## What changes were proposed in this pull request?
Change the Driver resource discovery argument for standalone mode to be a file rather then separate address configs per resource. This makes it consistent with how the Executor is doing it and makes it more flexible in the future, and it makes for less configs if you have multiple resources.
## How was this patch tested?
Unit tests and basic manually testing to make sure files were parsed properly.
Closes#24730 from tgravescs/SPARK-27835-driver-resourcesFile.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
This pr wrap all `PrintWriter` with `Utils.tryWithResource` to prevent resource leak.
## How was this patch tested?
Existing test
Closes#24739 from wangyum/SPARK-27875.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Example GPU resource discovery script that can be used with Nvidia GPUs and passed into SPARK via spark.{driver/executor}.resource.gpu.discoveryScript
For example:
./bin/spark-shell --master yarn --deploy-mode client --driver-memory 1g --conf spark.yarn.am.memory=3g --num-executors 1 --executor-memory 1g --conf spark.driver.resource.gpu.count=2 --executor-cores 1 --conf spark.driver.resource.gpu.discoveryScript=/home/tgraves/workspace/tgravescs-spark/examples/src/main/resources/getGpusResources.sh --conf spark.executor.resource.gpu.count=1 --conf spark.task.resource.gpu.count=1 --conf spark.executor.resource.gpu.discoveryScript=/home/tgraves/workspace/tgravescs-spark/examples/src/main/resources/getGpusResources.sh
## How was this patch tested?
Manually tested local cluster mode and yarn mode. Tested on a node with 8 GPUs and one with 2 GPUs.
Closes#24731 from tgravescs/SPARK-27725.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Require the lookup function with interface LookupCatalog. Rationale is in the review comments below.
Make `Analyzer` abstract. BaseSessionStateBuilder and HiveSessionStateBuilder implements lookupCatalog with a call to SparkSession.catalog().
Existing test cases and those that don't need catalog lookup will use a newly added `TestAnalyzer` with a default lookup function that throws` CatalogNotFoundException("No catalog lookup function")`.
Rewrote the unit test for LookupCatalog to demonstrate the interface can be used anywhere, not just Analyzer.
Removed Analyzer parameter `lookupCatalog` because we can override in the following manner:
```
new Analyzer() {
override def lookupCatalog(name: String): CatalogPlugin = ???
}
```
## How was this patch tested?
Existing unit tests.
Closes#24689 from jzhuge/SPARK-26946-follow.
Authored-by: John Zhuge <jzhuge@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
`A very little spelling mistake.`
## How was this patch tested?
No
Closes#24710 from LiShuMing/minor-spelling.
Authored-by: ShuMingLi <ming.moriarty@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
First, there is currently no public documentation for this setting. So it's hard
to even know that it could be a problem if your application starts failing with
weird shuffle errors.
Second, the javadoc attached to the code was incorrect; the default value just uses
the default value from the JRE, which is 50, instead of having an unbounded queue
as the comment implies.
So use a default that is a "rounded" version of the JRE default, and provide
documentation explaining that this value may need to be adjusted. Also added
a log message that was very helpful in debugging an issue caused by this
problem.
Closes#24732 from vanzin/SPARK-27868.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
To follow https://github.com/apache/spark/pull/17397, the output of FileTable and DataSourceV2ScanExecBase can contain sensitive information (like Amazon keys). Such information should not end up in logs, or be exposed to non-privileged users.
This PR is to add a redaction facility for these outputs to resolve the issue. A user can enable this by setting a regex in the same spark.redaction.string.regex configuration as V1.
## How was this patch tested?
Unit test
Closes#24719 from gengliangwang/RedactionSuite.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Currently system properties are not redacted. This PR fixes that, so that any credentials passed as System properties are redacted as well.
## How was this patch tested?
Manual test. Run the following and see the UI.
```
bin/spark-shell --conf 'spark.driver.extraJavaOptions=-DMYSECRET=app'
```
Closes#24733 from aaruna/27869.
Authored-by: Aaruna <aaruna.godthi@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
In order to support outer joins with null top-level objects, SPARK-15441 modified Dataset.joinWith to project both inputs into single-column structs prior to the join.
For inner joins, however, this step is unnecessary and actually harms performance: performing the nesting before the join increases the shuffled data size. As an optimization for inner joins only, we can move this nesting to occur after the join (effectively switching back to the pre-SPARK-15441 behavior; see #13425).
## How was this patch tested?
Existing tests, which I strengthened to also make assertions about the join result's nullability (since this guards against a bug I almost introduced during prototyping).
Here's a quick `spark-shell` experiment demonstrating the reduction in shuffle size:
```scala
// With --conf spark.shuffle.compress=false
sql("set spark.sql.autoBroadcastJoinThreshold=-1") // for easier shuffle measurements
case class Foo(a: Long, b: Long)
val left = spark.range(10000).map(x => Foo(x, x))
val right = spark.range(10000).map(x => Foo(x, x))
left.joinWith(right, left("a") === right("a"), "inner").rdd.count()
left.joinWith(right, left("a") === right("a"), "left").rdd.count()
```
With inner join (which benefits from this PR's optimization) we shuffle 546.9 KiB. With left outer join (whose plan hasn't changed, therefore being a representation of the state before this PR) we shuffle 859.4 KiB. Shuffle compression (which is enabled by default) narrows this gap a bit: with compression, outer joins shuffle about 12% more than inner joins.
Closes#24693 from JoshRosen/fast-join-with-for-inner-joins.
Lead-authored-by: Josh Rosen <rosenville@gmail.com>
Co-authored-by: Josh Rosen <joshrosen@stripe.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This pr moves `sql/hive-thriftserver/v2.3.4` to `sql/hive-thriftserver/v2.3.5` based on ([comment](https://github.com/apache/spark/pull/24628#issuecomment-496459258)).
## How was this patch tested?
N/A
Closes#24728 from wangyum/SPARK-27737-thriftserver.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
`ExecutorClassLoader`'s `findClass` may fail to fetch a class due to transient exceptions. For example, when a task is interrupted, if `ExecutorClassLoader` is fetching a class, you may see `InterruptedException` or `IOException` wrapped by `ClassNotFoundException`, even if this class can be loaded. Then the result of `findClass` will be cached by JVM, and later when the same class is being loaded in the same executor, it will just throw NoClassDefFoundError even if the class can be loaded.
I found JVM only caches `LinkageError` and `ClassNotFoundException`. Hence in this PR, I changed ExecutorClassLoader to throw `RemoteClassLoadedError` if we cannot get a response from driver.
## How was this patch tested?
New unit tests.
Closes#24683 from zsxwing/SPARK-20547-fix.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
…lure
## What changes were proposed in this pull request?
The failure log format is fixed according to the jdk implementation.
## How was this patch tested?
Manual tests have been done. The new failure log format would be like:
java.lang.RuntimeException: Failed to finish the task
at com.xxx.Test.test(Test.java:106)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.testng.internal.MethodInvocationHelper.invokeMethod(MethodInvocationHelper.java:124)
at org.testng.internal.Invoker.invokeMethod(Invoker.java:571)
at org.testng.internal.Invoker.invokeTestMethod(Invoker.java:707)
at org.testng.internal.Invoker.invokeTestMethods(Invoker.java:979)
at org.testng.internal.TestMethodWorker.invokeTestMethods(TestMethodWorker.java:125)
at org.testng.internal.TestMethodWorker.run(TestMethodWorker.java:109)
at org.testng.TestRunner.privateRun(TestRunner.java:648)
at org.testng.TestRunner.run(TestRunner.java:505)
at org.testng.SuiteRunner.runTest(SuiteRunner.java:455)
at org.testng.SuiteRunner.runSequentially(SuiteRunner.java:450)
at org.testng.SuiteRunner.privateRun(SuiteRunner.java:415)
at org.testng.SuiteRunner.run(SuiteRunner.java:364)
at org.testng.SuiteRunnerWorker.runSuite(SuiteRunnerWorker.java:52)
at org.testng.SuiteRunnerWorker.run(SuiteRunnerWorker.java:84)
at org.testng.TestNG.runSuitesSequentially(TestNG.java:1187)
at org.testng.TestNG.runSuitesLocally(TestNG.java:1116)
at org.testng.TestNG.runSuites(TestNG.java:1028)
at org.testng.TestNG.run(TestNG.java:996)
at org.testng.IDEARemoteTestNG.run(IDEARemoteTestNG.java:72)
at org.testng.RemoteTestNGStarter.main(RemoteTestNGStarter.java:123)
Caused by: java.io.FileNotFoundException: File is not found
at com.xxx.Test.test(Test.java:105)
... 24 more
Closes#24684 from breakdawn/master.
Authored-by: MJ Tang <mingjtang@ebay.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
I checked the code of
`org.apache.spark.sql.execution.datasources.DataSource`
, there exists duplicate Java reflection.
`sourceSchema`,`createSource`,`createSink`,`resolveRelation`,`writeAndRead`, all the methods call the `providingClass.getConstructor().newInstance()`.
The instance of `providingClass` is stateless, such as:
`KafkaSourceProvider`
`RateSourceProvider`
`TextSocketSourceProvider`
`JdbcRelationProvider`
`ConsoleSinkProvider`
AFAIK, Java reflection will result in significant performance issue.
The oracle website [https://docs.oracle.com/javase/tutorial/reflect/index.html](https://docs.oracle.com/javase/tutorial/reflect/index.html) contains some performance description about Java reflection:
```
Performance Overhead
Because reflection involves types that are dynamically resolved, certain Java virtual machine optimizations can not be performed. Consequently, reflective operations have slower performance than their non-reflective counterparts, and should be avoided in sections of code which are called frequently in performance-sensitive applications.
```
I have found some performance cost test of Java reflection as follows:
[https://blog.frankel.ch/performance-cost-of-reflection/](https://blog.frankel.ch/performance-cost-of-reflection/) contains performance cost test.
[https://stackoverflow.com/questions/435553/java-reflection-performance](https://stackoverflow.com/questions/435553/java-reflection-performance) has a discussion of java reflection.
So I think should avoid duplicate Java reflection and reuse the instance of `providingClass`.
## How was this patch tested?
Exists UT.
Closes#24647 from beliefer/optimize-DataSource.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
R 3.6.0 is released 2019-04-26. This PR targets to change R version from 3.5.1 to 3.6.0 in AppVeyor.
This PR sets `R_REMOTES_NO_ERRORS_FROM_WARNINGS` to `true` to avoid the warnings below:
```
Error in strptime(xx, f, tz = tz) :
(converted from warning) unable to identify current timezone 'C':
please set environment variable 'TZ'
Error in i.p(...) :
(converted from warning) installation of package 'praise' had non-zero exit status
Calls: <Anonymous> ... with_rprofile_user -> with_envvar -> force -> force -> i.p
Execution halted
```
## How was this patch tested?
AppVeyor
Closes#24716 from HyukjinKwon/SPARK-27848.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
descending sort in HDFSMetadataLog.getLatest instead of two action of ascending sort and reverse
## How was this patch tested?
Jenkins
Closes#24711 from wenxuanguan/bug-fix-hdfsmetadatalog.
Authored-by: wenxuanguan <choose_home@126.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
### Standalone HA Background
In Spark Standalone HA mode, we'll have multiple masters running at the same time. But, there's only one master leader, which actively serving scheduling requests. Once this master leader crashes, other masters would compete for the leader and only one master is guaranteed to be elected as new master leader, which would reconstruct the state from the original master leader and continute to serve scheduling requests.
### Related Issues
#2828 firstly introduces the bug of *duplicate Worker registration*, and #3447 fixed it. But there're still corner cases(see SPARK-23191 for details) where #3447 can not cover it:
* CASE 1
(1) Initially, Worker registered with Master A.
(2) After a while, the connection channel between Master A and Worker becomes inactive(e.g. due to network drop), and Worker is notified about that by calling `onDisconnected` from NettyRpcEnv
(3) When Worker invokes `onDisconnected`, then, it will attempt to reconnect to all masters(including Master A)
(4) At the meanwhile, network between Worker and Master A recover, Worker successfully register to Master A again
(5) Master A response with `RegisterWorkerFailed("Duplicate worker ID")`
(6) Worker receives that msg, exit
* CASE 2
(1) Master A lost leadership(sends `RevokedLeadership` to itself). Master B takes over and recovery everything from master A(which would register workers for the first time in Master B) and sends `MasterChanged` to Worker
(2) Before Master A receives `RevokedLeadership`, it receives a late `HeartBeat` from Worker(which had been removed in Master A due to heartbeat timeout previously), so it sends `ReconnectWorker` to worker
(3) Worker receives `MasterChanged` before `ReconnectWorker` , changing masterRef to Master B
(4) Subsequently, Worker receives `ReconnectWorker` from Master A, then it reconnects to all masters
(5) Master B receives register request again from the Worker, response with `RegisterWorkerFailed("Duplicate worker ID")`
(6) Worker receives that msg, exit
In CASE 1, it is difficult for the Worker to know Master A's state. Normally, Worker thinks Master A has already died and is impossible that Master A would response with Worker's re-connect request.
In CASE 2, we can see race condition between `RevokedLeadership` and `HeartBeat`. Actually, Master A has already been revoked leadership while processing `HeartBeat` msg. That's means the state between Master and Zookeeper could be out of sync for a while.
### Solutions
In this PR, instead of exiting Worker process when *duplicate Worker registration* happens, we suggest to log warn about it. This would be fine since Master actually perform no-op when it receives duplicate registration from a Worker. In turn, Worker could continue living with that Master normally without any side effect.
## How was this patch tested?
Tested Manually.
I followed the steps as Neeraj Gupta suggested in JIRA SPARK-23191 to reproduce the case 1.
Before this pr, Worker would be DEAD from UI.
After this pr, Worker just warn the duplicate register behavior (as you can see the second last row in log snippet below), and still be ALIVE from UI.
```
19/05/09 20:58:32 ERROR Worker: Connection to master failed! Waiting for master to reconnect...
19/05/09 20:58:32 INFO Worker: wuyi.local:7077 Disassociated !
19/05/09 20:58:32 INFO Worker: Connecting to master wuyi.local:7077...
19/05/09 20:58:32 ERROR Worker: Connection to master failed! Waiting for master to reconnect...
19/05/09 20:58:32 INFO Worker: Not spawning another attempt to register with the master, since there is an attempt scheduled already.
19/05/09 20:58:37 WARN TransportClientFactory: DNS resolution for wuyi.local/127.0.0.1:7077 took 5005 ms
19/05/09 20:58:37 INFO TransportClientFactory: Found inactive connection to wuyi.local/127.0.0.1:7077, creating a new one.
19/05/09 20:58:37 INFO TransportClientFactory: Successfully created connection to wuyi.local/127.0.0.1:7077 after 3 ms (0 ms spent in bootstraps)
19/05/09 20:58:37 WARN Worker: Duplicate registration at master spark://wuyi.local:7077
19/05/09 20:58:37 INFO Worker: Successfully registered with master spark://wuyi.local:7077
```
Closes#24569 from Ngone51/fix-worker-dup-register-error.
Authored-by: wuyi <ngone_5451@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR aims to fix an issue on a union avro type with more than one non-null value (for instance `["string", "null", "int"]`) whose the deserialization to a DataFrame would throw a `java.lang.ArrayIndexOutOfBoundsException`. The issue was that the `fieldWriter` relied on the index from the avro schema before nulls were filtered out.
## How was this patch tested?
A test for the case of multiple non-null values was added and the tests were run using sbt by running `testOnly org.apache.spark.sql.avro.AvroSuite`
Closes#24722 from gcmerz/master.
Authored-by: Gabbi Merz <gmerz@palantir.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR exposes additional metrics in `status.api.v1.StageData`. These metrics were already computed for `LiveStage`, but they were never exposed to the user. This includes extra metrics about the JVM GC, executor (de)serialization times, shuffle reads and writes, and more.
## How was this patch tested?
Existing tests.
cc hvanhovell
Closes#24011 from tomvanbussel/SPARK-27071.
Authored-by: Tom van Bussel <tom.vanbussel@databricks.com>
Signed-off-by: herman <herman@databricks.com>
## What changes were proposed in this pull request?
compute AUC on one pass
## How was this patch tested?
existing tests
performance tests:
```
import org.apache.spark.mllib.evaluation._
val scoreAndLabels = sc.parallelize(Array.range(0, 100000).map{ i => (i.toDouble / 100000, (i % 2).toDouble) }, 4)
scoreAndLabels.persist()
scoreAndLabels.count()
val tic = System.currentTimeMillis
(0 until 100).foreach{i => val metrics = new BinaryClassificationMetrics(scoreAndLabels, 0); val auc = metrics.areaUnderROC; metrics.unpersist}
val toc = System.currentTimeMillis
toc - tic
```
|New| Existing|
|------|----------|
|87532|103644|
One-pass AUC saves about 16% computation time.
Closes#24648 from zhengruifeng/auc_opt.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
As the current approach in OneForOneBlockFetcher, we reuse the OpenBlocks protocol to describe the fetch request for shuffle blocks, and it causes the extension work for shuffle fetching like #19788 and #24110 very awkward.
In this PR, we split the fetch request for shuffle blocks from OpenBlocks which named FetchShuffleBlocks. It's a loose bind with ShuffleBlockId and can easily extend by adding new fields in this protocol.
## How was this patch tested?
Existing and new added UT.
Closes#24565 from xuanyuanking/SPARK-27665.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In https://github.com/apache/spark/pull/22104 , we create the python-eval nodes at the end of the optimization phase, which causes a problem.
After the main optimization batch, Filter and Project nodes are usually pushed to the bottom, near the scan node. However, if we extract Python UDFs from Filter/Project, and create a python-eval node under Filter/Project, it will break column pruning/filter pushdown of the scan node.
There are some hacks in the `ExtractPythonUDFs` rule, to duplicate the column pruning and filter pushdown logic. However, it has some bugs as demonstrated in the new test case(only column pruning is broken). This PR removes the hacks and re-apply the column pruning and filter pushdown rules explicitly.
**Before:**
```
...
== Analyzed Logical Plan ==
a: bigint
Project [a#168L]
+- Filter dummyUDF(a#168L)
+- Relation[a#168L,b#169L] parquet
== Optimized Logical Plan ==
Project [a#168L]
+- Project [a#168L, b#169L]
+- Filter pythonUDF0#174: boolean
+- BatchEvalPython [dummyUDF(a#168L)], [a#168L, b#169L, pythonUDF0#174]
+- Relation[a#168L,b#169L] parquet
== Physical Plan ==
*(2) Project [a#168L]
+- *(2) Project [a#168L, b#169L]
+- *(2) Filter pythonUDF0#174: boolean
+- BatchEvalPython [dummyUDF(a#168L)], [a#168L, b#169L, pythonUDF0#174]
+- *(1) FileScan parquet [a#168L,b#169L] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/private/var/folders/_1/bzcp960d0hlb988k90654z2w0000gp/T/spark-798bae3c-a2..., PartitionFilters: [], PushedFilters: [], ReadSchema: struct<a:bigint,b:bigint>
```
**After:**
```
...
== Analyzed Logical Plan ==
a: bigint
Project [a#168L]
+- Filter dummyUDF(a#168L)
+- Relation[a#168L,b#169L] parquet
== Optimized Logical Plan ==
Project [a#168L]
+- Filter pythonUDF0#174: boolean
+- BatchEvalPython [dummyUDF(a#168L)], [pythonUDF0#174]
+- Project [a#168L]
+- Relation[a#168L,b#169L] parquet
== Physical Plan ==
*(2) Project [a#168L]
+- *(2) Filter pythonUDF0#174: boolean
+- BatchEvalPython [dummyUDF(a#168L)], [pythonUDF0#174]
+- *(1) FileScan parquet [a#168L] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/private/var/folders/_1/bzcp960d0hlb988k90654z2w0000gp/T/spark-9500cafb-78..., PartitionFilters: [], PushedFilters: [], ReadSchema: struct<a:bigint>
```
## How was this patch tested?
new test
Closes#24675 from cloud-fan/python.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This is a minor pr to use `#` as a marker for expression id that is embedded in the name field of SubqueryExec operator.
## How was this patch tested?
Added a small test in SubquerySuite.
Closes#24652 from dilipbiswal/subquery-name.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Avoid hard-coded config: `spark.rdd.parallelListingThreshold`.
## How was this patch tested?
N/A
Closes#24708 from wangyum/spark.rdd.parallelListingThreshold.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
The versions between Hive, Parquet and ORC after the built-in Hive upgraded to 2.3.5 for Hadoop 3.2:
- built-in Hive is 1.2.1.spark2:
| ORC | Parquet
-- | -- | --
Spark datasource table | 1.5.5 | 1.10.1
Spark hive table | Hive built-in | 1.6.0
Apache Hive 1.2.1 | Hive built-in | 1.6.0
- built-in Hive is 2.3.5:
| ORC | Parquet
-- | -- | --
Spark datasource table | 1.5.5 | 1.10.1
Spark hive table | 1.5.5 | [1.10.1](https://github.com/apache/spark/pull/24346)
Apache Hive 2.3.5 | 1.3.4 | 1.8.1
We should add a test for Hive Serde table. This pr adds tests to test read/write of all supported data types using Parquet and ORC.
## How was this patch tested?
unit tests
Closes#24345 from wangyum/SPARK-27441.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Hive 3.1.1's `CommandProcessor` have 2 changes:
1. [HIVE-17626](https://issues.apache.org/jira/browse/HIVE-17626)(Hive 3.0.0) add ReExecDriver. So the current code path is: 02bbe977ab/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala (L736-L742)
We can disable `hive.query.reexecution.enabled` to workaround this change.
2. [HIVE-18238](http://issues.apache.org/jira/browse/HIVE-18238)(Hive 3.0.0) changed the `Driver.close()` function return type. We can workaround it by ` driver.getClass.getMethod("close").invoke(driver)`
So Hive 3.1 metastore could support `HiveClientImpl.runHive` after this pr.
## How was this patch tested?
unit tests
Closes#23992 from wangyum/SPARK-27074.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Eliminate uncessary job to compute SSreg
Compute SSreg based on the summary of predictions
## How was this patch tested?
existing tests
Closes#24656 from zhengruifeng/RegressionMetrics_opt.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
There are no unit test cases for this SortShuffleWriter,so add new test cases;
## How was this patch tested?
new test cases
Closes#24080 from wangjiaochun/UtestForSortShuffleWriter.
Authored-by: 10087686 <wang.jiaochun@zte.com.cn>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
InMemoryFileIndex.listLeafFiles should use listLocatedStatus for DistributedFileSystem. DistributedFileSystem overrides the listLocatedStatus method in order to do it with 1 single namenode call thus saving thousands of calls to getBlockLocations.
Currently in InMemoryFileIndex, all directory listings are done using FileSystem.listStatus following by individual calls to FileSystem.getFileBlockLocations. This is painstakingly slow for folders that have large numbers of files because this process happens serially and parallelism is only applied at the folder level, not the file level.
FileSystem also provides another API listLocatedStatus which returns the LocatedFileStatus objects that already have the block locations. In FileSystem main class this just delegates to listStatus and getFileBlockLocations similarly to the way Spark does it. However when HDFS specifically is the backing file system, DistributedFileSystem overrides this method and simply makes one single call to the namenode to retrieve the directory listing with the block locations. This avoids potentially thousands or more calls to namenode and also is more consistent because files will either exist with locations or not exist instead of having the FileNotFoundException exception case.
For our example directory with 6500 files, the load time of spark.read.parquet was reduced 96x from 76 seconds to .8 seconds. This savings only goes up with the number of files in the directory.
In the pull request instead of using this method always which could lead to a FileNotFoundException that could be tough to decipher in the default FileSystem implementation, this method is only used when the FileSystem is a DistributedFileSystem and otherwise the old logic still applies.
## How was this patch tested?
test suite ran
Closes#24672 from rrusso2007/master.
Authored-by: rrusso2007 <rrusso2007@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR aims to show Spark version at application lists of Spark History UI.
From the following, the first `Version` column is added. When the application has multiple attempts, this will show the first attempt's version number.
**COMPLETED APPLICATION LIST**
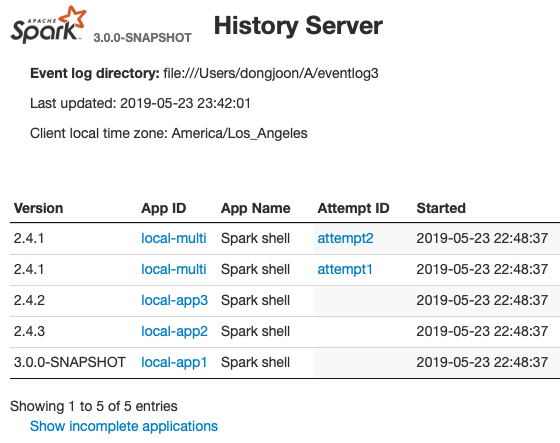
**INCOMPLETE APPLICATION LIST**
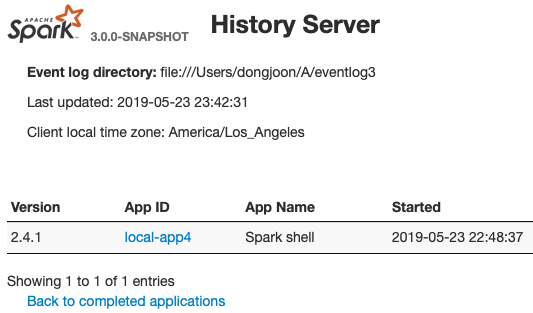
## How was this patch tested?
Manually launch Spark history server and see the UI. Please use *Private New Window (Safari)* or *New Incognito Window (Chrome)* to avoid browser caching.
```
sbin/start-history-server.sh
```
Closes#24694 from dongjoon-hyun/SPARK-27830.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Each time, when I write a complex CREATE DATABASE/VIEW statements, I have to open the .g4 file to find the EXACT order of clauses in CREATE TABLE statement. When the order is not right, I will get A strange confusing error message generated from ANTLR4.
The original g4 grammar for CREATE VIEW is
```
CREATE [OR REPLACE] [[GLOBAL] TEMPORARY] VIEW [db_name.]view_name
[(col_name1 [COMMENT col_comment1], ...)]
[COMMENT table_comment]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
AS select_statement
```
The proposal is to make the following clauses order insensitive.
```
[COMMENT table_comment]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
```
–
The original g4 grammar for CREATE DATABASE is
```
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] db_name
[COMMENT comment_text]
[LOCATION path]
[WITH DBPROPERTIES (key1=val1, key2=val2, ...)]
```
The proposal is to make the following clauses order insensitive.
```
[COMMENT comment_text]
[LOCATION path]
[WITH DBPROPERTIES (key1=val1, key2=val2, ...)]
```
## How was this patch tested?
By adding new unit tests to test duplicate clauses and modifying some existing unit tests to test whether those clauses are actually order insensitive
Closes#24681 from yeshengm/create-view-parser.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
When the data is read from the sources, the catalyst schema is always nullable. Since Avro uses Union type to represent nullable, when any non-nullable avro file is read and then written out, the schema will always be changed.
This PR provides a solution for users to keep the Avro schema without being forced to use Union type.
## How was this patch tested?
One test is added.
Closes#24682 from dbtsai/avroNull.
Authored-by: DB Tsai <d_tsai@apple.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
In the PR the config `spark.shuffle.service.fetch.rdd.enabled` default is changed to **false** to avoid breaking any compatibility with older external shuffle service installations. As external shuffle service is deployed separately and disk persisted RDD block fetching had even introduced new network messages (`RemoveBlocks` and `BlocksRemoved`) and changed the behaviour of the already existing fetching: extended it for RDD blocks.
## How was this patch tested?
With existing unit tests.
Closes#24697 from attilapiros/minor-ext-shuffle-fetch-disabled.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This fix prevents the rule EliminateResolvedHint from being applied again if it's already applied.
## How was this patch tested?
Added new UT.
Closes#24692 from maryannxue/eliminatehint-bug.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
In data source v1, save mode specified in `DataFrameWriter` is passed to data source implementation directly, and each data source can define its own behavior about save mode. This is confusing and we want to get rid of save mode in data source v2.
For data source v2, we expect data source to implement the `TableCatalog` API, and end-users use SQL(or the new write API described in [this doc](https://docs.google.com/document/d/1gYm5Ji2Mge3QBdOliFV5gSPTKlX4q1DCBXIkiyMv62A/edit?ts=5ace0718#heading=h.e9v1af12g5zo)) to acess data sources. The SQL API has very clear semantic and we don't need save mode at all.
However, for simple data sources that do not have table management (like a JIRA data source, a noop sink, etc.), it's not ideal to ask them to implement the `TableCatalog` API, and throw exception here and there.
`TableProvider` API is created for simple data sources. It can only get tables, without any other table management methods. This means, it can only deal with existing tables.
`TableProvider` fits well with `DataStreamReader` and `DataStreamWriter`, as they can only read/write existing tables. However, `TableProvider` doesn't fit `DataFrameWriter` well, as the save mode requires more than just get table. More specifically, `ErrorIfExists` mode needs to check if table exists, and create table. `Ignore` mode needs to check if table exists. When end-users specify `ErrorIfExists` or `Ignore` mode and write data to `TableProvider` via `DataFrameWriter`, Spark fails the query and asks users to use `Append` or `Overwrite` mode.
The file source is in the middle of `TableProvider` and `TableCatalog`: it's simple but it can check table(path) exists and create table(path). That said, file source supports all the save modes.
Currently file source implements `TableProvider`, and it's not working because `TableProvider` doesn't support `ErrorIfExists` and `Ignore` modes. Ideally we should create a new API for path-based data sources, but to unblock the work of file source v2 migration, this PR proposes to special-case file source v2 in `DataFrameWriter`, to make it work.
This PR also removes `SaveMode` from data source v2, as now only the internal file source v2 needs it.
## How was this patch tested?
existing tests
Closes#24233 from cloud-fan/file.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
To address https://github.com/apache/spark/pull/24506#discussion_r280964509
## How was this patch tested?
N/A
Closes#24701 from HyukjinKwon/minor-arrow-r-doc.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr moves Hive test jars(`hive-contrib-0.13.1.jar`, `hive-hcatalog-core-0.13.1.jar`, `hive-contrib-2.3.5.jar` and `hive-hcatalog-core-2.3.5.jar`) to maven dependency.
## How was this patch tested?
Existing test
Closes#24695 from wangyum/SPARK-27831.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
ForeachBatch doc is wrongly formatted. This PR formats it.
## How was this patch tested?
```
cd docs
SKIP_API=1 jekyll build
```
Manual webpage check.
Closes#24698 from gaborgsomogyi/foreachbatchdoc.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This adds a v2 implementation of create table:
* `CreateV2Table` is the logical plan, named using v2 to avoid conflicting with the existing plan
* `CreateTableExec` is the physical plan
## How was this patch tested?
Added resolution and v2 SQL tests.
Closes#24617 from rdblue/SPARK-27732-add-v2-create-table.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Leave avro, avro-ipc dependendencies as compile scope even for hadoop-provided usages, to ensure 1.8 is used. Hadoop 2.7 has Avro 1.7, and Spark won't generally work with that. Reports from the field are that this works, to include avro 1.8 with the Spark distro on Hadoop 2.7.
## How was this patch tested?
Existing tests
Closes#24680 from srowen/SPARK-26045.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
# What changes were proposed in this pull request?
## Problem statement
An executor which has persisted blocks does not consider to be idle and this way ready to be released by dynamic allocation after the regular timeout `spark.dynamicAllocation.executorIdleTimeout` but there is separate configuration `spark.dynamicAllocation.cachedExecutorIdleTimeout` which defaults to `Integer.MAX_VALUE`. This is because releasing the executor also means losing the persisted blocks (as the metadata for individual blocks called `BlockInfo` are kept in memory) and when the RDD is referenced latter on this lost blocks will be recomputed.
On the other hand keeping the executors too long without any task to work on is also a waste of resources (as executors are reserved for the application by the resource manager).
## Solution
This PR focuses on the first part of SPARK-25888: it extends the external shuffle service with the capability to serve RDD blocks which are persisted on the local disk store by the executors. Moreover when this feature is enabled by setting the `spark.shuffle.service.fetch.rdd.enabled` config to true and a block is reported to be persisted on to disk the external shuffle service instance running on the same host as the executor is also registered (along with the reporting block manager) as a possible location for fetching it.
## Some implementation detail
Some explanation about the decisions made during the development:
- the location list to fetch a block was randomized but the groups (same host, same rack, others) order was kept. In this PR the order of groups are kept and external shuffle service added to the end of the each group.
- `BlockManagerInfo` is not introduced for external shuffle service but only a lightweight solution is taken. A hash map from `BlockId` to `BlockStatus` is introduced. A type alias would make the source more readable but I know it is discouraged. On the other hand a new class wrapping this hash map would introduce unnecessary indirection.
- when this feature is on the cleanup triggered during removing of executors (which is handled in `ExternalShuffleBlockResolver`) is modified to keep the disk persisted RDD blocks. This cleanup is triggered in standalone mode when the `spark.storage.cleanupFilesAfterExecutorExit` config is set.
- the unpersisting of an RDD is extended to use the external shuffle service for disk persisted RDD blocks when the original executor which created the blocks are already released. New block transport messages are introduced to support this: `RemoveBlocks` and `BlocksRemoved`.
# How was this patch tested?
## Unit tests
### ExternalShuffleServiceSuite
Here the complete use case is tested by the "SPARK-25888: using external shuffle service fetching disk persisted blocks" with a tiny difference: here the executor is killed manually, this way the test is a bit faster than waiting for the idle timeout.
### ExternalShuffleBlockHandlerSuite
Tests the fetching of the RDD blocks via the external shuffle service.
### BlockManagerInfoSuite
This a new suite. As the `BlockManagerInfo` behaviour depends very much on whether the external shuffle service enabled or not all the tests are executed with and without it.
### BlockManagerSuite
Tests the sorting of the block locations.
## Manually on YARN
Spark App was:
~~~scala
package com.mycompany
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.storage.StorageLevel
object TestAppDiskOnlyLevel {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test-app")
println("Attila: START")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(0 until 100, 10)
.map { i =>
println(s"Attila: calculate first rdd i=$i")
Thread.sleep(1000)
i
}
rdd.persist(StorageLevel.DISK_ONLY)
rdd.count()
println("Attila: First RDD is processed, waiting for 60 sec")
Thread.sleep(60 * 1000)
println("Attila: Num executors must be 0 as executorIdleTimeout is way over")
val rdd2 = sc.parallelize(0 until 10, 1)
.map(i => (i, 1))
.persist(StorageLevel.DISK_ONLY)
rdd2.count()
println("Attila: Second RDD with one partition (only one executors must be alive)")
// reduce runs as user code to detect the empty seq (empty blocks)
println("Calling collect on the first RDD: " + rdd.collect().reduce(_ + _))
println("Attila: STOP")
}
}
~~~
I have submitted with the following configuration:
~~~bash
spark-submit --master yarn \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.dynamicAllocation.executorIdleTimeout=30 \
--conf spark.dynamicAllocation.cachedExecutorIdleTimeout=90 \
--class com.mycompany.TestAppDiskOnlyLevel dyn_alloc_demo-core_2.11-0.1.0-SNAPSHOT-jar-with-dependencies.jar
~~~
Checked the result by filtering for the side effect of the task calculations:
~~~bash
[userserver ~]$ yarn logs -applicationId application_1556299359453_0001 | grep "Attila: calculate" | wc -l
WARNING: YARN_OPTS has been replaced by HADOOP_OPTS. Using value of YARN_OPTS.
19/04/26 10:31:59 INFO client.RMProxy: Connecting to ResourceManager at apiros-1.gce.company.com/172.31.115.165:8032
100
~~~
So it is only 100 task execution and not 200 (which would be the case for re-computation).
Moreover from the submit/launcher log we can see executors really stopped in between (see the new total is 0 before the last line):
~~~
[userserver ~]$ grep "Attila: Num executors must be 0" -B 2 spark-submit.log
19/04/26 10:24:27 INFO cluster.YarnScheduler: Executor 9 on apiros-3.gce.company.com killed by driver.
19/04/26 10:24:27 INFO spark.ExecutorAllocationManager: Existing executor 9 has been removed (new total is 0)
Attila: Num executors must be 0 as executorIdleTimeout is way over
~~~
[Full spark submit log](https://github.com/attilapiros/spark/files/3122465/spark-submit.log)
I have done a test also after changing the `DISK_ONLY` storage level to `MEMORY_ONLY` for the first RDD. After this change during the 60sec waiting no executor was removed.
Closes#24499 from attilapiros/SPARK-25888-final.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Add type parameter to `TreeNodeTag`.
## How was this patch tested?
existing tests
Closes#24687 from cloud-fan/tag.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Added the driver functionality to get the resources.
The user interface is: SparkContext.resources - I called it this to match the TaskContext.resources api proposed in the other PR. Originally it was going to be called SparkContext.getResources but changed to be consistent, if people have strong feelings I can change it.
There are 2 ways the driver can discover what resources it has.
1) user specifies a discoveryScript, this is similar to the executors and is meant for yarn and k8s where they don't tell you what you were allocated but you are running in isolated environment.
2) read the config spark.driver.resource.resourceName.addresses. The config is meant to be used with standalone mode where the Worker will have to assign what GPU addresses the Driver is allowed to use by setting that config.
When the user runs a spark application, if they want the driver to have GPU's they would specify the conf spark.driver.resource.gpu.count=X where x is the number they want. If they are running on yarn or k8s they will also have to specify the discoveryScript as specified above, if they are on standalone mode and cluster is setup properly they wouldn't have to specify anything else. We could potentially get rid of the spark.driver.resources.gpu.addresses config which is really meant to be an internal config for worker to set if the standalone mode Worker wanted to write a discoveryScript out and set that for the user. I'll wait for the jira that implements that to decide if we can remove.
- This PR also has changes to be consistent about using resourceName everywhere.
- change the config names from POSTFIX to SUFFIX to be more consistent with other areas in Spark
- Moved the config checks around a bit since now used by both executor and driver. Note those might overlap a bit with https://github.com/apache/spark/pull/24374 so we will have to figure out which one should go in first.
## How was this patch tested?
Unit tests and manually test the interface.
Closes#24615 from tgravescs/SPARK-27488.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
When writing a query to data source v2, we have 2 modes to resolve the input query's output: byName or byPosition.
For byName mode, we would reorder the top level columns according to the name, and add type cast if possible. If the names don't match, we fail.
For byPosition mode, we don't do the reorder, and just add type cast directly if possible.
However, for struct type fields, we always apply byName mode. We should ignore the name difference if byPosition mode is used.
## How was this patch tested?
new tests
Closes#24678 from cloud-fan/write.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Unset InputFileBlockHolder at the end of tasks to stop the file name from leaking over to other tasks in the same thread. This happens in particular in Pyspark because of its complex threading model.
## How was this patch tested?
new pyspark test
Closes#24605 from jose-torres/fix254.
Authored-by: Jose Torres <torres.joseph.f+github@gmail.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
{kind=link}
{kind=link}