## What changes were proposed in this pull request?
Currently shuffle repartition uses RoundRobinPartitioning, the generated result is nondeterministic since the sequence of input rows are not determined.
The bug can be triggered when there is a repartition call following a shuffle (which would lead to non-deterministic row ordering), as the pattern shows below:
upstream stage -> repartition stage -> result stage
(-> indicate a shuffle)
When one of the executors process goes down, some tasks on the repartition stage will be retried and generate inconsistent ordering, and some tasks of the result stage will be retried generating different data.
The following code returns 931532, instead of 1000000:
```
import scala.sys.process._
import org.apache.spark.TaskContext
val res = spark.range(0, 1000 * 1000, 1).repartition(200).map { x =>
x
}.repartition(200).map { x =>
if (TaskContext.get.attemptNumber == 0 && TaskContext.get.partitionId < 2) {
throw new Exception("pkill -f java".!!)
}
x
}
res.distinct().count()
```
In this PR, we propose a most straight-forward way to fix this problem by performing a local sort before partitioning, after we make the input row ordering deterministic, the function from rows to partitions is fully deterministic too.
The downside of the approach is that with extra local sort inserted, the performance of repartition() will go down, so we add a new config named `spark.sql.execution.sortBeforeRepartition` to control whether this patch is applied. The patch is default enabled to be safe-by-default, but user may choose to manually turn it off to avoid performance regression.
This patch also changes the output rows ordering of repartition(), that leads to a bunch of test cases failure because they are comparing the results directly.
## How was this patch tested?
Add unit test in ExchangeSuite.
With this patch(and `spark.sql.execution.sortBeforeRepartition` set to true), the following query returns 1000000:
```
import scala.sys.process._
import org.apache.spark.TaskContext
spark.conf.set("spark.sql.execution.sortBeforeRepartition", "true")
val res = spark.range(0, 1000 * 1000, 1).repartition(200).map { x =>
x
}.repartition(200).map { x =>
if (TaskContext.get.attemptNumber == 0 && TaskContext.get.partitionId < 2) {
throw new Exception("pkill -f java".!!)
}
x
}
res.distinct().count()
res7: Long = 1000000
```
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#20393 from jiangxb1987/shuffle-repartition.
## What changes were proposed in this pull request?
The code logic between `MemoryStore.putIteratorAsValues` and `Memory.putIteratorAsBytes` are almost same, so we should reduce the duplicate code between them.
## How was this patch tested?
Existing UT.
Author: Xianyang Liu <xianyang.liu@intel.com>
Closes#19285 from ConeyLiu/rmemorystore.
## What changes were proposed in this pull request?
Currently,the deserializeStream in ExternalAppendOnlyMap#DiskMapIterator init when DiskMapIterator instance created.This will cause memory use overhead when ExternalAppendOnlyMap spill too much times.
We can avoid this by making deserializeStream init when it is used the first time.
This patch make deserializeStream init lazily.
## How was this patch tested?
Exist tests
Author: zhoukang <zhoukang199191@gmail.com>
Closes#20292 from caneGuy/zhoukang/lay-diskmapiterator.
## What changes were proposed in this pull request?
[Ticket](https://issues.apache.org/jira/browse/SPARK-22297)
- one of the tests seems to produce unreliable results due to execution speed variability
Since the original test was trying to connect to the test server with `40 ms` timeout, and the test server replied after `50 ms`, the error might be produced under the following conditions:
- it might occur that the test server replies correctly after `50 ms`
- but the client does only receive the timeout after `51 ms`s
- this might happen if the executor has to schedule a big number of threads, and decides to delay the thread/actor that is responsible to watch the timeout, because of high CPU load
- running an entire test suite usually produces high loads on the CPU executing the tests
## How was this patch tested?
The test's check cases remain the same and the set-up emulates the previous version's.
Author: Mark Petruska <petruska.mark@gmail.com>
Closes#19671 from mpetruska/SPARK-22297.
## What changes were proposed in this pull request?
This is a follow-up of #20297 which broke lint-java checks.
This pr fixes the lint-java issues.
```
[ERROR] src/test/java/org/apache/spark/launcher/BaseSuite.java:[21,8] (imports) UnusedImports: Unused import - java.util.concurrent.TimeUnit.
[ERROR] src/test/java/org/apache/spark/launcher/SparkLauncherSuite.java:[27,8] (imports) UnusedImports: Unused import - java.util.concurrent.TimeUnit.
```
## How was this patch tested?
Checked manually in my local environment.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20376 from ueshin/issues/SPARK-23020/fup1.
## What changes were proposed in this pull request?
In this PR stage blacklisting is propagated to UI by introducing a new Spark listener event (SparkListenerExecutorBlacklistedForStage) which indicates the executor is blacklisted for a stage. Either because of the number of failures are exceeded a limit given for an executor (spark.blacklist.stage.maxFailedTasksPerExecutor) or because of the whole node is blacklisted for a stage (spark.blacklist.stage.maxFailedExecutorsPerNode). In case of the node is blacklisting all executors will listed as blacklisted for the stage.
Blacklisting state for a selected stage can be seen "Aggregated Metrics by Executor" table's blacklisting column, where after this change three possible labels could be found:
- "for application": when the executor is blacklisted for the application (see the configuration spark.blacklist.application.maxFailedTasksPerExecutor for details)
- "for stage": when the executor is **only** blacklisted for the stage
- "false" : when the executor is not blacklisted at all
## How was this patch tested?
It is tested both manually and with unit tests.
#### Unit tests
- HistoryServerSuite
- TaskSetBlacklistSuite
- AppStatusListenerSuite
#### Manual test for executor blacklisting
Running Spark as a local cluster:
```
$ bin/spark-shell --master "local-cluster[2,1,1024]" --conf "spark.blacklist.enabled=true" --conf "spark.blacklist.stage.maxFailedTasksPerExecutor=1" --conf "spark.blacklist.application.maxFailedTasksPerExecutor=10" --conf "spark.eventLog.enabled=true"
```
Executing:
``` scala
import org.apache.spark.SparkEnv
sc.parallelize(1 to 10, 10).map { x =>
if (SparkEnv.get.executorId == "0") throw new RuntimeException("Bad executor")
else (x % 3, x)
}.reduceByKey((a, b) => a + b).collect()
```
To see result check the "Aggregated Metrics by Executor" section at the bottom of picture:

#### Manual test for node blacklisting
Running Spark as on a cluster:
``` bash
./bin/spark-shell --master yarn --deploy-mode client --executor-memory=2G --num-executors=8 --conf "spark.blacklist.enabled=true" --conf "spark.blacklist.stage.maxFailedTasksPerExecutor=1" --conf "spark.blacklist.stage.maxFailedExecutorsPerNode=1" --conf "spark.blacklist.application.maxFailedTasksPerExecutor=10" --conf "spark.eventLog.enabled=true"
```
And the job was:
``` scala
import org.apache.spark.SparkEnv
sc.parallelize(1 to 10000, 10).map { x =>
if (SparkEnv.get.executorId.toInt >= 4) throw new RuntimeException("Bad executor")
else (x % 3, x)
}.reduceByKey((a, b) => a + b).collect()
```
The result is:

Here you can see apiros3.gce.test.com was node blacklisted for the stage because of failures on executor 4 and 5. As expected executor 3 is also blacklisted even it has no failures itself but sharing the node with 4 and 5.
Author: “attilapiros” <piros.attila.zsolt@gmail.com>
Author: Attila Zsolt Piros <2017933+attilapiros@users.noreply.github.com>
Closes#20203 from attilapiros/SPARK-22577.
## What changes were proposed in this pull request?
#20002 purposed a way to safe check the default partitioner, however, if `spark.default.parallelism` is set, the defaultParallelism still could be smaller than the proper number of partitions for upstreams RDDs. This PR tries to extend the approach to address the condition when `spark.default.parallelism` is set.
The requirements where the PR helps with are :
- Max partitioner is not eligible since it is atleast an order smaller, and
- User has explicitly set 'spark.default.parallelism', and
- Value of 'spark.default.parallelism' is lower than max partitioner
- Since max partitioner was discarded due to being at least an order smaller, default parallelism is worse - even though user specified.
Under the rest cases, the changes should be no-op.
## How was this patch tested?
Add corresponding test cases in `PairRDDFunctionsSuite` and `PartitioningSuite`.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#20091 from jiangxb1987/partitioner.
## What changes were proposed in this pull request?
Add support for using pandas UDFs with groupby().agg().
This PR introduces a new type of pandas UDF - group aggregate pandas UDF. This type of UDF defines a transformation of multiple pandas Series -> a scalar value. Group aggregate pandas UDFs can be used with groupby().agg(). Note group aggregate pandas UDF doesn't support partial aggregation, i.e., a full shuffle is required.
This PR doesn't support group aggregate pandas UDFs that return ArrayType, StructType or MapType. Support for these types is left for future PR.
## How was this patch tested?
GroupbyAggPandasUDFTests
Author: Li Jin <ice.xelloss@gmail.com>
Closes#19872 from icexelloss/SPARK-22274-groupby-agg.
## What changes were proposed in this pull request?
Typo fixes
## How was this patch tested?
Local build / Doc-only changes
Author: Jacek Laskowski <jacek@japila.pl>
Closes#20344 from jaceklaskowski/typo-fixes.
## What changes were proposed in this pull request?
The allJobs and the job pages attempt to use stage attempt and DAG visualization from the store, but for long running jobs they are not guaranteed to be retained, leading to exceptions when these pages are rendered.
To fix it `store.lastStageAttempt(stageId)` and `store.operationGraphForJob(jobId)` are wrapped in `store.asOption` and default values are used if the info is missing.
## How was this patch tested?
Manual testing of the UI, also using the test command reported in SPARK-23121:
./bin/spark-submit --class org.apache.spark.examples.streaming.HdfsWordCount ./examples/jars/spark-examples_2.11-2.4.0-SNAPSHOT.jar /spark
Closes#20287
Author: Sandor Murakozi <smurakozi@gmail.com>
Closes#20330 from smurakozi/SPARK-23121.
## What changes were proposed in this pull request?
ClosureCleaner moved from warning to debug
## How was this patch tested?
Existing tests
Author: Rekha Joshi <rekhajoshm@gmail.com>
Author: rjoshi2 <rekhajoshm@gmail.com>
Closes#20337 from rekhajoshm/SPARK-11630-1.
The race in the code is because the handle might update
its state to the wrong state if the connection handling
thread is still processing incoming data; so the handle
needs to wait for the connection to finish up before
checking the final state.
The race in the test is because when waiting for a handle
to reach a final state, the waitFor() method needs to wait
until all handle state is updated (which also includes
waiting for the connection thread above to finish).
Otherwise, waitFor() may return too early, which would cause
a bunch of different races (like the listener not being yet
notified of the state change, or being in the middle of
being notified, or the handle not being properly disposed
and causing postChecks() to assert).
On top of that I found, by code inspection, a couple of
potential races that could make a handle end up in the
wrong state when being killed.
The original version of this fix introduced the flipped
version of the first race described above; the connection
closing might override the handle state before the
handle might have a chance to do cleanup. The fix there
is to only dispose of the handle from the connection
when there is an error, and let the handle dispose
itself in the normal case.
The fix also caused a bug in YarnClusterSuite to be surfaced;
the code was checking for a file in the classpath that was
not expected to be there in client mode. Because of the above
issues, the error was not propagating correctly and the (buggy)
test was incorrectly passing.
Tested by running the existing unit tests a lot (and not
seeing the errors I was seeing before).
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20297 from vanzin/SPARK-23020.
## What changes were proposed in this pull request?
The clean up logic on the worker perviously determined the liveness of a
particular applicaiton based on whether or not it had running executors.
This would fail in the case that a directory was made for a driver
running in cluster mode if that driver had no running executors on the
same machine. To preserve driver directories we consider both executors
and running drivers when checking directory liveness.
## How was this patch tested?
Manually started up two node cluster with a single core on each node. Turned on worker directory cleanup and set the interval to 1 second and liveness to one second. Without the patch the driver directory is removed immediately after the app is launched. With the patch it is not
### Without Patch
```
INFO 2018-01-05 23:48:24,693 Logging.scala:54 - Asked to launch driver driver-20180105234824-0000
INFO 2018-01-05 23:48:25,293 Logging.scala:54 - Changing view acls to: cassandra
INFO 2018-01-05 23:48:25,293 Logging.scala:54 - Changing modify acls to: cassandra
INFO 2018-01-05 23:48:25,294 Logging.scala:54 - Changing view acls groups to:
INFO 2018-01-05 23:48:25,294 Logging.scala:54 - Changing modify acls groups to:
INFO 2018-01-05 23:48:25,294 Logging.scala:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(cassandra); groups with view permissions: Set(); users with modify permissions: Set(cassandra); groups with modify permissions: Set()
INFO 2018-01-05 23:48:25,330 Logging.scala:54 - Copying user jar file:/home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180105234824-0000/writeRead-0.1.jar
INFO 2018-01-05 23:48:25,332 Logging.scala:54 - Copying /home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180105234824-0000/writeRead-0.1.jar
INFO 2018-01-05 23:48:25,361 Logging.scala:54 - Launch Command: "/usr/lib/jvm/jdk1.8.0_40//bin/java" ....
****
INFO 2018-01-05 23:48:56,577 Logging.scala:54 - Removing directory: /var/lib/spark/worker/driver-20180105234824-0000 ### << Cleaned up
****
--
One minute passes while app runs (app has 1 minute sleep built in)
--
WARN 2018-01-05 23:49:58,080 ShuffleSecretManager.java:73 - Attempted to unregister application app-20180105234831-0000 when it is not registered
INFO 2018-01-05 23:49:58,081 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = false
INFO 2018-01-05 23:49:58,081 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = false
INFO 2018-01-05 23:49:58,082 ExternalShuffleBlockResolver.java:163 - Application app-20180105234831-0000 removed, cleanupLocalDirs = true
INFO 2018-01-05 23:50:00,999 Logging.scala:54 - Driver driver-20180105234824-0000 exited successfully
```
With Patch
```
INFO 2018-01-08 23:19:54,603 Logging.scala:54 - Asked to launch driver driver-20180108231954-0002
INFO 2018-01-08 23:19:54,975 Logging.scala:54 - Changing view acls to: automaton
INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing modify acls to: automaton
INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing view acls groups to:
INFO 2018-01-08 23:19:54,976 Logging.scala:54 - Changing modify acls groups to:
INFO 2018-01-08 23:19:54,976 Logging.scala:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(automaton); groups with view permissions: Set(); users with modify permissions: Set(automaton); groups with modify permissions: Set()
INFO 2018-01-08 23:19:55,029 Logging.scala:54 - Copying user jar file:/home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180108231954-0002/writeRead-0.1.jar
INFO 2018-01-08 23:19:55,031 Logging.scala:54 - Copying /home/automaton/writeRead-0.1.jar to /var/lib/spark/worker/driver-20180108231954-0002/writeRead-0.1.jar
INFO 2018-01-08 23:19:55,038 Logging.scala:54 - Launch Command: ......
INFO 2018-01-08 23:21:28,674 ShuffleSecretManager.java:69 - Unregistered shuffle secret for application app-20180108232000-0000
INFO 2018-01-08 23:21:28,675 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = false
INFO 2018-01-08 23:21:28,675 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = false
INFO 2018-01-08 23:21:28,681 ExternalShuffleBlockResolver.java:163 - Application app-20180108232000-0000 removed, cleanupLocalDirs = true
INFO 2018-01-08 23:21:31,703 Logging.scala:54 - Driver driver-20180108231954-0002 exited successfully
*****
INFO 2018-01-08 23:21:32,346 Logging.scala:54 - Removing directory: /var/lib/spark/worker/driver-20180108231954-0002 ### < Happening AFTER the Run completes rather than during it
*****
```
Author: Russell Spitzer <Russell.Spitzer@gmail.com>
Closes#20298 from RussellSpitzer/SPARK-22976-master.
The code was sorting "0" as "less than" negative values, which is a little
wrong. Fix is simple, most of the changes are the added test and related
cleanup.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20284 from vanzin/SPARK-23103.
Detect the deletion of event log files from storage, and remove
data about the related application attempt in the SHS.
Also contains code to fix SPARK-21571 based on code by ericvandenbergfb.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20138 from vanzin/SPARK-20664.
## What changes were proposed in this pull request?
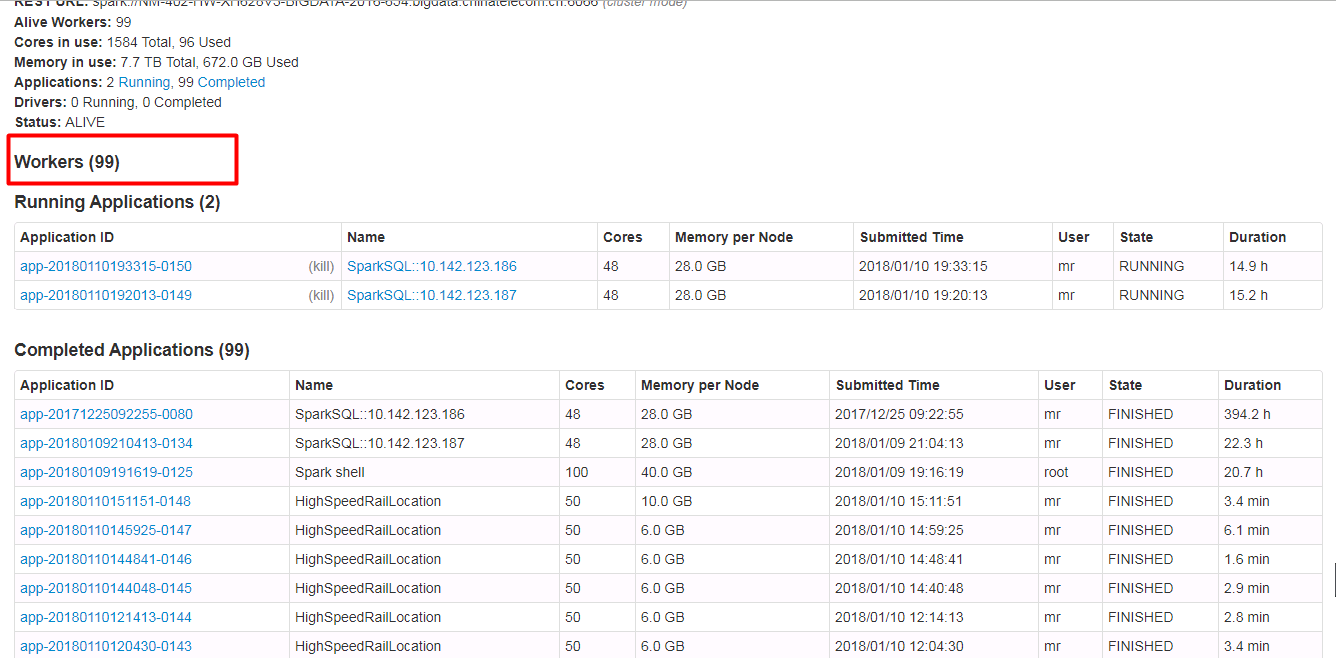
Spark ui about the contents of the form need to have hidden and show features, when the table records very much. Because sometimes you do not care about the record of the table, you just want to see the contents of the next table, but you have to scroll the scroll bar for a long time to see the contents of the next table.
Currently we have about 500 workers, but I just wanted to see the logs for the running applications table. I had to scroll through the scroll bars for a long time to see the logs for the running applications table.
In order to ensure functional consistency, I modified the Master Page, Worker Page, Job Page, Stage Page, Task Page, Configuration Page, Storage Page, Pool Page.
fix before:
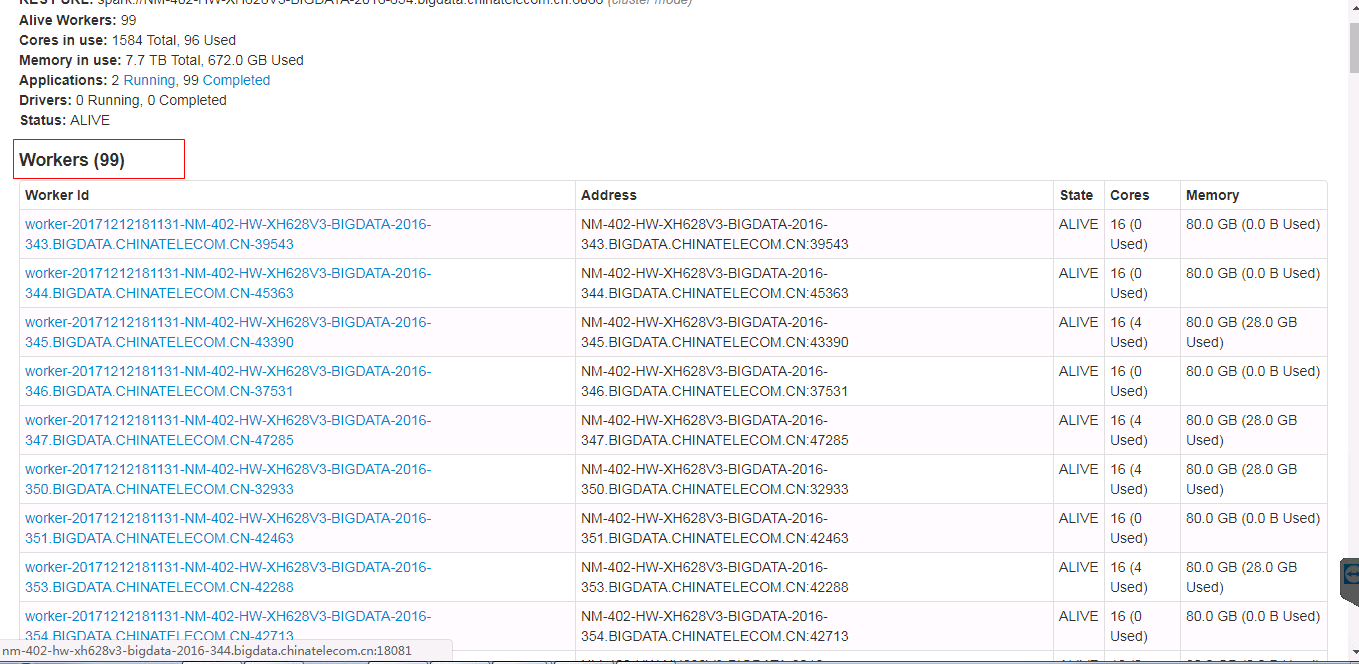
fix after:
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: guoxiaolong <guo.xiaolong1@zte.com.cn>
Closes#20216 from guoxiaolongzte/SPARK-23024.
## What changes were proposed in this pull request?
This PR completes the docs, specifying the default units assumed in configuration entries of type size.
This is crucial since unit-less values are accepted and the user might assume the base unit is bytes, which in most cases it is not, leading to hard-to-debug problems.
## How was this patch tested?
This patch updates only documentation only.
Author: Fernando Pereira <fernando.pereira@epfl.ch>
Closes#20269 from ferdonline/docs_units.
## What changes were proposed in this pull request?
Stage's task page table will throw an exception when there's no complete tasks. Furthermore, because the `dataSize` doesn't take running tasks into account, so sometimes UI cannot show the running tasks. Besides table will only be displayed when first task is finished according to the default sortColumn("index").
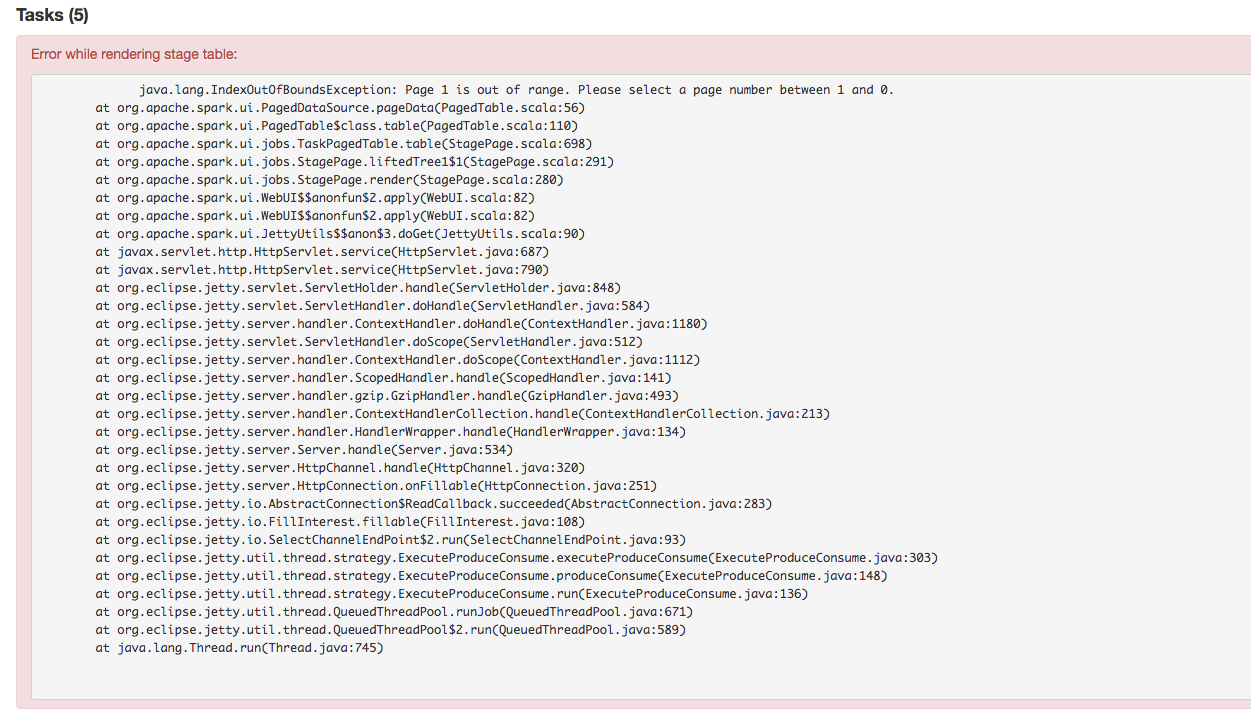
To reproduce this issue, user could try `sc.parallelize(1 to 20, 20).map { i => Thread.sleep(10000); i }.collect()` or `sc.parallelize(1 to 20, 20).map { i => Thread.sleep((20 - i) * 1000); i }.collect` to reproduce the above issue.
Here propose a solution to fix it. Not sure if it is a right fix, please help to review.
## How was this patch tested?
Manual test.
Author: jerryshao <sshao@hortonworks.com>
Closes#20315 from jerryshao/SPARK-23147.
## What changes were proposed in this pull request?
Temporarily ignoring flaky test `SparkLauncherSuite.testInProcessLauncher` to de-flake the builds. This should be re-enabled when SPARK-23020 is merged.
## How was this patch tested?
N/A (Test Only Change)
Author: Sameer Agarwal <sameerag@apache.org>
Closes#20291 from sameeragarwal/disable-test-2.
## What changes were proposed in this pull request?
Lots of our tests don't properly shutdown everything they create, and end up leaking lots of threads. For example, `TaskSetManagerSuite` doesn't stop the extra `TaskScheduler` and `DAGScheduler` it creates. There are a couple more instances, eg. in `DAGSchedulerSuite`.
This PR adds the possibility to print out the not properly stopped thread list after a test suite executed. The format is the following:
```
===== FINISHED o.a.s.scheduler.DAGSchedulerSuite: 'task end event should have updated accumulators (SPARK-20342)' =====
...
===== Global thread whitelist loaded with name /thread_whitelist from classpath: rpc-client.*, rpc-server.*, shuffle-client.*, shuffle-server.*' =====
ScalaTest-run:
===== THREADS NOT STOPPED PROPERLY =====
ScalaTest-run: dag-scheduler-event-loop
ScalaTest-run: globalEventExecutor-2-5
ScalaTest-run:
===== END OF THREAD DUMP =====
ScalaTest-run:
===== EITHER PUT THREAD NAME INTO THE WHITELIST FILE OR SHUT IT DOWN PROPERLY =====
```
With the help of this leaking threads has been identified in TaskSetManagerSuite. My intention is to hunt down and fix such bugs in later PRs.
## How was this patch tested?
Manual: TaskSetManagerSuite test executed and found out where are the leaking threads.
Automated: Pass the Jenkins.
Author: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Closes#19893 from gaborgsomogyi/SPARK-16139.
The race in the code is because the handle might update
its state to the wrong state if the connection handling
thread is still processing incoming data; so the handle
needs to wait for the connection to finish up before
checking the final state.
The race in the test is because when waiting for a handle
to reach a final state, the waitFor() method needs to wait
until all handle state is updated (which also includes
waiting for the connection thread above to finish).
Otherwise, waitFor() may return too early, which would cause
a bunch of different races (like the listener not being yet
notified of the state change, or being in the middle of
being notified, or the handle not being properly disposed
and causing postChecks() to assert).
On top of that I found, by code inspection, a couple of
potential races that could make a handle end up in the
wrong state when being killed.
Tested by running the existing unit tests a lot (and not
seeing the errors I was seeing before).
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20223 from vanzin/SPARK-23020.
## What changes were proposed in this pull request?
In 2.2, Spark UI displayed the stage description if the job description was not set. This functionality was broken, the GUI has shown no description in this case. In addition, the code uses jobName and
jobDescription instead of stageName and stageDescription when JobTableRowData is created.
In this PR the logic producing values for the job rows was modified to find the latest stage attempt for the job and use that as a fallback if job description was missing.
StageName and stageDescription are also set using values from stage and jobName/description is used only as a fallback.
## How was this patch tested?
Manual testing of the UI, using the code in the bug report.
Author: Sandor Murakozi <smurakozi@gmail.com>
Closes#20251 from smurakozi/SPARK-23051.
## What changes were proposed in this pull request?
We are now forced to use `pyspark/daemon.py` and `pyspark/worker.py` in PySpark.
This doesn't allow a custom modification for it (well, maybe we can still do this in a super hacky way though, for example, setting Python executable that has the custom modification). Because of this, for example, it's sometimes hard to debug what happens inside Python worker processes.
This is actually related with [SPARK-7721](https://issues.apache.org/jira/browse/SPARK-7721) too as somehow Coverage is unable to detect the coverage from `os.fork`. If we have some custom fixes to force the coverage, it works fine.
This is also related with [SPARK-20368](https://issues.apache.org/jira/browse/SPARK-20368). This JIRA describes Sentry support which (roughly) needs some changes within worker side.
With this configuration advanced users will be able to do a lot of pluggable workarounds and we can meet such potential needs in the future.
As an example, let's say if I configure the module `coverage_daemon` and had `coverage_daemon.py` in the python path:
```python
import os
from pyspark import daemon
if "COVERAGE_PROCESS_START" in os.environ:
from pyspark.worker import main
def _cov_wrapped(*args, **kwargs):
import coverage
cov = coverage.coverage(
config_file=os.environ["COVERAGE_PROCESS_START"])
cov.start()
try:
main(*args, **kwargs)
finally:
cov.stop()
cov.save()
daemon.worker_main = _cov_wrapped
if __name__ == '__main__':
daemon.manager()
```
I can track the coverages in worker side too.
More importantly, we can leave the main code intact but allow some workarounds.
## How was this patch tested?
Manually tested.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20151 from HyukjinKwon/configuration-daemon-worker.
## What changes were proposed in this pull request?
This pr to make `0` as a valid value for `spark.dynamicAllocation.executorIdleTimeout`.
For details, see the jira description: https://issues.apache.org/jira/browse/SPARK-22870.
## How was this patch tested?
N/A
Author: Yuming Wang <yumwang@ebay.com>
Author: Yuming Wang <wgyumg@gmail.com>
Closes#20080 from wangyum/SPARK-22870.
## What changes were proposed in this pull request?
Spark still use a few years old version 3.2.11. This change is to upgrade json4s to 3.5.3.
Note that this change does not include the Jackson update because the Jackson version referenced in json4s 3.5.3 is 2.8.4, which has a security vulnerability ([see](https://issues.apache.org/jira/browse/SPARK-20433)).
## How was this patch tested?
Existing unit tests and build.
Author: shimamoto <chibochibo@gmail.com>
Closes#20233 from shimamoto/upgrade-json4s.
## What changes were proposed in this pull request?
This patch bumps the master branch version to `2.4.0-SNAPSHOT`.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20222 from gatorsmile/bump24.
When resources happen to be constrained on an executor the first time a broadcast variable is instantiated it is persisted to disk by the BlockManager. Consequently, every subsequent call to TorrentBroadcast::readBroadcastBlock from other instances of that broadcast variable spawns another instance of the underlying value. That is, broadcast variables are spawned once per executor **unless** memory is constrained, in which case every instance of a broadcast variable is provided with a unique copy of the underlying value.
This patch fixes the above by explicitly caching the underlying values using weak references in a ReferenceMap.
Author: ho3rexqj <ho3rexqj@gmail.com>
Closes#20183 from ho3rexqj/fix/cache-broadcast-values.
There are two main changes to speed up rendering of the tasks list
when rendering the stage page.
The first one makes the code only load the tasks being shown in the
current page of the tasks table, and information related to only
those tasks. One side-effect of this change is that the graph that
shows task-related events now only shows events for the tasks in
the current page, instead of the previously hardcoded limit of "events
for the first 1000 tasks". That ends up helping with readability,
though.
To make sorting efficient when using a disk store, the task wrapper
was extended to include many new indices, one for each of the sortable
columns in the UI, and metrics for which quantiles are calculated.
The second changes the way metric quantiles are calculated for stages.
Instead of using the "Distribution" class to process data for all task
metrics, which requires scanning all tasks of a stage, the code now
uses the KVStore "skip()" functionality to only read tasks that contain
interesting information for the quantiles that are desired.
This is still not cheap; because there are many metrics that the UI
and API track, the code needs to scan the index for each metric to
gather the information. Savings come mainly from skipping deserialization
when using the disk store, but the in-memory code also seems to be
faster than before (most probably because of other changes in this
patch).
To make subsequent calls faster, some quantiles are cached in the
status store. This makes UIs much faster after the first time a stage
has been loaded.
With the above changes, a lot of code in the UI layer could be simplified.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20013 from vanzin/SPARK-20657.
## What changes were proposed in this pull request?
This patch modifies Spark's `MemoryAllocator` implementations so that `free(MemoryBlock)` mutates the passed block to clear pointers (in the off-heap case) or null out references to backing `long[]` arrays (in the on-heap case). The goal of this change is to add an extra layer of defense against use-after-free bugs because currently it's hard to detect corruption caused by blind writes to freed memory blocks.
## How was this patch tested?
New unit tests in `PlatformSuite`, including new tests for existing functionality because we did not have sufficient mutation coverage of the on-heap memory allocator's pooling logic.
Author: Josh Rosen <joshrosen@databricks.com>
Closes#20191 from JoshRosen/SPARK-22997-add-defenses-against-use-after-free-bugs-in-memory-allocator.
## What changes were proposed in this pull request?
This patch fixes a severe asynchronous IO bug in Spark's Netty-based file transfer code. At a high-level, the problem is that an unsafe asynchronous `close()` of a pipe's source channel creates a race condition where file transfer code closes a file descriptor then attempts to read from it. If the closed file descriptor's number has been reused by an `open()` call then this invalid read may cause unrelated file operations to return incorrect results. **One manifestation of this problem is incorrect query results.**
For a high-level overview of how file download works, take a look at the control flow in `NettyRpcEnv.openChannel()`: this code creates a pipe to buffer results, then submits an asynchronous stream request to a lower-level TransportClient. The callback passes received data to the sink end of the pipe. The source end of the pipe is passed back to the caller of `openChannel()`. Thus `openChannel()` returns immediately and callers interact with the returned pipe source channel.
Because the underlying stream request is asynchronous, errors may occur after `openChannel()` has returned and after that method's caller has started to `read()` from the returned channel. For example, if a client requests an invalid stream from a remote server then the "stream does not exist" error may not be received from the remote server until after `openChannel()` has returned. In order to be able to propagate the "stream does not exist" error to the file-fetching application thread, this code wraps the pipe's source channel in a special `FileDownloadChannel` which adds an `setError(t: Throwable)` method, then calls this `setError()` method in the FileDownloadCallback's `onFailure` method.
It is possible for `FileDownloadChannel`'s `read()` and `setError()` methods to be called concurrently from different threads: the `setError()` method is called from within the Netty RPC system's stream callback handlers, while the `read()` methods are called from higher-level application code performing remote stream reads.
The problem lies in `setError()`: the existing code closed the wrapped pipe source channel. Because `read()` and `setError()` occur in different threads, this means it is possible for one thread to be calling `source.read()` while another asynchronously calls `source.close()`. Java's IO libraries do not guarantee that this will be safe and, in fact, it's possible for these operations to interleave in such a way that a lower-level `read()` system call occurs right after a `close()` call. In the best-case, this fails as a read of a closed file descriptor; in the worst-case, the file descriptor number has been re-used by an intervening `open()` operation and the read corrupts the result of an unrelated file IO operation being performed by a different thread.
The solution here is to remove the `stream.close()` call in `onError()`: the thread that is performing the `read()` calls is responsible for closing the stream in a `finally` block, so there's no need to close it here. If that thread is blocked in a `read()` then it will become unblocked when the sink end of the pipe is closed in `FileDownloadCallback.onFailure()`.
After making this change, we also need to refine the `read()` method to always check for a `setError()` result, even if the underlying channel `read()` call has succeeded.
This patch also makes a slight cleanup to a dodgy-looking `catch e: Exception` block to use a safer `try-finally` error handling idiom.
This bug was introduced in SPARK-11956 / #9941 and is present in Spark 1.6.0+.
## How was this patch tested?
This fix was tested manually against a workload which non-deterministically hit this bug.
Author: Josh Rosen <joshrosen@databricks.com>
Closes#20179 from JoshRosen/SPARK-22982-fix-unsafe-async-io-in-file-download-channel.
## What changes were proposed in this pull request?
In current implementation of RDD.take, we overestimate the number of partitions we need to try by 50%:
`(1.5 * num * partsScanned / buf.size).toInt`
However, when the number is small, the result of `.toInt` is not what we want.
E.g, 2.9 will become 2, which should be 3.
Use Math.ceil to fix the problem.
Also clean up the code in RDD.scala.
## How was this patch tested?
Unit test
Author: Wang Gengliang <ltnwgl@gmail.com>
Closes#20200 from gengliangwang/Take.
## What changes were proposed in this pull request?
In current implementation, the function `isFairScheduler` is always false, since it is comparing String with `SchedulingMode`
Author: Wang Gengliang <ltnwgl@gmail.com>
Closes#20186 from gengliangwang/isFairScheduler.
## What changes were proposed in this pull request?
1. Deprecate attemptId in StageInfo and add `def attemptNumber() = attemptId`
2. Replace usage of stageAttemptId with stageAttemptNumber
## How was this patch tested?
I manually checked the compiler warning info
Author: Xianjin YE <advancedxy@gmail.com>
Closes#20178 from advancedxy/SPARK-22952.
## What changes were proposed in this pull request?
Register spark.history.ui.port as a known spark conf to be used in substitution expressions even if it's not set explicitly.
## How was this patch tested?
Added unit test to demonstrate the issue
Author: Gera Shegalov <gera@apache.org>
Author: Gera Shegalov <gshegalov@salesforce.com>
Closes#20098 from gerashegalov/gera/register-SHS-port-conf.
## What changes were proposed in this pull request?
We missed enabling `spark.files` and `spark.jars` in https://github.com/apache/spark/pull/19954. The result is that remote dependencies specified through `spark.files` or `spark.jars` are not included in the list of remote dependencies to be downloaded by the init-container. This PR fixes it.
## How was this patch tested?
Manual tests.
vanzin This replaces https://github.com/apache/spark/pull/20157.
foxish
Author: Yinan Li <liyinan926@gmail.com>
Closes#20160 from liyinan926/SPARK-22757.
The code in LiveListenerBus was queueing events before start in the
queues themselves; so in situations like the following:
bus.post(someEvent)
bus.addToEventLogQueue(listener)
bus.start()
"someEvent" would not be delivered to "listener" if that was the first
listener in the queue, because the queue wouldn't exist when the
event was posted.
This change buffers the events before starting the bus in the bus itself,
so that they can be delivered to all registered queues when the bus is
started.
Also tweaked the unit tests to cover the behavior above.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20039 from vanzin/SPARK-22850.
## What changes were proposed in this pull request?
When overwriting a partitioned table with dynamic partition columns, the behavior is different between data source and hive tables.
data source table: delete all partition directories that match the static partition values provided in the insert statement.
hive table: only delete partition directories which have data written into it
This PR adds a new config to make users be able to choose hive's behavior.
## How was this patch tested?
new tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#18714 from cloud-fan/overwrite-partition.
## What changes were proposed in this pull request?
stageAttemptId added in TaskContext and corresponding construction modification
## How was this patch tested?
Added a new test in TaskContextSuite, two cases are tested:
1. Normal case without failure
2. Exception case with resubmitted stages
Link to [SPARK-22897](https://issues.apache.org/jira/browse/SPARK-22897)
Author: Xianjin YE <advancedxy@gmail.com>
Closes#20082 from advancedxy/SPARK-22897.
## What changes were proposed in this pull request?
This reverts commit 5fd0294ff8 because of a huge performance regression.
I manually fixed a minor conflict in `OneForOneBlockFetcher.java`.
`Files.newInputStream` returns `sun.nio.ch.ChannelInputStream`. `ChannelInputStream` doesn't override `InputStream.skip`, so it's using the default `InputStream.skip` which just consumes and discards data. This causes a huge performance regression when reading shuffle files.
## How was this patch tested?
Jenkins
Author: Shixiong Zhu <zsxwing@gmail.com>
Closes#20119 from zsxwing/revert-SPARK-21475.
The scheduled task was racing with the test code and could influence
the values returned to the test, triggering assertions. The change adds
a new config that is only used during testing, and overrides it
on the affected test suite.
The issue in the bug can be reliably reproduced by reducing the interval
in the test (e.g. to 10ms).
While there, fixed an exception that shows up in the logs while these
tests run, and simplified some code (which was also causing misleading
log messages in the log output of the test).
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20050 from vanzin/SPARK-22864.
This change adds a new configuration option and support code that limits
how much disk space the SHS will use. The default value is pretty generous
so that applications will, hopefully, only rarely need to be replayed
because of their disk stored being evicted.
This works by keeping track of how much data each application is using.
Also, because it's not possible to know, before replaying, how much space
will be needed, it's possible that usage will exceed the configured limit
temporarily. The code uses the concept of a "lease" to try to limit how
much the SHS will exceed the limit in those cases.
Active UIs are also tracked, so they're never deleted. This works in
tandem with the existing option of how many active UIs are loaded; because
unused UIs will be unloaded, their disk stores will also become candidates
for deletion. If the data is not deleted, though, re-loading the UI is
pretty quick.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20011 from vanzin/SPARK-20654.
This change adds a new launcher that allows applications to be run
in a separate thread in the same process as the calling code. To
achieve that, some code from the child process implementation was
moved to abstract classes that implement the common functionality,
and the new launcher inherits from those.
The new launcher was added as a new class, instead of implemented
as a new option to the existing SparkLauncher, to avoid ambigous
APIs. For example, SparkLauncher has ways to set the child app's
environment, modify SPARK_HOME, or control the logging of the
child process, none of which apply to in-process apps.
The in-process launcher has limitations: it needs Spark in the
context class loader of the calling thread, and it's bound by
Spark's current limitation of a single client-mode application
per JVM. It also relies on the recently added SparkApplication
trait to make sure different apps don't mess up each other's
configuration, so config isolation is currently limited to cluster mode.
I also chose to keep the same socket-based communication for in-process
apps, even though it might be possible to avoid it for in-process
mode. That helps both implementations share more code.
Tested with new and existing unit tests, and with a simple app that
uses the launcher; also made sure the app ran fine with older launcher
jar to check binary compatibility.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#19591 from vanzin/SPARK-11035.
Port code from the old executors listener to the new one, so that
the driver logs present in the application start event are kept.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20038 from vanzin/SPARK-22836.
## What changes were proposed in this pull request?
This PR cleans up a few Java linter errors for Apache Spark 2.3 release.
## How was this patch tested?
```bash
$ dev/lint-java
Using `mvn` from path: /usr/local/bin/mvn
Checkstyle checks passed.
```
We can see the result from [Travis CI](https://travis-ci.org/dongjoon-hyun/spark/builds/322470787), too.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20101 from dongjoon-hyun/fix-java-lint.
## What changes were proposed in this pull request?
In SPARK-20586 the flag `deterministic` was added to Scala UDF, but it is not available for python UDF. This flag is useful for cases when the UDF's code can return different result with the same input. Due to optimization, duplicate invocations may be eliminated or the function may even be invoked more times than it is present in the query. This can lead to unexpected behavior.
This PR adds the deterministic flag, via the `asNondeterministic` method, to let the user mark the function as non-deterministic and therefore avoid the optimizations which might lead to strange behaviors.
## How was this patch tested?
Manual tests:
```
>>> from pyspark.sql.functions import *
>>> from pyspark.sql.types import *
>>> df_br = spark.createDataFrame([{'name': 'hello'}])
>>> import random
>>> udf_random_col = udf(lambda: int(100*random.random()), IntegerType()).asNondeterministic()
>>> df_br = df_br.withColumn('RAND', udf_random_col())
>>> random.seed(1234)
>>> udf_add_ten = udf(lambda rand: rand + 10, IntegerType())
>>> df_br.withColumn('RAND_PLUS_TEN', udf_add_ten('RAND')).show()
+-----+----+-------------+
| name|RAND|RAND_PLUS_TEN|
+-----+----+-------------+
|hello| 3| 13|
+-----+----+-------------+
```
Author: Marco Gaido <marcogaido91@gmail.com>
Author: Marco Gaido <mgaido@hortonworks.com>
Closes#19929 from mgaido91/SPARK-22629.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}