### What changes were proposed in this pull request?
Fix incorrect statement that state is no longer needed in the event of executor failure and document that it is needed in the case of a flaky app causing occasional executor failure.
SO [discussion](https://stackoverflow.com/questions/67466878/can-spark-with-external-shuffle-service-use-saved-shuffle-files-in-the-event-of/67507439#67507439).
### Why are the changes needed?
To fix the documentation and guide users as to additional use case for the Shuffle Service.
### Does this PR introduce _any_ user-facing change?
Documentation only.
### How was this patch tested?
N/A.
Closes#32538 from chrisheaththomas/shuffle-service-and-executor-failure.
Authored-by: Chris Thomas <chrisheaththomas@hotmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Add toc tag on monitoring.md
### Why are the changes needed?
fix doc
### Does this PR introduce _any_ user-facing change?
yes, the table of content of the monitoring page will be shown on the official doc site.
### How was this patch tested?
pass GA doc build
Closes#32545 from yaooqinn/minor.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
Generally, we would expect that x = y => hash( x ) = hash( y ). However +-0 hash to different values for floating point types.
```
scala> spark.sql("select hash(cast('0.0' as double)), hash(cast('-0.0' as double))").show
+-------------------------+--------------------------+
|hash(CAST(0.0 AS DOUBLE))|hash(CAST(-0.0 AS DOUBLE))|
+-------------------------+--------------------------+
| -1670924195| -853646085|
+-------------------------+--------------------------+
scala> spark.sql("select cast('0.0' as double) == cast('-0.0' as double)").show
+--------------------------------------------+
|(CAST(0.0 AS DOUBLE) = CAST(-0.0 AS DOUBLE))|
+--------------------------------------------+
| true|
+--------------------------------------------+
```
Here is an extract from IEEE 754:
> The two zeros are distinguishable arithmetically only by either division-byzero ( producing appropriately signed infinities ) or else by the CopySign function recommended by IEEE 754 /854. Infinities, SNaNs, NaNs and Subnormal numbers necessitate four more special cases
From this, I deduce that the hash function must produce the same result for 0 and -0.
### Why are the changes needed?
It is a correctness issue
### Does this PR introduce _any_ user-facing change?
This changes only affect to the hash function applied to -0 value in float and double types
### How was this patch tested?
Unit testing and manual testing
Closes#32496 from planga82/feature/spark35207_hashnegativezero.
Authored-by: Pablo Langa <soypab@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In this PR I'm adding Structured Streaming Web UI state information documentation.
### Why are the changes needed?
Missing documentation.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
```
cd docs/
SKIP_API=1 bundle exec jekyll build
```
Manual webpage check.
Closes#32433 from gaborgsomogyi/SPARK-35311.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Jungtaek Lim <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This proposes to document the available metrics for ExecutorAllocationManager in the Spark monitoring documentation.
### Why are the changes needed?
The ExecutorAllocationManager is instrumented with metrics using the Spark metrics system.
The relevant work is in SPARK-7007 and SPARK-33763
ExecutorAllocationManager metrics are currently undocumented.
### Does this PR introduce _any_ user-facing change?
This PR adds documentation only.
### How was this patch tested?
na
Closes#32500 from LucaCanali/followupMetricsDocSPARK33763.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR proposes to introduces three new configurations to limit the maximum number of jobs/stages/executors on the timeline view.
### Why are the changes needed?
If the number of items on the timeline view grows +1000, rendering can be significantly slow.
https://issues.apache.org/jira/browse/SPARK-35229
The maximum number of tasks on the timeline is already limited by `spark.ui.timeline.tasks.maximum` so l proposed to mitigate this issue with the same manner.
### Does this PR introduce _any_ user-facing change?
Yes. the maximum number of items shown on the timeline view is limited.
I proposed the default value 500 for jobs and stages, and 250 for executors.
A executor has at most 2 items (added and removed) 250 is chosen.
### How was this patch tested?
I manually confirm this change works with the following procedures.
```
# launch a cluster
$ bin/spark-shell --conf spark.ui.retainedDeadExecutors=300 --master "local-cluster[4, 1, 1024]"
// Confirm the maximum number of jobs
(1 to 1000).foreach { _ => sc.parallelize(List(1)).collect }
// Confirm the maximum number of stages
var df = sc.parallelize(1 to 2)
(1 to 1000).foreach { i => df = df.repartition(i % 5 + 1) }
df.collect
// Confirm the maximum number of executors
(1 to 300).foreach { _ => try sc.parallelize(List(1)).foreach { _ => System.exit(0) } catch { case e => }}
```
Screenshots here.



Closes#32381 from sarutak/mitigate-timeline-issue.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
1. Extend Spark SQL parser to support parsing of:
- `INTERVAL YEAR TO MONTH` to `YearMonthIntervalType`
- `INTERVAL DAY TO SECOND` to `DayTimeIntervalType`
2. Assign new names to the ANSI interval types according to the SQL standard to be able to parse the names back by Spark SQL parser. Override the `typeName()` name of `YearMonthIntervalType`/`DayTimeIntervalType`.
### Why are the changes needed?
To be able to use new ANSI interval types in SQL. The SQL standard requires the types to be defined according to the rules:
```
<interval type> ::= INTERVAL <interval qualifier>
<interval qualifier> ::= <start field> TO <end field> | <single datetime field>
<start field> ::= <non-second primary datetime field> [ <left paren> <interval leading field precision> <right paren> ]
<end field> ::= <non-second primary datetime field> | SECOND [ <left paren> <interval fractional seconds precision> <right paren> ]
<primary datetime field> ::= <non-second primary datetime field | SECOND
<non-second primary datetime field> ::= YEAR | MONTH | DAY | HOUR | MINUTE
<interval fractional seconds precision> ::= <unsigned integer>
<interval leading field precision> ::= <unsigned integer>
```
Currently, Spark SQL supports only `YEAR TO MONTH` and `DAY TO SECOND` as `<interval qualifier>`.
### Does this PR introduce _any_ user-facing change?
Should not since the types has not been released yet.
### How was this patch tested?
By running the affected tests such as:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "test:testOnly *ExpressionTypeCheckingSuite"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z windowFrameCoercion.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z literals.sql"
```
Closes#32409 from MaxGekk/parse-ansi-interval-types.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR extends `ADD FILE/JAR/ARCHIVE` commands to be able to take multiple path arguments like Hive.
### Why are the changes needed?
To make those commands more useful.
### Does this PR introduce _any_ user-facing change?
Yes. In the current implementation, those commands can take a path which contains whitespaces without enclose it by neither `'` nor `"` but after this change, users need to enclose such paths.
I've note this incompatibility in the migration guide.
### How was this patch tested?
New tests.
Closes#32205 from sarutak/add-multiple-files.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
This PR proposes to introduce a new JDBC option `refreshKrb5Config` which allows to reflect the change of `krb5.conf`.
### Why are the changes needed?
In the current master, JDBC datasources can't accept `refreshKrb5Config` which is defined in `Krb5LoginModule`.
So even if we change the `krb5.conf` after establishing a connection, the change will not be reflected.
The similar issue happens when we run multiple `*KrbIntegrationSuites` at the same time.
`MiniKDC` starts and stops every KerberosIntegrationSuite and different port number is recorded to `krb5.conf`.
Due to `SecureConnectionProvider.JDBCConfiguration` doesn't take `refreshKrb5Config`, KerberosIntegrationSuites except the first running one see the wrong port so those suites fail.
You can easily confirm with the following command.
```
build/sbt -Phive Phive-thriftserver -Pdocker-integration-tests "testOnly org.apache.spark.sql.jdbc.*KrbIntegrationSuite"
```
### Does this PR introduce _any_ user-facing change?
Yes. Users can set `refreshKrb5Config` to refresh krb5 relevant configuration.
### How was this patch tested?
New test.
Closes#32344 from sarutak/kerberos-refresh-issue.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
Add doc about `TRANSFORM` and related function.
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32257 from AngersZhuuuu/SPARK-33976-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Add JindoFS SDK documents link in the cloud integration section of Spark's official document.
### Why are the changes needed?
If Spark users need to interact with Alibaba Cloud OSS, JindoFS SDK is the official solution provided by Alibaba Cloud.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
tested the url manually.
Closes#32360 from adrian-wang/jindodoc.
Authored-by: Daoyuan Wang <daoyuan.wdy@alibaba-inc.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Add note in migration guide about DayTimeIntervalType/YearMonthIntervalType show different between Hive SerDe and row format delimited
### Why are the changes needed?
Add note
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32343 from AngersZhuuuu/SPARK-35220-FOLLOWUP.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Extract common doc about hive format for `sql-ref-syntax-ddl-create-table-hiveformat.md` and `sql-ref-syntax-qry-select-transform.md` to refer.

### Why are the changes needed?
Improve doc
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32264 from AngersZhuuuu/SPARK-35159.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
PG and Oracle both support use CUBE/ROLLUP/GROUPING SETS in GROUPING SETS's grouping set as a sugar syntax.

In this PR, we support it in Spark SQL too
### Why are the changes needed?
Keep consistent with PG and oracle
### Does this PR introduce _any_ user-facing change?
User can write grouping analytics like
```
SELECT a, b, count(1) FROM testData GROUP BY a, GROUPING SETS(ROLLUP(a, b));
SELECT a, b, count(1) FROM testData GROUP BY a, GROUPING SETS((a, b), (a), ());
SELECT a, b, count(1) FROM testData GROUP BY a, GROUPING SETS(GROUPING SETS((a, b), (a), ()));
```
### How was this patch tested?
Added Test
Closes#32201 from AngersZhuuuu/SPARK-35026.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In YARN, ship the `spark.jars.ivySettings` file to the driver when using `cluster` deploy mode so that `addJar` is able to find it in order to resolve ivy paths.
### Why are the changes needed?
SPARK-33084 introduced support for Ivy paths in `sc.addJar` or Spark SQL `ADD JAR`. If we use a custom ivySettings file using `spark.jars.ivySettings`, it is loaded at b26e7b510b/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala (L1280). However, this file is only accessible on the client machine. In YARN cluster mode, this file is not available on the driver and so `addJar` fails to find it.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added unit tests to verify that the `ivySettings` file is localized by the YARN client and that a YARN cluster mode application is able to find to load the `ivySettings` file.
Closes#31591 from shardulm94/SPARK-34472.
Authored-by: Shardul Mahadik <smahadik@linkedin.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
Add doc about `TRANSFORM` and related function.

### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#31010 from AngersZhuuuu/SPARK-33976.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to support a new configuration, `spark.kubernetes.driver.service.deleteOnTermination`, to clean up `Driver Service` resource during app termination.
### Why are the changes needed?
The K8s service is one of the important resources and sometimes it's controlled by quota.
```
$ k describe quota
Name: service
Namespace: default
Resource Used Hard
-------- ---- ----
services 1 3
```
Apache Spark creates a service for driver whose lifecycle is the same with driver pod.
It means a new Spark job submission fails if the number of completed Spark jobs equals the number of service quota.
**BEFORE**
```
$ k get pod
NAME READY STATUS RESTARTS AGE
org-apache-spark-examples-sparkpi-a32c9278e7061b4d-driver 0/1 Completed 0 31m
org-apache-spark-examples-sparkpi-a9f1f578e721ef62-driver 0/1 Completed 0 78s
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 80m
org-apache-spark-examples-sparkpi-a32c9278e7061b4d-driver-svc ClusterIP None <none> 7078/TCP,7079/TCP,4040/TCP 31m
org-apache-spark-examples-sparkpi-a9f1f578e721ef62-driver-svc ClusterIP None <none> 7078/TCP,7079/TCP,4040/TCP 80s
$ k describe quota
Name: service
Namespace: default
Resource Used Hard
-------- ---- ----
services 3 3
$ bin/spark-submit...
Exception in thread "main" io.fabric8.kubernetes.client.KubernetesClientException:
Failure executing: POST at: https://192.168.64.50:8443/api/v1/namespaces/default/services.
Message: Forbidden! User minikube doesn't have permission.
services "org-apache-spark-examples-sparkpi-843f6978e722819c-driver-svc" is forbidden:
exceeded quota: service, requested: services=1, used: services=3, limited: services=3.
```
**AFTER**
```
$ k get pod
NAME READY STATUS RESTARTS AGE
org-apache-spark-examples-sparkpi-23d5f278e77731a7-driver 0/1 Completed 0 26s
org-apache-spark-examples-sparkpi-d1292278e7768ed4-driver 0/1 Completed 0 67s
org-apache-spark-examples-sparkpi-e5bedf78e776ea9d-driver 0/1 Completed 0 44s
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 172m
$ k describe quota
Name: service
Namespace: default
Resource Used Hard
-------- ---- ----
services 1 3
```
### Does this PR introduce _any_ user-facing change?
Yes, this PR adds a new configuration, `spark.kubernetes.driver.service.deleteOnTermination`, and enables it by default.
The change is documented at the migration guide.
### How was this patch tested?
Pass the CIs.
This is tested with K8s IT manually.
```
KubernetesSuite:
- Run SparkPi with no resources
- Run SparkPi with a very long application name.
- Use SparkLauncher.NO_RESOURCE
- Run SparkPi with a master URL without a scheme.
- Run SparkPi with an argument.
- Run SparkPi with custom labels, annotations, and environment variables.
- All pods have the same service account by default
- Run extraJVMOptions check on driver
- Run SparkRemoteFileTest using a remote data file
- Verify logging configuration is picked from the provided SPARK_CONF_DIR/log4j.properties
- Run SparkPi with env and mount secrets.
- Run PySpark on simple pi.py example
- Run PySpark to test a pyfiles example
- Run PySpark with memory customization
- Run in client mode.
- Start pod creation from template
- PVs with local storage
- Launcher client dependencies
- SPARK-33615: Launcher client archives
- SPARK-33748: Launcher python client respecting PYSPARK_PYTHON
- SPARK-33748: Launcher python client respecting spark.pyspark.python and spark.pyspark.driver.python
- Launcher python client dependencies using a zip file
- Test basic decommissioning
- Test basic decommissioning with shuffle cleanup
- Test decommissioning with dynamic allocation & shuffle cleanups
- Test decommissioning timeouts
- Run SparkR on simple dataframe.R example
Run completed in 19 minutes, 9 seconds.
Total number of tests run: 27
Suites: completed 2, aborted 0
Tests: succeeded 27, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
Closes#32226 from dongjoon-hyun/SPARK-35131.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Parse the year-month interval literals like `INTERVAL '1-1' YEAR TO MONTH` to values of `YearMonthIntervalType`, and day-time interval literals to `DayTimeIntervalType` values. Currently, Spark SQL supports:
- DAY TO HOUR
- DAY TO MINUTE
- DAY TO SECOND
- HOUR TO MINUTE
- HOUR TO SECOND
- MINUTE TO SECOND
All such interval literals are converted to `DayTimeIntervalType`, and `YEAR TO MONTH` to `YearMonthIntervalType` while loosing info about `from` and `to` units.
**Note**: new behavior is under the SQL config `spark.sql.legacy.interval.enabled` which is `false` by default. When the config is set to `true`, the interval literals are parsed to `CaledarIntervalType` values.
Closes#32176
### Why are the changes needed?
To conform the ANSI SQL standard which assumes conversions of interval literals to year-month or day-time interval but not to mixed interval type like Catalyst's `CalendarIntervalType`.
### Does this PR introduce _any_ user-facing change?
Yes.
Before:
```sql
spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND;
1 days 1 hours 2 minutes 3.123 seconds
spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND);
interval
```
After:
```sql
spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND;
1 01:02:03.123000000
spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND);
day-time interval
```
### How was this patch tested?
1. By running the affected test suites:
```
$ ./build/sbt "test:testOnly *.ExpressionParserSuite"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z create_view.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
```
2. PostgresSQL tests are executed with `spark.sql.legacy.interval.enabled` is set to `true` to keep compatibility with PostgreSQL output:
```sql
> SELECT interval '999' second;
0 years 0 mons 0 days 0 hours 16 mins 39.00 secs
```
Closes#32209 from MaxGekk/parse-ansi-interval-literals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Support no-serde mode script transform use ArrayType/MapType/StructStpe data.
### Why are the changes needed?
Make user can process array/map/struct data
### Does this PR introduce _any_ user-facing change?
Yes, user can process array/map/struct data in script transform `no-serde` mode
### How was this patch tested?
Added UT
Closes#30957 from AngersZhuuuu/SPARK-31937.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Soften security warning and keep it in cluster management docs only, not in the main doc page, where it's not necessarily relevant.
### Why are the changes needed?
The statement is perhaps unnecessarily 'frightening' as the first section in the main docs page. It applies to clusters not local mode, anyhow.
### Does this PR introduce _any_ user-facing change?
Just a docs change.
### How was this patch tested?
N/A
Closes#32206 from srowen/SecurityStatement.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Use hadoop FileSystem instead of FileInputStream.
### Why are the changes needed?
Make `spark.scheduler.allocation.file` suport remote file. When using Spark as a server (e.g. SparkThriftServer), it's hard for user to specify a local path as the scheduler pool.
### Does this PR introduce _any_ user-facing change?
Yes, a minor feature.
### How was this patch tested?
Pass `core/src/test/scala/org/apache/spark/scheduler/PoolSuite.scala` and manul test
After add config `spark.scheduler.allocation.file=hdfs:///tmp/fairscheduler.xml`. We intrudoce the configed pool.

Closes#32184 from ulysses-you/SPARK-35083.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Normal function parameters should not support alias, hive not support too
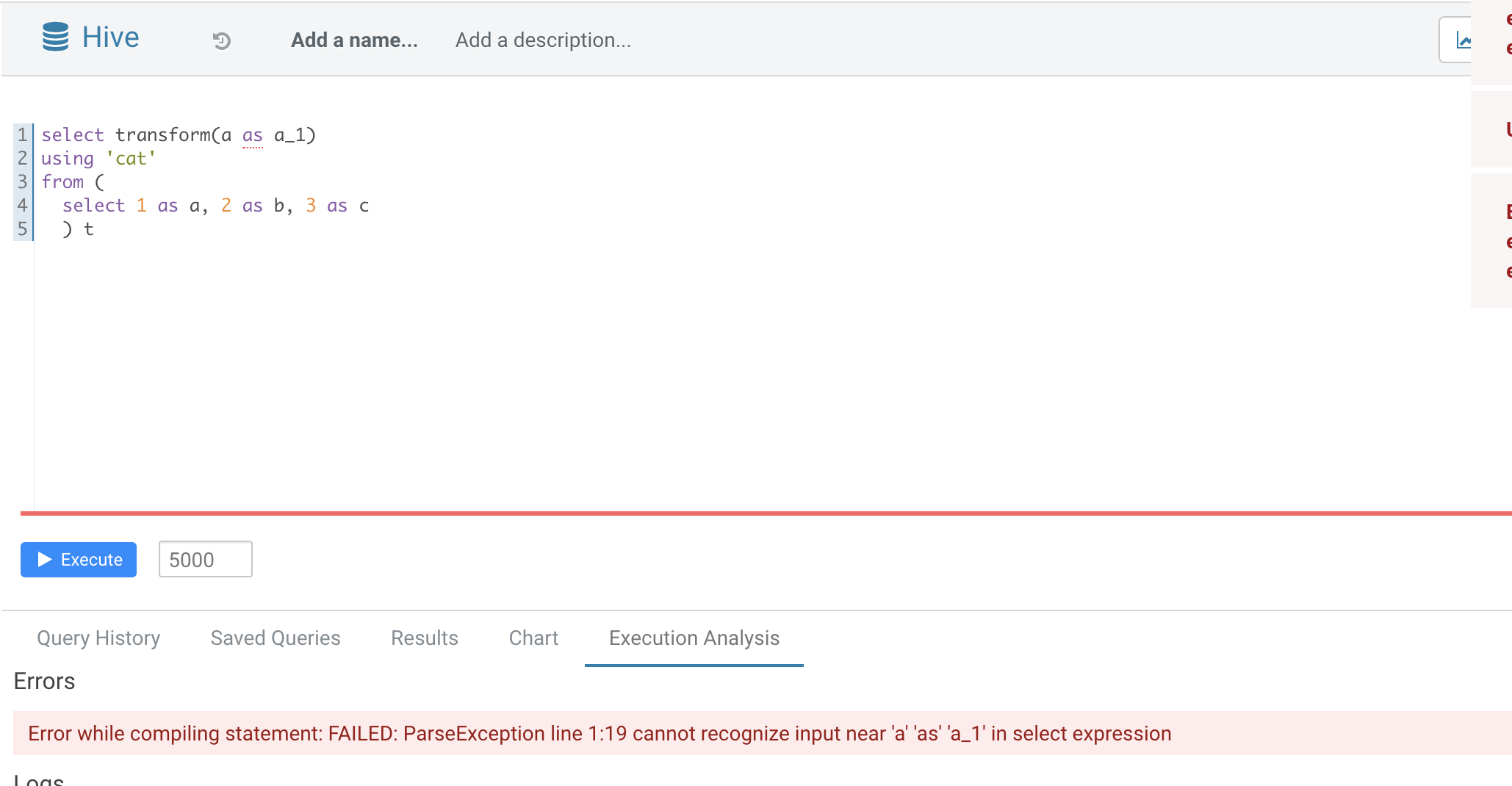
In this pr we forbid use alias in `TRANSFORM`'s inputs
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#32165 from AngersZhuuuu/SPARK-35070.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add change of `DESC NAMESPACE`'s schema to migration guide
### Why are the changes needed?
Update doc
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32155 from AngersZhuuuu/SPARK-34577-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Deprecate Apache Mesos support for Spark 3.2.0 by adding documentation to this effect.
### Why are the changes needed?
Apache Mesos is ceasing development (https://lists.apache.org/thread.html/rab2a820507f7c846e54a847398ab20f47698ec5bce0c8e182bfe51ba%40%3Cdev.mesos.apache.org%3E) ; at some point we'll want to drop support, so, deprecate it now.
This doesn't mean it'll go away in 3.3.0.
### Does this PR introduce _any_ user-facing change?
No, docs only.
### How was this patch tested?
N/A
Closes#32150 from srowen/SPARK-35050.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Disallow group by aliases under ANSI mode.
### Why are the changes needed?
As per the ANSI SQL standard secion 7.12 <group by clause>:
>Each `grouping column reference` shall unambiguously reference a column of the table resulting from the `from clause`. A column referenced in a `group by clause` is a grouping column.
By forbidding it, we can avoid ambiguous SQL queries like:
```
SELECT col + 1 as col FROM t GROUP BY col
```
### Does this PR introduce _any_ user-facing change?
Yes, group by aliases is not allowed under ANSI mode.
### How was this patch tested?
Unit tests
Closes#32129 from gengliangwang/disallowGroupByAlias.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This pr add test and document for Parquet Bloom filter push down.
### Why are the changes needed?
Improve document.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Generating docs:

Closes#32123 from wangyum/SPARK-34562.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Support GROUP BY use Separate columns and CUBE/ROLLUP
In postgres sql, it support
```
select a, b, c, count(1) from t group by a, b, cube (a, b, c);
select a, b, c, count(1) from t group by a, b, rollup(a, b, c);
select a, b, c, count(1) from t group by cube(a, b), rollup (a, b, c);
select a, b, c, count(1) from t group by a, b, grouping sets((a, b), (a), ());
```
In this pr, we have done two things as below:
1. Support partial grouping analytics such as `group by a, cube(a, b)`
2. Support mixed grouping analytics such as `group by cube(a, b), rollup(b,c)`
*Partial Groupings*
Partial Groupings means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
in GROUP BY clause. For example:
`GROUP BY warehouse, CUBE(product, location)` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse, location), (warehouse))`.
`GROUP BY warehouse, ROLLUP(product, location)` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse))`.
`GROUP BY warehouse, GROUPING SETS((product, location), (producet), ())` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, location), (warehouse))`.
*Concatenated Groupings*
Concatenated groupings offer a concise way to generate useful combinations of groupings. Groupings specified
with concatenated groupings yield the cross-product of groupings from each grouping set. The cross-product
operation enables even a small number of concatenated groupings to generate a large number of final groups.
The concatenated groupings are specified simply by listing multiple `GROUPING SETS`, `CUBES`, and `ROLLUP`,
and separating them with commas. For example:
`GROUP BY GROUPING SETS((warehouse), (producet)), GROUPING SETS((location), (size))` is equivalent to
`GROUP BY GROUPING SETS((warehouse, location), (warehouse, size), (product, location), (product, size))`.
`GROUP BY CUBE((warehouse), (producet)), ROLLUP((location), (size))` is equivalent to
`GROUP BY GROUPING SETS((warehouse, product), (warehouse), (producet), ()), GROUPING SETS((location, size), (location), ())`
`GROUP BY GROUPING SETS(
(warehouse, product, location, size), (warehouse, product, location), (warehouse, product),
(warehouse, location, size), (warehouse, location), (warehouse),
(product, location, size), (product, location), (product),
(location, size), (location), ())`.
`GROUP BY order, CUBE((warehouse), (producet)), ROLLUP((location), (size))` is equivalent to
`GROUP BY order, GROUPING SETS((warehouse, product), (warehouse), (producet), ()), GROUPING SETS((location, size), (location), ())`
`GROUP BY GROUPING SETS(
(order, warehouse, product, location, size), (order, warehouse, product, location), (order, warehouse, product),
(order, warehouse, location, size), (order, warehouse, location), (order, warehouse),
(order, product, location, size), (order, product, location), (order, product),
(order, location, size), (order, location), (order))`.
### Why are the changes needed?
Support more flexible grouping analytics
### Does this PR introduce _any_ user-facing change?
User can use sql like
```
select a, b, c, agg_expr() from table group by a, cube(b, c)
```
### How was this patch tested?
Added UT
Closes#30144 from AngersZhuuuu/SPARK-33229.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch fixes wrong Python code sample for doc.
### Why are the changes needed?
Sample code is wrong.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Doc only.
Closes#32119 from Hisssy/ss-doc-typo-1.
Authored-by: hissy <aozora@live.cn>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR aims to add a documentation on how to read and write TEXT files through various APIs such as Scala, Python and JAVA in Spark to [Data Source documents](https://spark.apache.org/docs/latest/sql-data-sources.html#data-sources).
### Why are the changes needed?
Documentation on how Spark handles TEXT files is missing. It should be added to the document for user convenience.
### Does this PR introduce _any_ user-facing change?
Yes, this PR adds a new page to Data Sources documents.
### How was this patch tested?
Manually build documents and check the page on local as below.

Closes#32053 from itholic/SPARK-34491-TEXT.
Authored-by: itholic <haejoon.lee@databricks.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
CREATE TABLE LIKE should respect the reserved properties of tables and fail if specified, using `spark.sql.legacy.notReserveProperties` to restore.
### Why are the changes needed?
Make DDLs consistently treat reserved properties
### Does this PR introduce _any_ user-facing change?
YES, this is a breaking change as using `create table like` w/ reserved properties will fail.
### How was this patch tested?
new test
Closes#32025 from yaooqinn/SPARK-34935.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
GROUP BY ... GROUPING SETS (...) is a weird SQL syntax we copied from Hive. It's not in the SQL standard or any other mainstream databases. This syntax requires users to repeat the expressions inside `GROUPING SETS (...)` after `GROUP BY`, and has a weird null semantic if `GROUP BY` contains extra expressions than `GROUPING SETS (...)`.
This PR deprecates this syntax:
1. Do not promote it in the document and only mention it as a Hive compatible sytax.
2. Simplify the code to only keep it for Hive compatibility.
### Why are the changes needed?
Deprecate a weird grammar.
### Does this PR introduce _any_ user-facing change?
No breaking change, but it removes a check to simplify the code: `GROUP BY a GROUPING SETS(a, b)` fails before and forces users to also put `b` after `GROUP BY`. Now this works just as `GROUP BY GROUPING SETS(a, b)`.
### How was this patch tested?
existing tests
Closes#32022 from cloud-fan/followup.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Fix [SPARK-34492], add Scala examples to read/write CSV files.
### Why are the changes needed?
Fix [SPARK-34492].
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Build the document with "SKIP_API=1 bundle exec jekyll build", and everything looks fine.
Closes#31827 from twoentartian/master.
Authored-by: twoentartian <twoentartian@hotmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR removes the description that `||` and `&&` can be used as logical operators from the migration guide.
### Why are the changes needed?
At the `Compatibility with Apache Hive` section in the migration guide, it describes that `||` and `&&` can be used as logical operators.
But, in fact, they cannot be used as described.
AFAIK, Hive also doesn't support `&&` and `||` as logical operators.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
I confirmed that `&&` and `||` cannot be used as logical operators with both Hive's interactive shell and `spark-sql`.
I also built the modified document and confirmed that the modified document doesn't break layout.
Closes#32023 from sarutak/modify-hive-compatibility-doc.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Add more flexable parameters for stage end point
endpoint /application/{app-id}/stages. It can be:
/application/{app-id}/stages?details=[true|false]&status=[ACTIVE|COMPLETE|FAILED|PENDING|SKIPPED]&withSummaries=[true|false]$quantiles=[comma separated quantiles string]&taskStatus=[RUNNING|SUCCESS|FAILED|PENDING]
where
```
query parameter details=true is to show the detailed task information within each stage. The default value is details=false;
query parameter status can select those stages with the specified status. When status parameter is not specified, a list of all stages are generated.
query parameter withSummaries=true is to show both task summary information in percentile distribution and executor summary information in percentile distribution. The default value is withSummaries=false.
query parameter quantiles support user defined quantiles, default quantiles is `0.0,0.25,0.5,0.75,1.0`
query parameter taskStatus is to show only those tasks with the specified status within their corresponding stages. This parameter will be set when details=true (i.e. this parameter will be ignored when details=false).
```
### Why are the changes needed?
More flexable restful API
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
UT
Closes#31204 from AngersZhuuuu/SPARK-26399-NEW.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Modify the `SubtractTimestamps` expression to return values of `DayTimeIntervalType` when `spark.sql.legacy.interval.enabled` is set to `false` (which is the default).
### Why are the changes needed?
To conform to the ANSI SQL standard which requires ANSI intervals as the result of timestamps subtraction, see
<img width="656" alt="Screenshot 2021-03-29 at 19 09 34" src="https://user-images.githubusercontent.com/1580697/112866455-7e2f0d00-90c2-11eb-96e6-3feb7eea7e09.png">
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateTimeUtilsSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
and some tests from `SQLQueryTestSuite`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#32016 from MaxGekk/subtract-timestamps-to-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Add a new SQL function `try_cast`.
`try_cast` is identical to `AnsiCast` (or `Cast` when `spark.sql.ansi.enabled` is true), except it returns NULL instead of raising an error.
This expression has one major difference from `cast` with `spark.sql.ansi.enabled` as true: when the source value can't be stored in the target integral(Byte/Short/Int/Long) type, `try_cast` returns null instead of returning the low order bytes of the source value.
Note that the result of `try_cast` is not affected by the configuration `spark.sql.ansi.enabled`.
This is learned from Google BigQuery and Snowflake:
https://docs.snowflake.com/en/sql-reference/functions/try_cast.htmlhttps://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators#safe_casting
### Why are the changes needed?
This is an useful for the following scenarios:
1. When ANSI mode is on, users can choose `try_cast` an alternative way to run SQL without errors for certain operations.
2. When ANSI mode is off, users can use `try_cast` to get a more reasonable result for casting a value to an integral type: when an overflow error happens, `try_cast` returns null while `cast` returns the low order bytes of the source value.
### Does this PR introduce _any_ user-facing change?
Yes, adding a new function `try_cast`
### How was this patch tested?
Unit tests.
Closes#31982 from gengliangwang/tryCast.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
Fix code not close issue in monitoring.md
### Why are the changes needed?
Fix doc issue
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32008 from AngersZhuuuu/SPARK-34911.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
1. Add the SQL config `spark.sql.legacy.interval.enabled` which will control when Spark SQL should use `CalendarIntervalType` instead of ANSI intervals.
2. Modify the `SubtractDates` expression to return values of `DayTimeIntervalType` when `spark.sql.legacy.interval.enabled` is set to `false` (which is the default).
### Why are the changes needed?
To conform to the ANSI SQL standard which requires ANSI intervals as the result of dates subtraction, see
<img width="656" alt="Screenshot 2021-03-29 at 19 09 34" src="https://user-images.githubusercontent.com/1580697/112866455-7e2f0d00-90c2-11eb-96e6-3feb7eea7e09.png">
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
and some tests from `SQLQueryTestSuite`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#31996 from MaxGekk/subtract-dates-to-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Add a new config, `spark.shuffle.service.name`, which allows for Spark applications to look for a YARN shuffle service which is defined at a name other than the default `spark_shuffle`.
Add a new config, `spark.yarn.shuffle.service.metrics.namespace`, which allows for configuring the namespace used when emitting metrics from the shuffle service into the NodeManager's `metrics2` system.
Add a new mechanism by which to override shuffle service configurations independently of the configurations in the NodeManager. When a resource `spark-shuffle-site.xml` is present on the classpath of the shuffle service, the configs present within it will be used to override the configs coming from `yarn-site.xml` (via the NodeManager).
### Why are the changes needed?
There are two use cases which can benefit from these changes.
One use case is to run multiple instances of the shuffle service side-by-side in the same NodeManager. This can be helpful, for example, when running a YARN cluster with a mixed workload of applications running multiple Spark versions, since a given version of the shuffle service is not always compatible with other versions of Spark (e.g. see SPARK-27780). With this PR, it is possible to run two shuffle services like `spark_shuffle` and `spark_shuffle_3.2.0`, one of which is "legacy" and one of which is for new applications. This is possible because YARN versions since 2.9.0 support the ability to run shuffle services within an isolated classloader (see YARN-4577), meaning multiple Spark versions can coexist.
Besides this, the separation of shuffle service configs into `spark-shuffle-site.xml` can be useful for administrators who want to change and/or deploy Spark shuffle service configurations independently of the configurations for the NodeManager (e.g., perhaps they are owned by two different teams).
### Does this PR introduce _any_ user-facing change?
Yes. There are two new configurations related to the external shuffle service, and a new mechanism which can optionally be used to configure the shuffle service. `docs/running-on-yarn.md` has been updated to provide user instructions; please see this guide for more details.
### How was this patch tested?
In addition to the new unit tests added, I have deployed this to a live YARN cluster and successfully deployed two Spark shuffle services simultaneously, one running a modified version of Spark 2.3.0 (which supports some of the newer shuffle protocols) and one running Spark 3.1.1. Spark applications of both versions are able to communicate with their respective shuffle services without issue.
Closes#31936 from xkrogen/xkrogen-SPARK-34828-shufflecompat-config-from-classpath.
Authored-by: Erik Krogen <xkrogen@apache.org>
Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
As discussed in
https://github.com/apache/spark/pull/30145#discussion_r514728642https://github.com/apache/spark/pull/30145#discussion_r514734648
We need to rewrite current Grouping Analytics grammar to support as flexible as Postgres SQL to support subsequent development.
In postgres sql, it support
```
select a, b, c, count(1) from t group by cube (a, b, c);
select a, b, c, count(1) from t group by cube(a, b, c);
select a, b, c, count(1) from t group by cube (a, b, c, (a, b), (a, b, c));
select a, b, c, count(1) from t group by rollup(a, b, c);
select a, b, c, count(1) from t group by rollup (a, b, c);
select a, b, c, count(1) from t group by rollup (a, b, c, (a, b), (a, b, c));
```
In this pr, we have done three things as below, and we will split it to different pr:
- Refactor CUBE/ROLLUP (regarding them as ANTLR tokens in a parser)
- Refactor GROUPING SETS (the logical node -> a new expr)
- Support new syntax for CUBE/ROLLUP (e.g., GROUP BY CUBE ((a, b), (a, c)))
### Why are the changes needed?
Rewrite current Grouping Analytics grammar to support as flexible as Postgres SQL to support subsequent development.
### Does this PR introduce _any_ user-facing change?
User can write Grouping Analytics grammar as flexible as Postgres SQL to support subsequent development.
### How was this patch tested?
Added UT
Closes#30212 from AngersZhuuuu/refact-grouping-analytics.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Co-authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, when a connection for TransportClient is marked as idled and closed, we suggest users adjust `spark.network.timeout` for all transport modules. As a lot of timeout configs will fallback to the `spark.network.timeout`, this could be a piece of overkill advice, we should give a more targeted one with `spark.${moduleName}.io.connectionTimeout`
### Why are the changes needed?
better advise for overloaded network traffic cases
### Does this PR introduce _any_ user-facing change?
yes, when a connection is zombied and closed by spark internally, users can use a more targeted config to tune their jobs
### How was this patch tested?
Just log and doc. Passing Jenkins and GA
Closes#31990 from yaooqinn/SPARK-34894.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
When we want to get stage's detail info with task information, it will return all tasks, the content is huge and always we just want to know some failed tasks/running tasks with whole stage info to judge is a task has some problem. This pr support
user to use
```
/application/[appid]/stages/[stage-id]?details=true&taskStatus=xxx
/application/[appid]/stages/[stage-id]/[stage-attempted-id]?details=true&taskStatus=xxx
```
to filter task details by task status
### Why are the changes needed?
More flexiable Restful API
### Does this PR introduce _any_ user-facing change?
User can use
```
/application/[appid]/stages/[stage-id]?details=true&taskStatus=xxx
/application/[appid]/stages/[stage-id]/[stage-attempted-id]?details=true&taskStatus=xxx
```
to filter task details by task status
### How was this patch tested?
Added
Closes#31165 from AngersZhuuuu/SPARK-34092.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Deprecating `spark.launcher.childConectionTimeout` in favor of `spark.launcher.childConnectionTimeout`
### Why are the changes needed?
srowen suggested it https://github.com/apache/spark/pull/30323#discussion_r521449342
### How was this patch tested?
No testing. Not even compiled
Closes#30679 from jsoref/spelling-connection.
Authored-by: Josh Soref <jsoref@users.noreply.github.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Allow casting complex types as string type in ANSI mode.
### Why are the changes needed?
Currently, complex types are not allowed to cast as string type. This breaks the DataFrame.show() API. E.g
```
scala> sql(“select array(1, 2, 2)“).show(false)
org.apache.spark.sql.AnalysisException: cannot resolve ‘CAST(`array(1, 2, 2)` AS STRING)’ due to data type mismatch:
cannot cast array<int> to string with ANSI mode on.
```
We should allow the conversion as the extension of the ANSI SQL standard, so that the DataFrame.show() still work in ANSI mode.
### Does this PR introduce _any_ user-facing change?
Yes, casting complex types as string type is now allowed in ANSI mode.
### How was this patch tested?
Unit tests.
Closes#31954 from gengliangwang/fixExplicitCast.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
For a specific stage, it is useful to show the task metrics in percentile distribution. This information can help users know whether or not there is a skew/bottleneck among tasks in a given stage. We list an example in taskMetricsDistributions.json
Similarly, it is useful to show the executor metrics in percentile distribution for a specific stage. This information can show whether or not there is a skewed load on some executors. We list an example in executorMetricsDistributions.json
We define `withSummaries` and `quantiles` query parameter in the REST API for a specific stage as:
applications/<application_id>/<application_attempt/stages/<stage_id>/<stage_attempt>?withSummaries=[true|false]& quantiles=0.05,0.25,0.5,0.75,0.95
1. withSummaries: default is false, define whether to show current stage's taskMetricsDistribution and executorMetricsDistribution
2. quantiles: default is `0.0,0.25,0.5,0.75,1.0` only effect when `withSummaries=true`, it define the quantiles we use when calculating metrics distributions.
When withSummaries=true, both task metrics in percentile distribution and executor metrics in percentile distribution are included in the REST API output. The default value of withSummaries is false, i.e. no metrics percentile distribution will be included in the REST API output.
### Why are the changes needed?
For a specific stage, it is useful to show the task metrics in percentile distribution. This information can help users know whether or not there is a skew/bottleneck among tasks in a given stage. We list an example in taskMetricsDistributions.json
### Does this PR introduce _any_ user-facing change?
User can use below restful API to get task metrics distribution and executor metrics distribution for indivial stage
```
applications/<application_id>/<application_attempt/stages/<stage_id>/<stage_attempt>?withSummaries=[true|false]
```
### How was this patch tested?
Added UT
Closes#31611 from AngersZhuuuu/SPARK-34488.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This patch adds a config `spark.yarn.kerberos.renewal.excludeHadoopFileSystems` which lists the filesystems to be excluded from delegation token renewal at YARN.
### Why are the changes needed?
MapReduce jobs can instruct YARN to skip renewal of tokens obtained from certain hosts by specifying the hosts with configuration mapreduce.job.hdfs-servers.token-renewal.exclude=<host1>,<host2>,..,<hostN>.
But seems Spark lacks of similar option. So the job submission fails if YARN fails to renew DelegationToken for any of the remote HDFS cluster. The failure in DT renewal can happen due to many reason like Remote HDFS does not trust Kerberos identity of YARN etc. We have a customer facing such issue.
### Does this PR introduce _any_ user-facing change?
No, if the config is not set. Yes, as users can use this config to instruct YARN not to renew delegation token from certain filesystems.
### How was this patch tested?
It is hard to do unit test for this. We did verify it work from the customer using this fix in the production environment.
Closes#31761 from viirya/SPARK-34295.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
the given example uses a non-standard syntax for CREATE TABLE, by defining the partitioning column with the other columns, instead of in PARTITION BY.
This works is this case, because the partitioning column happens to be the last column defined, but it will break if instead 'name' would be used for partitioning.
I suggest therefore to change the example to use a standard syntax, like in
https://spark.apache.org/docs/3.1.1/sql-ref-syntax-ddl-create-table-hiveformat.html
### Why are the changes needed?
To show the better documentation.
### Does this PR introduce _any_ user-facing change?
Yes, this fixes the user-facing docs.
### How was this patch tested?
CI should test it out.
Closes#31900 from robert4os/patch-1.
Authored-by: robert4os <robert4os@users.noreply.github.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}