## What changes were proposed in this pull request?
Implement `ALTER TABLE` for v2 tables:
* Add `AlterTable` logical plan and `AlterTableExec` physical plan
* Convert `ALTER TABLE` parsed plans to `AlterTable` when a v2 catalog is responsible for an identifier
* Validate that columns to alter exist in analyzer checks
* Fix nested type handling in `CatalogV2Util`
## How was this patch tested?
* Add extensive tests in `DataSourceV2SQLSuite`
Closes#24937 from rdblue/SPARK-28139-add-v2-alter-table.
Lead-authored-by: Ryan Blue <blue@apache.org>
Co-authored-by: Ryan Blue <rdblue@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The optimizer rule `NormalizeFloatingNumbers` is not idempotent. It will generate multiple `NormalizeNaNAndZero` and `ArrayTransform` expression nodes for multiple runs. This patch fixed this non-idempotence by adding a marking tag above normalized expressions. It also adds missing UTs for `NormalizeFloatingNumbers`.
## How was this patch tested?
New UTs.
Closes#25080 from yeshengm/spark-28306.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The new adaptive execution framework introduced configuration `spark.sql.runtime.reoptimization.enabled`. We now rename it back to `spark.sql.adaptive.enabled` as the umbrella configuration for adaptive execution.
## How was this patch tested?
Existing tests.
Closes#25102 from carsonwang/renameAE.
Authored-by: Carson Wang <carson.wang@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Fix `stringToDate()` for the formats `yyyy` and `yyyy-[m]m` that assumes there are no additional chars after the last components `yyyy` and `[m]m`. In the PR, I propose to check that entire input was consumed for the formats.
After the fix, the input `1999 08 01` will be invalid because it matches to the pattern `yyyy` but the strings contains additional chars ` 08 01`.
Since Spark 1.6.3 ~ 2.4.3, the behavior is the same.
```
spark-sql> SELECT CAST('1999 08 01' AS DATE);
1999-01-01
```
This PR makes it return NULL like Hive.
```
spark-sql> SELECT CAST('1999 08 01' AS DATE);
NULL
```
## How was this patch tested?
Added new checks to `DateTimeUtilsSuite` for the `1999 08 01` and `1999 08` inputs.
Closes#25097 from MaxGekk/spark-28015-invalid-date-format.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This fixes a problem where it is possible to create a v2 table using the default catalog that cannot be loaded with the session catalog. A session catalog should be used when the v1 catalog is responsible for tables with no catalog in the table identifier.
* Adds a v2 catalog implementation that delegates to the analyzer's SessionCatalog
* Uses the v2 session catalog for CTAS and CreateTable when the provider is a v2 provider and no v2 catalog is in the table identifier
* Updates catalog lookup to always provide the default if it is set for consistent behavior
## How was this patch tested?
* Adds a new test suite for the v2 session catalog that validates the TableCatalog API
* Adds test cases in PlanResolutionSuite to validate the v2 session catalog is used
* Adds test suite for LookupCatalog with a default catalog
Closes#24768 from rdblue/SPARK-27919-add-v2-session-catalog.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The interval conversion behavior is same with the PostgreSQL.
https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/interval.sql#L180-L203
## How was this patch tested?
UT.
Closes#25000 from lipzhu/SPARK-28107.
Lead-authored-by: Zhu, Lipeng <lipzhu@ebay.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Lipeng Zhu <lipzhu@icloud.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This is a followup of the discussion in https://github.com/apache/spark/pull/24675#discussion_r286786053
`QueryPlan#references` is an important property. The `ColumnPrunning` rule relies on it.
Some query plan nodes have `Seq[Attribute]` parameter, which is used as its output attributes. For example, leaf nodes, `Generate`, `MapPartitionsInPandas`, etc. These nodes override `producedAttributes` to make `missingInputs` correct.
However, these nodes also need to override `references` to make column pruning work. This PR proposes to exclude `producedAttributes` from the default implementation of `QueryPlan#references`, so that we don't need to override `references` in all these nodes.
Note that, technically we can remove `producedAttributes` and always ask query plan nodes to override `references`. But I do find the code can be simpler with `producedAttributes` in some places, where there is a base class for some specific query plan nodes.
## How was this patch tested?
existing tests
Closes#25052 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from `pgSQL/case.sql'` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
This PR also contains two minor fixes:
1. Change name of Scala UDF from `UDF:name(...)` to `name(...)` to be consistent with Python'
2. Fix Scala UDF at `IntegratedUDFTestUtils.scala ` to handle `null` in strings.
<details><summary>Diff comparing to 'pgSQL/case.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/pgSQL/case.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-case.sql.out
index fa078d16d6d..55bef64338f 100644
--- a/sql/core/src/test/resources/sql-tests/results/pgSQL/case.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-case.sql.out
-115,7 +115,7 struct<>
-- !query 13
SELECT '3' AS `One`,
CASE
- WHEN 1 < 2 THEN 3
+ WHEN CAST(udf(1 < 2) AS boolean) THEN 3
END AS `Simple WHEN`
-- !query 13 schema
struct<One:string,Simple WHEN:int>
-126,10 +126,10 struct<One:string,Simple WHEN:int>
-- !query 14
SELECT '<NULL>' AS `One`,
CASE
- WHEN 1 > 2 THEN 3
+ WHEN 1 > 2 THEN udf(3)
END AS `Simple default`
-- !query 14 schema
-struct<One:string,Simple default:int>
+struct<One:string,Simple default:string>
-- !query 14 output
<NULL> NULL
-137,17 +137,17 struct<One:string,Simple default:int>
-- !query 15
SELECT '3' AS `One`,
CASE
- WHEN 1 < 2 THEN 3
- ELSE 4
+ WHEN udf(1) < 2 THEN udf(3)
+ ELSE udf(4)
END AS `Simple ELSE`
-- !query 15 schema
-struct<One:string,Simple ELSE:int>
+struct<One:string,Simple ELSE:string>
-- !query 15 output
3 3
-- !query 16
-SELECT '4' AS `One`,
+SELECT udf('4') AS `One`,
CASE
WHEN 1 > 2 THEN 3
ELSE 4
-159,10 +159,10 struct<One:string,ELSE default:int>
-- !query 17
-SELECT '6' AS `One`,
+SELECT udf('6') AS `One`,
CASE
- WHEN 1 > 2 THEN 3
- WHEN 4 < 5 THEN 6
+ WHEN CAST(udf(1 > 2) AS boolean) THEN 3
+ WHEN udf(4) < 5 THEN 6
ELSE 7
END AS `Two WHEN with default`
-- !query 17 schema
-173,7 +173,7 struct<One:string,Two WHEN with default:int>
-- !query 18
SELECT '7' AS `None`,
- CASE WHEN rand() < 0 THEN 1
+ CASE WHEN rand() < udf(0) THEN 1
END AS `NULL on no matches`
-- !query 18 schema
struct<None:string,NULL on no matches:int>
-182,36 +182,36 struct<None:string,NULL on no matches:int>
-- !query 19
-SELECT CASE WHEN 1=0 THEN 1/0 WHEN 1=1 THEN 1 ELSE 2/0 END
+SELECT CASE WHEN CAST(udf(1=0) AS boolean) THEN 1/0 WHEN 1=1 THEN 1 ELSE 2/0 END
-- !query 19 schema
-struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
+struct<CASE WHEN CAST(udf((1 = 0)) AS BOOLEAN) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
-- !query 19 output
1.0
-- !query 20
-SELECT CASE 1 WHEN 0 THEN 1/0 WHEN 1 THEN 1 ELSE 2/0 END
+SELECT CASE 1 WHEN 0 THEN 1/udf(0) WHEN 1 THEN 1 ELSE 2/0 END
-- !query 20 schema
-struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
+struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(CAST(udf(0) AS DOUBLE) AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
-- !query 20 output
1.0
-- !query 21
-SELECT CASE WHEN i > 100 THEN 1/0 ELSE 0 END FROM case_tbl
+SELECT CASE WHEN i > 100 THEN udf(1/0) ELSE udf(0) END FROM case_tbl
-- !query 21 schema
-struct<CASE WHEN (i > 100) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) ELSE CAST(0 AS DOUBLE) END:double>
+struct<CASE WHEN (i > 100) THEN udf((cast(1 as double) / cast(0 as double))) ELSE udf(0) END:string>
-- !query 21 output
-0.0
-0.0
-0.0
-0.0
+0
+0
+0
+0
-- !query 22
-SELECT CASE 'a' WHEN 'a' THEN 1 ELSE 2 END
+SELECT CASE 'a' WHEN 'a' THEN udf(1) ELSE udf(2) END
-- !query 22 schema
-struct<CASE WHEN (a = a) THEN 1 ELSE 2 END:int>
+struct<CASE WHEN (a = a) THEN udf(1) ELSE udf(2) END:string>
-- !query 22 output
1
-283,7 +283,7 big
-- !query 27
-SELECT * FROM CASE_TBL WHERE COALESCE(f,i) = 4
+SELECT * FROM CASE_TBL WHERE udf(COALESCE(f,i)) = 4
-- !query 27 schema
struct<i:int,f:double>
-- !query 27 output
-291,7 +291,7 struct<i:int,f:double>
-- !query 28
-SELECT * FROM CASE_TBL WHERE NULLIF(f,i) = 2
+SELECT * FROM CASE_TBL WHERE udf(NULLIF(f,i)) = 2
-- !query 28 schema
struct<i:int,f:double>
-- !query 28 output
-299,10 +299,10 struct<i:int,f:double>
-- !query 29
-SELECT COALESCE(a.f, b.i, b.j)
+SELECT udf(COALESCE(a.f, b.i, b.j))
FROM CASE_TBL a, CASE2_TBL b
-- !query 29 schema
-struct<coalesce(f, CAST(i AS DOUBLE), CAST(j AS DOUBLE)):double>
+struct<udf(coalesce(f, cast(i as double), cast(j as double))):string>
-- !query 29 output
-30.3
-30.3
-332,8 +332,8 struct<coalesce(f, CAST(i AS DOUBLE), CAST(j AS DOUBLE)):double>
-- !query 30
SELECT *
- FROM CASE_TBL a, CASE2_TBL b
- WHERE COALESCE(a.f, b.i, b.j) = 2
+ FROM CASE_TBL a, CASE2_TBL b
+ WHERE udf(COALESCE(a.f, b.i, b.j)) = 2
-- !query 30 schema
struct<i:int,f:double,i:int,j:int>
-- !query 30 output
-342,7 +342,7 struct<i:int,f:double,i:int,j:int>
-- !query 31
-SELECT '' AS Five, NULLIF(a.i,b.i) AS `NULLIF(a.i,b.i)`,
+SELECT udf('') AS Five, NULLIF(a.i,b.i) AS `NULLIF(a.i,b.i)`,
NULLIF(b.i, 4) AS `NULLIF(b.i,4)`
FROM CASE_TBL a, CASE2_TBL b
-- !query 31 schema
-377,7 +377,7 struct<Five:string,NULLIF(a.i,b.i):int,NULLIF(b.i,4):int>
-- !query 32
SELECT '' AS `Two`, *
FROM CASE_TBL a, CASE2_TBL b
- WHERE COALESCE(f,b.i) = 2
+ WHERE CAST(udf(COALESCE(f,b.i) = 2) AS boolean)
-- !query 32 schema
struct<Two:string,i:int,f:double,i:int,j:int>
-- !query 32 output
-388,15 +388,15 struct<Two:string,i:int,f:double,i:int,j:int>
-- !query 33
SELECT CASE
(CASE vol('bar')
- WHEN 'foo' THEN 'it was foo!'
- WHEN vol(null) THEN 'null input'
+ WHEN udf('foo') THEN 'it was foo!'
+ WHEN udf(vol(null)) THEN 'null input'
WHEN 'bar' THEN 'it was bar!' END
)
- WHEN 'it was foo!' THEN 'foo recognized'
- WHEN 'it was bar!' THEN 'bar recognized'
- ELSE 'unrecognized' END
+ WHEN udf('it was foo!') THEN 'foo recognized'
+ WHEN 'it was bar!' THEN udf('bar recognized')
+ ELSE 'unrecognized' END AS col
-- !query 33 schema
-struct<CASE WHEN (CASE WHEN (UDF:vol(bar) = foo) THEN it was foo! WHEN (UDF:vol(bar) = UDF:vol(null)) THEN null input WHEN (UDF:vol(bar) = bar) THEN it was bar! END = it was foo!) THEN foo recognized WHEN (CASE WHEN (UDF:vol(bar) = foo) THEN it was foo! WHEN (UDF:vol(bar) = UDF:vol(null)) THEN null input WHEN (UDF:vol(bar) = bar) THEN it was bar! END = it was bar!) THEN bar recognized ELSE unrecognized END:string>
+struct<col:string>
-- !query 33 output
bar recognized
```
</p>
</details>
https://github.com/apache/spark/pull/25069 contains the same minor fixes as it's required to write the tests.
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25070 from HyukjinKwon/SPARK-28273.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
We changed our non-standard syntax for `trim` function in #24902 from `TRIM(trimStr, str)` to `TRIM(str, trimStr)` to be compatible with other databases. This pr update the migration guide.
I checked various databases(PostgreSQL, Teradata, Vertica, Oracle, DB2, SQL Server 2019, MySQL, Hive, Presto) and it seems that only PostgreSQL and Presto support this non-standard syntax.
**PostgreSQL**:
```sql
postgres=# select substr(version(), 0, 16), trim('yxTomxx', 'x');
substr | btrim
-----------------+-------
PostgreSQL 11.3 | yxTom
(1 row)
```
**Presto**:
```sql
presto> select trim('yxTomxx', 'x');
_col0
-------
yxTom
(1 row)
```
## How was this patch tested?
manual tests
Closes#24948 from wangyum/SPARK-28093-FOLLOW-UP-DOCS.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds some more WITH test cases as a follow-up to https://github.com/apache/spark/pull/24842
## How was this patch tested?
Add new UTs.
Closes#24949 from peter-toth/SPARK-28002-follow-up.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
- Currently, `ExpressionEncoder` does not handle bigdecimal overflow. Round-tripping overflowing java/scala BigDecimal/BigInteger returns null.
- The serializer encode java/scala BigDecimal to to sql Decimal, which still has the underlying data to the former.
- When writing out to UnsafeRow, `changePrecision` will be false and row has null value.
24e1e41648/sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/codegen/UnsafeRowWriter.java (L202-L206)
- In [SPARK-23179](https://github.com/apache/spark/pull/20350), an option to throw exception on decimal overflow was introduced.
- This PR adds the option in `ExpressionEncoder` to throw when detecting overflowing BigDecimal/BigInteger before its corresponding Decimal gets written to Row. This gives a consistent behavior between decimal arithmetic on sql expression (DecimalPrecision), and getting decimal from dataframe (RowEncoder)
Thanks to mgaido91 for the very first PR `SPARK-23179` and follow-up discussion on this change.
Thanks to JoshRosen for working with me on this.
## How was this patch tested?
added unit tests
Closes#25016 from mickjermsurawong-stripe/SPARK-28200.
Authored-by: Mick Jermsurawong <mickjermsurawong@stripe.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to rename `mapPartitionsInPandas` to `mapInPandas` with a separate evaluation type .
Had an offline discussion with rxin, mengxr and cloud-fan
The reason is basically:
1. `SCALAR_ITER` doesn't make sense with `mapPartitionsInPandas`.
2. It cannot share the same Pandas UDF, for instance, at `select` and `mapPartitionsInPandas` unlike `GROUPED_AGG` because iterator's return type is different.
3. `mapPartitionsInPandas` -> `mapInPandas` - see https://github.com/apache/spark/pull/25044#issuecomment-508298552 and https://github.com/apache/spark/pull/25044#issuecomment-508299764
Renaming `SCALAR_ITER` as `MAP_ITER` is abandoned due to 2. reason.
For `XXX_ITER`, it might have to have a different interface in the future if we happen to add other versions of them. But this is an orthogonal topic with `mapPartitionsInPandas`.
## How was this patch tested?
Existing tests should cover.
Closes#25044 from HyukjinKwon/SPARK-28198.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Before this PR inserting into a non-existing table returned a weird error message:
```
sql("INSERT INTO test VALUES (1)").show
org.apache.spark.sql.AnalysisException: unresolved operator 'InsertIntoTable 'UnresolvedRelation [test], false, false;;
'InsertIntoTable 'UnresolvedRelation [test], false, false
+- LocalRelation [col1#4]
```
after this PR the error message becomes:
```
org.apache.spark.sql.AnalysisException: Table not found: test;;
'InsertIntoTable 'UnresolvedRelation [test], false, false
+- LocalRelation [col1#0]
```
## How was this patch tested?
Added a new UT.
Closes#25054 from peter-toth/SPARK-28251.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds support of `WITH` clause within a subquery so this query becomes valid:
```
SELECT max(c) FROM (
WITH t AS (SELECT 1 AS c)
SELECT * FROM t
)
```
## How was this patch tested?
Added new UTs.
Closes#24831 from peter-toth/SPARK-19799-2.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This is to implement a ReduceNumShufflePartitions rule in the new adaptive execution framework introduced in #24706. This rule is used to adjust the post shuffle partitions based on the map output statistics.
## How was this patch tested?
Added ReduceNumShufflePartitionsSuite
Closes#24978 from carsonwang/reduceNumShufflePartitions.
Authored-by: Carson Wang <carson.wang@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR makes the predicate pushdown logic in catalyst optimizer more efficient by unifying two existing rules `PushdownPredicates` and `PushPredicateThroughJoin`. Previously pushing down a predicate for queries such as `Filter(Join(Join(Join)))` requires n steps. This patch essentially reduces this to a single pass.
To make this actually work, we need to unify a few rules such as `CombineFilters`, `PushDownPredicate` and `PushDownPrdicateThroughJoin`. Otherwise cases such as `Filter(Join(Filter(Join)))` still requires several passes to fully push down predicates. This unification is done by composing several partial functions, which makes a minimal code change and can reuse existing UTs.
Results show that this optimization can improve the catalyst optimization time by 16.5%. For queries with more joins, the performance is even better. E.g., for TPC-DS q64, the performance boost is 49.2%.
## How was this patch tested?
Existing UTs + new a UT for the new rule.
Closes#24956 from yeshengm/fixed-point-opt.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This pr add `PLACING` to `ansiNonReserved` and add `overlay` and `placing` to `TableIdentifierParserSuite`.
## How was this patch tested?
N/A
Closes#25013 from wangyum/SPARK-28077.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Right now they fail only for inner joins, because we implemented the check when that was the only supported type.
## How was this patch tested?
new unit test
Closes#25023 from jose-torres/changevalidation.
Authored-by: Jose Torres <torres.joseph.f+github@gmail.com>
Signed-off-by: Jose Torres <torres.joseph.f+github@gmail.com>
## What changes were proposed in this pull request?
This PR proposes to add `mapPartitionsInPandas` API to DataFrame by using existing `SCALAR_ITER` as below:
1. Filtering via setting the column
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
df = spark.createDataFrame([(1, 21), (2, 30)], ("id", "age"))
pandas_udf(df.schema, PandasUDFType.SCALAR_ITER)
def filter_func(iterator):
for pdf in iterator:
yield pdf[pdf.id == 1]
df.mapPartitionsInPandas(filter_func).show()
```
```
+---+---+
| id|age|
+---+---+
| 1| 21|
+---+---+
```
2. `DataFrame.loc`
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
import pandas as pd
df = spark.createDataFrame([['aa'], ['bb'], ['cc'], ['aa'], ['aa'], ['aa']], ["value"])
pandas_udf(df.schema, PandasUDFType.SCALAR_ITER)
def filter_func(iterator):
for pdf in iterator:
yield pdf.loc[pdf.value.str.contains('^a'), :]
df.mapPartitionsInPandas(filter_func).show()
```
```
+-----+
|value|
+-----+
| aa|
| aa|
| aa|
| aa|
+-----+
```
3. `pandas.melt`
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
import pandas as pd
df = spark.createDataFrame(
pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}}))
pandas_udf("A string, variable string, value long", PandasUDFType.SCALAR_ITER)
def filter_func(iterator):
for pdf in iterator:
import pandas as pd
yield pd.melt(pdf, id_vars=['A'], value_vars=['B', 'C'])
df.mapPartitionsInPandas(filter_func).show()
```
```
+---+--------+-----+
| A|variable|value|
+---+--------+-----+
| a| B| 1|
| a| C| 2|
| b| B| 3|
| b| C| 4|
| c| B| 5|
| c| C| 6|
+---+--------+-----+
```
The current limitation of `SCALAR_ITER` is that it doesn't allow different length of result, which is pretty critical in practice - for instance, we cannot simply filter by using Pandas APIs but we merely just map N to N. This PR allows map N to M like flatMap.
This API mimics the way of `mapPartitions` but keeps API shape of `SCALAR_ITER` by allowing different results.
### How does this PR implement?
This PR adds mimics both `dapply` with Arrow optimization and Grouped Map Pandas UDF. At Python execution side, it reuses existing `SCALAR_ITER` code path.
Therefore, externally, we don't introduce any new type of Pandas UDF but internally we use another evaluation type code `205` (`SQL_MAP_PANDAS_ITER_UDF`).
This approach is similar with Pandas' Windows function implementation with Grouped Aggregation Pandas UDF functions - internally we have `203` (`SQL_WINDOW_AGG_PANDAS_UDF`) but externally we just share the same `GROUPED_AGG`.
## How was this patch tested?
Manually tested and unittests were added.
Closes#24997 from HyukjinKwon/scalar-udf-iter.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In SPARK-23179, it has been introduced a flag to control the behavior in case of overflow on decimals. The behavior is: returning `null` when `spark.sql.decimalOperations.nullOnOverflow` (default and traditional Spark behavior); throwing an `ArithmeticException` if that conf is false (according to SQL standards, other DBs behavior).
`MakeDecimal` so far had an ambiguous behavior. In case of codegen mode, it returned `null` as the other operators, but in interpreted mode, it was throwing an `IllegalArgumentException`.
The PR aligns `MakeDecimal`'s behavior with the one of other operators as defined in SPARK-23179. So now both modes return `null` or throw `ArithmeticException` according to `spark.sql.decimalOperations.nullOnOverflow`'s value.
Credits for this PR to mickjermsurawong-stripe who pointed out the wrong behavior in #20350.
## How was this patch tested?
improved UTs
Closes#25010 from mgaido91/SPARK-28201.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This pr add two API for [SessionCatalog](df4cb471c9/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala):
```scala
def listTables(db: String, pattern: String, includeLocalTempViews: Boolean): Seq[TableIdentifier]
def listLocalTempViews(pattern: String): Seq[TableIdentifier]
```
Because in some cases `listTables` does not need local temporary view and sometimes only need list local temporary view.
## How was this patch tested?
unit tests
Closes#24995 from wangyum/SPARK-28196.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Currently, ORC's `inferSchema` is implemented as randomly choosing one ORC file and reading its schema.
This PR follows the behavior of Parquet, it implements merge schemas logic by reading all ORC files in parallel through a spark job.
Users can enable merge schema by `spark.read.orc("xxx").option("mergeSchema", "true")` or by setting `spark.sql.orc.mergeSchema` to `true`, the prior one has higher priority.
## How was this patch tested?
tested by UT OrcUtilsSuite.scala
Closes#24043 from WangGuangxin/SPARK-11412.
Lead-authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com>
Co-authored-by: wangguangxin.cn <wangguangxin.cn@bytedance.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This is the first part of [SPARK-27396](https://issues.apache.org/jira/browse/SPARK-27396). This is the minimum set of changes necessary to support a pluggable back end for columnar processing. Follow on JIRAs would cover removing some of the duplication between functionality in this patch and functionality currently covered by things like ColumnarBatchScan.
## How was this patch tested?
I added in a new unit test to cover new code not really covered in other places.
I also did manual testing by implementing two plugins/extensions that take advantage of the new APIs to allow for columnar processing for some simple queries. One version runs on the [CPU](https://gist.github.com/revans2/c3cad77075c4fa5d9d271308ee2f1b1d). The other version run on a GPU, but because it has unreleased dependencies I will not include a link to it yet.
The CPU version I would expect to add in as an example with other documentation in a follow on JIRA
This is contributed on behalf of NVIDIA Corporation.
Closes#24795 from revans2/columnar-basic.
Authored-by: Robert (Bobby) Evans <bobby@apache.org>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
The `OVERLAY` function is a `ANSI` `SQL`.
For example:
```
SELECT OVERLAY('abcdef' PLACING '45' FROM 4);
SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5);
SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5 FOR 0);
SELECT OVERLAY('babosa' PLACING 'ubb' FROM 2 FOR 4);
```
The results of the above four `SQL` are:
```
abc45f
yabadaba
yabadabadoo
bubba
```
Note: If the input string is null, then the result is null too.
There are some mainstream database support the syntax.
**PostgreSQL:**
https://www.postgresql.org/docs/11/functions-string.html
**Vertica:** https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/Functions/String/OVERLAY.htm?zoom_highlight=overlay
**Oracle:**
https://docs.oracle.com/en/database/oracle/oracle-database/19/arpls/UTL_RAW.html#GUID-342E37E7-FE43-4CE1-A0E9-7DAABD000369
**DB2:**
https://www.ibm.com/support/knowledgecenter/SSGMCP_5.3.0/com.ibm.cics.rexx.doc/rexx/overlay.html
There are some show of the PR on my production environment.
```
spark-sql> SELECT OVERLAY('abcdef' PLACING '45' FROM 4);
abc45f
Time taken: 6.385 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5);
yabadaba
Time taken: 0.191 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5 FOR 0);
yabadabadoo
Time taken: 0.186 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('babosa' PLACING 'ubb' FROM 2 FOR 4);
bubba
Time taken: 0.151 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING '45' FROM 4);
NULL
Time taken: 0.22 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'daba' FROM 5);
NULL
Time taken: 0.157 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'daba' FROM 5 FOR 0);
NULL
Time taken: 0.254 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'ubb' FROM 2 FOR 4);
NULL
Time taken: 0.159 seconds, Fetched 1 row(s)
```
## How was this patch tested?
Exists UT and new UT.
Closes#24918 from beliefer/ansi-sql-overlay.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
## What changes were proposed in this pull request?
Avoid hard-coded config: `spark.sql.globalTempDatabase`.
## How was this patch tested?
N/A
Closes#24979 from wangyum/SPARK-28179.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
For simplicity, all `LambdaVariable`s are globally unique, to avoid any potential conflicts. However, this causes a perf problem: we can never hit codegen cache for encoder expressions that deal with collections (which means they contain `LambdaVariable`).
To overcome this problem, `LambdaVariable` should have per-query unique IDs. This PR does 2 things:
1. refactor `LambdaVariable` to carry an ID, so that it's easier to change the ID.
2. add an optimizer rule to reassign `LambdaVariable` IDs, which are per-query unique.
## How was this patch tested?
new tests
Closes#24735 from cloud-fan/dataset.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
SQL ANSI 2011 states that in case of overflow during arithmetic operations, an exception should be thrown. This is what most of the SQL DBs do (eg. SQLServer, DB2). Hive currently returns NULL (as Spark does) but HIVE-18291 is open to be SQL compliant.
The PR introduce an option to decide which behavior Spark should follow, ie. returning NULL on overflow or throwing an exception.
## How was this patch tested?
added UTs
Closes#20350 from mgaido91/SPARK-23179.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
[PostgreSQL](7c850320d8/src/test/regress/sql/strings.sql (L624)) support another trim pattern: `TRIM(trimStr FROM str)`:
Function | Return Type | Description | Example | Result
--- | --- | --- | --- | ---
trim([leading \| trailing \| both] [characters] from string) | text | Remove the longest string containing only characters from characters (a space by default) from the start, end, or both ends (both is the default) of string | trim(both 'xyz' from 'yxTomxx') | Tom
This pr add support this trim pattern. After this pr. We can support all standard syntax except `TRIM(FROM str)` because it conflicts with our Literals:
```sql
Literals of type 'FROM' are currently not supported.(line 1, pos 12)
== SQL ==
SELECT TRIM(FROM ' SPARK SQL ')
```
PostgreSQL, Vertica and MySQL support this pattern. Teradata, Oracle, DB2, SQL Server, Hive and Presto
**PostgreSQL**:
```
postgres=# SELECT substr(version(), 0, 16), trim('xyz' FROM 'yxTomxx');
substr | btrim
-----------------+-------
PostgreSQL 11.3 | Tom
(1 row)
```
**Vertica**:
```
dbadmin=> SELECT version(), trim('xyz' FROM 'yxTomxx');
version | btrim
------------------------------------+-------
Vertica Analytic Database v9.1.1-0 | Tom
(1 row)
```
**MySQL**:
```
mysql> SELECT version(), trim('xyz' FROM 'yxTomxx');
+-----------+----------------------------+
| version() | trim('xyz' FROM 'yxTomxx') |
+-----------+----------------------------+
| 5.7.26 | yxTomxx |
+-----------+----------------------------+
1 row in set (0.00 sec)
```
More details:
https://www.postgresql.org/docs/11/functions-string.html
## How was this patch tested?
unit tests
Closes#24924 from wangyum/SPARK-28075-2.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The `mapChildren` method in the TreeNode class is commonly used across the whole Spark SQL codebase. In this method, there's a if statement that checks non-empty children. However, there's a cached lazy val `containsChild`, which can avoid unnecessary computation since `containsChild` is used in other methods and therefore constructed anyway.
Benchmark showed that this optimization can improve the whole TPC-DS planning time by 6.8%. There is no regression on any TPC-DS query.
## How was this patch tested?
Existing UTs.
Closes#24925 from yeshengm/treenode-children.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR significantly improves the performance of `UTF8String.replace()` by performing direct replacement over UTF8 bytes instead of decoding those bytes into Java Strings.
In cases where the search string is not found (i.e. no replacements are performed, a case which I expect to be common) this new implementation performs no object allocation or memory copying.
My implementation is modeled after `commons-lang3`'s `StringUtils.replace()` method. As part of my implementation, I needed a StringBuilder / resizable buffer, so I moved `UTF8StringBuilder` from the `catalyst` package to `unsafe`.
## How was this patch tested?
Copied tests from `StringExpressionSuite` to `UTF8StringSuite` and added a couple of new cases.
To evaluate performance, I did some quick local benchmarking by running the following code in `spark-shell` (with Java 1.8.0_191):
```scala
import org.apache.spark.unsafe.types.UTF8String
def benchmark(text: String, search: String, replace: String) {
val utf8Text = UTF8String.fromString(text)
val utf8Search = UTF8String.fromString(search)
val utf8Replace = UTF8String.fromString(replace)
val start = System.currentTimeMillis
var i = 0
while (i < 1000 * 1000 * 100) {
utf8Text.replace(utf8Search, utf8Replace)
i += 1
}
val end = System.currentTimeMillis
println(end - start)
}
benchmark("ABCDEFGH", "DEF", "ZZZZ") // replacement occurs
benchmark("ABCDEFGH", "Z", "") // no replacement occurs
```
On my laptop this took ~54 / ~40 seconds seconds before this patch's changes and ~6.5 / ~3.8 seconds afterwards.
Closes#24707 from JoshRosen/faster-string-replace.
Authored-by: Josh Rosen <rosenville@gmail.com>
Signed-off-by: Josh Rosen <rosenville@gmail.com>
## What changes were proposed in this pull request?
[SPARK-28093](https://issues.apache.org/jira/browse/SPARK-28093) fixed `TRIM/LTRIM/RTRIM('str', 'trimStr')` returns an incorrect value, but that fix introduced a new bug, `TRIM(type trimStr FROM str)` returns an incorrect value. This pr fix this issue.
## How was this patch tested?
unit tests and manual tests:
Before this PR:
```sql
spark-sql> SELECT trim('yxTomxx', 'xyz'), trim(BOTH 'xyz' FROM 'yxTomxx');
Tom z
spark-sql> SELECT trim('xxxbarxxx', 'x'), trim(BOTH 'x' FROM 'xxxbarxxx');
bar
spark-sql> SELECT ltrim('zzzytest', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytest');
test xyz
spark-sql> SELECT ltrim('zzzytestxyz', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytestxyz');
testxyz
spark-sql> SELECT ltrim('xyxXxyLAST WORD', 'xy'), trim(LEADING 'xy' FROM 'xyxXxyLAST WORD');
XxyLAST WORD
spark-sql> SELECT rtrim('testxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'testxxzx');
test xy
spark-sql> SELECT rtrim('xyztestxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'xyztestxxzx');
xyztest
spark-sql> SELECT rtrim('TURNERyxXxy', 'xy'), trim(TRAILING 'xy' FROM 'TURNERyxXxy');
TURNERyxX
```
After this PR:
```sql
spark-sql> SELECT trim('yxTomxx', 'xyz'), trim(BOTH 'xyz' FROM 'yxTomxx');
Tom Tom
spark-sql> SELECT trim('xxxbarxxx', 'x'), trim(BOTH 'x' FROM 'xxxbarxxx');
bar bar
spark-sql> SELECT ltrim('zzzytest', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytest');
test test
spark-sql> SELECT ltrim('zzzytestxyz', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytestxyz');
testxyz testxyz
spark-sql> SELECT ltrim('xyxXxyLAST WORD', 'xy'), trim(LEADING 'xy' FROM 'xyxXxyLAST WORD');
XxyLAST WORD XxyLAST WORD
spark-sql> SELECT rtrim('testxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'testxxzx');
test test
spark-sql> SELECT rtrim('xyztestxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'xyztestxxzx');
xyztest xyztest
spark-sql> SELECT rtrim('TURNERyxXxy', 'xy'), trim(TRAILING 'xy' FROM 'TURNERyxXxy');
TURNERyxX TURNERyxX
```
And PostgreSQL:
```sql
postgres=# SELECT trim('yxTomxx', 'xyz'), trim(BOTH 'xyz' FROM 'yxTomxx');
btrim | btrim
-------+-------
Tom | Tom
(1 row)
postgres=# SELECT trim('xxxbarxxx', 'x'), trim(BOTH 'x' FROM 'xxxbarxxx');
btrim | btrim
-------+-------
bar | bar
(1 row)
postgres=# SELECT ltrim('zzzytest', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytest');
ltrim | ltrim
-------+-------
test | test
(1 row)
postgres=# SELECT ltrim('zzzytestxyz', 'xyz'), trim(LEADING 'xyz' FROM 'zzzytestxyz');
ltrim | ltrim
---------+---------
testxyz | testxyz
(1 row)
postgres=# SELECT ltrim('xyxXxyLAST WORD', 'xy'), trim(LEADING 'xy' FROM 'xyxXxyLAST WORD');
ltrim | ltrim
--------------+--------------
XxyLAST WORD | XxyLAST WORD
(1 row)
postgres=# SELECT rtrim('testxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'testxxzx');
rtrim | rtrim
-------+-------
test | test
(1 row)
postgres=# SELECT rtrim('xyztestxxzx', 'xyz'), trim(TRAILING 'xyz' FROM 'xyztestxxzx');
rtrim | rtrim
---------+---------
xyztest | xyztest
(1 row)
postgres=# SELECT rtrim('TURNERyxXxy', 'xy'), trim(TRAILING 'xy' FROM 'TURNERyxXxy');
rtrim | rtrim
-----------+-----------
TURNERyxX | TURNERyxX
(1 row)
```
Closes#24911 from wangyum/SPARK-28109.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Current SQL parser's error message for hyphen-connected identifiers without surrounding backquotes(e.g. hyphen-table) is confusing for end users. A possible approach to tackle this is to explicitly capture these wrong usages in the SQL parser. In this way, the end users can fix these errors more quickly.
For example, for a simple query such as `SELECT * FROM test-table`, the original error message is
```
Error in SQL statement: ParseException:
mismatched input '-' expecting <EOF>(line 1, pos 18)
```
which can be confusing in a large query.
After the fix, the error message is:
```
Error in query:
Possibly unquoted identifier test-table detected. Please consider quoting it with back-quotes as `test-table`(line 1, pos 14)
== SQL ==
SELECT * FROM test-table
--------------^^^
```
which is easier for end users to identify the issue and fix.
We safely augmented the current grammar rule to explicitly capture these error cases. The error handling logic is implemented in the SQL parsing listener `PostProcessor`.
However, note that for cases such as `a - my-func(b)`, the parser can't actually tell whether this should be ``a -`my-func`(b) `` or `a - my - func(b)`. Therefore for these cases, we leave the parser as is. Also, in this patch we only provide better error messages for character-only identifiers.
## How was this patch tested?
Adding new unit tests.
Closes#24749 from yeshengm/hyphen-ident.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The original `references` and `validConstraints` implementations in a few `QueryPlan` and `Expression` classes are methods, which means unnecessary re-computation can happen at times. This PR resolves this problem by making these method `lazy val`s.
As shown in the following chart, the planning time(without cost-based optimization) was dramatically reduced after this optimization.
- The average planning time of TPC-DS queries was reduced by 19.63%.
- The planning time of the most time-consuming TPC-DS query (q64) was reduced by 43.03%.
- The running time for rule-based reordering joins(not cost-based join reordering) optimization, which are common in real-world OLAP queries, was largely reduced.
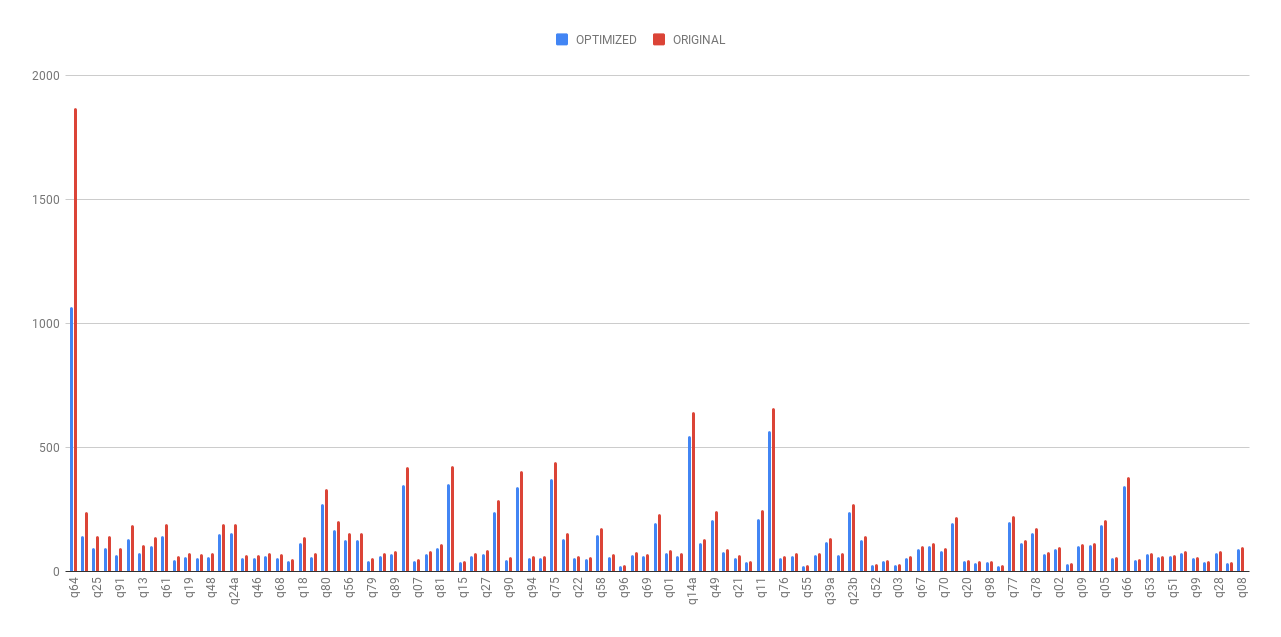
Detailed stats are listed in the following spreadsheet (we warmed up the queries 5 iterations and then took average of the next 5 iterations).
[Lazy val benchmark.xlsx](https://github.com/apache/spark/files/3303530/Lazy.val.benchmark.xlsx)
## How was this patch tested?
Existing UTs.
Closes#24866 from yeshengm/plannode-micro-opt.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Added an interface for handling hint errors, with a default implementation class that logs warnings in the callbacks.
## How was this patch tested?
Passed existing tests.
Closes#24653 from maryannxue/hint-handler.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
With JDK9+, the generate **bytecode** of `FromUnixTime` raise `java.lang.IncompatibleClassChangeError` due to [JDK-8145148](https://bugs.openjdk.java.net/browse/JDK-8145148) . This is a blocker in [Apache Spark JDK11 Jenkins job](https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7-jdk-11-ubuntu-testing/). Locally, this is reproducible by the following unit test suite with JDK9+.
```
$ build/sbt "catalyst/testOnly *.DateExpressionsSuite"
...
[info] org.apache.spark.sql.catalyst.expressions.DateExpressionsSuite *** ABORTED *** (23 seconds, 75 milliseconds)
[info] java.lang.IncompatibleClassChangeError: Method org.apache.spark.sql.catalyst.util.TimestampFormatter.apply(Ljava/lang/String;Ljava/time/ZoneId;Ljava/util/Locale;)Lorg/apache/spark/sql/catalyst/util/TimestampFormatter; must be InterfaceMeth
```
This bytecode issue is generated by `Janino` , so we replace `.apply` to `.MODULE$$.apply` and adds test coverage for similar codes.
## How was this patch tested?
Manually with the existing UTs by doing the following with JDK9+.
```
build/sbt "catalyst/testOnly *.DateExpressionsSuite"
```
Actually, this is the last JDK11 error in `catalyst` module. So, we can verify with the following, too.
```
$ build/sbt "project catalyst" test
...
[info] Total number of tests run: 3552
[info] Suites: completed 210, aborted 0
[info] Tests: succeeded 3552, failed 0, canceled 0, ignored 2, pending 0
[info] All tests passed.
[info] Passed: Total 3583, Failed 0, Errors 0, Passed 3583, Ignored 2
[success] Total time: 294 s, completed Jun 16, 2019, 10:15:08 PM
```
Closes#24889 from dongjoon-hyun/SPARK-28072.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
The `TRIM` function accept these patterns:
```sql
TRIM(str)
TRIM(trimStr, str)
TRIM(BOTH trimStr FROM str)
TRIM(LEADING trimStr FROM str)
TRIM(TRAILING trimStr FROM str)
```
This pr add support other three patterns:
```sql
TRIM(BOTH FROM str)
TRIM(LEADING FROM str)
TRIM(TRAILING FROM str)
```
PostgreSQL, Vertica, MySQL, Teradata, Oracle and DB2 support these patterns. Hive, Presto and SQL Server does not support this feature.
**PostgreSQL**:
```sql
postgres=# select substr(version(), 0, 16), trim(BOTH from ' SparkSQL '), trim(LEADING FROM ' SparkSQL '), trim(TRAILING FROM ' SparkSQL ');
substr | btrim | ltrim | rtrim
-----------------+----------+-------------+--------------
PostgreSQL 11.3 | SparkSQL | SparkSQL | SparkSQL
(1 row)
```
**Vertica**:
```
dbadmin=> select version(), trim(BOTH from ' SparkSQL '), trim(LEADING FROM ' SparkSQL '), trim(TRAILING FROM ' SparkSQL ');
version | btrim | ltrim | rtrim
------------------------------------+----------+-------------+--------------
Vertica Analytic Database v9.1.1-0 | SparkSQL | SparkSQL | SparkSQL
(1 row)
```
**MySQL**:
```
mysql> select version(), trim(BOTH from ' SparkSQL '), trim(LEADING FROM ' SparkSQL '), trim(TRAILING FROM ' SparkSQL ');
+-----------+-----------------------------------+--------------------------------------+---------------------------------------+
| version() | trim(BOTH from ' SparkSQL ') | trim(LEADING FROM ' SparkSQL ') | trim(TRAILING FROM ' SparkSQL ') |
+-----------+-----------------------------------+--------------------------------------+---------------------------------------+
| 5.7.26 | SparkSQL | SparkSQL | SparkSQL |
+-----------+-----------------------------------+--------------------------------------+---------------------------------------+
1 row in set (0.01 sec)
```
**Teradata**:

**Oracle**:

**DB2**:

## How was this patch tested?
unit tests
Closes#24891 from wangyum/SPARK-28075.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR aims to replace deprecated `.newInstance()` in DSv2 `Catalogs` and distinguish the plugin class errors more. According to the JDK11 build log, there is no other new instance.
- https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7-jdk-11-ubuntu-testing/978/consoleFull
SPARK-25984 removes all instances of the deprecated `.newInstance()` usages at Nov 10, 2018, but this was added at SPARK-24252 on March 8, 2019.
## How was this patch tested?
Pass the Jenkins with the updated test case.
Closes#24882 from dongjoon-hyun/SPARK-28063.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Currently `ArrayExists` always returns boolean values (if the arguments are not `null`), but it should follow the three-valued boolean logic:
- `true` if the predicate holds at least one `true`
- otherwise, `null` if the predicate holds `null`
- otherwise, `false`
This behavior change is made to match Postgres' equivalent function `ANY/SOME (array)`'s behavior: https://www.postgresql.org/docs/9.6/functions-comparisons.html#AEN21174
## How was this patch tested?
Modified tests and existing tests.
Closes#24873 from ueshin/issues/SPARK-28052/fix_exists.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Allow Pandas UDF to take an iterator of pd.Series or an iterator of tuple of pd.Series.
Note the UDF input args will be always one iterator:
* if the udf take only column as input, the iterator's element will be pd.Series (corresponding to the column values batch)
* if the udf take multiple columns as inputs, the iterator's element will be a tuple composed of multiple `pd.Series`s, each one corresponding to the multiple columns as inputs (keep the same order). For example:
```
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def the_udf(iterator):
for col1_batch, col2_batch in iterator:
yield col1_batch + col2_batch
df.select(the_udf("col1", "col2"))
```
The udf above will add col1 and col2.
I haven't add unit tests, but manually tests show it works fine. So it is ready for first pass review.
We can test several typical cases:
```
from pyspark.sql import SparkSession
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.functions import udf
from pyspark.taskcontext import TaskContext
df = spark.createDataFrame([(1, 20), (3, 40)], ["a", "b"])
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi1(it):
pid = TaskContext.get().partitionId()
print("DBG: fi1: do init stuff, partitionId=" + str(pid))
for batch in it:
yield batch + 100
print("DBG: fi1: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi2(it):
pid = TaskContext.get().partitionId()
print("DBG: fi2: do init stuff, partitionId=" + str(pid))
for batch in it:
yield batch + 10000
print("DBG: fi2: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi3(it):
pid = TaskContext.get().partitionId()
print("DBG: fi3: do init stuff, partitionId=" + str(pid))
for x, y in it:
yield x + y * 10 + 100000
print("DBG: fi3: do close stuff, partitionId=" + str(pid))
pandas_udf("int", PandasUDFType.SCALAR)
def fp1(x):
return x + 1000
udf("int")
def fu1(x):
return x + 10
# test select "pandas iter udf/pandas udf/sql udf" expressions at the same time.
# Note this case the `fi1("a"), fi2("b"), fi3("a", "b")` will generate only one plan,
# and `fu1("a")`, `fp1("a")` will generate another two separate plans.
df.select(fi1("a"), fi2("b"), fi3("a", "b"), fu1("a"), fp1("a")).show()
# test chain two pandas iter udf together
# Note this case `fi2(fi1("a"))` will generate only one plan
# Also note the init stuff/close stuff call order will be like:
# (debug output following)
# DBG: fi2: do init stuff, partitionId=0
# DBG: fi1: do init stuff, partitionId=0
# DBG: fi1: do close stuff, partitionId=0
# DBG: fi2: do close stuff, partitionId=0
df.select(fi2(fi1("a"))).show()
# test more complex chain
# Note this case `fi1("a"), fi2("a")` will generate one plan,
# and `fi3(fi1_output, fi2_output)` will generate another plan
df.select(fi3(fi1("a"), fi2("a"))).show()
```
## How was this patch tested?
To be added.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24643 from WeichenXu123/pandas_udf_iter.
Lead-authored-by: WeichenXu <weichen.xu@databricks.com>
Co-authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
Migrate Parquet to File Data Source V2
## How was this patch tested?
Unit test
Closes#24327 from gengliangwang/parquetV2.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Implemented a new SparkPlan that executes the query adaptively. It splits the query plan into independent stages and executes them in order according to their dependencies. The query stage materializes its output at the end. When one stage completes, the data statistics of the materialized output will be used to optimize the remainder of the query.
The adaptive mode is off by default, when turned on, user can see "AdaptiveSparkPlan" as the top node of a query or sub-query. The inner plan of "AdaptiveSparkPlan" is subject to change during query execution but becomes final once the execution is complete. Whether the inner plan is final is included in the EXPLAIN string. Below is an example of the EXPLAIN plan before and after execution:
Query:
```
SELECT * FROM testData JOIN testData2 ON key = a WHERE value = '1'
```
Before execution:
```
== Physical Plan ==
AdaptiveSparkPlan(isFinalPlan=false)
+- SortMergeJoin [key#13], [a#23], Inner
:- Sort [key#13 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(key#13, 5)
: +- Filter (isnotnull(value#14) AND (value#14 = 1))
: +- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).key AS key#13, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).value, true, false) AS value#14]
: +- Scan[obj#12]
+- Sort [a#23 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(a#23, 5)
+- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#23, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).b AS b#24]
+- Scan[obj#22]
```
After execution:
```
== Physical Plan ==
AdaptiveSparkPlan(isFinalPlan=true)
+- *(1) BroadcastHashJoin [key#13], [a#23], Inner, BuildLeft
:- BroadcastQueryStage 2
: +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
: +- ShuffleQueryStage 0
: +- Exchange hashpartitioning(key#13, 5)
: +- *(1) Filter (isnotnull(value#14) AND (value#14 = 1))
: +- *(1) SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).key AS key#13, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData, true])).value, true, false) AS value#14]
: +- Scan[obj#12]
+- ShuffleQueryStage 1
+- Exchange hashpartitioning(a#23, 5)
+- *(1) SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#23, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).b AS b#24]
+- Scan[obj#22]
```
Credit also goes to carsonwang and cloud-fan
## How was this patch tested?
Added new UT.
Closes#24706 from maryannxue/aqe.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: herman <herman@databricks.com>
## What changes were proposed in this pull request?
This PR adds support of column aliasing in a CTE so this query becomes valid:
```
WITH t(x) AS (SELECT 1)
SELECT * FROM t WHERE x = 1
```
## How was this patch tested?
Added new UTs.
Closes#24842 from peter-toth/SPARK-28002.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Implemented the `clone` method for `TreeNode` based on `mapChildren`.
## How was this patch tested?
Added new UT.
Closes#24876 from maryannxue/treenode-clone.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: herman <herman@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}