### What changes were proposed in this pull request?
Skip capture maven repo config for views.
### Why are the changes needed?
Due to the bad network, we always use the thirdparty maven repo to run test. e.g.,
```
build/sbt "test:testOnly *SQLQueryTestSuite" -Dspark.sql.maven.additionalRemoteRepositories=xxxxx
```
It's failed with such error msg
```
[info] - show-tblproperties.sql *** FAILED *** (128 milliseconds)
[info] show-tblproperties.sql
[info] Expected "...rredTempViewNames [][]", but got "...rredTempViewNames [][
[info] view.sqlConfig.spark.sql.maven.additionalRemoteRepositories xxxxx]" Result did not match for query #6
[info] SHOW TBLPROPERTIES view (SQLQueryTestSuite.scala:464)
```
It's not necessary to capture the maven config to view since it's a session level config.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
manual test pass
```
build/sbt "test:testOnly *SQLQueryTestSuite" -Dspark.sql.maven.additionalRemoteRepositories=xxx
```
Closes#31856 from ulysses-you/skip-maven-config.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
This PR proposes to follow Univocity's input buffer.
### Why are the changes needed?
- Firstly, it's best to trust their judgement on the default values. Also 128 is too low.
- Default values arguably have more test coverage in Univocity.
- It will also fix https://github.com/uniVocity/univocity-parsers/issues/449
- ^ is a regression compared to Spark 2.4
### Does this PR introduce _any_ user-facing change?
No. In addition, It fixes a regression.
### How was this patch tested?
Manually tested, and added a unit test.
Closes#31858 from HyukjinKwon/SPARK-34768.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR updates `InMemoryCatalog.tableExists` to return false if database doesn't exist, instead of failing. The new behavior is consistent with `HiveExternalCatalog` which is used in production, so this bug mostly only affects tests.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
a new test
Closes#31860 from cloud-fan/catalog.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
`TmpOutputFile` and `TmpErrOutputFile` are registered in `o.a.h.u.ShutdownHookManager `during creatation. The `state.close()` will delete them if they are not null and try remove them from the `o.a.h.u.ShutdownHookManager` which causes IllegalStateException when we call it in our ShutdownHookManager too.
In this PR, we delete them ahead with a high priority hook in Spark and set them to null to bypass the deletion and canceling in `state.close()`
### Why are the changes needed?
W/ or w/o this PR, the deletion of these files is not affected, we just mute an undesirable error log here.
### Does this PR introduce _any_ user-facing change?
no, this is a follow-up
### How was this patch tested?
#### the undesirable gone
```scala
spark-sql> 21/03/16 18:41:31 ERROR Utils: Uncaught exception in thread shutdown-hook-0
java.lang.IllegalStateException: Shutdown in progress, cannot cancel a deleteOnExit
at org.apache.hive.common.util.ShutdownHookManager.cancelDeleteOnExit(ShutdownHookManager.java:106)
at org.apache.hadoop.hive.common.FileUtils.deleteTmpFile(FileUtils.java:861)
at org.apache.hadoop.hive.ql.session.SessionState.deleteTmpErrOutputFile(SessionState.java:325)
at org.apache.hadoop.hive.ql.session.SessionState.dropSessionPaths(SessionState.java:829)
at org.apache.hadoop.hive.ql.session.SessionState.close(SessionState.java:1585)
at org.apache.hadoop.hive.cli.CliSessionState.close(CliSessionState.java:66)
at org.apache.spark.sql.hive.client.HiveClientImpl.closeState(HiveClientImpl.scala:172)
at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$new$1(HiveClientImpl.scala:175)
at org.apache.spark.util.SparkShutdownHook.run(ShutdownHookManager.scala:214)
at org.apache.spark.util.SparkShutdownHookManager.$anonfun$runAll$2(ShutdownHookManager.scala:188)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1994)
at org.apache.spark.util.SparkShutdownHookManager.$anonfun$runAll$1(ShutdownHookManager.scala:188)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at scala.util.Try$.apply(Try.scala:213)
at org.apache.spark.util.SparkShutdownHookManager.runAll(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anon$2.run(ShutdownHookManager.scala:178)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
(python) ✘ kentyaohulk ~/Downloads/spark/spark-3.2.0-SNAPSHOT-bin-20210316 cd ..
(python) kentyaohulk ~/Downloads/spark tar zxf spark-3.2.0-SNAPSHOT-bin-20210316.tgz
(python) kentyaohulk ~/Downloads/spark cd -
~/Downloads/spark/spark-3.2.0-SNAPSHOT-bin-20210316
(python) kentyaohulk ~/Downloads/spark/spark-3.2.0-SNAPSHOT-bin-20210316 bin/spark-sql --conf spark.local.dir=./local --conf spark.hive.exec.local.scratchdir=./local
21/03/16 18:42:15 WARN Utils: Your hostname, hulk.local resolves to a loopback address: 127.0.0.1; using 10.242.189.214 instead (on interface en0)
21/03/16 18:42:15 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
21/03/16 18:42:15 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
21/03/16 18:42:16 WARN SparkConf: Note that spark.local.dir will be overridden by the value set by the cluster manager (via SPARK_LOCAL_DIRS in mesos/standalone/kubernetes and LOCAL_DIRS in YARN).
21/03/16 18:42:18 WARN HiveConf: HiveConf of name hive.stats.jdbc.timeout does not exist
21/03/16 18:42:18 WARN HiveConf: HiveConf of name hive.stats.retries.wait does not exist
21/03/16 18:42:19 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 2.3.0
21/03/16 18:42:19 WARN ObjectStore: setMetaStoreSchemaVersion called but recording version is disabled: version = 2.3.0, comment = Set by MetaStore kentyao127.0.0.1
Spark master: local[*], Application Id: local-1615891336877
spark-sql> %
```
#### and the deletion is still fine
```shell
kentyaohulk ~/Downloads/spark/spark-3.2.0-SNAPSHOT-bin-20210316
ls -al local
total 0
drwxr-xr-x 7 kentyao staff 224 3 16 18:42 .
drwxr-xr-x 19 kentyao staff 608 3 16 18:42 ..
drwx------ 2 kentyao staff 64 3 16 18:42 16cc5238-e25e-4c0f-96ef-0c4bdecc7e51
-rw-r--r-- 1 kentyao staff 0 3 16 18:42 16cc5238-e25e-4c0f-96ef-0c4bdecc7e51219959790473242539.pipeout
-rw-r--r-- 1 kentyao staff 0 3 16 18:42 16cc5238-e25e-4c0f-96ef-0c4bdecc7e518816377057377724129.pipeout
drwxr-xr-x 2 kentyao staff 64 3 16 18:42 blockmgr-37a52ad2-eb56-43a5-8803-8f58d08fe9ad
drwx------ 3 kentyao staff 96 3 16 18:42 spark-101971df-f754-47c2-8764-58c45586be7e
kentyaohulk ~/Downloads/spark/spark-3.2.0-SNAPSHOT-bin-20210316 ls -al local
total 0
drwxr-xr-x 2 kentyao staff 64 3 16 19:22 .
drwxr-xr-x 19 kentyao staff 608 3 16 18:42 ..
kentyaohulk ~/Downloads/spark/spark-3.2.0-SNAPSHOT-bin-20210316
```
Closes#31850 from yaooqinn/followup.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
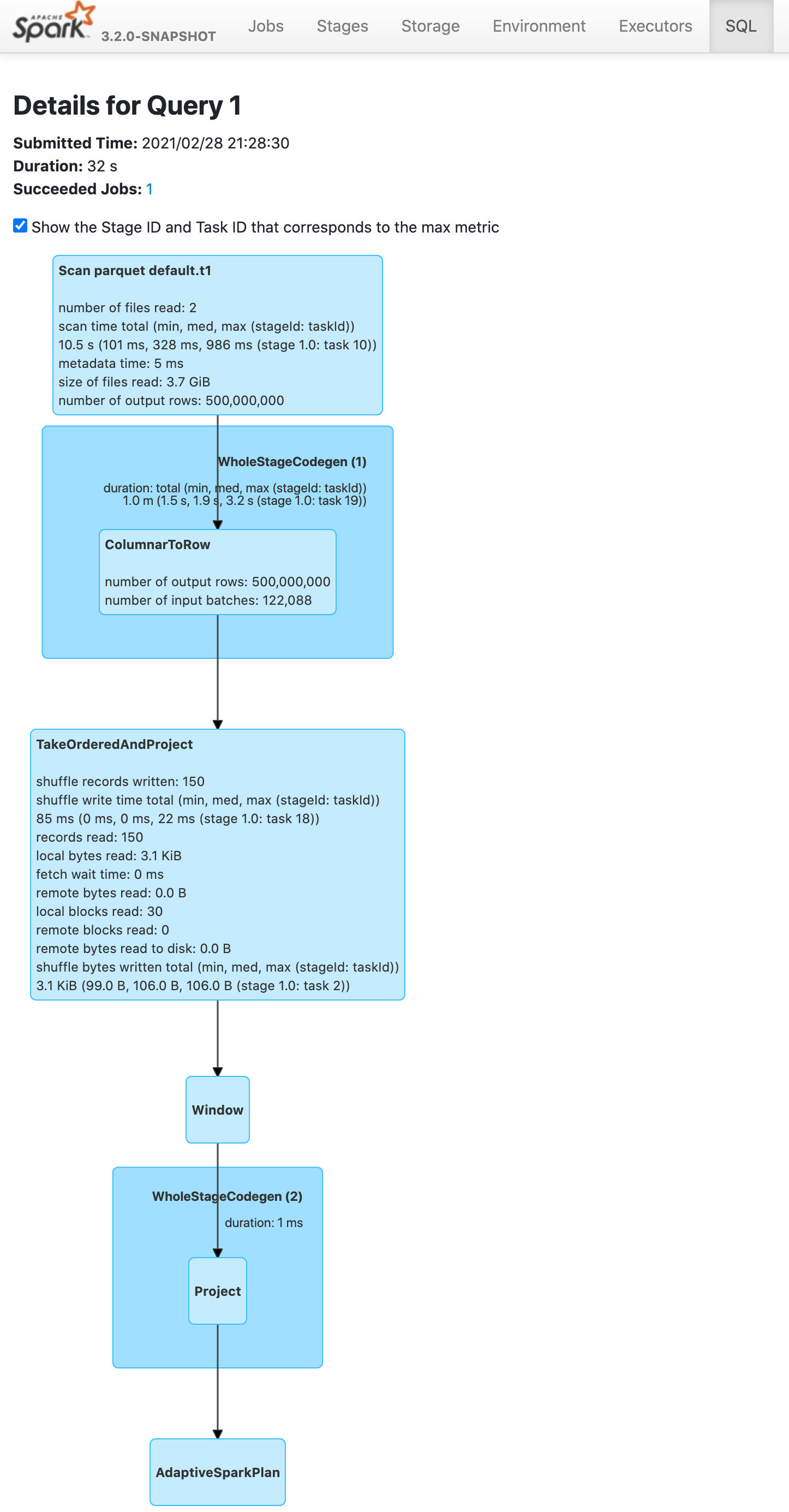
Push down limit through `Window` when the partitionSpec of all window functions is empty and the same order is used. This is a real case from production:

This pr support 2 cases:
1. All window functions have same orderSpec:
```sql
SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rn, RANK() OVER(ORDER BY a) AS rk FROM t1 LIMIT 5;
== Optimized Logical Plan ==
Window [row_number() windowspecdefinition(a#9L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rn#4, rank(a#9L) windowspecdefinition(a#9L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#5], [a#9L ASC NULLS FIRST]
+- GlobalLimit 5
+- LocalLimit 5
+- Sort [a#9L ASC NULLS FIRST], true
+- Relation default.t1[A#9L,B#10L,C#11L] parquet
```
2. There is a window function with a different orderSpec:
```sql
SELECT a, ROW_NUMBER() OVER(ORDER BY a) AS rn, RANK() OVER(ORDER BY b DESC) AS rk FROM t1 LIMIT 5;
== Optimized Logical Plan ==
Project [a#9L, rn#4, rk#5]
+- Window [rank(b#10L) windowspecdefinition(b#10L DESC NULLS LAST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#5], [b#10L DESC NULLS LAST]
+- GlobalLimit 5
+- LocalLimit 5
+- Sort [b#10L DESC NULLS LAST], true
+- Window [row_number() windowspecdefinition(a#9L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rn#4], [a#9L ASC NULLS FIRST]
+- Project [a#9L, b#10L]
+- Relation default.t1[A#9L,B#10L,C#11L] parquet
```
### Why are the changes needed?
Improve query performance.
```scala
spark.range(500000000L).selectExpr("id AS a", "id AS b").write.saveAsTable("t1")
spark.sql("SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rowId FROM t1 LIMIT 5").show
```
Before this pr | After this pr
-- | --
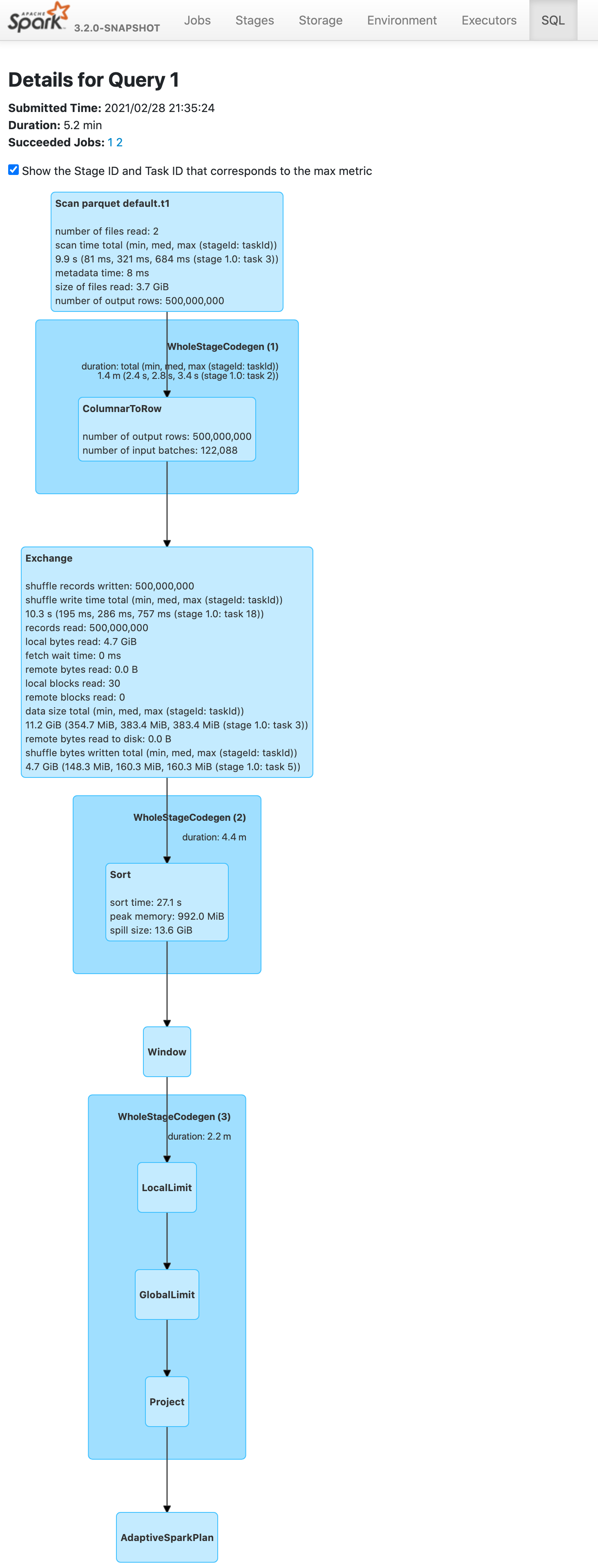 | 
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes#31691 from wangyum/SPARK-34575.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For the following cases, ABS should throw exceptions since the results are out of the range of the result data types in ANSI mode.
```
SELECT abs(${Int.MinValue});
SELECT abs(${Long.MinValue});
```
### Why are the changes needed?
Better ANSI compliance
### Does this PR introduce _any_ user-facing change?
Yes, Abs throws an exception if input is out of range in ANSI mode
### How was this patch tested?
Unit test
Closes#31836 from gengliangwang/ansiAbs.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes:
1. `CREATE OR REPLACE TEMP VIEW USING` should use `TemporaryViewRelation` to store temp views.
2. By doing #1, it fixes the issue where the temp view being replaced is not uncached.
### Why are the changes needed?
This is a part of an ongoing work to wrap all the temporary views with `TemporaryViewRelation`: [SPARK-34698](https://issues.apache.org/jira/browse/SPARK-34698).
This also fixes a bug where the temp view being replaced is not uncached.
### Does this PR introduce _any_ user-facing change?
Yes, the temp view being replaced with `CREATE OR REPLACE TEMP VIEW USING` is correctly uncached if the temp view is cached.
### How was this patch tested?
Added new tests.
Closes#31825 from imback82/create_temp_view_using.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For DDL commands like DROP VIEW, they don't really need to resolve the view (parse and analyze the view SQL text), they just need to get the view metadata.
This PR fixes the rule `ResolveTempViews` to only resolve the temp view for `UnresolvedRelation`. This also fixes a bug for DROP VIEW, as previously it tried to resolve the view and failed to drop invalid views.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
new test
Closes#31853 from cloud-fan/view-resolve.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a followup minor change from https://github.com/apache/spark/pull/31821#discussion_r594110622 , where we change from using `execute()` to `executeTake()`. Performance-wise there's no difference. We are just using a different API to be aligned with code path of `Dataset`.
### Why are the changes needed?
To align with other code paths in SQL/Dataset.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit tests same as https://github.com/apache/spark/pull/31821 .
Closes#31845 from c21/join-followup.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
We initialized a Hive `SessionState` to interact with the external hive metastore server but left it behind after we finished.
We should close the metastore client explicitly in case of connection leaks with HMS
and we should trigger the `SessionState` to close itself to clean the residual dirs to fix issues reported by SPARK-21449 and SPARK-23745.
`hive.downloaded.resources.dir` contains transient files, such as UDF jars, it will not be used anymore after spark applications exit.
### Why are the changes needed?
1. prevent potential metastore client leak
2. clean `hive.downloaded.resources.dir`
```
DOWNLOADED_RESOURCES_DIR("hive.downloaded.resources.dir", "${system:java.io.tmpdir}" + File.separator + "${hive.session.id}_resources", "Temporary local directory for added resources in the remote file system."),
```
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
passing jenkins and verify locally
Closes#31833 from yaooqinn/SPARK-21449-2.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
This PR removes one unused variable in `NewInstance.constructor`.
### Why are the changes needed?
This looks like a variable for debugging at the initial commit of SPARK-23584 .
- 1b08c4393c (diff-2a36e31684505fd22e2d12a864ce89fd350656d716a3f2d7789d2cdbe38e15fbR461)
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the CIs.
Closes#31838 from dongjoon-hyun/minor-object.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Support `timestamp +/- year-month interval`. In the PR, I propose to introduce new binary expression `TimestampAddYMInterval` similarly to `DateAddYMInterval`. It invokes new method `timestampAddMonths` from `DateTimeUtils` by passing a timestamp as an offset in microseconds since the epoch, amount of months from the giveb year-month interval, and the time zone ID in which the operation is performed. The `timestampAddMonths()` method converts the input microseconds to a local timestamp, adds months to it, and converts the results back to an instant in microseconds at the given time zone.
### Why are the changes needed?
To conform the ANSI SQL standard which requires to support such operation over timestamps and intervals:
<img width="811" alt="Screenshot 2021-03-12 at 11 36 14" src="https://user-images.githubusercontent.com/1580697/111081674-865d4900-8515-11eb-86c8-3538ecaf4804.png">
### Does this PR introduce _any_ user-facing change?
Should not since new intervals have not been released yet.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateTimeUtilsSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31832 from MaxGekk/timestamp-add-year-month-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR aims to make `ExpressionEncoderSuite` to use `deepEquals` instead of `equals` when `input` is `array of array`.
This comparison code itself was added by SPARK-11727 at Apache Spark 1.6.0.
### Why are the changes needed?
Currently, the interpreted mode fails for `array of array` because the following line is used.
```
Arrays.equals(b1.asInstanceOf[Array[AnyRef]], b2.asInstanceOf[Array[AnyRef]])
```
### Does this PR introduce _any_ user-facing change?
No. This is a test-only PR.
### How was this patch tested?
Pass the existing CIs.
Closes#31837 from dongjoon-hyun/SPARK-34743.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In `Analyzer.resolveExpression`, we have a parameter to decide if we should remove unnecessary `Alias` or not. This is over complicated and we can always remove unnecessary `Alias`.
This PR simplifies this part and removes the parameter.
### Why are the changes needed?
code cleanup
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing tests
Closes#31758 from cloud-fan/resolve.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For `BroadcastNestedLoopJoinExec` left semi and left anti join without condition. If we broadcast left side. Currently we check whether every row from broadcast side has a match or not by [iterating broadcast side a lot of time](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/joins/BroadcastNestedLoopJoinExec.scala#L256-L275). This is unnecessary and very inefficient when there's no condition, as we only need to check whether stream side is empty or not. Create this PR to add the optimization. This can boost the affected query execution performance a lot.
In addition, create a common method `getMatchedBroadcastRowsBitSet()` shared by several methods.
Refactor `defaultJoin()` to move
* left semi and left anti join related logic to `leftExistenceJoin`
* existence join related logic to `existenceJoin`.
After this, `defaultJoin()` holds logic only for outer join (left outer, right outer and full outer), which is much easier to read from my own opinion.
### Why are the changes needed?
Improve the affected query performance a lot.
Test with a simple query by modifying `JoinBenchmark.scala` locally:
```
val N = 20 << 20
val M = 1 << 4
val dim = broadcast(spark.range(M).selectExpr("id as k"))
val df = dim.join(spark.range(N), Seq.empty, "left_semi")
df.noop()
```
See >30x run time improvement. Note the stream side is only `spark.range(N)`. For complicated query with non-trivial stream side, the saving would be much more.
```
Running benchmark: broadcast nested loop left semi join
Running case: broadcast nested loop left semi join optimization off
Stopped after 2 iterations, 3163 ms
Running case: broadcast nested loop left semi join optimization on
Stopped after 5 iterations, 366 ms
Java HotSpot(TM) 64-Bit Server VM 1.8.0_181-b13 on Mac OS X 10.15.7
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
broadcast nested loop left semi join: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
-------------------------------------------------------------------------------------------------------------------------------------
broadcast nested loop left semi join optimization off 1568 1582 19 13.4 74.8 1.0X
broadcast nested loop left semi join optimization on 46 73 18 456.0 2.2 34.1X
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit test in `ExistenceJoinSuite.scala`.
Closes#31821 from c21/nested-join.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
The main change of this pr as follows:
- Use `org.junit.Assert.assertThrows(String, Class, ThrowingRunnable)` method instead of `ExpectedException.none()`
- Use `org.hamcrest.MatcherAssert.assertThat()` method instead of `org.junit.Assert.assertThat(T, org.hamcrest.Matcher<? super T>)`
### Why are the changes needed?
Clean up deprecated API usage
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the Jenkins or GitHub Action
Closes#31815 from LuciferYang/SPARK-34722.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In the PR, I propose to cast the input float to double in the `SecondsToTimestamp` expression in the same way as in the `Cast` expression.
### Why are the changes needed?
To have the same results from `CAST(<float> AS TIMESTAMP)` and from `TIMESTAMP_SECONDS`:
```sql
spark-sql> SELECT CAST(16777215.0f AS TIMESTAMP);
1970-07-14 07:20:15
spark-sql> SELECT TIMESTAMP_SECONDS(16777215.0f);
1970-07-14 07:20:14.951424
```
### Does this PR introduce _any_ user-facing change?
Yes. After the changes:
```sql
spark-sql> SELECT TIMESTAMP_SECONDS(16777215.0f);
1970-07-14 07:20:15
```
### How was this patch tested?
By running new test:
```
$ build/sbt "test:testOnly *DateExpressionsSuite"
```
Closes#31831 from MaxGekk/adjust-SecondsToTimestamp.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR aims to update SBT from 1.4.7 to 1.4.9.
### Why are the changes needed?
This will bring the following bug fixes and improvements.
- https://github.com/sbt/sbt/releases/tag/v1.4.9
- https://github.com/sbt/sbt/releases/tag/v1.4.8
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the CIs.
Closes#31828 from williamhyun/sbt149.
Authored-by: William Hyun <williamhyun3@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In non-ANSI mode, casting float to timestamp has different implementation for codegen on and off.
Codegen on:
1. Multiply float input by MICROS_PER_SECOND
2. Cast resulting float value to long
Codegen off:
1. CAST float input to double input
2. Multiply double input by MICROS_PER_SECOND
3. Cast resulting double value to long
In the PR, I propose to align to non-codegen code, and cast input float to double in codegen.
### Why are the changes needed?
This fixes the issue which is demonstrated by the code:
```sql
spark-sql> CREATE TEMP VIEW v1 AS SELECT 16777215.0f AS f;
spark-sql> SELECT * FROM v1;
1.6777215E7
spark-sql> SELECT CAST(f AS TIMESTAMP) FROM v1;
1970-07-14 07:20:15
spark-sql> CACHE TABLE v1;
spark-sql> SELECT * FROM v1;
1.6777215E7
spark-sql> SELECT CAST(f AS TIMESTAMP) FROM v1;
1970-07-14 07:20:14.951424
```
The result from the cached view **1970-07-14 07:20:14.951424** is different from un-cached view **1970-07-14 07:20:15**.
### Does this PR introduce _any_ user-facing change?
Yes. After the changes, the example above outputs the same timestamp for the cached view:
```sql
spark-sql> CACHE TABLE v1;
spark-sql> SELECT * FROM v1;
1.6777215E7
spark-sql> SELECT CAST(f AS TIMESTAMP) FROM v1;
1970-07-14 07:20:15
```
### How was this patch tested?
By running new test:
```
$ build/sbt "test:testOnly *CastSuite"
```
Closes#31819 from MaxGekk/fix-float-to-timestamp.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Fixing `IndexOutOfBoundsException` in `logForFailedTest` method when driver is not started.
### Why are the changes needed?
Before this PR when the driver is not started an `IndexOutOfBoundsException` as the first item is tried to be accessed from an empty list:
```
- PVs with local storage *** FAILED ***
java.lang.IndexOutOfBoundsException: Index: 0, Size: 0
at java.util.ArrayList.rangeCheck(ArrayList.java:659)
at java.util.ArrayList.get(ArrayList.java:435)
at org.apache.spark.deploy.k8s.integrationtest.KubernetesSuite.logForFailedTest(KubernetesSuite.scala:83)
at org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:181)
at org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:188)
at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:200)
at org.scalatest.SuperEngine.runTestImpl(Engine.scala:306)
at org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:200)
at org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:182)
at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:61)
...
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Running integration tests.
After this changes the above error become:
```
- PVs with local storage *** FAILED ***
java.io.IOException: No such file or directory
at java.io.UnixFileSystem.createFileExclusively(Native Method)
at java.io.File.createTempFile(File.java:2026)
at org.apache.spark.deploy.k8s.integrationtest.Utils$.createTempFile(Utils.scala:103)
at org.apache.spark.deploy.k8s.integrationtest.PVTestsSuite.$anonfun$$init$$1(PVTestsSuite.scala:135)
at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85)
at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83)
at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104)
at org.scalatest.Transformer.apply(Transformer.scala:22)
at org.scalatest.Transformer.apply(Transformer.scala:20)
at org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:190)
...
```
Closes#31824 from attilapiros/SPARK-34732.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch proposes to fix incorrect parameter type for subexpression elimination under whole-stage.
### Why are the changes needed?
If the parameter is a byte array, the subexpression elimination under wholestage codegen will use incorrect parameter type and cause compile error. Although Spark can automatically fallback to interpreted mode, we should fix it.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually test with customer application. Unit test.
Closes#31814 from viirya/SPARK-34723.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
Support `date +/- year-month interval`. In the PR, I propose to re-use existing code from the `AddMonths` expression, and extract it to the common base class `AddMonthsBase`. That base class is used in new expression `DateAddYMInterval` and in the existing one `AddMonths` (the `add_months` function).
### Why are the changes needed?
To conform the ANSI SQL standard which requires to support such operation over dates and intervals:
<img width="811" alt="Screenshot 2021-03-12 at 11 36 14" src="https://user-images.githubusercontent.com/1580697/110914390-5f412480-8327-11eb-9f8b-e92e73c0b9cd.png">
### Does this PR introduce _any_ user-facing change?
Should not since new intervals have not been released yet.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *ColumnExpressionSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
```
Closes#31812 from MaxGekk/date-add-year-month-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This bug was introduced by SPARK-23583 at Apache Spark 2.4.0.
This PR aims to use `getMethod` instead of `getDeclaredMethod`.
```scala
- obj.getClass.getDeclaredMethod(functionName, argClasses: _*)
+ obj.getClass.getMethod(functionName, argClasses: _*)
```
### Why are the changes needed?
`getDeclaredMethod` does not search the super class's method. To invoke `GenericArrayData.toIntArray`, we need to use `getMethod` because it's declared at the super class `ArrayData`.
```
[info] - encode/decode for array of int: [I74655d03 (interpreted path) *** FAILED *** (14 milliseconds)
[info] Exception thrown while decoding
[info] Converted: [0,1000000020,3,0,ffffff850000001f,4]
[info] Schema: value#680
[info] root
[info] -- value: array (nullable = true)
[info] |-- element: integer (containsNull = false)
[info]
[info]
[info] Encoder:
[info] class[value[0]: array<int>] (ExpressionEncoderSuite.scala:578)
[info] org.scalatest.exceptions.TestFailedException:
[info] at org.scalatest.Assertions.newAssertionFailedException(Assertions.scala:472)
[info] at org.scalatest.Assertions.newAssertionFailedException$(Assertions.scala:471)
[info] at org.scalatest.funsuite.AnyFunSuite.newAssertionFailedException(AnyFunSuite.scala:1563)
[info] at org.scalatest.Assertions.fail(Assertions.scala:949)
[info] at org.scalatest.Assertions.fail$(Assertions.scala:945)
[info] at org.scalatest.funsuite.AnyFunSuite.fail(AnyFunSuite.scala:1563)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.$anonfun$encodeDecodeTest$1(ExpressionEncoderSuite.scala:578)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.verifyNotLeakingReflectionObjects(ExpressionEncoderSuite.scala:656)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.$anonfun$testAndVerifyNotLeakingReflectionObjects$2(ExpressionEncoderSuite.scala:669)
[info] at org.apache.spark.sql.catalyst.plans.CodegenInterpretedPlanTest.$anonfun$test$4(PlanTest.scala:50)
[info] at org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf(SQLHelper.scala:54)
[info] at org.apache.spark.sql.catalyst.plans.SQLHelper.withSQLConf$(SQLHelper.scala:38)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.withSQLConf(ExpressionEncoderSuite.scala:118)
[info] at org.apache.spark.sql.catalyst.plans.CodegenInterpretedPlanTest.$anonfun$test$3(PlanTest.scala:50)
...
[info] Cause: java.lang.RuntimeException: Error while decoding: java.lang.NoSuchMethodException: org.apache.spark.sql.catalyst.util.GenericArrayData.toIntArray()
[info] mapobjects(lambdavariable(MapObject, IntegerType, false, -1), assertnotnull(lambdavariable(MapObject, IntegerType, false, -1)), input[0, array<int>, true], None).toIntArray
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoder$Deserializer.apply(ExpressionEncoder.scala:186)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.$anonfun$encodeDecodeTest$1(ExpressionEncoderSuite.scala:576)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.verifyNotLeakingReflectionObjects(ExpressionEncoderSuite.scala:656)
[info] at org.apache.spark.sql.catalyst.encoders.ExpressionEncoderSuite.$anonfun$testAndVerifyNotLeakingReflectionObjects$2(ExpressionEncoderSuite.scala:669)
```
### Does this PR introduce _any_ user-facing change?
This causes a runtime exception when we use the interpreted mode.
### How was this patch tested?
Pass the modified unit test case.
Closes#31816 from dongjoon-hyun/SPARK-34724.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR fixes an issue that `sql` method in the following classes which take qualified names don't quote the qualified names properly.
* UnresolvedAttribute
* AttributeReference
* Alias
One instance caused by this issue is reported in SPARK-34626.
```
UnresolvedAttribute("a" :: "b" :: Nil).sql
`a.b` // expected: `a`.`b`
```
And other instances are like as follows.
```
UnresolvedAttribute("a`b"::"c.d"::Nil).sql
a`b.`c.d` // expected: `a``b`.`c.d`
AttributeReference("a.b", IntegerType)(qualifier = "c.d"::Nil).sql
c.d.`a.b` // expected: `c.d`.`a.b`
Alias(AttributeReference("a", IntegerType)(), "b.c")(qualifier = "d.e"::Nil).sql
`a` AS d.e.`b.c` // expected: `a` AS `d.e`.`b.c`
```
### Why are the changes needed?
This is a bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New test.
Closes#31754 from sarutak/fix-qualified-names.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to override the `typeName()` method in `YearMonthIntervalType` and `DayTimeIntervalType`, and assign them names according to the ANSI SQL standard:
<img width="836" alt="Screenshot 2021-03-11 at 17 29 04" src="https://user-images.githubusercontent.com/1580697/110802854-a54aa980-828f-11eb-956d-dd4fbf14aa72.png">
but keep the type name as singular according existing naming convention for other types.
### Why are the changes needed?
To improve Spark SQL user experience, and have readable types in error messages.
### Does this PR introduce _any_ user-facing change?
Should not since the types has not been released yet.
### How was this patch tested?
By running the modified tests:
```
$ build/sbt "test:testOnly *ExpressionTypeCheckingSuite"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z windowFrameCoercion.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z literals.sql"
```
Closes#31810 from MaxGekk/interval-types-name.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Use HiveUtils.buildinHiveVersion to replace correspoding Ut about hive version
### Why are the changes needed?
Refactor UT about hive build in version, avoid to change every time when upgrade hive version
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#31807 from AngersZhuuuu/SPARK-34712.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a bug caused by https://issues.apache.org/jira/browse/SPARK-31670 . We remove the `Alias` when resolving column references in grouping expressions, which breaks `ResolveCreateNamedStruct`
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
new tests
Closes#31808 from cloud-fan/bug.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR upgrade Py4J from 0.10.9.1 to 0.10.9.2 that contains some bug fixes and improvements.
* expose shell parameter in Popen inside launch_gateway. ([bartdag/py4j220efc3](220efc3716))
* fixed Flake8 errors ([bartdag/py4j6c6ee9a](6c6ee9aedc))
### Why are the changes needed?
To leverage fixes from the upstream in Py4J.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Jenkins build and GitHub Actions will test it out.
Closes#31796 from wankunde/py4j.
Authored-by: wankunde <wankunde@163.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
In the PR, I propose to especially handle the amount of seconds `-9223372036855` in `IntervalUtils. durationToMicros()`. Starting from the amount (any durations with the second field < `-9223372036855`), input durations cannot fit to `Long` in the conversion to microseconds. For example, the amount of microseconds = `Long.MinValue = -9223372036854775808` can be represented in two forms:
1. seconds = -9223372036854, nanoAdjustment = -775808, or
2. seconds = -9223372036855, nanoAdjustment = +224192
And the method `Duration.ofSeconds()` produces the last form but such form causes overflow while converting `-9223372036855` seconds to microseconds.
In the PR, I propose to convert the second form to the first one if the second field of input duration is equal to `-9223372036855`.
### Why are the changes needed?
The changes fix the issue demonstrated by the code:
```scala
scala> durationToMicros(microsToDuration(Long.MinValue))
java.lang.ArithmeticException: long overflow
at java.lang.Math.multiplyExact(Math.java:892)
at org.apache.spark.sql.catalyst.util.IntervalUtils$.durationToMicros(IntervalUtils.scala:782)
... 49 elided
```
The `durationToMicros()` method cannot handle valid output of `microsToDuration()`.
### Does this PR introduce _any_ user-facing change?
Should not since new interval types has not been released yet.
### How was this patch tested?
By running new UT from `IntervalUtilsSuite`.
Closes#31799 from MaxGekk/fix-min-duration.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add `Not(In)` and `Not(InSet)` pattern when convert filter to metastore.
### Why are the changes needed?
`NOT IN` is a useful condition to prune partition, it would be better to support it.
Technically, we can convert `c not in(x,y)` to `c != x and c != y`, then push it to metastore.
Avoid metastore overflow and respect the config `spark.sql.hive.metastorePartitionPruningInSetThreshold`, `Not(InSet)` won't push to metastore if it's value exceeds the threshold.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Add test.
Closes#31646 from ulysses-you/SPARK-34538.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
As a followup from code review in https://github.com/apache/spark/pull/31736#discussion_r588134104 , for `JoinCodegenSupport.genBuildSideVars`, we only need to generate build side variables with default values for LEFT OUTER and RIGHT OUTER join, but not for other join types (i.e. LEFT SEMI and LEFT ANTI). Create this PR to clean up the code.
In addition, change `BroadcastNestedLoopJoinExec` unit test to cover both whole stage code-gen enabled and disabled. Harden the unit tests to exercise all code paths.
### Why are the changes needed?
Avoid unnecessary code generation.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit tests.
* BHJ and SHJ inner join is covered in `InnerJoinSuite.scala`
* BHJ and SHJ left outer and right outer join are covered in `OuterJoinSuite.scala`
* BHJ and SHJ left semi, left anti and existence join are covered in `ExistenceJoinSuite.scala`
Closes#31802 from c21/join-codegen-fix.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes the behavior of `SHOW FUNCTIONS` and `DESCRIBE FUNCTION` for the `||` operator.
The result of `SHOW FUNCTIONS` doesn't contains `||` and `DESCRIBE FUNCTION ||` says `Function: || not found.` even though `||` is supported.
### Why are the changes needed?
It's a bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Confirmed manually with the following commands.
```
spark-sql> DESCRIBE FUNCTION ||;
Function: ||
Usage: expr1 || expr2 - Returns the concatenation of `expr1` and `expr2`.
spark-sql> SHOW FUNCTIONS;
!
!=
%
...
|
||
~
```
Closes#31800 from sarutak/fix-describe-concat-pipe.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Extend the `Add`, `Subtract` and `UnaryMinus` expression to support `DayTimeIntervalType` and `YearMonthIntervalType` added by #31614.
Note: the expressions can throw the `overflow` exception independently from the SQL config `spark.sql.ansi.enabled`. In this way, the modified expressions always behave in the ANSI mode for the intervals.
### Why are the changes needed?
To conform to the ANSI SQL standard which defines `-/+` over intervals:
<img width="822" alt="Screenshot 2021-03-09 at 21 59 22" src="https://user-images.githubusercontent.com/1580697/110523128-bd50ea80-8122-11eb-9982-782da0088d27.png">
### Does this PR introduce _any_ user-facing change?
Should not since new types have not been released yet.
### How was this patch tested?
By running new tests in the test suites:
```
$ build/sbt "test:testOnly *ArithmeticExpressionSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#31789 from MaxGekk/add-subtruct-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
SPARK-23596 added `CodegenInterpretedPlanTest` at Apache Spark 2.4.0 in a wrong way because `withSQLConf` depends on the execution time `SQLConf.get` instead of `test` function declaration time. So, the following code executes the test twice without controlling the `CodegenObjectFactoryMode`. This PR aims to fix it correct and introduce a new function `testFallback`.
```scala
trait CodegenInterpretedPlanTest extends PlanTest {
override protected def test(
testName: String,
testTags: Tag*)(testFun: => Any)(implicit pos: source.Position): Unit = {
val codegenMode = CodegenObjectFactoryMode.CODEGEN_ONLY.toString
val interpretedMode = CodegenObjectFactoryMode.NO_CODEGEN.toString
withSQLConf(SQLConf.CODEGEN_FACTORY_MODE.key -> codegenMode) {
super.test(testName + " (codegen path)", testTags: _*)(testFun)(pos)
}
withSQLConf(SQLConf.CODEGEN_FACTORY_MODE.key -> interpretedMode) {
super.test(testName + " (interpreted path)", testTags: _*)(testFun)(pos)
}
}
}
```
### Why are the changes needed?
1. We need to use like the following.
```scala
super.test(testName + " (codegen path)", testTags: _*)(
withSQLConf(SQLConf.CODEGEN_FACTORY_MODE.key -> codegenMode) { testFun })(pos)
super.test(testName + " (interpreted path)", testTags: _*)(
withSQLConf(SQLConf.CODEGEN_FACTORY_MODE.key -> interpretedMode) { testFun })(pos)
```
2. After we fix this behavior with the above code, several test cases including SPARK-34596 and SPARK-34607 fail because they didn't work at both `CODEGEN` and `INTERPRETED` mode. Those test cases only work at `FALLBACK` mode. So, inevitably, we need to introduce `testFallback`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the CIs.
Closes#31766 from dongjoon-hyun/SPARK-34596-SPARK-34607.
Lead-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is just a minor fix. `HashJoin` already extends `JoinCodegenSupport`. So we don't need `CodegenSupport` here for `BroadcastHashJoinExec`. Submitted separately as a PR here per https://github.com/apache/spark/pull/31802#discussion_r592066686 .
### Why are the changes needed?
Clean up code.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit tests.
Closes#31805 from c21/bhj-minor.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Per comment in https://github.com/apache/spark/pull/31802#discussion_r592068440 , we would like to exercise whole stage code-gen enabled and disabled code paths in join unit test suites. This is for better test coverage of shuffled hash join.
### Why are the changes needed?
Better test coverage.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing and added unit tests here.
Closes#31806 from c21/test-minor.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR adds a default null ordering to public `SortDirection` to match the Catalyst behavior.
### Why are the changes needed?
The SQL standard does not define the default null ordering for a sort direction. That's why it is up to a query engine to assign one. We need to standardize this in our public connector expressions to avoid ambiguity. That's why I propose to match the behavior in our Catalyst expressions.
### Does this PR introduce _any_ user-facing change?
Yes, it affects unreleased connector expression API.
### How was this patch tested?
Existing tests.
Closes#31580 from aokolnychyi/spark-34457.
Authored-by: Anton Okolnychyi <aokolnychyi@apple.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes the following:
* `AlterViewAs.query` is currently analyzed in the physical operator `AlterViewAsCommand`, but it should be analyzed during the analysis phase.
* When `spark.sql.legacy.storeAnalyzedPlanForView` is set to true, store `TermporaryViewRelation` which wraps the analyzed plan, similar to #31273.
* Try to uncache the view you are altering.
### Why are the changes needed?
Analyzing a plan should be done in the analysis phase if possible.
Not uncaching the view (existing behavior) seems like a bug since the cache may not be used again.
### Does this PR introduce _any_ user-facing change?
Yes, now the view can be uncached if it's already cached.
### How was this patch tested?
Added new tests around uncaching.
The existing tests such as `SQLViewSuite` should cover the analysis changes.
Closes#31652 from imback82/alter_view_child.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The `change-scala-version.sh` script updates Scala versions across the build for cross-build purposes. It manually changes `scala.binary.version` but not `scala.version`.
### Why are the changes needed?
It seems that this has always been an oversight, and the cross-built builds of Spark have an incorrect scala.version. See 2.4.5's 2.12 POM for example, which shows a Scala 2.11 version.
https://search.maven.org/artifact/org.apache.spark/spark-core_2.12/2.4.5/pom
More comments in the JIRA.
### Does this PR introduce _any_ user-facing change?
Should be a build-only bug fix.
### How was this patch tested?
Existing tests, but really N/A
Closes#31801 from srowen/SPARK-34507.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### Why are the changes needed?
SPARK-34682 was merged prematurely. This PR implements feedback from the review. I wasn't sure whether I should create a new JIRA or not.
### Does this PR introduce _any_ user-facing change?
No. Just improves the test.
### How was this patch tested?
Updated test.
Closes#31798 from andygrove/SPARK-34682-follow-up.
Authored-by: Andy Grove <andygrove73@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
There is a regression in 3.1.1 compared to 3.0.2 when checking for a canonicalized plan when executing CustomShuffleReaderExec.
The regression was caused by the call to `sendDriverMetrics` which happens before the check and will always fail if the plan is canonicalized.
### Why are the changes needed?
This is a regression in a useful error check.
### Does this PR introduce _any_ user-facing change?
No. This is not an error that a user would typically see, as far as I know.
### How was this patch tested?
I tested this change locally by making a distribution from this PR branch. Before fixing the regression I saw:
```
java.util.NoSuchElementException: key not found: numPartitions
```
After fixing this regression I saw:
```
java.lang.IllegalStateException: operating on canonicalized plan
```
Closes#31793 from andygrove/SPARK-34682.
Lead-authored-by: Andy Grove <andygrove73@gmail.com>
Co-authored-by: Andy Grove <andygrove@nvidia.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
For full outer shuffled hash join with building hash map on left side, and having non-equal condition, the join can produce wrong result.
The root cause is `boundCondition` in `HashJoin.scala` always assumes the left side row is `streamedPlan` and right side row is `buildPlan` ([streamedPlan.output ++ buildPlan.output](https://github.com/apache/spark/blob/branch-3.1/sql/core/src/main/scala/org/apache/spark/sql/execution/joins/HashJoin.scala#L141)). This is valid assumption, except for full outer + build left case.
The fix is to correct `boundCondition` in `HashJoin.scala` to handle full outer + build left case properly. See reproduce in https://issues.apache.org/jira/browse/SPARK-32399?focusedCommentId=17298414&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17298414 .
### Why are the changes needed?
Fix data correctness bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Changed the test in `OuterJoinSuite.scala` to cover full outer shuffled hash join.
Before this change, the unit test `basic full outer join using ShuffledHashJoin` in `OuterJoinSuite.scala` is failed.
Closes#31792 from c21/join-bugfix.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Fixes a mistake in `TableCapabilityCheckSuite`, which runs some tests repeatedly.
### Why are the changes needed?
code cleanup
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
N/A
Closes#31788 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR adds `ADD ARCHIVE` and `LIST ARCHIVES` commands to SQL and updates relevant documents.
SPARK-33530 added `addArchive` and `listArchives` to `SparkContext` but it's not supported yet to add/list archives with SQL.
### Why are the changes needed?
To complement features.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added new test and confirmed the generated HTML from the updated documents.
Closes#31721 from sarutak/sql-archive.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposed to fix a bug introduced in #31273 (https://github.com/apache/spark/pull/31273/files#r589494855).
### Why are the changes needed?
This fixes a bug where global temp view's database name was not passed correctly.
### Does this PR introduce _any_ user-facing change?
Yes, now the global temp view's database is correctly stored.
### How was this patch tested?
Added a new test that catches the bug.
Closes#31783 from imback82/SPARK-34152-bug-fix.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Use resolved attributes instead of data-frame fields for replacing values.
### Why are the changes needed?
dataframe.na.replace() does not work for column having a dot in the name
### Does this PR introduce _any_ user-facing change?
None
### How was this patch tested?
Added unit tests for the same
Closes#31769 from amandeep-sharma/master.
Authored-by: Amandeep Sharma <happyaman91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR intends to remove unnecessary `SQLConf.withExistingConf` in `CastSuite`; since we've remove `ParVector ` in #31775, we no longer need to copy SQL configs into each thread env.
### Why are the changes needed?
Clean up the code.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Run the existing tests.
Closes#31785 from maropu/UpdateCastSuite.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}