### What changes were proposed in this pull request?
Add a configuration to control the legacy behavior of whether need to pad null value when value size less then schema size.
Since we can't decide whether it's a but and some use need it behavior same as Hive.
### Why are the changes needed?
Provides a compatible choice between historical behavior and Hive
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existed UT
Closes#30156 from AngersZhuuuu/SPARK-33284.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Return schema in SQL format instead of Catalog string from the SchemaOfCsv expression.
### Why are the changes needed?
To unify output of the `schema_of_json()` and `schema_of_csv()`.
### Does this PR introduce _any_ user-facing change?
Yes, they can but `schema_of_csv()` is usually used in combination with `from_csv()`, so, the format of schema shouldn't be much matter.
Before:
```
> SELECT schema_of_csv('1,abc');
struct<_c0:int,_c1:string>
```
After:
```
> SELECT schema_of_csv('1,abc');
STRUCT<`_c0`: INT, `_c1`: STRING>
```
### How was this patch tested?
By existing test suites `CsvFunctionsSuite` and `CsvExpressionsSuite`.
Closes#30180 from MaxGekk/schema_of_csv-sql-schema.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Return schema in SQL format instead of Catalog string from the `SchemaOfJson` expression.
### Why are the changes needed?
In some cases, `from_json()` cannot parse schemas returned by `schema_of_json`, for instance, when JSON fields have spaces (gaps). Such fields will be quoted after the changes, and can be parsed by `from_json()`.
Here is the example:
```scala
val in = Seq("""{"a b": 1}""").toDS()
in.select(from_json('value, schema_of_json("""{"a b": 100}""")) as "parsed")
```
raises the exception:
```
== SQL ==
struct<a b:bigint>
------^^^
at org.apache.spark.sql.catalyst.parser.ParseException.withCommand(ParseDriver.scala:263)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parse(ParseDriver.scala:130)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parseTableSchema(ParseDriver.scala:76)
at org.apache.spark.sql.types.DataType$.fromDDL(DataType.scala:131)
at org.apache.spark.sql.catalyst.expressions.ExprUtils$.evalTypeExpr(ExprUtils.scala:33)
at org.apache.spark.sql.catalyst.expressions.JsonToStructs.<init>(jsonExpressions.scala:537)
at org.apache.spark.sql.functions$.from_json(functions.scala:4141)
```
### Does this PR introduce _any_ user-facing change?
Yes. For example, `schema_of_json` for the input `{"col":0}`.
Before: `struct<col:bigint>`
After: `STRUCT<`col`: BIGINT>`
### How was this patch tested?
By existing test suites `JsonFunctionsSuite` and `JsonExpressionsSuite`.
Closes#30172 from MaxGekk/schema_of_json-sql-schema.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Set the default value for the SQL configs `spark.sql.legacy.parquet.int96RebaseModeInWrite` and `spark.sql.legacy.parquet.int96RebaseModeInRead` to `EXCEPTION`.
2. Update the SQL migration guide.
### Why are the changes needed?
Current default value `LEGACY` may lead to shifting timestamps in read or in write. We should leave the decision about rebasing to users.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
By existing test suites like `ParquetIOSuite`.
Closes#30121 from MaxGekk/int96-exception-by-default.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Address comments https://github.com/apache/spark/pull/29635#discussion_r507241899 to improve migration guide
### Why are the changes needed?
improve migration guide
### Does this PR introduce _any_ user-facing change?
NO,only doc update
### How was this patch tested?
passing GitHub action
Closes#30113 from yaooqinn/SPARK-32785-F.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR is a sub-task of [SPARK-33138](https://issues.apache.org/jira/browse/SPARK-33138). In order to make SQLConf.get reliable and stable, we need to make sure user can't pollute the SQLConf and SparkSession Context via calling setActiveSession and clearActiveSession.
Change of the PR:
* add legacy config spark.sql.legacy.allowModifyActiveSession to fallback to old behavior if user do need to call these two API.
* by default, if user call these two API, it will throw exception
* add extra two internal and private API setActiveSessionInternal and clearActiveSessionInternal for current internal usage
* change all internal reference to new internal API except for SQLContext.setActive and SQLContext.clearActive
### Why are the changes needed?
Make SQLConf.get reliable and stable.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
* Add UT in SparkSessionBuilderSuite to test the legacy config
* Existing test
Closes#30042 from leanken/leanken-SPARK-33139.
Authored-by: xuewei.linxuewei <xuewei.linxuewei@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
As [SPARK-13860](https://issues.apache.org/jira/browse/SPARK-13860) stated, TPCDS Query 39 returns wrong results using SparkSQL. The root cause is that when stddev_samp is applied to a single element set, with TPCDS answer, it return null; as in SparkSQL, it return Double.NaN which caused the wrong result.
Add an extra legacy config to fallback into the NaN logical, and return null by default to align with TPCDS standard.
### Why are the changes needed?
SQL correctness issue.
### Does this PR introduce any user-facing change?
Yes. See sql-migration-guide
In Spark 3.1, statistical aggregation function includes `std`, `stddev`, `stddev_samp`, `variance`, `var_samp`, `skewness`, `kurtosis`, `covar_samp`, `corr` will return `NULL` instead of `Double.NaN` when `DivideByZero` occurs during expression evaluation, for example, when `stddev_samp` applied on a single element set. In Spark version 3.0 and earlier, it will return `Double.NaN` in such case. To restore the behavior before Spark 3.1, you can set `spark.sql.legacy.statisticalAggregate` to `true`.
### How was this patch tested?
Updated DataFrameAggregateSuite/DataFrameWindowFunctionsSuite to test both default and legacy behavior.
Adjust DataFrameWindowFunctionsSuite/SQLQueryTestSuite and some R case to update to the default return null behavior.
Closes#29983 from leanken/leanken-SPARK-13860.
Authored-by: xuewei.linxuewei <xuewei.linxuewei@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
As of today,
- SPARK-30034 Apache Spark 3.0.0 switched its default Hive execution engine from Hive 1.2 to Hive 2.3. This removes the direct dependency to the forked Hive 1.2.1 in maven repository.
- SPARK-32981 Apache Spark 3.1.0(`master` branch) removed Hive 1.2 related artifacts from Apache Spark binary distributions.
This PR(SPARK-20202) aims to remove the following usage of unofficial Apache Hive fork completely from Apache Spark master for Apache Spark 3.1.0.
```
<hive.group>org.spark-project.hive</hive.group>
<hive.version>1.2.1.spark2</hive.version>
```
For the forked Hive 1.2.1.spark2 users, Apache Spark 2.4(LTS) and 3.0 (~ 2021.12) will provide it.
### Why are the changes needed?
- First, Apache Spark community should not use the unofficial forked release of another Apache project.
- Second, Apache Hive 1.2.1 was released at 2015-06-26 and the forked Hive `1.2.1.spark2` exposed many unfixable bugs in Apache because the forked `1.2.1.spark2` is not maintained at all. Apache Hive 2.3.0 was released at 2017-07-19 and it has been used with less number of bugs compared with `1.2.1.spark2`. Many bugs still exist in `hive-1.2` profile and new Apache Spark unit tests are added with `HiveUtils.isHive23` condition so far.
### Does this PR introduce _any_ user-facing change?
No. This is a dev-only change. PRBuilder will not accept `[test-hive1.2]` on master and `branch-3.1`.
### How was this patch tested?
1. SBT/Hadoop 3.2/Hive 2.3 (https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129366)
2. SBT/Hadoop 2.7/Hive 2.3 (https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129382)
3. SBT/Hadoop 3.2/Hive 1.2 (This has not been supported already due to Hive 1.2 doesn't work with Hadoop 3.2.)
4. SBT/Hadoop 2.7/Hive 1.2 (https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129383, This is rejected)
Closes#29936 from dongjoon-hyun/SPARK-REMOVE-HIVE1.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
bugfix for incomplete interval values, e.g. interval '1', interval '1 day 2', currently these cases will result null, but actually we should fail them with IllegalArgumentsException
### Why are the changes needed?
correctness
### Does this PR introduce _any_ user-facing change?
yes, incomplete intervals will throw exception now
#### before
```
bin/spark-sql -S -e "select interval '1', interval '+', interval '1 day -'"
NULL NULL NULL
```
#### after
```
-- !query
select interval '1'
-- !query schema
struct<>
-- !query output
org.apache.spark.sql.catalyst.parser.ParseException
Cannot parse the INTERVAL value: 1(line 1, pos 7)
== SQL ==
select interval '1'
```
### How was this patch tested?
unit tests added
Closes#29635 from yaooqinn/SPARK-32785.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow up PR to #29328 to apply the same constraint where `path` option cannot coexist with path parameter to `DataFrameWriter.save()`, `DataStreamReader.load()` and `DataStreamWriter.start()`.
### Why are the changes needed?
The current behavior silently overwrites the `path` option if path parameter is passed to `DataFrameWriter.save()`, `DataStreamReader.load()` and `DataStreamWriter.start()`.
For example,
```
Seq(1).toDF.write.option("path", "/tmp/path1").parquet("/tmp/path2")
```
will write the result to `/tmp/path2`.
### Does this PR introduce _any_ user-facing change?
Yes, if `path` option coexists with path parameter to any of the above methods, it will throw `AnalysisException`:
```
scala> Seq(1).toDF.write.option("path", "/tmp/path1").parquet("/tmp/path2")
org.apache.spark.sql.AnalysisException: There is a 'path' option set and save() is called with a path parameter. Either remove the path option, or call save() without the parameter. To ignore this check, set 'spark.sql.legacy.pathOptionBehavior.enabled' to 'true'.;
```
The user can restore the previous behavior by setting `spark.sql.legacy.pathOptionBehavior.enabled` to `true`.
### How was this patch tested?
Added new tests.
Closes#29543 from imback82/path_option.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes the doc error and add a migration guide for datetime pattern.
### Why are the changes needed?
This is a bug of the doc that we inherited from JDK https://bugs.openjdk.java.net/browse/JDK-8169482
The SimpleDateFormatter(**F Day of week in month**) we used in 2.x and the DatetimeFormatter(**F week-of-month**) we use now both have the opposite meanings to what they declared in the java docs. And unfortunately, this also leads to silent data change in Spark too.
The `week-of-month` is actually the pattern `W` in DatetimeFormatter, which is banned to use in Spark 3.x.
If we want to keep pattern `F`, we need to accept the behavior change with proper migration guide and fix the doc in Spark
### Does this PR introduce _any_ user-facing change?
Yes, doc changed
### How was this patch tested?
passing ci doc generating job
Closes#29538 from yaooqinn/SPARK-32683.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to make the behavior consistent for the `path` option when loading dataframes with a single path (e.g, `option("path", path).format("parquet").load(path)` vs. `option("path", path).parquet(path)`) by disallowing `path` option to coexist with `load`'s path parameters.
### Why are the changes needed?
The current behavior is inconsistent:
```scala
scala> Seq(1).toDF.write.mode("overwrite").parquet("/tmp/test")
scala> spark.read.option("path", "/tmp/test").format("parquet").load("/tmp/test").show
+-----+
|value|
+-----+
| 1|
+-----+
scala> spark.read.option("path", "/tmp/test").parquet("/tmp/test").show
+-----+
|value|
+-----+
| 1|
| 1|
+-----+
```
### Does this PR introduce _any_ user-facing change?
Yes, now if the `path` option is specified along with `load`'s path parameters, it would fail:
```scala
scala> Seq(1).toDF.write.mode("overwrite").parquet("/tmp/test")
scala> spark.read.option("path", "/tmp/test").format("parquet").load("/tmp/test").show
org.apache.spark.sql.AnalysisException: There is a path option set and load() is called with path parameters. Either remove the path option or move it into the load() parameters.;
at org.apache.spark.sql.DataFrameReader.verifyPathOptionDoesNotExist(DataFrameReader.scala:310)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:232)
... 47 elided
scala> spark.read.option("path", "/tmp/test").parquet("/tmp/test").show
org.apache.spark.sql.AnalysisException: There is a path option set and load() is called with path parameters. Either remove the path option or move it into the load() parameters.;
at org.apache.spark.sql.DataFrameReader.verifyPathOptionDoesNotExist(DataFrameReader.scala:310)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:250)
at org.apache.spark.sql.DataFrameReader.parquet(DataFrameReader.scala:778)
at org.apache.spark.sql.DataFrameReader.parquet(DataFrameReader.scala:756)
... 47 elided
```
The user can restore the previous behavior by setting `spark.sql.legacy.pathOptionBehavior.enabled` to `true`.
### How was this patch tested?
Added a test
Closes#29328 from imback82/dfw_option.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Convert `NULL` elements of maps, structs and arrays to the `"null"` string while converting maps/struct/array values to strings. The SQL config `spark.sql.legacy.omitNestedNullInCast.enabled` controls the behaviour. When it is `true`, `NULL` elements of structs/maps/arrays will be omitted otherwise, when it is `false`, `NULL` elements will be converted to `"null"`.
### Why are the changes needed?
1. It is impossible to distinguish empty string and null, for instance:
```scala
scala> Seq(Seq(""), Seq(null)).toDF().show
+-----+
|value|
+-----+
| []|
| []|
+-----+
```
2. Inconsistent NULL conversions for top-level values and nested columns, for instance:
```scala
scala> sql("select named_struct('c', null), null").show
+---------------------+----+
|named_struct(c, NULL)|NULL|
+---------------------+----+
| []|null|
+---------------------+----+
```
3. `.show()` is different from conversions to Hive strings, and as a consequence its output is different from `spark-sql` (sql tests):
```sql
spark-sql> select named_struct('c', null) as struct;
{"c":null}
```
```scala
scala> sql("select named_struct('c', null) as struct").show
+------+
|struct|
+------+
| []|
+------+
```
4. It is impossible to distinguish empty struct/array from struct/array with null in the current implementation:
```scala
scala> Seq[Seq[String]](Seq(), Seq(null)).toDF.show()
+-----+
|value|
+-----+
| []|
| []|
+-----+
```
### Does this PR introduce _any_ user-facing change?
Yes, before:
```scala
scala> Seq(Seq(""), Seq(null)).toDF().show
+-----+
|value|
+-----+
| []|
| []|
+-----+
```
After:
```scala
scala> Seq(Seq(""), Seq(null)).toDF().show
+------+
| value|
+------+
| []|
|[null]|
+------+
```
### How was this patch tested?
By existing test suite `CastSuite`.
Closes#29311 from MaxGekk/nested-null-to-string.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change casting of map and struct values to strings by using the `{}` brackets instead of `[]`. The behavior is controlled by the SQL config `spark.sql.legacy.castComplexTypesToString.enabled`. When it is `true`, `CAST` wraps maps and structs by `[]` in casting to strings. Otherwise, if this is `false`, which is the default, maps and structs are wrapped by `{}`.
### Why are the changes needed?
- To distinguish structs/maps from arrays.
- To make `show`'s output consistent with Hive and conversions to Hive strings.
- To display dataframe content in the same form by `spark-sql` and `show`
- To be consistent with the `*.sql` tests
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
By existing test suite `CastSuite`.
Closes#29308 from MaxGekk/show-struct-map.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change _To restore the behavior before Spark **3.0**_ to _To restore the behavior before Spark **3.1**_ in the SQL migration guide while telling about the behaviour before new version 3.1.
### Why are the changes needed?
To have correct info in the SQL migration guide.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
N/A
Closes#29336 from MaxGekk/fix-version-in-sql-migration.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
When `spark.sql.caseSensitive` is `false` (by default), check that there are not duplicate column names on the same level (top level or nested levels) in reading from in-built datasources Parquet, ORC, Avro and JSON. If such duplicate columns exist, throw the exception:
```
org.apache.spark.sql.AnalysisException: Found duplicate column(s) in the data schema:
```
### Why are the changes needed?
To make handling of duplicate nested columns is similar to handling of duplicate top-level columns i. e. output the same error when `spark.sql.caseSensitive` is `false`:
```Scala
org.apache.spark.sql.AnalysisException: Found duplicate column(s) in the data schema: `camelcase`
```
Checking of top-level duplicates was introduced by https://github.com/apache/spark/pull/17758.
### Does this PR introduce _any_ user-facing change?
Yes. For the example from SPARK-32431:
ORC:
```scala
java.io.IOException: Error reading file: file:/private/var/folders/p3/dfs6mf655d7fnjrsjvldh0tc0000gn/T/spark-c02c2f9a-0cdc-4859-94fc-b9c809ca58b1/part-00001-63e8c3f0-7131-4ec9-be02-30b3fdd276f4-c000.snappy.orc
at org.apache.orc.impl.RecordReaderImpl.nextBatch(RecordReaderImpl.java:1329)
at org.apache.orc.mapreduce.OrcMapreduceRecordReader.ensureBatch(OrcMapreduceRecordReader.java:78)
...
Caused by: java.io.EOFException: Read past end of RLE integer from compressed stream Stream for column 3 kind DATA position: 6 length: 6 range: 0 offset: 12 limit: 12 range 0 = 0 to 6 uncompressed: 3 to 3
at org.apache.orc.impl.RunLengthIntegerReaderV2.readValues(RunLengthIntegerReaderV2.java:61)
at org.apache.orc.impl.RunLengthIntegerReaderV2.next(RunLengthIntegerReaderV2.java:323)
```
JSON:
```scala
+------------+
|StructColumn|
+------------+
| [,,]|
+------------+
```
Parquet:
```scala
+------------+
|StructColumn|
+------------+
| [0,, 1]|
+------------+
```
Avro:
```scala
+------------+
|StructColumn|
+------------+
| [,,]|
+------------+
```
After the changes, Parquet, ORC, JSON and Avro output the same error:
```scala
Found duplicate column(s) in the data schema: `camelcase`;
org.apache.spark.sql.AnalysisException: Found duplicate column(s) in the data schema: `camelcase`;
at org.apache.spark.sql.util.SchemaUtils$.checkColumnNameDuplication(SchemaUtils.scala:112)
at org.apache.spark.sql.util.SchemaUtils$.checkSchemaColumnNameDuplication(SchemaUtils.scala:51)
at org.apache.spark.sql.util.SchemaUtils$.checkSchemaColumnNameDuplication(SchemaUtils.scala:67)
```
### How was this patch tested?
Run modified test suites:
```
$ build/sbt "sql/test:testOnly org.apache.spark.sql.FileBasedDataSourceSuite"
$ build/sbt "avro/test:testOnly org.apache.spark.sql.avro.*"
```
and added new UT to `SchemaUtilsSuite`.
Closes#29234 from MaxGekk/nested-case-insensitive-column.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1. Set the SQL config `spark.sql.legacy.allowCastNumericToTimestamp` to `true` by default
2. Remove explicit sets of `spark.sql.legacy.allowCastNumericToTimestamp` to `true` in the cast suites.
### Why are the changes needed?
To avoid breaking changes in minor versions (in the upcoming Spark 3.1.0) according to the the semantic versioning guidelines (https://spark.apache.org/versioning-policy.html)
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
By `CastSuite`.
Closes#29012 from MaxGekk/allow-cast-numeric-to-timestamp.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Set the JSON option `inferTimestamp` to `false` if an user don't pass it as datasource option.
### Why are the changes needed?
To prevent perf regression while inferring schemas from JSON with potential timestamps fields.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
- Modified existing tests in `JsonSuite` and `JsonInferSchemaSuite`.
- Regenerated results of `JsonBenchmark` in the environment:
| Item | Description |
| ---- | ----|
| Region | us-west-2 (Oregon) |
| Instance | r3.xlarge |
| AMI | ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20190722.1 (ami-06f2f779464715dc5) |
| Java | OpenJDK 64-Bit Server VM 1.8.0_252 and OpenJDK 64-Bit Server VM 11.0.7+10 |
Closes#28966 from MaxGekk/json-inferTimestamps-disable-by-default.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
we fail casting from numeric to timestamp by default.
## Why are the changes needed?
casting from numeric to timestamp is not a non-standard,meanwhile it may generate different result between spark and other systems,for example hive
## Does this PR introduce any user-facing change?
Yes,user cannot cast numeric to timestamp directly,user have to use the following function to achieve the same effect:TIMESTAMP_SECONDS/TIMESTAMP_MILLIS/TIMESTAMP_MICROS
## How was this patch tested?
unit test added
Closes#28593 from GuoPhilipse/31710-fix-compatibility.
Lead-authored-by: GuoPhilipse <guofei_ok@126.com>
Co-authored-by: GuoPhilipse <46367746+GuoPhilipse@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Currently, `date_format` and `from_unixtime`, `unix_timestamp`,`to_unix_timestamp`, `to_timestamp`, `to_date` have different exception handling behavior for formatting datetime values.
In this PR, we apply the exception handling behavior of `date_format` to `from_unixtime`, `unix_timestamp`,`to_unix_timestamp`, `to_timestamp` and `to_date`.
In the phase of creating the datetime formatted or formating, exceptions will be raised.
e.g.
```java
spark-sql> select date_format(make_timestamp(1, 1 ,1,1,1,1), 'yyyyyyyyyyy-MM-aaa');
20/05/28 15:25:38 ERROR SparkSQLDriver: Failed in [select date_format(make_timestamp(1, 1 ,1,1,1,1), 'yyyyyyyyyyy-MM-aaa')]
org.apache.spark.SparkUpgradeException: You may get a different result due to the upgrading of Spark 3.0: Fail to recognize 'yyyyyyyyyyy-MM-aaa' pattern in the DateTimeFormatter. 1) You can set spark.sql.legacy.timeParserPolicy to LEGACY to restore the behavior before Spark 3.0. 2) You can form a valid datetime pattern with the guide from https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html
```
```java
spark-sql> select date_format(make_timestamp(1, 1 ,1,1,1,1), 'yyyyyyyyyyy-MM-AAA');
20/05/28 15:26:10 ERROR SparkSQLDriver: Failed in [select date_format(make_timestamp(1, 1 ,1,1,1,1), 'yyyyyyyyyyy-MM-AAA')]
java.lang.IllegalArgumentException: Illegal pattern character: A
```
```java
spark-sql> select date_format(make_timestamp(1,1,1,1,1,1), 'yyyyyyyyyyy-MM-dd');
20/05/28 15:23:23 ERROR SparkSQLDriver: Failed in [select date_format(make_timestamp(1,1,1,1,1,1), 'yyyyyyyyyyy-MM-dd')]
java.lang.ArrayIndexOutOfBoundsException: 11
at java.time.format.DateTimeFormatterBuilder$NumberPrinterParser.format(DateTimeFormatterBuilder.java:2568)
```
In the phase of parsing, `DateTimeParseException | DateTimeException | ParseException` will be suppressed, but `SparkUpgradeException` will still be raised
e.g.
```java
spark-sql> set spark.sql.legacy.timeParserPolicy=exception;
spark.sql.legacy.timeParserPolicy exception
spark-sql> select to_timestamp("2020-01-27T20:06:11.847-0800", "yyyy-MM-dd'T'HH:mm:ss.SSSz");
20/05/28 15:31:15 ERROR SparkSQLDriver: Failed in [select to_timestamp("2020-01-27T20:06:11.847-0800", "yyyy-MM-dd'T'HH:mm:ss.SSSz")]
org.apache.spark.SparkUpgradeException: You may get a different result due to the upgrading of Spark 3.0: Fail to parse '2020-01-27T20:06:11.847-0800' in the new parser. You can set spark.sql.legacy.timeParserPolicy to LEGACY to restore the behavior before Spark 3.0, or set to CORRECTED and treat it as an invalid datetime string.
```
```java
spark-sql> set spark.sql.legacy.timeParserPolicy=corrected;
spark.sql.legacy.timeParserPolicy corrected
spark-sql> select to_timestamp("2020-01-27T20:06:11.847-0800", "yyyy-MM-dd'T'HH:mm:ss.SSSz");
NULL
spark-sql> set spark.sql.legacy.timeParserPolicy=legacy;
spark.sql.legacy.timeParserPolicy legacy
spark-sql> select to_timestamp("2020-01-27T20:06:11.847-0800", "yyyy-MM-dd'T'HH:mm:ss.SSSz");
2020-01-28 12:06:11.847
```
### Why are the changes needed?
Consistency
### Does this PR introduce _any_ user-facing change?
Yes, invalid datetime patterns will fail `from_unixtime`, `unix_timestamp`,`to_unix_timestamp`, `to_timestamp` and `to_date` instead of resulting `NULL`
### How was this patch tested?
add more tests
Closes#28650 from yaooqinn/SPARK-31830.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
add docs for sql migration-guide
### Why are the changes needed?
let user know more about the cast scenarios in which Hive and Spark generate different results
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
no need to test
Closes#28605 from GuoPhilipse/spark-docs.
Lead-authored-by: GuoPhilipse <guofei_ok@126.com>
Co-authored-by: GuoPhilipse <46367746+GuoPhilipse@users.noreply.github.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This patch effectively reverts SPARK-30098 via below changes:
* Removed the config
* Removed the changes done in parser rule
* Removed the usage of config in tests
* Removed tests which depend on the config
* Rolled back some tests to before SPARK-30098 which were affected by SPARK-30098
* Reflect the change into docs (migration doc, create table syntax)
### Why are the changes needed?
SPARK-30098 brought confusion and frustration on using create table DDL query, and we agreed about the bad effect on the change.
Please go through the [discussion thread](http://apache-spark-developers-list.1001551.n3.nabble.com/DISCUSS-Resolve-ambiguous-parser-rule-between-two-quot-create-table-quot-s-td29051i20.html) to see the details.
### Does this PR introduce _any_ user-facing change?
No, compared to Spark 2.4.x. End users tried to experiment with Spark 3.0.0 previews will see the change that the behavior is going back to Spark 2.4.x, but I believe we won't guarantee compatibility in preview releases.
### How was this patch tested?
Existing UTs.
Closes#28517 from HeartSaVioR/revert-SPARK-30098.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This reverts commit 43a73e387c. It sets `INT96` as the timestamp type while saving timestamps to parquet files.
### Why are the changes needed?
To be compatible with Hive and Presto that don't support the `TIMESTAMP_MICROS` type in current stable releases.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By existing test suites.
Closes#28450 from MaxGekk/parquet-int96.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Fixed typo in `docs` directory and in `project/MimaExcludes.scala`
### Why are the changes needed?
Better readability of documents
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
No test needed
Closes#28447 from kiszk/typo_20200504.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
- Rephrase the API doc for `Column.as`
- Simplify the UTs
### Why are the changes needed?
Address comments in https://github.com/apache/spark/pull/28326
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
New UT added.
Closes#28390 from xuanyuanking/SPARK-27340-follow.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR addresses two things:
- `SHOW TBLPROPERTIES` should supports view (a regression introduced by #26921)
- `SHOW TBLPROPERTIES` on a temporary view should return empty result (2.4 behavior instead of throwing `AnalysisException`.
### Why are the changes needed?
It's a bug.
### Does this PR introduce any user-facing change?
Yes, now `SHOW TBLPROPERTIES` works on views:
```
scala> sql("CREATE VIEW view TBLPROPERTIES('p1'='v1', 'p2'='v2') AS SELECT 1 AS c1")
scala> sql("SHOW TBLPROPERTIES view").show(truncate=false)
+---------------------------------+-------------+
|key |value |
+---------------------------------+-------------+
|view.catalogAndNamespace.numParts|2 |
|view.query.out.col.0 |c1 |
|view.query.out.numCols |1 |
|p2 |v2 |
|view.catalogAndNamespace.part.0 |spark_catalog|
|p1 |v1 |
|view.catalogAndNamespace.part.1 |default |
+---------------------------------+-------------+
```
And for a temporary view:
```
scala> sql("CREATE TEMPORARY VIEW tview TBLPROPERTIES('p1'='v1', 'p2'='v2') AS SELECT 1 AS c1")
scala> sql("SHOW TBLPROPERTIES tview").show(truncate=false)
+---+-----+
|key|value|
+---+-----+
+---+-----+
```
### How was this patch tested?
Added tests.
Closes#28375 from imback82/show_tblproperties_followup.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Give more friendly warning message/migration guide of deprecated scala udf to users.
### Why are the changes needed?
User can not distinguish function signature between typed and untyped scala udf. Instead, we shall tell user what to do directly.
### Does this PR introduce any user-facing change?
No, it's newly added in Spark 3.0.
### How was this patch tested?
Pass Jenkins.
Closes#28311 from Ngone51/update_udf_doc.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
**Hive 2.3.7** fixed these issues:
- HIVE-21508: ClassCastException when initializing HiveMetaStoreClient on JDK10 or newer
- HIVE-21980:Parsing time can be high in case of deeply nested subqueries
- HIVE-22249: Support Parquet through HCatalog
### Why are the changes needed?
Fix CCE during creating HiveMetaStoreClient in JDK11 environment: [SPARK-29245](https://issues.apache.org/jira/browse/SPARK-29245).
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
- [x] Test Jenkins with Hadoop 2.7 (https://github.com/apache/spark/pull/28148#issuecomment-616757840)
- [x] Test Jenkins with Hadoop 3.2 on JDK11 (https://github.com/apache/spark/pull/28148#issuecomment-616294353)
- [x] Manual test with remote hive metastore.
Hive side:
```
export JAVA_HOME=/usr/lib/jdk1.8.0_221
export PATH=$JAVA_HOME/bin:$PATH
cd /usr/lib/hive-2.3.6 # Start Hive metastore with Hive 2.3.6
bin/schematool -dbType derby -initSchema --verbose
bin/hive --service metastore
```
Spark side:
```
export JAVA_HOME=/usr/lib/jdk-11.0.3
export PATH=$JAVA_HOME/bin:$PATH
build/sbt clean package -Phive -Phadoop-3.2 -Phive-thriftserver
export SPARK_PREPEND_CLASSES=true
bin/spark-sql --conf spark.hadoop.hive.metastore.uris=thrift://localhost:9083
```
Closes#28148 from wangyum/SPARK-31381.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR is the follow-up PR of https://github.com/apache/spark/pull/28003
- add a migration guide
- add an end-to-end test case.
### Why are the changes needed?
The original PR made the major behavior change in the user-facing RESET command.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Added a new end-to-end test
Closes#28265 from gatorsmile/spark-31234followup.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Add migration guide for extracting second from datetimes
### Why are the changes needed?
doc the behavior change for extract expression
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A, just passing jenkins
Closes#28140 from yaooqinn/SPARK-29311.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR intends to add a new SQL config for controlling a plan explain mode in the events of (e.g., `SparkListenerSQLExecutionStart` and `SparkListenerSQLAdaptiveExecutionUpdate`) SQL listeners. In the current master, the output of `QueryExecution.toString` (this is equivalent to the "extended" explain mode) is stored in these events. I think it is useful to control the content via `SQLConf`. For example, the query "Details" content (TPCDS q66 query) of a SQL tab in a Spark web UI will be changed as follows;
Before this PR:

After this PR:

### Why are the changes needed?
For better usability.
### Does this PR introduce any user-facing change?
Yes; since Spark 3.1, SQL UI data adopts the `formatted` mode for the query plan explain results. To restore the behavior before Spark 3.0, you can set `spark.sql.ui.explainMode` to `extended`.
### How was this patch tested?
Added unit tests.
Closes#28097 from maropu/SPARK-31325.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request?
Based on the discussion in the mailing list [[Proposal] Modification to Spark's Semantic Versioning Policy](http://apache-spark-developers-list.1001551.n3.nabble.com/Proposal-Modification-to-Spark-s-Semantic-Versioning-Policy-td28938.html) , this PR is to add back the following APIs whose maintenance cost are relatively small.
- HiveContext
- createExternalTable APIs
### Why are the changes needed?
Avoid breaking the APIs that are commonly used.
### Does this PR introduce any user-facing change?
Adding back the APIs that were removed in 3.0 branch does not introduce the user-facing changes, because Spark 3.0 has not been released.
### How was this patch tested?
add a new test suite for createExternalTable APIs.
Closes#27815 from gatorsmile/addAPIsBack.
Lead-authored-by: gatorsmile <gatorsmile@gmail.com>
Co-authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
Spark introduced CHAR type for hive compatibility but it only works for hive tables. CHAR type is never documented and is treated as STRING type for non-Hive tables.
However, this leads to confusing behaviors
**Apache Spark 3.0.0-preview2**
```
spark-sql> CREATE TABLE t(a CHAR(3));
spark-sql> INSERT INTO TABLE t SELECT 'a ';
spark-sql> SELECT a, length(a) FROM t;
a 2
```
**Apache Spark 2.4.5**
```
spark-sql> CREATE TABLE t(a CHAR(3));
spark-sql> INSERT INTO TABLE t SELECT 'a ';
spark-sql> SELECT a, length(a) FROM t;
a 3
```
According to the SQL standard, `CHAR(3)` should guarantee all the values are of length 3. Since `CHAR(3)` is treated as STRING so Spark doesn't guarantee it.
This PR forbids CHAR type in non-Hive tables as it's not supported correctly.
### Why are the changes needed?
avoid confusing/wrong behavior
### Does this PR introduce any user-facing change?
yes, now users can't create/alter non-Hive tables with CHAR type.
### How was this patch tested?
new tests
Closes#27902 from cloud-fan/char.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
https://github.com/apache/spark/pull/26412 introduced a behavior change that `date_add`/`date_sub` functions can't accept string and double values in the second parameter. This is reasonable as it's error-prone to cast string/double to int at runtime.
However, using string literals as function arguments is very common in SQL databases. To avoid breaking valid use cases that the string literal is indeed an integer, this PR proposes to add ansi_cast for string literal in date_add/date_sub functions. If the string value is not a valid integer, we fail at query compiling time because of constant folding.
### Why are the changes needed?
avoid breaking changes
### Does this PR introduce any user-facing change?
Yes, now 3.0 can run `date_add('2011-11-11', '1')` like 2.4
### How was this patch tested?
new tests.
Closes#27965 from cloud-fan/string.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The current migration guide of SQL is too long for most readers to find the needed info. This PR is to group the items in the migration guide of Spark SQL based on the corresponding components.
Note. This PR does not change the contents of the migration guides. Attached figure is the screenshot after the change.

### Why are the changes needed?
The current migration guide of SQL is too long for most readers to find the needed info.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#27909 from gatorsmile/migrationGuideReorg.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Since we reverted the original change in https://github.com/apache/spark/pull/27540, this PR is to remove the corresponding migration guide made in the commit https://github.com/apache/spark/pull/24948
### Why are the changes needed?
N/A
### Does this PR introduce any user-facing change?
N/A
### How was this patch tested?
N/A
Closes#27896 from gatorsmile/SPARK-28093Followup.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
spark.sql.legacy.timeParser.enabled should be removed from SQLConf and the migration guide
spark.sql.legacy.timeParsePolicy is the right one
### Why are the changes needed?
fix doc
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
Pass the jenkins
Closes#27889 from yaooqinn/SPARK-31131.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR reverts https://github.com/apache/spark/pull/26051 and https://github.com/apache/spark/pull/26066
### Why are the changes needed?
There is no standard requiring that `size(null)` must return null, and returning -1 looks reasonable as well. This is kind of a cosmetic change and we should avoid it if it breaks existing queries. This is similar to reverting TRIM function parameter order change.
### Does this PR introduce any user-facing change?
Yes, change the behavior of `size(null)` back to be the same as 2.4.
### How was this patch tested?
N/A
Closes#27834 from cloud-fan/revert.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This pr intends to support 32 or more grouping attributes for GROUPING_ID. In the current master, an integer overflow can occur to compute grouping IDs;
e75d9afb2f/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala (L613)
For example, the query below generates wrong grouping IDs in the master;
```
scala> val numCols = 32 // or, 31
scala> val cols = (0 until numCols).map { i => s"c$i" }
scala> sql(s"create table test_$numCols (${cols.map(c => s"$c int").mkString(",")}, v int) using parquet")
scala> val insertVals = (0 until numCols).map { _ => 1 }.mkString(",")
scala> sql(s"insert into test_$numCols values ($insertVals,3)")
scala> sql(s"select grouping_id(), sum(v) from test_$numCols group by grouping sets ((${cols.mkString(",")}), (${cols.init.mkString(",")}))").show(10, false)
scala> sql(s"drop table test_$numCols")
// numCols = 32
+-------------+------+
|grouping_id()|sum(v)|
+-------------+------+
|0 |3 |
|0 |3 | // Wrong Grouping ID
+-------------+------+
// numCols = 31
+-------------+------+
|grouping_id()|sum(v)|
+-------------+------+
|0 |3 |
|1 |3 |
+-------------+------+
```
To fix this issue, this pr change code to use long values for `GROUPING_ID` instead of int values.
### Why are the changes needed?
To support more cases in `GROUPING_ID`.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added unit tests.
Closes#26918 from maropu/FixGroupingIdIssue.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
rename the config and make it non-internal.
### Why are the changes needed?
Now we fail the query if duplicated map keys are detected, and provide a legacy config to deduplicate it. However, we must provide a way to get users out of this situation, instead of just rejecting to run the query. This exit strategy should always be there, while legacy config indicates that it may be removed someday.
### Does this PR introduce any user-facing change?
no, just rename a config which was added in 3.0
### How was this patch tested?
add more tests for the fail behavior.
Closes#27772 from cloud-fan/map.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Fix the migration guide document for `spark.sql.legacy.ctePrecedence.enabled`, which is introduced in #27579.
### Why are the changes needed?
The config value changed.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Document only.
Closes#27782 from xuanyuanking/SPARK-30829-follow.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Rename `spark.sql.legacy.addDirectory.recursive.enabled` to `spark.sql.legacy.addSingleFileInAddFile`
### Why are the changes needed?
To follow the naming convention
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing UTs.
Closes#27725 from iRakson/SPARK-30234_CONFIG.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Renamed configuration from `spark.sql.legacy.useHashOnMapType` to `spark.sql.legacy.allowHashOnMapType`.
### Why are the changes needed?
Better readability of configuration.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing UTs.
Closes#27719 from iRakson/SPARK-27619_FOLLOWUP.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR groups all hive upgrade related migration guides inside Spark 3.0 together.
Also add another behavior change of `ScriptTransform` in the new Hive section.
### Why are the changes needed?
Make the doc more clearly to user.
### Does this PR introduce any user-facing change?
No, new doc for Spark 3.0.
### How was this patch tested?
N/A.
Closes#27670 from Ngone51/hive_migration.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
`hash()` and `xxhash64()` cannot be used on elements of `Maptype`. A new configuration `spark.sql.legacy.useHashOnMapType` is introduced to allow users to restore the previous behaviour.
When `spark.sql.legacy.useHashOnMapType` is set to false:
```
scala> spark.sql("select hash(map())");
org.apache.spark.sql.AnalysisException: cannot resolve 'hash(map())' due to data type mismatch: input to function hash cannot contain elements of MapType; line 1 pos 7;
'Project [unresolvedalias(hash(map(), 42), None)]
+- OneRowRelation
```
when `spark.sql.legacy.useHashOnMapType` is set to true :
```
scala> spark.sql("set spark.sql.legacy.useHashOnMapType=true");
res3: org.apache.spark.sql.DataFrame = [key: string, value: string]
scala> spark.sql("select hash(map())").first()
res4: org.apache.spark.sql.Row = [42]
```
### Why are the changes needed?
As discussed in Jira, SparkSql's map hashcodes depends on their order of insertion which is not consistent with the normal scala behaviour which might confuse users.
Code snippet from JIRA :
```
val a = spark.createDataset(Map(1->1, 2->2) :: Nil)
val b = spark.createDataset(Map(2->2, 1->1) :: Nil)
// Demonstration of how Scala Map equality is unaffected by insertion order:
assert(Map(1->1, 2->2).hashCode() == Map(2->2, 1->1).hashCode())
assert(Map(1->1, 2->2) == Map(2->2, 1->1))
assert(a.first() == b.first())
// In contrast, this will print two different hashcodes:
println(Seq(a, b).map(_.selectExpr("hash(*)").first()))
```
Also `MapType` is prohibited for aggregation / joins / equality comparisons #7819 and set operations #17236.
### Does this PR introduce any user-facing change?
Yes. Now users cannot use hash functions on elements of `mapType`. To restore the previous behaviour set `spark.sql.legacy.useHashOnMapType` to true.
### How was this patch tested?
UT added.
Closes#27580 from iRakson/SPARK-27619.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to throw exception by default when user use untyped UDF(a.k.a `org.apache.spark.sql.functions.udf(AnyRef, DataType)`).
And user could still use it by setting `spark.sql.legacy.useUnTypedUdf.enabled` to `true`.
### Why are the changes needed?
According to #23498, since Spark 3.0, the untyped UDF will return the default value of the Java type if the input value is null. For example, `val f = udf((x: Int) => x, IntegerType)`, `f($"x")` will return 0 in Spark 3.0 but null in Spark 2.4. And the behavior change is introduced due to Spark3.0 is built with Scala 2.12 by default.
As a result, this might change data silently and may cause correctness issue if user still expect `null` in some cases. Thus, we'd better to encourage user to use typed UDF to avoid this problem.
### Does this PR introduce any user-facing change?
Yeah. User will hit exception now when use untyped UDF.
### How was this patch tested?
Added test and updated some tests.
Closes#27488 from Ngone51/spark_26580_followup.
Lead-authored-by: yi.wu <yi.wu@databricks.com>
Co-authored-by: wuyi <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
mention the workaround if users do want to use map type as key, and add a test to demonstrate it.
### Why are the changes needed?
it's better to provide an alternative when we ban something.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
N/A
Closes#27621 from cloud-fan/map.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
mention that `INT96` timestamp is still useful for interoperability.
### Why are the changes needed?
Give users more context of the behavior changes.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
N/A
Closes#27622 from cloud-fan/parquet.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
[HIVE-15167](https://issues.apache.org/jira/browse/HIVE-15167) removed the `SerDe` interface. This may break custom `SerDe` builds for Hive 1.2. This PR update the migration guide for this change.
### Why are the changes needed?
Otherwise:
```
2020-01-27 05:11:20.446 - stderr> 20/01/27 05:11:20 INFO DAGScheduler: ResultStage 2 (main at NativeMethodAccessorImpl.java:0) failed in 1.000 s due to Job aborted due to stage failure: Task 0 in stage 2.0 failed 4 times, most recent failure: Lost task 0.3 in stage 2.0 (TID 13, 10.110.21.210, executor 1): java.lang.NoClassDefFoundError: org/apache/hadoop/hive/serde2/SerDe
2020-01-27 05:11:20.446 - stderr> at java.lang.ClassLoader.defineClass1(Native Method)
2020-01-27 05:11:20.446 - stderr> at java.lang.ClassLoader.defineClass(ClassLoader.java:756)
2020-01-27 05:11:20.446 - stderr> at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
2020-01-27 05:11:20.446 - stderr> at java.net.URLClassLoader.defineClass(URLClassLoader.java:468)
2020-01-27 05:11:20.446 - stderr> at java.net.URLClassLoader.access$100(URLClassLoader.java:74)
2020-01-27 05:11:20.446 - stderr> at java.net.URLClassLoader$1.run(URLClassLoader.java:369)
2020-01-27 05:11:20.446 - stderr> at java.net.URLClassLoader$1.run(URLClassLoader.java:363)
2020-01-27 05:11:20.446 - stderr> at java.security.AccessController.doPrivileged(Native Method)
2020-01-27 05:11:20.446 - stderr> at java.net.URLClassLoader.findClass(URLClassLoader.java:362)
2020-01-27 05:11:20.446 - stderr> at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
2020-01-27 05:11:20.446 - stderr> at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
2020-01-27 05:11:20.446 - stderr> at java.lang.ClassLoader.loadClass(ClassLoader.java:405)
2020-01-27 05:11:20.446 - stderr> at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
2020-01-27 05:11:20.446 - stderr> at java.lang.Class.forName0(Native Method)
2020-01-27 05:11:20.446 - stderr> at java.lang.Class.forName(Class.java:348)
2020-01-27 05:11:20.446 - stderr> at org.apache.hadoop.hive.ql.plan.TableDesc.getDeserializerClass(TableDesc.java:76)
.....
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manual test
Closes#27492 from wangyum/SPARK-30755.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a follow-up for #23124, add a new config `spark.sql.legacy.allowDuplicatedMapKeys` to control the behavior of removing duplicated map keys in build-in functions. With the default value `false`, Spark will throw a RuntimeException while duplicated keys are found.
### Why are the changes needed?
Prevent silent behavior changes.
### Does this PR introduce any user-facing change?
Yes, new config added and the default behavior for duplicated map keys changed to RuntimeException thrown.
### How was this patch tested?
Modify existing UT.
Closes#27478 from xuanyuanking/SPARK-25892-follow.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change the link to the Scala API document.
```
$ git grep "#org.apache.spark.package"
docs/_layouts/global.html: <li><a href="api/scala/index.html#org.apache.spark.package">Scala</a></li>
docs/index.md:* [Spark Scala API (Scaladoc)](api/scala/index.html#org.apache.spark.package)
docs/rdd-programming-guide.md:[Scala](api/scala/#org.apache.spark.package), [Java](api/java/), [Python](api/python/) and [R](api/R/).
```
### Why are the changes needed?
The home page link for Scala API document is incorrect after upgrade to 3.0
### Does this PR introduce any user-facing change?
Document UI change only.
### How was this patch tested?
Local test, attach screenshots below:
Before:

After:

Closes#27549 from xuanyuanking/scala-doc.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
`spark.sql("select map()")` returns {}.
After these changes it will return map<null,null>
### Why are the changes needed?
After changes introduced due to #27521, it is important to maintain consistency while using map().
### Does this PR introduce any user-facing change?
Yes. Now map() will give map<null,null> instead of {}.
### How was this patch tested?
UT added. Migration guide updated as well
Closes#27542 from iRakson/SPARK-30790.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This brings https://github.com/apache/spark/pull/26324 back. It was reverted basically because, firstly Hive compatibility, and the lack of investigations in other DBMSes and ANSI.
- In case of PostgreSQL seems coercing NULL literal to TEXT type.
- Presto seems coercing `array() + array(1)` -> array of int.
- Hive seems `array() + array(1)` -> array of strings
Given that, the design choices have been differently made for some reasons. If we pick one of both, seems coercing to array of int makes much more sense.
Another investigation was made offline internally. Seems ANSI SQL 2011, section 6.5 "<contextually typed value specification>" states:
> If ES is specified, then let ET be the element type determined by the context in which ES appears. The declared type DT of ES is Case:
>
> a) If ES simply contains ARRAY, then ET ARRAY[0].
>
> b) If ES simply contains MULTISET, then ET MULTISET.
>
> ES is effectively replaced by CAST ( ES AS DT )
From reading other related context, doing it to `NullType`. Given the investigation made, choosing to `null` seems correct, and we have a reference Presto now. Therefore, this PR proposes to bring it back.
### Why are the changes needed?
When empty array is created, it should be declared as array<null>.
### Does this PR introduce any user-facing change?
Yes, `array()` creates `array<null>`. Now `array(1) + array()` can correctly create `array(1)` instead of `array("1")`.
### How was this patch tested?
Tested manually
Closes#27521 from HyukjinKwon/SPARK-29462.
Lead-authored-by: HyukjinKwon <gurwls223@apache.org>
Co-authored-by: Aman Omer <amanomer1996@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a follow-up for #24938 to tweak error message and migration doc.
### Why are the changes needed?
Making user know workaround if SHOW CREATE TABLE doesn't work for some Hive tables.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing unit tests.
Closes#27505 from viirya/SPARK-27946-followup.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <liangchi@uber.com>
### What changes were proposed in this pull request?
This is a follow-up for #25029, in this PR we throw an AnalysisException when name conflict is detected in nested WITH clause. In this way, the config `spark.sql.legacy.ctePrecedence.enabled` should be set explicitly for the expected behavior.
### Why are the changes needed?
The original change might risky to end-users, it changes behavior silently.
### Does this PR introduce any user-facing change?
Yes, change the config `spark.sql.legacy.ctePrecedence.enabled` as optional.
### How was this patch tested?
New UT.
Closes#27454 from xuanyuanking/SPARK-28228-follow.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to partially revert the commit 51a6ba0181, and provide a legacy parser based on `FastDateFormat` which is compatible to `SimpleDateFormat`.
To enable the legacy parser, set `spark.sql.legacy.timeParser.enabled` to `true`.
### Why are the changes needed?
To allow users to restore old behavior in parsing timestamps/dates using `SimpleDateFormat` patterns. The main reason for restoring is `DateTimeFormatter`'s patterns are not fully compatible to `SimpleDateFormat` patterns, see https://issues.apache.org/jira/browse/SPARK-30668
### Does this PR introduce any user-facing change?
Yes
### How was this patch tested?
- Added new test to `DateFunctionsSuite`
- Restored additional test cases in `JsonInferSchemaSuite`.
Closes#27441 from MaxGekk/support-simpledateformat.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow-up for #22787. In #22787 we disallowed empty strings for json parser except for string and binary types. This follow-up adds a legacy config for restoring previous behavior of allowing empty string.
### Why are the changes needed?
Adding a legacy config to make migration easy for Spark users.
### Does this PR introduce any user-facing change?
Yes. If set this legacy config to true, the users can restore previous behavior prior to Spark 3.0.0.
### How was this patch tested?
Unit test.
Closes#27456 from viirya/SPARK-25040-followup.
Lead-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Co-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to update the SQL migration guide, and clarify behavior change of typed `TIMESTAMP` and `DATE` literals for input strings without time zone information - local timestamp and date strings.
### Why are the changes needed?
To inform users that the typed literals may change their behavior in Spark 3.0 because of different sources of the default time zone - JVM system time zone in Spark 2.4 and earlier, and `spark.sql.session.timeZone` in Spark 3.0.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#27435 from MaxGekk/timestamp-lit-migration-guide.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
We have upgraded the built-in Hive from 1.2 to 2.3. This may need to set `spark.sql.hive.metastore.version` and `spark.sql.hive.metastore.jars` according to the version of your Hive metastore. Example:
```
--conf spark.sql.hive.metastore.version=1.2.1 --conf spark.sql.hive.metastore.jars=/root/hive-1.2.1-lib/*
```
Otherwise:
```
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: Unable to fetch table spark_27686. Invalid method name: 'get_table_req';
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:110)
at org.apache.spark.sql.hive.HiveExternalCatalog.tableExists(HiveExternalCatalog.scala:841)
at org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.tableExists(ExternalCatalogWithListener.scala:146)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.tableExists(SessionCatalog.scala:431)
at org.apache.spark.sql.execution.command.CreateDataSourceTableCommand.run(createDataSourceTables.scala:52)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:79)
at org.apache.spark.sql.Dataset.$anonfun$logicalPlan$1(Dataset.scala:226)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3487)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$4(SQLExecution.scala:100)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:160)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:87)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3485)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:226)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:96)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:607)
... 47 elided
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Unable to fetch table spark_27686. Invalid method name: 'get_table_req'
at org.apache.hadoop.hive.ql.metadata.Hive.getTable(Hive.java:1282)
at org.apache.spark.sql.hive.client.HiveClientImpl.getRawTableOption(HiveClientImpl.scala:422)
at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$tableExists$1(HiveClientImpl.scala:436)
at scala.runtime.java8.JFunction0$mcZ$sp.apply(JFunction0$mcZ$sp.java:23)
at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$withHiveState$1(HiveClientImpl.scala:322)
at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:256)
at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:255)
at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:305)
at org.apache.spark.sql.hive.client.HiveClientImpl.tableExists(HiveClientImpl.scala:436)
at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$tableExists$1(HiveExternalCatalog.scala:841)
at scala.runtime.java8.JFunction0$mcZ$sp.apply(JFunction0$mcZ$sp.java:23)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:100)
... 63 more
Caused by: org.apache.thrift.TApplicationException: Invalid method name: 'get_table_req'
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:79)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_get_table_req(ThriftHiveMetastore.java:1567)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.get_table_req(ThriftHiveMetastore.java:1554)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.getTable(HiveMetaStoreClient.java:1350)
at org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient.getTable(SessionHiveMetaStoreClient.java:127)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:173)
at com.sun.proxy.$Proxy38.getTable(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetaStoreClient.java:2336)
at com.sun.proxy.$Proxy38.getTable(Unknown Source)
at org.apache.hadoop.hive.ql.metadata.Hive.getTable(Hive.java:1274)
... 74 more
```
### Why are the changes needed?
Improve documentation.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
```SKIP_API=1 jekyll build```:

Closes#27161 from wangyum/SPARK-27686.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This patch adds a DDL command `SHOW CREATE TABLE AS SERDE`. It is used to generate Hive DDL for a Hive table.
For original `SHOW CREATE TABLE`, it now shows Spark DDL always. If given a Hive table, it tries to generate Spark DDL.
For Hive serde to data source conversion, this uses the existing mapping inside `HiveSerDe`. If can't find a mapping there, throws an analysis exception on unsupported serde configuration.
It is arguably that some Hive fileformat + row serde might be mapped to Spark data source, e.g., CSV. It is not included in this PR. To be conservative, it may not be supported.
For Hive serde properties, for now this doesn't save it to Spark DDL because it may not useful to keep Hive serde properties in Spark table.
## How was this patch tested?
Added test.
Closes#24938 from viirya/SPARK-27946.
Lead-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Co-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
add supported hive features
### Why are the changes needed?
update doc
### Does this PR introduce any user-facing change?
Before change UI info:

After this pr:


### How was this patch tested?
For PR about Spark Doc Web UI, we need to show UI format before and after pr.
We can build our local web server about spark docs with reference `$SPARK_PROJECT/docs/README.md`
You should install python and ruby in your env and also install plugin like below
```sh
$ sudo gem install jekyll jekyll-redirect-from rouge
# Following is needed only for generating API docs
$ sudo pip install sphinx pypandoc mkdocs
$ sudo Rscript -e 'install.packages(c("knitr", "devtools", "rmarkdown"), repos="https://cloud.r-project.org/")'
$ sudo Rscript -e 'devtools::install_version("roxygen2", version = "5.0.1", repos="https://cloud.r-project.org/")'
$ sudo Rscript -e 'devtools::install_version("testthat", version = "1.0.2", repos="https://cloud.r-project.org/")'
```
Then we call `jekyll serve --watch` after build we see below message
```
~/Documents/project/AngersZhu/spark/sql
Moving back into docs dir.
Making directory api/sql
cp -r ../sql/site/. api/sql
Source: /Users/angerszhu/Documents/project/AngersZhu/spark/docs
Destination: /Users/angerszhu/Documents/project/AngersZhu/spark/docs/_site
Incremental build: disabled. Enable with --incremental
Generating...
done in 24.717 seconds.
Auto-regeneration: enabled for '/Users/angerszhu/Documents/project/AngersZhu/spark/docs'
Server address: http://127.0.0.1:4000
Server running... press ctrl-c to stop.
```
Visit http://127.0.0.1:4000 to get your newest change in doc web.
Closes#27106 from AngersZhuuuu/SPARK-30435.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This pr intends to rename `spark.sql.legacy.addDirectory.recursive` into `spark.sql.legacy.addDirectory.recursive.enabled`.
### Why are the changes needed?
For consistent option names.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#27372 from maropu/SPARK-30234-FOLLOWUP.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This pr removes the nonstandard `SET OWNER` syntax for namespaces and changes the owner reserved properties from `ownerName` and `ownerType` to `owner`.
### Why are the changes needed?
the `SET OWNER` syntax for namespaces is hive-specific and non-sql standard, we need a more future-proofing design before we implement user-facing changes for SQL security issues
### Does this PR introduce any user-facing change?
no, just revert an unpublic syntax
### How was this patch tested?
modified uts
Closes#27300 from yaooqinn/SPARK-30591.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR propose to disallow negative `scale` of `Decimal` in Spark. And this PR brings two behavior changes:
1) for literals like `1.23E4BD` or `1.23E4`(with `spark.sql.legacy.exponentLiteralAsDecimal.enabled`=true, see [SPARK-29956](https://issues.apache.org/jira/browse/SPARK-29956)), we set its `(precision, scale)` to (5, 0) rather than (3, -2);
2) add negative `scale` check inside the decimal method if it exposes to set `scale` explicitly. If check fails, `AnalysisException` throws.
And user could still use `spark.sql.legacy.allowNegativeScaleOfDecimal.enabled` to restore the previous behavior.
### Why are the changes needed?
According to SQL standard,
> 4.4.2 Characteristics of numbers
An exact numeric type has a precision P and a scale S. P is a positive integer that determines the number of significant digits in a particular radix R, where R is either 2 or 10. S is a non-negative integer.
scale of Decimal should always be non-negative. And other mainstream databases, like Presto, PostgreSQL, also don't allow negative scale.
Presto:
```
presto:default> create table t (i decimal(2, -1));
Query 20191213_081238_00017_i448h failed: line 1:30: mismatched input '-'. Expecting: <integer>, <type>
create table t (i decimal(2, -1))
```
PostgrelSQL:
```
postgres=# create table t(i decimal(2, -1));
ERROR: NUMERIC scale -1 must be between 0 and precision 2
LINE 1: create table t(i decimal(2, -1));
^
```
And, actually, Spark itself already doesn't allow to create table with negative decimal types using SQL:
```
scala> spark.sql("create table t(i decimal(2, -1))");
org.apache.spark.sql.catalyst.parser.ParseException:
no viable alternative at input 'create table t(i decimal(2, -'(line 1, pos 28)
== SQL ==
create table t(i decimal(2, -1))
----------------------------^^^
at org.apache.spark.sql.catalyst.parser.ParseException.withCommand(ParseDriver.scala:263)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parse(ParseDriver.scala:130)
at org.apache.spark.sql.execution.SparkSqlParser.parse(SparkSqlParser.scala:48)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parsePlan(ParseDriver.scala:76)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:605)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:605)
... 35 elided
```
However, it is still possible to create such table or `DatFrame` using Spark SQL programming API:
```
scala> val tb =
CatalogTable(
TableIdentifier("test", None),
CatalogTableType.MANAGED,
CatalogStorageFormat.empty,
StructType(StructField("i", DecimalType(2, -1) ) :: Nil))
```
```
scala> spark.sql("SELECT 1.23E4BD")
res2: org.apache.spark.sql.DataFrame = [1.23E+4: decimal(3,-2)]
```
while, these two different behavior could make user confused.
On the other side, even if user creates such table or `DataFrame` with negative scale decimal type, it can't write data out if using format, like `parquet` or `orc`. Because these formats have their own check for negative scale and fail on it.
```
scala> spark.sql("SELECT 1.23E4BD").write.saveAsTable("parquet")
19/12/13 17:37:04 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
java.lang.IllegalArgumentException: Invalid DECIMAL scale: -2
at org.apache.parquet.Preconditions.checkArgument(Preconditions.java:53)
at org.apache.parquet.schema.Types$BasePrimitiveBuilder.decimalMetadata(Types.java:495)
at org.apache.parquet.schema.Types$BasePrimitiveBuilder.build(Types.java:403)
at org.apache.parquet.schema.Types$BasePrimitiveBuilder.build(Types.java:309)
at org.apache.parquet.schema.Types$Builder.named(Types.java:290)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convertField(ParquetSchemaConverter.scala:428)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convertField(ParquetSchemaConverter.scala:334)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.$anonfun$convert$2(ParquetSchemaConverter.scala:326)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at org.apache.spark.sql.types.StructType.foreach(StructType.scala:99)
at scala.collection.TraversableLike.map(TraversableLike.scala:238)
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at org.apache.spark.sql.types.StructType.map(StructType.scala:99)
at org.apache.spark.sql.execution.datasources.parquet.SparkToParquetSchemaConverter.convert(ParquetSchemaConverter.scala:326)
at org.apache.spark.sql.execution.datasources.parquet.ParquetWriteSupport.init(ParquetWriteSupport.scala:97)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:388)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:349)
at org.apache.spark.sql.execution.datasources.parquet.ParquetOutputWriter.<init>(ParquetOutputWriter.scala:37)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$$anon$1.newInstance(ParquetFileFormat.scala:150)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.newOutputWriter(FileFormatDataWriter.scala:124)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.<init>(FileFormatDataWriter.scala:109)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:264)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$write$15(FileFormatWriter.scala:205)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:127)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:441)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:444)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
So, I think it would be better to disallow negative scale totally and make behaviors above be consistent.
### Does this PR introduce any user-facing change?
Yes, if `spark.sql.legacy.allowNegativeScaleOfDecimal.enabled=false`, user couldn't create Decimal value with negative scale anymore.
### How was this patch tested?
Added new tests in `ExpressionParserSuite` and `DecimalSuite`;
Updated `SQLQueryTestSuite`.
Closes#26881 from Ngone51/nonnegative-scale.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add `owner` property to v2 table, it is reversed by `TableCatalog`, indicates the table's owner.
### Why are the changes needed?
enhance ownership management of catalog API
### Does this PR introduce any user-facing change?
yes, add 1 reserved property - `owner` , and it is not allowed to use in OPTIONS/TBLPROPERTIES anymore, only if legacy on
### How was this patch tested?
add uts
Closes#27249 from yaooqinn/SPARK-30019.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds a migration guide for `SHOW TBLPROPERTIES` for Apache Spark 3.0.0.
### Why are the changes needed?
The behavior of `SHOW TBLPROPERTIES` changed when the table does not exist. The migration guide reflects this user facing change.
### Does this PR introduce any user-facing change?
Yes. This is a documentation change.
### How was this patch tested?
No tests were added because this is a doc change.
Closes#27276 from imback82/SPARK-30282-followup.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR adds a migration guide for MsSQLServer JDBC dialect for Apache Spark 2.4.4 and 2.4.5.
### Why are the changes needed?
Apache Spark 2.4.4 updates the type mapping correctly according to MS SQL Server, but missed to mention that in the migration guide. In addition, 2.4.4 adds a configuration for the legacy behavior.
### Does this PR introduce any user-facing change?
Yes. This is a documentation change.

### How was this patch tested?
Manually generate and see the doc.
Closes#27270 from dongjoon-hyun/SPARK-28152-DOC.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/26956 to add a migration document for 2.4.5.
### Why are the changes needed?
New legacy configuration will restore the previous behavior safely.
### Does this PR introduce any user-facing change?
This PR updates the doc.
<img width="763" alt="screenshot" src="https://user-images.githubusercontent.com/9700541/72639939-9da5a400-391b-11ea-87b1-14bca15db5a6.png">
### How was this patch tested?
Build the document and see the change manually.
Closes#27269 from dongjoon-hyun/SPARK-30312.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Use the new framework to resolve the SHOW TBLPROPERTIES command. This PR along with #27243 should update all the existing V2 commands with `UnresolvedV2Relation`.
### Why are the changes needed?
This is a part of effort to make the relation lookup behavior consistent: [SPARK-2990](https://issues.apache.org/jira/browse/SPARK-29900).
### Does this PR introduce any user-facing change?
Yes `SHOW TBLPROPERTIES temp_view` now fails with `AnalysisException` will be thrown with a message `temp_view is a temp view not table`. Previously, it was returning empty row.
### How was this patch tested?
Existing tests
Closes#26921 from imback82/consistnet_v2command.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
TableCatalog reserves some properties, e,g `provider`, `location` for internal usage. Some of them are static once create, some of them need specific syntax to modify. Instead of using `OPTIONS (k='v')` or TBLPROPERTIES (k='v'), if k is a reserved TableCatalog property, we should use its specific syntax to add/modify/delete it. e.g. `provider` is a reserved property, we should use the `USING` clause to specify it, and should not allow `ALTER TABLE ... UNSET TBLPROPERTIES('provider')` to delete it. Also, there are two paths for v1/v2 catalog tables to resolve these properties, e.g. the v1 session catalog tables will only use the `USING` clause to decide `provider` but v2 tables will also lookup OPTION/TBLPROPERTIES(although there is a bug prohibit it).
Additionally, 'path' is not reserved but holds special meaning for `LOCATION` and it is used in `CREATE/REPLACE TABLE`'s `OPTIONS` sub-clause. Now for the session catalog tables, the `path` is case-insensitive, but for the non-session catalog tables, it is case-sensitive, we should make it both case insensitive for disambiguation.
### Why are the changes needed?
prevent reserved properties from being modified unexpectedly
unify the property resolution for v1/v2.
fix some bugs.
### Does this PR introduce any user-facing change?
yes
1 . `location` and `provider` (case sensitive) cannot be used in `CREATE/REPLACE TABLE ... OPTIONS/TBLPROPETIES` and `ALTER TABLE ... SET TBLPROPERTIES (...)`, if legacy on, they will be ignored to let the command success without having side effects
3. Once `path` in `CREATE/REPLACE TABLE ... OPTIONS` is case insensitive for v1 but sensitive for v2, but now we change it case insensitive for both kinds of tables, then v2 tables will also fail if `LOCATION` and `OPTIONS('PaTh' ='abc')` are both specified or will pick `PaTh`'s value as table location if `LOCATION` is missing.
4. Now we will detect if there are two different case `path` keys or more in `CREATE/REPLACE TABLE ... OPTIONS`, once it is a kind of unexpected last-win policy for v1, and v2 is case sensitive.
### How was this patch tested?
add ut
Closes#27197 from yaooqinn/SPARK-30507.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Now users can add directories from sql CLI as well using ADD FILE command and setting spark.sql.addDirectory.recursive to true.
### Why are the changes needed?
In SPARK-4687, support was added for adding directories as resources. But sql users cannot use that feature from CLI.
`ADD FILE /path/to/folder` gives the following error:
`org.apache.spark.SparkException: Added file /path/to/folder is a directory and recursive is not turned on.`
Users need to turn on `recursive` for adding directories. Thus a configuration was required which will allow users to turn on `recursive`.
Also Hive allow users to add directories from their shell.
### Does this PR introduce any user-facing change?
Yes. Users can set recursive using `spark.sql.addDirectory.recursive`.
### How was this patch tested?
Manually.
Will add test cases soon.
SPARK SCREENSHOTS
When `spark.sql.addDirectory.recursive` is not turned on.
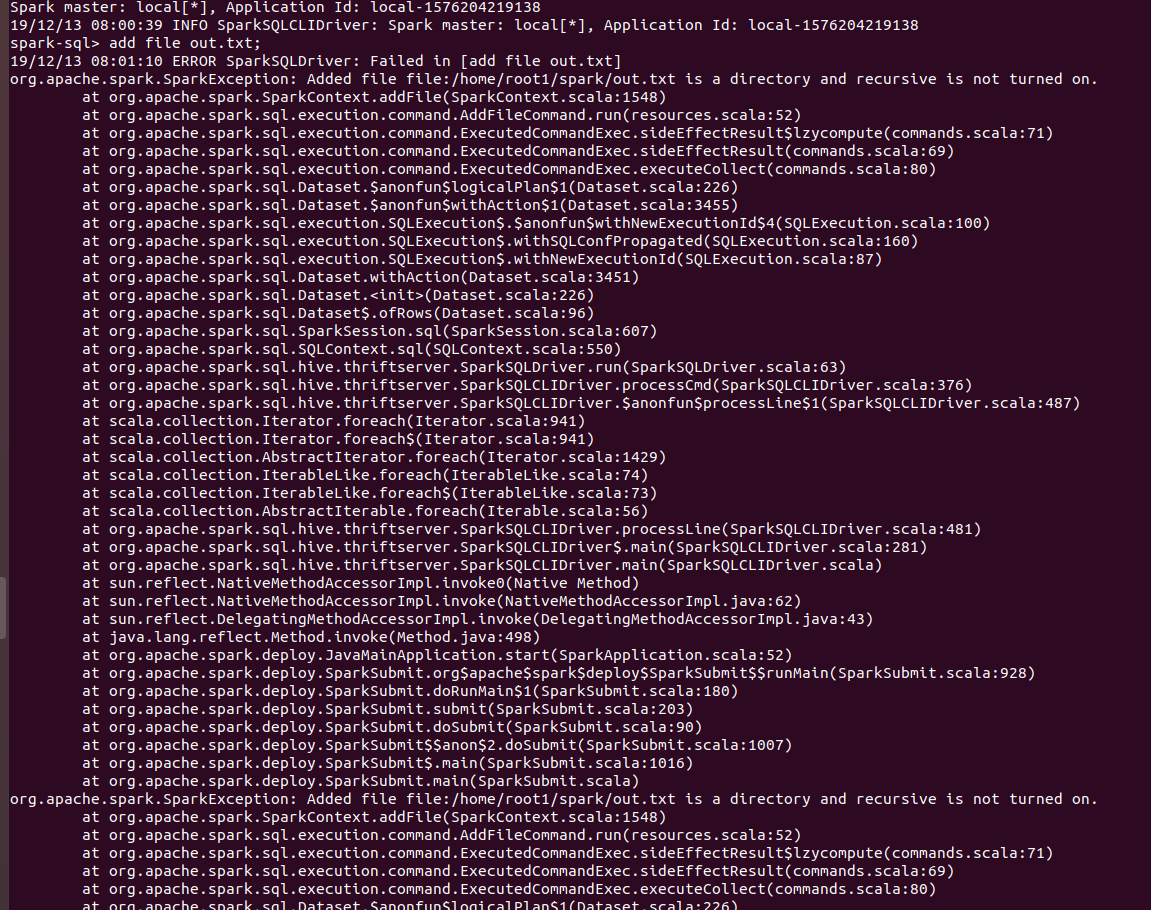
After setting `spark.sql.addDirectory.recursive` to true.

HIVE SCREENSHOT

`RELEASE_NOTES.txt` is text file while `dummy` is a directory.
Closes#26863 from iRakson/SPARK-30234.
Lead-authored-by: root1 <raksonrakesh@gmail.com>
Co-authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Currently, COMMENT and LOCATION are reserved properties for Datasource v2 namespaces. They can be set via specific clauses and via properties. And the ones specified in clauses take precede of properties. Since they are reserved, which means they are not able to visit directly. They should be used in COMMENT/LOCATION clauses ONLY.
### Why are the changes needed?
make reserved properties be reserved.
### Does this PR introduce any user-facing change?
yes, 'location', 'comment' are not allowed use in db properties
### How was this patch tested?
UNIT tests.
Closes#26806 from yaooqinn/SPARK-30183.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Change config name from `spark.sql.legacy.typeCoercion.datetimeToString` to `spark.sql.legacy.typeCoercion.datetimeToString.enabled`.
### Why are the changes needed?
To follow the other boolean conf naming convention.
### Does this PR introduce any user-facing change?
No, it's newly added in Spark 3.0.
### How was this patch tested?
Pass Jenkins
Closes#27065 from Ngone51/SPARK-27638-FOLLOWUP.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Create temporary or permanent function it should throw AnalysisException if the resource is not found. Need to keep behavior consistent across permanent and temporary functions.
## How was this patch tested?
Added UT and also tested manually
**Before Fix**
If the UDF resource is not present then on creation of temporary function it throws AnalysisException where as for permanent function it does not throw. Permanent funtcion throws AnalysisException only after select operation is performed.
**After Fix**
For temporary and permanent function check for the resource, if the UDF resource is not found then throw AnalysisException

Closes#25399 from sandeep-katta/funcIssue.
Authored-by: sandeep katta <sandeep.katta2007@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Update the Spark SQL document menu and join strategy hints.
### Why are the changes needed?
- Several new changes in the Spark SQL document didn't change the menu-sql.yaml correspondingly.
- Update the demo code for join strategy hints.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Document change only.
Closes#26917 from xuanyuanking/SPARK-30278.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
accuracyExpression can accept Long which may cause overflow error.
accuracyExpression can accept fractions which are implicitly floored.
accuracyExpression can accept null which is implicitly changed to 0.
percentageExpression can accept null but cause MatchError.
percentageExpression can accept ArrayType(_, nullable=true) in which the nulls are implicitly changed to zeros.
##### cases
```sql
select percentile_approx(10.0, 0.5, 2147483648); -- overflow and fail
select percentile_approx(10.0, 0.5, 4294967297); -- overflow but success
select percentile_approx(10.0, 0.5, null); -- null cast to 0
select percentile_approx(10.0, 0.5, 1.2); -- 1.2 cast to 1
select percentile_approx(10.0, null, 1); -- scala.MatchError
select percentile_approx(10.0, array(0.2, 0.4, null), 1); -- null cast to zero.
```
##### behavior before
```sql
+select percentile_approx(10.0, 0.5, 2147483648)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, CAST(0.5BD AS DOUBLE), CAST(2147483648L AS INT))' due to data type mismatch: The accuracy provided must be a positive integer literal (current value = -2147483648); line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 4294967297)
+10.0
+
+select percentile_approx(10.0, 0.5, null)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, CAST(0.5BD AS DOUBLE), CAST(NULL AS INT))' due to data type mismatch: The accuracy provided must be a positive integer literal (current value = 0); line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 1.2)
+10.0
+
+select percentile_approx(10.0, null, 1)
+scala.MatchError
+null
+
+
+select percentile_approx(10.0, array(0.2, 0.4, null), 1)
+[10.0,10.0,10.0]
```
##### behavior after
```sql
+select percentile_approx(10.0, 0.5, 2147483648)
+10.0
+
+select percentile_approx(10.0, 0.5, 4294967297)
+10.0
+
+select percentile_approx(10.0, 0.5, null)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, 0.5BD, NULL)' due to data type mismatch: argument 3 requires integral type, however, 'NULL' is of null type.; line 1 pos 7
+
+select percentile_approx(10.0, 0.5, 1.2)
+org.apache.spark.sql.AnalysisException
+cannot resolve 'percentile_approx(10.0BD, 0.5BD, 1.2BD)' due to data type mismatch: argument 3 requires integral type, however, '1.2BD' is of decimal(2,1) type.; line 1 pos 7
+
+select percentile_approx(10.0, null, 1)
+java.lang.IllegalArgumentException
+The value of percentage must be be between 0.0 and 1.0, but got null
+
+select percentile_approx(10.0, array(0.2, 0.4, null), 1)
+java.lang.IllegalArgumentException
+Each value of the percentage array must be be between 0.0 and 1.0, but got [0.2,0.4,null]
```
### Why are the changes needed?
bug fix
### Does this PR introduce any user-facing change?
yes, fix some improper usages of percentile_approx as cases list above
### How was this patch tested?
add ut
Closes#26905 from yaooqinn/SPARK-30266.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to update the SQL migration guide and clarify semantic of string conversion to typed `TIMESTAMP` and `DATE` literals.
### Why are the changes needed?
This is a follow-up of the PR https://github.com/apache/spark/pull/23541 which changed the behavior of `TIMESTAMP`/`DATE` literals, and can impact on results of user's queries.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
It should be checked by jenkins build.
Closes#26985 from MaxGekk/timestamp-date-constructors-followup.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Fixed typo in `docs` directory and in other directories
1. Find typo in `docs` and apply fixes to files in all directories
2. Fix `the the` -> `the`
### Why are the changes needed?
Better readability of documents
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
No test needed
Closes#26976 from kiszk/typo_20191221.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR update document for make Hive 2.3 dependency by default.
### Why are the changes needed?
The documentation is incorrect.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A
Closes#26919 from wangyum/SPARK-30280.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
add a migration guide for date_add and date_sub to indicates their behavior change. It a followup for #26412
### Why are the changes needed?
add a migration guide
### Does this PR introduce any user-facing change?
yes, doc change
### How was this patch tested?
no
Closes#26932 from yaooqinn/SPARK-29774-f.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
When `spark.shuffle.useOldFetchProtocol` is enabled then switching off the direct disk reading of host-local shuffle blocks and falling back to remote block fetching (and this way avoiding the `GetLocalDirsForExecutors` block transfer message which is introduced from Spark 3.0.0).
### Why are the changes needed?
In `[SPARK-27651][Core] Avoid the network when shuffle blocks are fetched from the same host` a new block transfer message is introduced, `GetLocalDirsForExecutors`. This new message could be sent to the external shuffle service and as it is not supported by the previous version of external shuffle service it should be avoided when `spark.shuffle.useOldFetchProtocol` is true.
In the migration guide I changed the exception type as `org.apache.spark.network.shuffle.protocol.BlockTransferMessage.Decoder#fromByteBuffer`
throws a IllegalArgumentException with the given text and uses the message type which is just a simple number (byte). I have checked and this is true for version 2.4.4 too.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
This specific case (considering one extra boolean to switch off host local disk reading feature) is not tested but existing tests were run.
Closes#26869 from attilapiros/SPARK-30235.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request?
In the PR, I propose new implementation of `fromDayTimeString` which strictly parses strings in day-time formats to intervals. New implementation accepts only strings that match to a pattern defined by the `from` and `to`. Here is the mapping of user's bounds and patterns:
- `[+|-]D+ H[H]:m[m]:s[s][.SSSSSSSSS]` for **DAY TO SECOND**
- `[+|-]D+ H[H]:m[m]` for **DAY TO MINUTE**
- `[+|-]D+ H[H]` for **DAY TO HOUR**
- `[+|-]H[H]:m[m]s[s][.SSSSSSSSS]` for **HOUR TO SECOND**
- `[+|-]H[H]:m[m]` for **HOUR TO MINUTE**
- `[+|-]m[m]:s[s][.SSSSSSSSS]` for **MINUTE TO SECOND**
Closes#26327Closes#26358
### Why are the changes needed?
- Improve user experience with Spark SQL, and respect to the bound specified by users.
- Behave the same as other broadly used DBMS - Oracle and MySQL.
### Does this PR introduce any user-facing change?
Yes, before:
```sql
spark-sql> SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE;
interval 1 weeks 3 days 11 hours 12 minutes
```
After:
```sql
spark-sql> SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE;
Error in query:
requirement failed: Interval string must match day-time format of '^(?<sign>[+|-])?(?<hour>\d{1,2}):(?<minute>\d{1,2})$': 10 11:12:13.123(line 1, pos 16)
== SQL ==
SELECT INTERVAL '10 11:12:13.123' HOUR TO MINUTE
----------------^^^
```
### How was this patch tested?
- Added tests to `IntervalUtilsSuite`
- By `ExpressionParserSuite`
- Updated `literals.sql`
Closes#26473 from MaxGekk/strict-from-daytime-string.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Now, we trim the string when casting string value to those `canCast` types values, e.g. int, double, decimal, interval, date, timestamps, except for boolean.
This behavior makes type cast and coercion inconsistency in Spark.
Not fitting ANSI SQL standard either.
```
If TD is boolean, then
Case:
a) If SD is character string, then SV is replaced by
TRIM ( BOTH ' ' FROM VE )
Case:
i) If the rules for literal in Subclause 5.3, “literal”, can be applied to SV to determine a valid
value of the data type TD, then let TV be that value.
ii) Otherwise, an exception condition is raised: data exception — invalid character value for cast.
b) If SD is boolean, then TV is SV
```
In this pull request, we trim all the whitespaces from both ends of the string before converting it to a bool value. This behavior is as same as others, but a bit different from sql standard, which trim only spaces.
### Why are the changes needed?
Type cast/coercion consistency
### Does this PR introduce any user-facing change?
yes, string with whitespaces in both ends will be trimmed before converted to booleans.
e.g. `select cast('\t true' as boolean)` results `true` now, before this pr it's `null`
### How was this patch tested?
add unit tests
Closes#26776 from yaooqinn/SPARK-30147.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
In this PR, we propose to use the value of `spark.sql.source.default` as the provider for `CREATE TABLE` syntax instead of `hive` in Spark 3.0.
And to help the migration, we introduce a legacy conf `spark.sql.legacy.respectHiveDefaultProvider.enabled` and set its default to `false`.
### Why are the changes needed?
1. Currently, `CREATE TABLE` syntax use hive provider to create table while `DataFrameWriter.saveAsTable` API using the value of `spark.sql.source.default` as a provider to create table. It would be better to make them consistent.
2. User may gets confused in some cases. For example:
```
CREATE TABLE t1 (c1 INT) USING PARQUET;
CREATE TABLE t2 (c1 INT);
```
In these two DDLs, use may think that `t2` should also use parquet as default provider since Spark always advertise parquet as the default format. However, it's hive in this case.
On the other hand, if we omit the USING clause in a CTAS statement, we do pick parquet by default if `spark.sql.hive.convertCATS=true`:
```
CREATE TABLE t3 USING PARQUET AS SELECT 1 AS VALUE;
CREATE TABLE t4 AS SELECT 1 AS VALUE;
```
And these two cases together can be really confusing.
3. Now, Spark SQL is very independent and popular. We do not need to be fully consistent with Hive's behavior.
### Does this PR introduce any user-facing change?
Yes, before this PR, using `CREATE TABLE` syntax will use hive provider. But now, it use the value of `spark.sql.source.default` as its provider.
### How was this patch tested?
Added tests in `DDLParserSuite` and `HiveDDlSuite`.
Closes#26736 from Ngone51/dev-create-table-using-parquet-by-default.
Lead-authored-by: wuyi <yi.wu@databricks.com>
Co-authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
`UnaryPositive` only accepts numeric and interval as we defined, but what we do for this in `AstBuider.visitArithmeticUnary` is just bypassing it.
This should not be omitted for the type checking requirement.
### Why are the changes needed?
bug fix, you can find a pre-discussion here https://github.com/apache/spark/pull/26578#discussion_r347350398
### Does this PR introduce any user-facing change?
yes, +non-numeric-or-interval is now invalid.
```
-- !query 14
select +date '1900-01-01'
-- !query 14 schema
struct<DATE '1900-01-01':date>
-- !query 14 output
1900-01-01
-- !query 15
select +timestamp '1900-01-01'
-- !query 15 schema
struct<TIMESTAMP '1900-01-01 00:00:00':timestamp>
-- !query 15 output
1900-01-01 00:00:00
-- !query 16
select +map(1, 2)
-- !query 16 schema
struct<map(1, 2):map<int,int>>
-- !query 16 output
{1:2}
-- !query 17
select +array(1,2)
-- !query 17 schema
struct<array(1, 2):array<int>>
-- !query 17 output
[1,2]
-- !query 18
select -'1'
-- !query 18 schema
struct<(- CAST(1 AS DOUBLE)):double>
-- !query 18 output
-1.0
-- !query 19
select -X'1'
-- !query 19 schema
struct<>
-- !query 19 output
org.apache.spark.sql.AnalysisException
cannot resolve '(- X'01')' due to data type mismatch: argument 1 requires (numeric or interval) type, however, 'X'01'' is of binary type.; line 1 pos 7
-- !query 20
select +X'1'
-- !query 20 schema
struct<X'01':binary>
-- !query 20 output
```
### How was this patch tested?
add ut check
Closes#26716 from yaooqinn/SPARK-30083.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
add `.enabled` postfix to `spark.sql.analyzer.failAmbiguousSelfJoin`.
### Why are the changes needed?
to follow the existing naming style
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
not needed
Closes#26694 from cloud-fan/conf.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In SPARK-29421 (#26097) , we can specify a different table provider for `CREATE TABLE LIKE` via `USING provider`.
Hive support `STORED AS` new file format syntax:
```sql
CREATE TABLE tbl(a int) STORED AS TEXTFILE;
CREATE TABLE tbl2 LIKE tbl STORED AS PARQUET;
```
For Hive compatibility, we should also support `STORED AS` in `CREATE TABLE LIKE`.
### Why are the changes needed?
See https://github.com/apache/spark/pull/26097#issue-327424759
### Does this PR introduce any user-facing change?
Add a new syntax based on current CTL:
CREATE TABLE tbl2 LIKE tbl [STORED AS hiveFormat];
### How was this patch tested?
Add UTs.
Closes#26466 from LantaoJin/SPARK-29839.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For a literal number with an exponent(e.g. 1e-45, 1E2), we'd parse it to Double by default rather than Decimal. And user could still use `spark.sql.legacy.exponentLiteralToDecimal.enabled=true` to fall back to previous behavior.
### Why are the changes needed?
According to ANSI standard of SQL, we see that the (part of) definition of `literal` :
```
<approximate numeric literal> ::=
<mantissa> E <exponent>
```
which indicates that a literal number with an exponent should be approximate numeric(e.g. Double) rather than exact numeric(e.g. Decimal).
And when we test Presto, we found that Presto also conforms to this standard:
```
presto:default> select typeof(1E2);
_col0
--------
double
(1 row)
```
```
presto:default> select typeof(1.2);
_col0
--------------
decimal(2,1)
(1 row)
```
We also find that, actually, literals like `1E2` are parsed as Double before Spark2.1, but changed to Decimal after #14828 due to *The difference between the two confuses most users* as it said. But we also see support(from DB2 test) of original behavior at #14828 (comment).
Although, we also see that PostgreSQL has its own implementation:
```
postgres=# select pg_typeof(1E2);
pg_typeof
-----------
numeric
(1 row)
postgres=# select pg_typeof(1.2);
pg_typeof
-----------
numeric
(1 row)
```
We still think that Spark should also conform to this standard while considering SQL standard and Spark own history and majority DBMS and also user experience.
### Does this PR introduce any user-facing change?
Yes.
For `1E2`, before this PR:
```
scala> spark.sql("select 1E2")
res0: org.apache.spark.sql.DataFrame = [1E+2: decimal(1,-2)]
```
After this PR:
```
scala> spark.sql("select 1E2")
res0: org.apache.spark.sql.DataFrame = [100.0: double]
```
And for `1E-45`, before this PR:
```
org.apache.spark.sql.catalyst.parser.ParseException:
decimal can only support precision up to 38
== SQL ==
select 1E-45
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parse(ParseDriver.scala:131)
at org.apache.spark.sql.execution.SparkSqlParser.parse(SparkSqlParser.scala:48)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parsePlan(ParseDriver.scala:76)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:605)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:605)
... 47 elided
```
after this PR:
```
scala> spark.sql("select 1E-45");
res1: org.apache.spark.sql.DataFrame = [1.0E-45: double]
```
And before this PR, user may feel super weird to see that `select 1e40` works but `select 1e-40 fails`. And now, both of them work well.
### How was this patch tested?
updated `literals.sql.out` and `ansi/literals.sql.out`
Closes#26595 from Ngone51/SPARK-29956.
Authored-by: wuyi <ngone_5451@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
[HIVE-12063](https://issues.apache.org/jira/browse/HIVE-12063) improved pad decimal numbers with trailing zeros to the scale of the column. The following description is copied from the description of HIVE-12063.
> HIVE-7373 was to address the problems of trimming tailing zeros by Hive, which caused many problems including treating 0.0, 0.00 and so on as 0, which has different precision/scale. Please refer to HIVE-7373 description. However, HIVE-7373 was reverted by HIVE-8745 while the underlying problems remained. HIVE-11835 was resolved recently to address one of the problems, where 0.0, 0.00, and so on cannot be read into decimal(1,1).
However, HIVE-11835 didn't address the problem of showing as 0 in query result for any decimal values such as 0.0, 0.00, etc. This causes confusion as 0 and 0.0 have different precision/scale than 0.
The proposal here is to pad zeros for query result to the type's scale. This not only removes the confusion described above, but also aligns with many other DBs. Internal decimal number representation doesn't change, however.
**Spark SQL**:
```sql
// bin/spark-sql
spark-sql> select cast(1 as decimal(38, 18));
1
spark-sql>
// bin/beeline
0: jdbc:hive2://localhost:10000/default> select cast(1 as decimal(38, 18));
+----------------------------+--+
| CAST(1 AS DECIMAL(38,18)) |
+----------------------------+--+
| 1.000000000000000000 |
+----------------------------+--+
// bin/spark-shell
scala> spark.sql("select cast(1 as decimal(38, 18))").show(false)
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
|1.000000000000000000 |
+-------------------------+
// bin/pyspark
>>> spark.sql("select cast(1 as decimal(38, 18))").show()
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
// bin/sparkR
> showDF(sql("SELECT cast(1 as decimal(38, 18))"))
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
```
**PostgreSQL**:
```sql
postgres=# select cast(1 as decimal(38, 18));
numeric
----------------------
1.000000000000000000
(1 row)
```
**Presto**:
```sql
presto> select cast(1 as decimal(38, 18));
_col0
----------------------
1.000000000000000000
(1 row)
```
## How was this patch tested?
unit tests and manual test:
```sql
spark-sql> select cast(1 as decimal(38, 18));
1.000000000000000000
```
Spark SQL Upgrading Guide:

Closes#26697 from wangyum/SPARK-28461.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
[HIVE-12063](https://issues.apache.org/jira/browse/HIVE-12063) improved pad decimal numbers with trailing zeros to the scale of the column. The following description is copied from the description of HIVE-12063.
> HIVE-7373 was to address the problems of trimming tailing zeros by Hive, which caused many problems including treating 0.0, 0.00 and so on as 0, which has different precision/scale. Please refer to HIVE-7373 description. However, HIVE-7373 was reverted by HIVE-8745 while the underlying problems remained. HIVE-11835 was resolved recently to address one of the problems, where 0.0, 0.00, and so on cannot be read into decimal(1,1).
However, HIVE-11835 didn't address the problem of showing as 0 in query result for any decimal values such as 0.0, 0.00, etc. This causes confusion as 0 and 0.0 have different precision/scale than 0.
The proposal here is to pad zeros for query result to the type's scale. This not only removes the confusion described above, but also aligns with many other DBs. Internal decimal number representation doesn't change, however.
**Spark SQL**:
```sql
// bin/spark-sql
spark-sql> select cast(1 as decimal(38, 18));
1
spark-sql>
// bin/beeline
0: jdbc:hive2://localhost:10000/default> select cast(1 as decimal(38, 18));
+----------------------------+--+
| CAST(1 AS DECIMAL(38,18)) |
+----------------------------+--+
| 1.000000000000000000 |
+----------------------------+--+
// bin/spark-shell
scala> spark.sql("select cast(1 as decimal(38, 18))").show(false)
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
|1.000000000000000000 |
+-------------------------+
// bin/pyspark
>>> spark.sql("select cast(1 as decimal(38, 18))").show()
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
// bin/sparkR
> showDF(sql("SELECT cast(1 as decimal(38, 18))"))
+-------------------------+
|CAST(1 AS DECIMAL(38,18))|
+-------------------------+
| 1.000000000000000000|
+-------------------------+
```
**PostgreSQL**:
```sql
postgres=# select cast(1 as decimal(38, 18));
numeric
----------------------
1.000000000000000000
(1 row)
```
**Presto**:
```sql
presto> select cast(1 as decimal(38, 18));
_col0
----------------------
1.000000000000000000
(1 row)
```
## How was this patch tested?
unit tests and manual test:
```sql
spark-sql> select cast(1 as decimal(38, 18));
1.000000000000000000
```
Spark SQL Upgrading Guide:

Closes#25214 from wangyum/SPARK-28461.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
A java like string trim method trims all whitespaces that less or equal than 0x20. currently, our UTF8String handle the space =0x20 ONLY. This is not suitable for many cases in Spark, like trim for interval strings, date, timestamps, PostgreSQL like cast string to boolean.
### Why are the changes needed?
improve the white spaces handling in UTF8String, also with some bugs fixed
### Does this PR introduce any user-facing change?
yes,
string with `control character` at either end can be convert to date/timestamp and interval now
### How was this patch tested?
add ut
Closes#26626 from yaooqinn/SPARK-29986.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Modify `UTF8String.toInt/toLong` to support trim spaces for both sides before converting it to byte/short/int/long.
With this kind of "cheap" trim can help improve performance for casting string to integrals. The idea is from https://github.com/apache/spark/pull/24872#issuecomment-556917834
### Why are the changes needed?
make the behavior consistent.
### Does this PR introduce any user-facing change?
yes, cast string to an integral type, and binary comparison between string and integrals will trim spaces first. their behavior will be consistent with float and double.
### How was this patch tested?
1. add ut.
2. benchmark tests
the benchmark is modified based on https://github.com/apache/spark/pull/24872#issuecomment-503827016
```scala
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.execution.benchmark
import org.apache.spark.benchmark.Benchmark
/**
* Benchmark trim the string when casting string type to Boolean/Numeric types.
* To run this benchmark:
* {{{
* 1. without sbt:
* bin/spark-submit --class <this class> --jars <spark core test jar> <spark sql test jar>
* 2. build/sbt "sql/test:runMain <this class>"
* 3. generate result: SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain <this class>"
* Results will be written to "benchmarks/CastBenchmark-results.txt".
* }}}
*/
object CastBenchmark extends SqlBasedBenchmark {
This conversation was marked as resolved by yaooqinn
override def runBenchmarkSuite(mainArgs: Array[String]): Unit = {
val title = "Cast String to Integral"
runBenchmark(title) {
withTempPath { dir =>
val N = 500L << 14
val df = spark.range(N)
val types = Seq("int", "long")
(1 to 5).by(2).foreach { i =>
df.selectExpr(s"concat(id, '${" " * i}') as str")
.write.mode("overwrite").parquet(dir + i.toString)
}
val benchmark = new Benchmark(title, N, minNumIters = 5, output = output)
Seq(true, false).foreach { trim =>
types.foreach { t =>
val str = if (trim) "trim(str)" else "str"
val expr = s"cast($str as $t) as c_$t"
(1 to 5).by(2).foreach { i =>
benchmark.addCase(expr + s" - with $i spaces") { _ =>
spark.read.parquet(dir + i.toString).selectExpr(expr).collect()
}
}
}
}
benchmark.run()
}
}
}
}
```
#### benchmark result.
normal trim v.s. trim in toInt/toLong
```java
================================================================================================
Cast String to Integral
================================================================================================
Java HotSpot(TM) 64-Bit Server VM 1.8.0_231-b11 on Mac OS X 10.15.1
Intel(R) Core(TM) i5-5287U CPU 2.90GHz
Cast String to Integral: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
cast(trim(str) as int) as c_int - with 1 spaces 10220 12994 1337 0.8 1247.5 1.0X
cast(trim(str) as int) as c_int - with 3 spaces 4763 8356 357 1.7 581.4 2.1X
cast(trim(str) as int) as c_int - with 5 spaces 4791 8042 NaN 1.7 584.9 2.1X
cast(trim(str) as long) as c_long - with 1 spaces 4014 6755 NaN 2.0 490.0 2.5X
cast(trim(str) as long) as c_long - with 3 spaces 4737 6938 NaN 1.7 578.2 2.2X
cast(trim(str) as long) as c_long - with 5 spaces 4478 6919 1404 1.8 546.6 2.3X
cast(str as int) as c_int - with 1 spaces 4443 6222 NaN 1.8 542.3 2.3X
cast(str as int) as c_int - with 3 spaces 3659 3842 170 2.2 446.7 2.8X
cast(str as int) as c_int - with 5 spaces 4372 7996 NaN 1.9 533.7 2.3X
cast(str as long) as c_long - with 1 spaces 3866 5838 NaN 2.1 471.9 2.6X
cast(str as long) as c_long - with 3 spaces 3793 5449 NaN 2.2 463.0 2.7X
cast(str as long) as c_long - with 5 spaces 4947 5961 1198 1.7 603.9 2.1X
```
Closes#26622 from yaooqinn/cheapstringtrim.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
remove the leading "interval" in `CalendarInterval.toString`.
### Why are the changes needed?
Although it's allowed to have "interval" prefix when casting string to int, it's not recommended.
This is also consistent with pgsql:
```
cloud0fan=# select interval '1' day;
interval
----------
1 day
(1 row)
```
### Does this PR introduce any user-facing change?
yes, when display a dataframe with interval type column, the result is different.
### How was this patch tested?
updated tests.
Closes#26401 from cloud-fan/interval.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}