### What changes were proposed in this pull request?
Hive 3.1.2 has been released. This PR upgrades the Hive Metastore Client to 3.1.2 for Hive 3.1.
Hive 3.1.2 release notes:
https://issues.apache.org/jira/secure/ReleaseNote.jspa?version=12344397&styleName=Html&projectId=12310843
### Why are the changes needed?
This is an improvement to support a newly release 3.1.2. Otherwise, it will throws `UnsupportedOperationException` if user `set spark.sql.hive.metastore.version=3.1.2`:
```scala
Exception in thread "main" java.lang.UnsupportedOperationException: Unsupported Hive Metastore version (3.1.2). Please set spark.sql.hive.metastore.version with a valid version.
at org.apache.spark.sql.hive.client.IsolatedClientLoader$.hiveVersion(IsolatedClientLoader.scala:109)
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing UT
Closes#25604 from wangyum/SPARK-28890.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR makes `spark.sql.statistics.fallBackToHdfs` not support Hive partitioned tables.
### Why are the changes needed?
The current implementation is incorrect for external partitions and it is expensive to support partitioned table with external partitions.
### Does this PR introduce any user-facing change?
Yes. But I think it will not change the join strategy because partitioned table usually very large.
### How was this patch tested?
unit test
Closes#25584 from wangyum/SPARK-28876.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR add test for set the partitioned bucketed data source table SerDe correctly.
### Why are the changes needed?
Improve test.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#25591 from wangyum/SPARK-27592-f1.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Currently we have 2 configs to specify which v2 sources should fallback to v1 code path. One config for read path, and one config for write path.
However, I found it's awkward to work with these 2 configs:
1. for `CREATE TABLE USING format`, should this be read path or write path?
2. for `V2SessionCatalog.loadTable`, we need to return `UnresolvedTable` if it's a DS v1 or we need to fallback to v1 code path. However, at that time, we don't know if the returned table will be used for read or write.
We don't have any new features or perf improvement in file source v2. The fallback API is just a safeguard if we have bugs in v2 implementations. There are not many benefits to support falling back to v1 for read and write path separately.
This PR proposes to merge these 2 configs into one.
## How was this patch tested?
existing tests
Closes#25465 from cloud-fan/merge-conf.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
This reverts commit 485ae6d181.
Closes#25563 from gatorsmile/revert.
Authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR removes the `canonicalize(attrs: AttributeSeq)` from `PlanExpression` and taking care of normalizing expressions in `QueryPlan`.
### Why are the changes needed?
`Expression` has already a `canonicalized` method and having the `canonicalize` method in `PlanExpression` is confusing.
### Does this PR introduce any user-facing change?
Removes the `canonicalize` plan from `PlanExpression`. Also renames the `normalizeExprId` to `normalizeExpressions` in query plan.
### How was this patch tested?
This PR is a refactoring and passes the existing tests
Closes#25534 from dbaliafroozeh/ImproveCanonicalizeAPI.
Authored-by: Ali Afroozeh <ali.afroozeh@databricks.com>
Signed-off-by: herman <herman@databricks.com>
### What changes were proposed in this pull request?
This PR aims to annotate `HiveExternalCatalogVersionsSuite` with `ExtendedHiveTest`.
### Why are the changes needed?
`HiveExternalCatalogVersionsSuite` is an outstanding test in terms of testing time. This PR aims to allow skipping this test suite when we use `ExtendedHiveTest`.

### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Since Jenkins doesn't exclude `ExtendedHiveTest`, there is no difference in Jenkins testing.
This PR should be tested by manually by the following.
**BEFORE**
```
$ cd sql/hive
$ mvn package -Dtest=none -DwildcardSuites=org.apache.spark.sql.hive.HiveExternalCatalogVersionsSuite -Dtest.exclude.tags=org.apache.spark.tags.ExtendedHiveTest
...
Run starting. Expected test count is: 1
HiveExternalCatalogVersionsSuite:
22:32:16.218 WARN org.apache.hadoop.util.NativeCodeLoader: Unable to load ...
```
**AFTER**
```
$ cd sql/hive
$ mvn package -Dtest=none -DwildcardSuites=org.apache.spark.sql.hive.HiveExternalCatalogVersionsSuite -Dtest.exclude.tags=org.apache.spark.tags.ExtendedHiveTest
...
Run starting. Expected test count is: 0
HiveExternalCatalogVersionsSuite:
Run completed in 772 milliseconds.
Total number of tests run: 0
Suites: completed 2, aborted 0
Tests: succeeded 0, failed 0, canceled 0, ignored 0, pending 0
No tests were executed.
...
```
Closes#25550 from dongjoon-hyun/SPARK-28847.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This is a pure refactor PR, which creates a new class `CatalogManager` to track the registered v2 catalogs, and provide the catalog up functionality.
`CatalogManager` also tracks the current catalog/namespace. We will implement corresponding commands in other PRs, like `USE CATALOG my_catalog`
## How was this patch tested?
existing tests
Closes#25368 from cloud-fan/refactor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Create Hive Partitioned Table without specifying data type for partition column will success unexpectedly.
```HiveQL
// create a hive table partition by b, but the data type of b isn't specified.
CREATE TABLE tbl(a int) PARTITIONED BY (b) STORED AS parquet
```
In https://issues.apache.org/jira/browse/SPARK-26435 , PARTITIONED BY clause are extended to support Hive CTAS as following:
```ANTLR
// Before
(PARTITIONED BY '(' partitionColumns=colTypeList ')'
// After
(PARTITIONED BY '(' partitionColumns=colTypeList ')'|
PARTITIONED BY partitionColumnNames=identifierList) |
```
Create Table Statement like above case will pass the syntax check, and recognized as (PARTITIONED BY partitionColumnNames=identifierList) 。
This PR will check this case in visitCreateHiveTable and throw a exception which contains explicit error message to user.
## How was this patch tested?
Added tests.
Closes#25390 from lidinghao/hive-ddl-fix.
Authored-by: lihao <lihaowhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Hive using incorrect **InputFormat**(`org.apache.hadoop.mapred.SequenceFileInputFormat`) to read Spark's **Parquet** bucketed data source table.
Spark side:
```sql
spark-sql> CREATE TABLE t (c1 INT, c2 INT) USING parquet CLUSTERED BY (c1) SORTED BY (c1) INTO 2 BUCKETS;
2019-04-29 17:52:05 WARN HiveExternalCatalog:66 - Persisting bucketed data source table `default`.`t` into Hive metastore in Spark SQL specific format, which is NOT compatible with Hive.
spark-sql> DESC FORMATTED t;
c1 int NULL
c2 int NULL
# Detailed Table Information
Database default
Table t
Owner yumwang
Created Time Mon Apr 29 17:52:05 CST 2019
Last Access Thu Jan 01 08:00:00 CST 1970
Created By Spark 2.4.0
Type MANAGED
Provider parquet
Num Buckets 2
Bucket Columns [`c1`]
Sort Columns [`c1`]
Table Properties [transient_lastDdlTime=1556531525]
Location file:/user/hive/warehouse/t
Serde Library org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat org.apache.hadoop.mapred.SequenceFileInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
Storage Properties [serialization.format=1]
```
Hive side:
```sql
hive> DESC FORMATTED t;
OK
# col_name data_type comment
c1 int
c2 int
# Detailed Table Information
Database: default
Owner: root
CreateTime: Wed May 08 03:38:46 GMT-07:00 2019
LastAccessTime: UNKNOWN
Retention: 0
Location: file:/user/hive/warehouse/t
Table Type: MANAGED_TABLE
Table Parameters:
bucketing_version spark
spark.sql.create.version 3.0.0-SNAPSHOT
spark.sql.sources.provider parquet
spark.sql.sources.schema.bucketCol.0 c1
spark.sql.sources.schema.numBucketCols 1
spark.sql.sources.schema.numBuckets 2
spark.sql.sources.schema.numParts 1
spark.sql.sources.schema.numSortCols 1
spark.sql.sources.schema.part.0 {\"type\":\"struct\",\"fields\":[{\"name\":\"c1\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}},{\"name\":\"c2\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}}]}
spark.sql.sources.schema.sortCol.0 c1
transient_lastDdlTime 1557311926
# Storage Information
SerDe Library: org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
path file:/user/hive/warehouse/t
serialization.format 1
```
So it's non-bucketed table at Hive side. This pr set the `SerDe` correctly so Hive can read these tables.
Related code:
33f3c48cac/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala (L976-L990)f9776e3892/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveExternalCatalog.scala (L444-L459)
## How was this patch tested?
unit tests
Closes#24486 from wangyum/SPARK-27592.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR skip more test when testing with `JAVA_9` or later:
1. Skip `HiveExternalCatalogVersionsSuite` when testing with `JAVA_9` or later because our previous version does not support `JAVA_9` or later.
2. Skip 3 tests in `HiveSparkSubmitSuite` because the `spark.sql.hive.metastore.version` of these tests is lower than `2.0`, however Datanucleus 3.x seem does not support `JAVA_9` or later. Hive upgrade Datanucleus to 4.x from Hive 2.0([HIVE-6113](https://issues.apache.org/jira/browse/HIVE-6113)):
```
[info] Cause: org.datanucleus.exceptions.NucleusException: The java type java.lang.Long (jdbc-type="", sql-type="") cant be mapped for this datastore. No mapping is available.
[info] at org.datanucleus.store.rdbms.mapping.RDBMSMappingManager.getDatastoreMappingClass(RDBMSMappingManager.java:1215)
[info] at org.datanucleus.store.rdbms.mapping.RDBMSMappingManager.createDatastoreMapping(RDBMSMappingManager.java:1378)
[info] at org.datanucleus.store.rdbms.table.AbstractClassTable.addDatastoreId(AbstractClassTable.java:392)
[info] at org.datanucleus.store.rdbms.table.ClassTable.initializePK(ClassTable.java:1087)
[info] at org.datanucleus.store.rdbms.table.ClassTable.preInitialize(ClassTable.java:247)
```
Please note that this exclude only the tests related to the old metastore library, some other tests of `HiveSparkSubmitSuite` still fail on JDK9+.
## How was this patch tested?
manual tests:
Test with JDK 11:
```
[info] HiveExternalCatalogVersionsSuite:
[info] - backward compatibility !!! CANCELED !!! (37 milliseconds)
[info] HiveSparkSubmitSuite:
...
[info] - SPARK-8020: set sql conf in spark conf !!! CANCELED !!! (30 milliseconds)
[info] org.apache.commons.lang3.SystemUtils.isJavaVersionAtLeast(JAVA_9) was true (HiveSparkSubmitSuite.scala:130)
...
[info] - SPARK-9757 Persist Parquet relation with decimal column !!! CANCELED !!! (1 millisecond)
[info] org.apache.commons.lang3.SystemUtils.isJavaVersionAtLeast(JAVA_9) was true (HiveSparkSubmitSuite.scala:168)
...
[info] - SPARK-16901: set javax.jdo.option.ConnectionURL !!! CANCELED !!! (1 millisecond)
[info] org.apache.commons.lang3.SystemUtils.isJavaVersionAtLeast(JAVA_9) was true (HiveSparkSubmitSuite.scala:260)
...
```
Closes#25426 from wangyum/SPARK-28703.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR moves `udf_radians` from `HiveCompatibilitySuite` to `HiveQuerySuite` to make it easy to test with JDK 11 because it returns different value from JDK 9:
```java
public class TestRadians {
public static void main(String[] args) {
System.out.println(java.lang.Math.toRadians(57.2958));
}
}
```
```sh
[rootspark-3267648 ~]# javac TestRadians.java
[rootspark-3267648 ~]# /usr/lib/jdk-9.0.4+11/bin/java TestRadians
1.0000003575641672
[rootspark-3267648 ~]# /usr/lib/jdk-11.0.3/bin/java TestRadians
1.0000003575641672
[rootspark-3267648 ~]# /usr/lib/jdk8u222-b10/bin/java TestRadians
1.000000357564167
```
## How was this patch tested?
manual tests
Closes#25417 from wangyum/SPARK-28686.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
It seems Datanucleus 3.x can not support JDK 11:
```java
[info] Cause: org.datanucleus.exceptions.NucleusException: The java type java.lang.Long (jdbc-type="", sql-type="") cant be mapped for this datastore. No mapping is available.
[info] at org.datanucleus.store.rdbms.mapping.RDBMSMappingManager.getDatastoreMappingClass(RDBMSMappingManager.java:1215)
[info] at org.datanucleus.store.rdbms.mapping.RDBMSMappingManager.createDatastoreMapping(RDBMSMappingManager.java:1378)
[info] at org.datanucleus.store.rdbms.table.AbstractClassTable.addDatastoreId(AbstractClassTable.java:392)
[info] at org.datanucleus.store.rdbms.table.ClassTable.initializePK(ClassTable.java:1087)
[info] at org.datanucleus.store.rdbms.table.ClassTable.preInitialize(ClassTable.java:247)
```
Hive upgrade Datanucleus to 4.x from Hive 2.0([HIVE-6113](https://issues.apache.org/jira/browse/HIVE-6113)). This PR makes it skip `0.12`, `0.13`, `0.14`, `1.0`, `1.1` and `1.2` when testing with JDK 11.
Note that, this pr will not fix sql read hive materialized view. It's another issue:
```
3.0: sql read hive materialized view *** FAILED *** (1 second, 521 milliseconds)
3.1: sql read hive materialized view *** FAILED *** (1 second, 536 milliseconds)
```
## How was this patch tested?
manual tests:
```shell
export JAVA_HOME="/usr/lib/jdk-11.0.3"
build/sbt "hive/test-only *.VersionsSuite *.HiveClientSuites" -Phive -Phadoop-3.2
```
Closes#25405 from wangyum/SPARK-28685.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Sometimes when you explain a query, you will get stuck for a while. What's worse, you will get stuck again if you explain again.
This is caused by `FileSourceScanExec`:
1. In its `toString`, it needs to report the number of partitions it reads. This needs to query the hive metastore.
2. In its `outputOrdering`, it needs to get all the files. This needs to query the hive metastore.
This PR fixes by:
1. `toString` do not need to report the number of partitions it reads. We should report it via SQL metrics.
2. The `outputOrdering` is not very useful. We can only apply it if a) all the bucket columns are read. b) there is only one file in each bucket. This condition is really hard to meet, and even if we meet, sorting an already sorted file is pretty fast and avoiding the sort is not that useful. I think it's worth to give up this optimization so that explain don't need to get stuck.
## How was this patch tested?
existing tests
Closes#25328 from cloud-fan/ui.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Implements the `DESCRIBE TABLE` logical and physical plans for data source v2 tables.
## How was this patch tested?
Added unit tests to `DataSourceV2SQLSuite`.
Closes#25040 from mccheah/describe-table-v2.
Authored-by: mcheah <mcheah@palantir.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This patch tries to keep consistency whenever UTF-8 charset is needed, as using `StandardCharsets.UTF_8` instead of using "UTF-8". If the String type is needed, `StandardCharsets.UTF_8.name()` is used.
This change also brings the benefit of getting rid of `UnsupportedEncodingException`, as we're providing `Charset` instead of `String` whenever possible.
This also changes some private Catalyst helper methods to operate on encodings as `Charset` objects rather than strings.
## How was this patch tested?
Existing unit tests.
Closes#25335 from HeartSaVioR/SPARK-28601.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This is an alternative solution of https://github.com/apache/spark/pull/24442 . It fails the query if ambiguous self join is detected, instead of trying to disambiguate it. The problem is that, it's hard to come up with a reasonable rule to disambiguate, the rule proposed by #24442 is mostly a heuristic.
### background of the self-join problem:
This is a long-standing bug and I've seen many people complaining about it in JIRA/dev list.
A typical example:
```
val df1 = …
val df2 = df1.filter(...)
df1.join(df2, df1("a") > df2("a")) // returns empty result
```
The root cause is, `Dataset.apply` is so powerful that users think it returns a column reference which can point to the column of the Dataset at anywhere. This is not true in many cases. `Dataset.apply` returns an `AttributeReference` . Different Datasets may share the same `AttributeReference`. In the example above, `df2` adds a Filter operator above the logical plan of `df1`, and the Filter operator reserves the output `AttributeReference` of its child. This means, `df1("a")` is exactly the same as `df2("a")`, and `df1("a") > df2("a")` always evaluates to false.
### The rule to detect ambiguous column reference caused by self join:
We can reuse the infra in #24442 :
1. each Dataset has a globally unique id.
2. the `AttributeReference` returned by `Dataset.apply` carries the ID and column position(e.g. 3rd column of the Dataset) via metadata.
3. the logical plan of a `Dataset` carries the ID via `TreeNodeTag`
When self-join happens, the analyzer asks the right side plan of join to re-generate output attributes with new exprIds. Based on it, a simple rule to detect ambiguous self join is:
1. find all column references (i.e. `AttributeReference`s with Dataset ID and col position) in the root node of a query plan.
2. for each column reference, traverse the query plan tree, find a sub-plan that carries Dataset ID and the ID is the same as the one in the column reference.
3. get the corresponding output attribute of the sub-plan by the col position in the column reference.
4. if the corresponding output attribute has a different exprID than the column reference, then it means this sub-plan is on the right side of a self-join and has regenerated its output attributes. This is an ambiguous self join because the column reference points to a table being self-joined.
## How was this patch tested?
existing tests and new test cases
Closes#25107 from cloud-fan/new-self-join.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
In case of CatalogFileIndex datasource table, sizeInBytes is always coming as default size in bytes, which is 8.0EB (Even when the user give fallBackToHdfsForStatsEnabled=true) . So, the datasource table which has CatalogFileIndex, always prefer SortMergeJoin, instead of BroadcastJoin, even though the size is below broadcast join threshold.
In this PR, In case of CatalogFileIndex table, if we enable "fallBackToHdfsForStatsEnabled=true", then the computeStatistics get the sizeInBytes from the hdfs and we get the actual size of the table. Hence, during join operation, when the table size is below broadcast threshold, it will prefer broadCastHashJoin instead of SortMergeJoin.
Added UT
Closes#22502 from shahidki31/SPARK-25474.
Authored-by: shahid <shahidki31@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Support multiple catalogs in the following InsertTable use cases:
- INSERT INTO [TABLE] catalog.db.tbl
- INSERT OVERWRITE TABLE catalog.db.tbl
Support matrix:
Overwrite|Partitioned Table|Partition Clause |Partition Overwrite Mode|Action
---------|-----------------|-----------------|------------------------|-----
false|*|*|*|AppendData
true|no|(empty)|*|OverwriteByExpression(true)
true|yes|p1,p2 or p1 or p2 or (empty)|STATIC|OverwriteByExpression(true)
true|yes|p2,p2 or p1 or p2 or (empty)|DYNAMIC|OverwritePartitionsDynamic
true|yes|p1=23,p2=3|*|OverwriteByExpression(p1=23 and p2=3)
true|yes|p1=23,p2 or p1=23|STATIC|OverwriteByExpression(p1=23)
true|yes|p1=23,p2 or p1=23|DYNAMIC|OverwritePartitionsDynamic
Notes:
- Assume the partitioned table has 2 partitions: p1 and p2.
- `STATIC` is the default Partition Overwrite Mode for data source tables.
- DSv2 tables currently do not support `IfPartitionNotExists`.
## How was this patch tested?
New tests.
All existing catalyst and sql/core tests.
Closes#24832 from jzhuge/SPARK-27845-pr.
Lead-authored-by: Ryan Blue <blue@apache.org>
Co-authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Burak Yavuz <brkyvz@gmail.com>
## What changes were proposed in this pull request?
The bug fixed by https://github.com/apache/spark/pull/24886 is caused by Hive's `loadDynamicPartitions`. It's better to keep the fix surgical and put it right before we call `loadDynamicPartitions`.
This also makes the fix safer, instead of analyzing all the callers of `saveAsHiveFile` and proving that they are safe.
## How was this patch tested?
N/A
Closes#25234 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR change `CalendarIntervalType`'s readable string representation from `calendarinterval` to `interval`.
## How was this patch tested?
Existing UT
Closes#25225 from wangyum/SPARK-28469.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
There are some hardcoded configs, using config entry to replace them.
## How was this patch tested?
Existing UT
Closes#25059 from WangGuangxin/ConfigEntry.
Authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This fixes a problem where it is possible to create a v2 table using the default catalog that cannot be loaded with the session catalog. A session catalog should be used when the v1 catalog is responsible for tables with no catalog in the table identifier.
* Adds a v2 catalog implementation that delegates to the analyzer's SessionCatalog
* Uses the v2 session catalog for CTAS and CreateTable when the provider is a v2 provider and no v2 catalog is in the table identifier
* Updates catalog lookup to always provide the default if it is set for consistent behavior
## How was this patch tested?
* Adds a new test suite for the v2 session catalog that validates the TableCatalog API
* Adds test cases in PlanResolutionSuite to validate the v2 session catalog is used
* Adds test suite for LookupCatalog with a default catalog
Closes#24768 from rdblue/SPARK-27919-add-v2-session-catalog.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The interval conversion behavior is same with the PostgreSQL.
https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/interval.sql#L180-L203
## How was this patch tested?
UT.
Closes#25000 from lipzhu/SPARK-28107.
Lead-authored-by: Zhu, Lipeng <lipzhu@ebay.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Lipeng Zhu <lipzhu@icloud.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
The sub-second part of the interval should be padded before parsing. Currently, Spark gives a correct value only when there is 9 digits below `.`.
```
spark-sql> select interval '0 0:0:0.123456789' day to second;
interval 123 milliseconds 456 microseconds
spark-sql> select interval '0 0:0:0.12345678' day to second;
interval 12 milliseconds 345 microseconds
spark-sql> select interval '0 0:0:0.1234' day to second;
interval 1 microseconds
```
## How was this patch tested?
Pass the Jenkins with the fixed test cases.
Closes#25079 from dongjoon-hyun/SPARK-28308.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr add calculate local directory size to `SQLTestUtils`.
We can avoid these changes after this pr:
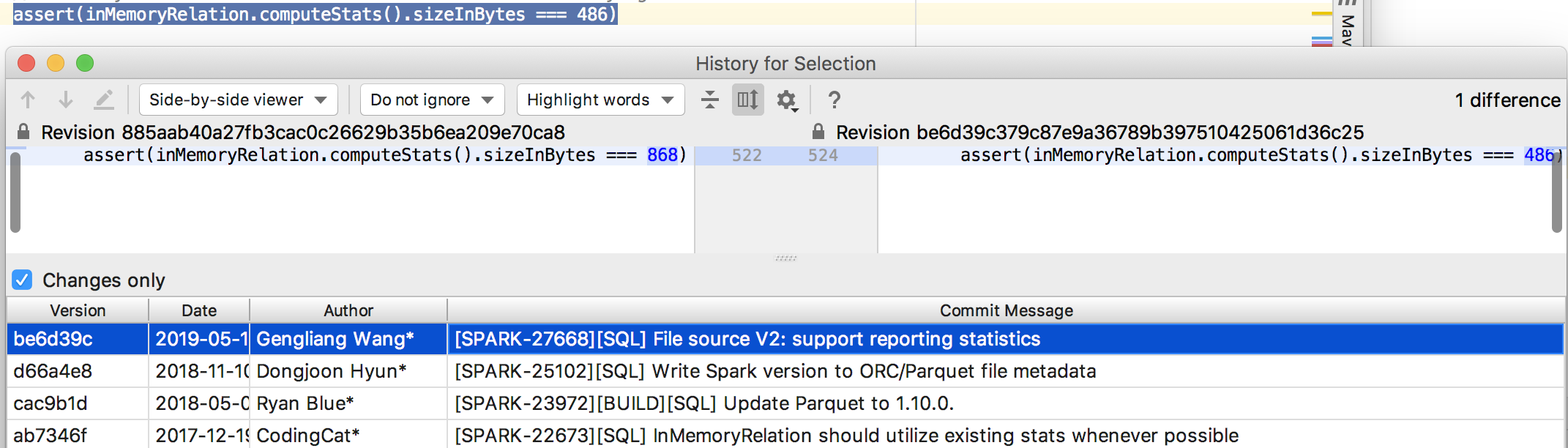
## How was this patch tested?
Existing test
Closes#25014 from wangyum/SPARK-28216.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This is a small follow-up for SPARK-28054 to fix wrong indent and use `withSQLConf` as suggested by gatorsmile.
## How was this patch tested?
Existing tests.
Closes#24971 from viirya/SPARK-28054-followup.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Currently, ORC's `inferSchema` is implemented as randomly choosing one ORC file and reading its schema.
This PR follows the behavior of Parquet, it implements merge schemas logic by reading all ORC files in parallel through a spark job.
Users can enable merge schema by `spark.read.orc("xxx").option("mergeSchema", "true")` or by setting `spark.sql.orc.mergeSchema` to `true`, the prior one has higher priority.
## How was this patch tested?
tested by UT OrcUtilsSuite.scala
Closes#24043 from WangGuangxin/SPARK-11412.
Lead-authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com>
Co-authored-by: wangguangxin.cn <wangguangxin.cn@bytedance.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Avoid hard-coded config: `spark.sql.globalTempDatabase`.
## How was this patch tested?
N/A
Closes#24979 from wangyum/SPARK-28179.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In #24068, IvanVergiliev fixes the issue that OrcFilters.createBuilder has exponential complexity in the height of the filter tree due to the way the check-and-build pattern is implemented.
Comparing to the approach in #24068, I propose a simple solution for the issue:
1. separate the logic of building a convertible filter tree and the actual SearchArgument builder, since the two procedures are different and their return types are different. Thus the new introduced class `ActionType`,`TrimUnconvertibleFilters` and `BuildSearchArgument` in #24068 can be dropped. The code is more readable.
2. For most of the leaf nodes, the convertible result is always Some(node), we can abstract it like this PR.
3. The code is actually small changes on the previous code. See https://github.com/apache/spark/pull/24783
## How was this patch tested?
Run the benchmark provided in #24068:
```
val schema = StructType.fromDDL("col INT")
(20 to 30).foreach { width =>
val whereFilter = (1 to width).map(i => EqualTo("col", i)).reduceLeft(Or)
val start = System.currentTimeMillis()
OrcFilters.createFilter(schema, Seq(whereFilter))
println(s"With $width filters, conversion takes ${System.currentTimeMillis() - start} ms")
}
```
Result:
```
With 20 filters, conversion takes 6 ms
With 21 filters, conversion takes 0 ms
With 22 filters, conversion takes 0 ms
With 23 filters, conversion takes 0 ms
With 24 filters, conversion takes 0 ms
With 25 filters, conversion takes 0 ms
With 26 filters, conversion takes 0 ms
With 27 filters, conversion takes 0 ms
With 28 filters, conversion takes 0 ms
With 29 filters, conversion takes 0 ms
With 30 filters, conversion takes 0 ms
```
Also verified with Unit tests.
Closes#24910 from gengliangwang/refactorOrcFilters.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
When we use upper case partition name in Hive table, like:
```
CREATE TABLE src (KEY STRING, VALUE STRING) PARTITIONED BY (DS STRING)
```
Then, `insert into table` query doesn't work
```
INSERT INTO TABLE src PARTITION(ds) SELECT 'k' key, 'v' value, '1' ds
// or
INSERT INTO TABLE src PARTITION(DS) SELECT 'k' KEY, 'v' VALUE, '1' DS
```
```
[info] org.apache.spark.sql.AnalysisException:
org.apache.hadoop.hive.ql.metadata.Table.ValidationFailureSemanticException: Partition spec {ds=, DS=1} contains non-partition columns;
```
As Hive metastore is not case preserving and keeps partition columns with lower cased names, we lowercase column names in partition spec before passing to Hive client. But we write upper case column names in partition paths.
However, when calling `loadDynamicPartitions` to do `insert into table` for dynamic partition, Hive calculates full path spec for partition paths. So it calculates a partition spec like `{ds=, DS=1}` in above case and fails partition column validation. This patch is proposed to fix the issue by lowercasing the column names in written partition paths for Hive partitioned table.
This fix touchs `saveAsHiveFile` method, which is used in `InsertIntoHiveDirCommand` and `InsertIntoHiveTable` commands. Among them, only `InsertIntoHiveTable` passes `partitionAttributes` parameter. So I think this change only affects `InsertIntoHiveTable` command.
## How was this patch tested?
Added test.
Closes#24886 from viirya/SPARK-28054.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Currently using hive udf, the parameter is struct type, there will be an exception thrown.
No handler for Hive UDF 'xxxUDF': java.lang.RuntimeException: Hive doesn't support the constant type [StructType(StructField(name,StringType,true), StructField(value,DecimalType(3,1),true))]
## How was this patch tested?
added new UT
Closes#24846 from cxzl25/hive_udf_literal_struct_type.
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The [SPARK-27403](https://issues.apache.org/jira/browse/SPARK-27403) fixed CTAS cannot update statistics even if `spark.sql.statistics.size.autoUpdate.enabled` is enabled, as mentioned in [SPARK-23263](https://issues.apache.org/jira/browse/SPARK-23263).
This pr adds tests for that fix.
## How was this patch tested?
N/A
Closes#20430 from wangyum/SPARK-23263.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
`OrcFilters.createBuilder` has exponential complexity in the height of the filter tree due to the way the check-and-build pattern is implemented. We've hit this in production by passing a `Column` filter to Spark directly, with a job taking multiple hours for a simple set of ~30 filters. This PR changes the checking logic so that the conversion has linear complexity in the size of the tree instead of exponential in its height.
Right now, due to the way ORC `SearchArgument` works, the code is forced to do two separate phases when converting a given Spark filter to an ORC filter:
1. Check if the filter is convertible.
2. Only if the check in 1. succeeds, perform the actual conversion into the resulting ORC filter.
However, there's one detail which is the culprit in the exponential complexity: phases 1. and 2. are both done using the exact same method. The resulting exponential complexity is easiest to see in the `NOT` case - consider the following code:
```
val f1 = col("id") === lit(5)
val f2 = !f1
val f3 = !f2
val f4 = !f3
val f5 = !f4
```
Now, when we run `createBuilder` on `f5`, we get the following behaviour:
1. call `createBuilder(f4)` to check if the child `f4` is convertible
2. call `createBuilder(f4)` to actually convert it
This seems fine when looking at a single level, but what actually ends up happening is:
- `createBuilder(f3)` will then recursively be called 4 times - 2 times in step 1., and two times in step 2.
- `createBuilder(f2)` will be called 8 times - 4 times in each top-level step, 2 times in each sub-step.
- `createBuilder(f1)` will be called 16 times.
As a result, having a tree of height > 30 leads to billions of calls to `createBuilder`, heap allocations, and so on and can take multiple hours.
The way this PR solves this problem is by separating the `check` and `convert` functionalities into separate functions. This way, the call to `createBuilder` on `f5` above would look like this:
1. call `isConvertible(f4)` to check if the child `f4` is convertible - amortized constant complexity
2. call `createBuilder(f4)` to actually convert it - linear complexity in the size of the subtree.
This way, we get an overall complexity that's linear in the size of the filter tree, allowing us to convert tree with 10s of thousands of nodes in milliseconds.
The reason this split (`check` and `build`) is possible is that the checking never actually depends on the actual building of the filter. The `check` part of `createBuilder` depends mainly on:
- `isSearchableType` for leaf nodes, and
- `check`-ing the child filters for composite nodes like NOT, AND and OR.
Situations like the `SearchArgumentBuilder` throwing an exception while building the resulting ORC filter are not handled right now - they just get thrown out of the class, and this change preserves this behaviour.
This PR extracts this part of the code to a separate class which allows the conversion to make very efficient checks to confirm that a given child is convertible before actually converting it.
Results:
Before:
- converting a skewed tree with a height of ~35 took about 6-7 hours.
- converting a skewed tree with hundreds or thousands of nodes would be completely impossible.
Now:
- filtering against a skewed tree with a height of 1500 in the benchmark suite finishes in less than 10 seconds.
## Steps to reproduce
```scala
val schema = StructType.fromDDL("col INT")
(20 to 30).foreach { width =>
val whereFilter = (1 to width).map(i => EqualTo("col", i)).reduceLeft(Or)
val start = System.currentTimeMillis()
OrcFilters.createFilter(schema, Seq(whereFilter))
println(s"With $width filters, conversion takes ${System.currentTimeMillis() - start} ms")
}
```
### Before this PR
```
With 20 filters, conversion takes 363 ms
With 21 filters, conversion takes 496 ms
With 22 filters, conversion takes 939 ms
With 23 filters, conversion takes 1871 ms
With 24 filters, conversion takes 3756 ms
With 25 filters, conversion takes 7452 ms
With 26 filters, conversion takes 14978 ms
With 27 filters, conversion takes 30519 ms
With 28 filters, conversion takes 60361 ms // 1 minute
With 29 filters, conversion takes 126575 ms // 2 minutes 6 seconds
With 30 filters, conversion takes 257369 ms // 4 minutes 17 seconds
```
### After this PR
```
With 20 filters, conversion takes 12 ms
With 21 filters, conversion takes 0 ms
With 22 filters, conversion takes 1 ms
With 23 filters, conversion takes 0 ms
With 24 filters, conversion takes 1 ms
With 25 filters, conversion takes 1 ms
With 26 filters, conversion takes 0 ms
With 27 filters, conversion takes 1 ms
With 28 filters, conversion takes 0 ms
With 29 filters, conversion takes 1 ms
With 30 filters, conversion takes 0 ms
```
## How was this patch tested?
There are no changes in behaviour, and the existing tests pass. Added new benchmarks that expose the problematic behaviour and they finish quickly with the changes applied.
Closes#24068 from IvanVergiliev/optimize-orc-filters.
Authored-by: Ivan Vergiliev <ivan.vergiliev@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Migrate Parquet to File Data Source V2
## How was this patch tested?
Unit test
Closes#24327 from gengliangwang/parquetV2.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Currently, SparkSQL can support interval format like this.
```sql
SELECT INTERVAL '0 23:59:59.155' DAY TO SECOND
```
Like Presto/Teradata, this PR aims to support grammar like below.
```sql
SELECT INTERVAL '23:59:59.155' HOUR TO SECOND
```
Although we can add a new function for this pattern, we had better extend the existing code to handle a missing day case. So, the following is also supported.
```sql
SELECT INTERVAL '23:59:59.155' DAY TO SECOND
SELECT INTERVAL '1 23:59:59.155' HOUR TO SECOND
```
Currently Vertica/Teradata/Postgresql/SQL Server have fully support of below interval functions.
- interval ... year to month
- interval ... day to hour
- interval ... day to minute
- interval ... day to second
- interval ... hour to minute
- interval ... hour to second
- interval ... minute to second
https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/LanguageElements/Literals/interval-qualifier.htmdf1a699e5b/src/test/regress/sql/interval.sql (L180-L203)https://docs.teradata.com/reader/S0Fw2AVH8ff3MDA0wDOHlQ/KdCtT3pYFo~_enc8~kGKVwhttps://docs.microsoft.com/en-us/sql/odbc/reference/appendixes/interval-literals?view=sql-server-2017
## How was this patch tested?
Pass the Jenkins with the updated test cases.
Closes#24472 from lipzhu/SPARK-27578.
Lead-authored-by: Zhu, Lipeng <lipzhu@ebay.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Lipeng Zhu <lipzhu@icloud.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Support multi-catalog in the following SELECT code paths:
- SELECT * FROM catalog.db.tbl
- TABLE catalog.db.tbl
- JOIN or UNION tables from different catalogs
- SparkSession.table("catalog.db.tbl")
- CTE relation
- View text
## How was this patch tested?
New unit tests.
All existing unit tests in catalyst and sql core.
Closes#24741 from jzhuge/SPARK-27322-pr.
Authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The new Spark ThriftServer SparkGetTablesOperation implemented in https://github.com/apache/spark/pull/22794 does a catalog.getTableMetadata request for every table. This can get very slow for large schemas (~50ms per table with an external Hive metastore).
Hive ThriftServer GetTablesOperation uses HiveMetastoreClient.getTableObjectsByName to get table information in bulk, but we don't expose that through our APIs that go through Hive -> HiveClientImpl (HiveClient) -> HiveExternalCatalog (ExternalCatalog) -> SessionCatalog.
If we added and exposed getTableObjectsByName through our catalog APIs, we could resolve that performance problem in SparkGetTablesOperation.
## How was this patch tested?
Add UT
Closes#24774 from LantaoJin/SPARK-27899.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
It seems that some users are using Hive 3.0.0. This pr makes it support Hive 3.0 metastore.
## How was this patch tested?
unit tests
Closes#24688 from wangyum/SPARK-26145.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This is a part of #24774, to reduce the code changes made by that.
## How was this patch tested?
Exist UTs.
Closes#24803 from LantaoJin/SPARK-27899_refactor.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR is a follow-up of https://github.com/apache/spark/pull/21790 which causes a regression to show misleading warnings always at first invocation for all Hive function. Hive fallback lookup should not be warned. It's a normal process in function lookups.
**CURRENT (Showing `NoSuchFunctionException` and working)**
```scala
scala> sql("select histogram_numeric(a,2) from values(1) T(a)").show
19/06/02 22:02:10 WARN HiveSessionCatalog: Encountered a failure during looking up
function: org.apache.spark.sql.catalyst.analysis.NoSuchFunctionException:
Undefined function: 'histogram_numeric'. This function is neither a registered temporary
function nor a permanent function registered in the database 'default'.;
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.failFunctionLookup(SessionCatalog.scala:1234)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.lookupFunction(SessionCatalog.scala:1302)
...
+------------------------+
|histogram_numeric( a, 2)|
+------------------------+
| [[1.0, 1.0]]|
+------------------------+
```
## How was this patch tested?
Manually execute the above query.
Closes#24773 from dongjoon-hyun/SPARK-24544.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr moves Hive test jars(`hive-contrib-0.13.1.jar`, `hive-hcatalog-core-0.13.1.jar`, `hive-contrib-2.3.5.jar` and `hive-hcatalog-core-2.3.5.jar`) to maven dependency.
## How was this patch tested?
Existing test
Please note that this pr need test with `maven` and `sbt`.
Closes#24751 from wangyum/SPARK-27831.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
When query returns zero rows, the HiveUDAFFunction throws NPE
## CASE 1:
create table abc(a int)
select histogram_numeric(a,2) from abc // NPE
```
Job aborted due to stage failure: Task 0 in stage 1.0 failed 1 times, most recent failure: Lost task 0.0 in stage 1.0 (TID 0, localhost, executor driver): java.lang.NullPointerException
at org.apache.spark.sql.hive.HiveUDAFFunction.eval(hiveUDFs.scala:471)
at org.apache.spark.sql.hive.HiveUDAFFunction.eval(hiveUDFs.scala:315)
at org.apache.spark.sql.catalyst.expressions.aggregate.TypedImperativeAggregate.eval(interfaces.scala:543)
at org.apache.spark.sql.execution.aggregate.AggregationIterator.$anonfun$generateResultProjection$5(AggregationIterator.scala:231)
at org.apache.spark.sql.execution.aggregate.ObjectAggregationIterator.outputForEmptyGroupingKeyWithoutInput(ObjectAggregationIterator.scala:97)
at org.apache.spark.sql.execution.aggregate.ObjectHashAggregateExec.$anonfun$doExecute$2(ObjectHashAggregateExec.scala:132)
at org.apache.spark.sql.execution.aggregate.ObjectHashAggregateExec.$anonfun$doExecute$2$adapted(ObjectHashAggregateExec.scala:107)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndexInternal$2(RDD.scala:839)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndexInternal$2$adapted(RDD.scala:839)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:327)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:291)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:327)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:291)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:327)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:291)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:122)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:425)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1350)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:428)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
```
## CASE 2:
create table abc(a int)
insert into abc values (1)
select histogram_numeric(a,2) from abc where a=3 // NPE
```
Job aborted due to stage failure: Task 0 in stage 4.0 failed 1 times, most recent failure: Lost task 0.0 in stage 4.0 (TID 5, localhost, executor driver): java.lang.NullPointerException
at org.apache.spark.sql.hive.HiveUDAFFunction.serialize(hiveUDFs.scala:477)
at org.apache.spark.sql.hive.HiveUDAFFunction.serialize(hiveUDFs.scala:315)
at org.apache.spark.sql.catalyst.expressions.aggregate.TypedImperativeAggregate.serializeAggregateBufferInPlace(interfaces.scala:570)
at org.apache.spark.sql.execution.aggregate.AggregationIterator.$anonfun$generateResultProjection$6(AggregationIterator.scala:254)
at org.apache.spark.sql.execution.aggregate.ObjectAggregationIterator.outputForEmptyGroupingKeyWithoutInput(ObjectAggregationIterator.scala:97)
at org.apache.spark.sql.execution.aggregate.ObjectHashAggregateExec.$anonfun$doExecute$2(ObjectHashAggregateExec.scala:132)
at org.apache.spark.sql.execution.aggregate.ObjectHashAggregateExec.$anonfun$doExecute$2$adapted(ObjectHashAggregateExec.scala:107)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndexInternal$2(RDD.scala:839)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndexInternal$2$adapted(RDD.scala:839)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:327)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:291)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:327)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:291)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:94)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:122)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:425)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1350)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:428)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
```
Hence add a check not avoid NPE
## How was this patch tested?
Added new UT case
Closes#24762 from ajithme/hiveudaf.
Authored-by: Ajith <ajith2489@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr wrap all `PrintWriter` with `Utils.tryWithResource` to prevent resource leak.
## How was this patch tested?
Existing test
Closes#24739 from wangyum/SPARK-27875.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}