## What changes were proposed in this pull request?
Add scala and java lint check rules to ban the usage of `throw new xxxErrors` and fix up all exists instance followed by https://github.com/apache/spark/pull/22989#issuecomment-437939830. See more details in https://github.com/apache/spark/pull/22969.
## How was this patch tested?
Local test with lint-scala and lint-java.
Closes#22989 from xuanyuanking/SPARK-25986.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
…. Other related changes to get JDK 11 working, to test
## What changes were proposed in this pull request?
- Access `sun.misc.Cleaner` (Java 8) and `jdk.internal.ref.Cleaner` (JDK 9+) by reflection (note: the latter only works if illegal reflective access is allowed)
- Access `sun.misc.Unsafe.invokeCleaner` in Java 9+ instead of `sun.misc.Cleaner` (Java 8)
In order to test anything on JDK 11, I also fixed a few small things, which I include here:
- Fix minor JDK 11 compile issues
- Update scala plugin, Jetty for JDK 11, to facilitate tests too
This doesn't mean JDK 11 tests all pass now, but lots do. Note also that the JDK 9+ solution for the Cleaner has a big caveat.
## How was this patch tested?
Existing tests. Manually tested JDK 11 build and tests, and tests covering this change appear to pass. All Java 8 tests should still pass, but this change alone does not achieve full JDK 11 compatibility.
Closes#22993 from srowen/SPARK-24421.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
Currently, we do not have a mechanism to collect driver logs if a user chooses
to run their application in client mode. This is a big issue as admin teams need
to create their own mechanisms to capture driver logs.
This commit adds a logger which, if enabled, adds a local log appender to the
root logger and asynchronously syncs it an application specific log file on hdfs
(Spark Driver Log Dir).
Additionally, this collects spark-shell driver logs at INFO level by default.
The change is that instead of setting root logger level to WARN, we will set the
consoleAppender threshold to WARN, in case of spark-shell. This ensures that
only WARN logs are printed on CONSOLE but other log appenders still capture INFO
(or the default log level logs).
1. Verified that logs are written to local and remote dir
2. Added a unit test case
3. Verified this for spark-shell, client mode and pyspark.
4. Verified in both non-kerberos and kerberos environment
5. Verified with following unexpected termination conditions: Ctrl + C, Driver
OOM, Large Log Files
6. Ran an application in spark-shell and ensured that driver logs were
captured at INFO level
7. Started the application at WARN level, programmatically changed the level to
INFO and ensured that logs on console were printed at INFO level
Closes#22504 from ankuriitg/ankurgupta/SPARK-25118.
Authored-by: ankurgupta <ankur.gupta@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
* Implement (optional) use of KryoPool in KryoSerializer, an alternative to the existing implementation of caching a Kryo instance inside KryoSerializerInstance
* Add config key & documentation of spark.kryo.pool in order to turn this on
* Add benchmark KryoSerializerBenchmark to compare new and old implementation
* Add results of benchmark
## How was this patch tested?
Added new tests inside KryoSerializerSuite to test the pool implementation as well as added the pool option to the existing regression testing for SPARK-7766
This is my original work and I license the work to the project under the project’s open source license.
Closes#22855 from patrickbrownsync/kryo-pool.
Authored-by: Patrick Brown <patrick.brown@blyncsy.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Deprecated in Java 11, replace Class.newInstance with Class.getConstructor.getInstance, and primtive wrapper class constructors with valueOf or equivalent
## How was this patch tested?
Existing tests.
Closes#22988 from srowen/SPARK-25984.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently, Spark writes Spark version number into Hive Table properties with `spark.sql.create.version`.
```
parameters:{
spark.sql.sources.schema.part.0={
"type":"struct",
"fields":[{"name":"a","type":"integer","nullable":true,"metadata":{}}]
},
transient_lastDdlTime=1541142761,
spark.sql.sources.schema.numParts=1,
spark.sql.create.version=2.4.0
}
```
This PR aims to write Spark versions to ORC/Parquet file metadata with `org.apache.spark.sql.create.version` because we used `org.apache.` prefix in Parquet metadata already. It's different from Hive Table property key `spark.sql.create.version`, but it seems that we cannot change Hive Table property for backward compatibility.
After this PR, ORC and Parquet file generated by Spark will have the following metadata.
**ORC (`native` and `hive` implmentation)**
```
$ orc-tools meta /tmp/o
File Version: 0.12 with ...
...
User Metadata:
org.apache.spark.sql.create.version=3.0.0
```
**PARQUET**
```
$ parquet-tools meta /tmp/p
...
creator: parquet-mr version 1.10.0 (build 031a6654009e3b82020012a18434c582bd74c73a)
extra: org.apache.spark.sql.create.version = 3.0.0
extra: org.apache.spark.sql.parquet.row.metadata = {"type":"struct","fields":[{"name":"id","type":"long","nullable":false,"metadata":{}}]}
```
## How was this patch tested?
Pass the Jenkins with newly added test cases.
This closes#22255.
Closes#22932 from dongjoon-hyun/SPARK-25102.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
HistoryPage.scala counts applications (with a predicate depending on if it is displaying incomplete or complete applications) to check if it must display the dataTable.
Since it only checks if allAppsSize > 0, we could use exists method on the iterator. This way we stop iterating at the first occurence found.
Such a change has been relevant (roughly 12s improvement on page loading) on our cluster that runs tens of thousands of jobs per day.
Closes#22982 from Willymontaz/SPARK-25973.
Authored-by: William Montaz <w.montaz@criteo.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
- Remove some AccumulableInfo .apply() methods
- Remove non-label-specific multiclass precision/recall/fScore in favor of accuracy
- Remove toDegrees/toRadians in favor of degrees/radians (SparkR: only deprecated)
- Remove approxCountDistinct in favor of approx_count_distinct (SparkR: only deprecated)
- Remove unused Python StorageLevel constants
- Remove Dataset unionAll in favor of union
- Remove unused multiclass option in libsvm parsing
- Remove references to deprecated spark configs like spark.yarn.am.port
- Remove TaskContext.isRunningLocally
- Remove ShuffleMetrics.shuffle* methods
- Remove BaseReadWrite.context in favor of session
- Remove Column.!== in favor of =!=
- Remove Dataset.explode
- Remove Dataset.registerTempTable
- Remove SQLContext.getOrCreate, setActive, clearActive, constructors
Not touched yet
- everything else in MLLib
- HiveContext
- Anything deprecated more recently than 2.0.0, generally
## How was this patch tested?
Existing tests
Closes#22921 from srowen/SPARK-25908.
Lead-authored-by: Sean Owen <sean.owen@databricks.com>
Co-authored-by: hyukjinkwon <gurwls223@apache.org>
Co-authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Removal of intermediate structures in HighlyCompressedMapStatus will speed up its creation and deserialization time.
https://issues.apache.org/jira/browse/SPARK-25885
## How was this patch tested?
Additional tests are not necessary for the patch.
Closes#22894 from Koraseg/mapStatusesOptimization.
Authored-by: koraseg <artem.kupchinsky@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
JVMs can't allocate arrays of length exactly Int.MaxValue, so ensure we never try to allocate an array that big. This commit changes some defaults & configs to gracefully fallover to something that doesn't require one large array in some cases; in other cases it simply improves an error message for cases which will still fail.
Closes#22818 from squito/SPARK-25827.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
Every time a task is unschedulable because of the condition where no. of task failures < no. of executors available, we currently abort the taskSet - failing the job. This change tries to acquire new executors so that we can complete the job successfully. We try to acquire a new executor only when we can kill an existing idle executor. We fallback to the older implementation where we abort the job if we cannot find an idle executor.
## How was this patch tested?
I performed some manual tests to check and validate the behavior.
```scala
val rdd = sc.parallelize(Seq(1 to 10), 3)
import org.apache.spark.TaskContext
val mapped = rdd.mapPartitionsWithIndex ( (index, iterator) => { if (index == 2) { Thread.sleep(30 * 1000); val attemptNum = TaskContext.get.attemptNumber; if (attemptNum < 3) throw new Exception("Fail for blacklisting")}; iterator.toList.map (x => x + " -> " + index).iterator } )
mapped.collect
```
Closes#22288 from dhruve/bug/SPARK-22148.
Lead-authored-by: Dhruve Ashar <dhruveashar@gmail.com>
Co-authored-by: Dhruve Ashar <dhruve@users.noreply.github.com>
Co-authored-by: Tom Graves <tgraves@apache.org>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
Upgrade ASM to 7.x to support JDK11
## How was this patch tested?
Existing tests.
Closes#22953 from dbtsai/asm7.
Authored-by: DB Tsai <d_tsai@apple.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
Currently definitions of config entries in `core` module are in several files separately. We should move them into `internal/config` to be easy to manage.
## How was this patch tested?
Existing tests.
Closes#22928 from ueshin/issues/SPARK-25926/single_config_file.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Fix typos and misspellings, per https://github.com/apache/spark-website/pull/158#issuecomment-435790366
## How was this patch tested?
Existing tests.
Closes#22950 from srowen/Typos.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In `UnsafeSorterSpillWriter.java`, when we write a record to a spill file wtih ` void write(Object baseObject, long baseOffset, int recordLength, long keyPrefix)`, `recordLength` and `keyPrefix` will be written the disk write buffer first, and these will take 12 bytes, so the disk write buffer size must be greater than 12.
If `diskWriteBufferSize` is 10, it will print this exception info:
_java.lang.ArrayIndexOutOfBoundsException: 10
at org.apache.spark.util.collection.unsafe.sort.UnsafeSorterSpillWriter.writeLongToBuffer (UnsafeSorterSpillWriter.java:91)
at org.apache.spark.util.collection.unsafe.sort.UnsafeSorterSpillWriter.write(UnsafeSorterSpillWriter.java:123)
at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.spillIterator(UnsafeExternalSorter.java:498)
at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.spill(UnsafeExternalSorter.java:222)
at org.apache.spark.memory.MemoryConsumer.spill(MemoryConsumer.java:65)_
## How was this patch tested?
Existing UT in `UnsafeExternalSorterSuite`
Closes#22754 from 10110346/diskWriteBufferSize.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
## What changes were proposed in this pull request?
Now we use only one `timer` (and thus a backing thread) in `BarrierTaskContext` companion object, and the objects can add `timerTasks` to that `timer`.
## How was this patch tested?
This was tested manually by generating logs and seeing that they look the same as ones before, namely, that is, a partition waiting on another partition for 5seconds generates 4-5 log messages when the frequency of logging is set to 1second.
Closes#22912 from yogeshg/thread.
Authored-by: Yogesh Garg <1059168+yogeshg@users.noreply.github.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
## What changes were proposed in this pull request?
'refreshInterval' is not used any where in the headerSparkPage method. So, we don't need to pass the parameter while calling the 'headerSparkPage' method.
## How was this patch tested?
Existing tests
Closes#22864 from shahidki31/unusedCode.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Avoid converting encrypted bocks to regular ByteBuffers, to ensure they can be sent over the network for replication & remote reads even when > 2GB.
Also updates some TODOs with links to a SPARK-25905 for improving the
handling here.
## How was this patch tested?
Tested on a cluster with encrypted data > 2GB (after SPARK-25904 was
applied as well).
Closes#22917 from squito/real_SPARK-25827.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
* Update `AppStatusListener` `cleanupStages` method to remove tasks for those stages in a single pass instead of 1 for each stage.
* This fixes an issue where the cleanupStages method would get backed up, causing a backup in the executor in ElementTrackingStore, resulting in stages and jobs not getting cleaned up properly.
Tasks seem most susceptible to this as there are a lot of them, however a similar issue could arise in other locations the `KVStore` `view` method is used. A broader fix might involve updates to `KVStoreView` and `InMemoryView` as it appears this interface and implementation can lead to multiple and inefficient traversals of the stored data.
## How was this patch tested?
Using existing tests in AppStatusListenerSuite
This is my original work and I license the work to the project under the project’s open source license.
Closes#22883 from patrickbrownsync/cleanup-stages-fix.
Authored-by: Patrick Brown <patrick.brown@blyncsy.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
I saw CoarseGrainedSchedulerBackendSuite failed in my PR and finally reproduced the following error on a very busy machine:
```
sbt.ForkMain$ForkError: org.scalatest.exceptions.TestFailedDueToTimeoutException: The code passed to eventually never returned normally. Attempted 400 times over 10.009828643999999 seconds. Last failure message: ArrayBuffer("2", "0", "3") had length 3 instead of expected length 4.
```
The logs in this test shows executor 1 was not up when the test failed.
```
18/10/30 11:34:03.563 dispatcher-event-loop-12 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.17.0.2:43656) with ID 2
18/10/30 11:34:03.593 dispatcher-event-loop-3 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.17.0.2:43658) with ID 3
18/10/30 11:34:03.629 dispatcher-event-loop-6 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.17.0.2:43654) with ID 0
18/10/30 11:34:03.885 pool-1-thread-1-ScalaTest-running-CoarseGrainedSchedulerBackendSuite INFO CoarseGrainedSchedulerBackendSuite:
===== FINISHED o.a.s.scheduler.CoarseGrainedSchedulerBackendSuite: 'compute max number of concurrent tasks can be launched' =====
```
And the following logs in executor 1 shows it was still doing the initialization when the timeout happened (at 18/10/30 11:34:03.885).
```
18/10/30 11:34:03.463 netty-rpc-connection-0 INFO TransportClientFactory: Successfully created connection to 54b6b6217301/172.17.0.2:33741 after 37 ms (0 ms spent in bootstraps)
18/10/30 11:34:03.959 main INFO DiskBlockManager: Created local directory at /home/jenkins/workspace/core/target/tmp/spark-383518bc-53bd-4d9c-885b-d881f03875bf/executor-61c406e4-178f-40a6-ac2c-7314ee6fb142/blockmgr-03fb84a1-eedc-4055-8743-682eb3ac5c67
18/10/30 11:34:03.993 main INFO MemoryStore: MemoryStore started with capacity 546.3 MB
```
Hence, I think our current 10 seconds is not enough on a slow Jenkins machine. This PR just increases the timeout from 10 seconds to 60 seconds to make the test more stable.
## How was this patch tested?
Jenkins
Closes#22910 from zsxwing/fix-flaky-test.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
This avoids having two classes to deal with tokens; now the above
class is a one-stop shop for dealing with delegation tokens. The
YARN backend extends that class instead of doing composition like
before, resulting in a bit less code there too.
The renewer functionality is basically the same code that used to
be in YARN's AMCredentialRenewer. That is also the reason why the
public API of HadoopDelegationTokenManager is a little bit odd;
the YARN AM has some odd requirements for how this all should be
initialized, and the weirdness is needed currently to support that.
Tested:
- YARN with stress app for DT renewal
- Mesos and K8S with basic kerberos tests (both tgt and keytab)
Closes#22624 from vanzin/SPARK-23781.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
This turns off hdfs erasure coding by default for event logs, regardless of filesystem defaults. Because this requires apis only available in hadoop 3, this uses reflection. EC isn't a very good choice for event logs, as hflush() is a no-op, and so updates to the file are not visible for a long time. This can still be configured by setting "spark.eventLog.allowErasureCoding=true", which will use filesystem defaults.
## How was this patch tested?
deployed a cluster with the changes with HDFS EC on. By default, event logs didn't use EC, but configuration still would allow EC. Also tried writing to the local fs (which doesn't support EC at all) and things worked fine.
Closes#22881 from squito/SPARK-25855.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Py4J 0.10.8.1 is released on October 21st and is the first release of Py4J to support Python 3.7 officially. We had better have this to get the official support. Also, there are some patches related to garbage collections.
https://www.py4j.org/changelog.html#py4j-0-10-8-and-py4j-0-10-8-1
## How was this patch tested?
Pass the Jenkins.
Closes#22901 from dongjoon-hyun/SPARK-25891.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
When a job finishes, there may be some zombie tasks still running due to stage retry. Since a result stage will never be used by other jobs, running these tasks are just wasting the cluster resource. This PR just asks TaskScheduler to cancel the running tasks of a result stage when it's already finished. Credits go to srinathshankar who suggested this idea to me.
This PR also fixes two minor issues while I'm touching DAGScheduler:
- Invalid spark.job.interruptOnCancel should not crash DAGScheduler.
- Non fatal errors should not crash DAGScheduler.
## How was this patch tested?
The new unit tests.
Closes#22771 from zsxwing/SPARK-25773.
Lead-authored-by: Shixiong Zhu <zsxwing@gmail.com>
Co-authored-by: Shixiong Zhu <shixiong@databricks.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
MetricGetter should rename to ExecutorMetricType in comments.
## How was this patch tested?
Just comments, no need to test.
Closes#22884 from LantaoJin/SPARK-23429_FOLLOWUP.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
Set main args correctly in BenchmarkBase, to make it accessible for its subclass.
It will benefit:
- BuiltInDataSourceWriteBenchmark
- AvroWriteBenchmark
## How was this patch tested?
manual tests
Closes#22872 from yucai/main_args.
Authored-by: yucai <yyu1@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
There is a race condition when releasing a Python worker. If `ReaderIterator.handleEndOfDataSection` is not running in the task thread, when a task is early terminated (such as `take(N)`), the task completion listener may close the worker but "handleEndOfDataSection" can still put the worker into the worker pool to reuse.
0e07b483d2 is a patch to reproduce this issue.
I also found a user reported this in the mail list: http://mail-archives.apache.org/mod_mbox/spark-user/201610.mbox/%3CCAAUq=H+YLUEpd23nwvq13Ms5hOStkhX3ao4f4zQV6sgO5zM-xAmail.gmail.com%3E
This PR fixes the issue by using `compareAndSet` to make sure we will never return a closed worker to the work pool.
## How was this patch tested?
Jenkins.
Closes#22816 from zsxwing/fix-socket-closed.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
## What changes were proposed in this pull request?
`hsync` has been added as part of SPARK-19531 to get the latest data in the history sever ui, but that is causing the performance overhead and also leading to drop many history log events. `hsync` uses the force `FileChannel.force` to sync the data to the disk and happens for the data pipeline, it is costly operation and making the application to face overhead and drop the events.
I think getting the latest data in history server can be done in different way (no impact to application while writing events), there is an api `DFSInputStream.getFileLength()` which gives the file length including the `lastBlockBeingWrittenLength`(different from `FileStatus.getLen()`), this api can be used when the file status length and previously cached length are equal to verify whether any new data has been written or not, if there is any update in data length then the history server can update the in progress history log. And also I made this change as configurable with the default value false, and can be enabled for history server if users want to see the updated data in ui.
## How was this patch tested?
Added new test and verified manually, with the added conf `spark.history.fs.inProgressAbsoluteLengthCheck.enabled=true`, history server is reading the logs including the last block data which is being written and updating the Web UI with the latest data.
Closes#22752 from devaraj-kavali/SPARK-24787.
Authored-by: Devaraj K <devaraj@apache.org>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
In standalone cluster mode, one could launch driver with supervise mode
enabled. StandaloneRestServer class uses the host and port of current
master as the spark.master property while launching the driver
(even if you are running in HA mode). This class also ignores the
spark.master property passed as part of the request.
Due to the above problem, if the Spark masters switch due to some reason
and your driver is killed unexpectedly and relaunched, it will try to
connect to the master which is in the driver command specified as
-Dspark.master. But this master will be in STANDBY mode and after trying
multiple times, the SparkContext will kill itself (even though secondary
master was alive and healthy).
This change picks the spark.master property from request and uses it to
launch the driver process. Due to this, the driver process has both
masters in -Dspark.master property. Even if the masters switch, SparkContext
can still connect to the ALIVE master and work correctly.
## How was this patch tested?
This patch was manually tested on a standalone cluster running 2.2.1. It was rebased on current master and all tests were executed. I have added a unit test for this change (but since I am new I hope I have covered all).
Closes#21816 from bsikander/rest_driver_fix.
Authored-by: Behroz Sikander <behroz.sikander@sap.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Before the code changes, I tried to run it with 8G memory:
```
build/sbt -mem 8000 "core/testOnly org.apache.spark.serializer.KryoBenchmark"
```
Still I got got OOM.
This is because the lengths of the arrays are random
669ade3a8e/core/src/test/scala/org/apache/spark/serializer/KryoBenchmark.scala (L90-L91)
And the 2D array is usually large: `10000 * Random.nextInt(0, 10000)`
This PR is to fix it and refactor it to use main method.
The benchmark result is also reason compared to the original one.
## How was this patch tested?
Run with
```
bin/spark-submit --class org.apache.spark.serializer.KryoBenchmark core/target/scala-2.11/spark-core_2.11-3.0.0-SNAPSHOT-tests.jar
```
and
```
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "core/test:runMain org.apache.spark.serializer.KryoBenchmark"
Closes#22663 from gengliangwang/kyroBenchmark.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove JavaSparkContextVarargsWorkaround
## How was this patch tested?
Existing tests.
Closes#22729 from srowen/SPARK-25737.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove deprecated accumulator v1
## How was this patch tested?
Existing tests.
Closes#22730 from srowen/SPARK-16775.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Fix the following issues in PythonWorkerFactory
1. MonitorThread.run uses a wrong lock.
2. `createSimpleWorker` misses `synchronized` when updating `simpleWorkers`.
Other changes are just to improve the code style to make the thread-safe contract clear.
## How was this patch tested?
Jenkins
Closes#22770 from zsxwing/pwf.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
This is a follow up of #21601, `StreamFileInputFormat` and `WholeTextFileInputFormat` have the same problem.
`Minimum split size pernode 5123456 cannot be larger than maximum split size 4194304
java.io.IOException: Minimum split size pernode 5123456 cannot be larger than maximum split size 4194304
at org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat.getSplits(CombineFileInputFormat.java: 201)
at org.apache.spark.rdd.BinaryFileRDD.getPartitions(BinaryFileRDD.scala:52)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:254)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:252)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2138)`
## How was this patch tested?
Added a unit test
Closes#22725 from 10110346/maxSplitSize_node_rack.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
Currently in PagedTable.scala pageNavigation() method, if it is having only one page, they were not using the pagination.
Now it is made to use the pagination, even if it is having one page.
## How was this patch tested?
This tested with Spark webUI and History page in spark local setup.

Author: shivusondur <shivusondur@gmail.com>
Closes#22668 from shivusondur/pagination.
JVMs don't you allocate arrays of length exactly Int.MaxValue, so leave
a little extra room. This is necessary when reading blocks >2GB off
the network (for remote reads or for cache replication).
Unit tests via jenkins, ran a test with blocks over 2gb on a cluster
Closes#22705 from squito/SPARK-25704.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
When the first dropEvent occurs, LastReportTimestamp was printing in the log as
Wed Dec 31 16:00:00 PST 1969
(Dropped 1 events from eventLog since Wed Dec 31 16:00:00 PST 1969.)
The reason is that lastReportTimestamp initialized with 0.
Now log is updated to print "... since the application starts" if 'lastReportTimestamp' == 0.
this will happens first dropEvent occurs.
## How was this patch tested?
Manually verified.
Closes#22677 from shivusondur/AsyncEvent1.
Authored-by: shivusondur <shivusondur@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
The SQL execution listener framework was created from scratch(see https://github.com/apache/spark/pull/9078). It didn't leverage what we already have in the spark listener framework, and one major problem is, the listener runs on the spark execution thread, which means a bad listener can block spark's query processing.
This PR re-implements the SQL execution listener framework. Now `ExecutionListenerManager` is just a normal spark listener, which watches the `SparkListenerSQLExecutionEnd` events and post events to the
user-provided SQL execution listeners.
## How was this patch tested?
existing tests.
Closes#22674 from cloud-fan/listener.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
- Exposes several metrics regarding application status as a source, useful to scrape them via jmx instead of mining the metrics rest api. Example use case: prometheus + jmx exporter.
- Metrics are gathered when a job ends at the AppStatusListener side, could be more fine-grained but most metrics like tasks completed are also counted by executors. More metrics could be exposed in the future to avoid scraping executors in some scenarios.
- a config option `spark.app.status.metrics.enabled` is added to disable/enable these metrics, by default they are disabled.
This was manually tested with jmx source enabled and prometheus server on k8s:

In the next pic the job delay is shown for repeated pi calculation (Spark action).

Closes#22381 from skonto/add_app_status_metrics.
Authored-by: Stavros Kontopoulos <stavros.kontopoulos@lightbend.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Remove Kafka 0.8 integration
## How was this patch tested?
Existing tests, build scripts
Closes#22703 from srowen/SPARK-25705.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This is the work on setting up Secure HDFS interaction with Spark-on-K8S.
The architecture is discussed in this community-wide google [doc](https://docs.google.com/document/d/1RBnXD9jMDjGonOdKJ2bA1lN4AAV_1RwpU_ewFuCNWKg)
This initiative can be broken down into 4 Stages
**STAGE 1**
- [x] Detecting `HADOOP_CONF_DIR` environmental variable and using Config Maps to store all Hadoop config files locally, while also setting `HADOOP_CONF_DIR` locally in the driver / executors
**STAGE 2**
- [x] Grabbing `TGT` from `LTC` or using keytabs+principle and creating a `DT` that will be mounted as a secret or using a pre-populated secret
**STAGE 3**
- [x] Driver
**STAGE 4**
- [x] Executor
## How was this patch tested?
Locally tested on a single-noded, pseudo-distributed Kerberized Hadoop Cluster
- [x] E2E Integration tests https://github.com/apache/spark/pull/22608
- [ ] Unit tests
## Docs and Error Handling?
- [x] Docs
- [x] Error Handling
## Contribution Credit
kimoonkim skonto
Closes#21669 from ifilonenko/secure-hdfs.
Lead-authored-by: Ilan Filonenko <if56@cornell.edu>
Co-authored-by: Ilan Filonenko <ifilondz@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Update the next version of Spark from 2.5 to 3.0
## How was this patch tested?
N/A
Closes#22717 from gatorsmile/followupSPARK-25372.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Currently, if we try run
```
./start-history-server.sh -h
```
We will get such error
```
java.io.FileNotFoundException: File -h does not exist
```
1. This is not User-Friendly. For option `-h` or `--help`, it should be parsed correctly and show the usage of the class/script.
2. We can remove deprecated options for setting event log directory through command line options.
After fix, we can get following output:
```
Usage: ./sbin/start-history-server.sh [options]
Options:
--properties-file FILE Path to a custom Spark properties file.
Default is conf/spark-defaults.conf.
Configuration options can be set by setting the corresponding JVM system property.
History Server options are always available; additional options depend on the provider.
History Server options:
spark.history.ui.port Port where server will listen for connections
(default 18080)
spark.history.acls.enable Whether to enable view acls for all applications
(default false)
spark.history.provider Name of history provider class (defaults to
file system-based provider)
spark.history.retainedApplications Max number of application UIs to keep loaded in memory
(default 50)
FsHistoryProvider options:
spark.history.fs.logDirectory Directory where app logs are stored
(default: file:/tmp/spark-events)
spark.history.fs.updateInterval How often to reload log data from storage
(in seconds, default: 10)
```
## How was this patch tested?
Manual test
Closes#22699 from gengliangwang/refactorSHSUsage.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Fix old oversight in API: Java `flatMapValues` needs a `FlatMapFunction`
## How was this patch tested?
Existing tests.
Closes#22690 from srowen/SPARK-19287.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Refactor `JoinBenchmark` to use main method.
1. use `spark-submit`:
```console
bin/spark-submit --class org.apache.spark.sql.execution.benchmark.JoinBenchmark --jars ./core/target/spark-core_2.11-3.0.0-SNAPSHOT-tests.jar ./sql/catalyst/target/spark-sql_2.11-3.0.0-SNAPSHOT-tests.jar
```
2. Generate benchmark result:
```console
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.JoinBenchmark"
```
## How was this patch tested?
manual tests
Closes#22661 from wangyum/SPARK-25664.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Yuming Wang <wgyumg@gmail.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
When we enable event log compression and compression codec as 'zstd', we are unable to open the webui of the running application from the history server page.
The reason is that, Replay listener was unable to read from the zstd compressed eventlog due to the zstd frame was not finished yet. This causes truncated error while reading the eventLog.
So, when we try to open the WebUI from the History server page, it throws "truncated error ", and we never able to open running application in the webui, when we enable zstd compression.
In this PR, when the IO excpetion happens, and if it is a running application, we log the error,
"Failed to read Spark event log: evetLogDirAppName.inprogress", instead of throwing exception.
## How was this patch tested?
Test steps:
1)spark.eventLog.compress = true
2)spark.io.compression.codec = zstd
3)restart history server
4) launch bin/spark-shell
5) run some queries
6) Open history server page
7) click on the application
**Before fix:**


**After fix:**


(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22689 from shahidki31/SPARK-25697.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently SQL tab in the WEBUI doesn't support pagination. Because of that following issues are happening.
1) For large number of executions, SQL page is throwing OOM exception (around 40,000)
2) For large number of executions, loading SQL page is taking time.
3) Difficult to analyse the execution table for large number of execution.
[Note: spark.sql.ui.retainedExecutions = 50000]
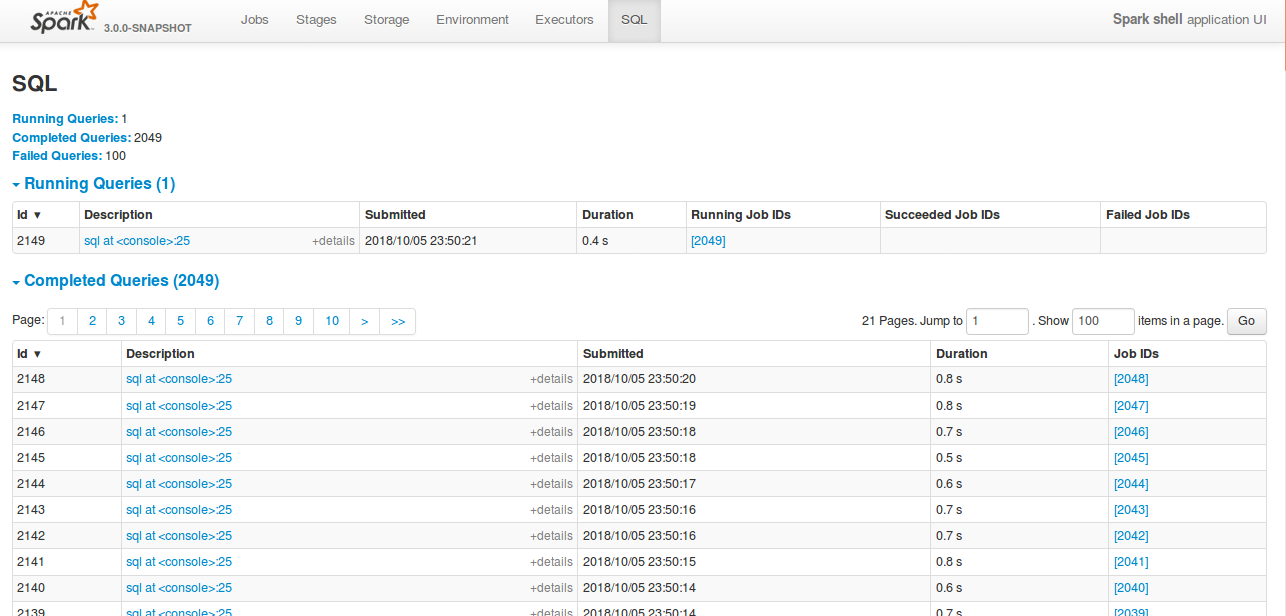
All the tabs, Jobs, Stages etc. supports pagination. So, to make it consistent with other tabs
SQL tab also should support pagination.
I have followed the similar flow of the pagination code in the Jobs and Stages page for SQL page.
Also, this patch doesn't make any behavior change for the SQL tab except the pagination support.
## How was this patch tested?
bin/spark-shell --conf spark.sql.ui.retainedExecutions=50000
Run 50,000 sql queries.
**Before this PR**
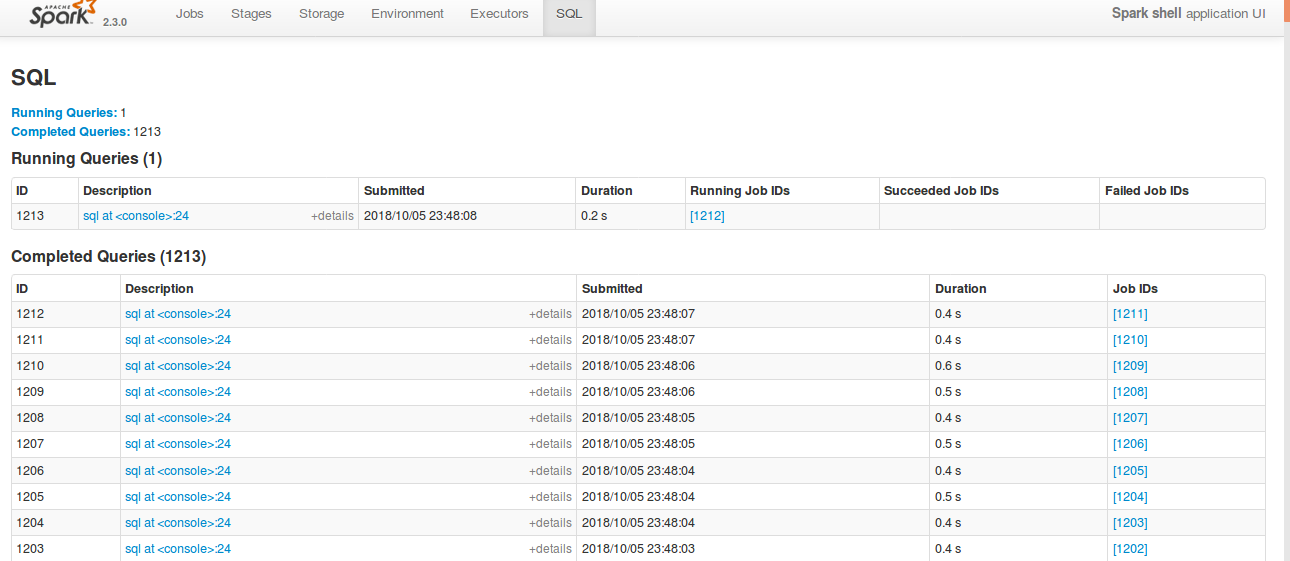
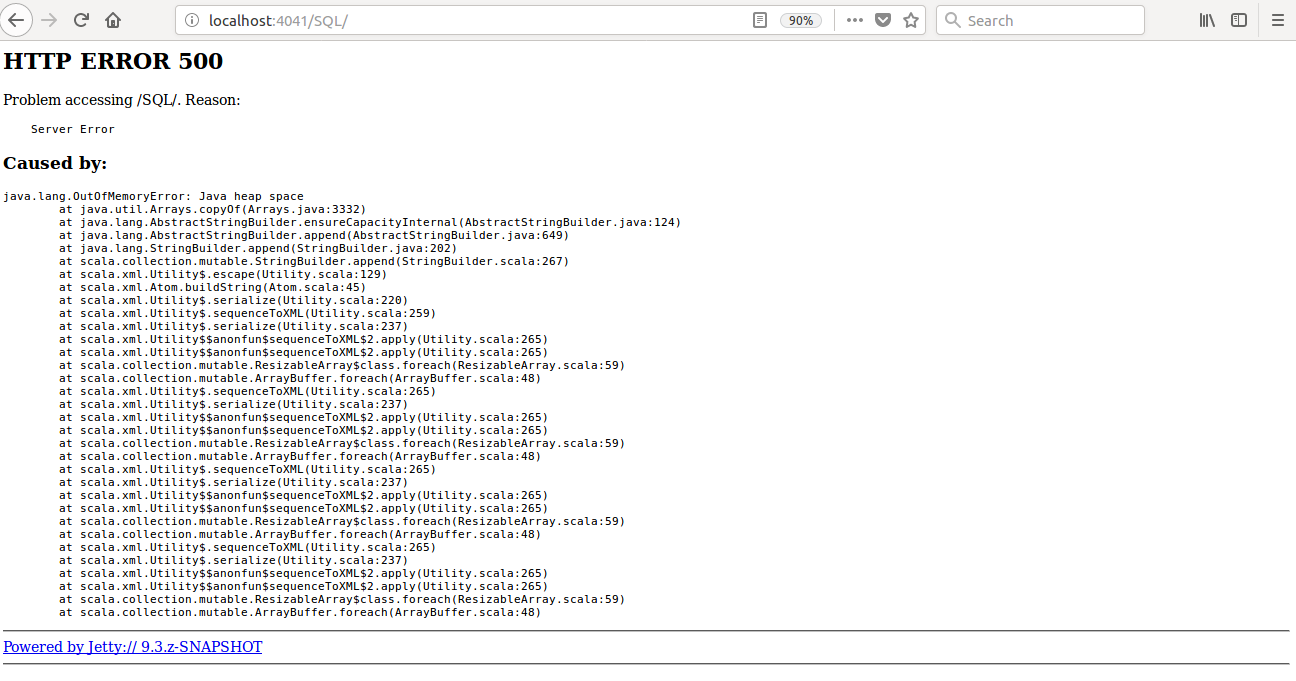
**After this PR**
Loading of the page is faster, and OOM issue doesn't happen.
Closes#22645 from shahidki31/SPARK-25566.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}