## What changes were proposed in this pull request?
This PR is to add back `unionAll`, which is widely used. The name is also consistent with our ANSI SQL. We also have the corresponding `intersectAll` and `exceptAll`, which were introduced in Spark 2.4.
## How was this patch tested?
Added a test case in DataFrameSuite
Closes#23131 from gatorsmile/addBackUnionAll.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The DOI foundation recommends [this new resolver](https://www.doi.org/doi_handbook/3_Resolution.html#3.8). Accordingly, this PR re`sed`s all static DOI links ;-)
## How was this patch tested?
It wasn't, since it seems as safe as a "[typo fix](https://spark.apache.org/contributing.html)".
In case any of the files is included from other projects, and should be updated there, please let me know.
Closes#23129 from katrinleinweber/resolve-DOIs-securely.
Authored-by: Katrin Leinweber <9948149+katrinleinweber@users.noreply.github.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
"Running on Kubernetes" references `spark.driver.pod.name` few places, and it should be `spark.kubernetes.driver.pod.name`.
## How was this patch tested?
See changes
Closes#23133 from Leemoonsoo/fix-driver-pod-name-prop.
Authored-by: Lee moon soo <moon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
When doing typed aggregation on a Dataset, for struct key type, the key attribute is named as "key". But for non-struct type, the key attribute is named as "value". This key attribute should also be named as "key" for non-struct type.
## How was this patch tested?
Added test.
Closes#23054 from viirya/SPARK-26085.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
An input without valid JSON tokens on the root level will be treated as a bad record, and handled according to `mode`. Previously such input was converted to `null`. After the changes, the input is converted to a row with `null`s in the `PERMISSIVE` mode according the schema. This allows to remove a code in the `from_json` function which can produce `null` as result rows.
## How was this patch tested?
It was tested by existing test suites. Some of them I have to modify (`JsonSuite` for example) because previously bad input was just silently ignored. For now such input is handled according to specified `mode`.
Closes#22938 from MaxGekk/json-nulls.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
bin/docker-image-tool.sh tries to build all docker images (JVM, PySpark
and SparkR) by default. But not all spark distributions are built with
SparkR and hence this script will fail on such distros.
With this change, we make building alternate language binding docker images (PySpark and SparkR) optional. User has to specify dockerfile for those language bindings using -p and -R flags accordingly, to build the binding docker images.
## How was this patch tested?
Tested following scenarios.
*bin/docker-image-tool.sh -r <repo> -t <tag> build* --> Builds only JVM docker image (default behavior)
*bin/docker-image-tool.sh -r <repo> -t <tag> -p kubernetes/dockerfiles/spark/bindings/python/Dockerfile build* --> Builds both JVM and PySpark docker images
*bin/docker-image-tool.sh -r <repo> -t <tag> -p kubernetes/dockerfiles/spark/bindings/python/Dockerfile -R kubernetes/dockerfiles/spark/bindings/R/Dockerfile build* --> Builds JVM, PySpark and SparkR docker images.
Author: Nagaram Prasad Addepally <ram@cloudera.com>
Closes#23053 from ramaddepally/SPARK-25957.
## What changes were proposed in this pull request?
Introducing spark.ui.requestHeaderSize for configuring Jetty's HTTP requestHeaderSize.
This way long authorization field does not lead to HTTP 413.
## How was this patch tested?
Manually with curl (which version must be at least 7.55).
With the original default value (8k limit):
```bash
# Starting history server with default requestHeaderSize
$ ./sbin/start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /Users/attilapiros/github/spark/logs/spark-attilapiros-org.apache.spark.deploy.history.HistoryServer-1-apiros-MBP.lan.out
# Creating huge header
$ echo -n "X-Custom-Header: " > cookie
$ printf 'A%.0s' {1..9500} >> cookie
# HTTP GET with huge header fails with 431
$ curl -H cookie http://458apiros-MBP.lan:18080/
<h1>Bad Message 431</h1><pre>reason: Request Header Fields Too Large</pre>
# The log contains the error
$ tail -1 /Users/attilapiros/github/spark/logs/spark-attilapiros-org.apache.spark.deploy.history.HistoryServer-1-apiros-MBP.lan.out
18/11/19 21:24:28 WARN HttpParser: Header is too large 8193>8192
```
After:
```bash
# Creating the history properties file with the increased requestHeaderSize
$ echo spark.ui.requestHeaderSize=10000 > history.properties
# Starting Spark History Server with the settings
$ ./sbin/start-history-server.sh --properties-file history.properties
starting org.apache.spark.deploy.history.HistoryServer, logging to /Users/attilapiros/github/spark/logs/spark-attilapiros-org.apache.spark.deploy.history.HistoryServer-1-apiros-MBP.lan.out
# HTTP GET with huge header gives back HTML5 (I have added here only just a part of the response)
$ curl -H cookie http://458apiros-MBP.lan:18080/
<!DOCTYPE html><html>
<head>...
<link rel="shortcut icon" href="/static/spark-logo-77x50px-hd.png"></link>
<title>History Server</title>
</head>
<body>
...
```
Closes#23090 from attilapiros/JettyHeaderSize.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
Due to implementation limitation, currently Spark can't compare or do equality check between map types. As a result, map values can't appear in EQUAL or comparison expressions, can't be grouping key, etc.
The more important thing is, map loop up needs to do equality check of the map key, and thus can't support map as map key when looking up values from a map. Thus it's not useful to have map as map key.
This PR proposes to stop users from creating maps using map type as key. The list of expressions that are updated: `CreateMap`, `MapFromArrays`, `MapFromEntries`, `MapConcat`, `TransformKeys`. I manually checked all the places that create `MapType`, and came up with this list.
Note that, maps with map type key still exist, via reading from parquet files, converting from scala/java map, etc. This PR is not to completely forbid map as map key, but to avoid creating it by Spark itself.
Motivation: when I was trying to fix the duplicate key problem, I found it's impossible to do it with map type map key. I think it's reasonable to avoid map type map key for builtin functions.
## How was this patch tested?
updated test
Closes#23045 from cloud-fan/map-key.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
[Hive 2.3.4 is released on Nov. 7th](https://hive.apache.org/downloads.html#7-november-2018-release-234-available). This PR aims to support that version.
## How was this patch tested?
Pass the Jenkins with the updated version
Closes#23059 from dongjoon-hyun/SPARK-26091.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Highlights specific security issues to be aware of with Spark on K8S and recommends K8S mechanisms that should be used to secure clusters.
## How was this patch tested?
N/A - Documentation only
CC felixcheung tgravescs skonto
Closes#23013 from rvesse/SPARK-25023.
Authored-by: Rob Vesse <rvesse@dotnetrdf.org>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to bump up the minimum versions of R from 3.1 to 3.4.
R version. 3.1.x is too old. It's released 4.5 years ago. R 3.4.0 is released 1.5 years ago. Considering the timing for Spark 3.0, deprecating lower versions, bumping up R to 3.4 might be reasonable option.
It should be good to deprecate and drop < R 3.4 support.
## How was this patch tested?
Jenkins tests.
Closes#23012 from HyukjinKwon/SPARK-26014.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR makes Spark's default Scala version as 2.12, and Scala 2.11 will be the alternative version. This implies that Scala 2.12 will be used by our CI builds including pull request builds.
We'll update the Jenkins to include a new compile-only jobs for Scala 2.11 to ensure the code can be still compiled with Scala 2.11.
## How was this patch tested?
existing tests
Closes#22967 from dbtsai/scala2.12.
Authored-by: DB Tsai <d_tsai@apple.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
Currently, we do not have a mechanism to collect driver logs if a user chooses
to run their application in client mode. This is a big issue as admin teams need
to create their own mechanisms to capture driver logs.
This commit adds a logger which, if enabled, adds a local log appender to the
root logger and asynchronously syncs it an application specific log file on hdfs
(Spark Driver Log Dir).
Additionally, this collects spark-shell driver logs at INFO level by default.
The change is that instead of setting root logger level to WARN, we will set the
consoleAppender threshold to WARN, in case of spark-shell. This ensures that
only WARN logs are printed on CONSOLE but other log appenders still capture INFO
(or the default log level logs).
1. Verified that logs are written to local and remote dir
2. Added a unit test case
3. Verified this for spark-shell, client mode and pyspark.
4. Verified in both non-kerberos and kerberos environment
5. Verified with following unexpected termination conditions: Ctrl + C, Driver
OOM, Large Log Files
6. Ran an application in spark-shell and ensured that driver logs were
captured at INFO level
7. Started the application at WARN level, programmatically changed the level to
INFO and ensured that logs on console were printed at INFO level
Closes#22504 from ankuriitg/ankurgupta/SPARK-25118.
Authored-by: ankurgupta <ankur.gupta@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Every time a task is unschedulable because of the condition where no. of task failures < no. of executors available, we currently abort the taskSet - failing the job. This change tries to acquire new executors so that we can complete the job successfully. We try to acquire a new executor only when we can kill an existing idle executor. We fallback to the older implementation where we abort the job if we cannot find an idle executor.
## How was this patch tested?
I performed some manual tests to check and validate the behavior.
```scala
val rdd = sc.parallelize(Seq(1 to 10), 3)
import org.apache.spark.TaskContext
val mapped = rdd.mapPartitionsWithIndex ( (index, iterator) => { if (index == 2) { Thread.sleep(30 * 1000); val attemptNum = TaskContext.get.attemptNumber; if (attemptNum < 3) throw new Exception("Fail for blacklisting")}; iterator.toList.map (x => x + " -> " + index).iterator } )
mapped.collect
```
Closes#22288 from dhruve/bug/SPARK-22148.
Lead-authored-by: Dhruve Ashar <dhruveashar@gmail.com>
Co-authored-by: Dhruve Ashar <dhruve@users.noreply.github.com>
Co-authored-by: Tom Graves <tgraves@apache.org>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
Fix typos and misspellings, per https://github.com/apache/spark-website/pull/158#issuecomment-435790366
## How was this patch tested?
Existing tests.
Closes#22950 from srowen/Typos.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Change ptats.Stats() to pstats.Stats() for `spark.python.profile.dump` in configuration.md.
## How was this patch tested?
Doc test
Closes#22933 from AlexHagerman/doc_fix.
Authored-by: Alex Hagerman <alex@unexpectedeof.net>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Propose changing the documentation to state that there are 4, not 3, cluster managers available.
## How was this patch tested?
This is a docs-only patch and doesn't need any new testing beyond the normal CI process for Spark.
Closes#22922 from jameslamb/bugfix/cluster_docs.
Authored-by: James Lamb <jaylamb20@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Clarify documentation about security.
## How was this patch tested?
None, just documentation
Closes#22852 from tgravescs/SPARK-25023.
Authored-by: Thomas Graves <tgraves@thirteenroutine.corp.gq1.yahoo.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
This turns off hdfs erasure coding by default for event logs, regardless of filesystem defaults. Because this requires apis only available in hadoop 3, this uses reflection. EC isn't a very good choice for event logs, as hflush() is a no-op, and so updates to the file are not visible for a long time. This can still be configured by setting "spark.eventLog.allowErasureCoding=true", which will use filesystem defaults.
## How was this patch tested?
deployed a cluster with the changes with HDFS EC on. By default, event logs didn't use EC, but configuration still would allow EC. Also tried writing to the local fs (which doesn't support EC at all) and things worked fine.
Closes#22881 from squito/SPARK-25855.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Both Spark and Hive support views. However in some cases views created by Hive are not readable by Spark. For example, if column aliases are not specified in view definition queries, both Spark and Hive will generate alias names, but in different ways. In order for Spark to be able to read views created by Hive, users should explicitly specify column aliases in view definition queries.
Given that it's not uncommon that Hive and Spark are used together in enterprise data warehouse, this PR aims to explicitly describe this compatibility issue to help users troubleshoot this issue easily.
## How was this patch tested?
Docs are manually generated and checked locally.
```
SKIP_API=1 jekyll serve
```
Closes#22868 from seancxmao/SPARK-25833.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
New feature to pass podspec files for driver and executor pods.
## How was this patch tested?
new unit and integration tests
- [x] more overwrites in integration tests
- [ ] invalid template integration test, documentation
Author: Onur Satici <osatici@palantir.com>
Author: Yifei Huang <yifeih@palantir.com>
Author: onursatici <onursatici@gmail.com>
Closes#22146 from onursatici/pod-template.
## What changes were proposed in this pull request?
This PR targets to document binary type in "Apache Arrow in Spark".
## How was this patch tested?
Manually built the documentation and checked.
Closes#22871 from HyukjinKwon/SPARK-25179.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Remove deprecated functions which includes:
SQLContext/HiveContext stuff
sparkR.init
jsonFile
parquetFile
registerTempTable
saveAsParquetFile
unionAll
createExternalTable
dropTempTable
## How was this patch tested?
jenkins
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#22843 from felixcheung/rrddapi.
## What changes were proposed in this pull request?
Changed the `kubernetes-client` version and refactored code that broke as a result
## How was this patch tested?
Unit and Integration tests
Closes#22820 from ifilonenko/SPARK-25828.
Authored-by: Ilan Filonenko <ifilondz@gmail.com>
Signed-off-by: Erik Erlandson <eerlands@redhat.com>
## What changes were proposed in this pull request?
Remove SQLContext methods deprecated in 1.4
## How was this patch tested?
Existing tests.
Closes#22815 from srowen/SPARK-25821.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Add note about AddJar return value change in migration guide
## How was this patch tested?
n/a
Closes#22826 from srowen/SPARK-25760.2.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Since Spark 2.2, view definitions are stored in a different way from prior versions. This may cause Spark unable to read views created by prior versions. See [SPARK-25797](https://issues.apache.org/jira/browse/SPARK-25797) for more details.
Basically, we have 2 options.
1) Make Spark 2.2+ able to get older view definitions back. Since the expanded text is buggy and unusable, we have to use original text (this is possible with [SPARK-25459](https://issues.apache.org/jira/browse/SPARK-25459)). However, because older Spark versions don't save the context for the database, we cannot always get correct view definitions without view default database.
2) Recreate the views by `ALTER VIEW AS` or `CREATE OR REPLACE VIEW AS`.
This PR aims to add migration doc to help users troubleshoot this issue by above option 2.
## How was this patch tested?
N/A.
Docs are generated and checked locally
```
cd docs
SKIP_API=1 jekyll serve --watch
```
Closes#22846 from seancxmao/SPARK-25797.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Current the function `from_avro` throws exception on reading corrupt records.
In practice, there could be various reasons of data corruption. It would be good to support `PERMISSIVE` mode and allow the function from_avro to process all the input file/streaming, which is consistent with from_json and from_csv. There is no obvious down side for supporting `PERMISSIVE` mode.
Different from `from_csv` and `from_json`, the default parse mode is `FAILFAST` for the following reasons:
1. Since Avro is structured data format, input data is usually able to be parsed by certain schema. In such case, exposing the problems of input data to users is better than hiding it.
2. For `PERMISSIVE` mode, we have to force the data schema as fully nullable. This seems quite unnecessary for Avro. Reversing non-null schema might archive more perf optimizations in Spark.
3. To be consistent with the behavior in Spark 2.4 .
## How was this patch tested?
Unit test
Manual previewing generated html for the Avro data source doc:

Closes#22814 from gengliangwang/improve_from_avro.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Check the `spark.sql.repl.eagerEval.enabled` configuration property in SparkDataFrame `show()` method. If the `SparkSession` has eager execution enabled, the data will be returned to the R client when the data frame is created. So instead of seeing this
```
> df <- createDataFrame(faithful)
> df
SparkDataFrame[eruptions:double, waiting:double]
```
you will see
```
> df <- createDataFrame(faithful)
> df
+---------+-------+
|eruptions|waiting|
+---------+-------+
| 3.6| 79.0|
| 1.8| 54.0|
| 3.333| 74.0|
| 2.283| 62.0|
| 4.533| 85.0|
| 2.883| 55.0|
| 4.7| 88.0|
| 3.6| 85.0|
| 1.95| 51.0|
| 4.35| 85.0|
| 1.833| 54.0|
| 3.917| 84.0|
| 4.2| 78.0|
| 1.75| 47.0|
| 4.7| 83.0|
| 2.167| 52.0|
| 1.75| 62.0|
| 4.8| 84.0|
| 1.6| 52.0|
| 4.25| 79.0|
+---------+-------+
only showing top 20 rows
```
## How was this patch tested?
Manual tests as well as unit tests (one new test case is added).
Author: adrian555 <v2ave10p>
Closes#22455 from adrian555/eager_execution.
## What changes were proposed in this pull request?
As this is targeted for 3.0.0 and Python2 will be deprecated by Jan 1st, 2020, I feel it is appropriate to change the default to Python3. Especially as these projects [found here](https://python3statement.org/) are deprecating their support.
## How was this patch tested?
Unit and Integration tests
Author: Ilan Filonenko <ifilondz@gmail.com>
Closes#22810 from ifilonenko/SPARK-24516.
## What changes were proposed in this pull request?
In the PR, I propose to switch `from_json` on `FailureSafeParser`, and to make the function compatible to `PERMISSIVE` mode by default, and to support the `FAILFAST` mode as well. The `DROPMALFORMED` mode is not supported by `from_json`.
## How was this patch tested?
It was tested by existing `JsonSuite`/`CSVSuite`, `JsonFunctionsSuite` and `JsonExpressionsSuite` as well as new tests for `from_json` which checks different modes.
Closes#22237 from MaxGekk/from_json-failuresafe.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Our current doc does not explain how we are passing the data source specific options to the underlying data source. According to [the review comment](https://github.com/apache/spark/pull/22622#discussion_r222911529), this PR aims to add more detailed information and examples
## How was this patch tested?
Manual.
Closes#22801 from dongjoon-hyun/SPARK-25656.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This takes over original PR at #22019. The original proposal is to have null for float and double types. Later a more reasonable proposal is to disallow empty strings. This patch adds logic to throw exception when finding empty strings for non string types.
## How was this patch tested?
Added test.
Closes#22787 from viirya/SPARK-25040.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
add R API for PrefixSpan
## How was this patch tested?
add test in test_mllib_fpm.R
Author: Huaxin Gao <huaxing@us.ibm.com>
Closes#21710 from huaxingao/spark-24207.
## What changes were proposed in this pull request?
Fix minor error in the code "sketch of pregel implementation" of GraphX guide.
This fixed error relates to `[SPARK-12995][GraphX] Remove deprecate APIs from Pregel`
## How was this patch tested?
N/A
Closes#22780 from WeichenXu123/minor_doc_update1.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Since we didn't test Java 9 ~ 11 up to now in the community, fix the document to describe Java 8 only.
## How was this patch tested?
N/A (This is a document only change.)
Closes#22781 from dongjoon-hyun/SPARK-JDK-DOC.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Fix some broken links in the new document. I have clicked through all the links. Hopefully i haven't missed any :-)
## How was this patch tested?
Built using jekyll and verified the links.
Closes#22772 from dilipbiswal/doc_check.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
1. Split the main page of sql-programming-guide into 7 parts:
- Getting Started
- Data Sources
- Performance Turing
- Distributed SQL Engine
- PySpark Usage Guide for Pandas with Apache Arrow
- Migration Guide
- Reference
2. Add left menu for sql-programming-guide, keep first level index for each part in the menu.

## How was this patch tested?
Local test with jekyll build/serve.
Closes#22746 from xuanyuanking/SPARK-24499.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Remove Kafka 0.8 integration
## How was this patch tested?
Existing tests, build scripts
Closes#22703 from srowen/SPARK-25705.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This is the work on setting up Secure HDFS interaction with Spark-on-K8S.
The architecture is discussed in this community-wide google [doc](https://docs.google.com/document/d/1RBnXD9jMDjGonOdKJ2bA1lN4AAV_1RwpU_ewFuCNWKg)
This initiative can be broken down into 4 Stages
**STAGE 1**
- [x] Detecting `HADOOP_CONF_DIR` environmental variable and using Config Maps to store all Hadoop config files locally, while also setting `HADOOP_CONF_DIR` locally in the driver / executors
**STAGE 2**
- [x] Grabbing `TGT` from `LTC` or using keytabs+principle and creating a `DT` that will be mounted as a secret or using a pre-populated secret
**STAGE 3**
- [x] Driver
**STAGE 4**
- [x] Executor
## How was this patch tested?
Locally tested on a single-noded, pseudo-distributed Kerberized Hadoop Cluster
- [x] E2E Integration tests https://github.com/apache/spark/pull/22608
- [ ] Unit tests
## Docs and Error Handling?
- [x] Docs
- [x] Error Handling
## Contribution Credit
kimoonkim skonto
Closes#21669 from ifilonenko/secure-hdfs.
Lead-authored-by: Ilan Filonenko <if56@cornell.edu>
Co-authored-by: Ilan Filonenko <ifilondz@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This PR adds CLI support for YARN custom resources, e.g. GPUs and any other resources YARN defines.
The custom resources are defined with Spark properties, no additional CLI arguments were introduced.
The properties can be defined in the following form:
**AM resources, client mode:**
Format: `spark.yarn.am.resource.<resource-name>`
The property name follows the naming convention of YARN AM cores / memory properties: `spark.yarn.am.memory and spark.yarn.am.cores
`
**Driver resources, cluster mode:**
Format: `spark.yarn.driver.resource.<resource-name>`
The property name follows the naming convention of driver cores / memory properties: `spark.driver.memory and spark.driver.cores.`
**Executor resources:**
Format: `spark.yarn.executor.resource.<resource-name>`
The property name follows the naming convention of executor cores / memory properties: `spark.executor.memory / spark.executor.cores`.
For the driver resources (cluster mode) and executor resources properties, we use the `yarn` prefix here as custom resource types are specific to YARN, currently.
**Validation:**
Please note that a validation logic is added to avoid having requested resources defined in 2 ways, for example defining the following configs:
```
"--conf", "spark.driver.memory=2G",
"--conf", "spark.yarn.driver.resource.memory=1G"
```
will not start execution and will print an error message.
## How was this patch tested?
Unit tests + manual execution with Hadoop2 and Hadoop 3 builds.
Testing have been performed on a real cluster with Spark and YARN configured:
Cluster and client mode
Request Resource Types with lowercase and uppercase units
Start Spark job with only requesting standard resources (mem / cpu)
Error handling cases:
- Request unknown resource type
- Request Resource type (either memory / cpu) with duplicate configs at the same time (e.g. with this config:
```
--conf spark.yarn.am.resource.memory=1G \
--conf spark.yarn.driver.resource.memory=2G \
--conf spark.yarn.executor.resource.memory=3G \
```
), ResourceTypeValidator handles these cases well, so it is not permitted
- Request standard resource (memory / cpu) with the new style configs, e.g. --conf spark.yarn.am.resource.memory=1G, this is not permitted and handled well.
An example about how I ran the testcases:
```
cd ~;export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop/;
./spark-2.4.0-SNAPSHOT-bin-custom-spark/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1G \
--driver-cores 1 \
--executor-memory 1G \
--executor-cores 1 \
--conf spark.logConf=true \
--conf spark.yarn.executor.resource.gpu=3G \
--verbose \
./spark-2.4.0-SNAPSHOT-bin-custom-spark/examples/jars/spark-examples_2.11-2.4.0-SNAPSHOT.jar \
10;
```
Closes#20761 from szyszy/SPARK-20327.
Authored-by: Szilard Nemeth <snemeth@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Many companies have their own enterprise GitHub to manage Spark code. To build and test in those repositories with Jenkins need to modify this script.
So I suggest to add some environment variables to allow regression testing in enterprise Jenkins instead of default Spark repository in GitHub.
## How was this patch tested?
Manually test.
Closes#22678 from LantaoJin/SPARK-25685.
Lead-authored-by: lajin <lajin@ebay.com>
Co-authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
According to the SQL standard, when a query contains `HAVING`, it indicates an aggregate operator. For more details please refer to https://blog.jooq.org/2014/12/04/do-you-really-understand-sqls-group-by-and-having-clauses/
However, in Spark SQL parser, we treat HAVING as a normal filter when there is no GROUP BY, which breaks SQL semantic and lead to wrong result. This PR fixes the parser.
## How was this patch tested?
new test
Closes#22696 from cloud-fan/having.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Removes all vestiges of Flume in the build, for Spark 3.
I don't think this needs Jenkins config changes.
## How was this patch tested?
Existing tests.
Closes#22692 from srowen/SPARK-25598.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove Hadoop 2.6 references and make 2.7 the default.
Obviously, this is for master/3.0.0 only.
After this we can also get rid of the separate test jobs for Hadoop 2.6.
## How was this patch tested?
Existing tests
Closes#22615 from srowen/SPARK-25016.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This is a follow-up pr of #18536 and #22545 to update the migration guide.
## How was this patch tested?
Build and check the doc locally.
Closes#22682 from ueshin/issues/SPARK-20946_25525/migration_guide.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Added
- Python foreach
- Scala, Java and Python foreachBatch
- Multiple watermark policy
- The semantics of what changes are allowed to the streaming between restarts.
## How was this patch tested?
No tests
Closes#22627 from tdas/SPARK-25639.
Authored-by: Tathagata Das <tathagata.das1565@gmail.com>
Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com>
## What changes were proposed in this pull request?
Documentation is updated with proper classname org.apache.spark.io.ZStdCompressionCodec
## How was this patch tested?
we used the spark.io.compression.codec = org.apache.spark.io.ZStdCompressionCodec
and verified the logs.
Closes#22669 from shivusondur/CompressionIssue.
Authored-by: shivusondur <shivusondur@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This patch is to bump the master branch version to 3.0.0-SNAPSHOT.
## How was this patch tested?
N/A
Closes#22606 from gatorsmile/bump3.0.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR aims to fix the failed test of `OracleIntegrationSuite`.
## How was this patch tested?
Existing integration tests.
Closes#22461 from seancxmao/SPARK-25453.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Since we don't fail a job when `AccumulatorV2.merge` fails, we should try to update the remaining accumulators so that they can still report correct values.
## How was this patch tested?
The new unit test.
Closes#22586 from zsxwing/SPARK-25568.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Markdown links are not working inside html table. We should use html link tag.
## How was this patch tested?
Verified in IntelliJ IDEA's markdown editor and online markdown editor.
Closes#22588 from viirya/SPARK-25262-followup.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This adds a missing end markup tag. This should go `master` branch only.
## How was this patch tested?
This is a doc-only change. Manual via `SKIP_API=1 jekyll build`.
Closes#22584 from dongjoon-hyun/SPARK-25262.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This adds a missing markup tag. This should go to `master/branch-2.4`.
## How was this patch tested?
Manual via `SKIP_API=1 jekyll build`.
Closes#22585 from dongjoon-hyun/SPARK-23285.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
SparkSubmit already logs in the user if a keytab is provided, the only issue is that it uses the existing configs which have "yarn" in their name. As such, the configs were changed to:
`spark.kerberos.keytab` and `spark.kerberos.principal`.
## How was this patch tested?
Will be tested with K8S tests, but needs to be tested with Yarn
- [x] K8S Secure HDFS tests
- [x] Yarn Secure HDFS tests vanzin
Closes#22362 from ifilonenko/SPARK-25372.
Authored-by: Ilan Filonenko <if56@cornell.edu>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Describe spark.sql.parquet.writeLegacyFormat property in Spark SQL, DataFrames and Datasets Guide.
## How was this patch tested?
N/A
Closes#22453 from seancxmao/SPARK-20937.
Authored-by: seancxmao <seancxmao@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
One more legacy config to go ...
Closes#22515 from rxin/allowCreatingManagedTableUsingNonemptyLocation.
Authored-by: Reynold Xin <rxin@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
See title. Makes our legacy backward compatibility configs more consistent.
## How was this patch tested?
Make sure all references have been updated:
```
> git grep compareDateTimestampInTimestamp
docs/sql-programming-guide.md: - Since Spark 2.4, Spark compares a DATE type with a TIMESTAMP type after promotes both sides to TIMESTAMP. To set `false` to `spark.sql.legacy.compareDateTimestampInTimestamp` restores the previous behavior. This option will be removed in Spark 3.0.
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/TypeCoercion.scala: // if conf.compareDateTimestampInTimestamp is true
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/TypeCoercion.scala: => if (conf.compareDateTimestampInTimestamp) Some(TimestampType) else Some(StringType)
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/TypeCoercion.scala: => if (conf.compareDateTimestampInTimestamp) Some(TimestampType) else Some(StringType)
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala: buildConf("spark.sql.legacy.compareDateTimestampInTimestamp")
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala: def compareDateTimestampInTimestamp : Boolean = getConf(COMPARE_DATE_TIMESTAMP_IN_TIMESTAMP)
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/TypeCoercionSuite.scala: "spark.sql.legacy.compareDateTimestampInTimestamp" -> convertToTS.toString) {
```
Closes#22508 from rxin/SPARK-23549.
Authored-by: Reynold Xin <rxin@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This reverts commit 417ad92502.
We decided to keep the current behaviors unchanged and will consider whether we will deprecate the these functions in 3.0. For more details, see the discussion in https://issues.apache.org/jira/browse/SPARK-23715
## How was this patch tested?
The existing tests.
Closes#22505 from gatorsmile/revertSpark-23715.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Hadoop2.6 and hadoop2.7 do not contain zstd and brotli compressioncodec ,hadoop 3.1 also contains only zstd compressioncodec .
So I think we should remove zstd and brotil for the time being.
**set `spark.sql.parquet.compression.codec=brotli`:**
Caused by: org.apache.parquet.hadoop.BadConfigurationException: Class org.apache.hadoop.io.compress.BrotliCodec was not found
at org.apache.parquet.hadoop.CodecFactory.getCodec(CodecFactory.java:235)
at org.apache.parquet.hadoop.CodecFactory$HeapBytesCompressor.<init>(CodecFactory.java:142)
at org.apache.parquet.hadoop.CodecFactory.createCompressor(CodecFactory.java:206)
at org.apache.parquet.hadoop.CodecFactory.getCompressor(CodecFactory.java:189)
at org.apache.parquet.hadoop.ParquetRecordWriter.<init>(ParquetRecordWriter.java:153)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:411)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:349)
at org.apache.spark.sql.execution.datasources.parquet.ParquetOutputWriter.<init>(ParquetOutputWriter.scala:37)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$$anon$1.newInstance(ParquetFileFormat.scala:161)
**set `spark.sql.parquet.compression.codec=zstd`:**
Caused by: org.apache.parquet.hadoop.BadConfigurationException: Class org.apache.hadoop.io.compress.ZStandardCodec was not found
at org.apache.parquet.hadoop.CodecFactory.getCodec(CodecFactory.java:235)
at org.apache.parquet.hadoop.CodecFactory$HeapBytesCompressor.<init>(CodecFactory.java:142)
at org.apache.parquet.hadoop.CodecFactory.createCompressor(CodecFactory.java:206)
at org.apache.parquet.hadoop.CodecFactory.getCompressor(CodecFactory.java:189)
at org.apache.parquet.hadoop.ParquetRecordWriter.<init>(ParquetRecordWriter.java:153)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:411)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:349)
at org.apache.spark.sql.execution.datasources.parquet.ParquetOutputWriter.<init>(ParquetOutputWriter.scala:37)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$$anon$1.newInstance(ParquetFileFormat.scala:161)
## How was this patch tested?
Exist unit test
Closes#22358 from 10110346/notsupportzstdandbrotil.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In ArrayContains, we currently cast the right hand side expression to match the element type of the left hand side Array. This may result in down casting and may return wrong result or questionable result.
Example :
```SQL
spark-sql> select array_contains(array(1), 1.34);
true
```
```SQL
spark-sql> select array_contains(array(1), 'foo');
null
```
We should safely coerce both left and right hand side expressions.
## How was this patch tested?
Added tests in DataFrameFunctionsSuite
Closes#22408 from dilipbiswal/SPARK-25417.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The PR updates the migration guide in order to explain the changes introduced in the behavior of the IN operator with subqueries, in particular, the improved handling of struct attributes in these situations.
## How was this patch tested?
NA
Closes#22469 from mgaido91/SPARK-24341_followup.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
To be more consistent with other statistics based configs.
## How was this patch tested?
N/A - straightforward rename of config option. Used `git grep` to make sure there are no mention of it.
Closes#22457 from rxin/SPARK-24626.
Authored-by: Reynold Xin <rxin@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Update `tuning.md` and `rdd-programming-guide.md` to use JDK8.
## How was this patch tested?
manual tests
Closes#22446 from wangyum/java8.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
SPARK-22333 introduced a regression in the resolution of `CURRENT_DATE` and `CURRENT_TIMESTAMP`. Before that ticket, these 2 functions were resolved in a case insensitive way. After, this depends on the value of `spark.sql.caseSensitive`.
The PR restores the previous behavior and makes their resolution case insensitive anyhow. The PR takes over #21217, therefore it closes#21217 and credit for this patch should be given to jamesthomp.
## How was this patch tested?
added UT
Closes#22440 from mgaido91/SPARK-24151.
Lead-authored-by: James Thompson <jamesthomp@users.noreply.github.com>
Co-authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
What changes were proposed in this pull request
Updated the Migration guide for the behavior changes done in the JIRA issue SPARK-23425.
How was this patch tested?
Manually verified.
Closes#22396 from sujith71955/master_newtest.
Authored-by: s71955 <sujithchacko.2010@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In the dev list, we can still discuss whether the next version is 2.5.0 or 3.0.0. Let us first bump the master branch version to `2.5.0-SNAPSHOT`.
## How was this patch tested?
N/A
Closes#22426 from gatorsmile/bumpVersionMaster.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Add description of Executor Task Metrics to the documentation.
Closes#22397 from LucaCanali/docMonitoringTaskMetrics.
Authored-by: LucaCanali <luca.canali@cern.ch>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
This is a rework of #21433 to address some concerns there.
Closes#22398 from michaelmior/long-callsite2.
Authored-by: Michael Mior <mmior@uwaterloo.ca>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In the PR, I propose new CSV option `emptyValue` and an update in the SQL Migration Guide which describes how to revert previous behavior when empty strings were not written at all. Since Spark 2.4, empty strings are saved as `""` to distinguish them from saved `null`s.
Closes#22234Closes#22367
## How was this patch tested?
It was tested by `CSVSuite` and new tests added in the PR #22234Closes#22389 from MaxGekk/csv-empty-value-master.
Lead-authored-by: Mario Molina <mmolimar@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Add spark.executor.pyspark.memory limit for K8S
## How was this patch tested?
Unit and Integration tests
Closes#22298 from ifilonenko/SPARK-25021.
Authored-by: Ilan Filonenko <if56@cornell.edu>
Signed-off-by: Holden Karau <holden@pigscanfly.ca>
## What changes were proposed in this pull request?
How to reproduce permission issue:
```sh
# build spark
./dev/make-distribution.sh --name SPARK-25330 --tgz -Phadoop-2.7 -Phive -Phive-thriftserver -Pyarn
tar -zxf spark-2.4.0-SNAPSHOT-bin-SPARK-25330.tar && cd spark-2.4.0-SNAPSHOT-bin-SPARK-25330
export HADOOP_PROXY_USER=user_a
bin/spark-sql
export HADOOP_PROXY_USER=user_b
bin/spark-sql
```
```java
Exception in thread "main" java.lang.RuntimeException: org.apache.hadoop.security.AccessControlException: Permission denied: user=user_b, access=EXECUTE, inode="/tmp/hive-$%7Buser.name%7D/user_b/668748f2-f6c5-4325-a797-fd0a7ee7f4d4":user_b:hadoop:drwx------
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:319)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:259)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:205)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:190)
```
The issue occurred in this commit: feb886f209. This pr revert Hadoop 2.7 to 2.7.3 to avoid this issue.
## How was this patch tested?
unit tests and manual tests.
Closes#22327 from wangyum/SPARK-25330.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The default behaviour of Spark on K8S currently is to create `emptyDir` volumes to back `SPARK_LOCAL_DIRS`. In some environments e.g. diskless compute nodes this may actually hurt performance because these are backed by the Kubelet's node storage which on a diskless node will typically be some remote network storage.
Even if this is enterprise grade storage connected via a high speed interconnect the way Spark uses these directories as scratch space (lots of relatively small short lived files) has been observed to cause serious performance degradation. Therefore we would like to provide the option to use K8S's ability to instead back these `emptyDir` volumes with `tmpfs`. Therefore this PR adds a configuration option that enables `SPARK_LOCAL_DIRS` to be backed by Memory backed `emptyDir` volumes rather than the default.
Documentation is added to describe both the default behaviour plus this new option and its implications. One of which is that scratch space then counts towards your pods memory limits and therefore users will need to adjust their memory requests accordingly.
*NB* - This is an alternative version of PR #22256 reduced to just the `tmpfs` piece
## How was this patch tested?
Ran with this option in our diskless compute environments to verify functionality
Author: Rob Vesse <rvesse@dotnetrdf.org>
Closes#22323 from rvesse/SPARK-25262-tmpfs.
## What changes were proposed in this pull request?
Upgrade chill to 0.9.3, Kryo to 4.0.2, to get bug fixes and improvements.
The resolved tickets includes:
- SPARK-25258 Upgrade kryo package to version 4.0.2
- SPARK-23131 Kryo raises StackOverflow during serializing GLR model
- SPARK-25176 Kryo fails to serialize a parametrised type hierarchy
More details:
https://github.com/twitter/chill/releases/tag/v0.9.3cc3910d501
## How was this patch tested?
Existing tests.
Closes#22179 from wangyum/SPARK-23131.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Improve build for Scala 2.12. Current build for sbt fails on the subproject `repl`:
```
[info] Compiling 6 Scala sources to /Users/rendong/wdi/spark/repl/target/scala-2.12/classes...
[error] /Users/rendong/wdi/spark/repl/scala-2.11/src/main/scala/org/apache/spark/repl/SparkILoopInterpreter.scala:80: overriding lazy value importableSymbolsWithRenames in class ImportHandler of type List[(this.intp.global.Symbol, this.intp.global.Name)];
[error] lazy value importableSymbolsWithRenames needs `override' modifier
[error] lazy val importableSymbolsWithRenames: List[(Symbol, Name)] = {
[error] ^
[warn] /Users/rendong/wdi/spark/repl/src/main/scala/org/apache/spark/repl/SparkILoop.scala:53: variable addedClasspath in class ILoop is deprecated (since 2.11.0): use reset, replay or require to update class path
[warn] if (addedClasspath != "") {
[warn] ^
[warn] /Users/rendong/wdi/spark/repl/src/main/scala/org/apache/spark/repl/SparkILoop.scala:54: variable addedClasspath in class ILoop is deprecated (since 2.11.0): use reset, replay or require to update class path
[warn] settings.classpath append addedClasspath
[warn] ^
[warn] two warnings found
[error] one error found
[error] (repl/compile:compileIncremental) Compilation failed
[error] Total time: 93 s, completed 2018-9-3 10:07:26
```
## How was this patch tested?
```
./dev/change-scala-version.sh 2.12
## For Maven
./build/mvn -Pscala-2.12 [mvn commands]
## For SBT
sbt -Dscala.version=2.12.6
```
Closes#22310 from sadhen/SPARK-25298.
Authored-by: Darcy Shen <sadhen@zoho.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
As described in [SPARK-25261](https://issues.apache.org/jira/projects/SPARK/issues/SPARK-25261),the unit of spark.executor.memory and spark.driver.memory is parsed as bytes in some cases if no unit specified, while in https://spark.apache.org/docs/latest/configuration.html#application-properties, they are descibed as MiB, which may lead to some misunderstandings.
## How was this patch tested?
N/A
Closes#22252 from ivoson/branch-correct-configuration.
Lead-authored-by: huangtengfei02 <huangtengfei02@baidu.com>
Co-authored-by: Huang Tengfei <tengfei.h@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
After SPARK-18371, it is guaranteed that there would be at least one message per partition per batch using direct kafka API when new messages exist in the topics. This change will give the user the option of setting the minimum instead of just a hard coded 1 limit
The related unit test is updated and some internal tests verified that the topic partitions with new messages will be progressed by the specified minimum.
Author: Reza Safi <rezasafi@cloudera.com>
Closes#22223 from rezasafi/streaminglag.
## What changes were proposed in this pull request?
R tests require `testthat` v1.0.2. In the PR, I described how to install the version in the section http://spark.apache.org/docs/latest/building-spark.html#running-r-tests.
Closes#22272 from MaxGekk/r-testthat-doc.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This adds `spark.executor.pyspark.memory` to configure Python's address space limit, [`resource.RLIMIT_AS`](https://docs.python.org/3/library/resource.html#resource.RLIMIT_AS). Limiting Python's address space allows Python to participate in memory management. In practice, we see fewer cases of Python taking too much memory because it doesn't know to run garbage collection. This results in YARN killing fewer containers. This also improves error messages so users know that Python is consuming too much memory:
```
File "build/bdist.linux-x86_64/egg/package/library.py", line 265, in fe_engineer
fe_eval_rec.update(f(src_rec_prep, mat_rec_prep))
File "build/bdist.linux-x86_64/egg/package/library.py", line 163, in fe_comp
comparisons = EvaluationUtils.leven_list_compare(src_rec_prep.get(item, []), mat_rec_prep.get(item, []))
File "build/bdist.linux-x86_64/egg/package/evaluationutils.py", line 25, in leven_list_compare
permutations = sorted(permutations, reverse=True)
MemoryError
```
The new pyspark memory setting is used to increase requested YARN container memory, instead of sharing overhead memory between python and off-heap JVM activity.
## How was this patch tested?
Tested memory limits in our YARN cluster and verified that MemoryError is thrown.
Author: Ryan Blue <blue@apache.org>
Closes#21977 from rdblue/SPARK-25004-add-python-memory-limit.
## What changes were proposed in this pull request?
Updated documentation for Spark on Kubernetes for the upcoming 2.4.0.
Please review http://spark.apache.org/contributing.html before opening a pull request.
mccheah erikerlandson
Closes#22224 from liyinan926/master.
Authored-by: Yinan Li <ynli@google.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22189 from movrsprbp/patch-1.
Authored-by: jaroslav chládek <mastermism@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Fix a few broken links and typos, and, nit, use HTTPS more consistently esp. on scripts and Apache links
## How was this patch tested?
Doc build
Closes#22172 from srowen/DocTypo.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
When j is 0, log(j+1) will be 0, and this leads to division by 0 issue.
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22090 from yueguoguo/patch-1.
Authored-by: Zhang Le <yueguoguo@users.noreply.github.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In MultilayerPerceptronClassifier, we use RDD operation to encode labels for now. I think we should use ML's OneHotEncoderEstimator/Model to do the encoding.
## How was this patch tested?
Existing tests.
Closes#20232 from viirya/SPARK-23042.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
changed $SPARK_HOME/conf/spark-default.conf to $SPARK_HOME/conf/spark-defaults.conf
no testing necessary as this was a change to documentation.
Closes#22116 from KraFusion/patch-1.
Authored-by: Joey Krabacher <jkrabacher@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Small formatting change to have Python Version be camelCase as per request during PR review.
## How was this patch tested?
Tested with unit and integration tests
Author: Ilan Filonenko <if56@cornell.edu>
Closes#22095 from ifilonenko/spark-py-edits.
## What changes were proposed in this pull request?
(a) disabled rest submission server by default in standalone mode
(b) fails the standalone master if rest server enabled & authentication secret set
(c) fails the mesos cluster dispatcher if authentication secret set
(d) doc updates
(e) when submitting a standalone app, only try the rest submission first if spark.master.rest.enabled=true
otherwise you'd see a 10 second pause like
18/08/09 08:13:22 INFO RestSubmissionClient: Submitting a request to launch an application in spark://...
18/08/09 08:13:33 WARN RestSubmissionClient: Unable to connect to server spark://...
I also made sure the mesos cluster dispatcher failed with the secret enabled, though I had to do that on slightly different code as I don't have mesos native libs around.
## How was this patch tested?
I ran the tests in the mesos module & in core for org.apache.spark.deploy.*
I ran a test on a cluster with standalone master to make sure I could still start with the right configs, and would fail the right way too.
Closes#22071 from squito/rest_doc_updates.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Fixing typos is sometimes very hard. It's not so easy to visually review them. Recently, I discovered a very useful tool for it, [misspell](https://github.com/client9/misspell).
This pull request fixes minor typos detected by [misspell](https://github.com/client9/misspell) except for the false positives. If you would like me to work on other files as well, let me know.
## How was this patch tested?
### before
```
$ misspell . | grep -v '.js'
R/pkg/R/SQLContext.R:354:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:424:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:445:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:495:43: "definiton" is a misspelling of "definition"
NOTICE-binary:454:16: "containd" is a misspelling of "contained"
R/pkg/R/context.R:46:43: "definiton" is a misspelling of "definition"
R/pkg/R/context.R:74:43: "definiton" is a misspelling of "definition"
R/pkg/R/DataFrame.R:591:48: "persistance" is a misspelling of "persistence"
R/pkg/R/streaming.R:166:44: "occured" is a misspelling of "occurred"
R/pkg/inst/worker/worker.R:65:22: "ouput" is a misspelling of "output"
R/pkg/tests/fulltests/test_utils.R:106:25: "environemnt" is a misspelling of "environment"
common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java:38:39: "existant" is a misspelling of "existent"
common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java:83:39: "existant" is a misspelling of "existent"
common/network-common/src/main/java/org/apache/spark/network/crypto/TransportCipher.java:243:46: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:234:19: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:238:63: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:244:46: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:276:39: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/util/AbstractFileRegion.java:27:20: "transfered" is a misspelling of "transferred"
common/unsafe/src/test/scala/org/apache/spark/unsafe/types/UTF8StringPropertyCheckSuite.scala:195:15: "orgin" is a misspelling of "origin"
core/src/main/scala/org/apache/spark/api/python/PythonRDD.scala:621:39: "gauranteed" is a misspelling of "guaranteed"
core/src/main/scala/org/apache/spark/status/storeTypes.scala:113:29: "ect" is a misspelling of "etc"
core/src/main/scala/org/apache/spark/storage/DiskStore.scala:282:18: "transfered" is a misspelling of "transferred"
core/src/main/scala/org/apache/spark/util/ListenerBus.scala:64:17: "overriden" is a misspelling of "overridden"
core/src/test/scala/org/apache/spark/ShuffleSuite.scala:211:7: "substracted" is a misspelling of "subtracted"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:1922:49: "agriculteur" is a misspelling of "agriculture"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:2468:84: "truely" is a misspelling of "truly"
core/src/test/scala/org/apache/spark/storage/FlatmapIteratorSuite.scala:25:18: "persistance" is a misspelling of "persistence"
core/src/test/scala/org/apache/spark/storage/FlatmapIteratorSuite.scala:26:69: "persistance" is a misspelling of "persistence"
data/streaming/AFINN-111.txt:1219:0: "humerous" is a misspelling of "humorous"
dev/run-pip-tests:55:28: "enviroments" is a misspelling of "environments"
dev/run-pip-tests:91:37: "virutal" is a misspelling of "virtual"
dev/merge_spark_pr.py:377:72: "accross" is a misspelling of "across"
dev/merge_spark_pr.py:378:66: "accross" is a misspelling of "across"
dev/run-pip-tests:126:25: "enviroments" is a misspelling of "environments"
docs/configuration.md:1830:82: "overriden" is a misspelling of "overridden"
docs/structured-streaming-programming-guide.md:525:45: "processs" is a misspelling of "processes"
docs/structured-streaming-programming-guide.md:1165:61: "BETWEN" is a misspelling of "BETWEEN"
docs/sql-programming-guide.md:1891:810: "behaivor" is a misspelling of "behavior"
examples/src/main/python/sql/arrow.py:98:8: "substract" is a misspelling of "subtract"
examples/src/main/python/sql/arrow.py:103:27: "substract" is a misspelling of "subtract"
licenses/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/hungarian.txt:170:0: "teh" is a misspelling of "the"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/portuguese.txt:53:0: "eles" is a misspelling of "eels"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:99:20: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:539:11: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/mllib/clustering/LDAOptimizer.scala:77:36: "Teh" is a misspelling of "The"
mllib/src/main/scala/org/apache/spark/mllib/clustering/StreamingKMeans.scala:230:24: "inital" is a misspelling of "initial"
mllib/src/main/scala/org/apache/spark/mllib/stat/MultivariateOnlineSummarizer.scala:276:9: "Euclidian" is a misspelling of "Euclidean"
mllib/src/test/scala/org/apache/spark/ml/clustering/KMeansSuite.scala:237:26: "descripiton" is a misspelling of "descriptions"
python/pyspark/find_spark_home.py:30:13: "enviroment" is a misspelling of "environment"
python/pyspark/context.py:937:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:938:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:939:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:940:12: "supress" is a misspelling of "suppress"
python/pyspark/heapq3.py:6:63: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:7:2: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:263:29: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:263:39: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:270:49: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:270:59: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:275:2: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:275:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:277:29: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:277:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:713:8: "probabilty" is a misspelling of "probability"
python/pyspark/ml/clustering.py:1038:8: "Currenlty" is a misspelling of "Currently"
python/pyspark/ml/stat.py:339:23: "Euclidian" is a misspelling of "Euclidean"
python/pyspark/ml/regression.py:1378:20: "paramter" is a misspelling of "parameter"
python/pyspark/mllib/stat/_statistics.py:262:8: "probabilty" is a misspelling of "probability"
python/pyspark/rdd.py:1363:32: "paramter" is a misspelling of "parameter"
python/pyspark/streaming/tests.py:825:42: "retuns" is a misspelling of "returns"
python/pyspark/sql/tests.py:768:29: "initalization" is a misspelling of "initialization"
python/pyspark/sql/tests.py:3616:31: "initalize" is a misspelling of "initialize"
resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosSchedulerBackendUtil.scala:120:39: "arbitary" is a misspelling of "arbitrary"
resource-managers/mesos/src/test/scala/org/apache/spark/deploy/mesos/MesosClusterDispatcherArgumentsSuite.scala:26:45: "sucessfully" is a misspelling of "successfully"
resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosSchedulerUtils.scala:358:27: "constaints" is a misspelling of "constraints"
resource-managers/yarn/src/test/scala/org/apache/spark/deploy/yarn/YarnClusterSuite.scala:111:24: "senstive" is a misspelling of "sensitive"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala:1063:5: "overwirte" is a misspelling of "overwrite"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala:1348:17: "compatability" is a misspelling of "compatibility"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala:77:36: "paramter" is a misspelling of "parameter"
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:1374:22: "precendence" is a misspelling of "precedence"
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/AnalysisSuite.scala:238:27: "unnecassary" is a misspelling of "unnecessary"
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ConditionalExpressionSuite.scala:212:17: "whn" is a misspelling of "when"
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamingSymmetricHashJoinHelper.scala:147:60: "timestmap" is a misspelling of "timestamp"
sql/core/src/test/scala/org/apache/spark/sql/TPCDSQuerySuite.scala:150:45: "precentage" is a misspelling of "percentage"
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVInferSchemaSuite.scala:135:29: "infered" is a misspelling of "inferred"
sql/hive/src/test/resources/golden/udf_instr-1-2e76f819563dbaba4beb51e3a130b922:1:52: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_instr-2-32da357fc754badd6e3898dcc8989182:1:52: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_locate-1-6e41693c9c6dceea4d7fab4c02884e4e:1:63: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_locate-2-d9b5934457931447874d6bb7c13de478:1:63: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_translate-2-f7aa38a33ca0df73b7a1e6b6da4b7fe8:9:79: "occurence" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_translate-2-f7aa38a33ca0df73b7a1e6b6da4b7fe8:13:110: "occurence" is a misspelling of "occurrence"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/annotate_stats_join.q:46:105: "distint" is a misspelling of "distinct"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/auto_sortmerge_join_11.q:29:3: "Currenly" is a misspelling of "Currently"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/avro_partitioned.q:72:15: "existant" is a misspelling of "existent"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/decimal_udf.q:25:3: "substraction" is a misspelling of "subtraction"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/groupby2_map_multi_distinct.q:16:51: "funtion" is a misspelling of "function"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/groupby_sort_8.q:15:30: "issueing" is a misspelling of "issuing"
sql/hive/src/test/scala/org/apache/spark/sql/sources/HadoopFsRelationTest.scala:669:52: "wiht" is a misspelling of "with"
sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java:474:9: "Refering" is a misspelling of "Referring"
```
### after
```
$ misspell . | grep -v '.js'
common/network-common/src/main/java/org/apache/spark/network/util/AbstractFileRegion.java:27:20: "transfered" is a misspelling of "transferred"
core/src/main/scala/org/apache/spark/status/storeTypes.scala:113:29: "ect" is a misspelling of "etc"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:1922:49: "agriculteur" is a misspelling of "agriculture"
data/streaming/AFINN-111.txt:1219:0: "humerous" is a misspelling of "humorous"
licenses/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/hungarian.txt:170:0: "teh" is a misspelling of "the"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/portuguese.txt:53:0: "eles" is a misspelling of "eels"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:99:20: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:539:11: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/mllib/clustering/LDAOptimizer.scala:77:36: "Teh" is a misspelling of "The"
mllib/src/main/scala/org/apache/spark/mllib/stat/MultivariateOnlineSummarizer.scala:276:9: "Euclidian" is a misspelling of "Euclidean"
python/pyspark/heapq3.py:6:63: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:7:2: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:263:29: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:263:39: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:270:49: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:270:59: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:275:2: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:275:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:277:29: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:277:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/ml/stat.py:339:23: "Euclidian" is a misspelling of "Euclidean"
```
Closes#22070 from seratch/fix-typo.
Authored-by: Kazuhiro Sera <seratch@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
## What changes were proposed in this pull request?
Currently, Analyze table calculates table size sequentially for each partition. We can parallelize size calculations over partitions.
Results : Tested on a table with 100 partitions and data stored in S3.
With changes :
- 10.429s
- 10.557s
- 10.439s
- 9.893s
Without changes :
- 110.034s
- 99.510s
- 100.743s
- 99.106s
## How was this patch tested?
Simple unit test.
Closes#21608 from Achuth17/improveAnalyze.
Lead-authored-by: Achuth17 <Achuth.narayan@gmail.com>
Co-authored-by: arajagopal17 <arajagopal@qubole.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Update Hadoop 2.7 to 2.7.7 to pull in bug and security fixes.
## How was this patch tested?
Existing tests.
Author: Sean Owen <srowen@gmail.com>
Closes#21987 from srowen/SPARK-25015.
## What changes were proposed in this pull request?
Currently the set operations INTERSECT, UNION and EXCEPT are assigned the same precedence. This PR fixes the problem by giving INTERSECT higher precedence than UNION and EXCEPT. UNION and EXCEPT operators are evaluated in the order in which they appear in the query from left to right.
This results in change in behavior because of the change in order of evaluations of set operators in a query. The old behavior is still preserved under a newly added config parameter.
Query `:`
```
SELECT * FROM t1
UNION
SELECT * FROM t2
EXCEPT
SELECT * FROM t3
INTERSECT
SELECT * FROM t4
```
Parsed plan before the change `:`
```
== Parsed Logical Plan ==
'Intersect false
:- 'Except false
: :- 'Distinct
: : +- 'Union
: : :- 'Project [*]
: : : +- 'UnresolvedRelation `t1`
: : +- 'Project [*]
: : +- 'UnresolvedRelation `t2`
: +- 'Project [*]
: +- 'UnresolvedRelation `t3`
+- 'Project [*]
+- 'UnresolvedRelation `t4`
```
Parsed plan after the change `:`
```
== Parsed Logical Plan ==
'Except false
:- 'Distinct
: +- 'Union
: :- 'Project [*]
: : +- 'UnresolvedRelation `t1`
: +- 'Project [*]
: +- 'UnresolvedRelation `t2`
+- 'Intersect false
:- 'Project [*]
: +- 'UnresolvedRelation `t3`
+- 'Project [*]
+- 'UnresolvedRelation `t4`
```
## How was this patch tested?
Added tests in PlanParserSuite, SQLQueryTestSuite.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Dilip Biswal <dbiswal@us.ibm.com>
Closes#21941 from dilipbiswal/SPARK-24966.
## What changes were proposed in this pull request?
According to the discussion in https://github.com/apache/spark/pull/21599, changing the behavior of arithmetic operations so that they can check for overflow is not nice in a minor release. What we can do for 2.4 is warn users about the current behavior in the documentation, so that they are aware of the issue and can take proper actions.
## How was this patch tested?
NA
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#21967 from mgaido91/SPARK-24598_doc.
## What changes were proposed in this pull request?
In response to a recent question, this reiterates that network access to a Spark cluster should be disabled by default, and that access to its hosts and services from outside a private network should be added back explicitly.
Also, some minor touch-ups while I was at it.
## How was this patch tested?
N/A
Author: Sean Owen <srowen@gmail.com>
Closes#21947 from srowen/SecurityNote.
## What changes were proposed in this pull request?
This pr add `spark.broadcast.checksum` to configuration.
## How was this patch tested?
manually tested
Author: liuxian <liu.xian3@zte.com.cn>
Closes#21825 from 10110346/checksum_config.
## What changes were proposed in this pull request?
Update Pandas UDFs section in sql-programming-guide. Add section for grouped aggregate pandas UDF.
## How was this patch tested?
Author: Li Jin <ice.xelloss@gmail.com>
Closes#21887 from icexelloss/SPARK-23633-sql-programming-guide.
## What changes were proposed in this pull request?
This pr supported Date/Timestamp in a JDBC partition column (a numeric column is only supported in the master). This pr also modified code to verify a partition column type;
```
val jdbcTable = spark.read
.option("partitionColumn", "text")
.option("lowerBound", "aaa")
.option("upperBound", "zzz")
.option("numPartitions", 2)
.jdbc("jdbc:postgresql:postgres", "t", options)
// with this pr
org.apache.spark.sql.AnalysisException: Partition column type should be numeric, date, or timestamp, but string found.;
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRelation$.verifyAndGetNormalizedPartitionColumn(JDBCRelation.scala:165)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRelation$.columnPartition(JDBCRelation.scala:85)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:36)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:317)
// without this pr
java.lang.NumberFormatException: For input string: "aaa"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Long.parseLong(Long.java:589)
at java.lang.Long.parseLong(Long.java:631)
at scala.collection.immutable.StringLike$class.toLong(StringLike.scala:277)
```
Closes#19999
## How was this patch tested?
Added tests in `JDBCSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#21834 from maropu/SPARK-22814.
## What changes were proposed in this pull request?
Add a JDBC Option "pushDownPredicate" (default `true`) to allow/disallow predicate push-down in JDBC data source.
## How was this patch tested?
Add a test in `JDBCSuite`
Author: maryannxue <maryannxue@apache.org>
Closes#21875 from maryannxue/spark-24288.
## What changes were proposed in this pull request?
Support client mode for the Kubernetes scheduler.
Client mode works more or less identically to cluster mode. However, in client mode, the Spark Context needs to be manually bootstrapped with certain properties which would have otherwise been set up by spark-submit in cluster mode. Specifically:
- If the user doesn't provide a driver pod name, we don't add an owner reference. This is for usage when the driver is not running in a pod in the cluster. In such a case, the driver can only provide a best effort to clean up the executors when the driver exits, but cleaning up the resources is not guaranteed. The executor JVMs should exit if the driver JVM exits, but the pods will still remain in the cluster in a COMPLETED or FAILED state.
- The user must provide a host (spark.driver.host) and port (spark.driver.port) that the executors can connect to. When using spark-submit in cluster mode, spark-submit generates the headless service automatically; in client mode, the user is responsible for setting up their own connectivity.
We also change the authentication configuration prefixes for client mode.
## How was this patch tested?
Adding an integration test to exercise client mode support.
Author: mcheah <mcheah@palantir.com>
Closes#21748 from mccheah/k8s-client-mode.
Fetch-to-mem is guaranteed to fail if the message is bigger than 2 GB,
so we might as well use fetch-to-disk in that case. The message includes
some metadata in addition to the block data itself (in particular
UploadBlock has a lot of metadata), so we leave a little room.
Author: Imran Rashid <irashid@cloudera.com>
Closes#21474 from squito/SPARK-24297.
## What changes were proposed in this pull request?
Last Access Time will always displayed wrong date Thu Jan 01 05:30:00 IST 1970 when user run DESC FORMATTED table command
In hive its displayed as "UNKNOWN" which makes more sense than displaying wrong date. seems to be a limitation as of now even from hive, better we can follow the hive behavior unless the limitation has been resolved from hive.
spark client output

Hive client output

## How was this patch tested?
UT has been added which makes sure that the wrong date "Thu Jan 01 05:30:00 IST 1970 "
shall not be added as value for the Last Access property
Author: s71955 <sujithchacko.2010@gmail.com>
Closes#21775 from sujith71955/master_hive.
## What changes were proposed in this pull request?
In this PR metrics are introduced for YARN. As up to now there was no metrics in the YARN module a new metric system is created with the name "applicationMaster".
To support both client and cluster mode the metric system lifecycle is bound to the AM.
## How was this patch tested?
Both client and cluster mode was tested manually.
Before the test on one of the YARN node spark-core was removed to cause the allocation failure.
Spark was started as (in case of client mode):
```
spark2-submit \
--class org.apache.spark.examples.SparkPi \
--conf "spark.yarn.blacklist.executor.launch.blacklisting.enabled=true" --conf "spark.blacklist.application.maxFailedExecutorsPerNode=2" --conf "spark.dynamicAllocation.enabled=true" --conf "spark.metrics.conf.*.sink.console.class=org.apache.spark.metrics.sink.ConsoleSink" \
--master yarn \
--deploy-mode client \
original-spark-examples_2.11-2.4.0-SNAPSHOT.jar \
1000
```
In both cases the YARN logs contained the new metrics as:
```
$ yarn logs --applicationId application_1529926424933_0015
...
-- Gauges ----------------------------------------------------------------------
application_1531751594108_0046.applicationMaster.numContainersPendingAllocate
value = 0
application_1531751594108_0046.applicationMaster.numExecutorsFailed
value = 3
application_1531751594108_0046.applicationMaster.numExecutorsRunning
value = 9
application_1531751594108_0046.applicationMaster.numLocalityAwareTasks
value = 0
application_1531751594108_0046.applicationMaster.numReleasedContainers
value = 0
...
```
Author: “attilapiros” <piros.attila.zsolt@gmail.com>
Author: Attila Zsolt Piros <2017933+attilapiros@users.noreply.github.com>
Closes#21635 from attilapiros/SPARK-24594.
## What changes were proposed in this pull request?
add doc for string indexer ordering
## How was this patch tested?
existing tests
Author: zhengruifeng3 <zhengruifeng@jd.com>
Author: zhengruifeng <ruifengz@foxmail.com>
Closes#21792 from zhengruifeng/doc_string_indexer_ordering.
This commit adds the `cascadeTruncate` option to the JDBC datasource
API, for databases that support this functionality (PostgreSQL and
Oracle at the moment). This allows for applying a cascading truncate
that affects tables that have foreign key constraints on the table
being truncated.
## What changes were proposed in this pull request?
Add `cascadeTruncate` option to JDBC datasource API. Allow this to affect the
`TRUNCATE` query for databases that support this option.
## How was this patch tested?
Existing tests for `truncateQuery` were updated. Also, an additional test was added
to ensure that the correct syntax was applied, and that enabling the config for databases
that do not support this option does not result in invalid queries.
Author: Daniel van der Ende <daniel.vanderende@gmail.com>
Closes#20057 from danielvdende/SPARK-22880.
## What changes were proposed in this pull request?
The example wants to create a dense matrix ((1.0, 2.0), (3.0, 4.0), (5.0, 6.0)), but the list is given as [1, 2, 3, 4, 5, 6]. Now it is changed as [1, 3, 5, 2, 4, 6].
And the example wants to create an RDD of coordinate entries like:
entries = sc.parallelize([(0, 0, 1.2), (1, 0, 2.1), (2, 1, 3.7)]).
However, it is done with the MatrixEntry class like:
entries = sc.parallelize([MatrixEntry(0, 0, 1.2), MatrixEntry(1, 0, 2.1), MatrixEntry(6, 1, 3.7)]),
where the third MatrixEntry has a different row index.
Now it is changed as MatrixEntry(2, 1, 3.7).
## How was this patch tested?
This is trivial enough that it should not affect tests.
Author: Weizhe Huang <huangweizhebbdservice.com>
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Huangweizhe <huangweizhe@bbdservice.com>
Closes#21612 from huangweizhe123/my_change.
## What changes were proposed in this pull request?
The thrift scheduling pool configuration was removed from a previous release. Adding this back to the job scheduling configuration docs.
This PR takes over #17536 and handle some comments here.
## How was this patch tested?
Manually.
Closes#17536
Author: hyukjinkwon <gurwls223@apache.org>
Closes#21778 from HyukjinKwon/SPARK-20220.
This PR continues #21095 and intersects with #21238. I've added volume mounts as a separate step and added PersistantVolumeClaim support.
There is a fundamental problem with how we pass the options through spark conf to fabric8. For each volume type and all possible volume options we would have to implement some custom code to map config values to fabric8 calls. This will result in big body of code we would have to support and means that Spark will always be somehow out of sync with k8s.
I think there needs to be a discussion on how to proceed correctly (eg use PodPreset instead)
----
Due to the complications of provisioning and managing actual resources this PR addresses only volume mounting of already present resources.
----
- [x] emptyDir support
- [x] Testing
- [x] Documentation
- [x] KubernetesVolumeUtils tests
Author: Andrew Korzhuev <andrew.korzhuev@klarna.com>
Author: madanadit <adit@alluxio.com>
Closes#21260 from andrusha/k8s-vol.
## What changes were proposed in this pull request?
In the case of getting tokens via customized `ServiceCredentialProvider`, it is required that `ServiceCredentialProvider` be available in local spark-submit process classpath. In this case, all the configured remote sources should be forced to download to local.
For the ease of using this configuration, here propose to add wildcard '*' support to `spark.yarn.dist.forceDownloadSchemes`, also clarify the usage of this configuration.
## How was this patch tested?
New UT added.
Author: jerryshao <sshao@hortonworks.com>
Closes#21633 from jerryshao/SPARK-21917-followup.
## What changes were proposed in this pull request?
If table is renamed to a existing new location, data won't show up.
```
scala> Seq("hello").toDF("a").write.format("parquet").saveAsTable("t")
scala> sql("select * from t").show()
+-----+
| a|
+-----+
|hello|
+-----+
scala> sql("alter table t rename to test")
res2: org.apache.spark.sql.DataFrame = []
scala> sql("select * from test").show()
+---+
| a|
+---+
+---+
```
The file layout is like
```
$ tree test
test
├── gabage
└── t
├── _SUCCESS
└── part-00000-856b0f10-08f1-42d6-9eb3-7719261f3d5e-c000.snappy.parquet
```
In Hive, if the new location exists, the renaming will fail even the location is empty.
We should have the same validation in Catalog, in case of unexpected bugs.
## How was this patch tested?
New unit test.
Author: Gengliang Wang <gengliang.wang@databricks.com>
Closes#21655 from gengliangwang/validate_rename_table.
## What changes were proposed in this pull request?
Updated streaming guide for direct stream and link to integration guide.
## How was this patch tested?
jekyll build
Author: Rekha Joshi <rekhajoshm@gmail.com>
Closes#21683 from rekhajoshm/SPARK-24507.
## What changes were proposed in this pull request?
Address comments in #21370 and add more test.
## How was this patch tested?
Enhance test in pyspark/sql/test.py and DataFrameSuite
Author: Yuanjian Li <xyliyuanjian@gmail.com>
Closes#21553 from xuanyuanking/SPARK-24215-follow.
## What changes were proposed in this pull request?
Document a change for un-aliased subquery use case, to address the last question in PR #18559:
https://github.com/apache/spark/pull/18559#issuecomment-316884858
(Please fill in changes proposed in this fix)
## How was this patch tested?
it does not affect tests.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Yuexin Zhang <zach.yx.zhang@gmail.com>
Closes#21647 from cnZach/doc_change_for_SPARK-20690_SPARK-21335.
## What changes were proposed in this pull request?
Here is the description in the JIRA -
Currently, our JDBC connector provides the option `dbtable` for users to specify the to-be-loaded JDBC source table.
```SQL
val jdbcDf = spark.read
.format("jdbc")
.option("dbtable", "dbName.tableName")
.options(jdbcCredentials: Map)
.load()
```
Normally, users do not fetch the whole JDBC table due to the poor performance/throughput of JDBC. Thus, they normally just fetch a small set of tables. For advanced users, they can pass a subquery as the option.
```SQL
val query = """ (select * from tableName limit 10) as tmp """
val jdbcDf = spark.read
.format("jdbc")
.option("dbtable", query)
.options(jdbcCredentials: Map)
.load()
```
However, this is straightforward to end users. We should simply allow users to specify the query by a new option `query`. We will handle the complexity for them.
```SQL
val query = """select * from tableName limit 10"""
val jdbcDf = spark.read
.format("jdbc")
.option("query", query)
.options(jdbcCredentials: Map)
.load()
```
## How was this patch tested?
Added tests in JDBCSuite and JDBCWriterSuite.
Also tested against MySQL, Postgress, Oracle, DB2 (using docker infrastructure) to make sure there are no syntax issues.
Author: Dilip Biswal <dbiswal@us.ibm.com>
Closes#21590 from dilipbiswal/SPARK-24423.
## What changes were proposed in this pull request?
This update tells the reader how to build Spark with SBT such that pyspark-sql tests will succeed.
If you follow the current instructions for building Spark with SBT, pyspark/sql/udf.py fails with:
<pre>
AnalysisException: u'Can not load class test.org.apache.spark.sql.JavaStringLength, please make sure it is on the classpath;'
</pre>
## How was this patch tested?
I ran the doc build command (SKIP_API=1 jekyll build) and eyeballed the result.
Author: Bruce Robbins <bersprockets@gmail.com>
Closes#21628 from bersprockets/SPARK-23776_doc.
## What changes were proposed in this pull request?
1. Add parameter 'cascade' in CacheManager.uncacheQuery(). Under 'cascade=false' mode, only invalidate the current cache, and for other dependent caches, rebuild execution plan and reuse cached buffer.
2. Pass true/false from callers in different uncache scenarios:
- Drop tables and regular (persistent) views: regular mode
- Drop temporary views: non-cascading mode
- Modify table contents (INSERT/UPDATE/MERGE/DELETE): regular mode
- Call `DataSet.unpersist()`: non-cascading mode
- Call `Catalog.uncacheTable()`: follow the same convention as drop tables/view, which is, use non-cascading mode for temporary views and regular mode for the rest
Note that a regular (persistent) view is a database object just like a table, so after dropping a regular view (whether cached or not cached), any query referring to that view should no long be valid. Hence if a cached persistent view is dropped, we need to invalidate the all dependent caches so that exceptions will be thrown for any later reference. On the other hand, a temporary view is in fact equivalent to an unnamed DataSet, and dropping a temporary view should have no impact on queries referencing that view. Thus we should do non-cascading uncaching for temporary views, which also guarantees a consistent uncaching behavior between temporary views and unnamed DataSets.
## How was this patch tested?
New tests in CachedTableSuite and DatasetCacheSuite.
Author: Maryann Xue <maryannxue@apache.org>
Closes#21594 from maryannxue/noncascading-cache.
## What changes were proposed in this pull request?
Minor typo in docs/cloud-integration.md
## How was this patch tested?
This is trivial enough that it should not affect tests.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Jim Kleckner <jim@cloudphysics.com>
Closes#21629 from jkleckner/fix-doc-typo.
## What changes were proposed in this pull request?
Currently, a `pandas_udf` of type `PandasUDFType.GROUPED_MAP` will assign the resulting columns based on index of the return pandas.DataFrame. If a new DataFrame is returned and constructed using a dict, then the order of the columns could be arbitrary and be different than the defined schema for the UDF. If the schema types still match, then no error will be raised and the user will see column names and column data mixed up.
This change will first try to assign columns using the return type field names. If a KeyError occurs, then the column index is checked if it is string based. If so, then the error is raised as it is most likely a naming mistake, else it will fallback to assign columns by position and raise a TypeError if the field types do not match.
## How was this patch tested?
Added a test that returns a new DataFrame with column order different than the schema.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#21427 from BryanCutler/arrow-grouped-map-mixesup-cols-SPARK-24324.
## What changes were proposed in this pull request?
In our distribution, because we don't do such fine-grained access control of config file, also configuration file is world readable shared between different components, so password may leak to different users.
Hadoop credential provider API support storing password in a secure way, in which Spark could read it in a secure way, so here propose to add support of using credential provider API to get password.
## How was this patch tested?
Adding tests and verified locally.
Author: jerryshao <sshao@hortonworks.com>
Closes#21548 from jerryshao/SPARK-24518.
## What changes were proposed in this pull request?
This change extends YARN resource allocation handling with blacklisting functionality.
This handles cases when node is messed up or misconfigured such that a container won't launch on it. Before this change backlisting only focused on task execution but this change introduces YarnAllocatorBlacklistTracker which tracks allocation failures per host (when enabled via "spark.yarn.blacklist.executor.launch.blacklisting.enabled").
## How was this patch tested?
### With unit tests
Including a new suite: YarnAllocatorBlacklistTrackerSuite.
#### Manually
It was tested on a cluster by deleting the Spark jars on one of the node.
#### Behaviour before these changes
Starting Spark as:
```
spark2-shell --master yarn --deploy-mode client --num-executors 4 --conf spark.executor.memory=4g --conf "spark.yarn.max.executor.failures=6"
```
Log is:
```
18/04/12 06:49:36 INFO yarn.ApplicationMaster: Final app status: FAILED, exitCode: 11, (reason: Max number of executor failures (6) reached)
18/04/12 06:49:39 INFO yarn.ApplicationMaster: Unregistering ApplicationMaster with FAILED (diag message: Max number of executor failures (6) reached)
18/04/12 06:49:39 INFO impl.AMRMClientImpl: Waiting for application to be successfully unregistered.
18/04/12 06:49:39 INFO yarn.ApplicationMaster: Deleting staging directory hdfs://apiros-1.gce.test.com:8020/user/systest/.sparkStaging/application_1523459048274_0016
18/04/12 06:49:39 INFO util.ShutdownHookManager: Shutdown hook called
```
#### Behaviour after these changes
Starting Spark as:
```
spark2-shell --master yarn --deploy-mode client --num-executors 4 --conf spark.executor.memory=4g --conf "spark.yarn.max.executor.failures=6" --conf "spark.yarn.blacklist.executor.launch.blacklisting.enabled=true"
```
And the log is:
```
18/04/13 05:37:43 INFO yarn.YarnAllocator: Will request 1 executor container(s), each with 1 core(s) and 4505 MB memory (including 409 MB of overhead)
18/04/13 05:37:43 INFO yarn.YarnAllocator: Submitted 1 unlocalized container requests.
18/04/13 05:37:43 INFO yarn.YarnAllocator: Launching container container_1523459048274_0025_01_000008 on host apiros-4.gce.test.com for executor with ID 6
18/04/13 05:37:43 INFO yarn.YarnAllocator: Received 1 containers from YARN, launching executors on 1 of them.
18/04/13 05:37:43 INFO yarn.YarnAllocator: Completed container container_1523459048274_0025_01_000007 on host: apiros-4.gce.test.com (state: COMPLETE, exit status: 1)
18/04/13 05:37:43 INFO yarn.YarnAllocatorBlacklistTracker: blacklisting host as YARN allocation failed: apiros-4.gce.test.com
18/04/13 05:37:43 INFO yarn.YarnAllocatorBlacklistTracker: adding nodes to YARN application master's blacklist: List(apiros-4.gce.test.com)
18/04/13 05:37:43 WARN yarn.YarnAllocator: Container marked as failed: container_1523459048274_0025_01_000007 on host: apiros-4.gce.test.com. Exit status: 1. Diagnostics: Exception from container-launch.
Container id: container_1523459048274_0025_01_000007
Exit code: 1
Stack trace: ExitCodeException exitCode=1:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:604)
at org.apache.hadoop.util.Shell.run(Shell.java:507)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:789)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:213)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
Where the most important part is:
```
18/04/13 05:37:43 INFO yarn.YarnAllocatorBlacklistTracker: blacklisting host as YARN allocation failed: apiros-4.gce.test.com
18/04/13 05:37:43 INFO yarn.YarnAllocatorBlacklistTracker: adding nodes to YARN application master's blacklist: List(apiros-4.gce.test.com)
```
And execution was continued (no shutdown called).
### Testing the backlisting of the whole cluster
Starting Spark with YARN blacklisting enabled then removing a the Spark core jar one by one from all the cluster nodes. Then executing a simple spark job which fails checking the yarn log the expected exit status is contained:
```
18/06/15 01:07:10 INFO yarn.ApplicationMaster: Final app status: FAILED, exitCode: 11, (reason: Due to executor failures all available nodes are blacklisted)
18/06/15 01:07:13 INFO util.ShutdownHookManager: Shutdown hook called
```
Author: “attilapiros” <piros.attila.zsolt@gmail.com>
Closes#21068 from attilapiros/SPARK-16630.
## What changes were proposed in this pull request?
spark.blacklist.killBlacklistedExecutors is defined as
(Experimental) If set to "true", allow Spark to automatically kill, and attempt to re-create, executors when they are blacklisted. Note that, when an entire node is added to the blacklist, all of the executors on that node will be killed.
I presume the killing of blacklisted executors only happens after the stage completes successfully and all tasks have completed or on fetch failures (updateBlacklistForFetchFailure/updateBlacklistForSuccessfulTaskSet). It is confusing because the definition states that the executor will be attempted to be recreated as soon as it is blacklisted. This is not true while the stage is in progress and an executor is blacklisted, it will not attempt to cleanup until the stage finishes.
Author: Sanket Chintapalli <schintap@yahoo-inc.com>
Closes#21475 from redsanket/SPARK-24416.
There are double braces in the markdown, which break the link.
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Closes#21528 from Fokko/patch-1.
## What changes were proposed in this pull request?
Introducing Python Bindings for PySpark.
- [x] Running PySpark Jobs
- [x] Increased Default Memory Overhead value
- [ ] Dependency Management for virtualenv/conda
## How was this patch tested?
This patch was tested with
- [x] Unit Tests
- [x] Integration tests with [this addition](https://github.com/apache-spark-on-k8s/spark-integration/pull/46)
```
KubernetesSuite:
- Run SparkPi with no resources
- Run SparkPi with a very long application name.
- Run SparkPi with a master URL without a scheme.
- Run SparkPi with an argument.
- Run SparkPi with custom labels, annotations, and environment variables.
- Run SparkPi with a test secret mounted into the driver and executor pods
- Run extraJVMOptions check on driver
- Run SparkRemoteFileTest using a remote data file
- Run PySpark on simple pi.py example
- Run PySpark with Python2 to test a pyfiles example
- Run PySpark with Python3 to test a pyfiles example
Run completed in 4 minutes, 28 seconds.
Total number of tests run: 11
Suites: completed 2, aborted 0
Tests: succeeded 11, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
Author: Ilan Filonenko <if56@cornell.edu>
Author: Ilan Filonenko <ifilondz@gmail.com>
Closes#21092 from ifilonenko/master.
## What changes were proposed in this pull request?
PR https://github.com/apache/spark/pull/20811 introduced a new Spark configuration property `spark.kubernetes.container.image.pullSecrets` for specifying image pull secrets. However, the documentation wasn't updated accordingly. This PR adds the property introduced into running-on-kubernetes.md.
## How was this patch tested?
N/A.
foxish mccheah please help merge this. Thanks!
Author: Yinan Li <ynli@google.com>
Closes#21480 from liyinan926/master.
## What changes were proposed in this pull request?
Currently we only clean up the local directories on application removed. However, when executors die and restart repeatedly, many temp files are left untouched in the local directories, which is undesired behavior and could cause disk space used up gradually.
We can detect executor death in the Worker, and clean up the non-shuffle files (files not ended with ".index" or ".data") in the local directories, we should not touch the shuffle files since they are expected to be used by the external shuffle service.
Scope of this PR is limited to only implement the cleanup logic on a Standalone cluster, we defer to experts familiar with other cluster managers(YARN/Mesos/K8s) to determine whether it's worth to add similar support.
## How was this patch tested?
Add new test suite to cover.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#21390 from jiangxb1987/cleanupNonshuffleFiles.
## What changes were proposed in this pull request?
* Adds support for local:// scheme like in k8s case for image based deployments where the jar is already in the image. Affects cluster mode and the mesos dispatcher. Covers also file:// scheme. Keeps the default case where jar resolution happens on the host.
## How was this patch tested?
Dispatcher image with the patch, use it to start DC/OS Spark service:
skonto/spark-local-disp:test
Test image with my application jar located at the root folder:
skonto/spark-local:test
Dockerfile for that image.
From mesosphere/spark:2.3.0-2.2.1-2-hadoop-2.6
COPY spark-examples_2.11-2.2.1.jar /
WORKDIR /opt/spark/dist
Tests:
The following work as expected:
* local normal example
```
dcos spark run --submit-args="--conf spark.mesos.appJar.local.resolution.mode=container --conf spark.executor.memory=1g --conf spark.mesos.executor.docker.image=skonto/spark-local:test
--conf spark.executor.cores=2 --conf spark.cores.max=8
--class org.apache.spark.examples.SparkPi local:///spark-examples_2.11-2.2.1.jar"
```
* make sure the flag does not affect other uris
```
dcos spark run --submit-args="--conf spark.mesos.appJar.local.resolution.mode=container --conf spark.executor.memory=1g --conf spark.executor.cores=2 --conf spark.cores.max=8
--class org.apache.spark.examples.SparkPi https://s3-eu-west-1.amazonaws.com/fdp-stavros-test/spark-examples_2.11-2.1.1.jar"
```
* normal example no local
```
dcos spark run --submit-args="--conf spark.executor.memory=1g --conf spark.executor.cores=2 --conf spark.cores.max=8
--class org.apache.spark.examples.SparkPi https://s3-eu-west-1.amazonaws.com/fdp-stavros-test/spark-examples_2.11-2.1.1.jar"
```
The following fails
* uses local with no setting, default is host.
```
dcos spark run --submit-args="--conf spark.executor.memory=1g --conf spark.mesos.executor.docker.image=skonto/spark-local:test
--conf spark.executor.cores=2 --conf spark.cores.max=8
--class org.apache.spark.examples.SparkPi local:///spark-examples_2.11-2.2.1.jar"
```

Author: Stavros Kontopoulos <stavros.kontopoulos@lightbend.com>
Closes#21378 from skonto/local-upstream.
## What changes were proposed in this pull request?
Added sections to pandas_udf docs, in the grouped map section, to indicate columns are assigned by position.
## How was this patch tested?
NA
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#21471 from BryanCutler/arrow-doc-pandas_udf-column_by_pos-SPARK-21427.
## What changes were proposed in this pull request?
The pandas_udf functionality was introduced in 2.3.0, but is not completely stable and still evolving. This adds a label to indicate it is still an experimental API.
## How was this patch tested?
NA
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#21435 from BryanCutler/arrow-pandas_udf-experimental-SPARK-24392.
## What changes were proposed in this pull request?
Spark provides four codecs: `lz4`, `lzf`, `snappy`, and `zstd`. This pr add missing shortCompressionCodecNames to configuration.
## How was this patch tested?
manually tested
Author: Yuming Wang <yumwang@ebay.com>
Closes#21431 from wangyum/SPARK-19112.
## What changes were proposed in this pull request?
uniVocity parser allows to specify only required column names or indexes for [parsing](https://www.univocity.com/pages/parsers-tutorial) like:
```
// Here we select only the columns by their indexes.
// The parser just skips the values in other columns
parserSettings.selectIndexes(4, 0, 1);
CsvParser parser = new CsvParser(parserSettings);
```
In this PR, I propose to extract indexes from required schema and pass them into the CSV parser. Benchmarks show the following improvements in parsing of 1000 columns:
```
Select 100 columns out of 1000: x1.76
Select 1 column out of 1000: x2
```
**Note**: Comparing to current implementation, the changes can return different result for malformed rows in the `DROPMALFORMED` and `FAILFAST` modes if only subset of all columns is requested. To have previous behavior, set `spark.sql.csv.parser.columnPruning.enabled` to `false`.
## How was this patch tested?
It was tested by new test which selects 3 columns out of 15, by existing tests and by new benchmarks.
Author: Maxim Gekk <maxim.gekk@databricks.com>
Author: Maxim Gekk <max.gekk@gmail.com>
Closes#21415 from MaxGekk/csv-column-pruning2.
## What changes were proposed in this pull request?
uniVocity parser allows to specify only required column names or indexes for [parsing](https://www.univocity.com/pages/parsers-tutorial) like:
```
// Here we select only the columns by their indexes.
// The parser just skips the values in other columns
parserSettings.selectIndexes(4, 0, 1);
CsvParser parser = new CsvParser(parserSettings);
```
In this PR, I propose to extract indexes from required schema and pass them into the CSV parser. Benchmarks show the following improvements in parsing of 1000 columns:
```
Select 100 columns out of 1000: x1.76
Select 1 column out of 1000: x2
```
**Note**: Comparing to current implementation, the changes can return different result for malformed rows in the `DROPMALFORMED` and `FAILFAST` modes if only subset of all columns is requested. To have previous behavior, set `spark.sql.csv.parser.columnPruning.enabled` to `false`.
## How was this patch tested?
It was tested by new test which selects 3 columns out of 15, by existing tests and by new benchmarks.
Author: Maxim Gekk <maxim.gekk@databricks.com>
Closes#21296 from MaxGekk/csv-column-pruning.
## What changes were proposed in this pull request?
This change changes spark behavior to use the correct environment variable set by Mesos in the container on startup.
Author: Jake Charland <jakec@uber.com>
Closes#18894 from jakecharland/MesosSandbox.
## What changes were proposed in this pull request?
This pr added an option `queryTimeout` for the number of seconds the the driver will wait for a Statement object to execute.
## How was this patch tested?
Added tests in `JDBCSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#21173 from maropu/SPARK-23856.
## What changes were proposed in this pull request?
Hadoop 3 introduces HDFS federation. This means that multiple namespaces are allowed on the same HDFS cluster. In Spark, we need to ask the delegation token for all the namenodes (for each namespace), otherwise accessing any other namespace different from the default one (for which we already fetch the delegation token) fails.
The PR adds the automatic discovery of all the namenodes related to all the namespaces available according to the configs in hdfs-site.xml.
## How was this patch tested?
manual tests in dockerized env
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#21216 from mgaido91/SPARK-24149.
Instead of always throwing a generic exception when the AM fails,
print a generic error and throw the exception with the YARN
diagnostics containing the reason for the failure.
There was an issue with YARN sometimes providing a generic diagnostic
message, even though the AM provides a failure reason when
unregistering. That was happening because the AM was registering
too late, and if errors happened before the registration, YARN would
just create a generic "ExitCodeException" which wasn't very helpful.
Since most errors in this path are a result of not being able to
connect to the driver, this change modifies the AM registration
a bit so that the AM is registered before the connection to the
driver is established. That way, errors are properly propagated
through YARN back to the driver.
As part of that, I also removed the code that retried connections
to the driver from the client AM. At that point, the driver should
already be up and waiting for connections, so it's unlikely that
retrying would help - and in case it does, that means a flaky
network, which would mean problems would probably show up again.
The effect of that is that connection-related errors are reported
back to the driver much faster now (through the YARN report).
One thing to note is that there seems to be a race on the YARN
side that causes a report to be sent to the client without the
corresponding diagnostics string from the AM; the diagnostics are
available later from the RM web page. For that reason, the generic
error messages are kept in the Spark scheduler code, to help
guide users to a way of debugging their failure.
Also of note is that if YARN's max attempts configuration is lower
than Spark's, Spark will not unregister the AM with a proper
diagnostics message. Unfortunately there seems to be no way to
unregister the AM and still allow further re-attempts to happen.
Testing:
- existing unit tests
- some of our integration tests
- hardcoded an invalid driver address in the code and verified
the error in the shell. e.g.
```
scala> 18/05/04 15:09:34 ERROR cluster.YarnClientSchedulerBackend: YARN application has exited unexpectedly with state FAILED! Check the YARN application logs for more details.
18/05/04 15:09:34 ERROR cluster.YarnClientSchedulerBackend: Diagnostics message: Uncaught exception: org.apache.spark.SparkException: Exception thrown in awaitResult:
<AM stack trace>
Caused by: java.io.IOException: Failed to connect to localhost/127.0.0.1:1234
<More stack trace>
```
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#21243 from vanzin/SPARK-24182.
## What changes were proposed in this pull request?
We reverted `spark.sql.hive.convertMetastoreOrc` at https://github.com/apache/spark/pull/20536 because we should not ignore the table-specific compression conf. Now, it's resolved via [SPARK-23355](8aa1d7b0ed).
## How was this patch tested?
Pass the Jenkins.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#21186 from dongjoon-hyun/SPARK-24112.
## What changes were proposed in this pull request?
This copies the material from the spark.mllib user guide page for Naive Bayes to the spark.ml user guide page. I also improved the wording and organization slightly.
## How was this patch tested?
Built docs locally.
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#21272 from jkbradley/nb-doc-update.
## What changes were proposed in this pull request?
This updates Parquet to 1.10.0 and updates the vectorized path for buffer management changes. Parquet 1.10.0 uses ByteBufferInputStream instead of byte arrays in encoders. This allows Parquet to break allocations into smaller chunks that are better for garbage collection.
## How was this patch tested?
Existing Parquet tests. Running in production at Netflix for about 3 months.
Author: Ryan Blue <blue@apache.org>
Closes#21070 from rdblue/SPARK-23972-update-parquet-to-1.10.0.
## What changes were proposed in this pull request?
In Apache Spark 2.4, [SPARK-23355](https://issues.apache.org/jira/browse/SPARK-23355) fixes a bug which ignores table properties during convertMetastore for tables created by STORED AS ORC/PARQUET.
For some Parquet tables having table properties like TBLPROPERTIES (parquet.compression 'NONE'), it was ignored by default before Apache Spark 2.4. After upgrading cluster, Spark will write uncompressed file which is different from Apache Spark 2.3 and old.
This PR adds a migration note for that.
## How was this patch tested?
N/A
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#21269 from dongjoon-hyun/SPARK-23355-DOC.
## What changes were proposed in this pull request?
This PR fixes the migration note for SPARK-23291 since it's going to backport to 2.3.1. See the discussion in https://issues.apache.org/jira/browse/SPARK-23291
## How was this patch tested?
N/A
Author: hyukjinkwon <gurwls223@apache.org>
Closes#21249 from HyukjinKwon/SPARK-23291.
## What changes were proposed in this pull request?
`from_utc_timestamp` assumes its input is in UTC timezone and shifts it to the specified timezone. When the timestamp contains timezone(e.g. `2018-03-13T06:18:23+00:00`), Spark breaks the semantic and respect the timezone in the string. This is not what user expects and the result is different from Hive/Impala. `to_utc_timestamp` has the same problem.
More details please refer to the JIRA ticket.
This PR fixes this by returning null if the input timestamp contains timezone.
## How was this patch tested?
new tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#21169 from cloud-fan/from_utc_timezone.
## What changes were proposed in this pull request?
Added support to specify the 'spark.executor.extraJavaOptions' value in terms of the `{{APP_ID}}` and/or `{{EXECUTOR_ID}}`, `{{APP_ID}}` will be replaced by Application Id and `{{EXECUTOR_ID}}` will be replaced by Executor Id while starting the executor.
## How was this patch tested?
I have verified this by checking the executor process command and gc logs. I verified the same in different deployment modes(Standalone, YARN, Mesos) client and cluster modes.
Author: Devaraj K <devaraj@apache.org>
Closes#21088 from devaraj-kavali/SPARK-24003.
## What changes were proposed in this pull request?
By default, the dynamic allocation will request enough executors to maximize the
parallelism according to the number of tasks to process. While this minimizes the
latency of the job, with small tasks this setting can waste a lot of resources due to
executor allocation overhead, as some executor might not even do any work.
This setting allows to set a ratio that will be used to reduce the number of
target executors w.r.t. full parallelism.
The number of executors computed with this setting is still fenced by
`spark.dynamicAllocation.maxExecutors` and `spark.dynamicAllocation.minExecutors`
## How was this patch tested?
Units tests and runs on various actual workloads on a Yarn Cluster
Author: Julien Cuquemelle <j.cuquemelle@criteo.com>
Closes#19881 from jcuquemelle/AddTaskPerExecutorSlot.
## What changes were proposed in this pull request?
Currently we find the wider common type by comparing the two types from left to right, this can be a problem when you have two data types which don't have a common type but each can be promoted to StringType.
For instance, if you have a table with the schema:
[c1: date, c2: string, c3: int]
The following succeeds:
SELECT coalesce(c1, c2, c3) FROM table
While the following produces an exception:
SELECT coalesce(c1, c3, c2) FROM table
This is only a issue when the seq of dataTypes contains `StringType` and all the types can do string promotion.
close#19033
## How was this patch tested?
Add test in `TypeCoercionSuite`
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#21074 from jiangxb1987/typeCoercion.
## What changes were proposed in this pull request?
This PR proposes to fix `roxygen2` to `5.0.1` in `docs/README.md` for SparkR documentation generation.
If I use higher version and creates the doc, it shows the diff below. Not a big deal but it bothered me.
```diff
diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION
index 855eb5bf77f..159fca61e06 100644
--- a/R/pkg/DESCRIPTION
+++ b/R/pkg/DESCRIPTION
-57,6 +57,6 Collate:
'types.R'
'utils.R'
'window.R'
-RoxygenNote: 5.0.1
+RoxygenNote: 6.0.1
VignetteBuilder: knitr
NeedsCompilation: no
```
## How was this patch tested?
Manually tested. I met this every time I set the new environment for Spark dev but I have kept forgetting to fix it.
Author: hyukjinkwon <gurwls223@apache.org>
Closes#21020 from HyukjinKwon/minor-r-doc.
## What changes were proposed in this pull request?
Easy fix in the documentation.
## How was this patch tested?
N/A
Closes#20948
Author: Daniel Sakuma <dsakuma@gmail.com>
Closes#20928 from dsakuma/fix_typo_configuration_docs.
## What changes were proposed in this pull request?
This PR is to finish https://github.com/apache/spark/pull/17272
This JIRA is a follow up work after SPARK-19583
As we discussed in that PR
The following DDL for a managed table with an existed default location should throw an exception:
CREATE TABLE ... (PARTITIONED BY ...) AS SELECT ...
CREATE TABLE ... (PARTITIONED BY ...)
Currently there are some situations which are not consist with above logic:
CREATE TABLE ... (PARTITIONED BY ...) succeed with an existed default location
situation: for both hive/datasource(with HiveExternalCatalog/InMemoryCatalog)
CREATE TABLE ... (PARTITIONED BY ...) AS SELECT ...
situation: hive table succeed with an existed default location
This PR is going to make above two situations consist with the logic that it should throw an exception
with an existed default location.
## How was this patch tested?
unit test added
Author: Gengliang Wang <gengliang.wang@databricks.com>
Closes#20886 from gengliangwang/pr-17272.
## What changes were proposed in this pull request?
Easy fix in the markdown.
## How was this patch tested?
jekyII build test manually.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: lemonjing <932191671@qq.com>
Closes#20897 from Lemonjing/master.
## What changes were proposed in this pull request?
As mentioned in SPARK-23285, this PR introduces a new configuration property `spark.kubernetes.executor.cores` for specifying the physical CPU cores requested for each executor pod. This is to avoid changing the semantics of `spark.executor.cores` and `spark.task.cpus` and their role in task scheduling, task parallelism, dynamic resource allocation, etc. The new configuration property only determines the physical CPU cores available to an executor. An executor can still run multiple tasks simultaneously by using appropriate values for `spark.executor.cores` and `spark.task.cpus`.
## How was this patch tested?
Unit tests.
felixcheung srowen jiangxb1987 jerryshao mccheah foxish
Author: Yinan Li <ynli@google.com>
Author: Yinan Li <liyinan926@gmail.com>
Closes#20553 from liyinan926/master.
This change basically rewrites the security documentation so that it's
up to date with new features, more correct, and more complete.
Because security is such an important feature, I chose to move all the
relevant configuration documentation to the security page, instead of
having them peppered all over the place in the configuration page. This
allows an almost one-stop shop for security configuration in Spark. The
only exceptions are some YARN-specific minor features which I left in
the YARN page.
I also re-organized the page's topics, since they didn't make a lot of
sense. You had kerberos features described inside paragraphs talking
about UI access control, and other oddities. It should be easier now
to find information about specific Spark security features. I also
enabled TOCs for both the Security and YARN pages, since that makes it
easier to see what is covered.
I removed most of the comments from the SecurityManager javadoc since
they just replicated information in the security doc, with different
levels of out-of-dateness.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20742 from vanzin/SPARK-23572.
## What changes were proposed in this pull request?
This PR fixes an incorrect comparison in SQL between timestamp and date. This is because both of them are casted to `string` and then are compared lexicographically. This implementation shows `false` regarding this query `spark.sql("select cast('2017-03-01 00:00:00' as timestamp) between cast('2017-02-28' as date) and cast('2017-03-01' as date)").show`.
This PR shows `true` for this query by casting `date("2017-03-01")` to `timestamp("2017-03-01 00:00:00")`.
(Please fill in changes proposed in this fix)
## How was this patch tested?
Added new UTs to `TypeCoercionSuite`.
Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Closes#20774 from kiszk/SPARK-23549.
## What changes were proposed in this pull request?
Currently we allow writing data frames with empty schema into a file based datasource for certain file formats such as JSON, ORC etc. For formats such as Parquet and Text, we raise error at different times of execution. For text format, we return error from the driver early on in processing where as for format such as parquet, the error is raised from executor.
**Example**
spark.emptyDataFrame.write.format("parquet").mode("overwrite").save(path)
**Results in**
``` SQL
org.apache.parquet.schema.InvalidSchemaException: Cannot write a schema with an empty group: message spark_schema {
}
at org.apache.parquet.schema.TypeUtil$1.visit(TypeUtil.java:27)
at org.apache.parquet.schema.TypeUtil$1.visit(TypeUtil.java:37)
at org.apache.parquet.schema.MessageType.accept(MessageType.java:58)
at org.apache.parquet.schema.TypeUtil.checkValidWriteSchema(TypeUtil.java:23)
at org.apache.parquet.hadoop.ParquetFileWriter.<init>(ParquetFileWriter.java:225)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:342)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:302)
at org.apache.spark.sql.execution.datasources.parquet.ParquetOutputWriter.<init>(ParquetOutputWriter.scala:37)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$$anon$1.newInstance(ParquetFileFormat.scala:151)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$SingleDirectoryWriteTask.newOutputWriter(FileFormatWriter.scala:376)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$SingleDirectoryWriteTask.execute(FileFormatWriter.scala:387)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:278)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:276)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1411)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:281)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:206)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:205)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.
```
In this PR, we unify the error processing and raise error on attempt to write empty schema based dataframes into file based datasource (orc, parquet, text , csv, json etc) early on in the processing.
## How was this patch tested?
Unit tests added in FileBasedDatasourceSuite.
Author: Dilip Biswal <dbiswal@us.ibm.com>
Closes#20579 from dilipbiswal/spark-23372.
## What changes were proposed in this pull request?
To drop `exprId`s for `Alias` in user-facing info., this pr added an entry for `Alias` in `NonSQLExpression.sql`
## How was this patch tested?
Added tests in `UDFSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#20827 from maropu/SPARK-23666.
## What changes were proposed in this pull request?
Removal of the init-container for downloading remote dependencies. Built off of the work done by vanzin in an attempt to refactor driver/executor configuration elaborated in [this](https://issues.apache.org/jira/browse/SPARK-22839) ticket.
## How was this patch tested?
This patch was tested with unit and integration tests.
Author: Ilan Filonenko <if56@cornell.edu>
Closes#20669 from ifilonenko/remove-init-container.
## What changes were proposed in this pull request?
In the PR https://github.com/apache/spark/pull/20671, I forgot to update the doc about this new support.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20789 from gatorsmile/docUpdate.
## What changes were proposed in this pull request?
Below are the two cases.
``` SQL
case 1
scala> List.empty[String].toDF().rdd.partitions.length
res18: Int = 1
```
When we write the above data frame as parquet, we create a parquet file containing
just the schema of the data frame.
Case 2
``` SQL
scala> val anySchema = StructType(StructField("anyName", StringType, nullable = false) :: Nil)
anySchema: org.apache.spark.sql.types.StructType = StructType(StructField(anyName,StringType,false))
scala> spark.read.schema(anySchema).csv("/tmp/empty_folder").rdd.partitions.length
res22: Int = 0
```
For the 2nd case, since number of partitions = 0, we don't call the write task (the task has logic to create the empty metadata only parquet file)
The fix is to create a dummy single partition RDD and set up the write task based on it to ensure
the metadata-only file.
## How was this patch tested?
A new test is added to DataframeReaderWriterSuite.
Author: Dilip Biswal <dbiswal@us.ibm.com>
Closes#20525 from dilipbiswal/spark-23271.
## What changes were proposed in this pull request?
This PR adds a configuration to control the fallback of Arrow optimization for `toPandas` and `createDataFrame` with Pandas DataFrame.
## How was this patch tested?
Manually tested and unit tests added.
You can test this by:
**`createDataFrame`**
```python
spark.conf.set("spark.sql.execution.arrow.enabled", False)
pdf = spark.createDataFrame([[{'a': 1}]]).toPandas()
spark.conf.set("spark.sql.execution.arrow.enabled", True)
spark.conf.set("spark.sql.execution.arrow.fallback.enabled", True)
spark.createDataFrame(pdf, "a: map<string, int>")
```
```python
spark.conf.set("spark.sql.execution.arrow.enabled", False)
pdf = spark.createDataFrame([[{'a': 1}]]).toPandas()
spark.conf.set("spark.sql.execution.arrow.enabled", True)
spark.conf.set("spark.sql.execution.arrow.fallback.enabled", False)
spark.createDataFrame(pdf, "a: map<string, int>")
```
**`toPandas`**
```python
spark.conf.set("spark.sql.execution.arrow.enabled", True)
spark.conf.set("spark.sql.execution.arrow.fallback.enabled", True)
spark.createDataFrame([[{'a': 1}]]).toPandas()
```
```python
spark.conf.set("spark.sql.execution.arrow.enabled", True)
spark.conf.set("spark.sql.execution.arrow.fallback.enabled", False)
spark.createDataFrame([[{'a': 1}]]).toPandas()
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20678 from HyukjinKwon/SPARK-23380-conf.
## What changes were proposed in this pull request?
Seems R's substr API treats Scala substr API as zero based and so subtracts the given starting position by 1.
Because Scala's substr API also accepts zero-based starting position (treated as the first element), so the current R's substr test results are correct as they all use 1 as starting positions.
## How was this patch tested?
Modified tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20464 from viirya/SPARK-23291.
These options were used to configure the built-in JRE SSL libraries
when downloading files from HTTPS servers. But because they were also
used to set up the now (long) removed internal HTTPS file server,
their default configuration chose convenience over security by having
overly lenient settings.
This change removes the configuration options that affect the JRE SSL
libraries. The JRE trust store can still be configured via system
properties (or globally in the JRE security config). The only lost
functionality is not being able to disable the default hostname
verifier when using spark-submit, which should be fine since Spark
itself is not using https for any internal functionality anymore.
I also removed the HTTP-related code from the REPL class loader, since
we haven't had a HTTP server for REPL-generated classes for a while.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20723 from vanzin/SPARK-23538.
## What changes were proposed in this pull request?
If spark is run with "spark.authenticate=true", then it will fail to start in local mode.
This PR generates secret in local mode when authentication on.
## How was this patch tested?
Modified existing unit test.
Manually started spark-shell.
Author: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Closes#20652 from gaborgsomogyi/SPARK-23476.
## What changes were proposed in this pull request?
- Added clear information about triggers
- Made the semantics guarantees of watermarks more clear for streaming aggregations and stream-stream joins.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20631 from tdas/SPARK-23454.
## What changes were proposed in this pull request?
Apache Spark 2.3 introduced `native` ORC supports with vectorization and many fixes. However, it's shipped as a not-default option. This PR enables `native` ORC implementation and predicate-pushdown by default for Apache Spark 2.4. We will improve and stabilize ORC data source before Apache Spark 2.4. And, eventually, Apache Spark will drop old Hive-based ORC code.
## How was this patch tested?
Pass the Jenkins with existing tests.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20634 from dongjoon-hyun/SPARK-23456.
## What changes were proposed in this pull request?
To prevent any regressions, this PR changes ORC implementation to `hive` by default like Spark 2.2.X.
Users can enable `native` ORC. Also, ORC PPD is also restored to `false` like Spark 2.2.X.

## How was this patch tested?
Pass all test cases.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20610 from dongjoon-hyun/SPARK-ORC-DISABLE.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/19579 introduces a behavior change. We need to document it in the migration guide.
## How was this patch tested?
Also update the HiveExternalCatalogVersionsSuite to verify it.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20606 from gatorsmile/addMigrationGuide.
## What changes were proposed in this pull request?
Added documentation about what MLlib guarantees in terms of loading ML models and Pipelines from old Spark versions. Discussed & confirmed on linked JIRA.
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#20592 from jkbradley/SPARK-23154-backwards-compat-doc.
## What changes were proposed in this pull request?
This PR targets to explicitly specify supported types in Pandas UDFs.
The main change here is to add a deduplicated and explicit type checking in `returnType` ahead with documenting this; however, it happened to fix multiple things.
1. Currently, we don't support `BinaryType` in Pandas UDFs, for example, see:
```python
from pyspark.sql.functions import pandas_udf
pudf = pandas_udf(lambda x: x, "binary")
df = spark.createDataFrame([[bytearray(1)]])
df.select(pudf("_1")).show()
```
```
...
TypeError: Unsupported type in conversion to Arrow: BinaryType
```
We can document this behaviour for its guide.
2. Also, the grouped aggregate Pandas UDF fails fast on `ArrayType` but seems we can support this case.
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
foo = pandas_udf(lambda v: v.mean(), 'array<double>', PandasUDFType.GROUPED_AGG)
df = spark.range(100).selectExpr("id", "array(id) as value")
df.groupBy("id").agg(foo("value")).show()
```
```
...
NotImplementedError: ArrayType, StructType and MapType are not supported with PandasUDFType.GROUPED_AGG
```
3. Since we can check the return type ahead, we can fail fast before actual execution.
```python
# we can fail fast at this stage because we know the schema ahead
pandas_udf(lambda x: x, BinaryType())
```
## How was this patch tested?
Manually tested and unit tests for `BinaryType` and `ArrayType(...)` were added.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20531 from HyukjinKwon/pudf-cleanup.
This commit modifies the Mesos submission client to allow the principal
and secret to be provided indirectly via files. The path to these files
can be specified either via Spark configuration or via environment
variable.
Assuming these files are appropriately protected by FS/OS permissions
this means we don't ever leak the actual values in process info like ps
Environment variable specification is useful because it allows you to
interpolate the location of this file when using per-user Mesos
credentials.
For some background as to why we have taken this approach I will briefly describe our set up. On our systems we provide each authorised user account with their own Mesos credentials to provide certain security and audit guarantees to our customers. These credentials are managed by a central Secret management service. In our `spark-env.sh` we determine the appropriate secret and principal files to use depending on the user who is invoking Spark hence the need to inject these via environment variables as well as by configuration properties. So we set these environment variables appropriately and our Spark read in the contents of those files to authenticate itself with Mesos.
This is functionality we have been using it in production across multiple customer sites for some time. This has been in the field for around 18 months with no reported issues. These changes have been sufficient to meet our customer security and audit requirements.
We have been building and deploying custom builds of Apache Spark with various minor tweaks like this which we are now looking to contribute back into the community in order that we can rely upon stock Apache Spark builds and stop maintaining our own internal fork.
Author: Rob Vesse <rvesse@dotnetrdf.org>
Closes#20167 from rvesse/SPARK-16501.
## What changes were proposed in this pull request?
This PR proposes to disallow default value None when 'to_replace' is not a dictionary.
It seems weird we set the default value of `value` to `None` and we ended up allowing the case as below:
```python
>>> df.show()
```
```
+----+------+-----+
| age|height| name|
+----+------+-----+
| 10| 80|Alice|
...
```
```python
>>> df.na.replace('Alice').show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
**After**
This PR targets to disallow the case above:
```python
>>> df.na.replace('Alice').show()
```
```
...
TypeError: value is required when to_replace is not a dictionary.
```
while we still allow when `to_replace` is a dictionary:
```python
>>> df.na.replace({'Alice': None}).show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
## How was this patch tested?
Manually tested, tests were added in `python/pyspark/sql/tests.py` and doctests were fixed.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20499 from HyukjinKwon/SPARK-19454-followup.
## What changes were proposed in this pull request?
Further clarification of caveats in using stream-stream outer joins.
## How was this patch tested?
N/A
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20494 from tdas/SPARK-23064-2.
Add breaking changes, as well as update behavior changes, to `2.3` ML migration guide.
## How was this patch tested?
Doc only
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#20421 from MLnick/SPARK-23112-ml-guide.
## What changes were proposed in this pull request?
Rename the public APIs and names of pandas udfs.
- `PANDAS SCALAR UDF` -> `SCALAR PANDAS UDF`
- `PANDAS GROUP MAP UDF` -> `GROUPED MAP PANDAS UDF`
- `PANDAS GROUP AGG UDF` -> `GROUPED AGG PANDAS UDF`
## How was this patch tested?
The existing tests
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20428 from gatorsmile/renamePandasUDFs.
## What changes were proposed in this pull request?
User guide and examples are updated to reflect multiclass logistic regression summary which was added in [SPARK-17139](https://issues.apache.org/jira/browse/SPARK-17139).
I did not make a separate summary example, but added the summary code to the multiclass example that already existed. I don't see the need for a separate example for the summary.
## How was this patch tested?
Docs and examples only. Ran all examples locally using spark-submit.
Author: sethah <shendrickson@cloudera.com>
Closes#20332 from sethah/multiclass_summary_example.
## What changes were proposed in this pull request?
Adding user facing documentation for working with Arrow in Spark
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Li Jin <ice.xelloss@gmail.com>
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19575 from BryanCutler/arrow-user-docs-SPARK-2221.
Update ML user guide with highlights and migration guide for `2.3`.
## How was this patch tested?
Doc only.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#20363 from MLnick/SPARK-23112-ml-guide.
## What changes were proposed in this pull request?
Added documentation for new transformer.
Author: Bago Amirbekian <bago@databricks.com>
Closes#20285 from MrBago/sizeHintDocs.
## What changes were proposed in this pull request?
The example jar file is now in ./examples/jars directory of Spark distribution.
Author: Arseniy Tashoyan <tashoyan@users.noreply.github.com>
Closes#20349 from tashoyan/patch-1.
## What changes were proposed in this pull request?
streaming programming guide changes
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#20340 from felixcheung/rstreamdoc.
## What changes were proposed in this pull request?
Fix spelling in quick-start doc.
## How was this patch tested?
Doc only.
Author: Shashwat Anand <me@shashwat.me>
Closes#20336 from ashashwat/SPARK-23165.
## What changes were proposed in this pull request?
Docs changes:
- Adding a warning that the backend is experimental.
- Removing a defunct internal-only option from documentation
- Clarifying that node selectors can be used right away, and other minor cosmetic changes
## How was this patch tested?
Docs only change
Author: foxish <ramanathana@google.com>
Closes#20314 from foxish/ambiguous-docs.
## What changes were proposed in this pull request?
We have `OneHotEncoderEstimator` now and `OneHotEncoder` will be deprecated since 2.3.0. We should add `OneHotEncoderEstimator` into mllib document.
We also need to provide corresponding examples for `OneHotEncoderEstimator` which are used in the document too.
## How was this patch tested?
Existing tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20257 from viirya/SPARK-23048.
Update user guide entry for `FeatureHasher` to match the Scala / Python doc, to describe the `categoricalCols` parameter.
## How was this patch tested?
Doc only
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#20293 from MLnick/SPARK-23127-catCol-userguide.
## What changes were proposed in this pull request?
In latest structured-streaming-kafka-integration document, Java code example for Kafka integration is using `DataFrame<Row>`, shouldn't it be changed to `DataSet<Row>`?
## How was this patch tested?
manual test has been performed to test the updated example Java code in Spark 2.2.1 with Kafka 1.0
Author: brandonJY <brandonJY@users.noreply.github.com>
Closes#20312 from brandonJY/patch-2.
## What changes were proposed in this pull request?
In the Kubernetes mode, fails fast in the submission process if any submission client local dependencies are used as the use case is not supported yet.
## How was this patch tested?
Unit tests, integration tests, and manual tests.
vanzin foxish
Author: Yinan Li <liyinan926@gmail.com>
Closes#20320 from liyinan926/master.
## What changes were proposed in this pull request?
This PR completes the docs, specifying the default units assumed in configuration entries of type size.
This is crucial since unit-less values are accepted and the user might assume the base unit is bytes, which in most cases it is not, leading to hard-to-debug problems.
## How was this patch tested?
This patch updates only documentation only.
Author: Fernando Pereira <fernando.pereira@epfl.ch>
Closes#20269 from ferdonline/docs_units.
## What changes were proposed in this pull request?
When there is an operation between Decimals and the result is a number which is not representable exactly with the result's precision and scale, Spark is returning `NULL`. This was done to reflect Hive's behavior, but it is against SQL ANSI 2011, which states that "If the result cannot be represented exactly in the result type, then whether it is rounded or truncated is implementation-defined". Moreover, Hive now changed its behavior in order to respect the standard, thanks to HIVE-15331.
Therefore, the PR propose to:
- update the rules to determine the result precision and scale according to the new Hive's ones introduces in HIVE-15331;
- round the result of the operations, when it is not representable exactly with the result's precision and scale, instead of returning `NULL`
- introduce a new config `spark.sql.decimalOperations.allowPrecisionLoss` which default to `true` (ie. the new behavior) in order to allow users to switch back to the previous one.
Hive behavior reflects SQLServer's one. The only difference is that the precision and scale are adjusted for all the arithmetic operations in Hive, while SQL Server is said to do so only for multiplications and divisions in the documentation. This PR follows Hive's behavior.
A more detailed explanation is available here: https://mail-archives.apache.org/mod_mbox/spark-dev/201712.mbox/%3CCAEorWNAJ4TxJR9NBcgSFMD_VxTg8qVxusjP%2BAJP-x%2BJV9zH-yA%40mail.gmail.com%3E.
## How was this patch tested?
modified and added UTs. Comparisons with results of Hive and SQLServer.
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20023 from mgaido91/SPARK-22036.
## What changes were proposed in this pull request?
This patch bumps the master branch version to `2.4.0-SNAPSHOT`.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20222 from gatorsmile/bump24.
## What changes were proposed in this pull request?
Small typing correction - double word
## How was this patch tested?
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Matthias Beaupère <matthias.beaupere@gmail.com>
Closes#20212 from matthiasbe/patch-1.
This change allows a user to submit a Spark application on kubernetes
having to provide a single image, instead of one image for each type
of container. The image's entry point now takes an extra argument that
identifies the process that is being started.
The configuration still allows the user to provide different images
for each container type if they so desire.
On top of that, the entry point was simplified a bit to share more
code; mainly, the same env variable is used to propagate the user-defined
classpath to the different containers.
Aside from being modified to match the new behavior, the
'build-push-docker-images.sh' script was renamed to 'docker-image-tool.sh'
to more closely match its purpose; the old name was a little awkward
and now also not entirely correct, since there is a single image. It
was also moved to 'bin' since it's not necessarily an admin tool.
Docs have been updated to match the new behavior.
Tested locally with minikube.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20192 from vanzin/SPARK-22994.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/18164 introduces the behavior changes. We need to document it.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20234 from gatorsmile/docBehaviorChange.
## What changes were proposed in this pull request?
doc update
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#20198 from felixcheung/rrefreshdoc.
[SPARK-21786][SQL] When acquiring 'compressionCodecClassName' in 'ParquetOptions', `parquet.compression` needs to be considered.
## What changes were proposed in this pull request?
Since Hive 1.1, Hive allows users to set parquet compression codec via table-level properties parquet.compression. See the JIRA: https://issues.apache.org/jira/browse/HIVE-7858 . We do support orc.compression for ORC. Thus, for external users, it is more straightforward to support both. See the stackflow question: https://stackoverflow.com/questions/36941122/spark-sql-ignores-parquet-compression-propertie-specified-in-tblproperties
In Spark side, our table-level compression conf compression was added by #11464 since Spark 2.0.
We need to support both table-level conf. Users might also use session-level conf spark.sql.parquet.compression.codec. The priority rule will be like
If other compression codec configuration was found through hive or parquet, the precedence would be compression, parquet.compression, spark.sql.parquet.compression.codec. Acceptable values include: none, uncompressed, snappy, gzip, lzo.
The rule for Parquet is consistent with the ORC after the change.
Changes:
1.Increased acquiring 'compressionCodecClassName' from `parquet.compression`,and the precedence order is `compression`,`parquet.compression`,`spark.sql.parquet.compression.codec`, just like what we do in `OrcOptions`.
2.Change `spark.sql.parquet.compression.codec` to support "none".Actually in `ParquetOptions`,we do support "none" as equivalent to "uncompressed", but it does not allowed to configured to "none".
3.Change `compressionCode` to `compressionCodecClassName`.
## How was this patch tested?
Add test.
Author: fjh100456 <fu.jinhua6@zte.com.cn>
Closes#20076 from fjh100456/ParquetOptionIssue.
## What changes were proposed in this pull request?
This pr modified `elt` to output binary for binary inputs.
`elt` in the current master always output data as a string. But, in some databases (e.g., MySQL), if all inputs are binary, `elt` also outputs binary (Also, this might be a small surprise).
This pr is related to #19977.
## How was this patch tested?
Added tests in `SQLQueryTestSuite` and `TypeCoercionSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#20135 from maropu/SPARK-22937.
- Make it possible to build images from a git clone.
- Make it easy to use minikube to test things.
Also fixed what seemed like a bug: the base image wasn't getting the tag
provided in the command line. Adding the tag allows users to use multiple
Spark builds in the same kubernetes cluster.
Tested by deploying images on minikube and running spark-submit from a dev
environment; also by building the images with different tags and verifying
"docker images" in minikube.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20154 from vanzin/SPARK-22960.
## What changes were proposed in this pull request?
update R migration guide and vignettes
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#20106 from felixcheung/rreleasenote23.
## What changes were proposed in this pull request?
Fixing three small typos in the docs, in particular:
It take a `RDD` -> It takes an `RDD` (twice)
It take an `JavaRDD` -> It takes a `JavaRDD`
I didn't create any Jira issue for this minor thing, I hope it's ok.
## How was this patch tested?
visually by clicking on 'preview'
Author: Jirka Kremser <jkremser@redhat.com>
Closes#20108 from Jiri-Kremser/docs-typo.
## What changes were proposed in this pull request?
Currently, we do not guarantee an order evaluation of conjuncts in either Filter or Join operator. This is also true to the mainstream RDBMS vendors like DB2 and MS SQL Server. Thus, we should also push down the deterministic predicates that are after the first non-deterministic, if possible.
## How was this patch tested?
Updated the existing test cases.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20069 from gatorsmile/morePushDown.
## What changes were proposed in this pull request?
This pr modified `concat` to concat binary inputs into a single binary output.
`concat` in the current master always output data as a string. But, in some databases (e.g., PostgreSQL), if all inputs are binary, `concat` also outputs binary.
## How was this patch tested?
Added tests in `SQLQueryTestSuite` and `TypeCoercionSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#19977 from maropu/SPARK-22771.
## What changes were proposed in this pull request?
This PR updates the Kubernetes documentation corresponding to the following features/changes in #19954.
* Ability to use remote dependencies through the init-container.
* Ability to mount user-specified secrets into the driver and executor pods.
vanzin jiangxb1987 foxish
Author: Yinan Li <liyinan926@gmail.com>
Closes#20059 from liyinan926/doc-update.
What changes were proposed in this pull request?
This PR contains documentation on the usage of Kubernetes scheduler in Spark 2.3, and a shell script to make it easier to build docker images required to use the integration. The changes detailed here are covered by https://github.com/apache/spark/pull/19717 and https://github.com/apache/spark/pull/19468 which have merged already.
How was this patch tested?
The script has been in use for releases on our fork. Rest is documentation.
cc rxin mateiz (shepherd)
k8s-big-data SIG members & contributors: foxish ash211 mccheah liyinan926 erikerlandson ssuchter varunkatta kimoonkim tnachen ifilonenko
reviewers: vanzin felixcheung jiangxb1987 mridulm
TODO:
- [x] Add dockerfiles directory to built distribution. (https://github.com/apache/spark/pull/20007)
- [x] Change references to docker to instead say "container" (https://github.com/apache/spark/pull/19995)
- [x] Update configuration table.
- [x] Modify spark.kubernetes.allocation.batch.delay to take time instead of int (#20032)
Author: foxish <ramanathana@google.com>
Closes#19946 from foxish/update-k8s-docs.
## What changes were proposed in this pull request?
Like `Parquet`, users can use `ORC` with Apache Spark structured streaming. This PR adds `orc()` to `DataStreamReader`(Scala/Python) in order to support creating streaming dataset with ORC file format more easily like the other file formats. Also, this adds a test coverage for ORC data source and updates the document.
**BEFORE**
```scala
scala> spark.readStream.schema("a int").orc("/tmp/orc_ss").writeStream.format("console").start()
<console>:24: error: value orc is not a member of org.apache.spark.sql.streaming.DataStreamReader
spark.readStream.schema("a int").orc("/tmp/orc_ss").writeStream.format("console").start()
```
**AFTER**
```scala
scala> spark.readStream.schema("a int").orc("/tmp/orc_ss").writeStream.format("console").start()
res0: org.apache.spark.sql.streaming.StreamingQuery = org.apache.spark.sql.execution.streaming.StreamingQueryWrapper678b3746
scala>
-------------------------------------------
Batch: 0
-------------------------------------------
+---+
| a|
+---+
| 1|
+---+
```
## How was this patch tested?
Pass the newly added test cases.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19975 from dongjoon-hyun/SPARK-22781.
## What changes were proposed in this pull request?
Easy fix in the link.
## How was this patch tested?
Tested manually
Author: Mahmut CAVDAR <mahmutcvdr@gmail.com>
Closes#19996 from mcavdar/master.
This PR contains implementation of the basic submission client for the cluster mode of Spark on Kubernetes. It's step 2 from the step-wise plan documented [here](https://github.com/apache-spark-on-k8s/spark/issues/441#issuecomment-330802935).
This addition is covered by the [SPIP](http://apache-spark-developers-list.1001551.n3.nabble.com/SPIP-Spark-on-Kubernetes-td22147.html) vote which passed on Aug 31.
This PR and #19468 together form a MVP of Spark on Kubernetes that allows users to run Spark applications that use resources locally within the driver and executor containers on Kubernetes 1.6 and up. Some changes on pom and build/test setup are copied over from #19468 to make this PR self contained and testable.
The submission client is mainly responsible for creating the Kubernetes pod that runs the Spark driver. It follows a step-based approach to construct the driver pod, as the code under the `submit.steps` package shows. The steps are orchestrated by `DriverConfigurationStepsOrchestrator`. `Client` creates the driver pod and waits for the application to complete if it's configured to do so, which is the case by default.
This PR also contains Dockerfiles of the driver and executor images. They are included because some of the environment variables set in the code would not make sense without referring to the Dockerfiles.
* The patch contains unit tests which are passing.
* Manual testing: ./build/mvn -Pkubernetes clean package succeeded.
* It is a subset of the entire changelist hosted at http://github.com/apache-spark-on-k8s/spark which is in active use in several organizations.
* There is integration testing enabled in the fork currently hosted by PepperData which is being moved over to RiseLAB CI.
* Detailed documentation on trying out the patch in its entirety is in: https://apache-spark-on-k8s.github.io/userdocs/running-on-kubernetes.html
cc rxin felixcheung mateiz (shepherd)
k8s-big-data SIG members & contributors: mccheah foxish ash211 ssuchter varunkatta kimoonkim erikerlandson tnachen ifilonenko liyinan926
Author: Yinan Li <liyinan926@gmail.com>
Closes#19717 from liyinan926/spark-kubernetes-4.
## What changes were proposed in this pull request?
Update broadcast behavior changes in migration section.
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Closes#19858 from wangyum/SPARK-22489-migration.
## What changes were proposed in this pull request?
The spark properties for configuring the ContextCleaner are not documented in the official documentation at https://spark.apache.org/docs/latest/configuration.html#available-properties.
This PR adds the doc.
## How was this patch tested?
Manual.
```
cd docs
jekyll build
open _site/configuration.html
```
Author: gaborgsomogyi <gabor.g.somogyi@gmail.com>
Closes#19826 from gaborgsomogyi/SPARK-22428.
## What changes were proposed in this pull request?
How to reproduce:
```scala
import org.apache.spark.sql.execution.joins.BroadcastHashJoinExec
spark.createDataFrame(Seq((1, "4"), (2, "2"))).toDF("key", "value").createTempView("table1")
spark.createDataFrame(Seq((1, "1"), (2, "2"))).toDF("key", "value").createTempView("table2")
val bl = sql("SELECT /*+ MAPJOIN(t1) */ * FROM table1 t1 JOIN table2 t2 ON t1.key = t2.key").queryExecution.executedPlan
println(bl.children.head.asInstanceOf[BroadcastHashJoinExec].buildSide)
```
The result is `BuildRight`, but should be `BuildLeft`. This PR fix this issue.
## How was this patch tested?
unit tests
Author: Yuming Wang <wgyumg@gmail.com>
Closes#19714 from wangyum/SPARK-22489.
## What changes were proposed in this pull request?
This is a stripped down version of the `KubernetesClusterSchedulerBackend` for Spark with the following components:
- Static Allocation of Executors
- Executor Pod Factory
- Executor Recovery Semantics
It's step 1 from the step-wise plan documented [here](https://github.com/apache-spark-on-k8s/spark/issues/441#issuecomment-330802935).
This addition is covered by the [SPIP vote](http://apache-spark-developers-list.1001551.n3.nabble.com/SPIP-Spark-on-Kubernetes-td22147.html) which passed on Aug 31 .
## How was this patch tested?
- The patch contains unit tests which are passing.
- Manual testing: `./build/mvn -Pkubernetes clean package` succeeded.
- It is a **subset** of the entire changelist hosted in http://github.com/apache-spark-on-k8s/spark which is in active use in several organizations.
- There is integration testing enabled in the fork currently [hosted by PepperData](spark-k8s-jenkins.pepperdata.org:8080) which is being moved over to RiseLAB CI.
- Detailed documentation on trying out the patch in its entirety is in: https://apache-spark-on-k8s.github.io/userdocs/running-on-kubernetes.html
cc rxin felixcheung mateiz (shepherd)
k8s-big-data SIG members & contributors: mccheah ash211 ssuchter varunkatta kimoonkim erikerlandson liyinan926 tnachen ifilonenko
Author: Yinan Li <liyinan926@gmail.com>
Author: foxish <ramanathana@google.com>
Author: mcheah <mcheah@palantir.com>
Closes#19468 from foxish/spark-kubernetes-3.
## What changes were proposed in this pull request?
When converting Pandas DataFrame/Series from/to Spark DataFrame using `toPandas()` or pandas udfs, timestamp values behave to respect Python system timezone instead of session timezone.
For example, let's say we use `"America/Los_Angeles"` as session timezone and have a timestamp value `"1970-01-01 00:00:01"` in the timezone. Btw, I'm in Japan so Python timezone would be `"Asia/Tokyo"`.
The timestamp value from current `toPandas()` will be the following:
```
>>> spark.conf.set("spark.sql.session.timeZone", "America/Los_Angeles")
>>> df = spark.createDataFrame([28801], "long").selectExpr("timestamp(value) as ts")
>>> df.show()
+-------------------+
| ts|
+-------------------+
|1970-01-01 00:00:01|
+-------------------+
>>> df.toPandas()
ts
0 1970-01-01 17:00:01
```
As you can see, the value becomes `"1970-01-01 17:00:01"` because it respects Python timezone.
As we discussed in #18664, we consider this behavior is a bug and the value should be `"1970-01-01 00:00:01"`.
## How was this patch tested?
Added tests and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#19607 from ueshin/issues/SPARK-22395.
## What changes were proposed in this pull request?
A discussed in SPARK-19606, the addition of a new config property named "spark.mesos.constraints.driver" for constraining drivers running on a Mesos cluster
## How was this patch tested?
Corresponding unit test added also tested locally on a Mesos cluster
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Paul Mackles <pmackles@adobe.com>
Closes#19543 from pmackles/SPARK-19606.
## What changes were proposed in this pull request?
Documentation about Mesos Reject Offer Configurations
## Related PR
https://github.com/apache/spark/pull/19510 for `spark.mem.max`
Author: Li, YanKit | Wilson | RIT <yankit.li@rakuten.com>
Closes#19555 from windkit/spark_22133.
## What changes were proposed in this pull request?
Add incompatible Hive UDF describe to DOC.
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Closes#18833 from wangyum/SPARK-21625.
## What changes were proposed in this pull request?
Easy fix in the documentation, which is reporting that only numeric types and string are supported in type inference for partition columns, while Date and Timestamp are supported too since 2.1.0, thanks to SPARK-17388.
## How was this patch tested?
n/a
Author: Marco Gaido <mgaido@hortonworks.com>
Closes#19628 from mgaido91/SPARK-22398.
## What changes were proposed in this pull request?
Using zstd compression for Spark jobs spilling 100s of TBs of data, we could reduce the amount of data written to disk by as much as 50%. This translates to significant latency gain because of reduced disk io operations. There is a degradation CPU time by 2 - 5% because of zstd compression overhead, but for jobs which are bottlenecked by disk IO, this hit can be taken.
## Benchmark
Please note that this benchmark is using real world compute heavy production workload spilling TBs of data to disk
| | zstd performance as compred to LZ4 |
| ------------- | -----:|
| spill/shuffle bytes | -48% |
| cpu time | + 3% |
| cpu reservation time | -40%|
| latency | -40% |
## How was this patch tested?
Tested by running few jobs spilling large amount of data on the cluster and amount of intermediate data written to disk reduced by as much as 50%.
Author: Sital Kedia <skedia@fb.com>
Closes#18805 from sitalkedia/skedia/upstream_zstd.
## What changes were proposed in this pull request?
Update the url of reference paper.
## How was this patch tested?
It is comments, so nothing tested.
Author: bomeng <bmeng@us.ibm.com>
Closes#19614 from bomeng/22399.
Often times we want to impute custom values other than 'NaN'. My addition helps people locate this function without reading the API.
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: tengpeng <tengpeng@users.noreply.github.com>
Closes#19600 from tengpeng/patch-5.
## Background
In #18837 , ArtRand added Mesos secrets support to the dispatcher. **This PR is to add the same secrets support to the drivers.** This means if the secret configs are set, the driver will launch executors that have access to either env or file-based secrets.
One use case for this is to support TLS in the driver <=> executor communication.
## What changes were proposed in this pull request?
Most of the changes are a refactor of the dispatcher secrets support (#18837) - moving it to a common place that can be used by both the dispatcher and drivers. The same goes for the unit tests.
## How was this patch tested?
There are four config combinations: [env or file-based] x [value or reference secret]. For each combination:
- Added a unit test.
- Tested in DC/OS.
Author: Susan X. Huynh <xhuynh@mesosphere.com>
Closes#19437 from susanxhuynh/sh-mesos-driver-secret.
## What changes were proposed in this pull request?
Event Log Server has a total of five configuration parameters, and now the description of the other two configuration parameters on the doc, user-friendly access and use.
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: guoxiaolong <guo.xiaolong1@zte.com.cn>
Closes#19242 from guoxiaolongzte/addEventLogConf.
## What changes were proposed in this pull request?
The HTTP Strict-Transport-Security response header (often abbreviated as HSTS) is a security feature that lets a web site tell browsers that it should only be communicated with using HTTPS, instead of using HTTP.
Note: The Strict-Transport-Security header is ignored by the browser when your site is accessed using HTTP; this is because an attacker may intercept HTTP connections and inject the header or remove it. When your site is accessed over HTTPS with no certificate errors, the browser knows your site is HTTPS capable and will honor the Strict-Transport-Security header.
The HTTP X-XSS-Protection response header is a feature of Internet Explorer, Chrome and Safari that stops pages from loading when they detect reflected cross-site scripting (XSS) attacks.
The HTTP X-Content-Type-Options response header is used to protect against MIME sniffing vulnerabilities.
## How was this patch tested?
Checked on my system locally.
<img width="750" alt="screen shot 2017-10-03 at 6 49 20 pm" src="https://user-images.githubusercontent.com/6433184/31127234-eadf7c0c-a86b-11e7-8e5d-f6ea3f97b210.png">
Author: krishna-pandey <krish.pandey21@gmail.com>
Author: Krishna Pandey <krish.pandey21@gmail.com>
Closes#19419 from krishna-pandey/SPARK-22188.
Hive delegation tokens are only needed when the Spark driver has no access
to the kerberos TGT. That happens only in two situations:
- when using a proxy user
- when using cluster mode without a keytab
This change modifies the Hive provider so that it only generates delegation
tokens in those situations, and tweaks the YARN AM so that it makes the proper
user visible to the Hive code when running with keytabs, so that the TGT
can be used instead of a delegation token.
The effect of this change is that now it's possible to initialize multiple,
non-concurrent SparkContext instances in the same JVM. Before, the second
invocation would fail to fetch a new Hive delegation token, which then could
make the second (or third or...) application fail once the token expired.
With this change, the TGT will be used to authenticate to the HMS instead.
This change also avoids polluting the current logged in user's credentials
when launching applications. The credentials are copied only when running
applications as a proxy user. This makes it possible to implement SPARK-11035
later, where multiple threads might be launching applications, and each app
should have its own set of credentials.
Tested by verifying HDFS and Hive access in following scenarios:
- client and cluster mode
- client and cluster mode with proxy user
- client and cluster mode with principal / keytab
- long-running cluster app with principal / keytab
- pyspark app that creates (and stops) multiple SparkContext instances
through its lifetime
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19509 from vanzin/SPARK-22290.
## What changes were proposed in this pull request?
I see that block updates are not logged to the event log.
This makes sense as a default for performance reasons.
However, I find it helpful when trying to get a better understanding of caching for a job to be able to log these updates.
This PR adds a configuration setting `spark.eventLog.blockUpdates` (defaulting to false) which allows block updates to be recorded in the log.
This contribution is original work which is licensed to the Apache Spark project.
## How was this patch tested?
Current and additional unit tests.
Author: Michael Mior <mmior@uwaterloo.ca>
Closes#19263 from michaelmior/log-block-updates.
## What changes were proposed in this pull request?
In the current BlockManager's `getRemoteBytes`, it will call `BlockTransferService#fetchBlockSync` to get remote block. In the `fetchBlockSync`, Spark will allocate a temporary `ByteBuffer` to store the whole fetched block. This will potentially lead to OOM if block size is too big or several blocks are fetched simultaneously in this executor.
So here leveraging the idea of shuffle fetch, to spill the large block to local disk before consumed by upstream code. The behavior is controlled by newly added configuration, if block size is smaller than the threshold, then this block will be persisted in memory; otherwise it will first spill to disk, and then read from disk file.
To achieve this feature, what I did is:
1. Rename `TempShuffleFileManager` to `TempFileManager`, since now it is not only used by shuffle.
2. Add a new `TempFileManager` to manage the files of fetched remote blocks, the files are tracked by weak reference, will be deleted when no use at all.
## How was this patch tested?
This was tested by adding UT, also manual verification in local test to perform GC to clean the files.
Author: jerryshao <sshao@hortonworks.com>
Closes#19476 from jerryshao/SPARK-22062.
## What changes were proposed in this pull request?
Adds links to the fork that provides integration with Nomad, in the same places the k8s integration is linked to.
## How was this patch tested?
I clicked on the links to make sure they're correct ;)
Author: Ben Barnard <barnardb@gmail.com>
Closes#19354 from barnardb/link-to-nomad-integration.
## What changes were proposed in this pull request?
Added documentation for loading csv files into Dataframes
## How was this patch tested?
/dev/run-tests
Author: Jorge Machado <jorge.w.machado@hotmail.com>
Closes#19429 from jomach/master.
## What changes were proposed in this pull request?
The number of cores assigned to each executor is configurable. When this is not explicitly set, multiple executors from the same application may be launched on the same worker too.
## How was this patch tested?
N/A
Author: liuxian <liu.xian3@zte.com.cn>
Closes#18711 from 10110346/executorcores.
## What changes were proposed in this pull request?
Move flume behind a profile, take 2. See https://github.com/apache/spark/pull/19365 for most of the back-story.
This change should fix the problem by removing the examples module dependency and moving Flume examples to the module itself. It also adds deprecation messages, per a discussion on dev about deprecating for 2.3.0.
## How was this patch tested?
Existing tests, which still enable flume integration.
Author: Sean Owen <sowen@cloudera.com>
Closes#19412 from srowen/SPARK-22142.2.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
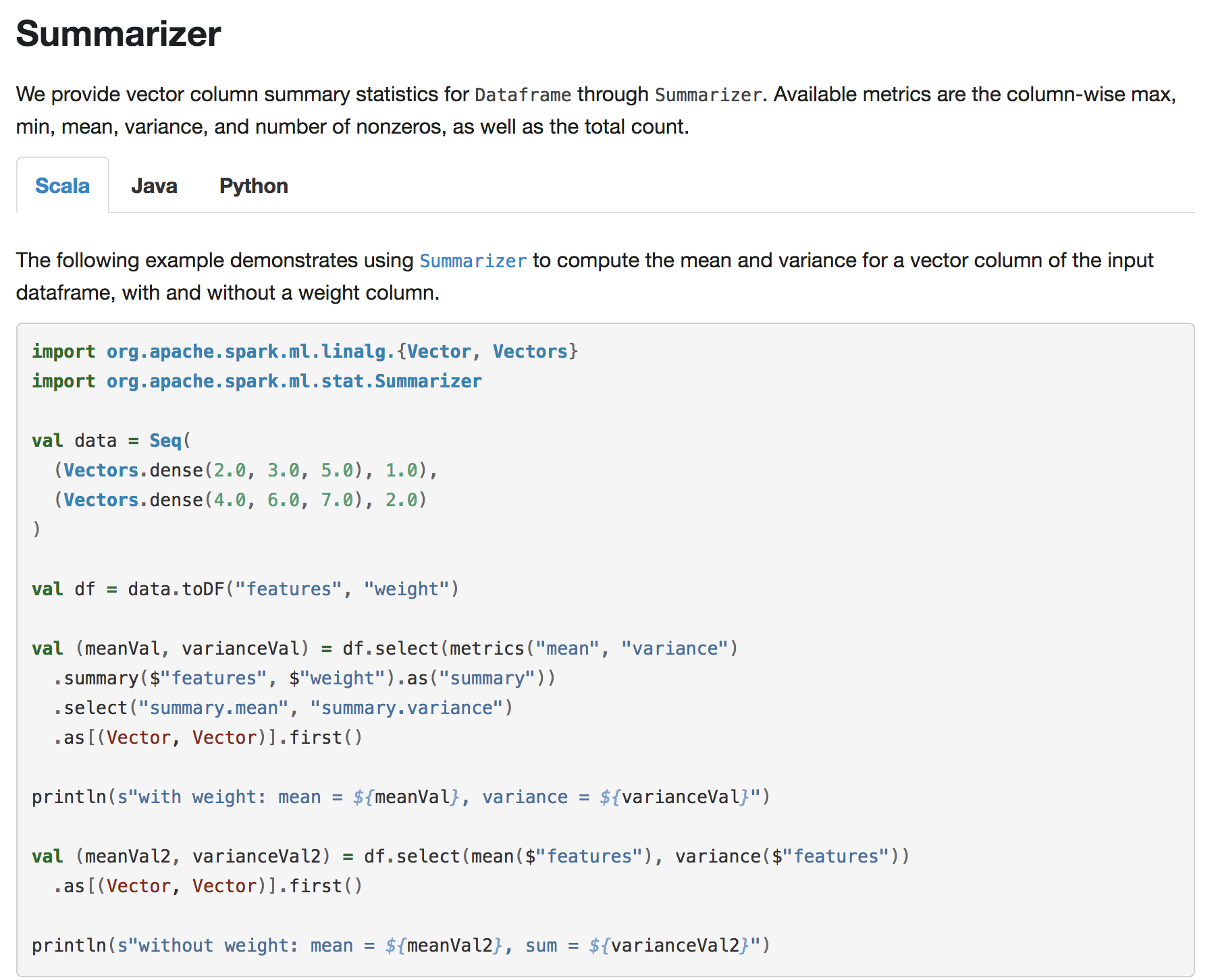{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
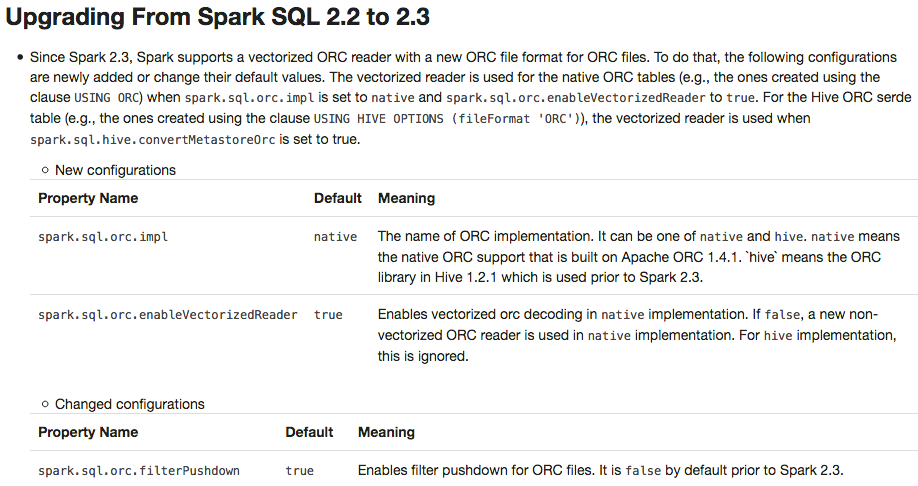{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}