### What changes were proposed in this pull request?
Current checkstyle checking folder can't cover all folder.
Since for support multi version hive, we have some divided hive folder.
We should check it too.
### Why are the changes needed?
Fix build bug
### Does this PR introduce any user-facing change?
NO
### How was this patch tested?
NO
Closes#26385 from AngersZhuuuu/SPARK-29742.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Support FETCH_PRIOR fetching in Thriftserver, and report correct fetch start offset it TFetchResultsResp.results.startRowOffset
The semantics of FETCH_PRIOR are as follow: Assuming the previous fetch returned a block of rows from offsets [10, 20)
* calling FETCH_PRIOR(maxRows=5) will scroll back and return rows [5, 10)
* calling FETCH_PRIOR(maxRows=10) again, will scroll back, but can't go earlier than 0. It will nevertheless return 10 rows, returning rows [0, 10) (overlapping with the previous fetch)
* calling FETCH_PRIOR(maxRows=4) again will again return rows starting from offset 0 - [0, 4)
* calling FETCH_NEXT(maxRows=6) after that will move the cursor forward and return rows [4, 10)
##### Client/server backwards/forwards compatibility:
Old driver with new server:
* Drivers that don't support FETCH_PRIOR will not attempt to use it
* Field TFetchResultsResp.results.startRowOffset was not set, old drivers don't depend on it.
New driver with old server
* Using an older thriftserver with FETCH_PRIOR will make the thriftserver return unsupported operation error. The driver can then recognize that it's an old server.
* Older thriftserver will return TFetchResultsResp.results.startRowOffset=0. If the client driver receives 0, it can know that it can not rely on it as correct offset. If the client driver intentionally wants to fetch from 0, it can use FETCH_FIRST.
### Why are the changes needed?
It's intended to be used to recover after connection errors. If a client lost connection during fetching (e.g. of rows [10, 20)), and wants to reconnect and continue, it could not know whether the request got lost before reaching the server, or on the response back. When it issued another FETCH_NEXT(10) request after reconnecting, because TFetchResultsResp.results.startRowOffset was not set, it could not know if the server will return rows [10,20) (because the previous request didn't reach it) or rows [20, 30) (because it returned data from the previous request but the connection got broken on the way back). Now, with TFetchResultsResp.results.startRowOffset the client can know after reconnecting which rows it is getting, and use FETCH_PRIOR to scroll back if a fetch block was lost in transmission.
Driver should always use FETCH_PRIOR after a broken connection.
* If the Thriftserver returns unsuported operation error, the driver knows that it's an old server that doesn't support it. The driver then must error the query, as it will also not support returning the correct startRowOffset, so the driver cannot reliably guarantee if it hadn't lost any rows on the fetch cursor.
* If the driver gets a response to FETCH_PRIOR, it should also have a correctly set startRowOffset, which the driver can use to position itself back where it left off before the connection broke.
* If FETCH_NEXT was used after a broken connection on the first fetch, and returned with an startRowOffset=0, then the client driver can't know if it's 0 because it's the older server version, or if it's genuinely 0. Better to call FETCH_PRIOR, as scrolling back may anyway be possibly required after a broken connection.
This way it is implemented in a backwards/forwards compatible way, and doesn't require bumping the protocol version. FETCH_ABSOLUTE might have been better, but that would require a bigger protocol change, as there is currently no field to specify the requested absolute offset.
### Does this PR introduce any user-facing change?
ODBC/JDBC drivers connecting to Thriftserver may now implement using the FETCH_PRIOR fetch order to scroll back in query results, and check TFetchResultsResp.results.startRowOffset if their cursor position is consistent after connection errors.
### How was this patch tested?
Added tests to HiveThriftServer2Suites
Closes#26014 from juliuszsompolski/SPARK-29349.
Authored-by: Juliusz Sompolski <julek@databricks.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
Current Spark Thrift Server return TypeInfo includes
1. INTERVAL_YEAR_MONTH
2. INTERVAL_DAY_TIME
3. UNION
4. USER_DEFINED
Spark doesn't support INTERVAL_YEAR_MONTH, INTERVAL_YEAR_MONTH, UNION
and won't return USER)DEFINED type.
This PR overwrite GetTypeInfoOperation with SparkGetTypeInfoOperation to exclude types which we don't need.
In hive-1.2.1 Type class is `org.apache.hive.service.cli.Type`
In hive-2.3.x Type class is `org.apache.hadoop.hive.serde2.thrift.Type`
Use ThrifrserverShimUtils to fit version problem and exclude types we don't need
### Why are the changes needed?
We should return type info of Spark's own type info
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manuel test & Added UT
Closes#25694 from AngersZhuuuu/SPARK-28982.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
This PR implements `SparkGetCatalogsOperation` for Thrift Server metadata completeness.
### Why are the changes needed?
Thrift Server metadata completeness.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Unit test
Closes#25555 from wangyum/SPARK-28852.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
While processing the Rowdata in the server side ColumnValue BigDecimal type value processed by server has to converted to the HiveDecmal data type for successful processing of query using Hive ODBC client.As per current logic corresponding to the Decimal column datatype, the Spark server uses BigDecimal, and the ODBC client uses HiveDecimal. If the data type does not match, the client fail to parse
Since this handing was missing the query executed in Hive ODBC client wont return or provides result to the user even though the decimal type column value data present.
## How was this patch tested?
Manual test report and impact assessment is done using existing test-cases
Before fix

After Fix

Closes#23899 from sujith71955/master_decimalissue.
Authored-by: s71955 <sujithchacko.2010@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR fix Hive 0.12 JDBC client can not handle binary type:
```sql
Connected to: Hive (version 3.0.0-SNAPSHOT)
Driver: Hive (version 0.12.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 0.12.0 by Apache Hive
0: jdbc:hive2://localhost:10000> SELECT cast('ABC' as binary);
Error: java.lang.ClassCastException: [B incompatible with java.lang.String (state=,code=0)
```
Server log:
```
19/08/07 10:10:04 WARN ThriftCLIService: Error fetching results:
java.lang.RuntimeException: java.lang.ClassCastException: [B incompatible with java.lang.String
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:83)
at org.apache.hive.service.cli.session.HiveSessionProxy.access$000(HiveSessionProxy.java:36)
at org.apache.hive.service.cli.session.HiveSessionProxy$1.run(HiveSessionProxy.java:63)
at java.security.AccessController.doPrivileged(AccessController.java:770)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1746)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:59)
at com.sun.proxy.$Proxy26.fetchResults(Unknown Source)
at org.apache.hive.service.cli.CLIService.fetchResults(CLIService.java:455)
at org.apache.hive.service.cli.thrift.ThriftCLIService.FetchResults(ThriftCLIService.java:621)
at org.apache.hive.service.cli.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1553)
at org.apache.hive.service.cli.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1538)
at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:38)
at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)
at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:53)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:310)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:819)
Caused by: java.lang.ClassCastException: [B incompatible with java.lang.String
at org.apache.hive.service.cli.ColumnValue.toTColumnValue(ColumnValue.java:198)
at org.apache.hive.service.cli.RowBasedSet.addRow(RowBasedSet.java:60)
at org.apache.hive.service.cli.RowBasedSet.addRow(RowBasedSet.java:32)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.$anonfun$getNextRowSet$1(SparkExecuteStatementOperation.scala:151)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$Lambda$1923.000000009113BFE0.apply(Unknown Source)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.withSchedulerPool(SparkExecuteStatementOperation.scala:299)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.getNextRowSet(SparkExecuteStatementOperation.scala:113)
at org.apache.hive.service.cli.operation.OperationManager.getOperationNextRowSet(OperationManager.java:220)
at org.apache.hive.service.cli.session.HiveSessionImpl.fetchResults(HiveSessionImpl.java:785)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:78)
... 18 more
```
## How was this patch tested?
unit tests
Closes#25379 from wangyum/SPARK-28474.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This patch tries to keep consistency whenever UTF-8 charset is needed, as using `StandardCharsets.UTF_8` instead of using "UTF-8". If the String type is needed, `StandardCharsets.UTF_8.name()` is used.
This change also brings the benefit of getting rid of `UnsupportedEncodingException`, as we're providing `Charset` instead of `String` whenever possible.
This also changes some private Catalyst helper methods to operate on encodings as `Charset` objects rather than strings.
## How was this patch tested?
Existing unit tests.
Closes#25335 from HeartSaVioR/SPARK-28601.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR implements Spark's own GetFunctionsOperation which mitigates the differences between Spark SQL and Hive UDFs. But our implementation is different from Hive's implementation:
- Our implementation always returns results. Hive only returns results when [(null == catalogName || "".equals(catalogName)) && (null == schemaName || "".equals(schemaName))](https://github.com/apache/hive/blob/rel/release-3.1.1/service/src/java/org/apache/hive/service/cli/operation/GetFunctionsOperation.java#L101-L119).
- Our implementation pads the `REMARKS` field with the function usage - Hive returns an empty string.
- Our implementation does not support `FUNCTION_TYPE`, but Hive does.
## How was this patch tested?
unit tests
Closes#25252 from wangyum/SPARK-28510.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
How to reproduce this issue:
```shell
build/sbt clean package -Phive -Phive-thriftserver -Phadoop-3.2
export SPARK_PREPEND_CLASSES=true
sbin/start-thriftserver.sh
[rootspark-3267648 spark]# bin/beeline -u jdbc:hive2://localhost:10000/default -e "select cast(1 as decimal(38, 18));"
Connecting to jdbc:hive2://localhost:10000/default
Connected to: Spark SQL (version 3.0.0-SNAPSHOT)
Driver: Hive JDBC (version 2.3.5)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Error: java.lang.ClassCastException: java.math.BigDecimal incompatible with org.apache.hadoop.hive.common.type.HiveDecimal (state=,code=0)
Closing: 0: jdbc:hive2://localhost:10000/default
```
This pr fix this issue.
## How was this patch tested?
unit tests
Closes#25217 from wangyum/SPARK-28463.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
For Thrift server, It's downward compatible. Such as if a PROTOCOL_VERSION_V7 client connect to a PROTOCOL_VERSION_V8 server, when OpenSession, server will change his response's protocol version to min of (client and server).
`TProtocolVersion protocol = getMinVersion(CLIService.SERVER_VERSION,`
` req.getClient_protocol());`
then set it to OpenSession's response.
But if OpenSession failed , it won't execute behavior of reset response's protocol_version.
Then it will return server's origin protocol version.
Finally client will get en error as below:
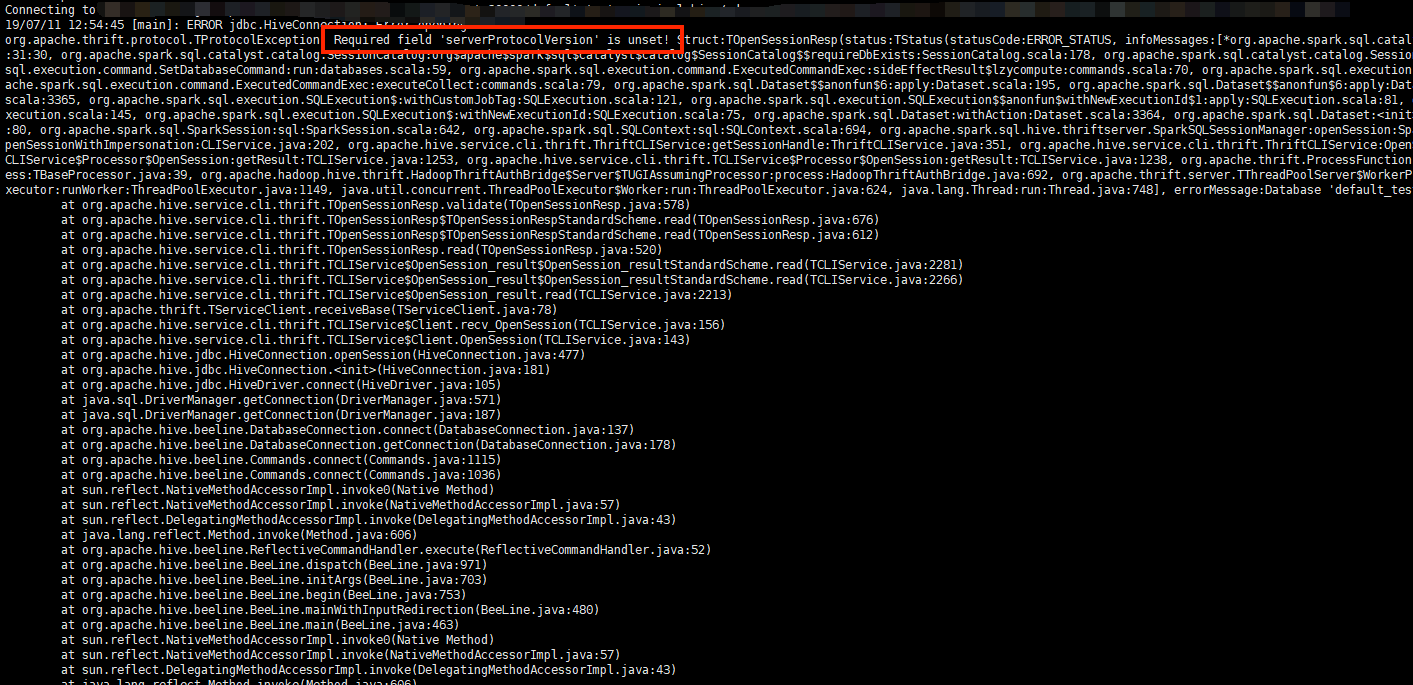
Since we write a wrong database,, OpenSession failed, right protocol version haven't been rest.
## How was this patch tested?
Since I really don't know how to write unit test about this, so I build a jar with this PR,and retry the error above, then it will return a reasonable Error of DB not found :

Closes#25083 from AngersZhuuuu/SPARK-28311.
Authored-by: 朱夷 <zhuyi01@corp.netease.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
`SslContextFactory` is deprecated at Jetty 9.4 and we are using `9.4.18.v20190429`. This PR aims to replace it with `SslContextFactory.Server`.
- https://www.eclipse.org/jetty/javadoc/9.4.19.v20190610/org/eclipse/jetty/util/ssl/SslContextFactory.html
- https://www.eclipse.org/jetty/javadoc/9.3.24.v20180605/org/eclipse/jetty/util/ssl/SslContextFactory.html
```
[WARNING] /Users/dhyun/APACHE/spark/core/src/main/scala/org/apache/spark/SSLOptions.scala:71:
constructor SslContextFactory in class SslContextFactory is deprecated:
see corresponding Javadoc for more information.
[WARNING] val sslContextFactory = new SslContextFactory()
[WARNING] ^
```
## How was this patch tested?
Pass the Jenkins with the existing tests.
Closes#25067 from dongjoon-hyun/SPARK-28290.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr moves `sql/hive-thriftserver/v2.3.4` to `sql/hive-thriftserver/v2.3.5` based on ([comment](https://github.com/apache/spark/pull/24628#issuecomment-496459258)).
## How was this patch tested?
N/A
Closes#24728 from wangyum/SPARK-27737-thriftserver.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}