### What changes were proposed in this pull request?
This PR aims to add a documentation on how to read and write TEXT files through various APIs such as Scala, Python and JAVA in Spark to [Data Source documents](https://spark.apache.org/docs/latest/sql-data-sources.html#data-sources).
### Why are the changes needed?
Documentation on how Spark handles TEXT files is missing. It should be added to the document for user convenience.
### Does this PR introduce _any_ user-facing change?
Yes, this PR adds a new page to Data Sources documents.
### How was this patch tested?
Manually build documents and check the page on local as below.

Closes#32053 from itholic/SPARK-34491-TEXT.
Authored-by: itholic <haejoon.lee@databricks.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Fix [SPARK-34492], add Scala examples to read/write CSV files.
### Why are the changes needed?
Fix [SPARK-34492].
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Build the document with "SKIP_API=1 bundle exec jekyll build", and everything looks fine.
Closes#31827 from twoentartian/master.
Authored-by: twoentartian <twoentartian@hotmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR adds `ADD ARCHIVE` and `LIST ARCHIVES` commands to SQL and updates relevant documents.
SPARK-33530 added `addArchive` and `listArchives` to `SparkContext` but it's not supported yet to add/list archives with SQL.
### Why are the changes needed?
To complement features.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added new test and confirmed the generated HTML from the updated documents.
Closes#31721 from sarutak/sql-archive.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Change "Apache Arrow in Spark" to "Apache Arrow in PySpark"
and the link to “/sql-pyspark-pandas-with-arrow.html#apache-arrow-in-pyspark”
### Why are the changes needed?
When I click on the menu item it doesn't point to the correct page, and from the parent menu I can infer that the correct menu item name and link should be "Apache Arrow in PySpark".
like this:
image

### Does this PR introduce any user-facing change?
Yes, clicking on the menu item will take you to the correct guide page
### How was this patch tested?
Manually build the doc. This can be verified as below:
cd docs
SKIP_API=1 jekyll build
open _site/sql-pyspark-pandas-with-arrow.html
Closes#30466 from liucht-inspur/master.
Authored-by: liucht <liucht@inspur.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
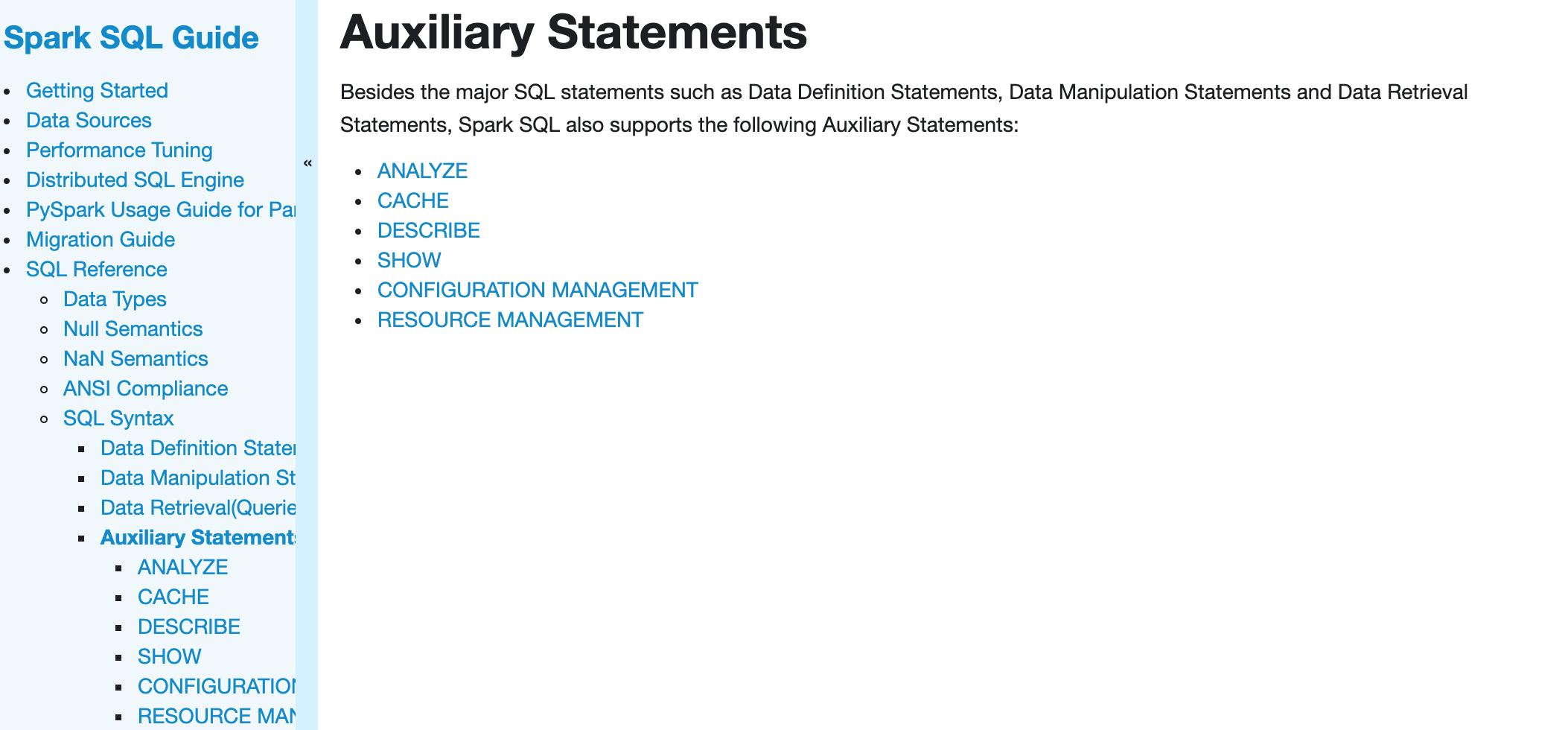
### What changes were proposed in this pull request?
Add the missing sub-bullets in the left side of `Spark SQL Guide`
### Why are the changes needed?
The three sub-bullets in the left side is not consistent with the contents (five bullets) in the right side.

### Does this PR introduce _any_ user-facing change?
Yes, you can see more lines in the left menu.
### How was this patch tested?
Manually build the doc as follows. This can be verified as attached:
```
cd docs
SKIP_API=1 jekyll build
firefox _site/sql-pyspark-pandas-with-arrow.html
```

Closes#30537 from kiszk/SPARK-33590.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR intends to add a dedicated page for SQL-on-file in SQL documents.
This comes from the comment: https://github.com/apache/spark/pull/30095/files#r508965149
### Why are the changes needed?
For better documentations.
### Does this PR introduce _any_ user-facing change?
<img width="544" alt="Screen Shot 2020-10-28 at 9 56 59" src="https://user-images.githubusercontent.com/692303/97378051-c1fbcb80-1904-11eb-86c0-a88c5269d41c.png">
### How was this patch tested?
N/A
Closes#30165 from maropu/DocForFile.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In Hive mode, permanent functions are shared with Hive metastore so that functions may be modified by other Hive client. With in long-lived spark scene, it's hard to update the change of function.
Here are 2 reasons:
* Spark cache the function in memory using `FunctionRegistry`.
* User may not know the location or classname of udf when using `replace function`.
Note that we use v2 command code path to add new command.
### Why are the changes needed?
Give a easy way to make spark function registry sync with Hive metastore.
Then we can call
```
refresh function functionName
```
### Does this PR introduce _any_ user-facing change?
Yes, new command.
### How was this patch tested?
New UT.
Closes#28840 from ulysses-you/SPARK-31999.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds the SQL standard command - `SET TIME ZONE` to the current default time zone displacement for the current SQL-session, which is the same as the existing `set spark.sql.session.timeZone=xxx'.
All in all, this PR adds syntax as following,
```
SET TIME ZONE LOCAL;
SET TIME ZONE 'valid time zone'; -- zone offset or region
SET TIME ZONE INTERVAL XXXX; -- xxx must in [-18, + 18] hours, * this range is bigger than ansi [-14, + 14]
```
### Why are the changes needed?
ANSI compliance and supply pure SQL users a way to retrieve all supported TimeZones
### Does this PR introduce _any_ user-facing change?
yes, add new syntax.
### How was this patch tested?
add unit tests.
and locally verified reference doc

Closes#29064 from yaooqinn/SPARK-32272.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
docs/sql-ref-syntax-qry-select-usedb.md -> docs/sql-ref-syntax-ddl-usedb.md
docs/sql-ref-syntax-aux-refresh-table.md -> docs/sql-ref-syntax-aux-cache-refresh-table.md
### Why are the changes needed?
usedb belongs to DDL. Its location should be consistent with other DDL commands file locations
similar reason for refresh table
### Does this PR introduce _any_ user-facing change?
before change, when clicking USE DATABASE, the side bar menu shows select commands
<img width="1200" alt="Screen Shot 2020-07-04 at 9 05 35 AM" src="https://user-images.githubusercontent.com/13592258/86516696-b45f8a80-bdd7-11ea-8dba-3a5cca22aad3.png">
after change, when clicking USE DATABASE, the side bar menu shows DDL commands
<img width="1120" alt="Screen Shot 2020-07-04 at 9 06 06 AM" src="https://user-images.githubusercontent.com/13592258/86516703-bf1a1f80-bdd7-11ea-8a90-ae7eaaafd44c.png">
before change, when clicking refresh table, the side bar menu shows Auxiliary statements
<img width="1200" alt="Screen Shot 2020-07-04 at 9 30 40 AM" src="https://user-images.githubusercontent.com/13592258/86516877-3d2af600-bdd9-11ea-9568-0a6f156f57da.png">
after change, when clicking refresh table, the side bar menu shows Cache statements
<img width="1199" alt="Screen Shot 2020-07-04 at 9 35 21 AM" src="https://user-images.githubusercontent.com/13592258/86516937-b4f92080-bdd9-11ea-8ad1-5f5a7f58d76b.png">
### How was this patch tested?
Manually build and check
Closes#28995 from huaxingao/docs_fix.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Huaxin Gao <huaxing@us.ibm.com>
### What changes were proposed in this pull request?
Remove the unneeded embedded inline HTML markup by using the basic markdown syntax.
Please see #28414
### Why are the changes needed?
Make the doc cleaner and easily editable by MD editors.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually build and check
Closes#28451 from huaxingao/html_cleanup.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR intends to drop the built-in function pages from SQL references. We've already had a complete list of built-in functions in the API documents.
See related discussions for more details:
https://github.com/apache/spark/pull/28170#issuecomment-611917191
### Why are the changes needed?
For better SQL documents.
### Does this PR introduce any user-facing change?

### How was this patch tested?
Manually checked.
Closes#28203 from maropu/DropBuiltinFunctionDocs.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Previously, user can issue `SHOW TABLES` to get info of both tables and views.
This PR (SPARK-31113) implements `SHOW VIEWS` SQL command similar to HIVE to get views only.(https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-ShowViews)
**Hive** -- Only show view names
```
hive> SHOW VIEWS;
OK
view_1
view_2
...
```
**Spark(Hive-Compatible)** -- Only show view names, used in tests and `SparkSQLDriver` for CLI applications
```
SHOW VIEWS IN showdb;
view_1
view_2
...
```
**Spark** -- Show more information database/viewName/isTemporary
```
spark-sql> SHOW VIEWS;
userdb view_1 false
userdb view_2 false
...
```
### Why are the changes needed?
`SHOW VIEWS` command provides better granularity to only get information of views.
### Does this PR introduce any user-facing change?
Add new `SHOW VIEWS` SQL command
### How was this patch tested?
Add new test `show-views.sql` and pass existing tests
Closes#27897 from Eric5553/ShowViews.
Authored-by: Eric Wu <492960551@qq.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Fix a broken link and make the relevant docs reference to the new doc
### Why are the changes needed?
### Does this PR introduce any user-facing change?
Yes, make CACHE TABLE, UNCACHE TABLE, CLEAR CACHE, REFRESH TABLE link to the new doc
### How was this patch tested?
Manually build and check
Closes#28065 from huaxingao/spark-30363-follow-up.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR adds "Pandas Function API" into the menu.
### Why are the changes needed?
To be consistent and to make easier to navigate.
### Does this PR introduce any user-facing change?
No, master only.

### How was this patch tested?
Manually verified by `SKIP_API=1 jekyll build`.
Closes#28054 from HyukjinKwon/followup-spark-30722.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
In Spark version 2.4 and earlier, datetime parsing, formatting and conversion are performed by using the hybrid calendar (Julian + Gregorian).
Since the Proleptic Gregorian calendar is de-facto calendar worldwide, as well as the chosen one in ANSI SQL standard, Spark 3.0 switches to it by using Java 8 API classes (the java.time packages that are based on ISO chronology ). The switching job is completed in SPARK-26651.
But after the switching, there are some patterns not compatible between Java 8 and Java 7, Spark needs its own definition on the patterns rather than depends on Java API.
In this PR, we achieve this by writing the document and shadow the incompatible letters. See more details in [SPARK-31030](https://issues.apache.org/jira/browse/SPARK-31030)
### Why are the changes needed?
For backward compatibility.
### Does this PR introduce any user-facing change?
No.
After we define our own datetime parsing and formatting patterns, it's same to old Spark version.
### How was this patch tested?
Existing and new added UT.
Locally document test:

Closes#27830 from xuanyuanking/SPARK-31030.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
- Sets up links between related sections.
- Add "Related sections" for each section.
- Change to the left hand side menu to reflect the current status of the doc.
- Other minor cleanups.
### Why are the changes needed?
Currently Spark lacks documentation on the supported SQL constructs causing
confusion among users who sometimes have to look at the code to understand the
usage. This is aimed at addressing this issue.
### Does this PR introduce any user-facing change?
Yes.
### How was this patch tested?
Tested using jykyll build --serve
Closes#27371 from dilipbiswal/select_finalization.
Authored-by: Dilip Biswal <dkbiswal@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Documentation added for refresh resources command in spark-sql.
### Why are the changes needed?
Previously, only refresh table command was documented.
### Does this PR introduce any user-facing change?
Yes. Now users can access documentation for refresh resources command.
### How was this patch tested?
Manually.
Closes#27023 from iRakson/SPARK-30363.
Authored-by: root1 <raksonrakesh@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Update the Spark SQL document menu and join strategy hints.
### Why are the changes needed?
- Several new changes in the Spark SQL document didn't change the menu-sql.yaml correspondingly.
- Update the demo code for join strategy hints.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Document change only.
Closes#26917 from xuanyuanking/SPARK-30278.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Fixed typo in `docs` directory and in other directories
1. Find typo in `docs` and apply fixes to files in all directories
2. Fix `the the` -> `the`
### Why are the changes needed?
Better readability of documents
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
No test needed
Closes#26976 from kiszk/typo_20191221.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Added document reference for USE databse sql command
### Why are the changes needed?
For USE database command usage
### Does this PR introduce any user-facing change?
It is adding the USE database sql command refernce information in the doc
### How was this patch tested?
Attached the test snap

Closes#25572 from shivusondur/jiraUSEDaBa1.
Lead-authored-by: shivusondur <shivusondur@gmail.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Currently, there is no migration section for PySpark, SparkCore and Structured Streaming.
It is difficult for users to know what to do when they upgrade.
This PR proposes to create create a "Migration Guide" tap at Spark documentation.


This page will contain migration guides for Spark SQL, PySpark, SparkR, MLlib, Structured Streaming and Core. Basically it is a refactoring.
There are some new information added, which I will leave a comment inlined for easier review.
1. **MLlib**
Merge [ml-guide.html#migration-guide](https://spark.apache.org/docs/latest/ml-guide.html#migration-guide) and [ml-migration-guides.html](https://spark.apache.org/docs/latest/ml-migration-guides.html)
```
'docs/ml-guide.md'
↓ Merge new/old migration guides
'docs/ml-migration-guide.md'
```
2. **PySpark**
Extract PySpark specific items from https://spark.apache.org/docs/latest/sql-migration-guide-upgrade.html
```
'docs/sql-migration-guide-upgrade.md'
↓ Extract PySpark specific items
'docs/pyspark-migration-guide.md'
```
3. **SparkR**
Move [sparkr.html#migration-guide](https://spark.apache.org/docs/latest/sparkr.html#migration-guide) into a separate file, and extract from [sql-migration-guide-upgrade.html](https://spark.apache.org/docs/latest/sql-migration-guide-upgrade.html)
```
'docs/sparkr.md' 'docs/sql-migration-guide-upgrade.md'
Move migration guide section ↘ ↙ Extract SparkR specific items
docs/sparkr-migration-guide.md
```
4. **Core**
Newly created at `'docs/core-migration-guide.md'`. I skimmed resolved JIRAs at 3.0.0 and found some items to note.
5. **Structured Streaming**
Newly created at `'docs/ss-migration-guide.md'`. I skimmed resolved JIRAs at 3.0.0 and found some items to note.
6. **SQL**
Merged [sql-migration-guide-upgrade.html](https://spark.apache.org/docs/latest/sql-migration-guide-upgrade.html) and [sql-migration-guide-hive-compatibility.html](https://spark.apache.org/docs/latest/sql-migration-guide-hive-compatibility.html)
```
'docs/sql-migration-guide-hive-compatibility.md' 'docs/sql-migration-guide-upgrade.md'
Move Hive compatibility section ↘ ↙ Left over after filtering PySpark and SparkR items
'docs/sql-migration-guide.md'
```
### Why are the changes needed?
In order for users in production to effectively migrate to higher versions, and detect behaviour or breaking changes before upgrading and/or migrating.
### Does this PR introduce any user-facing change?
Yes, this changes Spark's documentation at https://spark.apache.org/docs/latest/index.html.
### How was this patch tested?
Manually build the doc. This can be verified as below:
```bash
cd docs
SKIP_API=1 jekyll build
open _site/index.html
```
Closes#25757 from HyukjinKwon/migration-doc.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Document REFRESH TABLE statement in the SQL Reference Guide.
### Why are the changes needed?
Currently there is no documentation in the SPARK SQL to describe how to use this command, it is to address this issue.
### Does this PR introduce any user-facing change?
Yes.
#### Before:
There is no documentation for this.
#### After:
<img width="826" alt="Screen Shot 2019-09-12 at 11 39 21 AM" src="https://user-images.githubusercontent.com/7550280/64811385-01752600-d552-11e9-876d-91ebb005b851.png">
### How was this patch tested?
Using jykll build --serve
Closes#25549 from kevinyu98/spark-28828-refreshTable.
Authored-by: Kevin Yu <qyu@us.ibm.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This is a initial PR that creates the table of content for SQL reference guide. The left side bar will displays additional menu items corresponding to supported SQL constructs. One this PR is merged, we will fill in the content incrementally. Additionally this PR contains a minor change to make the left sidebar scrollable. Currently it is not possible to scroll in the left hand side window.
## How was this patch tested?
Used jekyll build and serve to verify.
Closes#25459 from dilipbiswal/ref-doc.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This pr targeted to define reserved/non-reserved keywords for Spark SQL based on the ANSI SQL standards and the other database-like systems (e.g., PostgreSQL). We assume that they basically follow the ANSI SQL-2011 standard, but it is slightly different between each other. Therefore, this pr documented all the keywords in `docs/sql-reserved-and-non-reserved-key-words.md`.
NOTE: This pr only added a small set of keywords as reserved ones and these keywords are reserved in all the ANSI SQL standards (SQL-92, SQL-99, SQL-2003, SQL-2008, SQL-2011, and SQL-2016) and PostgreSQL. This is because there is room to discuss which keyword should be reserved or not, .e.g., interval units (day, hour, minute, second, ...) are reserved in the ANSI SQL standards though, they are not reserved in PostgreSQL. Therefore, we need more researches about the other database-like systems (e.g., Oracle Databases, DB2, SQL server) in follow-up activities.
References:
- The reserved/non-reserved SQL keywords in the ANSI SQL standards: https://developer.mimer.com/wp-content/uploads/2018/05/Standard-SQL-Reserved-Words-Summary.pdf
- SQL Key Words in PostgreSQL: https://www.postgresql.org/docs/current/sql-keywords-appendix.html
## How was this patch tested?
Added tests in `TableIdentifierParserSuite`.
Closes#23259 from maropu/SPARK-26215-WIP.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}