## What changes were proposed in this pull request?
The hint of the plan segment is lost, if the plan segment is replaced by the cached data.
```Scala
val df1 = spark.createDataFrame(Seq((1, "4"), (2, "2"))).toDF("key", "value")
val df2 = spark.createDataFrame(Seq((1, "1"), (2, "2"))).toDF("key", "value")
df2.cache()
val df3 = df1.join(broadcast(df2), Seq("key"), "inner")
```
This PR is to fix it.
## How was this patch tested?
Added a test
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20365 from gatorsmile/fixBroadcastHintloss.
## What changes were proposed in this pull request?
Added documentation for new transformer.
Author: Bago Amirbekian <bago@databricks.com>
Closes#20285 from MrBago/sizeHintDocs.
Because the call to the constructor of HiveClientImpl crosses class loader
boundaries, different versions of the same class (Configuration in this
case) were loaded, and that caused a runtime error when instantiating the
client. By using a safer type in the signature of the constructor, it's
possible to avoid the problem.
I considered removing 'sharesHadoopClasses', but it may still be desired
(even though there are 0 users of it since it was not working). When Spark
starts to support Hadoop 3, it may be necessary to use that option to
load clients for older Hive metastore versions that don't know about
Hadoop 3.
Tested with added unit test.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20169 from vanzin/SPARK-17088.
## What changes were proposed in this pull request?
We need to override the prettyName for bit_length and octet_length for getting the expected auto-generated alias name.
## How was this patch tested?
The existing tests
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20358 from gatorsmile/test2.3More.
## What changes were proposed in this pull request?
#20002 purposed a way to safe check the default partitioner, however, if `spark.default.parallelism` is set, the defaultParallelism still could be smaller than the proper number of partitions for upstreams RDDs. This PR tries to extend the approach to address the condition when `spark.default.parallelism` is set.
The requirements where the PR helps with are :
- Max partitioner is not eligible since it is atleast an order smaller, and
- User has explicitly set 'spark.default.parallelism', and
- Value of 'spark.default.parallelism' is lower than max partitioner
- Since max partitioner was discarded due to being at least an order smaller, default parallelism is worse - even though user specified.
Under the rest cases, the changes should be no-op.
## How was this patch tested?
Add corresponding test cases in `PairRDDFunctionsSuite` and `PartitioningSuite`.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#20091 from jiangxb1987/partitioner.
## What changes were proposed in this pull request?
Add support for using pandas UDFs with groupby().agg().
This PR introduces a new type of pandas UDF - group aggregate pandas UDF. This type of UDF defines a transformation of multiple pandas Series -> a scalar value. Group aggregate pandas UDFs can be used with groupby().agg(). Note group aggregate pandas UDF doesn't support partial aggregation, i.e., a full shuffle is required.
This PR doesn't support group aggregate pandas UDFs that return ArrayType, StructType or MapType. Support for these types is left for future PR.
## How was this patch tested?
GroupbyAggPandasUDFTests
Author: Li Jin <ice.xelloss@gmail.com>
Closes#19872 from icexelloss/SPARK-22274-groupby-agg.
## What changes were proposed in this pull request?
a new interface which allows data source to report partitioning and avoid shuffle at Spark side.
The design is pretty like the internal distribution/partitioing framework. Spark defines a `Distribution` interfaces and several concrete implementations, and ask the data source to report a `Partitioning`, the `Partitioning` should tell Spark if it can satisfy a `Distribution` or not.
## How was this patch tested?
new test
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20201 from cloud-fan/partition-reporting.
## What changes were proposed in this pull request?
Typo fixes
## How was this patch tested?
Local build / Doc-only changes
Author: Jacek Laskowski <jacek@japila.pl>
Closes#20344 from jaceklaskowski/typo-fixes.
## What changes were proposed in this pull request?
The allJobs and the job pages attempt to use stage attempt and DAG visualization from the store, but for long running jobs they are not guaranteed to be retained, leading to exceptions when these pages are rendered.
To fix it `store.lastStageAttempt(stageId)` and `store.operationGraphForJob(jobId)` are wrapped in `store.asOption` and default values are used if the info is missing.
## How was this patch tested?
Manual testing of the UI, also using the test command reported in SPARK-23121:
./bin/spark-submit --class org.apache.spark.examples.streaming.HdfsWordCount ./examples/jars/spark-examples_2.11-2.4.0-SNAPSHOT.jar /spark
Closes#20287
Author: Sandor Murakozi <smurakozi@gmail.com>
Closes#20330 from smurakozi/SPARK-23121.
## What changes were proposed in this pull request?
ClosureCleaner moved from warning to debug
## How was this patch tested?
Existing tests
Author: Rekha Joshi <rekhajoshm@gmail.com>
Author: rjoshi2 <rekhajoshm@gmail.com>
Closes#20337 from rekhajoshm/SPARK-11630-1.
## What changes were proposed in this pull request?
Note that this PR was made based on the top of https://github.com/apache/spark/pull/20151. So, it almost leaves the main codes intact.
This PR proposes to add a script for the preparation of automatic PySpark coverage generation. Now, it's difficult to check the actual coverage in case of PySpark. With this script, it allows to run tests by the way we did via `run-tests` script before. The usage is exactly the same with `run-tests` script as this basically wraps it.
This script and PR alone should also be useful. I was asked about how to run this before, and seems some reviewers (including me) need this. It would be also useful to run it manually.
It usually requires a small diff in normal Python projects but PySpark cases are a bit different because apparently we are unable to track the coverage after it's forked. So, here, I made a custom worker that forces the coverage, based on the top of https://github.com/apache/spark/pull/20151.
I made a simple demo. Please take a look - https://spark-test.github.io/pyspark-coverage-site.
To show up the structure, this PR adds the files as below:
```
python
├── .coveragerc # Runtime configuration when we run the script.
├── run-tests-with-coverage # The script that has coverage support and wraps run-tests script.
└── test_coverage # Directories that have files required when running coverage.
├── conf
│ └── spark-defaults.conf # Having the configuration 'spark.python.daemon.module'.
├── coverage_daemon.py # A daemon having custom fix and wrapping our daemon.py
└── sitecustomize.py # Initiate coverage with COVERAGE_PROCESS_START
```
Note that this PR has a minor nit:
[This scope](04e44b37cc/python/pyspark/daemon.py (L148-L169)) in `daemon.py` is not in the coverage results as basically I am producing the coverage results in `worker.py` separately and then merging it. I believe it's not a big deal.
In a followup, I might have a site that has a single up-to-date PySpark coverage from the master branch as the fallback / default, or have a site that has multiple PySpark coverages and the site link will be left to each pull request.
## How was this patch tested?
Manually tested. Usage is the same with the existing Python test script - `./python/run-tests`. For example,
```
sh run-tests-with-coverage --python-executables=python3 --modules=pyspark-sql
```
Running this will generate HTMLs under `./python/test_coverage/htmlcov`.
Console output example:
```
sh run-tests-with-coverage --python-executables=python3,python --modules=pyspark-core
Running PySpark tests. Output is in /.../spark/python/unit-tests.log
Will test against the following Python executables: ['python3', 'python']
Will test the following Python modules: ['pyspark-core']
Starting test(python): pyspark.tests
Starting test(python3): pyspark.tests
...
Tests passed in 231 seconds
Combining collected coverage data under /.../spark/python/test_coverage/coverage_data
Reporting the coverage data at /...spark/python/test_coverage/coverage_data/coverage
Name Stmts Miss Branch BrPart Cover
--------------------------------------------------------------
pyspark/__init__.py 41 0 8 2 96%
...
pyspark/profiler.py 74 11 22 5 83%
pyspark/rdd.py 871 40 303 32 93%
pyspark/rddsampler.py 68 10 32 2 82%
...
--------------------------------------------------------------
TOTAL 8521 3077 2748 191 59%
Generating HTML files for PySpark coverage under /.../spark/python/test_coverage/htmlcov
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20204 from HyukjinKwon/python-coverage.
## What changes were proposed in this pull request?
Several improvements:
* provide a default implementation for the batch get methods
* rename `getChildColumn` to `getChild`, which is more concise
* remove `getStruct(int, int)`, it's only used to simplify the codegen, which is an internal thing, we should not add a public API for this purpose.
## How was this patch tested?
existing tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20277 from cloud-fan/column-vector.
## What changes were proposed in this pull request?
Revert the unneeded test case changes we made in SPARK-23000
Also fixes the test suites that do not call `super.afterAll()` in the local `afterAll`. The `afterAll()` of `TestHiveSingleton` actually reset the environments.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20341 from gatorsmile/testRelated.
## What changes were proposed in this pull request?
This PR is to update the docs for UDF registration
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20348 from gatorsmile/testUpdateDoc.
## What changes were proposed in this pull request?
The example jar file is now in ./examples/jars directory of Spark distribution.
Author: Arseniy Tashoyan <tashoyan@users.noreply.github.com>
Closes#20349 from tashoyan/patch-1.
The race in the code is because the handle might update
its state to the wrong state if the connection handling
thread is still processing incoming data; so the handle
needs to wait for the connection to finish up before
checking the final state.
The race in the test is because when waiting for a handle
to reach a final state, the waitFor() method needs to wait
until all handle state is updated (which also includes
waiting for the connection thread above to finish).
Otherwise, waitFor() may return too early, which would cause
a bunch of different races (like the listener not being yet
notified of the state change, or being in the middle of
being notified, or the handle not being properly disposed
and causing postChecks() to assert).
On top of that I found, by code inspection, a couple of
potential races that could make a handle end up in the
wrong state when being killed.
The original version of this fix introduced the flipped
version of the first race described above; the connection
closing might override the handle state before the
handle might have a chance to do cleanup. The fix there
is to only dispose of the handle from the connection
when there is an error, and let the handle dispose
itself in the normal case.
The fix also caused a bug in YarnClusterSuite to be surfaced;
the code was checking for a file in the classpath that was
not expected to be there in client mode. Because of the above
issues, the error was not propagating correctly and the (buggy)
test was incorrectly passing.
Tested by running the existing unit tests a lot (and not
seeing the errors I was seeing before).
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20297 from vanzin/SPARK-23020.
## What changes were proposed in this pull request?
This PR fixes the wrong comment on `org.apache.spark.sql.parquet.row.attributes`
which is useful for UDTs like Vector/Matrix. Please see [SPARK-22320](https://issues.apache.org/jira/browse/SPARK-22320) for the usage.
Originally, [SPARK-19411](bf493686eb (diff-ee26d4c4be21e92e92a02e9f16dbc285L314)) left this behind during removing optional column metadatas. In the same PR, the same comment was removed at line 310-311.
## How was this patch tested?
N/A (This is about comments).
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20346 from dongjoon-hyun/minor_comment_parquet.
## What changes were proposed in this pull request?
The clean up logic on the worker perviously determined the liveness of a
particular applicaiton based on whether or not it had running executors.
This would fail in the case that a directory was made for a driver
running in cluster mode if that driver had no running executors on the
same machine. To preserve driver directories we consider both executors
and running drivers when checking directory liveness.
## How was this patch tested?
Manually started up two node cluster with a single core on each node. Turned on worker directory cleanup and set the interval to 1 second and liveness to one second. Without the patch the driver directory is removed immediately after the app is launched. With the patch it is not
### Without Patch
```
INFO 2018-01-05 23:48:24,693 Logging.scala:54 - Asked to launch driver driver-20180105234824-0000
INFO 2018-01-05 23:48:25,293 Logging.scala:54 - Changing view acls to: cassandra
INFO 2018-01-05 23:48:25,293 Logging.scala:54 - Changing modify acls to: cassandra
INFO 2018-01-05 23:48:25,294 Logging.scala:54 - Changing view acls groups to:
INFO 2018-01-05 23:48:25,294 Logging.scala:54 - Changing modify acls groups to:
INFO 2018-01-05 23:48:25,294 Logging.scala:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(cassandra); groups with view permissions: Set(); users with modify permissions: Set(cassandra); groups with modify permissions: Set()
INFO 2018-01-05 23:48:25,330 Logging.scala:54 - Copying user jar file:/home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180105234824-0000/writeRead-0.1.jar
INFO 2018-01-05 23:48:25,332 Logging.scala:54 - Copying /home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180105234824-0000/writeRead-0.1.jar
INFO 2018-01-05 23:48:25,361 Logging.scala:54 - Launch Command: "/usr/lib/jvm/jdk1.8.0_40//bin/java" ....
****
INFO 2018-01-05 23:48:56,577 Logging.scala:54 - Removing directory: /var/lib/spark/worker/driver-20180105234824-0000 ### << Cleaned up
****
--
One minute passes while app runs (app has 1 minute sleep built in)
--
WARN 2018-01-05 23:49:58,080 ShuffleSecretManager.java:73 - Attempted to unregister application app-20180105234831-0000 when it is not registered
INFO 2018-01-05 23:49:58,081 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = false
INFO 2018-01-05 23:49:58,081 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = false
INFO 2018-01-05 23:49:58,082 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = true
INFO 2018-01-05 23:50:00,999 Logging.scala:54 - Driver driver-20180105234824-0000 exited successfully
```
With Patch
```
INFO 2018-01-08 23:19:54,603 Logging.scala:54 - Asked to launch driver driver-20180108231954-0002
INFO 2018-01-08 23:19:54,975 Logging.scala:54 - Changing view acls to: automaton
INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing modify acls to: automaton
INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing view acls groups to:
INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing modify acls groups to:
INFO 2018-01-08 23:19:54,976 Logging.scala:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(automaton); groups with view permissions: Set(); users with modify permissions: Set(automaton); groups with modify permissions: Set()
INFO 2018-01-08 23:19:55,029 Logging.scala:54 - Copying user jar file:/home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180108231954-0002/writeRead-0.1.jar
INFO 2018-01-08 23:19:55,031 Logging.scala:54 - Copying /home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180108231954-0002/writeRead-0.1.jar
INFO 2018-01-08 23:19:55,038 Logging.scala:54 - Launch Command: ......
INFO 2018-01-08 23:21:28,674 ShuffleSecretManager.java:69 - Unregistered shuffle secret for application app-20180108232000-0000
INFO 2018-01-08 23:21:28,675 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = false
INFO 2018-01-08 23:21:28,675 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = false
INFO 2018-01-08 23:21:28,681 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = true
INFO 2018-01-08 23:21:31,703 Logging.scala:54 - Driver driver-20180108231954-0002 exited successfully
*****
INFO 2018-01-08 23:21:32,346 Logging.scala:54 - Removing directory: /var/lib/spark/worker/driver-20180108231954-0002 ### < Happening AFTER the Run completes rather than during it
*****
```
Author: Russell Spitzer <Russell.Spitzer@gmail.com>
Closes#20298 from RussellSpitzer/SPARK-22976-master.
## What changes were proposed in this pull request?
Pipe action convert objects into strings using a way that was affected by the default encoding setting of Python environment.
This patch fixed the problem. The detailed description is added here:
https://issues.apache.org/jira/browse/SPARK-20947
## How was this patch tested?
Run the following statement in pyspark-shell, and it will NOT raise exception if this patch is applied:
```python
sc.parallelize([u'\u6d4b\u8bd5']).pipe('cat').collect()
```
Author: 王晓哲 <wxz@linkdoc.com>
Closes#18277 from chaoslawful/fix_pipe_encoding_error.
## What changes were proposed in this pull request?
When running the `run-tests` script, seems we don't run lintr on the changes of `lint-r` script and `.lintr` configuration.
## How was this patch tested?
Jenkins builds
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20339 from HyukjinKwon/check-r-changed.
## What changes were proposed in this pull request?
streaming programming guide changes
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#20340 from felixcheung/rstreamdoc.
## What changes were proposed in this pull request?
Currently, KMeans assumes the only possible distance measure to be used is the Euclidean. This PR aims to add the cosine distance support to the KMeans algorithm.
## How was this patch tested?
existing and added UTs.
Author: Marco Gaido <marcogaido91@gmail.com>
Author: Marco Gaido <mgaido@hortonworks.com>
Closes#19340 from mgaido91/SPARK-22119.
## What changes were proposed in this pull request?
CheckCartesianProduct raises an AnalysisException also when the join condition is always false/null. In this case, we shouldn't raise it, since the result will not be a cartesian product.
## How was this patch tested?
added UT
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20333 from mgaido91/SPARK-23087.
[SPARK-21786][SQL] The 'spark.sql.parquet.compression.codec' and 'spark.sql.orc.compression.codec' configuration doesn't take effect on hive table writing
What changes were proposed in this pull request?
Pass ‘spark.sql.parquet.compression.codec’ value to ‘parquet.compression’.
Pass ‘spark.sql.orc.compression.codec’ value to ‘orc.compress’.
How was this patch tested?
Add test.
Note:
This is the same issue mentioned in #19218 . That branch was deleted mistakenly, so make a new pr instead.
gatorsmile maropu dongjoon-hyun discipleforteen
Author: fjh100456 <fu.jinhua6@zte.com.cn>
Author: Takeshi Yamamuro <yamamuro@apache.org>
Author: Wenchen Fan <wenchen@databricks.com>
Author: gatorsmile <gatorsmile@gmail.com>
Author: Yinan Li <liyinan926@gmail.com>
Author: Marcelo Vanzin <vanzin@cloudera.com>
Author: Juliusz Sompolski <julek@databricks.com>
Author: Felix Cheung <felixcheung_m@hotmail.com>
Author: jerryshao <sshao@hortonworks.com>
Author: Li Jin <ice.xelloss@gmail.com>
Author: Gera Shegalov <gera@apache.org>
Author: chetkhatri <ckhatrimanjal@gmail.com>
Author: Joseph K. Bradley <joseph@databricks.com>
Author: Bago Amirbekian <bago@databricks.com>
Author: Xianjin YE <advancedxy@gmail.com>
Author: Bruce Robbins <bersprockets@gmail.com>
Author: zuotingbing <zuo.tingbing9@zte.com.cn>
Author: Kent Yao <yaooqinn@hotmail.com>
Author: hyukjinkwon <gurwls223@gmail.com>
Author: Adrian Ionescu <adrian@databricks.com>
Closes#20087 from fjh100456/HiveTableWriting.
## What changes were proposed in this pull request?
Fix spelling in quick-start doc.
## How was this patch tested?
Doc only.
Author: Shashwat Anand <me@shashwat.me>
Closes#20336 from ashashwat/SPARK-23165.
## What changes were proposed in this pull request?
Narrow bound on approx quantile test to epsilon from 2*epsilon to match paper
## How was this patch tested?
Existing tests.
Author: Sean Owen <sowen@cloudera.com>
Closes#20324 from srowen/SPARK-23091.
## What changes were proposed in this pull request?
Once a meta hive client is created, it generates its SessionState which creates a lot of session related directories, some deleteOnExit, some does not. if a hive client is useless we may not create it at the very start.
## How was this patch tested?
N/A
cc hvanhovell cloud-fan
Author: Kent Yao <11215016@zju.edu.cn>
Closes#18983 from yaooqinn/patch-1.
The code was sorting "0" as "less than" negative values, which is a little
wrong. Fix is simple, most of the changes are the added test and related
cleanup.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20284 from vanzin/SPARK-23103.
Detect the deletion of event log files from storage, and remove
data about the related application attempt in the SHS.
Also contains code to fix SPARK-21571 based on code by ericvandenbergfb.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20138 from vanzin/SPARK-20664.
## What changes were proposed in this pull request?
Docs changes:
- Adding a warning that the backend is experimental.
- Removing a defunct internal-only option from documentation
- Clarifying that node selectors can be used right away, and other minor cosmetic changes
## How was this patch tested?
Docs only change
Author: foxish <ramanathana@google.com>
Closes#20314 from foxish/ambiguous-docs.
## What changes were proposed in this pull request?
Several cleanups in `ColumnarBatch`
* remove `schema`. The `ColumnVector`s inside `ColumnarBatch` already have the data type information, we don't need this `schema`.
* remove `capacity`. `ColumnarBatch` is just a wrapper of `ColumnVector`s, not builders, it doesn't need a capacity property.
* remove `DEFAULT_BATCH_SIZE`. As a wrapper, `ColumnarBatch` can't decide the batch size, it should be decided by the reader, e.g. parquet reader, orc reader, cached table reader. The default batch size should also be defined by the reader.
## How was this patch tested?
existing tests.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20316 from cloud-fan/columnar-batch.
## What changes were proposed in this pull request?
`ML.Vectors#sparse(size: Int, elements: Seq[(Int, Double)])` support zero-length
## How was this patch tested?
existing tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#20275 from zhengruifeng/SparseVector_size.
## What changes were proposed in this pull request?
After session cloning in `TestHive`, the conf of the singleton SparkContext for derby DB location is changed to a new directory. The new directory is created in `HiveUtils.newTemporaryConfiguration(useInMemoryDerby = false)`.
This PR is to keep the conf value of `ConfVars.METASTORECONNECTURLKEY.varname` unchanged during the session clone.
## How was this patch tested?
The issue can be reproduced by the command:
> build/sbt -Phive "hive/test-only org.apache.spark.sql.hive.HiveSessionStateSuite org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite"
Also added a test case.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20328 from gatorsmile/fixTestFailure.
## What changes were proposed in this pull request?
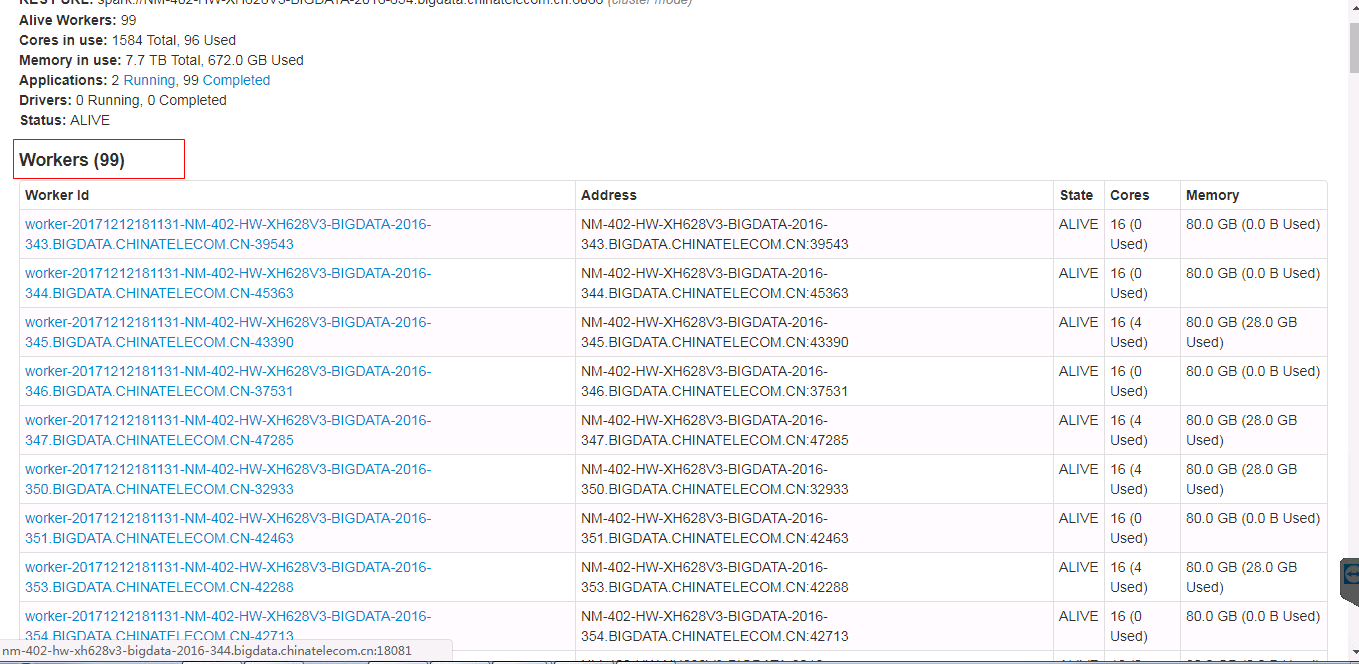
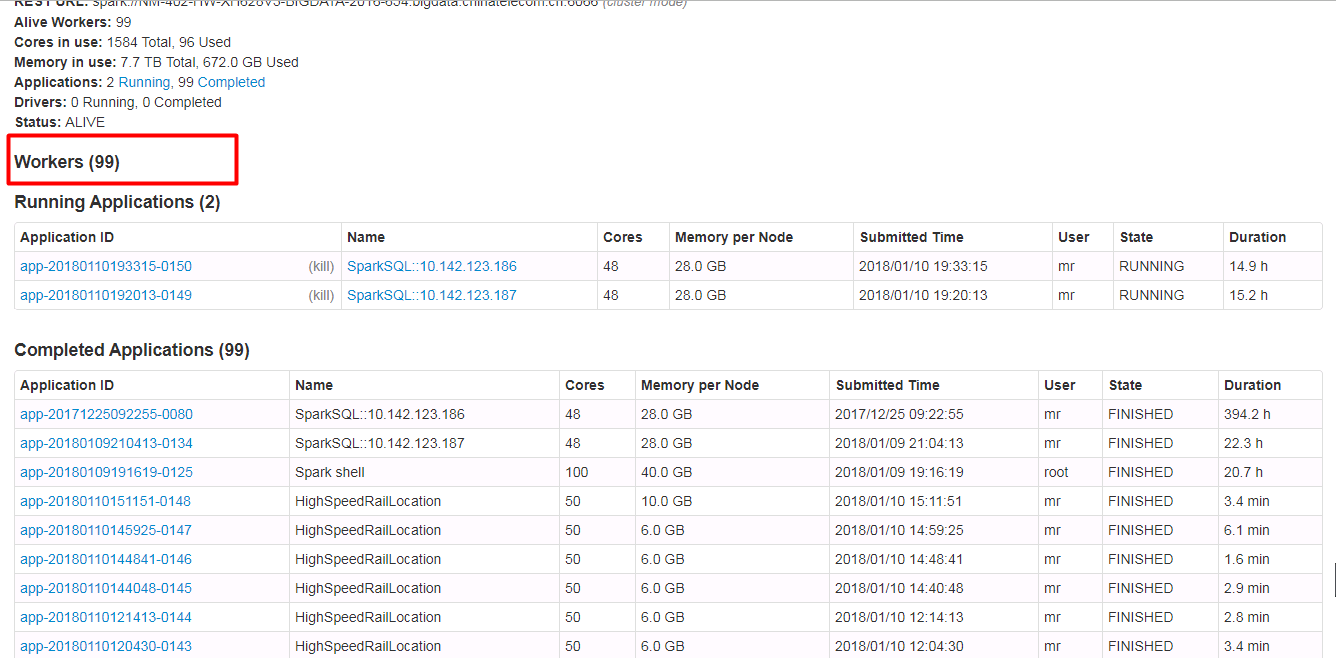
Spark ui about the contents of the form need to have hidden and show features, when the table records very much. Because sometimes you do not care about the record of the table, you just want to see the contents of the next table, but you have to scroll the scroll bar for a long time to see the contents of the next table.
Currently we have about 500 workers, but I just wanted to see the logs for the running applications table. I had to scroll through the scroll bars for a long time to see the logs for the running applications table.
In order to ensure functional consistency, I modified the Master Page, Worker Page, Job Page, Stage Page, Task Page, Configuration Page, Storage Page, Pool Page.
fix before:
fix after:
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: guoxiaolong <guo.xiaolong1@zte.com.cn>
Closes#20216 from guoxiaolongzte/SPARK-23024.
## What changes were proposed in this pull request?
When creating a session directory, Thrift should create the parent directory (i.e. /tmp/base_session_log_dir) if it is not present. It is common that many tools delete empty directories, so the directory may be deleted. This can cause the session log to be disabled.
This was fixed in HIVE-12262: this PR brings it in Spark too.
## How was this patch tested?
manual tests
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20281 from mgaido91/SPARK-23089.
## What changes were proposed in this pull request?
We have `OneHotEncoderEstimator` now and `OneHotEncoder` will be deprecated since 2.3.0. We should add `OneHotEncoderEstimator` into mllib document.
We also need to provide corresponding examples for `OneHotEncoderEstimator` which are used in the document too.
## How was this patch tested?
Existing tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20257 from viirya/SPARK-23048.
Update user guide entry for `FeatureHasher` to match the Scala / Python doc, to describe the `categoricalCols` parameter.
## How was this patch tested?
Doc only
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#20293 from MLnick/SPARK-23127-catCol-userguide.
## What changes were proposed in this pull request?
This patch fixes a few recently introduced java style check errors in master and release branch.
As an aside, given that [java linting currently fails](https://github.com/apache/spark/pull/10763
) on machines with a clean maven cache, it'd be great to find another workaround to [re-enable the java style checks](3a07eff5af/dev/run-tests.py (L577)) as part of Spark PRB.
/cc zsxwing JoshRosen srowen for any suggestions
## How was this patch tested?
Manual Check
Author: Sameer Agarwal <sameerag@apache.org>
Closes#20323 from sameeragarwal/java.
## What changes were proposed in this pull request?
This is a follow-up of #20246.
If a UDT in Python doesn't have its corresponding Scala UDT, cast to string will be the raw string of the internal value, e.g. `"org.apache.spark.sql.catalyst.expressions.UnsafeArrayDataxxxxxxxx"` if the internal type is `ArrayType`.
This pr fixes it by using its `sqlType` casting.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20306 from ueshin/issues/SPARK-23054/fup1.
## What changes were proposed in this pull request?
In latest structured-streaming-kafka-integration document, Java code example for Kafka integration is using `DataFrame<Row>`, shouldn't it be changed to `DataSet<Row>`?
## How was this patch tested?
manual test has been performed to test the updated example Java code in Spark 2.2.1 with Kafka 1.0
Author: brandonJY <brandonJY@users.noreply.github.com>
Closes#20312 from brandonJY/patch-2.
## What changes were proposed in this pull request?
In the Kubernetes mode, fails fast in the submission process if any submission client local dependencies are used as the use case is not supported yet.
## How was this patch tested?
Unit tests, integration tests, and manual tests.
vanzin foxish
Author: Yinan Li <liyinan926@gmail.com>
Closes#20320 from liyinan926/master.
## What changes were proposed in this pull request?
There were two related fixes regarding `from_json`, `get_json_object` and `json_tuple` ([Fix#1](c8803c0685),
[Fix#2](86174ea89b)), but they weren't comprehensive it seems. I wanted to extend those fixes to all the parsers, and add tests for each case.
## How was this patch tested?
Regression tests
Author: Burak Yavuz <brkyvz@gmail.com>
Closes#20302 from brkyvz/json-invfix.
Pass through spark java options to the executor in context of docker image.
Closes#20296
andrusha: Deployed two version of containers to local k8s, checked that java options were present in the updated image on the running executor.
Manual test
Author: Andrew Korzhuev <korzhuev@andrusha.me>
Closes#20322 from foxish/patch-1.
## What changes were proposed in this pull request?
Refactored ConsoleWriter into ConsoleMicrobatchWriter and ConsoleContinuousWriter.
## How was this patch tested?
new unit test
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20311 from tdas/SPARK-23144.
## What changes were proposed in this pull request?
Self-explanatory.
## How was this patch tested?
New python tests.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20309 from tdas/SPARK-23143.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}