### What changes were proposed in this pull request?
In the PR, I propose to disable ANSI intervals as the result of dates/timestamp subtraction in `ExtractBenchmark` and benchmark only legacy intervals because `EXTRACT( .. FROM ..)` doesn't support ANSI intervals so far.
### Why are the changes needed?
This fixes the benchmark failure:
```
[info] Running case: YEAR of interval
[error] Exception in thread "main" org.apache.spark.sql.AnalysisException: cannot resolve 'year((subtractdates(CAST(timestamp_seconds(id) AS DATE), DATE '0001-01-01') + subtracttimestamps(timestamp_seconds(id), TIMESTAMP '1000-01-01 01:02:03.123456')))' due to data type mismatch: argument 1 requires date type, however, '(subtractdates(CAST(timestamp_seconds(id) AS DATE), DATE '0001-01-01') + subtracttimestamps(timestamp_seconds(id), TIMESTAMP '1000-01-01 01:02:03.123456'))' is of day-time interval type.; line 1 pos 0;
[error] 'Project [extract(YEAR, (subtractdates(cast(timestamp_seconds(id#1456L) as date), 0001-01-01, false) + subtracttimestamps(timestamp_seconds(id#1456L), 1000-01-01 01:02:03.123456, false, Some(Europe/Moscow)))) AS YEAR#1458]
[error] +- Range (1262304000, 1272304000, step=1, splits=Some(1))
[error] at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:42)
[error] at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$$nestedInanonfun$checkAnalysis$1$2.applyOrElse(CheckAnalysis.scala:194)
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the `ExtractBenchmark` benchmark via:
```
$ build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.ExtractBenchmark"
```
Closes#32035 from MaxGekk/fix-ExtractBenchmark.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR introduces a new analysis rule `DeduplicateRelations`, which deduplicates any duplicate relations in a plan first and then deduplicates conflicting attributes(which resued the `dedupRight` of `ResolveReferences`).
### Why are the changes needed?
`CostBasedJoinReorder` could fail when applying on self-join, e.g.,
```scala
// test in JoinReorderSuite
test("join reorder with self-join") {
val plan = t2.join(t1, Inner, Some(nameToAttr("t1.k-1-2") === nameToAttr("t2.k-1-5")))
.select(nameToAttr("t1.v-1-10"))
.join(t2, Inner, Some(nameToAttr("t1.v-1-10") === nameToAttr("t2.k-1-5")))
// this can fail
Optimize.execute(plan.analyze)
}
```
Besides, with the new rule `DeduplicateRelations`, we'd be able to enable some optimizations, e.g., LeftSemiAnti pushdown, redundant project removal, as reflects in updated unit tests.
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Added and updated unit tests.
Closes#32027 from Ngone51/join-reorder-3.
Lead-authored-by: yi.wu <yi.wu@databricks.com>
Co-authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR is to support nested column type in Spark ORC vectorized reader. Currently ORC vectorized reader [does not support nested column type (struct, array and map)](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcFileFormat.scala#L138). We implemented nested column vectorized reader for FB-ORC in our internal fork of Spark. We are seeing performance improvement compared to non-vectorized reader when reading nested columns. In addition, this can also help improve the non-nested column performance when reading non-nested and nested columns together in one query.
Before this PR:
* `OrcColumnVector` is the implementation class for Spark's `ColumnVector` to wrap Hive's/ORC's `ColumnVector` to read `AtomicType` data.
After this PR:
* `OrcColumnVector` is an abstract class to keep interface being shared between multiple implementation class of orc column vectors, namely `OrcAtomicColumnVector` (for `AtomicType`), `OrcArrayColumnVector` (for `ArrayType`), `OrcMapColumnVector` (for `MapType`), `OrcStructColumnVector` (for `StructType`). So the original logic to read `AtomicType` data is moved from `OrcColumnVector` to `OrcAtomicColumnVector`. The abstract class of `OrcColumnVector` is needed here because of supporting nested column (i.e. nested column vectors).
* A utility method `OrcColumnVectorUtils.toOrcColumnVector` is added to create Spark's `OrcColumnVector` from Hive's/ORC's `ColumnVector`.
* A new user-facing config `spark.sql.orc.enableNestedColumnVectorizedReader` is added to control enabling/disabling vectorized reader for nested columns. The default value is false (i.e. disabling by default). For certain tables having deep nested columns, vectorized reader might take too much memory for each sub-column vectors, compared to non-vectorized reader. So providing a config here to work around OOM for query reading wide and deep nested columns if any. We plan to enable it by default on 3.3. Leave it disable in 3.2 in case for any unknown bugs.
### Why are the changes needed?
Improve query performance when reading nested columns from ORC file format.
Tested with locally adding a small benchmark in `OrcReadBenchmark.scala`. Seeing more than 1x run time improvement.
```
Running benchmark: SQL Nested Column Scan
Running case: Native ORC MR
Stopped after 2 iterations, 37850 ms
Running case: Native ORC Vectorized (Enabled Nested Column)
Stopped after 2 iterations, 15892 ms
Running case: Native ORC Vectorized (Disabled Nested Column)
Stopped after 2 iterations, 37954 ms
Running case: Hive built-in ORC
Stopped after 2 iterations, 35118 ms
Java HotSpot(TM) 64-Bit Server VM 1.8.0_181-b13 on Mac OS X 10.15.7
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
SQL Nested Column Scan: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------------
Native ORC MR 18706 18925 310 0.1 17839.6 1.0X
Native ORC Vectorized (Enabled Nested Column) 7625 7946 455 0.1 7271.6 2.5X
Native ORC Vectorized (Disabled Nested Column) 18415 18977 796 0.1 17561.5 1.0X
Hive built-in ORC 17469 17559 127 0.1 16660.1 1.1X
```
Benchmark:
```
nestedColumnScanBenchmark(1024 * 1024)
def nestedColumnScanBenchmark(values: Int): Unit = {
val benchmark = new Benchmark(s"SQL Nested Column Scan", values, output = output)
withTempPath { dir =>
withTempTable("t1", "nativeOrcTable", "hiveOrcTable") {
import spark.implicits._
spark.range(values).map(_ => Random.nextLong).map { x =>
val arrayOfStructColumn = (0 until 5).map(i => (x + i, s"$x" * 5))
val mapOfStructColumn = Map(
s"$x" -> (x * 0.1, (x, s"$x" * 100)),
(s"$x" * 2) -> (x * 0.2, (x, s"$x" * 200)),
(s"$x" * 3) -> (x * 0.3, (x, s"$x" * 300)))
(arrayOfStructColumn, mapOfStructColumn)
}.toDF("col1", "col2")
.createOrReplaceTempView("t1")
prepareTable(dir, spark.sql(s"SELECT * FROM t1"))
benchmark.addCase("Native ORC MR") { _ =>
withSQLConf(SQLConf.ORC_VECTORIZED_READER_ENABLED.key -> "false") {
spark.sql("SELECT SUM(SIZE(col1)), SUM(SIZE(col2)) FROM nativeOrcTable").noop()
}
}
benchmark.addCase("Native ORC Vectorized (Enabled Nested Column)") { _ =>
spark.sql("SELECT SUM(SIZE(col1)), SUM(SIZE(col2)) FROM nativeOrcTable").noop()
}
benchmark.addCase("Native ORC Vectorized (Disabled Nested Column)") { _ =>
withSQLConf(SQLConf.ORC_VECTORIZED_READER_NESTED_COLUMN_ENABLED.key -> "false") {
spark.sql("SELECT SUM(SIZE(col1)), SUM(SIZE(col2)) FROM nativeOrcTable").noop()
}
}
benchmark.addCase("Hive built-in ORC") { _ =>
spark.sql("SELECT SUM(SIZE(col1)), SUM(SIZE(col2)) FROM hiveOrcTable").noop()
}
benchmark.run()
}
}
}
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added one simple test in `OrcSourceSuite.scala` to verify correctness.
Definitely need more unit tests and add benchmark here, but I want to first collect feedback before crafting more tests.
Closes#31958 from c21/orc-vector.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Using char and varchar with the string functions and some other expressions might be confusing and ambiguous. In this PR we add test cases for char and varchar with these operations to reveal these behavior and see if we can come up with a general pattern for them.
### Why are the changes needed?
test coverage
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
new tests
Closes#32010 from yaooqinn/SPARK-34908.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Modify the `SubtractTimestamps` expression to return values of `DayTimeIntervalType` when `spark.sql.legacy.interval.enabled` is set to `false` (which is the default).
### Why are the changes needed?
To conform to the ANSI SQL standard which requires ANSI intervals as the result of timestamps subtraction, see
<img width="656" alt="Screenshot 2021-03-29 at 19 09 34" src="https://user-images.githubusercontent.com/1580697/112866455-7e2f0d00-90c2-11eb-96e6-3feb7eea7e09.png">
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateTimeUtilsSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
and some tests from `SQLQueryTestSuite`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#32016 from MaxGekk/subtract-timestamps-to-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Change partitioning to `SinglePartition`.
### Why are the changes needed?
For node `Repartition` and `RepartitionByExpression`, if partition number is 1 we can use `SinglePartition` instead of other `Partitioning`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Add test
Closes#32012 from ulysses-you/SPARK-34919.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes JDK 11 compilation failed:
```
/home/runner/work/spark/spark/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/TryCast.scala:35: error: annotation argument needs to be a constant; found: "_FUNC_(expr AS type) - Casts the value `expr` to the target data type `type`. ".+("This expression is identical to CAST with configuration `spark.sql.ansi.enabled` as ").+("true, except it returns NULL instead of raising an error. Note that the behavior of this ").+("expression doesn\'t depend on configuration `spark.sql.ansi.enabled`.")
"true, except it returns NULL instead of raising an error. Note that the behavior of this " +
```
For whatever reason, it doesn't know that the string is actually a constant. This PR simply switches it to multi-line style (which is actually more correct).
Reference:
bd0990e3e8/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/aggregate/ApproximatePercentile.scala (L53-L57)
### Why are the changes needed?
To recover the build.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
CI in this PR
Closes#32019 from HyukjinKwon/SPARK-34881.
Lead-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
Replaced the `agg(if (('gid = 1)) 'cat1 else null)` pattern in `RewriteDistinctAggregates` with `agg('cat1) FILTER (WHERE 'gid = 1)`
### Why are the changes needed?
For aggregate functions, that do not ignore NULL values (`First`, `Last` or `UDAF`s) the current approach can return wrong results.
In the added UT there are no nulls in the input `testData`. The query returned `Row(0, 1, 0, 51, 100)` before this PR.
### Does this PR introduce _any_ user-facing change?
Bugfix
### How was this patch tested?
UT
Closes#31983 from tanelk/SPARK-34882_distinct_agg_filter.
Lead-authored-by: Tanel Kiis <tanel.kiis@gmail.com>
Co-authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Add a new SQL function `try_cast`.
`try_cast` is identical to `AnsiCast` (or `Cast` when `spark.sql.ansi.enabled` is true), except it returns NULL instead of raising an error.
This expression has one major difference from `cast` with `spark.sql.ansi.enabled` as true: when the source value can't be stored in the target integral(Byte/Short/Int/Long) type, `try_cast` returns null instead of returning the low order bytes of the source value.
Note that the result of `try_cast` is not affected by the configuration `spark.sql.ansi.enabled`.
This is learned from Google BigQuery and Snowflake:
https://docs.snowflake.com/en/sql-reference/functions/try_cast.htmlhttps://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators#safe_casting
### Why are the changes needed?
This is an useful for the following scenarios:
1. When ANSI mode is on, users can choose `try_cast` an alternative way to run SQL without errors for certain operations.
2. When ANSI mode is off, users can use `try_cast` to get a more reasonable result for casting a value to an integral type: when an overflow error happens, `try_cast` returns null while `cast` returns the low order bytes of the source value.
### Does this PR introduce _any_ user-facing change?
Yes, adding a new function `try_cast`
### How was this patch tested?
Unit tests.
Closes#31982 from gengliangwang/tryCast.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This PR introduces a new analysis rule `DeduplicateRelations`, which deduplicates any duplicate relations in a plan first and then deduplicates conflicting attributes(which resued the `dedupRight` of `ResolveReferences`).
### Why are the changes needed?
`CostBasedJoinReorder` could fail when applying on self-join, e.g.,
```scala
// test in JoinReorderSuite
test("join reorder with self-join") {
val plan = t2.join(t1, Inner, Some(nameToAttr("t1.k-1-2") === nameToAttr("t2.k-1-5")))
.select(nameToAttr("t1.v-1-10"))
.join(t2, Inner, Some(nameToAttr("t1.v-1-10") === nameToAttr("t2.k-1-5")))
// this can fail
Optimize.execute(plan.analyze)
}
```
Besides, with the new rule `DeduplicateRelations`, we'd be able to enable some optimizations, e.g., LeftSemiAnti pushdown, redundant project removal, as reflects in updated unit tests.
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Added and updated unit tests.
Closes#31470 from Ngone51/join-reorder.
Lead-authored-by: yi.wu <yi.wu@databricks.com>
Co-authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When SparkContext is initialed, if we want to start SparkSession, when we call
`SparkSession.builder.enableHiveSupport().getOrCreate()`, the SparkSession we created won't have hive support since
we have't reset existed SC's conf's `spark.sql.catalogImplementation`.
In this PR we use sharedState.conf to decide whether we should enable Hive Support.
### Why are the changes needed?
We should respect `enableHiveSupport`
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#31680 from AngersZhuuuu/SPARK-34568.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Add the SQL config `spark.sql.legacy.interval.enabled` which will control when Spark SQL should use `CalendarIntervalType` instead of ANSI intervals.
2. Modify the `SubtractDates` expression to return values of `DayTimeIntervalType` when `spark.sql.legacy.interval.enabled` is set to `false` (which is the default).
### Why are the changes needed?
To conform to the ANSI SQL standard which requires ANSI intervals as the result of dates subtraction, see
<img width="656" alt="Screenshot 2021-03-29 at 19 09 34" src="https://user-images.githubusercontent.com/1580697/112866455-7e2f0d00-90c2-11eb-96e6-3feb7eea7e09.png">
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
and some tests from `SQLQueryTestSuite`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#31996 from MaxGekk/subtract-dates-to-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Use `java.lang.Long.divideUnsigned()` to do integer division in `NumberConverter` to avoid a bug in `unsignedLongDiv` that produced invalid results.
### Why are the changes needed?
The previous results are incorrect, the result of the below query should be 45012021522523134134555
```
scala> spark.sql("select conv('-10', 11, 7)").show(20, 150)
+-----------------------+
| conv(-10, 11, 7)|
+-----------------------+
|4501202152252313413456|
+-----------------------+
scala> spark.sql("select hex(conv('-10', 11, 7))").show(20, 150)
+----------------------------------------------+
| hex(conv(-10, 11, 7))|
+----------------------------------------------+
|3435303132303231353232353233313334313334353600|
+----------------------------------------------+
```
### Does this PR introduce _any_ user-facing change?
`conv()` will produce different results because the bug is fixed.
### How was this patch tested?
Added a simple unit test.
Closes#32006 from timarmstrong/conv-unsigned.
Authored-by: Tim Armstrong <tim.armstrong@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to add a new job in GitHub Actions to check the output of TPC-DS queries.
NOTE: I've checked that the new job took 17m 35s in the GitHub Actions env.
### Why are the changes needed?
There are some cases where we noticed runtime-realted bugs after merging commits (e.g. .SPARK-33822). Therefore, I think it is worth adding a new job in GitHub Actions to check query output of TPC-DS (sf=1).
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
The new test added.
Closes#31886 from maropu/TPCDSQueryTestSuite.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
After https://github.com/apache/spark/pull/31954/, Array type is allowed to be cast as String type. So the customized conversion failure message branch from AnsiCast.typeCheckFailureMessage won't be reached anymore.
This PR is to remove the dead code.
### Why are the changes needed?
Code clean up.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Just removing dead code.
Closes#32004 from gengliangwang/SPARK-34856-followup.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Spark query plan node hierarchy has specialized traits (or abstract classes) for handling nodes with fixed number of children, for example `UnaryExpression`, `UnaryNode` and `UnaryExec` for representing an expression, a logical plan and a physical plan with only one child, respectively. This PR refactors the `TreeNode` hierarchy by extracting the children handling functionality into the following traits. `UnaryExpression` and other similar classes now extend the corresponding new trait:
```
trait LeafLike[T <: TreeNode[T]] { self: TreeNode[T] =>
override final def children: Seq[T] = Nil
}
trait UnaryLike[T <: TreeNode[T]] { self: TreeNode[T] =>
def child: T
transient override final lazy val children: Seq[T] = child :: Nil
}
trait BinaryLike[T <: TreeNode[T]] { self: TreeNode[T] =>
def left: T
def right: T
transient override final lazy val children: Seq[T] = left :: right :: Nil
}
trait TernaryLike[T <: TreeNode[T]] { self: TreeNode[T] =>
def first: T
def second: T
def third: T
transient override final lazy val children: Seq[T] = first :: second :: third :: Nil
}
```
This refactoring, which is part of a bigger effort to make tree transformations in Spark more efficient, has two benefits:
- It moves the children handling methods to a single place, instead of being spread in specific subclasses, which will help the future optimizations for tree traversals.
- It allows to mix in these traits with some concrete node types that could not extend the previous classes. For example, expressions with one child that extend `AggregateFunction` cannot extend `UnaryExpression` as `AggregateFunction` defines the `foldable` method final while `UnaryExpression` defines it as non final. With the new traits, we can directly extend the concrete class from `UnaryLike` in these cases. Classes with more specific child handling will make tree traversal methods faster.
In this PR we have also updated many concrete node types to extend these traits to benefit from more specific child handling.
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
This is a refactoring, passes existing tests.
Closes#31932 from dbaliafroozeh/FactorOutChildHandlnigIntoSeparateTraits.
Authored-by: Ali Afroozeh <ali.afroozeh@databricks.com>
Signed-off-by: herman <herman@databricks.com>
### What changes were proposed in this pull request?
Add check if `CoalesceShufflePartitions` really coalesce shuffle partition number.
### Why are the changes needed?
The `CoalesceShufflePartitions` can not coalesce such case if the total shuffle partitions size of mappers are big enough. Then it's confused to use `CustomShuffleReaderExec` which marked as `coalesced` but has no affect with partition number.
### Does this PR introduce _any_ user-facing change?
Probably yes, the plan changed.
### How was this patch tested?
Add test.
Closes#31994 from ulysses-you/SPARK-34899.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Improve dynamic partition pruning evaluation to make filtering side must can broadcast by size or broadcast by hint.
### Why are the changes needed?
1. Fast fail if filtering side can not broadcast by size or broadcast by hint.
2. We can safely disable `spark.sql.optimizer.dynamicPartitionPruning.reuseBroadcastOnly`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit test.
Closes#31984 from wangyum/SPARK-34884.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
As discussed in
https://github.com/apache/spark/pull/30145#discussion_r514728642https://github.com/apache/spark/pull/30145#discussion_r514734648
We need to rewrite current Grouping Analytics grammar to support as flexible as Postgres SQL to support subsequent development.
In postgres sql, it support
```
select a, b, c, count(1) from t group by cube (a, b, c);
select a, b, c, count(1) from t group by cube(a, b, c);
select a, b, c, count(1) from t group by cube (a, b, c, (a, b), (a, b, c));
select a, b, c, count(1) from t group by rollup(a, b, c);
select a, b, c, count(1) from t group by rollup (a, b, c);
select a, b, c, count(1) from t group by rollup (a, b, c, (a, b), (a, b, c));
```
In this pr, we have done three things as below, and we will split it to different pr:
- Refactor CUBE/ROLLUP (regarding them as ANTLR tokens in a parser)
- Refactor GROUPING SETS (the logical node -> a new expr)
- Support new syntax for CUBE/ROLLUP (e.g., GROUP BY CUBE ((a, b), (a, c)))
### Why are the changes needed?
Rewrite current Grouping Analytics grammar to support as flexible as Postgres SQL to support subsequent development.
### Does this PR introduce _any_ user-facing change?
User can write Grouping Analytics grammar as flexible as Postgres SQL to support subsequent development.
### How was this patch tested?
Added UT
Closes#30212 from AngersZhuuuu/refact-grouping-analytics.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Co-authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR is a followup change to address comments in https://github.com/apache/spark/pull/31413#discussion_r603280965 and https://github.com/apache/spark/pull/31413#discussion_r603296475 . Minor change in `FileSourceScanExec`. No actual logic change here.
### Why are the changes needed?
Better readability.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit tests.
Closes#32000 from c21/bucket-scan.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
As a followup for #29818, document caveats of using the Arrow selfDestruct option in toPandas, which include:
- toPandas() may be slower;
- the resulting dataframe may not support some Pandas operations due to immutable backing arrays.
### Why are the changes needed?
This will hopefully reduce user confusion as with SPARK-34463.
### Does this PR introduce _any_ user-facing change?
Yes - documentation is updated and a config setting description is updated to clearly indicate the config is experimental.
### How was this patch tested?
This is a documentation-only change.
Closes#31738 from lidavidm/spark-34463.
Authored-by: David Li <li.davidm96@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Some `spark-submit` commands used to run benchmarks in the user's guide is wrong, we can't use these commands to run benchmarks successful.
So the major changes of this pr is correct these wrong commands, for example, run a benchmark which inherits from `SqlBasedBenchmark`, we must specify `--jars <spark core test jar>,<spark catalyst test jar>` because `SqlBasedBenchmark` based benchmark extends `BenchmarkBase(defined in spark core test jar)` and `SQLHelper(defined in spark catalyst test jar)`.
Another change of this pr is removed the `scalatest Assertions` dependency of Benchmarks because `scalatest-*.jar` are not in the distribution package, it will be troublesome to use.
### Why are the changes needed?
Make sure benchmarks can run using spark-submit cmd described in the guide
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Use the corrected `spark-submit` commands to run benchmarks successfully.
Closes#31995 from LuciferYang/fix-benchmark-guide.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
There is a `Project` between `LocalLimit` and `Join` if `Join`'s output do not match the `LocalLimit`'s output. This pr add support push down limit through this case. For example:
```scala
spark.sql("create table t1(a int, b int, c int) using parquet")
spark.sql("create table t2(x int, y int, z int) using parquet")
spark.sql("select a from t1 left join t2 on a = x and b = y limit 5").explain("extended")
```
```
== Optimized Logical Plan ==
GlobalLimit 5
+- LocalLimit 5
+- Project [a#0]
+- Join LeftOuter, ((a#0 = x#3) AND (b#1 = y#4))
:- Project [a#0, b#1]
: +- Relation default.t1[a#0,b#1,c#2] parquet
+- Project [x#3, y#4]
+- Filter (isnotnull(x#3) AND isnotnull(y#4))
+- Relation default.t2[x#3,y#4,z#5] parquet
```
After this pr:
```
== Optimized Logical Plan ==
GlobalLimit 5
+- LocalLimit 5
+- Project [a#0]
+- Join LeftOuter, ((a#0 = x#3) AND (b#1 = y#4))
:- LocalLimit 5
: +- Project [a#0, b#1]
: +- Relation default.t1[a#0,b#1,c#2] parquet
+- Project [x#3, y#4]
+- Filter (isnotnull(x#3) AND isnotnull(y#4))
+- Relation default.t2[x#3,y#4,z#5] parquet
```
### Why are the changes needed?
Improve limit push down to improve query performance.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#31739 from wangyum/SPARK-34622.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR proposes to extend the functionality of requirement for distribution and ordering on V2 write to specify the number of partitioning on repartition, so that data source is able to control the parallelism and determine the data distribution per partition in prior.
The partitioning with static number is optional, and by default disabled via default method, so only implementations required to restrict the number of partition statically need to override the method and provide the number.
Note that we don't support static number of partitions with unspecified distribution for this PR, as we haven't found the real use cases, and for hypothetical case the static number isn't good enough. Javadoc clearly describes the limitation.
### Why are the changes needed?
The use case comes from feature parity with DSv1.
I have state data source which enables the state in SS to be rewritten, which enables repartitioning, schema evolution, etc via batch query. The writer requires hash partitioning against group key, with the "desired number of partitions", which is same as what Spark does read and write against state.
This is now implemented as DSv1, and the requirement is simply done by calling repartition with the "desired number".
```
val fullPathsForKeyColumns = keySchema.map(key => new Column(s"key.${key.name}"))
data
.repartition(newPartitions, fullPathsForKeyColumns: _*)
.queryExecution
.toRdd
.foreachPartition(
writeFn(resolvedCpLocation, version, operatorId, storeName, keySchema, valueSchema,
storeConf, hadoopConfBroadcast, queryId))
```
Thanks to SPARK-34026, it's now possible to require the hash partitioning, but still not able to require the number of partitions. This PR will enable to let data source require the number of partitions.
### Does this PR introduce _any_ user-facing change?
Yes, but only for data source implementors. Even for them, this is no breaking change as default method is added.
### How was this patch tested?
Added UTs.
Closes#31355 from HeartSaVioR/SPARK-34255.
Lead-authored-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
Co-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes an issue that `quoteIfNeeded` quotes a name only if it contains `.` or ``` ` ```.
This method should quote it if it contains non-word characters.
### Why are the changes needed?
It's a potential bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New test.
Closes#31964 from sarutak/fix-quoteIfNeeded.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Make HiveInspector support DayTimeIntervalType and YearMonthIntervalType.
Then we can use these two types in HiveUDF and HiveScriptTransformation
### Why are the changes needed?
Support more data type when use hive serde
### Does this PR introduce _any_ user-facing change?
User can use `DayTimeIntervalType` and `YearMonthIntervalType` in HiveUDF and HiveScriptTransformation
### How was this patch tested?
Added UT
Closes#31979 from AngersZhuuuu/SPARK-34879.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
LikeSimplification should handle NULL.
UT will failed before this pr
```
test("SPARK-34814: LikeSimplification should handle NULL") {
withSQLConf(SQLConf.OPTIMIZER_EXCLUDED_RULES.key ->
ConstantFolding.getClass.getName.stripSuffix("$")) {
checkEvaluation(Literal.create("foo", StringType)
.likeAll("%foo%", Literal.create(null, StringType)), null)
}
}
[info] - test *** FAILED *** (2 seconds, 443 milliseconds)
[info] java.lang.NullPointerException:
[info] at org.apache.spark.sql.catalyst.optimizer.LikeSimplification$.$anonfun$simplifyMultiLike$1(expressions.scala:697)
[info] at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
[info] at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
[info] at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
[info] at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
[info] at scala.collection.TraversableLike.map(TraversableLike.scala:238)
[info] at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
[info] at scala.collection.AbstractTraversable.map(Traversable.scala:108)
[info] at org.apache.spark.sql.catalyst.optimizer.LikeSimplification$.org$apache$spark$sql$catalyst$optimizer$LikeSimplification$$simplifyMultiLike(expressions.scala:697)
[info] at org.apache.spark.sql.catalyst.optimizer.LikeSimplification$$anonfun$apply$9.applyOrElse(expressions.scala:722)
[info] at org.apache.spark.sql.catalyst.optimizer.LikeSimplification$$anonfun$apply$9.applyOrElse(expressions.scala:714)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDown$1(TreeNode.scala:316)
[info] at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:72)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:316)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDown$3(TreeNode.scala:321)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$mapChildren$1(TreeNode.scala:406)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:242)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:404)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:357)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:321)
[info] at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$transformExpressionsDown$1(QueryPlan.scala:94)
[info] at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$1(QueryPlan.scala:116)
[info] at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:72)
```
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#31976 from AngersZhuuuu/SPARK-34814.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Filled the `defaultResult` field on non-nullable aggregates
### Why are the changes needed?
The `defaultResult` defaults to `None` and in some situations (like correlated scalar subqueries) it is used for the value of the aggregation.
The UT result before the fix:
```
-- !query
SELECT t1a,
(SELECT count(t2d) FROM t2 WHERE t2a = t1a) count_t2,
(SELECT count_if(t2d > 0) FROM t2 WHERE t2a = t1a) count_if_t2,
(SELECT approx_count_distinct(t2d) FROM t2 WHERE t2a = t1a) approx_count_distinct_t2,
(SELECT collect_list(t2d) FROM t2 WHERE t2a = t1a) collect_list_t2,
(SELECT collect_set(t2d) FROM t2 WHERE t2a = t1a) collect_set_t2,
(SELECT hex(count_min_sketch(t2d, 0.5d, 0.5d, 1)) FROM t2 WHERE t2a = t1a) collect_set_t2
FROM t1
-- !query schema
struct<t1a:string,count_t2:bigint,count_if_t2:bigint,approx_count_distinct_t2:bigint,collect_list_t2:array<bigint>,collect_set_t2:array<bigint>,collect_set_t2:string>
-- !query output
val1a 0 0 NULL NULL NULL NULL
val1a 0 0 NULL NULL NULL NULL
val1a 0 0 NULL NULL NULL NULL
val1a 0 0 NULL NULL NULL NULL
val1b 6 6 3 [19,119,319,19,19,19] [19,119,319] 0000000100000000000000060000000100000004000000005D8D6AB90000000000000000000000000000000400000000000000010000000000000001
val1c 2 2 2 [219,19] [219,19] 0000000100000000000000020000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000001
val1d 0 0 NULL NULL NULL NULL
val1d 0 0 NULL NULL NULL NULL
val1d 0 0 NULL NULL NULL NULL
val1e 1 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000
val1e 1 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000
val1e 1 1 1 [19] [19] 0000000100000000000000010000000100000004000000005D8D6AB90000000000000000000000000000000100000000000000000000000000000000
```
### Does this PR introduce _any_ user-facing change?
Bugfix
### How was this patch tested?
UT
Closes#31973 from tanelk/SPARK-34876_non_nullable_agg_subquery.
Authored-by: Tanel Kiis <tanel.kiis@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The changes being proposed are to increase the accuracy of JDBCRelation's stride calculation, as outlined in: https://issues.apache.org/jira/browse/SPARK-34843
In summary:
Currently, in JDBCRelation (line 123), the stride size is calculated as follows:
val stride: Long = upperBound / numPartitions - lowerBound / numPartitions
Due to truncation happening on both divisions, the stride size can fall short of what it should be. This can lead to a big difference between the provided upper bound and the actual start of the last partition.
I'm proposing a different formula that doesn't truncate to early, and also maintains accuracy using fixed-point decimals. This helps tremendously with the size of the last partition, which can be even more amplified if there is data skew in that direction. In a real-life test, I've seen a 27% increase in performance with this more proper stride alignment. The reason for fixed-point decimals instead of floating-point decimals is because inaccuracy due to limitation of what the float can represent. This may seem small, but could shift the midpoint a bit, and depending on how granular the data is, that could translate to quite a difference. It's also just inaccurate, and I'm striving to make the partitioning as accurate as possible, within reason.
Lastly, since the last partition's predicate is determined by how the strides align starting from the lower bound (plus one stride), there can be skew introduced creating a larger last partition compared to the first partition. Therefore, after calculating a more precise stride size, I've also introduced logic to move the first partition's predicate (which is an offset from the lower bound) to a position that closely matches the offset of the last partition's predicate (in relation to the upper bound). This makes the first and last partition more evenly distributed compared to each other, and helps with the last task being the largest (reducing its size).
### Why are the changes needed?
The current implementation is inaccurate and can lead to the last task/partition running much longer than previous tasks. Therefore, you can end up with a single node/core running for an extended period while other nodes/cores are sitting idle.
### Does this PR introduce _any_ user-facing change?
No. I would suspect some users will just get a good performance increase. As stated above, if we were to run our code on Spark that has this change implemented, we would have all of the sudden got a 27% increase in performance.
### How was this patch tested?
I've added two new unit tests. I did need to update one unit test, but when you look at the comparison of the before and after, you'll see better alignment of the partitioning with the new implementation. Given that the lower partition's predicate is exclusive and the upper's is inclusive, the offset of the lower was 3 days, and the offset of the upper was 6 days... that's potentially twice the amount of data in that upper partition (could be much more depending on how the user's data is distributed).
Other unit tests that utilize timestamps and two partitions have maintained their midpoint.
### Examples
I've added results with and without the realignment logic to better highlight both improvements this PR brings.
**Example 1:**
Given the following partition config:
"lowerBound" -> "1930-01-01"
"upperBound" -> "2020-12-31"
"numPartitions" -> 1000
_Old method (exactly what it would be BEFORE this PR):_
First partition: "PartitionColumn" < '1930-02-02' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2017-07-11'
_Old method, but with new realingment logic of first partition:_
First partition: "PartitionColumn" < '1931-10-14' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2019-03-22'
_New method:_
First partition: "PartitionColumn" < '1930-02-03' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2020-04-05'
_New with new realingment logic of first partition (exactly what it would be AFTER this PR):_
First partition: "PartitionColumn" < '1930-06-02' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2020-08-02'
**Example 2:**
Given the following partition config:
"lowerBound" -> "1927-04-05",
"upperBound" -> "2020-10-16"
"numPartitions" -> 2000
_Old method (exactly what it would be BEFORE this PR):_
First partition: "PartitionColumn" < '1927-04-21' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2014-10-29'
_Old method, but with new realingment logic of first partition::_
First partition: "PartitionColumn" < '1930-04-07' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2017-10-15'
_New method:_
First partition: "PartitionColumn" < '1927-04-22' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2020-04-19'
_New method with new realingment logic of first partition (exactly what it would be AFTER this PR):_
First partition: "PartitionColumn" < '1927-07-13' or "PartitionColumn" is null
Last partition: "PartitionColumn" >= '2020-07-10'
Closes#31965 from hanover-fiste/SPARK-34843.
Authored-by: hanover-fiste <jyarbrough.git@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR fixes a correctness issue with higher order functions. The results of function expressions needs to be copied in some higher order functions as such an expression can return with internal buffers and higher order functions can call multiple times the expression.
The issue was discovered with typed `ScalaUDF`s after https://github.com/apache/spark/pull/28979.
### Why are the changes needed?
To fix a bug.
### Does this PR introduce _any_ user-facing change?
Yes, some queries return the right results again.
### How was this patch tested?
Added new UT.
Closes#31955 from peter-toth/SPARK-34829-fix-scalaudf-resultconversion.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Fix code format in `SQLConf` and comment in `PartitionPruning`.
### Why are the changes needed?
Make code more readable.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
N/A
Closes#31969 from wangyum/SPARK-32855-2.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Apache Parquet 1.12.0 switches its ZSTD compression from Hadoop codec to its own codec.
### Why are the changes needed?
**Apache Spark 3.1 (It requires libhadoop built with zstd)**
```scala
scala> spark.range(10).write.option("compression", "zstd").parquet("/tmp/a")
21/03/27 08:49:38 ERROR Executor: Exception in task 11.0 in stage 0.0 (TID 11)2]
java.lang.RuntimeException: native zStandard library not available:
this version of libhadoop was built without zstd support.
```
**Apache Spark 3.2 (No libhadoop requirement)**
```scala
scala> spark.range(10).write.option("compression", "zstd").parquet("/tmp/a")
```
### Does this PR introduce _any_ user-facing change?
Yes, this is an improvement.
### How was this patch tested?
Pass the CI with the newly added test coverage.
Closes#31981 from dongjoon-hyun/SPARK-34880.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Push ANSI interval binary expressions into into (if / case) branches
### Why are the changes needed?
Support more binary expression to push into if/else and casewhen
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#31978 from AngersZhuuuu/SPARK-34841.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Improve error message for casting cause overflow error. We should use DataType's catalogString.
### Why are the changes needed?
Improve error message
### Does this PR introduce _any_ user-facing change?
For example:
```
set spark.sql.ansi.enabled=true;
select tinyint(128) * tinyint(2);
```
Error message before this pr:
```
Casting 128 to scala.Byte$ causes overflow
```
After this pr:
```
Casting 128 to tinyint causes overflow
```
### How was this patch tested?
Added UT
Closes#31971 from AngersZhuuuu/SPARK-34744.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
1. Add new expression `DivideDTInterval` which multiplies a `DayTimeIntervalType` expression by a `NumericType` expression including ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType, DecimalType.
2. Extend binary arithmetic rules to support `day-time interval / numeric`.
### Why are the changes needed?
To conform the ANSI SQL standard which requires such operation over day-time intervals:
<img width="656" alt="Screenshot 2021-03-25 at 18 44 58" src="https://user-images.githubusercontent.com/1580697/112501559-68f07080-8d9a-11eb-8781-66e6631bb7ef.png">
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *IntervalExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31972 from MaxGekk/div-dt-interval-by-num.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Add new expression `DivideYMInterval` which multiplies a `YearMonthIntervalType` expression by a `NumericType` expression including ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType, DecimalType.
2. Extend binary arithmetic rules to support `year-month interval / numeric`.
### Why are the changes needed?
To conform the ANSI SQL standard which requires such operation over year-month intervals:
<img width="656" alt="Screenshot 2021-03-25 at 18 44 58" src="https://user-images.githubusercontent.com/1580697/112501559-68f07080-8d9a-11eb-8781-66e6631bb7ef.png">
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *IntervalExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31961 from MaxGekk/div-ym-interval-by-num.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This pr improve the cost model in `pruningHasBenefit` for filtering side can not build broadcast by join type:
1. The filtering side must be small enough to build broadcast by size.
2. The estimated size of the pruning side must be big enough: `estimatePruningSideSize * spark.sql.optimizer.dynamicPartitionPruning.pruningSideExtraFilterRatio > overhead`.
### Why are the changes needed?
Improve query performance for these cases.
This a real case from cluster. Left join and left size very small and right side can build DPP:
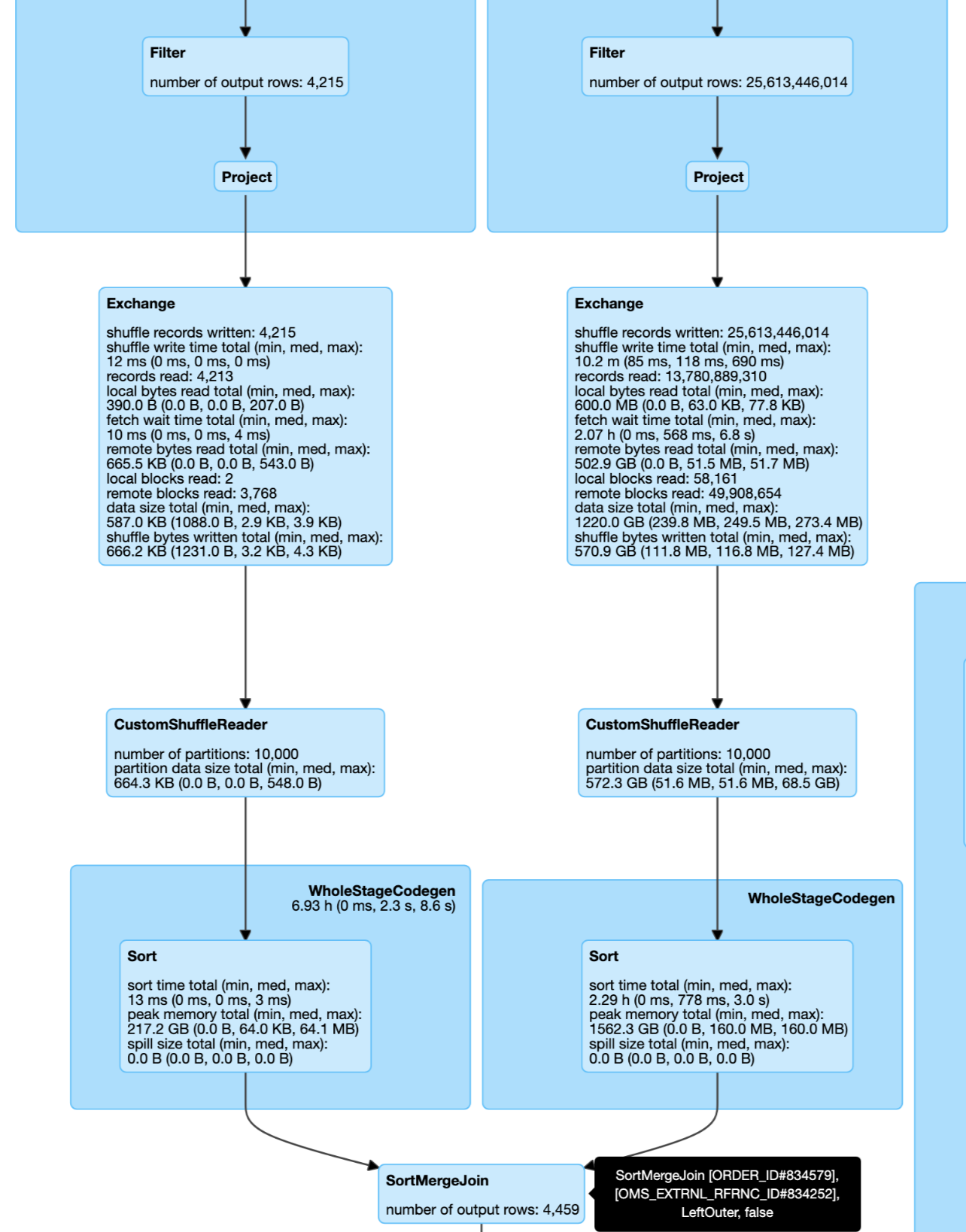
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#29726 from wangyum/SPARK-32855.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
A companion PR for SPARK-34817, when we handle the unsigned int(<=32) logical types. In this PR, we map the unsigned int64 to decimal(20, 0) for better compatibility.
### Why are the changes needed?
Spark won't have unsigned types, but spark should be able to read existing parquet files written by other systems that support unsigned types for better compatibility.
### Does this PR introduce _any_ user-facing change?
yes, we can read parquet uint64 now
### How was this patch tested?
new unit tests
Closes#31960 from yaooqinn/SPARK-34786-2.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
Move the checkpoint location resolving into the rule ResolveWriteToStream, which is added in SPARK-34748.
### Why are the changes needed?
After SPARK-34748, we have a rule ResolveWriteToStream for the analysis logic for the resolving logic of stream write plans. Based on it, we can further move the checkpoint location resolving work in the rule. Then, all the checkpoint resolving logic was done in the analyzer.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing UT.
Closes#31963 from xuanyuanking/SPARK-34871.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/31940 . This PR generalizes the matching of attributes and outer references, so that outer references are handled everywhere.
Note that, currently correlated subquery has a lot of limitations in Spark, and the newly covered cases are not possible to happen. So this PR is a code refactor.
### Why are the changes needed?
code cleanup
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing tests
Closes#31959 from cloud-fan/follow.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Allow casting complex types as string type in ANSI mode.
### Why are the changes needed?
Currently, complex types are not allowed to cast as string type. This breaks the DataFrame.show() API. E.g
```
scala> sql(“select array(1, 2, 2)“).show(false)
org.apache.spark.sql.AnalysisException: cannot resolve ‘CAST(`array(1, 2, 2)` AS STRING)’ due to data type mismatch:
cannot cast array<int> to string with ANSI mode on.
```
We should allow the conversion as the extension of the ANSI SQL standard, so that the DataFrame.show() still work in ANSI mode.
### Does this PR introduce _any_ user-facing change?
Yes, casting complex types as string type is now allowed in ANSI mode.
### How was this patch tested?
Unit tests.
Closes#31954 from gengliangwang/fixExplicitCast.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This PR groups exception messages in `execution/datasources/v2`.
### Why are the changes needed?
It will largely help with standardization of error messages and its maintenance.
### Does this PR introduce _any_ user-facing change?
No. Error messages remain unchanged.
### How was this patch tested?
No new tests - pass all original tests to make sure it doesn't break any existing behavior.
Closes#31619 from karenfeng/spark-33600.
Authored-by: Karen Feng <karen.feng@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update the plan stability golden files even if only the `explain.txt` changes.
This is resubmition of #31927. The schema for one of the TPCDS tables was updated and that changed the `explain.txt` for the q17.
### Why are the changes needed?
Currently only `simplified.txt` change is checked. There are some PRs, that update the `explain.txt`, that do not change the `simplified.txt`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
The updated golden files.
Closes#31957 from tanelk/SPARK-34822_update_plan_stability.
Lead-authored-by: Tanel Kiis <tanel.kiis@gmail.com>
Co-authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Removed the custom toString implementation of AtLeastNNoneNulls.
### Why are the changes needed?
It shows up wrong in the explain plan. The name of the function is wrong and the actual value of the first argument is not shown. Both of these would make it easier to understand the plan.
```
(12) Filter
Input [3]: [c1#2410L, c2#2419, c3#2422]
Condition : AtLeastNNulls(n, c1#2410L)
```
### Does this PR introduce _any_ user-facing change?
Only the explain plan changes if this function is used.
### How was this patch tested?
Added a simple unit test to make sure that the toString output is correct.
Closes#31956 from timarmstrong/atleastnnonnulls.
Authored-by: Tim Armstrong <tim.armstrong@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Add new expression `MultiplyDTInterval` which multiplies a `DayTimeIntervalType` expression by a `NumericType` expression including ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType, DecimalType.
2. Extend binary arithmetic rules to support `numeric * day-time interval` and `day-time interval * numeric`.
3. Invoke `DoubleMath.roundToInt` in `double/float * year-month interval`.
### Why are the changes needed?
To conform the ANSI SQL standard which requires such operation over day-time intervals:
<img width="667" alt="Screenshot 2021-03-22 at 16 33 16" src="https://user-images.githubusercontent.com/1580697/111997810-77d1eb80-8b2c-11eb-951d-e43911d9c5db.png">
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *IntervalExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31951 from MaxGekk/mul-day-time-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Unsigned types may be used to produce smaller in-memory representations of the data. These types used by frameworks(e.g. hive, pig) using parquet. And parquet will map them to its base types.
see more https://github.com/apache/parquet-format/blob/master/LogicalTypes.mdhttps://github.com/apache/parquet-format/blob/master/src/main/thrift/parquet.thrift
```thrift
/**
* An unsigned integer value.
*
* The number describes the maximum number of meaningful data bits in
* the stored value. 8, 16 and 32 bit values are stored using the
* INT32 physical type. 64 bit values are stored using the INT64
* physical type.
*
*/
UINT_8 = 11;
UINT_16 = 12;
UINT_32 = 13;
UINT_64 = 14;
```
```
UInt8-[0:255]
UInt16-[0:65535]
UInt32-[0:4294967295]
UInt64-[0:18446744073709551615]
```
In this PR, we support read UINT_8 as ShortType, UINT_16 as IntegerType, UINT_32 as LongType to fit their range. Support for UINT_64 will be in another PR.
### Why are the changes needed?
better parquet support
### Does this PR introduce _any_ user-facing change?
yes, we can read unit[8/16/32] from parquet files
### How was this patch tested?
new tests
Closes#31921 from yaooqinn/SPARK-34817.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to remove re-analyzing the already analyzed plan for `CreateViewCommand` as discussed https://github.com/apache/spark/pull/31273/files#r581592786.
### Why are the changes needed?
No need to analyze the plan if it's already analyzed.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests should cover this.
Closes#31933 from imback82/remove_analyzed_from_create_temp_view.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}