala-2.13 -am
mvn clean test -pl external/avro -Pscala-2.13
```
**Before**
```
Tests: succeeded 197, failed 14, canceled 0, ignored 2, pending 0
*** 14 TESTS FAILED ***
```
**After**
```
Tests: succeeded 211, failed 0, canceled 0, ignored 2, pending 0
All tests passed.
```
Closes#29801 from LuciferYang/fix-external-avro-213.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Found via discussion https://github.com/apache/spark/pull/29746#issuecomment-694726504
and the root cause it that hive-1.2 does not recognize NULL
```scala
sbt.ForkMain$ForkError: java.sql.SQLException: Unrecognized column type: NULL
at org.apache.hive.jdbc.JdbcColumn.typeStringToHiveType(JdbcColumn.java:160)
at org.apache.hive.jdbc.HiveResultSetMetaData.getHiveType(HiveResultSetMetaData.java:48)
at org.apache.hive.jdbc.HiveResultSetMetaData.getPrecision(HiveResultSetMetaData.java:86)
at org.apache.spark.sql.hive.thriftserver.SparkThriftServerProtocolVersionsSuite.$anonfun$new$35(SparkThriftServerProtocolVersionsSuite.scala:358)
at org.apache.spark.sql.hive.thriftserver.SparkThriftServerProtocolVersionsSuite.$anonfun$new$35$adapted(SparkThriftServerProtocolVersionsSuite.scala:351)
at org.apache.spark.sql.hive.thriftserver.SparkThriftServerProtocolVersionsSuite.testExecuteStatementWithProtocolVersion(SparkThriftServerProtocolVersionsSuite.scala:66)
at org.apache.spark.sql.hive.thriftserver.SparkThriftServerProtocolVersionsSuite.$anonfun$new$34(SparkThriftServerProtocolVersionsSuite.scala:351)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85)
at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83)
at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104)
at org.scalatest.Transformer.apply(Transformer.scala:22)
at org.scalatest.Transformer.apply(Transformer.scala:20)
at org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:189)
at org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:176)
at org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:187)
at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:199)
at org.scalatest.SuperEngine.runTestImpl(Engine.scala:306)
at org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:199)
at org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:181)
at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:61)
at org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:234)
at org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:227)
at org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:61)
at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTests$1(AnyFunSuiteLike.scala:232)
at org.scalatest.SuperEngine.$anonfun$runTestsInBranch$1(Engine.scala:413)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.scalatest.SuperEngine.traverseSubNodes$1(Engine.scala:401)
at org.scalatest.SuperEngine.runTestsInBranch(Engine.scala:396)
at org.scalatest.SuperEngine.runTestsImpl(Engine.scala:475)
at org.scalatest.funsuite.AnyFunSuiteLike.runTests(AnyFunSuiteLike.scala:232)
at org.scalatest.funsuite.AnyFunSuiteLike.runTests$(AnyFunSuiteLike.scala:231)
at org.scalatest.funsuite.AnyFunSuite.runTests(AnyFunSuite.scala:1562)
at org.scalatest.Suite.run(Suite.scala:1112)
at org.scalatest.Suite.run$(Suite.scala:1094)
at org.scalatest.funsuite.AnyFunSuite.org$scalatest$funsuite$AnyFunSuiteLike$$super$run(AnyFunSuite.scala:1562)
at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$run$1(AnyFunSuiteLike.scala:236)
at org.scalatest.SuperEngine.runImpl(Engine.scala:535)
at org.scalatest.funsuite.AnyFunSuiteLike.run(AnyFunSuiteLike.scala:236)
at org.scalatest.funsuite.AnyFunSuiteLike.run$(AnyFunSuiteLike.scala:235)
at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterAll$$super$run(SparkFunSuite.scala:61)
at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:213)
at org.scalatest.BeforeAndAfterAll.run(BeforeAndAfterAll.scala:210)
at org.scalatest.BeforeAndAfterAll.run$(BeforeAndAfterAll.scala:208)
at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:61)
at org.scalatest.tools.Framework.org$scalatest$tools$Framework$$runSuite(Framework.scala:318)
at org.scalatest.tools.Framework$ScalaTestTask.execute(Framework.scala:513)
at sbt.ForkMain$Run$2.call(ForkMain.java:296)
at sbt.ForkMain$Run$2.call(ForkMain.java:286)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
In this PR, we simply ignore these checks for hive 1.2
### Why are the changes needed?
fix jenkins
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
test itself.
Closes#29803 from yaooqinn/SPARK-32874-F.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR changes `UnsafeExternalSorter.SpillableIterator` to free its memory (except for the page holding the last record) if it is forced to spill after all of its records have been read. It also makes sure that `lastPage` is freed if `loadNext` is never called the again. The latter was necessary to get my test case to succeed (otherwise it would complain about a leak).
### Why are the changes needed?
No memory is freed after calling `UnsafeExternalSorter.SpillableIterator.spill()` when all records have been read, even though it is still holding onto some memory. This may cause a `SparkOutOfMemoryError` to be thrown, even though we could have just freed the memory instead.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
A test was added to `UnsafeExternalSorterSuite`.
Closes#29787 from tomvanbussel/SPARK-32911.
Authored-by: Tom van Bussel <tom.vanbussel@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to replace deprecated `isFile` and `isDirectory` methods.
```diff
- fs.isDirectory(hadoopPath)
+ fs.getFileStatus(hadoopPath).isDirectory
```
```diff
- fs.isFile(new Path(inProgressLog))
+ fs.getFileStatus(new Path(inProgressLog)).isFile
```
### Why are the changes needed?
It shows deprecation warnings.
- https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-3.2-hive-2.3/1244/consoleFull
```
[warn] /home/jenkins/workspace/spark-master-test-sbt-hadoop-3.2-hive-2.3/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala:815: method isFile in class FileSystem is deprecated: see corresponding Javadoc for more information.
[warn] if (!fs.isFile(new Path(inProgressLog))) {
```
```
[warn] /home/jenkins/workspace/spark-master-test-sbt-hadoop-3.2-hive-2.3/core/src/main/scala/org/apache/spark/SparkContext.scala:1884: method isDirectory in class FileSystem is deprecated: see corresponding Javadoc for more information.
[warn] if (fs.isDirectory(hadoopPath)) {
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the Jenkins.
Closes#29796 from williamhyun/filesystem.
Authored-by: William Hyun <williamhyun3@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
With a long-running application in kerberized mode, the AMEndpiont handles `UpdateDelegationTokens` message wrong, which is an OneWayMessage that should be handled in the `receive` function.
```java
20-09-15 18:53:01 INFO yarn.YarnAllocator: Received 22 containers from YARN, launching executors on 0 of them.
20-09-16 12:52:28 ERROR netty.Inbox: Ignoring error
org.apache.spark.SparkException: NettyRpcEndpointRef(spark-client://YarnAM) does not implement 'receive'
at org.apache.spark.rpc.RpcEndpoint$$anonfun$receive$1.applyOrElse(RpcEndpoint.scala:70)
at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115)
at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:203)
at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100)
at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$$receiveLoop(MessageLoop.scala:75)
at org.apache.spark.rpc.netty.MessageLoop$$anon$1.run(MessageLoop.scala:41)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
20-09-17 06:52:28 ERROR netty.Inbox: Ignoring error
org.apache.spark.SparkException: NettyRpcEndpointRef(spark-client://YarnAM) does not implement 'receive'
at org.apache.spark.rpc.RpcEndpoint$$anonfun$receive$1.applyOrElse(RpcEndpoint.scala:70)
at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115)
at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:203)
at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100)
at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$$receiveLoop(MessageLoop.scala:75)
at org.apache.spark.rpc.netty.MessageLoop$$anon$1.run(MessageLoop.scala:41)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
### Why are the changes needed?
bugfix, without a proper token refresher, the long-running apps are going to fail potentially in kerberized cluster
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
Passing jenkins
and verify manually
I am running the sub-module `kyuubi-spark-sql-engine` of https://github.com/yaooqinn/kyuubi
The simplest way to reproduce the bug and verify this fix is to follow these steps
#### 1 build the `kyuubi-spark-sql-engine` module
```
mvn clean package -pl :kyuubi-spark-sql-engine
```
#### 2. config the spark with Kerberos settings towards your secured cluster
#### 3. start it in the background
```
nohup bin/spark-submit --class org.apache.kyuubi.engine.spark.SparkSQLEngine ../kyuubi-spark-sql-engine-1.0.0-SNAPSHOT.jar > kyuubi.log &
```
#### 4. check the AM log and see
"Updating delegation tokens ..." for SUCCESS
"Inbox: Ignoring error ...... does not implement 'receive'" for FAILURE
Closes#29777 from yaooqinn/SPARK-32905.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Change the target error calculation according to the paper [Space-Efficient Online Computation of Quantile Summaries](http://infolab.stanford.edu/~datar/courses/cs361a/papers/quantiles.pdf). It says that the error `e = max(gi, deltai)/2` (see the page 59). Also this has clear explanation [ε-approximate quantiles](http://www.mathcs.emory.edu/~cheung/Courses/584/Syllabus/08-Quantile/Greenwald.html#proofprop1).
2. Added a test to check different accuracies.
3. Added an input CSV file `percentile_approx-input.csv.bz2` to the resource folder `sql/catalyst/src/main/resources` for the test.
### Why are the changes needed?
To fix incorrect percentile calculation, see an example in SPARK-32908.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
- By running existing tests in `QuantileSummariesSuite` and in `ApproximatePercentileQuerySuite`.
- Added new test `SPARK-32908: maximum target error in percentile_approx` to `ApproximatePercentileQuerySuite`.
Closes#29784 from MaxGekk/fix-percentile_approx-2.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1, simplify the aggregation by get `count` via `summary.count`
2, ignore nan values like the old impl:
```
val relativeError = 0.05
val approxQuantile = numNearestNeighbors.toDouble / count + relativeError
val modelDatasetWithDist = modelDataset.withColumn(distCol, hashDistCol)
if (approxQuantile >= 1) {
modelDatasetWithDist
} else {
val hashThreshold = modelDatasetWithDist.stat
.approxQuantile(distCol, Array(approxQuantile), relativeError)
// Filter the dataset where the hash value is less than the threshold.
modelDatasetWithDist.filter(hashDistCol <= hashThreshold(0))
}
```
### Why are the changes needed?
simplify the aggregation
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing testsuites
Closes#29778 from zhengruifeng/lsh_nit.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
Recently, we added code to log plan changes in the preparation phase in `QueryExecution` for execution (https://github.com/apache/spark/pull/29544). This PR intends to apply the same fix for logging plan changes in AQE.
### Why are the changes needed?
Easy debugging for AQE plans
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit tests.
Closes#29774 from maropu/PlanChangeLogForAQE.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR rewrites `FoldablePropagation` rule to replace attribute references in a node with foldables coming only from the node's children.
Before this PR in the case of this example (with setting`spark.sql.optimizer.excludedRules=org.apache.spark.sql.catalyst.optimizer.ConvertToLocalRelation`):
```scala
val a = Seq("1").toDF("col1").withColumn("col2", lit("1"))
val b = Seq("2").toDF("col1").withColumn("col2", lit("2"))
val aub = a.union(b)
val c = aub.filter($"col1" === "2").cache()
val d = Seq("2").toDF( "col4")
val r = d.join(aub, $"col2" === $"col4").select("col4")
val l = c.select("col2")
val df = l.join(r, $"col2" === $"col4", "LeftOuter")
df.show()
```
foldable propagation happens incorrectly:
```
Join LeftOuter, (col2#6 = col4#34) Join LeftOuter, (col2#6 = col4#34)
!:- Project [col2#6] :- Project [1 AS col2#6]
: +- InMemoryRelation [col1#4, col2#6], StorageLevel(disk, memory, deserialized, 1 replicas) : +- InMemoryRelation [col1#4, col2#6], StorageLevel(disk, memory, deserialized, 1 replicas)
: +- Union : +- Union
: :- *(1) Project [value#1 AS col1#4, 1 AS col2#6] : :- *(1) Project [value#1 AS col1#4, 1 AS col2#6]
: : +- *(1) Filter (isnotnull(value#1) AND (value#1 = 2)) : : +- *(1) Filter (isnotnull(value#1) AND (value#1 = 2))
: : +- *(1) LocalTableScan [value#1] : : +- *(1) LocalTableScan [value#1]
: +- *(2) Project [value#10 AS col1#13, 2 AS col2#15] : +- *(2) Project [value#10 AS col1#13, 2 AS col2#15]
: +- *(2) Filter (isnotnull(value#10) AND (value#10 = 2)) : +- *(2) Filter (isnotnull(value#10) AND (value#10 = 2))
: +- *(2) LocalTableScan [value#10] : +- *(2) LocalTableScan [value#10]
+- Project [col4#34] +- Project [col4#34]
+- Join Inner, (col2#6 = col4#34) +- Join Inner, (col2#6 = col4#34)
:- Project [value#31 AS col4#34] :- Project [value#31 AS col4#34]
: +- LocalRelation [value#31] : +- LocalRelation [value#31]
+- Project [col2#6] +- Project [col2#6]
+- Union false, false +- Union false, false
:- Project [1 AS col2#6] :- Project [1 AS col2#6]
: +- LocalRelation [value#1] : +- LocalRelation [value#1]
+- Project [2 AS col2#15] +- Project [2 AS col2#15]
+- LocalRelation [value#10] +- LocalRelation [value#10]
```
and so the result is wrong:
```
+----+----+
|col2|col4|
+----+----+
| 1|null|
+----+----+
```
After this PR foldable propagation will not happen incorrectly and the result is correct:
```
+----+----+
|col2|col4|
+----+----+
| 2| 2|
+----+----+
```
### Why are the changes needed?
To fix a correctness issue.
### Does this PR introduce _any_ user-facing change?
Yes, fixes a correctness issue.
### How was this patch tested?
Existing and new UTs.
Closes#29771 from peter-toth/SPARK-32635-fix-foldable-propagation.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
make orc table column name support special characters like `$`
### Why are the changes needed?
Special characters like `$` are allowed in orc table column name by Hive.
But it's error when execute command "CREATE TABLE tbl(`$` INT, b INT) using orc" in spark. it's not compatible with Hive.
`Column name "$" contains invalid character(s). Please use alias to rename it.;Column name "$" contains invalid character(s). Please use alias to rename it.;org.apache.spark.sql.AnalysisException: Column name "$" contains invalid character(s). Please use alias to rename it.;
at org.apache.spark.sql.execution.datasources.orc.OrcFileFormat$.checkFieldName(OrcFileFormat.scala:51)
at org.apache.spark.sql.execution.datasources.orc.OrcFileFormat$.$anonfun$checkFieldNames$1(OrcFileFormat.scala:59)
at org.apache.spark.sql.execution.datasources.orc.OrcFileFormat$.$anonfun$checkFieldNames$1$adapted(OrcFileFormat.scala:59)
at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.WrappedArray.foreach(WrappedArray.scala:38) `
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Add unit test
Closes#29761 from jzc928/orcColSpecialChar.
Authored-by: jzc <jzc@jzcMacBookPro.local>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This pr fix failed and aborted cases in sql hive-thriftserver module in Scala 2.13, the main change of this pr as follow:
- Use `s.c.Seq` instead of `Seq` in `HiveResult` because the input type maybe `mutable.ArraySeq`, but `Seq` represent `immutable.Seq` in Scala 2.13.
- Reset classLoader after `HiveMetastoreLazyInitializationSuite` completed because context class loader is `NonClosableMutableURLClassLoader` in `HiveMetastoreLazyInitializationSuite` running process, and it propagate to `HiveThriftServer2ListenerSuite` trigger following problems in Scala 2.13:
```
HiveThriftServer2ListenerSuite:
*** RUN ABORTED ***
java.lang.LinkageError: loader constraint violation: loader (instance of net/bytebuddy/dynamic/loading/MultipleParentClassLoader) previously initiated loading for a different type with name "org/apache/hive/service/ServiceStateChangeListener"
at org.mockito.codegen.HiveThriftServer2$MockitoMock$1850222569.<clinit>(Unknown Source)
at sun.reflect.GeneratedSerializationConstructorAccessor530.newInstance(Unknown Source)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.objenesis.instantiator.sun.SunReflectionFactoryInstantiator.newInstance(SunReflectionFactoryInstantiator.java:48)
at org.objenesis.ObjenesisBase.newInstance(ObjenesisBase.java:73)
at org.mockito.internal.creation.instance.ObjenesisInstantiator.newInstance(ObjenesisInstantiator.java:19)
at org.mockito.internal.creation.bytebuddy.SubclassByteBuddyMockMaker.createMock(SubclassByteBuddyMockMaker.java:47)
at org.mockito.internal.creation.bytebuddy.ByteBuddyMockMaker.createMock(ByteBuddyMockMaker.java:25)
at org.mockito.internal.util.MockUtil.createMock(MockUtil.java:35)
at org.mockito.internal.MockitoCore.mock(MockitoCore.java:63)
...
```
After this pr `HiveThriftServer2Suites` and `HiveThriftServer2ListenerSuite` was fixed and all 461 test passed
### Why are the changes needed?
We need to support a Scala 2.13 build.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Scala 2.12: Pass the Jenkins or GitHub Action
- Scala 2.13: All tests passed.
Do the following:
```
dev/change-scala-version.sh 2.13
mvn clean install -DskipTests -pl sql/hive-thriftserver -am -Phive-thriftserver -Pscala-2.13
mvn test -pl sql/hive-thriftserver -Phive -Phive-thriftserver -Pscala-2.13
```
**Before**
```
HiveThriftServer2ListenerSuite:
*** RUN ABORTED ***
```
**After**
```
Tests: succeeded 461, failed 0, canceled 0, ignored 17, pending 0
All tests passed.
```
Closes#29783 from LuciferYang/sql-thriftserver-tests.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
The PR aims to add Scala 2.13 build test coverage into GitHub Action for Apache Spark 3.1.0.
### Why are the changes needed?
The branch is ready for Scala 2.13 and this will prevent any regression.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass the GitHub Action.
Closes#29793 from dongjoon-hyun/SPARK-32926.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Correct the typo in Show Table document
### Why are the changes needed?
Current Document of Show Table returns in parse error, so it is misleading to users
### Does this PR introduce _any_ user-facing change?
Yes, the document of show table is corrected now
### How was this patch tested?
NA
Closes#29758 from Udbhav30/showtable.
Authored-by: Udbhav30 <u.agrawal30@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a follow-up on #29565, and addresses a few issues in the last PR:
- style issue pointed by [this comment](https://github.com/apache/spark/pull/29565#discussion_r487646749)
- skip optimization when `fromExp` is foldable (by [this comment](https://github.com/apache/spark/pull/29565#discussion_r487646973)) as there could be more efficient rule to apply for this case.
- pass timezone info to the generated cast on the literal value
- a bunch of cleanups and test improvements
Originally I plan to handle this when implementing [SPARK-32858](https://issues.apache.org/jira/browse/SPARK-32858) but now think it's better to isolate these changes from that.
### Why are the changes needed?
To fix a few left over issues in the above PR.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added a test for the foldable case. Otherwise relying on existing tests.
Closes#29775 from sunchao/SPARK-24994-followup.
Authored-by: Chao Sun <sunchao@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
To fix the flaky `ExecutorAllocationManagerSuite`: Avoid first `schedule()` invocation after `ExecutorAllocationManager` started.
### Why are the changes needed?
`ExecutorAllocationManagerSuite` is still flaky, see:
https://github.com/apache/spark/pull/29722/checks?check_run_id=1117979237
By checking the below logs, we can see that there's a race condition between thread `pool-1-thread-1-ScalaTest-running` and thread `spark-dynamic-executor-allocation`. The only possibility of thread `spark-dynamic-executor-allocation` becoming active is the first time invocation of `schedule()`(since the `TEST_SCHEDULE_INTERVAL`(30s) is really long, so it's impossible the second invocation would happen). Thus, I think we shall avoid the first invocation too.
```scala
20/09/15 12:41:20.831 pool-1-thread-1-ScalaTest-running-ExecutorAllocationManagerSuite INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 2 for resource profile id: 0)
20/09/15 12:41:20.832 spark-dynamic-executor-allocation INFO ExecutorAllocationManager: Requesting 2 new executors because tasks are backlogged (new desired total will be 4 for resource profile id: 0)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
The flaky can't be reproduced locally so it's hard to say it has been completely fixed by now. We need time to see the result.
Closes#29773 from Ngone51/fix-SPARK-32287.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR changes the way `UnsafeExternalSorter.SpillableIterator` checks whether it has spilled already, by checking whether `inMemSorter` is null. It also allows it to spill other `UnsafeSorterIterator`s than `UnsafeInMemorySorter.SortedIterator`.
### Why are the changes needed?
Before this PR `UnsafeExternalSorter.SpillableIterator` could not spill when there are NULLs in the input and radix sorting is used. Currently, Spark determines whether UnsafeExternalSorter.SpillableIterator has not spilled yet by checking whether `upstream` is an instance of `UnsafeInMemorySorter.SortedIterator`. When radix sorting is used and there are NULLs in the input however, `upstream` will be an instance of `UnsafeExternalSorter.ChainedIterator` instead, and Spark will assume that the `SpillableIterator` iterator has spilled already, and therefore cannot spill again when it's supposed to spill.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
A test was added to `UnsafeExternalSorterSuite` (and therefore also to `UnsafeExternalSorterRadixSortSuite`). I manually confirmed that the test failed in `UnsafeExternalSorterRadixSortSuite` without this patch.
Closes#29772 from tomvanbussel/SPARK-32900.
Authored-by: Tom van Bussel <tom.vanbussel@databricks.com>
Signed-off-by: herman <herman@databricks.com>
### What changes were proposed in this pull request?
Write to static partition, check in advance that the partition field is empty.
### Why are the changes needed?
When writing to the current static partition, the partition field is empty, and an error will be reported when all tasks are completed.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
add ut
Closes#29316 from cxzl25/SPARK-32508.
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch proposes to make GeneratePredicate eliminate common sub-expressions.
### Why are the changes needed?
Both GenerateMutableProjection and GenerateUnsafeProjection, such codegen objects can eliminate common sub-expressions. But GeneratePredicate currently doesn't do it.
We encounter a customer issue that a Filter pushed down through a Project causes performance issue, compared with not pushed down case. The issue is one expression used in Filter predicates are run many times. Due to the complex schema, the query nodes are not wholestage codegen, so it runs Filter.doExecute and then call GeneratePredicate. The common expression was run many time and became performance bottleneck. GeneratePredicate should be able to eliminate common sub-expressions for such case.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests.
Closes#29776 from viirya/filter-pushdown.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Credits to tdas who reported and described the fix to [SPARK-26425](https://issues.apache.org/jira/browse/SPARK-26425). I just followed the description of the issue.
This patch adds more checks on commit log as well as file streaming source so that multiple concurrent runs of streaming query don't mess up the status of query/checkpoint. This patch addresses two different spots which are having a bit different issues:
1. FileStreamSource.fetchMaxOffset()
In structured streaming, we don't allow multiple streaming queries to run with same checkpoint (including concurrent runs of same query), so query should fail if it fails to write the metadata of specific batch ID due to same batch ID being written by others.
2. commit log
As described in JIRA issue, assertion is already applied to the `offsetLog` for the same reason.
8167714cab/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala (L394-L402)
This patch applied the same for commit log.
### Why are the changes needed?
This prevents the inconsistent behavior on streaming query and lets query fail instead.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A, as the change is simple and obvious, and it's really hard to artificially reproduce the issue.
Closes#25965 from HeartSaVioR/SPARK-26425.
Lead-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Co-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This pr fix failed cases in sql hive module in Scala 2.13 as follow:
- HiveSchemaInferenceSuite (1 FAILED -> PASS)
- HiveSparkSubmitSuite (1 FAILED-> PASS)
- StatisticsSuite (1 FAILED-> PASS)
- HiveDDLSuite (1 FAILED-> PASS)
After this patch all test passed in sql hive module in Scala 2.13.
### Why are the changes needed?
We need to support a Scala 2.13 build.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Scala 2.12: Pass the Jenkins or GitHub Action
- Scala 2.13: All tests passed.
Do the following:
```
dev/change-scala-version.sh 2.13
mvn clean install -DskipTests -pl sql/hive -am -Pscala-2.13 -Phive
mvn clean test -pl sql/hive -Pscala-2.13 -Phive
```
**Before**
```
Tests: succeeded 3662, failed 4, canceled 0, ignored 601, pending 0
*** 4 TESTS FAILED ***
```
**After**
```
Tests: succeeded 3666, failed 0, canceled 0, ignored 601, pending 0
All tests passed.
```
Closes#29760 from LuciferYang/sql-hive-test.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
In PySpark shell, if you call `SparkSession.builder.getOrCreate` as below:
```python
import warnings
from pyspark.sql import SparkSession, SQLContext
warnings.simplefilter('always', DeprecationWarning)
spark.stop()
SparkSession.builder.getOrCreate()
```
it shows the deprecation warning as below:
```
/.../spark/python/pyspark/sql/context.py:72: DeprecationWarning: Deprecated in 3.0.0. Use SparkSession.builder.getOrCreate() instead.
DeprecationWarning)
```
via d3304268d3/python/pyspark/sql/session.py (L222)
We shouldn't print the deprecation warning from it. This is the only place ^.
### Why are the changes needed?
To prevent to inform users that `SparkSession.builder.getOrCreate` is deprecated mistakenly.
### Does this PR introduce _any_ user-facing change?
Yes, it won't show a deprecation warning to end users for calling `SparkSession.builder.getOrCreate`.
### How was this patch tested?
Manually tested as above.
Closes#29768 from HyukjinKwon/SPARK-32897.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
### What changes were proposed in this pull request?
This PR fixes a conflict between `RewriteDistinctAggregates` and `DecimalAggregates`.
In some cases, `DecimalAggregates` will wrap the decimal column to `UnscaledValue` using
different rules for different aggregates.
This means, same distinct column with different aggregates will change to different distinct columns
after `DecimalAggregates`. For example:
`avg(distinct decimal_col), sum(distinct decimal_col)` may change to
`avg(distinct UnscaledValue(decimal_col)), sum(distinct decimal_col)`
We assume after `RewriteDistinctAggregates`, there will be at most one distinct column in aggregates,
but `DecimalAggregates` breaks this assumption. To fix this, we have to switch the order of these two
rules.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
added test cases
Closes#29673 from linhongliu-db/SPARK-32816.
Authored-by: Linhong Liu <linhong.liu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR cleans up the RPC message flow among the multiple decommission use cases, it includes changes:
* Keep `Worker`'s decommission status be consistent between the case where decommission starts from `Worker` and the case where decommission starts from the `MasterWebUI`: sending `DecommissionWorker` from `Master` to `Worker` in the latter case.
* Change from two-way communication to one-way communication when notifying decommission between driver and executor: it's obviously unnecessary for the executor to acknowledge the decommission status to the driver since the decommission request is from the driver. And it's same in reverse.
* Only send one message instead of two(`DecommissionSelf`/`DecommissionBlockManager`) when decommission the executor: executor and `BlockManager` are in the same JVM.
* Clean up codes around here.
### Why are the changes needed?
Before:
<img width="1948" alt="WeChat56c00cc34d9785a67a544dca036d49da" src="https://user-images.githubusercontent.com/16397174/92850308-dc461c80-f41e-11ea-8ac0-287825f4e0c4.png">
After:
<img width="1968" alt="WeChat05f7afb017e3f0132394c5e54245e49e" src="https://user-images.githubusercontent.com/16397174/93189571-de88dd80-f774-11ea-9300-1943920aa27d.png">
(Note the diagrams only counts those RPC calls that needed to go through the network. Local RPC calls are not counted here.)
After this change, We reduced 6 original RPC calls and added one more RPC call for keeping the consistent decommission status for the Worker. And the RPC flow becomes more clear.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Updated existing tests.
Closes#29722 from Ngone51/simplify-decommission-rpc.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
It's a followup of https://github.com/apache/spark/pull/29653.
Tests in `SparkSubmitCommandBuilderSuite` may fail if you didn't build first and have jars before test,
so if `isTesting` we should set a dummy `SparkLauncher.NO_RESOURCE`.
### Why are the changes needed?
Fix tests failure.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
mvn clean test (test without jars built first).
Closes#29769 from KevinSmile/bug-fix-master.
Authored-by: KevinSmile <kevinwang013@hotmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This pr makes cast string type to decimal decimal type fast fail if precision larger that 38.
### Why are the changes needed?
It is very slow if precision very large.
Benchmark and benchmark result:
```scala
import org.apache.spark.benchmark.Benchmark
val bd1 = new java.math.BigDecimal("6.0790316E+25569151")
val bd2 = new java.math.BigDecimal("6.0790316E+25");
val benchmark = new Benchmark("Benchmark string to decimal", 1, minNumIters = 2)
benchmark.addCase(bd1.toString) { _ =>
println(Decimal(bd1).precision)
}
benchmark.addCase(bd2.toString) { _ =>
println(Decimal(bd2).precision)
}
benchmark.run()
```
```
Java HotSpot(TM) 64-Bit Server VM 1.8.0_251-b08 on Mac OS X 10.15.6
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
Benchmark string to decimal: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
6.0790316E+25569151 9340 9381 57 0.0 9340094625.0 1.0X
6.0790316E+25 0 0 0 0.5 2150.0 4344230.1X
```
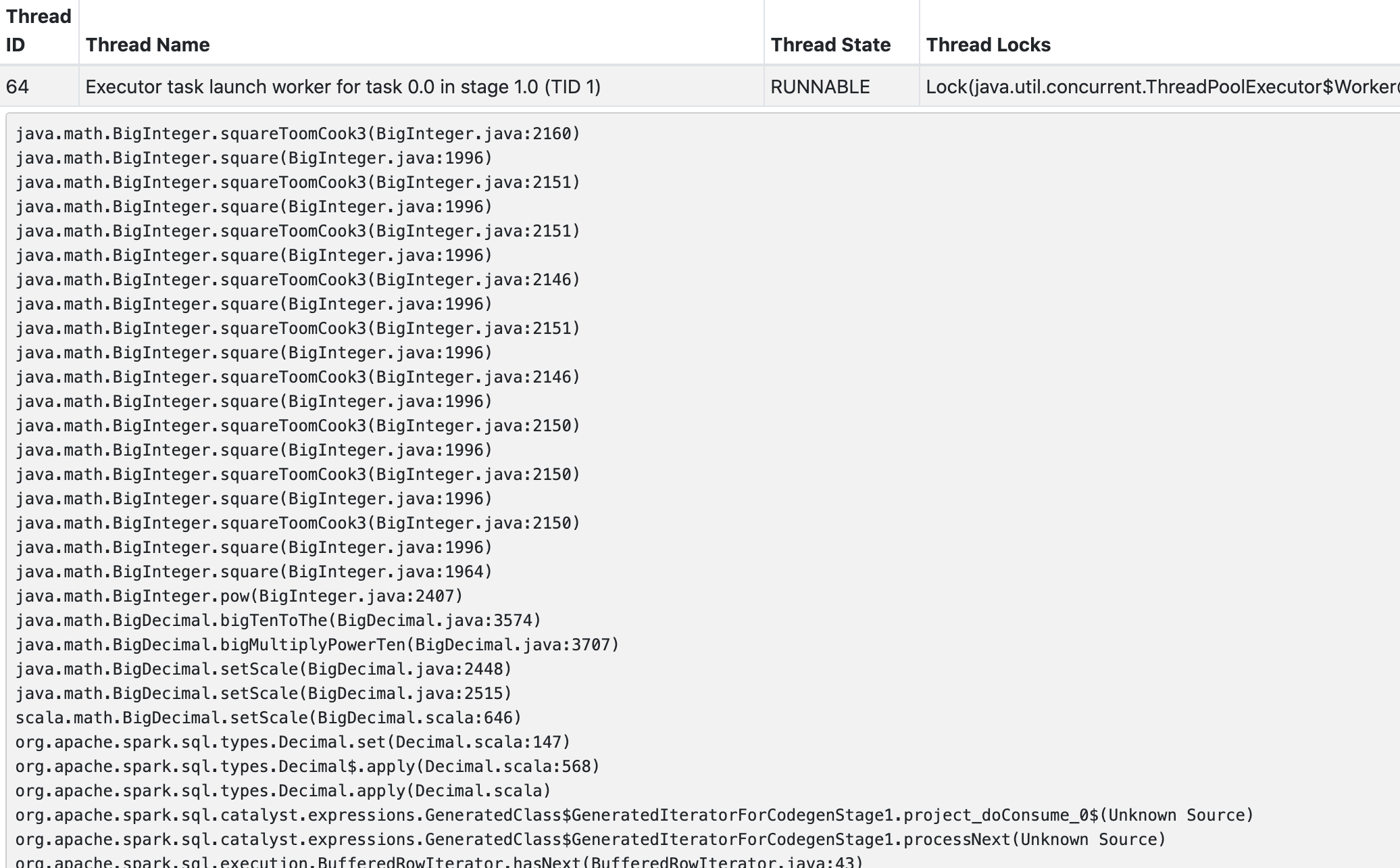
Stacktrace:
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test and benchmark test:
Dataset | Before this pr (Seconds) | After this pr (Seconds)
-- | -- | --
https://issues.apache.org/jira/secure/attachment/13011406/part-00000.parquet | 2640 | 2
Closes#29731 from wangyum/SPARK-32706.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Replace `__metaclass__` fields with `metaclass` keyword in the class statements.
### Why are the changes needed?
`__metaclass__` is no longer supported in Python 3. This means, for example, that types are no longer handled as singletons.
```
>>> from pyspark.sql.types import BooleanType
>>> BooleanType() is BooleanType()
False
```
and classes, which suppose to be abstract, are not
```
>>> import inspect
>>> from pyspark.ml import Estimator
>>> inspect.isabstract(Estimator)
False
```
### Does this PR introduce _any_ user-facing change?
Yes (classes which were no longer abstract or singleton in Python 3, are now), though visible changes should be consider a bug-fix.
### How was this patch tested?
Existing tests.
Closes#29664 from zero323/SPARK-32138-FOLLOW-UP-METACLASS.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR adds a `withField` method on the pyspark Column class to call the Scala API method added in https://github.com/apache/spark/pull/27066.
### Why are the changes needed?
To update the Python API to match a new feature in the Scala API.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New unit test
Closes#29699 from Kimahriman/feature/pyspark-with-field.
Authored-by: Adam Binford <adam.binford@radiantsolutions.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This proposes to enhance user document of the API for loading a Dataset of strings storing CSV rows. If the header option is set to true, the API will remove all lines same with the header.
### Why are the changes needed?
This behavior can confuse users. We should explicitly document it.
### Does this PR introduce _any_ user-facing change?
No. Only doc change.
### How was this patch tested?
Only doc change.
Closes#29765 from viirya/SPARK-32888.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR updates the `RemoveRedundantProjects` rule to make `GenerateExec` require column ordering.
### Why are the changes needed?
`GenerateExec` was originally considered as a node that does not require column ordering. However, `GenerateExec` binds its input rows directly with its `requiredChildOutput` without using the child's output schema.
In `doExecute()`:
```scala
val proj = UnsafeProjection.create(output, output)
```
In `doConsume()`:
```scala
val values = if (requiredChildOutput.nonEmpty) {
input
} else {
Seq.empty
}
```
In this case, changing input column ordering will result in `GenerateExec` binding the wrong schema to the input columns. For example, if we do not require child columns to be ordered, the `requiredChildOutput` [a, b, c] will directly bind to the schema of the input columns [c, b, a], which is incorrect:
```
GenerateExec explode(array(a, b, c)), [a, b, c], false, [d]
HashAggregate(keys=[a, b, c], functions=[], output=[c, b, a])
...
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#29734 from allisonwang-db/generator.
Authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The `LiteralGenerator` for float and double datatypes was supposed to yield special values (NaN, +-inf) among others, but the `Gen.chooseNum` method does not yield values that are outside the defined range. The `Gen.chooseNum` for a wide range of floats and doubles does not yield values in the "everyday" range as stated in https://github.com/typelevel/scalacheck/issues/113 .
There is an similar class `RandomDataGenerator` that is used in some other tests. Added `-0.0` and `-0.0f` as special values to there too.
These changes revealed an inconsistency with the equality check between `-0.0` and `0.0`.
### Why are the changes needed?
The `LiteralGenerator` is mostly used in the `checkConsistencyBetweenInterpretedAndCodegen` method in `MathExpressionsSuite`. This change would have caught the bug fixed in #29495 .
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Locally reverted #29495 and verified that the existing test cases caught the bug.
Closes#29515 from tanelk/SPARK-32688.
Authored-by: Tanel Kiis <tanel.kiis@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR only checks if there's any physical rule runs instead of a specific rule. This is rather just a trivial fix to make the tests more robust.
In fact, I faced a test failure from a in-house fork that applies a different physical rule that makes `CollapseCodegenStages` ineffective.
### Why are the changes needed?
To make the test more robust by unrelated changes.
### Does this PR introduce _any_ user-facing change?
No, test-only
### How was this patch tested?
Manually tested. Jenkins tests should pass.
Closes#29766 from HyukjinKwon/SPARK-32704.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR skips the test if trash directory cannot be created. It is possible that the trash directory cannot be created, for example, by permission. And the test fails below:
```
- SPARK-32481 Move data to trash on truncate table if enabled *** FAILED *** (154 milliseconds)
fs.exists(trashPath) was false (DDLSuite.scala:3184)
org.scalatest.exceptions.TestFailedException:
at org.scalatest.Assertions.newAssertionFailedException(Assertions.scala:530)
at org.scalatest.Assertions.newAssertionFailedException$(Assertions.scala:529)
at org.scalatest.FunSuite.newAssertionFailedException(FunSuite.scala:1560)
at org.scalatest.Assertions$AssertionsHelper.macroAssert(Assertions.scala:503)
```
### Why are the changes needed?
To make the tests pass independently.
### Does this PR introduce _any_ user-facing change?
No, test-only.
### How was this patch tested?
Manually tested.
Closes#29759 from HyukjinKwon/SPARK-32481.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add a new config `spark.sql.maxMetadataStringLength`. This config aims to limit metadata value length, e.g. file location.
### Why are the changes needed?
Some metadata have been abbreviated by `...` when I tried to add some test in `SQLQueryTestSuite`. We need to replace such value to `notIncludedMsg`. That caused we can't replace that like location value by `className` since the `className` has been abbreviated.
Here is a case:
```
CREATE table explain_temp1 (key int, val int) USING PARQUET;
EXPLAIN EXTENDED SELECT sum(distinct val) FROM explain_temp1;
-- ignore parsed,analyzed,optimized
-- The output like
== Physical Plan ==
*HashAggregate(keys=[], functions=[sum(distinct cast(val#x as bigint)#xL)], output=[sum(DISTINCT val)#xL])
+- Exchange SinglePartition, true, [id=#x]
+- *HashAggregate(keys=[], functions=[partial_sum(distinct cast(val#x as bigint)#xL)], output=[sum#xL])
+- *HashAggregate(keys=[cast(val#x as bigint)#xL], functions=[], output=[cast(val#x as bigint)#xL])
+- Exchange hashpartitioning(cast(val#x as bigint)#xL, 4), true, [id=#x]
+- *HashAggregate(keys=[cast(val#x as bigint) AS cast(val#x as bigint)#xL], functions=[], output=[cast(val#x as bigint)#xL])
+- *ColumnarToRow
+- FileScan parquet default.explain_temp1[val#x] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/home/runner/work/spark/spark/sql/core/spark-warehouse/org.apache.spark.sq...], PartitionFilters: ...
```
### Does this PR introduce _any_ user-facing change?
No, a new config.
### How was this patch tested?
new test.
Closes#29688 from ulysses-you/SPARK-32827.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Since the data is serialized on the Python side, we should make cache() in PySpark dataframes use StorageLevel.MEMORY_AND_DISK mode which has deserialized=false. This change was done to `pyspark/rdd.py` as part of SPARK-2014 but was missed from `pyspark/dataframe.py`
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Using existing tests
Closes#29242 from abhishekd0907/SPARK-31448.
Authored-by: Abhishek Dixit <abhishekdixit0907@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR adds test cases for the result set metadata checking for Spark's `ExecuteStatementOperation` to make the JDBC API more future-proofing because any server-side change may affect the client compatibility.
### Why are the changes needed?
add test to prevent potential silent behavior change for JDBC users.
### Does this PR introduce _any_ user-facing change?
NO, test only
### How was this patch tested?
add new test
Closes#29746 from yaooqinn/SPARK-32874.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Processing for `ThreadSafeRpcEndpoint` is controlled by `numActiveThreads` in `Inbox`. Now if any fatal error happens during `Inbox.process`, `numActiveThreads` is not reduced. Then other threads can not process messages in that inbox, which causes the endpoint to "hang". For other type of endpoints, we also should keep `numActiveThreads` correct.
This problem is more serious in previous Spark 2.x versions since the driver, executor and block manager endpoints are all thread safe endpoints.
To fix this, we should reduce the number of active threads if fatal error happens in `Inbox.process`.
### Why are the changes needed?
`numActiveThreads` is not correct when fatal error happens and will cause the described problem.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Add a new test.
Closes#29580 from wzhfy/deal_with_fatal_error.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR refactors the way we propagate the options from the `SparkSession.Builder` to the` SessionState`. This currently done via a mutable map inside the SparkSession. These setting settings are then applied **after** the Session. This is a bit confusing when you expect something to be set when constructing the `SessionState`. This PR passes the options as a constructor parameter to the `SessionStateBuilder` and this will set the options when the configuration is created.
### Why are the changes needed?
It makes it easier to reason about the configurations set in a SessionState than before. We recently had an incident where someone was using `SparkSessionExtensions` to create a planner rule that relied on a conf to be set. While this is in itself probably incorrect usage, it still illustrated this somewhat funky behavior.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests.
Closes#29752 from hvanhovell/SPARK-32879.
Authored-by: herman <herman@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to mark the following suite as `ExtendedSQLTest` to reduce GitHub Action test time.
- TPCDSQuerySuite
- TPCDSQueryANSISuite
- TPCDSQueryWithStatsSuite
### Why are the changes needed?
Currently, the longest GitHub Action task is `Build and test / Build modules: sql - other tests` with `1h 57m 10s` while `Build and test / Build modules: sql - slow tests` takes `42m 20s`. With this PR, we can move the workload from `other tests` to `slow tests` task and reduce the total waiting time about 7 ~ 8 minutes.
### Does this PR introduce _any_ user-facing change?
No. This is a test-only change.
### How was this patch tested?
Pass the GitHub Action with the reduced running time.
Closes#29755 from dongjoon-hyun/SPARK-SLOWTEST.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to avoid scheduling the (non-zombie) TaskSetManager which has no pending tasks.
### Why are the changes needed?
Currently, Spark always tries to schedule a (non-zombie) TaskSetManager even if it has no pending tasks. This causes notable problems for the barrier TaskSetManager: 1. `calculateAvailableSlots` can be called for multiple times for a launched barrier TaskSetManager; 2. user would see "Skip current round of resource offers for barrier stage" log message for
a launched barrier TaskSetManager all the time until the barrier TaskSetManager finishes, which is quite confused.
Besides, scheduling a TaskSetManager always involves many function invocations even if there're no pending tasks.
Therefore, I think we can skip those un-schedulable TasksetManagers to avoid the potential overhead.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass existing tests.
Closes#29750 from Ngone51/filter-out-unschedulable-stage.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
In TorrentBroadcast.scala
```scala
L133: if (!blockManager.putSingle(broadcastId, value, MEMORY_AND_DISK, tellMaster = false))
L137: TorrentBroadcast.blockifyObject(value, blockSize, SparkEnv.get.serializer, compressionCodec)
L147: if (!blockManager.putBytes(pieceId, bytes, MEMORY_AND_DISK_SER, tellMaster = true))
```
After the original value is saved successfully(TorrentBroadcast.scala: L133), but the following `blockifyObject()`(L137) or store piece(L147) steps are failed. There is no opportunity to release broadcast from memory.
This patch is to remove all pieces of the broadcast when failed to blockify or failed to store some pieces of a broadcast.
### Why are the changes needed?
We use Spark thrift-server as a long-running service. A bad query submitted a heavy BroadcastNestLoopJoin operation and made driver full GC. We killed the bad query but we found the driver's memory usage was still high and full GCs were still frequent. By investigating with GC dump and log, we found the broadcast may memory leak.
> 2020-08-19T18:54:02.824-0700: [Full GC (Allocation Failure)
2020-08-19T18:54:02.824-0700: [Class Histogram (before full gc):
116G->112G(170G), 184.9121920 secs]
[Eden: 32.0M(7616.0M)->0.0B(8704.0M) Survivors: 1088.0M->0.0B Heap: 116.4G(170.0G)->112.9G(170.0G)], [Metaspace: 177285K->177270K(182272K)]
1: 676531691 72035438432 [B
2: 676502528 32472121344 org.apache.spark.sql.catalyst.expressions.UnsafeRow
3: 99551 12018117568 [Ljava.lang.Object;
4: 26570 4349629040 [I
5: 6 3264536688 [Lorg.apache.spark.sql.catalyst.InternalRow;
6: 1708819 256299456 [C
7: 2338 179615208 [J
8: 1703669 54517408 java.lang.String
9: 103860 34896960 org.apache.spark.status.TaskDataWrapper
10: 177396 25545024 java.net.URI
...
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually test. This UT is hard to write and the patch is straightforward.
Closes#29558 from LantaoJin/SPARK-32715.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR appends `toMap` to `Map` instances with `filterKeys` if such maps is to be concatenated with another maps.
### Why are the changes needed?
As of Scala 2.13, Map#filterKeys return a MapView, not the original Map type.
This can cause compile error.
```
/sql/DataFrameReader.scala:279: type mismatch;
[error] found : Iterable[(String, String)]
[error] required: java.util.Map[String,String]
[error] Error occurred in an application involving default arguments.
[error] val dsOptions = new CaseInsensitiveStringMap(finalOptions.asJava)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Compile passed with the following command.
`build/mvn -Pscala-2.13 -Phive -Phive-thriftserver -Pyarn -Pkubernetes -DskipTests test-compile`
Closes#29742 from sarutak/fix-filterKeys-issue.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}