## What changes were proposed in this pull request?
This PR wraps the `asNondeterministic` attribute in the wrapped UDF function to set the docstring properly.
```python
from pyspark.sql.functions import udf
help(udf(lambda x: x).asNondeterministic)
```
Before:
```
Help on function <lambda> in module pyspark.sql.udf:
<lambda> lambda
(END
```
After:
```
Help on function asNondeterministic in module pyspark.sql.udf:
asNondeterministic()
Updates UserDefinedFunction to nondeterministic.
.. versionadded:: 2.3
(END)
```
## How was this patch tested?
Manually tested and a simple test was added.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20173 from HyukjinKwon/SPARK-22901-followup.
## What changes were proposed in this pull request?
Add tests for using non deterministic UDFs in aggregate.
Update pandas_udf docstring w.r.t to determinism.
## How was this patch tested?
test_nondeterministic_udf_in_aggregate
Author: Li Jin <ice.xelloss@gmail.com>
Closes#20142 from icexelloss/SPARK-22930-pandas-udf-deterministic.
## What changes were proposed in this pull request?
```Python
import random
from pyspark.sql.functions import udf
from pyspark.sql.types import IntegerType, StringType
random_udf = udf(lambda: int(random.random() * 100), IntegerType()).asNondeterministic()
spark.catalog.registerFunction("random_udf", random_udf, StringType())
spark.sql("SELECT random_udf()").collect()
```
We will get the following error.
```
Py4JError: An error occurred while calling o29.__getnewargs__. Trace:
py4j.Py4JException: Method __getnewargs__([]) does not exist
at py4j.reflection.ReflectionEngine.getMethod(ReflectionEngine.java:318)
at py4j.reflection.ReflectionEngine.getMethod(ReflectionEngine.java:326)
at py4j.Gateway.invoke(Gateway.java:274)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:214)
at java.lang.Thread.run(Thread.java:745)
```
This PR is to support it.
## How was this patch tested?
WIP
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20137 from gatorsmile/registerFunction.
## What changes were proposed in this pull request?
R Structured Streaming API for withWatermark, trigger, partitionBy
## How was this patch tested?
manual, unit tests
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#20129 from felixcheung/rwater.
## What changes were proposed in this pull request?
This change adds `ArrayType` support for working with Arrow in pyspark when creating a DataFrame, calling `toPandas()`, and using vectorized `pandas_udf`.
## How was this patch tested?
Added new Python unit tests using Array data.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#20114 from BryanCutler/arrow-ArrayType-support-SPARK-22530.
Previously, `FeatureHasher` always treats numeric type columns as numbers and never as categorical features. It is quite common to have categorical features represented as numbers or codes in data sources.
In order to hash these features as categorical, users must first explicitly convert them to strings which is cumbersome.
Add a new param `categoricalCols` which specifies the numeric columns that should be treated as categorical features.
## How was this patch tested?
New unit tests.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#19991 from MLnick/hasher-num-cat.
## What changes were proposed in this pull request?
This pr modified `concat` to concat binary inputs into a single binary output.
`concat` in the current master always output data as a string. But, in some databases (e.g., PostgreSQL), if all inputs are binary, `concat` also outputs binary.
## How was this patch tested?
Added tests in `SQLQueryTestSuite` and `TypeCoercionSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#19977 from maropu/SPARK-22771.
(Please fill in changes proposed in this fix)
Python API for VectorSizeHint Transformer.
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
doc-tests.
Author: Bago Amirbekian <bago@databricks.com>
Closes#20112 from MrBago/vectorSizeHint-PythonAPI.
## What changes were proposed in this pull request?
Adding fitMultiple API to `Estimator` with default implementation. Also update have ml.tuning meta-estimators use this API.
## How was this patch tested?
Unit tests.
Author: Bago Amirbekian <bago@databricks.com>
Closes#20058 from MrBago/python-fitMultiple.
## What changes were proposed in this pull request?
This is a follow-up pr of #19587.
If `xmlrunner` is installed, `VectorizedUDFTests.test_vectorized_udf_check_config` fails by the following error because the `self` which is a subclass of `unittest.TestCase` in the UDF `check_records_per_batch` can't be pickled anymore.
```
PicklingError: Cannot pickle files that are not opened for reading: w
```
This changes the UDF not to refer the `self`.
## How was this patch tested?
Tested locally.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20115 from ueshin/issues/SPARK-22370_fup1.
## What changes were proposed in this pull request?
This PR explicitly imports the missing `warnings` in `flume.py`.
## How was this patch tested?
Manually tested.
```python
>>> import warnings
>>> warnings.simplefilter('always', DeprecationWarning)
>>> from pyspark.streaming import flume
>>> flume.FlumeUtils.createStream(None, None, None)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/.../spark/python/pyspark/streaming/flume.py", line 60, in createStream
warnings.warn(
NameError: global name 'warnings' is not defined
```
```python
>>> import warnings
>>> warnings.simplefilter('always', DeprecationWarning)
>>> from pyspark.streaming import flume
>>> flume.FlumeUtils.createStream(None, None, None)
/.../spark/python/pyspark/streaming/flume.py:65: DeprecationWarning: Deprecated in 2.3.0. Flume support is deprecated as of Spark 2.3.0. See SPARK-22142.
DeprecationWarning)
...
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20110 from HyukjinKwon/SPARK-22313-followup.
## What changes were proposed in this pull request?
Escape of escape should be considered when using the UniVocity csv encoding/decoding library.
Ref: https://github.com/uniVocity/univocity-parsers#escaping-quote-escape-characters
One option is added for reading and writing CSV: `escapeQuoteEscaping`
## How was this patch tested?
Unit test added.
Author: soonmok-kwon <soonmok.kwon@navercorp.com>
Closes#20004 from ep1804/SPARK-22818.
## What changes were proposed in this pull request?
In SPARK-20586 the flag `deterministic` was added to Scala UDF, but it is not available for python UDF. This flag is useful for cases when the UDF's code can return different result with the same input. Due to optimization, duplicate invocations may be eliminated or the function may even be invoked more times than it is present in the query. This can lead to unexpected behavior.
This PR adds the deterministic flag, via the `asNondeterministic` method, to let the user mark the function as non-deterministic and therefore avoid the optimizations which might lead to strange behaviors.
## How was this patch tested?
Manual tests:
```
>>> from pyspark.sql.functions import *
>>> from pyspark.sql.types import *
>>> df_br = spark.createDataFrame([{'name': 'hello'}])
>>> import random
>>> udf_random_col = udf(lambda: int(100*random.random()), IntegerType()).asNondeterministic()
>>> df_br = df_br.withColumn('RAND', udf_random_col())
>>> random.seed(1234)
>>> udf_add_ten = udf(lambda rand: rand + 10, IntegerType())
>>> df_br.withColumn('RAND_PLUS_TEN', udf_add_ten('RAND')).show()
+-----+----+-------------+
| name|RAND|RAND_PLUS_TEN|
+-----+----+-------------+
|hello| 3| 13|
+-----+----+-------------+
```
Author: Marco Gaido <marcogaido91@gmail.com>
Author: Marco Gaido <mgaido@hortonworks.com>
Closes#19929 from mgaido91/SPARK-22629.
## What changes were proposed in this pull request?
Decimal type is not yet supported in `ArrowWriter`.
This is adding the decimal type support.
## How was this patch tested?
Added a test to `ArrowConvertersSuite`.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#18754 from ueshin/issues/SPARK-21552.
## What changes were proposed in this pull request?
This is a follow-up pr of #20054 modifying error messages for both pandas and pyarrow to show actual versions.
## How was this patch tested?
Existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20074 from ueshin/issues/SPARK-22874_fup1.
## What changes were proposed in this pull request?
Currently we check pandas version by capturing if `ImportError` for the specific imports is raised or not but we can compare `LooseVersion` of the version strings as the same as we're checking pyarrow version.
## How was this patch tested?
Existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20054 from ueshin/issues/SPARK-22874.
## What changes were proposed in this pull request?
Upgrade Spark to Arrow 0.8.0 for Java and Python. Also includes an upgrade of Netty to 4.1.17 to resolve dependency requirements.
The highlights that pertain to Spark for the update from Arrow versoin 0.4.1 to 0.8.0 include:
* Java refactoring for more simple API
* Java reduced heap usage and streamlined hot code paths
* Type support for DecimalType, ArrayType
* Improved type casting support in Python
* Simplified type checking in Python
## How was this patch tested?
Existing tests
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Shixiong Zhu <zsxwing@gmail.com>
Closes#19884 from BryanCutler/arrow-upgrade-080-SPARK-22324.
## What changes were proposed in this pull request?
Expose Python API for _LinearRegression_ with _huber_ loss.
## How was this patch tested?
Unit test.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#19994 from yanboliang/spark-22810.
## What changes were proposed in this pull request?
Like `Parquet`, users can use `ORC` with Apache Spark structured streaming. This PR adds `orc()` to `DataStreamReader`(Scala/Python) in order to support creating streaming dataset with ORC file format more easily like the other file formats. Also, this adds a test coverage for ORC data source and updates the document.
**BEFORE**
```scala
scala> spark.readStream.schema("a int").orc("/tmp/orc_ss").writeStream.format("console").start()
<console>:24: error: value orc is not a member of org.apache.spark.sql.streaming.DataStreamReader
spark.readStream.schema("a int").orc("/tmp/orc_ss").writeStream.format("console").start()
```
**AFTER**
```scala
scala> spark.readStream.schema("a int").orc("/tmp/orc_ss").writeStream.format("console").start()
res0: org.apache.spark.sql.streaming.StreamingQuery = org.apache.spark.sql.execution.streaming.StreamingQueryWrapper678b3746
scala>
-------------------------------------------
Batch: 0
-------------------------------------------
+---+
| a|
+---+
| 1|
+---+
```
## How was this patch tested?
Pass the newly added test cases.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19975 from dongjoon-hyun/SPARK-22781.
## What changes were proposed in this pull request?
This change adds local checkpoint support to datasets and respective bind from Python Dataframe API.
If reliability requirements can be lowered to favor performance, as in cases of further quick transformations followed by a reliable save, localCheckpoints() fit very well.
Furthermore, at the moment Reliable checkpoints still incur double computation (see #9428)
In general it makes the API more complete as well.
## How was this patch tested?
Python land quick use case:
```python
>>> from time import sleep
>>> from pyspark.sql import types as T
>>> from pyspark.sql import functions as F
>>> def f(x):
sleep(1)
return x*2
...:
>>> df1 = spark.range(30, numPartitions=6)
>>> df2 = df1.select(F.udf(f, T.LongType())("id"))
>>> %time _ = df2.collect()
CPU times: user 7.79 ms, sys: 5.84 ms, total: 13.6 ms
Wall time: 12.2 s
>>> %time df3 = df2.localCheckpoint()
CPU times: user 2.38 ms, sys: 2.3 ms, total: 4.68 ms
Wall time: 10.3 s
>>> %time _ = df3.collect()
CPU times: user 5.09 ms, sys: 410 µs, total: 5.5 ms
Wall time: 148 ms
>>> sc.setCheckpointDir(".")
>>> %time df3 = df2.checkpoint()
CPU times: user 4.04 ms, sys: 1.63 ms, total: 5.67 ms
Wall time: 20.3 s
```
Author: Fernando Pereira <fernando.pereira@epfl.ch>
Closes#19805 from ferdonline/feature_dataset_localCheckpoint.
## What changes were proposed in this pull request?
pyspark.ml.tests is missing a py4j import. I've added the import and fixed the test that uses it. This test was only failing when testing without Hive.
## How was this patch tested?
Existing tests.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Bago Amirbekian <bago@databricks.com>
Closes#19997 from MrBago/fix-ImageReaderTest2.
## What changes were proposed in this pull request?
In multiple text analysis problems, it is not often desirable for the rows to be split by "\n". There exists a wholeText reader for RDD API, and this JIRA just adds the same support for Dataset API.
## How was this patch tested?
Added relevant new tests for both scala and Java APIs
Author: Prashant Sharma <prashsh1@in.ibm.com>
Author: Prashant Sharma <prashant@apache.org>
Closes#14151 from ScrapCodes/SPARK-16496/wholetext.
## What changes were proposed in this pull request?
Calling `ImageSchema.readImages` multiple times as below in PySpark shell:
```python
from pyspark.ml.image import ImageSchema
data_path = 'data/mllib/images/kittens'
_ = ImageSchema.readImages(data_path, recursive=True, dropImageFailures=True).collect()
_ = ImageSchema.readImages(data_path, recursive=True, dropImageFailures=True).collect()
```
throws an error as below:
```
...
org.datanucleus.exceptions.NucleusDataStoreException: Unable to open a test connection to the given database. JDBC url = jdbc:derby:;databaseName=metastore_db;create=true, username = APP. Terminating connection pool (set lazyInit to true if you expect to start your database after your app). Original Exception: ------
java.sql.SQLException: Failed to start database 'metastore_db' with class loader org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1742f639f, see the next exception for details.
...
at org.apache.derby.jdbc.AutoloadedDriver.connect(Unknown Source)
...
at org.apache.hadoop.hive.metastore.HiveMetaStore.newRetryingHMSHandler(HiveMetaStore.java:5762)
...
at org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:180)
...
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:195)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:195)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:195)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:97)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:194)
at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:100)
at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:88)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.externalCatalog(HiveSessionStateBuilder.scala:39)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog$lzycompute(HiveSessionStateBuilder.scala:54)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog(HiveSessionStateBuilder.scala:52)
at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anon$1.<init>(HiveSessionStateBuilder.scala:69)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.analyzer(HiveSessionStateBuilder.scala:69)
at org.apache.spark.sql.internal.BaseSessionStateBuilder$$anonfun$build$2.apply(BaseSessionStateBuilder.scala:293)
at org.apache.spark.sql.internal.BaseSessionStateBuilder$$anonfun$build$2.apply(BaseSessionStateBuilder.scala:293)
at org.apache.spark.sql.internal.SessionState.analyzer$lzycompute(SessionState.scala:79)
at org.apache.spark.sql.internal.SessionState.analyzer(SessionState.scala:79)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:70)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:68)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:51)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:70)
at org.apache.spark.sql.SparkSession.internalCreateDataFrame(SparkSession.scala:574)
at org.apache.spark.sql.SparkSession.createDataFrame(SparkSession.scala:593)
at org.apache.spark.sql.SparkSession.createDataFrame(SparkSession.scala:348)
at org.apache.spark.sql.SparkSession.createDataFrame(SparkSession.scala:348)
at org.apache.spark.ml.image.ImageSchema$$anonfun$readImages$2$$anonfun$apply$1.apply(ImageSchema.scala:253)
...
Caused by: ERROR XJ040: Failed to start database 'metastore_db' with class loader org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1742f639f, see the next exception for details.
at org.apache.derby.iapi.error.StandardException.newException(Unknown Source)
at org.apache.derby.impl.jdbc.SQLExceptionFactory.wrapArgsForTransportAcrossDRDA(Unknown Source)
... 121 more
Caused by: ERROR XSDB6: Another instance of Derby may have already booted the database /.../spark/metastore_db.
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/.../spark/python/pyspark/ml/image.py", line 190, in readImages
dropImageFailures, float(sampleRatio), seed)
File "/.../spark/python/lib/py4j-0.10.6-src.zip/py4j/java_gateway.py", line 1160, in __call__
File "/.../spark/python/pyspark/sql/utils.py", line 69, in deco
raise AnalysisException(s.split(': ', 1)[1], stackTrace)
pyspark.sql.utils.AnalysisException: u'java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient;'
```
Seems we better stick to `SparkSession.builder.getOrCreate()` like:
51620e288b/python/pyspark/sql/streaming.py (L329)dc5d34d8dc/python/pyspark/sql/column.py (L541)33d43bf1b6/python/pyspark/sql/readwriter.py (L105)
## How was this patch tested?
This was tested as below in PySpark shell:
```python
from pyspark.ml.image import ImageSchema
data_path = 'data/mllib/images/kittens'
_ = ImageSchema.readImages(data_path, recursive=True, dropImageFailures=True).collect()
_ = ImageSchema.readImages(data_path, recursive=True, dropImageFailures=True).collect()
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19845 from HyukjinKwon/SPARK-22651.
## What changes were proposed in this pull request?
Image test seems failed in Python 3.6.0 / NumPy 1.13.3. I manually tested as below:
```
======================================================================
ERROR: test_read_images (pyspark.ml.tests.ImageReaderTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/.../spark/python/pyspark/ml/tests.py", line 1831, in test_read_images
self.assertEqual(ImageSchema.toImage(array, origin=first_row[0]), first_row)
File "/.../spark/python/pyspark/ml/image.py", line 149, in toImage
data = bytearray(array.astype(dtype=np.uint8).ravel())
TypeError: only integer scalar arrays can be converted to a scalar index
----------------------------------------------------------------------
Ran 1 test in 7.606s
```
To be clear, I think the error seems from NumPy - 75b2d5d427/numpy/core/src/multiarray/number.c (L947)
For a smaller scope:
```python
>>> import numpy as np
>>> bytearray(np.array([1]).astype(dtype=np.uint8))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: only integer scalar arrays can be converted to a scalar index
```
In Python 2.7 / NumPy 1.13.1, it prints:
```
bytearray(b'\x01')
```
So, here, I simply worked around it by converting it to bytes as below:
```python
>>> bytearray(np.array([1]).astype(dtype=np.uint8).tobytes())
bytearray(b'\x01')
```
Also, while looking into it again, I realised few arguments could be quite confusing, for example, `Row` that needs some specific attributes and `numpy.ndarray`. I added few type checking and added some tests accordingly. So, it shows an error message as below:
```
TypeError: array argument should be numpy.ndarray; however, it got [<class 'str'>].
```
## How was this patch tested?
Manually tested with `./python/run-tests`.
And also:
```
PYSPARK_PYTHON=python3 SPARK_TESTING=1 bin/pyspark pyspark.ml.tests ImageReaderTest
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19835 from HyukjinKwon/SPARK-21866-followup.
## What changes were proposed in this pull request?
When converting Pandas DataFrame/Series from/to Spark DataFrame using `toPandas()` or pandas udfs, timestamp values behave to respect Python system timezone instead of session timezone.
For example, let's say we use `"America/Los_Angeles"` as session timezone and have a timestamp value `"1970-01-01 00:00:01"` in the timezone. Btw, I'm in Japan so Python timezone would be `"Asia/Tokyo"`.
The timestamp value from current `toPandas()` will be the following:
```
>>> spark.conf.set("spark.sql.session.timeZone", "America/Los_Angeles")
>>> df = spark.createDataFrame([28801], "long").selectExpr("timestamp(value) as ts")
>>> df.show()
+-------------------+
| ts|
+-------------------+
|1970-01-01 00:00:01|
+-------------------+
>>> df.toPandas()
ts
0 1970-01-01 17:00:01
```
As you can see, the value becomes `"1970-01-01 17:00:01"` because it respects Python timezone.
As we discussed in #18664, we consider this behavior is a bug and the value should be `"1970-01-01 00:00:01"`.
## How was this patch tested?
Added tests and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#19607 from ueshin/issues/SPARK-22395.
## What changes were proposed in this pull request?
In PySpark API Document, DataFrame.write.csv() says that setting the quote parameter to an empty string should turn off quoting. Instead, it uses the [null character](https://en.wikipedia.org/wiki/Null_character) as the quote.
This PR fixes the doc.
## How was this patch tested?
Manual.
```
cd python/docs
make html
open _build/html/pyspark.sql.html
```
Author: gaborgsomogyi <gabor.g.somogyi@gmail.com>
Closes#19814 from gaborgsomogyi/SPARK-22484.
## What changes were proposed in this pull request?
Adding spark image reader, an implementation of schema for representing images in spark DataFrames
The code is taken from the spark package located here:
(https://github.com/Microsoft/spark-images)
Please see the JIRA for more information (https://issues.apache.org/jira/browse/SPARK-21866)
Please see mailing list for SPIP vote and approval information:
(http://apache-spark-developers-list.1001551.n3.nabble.com/VOTE-SPIP-SPARK-21866-Image-support-in-Apache-Spark-td22510.html)
# Background and motivation
As Apache Spark is being used more and more in the industry, some new use cases are emerging for different data formats beyond the traditional SQL types or the numerical types (vectors and matrices). Deep Learning applications commonly deal with image processing. A number of projects add some Deep Learning capabilities to Spark (see list below), but they struggle to communicate with each other or with MLlib pipelines because there is no standard way to represent an image in Spark DataFrames. We propose to federate efforts for representing images in Spark by defining a representation that caters to the most common needs of users and library developers.
This SPIP proposes a specification to represent images in Spark DataFrames and Datasets (based on existing industrial standards), and an interface for loading sources of images. It is not meant to be a full-fledged image processing library, but rather the core description that other libraries and users can rely on. Several packages already offer various processing facilities for transforming images or doing more complex operations, and each has various design tradeoffs that make them better as standalone solutions.
This project is a joint collaboration between Microsoft and Databricks, which have been testing this design in two open source packages: MMLSpark and Deep Learning Pipelines.
The proposed image format is an in-memory, decompressed representation that targets low-level applications. It is significantly more liberal in memory usage than compressed image representations such as JPEG, PNG, etc., but it allows easy communication with popular image processing libraries and has no decoding overhead.
## How was this patch tested?
Unit tests in scala ImageSchemaSuite, unit tests in python
Author: Ilya Matiach <ilmat@microsoft.com>
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19439 from imatiach-msft/ilmat/spark-images.
## What changes were proposed in this pull request?
Add python api for VectorIndexerModel support handle unseen categories via handleInvalid.
## How was this patch tested?
doctest added.
Author: WeichenXu <weichen.xu@databricks.com>
Closes#19753 from WeichenXu123/vector_indexer_invalid_py.
## What changes were proposed in this pull request?
Besides conditional expressions such as `when` and `if`, users may want to conditionally execute python udfs by short-curcuit evaluation. We should also explicitly note that python udfs don't support this kind of conditional execution too.
## How was this patch tested?
N/A, just document change.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#19787 from viirya/SPARK-22541.
## What changes were proposed in this pull request?
* Add a "function type" argument to pandas_udf.
* Add a new public enum class `PandasUdfType` in pyspark.sql.functions
* Refactor udf related code from pyspark.sql.functions to pyspark.sql.udf
* Merge "PythonUdfType" and "PythonEvalType" into a single enum class "PythonEvalType"
Example:
```
from pyspark.sql.functions import pandas_udf, PandasUDFType
pandas_udf('double', PandasUDFType.SCALAR):
def plus_one(v):
return v + 1
```
## Design doc
https://docs.google.com/document/d/1KlLaa-xJ3oz28xlEJqXyCAHU3dwFYkFs_ixcUXrJNTc/edit
## How was this patch tested?
Added PandasUDFTests
## TODO:
* [x] Implement proper enum type for `PandasUDFType`
* [x] Update documentation
* [x] Add more tests in PandasUDFTests
Author: Li Jin <ice.xelloss@gmail.com>
Closes#19630 from icexelloss/spark-22409-pandas-udf-type.
## What changes were proposed in this pull request?
In PySpark API Document, [SparkSession.build](http://spark.apache.org/docs/2.2.0/api/python/pyspark.sql.html) is not documented and shows default value description.
```
SparkSession.builder = <pyspark.sql.session.Builder object ...
```
This PR adds the doc.

The following is the diff of the generated result.
```
$ diff old.html new.html
95a96,101
> <dl class="attribute">
> <dt id="pyspark.sql.SparkSession.builder">
> <code class="descname">builder</code><a class="headerlink" href="#pyspark.sql.SparkSession.builder" title="Permalink to this definition">¶</a></dt>
> <dd><p>A class attribute having a <a class="reference internal" href="#pyspark.sql.SparkSession.Builder" title="pyspark.sql.SparkSession.Builder"><code class="xref py py-class docutils literal"><span class="pre">Builder</span></code></a> to construct <a class="reference internal" href="#pyspark.sql.SparkSession" title="pyspark.sql.SparkSession"><code class="xref py py-class docutils literal"><span class="pre">SparkSession</span></code></a> instances</p>
> </dd></dl>
>
212,216d217
< <dt id="pyspark.sql.SparkSession.builder">
< <code class="descname">builder</code><em class="property"> = <pyspark.sql.session.SparkSession.Builder object></em><a class="headerlink" href="#pyspark.sql.SparkSession.builder" title="Permalink to this definition">¶</a></dt>
< <dd></dd></dl>
<
< <dl class="attribute">
```
## How was this patch tested?
Manual.
```
cd python/docs
make html
open _build/html/pyspark.sql.html
```
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19726 from dongjoon-hyun/SPARK-22490.
## What changes were proposed in this pull request?
If schema is passed as a list of unicode strings for column names, they should be re-encoded to 'utf-8' to be consistent. This is similar to the #13097 but for creation of DataFrame using Arrow.
## How was this patch tested?
Added new test of using unicode names for schema.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#19738 from BryanCutler/arrow-createDataFrame-followup-unicode-SPARK-20791.
## What changes were proposed in this pull request?
This change uses Arrow to optimize the creation of a Spark DataFrame from a Pandas DataFrame. The input df is sliced according to the default parallelism. The optimization is enabled with the existing conf "spark.sql.execution.arrow.enabled" and is disabled by default.
## How was this patch tested?
Added new unit test to create DataFrame with and without the optimization enabled, then compare results.
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#19459 from BryanCutler/arrow-createDataFrame-from_pandas-SPARK-20791.
## What changes were proposed in this pull request?
This PR proposes to add `errorifexists` to SparkR API and fix the rest of them describing the mode, mainly, in API documentations as well.
This PR also replaces `convertToJSaveMode` to `setWriteMode` so that string as is is passed to JVM and executes:
b034f2565f/sql/core/src/main/scala/org/apache/spark/sql/DataFrameWriter.scala (L72-L82)
and remove the duplication here:
3f958a9992/sql/core/src/main/scala/org/apache/spark/sql/api/r/SQLUtils.scala (L187-L194)
## How was this patch tested?
Manually checked the built documentation. These were mainly found by `` grep -r `error` `` and `grep -r 'error'`.
Also, unit tests added in `test_sparkSQL.R`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19673 from HyukjinKwon/SPARK-21640-followup.
## What changes were proposed in this pull request?
This PR adds support for a new function called `dayofweek` that returns the day of the week of the given argument as an integer value in the range 1-7, where 1 represents Sunday.
## How was this patch tested?
Unit tests and manual tests.
Author: ptkool <michael.styles@shopify.com>
Closes#19672 from ptkool/day_of_week_function.
## What changes were proposed in this pull request?
Currently, a pandas.DataFrame that contains a timestamp of type 'datetime64[ns]' when converted to a Spark DataFrame with `createDataFrame` will interpret the values as LongType. This fix will check for a timestamp type and convert it to microseconds which will allow Spark to read as TimestampType.
## How was this patch tested?
Added unit test to verify Spark schema is expected for TimestampType and DateType when created from pandas
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#19646 from BryanCutler/pyspark-non-arrow-createDataFrame-ts-fix-SPARK-22417.
## What changes were proposed in this pull request?
When writing using jdbc with python currently we are wrongly assigning by default None as writing mode. This is due to wrongly calling mode on the `_jwrite` object instead of `self` and it causes an exception.
## How was this patch tested?
manual tests
Author: Marco Gaido <mgaido@hortonworks.com>
Closes#19654 from mgaido91/SPARK-22437.
## What changes were proposed in this pull request?
Under the current execution mode of Python UDFs, we don't well support Python UDFs as branch values or else value in CaseWhen expression.
Since to fix it might need the change not small (e.g., #19592) and this issue has simpler workaround. We should just notice users in the document about this.
## How was this patch tested?
Only document change.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#19617 from viirya/SPARK-22347-3.
## What changes were proposed in this pull request?
Update the url of reference paper.
## How was this patch tested?
It is comments, so nothing tested.
Author: bomeng <bmeng@us.ibm.com>
Closes#19614 from bomeng/22399.
## What changes were proposed in this pull request?
This PR propose to add `ReusedSQLTestCase` which deduplicate `setUpClass` and `tearDownClass` in `sql/tests.py`.
## How was this patch tested?
Jenkins tests and manual tests.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19595 from HyukjinKwon/reduce-dupe.
## What changes were proposed in this pull request?
`ArrowEvalPythonExec` and `FlatMapGroupsInPandasExec` are refering config values of `SQLConf` in function for `mapPartitions`/`mapPartitionsInternal`, but we should capture them in Driver.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#19587 from ueshin/issues/SPARK-22370.
## What changes were proposed in this pull request?
Add parallelism support for ML tuning in pyspark.
## How was this patch tested?
Test updated.
Author: WeichenXu <weichen.xu@databricks.com>
Closes#19122 from WeichenXu123/par-ml-tuning-py.
## What changes were proposed in this pull request?
Adding date and timestamp support with Arrow for `toPandas()` and `pandas_udf`s. Timestamps are stored in Arrow as UTC and manifested to the user as timezone-naive localized to the Python system timezone.
## How was this patch tested?
Added Scala tests for date and timestamp types under ArrowConverters, ArrowUtils, and ArrowWriter suites. Added Python tests for `toPandas()` and `pandas_udf`s with date and timestamp types.
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#18664 from BryanCutler/arrow-date-timestamp-SPARK-21375.
## What changes were proposed in this pull request?
This PR proposes to mark the existing warnings as `DeprecationWarning` and print out warnings for deprecated functions.
This could be actually useful for Spark app developers. I use (old) PyCharm and this IDE can detect this specific `DeprecationWarning` in some cases:
**Before**
<img src="https://user-images.githubusercontent.com/6477701/31762664-df68d9f8-b4f6-11e7-8773-f0468f70a2cc.png" height="45" />
**After**
<img src="https://user-images.githubusercontent.com/6477701/31762662-de4d6868-b4f6-11e7-98dc-3c8446a0c28a.png" height="70" />
For console usage, `DeprecationWarning` is usually disabled (see https://docs.python.org/2/library/warnings.html#warning-categories and https://docs.python.org/3/library/warnings.html#warning-categories):
```
>>> import warnings
>>> filter(lambda f: f[2] == DeprecationWarning, warnings.filters)
[('ignore', <_sre.SRE_Pattern object at 0x10ba58c00>, <type 'exceptions.DeprecationWarning'>, <_sre.SRE_Pattern object at 0x10bb04138>, 0), ('ignore', None, <type 'exceptions.DeprecationWarning'>, None, 0)]
```
so, it won't actually mess up the terminal much unless it is intended.
If this is intendedly enabled, it'd should as below:
```
>>> import warnings
>>> warnings.simplefilter('always', DeprecationWarning)
>>>
>>> from pyspark.sql import functions
>>> functions.approxCountDistinct("a")
.../spark/python/pyspark/sql/functions.py:232: DeprecationWarning: Deprecated in 2.1, use approx_count_distinct instead.
"Deprecated in 2.1, use approx_count_distinct instead.", DeprecationWarning)
...
```
These instances were found by:
```
cd python/pyspark
grep -r "Deprecated" .
grep -r "deprecated" .
grep -r "deprecate" .
```
## How was this patch tested?
Manually tested.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19535 from HyukjinKwon/deprecated-warning.
## What changes were proposed in this pull request?
This is a follow-up of #18732.
This pr modifies `GroupedData.apply()` method to convert pandas udf to grouped udf implicitly.
## How was this patch tested?
Exisiting tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#19517 from ueshin/issues/SPARK-20396/fup2.
## What changes were proposed in this pull request?
Currently percentile_approx never returns the first element when percentile is in (relativeError, 1/N], where relativeError default 1/10000, and N is the total number of elements. But ideally, percentiles in [0, 1/N] should all return the first element as the answer.
For example, given input data 1 to 10, if a user queries 10% (or even less) percentile, it should return 1, because the first value 1 already reaches 10%. Currently it returns 2.
Based on the paper, targetError is not rounded up, and searching index should start from 0 instead of 1. By following the paper, we should be able to fix the cases mentioned above.
## How was this patch tested?
Added a new test case and fix existing test cases.
Author: Zhenhua Wang <wzh_zju@163.com>
Closes#19438 from wzhfy/improve_percentile_approx.
## What changes were proposed in this pull request?
This PR adds an apply() function on df.groupby(). apply() takes a pandas udf that is a transformation on `pandas.DataFrame` -> `pandas.DataFrame`.
Static schema
-------------------
```
schema = df.schema
pandas_udf(schema)
def normalize(df):
df = df.assign(v1 = (df.v1 - df.v1.mean()) / df.v1.std()
return df
df.groupBy('id').apply(normalize)
```
Dynamic schema
-----------------------
**This use case is removed from the PR and we will discuss this as a follow up. See discussion https://github.com/apache/spark/pull/18732#pullrequestreview-66583248**
Another example to use pd.DataFrame dtypes as output schema of the udf:
```
sample_df = df.filter(df.id == 1).toPandas()
def foo(df):
ret = # Some transformation on the input pd.DataFrame
return ret
foo_udf = pandas_udf(foo, foo(sample_df).dtypes)
df.groupBy('id').apply(foo_udf)
```
In interactive use case, user usually have a sample pd.DataFrame to test function `foo` in their notebook. Having been able to use `foo(sample_df).dtypes` frees user from specifying the output schema of `foo`.
Design doc: https://github.com/icexelloss/spark/blob/pandas-udf-doc/docs/pyspark-pandas-udf.md
## How was this patch tested?
* Added GroupbyApplyTest
Author: Li Jin <ice.xelloss@gmail.com>
Author: Takuya UESHIN <ueshin@databricks.com>
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#18732 from icexelloss/groupby-apply-SPARK-20396.
## What changes were proposed in this pull request?
This is a follow-up of #19384.
In the previous pr, only definitions of the config names were modified, but we also need to modify the names in runtime or tests specified as string literal.
## How was this patch tested?
Existing tests but modified the config names.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#19462 from ueshin/issues/SPARK-22159/fup1.
This PR adds methods `recommendForUserSubset` and `recommendForItemSubset` to `ALSModel`. These allow recommending for a specified set of user / item ids rather than for every user / item (as in the `recommendForAllX` methods).
The subset methods take a `DataFrame` as input, containing ids in the column specified by the param `userCol` or `itemCol`. The model will generate recommendations for each _unique_ id in this input dataframe.
## How was this patch tested?
New unit tests in `ALSSuite` and Python doctests in `ALS`. Ran updated examples locally.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#18748 from MLnick/als-recommend-df.
## What changes were proposed in this pull request?
Move flume behind a profile, take 2. See https://github.com/apache/spark/pull/19365 for most of the back-story.
This change should fix the problem by removing the examples module dependency and moving Flume examples to the module itself. It also adds deprecation messages, per a discussion on dev about deprecating for 2.3.0.
## How was this patch tested?
Existing tests, which still enable flume integration.
Author: Sean Owen <sowen@cloudera.com>
Closes#19412 from srowen/SPARK-22142.2.
## What changes were proposed in this pull request?
Add 'flume' profile to enable Flume-related integration modules
## How was this patch tested?
Existing tests; no functional change
Author: Sean Owen <sowen@cloudera.com>
Closes#19365 from srowen/SPARK-22142.
## What changes were proposed in this pull request?
Fixed some minor issues with pandas_udf related docs and formatting.
## How was this patch tested?
NA
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#19375 from BryanCutler/arrow-pandas_udf-cleanup-minor.
## What changes were proposed in this pull request?
Currently we use Arrow File format to communicate with Python worker when invoking vectorized UDF but we can use Arrow Stream format.
This pr replaces the Arrow File format with the Arrow Stream format.
## How was this patch tested?
Existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#19349 from ueshin/issues/SPARK-22125.
## What changes were proposed in this pull request?
We added a method to the scala API for creating a `DataFrame` from `DataSet[String]` storing CSV in [SPARK-15463](https://issues.apache.org/jira/browse/SPARK-15463) but PySpark doesn't have `Dataset` to support this feature. Therfore, I add an API to create a `DataFrame` from `RDD[String]` storing csv and it's also consistent with PySpark's `spark.read.json`.
For example as below
```
>>> rdd = sc.textFile('python/test_support/sql/ages.csv')
>>> df2 = spark.read.csv(rdd)
>>> df2.dtypes
[('_c0', 'string'), ('_c1', 'string')]
```
## How was this patch tested?
add unit test cases.
Author: goldmedal <liugs963@gmail.com>
Closes#19339 from goldmedal/SPARK-22112.
## What changes were proposed in this pull request?
This change disables the use of 0-parameter pandas_udfs due to the API being overly complex and awkward, and can easily be worked around by using an index column as an input argument. Also added doctests for pandas_udfs which revealed bugs for handling empty partitions and using the pandas_udf decorator.
## How was this patch tested?
Reworked existing 0-parameter test to verify error is raised, added doctest for pandas_udf, added new tests for empty partition and decorator usage.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#19325 from BryanCutler/arrow-pandas_udf-0-param-remove-SPARK-22106.
## What changes were proposed in this pull request?
The `percentile_approx` function previously accepted numeric type input and output double type results.
But since all numeric types, date and timestamp types are represented as numerics internally, `percentile_approx` can support them easily.
After this PR, it supports date type, timestamp type and numeric types as input types. The result type is also changed to be the same as the input type, which is more reasonable for percentiles.
This change is also required when we generate equi-height histograms for these types.
## How was this patch tested?
Added a new test and modified some existing tests.
Author: Zhenhua Wang <wangzhenhua@huawei.com>
Closes#19321 from wzhfy/approx_percentile_support_types.
## What changes were proposed in this pull request?
When calling `DataFrame.toPandas()` (without Arrow enabled), if there is a `IntegralType` column (`IntegerType`, `ShortType`, `ByteType`) that has null values the following exception is thrown:
ValueError: Cannot convert non-finite values (NA or inf) to integer
This is because the null values first get converted to float NaN during the construction of the Pandas DataFrame in `from_records`, and then it is attempted to be converted back to to an integer where it fails.
The fix is going to check if the Pandas DataFrame can cause such failure when converting, if so, we don't do the conversion and use the inferred type by Pandas.
Closes#18945
## How was this patch tested?
Added pyspark test.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#19319 from viirya/SPARK-21766.
This PR adds vectorized UDFs to the Python API
**Proposed API**
Introduce a flag to turn on vectorization for a defined UDF, for example:
```
pandas_udf(DoubleType())
def plus(a, b)
return a + b
```
or
```
plus = pandas_udf(lambda a, b: a + b, DoubleType())
```
Usage is the same as normal UDFs
0-parameter UDFs
pandas_udf functions can declare an optional `**kwargs` and when evaluated, will contain a key "size" that will give the required length of the output. For example:
```
pandas_udf(LongType())
def f0(**kwargs):
return pd.Series(1).repeat(kwargs["size"])
df.select(f0())
```
Added new unit tests in pyspark.sql that are enabled if pyarrow and Pandas are available.
- [x] Fix support for promoted types with null values
- [ ] Discuss 0-param UDF API (use of kwargs)
- [x] Add tests for chained UDFs
- [ ] Discuss behavior when pyarrow not installed / enabled
- [ ] Cleanup pydoc and add user docs
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#18659 from BryanCutler/arrow-vectorized-udfs-SPARK-21404.
## What changes were proposed in this pull request?
Added Python interface for ClusteringEvaluator
## How was this patch tested?
Manual test, eg. the example Python code in the comments.
cc yanboliang
Author: Marco Gaido <mgaido@hortonworks.com>
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#19204 from mgaido91/SPARK-21981.
## What changes were proposed in this pull request?
Clarify behavior of to_utc_timestamp/from_utc_timestamp with an example
## How was this patch tested?
Doc only change / existing tests
Author: Sean Owen <sowen@cloudera.com>
Closes#19276 from srowen/SPARK-22049.
## What changes were proposed in this pull request?
Remove unnecessary default value setting for all evaluators, as we have set them in corresponding _HasXXX_ base classes.
## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#19262 from yanboliang/evaluation.
## What changes were proposed in this pull request?
This PR proposes to improve error message from:
```
>>> sc.show_profiles()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../spark/python/pyspark/context.py", line 1000, in show_profiles
self.profiler_collector.show_profiles()
AttributeError: 'NoneType' object has no attribute 'show_profiles'
>>> sc.dump_profiles("/tmp/abc")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../spark/python/pyspark/context.py", line 1005, in dump_profiles
self.profiler_collector.dump_profiles(path)
AttributeError: 'NoneType' object has no attribute 'dump_profiles'
```
to
```
>>> sc.show_profiles()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../spark/python/pyspark/context.py", line 1003, in show_profiles
raise RuntimeError("'spark.python.profile' configuration must be set "
RuntimeError: 'spark.python.profile' configuration must be set to 'true' to enable Python profile.
>>> sc.dump_profiles("/tmp/abc")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../spark/python/pyspark/context.py", line 1012, in dump_profiles
raise RuntimeError("'spark.python.profile' configuration must be set "
RuntimeError: 'spark.python.profile' configuration must be set to 'true' to enable Python profile.
```
## How was this patch tested?
Unit tests added in `python/pyspark/tests.py` and manual tests.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19260 from HyukjinKwon/profile-errors.
## What changes were proposed in this pull request?
(edited)
Fixes a bug introduced in #16121
In PairDeserializer convert each batch of keys and values to lists (if they do not have `__len__` already) so that we can check that they are the same size. Normally they already are lists so this should not have a performance impact, but this is needed when repeated `zip`'s are done.
## How was this patch tested?
Additional unit test
Author: Andrew Ray <ray.andrew@gmail.com>
Closes#19226 from aray/SPARK-21985.
## What changes were proposed in this pull request?
StructType.fromInternal is calling f.fromInternal(v) for every field.
We can use precalculated information about type to limit the number of function calls. (its calculated once per StructType and used in per record calculations)
Benchmarks (Python profiler)
```
df = spark.range(10000000).selectExpr("id as id0", "id as id1", "id as id2", "id as id3", "id as id4", "id as id5", "id as id6", "id as id7", "id as id8", "id as id9", "struct(id) as s").cache()
df.count()
df.rdd.map(lambda x: x).count()
```
Before
```
310274584 function calls (300272456 primitive calls) in 1320.684 seconds
Ordered by: internal time, cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
10000000 253.417 0.000 486.991 0.000 types.py:619(<listcomp>)
30000000 192.272 0.000 1009.986 0.000 types.py:612(fromInternal)
100000000 176.140 0.000 176.140 0.000 types.py:88(fromInternal)
20000000 156.832 0.000 328.093 0.000 types.py:1471(_create_row)
14000 107.206 0.008 1237.917 0.088 {built-in method loads}
20000000 80.176 0.000 1090.162 0.000 types.py:1468(<lambda>)
```
After
```
210274584 function calls (200272456 primitive calls) in 1035.974 seconds
Ordered by: internal time, cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
30000000 215.845 0.000 698.748 0.000 types.py:612(fromInternal)
20000000 165.042 0.000 351.572 0.000 types.py:1471(_create_row)
14000 116.834 0.008 946.791 0.068 {built-in method loads}
20000000 87.326 0.000 786.073 0.000 types.py:1468(<lambda>)
20000000 85.477 0.000 134.607 0.000 types.py:1519(__new__)
10000000 65.777 0.000 126.712 0.000 types.py:619(<listcomp>)
```
Main difference is types.py:619(<listcomp>) and types.py:88(fromInternal) (which is removed in After)
The number of function calls is 100 million less. And performance is 20% better.
Benchmark (worst case scenario.)
Test
```
df = spark.range(1000000).selectExpr("current_timestamp as id0", "current_timestamp as id1", "current_timestamp as id2", "current_timestamp as id3", "current_timestamp as id4", "current_timestamp as id5", "current_timestamp as id6", "current_timestamp as id7", "current_timestamp as id8", "current_timestamp as id9").cache()
df.count()
df.rdd.map(lambda x: x).count()
```
Before
```
31166064 function calls (31163984 primitive calls) in 150.882 seconds
```
After
```
31166064 function calls (31163984 primitive calls) in 153.220 seconds
```
IMPORTANT:
The benchmark was done on top of https://github.com/apache/spark/pull/19246.
Without https://github.com/apache/spark/pull/19246 the performance improvement will be even greater.
## How was this patch tested?
Existing tests.
Performance benchmark.
Author: Maciej Bryński <maciek-github@brynski.pl>
Closes#19249 from maver1ck/spark_22032.
## What changes were proposed in this pull request?
In previous work SPARK-21513, we has allowed `MapType` and `ArrayType` of `MapType`s convert to a json string but only for Scala API. In this follow-up PR, we will make SparkSQL support it for PySpark and SparkR, too. We also fix some little bugs and comments of the previous work in this follow-up PR.
### For PySpark
```
>>> data = [(1, {"name": "Alice"})]
>>> df = spark.createDataFrame(data, ("key", "value"))
>>> df.select(to_json(df.value).alias("json")).collect()
[Row(json=u'{"name":"Alice")']
>>> data = [(1, [{"name": "Alice"}, {"name": "Bob"}])]
>>> df = spark.createDataFrame(data, ("key", "value"))
>>> df.select(to_json(df.value).alias("json")).collect()
[Row(json=u'[{"name":"Alice"},{"name":"Bob"}]')]
```
### For SparkR
```
# Converts a map into a JSON object
df2 <- sql("SELECT map('name', 'Bob')) as people")
df2 <- mutate(df2, people_json = to_json(df2$people))
# Converts an array of maps into a JSON array
df2 <- sql("SELECT array(map('name', 'Bob'), map('name', 'Alice')) as people")
df2 <- mutate(df2, people_json = to_json(df2$people))
```
## How was this patch tested?
Add unit test cases.
cc viirya HyukjinKwon
Author: goldmedal <liugs963@gmail.com>
Closes#19223 from goldmedal/SPARK-21513-fp-PySaprkAndSparkR.
## What changes were proposed in this pull request?
#19197 fixed double caching for MLlib algorithms, but missed PySpark ```OneVsRest```, this PR fixed it.
## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#19220 from yanboliang/SPARK-18608.
## What changes were proposed in this pull request?
Added LogisticRegressionTrainingSummary for MultinomialLogisticRegression in Python API
## How was this patch tested?
Added unit test
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Ming Jiang <mjiang@fanatics.com>
Author: Ming Jiang <jmwdpk@gmail.com>
Author: jmwdpk <jmwdpk@gmail.com>
Closes#19185 from jmwdpk/SPARK-21854.
## What changes were proposed in this pull request?
Put Kafka 0.8 support behind a kafka-0-8 profile.
## How was this patch tested?
Existing tests, but, until PR builder and Jenkins configs are updated the effect here is to not build or test Kafka 0.8 support at all.
Author: Sean Owen <sowen@cloudera.com>
Closes#19134 from srowen/SPARK-21893.
# What changes were proposed in this pull request?
Added tunable parallelism to the pyspark implementation of one vs. rest classification. Added a parallelism parameter to the Scala implementation of one vs. rest along with functionality for using the parameter to tune the level of parallelism.
I take this PR #18281 over because the original author is busy but we need merge this PR soon.
After this been merged, we can close#18281 .
## How was this patch tested?
Test suite added.
Author: Ajay Saini <ajays725@gmail.com>
Author: WeichenXu <weichen.xu@databricks.com>
Closes#19110 from WeichenXu123/spark-21027.
Probability and rawPrediction has been added to MultilayerPerceptronClassifier for Python
Add unit test.
Author: Chunsheng Ji <chunsheng.ji@gmail.com>
Closes#19172 from chunshengji/SPARK-21856.
## What changes were proposed in this pull request?
`typeName` classmethod has been fixed by using type -> typeName map.
## How was this patch tested?
local build
Author: Peter Szalai <szalaipeti.vagyok@gmail.com>
Closes#17435 from szalai1/datatype-gettype-fix.
## What changes were proposed in this pull request?
Correct DataFrame doc.
## How was this patch tested?
Only doc change, no tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#19173 from yanboliang/df-doc.
https://issues.apache.org/jira/browse/SPARK-19866
## What changes were proposed in this pull request?
Add Python API for findSynonymsArray matching Scala API.
## How was this patch tested?
Manual test
`./python/run-tests --python-executables=python2.7 --modules=pyspark-ml`
Author: Xin Ren <iamshrek@126.com>
Author: Xin Ren <renxin.ubc@gmail.com>
Author: Xin Ren <keypointt@users.noreply.github.com>
Closes#17451 from keypointt/SPARK-19866.
## What changes were proposed in this pull request?
This PR proposes to support unicodes in Param methods in ML, other missed functions in DataFrame.
For example, this causes a `ValueError` in Python 2.x when param is a unicode string:
```python
>>> from pyspark.ml.classification import LogisticRegression
>>> lr = LogisticRegression()
>>> lr.hasParam("threshold")
True
>>> lr.hasParam(u"threshold")
Traceback (most recent call last):
...
raise TypeError("hasParam(): paramName must be a string")
TypeError: hasParam(): paramName must be a string
```
This PR is based on https://github.com/apache/spark/pull/13036
## How was this patch tested?
Unit tests in `python/pyspark/ml/tests.py` and `python/pyspark/sql/tests.py`.
Author: hyukjinkwon <gurwls223@gmail.com>
Author: sethah <seth.hendrickson16@gmail.com>
Closes#17096 from HyukjinKwon/SPARK-15243.
## What changes were proposed in this pull request?
`pyspark.sql.tests.SQLTests2` doesn't stop newly created spark context in the test and it might affect the following tests.
This pr makes `pyspark.sql.tests.SQLTests2` stop `SparkContext`.
## How was this patch tested?
Existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#19158 from ueshin/issues/SPARK-21950.
## What changes were proposed in this pull request?
This PR proposes to add a wrapper for `unionByName` API to R and Python as well.
**Python**
```python
df1 = spark.createDataFrame([[1, 2, 3]], ["col0", "col1", "col2"])
df2 = spark.createDataFrame([[4, 5, 6]], ["col1", "col2", "col0"])
df1.unionByName(df2).show()
```
```
+----+----+----+
|col0|col1|col3|
+----+----+----+
| 1| 2| 3|
| 6| 4| 5|
+----+----+----+
```
**R**
```R
df1 <- select(createDataFrame(mtcars), "carb", "am", "gear")
df2 <- select(createDataFrame(mtcars), "am", "gear", "carb")
head(unionByName(limit(df1, 2), limit(df2, 2)))
```
```
carb am gear
1 4 1 4
2 4 1 4
3 4 1 4
4 4 1 4
```
## How was this patch tested?
Doctests for Python and unit test added in `test_sparkSQL.R` for R.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19105 from HyukjinKwon/unionByName-r-python.
## What changes were proposed in this pull request?
This PR proposes to remove private functions that look not used in the main codes, `_split_schema_abstract`, `_parse_field_abstract`, `_parse_schema_abstract` and `_infer_schema_type`.
## How was this patch tested?
Existing tests.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18647 from HyukjinKwon/remove-abstract.
## What changes were proposed in this pull request?
This PR make `DataFrame.sample(...)` can omit `withReplacement` defaulting `False`, consistently with equivalent Scala / Java API.
In short, the following examples are allowed:
```python
>>> df = spark.range(10)
>>> df.sample(0.5).count()
7
>>> df.sample(fraction=0.5).count()
3
>>> df.sample(0.5, seed=42).count()
5
>>> df.sample(fraction=0.5, seed=42).count()
5
```
In addition, this PR also adds some type checking logics as below:
```python
>>> df = spark.range(10)
>>> df.sample().count()
...
TypeError: withReplacement (optional), fraction (required) and seed (optional) should be a bool, float and number; however, got [].
>>> df.sample(True).count()
...
TypeError: withReplacement (optional), fraction (required) and seed (optional) should be a bool, float and number; however, got [<type 'bool'>].
>>> df.sample(42).count()
...
TypeError: withReplacement (optional), fraction (required) and seed (optional) should be a bool, float and number; however, got [<type 'int'>].
>>> df.sample(fraction=False, seed="a").count()
...
TypeError: withReplacement (optional), fraction (required) and seed (optional) should be a bool, float and number; however, got [<type 'bool'>, <type 'str'>].
>>> df.sample(seed=[1]).count()
...
TypeError: withReplacement (optional), fraction (required) and seed (optional) should be a bool, float and number; however, got [<type 'list'>].
>>> df.sample(withReplacement="a", fraction=0.5, seed=1)
...
TypeError: withReplacement (optional), fraction (required) and seed (optional) should be a bool, float and number; however, got [<type 'str'>, <type 'float'>, <type 'int'>].
```
## How was this patch tested?
Manually tested, unit tests added in doc tests and manually checked the built documentation for Python.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18999 from HyukjinKwon/SPARK-21779.
## What changes were proposed in this pull request?
`PickleException` is thrown when creating dataframe from python row with empty bytearray
spark.createDataFrame(spark.sql("select unhex('') as xx").rdd.map(lambda x: {"abc": x.xx})).show()
net.razorvine.pickle.PickleException: invalid pickle data for bytearray; expected 1 or 2 args, got 0
at net.razorvine.pickle.objects.ByteArrayConstructor.construct(ByteArrayConstructor.java
...
`ByteArrayConstructor` doesn't deal with empty byte array pickled by Python3.
## How was this patch tested?
Added test.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#19085 from viirya/SPARK-21534.
## What changes were proposed in this pull request?
This PR aims to support `spark.sql.orc.compression.codec` like Parquet's `spark.sql.parquet.compression.codec`. Users can use SQLConf to control ORC compression, too.
## How was this patch tested?
Pass the Jenkins with new and updated test cases.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19055 from dongjoon-hyun/SPARK-21839.
## What changes were proposed in this pull request?
This patch adds allowUnquotedControlChars option in JSON data source to allow JSON Strings to contain unquoted control characters (ASCII characters with value less than 32, including tab and line feed characters)
## How was this patch tested?
Add new test cases
Author: vinodkc <vinod.kc.in@gmail.com>
Closes#19008 from vinodkc/br_fix_SPARK-21756.
## What changes were proposed in this pull request?
While preparing to take over https://github.com/apache/spark/pull/16537, I realised a (I think) better approach to make the exception handling in one point.
This PR proposes to fix `_to_java_column` in `pyspark.sql.column`, which most of functions in `functions.py` and some other APIs use. This `_to_java_column` basically looks not working with other types than `pyspark.sql.column.Column` or string (`str` and `unicode`).
If this is not `Column`, then it calls `_create_column_from_name` which calls `functions.col` within JVM:
42b9eda80e/sql/core/src/main/scala/org/apache/spark/sql/functions.scala (L76)
And it looks we only have `String` one with `col`.
So, these should work:
```python
>>> from pyspark.sql.column import _to_java_column, Column
>>> _to_java_column("a")
JavaObject id=o28
>>> _to_java_column(u"a")
JavaObject id=o29
>>> _to_java_column(spark.range(1).id)
JavaObject id=o33
```
whereas these do not:
```python
>>> _to_java_column(1)
```
```
...
py4j.protocol.Py4JError: An error occurred while calling z:org.apache.spark.sql.functions.col. Trace:
py4j.Py4JException: Method col([class java.lang.Integer]) does not exist
...
```
```python
>>> _to_java_column([])
```
```
...
py4j.protocol.Py4JError: An error occurred while calling z:org.apache.spark.sql.functions.col. Trace:
py4j.Py4JException: Method col([class java.util.ArrayList]) does not exist
...
```
```python
>>> class A(): pass
>>> _to_java_column(A())
```
```
...
AttributeError: 'A' object has no attribute '_get_object_id'
```
Meaning most of functions using `_to_java_column` such as `udf` or `to_json` or some other APIs throw an exception as below:
```python
>>> from pyspark.sql.functions import udf
>>> udf(lambda x: x)(None)
```
```
...
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.sql.functions.col.
: java.lang.NullPointerException
...
```
```python
>>> from pyspark.sql.functions import to_json
>>> to_json(None)
```
```
...
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.sql.functions.col.
: java.lang.NullPointerException
...
```
**After this PR**:
```python
>>> from pyspark.sql.functions import udf
>>> udf(lambda x: x)(None)
...
```
```
TypeError: Invalid argument, not a string or column: None of type <type 'NoneType'>. For column literals, use 'lit', 'array', 'struct' or 'create_map' functions.
```
```python
>>> from pyspark.sql.functions import to_json
>>> to_json(None)
```
```
...
TypeError: Invalid argument, not a string or column: None of type <type 'NoneType'>. For column literals, use 'lit', 'array', 'struct' or 'create_map' functions.
```
## How was this patch tested?
Unit tests added in `python/pyspark/sql/tests.py` and manual tests.
Author: hyukjinkwon <gurwls223@gmail.com>
Author: zero323 <zero323@users.noreply.github.com>
Closes#19027 from HyukjinKwon/SPARK-19165.
## What changes were proposed in this pull request?
Modify MLP model to inherit `ProbabilisticClassificationModel` and so that it can expose the probability column when transforming data.
## How was this patch tested?
Test added.
Author: WeichenXu <WeichenXu123@outlook.com>
Closes#17373 from WeichenXu123/expose_probability_in_mlp_model.
## What changes were proposed in this pull request?
Added call to copy values of Params from Estimator to Model after fit in PySpark ML. This will copy values for any params that are also defined in the Model. Since currently most Models do not define the same params from the Estimator, also added method to create new Params from looking at the Java object if they do not exist in the Python object. This is a temporary fix that can be removed once the PySpark models properly define the params themselves.
## How was this patch tested?
Refactored the `check_params` test to optionally check if the model params for Python and Java match and added this check to an existing fitted model that shares params between Estimator and Model.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#17849 from BryanCutler/pyspark-models-own-params-SPARK-10931.
## What changes were proposed in this pull request?
Based on https://github.com/apache/spark/pull/18282 by rgbkrk this PR attempts to update to the current released cloudpickle and minimize the difference between Spark cloudpickle and "stock" cloud pickle with the goal of eventually using the stock cloud pickle.
Some notable changes:
* Import submodules accessed by pickled functions (cloudpipe/cloudpickle#80)
* Support recursive functions inside closures (cloudpipe/cloudpickle#89, cloudpipe/cloudpickle#90)
* Fix ResourceWarnings and DeprecationWarnings (cloudpipe/cloudpickle#88)
* Assume modules with __file__ attribute are not dynamic (cloudpipe/cloudpickle#85)
* Make cloudpickle Python 3.6 compatible (cloudpipe/cloudpickle#72)
* Allow pickling of builtin methods (cloudpipe/cloudpickle#57)
* Add ability to pickle dynamically created modules (cloudpipe/cloudpickle#52)
* Support method descriptor (cloudpipe/cloudpickle#46)
* No more pickling of closed files, was broken on Python 3 (cloudpipe/cloudpickle#32)
* ** Remove non-standard __transient__check (cloudpipe/cloudpickle#110)** -- while we don't use this internally, and have no tests or documentation for its use, downstream code may use __transient__, although it has never been part of the API, if we merge this we should include a note about this in the release notes.
* Support for pickling loggers (yay!) (cloudpipe/cloudpickle#96)
* BUG: Fix crash when pickling dynamic class cycles. (cloudpipe/cloudpickle#102)
## How was this patch tested?
Existing PySpark unit tests + the unit tests from the cloudpickle project on their own.
Author: Holden Karau <holden@us.ibm.com>
Author: Kyle Kelley <rgbkrk@gmail.com>
Closes#18734 from holdenk/holden-rgbkrk-cloudpickle-upgrades.
Add Python API for `FeatureHasher` transformer.
## How was this patch tested?
New doc test.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#18970 from MLnick/SPARK-21468-pyspark-hasher.
## What changes were proposed in this pull request?
Adds the recently added `summary` method to the python dataframe interface.
## How was this patch tested?
Additional inline doctests.
Author: Andrew Ray <ray.andrew@gmail.com>
Closes#18762 from aray/summary-py.
Proposed changes:
* Clarify the type error that `Column.substr()` gives.
Test plan:
* Tested this manually.
* Test code:
```python
from pyspark.sql.functions import col, lit
spark.createDataFrame([['nick']], schema=['name']).select(col('name').substr(0, lit(1)))
```
* Before:
```
TypeError: Can not mix the type
```
* After:
```
TypeError: startPos and length must be the same type. Got <class 'int'> and
<class 'pyspark.sql.column.Column'>, respectively.
```
Author: Nicholas Chammas <nicholas.chammas@gmail.com>
Closes#18926 from nchammas/SPARK-21712-substr-type-error.
## What changes were proposed in this pull request?
JIRA issue: https://issues.apache.org/jira/browse/SPARK-21658
Add default None for value in `na.replace` since `Dataframe.replace` and `DataframeNaFunctions.replace` are alias.
The default values are the same now.
```
>>> df = sqlContext.createDataFrame([('Alice', 10, 80.0)])
>>> df.replace({"Alice": "a"}).first()
Row(_1=u'a', _2=10, _3=80.0)
>>> df.na.replace({"Alice": "a"}).first()
Row(_1=u'a', _2=10, _3=80.0)
```
## How was this patch tested?
Existing tests.
cc viirya
Author: byakuinss <grace.chinhanyu@gmail.com>
Closes#18895 from byakuinss/SPARK-21658.
## What changes were proposed in this pull request?
Implemented a Python-only persistence framework for pipelines containing stages that cannot be saved using Java.
## How was this patch tested?
Created a custom Python-only UnaryTransformer, included it in a Pipeline, and saved/loaded the pipeline. The loaded pipeline was compared against the original using _compare_pipelines() in tests.py.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18888 from ajaysaini725/PythonPipelines.
## What changes were proposed in this pull request?
Currently `df.na.replace("*", Map[String, String]("NULL" -> null))` will produce exception.
This PR enables passing null/None as value in the replacement map in DataFrame.replace().
Note that the replacement map keys and values should still be the same type, while the values can have a mix of null/None and that type.
This PR enables following operations for example:
`df.na.replace("*", Map[String, String]("NULL" -> null))`(scala)
`df.na.replace("*", Map[Any, Any](60 -> null, 70 -> 80))`(scala)
`df.na.replace('Alice', None)`(python)
`df.na.replace([10, 20])`(python, replacing with None is by default)
One use case could be: I want to replace all the empty strings with null/None because they were incorrectly generated and then drop all null/None data
`df.na.replace("*", Map("" -> null)).na.drop()`(scala)
`df.replace(u'', None).dropna()`(python)
## How was this patch tested?
Scala unit test.
Python doctest and unit test.
Author: bravo-zhang <mzhang1230@gmail.com>
Closes#18820 from bravo-zhang/spark-14932.
## What changes were proposed in this pull request?
This modification increases the timeout for `serveIterator` (which is not dynamically configurable). This fixes timeout issues in pyspark when using `collect` and similar functions, in cases where Python may take more than a couple seconds to connect.
See https://issues.apache.org/jira/browse/SPARK-21551
## How was this patch tested?
Ran the tests.
cc rxin
Author: peay <peay@protonmail.com>
Closes#18752 from peay/spark-21551.
## What changes were proposed in this pull request?
Update breeze to 0.13.1 for an emergency bugfix in strong wolfe line search
https://github.com/scalanlp/breeze/pull/651
## How was this patch tested?
N/A
Author: WeichenXu <WeichenXu123@outlook.com>
Closes#18797 from WeichenXu123/update-breeze.
## What changes were proposed in this pull request?
PySpark GLR ```model.summary``` should return a printable representation by calling Scala ```toString```.
## How was this patch tested?
```
from pyspark.ml.regression import GeneralizedLinearRegression
dataset = spark.read.format("libsvm").load("data/mllib/sample_linear_regression_data.txt")
glr = GeneralizedLinearRegression(family="gaussian", link="identity", maxIter=10, regParam=0.3)
model = glr.fit(dataset)
model.summary
```
Before this PR:

After this PR:
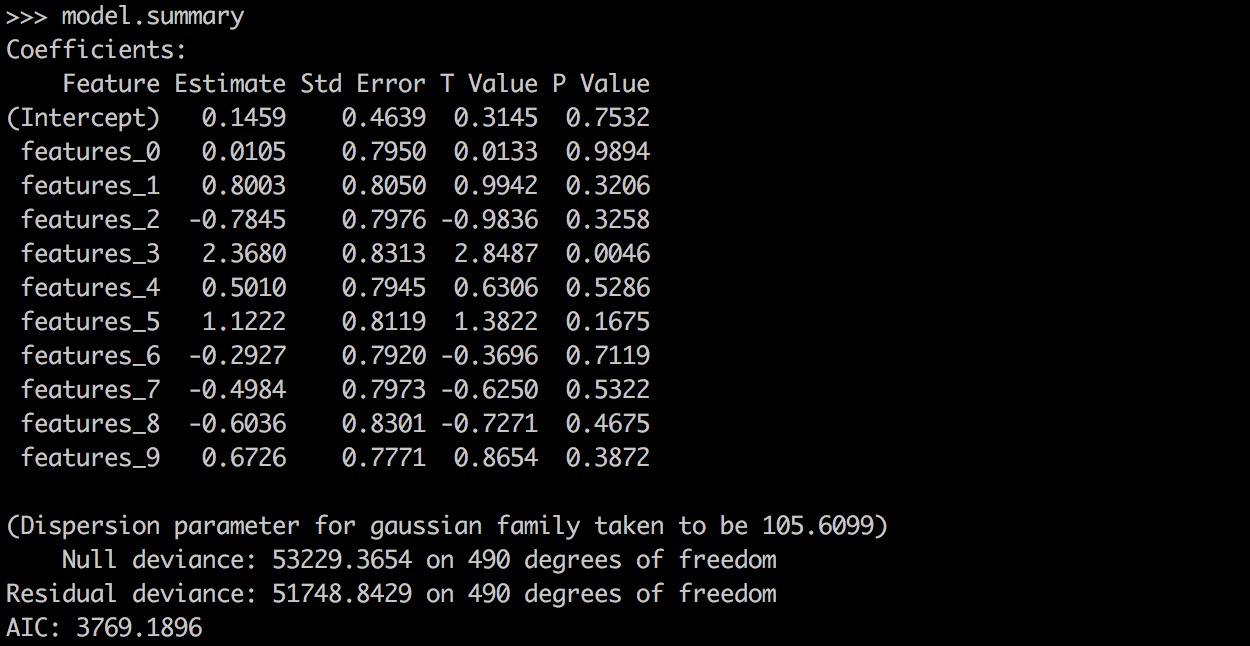
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18870 from yanboliang/spark-19270.
## What changes were proposed in this pull request?
Added DefaultParamsWriteable, DefaultParamsReadable, DefaultParamsWriter, and DefaultParamsReader to Python to support Python-only persistence of Json-serializable parameters.
## How was this patch tested?
Instantiated an estimator with Json-serializable parameters (ex. LogisticRegression), saved it using the added helper functions, and loaded it back, and compared it to the original instance to make sure it is the same. This test was both done in the Python REPL and implemented in the unit tests.
Note to reviewers: there are a few excess comments that I left in the code for clarity but will remove before the code is merged to master.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18742 from ajaysaini725/PythonPersistenceHelperFunctions.
## What changes were proposed in this pull request?
Enhanced some existing documentation
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Mac <maclockard@gmail.com>
Closes#18710 from maclockard/maclockard-patch-1.
## What changes were proposed in this pull request?
Implemented UnaryTransformer in Python.
## How was this patch tested?
This patch was tested by creating a MockUnaryTransformer class in the unit tests that extends UnaryTransformer and testing that the transform function produced correct output.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18746 from ajaysaini725/AddPythonUnaryTransformer.
## What changes were proposed in this pull request?
Python API for Constrained Logistic Regression based on #17922 , thanks for the original contribution from zero323 .
## How was this patch tested?
Unit tests.
Author: zero323 <zero323@users.noreply.github.com>
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18759 from yanboliang/SPARK-20601.
## What changes were proposed in this pull request?
When using PySpark broadcast variables in a multi-threaded environment, `SparkContext._pickled_broadcast_vars` becomes a shared resource. A race condition can occur when broadcast variables that are pickled from one thread get added to the shared ` _pickled_broadcast_vars` and become part of the python command from another thread. This PR introduces a thread-safe pickled registry using thread local storage so that when python command is pickled (causing the broadcast variable to be pickled and added to the registry) each thread will have their own view of the pickle registry to retrieve and clear the broadcast variables used.
## How was this patch tested?
Added a unit test that causes this race condition using another thread.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#18695 from BryanCutler/pyspark-bcast-threadsafe-SPARK-12717.
## What changes were proposed in this pull request?
GBTs inherit from HasStepSize & LInearSVC/Binarizer from HasThreshold
## How was this patch tested?
existing tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Author: Ruifeng Zheng <ruifengz@foxmail.com>
Closes#18612 from zhengruifeng/override_HasXXX.
## What changes were proposed in this pull request?
This PR proposes `StructType.fieldNames` that returns a copy of a field name list rather than a (undocumented) `StructType.names`.
There are two points here:
- API consistency with Scala/Java
- Provide a safe way to get the field names. Manipulating these might cause unexpected behaviour as below:
```python
from pyspark.sql.types import *
struct = StructType([StructField("f1", StringType(), True)])
names = struct.names
del names[0]
spark.createDataFrame([{"f1": 1}], struct).show()
```
```
...
java.lang.IllegalStateException: Input row doesn't have expected number of values required by the schema. 1 fields are required while 0 values are provided.
at org.apache.spark.sql.execution.python.EvaluatePython$.fromJava(EvaluatePython.scala:138)
at org.apache.spark.sql.SparkSession$$anonfun$6.apply(SparkSession.scala:741)
at org.apache.spark.sql.SparkSession$$anonfun$6.apply(SparkSession.scala:741)
...
```
## How was this patch tested?
Added tests in `python/pyspark/sql/tests.py`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18618 from HyukjinKwon/SPARK-20090.
## What changes were proposed in this pull request?
add `setWeightCol` method for OneVsRest.
`weightCol` is ignored if classifier doesn't inherit HasWeightCol trait.
## How was this patch tested?
+ [x] add an unit test.
Author: Yan Facai (颜发才) <facai.yan@gmail.com>
Closes#18554 from facaiy/BUG/oneVsRest_missing_weightCol.
## What changes were proposed in this pull request?
This is a refactoring of `ArrowConverters` and related classes.
1. Refactor `ColumnWriter` as `ArrowWriter`.
2. Add `ArrayType` and `StructType` support.
3. Refactor `ArrowConverters` to skip intermediate `ArrowRecordBatch` creation.
## How was this patch tested?
Added some tests and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#18655 from ueshin/issues/SPARK-21440.
### What changes were proposed in this pull request?
Like [Hive UDFType](https://hive.apache.org/javadocs/r2.0.1/api/org/apache/hadoop/hive/ql/udf/UDFType.html), we should allow users to add the extra flags for ScalaUDF and JavaUDF too. _stateful_/_impliesOrder_ are not applicable to our Scala UDF. Thus, we only add the following two flags.
- deterministic: Certain optimizations should not be applied if UDF is not deterministic. Deterministic UDF returns same result each time it is invoked with a particular input. This determinism just needs to hold within the context of a query.
When the deterministic flag is not correctly set, the results could be wrong.
For ScalaUDF in Dataset APIs, users can call the following extra APIs for `UserDefinedFunction` to make the corresponding changes.
- `nonDeterministic`: Updates UserDefinedFunction to non-deterministic.
Also fixed the Java UDF name loss issue.
Will submit a separate PR for `distinctLike` for UDAF
### How was this patch tested?
Added test cases for both ScalaUDF
Author: gatorsmile <gatorsmile@gmail.com>
Author: Wenchen Fan <cloud0fan@gmail.com>
Closes#17848 from gatorsmile/udfRegister.
## What changes were proposed in this pull request?
After SPARK-12661, I guess we officially dropped Python 2.6 support. It looks there are few places missing this notes.
I grepped "Python 2.6" and "python 2.6" and the results were below:
```
./core/src/main/scala/org/apache/spark/api/python/SerDeUtil.scala: // Unpickle array.array generated by Python 2.6
./docs/index.md:Note that support for Java 7, Python 2.6 and old Hadoop versions before 2.6.5 were removed as of Spark 2.2.0.
./docs/rdd-programming-guide.md:Spark {{site.SPARK_VERSION}} works with Python 2.6+ or Python 3.4+. It can use the standard CPython interpreter,
./docs/rdd-programming-guide.md:Note that support for Python 2.6 is deprecated as of Spark 2.0.0, and may be removed in Spark 2.2.0.
./python/pyspark/context.py: warnings.warn("Support for Python 2.6 is deprecated as of Spark 2.0.0")
./python/pyspark/ml/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/mllib/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/serializers.py: # On Python 2.6, we can't write bytearrays to streams, so we need to convert them
./python/pyspark/sql/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/streaming/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/tests.py: # NOTE: dict is used instead of collections.Counter for Python 2.6
./python/pyspark/tests.py: # NOTE: dict is used instead of collections.Counter for Python 2.6
```
This PR only proposes to change visible changes as below:
```
./docs/rdd-programming-guide.md:Spark {{site.SPARK_VERSION}} works with Python 2.6+ or Python 3.4+. It can use the standard CPython interpreter,
./docs/rdd-programming-guide.md:Note that support for Python 2.6 is deprecated as of Spark 2.0.0, and may be removed in Spark 2.2.0.
./python/pyspark/context.py: warnings.warn("Support for Python 2.6 is deprecated as of Spark 2.0.0")
```
This one is already correct:
```
./docs/index.md:Note that support for Java 7, Python 2.6 and old Hadoop versions before 2.6.5 were removed as of Spark 2.2.0.
```
## How was this patch tested?
```bash
grep -r "Python 2.6" .
grep -r "python 2.6" .
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18682 from HyukjinKwon/minor-python.26.
## What changes were proposed in this pull request?
This is the reopen of https://github.com/apache/spark/pull/14198, with merge conflicts resolved.
ueshin Could you please take a look at my code?
Fix bugs about types that result an array of null when creating DataFrame using python.
Python's array.array have richer type than python itself, e.g. we can have `array('f',[1,2,3])` and `array('d',[1,2,3])`. Codes in spark-sql and pyspark didn't take this into consideration which might cause a problem that you get an array of null values when you have `array('f')` in your rows.
A simple code to reproduce this bug is:
```
from pyspark import SparkContext
from pyspark.sql import SQLContext,Row,DataFrame
from array import array
sc = SparkContext()
sqlContext = SQLContext(sc)
row1 = Row(floatarray=array('f',[1,2,3]), doublearray=array('d',[1,2,3]))
rows = sc.parallelize([ row1 ])
df = sqlContext.createDataFrame(rows)
df.show()
```
which have output
```
+---------------+------------------+
| doublearray| floatarray|
+---------------+------------------+
|[1.0, 2.0, 3.0]|[null, null, null]|
+---------------+------------------+
```
## How was this patch tested?
New test case added
Author: Xiang Gao <qasdfgtyuiop@gmail.com>
Author: Gao, Xiang <qasdfgtyuiop@gmail.com>
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#18444 from zasdfgbnm/fix_array_infer.
## What changes were proposed in this pull request?
Added functionality for CrossValidator and TrainValidationSplit to persist nested estimators such as OneVsRest. Also added CrossValidator and TrainValidation split persistence to pyspark.
## How was this patch tested?
Performed both cross validation and train validation split with a one vs. rest estimator and tested read/write functionality of the estimator parameter maps required by these meta-algorithms.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18428 from ajaysaini725/MetaAlgorithmPersistNestedEstimators.
## What changes were proposed in this pull request?
This PR proposes to avoid `__name__` in the tuple naming the attributes assigned directly from the wrapped function to the wrapper function, and use `self._name` (`func.__name__` or `obj.__class__.name__`).
After SPARK-19161, we happened to break callable objects as UDFs in Python as below:
```python
from pyspark.sql import functions
class F(object):
def __call__(self, x):
return x
foo = F()
udf = functions.udf(foo)
```
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../spark/python/pyspark/sql/functions.py", line 2142, in udf
return _udf(f=f, returnType=returnType)
File ".../spark/python/pyspark/sql/functions.py", line 2133, in _udf
return udf_obj._wrapped()
File ".../spark/python/pyspark/sql/functions.py", line 2090, in _wrapped
functools.wraps(self.func)
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/functools.py", line 33, in update_wrapper
setattr(wrapper, attr, getattr(wrapped, attr))
AttributeError: F instance has no attribute '__name__'
```
This worked in Spark 2.1:
```python
from pyspark.sql import functions
class F(object):
def __call__(self, x):
return x
foo = F()
udf = functions.udf(foo)
spark.range(1).select(udf("id")).show()
```
```
+-----+
|F(id)|
+-----+
| 0|
+-----+
```
**After**
```python
from pyspark.sql import functions
class F(object):
def __call__(self, x):
return x
foo = F()
udf = functions.udf(foo)
spark.range(1).select(udf("id")).show()
```
```
+-----+
|F(id)|
+-----+
| 0|
+-----+
```
_In addition, we also happened to break partial functions as below_:
```python
from pyspark.sql import functions
from functools import partial
partial_func = partial(lambda x: x, x=1)
udf = functions.udf(partial_func)
```
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../spark/python/pyspark/sql/functions.py", line 2154, in udf
return _udf(f=f, returnType=returnType)
File ".../spark/python/pyspark/sql/functions.py", line 2145, in _udf
return udf_obj._wrapped()
File ".../spark/python/pyspark/sql/functions.py", line 2099, in _wrapped
functools.wraps(self.func, assigned=assignments)
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/functools.py", line 33, in update_wrapper
setattr(wrapper, attr, getattr(wrapped, attr))
AttributeError: 'functools.partial' object has no attribute '__module__'
```
This worked in Spark 2.1:
```python
from pyspark.sql import functions
from functools import partial
partial_func = partial(lambda x: x, x=1)
udf = functions.udf(partial_func)
spark.range(1).select(udf()).show()
```
```
+---------+
|partial()|
+---------+
| 1|
+---------+
```
**After**
```python
from pyspark.sql import functions
from functools import partial
partial_func = partial(lambda x: x, x=1)
udf = functions.udf(partial_func)
spark.range(1).select(udf()).show()
```
```
+---------+
|partial()|
+---------+
| 1|
+---------+
```
## How was this patch tested?
Unit tests in `python/pyspark/sql/tests.py` and manual tests.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18615 from HyukjinKwon/callable-object.
## What changes were proposed in this pull request?
```RFormula``` should handle invalid for both features and label column.
#18496 only handle invalid values in features column. This PR add handling invalid values for label column and test cases.
## How was this patch tested?
Add test cases.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18613 from yanboliang/spark-20307.
## What changes were proposed in this pull request?
1, HasHandleInvaild support override
2, Make QuantileDiscretizer/Bucketizer/StringIndexer/RFormula inherit from HasHandleInvalid
## How was this patch tested?
existing tests
[JIRA](https://issues.apache.org/jira/browse/SPARK-18619)
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#18582 from zhengruifeng/heritate_HasHandleInvalid.
## What changes were proposed in this pull request?
This PR deals with four points as below:
- Reuse existing DDL parser APIs rather than reimplementing within PySpark
- Support DDL formatted string, `field type, field type`.
- Support case-insensitivity for parsing.
- Support nested data types as below:
**Before**
```
>>> spark.createDataFrame([[[1]]], "struct<a: struct<b: int>>").show()
...
ValueError: The strcut field string format is: 'field_name:field_type', but got: a: struct<b: int>
```
```
>>> spark.createDataFrame([[[1]]], "a: struct<b: int>").show()
...
ValueError: The strcut field string format is: 'field_name:field_type', but got: a: struct<b: int>
```
```
>>> spark.createDataFrame([[1]], "a int").show()
...
ValueError: Could not parse datatype: a int
```
**After**
```
>>> spark.createDataFrame([[[1]]], "struct<a: struct<b: int>>").show()
+---+
| a|
+---+
|[1]|
+---+
```
```
>>> spark.createDataFrame([[[1]]], "a: struct<b: int>").show()
+---+
| a|
+---+
|[1]|
+---+
```
```
>>> spark.createDataFrame([[1]], "a int").show()
+---+
| a|
+---+
| 1|
+---+
```
## How was this patch tested?
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18590 from HyukjinKwon/deduplicate-python-ddl.
## What changes were proposed in this pull request?
This PR proposes to simply ignore the results in examples that are timezone-dependent in `unix_timestamp` and `from_unixtime`.
```
Failed example:
time_df.select(unix_timestamp('dt', 'yyyy-MM-dd').alias('unix_time')).collect()
Expected:
[Row(unix_time=1428476400)]
Got:unix_timestamp
[Row(unix_time=1428418800)]
```
```
Failed example:
time_df.select(from_unixtime('unix_time').alias('ts')).collect()
Expected:
[Row(ts=u'2015-04-08 00:00:00')]
Got:
[Row(ts=u'2015-04-08 16:00:00')]
```
## How was this patch tested?
Manually tested and `./run-tests --modules pyspark-sql`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18597 from HyukjinKwon/SPARK-20456.
## What changes were proposed in this pull request?
At example of repartitionAndSortWithinPartitions at rdd.py, third argument should be True or False.
I proposed fix of example code.
## How was this patch tested?
* I rename test_repartitionAndSortWithinPartitions to test_repartitionAndSortWIthinPartitions_asc to specify boolean argument.
* I added test_repartitionAndSortWithinPartitions_desc to test False pattern at third argument.
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: chie8842 <chie8842@gmail.com>
Closes#18586 from chie8842/SPARK-21358.
## What changes were proposed in this pull request?
Integrate Apache Arrow with Spark to increase performance of `DataFrame.toPandas`. This has been done by using Arrow to convert data partitions on the executor JVM to Arrow payload byte arrays where they are then served to the Python process. The Python DataFrame can then collect the Arrow payloads where they are combined and converted to a Pandas DataFrame. Data types except complex, date, timestamp, and decimal are currently supported, otherwise an `UnsupportedOperation` exception is thrown.
Additions to Spark include a Scala package private method `Dataset.toArrowPayload` that will convert data partitions in the executor JVM to `ArrowPayload`s as byte arrays so they can be easily served. A package private class/object `ArrowConverters` that provide data type mappings and conversion routines. In Python, a private method `DataFrame._collectAsArrow` is added to collect Arrow payloads and a SQLConf "spark.sql.execution.arrow.enable" can be used in `toPandas()` to enable using Arrow (uses the old conversion by default).
## How was this patch tested?
Added a new test suite `ArrowConvertersSuite` that will run tests on conversion of Datasets to Arrow payloads for supported types. The suite will generate a Dataset and matching Arrow JSON data, then the dataset is converted to an Arrow payload and finally validated against the JSON data. This will ensure that the schema and data has been converted correctly.
Added PySpark tests to verify the `toPandas` method is producing equal DataFrames with and without pyarrow. A roundtrip test to ensure the pandas DataFrame produced by pyspark is equal to a one made directly with pandas.
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Li Jin <ice.xelloss@gmail.com>
Author: Li Jin <li.jin@twosigma.com>
Author: Wes McKinney <wes.mckinney@twosigma.com>
Closes#18459 from BryanCutler/toPandas_with_arrow-SPARK-13534.
## What changes were proposed in this pull request?
This PR supports schema in a DDL formatted string for `from_json` in R/Python and `dapply` and `gapply` in R, which are commonly used and/or consistent with Scala APIs.
Additionally, this PR exposes `structType` in R to allow working around in other possible corner cases.
**Python**
`from_json`
```python
from pyspark.sql.functions import from_json
data = [(1, '''{"a": 1}''')]
df = spark.createDataFrame(data, ("key", "value"))
df.select(from_json(df.value, "a INT").alias("json")).show()
```
**R**
`from_json`
```R
df <- sql("SELECT named_struct('name', 'Bob') as people")
df <- mutate(df, people_json = to_json(df$people))
head(select(df, from_json(df$people_json, "name STRING")))
```
`structType.character`
```R
structType("a STRING, b INT")
```
`dapply`
```R
dapply(createDataFrame(list(list(1.0)), "a"), function(x) {x}, "a DOUBLE")
```
`gapply`
```R
gapply(createDataFrame(list(list(1.0)), "a"), "a", function(key, x) { x }, "a DOUBLE")
```
## How was this patch tested?
Doc tests for `from_json` in Python and unit tests `test_sparkSQL.R` in R.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18498 from HyukjinKwon/SPARK-21266.
## What changes were proposed in this pull request?
This adds documentation to many functions in pyspark.sql.functions.py:
`upper`, `lower`, `reverse`, `unix_timestamp`, `from_unixtime`, `rand`, `randn`, `collect_list`, `collect_set`, `lit`
Add units to the trigonometry functions.
Renames columns in datetime examples to be more informative.
Adds links between some functions.
## How was this patch tested?
`./dev/lint-python`
`python python/pyspark/sql/functions.py`
`./python/run-tests.py --module pyspark-sql`
Author: Michael Patterson <map222@gmail.com>
Closes#17865 from map222/spark-20456.
## What changes were proposed in this pull request?
Currently `ArrayConstructor` handles an array of typecode `'l'` as `int` when converting Python object in Python 2 into Java object, so if the value is larger than `Integer.MAX_VALUE` or smaller than `Integer.MIN_VALUE` then the overflow occurs.
```python
import array
data = [Row(longarray=array.array('l', [-9223372036854775808, 0, 9223372036854775807]))]
df = spark.createDataFrame(data)
df.show(truncate=False)
```
```
+----------+
|longarray |
+----------+
|[0, 0, -1]|
+----------+
```
This should be:
```
+----------------------------------------------+
|longarray |
+----------------------------------------------+
|[-9223372036854775808, 0, 9223372036854775807]|
+----------------------------------------------+
```
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#18553 from ueshin/issues/SPARK-21327.
## What changes were proposed in this pull request?
Support register Java UDAFs in PySpark so that user can use Java UDAF in PySpark. Besides that I also add api in `UDFRegistration`
## How was this patch tested?
Unit test is added
Author: Jeff Zhang <zjffdu@apache.org>
Closes#17222 from zjffdu/SPARK-19439.
## What changes were proposed in this pull request?
Add offset to PySpark in GLM as in #16699.
## How was this patch tested?
Python test
Author: actuaryzhang <actuaryzhang10@gmail.com>
Closes#18534 from actuaryzhang/pythonOffset.
## What changes were proposed in this pull request?
**Context**
While reviewing https://github.com/apache/spark/pull/17227, I realised here we type-dispatch per record. The PR itself is fine in terms of performance as is but this prints a prefix, `"obj"` in exception message as below:
```
from pyspark.sql.types import *
schema = StructType([StructField('s', IntegerType(), nullable=False)])
spark.createDataFrame([["1"]], schema)
...
TypeError: obj.s: IntegerType can not accept object '1' in type <type 'str'>
```
I suggested to get rid of this but during investigating this, I realised my approach might bring a performance regression as it is a hot path.
Only for SPARK-19507 and https://github.com/apache/spark/pull/17227, It needs more changes to cleanly get rid of the prefix and I rather decided to fix both issues together.
**Propersal**
This PR tried to
- get rid of per-record type dispatch as we do in many code paths in Scala so that it improves the performance (roughly ~25% improvement) - SPARK-21296
This was tested with a simple code `spark.createDataFrame(range(1000000), "int")`. However, I am quite sure the actual improvement in practice is larger than this, in particular, when the schema is complicated.
- improve error message in exception describing field information as prose - SPARK-19507
## How was this patch tested?
Manually tested and unit tests were added in `python/pyspark/sql/tests.py`.
Benchmark - codes: https://gist.github.com/HyukjinKwon/c3397469c56cb26c2d7dd521ed0bc5a3
Error message - codes: https://gist.github.com/HyukjinKwon/b1b2c7f65865444c4a8836435100e398
**Before**
Benchmark:
- Results: https://gist.github.com/HyukjinKwon/4a291dab45542106301a0c1abcdca924
Error message
- Results: https://gist.github.com/HyukjinKwon/57b1916395794ce924faa32b14a3fe19
**After**
Benchmark
- Results: https://gist.github.com/HyukjinKwon/21496feecc4a920e50c4e455f836266e
Error message
- Results: https://gist.github.com/HyukjinKwon/7a494e4557fe32a652ce1236e504a395Closes#17227
Author: hyukjinkwon <gurwls223@gmail.com>
Author: David Gingrich <david@textio.com>
Closes#18521 from HyukjinKwon/python-type-dispatch.
## What changes were proposed in this pull request?
Currently, it throws a NPE when missing columns but join type is speicified in join at PySpark as below:
```python
spark.conf.set("spark.sql.crossJoin.enabled", "false")
spark.range(1).join(spark.range(1), how="inner").show()
```
```
Traceback (most recent call last):
...
py4j.protocol.Py4JJavaError: An error occurred while calling o66.join.
: java.lang.NullPointerException
at org.apache.spark.sql.Dataset.join(Dataset.scala:931)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
...
```
```python
spark.conf.set("spark.sql.crossJoin.enabled", "true")
spark.range(1).join(spark.range(1), how="inner").show()
```
```
...
py4j.protocol.Py4JJavaError: An error occurred while calling o84.join.
: java.lang.NullPointerException
at org.apache.spark.sql.Dataset.join(Dataset.scala:931)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
...
```
This PR suggests to follow Scala's one as below:
```scala
scala> spark.conf.set("spark.sql.crossJoin.enabled", "false")
scala> spark.range(1).join(spark.range(1), Seq.empty[String], "inner").show()
```
```
org.apache.spark.sql.AnalysisException: Detected cartesian product for INNER join between logical plans
Range (0, 1, step=1, splits=Some(8))
and
Range (0, 1, step=1, splits=Some(8))
Join condition is missing or trivial.
Use the CROSS JOIN syntax to allow cartesian products between these relations.;
...
```
```scala
scala> spark.conf.set("spark.sql.crossJoin.enabled", "true")
scala> spark.range(1).join(spark.range(1), Seq.empty[String], "inner").show()
```
```
+---+---+
| id| id|
+---+---+
| 0| 0|
+---+---+
```
**After**
```python
spark.conf.set("spark.sql.crossJoin.enabled", "false")
spark.range(1).join(spark.range(1), how="inner").show()
```
```
Traceback (most recent call last):
...
pyspark.sql.utils.AnalysisException: u'Detected cartesian product for INNER join between logical plans\nRange (0, 1, step=1, splits=Some(8))\nand\nRange (0, 1, step=1, splits=Some(8))\nJoin condition is missing or trivial.\nUse the CROSS JOIN syntax to allow cartesian products between these relations.;'
```
```python
spark.conf.set("spark.sql.crossJoin.enabled", "true")
spark.range(1).join(spark.range(1), how="inner").show()
```
```
+---+---+
| id| id|
+---+---+
| 0| 0|
+---+---+
```
## How was this patch tested?
Added tests in `python/pyspark/sql/tests.py`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18484 from HyukjinKwon/SPARK-21264.
## What changes were proposed in this pull request?
This PR is to maintain API parity with changes made in SPARK-17498 to support a new option
'keep' in StringIndexer to handle unseen labels or NULL values with PySpark.
Note: This is updated version of #17237 , the primary author of this PR is VinceShieh .
## How was this patch tested?
Unit tests.
Author: VinceShieh <vincent.xie@intel.com>
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18453 from yanboliang/spark-19852.
## What changes were proposed in this pull request?
1, make param support non-final with `finalFields` option
2, generate `HasSolver` with `finalFields = false`
3, override `solver` in LiR, GLR, and make MLPC inherit `HasSolver`
## How was this patch tested?
existing tests
Author: Ruifeng Zheng <ruifengz@foxmail.com>
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#16028 from zhengruifeng/param_non_final.
## What changes were proposed in this pull request?
This pr supported a DDL-formatted string in `DataStreamReader.schema`.
This fix could make users easily define a schema without importing the type classes.
For example,
```scala
scala> spark.readStream.schema("col0 INT, col1 DOUBLE").load("/tmp/abc").printSchema()
root
|-- col0: integer (nullable = true)
|-- col1: double (nullable = true)
```
## How was this patch tested?
Added tests in `DataStreamReaderWriterSuite`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18373 from HyukjinKwon/SPARK-20431.
## What changes were proposed in this pull request?
Integrate Apache Arrow with Spark to increase performance of `DataFrame.toPandas`. This has been done by using Arrow to convert data partitions on the executor JVM to Arrow payload byte arrays where they are then served to the Python process. The Python DataFrame can then collect the Arrow payloads where they are combined and converted to a Pandas DataFrame. All non-complex data types are currently supported, otherwise an `UnsupportedOperation` exception is thrown.
Additions to Spark include a Scala package private method `Dataset.toArrowPayloadBytes` that will convert data partitions in the executor JVM to `ArrowPayload`s as byte arrays so they can be easily served. A package private class/object `ArrowConverters` that provide data type mappings and conversion routines. In Python, a public method `DataFrame.collectAsArrow` is added to collect Arrow payloads and an optional flag in `toPandas(useArrow=False)` to enable using Arrow (uses the old conversion by default).
## How was this patch tested?
Added a new test suite `ArrowConvertersSuite` that will run tests on conversion of Datasets to Arrow payloads for supported types. The suite will generate a Dataset and matching Arrow JSON data, then the dataset is converted to an Arrow payload and finally validated against the JSON data. This will ensure that the schema and data has been converted correctly.
Added PySpark tests to verify the `toPandas` method is producing equal DataFrames with and without pyarrow. A roundtrip test to ensure the pandas DataFrame produced by pyspark is equal to a one made directly with pandas.
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Li Jin <ice.xelloss@gmail.com>
Author: Li Jin <li.jin@twosigma.com>
Author: Wes McKinney <wes.mckinney@twosigma.com>
Closes#15821 from BryanCutler/wip-toPandas_with_arrow-SPARK-13534.
## What changes were proposed in this pull request?
Currently we convert a spark DataFrame to Pandas Dataframe by `pd.DataFrame.from_records`. It infers the data type from the data and doesn't respect the spark DataFrame Schema. This PR fixes it.
## How was this patch tested?
a new regression test
Author: hyukjinkwon <gurwls223@gmail.com>
Author: Wenchen Fan <wenchen@databricks.com>
Author: Wenchen Fan <cloud0fan@gmail.com>
Closes#18378 from cloud-fan/to_pandas.
## What changes were proposed in this pull request?
Add Python wrappers for `o.a.s.sql.functions.explode_outer` and `o.a.s.sql.functions.posexplode_outer`.
## How was this patch tested?
Unit tests, doctests.
Author: zero323 <zero323@users.noreply.github.com>
Closes#18049 from zero323/SPARK-20830.
## What changes were proposed in this pull request?
Extend setJobDescription to PySpark and JavaSpark APIs
SPARK-21125
## How was this patch tested?
Testing was done by running a local Spark shell on the built UI. I originally had added a unit test but the PySpark context cannot easily access the Scala Spark Context's private variable with the Job Description key so I omitted the test, due to the simplicity of this addition.
Also ran the existing tests.
# Misc
This contribution is my original work and that I license the work to the project under the project's open source license.
Author: sjarvie <sjarvie@uber.com>
Closes#18332 from sjarvie/add_python_set_job_description.
## What changes were proposed in this pull request?
LinearSVC should use its own threshold param, rather than the shared one, since it applies to rawPrediction instead of probability. This PR changes the param in the Scala, Python and R APIs.
## How was this patch tested?
New unit test to make sure the threshold can be set to any Double value.
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#18151 from jkbradley/ml-2.2-linearsvc-cleanup.
## What changes were proposed in this pull request?
Fix some typo of the document.
## How was this patch tested?
Existing tests.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Xianyang Liu <xianyang.liu@intel.com>
Closes#18350 from ConeyLiu/fixtypo.
## What changes were proposed in this pull request?
This fix tries to address the issue in SPARK-19975 where we
have `map_keys` and `map_values` functions in SQL yet there
is no Python equivalent functions.
This fix adds `map_keys` and `map_values` functions to Python.
## How was this patch tested?
This fix is tested manually (See Python docs for examples).
Author: Yong Tang <yong.tang.github@outlook.com>
Closes#17328 from yongtang/SPARK-19975.
### What changes were proposed in this pull request?
The current option name `wholeFile` is misleading for CSV users. Currently, it is not representing a record per file. Actually, one file could have multiple records. Thus, we should rename it. Now, the proposal is `multiLine`.
### How was this patch tested?
N/A
Author: Xiao Li <gatorsmile@gmail.com>
Closes#18202 from gatorsmile/renameCVSOption.
## What changes were proposed in this pull request?
Document Dataset.union is resolution by position, not by name, since this has been a confusing point for a lot of users.
## How was this patch tested?
N/A - doc only change.
Author: Reynold Xin <rxin@databricks.com>
Closes#18256 from rxin/SPARK-21042.
## What changes were proposed in this pull request?
Allow fill/replace of NAs with booleans, both in Python and Scala
## How was this patch tested?
Unit tests, doctests
This PR is original work from me and I license this work to the Spark project
Author: Ruben Berenguel Montoro <ruben@mostlymaths.net>
Author: Ruben Berenguel <ruben@mostlymaths.net>
Closes#18164 from rberenguel/SPARK-19732-fillna-bools.
### What changes were proposed in this pull request?
This PR does the following tasks:
- Added since
- Added the Python API
- Added test cases
### How was this patch tested?
Added test cases to both Scala and Python
Author: gatorsmile <gatorsmile@gmail.com>
Closes#18147 from gatorsmile/createOrReplaceGlobalTempView.
## What changes were proposed in this pull request?
PySpark supports stringIndexerOrderType in RFormula as in #17967.
## How was this patch tested?
docstring test
Author: actuaryzhang <actuaryzhang10@gmail.com>
Closes#18122 from actuaryzhang/PythonRFormula.
Now that Structured Streaming has been out for several Spark release and has large production use cases, the `Experimental` label is no longer appropriate. I've left `InterfaceStability.Evolving` however, as I think we may make a few changes to the pluggable Source & Sink API in Spark 2.3.
Author: Michael Armbrust <michael@databricks.com>
Closes#18065 from marmbrus/streamingGA.
## What changes were proposed in this pull request?
Expose numPartitions (expert) param of PySpark FPGrowth.
## How was this patch tested?
+ [x] Pass all unit tests.
Author: Yan Facai (颜发才) <facai.yan@gmail.com>
Closes#18058 from facaiy/ENH/pyspark_fpg_add_num_partition.
## What changes were proposed in this pull request?
Follow-up for #17218, some minor fix for PySpark ```FPGrowth```.
## How was this patch tested?
Existing UT.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18089 from yanboliang/spark-19281.
## What changes were proposed in this pull request?
Fixed TypeError with python3 and numpy 1.12.1. Numpy's `reshape` no longer takes floats as arguments as of 1.12. Also, python3 uses float division for `/`, we should be using `//` to ensure that `_dataWithBiasSize` doesn't get set to a float.
## How was this patch tested?
Existing tests run using python3 and numpy 1.12.
Author: Bago Amirbekian <bago@databricks.com>
Closes#18081 from MrBago/BF-py3floatbug.
## What changes were proposed in this pull request?
- Fix incorrect tests for `_check_thresholds`.
- Move test to `ParamTests`.
## How was this patch tested?
Unit tests.
Author: zero323 <zero323@users.noreply.github.com>
Closes#18085 from zero323/SPARK-20631-FOLLOW-UP.
## What changes were proposed in this pull request?
Add test cases for PR-18062
## How was this patch tested?
The existing UT
Author: Peng <peng.meng@intel.com>
Closes#18068 from mpjlu/moreTest.
Changes:
pyspark.ml Estimators can take either a list of param maps or a dict of params. This change allows the CrossValidator and TrainValidationSplit Estimators to pass through lists of param maps to the underlying estimators so that those estimators can handle parallelization when appropriate (eg distributed hyper parameter tuning).
Testing:
Existing unit tests.
Author: Bago Amirbekian <bago@databricks.com>
Closes#18077 from MrBago/delegate_params.
## What changes were proposed in this pull request?
SPARK-20097 exposed degreesOfFreedom in LinearRegressionSummary and numInstances in GeneralizedLinearRegressionSummary. Python API should be updated to reflect these changes.
## How was this patch tested?
The existing UT
Author: Peng <peng.meng@intel.com>
Closes#18062 from mpjlu/spark-20764.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}