### What changes were proposed in this pull request?
Current Spark Thrift Server return TypeInfo includes
1. INTERVAL_YEAR_MONTH
2. INTERVAL_DAY_TIME
3. UNION
4. USER_DEFINED
Spark doesn't support INTERVAL_YEAR_MONTH, INTERVAL_YEAR_MONTH, UNION
and won't return USER)DEFINED type.
This PR overwrite GetTypeInfoOperation with SparkGetTypeInfoOperation to exclude types which we don't need.
In hive-1.2.1 Type class is `org.apache.hive.service.cli.Type`
In hive-2.3.x Type class is `org.apache.hadoop.hive.serde2.thrift.Type`
Use ThrifrserverShimUtils to fit version problem and exclude types we don't need
### Why are the changes needed?
We should return type info of Spark's own type info
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manuel test & Added UT
Closes#25694 from AngersZhuuuu/SPARK-28982.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
### What changes were proposed in this pull request?
The intent to use the --hiveconf/--hivevar parameter is just an initialization value, so setting it once in ```SparkSQLSessionManager#openSession``` is sufficient, and each time the ```SparkExecuteStatementOperation``` setting causes the variable to not be modified.
### Why are the changes needed?
It is wrong to set the --hivevar/--hiveconf variable in every ```SparkExecuteStatementOperation```, which prevents variable updates.
### Does this PR introduce any user-facing change?
```
cat <<EOF > test.sql
select '\${a}', '\${b}';
set b=bvalue_MOD_VALUE;
set b;
EOF
beeline -u jdbc:hive2://localhost:10000 --hiveconf a=avalue --hivevar b=bvalue -f test.sql
```
current result:
```
+-----------------+-----------------+--+
| avalue | bvalue |
+-----------------+-----------------+--+
| avalue | bvalue |
+-----------------+-----------------+--+
+-----------------+-----------------+--+
| key | value |
+-----------------+-----------------+--+
| b | bvalue |
+-----------------+-----------------+--+
1 row selected (0.022 seconds)
```
after modification:
```
+-----------------+-----------------+--+
| avalue | bvalue |
+-----------------+-----------------+--+
| avalue | bvalue |
+-----------------+-----------------+--+
+-----------------+-----------------+--+
| key | value |
+-----------------+-----------------+--+
| b | bvalue_MOD_VALUE|
+-----------------+-----------------+--+
1 row selected (0.022 seconds)
```
### How was this patch tested?
modified the existing unit test
Closes#25722 from cxzl25/fix_SPARK-26598.
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Yuming Wang <wgyumg@gmail.com>
## What changes were proposed in this pull request?
`bin/spark-shell` support query interval value:
```scala
scala> spark.sql("SELECT interval 3 months 1 hours AS i").show(false)
+-------------------------+
|i |
+-------------------------+
|interval 3 months 1 hours|
+-------------------------+
```
But `sbin/start-thriftserver.sh` can't support query interval value:
```sql
0: jdbc:hive2://localhost:10000/default> SELECT interval 3 months 1 hours AS i;
Error: java.lang.IllegalArgumentException: Unrecognized type name: interval (state=,code=0)
```
This PR maps `CalendarIntervalType` to `StringType` for `TableSchema` to make Thriftserver support query interval value because we do not support `INTERVAL_YEAR_MONTH` type and `INTERVAL_DAY_TIME`:
02c33694c8/sql/hive-thriftserver/v1.2.1/src/main/java/org/apache/hive/service/cli/Type.java (L73-L78)
[SPARK-27791](https://issues.apache.org/jira/browse/SPARK-27791): Support SQL year-month INTERVAL type
[SPARK-27793](https://issues.apache.org/jira/browse/SPARK-27793): Support SQL day-time INTERVAL type
## How was this patch tested?
unit tests
Closes#25277 from wangyum/Thriftserver-support-interval-type.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
### What changes were proposed in this pull request?
This PR ignores Thrift server `ThriftServerQueryTestSuite`.
### Why are the changes needed?
This ThriftServerQueryTestSuite test case led to frequent Jenkins build failure.
### Does this PR introduce any user-facing change?
Yes.
### How was this patch tested?
N/A
Closes#25592 from wangyum/SPARK-28527-f1.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR implements `SparkGetCatalogsOperation` for Thrift Server metadata completeness.
### Why are the changes needed?
Thrift Server metadata completeness.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Unit test
Closes#25555 from wangyum/SPARK-28852.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
While processing the Rowdata in the server side ColumnValue BigDecimal type value processed by server has to converted to the HiveDecmal data type for successful processing of query using Hive ODBC client.As per current logic corresponding to the Decimal column datatype, the Spark server uses BigDecimal, and the ODBC client uses HiveDecimal. If the data type does not match, the client fail to parse
Since this handing was missing the query executed in Hive ODBC client wont return or provides result to the user even though the decimal type column value data present.
## How was this patch tested?
Manual test report and impact assessment is done using existing test-cases
Before fix

After Fix

Closes#23899 from sujith71955/master_decimalissue.
Authored-by: s71955 <sujithchacko.2010@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR port [HIVE-10646](https://issues.apache.org/jira/browse/HIVE-10646) to fix Hive 0.12's JDBC client can not handle `NULL_TYPE`:
```sql
Connected to: Hive (version 3.0.0-SNAPSHOT)
Driver: Hive (version 0.12.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 0.12.0 by Apache Hive
0: jdbc:hive2://localhost:10000> select null;
org.apache.thrift.transport.TTransportException
at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:132)
at org.apache.thrift.transport.TTransport.readAll(TTransport.java:84)
at org.apache.thrift.transport.TSaslTransport.readLength(TSaslTransport.java:346)
at org.apache.thrift.transport.TSaslTransport.readFrame(TSaslTransport.java:423)
at org.apache.thrift.transport.TSaslTransport.read(TSaslTransport.java:405)
```
Server log:
```
19/08/07 09:34:07 ERROR TThreadPoolServer: Error occurred during processing of message.
java.lang.NullPointerException
at org.apache.hive.service.cli.thrift.TRow$TRowStandardScheme.write(TRow.java:388)
at org.apache.hive.service.cli.thrift.TRow$TRowStandardScheme.write(TRow.java:338)
at org.apache.hive.service.cli.thrift.TRow.write(TRow.java:288)
at org.apache.hive.service.cli.thrift.TRowSet$TRowSetStandardScheme.write(TRowSet.java:605)
at org.apache.hive.service.cli.thrift.TRowSet$TRowSetStandardScheme.write(TRowSet.java:525)
at org.apache.hive.service.cli.thrift.TRowSet.write(TRowSet.java:455)
at org.apache.hive.service.cli.thrift.TFetchResultsResp$TFetchResultsRespStandardScheme.write(TFetchResultsResp.java:550)
at org.apache.hive.service.cli.thrift.TFetchResultsResp$TFetchResultsRespStandardScheme.write(TFetchResultsResp.java:486)
at org.apache.hive.service.cli.thrift.TFetchResultsResp.write(TFetchResultsResp.java:412)
at org.apache.hive.service.cli.thrift.TCLIService$FetchResults_result$FetchResults_resultStandardScheme.write(TCLIService.java:13192)
at org.apache.hive.service.cli.thrift.TCLIService$FetchResults_result$FetchResults_resultStandardScheme.write(TCLIService.java:13156)
at org.apache.hive.service.cli.thrift.TCLIService$FetchResults_result.write(TCLIService.java:13107)
at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:58)
at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)
at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:53)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:310)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:819)
```
## How was this patch tested?
unit tests
Closes#25378 from wangyum/SPARK-28644.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR fix Hive 0.12 JDBC client can not handle binary type:
```sql
Connected to: Hive (version 3.0.0-SNAPSHOT)
Driver: Hive (version 0.12.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 0.12.0 by Apache Hive
0: jdbc:hive2://localhost:10000> SELECT cast('ABC' as binary);
Error: java.lang.ClassCastException: [B incompatible with java.lang.String (state=,code=0)
```
Server log:
```
19/08/07 10:10:04 WARN ThriftCLIService: Error fetching results:
java.lang.RuntimeException: java.lang.ClassCastException: [B incompatible with java.lang.String
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:83)
at org.apache.hive.service.cli.session.HiveSessionProxy.access$000(HiveSessionProxy.java:36)
at org.apache.hive.service.cli.session.HiveSessionProxy$1.run(HiveSessionProxy.java:63)
at java.security.AccessController.doPrivileged(AccessController.java:770)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1746)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:59)
at com.sun.proxy.$Proxy26.fetchResults(Unknown Source)
at org.apache.hive.service.cli.CLIService.fetchResults(CLIService.java:455)
at org.apache.hive.service.cli.thrift.ThriftCLIService.FetchResults(ThriftCLIService.java:621)
at org.apache.hive.service.cli.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1553)
at org.apache.hive.service.cli.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1538)
at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:38)
at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)
at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:53)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:310)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:819)
Caused by: java.lang.ClassCastException: [B incompatible with java.lang.String
at org.apache.hive.service.cli.ColumnValue.toTColumnValue(ColumnValue.java:198)
at org.apache.hive.service.cli.RowBasedSet.addRow(RowBasedSet.java:60)
at org.apache.hive.service.cli.RowBasedSet.addRow(RowBasedSet.java:32)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.$anonfun$getNextRowSet$1(SparkExecuteStatementOperation.scala:151)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$Lambda$1923.000000009113BFE0.apply(Unknown Source)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.withSchedulerPool(SparkExecuteStatementOperation.scala:299)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.getNextRowSet(SparkExecuteStatementOperation.scala:113)
at org.apache.hive.service.cli.operation.OperationManager.getOperationNextRowSet(OperationManager.java:220)
at org.apache.hive.service.cli.session.HiveSessionImpl.fetchResults(HiveSessionImpl.java:785)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:78)
... 18 more
```
## How was this patch tested?
unit tests
Closes#25379 from wangyum/SPARK-28474.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR implements Spark's own GetFunctionsOperation which mitigates the differences between Spark SQL and Hive UDFs. But our implementation is different from Hive's implementation:
- Our implementation always returns results. Hive only returns results when [(null == catalogName || "".equals(catalogName)) && (null == schemaName || "".equals(schemaName))](https://github.com/apache/hive/blob/rel/release-3.1.1/service/src/java/org/apache/hive/service/cli/operation/GetFunctionsOperation.java#L101-L119).
- Our implementation pads the `REMARKS` field with the function usage - Hive returns an empty string.
- Our implementation does not support `FUNCTION_TYPE`, but Hive does.
## How was this patch tested?
unit tests
Closes#25252 from wangyum/SPARK-28510.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
How to reproduce this issue:
```shell
build/sbt clean package -Phive -Phive-thriftserver -Phadoop-3.2
export SPARK_PREPEND_CLASSES=true
sbin/start-thriftserver.sh
[rootspark-3267648 spark]# bin/beeline -u jdbc:hive2://localhost:10000/default -e "select cast(1 as decimal(38, 18));"
Connecting to jdbc:hive2://localhost:10000/default
Connected to: Spark SQL (version 3.0.0-SNAPSHOT)
Driver: Hive JDBC (version 2.3.5)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Error: java.lang.ClassCastException: java.math.BigDecimal incompatible with org.apache.hadoop.hive.common.type.HiveDecimal (state=,code=0)
Closing: 0: jdbc:hive2://localhost:10000/default
```
This pr fix this issue.
## How was this patch tested?
unit tests
Closes#25217 from wangyum/SPARK-28463.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
There are some hardcoded configs, using config entry to replace them.
## How was this patch tested?
Existing UT
Closes#25059 from WangGuangxin/ConfigEntry.
Authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
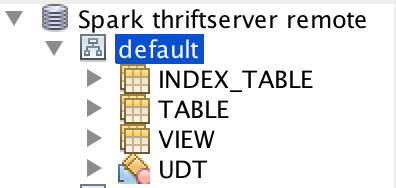
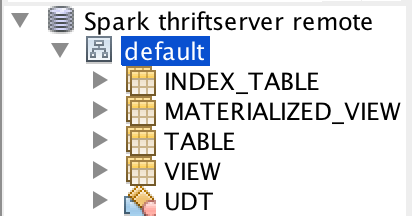
This pr add support show global temporary view and local temporary view in database tool.
TODO: Database tools should support show temporary views because it's schema is null.
## How was this patch tested?
unit tests and manual tests:
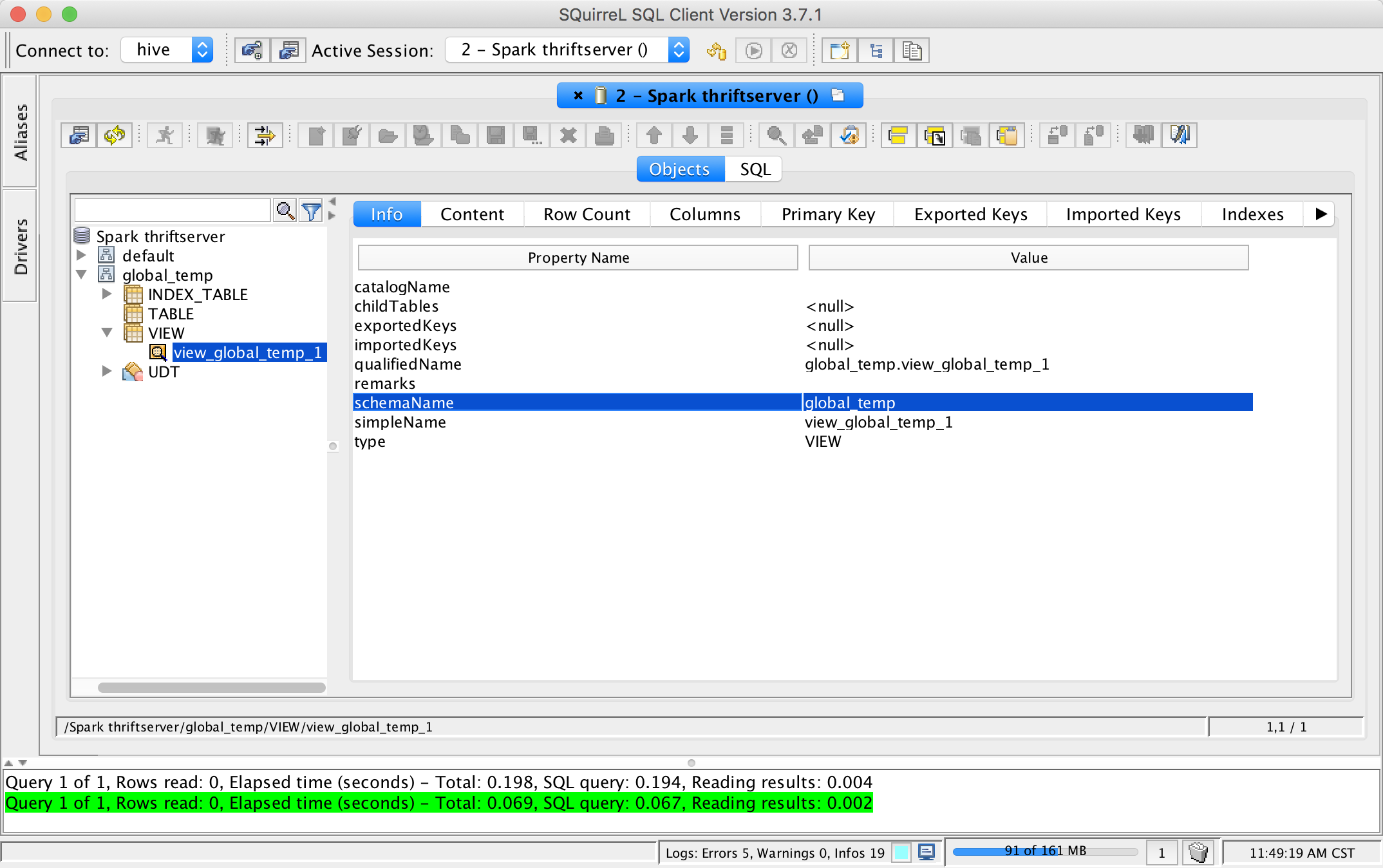
Closes#24972 from wangyum/SPARK-28167.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
To make the #24972 change smaller. This pr improves `SparkMetadataOperationSuite` to avoid creating new sessions when getSchemas/getTables/getColumns.
## How was this patch tested?
N/A
Closes#24985 from wangyum/SPARK-28184.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This pr moves Hive test jars(`hive-contrib-0.13.1.jar`, `hive-hcatalog-core-0.13.1.jar`, `hive-contrib-2.3.5.jar` and `hive-hcatalog-core-2.3.5.jar`) to maven dependency.
## How was this patch tested?
Existing test
Please note that this pr need test with `maven` and `sbt`.
Closes#24751 from wangyum/SPARK-27831.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr moves Hive test jars(`hive-contrib-0.13.1.jar`, `hive-hcatalog-core-0.13.1.jar`, `hive-contrib-2.3.5.jar` and `hive-hcatalog-core-2.3.5.jar`) to maven dependency.
## How was this patch tested?
Existing test
Closes#24695 from wangyum/SPARK-27831.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Fix build warnings -- see some details below.
But mostly, remove use of postfix syntax where it causes warnings without the `scala.language.postfixOps` import. This is mostly in expressions like "120000 milliseconds". Which, I'd like to simplify to things like "2.minutes" anyway.
## How was this patch tested?
Existing tests.
Closes#24314 from srowen/SPARK-27404.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The build has a lot of deprecation warnings. Some are new in Scala 2.12 and Java 11. We've fixed some, but I wanted to take a pass at fixing lots of easy miscellaneous ones here.
They're too numerous and small to list here; see the pull request. Some highlights:
- `BeanInfo` is deprecated in 2.12, and BeanInfo classes are pretty ancient in Java. Instead, case classes can explicitly declare getters
- Eta expansion of zero-arg methods; foo() becomes () => foo() in many cases
- Floating-point Range is inexact and deprecated, like 0.0 to 100.0 by 1.0
- finalize() is finally deprecated (just needs to be suppressed)
- StageInfo.attempId was deprecated and easiest to remove here
I'm not now going to touch some chunks of deprecation warnings:
- Parquet deprecations
- Hive deprecations (particularly serde2 classes)
- Deprecations in generated code (mostly Thriftserver CLI)
- ProcessingTime deprecations (we may need to revive this class as internal)
- many MLlib deprecations because they concern methods that may be removed anyway
- a few Kinesis deprecations I couldn't figure out
- Mesos get/setRole, which I don't know well
- Kafka/ZK deprecations (e.g. poll())
- Kinesis
- a few other ones that will probably resolve by deleting a deprecated method
## How was this patch tested?
Existing tests, including manual testing with the 2.11 build and Java 11.
Closes#23065 from srowen/SPARK-26090.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR ensures to call `super.afterAll()` in `override afterAll()` method for test suites.
* Some suites did not call `super.afterAll()`
* Some suites may call `super.afterAll()` only under certain condition
* Others never call `super.afterAll()`.
This PR also ensures to call `super.beforeAll()` in `override beforeAll()` for test suites.
## How was this patch tested?
Existing UTs
Closes#22337 from kiszk/SPARK-25338.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
A few different things going on:
- Remove unused methods.
- Move JSON methods to the only class that uses them.
- Move test-only methods to TestUtils.
- Make getMaxResultSize() a config constant.
- Reuse functionality from existing libraries (JRE or JavaUtils) where possible.
The change also includes changes to a few tests to call `Utils.createTempFile` correctly,
so that temp dirs are created under the designated top-level temp dir instead of
potentially polluting git index.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20706 from vanzin/SPARK-23550.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/18944 added one patch, which allowed a spark session to be created when the hive metastore server is down. However, it did not allow running any commands with the spark session. This brings troubles to the user who only wants to read / write data frames without metastore setup.
## How was this patch tested?
Added some unit tests to read and write data frames based on the original HiveMetastoreLazyInitializationSuite.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Feng Liu <fengliu@databricks.com>
Closes#20681 from liufengdb/completely-lazy.
## What changes were proposed in this pull request?
`--hiveconf` and `--hivevar` variables no longer work since Spark 2.0. The `spark-sql` client has fixed by [SPARK-15730](https://issues.apache.org/jira/browse/SPARK-15730) and [SPARK-18086](https://issues.apache.org/jira/browse/SPARK-18086). but `beeline`/[`Spark SQL HiveThriftServer2`](https://github.com/apache/spark/blob/v2.1.1/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2.scala) is still broken. This pull request fix it.
This pull request works for both `JDBC client` and `beeline`.
## How was this patch tested?
unit tests for `JDBC client`
manual tests for `beeline`:
```
git checkout origin/pr/17886
dev/make-distribution.sh --mvn mvn --tgz -Phive -Phive-thriftserver -Phadoop-2.6 -DskipTests
tar -zxf spark-2.3.0-SNAPSHOT-bin-2.6.5.tgz && cd spark-2.3.0-SNAPSHOT-bin-2.6.5
sbin/start-thriftserver.sh
```
```
cat <<EOF > test.sql
select '\${a}', '\${b}';
EOF
beeline -u jdbc:hive2://localhost:10000 --hiveconf a=avalue --hivevar b=bvalue -f test.sql
```
Author: Yuming Wang <wgyumg@gmail.com>
Closes#17886 from wangyum/SPARK-13983-dev.
## What changes were proposed in this pull request?
a followup of https://github.com/apache/spark/pull/19712 , adds back the `spark.sql.hive.version`, so that if users try to read this config, they can still get a default value instead of null.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes#19719 from cloud-fan/minor.
## What changes were proposed in this pull request?
At the beginning https://github.com/apache/spark/pull/2843 added `spark.sql.hive.version` to reveal underlying hive version for jdbc connections. For some time afterwards, it was used as a version identifier for the execution hive client.
Actually there is no hive client for executions in spark now and there are no usages of HIVE_EXECUTION_VERSION found in whole spark project. HIVE_EXECUTION_VERSION is set by `spark.sql.hive.version`, which is still set internally in some places or by users, this may confuse developers and users with HIVE_METASTORE_VERSION(spark.sql.hive.metastore.version).
It might better to be removed.
## How was this patch tested?
modify some existing ut
cc cloud-fan gatorsmile
Author: Kent Yao <yaooqinn@hotmail.com>
Closes#19712 from yaooqinn/SPARK-22487.
## What changes were proposed in this pull request?
Set isolated to false while using builtin hive jars and `SessionState.get` returns a `CliSessionState` instance.
## How was this patch tested?
1 Unit Tests
2 Manually verified: `hive.exec.strachdir` was only created once because of reusing cliSessionState
```java
➜ spark git:(SPARK-21428) ✗ bin/spark-sql --conf spark.sql.hive.metastore.jars=builtin
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
17/07/16 23:59:27 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/16 23:59:27 INFO HiveMetaStore: 0: Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore
17/07/16 23:59:27 INFO ObjectStore: ObjectStore, initialize called
17/07/16 23:59:28 INFO Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored
17/07/16 23:59:28 INFO Persistence: Property datanucleus.cache.level2 unknown - will be ignored
17/07/16 23:59:29 INFO ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
17/07/16 23:59:30 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
17/07/16 23:59:30 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
17/07/16 23:59:31 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
17/07/16 23:59:31 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
17/07/16 23:59:31 INFO MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY
17/07/16 23:59:31 INFO ObjectStore: Initialized ObjectStore
17/07/16 23:59:31 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
17/07/16 23:59:31 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
17/07/16 23:59:32 INFO HiveMetaStore: Added admin role in metastore
17/07/16 23:59:32 INFO HiveMetaStore: Added public role in metastore
17/07/16 23:59:32 INFO HiveMetaStore: No user is added in admin role, since config is empty
17/07/16 23:59:32 INFO HiveMetaStore: 0: get_all_databases
17/07/16 23:59:32 INFO audit: ugi=Kent ip=unknown-ip-addr cmd=get_all_databases
17/07/16 23:59:32 INFO HiveMetaStore: 0: get_functions: db=default pat=*
17/07/16 23:59:32 INFO audit: ugi=Kent ip=unknown-ip-addr cmd=get_functions: db=default pat=*
17/07/16 23:59:32 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MResourceUri" is tagged as "embedded-only" so does not have its own datastore table.
17/07/16 23:59:32 INFO SessionState: Created local directory: /var/folders/k2/04p4k4ws73l6711h_mz2_tq00000gn/T/beea7261-221a-4711-89e8-8b12a9d37370_resources
17/07/16 23:59:32 INFO SessionState: Created HDFS directory: /tmp/hive/Kent/beea7261-221a-4711-89e8-8b12a9d37370
17/07/16 23:59:32 INFO SessionState: Created local directory: /var/folders/k2/04p4k4ws73l6711h_mz2_tq00000gn/T/Kent/beea7261-221a-4711-89e8-8b12a9d37370
17/07/16 23:59:32 INFO SessionState: Created HDFS directory: /tmp/hive/Kent/beea7261-221a-4711-89e8-8b12a9d37370/_tmp_space.db
17/07/16 23:59:32 INFO SparkContext: Running Spark version 2.3.0-SNAPSHOT
17/07/16 23:59:32 INFO SparkContext: Submitted application: SparkSQL::10.0.0.8
17/07/16 23:59:32 INFO SecurityManager: Changing view acls to: Kent
17/07/16 23:59:32 INFO SecurityManager: Changing modify acls to: Kent
17/07/16 23:59:32 INFO SecurityManager: Changing view acls groups to:
17/07/16 23:59:32 INFO SecurityManager: Changing modify acls groups to:
17/07/16 23:59:32 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Kent); groups with view permissions: Set(); users with modify permissions: Set(Kent); groups with modify permissions: Set()
17/07/16 23:59:33 INFO Utils: Successfully started service 'sparkDriver' on port 51889.
17/07/16 23:59:33 INFO SparkEnv: Registering MapOutputTracker
17/07/16 23:59:33 INFO SparkEnv: Registering BlockManagerMaster
17/07/16 23:59:33 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
17/07/16 23:59:33 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
17/07/16 23:59:33 INFO DiskBlockManager: Created local directory at /private/var/folders/k2/04p4k4ws73l6711h_mz2_tq00000gn/T/blockmgr-9cfae28a-01e9-4c73-a1f1-f76fa52fc7a5
17/07/16 23:59:33 INFO MemoryStore: MemoryStore started with capacity 366.3 MB
17/07/16 23:59:33 INFO SparkEnv: Registering OutputCommitCoordinator
17/07/16 23:59:33 INFO Utils: Successfully started service 'SparkUI' on port 4040.
17/07/16 23:59:33 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://10.0.0.8:4040
17/07/16 23:59:33 INFO Executor: Starting executor ID driver on host localhost
17/07/16 23:59:33 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 51890.
17/07/16 23:59:33 INFO NettyBlockTransferService: Server created on 10.0.0.8:51890
17/07/16 23:59:33 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
17/07/16 23:59:33 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 10.0.0.8, 51890, None)
17/07/16 23:59:33 INFO BlockManagerMasterEndpoint: Registering block manager 10.0.0.8:51890 with 366.3 MB RAM, BlockManagerId(driver, 10.0.0.8, 51890, None)
17/07/16 23:59:33 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 10.0.0.8, 51890, None)
17/07/16 23:59:33 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 10.0.0.8, 51890, None)
17/07/16 23:59:34 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('file:/Users/Kent/Documents/spark/spark-warehouse').
17/07/16 23:59:34 INFO SharedState: Warehouse path is 'file:/Users/Kent/Documents/spark/spark-warehouse'.
17/07/16 23:59:34 INFO HiveUtils: Initializing HiveMetastoreConnection version 1.2.1 using Spark classes.
17/07/16 23:59:34 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.2) is /user/hive/warehouse
17/07/16 23:59:34 INFO HiveMetaStore: 0: get_database: default
17/07/16 23:59:34 INFO audit: ugi=Kent ip=unknown-ip-addr cmd=get_database: default
17/07/16 23:59:34 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.2) is /user/hive/warehouse
17/07/16 23:59:34 INFO HiveMetaStore: 0: get_database: global_temp
17/07/16 23:59:34 INFO audit: ugi=Kent ip=unknown-ip-addr cmd=get_database: global_temp
17/07/16 23:59:34 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
17/07/16 23:59:34 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.2) is /user/hive/warehouse
17/07/16 23:59:34 INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
spark-sql>
```
cc cloud-fan gatorsmile
Author: Kent Yao <yaooqinn@hotmail.com>
Author: hzyaoqin <hzyaoqin@corp.netease.com>
Closes#18648 from yaooqinn/SPARK-21428.
This version fixes a few issues in the import order checker; it provides
better error messages, and detects more improper ordering (thus the need
to change a lot of files in this patch). The main fix is that it correctly
complains about the order of packages vs. classes.
As part of the above, I moved some "SparkSession" import in ML examples
inside the "$example on$" blocks; that didn't seem consistent across
different source files to start with, and avoids having to add more on/off blocks
around specific imports.
The new scalastyle also seems to have a better header detector, so a few
license headers had to be updated to match the expected indentation.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18943 from vanzin/SPARK-21731.
## What changes were proposed in this pull request?
This PR changes the codes to lazily init hive metastore client so that we can create SparkSession without talking to the hive metastore sever.
It's pretty helpful when you set a hive metastore server but it's down. You can still start the Spark shell to debug.
## How was this patch tested?
The new unit test.
Author: Shixiong Zhu <shixiong@databricks.com>
Closes#18944 from zsxwing/hive-lazy-init.
## What changes were proposed in this pull request?
When we use `bin/spark-sql` command configuring `--conf spark.hadoop.foo=bar`, the `SparkSQLCliDriver` initializes an instance of hiveconf, it does not add `foo->bar` to it.
this pr gets `spark.hadoop.*` properties from sysProps to this hiveconf
## How was this patch tested?
UT
Author: hzyaoqin <hzyaoqin@corp.netease.com>
Author: Kent Yao <yaooqinn@hotmail.com>
Closes#18668 from yaooqinn/SPARK-21451.
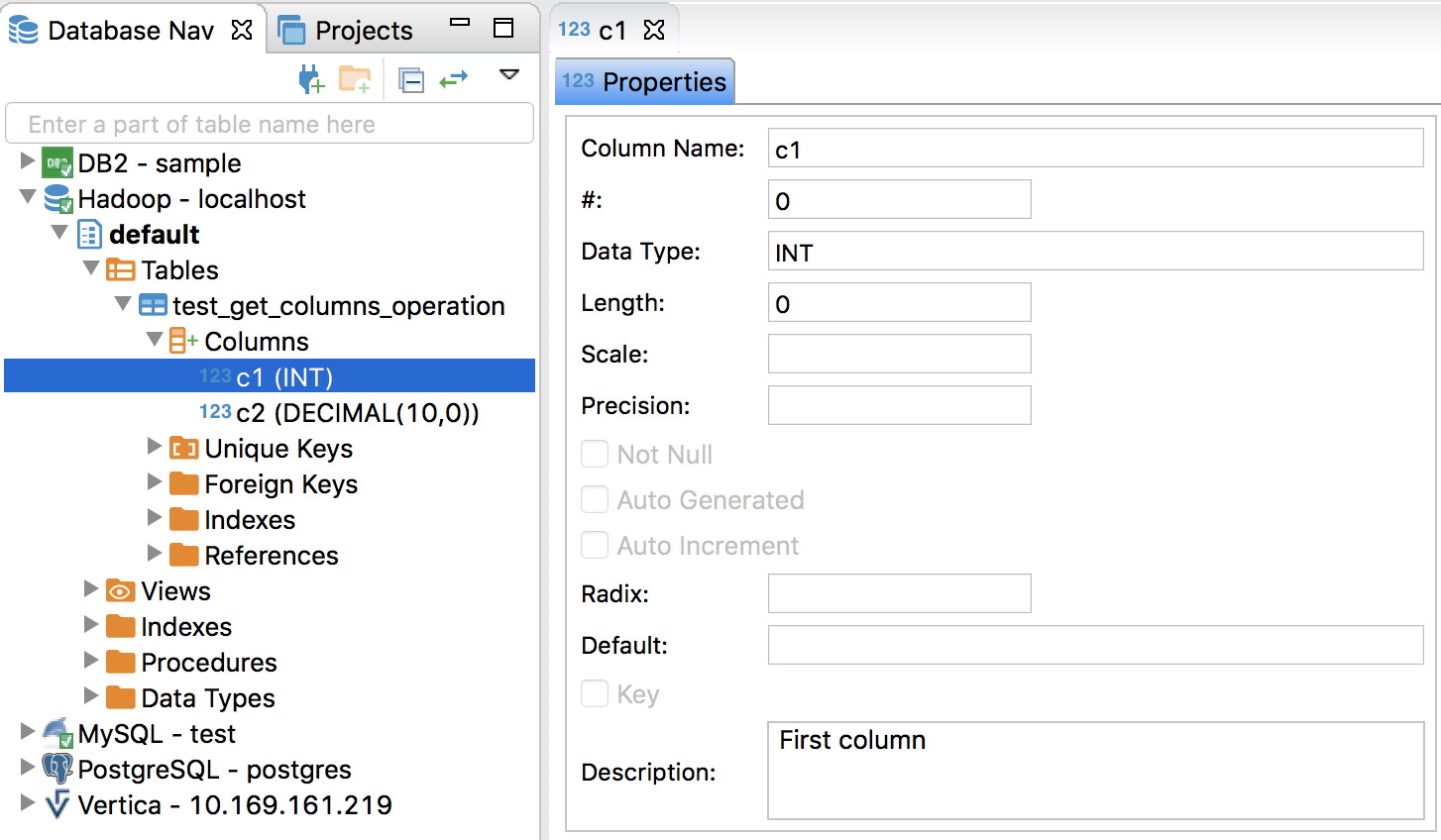
## What changes were proposed in this pull request?
The column comment was missing while constructing the Hive TableSchema. This fix will preserve the original comment.
## How was this patch tested?
I have added a new test case to test the column with/without comment.
Author: bomeng <bmeng@us.ibm.com>
Closes#17470 from bomeng/SPARK-20146.
### What changes were proposed in this pull request?
Since `spark.sql.hive.thriftServer.singleSession` is a configuration of SQL component, this conf can be moved from `SparkConf` to `StaticSQLConf`.
When we introduced `spark.sql.hive.thriftServer.singleSession`, all the SQL configuration are session specific. They can be modified in different sessions.
In Spark 2.1, static SQL configuration is added. It is a perfect fit for `spark.sql.hive.thriftServer.singleSession`. Previously, we did the same move for `spark.sql.warehouse.dir` from `SparkConf` to `StaticSQLConf`
### How was this patch tested?
Added test cases in HiveThriftServer2Suites.scala
Author: gatorsmile <gatorsmile@gmail.com>
Closes#16392 from gatorsmile/hiveThriftServerSingleSession.
## What changes were proposed in this pull request?
This is a follow-up work of #15618.
Close file source;
For any newly created streaming context outside the withContext, explicitly close the context.
## How was this patch tested?
Existing unit tests.
Author: wm624@hotmail.com <wm624@hotmail.com>
Closes#15818 from wangmiao1981/rtest.
## What changes were proposed in this pull request?
Currently, Spark Thrift Server ignores the default database in URI. This PR supports that like the following.
```sql
$ bin/beeline -u jdbc:hive2://localhost:10000 -e "create database testdb"
$ bin/beeline -u jdbc:hive2://localhost:10000/testdb -e "create table t(a int)"
$ bin/beeline -u jdbc:hive2://localhost:10000/testdb -e "show tables"
...
+------------+--------------+--+
| tableName | isTemporary |
+------------+--------------+--+
| t | false |
+------------+--------------+--+
1 row selected (0.347 seconds)
$ bin/beeline -u jdbc:hive2://localhost:10000 -e "show tables"
...
+------------+--------------+--+
| tableName | isTemporary |
+------------+--------------+--+
+------------+--------------+--+
No rows selected (0.098 seconds)
```
## How was this patch tested?
Manual.
Note: I tried to add a test case for this, but I cannot found a suitable testsuite for this. I'll add the testcase if some advice is given.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#15399 from dongjoon-hyun/SPARK-17819.
## What changes were proposed in this pull request?
Add a constant iterator which point to head of result. The header will be used to reset iterator when fetch result from first row repeatedly.
JIRA ticket https://issues.apache.org/jira/browse/SPARK-16563
## How was this patch tested?
This bug was found when using Cloudera HUE connecting to spark sql thrift server, currently SQL statement result can be only fetched for once. The fix was tested manually with Cloudera HUE, With this fix, HUE can fetch spark SQL results repeatedly through thrift server.
Author: Alice <alice.gugu@gmail.com>
Author: Alice <guhq@garena.com>
Closes#14218 from alicegugu/SparkSQLFetchResultsBug.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}