When deserializing values of ArrayType with struct elements in java beans, fields of structs get mixed up.
I suggest using struct data types retrieved from resolved input data instead of inferring them from java beans.
## What changes were proposed in this pull request?
MapObjects expression is used to map array elements to java beans. Struct type of elements is inferred from java bean structure and ends up with mixed up field order.
I used UnresolvedMapObjects instead of MapObjects, which allows to provide element type for MapObjects during analysis based on the resolved input data, not on the java bean.
## How was this patch tested?
Added a test case.
Built complete project on travis.
michalsenkyr cloud-fan marmbrus liancheng
Closes#22708 from vofque/SPARK-21402.
Lead-authored-by: Vladimir Kuriatkov <vofque@gmail.com>
Co-authored-by: Vladimir Kuriatkov <Vladimir_Kuriatkov@epam.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The SQL execution listener framework was created from scratch(see https://github.com/apache/spark/pull/9078). It didn't leverage what we already have in the spark listener framework, and one major problem is, the listener runs on the spark execution thread, which means a bad listener can block spark's query processing.
This PR re-implements the SQL execution listener framework. Now `ExecutionListenerManager` is just a normal spark listener, which watches the `SparkListenerSQLExecutionEnd` events and post events to the
user-provided SQL execution listeners.
## How was this patch tested?
existing tests.
Closes#22674 from cloud-fan/listener.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
this PR correct some comment error:
1. change from "as low a possible" to "as low as possible" in RewriteDistinctAggregates.scala
2. delete redundant word “with” in HiveTableScanExec’s doExecute() method
## How was this patch tested?
Existing unit tests.
Closes#22694 from CarolinePeng/update_comment.
Authored-by: 彭灿00244106 <00244106@zte.intra>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
`Literal.value` should have a value a value corresponding to `dataType`. This pr added code to verify it and fixed the existing tests to do so.
## How was this patch tested?
Modified the existing tests.
Closes#22724 from maropu/SPARK-25734.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The PR adds new function `from_csv()` similar to `from_json()` to parse columns with CSV strings. I added the following methods:
```Scala
def from_csv(e: Column, schema: StructType, options: Map[String, String]): Column
```
and this signature to call it from Python, R and Java:
```Scala
def from_csv(e: Column, schema: String, options: java.util.Map[String, String]): Column
```
## How was this patch tested?
Added new test suites `CsvExpressionsSuite`, `CsvFunctionsSuite` and sql tests.
Closes#22379 from MaxGekk/from_csv.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Co-authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Set a reasonable poll timeout thats used while consuming topics/partitions from kafka. In the
absence of it, a default of 2 minute is used as the timeout values. And all the negative tests take a minimum of 2 minute to execute.
After this change, we save about 4 minutes in this suite.
## How was this patch tested?
Test fix.
Closes#22670 from dilipbiswal/SPARK-25631.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
- Exposes several metrics regarding application status as a source, useful to scrape them via jmx instead of mining the metrics rest api. Example use case: prometheus + jmx exporter.
- Metrics are gathered when a job ends at the AppStatusListener side, could be more fine-grained but most metrics like tasks completed are also counted by executors. More metrics could be exposed in the future to avoid scraping executors in some scenarios.
- a config option `spark.app.status.metrics.enabled` is added to disable/enable these metrics, by default they are disabled.
This was manually tested with jmx source enabled and prometheus server on k8s:

In the next pic the job delay is shown for repeated pi calculation (Spark action).

Closes#22381 from skonto/add_app_status_metrics.
Authored-by: Stavros Kontopoulos <stavros.kontopoulos@lightbend.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Remove Kafka 0.8 integration
## How was this patch tested?
Existing tests, build scripts
Closes#22703 from srowen/SPARK-25705.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
AFAIK multi-column count is not widely supported by the mainstream databases(postgres doesn't support), and the SQL standard doesn't define it clearly, as near as I can tell.
Since Spark supports it, we should clearly document the current behavior and add tests to verify it.
## How was this patch tested?
N/A
Closes#22728 from cloud-fan/doc.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Only test these 4 cases is enough:
be2238fb50/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetWriteSupport.scala (L269-L279)
## How was this patch tested?
Manual tests on my local machine.
before:
```
- filter pushdown - decimal (13 seconds, 683 milliseconds)
```
after:
```
- filter pushdown - decimal (9 seconds, 713 milliseconds)
```
Closes#22636 from wangyum/SPARK-25629.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
LOAD DATA INPATH didn't work if the defaultFS included a port for hdfs.
Handling this just requires a small change to use the correct URI
constructor.
## How was this patch tested?
Added a unit test, ran all tests via jenkins
Closes#22733 from squito/SPARK-25738.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This PR is a follow-up of https://github.com/apache/spark/pull/22594 . This alternative can avoid the unneeded computation in the hot code path.
- For row-based scan, we keep the original way.
- For the columnar scan, we just need to update the stats after each batch.
## How was this patch tested?
N/A
Closes#22731 from gatorsmile/udpateStatsFileScanRDD.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This is the work on setting up Secure HDFS interaction with Spark-on-K8S.
The architecture is discussed in this community-wide google [doc](https://docs.google.com/document/d/1RBnXD9jMDjGonOdKJ2bA1lN4AAV_1RwpU_ewFuCNWKg)
This initiative can be broken down into 4 Stages
**STAGE 1**
- [x] Detecting `HADOOP_CONF_DIR` environmental variable and using Config Maps to store all Hadoop config files locally, while also setting `HADOOP_CONF_DIR` locally in the driver / executors
**STAGE 2**
- [x] Grabbing `TGT` from `LTC` or using keytabs+principle and creating a `DT` that will be mounted as a secret or using a pre-populated secret
**STAGE 3**
- [x] Driver
**STAGE 4**
- [x] Executor
## How was this patch tested?
Locally tested on a single-noded, pseudo-distributed Kerberized Hadoop Cluster
- [x] E2E Integration tests https://github.com/apache/spark/pull/22608
- [ ] Unit tests
## Docs and Error Handling?
- [x] Docs
- [x] Error Handling
## Contribution Credit
kimoonkim skonto
Closes#21669 from ifilonenko/secure-hdfs.
Lead-authored-by: Ilan Filonenko <if56@cornell.edu>
Co-authored-by: Ilan Filonenko <ifilondz@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Project logical operator generates valid constraints using two opposite operations. It substracts child constraints from all constraints, than union child constraints again. I think it may be not necessary.
Aggregate operator has the same problem with Project.
This PR try to remove these two opposite collection operations.
## How was this patch tested?
Related unit tests:
ProjectEstimationSuite
CollapseProjectSuite
PushProjectThroughUnionSuite
UnsafeProjectionBenchmark
GeneratedProjectionSuite
CodeGeneratorWithInterpretedFallbackSuite
TakeOrderedAndProjectSuite
GenerateUnsafeProjectionSuite
BucketedRandomProjectionLSHSuite
RemoveRedundantAliasAndProjectSuite
AggregateBenchmark
AggregateOptimizeSuite
AggregateEstimationSuite
DecimalAggregatesSuite
DateFrameAggregateSuite
ObjectHashAggregateSuite
TwoLevelAggregateHashMapSuite
ObjectHashAggregateExecBenchmark
SingleLevelAggregateHaspMapSuite
TypedImperativeAggregateSuite
RewriteDistinctAggregatesSuite
HashAggregationQuerySuite
HashAggregationQueryWithControlledFallbackSuite
TypedImperativeAggregateSuite
TwoLevelAggregateHashMapWithVectorizedMapSuite
Closes#22706 from SongYadong/generate_constraints.
Authored-by: SongYadong <song.yadong1@zte.com.cn>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The PR addresses [the comment](https://github.com/apache/spark/pull/22715#discussion_r225024084) in the previous one. `outputOrdering` becomes a field of `InMemoryRelation`.
## How was this patch tested?
existing UTs
Closes#22726 from mgaido91/SPARK-25727_followup.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Update the next version of Spark from 2.5 to 3.0
## How was this patch tested?
N/A
Closes#22717 from gatorsmile/followupSPARK-25372.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Add `outputOrdering ` to `otherCopyArgs` in InMemoryRelation so that this field will be copied when we doing the tree transformation.
```
val data = Seq(100).toDF("count").cache()
data.queryExecution.optimizedPlan.toJSON
```
The above code can generate the following error:
```
assertion failed: InMemoryRelation fields: output, cacheBuilder, statsOfPlanToCache, outputOrdering, values: List(count#178), CachedRDDBuilder(true,10000,StorageLevel(disk, memory, deserialized, 1 replicas),*(1) Project [value#176 AS count#178]
+- LocalTableScan [value#176]
,None), Statistics(sizeInBytes=12.0 B, hints=none)
java.lang.AssertionError: assertion failed: InMemoryRelation fields: output, cacheBuilder, statsOfPlanToCache, outputOrdering, values: List(count#178), CachedRDDBuilder(true,10000,StorageLevel(disk, memory, deserialized, 1 replicas),*(1) Project [value#176 AS count#178]
+- LocalTableScan [value#176]
,None), Statistics(sizeInBytes=12.0 B, hints=none)
at scala.Predef$.assert(Predef.scala:170)
at org.apache.spark.sql.catalyst.trees.TreeNode.jsonFields(TreeNode.scala:611)
at org.apache.spark.sql.catalyst.trees.TreeNode.org$apache$spark$sql$catalyst$trees$TreeNode$$collectJsonValue$1(TreeNode.scala:599)
at org.apache.spark.sql.catalyst.trees.TreeNode.jsonValue(TreeNode.scala:604)
at org.apache.spark.sql.catalyst.trees.TreeNode.toJSON(TreeNode.scala:590)
```
## How was this patch tested?
Added a test
Closes#22715 from gatorsmile/copyArgs1.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
[SPARK-22479](https://github.com/apache/spark/pull/19708/files#diff-5c22ac5160d3c9d81225c5dd86265d27R31) adds a test case which sometimes fails because the used password string `123` matches `41230802`. This PR aims to fix the flakiness.
- https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97343/consoleFull
```scala
SaveIntoDataSourceCommandSuite:
- simpleString is redacted *** FAILED ***
"SaveIntoDataSourceCommand .org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider41230802, Map(password -> *********(redacted), url -> *********(redacted), driver -> mydriver), ErrorIfExists
+- Range (0, 1, step=1, splits=Some(2))
" contained "123" (SaveIntoDataSourceCommandSuite.scala:42)
```
## How was this patch tested?
Pass the Jenkins with the updated test case
Closes#22716 from dongjoon-hyun/SPARK-25726.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
improve the code comment added in https://github.com/apache/spark/pull/22702/files
## How was this patch tested?
N/A
Closes#22711 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Currently, if we try run
```
./start-history-server.sh -h
```
We will get such error
```
java.io.FileNotFoundException: File -h does not exist
```
1. This is not User-Friendly. For option `-h` or `--help`, it should be parsed correctly and show the usage of the class/script.
2. We can remove deprecated options for setting event log directory through command line options.
After fix, we can get following output:
```
Usage: ./sbin/start-history-server.sh [options]
Options:
--properties-file FILE Path to a custom Spark properties file.
Default is conf/spark-defaults.conf.
Configuration options can be set by setting the corresponding JVM system property.
History Server options are always available; additional options depend on the provider.
History Server options:
spark.history.ui.port Port where server will listen for connections
(default 18080)
spark.history.acls.enable Whether to enable view acls for all applications
(default false)
spark.history.provider Name of history provider class (defaults to
file system-based provider)
spark.history.retainedApplications Max number of application UIs to keep loaded in memory
(default 50)
FsHistoryProvider options:
spark.history.fs.logDirectory Directory where app logs are stored
(default: file:/tmp/spark-events)
spark.history.fs.updateInterval How often to reload log data from storage
(in seconds, default: 10)
```
## How was this patch tested?
Manual test
Closes#22699 from gengliangwang/refactorSHSUsage.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Avro schema allows recursive reference, e.g. the schema for linked-list in https://avro.apache.org/docs/1.8.2/spec.html#schema_record
```
{
"type": "record",
"name": "LongList",
"aliases": ["LinkedLongs"], // old name for this
"fields" : [
{"name": "value", "type": "long"}, // each element has a long
{"name": "next", "type": ["null", "LongList"]} // optional next element
]
}
```
In current Spark SQL, it is impossible to convert the schema as `StructType` . Run `SchemaConverters.toSqlType(avroSchema)` and we will get stack overflow exception.
We should detect the recursive reference and throw exception for it.
## How was this patch tested?
New unit test case.
Closes#22709 from gengliangwang/avroRecursiveRef.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Currently `Range` reports metrics in batch granularity. This is acceptable, but it's better if we can make it row granularity without performance penalty.
Before this PR, the metrics are updated when preparing the batch, which is before we actually consume data. In this PR, the metrics are updated after the data are consumed. There are 2 different cases:
1. The data processing loop has a stop check. The metrics are updated when we need to stop.
2. no stop check. The metrics are updated after the loop.
## How was this patch tested?
existing tests and a new benchmark
Closes#22698 from cloud-fan/range.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
```Scala
val df1 = Seq(("abc", 1), (null, 3)).toDF("col1", "col2")
df1.write.mode(SaveMode.Overwrite).parquet("/tmp/test1")
val df2 = spark.read.parquet("/tmp/test1")
df2.filter("col1 = 'abc' OR (col1 != 'abc' AND col2 == 3)").show()
```
Before the PR, it returns both rows. After the fix, it returns `Row ("abc", 1))`. This is to fix the bug in NULL handling in BooleanSimplification. This is a bug introduced in Spark 1.6 release.
## How was this patch tested?
Added test cases
Closes#22702 from gatorsmile/fixBooleanSimplify2.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR adds CLI support for YARN custom resources, e.g. GPUs and any other resources YARN defines.
The custom resources are defined with Spark properties, no additional CLI arguments were introduced.
The properties can be defined in the following form:
**AM resources, client mode:**
Format: `spark.yarn.am.resource.<resource-name>`
The property name follows the naming convention of YARN AM cores / memory properties: `spark.yarn.am.memory and spark.yarn.am.cores
`
**Driver resources, cluster mode:**
Format: `spark.yarn.driver.resource.<resource-name>`
The property name follows the naming convention of driver cores / memory properties: `spark.driver.memory and spark.driver.cores.`
**Executor resources:**
Format: `spark.yarn.executor.resource.<resource-name>`
The property name follows the naming convention of executor cores / memory properties: `spark.executor.memory / spark.executor.cores`.
For the driver resources (cluster mode) and executor resources properties, we use the `yarn` prefix here as custom resource types are specific to YARN, currently.
**Validation:**
Please note that a validation logic is added to avoid having requested resources defined in 2 ways, for example defining the following configs:
```
"--conf", "spark.driver.memory=2G",
"--conf", "spark.yarn.driver.resource.memory=1G"
```
will not start execution and will print an error message.
## How was this patch tested?
Unit tests + manual execution with Hadoop2 and Hadoop 3 builds.
Testing have been performed on a real cluster with Spark and YARN configured:
Cluster and client mode
Request Resource Types with lowercase and uppercase units
Start Spark job with only requesting standard resources (mem / cpu)
Error handling cases:
- Request unknown resource type
- Request Resource type (either memory / cpu) with duplicate configs at the same time (e.g. with this config:
```
--conf spark.yarn.am.resource.memory=1G \
--conf spark.yarn.driver.resource.memory=2G \
--conf spark.yarn.executor.resource.memory=3G \
```
), ResourceTypeValidator handles these cases well, so it is not permitted
- Request standard resource (memory / cpu) with the new style configs, e.g. --conf spark.yarn.am.resource.memory=1G, this is not permitted and handled well.
An example about how I ran the testcases:
```
cd ~;export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop/;
./spark-2.4.0-SNAPSHOT-bin-custom-spark/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1G \
--driver-cores 1 \
--executor-memory 1G \
--executor-cores 1 \
--conf spark.logConf=true \
--conf spark.yarn.executor.resource.gpu=3G \
--verbose \
./spark-2.4.0-SNAPSHOT-bin-custom-spark/examples/jars/spark-examples_2.11-2.4.0-SNAPSHOT.jar \
10;
```
Closes#20761 from szyszy/SPARK-20327.
Authored-by: Szilard Nemeth <snemeth@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Fix old oversight in API: Java `flatMapValues` needs a `FlatMapFunction`
## How was this patch tested?
Existing tests.
Closes#22690 from srowen/SPARK-19287.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Refactor `JoinBenchmark` to use main method.
1. use `spark-submit`:
```console
bin/spark-submit --class org.apache.spark.sql.execution.benchmark.JoinBenchmark --jars ./core/target/spark-core_2.11-3.0.0-SNAPSHOT-tests.jar ./sql/catalyst/target/spark-sql_2.11-3.0.0-SNAPSHOT-tests.jar
```
2. Generate benchmark result:
```console
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.JoinBenchmark"
```
## How was this patch tested?
manual tests
Closes#22661 from wangyum/SPARK-25664.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Yuming Wang <wgyumg@gmail.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
The PR addresses the exception raised on accessing chars out of delimiter string. In particular, the backward slash `\` as the CSV fields delimiter causes the following exception on reading `abc\1`:
```Scala
String index out of range: 1
java.lang.StringIndexOutOfBoundsException: String index out of range: 1
at java.lang.String.charAt(String.java:658)
```
because `str.charAt(1)` tries to access a char out of `str` in `CSVUtils.toChar`
## How was this patch tested?
Added tests for empty string and string containing the backward slash to `CSVUtilsSuite`. Besides of that I added an end-to-end test to check how the backward slash is handled in reading CSV string with it.
Closes#22654 from MaxGekk/csv-slash-delim.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
When we enable event log compression and compression codec as 'zstd', we are unable to open the webui of the running application from the history server page.
The reason is that, Replay listener was unable to read from the zstd compressed eventlog due to the zstd frame was not finished yet. This causes truncated error while reading the eventLog.
So, when we try to open the WebUI from the History server page, it throws "truncated error ", and we never able to open running application in the webui, when we enable zstd compression.
In this PR, when the IO excpetion happens, and if it is a running application, we log the error,
"Failed to read Spark event log: evetLogDirAppName.inprogress", instead of throwing exception.
## How was this patch tested?
Test steps:
1)spark.eventLog.compress = true
2)spark.io.compression.codec = zstd
3)restart history server
4) launch bin/spark-shell
5) run some queries
6) Open history server page
7) click on the application
**Before fix:**


**After fix:**


(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22689 from shahidki31/SPARK-25697.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently if we run
```
./sbin/start-master.sh -h
```
We get
```
Usage: ./sbin/start-master.sh [options]
18/10/11 23:38:30 INFO Master: Started daemon with process name: 33907C02TL2JZGTF1
18/10/11 23:38:30 INFO SignalUtils: Registered signal handler for TERM
18/10/11 23:38:30 INFO SignalUtils: Registered signal handler for HUP
18/10/11 23:38:30 INFO SignalUtils: Registered signal handler for INT
Options:
-i HOST, --ip HOST Hostname to listen on (deprecated, please use --host or -h)
-h HOST, --host HOST Hostname to listen on
-p PORT, --port PORT Port to listen on (default: 7077)
--webui-port PORT Port for web UI (default: 8080)
--properties-file FILE Path to a custom Spark properties file.
Default is conf/spark-defaults.conf.
```
We can filter out some useless output.
## How was this patch tested?
Manual test
Closes#22700 from gengliangwang/improveStartScript.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Many companies have their own enterprise GitHub to manage Spark code. To build and test in those repositories with Jenkins need to modify this script.
So I suggest to add some environment variables to allow regression testing in enterprise Jenkins instead of default Spark repository in GitHub.
## How was this patch tested?
Manually test.
Closes#22678 from LantaoJin/SPARK-25685.
Lead-authored-by: lajin <lajin@ebay.com>
Co-authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
After the changes, total execution time of `JsonExpressionsSuite.scala` dropped from 12.5 seconds to 3 seconds.
Closes#22657 from MaxGekk/json-timezone-test.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently SQL tab in the WEBUI doesn't support pagination. Because of that following issues are happening.
1) For large number of executions, SQL page is throwing OOM exception (around 40,000)
2) For large number of executions, loading SQL page is taking time.
3) Difficult to analyse the execution table for large number of execution.
[Note: spark.sql.ui.retainedExecutions = 50000]
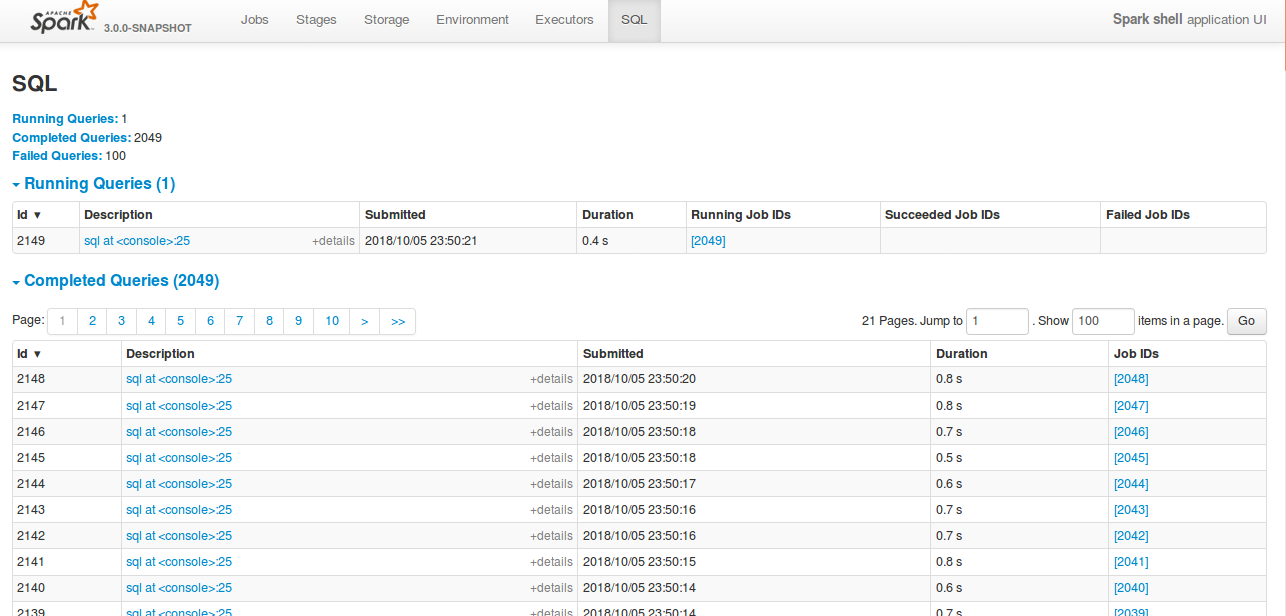
All the tabs, Jobs, Stages etc. supports pagination. So, to make it consistent with other tabs
SQL tab also should support pagination.
I have followed the similar flow of the pagination code in the Jobs and Stages page for SQL page.
Also, this patch doesn't make any behavior change for the SQL tab except the pagination support.
## How was this patch tested?
bin/spark-shell --conf spark.sql.ui.retainedExecutions=50000
Run 50,000 sql queries.
**Before this PR**
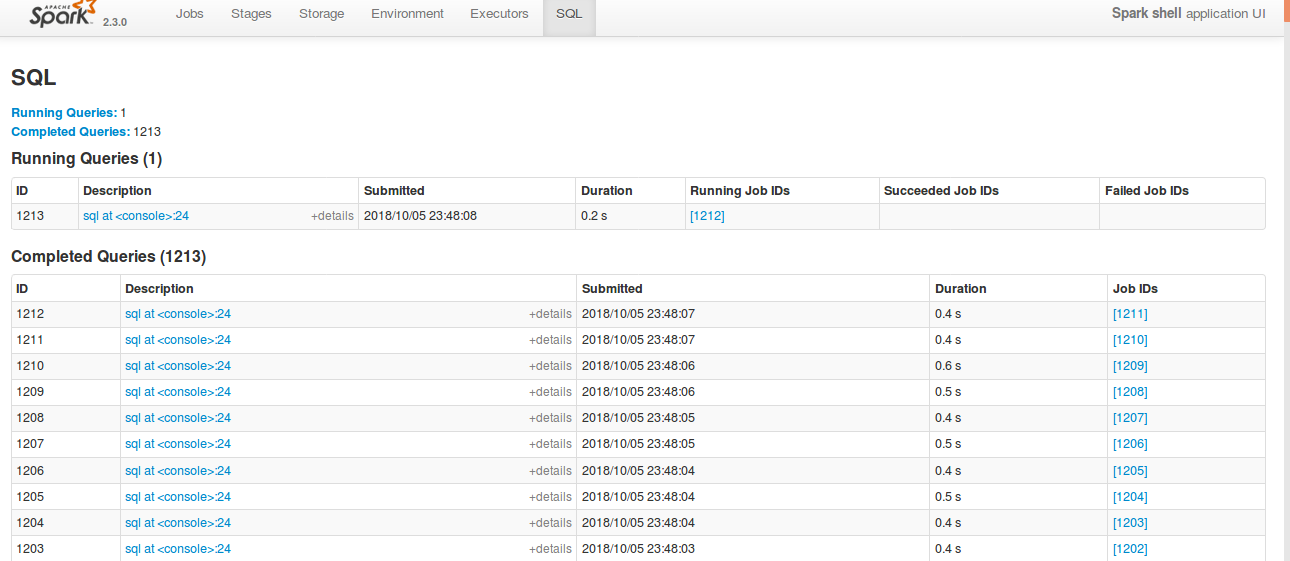
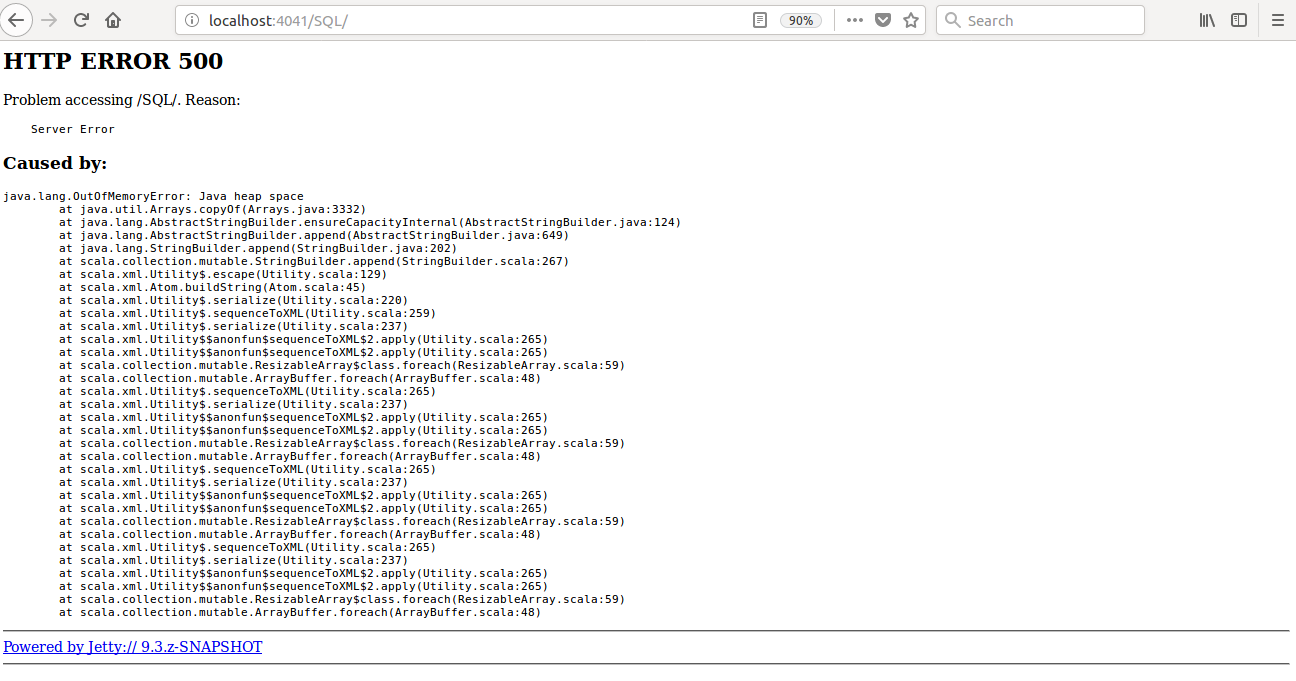
**After this PR**
Loading of the page is faster, and OOM issue doesn't happen.
Closes#22645 from shahidki31/SPARK-25566.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
According to the SQL standard, when a query contains `HAVING`, it indicates an aggregate operator. For more details please refer to https://blog.jooq.org/2014/12/04/do-you-really-understand-sqls-group-by-and-having-clauses/
However, in Spark SQL parser, we treat HAVING as a normal filter when there is no GROUP BY, which breaks SQL semantic and lead to wrong result. This PR fixes the parser.
## How was this patch tested?
new test
Closes#22696 from cloud-fan/having.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The HandleNullInputsForUDF rule can generate new If node infinitely, thus causing problems like match of SQL cache missed.
This was fixed in SPARK-24891 and was then broken by SPARK-25044.
The unit test in `AnalysisSuite` added in SPARK-24891 should have failed but didn't because it wasn't properly updated after the `ScalaUDF` constructor signature change. So this PR also updates the test accordingly based on the new `ScalaUDF` constructor.
## How was this patch tested?
Updated the original UT. This should be justified as the original UT became invalid after SPARK-25044.
Closes#22701 from maryannxue/spark-25690.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR can correctly cause assertion failure when incorrect nullable of DataType in the result is generated by a target function to be tested.
Let us think the following example. In the future, a developer would write incorrect code that returns unexpected result. We have to correctly cause fail in this test since `valueContainsNull=false` while `expr` includes `null`. However, without this PR, this test passes. This PR can correctly cause fail.
```
test("test TARGETFUNCTON") {
val expr = TARGETMAPFUNCTON()
// expr = UnsafeMap(3 -> 6, 7 -> null)
// expr.dataType = (IntegerType, IntegerType, false)
expected = Map(3 -> 6, 7 -> null)
checkEvaluation(expr, expected)
```
In [`checkEvaluationWithUnsafeProjection`](https://github.com/apache/spark/blob/master/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ExpressionEvalHelper.scala#L208-L235), the results are compared using `UnsafeRow`. When the given `expected` is [converted](https://github.com/apache/spark/blob/master/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ExpressionEvalHelper.scala#L226-L227)) to `UnsafeRow` using the `DataType` of `expr`.
```
val expectedRow = UnsafeProjection.create(Array(expression.dataType, expression.dataType)).apply(lit)
```
In summary, `expr` is `[0,1800000038,5000000038,18,2,0,700000003,2,0,6,18,2,0,700000003,2,0,6]` with and w/o this PR. `expected` is converted to
* w/o this PR, `[0,1800000038,5000000038,18,2,0,700000003,2,0,6,18,2,0,700000003,2,0,6]`
* with this PR, `[0,1800000038,5000000038,18,2,0,700000003,2,2,6,18,2,0,700000003,2,2,6]`
As a result, w/o this PR, the test unexpectedly passes.
This is because, w/o this PR, based on given `dataType`, generated code of projection for `expected` avoids to set nullbit.
```
// tmpInput_2 is expected
/* 155 */ for (int index_1 = 0; index_1 < numElements_1; index_1++) {
/* 156 */ mutableStateArray_1[1].write(index_1, tmpInput_2.getInt(index_1));
/* 157 */ }
```
With this PR, generated code of projection for `expected` always checks whether nullbit should be set by `isNullAt`
```
// tmpInput_2 is expected
/* 161 */ for (int index_1 = 0; index_1 < numElements_1; index_1++) {
/* 162 */
/* 163 */ if (tmpInput_2.isNullAt(index_1)) {
/* 164 */ mutableStateArray_1[1].setNull4Bytes(index_1);
/* 165 */ } else {
/* 166 */ mutableStateArray_1[1].write(index_1, tmpInput_2.getInt(index_1));
/* 167 */ }
/* 168 */
/* 169 */ }
```
## How was this patch tested?
Existing UTs
Closes#22375 from kiszk/SPARK-25388.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
1. Move `CSVDataSource.makeSafeHeader` to `CSVUtils.makeSafeHeader` (as is).
- Historically and at the first place of refactoring (which I did), I intended to put all CSV specific handling (like options), filtering, extracting header, etc.
- See `JsonDataSource`. Now `CSVDataSource` is quite consistent with `JsonDataSource`. Since CSV's code path is quite complicated, we might better match them as possible as we can.
2. Create `CSVHeaderChecker` and put `enforceSchema` logics into that.
- The checking header and column pruning stuff were added (per https://github.com/apache/spark/pull/20894 and https://github.com/apache/spark/pull/21296) but some of codes such as https://github.com/apache/spark/pull/22123 are duplicated
- Also, checking header code is basically here and there. We better put them in a single place, which was quite error-prone. See (https://github.com/apache/spark/pull/22656).
3. Move `CSVDataSource.checkHeaderColumnNames` to `CSVHeaderChecker.checkHeaderColumnNames` (as is).
- Similar reasons above with 1.
## How was this patch tested?
Existing tests should cover this.
Closes#22676 from HyukjinKwon/refactoring-csv.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Removes all vestiges of Flume in the build, for Spark 3.
I don't think this needs Jenkins config changes.
## How was this patch tested?
Existing tests.
Closes#22692 from srowen/SPARK-25598.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
If the records are incremented by more than 1 at a time,the number of bytes might rarely ever get updated,because it might skip over the count that is an exact multiple of UPDATE_INPUT_METRICS_INTERVAL_RECORDS.
This PR just checks whether the increment causes the value to exceed a higher multiple of UPDATE_INPUT_METRICS_INTERVAL_RECORDS.
## How was this patch tested?
existed unit tests
Closes#22594 from 10110346/inputMetrics.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Specify `kafka.max.block.ms` to 10 seconds while creating the kafka writer. In the absence of this overridden config, by default it uses a default time out of 60 seconds.
With this change the test completes in close to 10 seconds as opposed to 1 minute.
## How was this patch tested?
This is a test fix.
Closes#22671 from dilipbiswal/SPARK-25615.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove SnappyOutputStreamWrapper and other workaround now that new Snappy fixes these.
See also https://github.com/apache/spark/pull/21176 and comments it links to.
## How was this patch tested?
Existing tests
Closes#22691 from srowen/SPARK-24109.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
remove Redundant semicolons in SortMergeJoinExec, thanks.
## How was this patch tested?
N/A
Closes#22695 from heary-cao/RedundantSemicolons.
Authored-by: caoxuewen <cao.xuewen@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
1. Refactor DataSourceReadBenchmark
## How was this patch tested?
Manually tested and regenerated results.
```
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.DataSourceReadBenchmark"
```
Closes#22664 from peter-toth/SPARK-25662.
Lead-authored-by: Peter Toth <peter.toth@gmail.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
Remove Hadoop 2.6 references and make 2.7 the default.
Obviously, this is for master/3.0.0 only.
After this we can also get rid of the separate test jobs for Hadoop 2.6.
## How was this patch tested?
Existing tests
Closes#22615 from srowen/SPARK-25016.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Inspired by https://github.com/apache/spark/pull/22574 .
We can partially push down top level conjunctive predicates to Orc.
This PR improves Orc predicate push down in both SQL and Hive module.
## How was this patch tested?
New unit test.
Closes#22684 from gengliangwang/pushOrcFilters.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}