### What changes were proposed in this pull request?
This pr fix failed cases in sql hive module in Scala 2.13 as follow:
- HiveSchemaInferenceSuite (1 FAILED -> PASS)
- HiveSparkSubmitSuite (1 FAILED-> PASS)
- StatisticsSuite (1 FAILED-> PASS)
- HiveDDLSuite (1 FAILED-> PASS)
After this patch all test passed in sql hive module in Scala 2.13.
### Why are the changes needed?
We need to support a Scala 2.13 build.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Scala 2.12: Pass the Jenkins or GitHub Action
- Scala 2.13: All tests passed.
Do the following:
```
dev/change-scala-version.sh 2.13
mvn clean install -DskipTests -pl sql/hive -am -Pscala-2.13 -Phive
mvn clean test -pl sql/hive -Pscala-2.13 -Phive
```
**Before**
```
Tests: succeeded 3662, failed 4, canceled 0, ignored 601, pending 0
*** 4 TESTS FAILED ***
```
**After**
```
Tests: succeeded 3666, failed 0, canceled 0, ignored 601, pending 0
All tests passed.
```
Closes#29760 from LuciferYang/sql-hive-test.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR fixes a conflict between `RewriteDistinctAggregates` and `DecimalAggregates`.
In some cases, `DecimalAggregates` will wrap the decimal column to `UnscaledValue` using
different rules for different aggregates.
This means, same distinct column with different aggregates will change to different distinct columns
after `DecimalAggregates`. For example:
`avg(distinct decimal_col), sum(distinct decimal_col)` may change to
`avg(distinct UnscaledValue(decimal_col)), sum(distinct decimal_col)`
We assume after `RewriteDistinctAggregates`, there will be at most one distinct column in aggregates,
but `DecimalAggregates` breaks this assumption. To fix this, we have to switch the order of these two
rules.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
added test cases
Closes#29673 from linhongliu-db/SPARK-32816.
Authored-by: Linhong Liu <linhong.liu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This pr makes cast string type to decimal decimal type fast fail if precision larger that 38.
### Why are the changes needed?
It is very slow if precision very large.
Benchmark and benchmark result:
```scala
import org.apache.spark.benchmark.Benchmark
val bd1 = new java.math.BigDecimal("6.0790316E+25569151")
val bd2 = new java.math.BigDecimal("6.0790316E+25");
val benchmark = new Benchmark("Benchmark string to decimal", 1, minNumIters = 2)
benchmark.addCase(bd1.toString) { _ =>
println(Decimal(bd1).precision)
}
benchmark.addCase(bd2.toString) { _ =>
println(Decimal(bd2).precision)
}
benchmark.run()
```
```
Java HotSpot(TM) 64-Bit Server VM 1.8.0_251-b08 on Mac OS X 10.15.6
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
Benchmark string to decimal: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
6.0790316E+25569151 9340 9381 57 0.0 9340094625.0 1.0X
6.0790316E+25 0 0 0 0.5 2150.0 4344230.1X
```
Stacktrace:
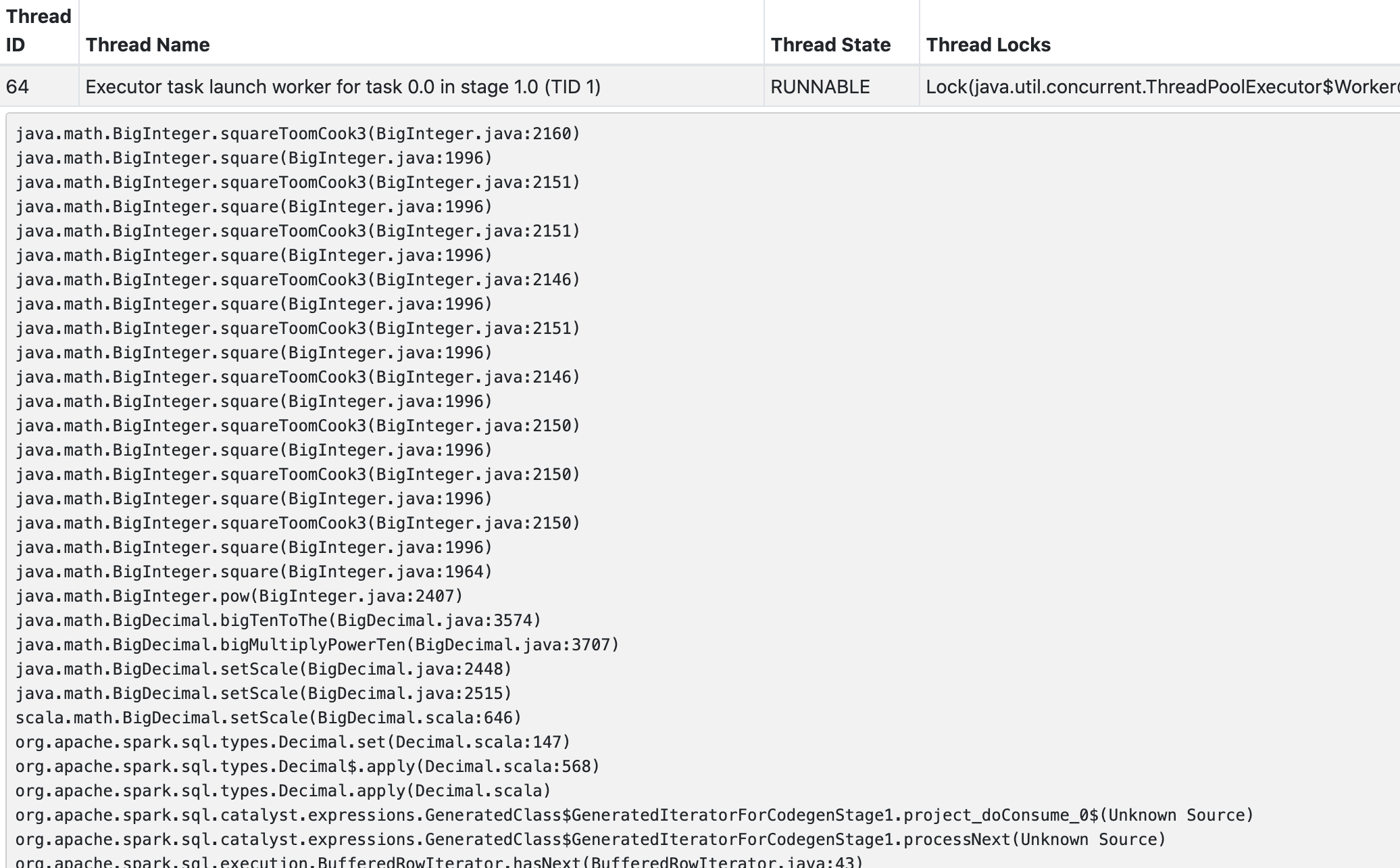
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test and benchmark test:
Dataset | Before this pr (Seconds) | After this pr (Seconds)
-- | -- | --
https://issues.apache.org/jira/secure/attachment/13011406/part-00000.parquet | 2640 | 2
Closes#29731 from wangyum/SPARK-32706.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This proposes to enhance user document of the API for loading a Dataset of strings storing CSV rows. If the header option is set to true, the API will remove all lines same with the header.
### Why are the changes needed?
This behavior can confuse users. We should explicitly document it.
### Does this PR introduce _any_ user-facing change?
No. Only doc change.
### How was this patch tested?
Only doc change.
Closes#29765 from viirya/SPARK-32888.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR updates the `RemoveRedundantProjects` rule to make `GenerateExec` require column ordering.
### Why are the changes needed?
`GenerateExec` was originally considered as a node that does not require column ordering. However, `GenerateExec` binds its input rows directly with its `requiredChildOutput` without using the child's output schema.
In `doExecute()`:
```scala
val proj = UnsafeProjection.create(output, output)
```
In `doConsume()`:
```scala
val values = if (requiredChildOutput.nonEmpty) {
input
} else {
Seq.empty
}
```
In this case, changing input column ordering will result in `GenerateExec` binding the wrong schema to the input columns. For example, if we do not require child columns to be ordered, the `requiredChildOutput` [a, b, c] will directly bind to the schema of the input columns [c, b, a], which is incorrect:
```
GenerateExec explode(array(a, b, c)), [a, b, c], false, [d]
HashAggregate(keys=[a, b, c], functions=[], output=[c, b, a])
...
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#29734 from allisonwang-db/generator.
Authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The `LiteralGenerator` for float and double datatypes was supposed to yield special values (NaN, +-inf) among others, but the `Gen.chooseNum` method does not yield values that are outside the defined range. The `Gen.chooseNum` for a wide range of floats and doubles does not yield values in the "everyday" range as stated in https://github.com/typelevel/scalacheck/issues/113 .
There is an similar class `RandomDataGenerator` that is used in some other tests. Added `-0.0` and `-0.0f` as special values to there too.
These changes revealed an inconsistency with the equality check between `-0.0` and `0.0`.
### Why are the changes needed?
The `LiteralGenerator` is mostly used in the `checkConsistencyBetweenInterpretedAndCodegen` method in `MathExpressionsSuite`. This change would have caught the bug fixed in #29495 .
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Locally reverted #29495 and verified that the existing test cases caught the bug.
Closes#29515 from tanelk/SPARK-32688.
Authored-by: Tanel Kiis <tanel.kiis@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR only checks if there's any physical rule runs instead of a specific rule. This is rather just a trivial fix to make the tests more robust.
In fact, I faced a test failure from a in-house fork that applies a different physical rule that makes `CollapseCodegenStages` ineffective.
### Why are the changes needed?
To make the test more robust by unrelated changes.
### Does this PR introduce _any_ user-facing change?
No, test-only
### How was this patch tested?
Manually tested. Jenkins tests should pass.
Closes#29766 from HyukjinKwon/SPARK-32704.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR skips the test if trash directory cannot be created. It is possible that the trash directory cannot be created, for example, by permission. And the test fails below:
```
- SPARK-32481 Move data to trash on truncate table if enabled *** FAILED *** (154 milliseconds)
fs.exists(trashPath) was false (DDLSuite.scala:3184)
org.scalatest.exceptions.TestFailedException:
at org.scalatest.Assertions.newAssertionFailedException(Assertions.scala:530)
at org.scalatest.Assertions.newAssertionFailedException$(Assertions.scala:529)
at org.scalatest.FunSuite.newAssertionFailedException(FunSuite.scala:1560)
at org.scalatest.Assertions$AssertionsHelper.macroAssert(Assertions.scala:503)
```
### Why are the changes needed?
To make the tests pass independently.
### Does this PR introduce _any_ user-facing change?
No, test-only.
### How was this patch tested?
Manually tested.
Closes#29759 from HyukjinKwon/SPARK-32481.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add a new config `spark.sql.maxMetadataStringLength`. This config aims to limit metadata value length, e.g. file location.
### Why are the changes needed?
Some metadata have been abbreviated by `...` when I tried to add some test in `SQLQueryTestSuite`. We need to replace such value to `notIncludedMsg`. That caused we can't replace that like location value by `className` since the `className` has been abbreviated.
Here is a case:
```
CREATE table explain_temp1 (key int, val int) USING PARQUET;
EXPLAIN EXTENDED SELECT sum(distinct val) FROM explain_temp1;
-- ignore parsed,analyzed,optimized
-- The output like
== Physical Plan ==
*HashAggregate(keys=[], functions=[sum(distinct cast(val#x as bigint)#xL)], output=[sum(DISTINCT val)#xL])
+- Exchange SinglePartition, true, [id=#x]
+- *HashAggregate(keys=[], functions=[partial_sum(distinct cast(val#x as bigint)#xL)], output=[sum#xL])
+- *HashAggregate(keys=[cast(val#x as bigint)#xL], functions=[], output=[cast(val#x as bigint)#xL])
+- Exchange hashpartitioning(cast(val#x as bigint)#xL, 4), true, [id=#x]
+- *HashAggregate(keys=[cast(val#x as bigint) AS cast(val#x as bigint)#xL], functions=[], output=[cast(val#x as bigint)#xL])
+- *ColumnarToRow
+- FileScan parquet default.explain_temp1[val#x] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/home/runner/work/spark/spark/sql/core/spark-warehouse/org.apache.spark.sq...], PartitionFilters: ...
```
### Does this PR introduce _any_ user-facing change?
No, a new config.
### How was this patch tested?
new test.
Closes#29688 from ulysses-you/SPARK-32827.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds test cases for the result set metadata checking for Spark's `ExecuteStatementOperation` to make the JDBC API more future-proofing because any server-side change may affect the client compatibility.
### Why are the changes needed?
add test to prevent potential silent behavior change for JDBC users.
### Does this PR introduce _any_ user-facing change?
NO, test only
### How was this patch tested?
add new test
Closes#29746 from yaooqinn/SPARK-32874.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR refactors the way we propagate the options from the `SparkSession.Builder` to the` SessionState`. This currently done via a mutable map inside the SparkSession. These setting settings are then applied **after** the Session. This is a bit confusing when you expect something to be set when constructing the `SessionState`. This PR passes the options as a constructor parameter to the `SessionStateBuilder` and this will set the options when the configuration is created.
### Why are the changes needed?
It makes it easier to reason about the configurations set in a SessionState than before. We recently had an incident where someone was using `SparkSessionExtensions` to create a planner rule that relied on a conf to be set. While this is in itself probably incorrect usage, it still illustrated this somewhat funky behavior.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests.
Closes#29752 from hvanhovell/SPARK-32879.
Authored-by: herman <herman@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to mark the following suite as `ExtendedSQLTest` to reduce GitHub Action test time.
- TPCDSQuerySuite
- TPCDSQueryANSISuite
- TPCDSQueryWithStatsSuite
### Why are the changes needed?
Currently, the longest GitHub Action task is `Build and test / Build modules: sql - other tests` with `1h 57m 10s` while `Build and test / Build modules: sql - slow tests` takes `42m 20s`. With this PR, we can move the workload from `other tests` to `slow tests` task and reduce the total waiting time about 7 ~ 8 minutes.
### Does this PR introduce _any_ user-facing change?
No. This is a test-only change.
### How was this patch tested?
Pass the GitHub Action with the reduced running time.
Closes#29755 from dongjoon-hyun/SPARK-SLOWTEST.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR appends `toMap` to `Map` instances with `filterKeys` if such maps is to be concatenated with another maps.
### Why are the changes needed?
As of Scala 2.13, Map#filterKeys return a MapView, not the original Map type.
This can cause compile error.
```
/sql/DataFrameReader.scala:279: type mismatch;
[error] found : Iterable[(String, String)]
[error] required: java.util.Map[String,String]
[error] Error occurred in an application involving default arguments.
[error] val dsOptions = new CaseInsensitiveStringMap(finalOptions.asJava)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Compile passed with the following command.
`build/mvn -Pscala-2.13 -Phive -Phive-thriftserver -Pyarn -Pkubernetes -DskipTests test-compile`
Closes#29742 from sarutak/fix-filterKeys-issue.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The Jenkins job fails to get the versions. This was fixed by adding temporary fallbacks at https://github.com/apache/spark/pull/28536.
This still doesn't work without the temporary fallbacks. See https://github.com/apache/spark/pull/29694
This PR adds new fallbacks since 2.3 is EOL and Spark 3.0.1 and 2.4.7 are released.
### Why are the changes needed?
To test correctly in Jenkins.
### Does this PR introduce _any_ user-facing change?
No, dev-only
### How was this patch tested?
Jenkins and GitHub Actions builds should test.
Closes#29748 from HyukjinKwon/SPARK-32876.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Mark `BitAggregate` as order irrelevant in `EliminateSorts`.
### Why are the changes needed?
Performance improvements in some queries
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Generalized an existing UT
Closes#29740 from tanelk/SPARK-32868.
Authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Make `DataFrameReader.table` take the specified options for datasource v1.
### Why are the changes needed?
Keep the same behavior of v1/v2 datasource, the v2 fix has been done in SPARK-32592.
### Does this PR introduce _any_ user-facing change?
Yes. The DataFrameReader.table will take the specified options. Also, if there are the same key and value exists in specified options and table properties, an exception will be thrown.
### How was this patch tested?
New UT added.
Closes#29712 from xuanyuanking/SPARK-32844.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Several minor code and documentation improvement for stream-stream join. Specifically:
* Remove extending from `SparkPlan`, as extending from `BinaryExecNode` is enough.
* Return `left/right.outputPartitioning` for `Left/RightOuter` in `outputPartitioning`, as the `PartitioningCollection` wrapper is unnecessary (similar to batch joins `ShuffledHashJoinExec`, `SortMergeJoinExec`).
* Avoid per-row check for join type (https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamingSymmetricHashJoinExec.scala#L486-L492), by creating the method before the loop of reading rows (`generateFilteredJoinedRow` in `storeAndJoinWithOtherSide`). Similar optimization (i.e. create auxiliary method/variable per different join type before the iterator of input rows) has been done in batch join world (`SortMergeJoinExec`, `ShuffledHashJoinExec`).
* Minor fix for comment/indentation for better readability.
### Why are the changes needed?
Minor optimization to avoid per-row unnecessary work (this probably can be optimized away by compiler, but we can do a better join to avoid it at the first place). And other comment/indentation fix to have better code readability for future developers.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests in `StreamingJoinSuite.scala` as no new logic is introduced.
Closes#29724 from c21/streaming.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fix code which causes error when build with sbt and Scala 2.13 like as follows.
```
[error] [warn] /home/kou/work/oss/spark-scala-2.13/external/kafka-0-10/src/main/scala/org/apache/spark/streaming/kafka010/KafkaRDD.scala:251: method with a single empty parameter list overrides method without any parameter list
[error] [warn] override def hasNext(): Boolean = requestOffset < part.untilOffset
[error] [warn]
[error] [warn] /home/kou/work/oss/spark-scala-2.13/external/kafka-0-10/src/main/scala/org/apache/spark/streaming/kafka010/KafkaRDD.scala:294: method with a single empty parameter list overrides method without any parameter list
[error] [warn] override def hasNext(): Boolean = okNext
```
More specifically, what this PR fixes are
* Methods which has an empty parameter list and overrides an method which has no parameter list.
```
override def hasNext(): Boolean = okNext
```
* Methods which has no parameter list and overrides an method which has an empty parameter list.
```
override def next: (Int, Double) = {
```
* Infix operator expression that the operator wraps.
```
3L * math.min(k, numFeatures) * math.min(k, numFeatures)
3L * math.min(k, numFeatures) * math.min(k, numFeatures) +
+ math.max(math.max(k, numFeatures), 4L * math.min(k, numFeatures)
math.max(math.max(k, numFeatures), 4L * math.min(k, numFeatures) *
* math.min(k, numFeatures) + 4L * math.min(k, numFeatures))
```
### Why are the changes needed?
For building Spark with sbt and Scala 2.13.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
After this change and #29742 applied, compile passed with the following command.
```
build/sbt -Pscala-2.13 -Phive -Phive-thriftserver -Pyarn -Pkubernetes compile test:compile
```
Closes#29745 from sarutak/fix-code-for-sbt-and-spark-2.13.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Currently, in cases like the following:
```sql
SELECT * FROM t WHERE age < 40
```
where `age` is of short type, Spark won't be able to simplify this and can only generate filter `cast(age, int) < 40`. This won't get pushed down to datasources and therefore is not optimized.
This PR proposes a optimizer rule to improve this when the following constraints are satisfied:
- input expression is binary comparisons when one side is a cast operation and another is a literal.
- both the cast child expression and literal are of integral type (i.e., byte, short, int or long)
When this is true, it tries to do several optimizations to either simplify the expression or move the cast to the literal side, so
result filter for the above case becomes `age < cast(40 as smallint)`. This is better since the cast can be optimized away later and the filter can be pushed down to data sources.
This PR follows a similar effort in Presto (https://prestosql.io/blog/2019/05/21/optimizing-the-casts-away.html). Here we only handles integral types but plan to extend to other types as follow-ups.
### Why are the changes needed?
As mentioned in the previous section, when cast is not optimized, it cannot be pushed down to data sources which can lead
to unnecessary IO and therefore longer job time and waste of resources. This helps to improve that.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit tests for both the optimizer rule and filter pushdown on datasource level for both Orc and Parquet.
Closes#29565 from sunchao/SPARK-24994.
Authored-by: Chao Sun <sunchao@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This is an attempt to adapt Spark REPL to Scala 2.13.
It is based on a [scala-2.13 branch](https://github.com/smarter/spark/tree/scala-2.13) made by smarter.
I had to set Scala version to 2.13 in some places, and to adapt some other modules, before I could start working on the REPL itself. These are separate commits on the branch that probably would be fixed beforehand, and thus dropped before the merge of this PR.
I couldn't find a way to run the initialization code with existing REPL classes in Scala 2.13.2, so I [modified REPL in Scala](e9cc0dd547) to make it work. With this modification I managed to run Spark Shell, along with the units tests passing, which is good news.
The bad news is that it requires an upstream change in Scala, which must be accepted first. I'd be happy to change it if someone points a way to do it differently. If not, I'd propose a PR in Scala to introduce `ILoop.internalReplAutorunCode`.
### Why are the changes needed?
REPL in Scala changed quite a lot, so current version of Spark REPL needed to be adapted.
### Does this PR introduce _any_ user-facing change?
In the previous version of `SparkILoop`, a lot of Scala's `ILoop` code was [overridden and duplicated](2bc7b75537) to make the welcome message a bit more pleasant. In this PR, the message is in a bit different order, but it's still acceptable IMHO.
Before this PR:
```
20/05/15 15:32:39 WARN Utils: Your hostname, hermes resolves to a loopback address: 127.0.1.1; using 192.168.1.28 instead (on interface enp0s31f6)
20/05/15 15:32:39 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/05/15 15:32:39 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
20/05/15 15:32:45 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
Spark context Web UI available at http://192.168.1.28:4041
Spark context available as 'sc' (master = local[*], app id = local-1589549565502).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.1-SNAPSHOT
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 1.8.0_242)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
```
With this PR:
```
20/05/15 15:32:15 WARN Utils: Your hostname, hermes resolves to a loopback address: 127.0.1.1; using 192.168.1.28 instead (on interface enp0s31f6)
20/05/15 15:32:15 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/05/15 15:32:15 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0-SNAPSHOT
/_/
Using Scala version 2.13.2-20200422-211118-706ef1b (OpenJDK 64-Bit Server VM, Java 1.8.0_242)
Type in expressions to have them evaluated.
Type :help for more information.
Spark context Web UI available at http://192.168.1.28:4040
Spark context available as 'sc' (master = local[*], app id = local-1589549541259).
Spark session available as 'spark'.
scala>
```
It seems that currently the welcoming message is still an improvement from [the original ticket](https://issues.apache.org/jira/browse/SPARK-24785), albeit in a different order. As a bonus, some fragile code duplication was removed.
### How was this patch tested?
Existing tests pass in `repl`module. The REPL runs in a terminal and the following code executed correctly:
```
scala> spark.range(1000 * 1000 * 1000).count()
val res0: Long = 1000000000
```
Closes#28545 from karolchmist/scala-2.13-repl.
Authored-by: Karol Chmist <info+github@chmist.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Follow-up PR as per the review comments in [29649](8d45542e91 (r487140171))
### Why are the changes needed?
Delete the un used code
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing UT
Closes#29736 from sandeep-katta/deadlockfollowup.
Authored-by: sandeep.katta <sandeep.katta2007@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR intends to set `CODEGEN_ONLY` at `CODEGEN_FACTORY_MODE` in test spark context so that tests can fail if errors happen when generating expr code.
### Why are the changes needed?
I noticed that the code generation of `SafeProjection` failed in the existing test (https://issues.apache.org/jira/browse/SPARK-32828) but it passed because `FALLBACK` was set at `CODEGEN_FACTORY_MODE` (by default) in `SharedSparkSession`. To get aware of these failures quickly, I think its worth setting `CODEGEN_ONLY` at `CODEGEN_FACTORY_MODE`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#29721 from maropu/ExprCodegenTest.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR aims to add `sinkParameter` to check sink options robustly and independently in DataStreamReaderWriterSuite
### Why are the changes needed?
`LastOptions.parameters` is designed to catch three cases: `sourceSchema`, `createSource`, `createSink`. However, `StreamQuery.stop` invokes `queryExecutionThread.join`, `runStream`, `createSource` immediately and reset the stored options by `createSink`.
To catch `createSink` options, currently, the test suite is trying a workaround pattern. However, we observed a flakiness in this pattern sometimes. If we split `createSink` option separately, we don't need this workaround and can eliminate this flakiness.
```scala
val query = df.writeStream.
...
.start()
assert(LastOptions.paramters(..))
query.stop()
```
### Does this PR introduce _any_ user-facing change?
No. This is a test-only change.
### How was this patch tested?
Pass the newly updated test case.
Closes#29730 from dongjoon-hyun/SPARK-32845.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This is a follow-up to https://github.com/apache/spark/pull/29572.
LeftAnti SortMergeJoin should not buffer all matching right side rows when bound condition is empty, this is unnecessary and can lead to performance degradation especially when spilling happens.
### Why are the changes needed?
Performance improvement.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New UT.
Closes#29727 from peter-toth/SPARK-32730-improve-leftsemi-sortmergejoin-followup.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/29328
In https://github.com/apache/spark/pull/29328 , we forbid the use case that path option and path parameter are both specified. However, it breaks some use cases:
```
val dfr = spark.read.format(...).option(...)
dfr.load(path1).xxx
dfr.load(path2).xxx
```
The reason is that: `load` has side effects. It will set path option to the `DataFrameReader` instance. The next time you call `load`, Spark will fail because both path option and path parameter are specified.
This PR removes the side effect of `save`/`load`/`start` to not set the path option.
### Why are the changes needed?
recover some use cases
### Does this PR introduce _any_ user-facing change?
Yes, some use cases fail before this PR, and can run successfully after this PR.
### How was this patch tested?
new tests
Closes#29723 from cloud-fan/df.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
fix typo in SQLConf
### Why are the changes needed?
typo fix to increase readability
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
no test
Closes#29668 from Ted-Jiang/fix_annotate.
Authored-by: yangjiang <yangjiang@ebay.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
We made a mistake in https://github.com/apache/spark/pull/29502, as there is no code comment to explain why we can't load the UDF class when creating functions. This PR improves the code comment.
### Why are the changes needed?
To avoid making the same mistake.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
N/A
Closes#29713 from cloud-fan/comment.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR changes the behavior of RangeExec with WholeStageCodegen disabled or falled back to change the number of partitions to zero when a range is empty.
In the current master, if WholeStageCodegen effects, the number of partitions of an empty range will be changed to zero.
```
spark.range(1, 1, 1, 1000).rdd.getNumPartitions
res0: Int = 0
```
But it doesn't if WholeStageCodegen is disabled or falled back.
```
spark.conf.set("spark.sql.codegen.wholeStage", false)
spark.range(1, 1, 1, 1000).rdd.getNumPartitions
res2: Int = 1000
```
### Why are the changes needed?
To archive better performance even though WholeStageCodegen disabled or falled back.
### Does this PR introduce _any_ user-facing change?
Yes. the number of partitions gotten with `getNumPartitions` for an empty range will be changed when WholeStageCodegen is disabled.
### How was this patch tested?
New test.
Closes#29681 from sarutak/zero-size-range.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Spark SQL exists a bug show below:
```
spark.sql(
" SELECT COUNT(DISTINCT 2), COUNT(DISTINCT 2, 3)")
.show()
+-----------------+--------------------+
|count(DISTINCT 2)|count(DISTINCT 2, 3)|
+-----------------+--------------------+
| 1| 1|
+-----------------+--------------------+
spark.sql(
" SELECT COUNT(DISTINCT 2), COUNT(DISTINCT 3, 2)")
.show()
+-----------------+--------------------+
|count(DISTINCT 2)|count(DISTINCT 3, 2)|
+-----------------+--------------------+
| 1| 0|
+-----------------+--------------------+
```
The first query is correct, but the second query is not.
The root reason is the second query rewrited by `RewriteDistinctAggregates` who expand the output but lost the 2.
### Why are the changes needed?
Fix a bug.
`SELECT COUNT(DISTINCT 2), COUNT(DISTINCT 3, 2)` should return `1, 1`
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
New UT
Closes#29626 from beliefer/support-multiple-foldable-distinct-expressions.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: beliefer <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In this PR, we add a checker for STRING form interval value ahead for parsing multiple units intervals and fail directly if the interval value contains alphabets to prevent correctness issues like `interval '1 day 2' day`=`3 days`.
### Why are the changes needed?
fix correctness issue
### Does this PR introduce _any_ user-facing change?
yes, in spark 3.0.0 `interval '1 day 2' day`=`3 days` but now we fail with ParseException
### How was this patch tested?
add a test.
Closes#29708 from yaooqinn/SPARK-32840.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR intends to fix an existing bug below in `UserDefinedTypeSuite`;
```
[info] - SPARK-19311: UDFs disregard UDT type hierarchy (931 milliseconds)
16:22:35.936 WARN org.apache.spark.sql.catalyst.expressions.SafeProjection: Expr codegen error and falling back to interpreter mode
org.apache.spark.SparkException: Cannot cast org.apache.spark.sql.ExampleSubTypeUDT46b1771f to org.apache.spark.sql.ExampleBaseTypeUDT31e8d979.
at org.apache.spark.sql.catalyst.expressions.CastBase.nullSafeCastFunction(Cast.scala:891)
at org.apache.spark.sql.catalyst.expressions.CastBase.doGenCode(Cast.scala:852)
at org.apache.spark.sql.catalyst.expressions.Expression.$anonfun$genCode$3(Expression.scala:147)
...
```
### Why are the changes needed?
bugfix
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit tests.
Closes#29691 from maropu/FixUdtBug.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This patch proposes to update the doc (both SS guide doc and Dataset dropDuplicates method doc) to leave a note to check on using SQL statements with streaming Dataset.
Once end users create a temp view based on streaming Dataset, they won't bother with thinking about "streaming" and do whatever they do with batch query. In many cases it works, but not just smoothly for the case when streaming aggregation is involved. They still need to concern about maintaining state store.
### Why are the changes needed?
Although SPARK-32456 fixed the weird error message, as a side effect some operations are enabled on streaming workload via SQL statement, which is error-prone if end users don't indicate what they're doing.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Only doc change.
Closes#29461 from HeartSaVioR/SPARK-32456-FOLLOWUP-DOC.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to fix indeterministic behavior on DataStreamReader/Writer options like the following.
```scala
scala> spark.readStream.format("parquet").option("paTh", "1").option("PATH", "2").option("Path", "3").option("patH", "4").option("path", "5").load()
org.apache.spark.sql.AnalysisException: Path does not exist: 1;
```
### Why are the changes needed?
This will make the behavior deterministic.
### Does this PR introduce _any_ user-facing change?
Yes, but the previous behavior is indeterministic.
### How was this patch tested?
Pass the newly test cases.
Closes#29702 from dongjoon-hyun/SPARK-32832.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR renames `SupportsStreamingUpdate` to `SupportsStreamingUpdateAsAppend` as the new interface name represents the actual behavior clearer. This PR also removes the `update()` method (so the interface is more likely a marker), as the implementations of `SupportsStreamingUpdateAsAppend` should support append mode by default, hence no need to trigger some flag on it.
### Why are the changes needed?
SupportsStreamingUpdate was intended to revive the functionality of Streaming update output mode for internal data sources, but despite the name, that interface isn't really used to do actual update on sink; all sinks are implementing this interface to do append, so strictly saying, it's just to support update as append. Renaming the interface would make it clear.
### Does this PR introduce _any_ user-facing change?
No, as the class is only for internal data sources.
### How was this patch tested?
Jenkins test will follow.
Closes#29693 from HeartSaVioR/SPARK-32831.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
Upgrade Apache Arrow to version 1.0.1 for the Java dependency and increase minimum version of PyArrow to 1.0.0.
This release marks a transition to binary stability of the columnar format (which was already informally backward-compatible going back to December 2017) and a transition to Semantic Versioning for the Arrow software libraries. Also note that the Java arrow-memory artifact has been split to separate dependence on netty-buffer and allow users to select an allocator. Spark will continue to use `arrow-memory-netty` to maintain performance benefits.
Version 1.0.0 - 1.0.0 include the following selected fixes/improvements relevant to Spark users:
ARROW-9300 - [Java] Separate Netty Memory to its own module
ARROW-9272 - [C++][Python] Reduce complexity in python to arrow conversion
ARROW-9016 - [Java] Remove direct references to Netty/Unsafe Allocators
ARROW-8664 - [Java] Add skip null check to all Vector types
ARROW-8485 - [Integration][Java] Implement extension types integration
ARROW-8434 - [C++] Ipc RecordBatchFileReader deserializes the Schema multiple times
ARROW-8314 - [Python] Provide a method to select a subset of columns of a Table
ARROW-8230 - [Java] Move Netty memory manager into a separate module
ARROW-8229 - [Java] Move ArrowBuf into the Arrow package
ARROW-7955 - [Java] Support large buffer for file/stream IPC
ARROW-7831 - [Java] unnecessary buffer allocation when calling splitAndTransferTo on variable width vectors
ARROW-6111 - [Java] Support LargeVarChar and LargeBinary types and add integration test with C++
ARROW-6110 - [Java] Support LargeList Type and add integration test with C++
ARROW-5760 - [C++] Optimize Take implementation
ARROW-300 - [Format] Add body buffer compression option to IPC message protocol using LZ4 or ZSTD
ARROW-9098 - RecordBatch::ToStructArray cannot handle record batches with 0 column
ARROW-9066 - [Python] Raise correct error in isnull()
ARROW-9223 - [Python] Fix to_pandas() export for timestamps within structs
ARROW-9195 - [Java] Wrong usage of Unsafe.get from bytearray in ByteFunctionsHelper class
ARROW-7610 - [Java] Finish support for 64 bit int allocations
ARROW-8115 - [Python] Conversion when mixing NaT and datetime objects not working
ARROW-8392 - [Java] Fix overflow related corner cases for vector value comparison
ARROW-8537 - [C++] Performance regression from ARROW-8523
ARROW-8803 - [Java] Row count should be set before loading buffers in VectorLoader
ARROW-8911 - [C++] Slicing a ChunkedArray with zero chunks segfaults
View release notes here:
https://arrow.apache.org/release/1.0.1.htmlhttps://arrow.apache.org/release/1.0.0.html
### Why are the changes needed?
Upgrade brings fixes, improvements and stability guarantees.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests with pyarrow 1.0.0 and 1.0.1
Closes#29686 from BryanCutler/arrow-upgrade-100-SPARK-32312.
Authored-by: Bryan Cutler <cutlerb@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In Spark 3.0.0, the SparkGetColumnsOperation can not recognize NULL columns but now we can because the side effect of https://issues.apache.org/jira/browse/SPARK-32696 / f14f3742e0, but the test coverage for this change was not added.
In Spark, the column size for null fields should be 1, in this PR, we set the right column size for the null type.
### Why are the changes needed?
test coverage and fix the client-side information about the null type through jdbc
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
added ut both for this pr and SPARK-32696
Closes#29687 from yaooqinn/SPARK-32826.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch proposes to check `ignoreNullability` parameter recursively in `equalsStructurally` method.
### Why are the changes needed?
`equalsStructurally` is used to check type equality. We can optionally ask to ignore nullability check. But the parameter `ignoreNullability` is not passed recursively down to nested types. So it produces weird error like:
```
data type mismatch: argument 3 requires array<array<string>> type, however ... is of array<array<string>> type.
```
when running the query `select aggregate(split('abcdefgh',''), array(array('')), (acc, x) -> array(array( x ) ) )`.
### Does this PR introduce _any_ user-facing change?
Yes, fixed a bug when running user query.
### How was this patch tested?
Unit tests.
Closes#29698 from viirya/SPARK-32819.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to fix the test coverage at `DataStreamReaderWriterSuite`.
### Why are the changes needed?
Currently, the test case checks `DataStreamReader` options instead of `DataStreamWriter` options.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the revised test case.
Closes#29701 from dongjoon-hyun/SPARK-32836.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR is a follow up to https://github.com/apache/spark/pull/29543#discussion_r485409606, which correctly points out that the check for the empty string is not necessary.
### Why are the changes needed?
The unnecessary check actually could cause more confusion.
For example,
```scala
scala> Seq(1).toDF.write.option("path", "/tmp/path1").parquet("")
java.lang.IllegalArgumentException: Can not create a Path from an empty string
at org.apache.hadoop.fs.Path.checkPathArg(Path.java:168)
```
even when `path` option is available. This PR addresses to fix this confusion.
### Does this PR introduce _any_ user-facing change?
Yes, now the above example prints the consistent exception message whether the path parameter value is empty or not.
```scala
scala> Seq(1).toDF.write.option("path", "/tmp/path1").parquet("")
org.apache.spark.sql.AnalysisException: There is a 'path' option set and save() is called with a path parameter. Either remove the path option, or call save() without the parameter. To ignore this check, set 'spark.sql.legacy.pathOptionBehavior.enabled' to 'true'.;
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:290)
at org.apache.spark.sql.DataFrameWriter.parquet(DataFrameWriter.scala:856)
... 47 elided
```
### How was this patch tested?
Added unit tests.
Closes#29697 from imback82/SPARK-32516-followup.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Make MicroBatchExecution explicitly call `getBatch` when the start and end offsets are the same.
### Why are the changes needed?
Structured Streaming micro-batch engine has the contract with V1 data sources that, after a restart, it will call `source.getBatch()` on the last batch attempted before the restart. However, a very rare combination of sequences violates this contract. It occurs only when
- The streaming query has specific types of stateful operations with watermarks (e.g., aggregation in append, mapGroupsWithState with timeouts).
- These queries can execute a batch even without new data when the previous updates the watermark and the stateful ops are such that the new watermark can cause new output/cleanup. Such batches are called no-data-batches.
- The last batch before termination was an incomplete no-data-batch. Upon restart, the micro-batch engine fails to call `source.getBatch` when attempting to re-execute the incomplete no-data-batch.
This occurs because no-data-batches has the same and end offsets, and when a batch is executed, if the start and end offset is same then calling `source.getBatch` is skipped as it is assumed the generated plan will be empty. This only affects V1 data sources like Delta and Autoloader which rely on this invariant to detect in the source whether the query is being started from scratch or restarted.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
New unit test with a mock v1 source that fails without the fix.
Closes#29651 from tdas/SPARK-32794.
Authored-by: Tathagata Das <tathagata.das1565@gmail.com>
Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com>
### What changes were proposed in this pull request?
`--` method of `AttributeSet` behave differently under Scala 2.12 and 2.13 because `--` method of `LinkedHashSet` in Scala 2.13 can't maintains the insertion order.
This pr use a Scala 2.12 based code to ensure `--` method of AttributeSet have same behavior under Scala 2.12 and 2.13.
### Why are the changes needed?
The behavior of `AttributeSet` needs to be compatible with Scala 2.12 and 2.13
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Scala 2.12: Pass the Jenkins or GitHub Action
Scala 2.13: Manual test sub-suites of `PlanStabilitySuite`
- **Before** :293 TESTS FAILED
- **After**:13 TESTS FAILED(The remaining failures are not associated with the current issue)
Closes#29689 from LuciferYang/SPARK-32755-FOLLOWUP.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The purpose of this pr is to partial resolve [SPARK-32808](https://issues.apache.org/jira/browse/SPARK-32808), total of 26 failed test cases were fixed, the related suite as follow:
- `StreamingAggregationSuite` related test cases (2 FAILED -> Pass)
- `GeneratorFunctionSuite` related test cases (2 FAILED -> Pass)
- `UDFSuite` related test cases (2 FAILED -> Pass)
- `SQLQueryTestSuite` related test cases (5 FAILED -> Pass)
- `WholeStageCodegenSuite` related test cases (1 FAILED -> Pass)
- `DataFrameSuite` related test cases (3 FAILED -> Pass)
- `OrcV1QuerySuite\OrcV2QuerySuite` related test cases (4 FAILED -> Pass)
- `ExpressionsSchemaSuite` related test cases (1 FAILED -> Pass)
- `DataFrameStatSuite` related test cases (1 FAILED -> Pass)
- `JsonV1Suite\JsonV2Suite\JsonLegacyTimeParserSuite` related test cases (6 FAILED -> Pass)
The main change of this pr as following:
- Fix Scala 2.13 compilation problems in `ShuffleBlockFetcherIterator` and `Analyzer`
- Specified `Seq` to `scala.collection.Seq` in `objects.scala` and `GenericArrayData` because internal use `Seq` maybe `mutable.ArraySeq` and not easy to call `.toSeq`
- Should specified `Seq` to `scala.collection.Seq` when we call `Row.getAs[Seq]` and `Row.get(i).asInstanceOf[Seq]` because the data maybe `mutable.ArraySeq` but `Seq` is `immutable.Seq` in Scala 2.13
- Use a compatible way to let `+` and `-` method of `Decimal` having the same behavior in Scala 2.12 and Scala 2.13
- Call `toList` in `RelationalGroupedDataset.toDF` method when `groupingExprs` is `Stream` type because `Stream` can't serialize in Scala 2.13
- Add a manual sort to `classFunsMap` in `ExpressionsSchemaSuite` because `Iterable.groupBy` in Scala 2.13 has different result with `TraversableLike.groupBy` in Scala 2.12
### Why are the changes needed?
We need to support a Scala 2.13 build.
### Does this PR introduce _any_ user-facing change?
Should specified `Seq` to `scala.collection.Seq` when we call `Row.getAs[Seq]` and `Row.get(i).asInstanceOf[Seq]` because the data maybe `mutable.ArraySeq` but the `Seq` is `immutable.Seq` in Scala 2.13
### How was this patch tested?
- Scala 2.12: Pass the Jenkins or GitHub Action
- Scala 2.13: Do the following:
```
dev/change-scala-version.sh 2.13
mvn clean install -DskipTests -pl sql/core -Pscala-2.13 -am
mvn test -pl sql/core -Pscala-2.13
```
**Before**
```
Tests: succeeded 8166, failed 319, canceled 1, ignored 52, pending 0
*** 319 TESTS FAILED ***
```
**After**
```
Tests: succeeded 8204, failed 286, canceled 1, ignored 52, pending 0
*** 286 TESTS FAILED ***
```
Closes#29660 from LuciferYang/SPARK-32808.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
If no active SparkSession is available, let `FileSourceScanExec.needsUnsafeRowConversion` look at default SQL config of ParquetSource vectorized reader instead of failing the query execution.
### Why are the changes needed?
Fix a bug that if no active SparkSession is available, file-based data source scan for Parquet Source will throw exception.
### Does this PR introduce _any_ user-facing change?
Yes, this change fixes the bug.
### How was this patch tested?
Unit test.
Closes#29667 from viirya/SPARK-32813.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In the PR, I propose to move the test `SPARK-32810: CSV and JSON data sources should be able to read files with escaped glob metacharacter in the paths` from `DataFrameReaderWriterSuite` to `CSVSuite` and to `JsonSuite`. This will allow to run the same test in `CSVv1Suite`/`CSVv2Suite` and in `JsonV1Suite`/`JsonV2Suite`.
### Why are the changes needed?
To improve test coverage by checking JSON/CSV datasources v1 and v2.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running affected test suites:
```
$ build/sbt "sql/test:testOnly org.apache.spark.sql.execution.datasources.csv.*"
$ build/sbt "sql/test:testOnly org.apache.spark.sql.execution.datasources.json.*"
```
Closes#29684 from MaxGekk/globbing-paths-when-inferring-schema-dsv2.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Fix indentation and clean up view in the test added by https://github.com/apache/spark/pull/29593.
### Why are the changes needed?
Address review comments in https://github.com/apache/spark/pull/29665.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Updated test.
Closes#29682 from manuzhang/spark-32753-followup.
Authored-by: manuzhang <owenzhang1990@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
In `SubqueryBroadcastExec.relationFuture`, if the `broadcastRelation` is an `EmptyHashedRelation`, then `broadcastRelation.keys()` will throw `UnsupportedOperationException`.
### Why are the changes needed?
To fix a bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added a new test.
Closes#29671 from wzhfy/dpp_empty_broadcast.
Authored-by: Zhenhua Wang <wzh_zju@163.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Before SPARK-31511 is fixed, `BytesToBytesMap` iterator() is not thread-safe and may cause data inaccuracy.
We need to add a unit test.
### Why are the changes needed?
Increase test coverage to ensure that iterator() is thread-safe.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
add ut
Closes#29669 from cxzl25/SPARK-31511-test.
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}