This change refactors the portions of the ExecutorAllocationManager class that
track executor state into a new class, to achieve a few goals:
- make the code easier to understand
- better separate concerns (task backlog vs. executor state)
- less synchronization between event and allocation threads
- less coupling between the allocation code and executor state tracking
The executor tracking code was moved to a new class (ExecutorMonitor) that
encapsulates all the logic of tracking what happens to executors and when
they can be timed out. The logic to actually remove the executors remains
in the EAM, since it still requires information that is not tracked by the
new executor monitor code.
In the executor monitor itself, of interest, specifically, is a change in
how cached blocks are tracked; instead of polling the block manager, the
monitor now uses events to track which executors have cached blocks, and
is able to detect also unpersist events and adjust the time when the executor
should be removed accordingly. (That's the bug mentioned in the PR title.)
Because of the refactoring, a few tests in the old EAM test suite were removed,
since they're now covered by the newly added test suite. The EAM suite was
also changed a little bit to not instantiate a SparkContext every time. This
allowed some cleanup, and the tests also run faster.
Tested with new and updated unit tests, and with multiple TPC-DS workloads
running with dynamic allocation on; also some manual tests for the caching
behavior.
Closes#24704 from vanzin/SPARK-20286.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
Use objects in `ResourceName` to represent resource names.
## How was this patch tested?
Existing tests.
Closes#24799 from jiangxb1987/ResourceName.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds support to schedule tasks with extra resource requirements (eg. GPUs) on executors with available resources. It also introduce a new method `TaskContext.resources()` so tasks can access available resource addresses allocated to them.
## How was this patch tested?
* Added new end-to-end test cases in `SparkContextSuite`;
* Added new test case in `CoarseGrainedSchedulerBackendSuite`;
* Added new test case in `CoarseGrainedExecutorBackendSuite`;
* Added new test case in `TaskSchedulerImplSuite`;
* Added new test case in `TaskSetManagerSuite`;
* Updated existing tests.
Closes#24374 from jiangxb1987/gpu.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
This PR targets to deduplicate hardcoded `py4j-0.10.8.1-src.zip` in order to make py4j upgrade easier.
## How was this patch tested?
N/A
Closes#24770 from HyukjinKwon/minor-py4j-dedup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR targets to add an integrated test base for various UDF test cases so that Scalar UDF, Python UDF and Scalar Pandas UDFs can be tested in SBT & Maven tests.
### Problem
One of the problems we face is that: `ExtractPythonUDFs` (for Python UDF and Scalar Pandas UDF) has unevaluable expressions that always has to be wrapped with special plans. This special rule seems producing many issues, for instance, SPARK-27803, SPARK-26147, SPARK-26864, SPARK-26293, SPARK-25314 and SPARK-24721.
### Why do we have less test cases dedicated for SQL and plans with Python UDFs?
We have virtually no such SQL (or plan) dedicated tests in PySpark to catch such issues because:
- A developer should know all the analyzer, the optimizer, SQL, PySpark, Py4J and version differences in Python to write such good test cases
- To test plans, we should access to plans in JVM via Py4J which is tricky, messy and duplicates Scala test cases
- Usually we just add end-to-end test cases in PySpark therefore there are not so many dedicated examples to refer to write in PySpark
It is also a non-trivial overhead to switch test base and method (IMHO).
### How does this PR fix?
This PR adds Python UDF and Scalar Pandas UDF into our `*.sql` file based test base in runtime of SBT / Maven test cases. It generates Python-pickled instance (consisting of return type and Python native function) that is used in Python or Scalar Pandas UDF and directly brings into JVM.
After that, (we don't interact via Py4J) run the tests directly in JVM - we can just register and run Python UDF and Scalar Pandas UDF in JVM.
Currently, I only integrated this change into SQL file based testing. This is how works with test files under `udf` directory:
After the test files under 'inputs/udf' directory are detected, it creates three test cases:
- Scala UDF test case with a Scalar UDF registered named 'udf'.
- Python UDF test case with a Python UDF registered named 'udf' iff Python executable and pyspark are available.
- Scalar Pandas UDF test case with a Scalar Pandas UDF registered named 'udf' iff Python executable, pandas, pyspark and pyarrow are available.
Therefore, UDF test cases should have single input and output files but executed by three different types of UDFs.
For instance,
```sql
CREATE TEMPORARY VIEW ta AS
SELECT udf(a) AS a, udf('a') AS tag FROM t1
UNION ALL
SELECT udf(a) AS a, udf('b') AS tag FROM t2;
CREATE TEMPORARY VIEW tb AS
SELECT udf(a) AS a, udf('a') AS tag FROM t3
UNION ALL
SELECT udf(a) AS a, udf('b') AS tag FROM t4;
SELECT tb.* FROM ta INNER JOIN tb ON ta.a = tb.a AND ta.tag = tb.tag;
```
will be ran 3 times with Scalar UDF, Python UDF and Scalar Pandas UDF each.
### Appendix
Plus, this PR adds `IntegratedUDFTestUtils` which enables to test and execute Python UDF and Scalar Pandas UDFs as below:
To register Python UDF in SQL:
```scala
IntegratedUDFTestUtils.registerTestUDF(TestPythonUDF(name = "udf"), spark)
```
To register Scalar Pandas UDF in SQL:
```scala
IntegratedUDFTestUtils.registerTestUDF(TestScalarPandasUDF(name = "udf"), spark)
```
To use it in Scala API:
```scala
spark.select(expr("udf(1)").show()
```
To use it in SQL:
```scala
sql("SELECT udf(1)").show()
```
This util could be used in the future for better coverage with Scala API combinations as well.
## How was this patch tested?
Tested via the command below:
```bash
build/sbt "sql/test-only *SQLQueryTestSuite -- -z udf/udf-inner-join.sql"
```
```
[info] SQLQueryTestSuite:
[info] - udf/udf-inner-join.sql - Scala UDF (5 seconds, 47 milliseconds)
[info] - udf/udf-inner-join.sql - Python UDF (4 seconds, 335 milliseconds)
[info] - udf/udf-inner-join.sql - Scalar Pandas UDF (5 seconds, 423 milliseconds)
```
[python] unavailable:
```
[info] SQLQueryTestSuite:
[info] - udf/udf-inner-join.sql - Scala UDF (4 seconds, 577 milliseconds)
[info] - udf/udf-inner-join.sql - Python UDF is skipped because [pyton] and/or pyspark were not available. !!! IGNORED !!!
[info] - udf/udf-inner-join.sql - Scalar Pandas UDF is skipped because pyspark,pandas and/or pyarrow were not available in [pyton]. !!! IGNORED !!!
```
pyspark unavailable:
```
[info] SQLQueryTestSuite:
[info] - udf/udf-inner-join.sql - Scala UDF (4 seconds, 991 milliseconds)
[info] - udf/udf-inner-join.sql - Python UDF is skipped because [python] and/or pyspark were not available. !!! IGNORED !!!
[info] - udf/udf-inner-join.sql - Scalar Pandas UDF is skipped because pyspark,pandas and/or pyarrow were not available in [python]. !!! IGNORED !!!
```
pandas and/or pyarrow unavailable:
```
[info] SQLQueryTestSuite:
[info] - udf/udf-inner-join.sql - Scala UDF (4 seconds, 713 milliseconds)
[info] - udf/udf-inner-join.sql - Python UDF (3 seconds, 89 milliseconds)
[info] - udf/udf-inner-join.sql - Scalar Pandas UDF is skipped because pandas and/or pyarrow were not available in [python]. !!! IGNORED !!!
```
Closes#24752 from HyukjinKwon/udf-tests.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
I found the docs of `spark.driver.memoryOverhead` and `spark.executor.memoryOverhead` exists a little ambiguity.
For example, the origin docs of `spark.driver.memoryOverhead` start with `The amount of off-heap memory to be allocated per driver in cluster mode`.
But `MemoryManager` also managed a memory area named off-heap used to allocate memory in tungsten mode.
So I think the description of `spark.driver.memoryOverhead` always make confused.
`spark.executor.memoryOverhead` has the same confused with `spark.driver.memoryOverhead`.
## How was this patch tested?
Exists UT.
Closes#24671 from beliefer/improve-docs-of-overhead.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Add ability to map the spark resource configs spark.{executor/driver}.resource.{resourceName} to kubernetes Container builder so that we request resources (gpu,s/fpgas/etc) from kubernetes.
Note that the spark configs will overwrite any resource configs users put into a pod template.
I added a generic vendor config which is only used by kubernetes right now. I intentionally didn't put it into the kubernetes config namespace just to avoid adding more config prefixes.
I will add more documentation for this under jira SPARK-27492. I think it will be easier to do all at once to get cohesive story.
## How was this patch tested?
Unit tests and manually testing on k8s cluster.
Closes#24703 from tgravescs/SPARK-27362.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
Change the Driver resource discovery argument for standalone mode to be a file rather then separate address configs per resource. This makes it consistent with how the Executor is doing it and makes it more flexible in the future, and it makes for less configs if you have multiple resources.
## How was this patch tested?
Unit tests and basic manually testing to make sure files were parsed properly.
Closes#24730 from tgravescs/SPARK-27835-driver-resourcesFile.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
This pr wrap all `PrintWriter` with `Utils.tryWithResource` to prevent resource leak.
## How was this patch tested?
Existing test
Closes#24739 from wangyum/SPARK-27875.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
`A very little spelling mistake.`
## How was this patch tested?
No
Closes#24710 from LiShuMing/minor-spelling.
Authored-by: ShuMingLi <ming.moriarty@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently system properties are not redacted. This PR fixes that, so that any credentials passed as System properties are redacted as well.
## How was this patch tested?
Manual test. Run the following and see the UI.
```
bin/spark-shell --conf 'spark.driver.extraJavaOptions=-DMYSECRET=app'
```
Closes#24733 from aaruna/27869.
Authored-by: Aaruna <aaruna.godthi@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
### Standalone HA Background
In Spark Standalone HA mode, we'll have multiple masters running at the same time. But, there's only one master leader, which actively serving scheduling requests. Once this master leader crashes, other masters would compete for the leader and only one master is guaranteed to be elected as new master leader, which would reconstruct the state from the original master leader and continute to serve scheduling requests.
### Related Issues
#2828 firstly introduces the bug of *duplicate Worker registration*, and #3447 fixed it. But there're still corner cases(see SPARK-23191 for details) where #3447 can not cover it:
* CASE 1
(1) Initially, Worker registered with Master A.
(2) After a while, the connection channel between Master A and Worker becomes inactive(e.g. due to network drop), and Worker is notified about that by calling `onDisconnected` from NettyRpcEnv
(3) When Worker invokes `onDisconnected`, then, it will attempt to reconnect to all masters(including Master A)
(4) At the meanwhile, network between Worker and Master A recover, Worker successfully register to Master A again
(5) Master A response with `RegisterWorkerFailed("Duplicate worker ID")`
(6) Worker receives that msg, exit
* CASE 2
(1) Master A lost leadership(sends `RevokedLeadership` to itself). Master B takes over and recovery everything from master A(which would register workers for the first time in Master B) and sends `MasterChanged` to Worker
(2) Before Master A receives `RevokedLeadership`, it receives a late `HeartBeat` from Worker(which had been removed in Master A due to heartbeat timeout previously), so it sends `ReconnectWorker` to worker
(3) Worker receives `MasterChanged` before `ReconnectWorker` , changing masterRef to Master B
(4) Subsequently, Worker receives `ReconnectWorker` from Master A, then it reconnects to all masters
(5) Master B receives register request again from the Worker, response with `RegisterWorkerFailed("Duplicate worker ID")`
(6) Worker receives that msg, exit
In CASE 1, it is difficult for the Worker to know Master A's state. Normally, Worker thinks Master A has already died and is impossible that Master A would response with Worker's re-connect request.
In CASE 2, we can see race condition between `RevokedLeadership` and `HeartBeat`. Actually, Master A has already been revoked leadership while processing `HeartBeat` msg. That's means the state between Master and Zookeeper could be out of sync for a while.
### Solutions
In this PR, instead of exiting Worker process when *duplicate Worker registration* happens, we suggest to log warn about it. This would be fine since Master actually perform no-op when it receives duplicate registration from a Worker. In turn, Worker could continue living with that Master normally without any side effect.
## How was this patch tested?
Tested Manually.
I followed the steps as Neeraj Gupta suggested in JIRA SPARK-23191 to reproduce the case 1.
Before this pr, Worker would be DEAD from UI.
After this pr, Worker just warn the duplicate register behavior (as you can see the second last row in log snippet below), and still be ALIVE from UI.
```
19/05/09 20:58:32 ERROR Worker: Connection to master failed! Waiting for master to reconnect...
19/05/09 20:58:32 INFO Worker: wuyi.local:7077 Disassociated !
19/05/09 20:58:32 INFO Worker: Connecting to master wuyi.local:7077...
19/05/09 20:58:32 ERROR Worker: Connection to master failed! Waiting for master to reconnect...
19/05/09 20:58:32 INFO Worker: Not spawning another attempt to register with the master, since there is an attempt scheduled already.
19/05/09 20:58:37 WARN TransportClientFactory: DNS resolution for wuyi.local/127.0.0.1:7077 took 5005 ms
19/05/09 20:58:37 INFO TransportClientFactory: Found inactive connection to wuyi.local/127.0.0.1:7077, creating a new one.
19/05/09 20:58:37 INFO TransportClientFactory: Successfully created connection to wuyi.local/127.0.0.1:7077 after 3 ms (0 ms spent in bootstraps)
19/05/09 20:58:37 WARN Worker: Duplicate registration at master spark://wuyi.local:7077
19/05/09 20:58:37 INFO Worker: Successfully registered with master spark://wuyi.local:7077
```
Closes#24569 from Ngone51/fix-worker-dup-register-error.
Authored-by: wuyi <ngone_5451@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR exposes additional metrics in `status.api.v1.StageData`. These metrics were already computed for `LiveStage`, but they were never exposed to the user. This includes extra metrics about the JVM GC, executor (de)serialization times, shuffle reads and writes, and more.
## How was this patch tested?
Existing tests.
cc hvanhovell
Closes#24011 from tomvanbussel/SPARK-27071.
Authored-by: Tom van Bussel <tom.vanbussel@databricks.com>
Signed-off-by: herman <herman@databricks.com>
## What changes were proposed in this pull request?
As the current approach in OneForOneBlockFetcher, we reuse the OpenBlocks protocol to describe the fetch request for shuffle blocks, and it causes the extension work for shuffle fetching like #19788 and #24110 very awkward.
In this PR, we split the fetch request for shuffle blocks from OpenBlocks which named FetchShuffleBlocks. It's a loose bind with ShuffleBlockId and can easily extend by adding new fields in this protocol.
## How was this patch tested?
Existing and new added UT.
Closes#24565 from xuanyuanking/SPARK-27665.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
There are no unit test cases for this SortShuffleWriter,so add new test cases;
## How was this patch tested?
new test cases
Closes#24080 from wangjiaochun/UtestForSortShuffleWriter.
Authored-by: 10087686 <wang.jiaochun@zte.com.cn>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR aims to show Spark version at application lists of Spark History UI.
From the following, the first `Version` column is added. When the application has multiple attempts, this will show the first attempt's version number.
**COMPLETED APPLICATION LIST**
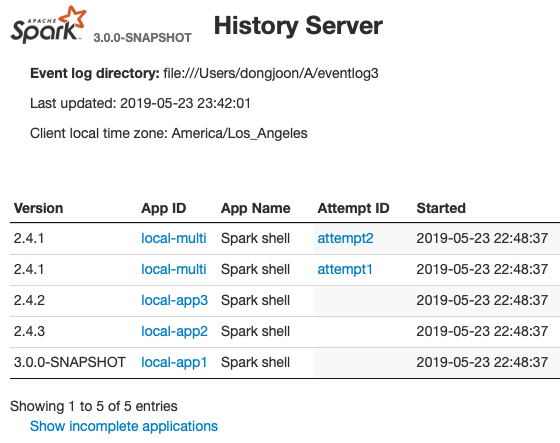
**INCOMPLETE APPLICATION LIST**
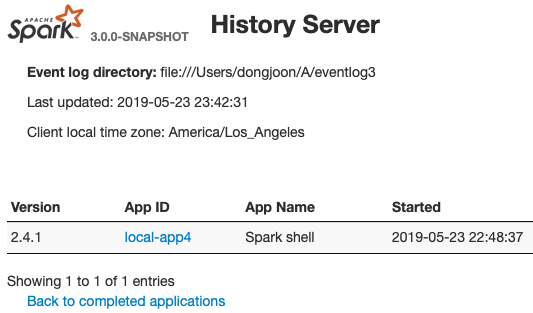
## How was this patch tested?
Manually launch Spark history server and see the UI. Please use *Private New Window (Safari)* or *New Incognito Window (Chrome)* to avoid browser caching.
```
sbin/start-history-server.sh
```
Closes#24694 from dongjoon-hyun/SPARK-27830.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
In the PR the config `spark.shuffle.service.fetch.rdd.enabled` default is changed to **false** to avoid breaking any compatibility with older external shuffle service installations. As external shuffle service is deployed separately and disk persisted RDD block fetching had even introduced new network messages (`RemoveBlocks` and `BlocksRemoved`) and changed the behaviour of the already existing fetching: extended it for RDD blocks.
## How was this patch tested?
With existing unit tests.
Closes#24697 from attilapiros/minor-ext-shuffle-fetch-disabled.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
# What changes were proposed in this pull request?
## Problem statement
An executor which has persisted blocks does not consider to be idle and this way ready to be released by dynamic allocation after the regular timeout `spark.dynamicAllocation.executorIdleTimeout` but there is separate configuration `spark.dynamicAllocation.cachedExecutorIdleTimeout` which defaults to `Integer.MAX_VALUE`. This is because releasing the executor also means losing the persisted blocks (as the metadata for individual blocks called `BlockInfo` are kept in memory) and when the RDD is referenced latter on this lost blocks will be recomputed.
On the other hand keeping the executors too long without any task to work on is also a waste of resources (as executors are reserved for the application by the resource manager).
## Solution
This PR focuses on the first part of SPARK-25888: it extends the external shuffle service with the capability to serve RDD blocks which are persisted on the local disk store by the executors. Moreover when this feature is enabled by setting the `spark.shuffle.service.fetch.rdd.enabled` config to true and a block is reported to be persisted on to disk the external shuffle service instance running on the same host as the executor is also registered (along with the reporting block manager) as a possible location for fetching it.
## Some implementation detail
Some explanation about the decisions made during the development:
- the location list to fetch a block was randomized but the groups (same host, same rack, others) order was kept. In this PR the order of groups are kept and external shuffle service added to the end of the each group.
- `BlockManagerInfo` is not introduced for external shuffle service but only a lightweight solution is taken. A hash map from `BlockId` to `BlockStatus` is introduced. A type alias would make the source more readable but I know it is discouraged. On the other hand a new class wrapping this hash map would introduce unnecessary indirection.
- when this feature is on the cleanup triggered during removing of executors (which is handled in `ExternalShuffleBlockResolver`) is modified to keep the disk persisted RDD blocks. This cleanup is triggered in standalone mode when the `spark.storage.cleanupFilesAfterExecutorExit` config is set.
- the unpersisting of an RDD is extended to use the external shuffle service for disk persisted RDD blocks when the original executor which created the blocks are already released. New block transport messages are introduced to support this: `RemoveBlocks` and `BlocksRemoved`.
# How was this patch tested?
## Unit tests
### ExternalShuffleServiceSuite
Here the complete use case is tested by the "SPARK-25888: using external shuffle service fetching disk persisted blocks" with a tiny difference: here the executor is killed manually, this way the test is a bit faster than waiting for the idle timeout.
### ExternalShuffleBlockHandlerSuite
Tests the fetching of the RDD blocks via the external shuffle service.
### BlockManagerInfoSuite
This a new suite. As the `BlockManagerInfo` behaviour depends very much on whether the external shuffle service enabled or not all the tests are executed with and without it.
### BlockManagerSuite
Tests the sorting of the block locations.
## Manually on YARN
Spark App was:
~~~scala
package com.mycompany
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.storage.StorageLevel
object TestAppDiskOnlyLevel {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test-app")
println("Attila: START")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(0 until 100, 10)
.map { i =>
println(s"Attila: calculate first rdd i=$i")
Thread.sleep(1000)
i
}
rdd.persist(StorageLevel.DISK_ONLY)
rdd.count()
println("Attila: First RDD is processed, waiting for 60 sec")
Thread.sleep(60 * 1000)
println("Attila: Num executors must be 0 as executorIdleTimeout is way over")
val rdd2 = sc.parallelize(0 until 10, 1)
.map(i => (i, 1))
.persist(StorageLevel.DISK_ONLY)
rdd2.count()
println("Attila: Second RDD with one partition (only one executors must be alive)")
// reduce runs as user code to detect the empty seq (empty blocks)
println("Calling collect on the first RDD: " + rdd.collect().reduce(_ + _))
println("Attila: STOP")
}
}
~~~
I have submitted with the following configuration:
~~~bash
spark-submit --master yarn \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.dynamicAllocation.executorIdleTimeout=30 \
--conf spark.dynamicAllocation.cachedExecutorIdleTimeout=90 \
--class com.mycompany.TestAppDiskOnlyLevel dyn_alloc_demo-core_2.11-0.1.0-SNAPSHOT-jar-with-dependencies.jar
~~~
Checked the result by filtering for the side effect of the task calculations:
~~~bash
[userserver ~]$ yarn logs -applicationId application_1556299359453_0001 | grep "Attila: calculate" | wc -l
WARNING: YARN_OPTS has been replaced by HADOOP_OPTS. Using value of YARN_OPTS.
19/04/26 10:31:59 INFO client.RMProxy: Connecting to ResourceManager at apiros-1.gce.company.com/172.31.115.165:8032
100
~~~
So it is only 100 task execution and not 200 (which would be the case for re-computation).
Moreover from the submit/launcher log we can see executors really stopped in between (see the new total is 0 before the last line):
~~~
[userserver ~]$ grep "Attila: Num executors must be 0" -B 2 spark-submit.log
19/04/26 10:24:27 INFO cluster.YarnScheduler: Executor 9 on apiros-3.gce.company.com killed by driver.
19/04/26 10:24:27 INFO spark.ExecutorAllocationManager: Existing executor 9 has been removed (new total is 0)
Attila: Num executors must be 0 as executorIdleTimeout is way over
~~~
[Full spark submit log](https://github.com/attilapiros/spark/files/3122465/spark-submit.log)
I have done a test also after changing the `DISK_ONLY` storage level to `MEMORY_ONLY` for the first RDD. After this change during the 60sec waiting no executor was removed.
Closes#24499 from attilapiros/SPARK-25888-final.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Added the driver functionality to get the resources.
The user interface is: SparkContext.resources - I called it this to match the TaskContext.resources api proposed in the other PR. Originally it was going to be called SparkContext.getResources but changed to be consistent, if people have strong feelings I can change it.
There are 2 ways the driver can discover what resources it has.
1) user specifies a discoveryScript, this is similar to the executors and is meant for yarn and k8s where they don't tell you what you were allocated but you are running in isolated environment.
2) read the config spark.driver.resource.resourceName.addresses. The config is meant to be used with standalone mode where the Worker will have to assign what GPU addresses the Driver is allowed to use by setting that config.
When the user runs a spark application, if they want the driver to have GPU's they would specify the conf spark.driver.resource.gpu.count=X where x is the number they want. If they are running on yarn or k8s they will also have to specify the discoveryScript as specified above, if they are on standalone mode and cluster is setup properly they wouldn't have to specify anything else. We could potentially get rid of the spark.driver.resources.gpu.addresses config which is really meant to be an internal config for worker to set if the standalone mode Worker wanted to write a discoveryScript out and set that for the user. I'll wait for the jira that implements that to decide if we can remove.
- This PR also has changes to be consistent about using resourceName everywhere.
- change the config names from POSTFIX to SUFFIX to be more consistent with other areas in Spark
- Moved the config checks around a bit since now used by both executor and driver. Note those might overlap a bit with https://github.com/apache/spark/pull/24374 so we will have to figure out which one should go in first.
## How was this patch tested?
Unit tests and manually test the interface.
Closes#24615 from tgravescs/SPARK-27488.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
Unset InputFileBlockHolder at the end of tasks to stop the file name from leaking over to other tasks in the same thread. This happens in particular in Pyspark because of its complex threading model.
## How was this patch tested?
new pyspark test
Closes#24605 from jose-torres/fix254.
Authored-by: Jose Torres <torres.joseph.f+github@gmail.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
## What changes were proposed in this pull request?
- solves the current issue with --packages in cluster mode (there is no ticket for it). Also note of some [issues](https://issues.apache.org/jira/browse/SPARK-22657) of the past here when hadoop libs are used at the spark submit side.
- supports spark.jars, spark.files, app jar.
It works as follows:
Spark submit uploads the deps to the HCFS. Then the driver serves the deps via the Spark file server.
No hcfs uris are propagated.
The related design document is [here](https://docs.google.com/document/d/1peg_qVhLaAl4weo5C51jQicPwLclApBsdR1To2fgc48/edit). the next option to add is the RSS but has to be improved given the discussion in the past about it (Spark 2.3).
## How was this patch tested?
- Run integration test suite.
- Run an example using S3:
```
./bin/spark-submit \
...
--packages com.amazonaws:aws-java-sdk:1.7.4,org.apache.hadoop:hadoop-aws:2.7.6 \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.memory=1G \
--conf spark.kubernetes.namespace=spark \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-sa \
--conf spark.driver.memory=1G \
--conf spark.executor.instances=2 \
--conf spark.sql.streaming.metricsEnabled=true \
--conf "spark.driver.extraJavaOptions=-Divy.cache.dir=/tmp -Divy.home=/tmp" \
--conf spark.kubernetes.container.image.pullPolicy=Always \
--conf spark.kubernetes.container.image=skonto/spark:k8s-3.0.0 \
--conf spark.kubernetes.file.upload.path=s3a://fdp-stavros-test \
--conf spark.hadoop.fs.s3a.access.key=... \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.hadoop.fs.s3a.fast.upload=true \
--conf spark.kubernetes.executor.deleteOnTermination=false \
--conf spark.hadoop.fs.s3a.secret.key=... \
--conf spark.files=client:///...resolv.conf \
file:///my.jar **
```
Added integration tests based on [Ceph nano](https://github.com/ceph/cn). Looks very [active](http://www.sebastien-han.fr/blog/2019/02/24/Ceph-nano-is-getting-better-and-better/).
Unfortunately minio needs hadoop >= 2.8.
Closes#23546 from skonto/support-client-deps.
Authored-by: Stavros Kontopoulos <stavros.kontopoulos@lightbend.com>
Signed-off-by: Erik Erlandson <eerlands@redhat.com>
## What changes were proposed in this pull request?
avoid hardcoded configs in `SparkConf` and `SparkSubmit` and test
## How was this patch tested?
N/A
Closes#24631 from wenxuanguan/minor-fix.
Authored-by: wenxuanguan <choose_home@126.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
The details of the PR are explored in-depth in the sub-tasks of the umbrella jira SPARK-27726.
Briefly:
1. Stop issuing asynchronous requests to cleanup elements in the tracking store when a request is already pending
2. Fix a couple of thread-safety issues (mutable state and mis-ordered updates)
3. Move Summary deletion outside of Stage deletion loop like Tasks already are
4. Reimplement multi-delete in a removeAllKeys call which allows InMemoryStore to implement it in a performant manner.
5. Some generic typing and exception handling cleanup
We see about five orders of magnitude improvement in the deletion code, which for us is the difference between a server that needs restarting daily, and one that is stable over weeks.
Unit tests for the fire-once asynchronous code and the removeAll calls in both LevelDB and InMemoryStore are supplied. It was noted that the testing code for the LevelDB and InMemoryStore is highly repetitive, and should probably be merged, but we did not attempt that in this PR.
A version of this code was run in our production 2.3.3 and we were able to sustain higher throughput without going into GC overload (which was happening on a daily basis some weeks ago).
A version of this code was also put under a purpose-built Performance Suite of tests to verify performance under both types of Store implementations for both before and after code streams and for both total and partial delete cases (this code is not included in this PR).
Closes#24616 from davidnavas/PentaBugFix.
Authored-by: David Navas <davidn@clearstorydata.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
There are several kinds of shuffle client, blockTransferService and externalShuffleClient.
For the externalShuffleClient, there are relative external shuffle service, which guarantees the shuffle block data and regardless the state of executors.
For the blockTransferService, it is used to fetch broadcast block, and fetch the shuffle data when external shuffle service is not enabled.
When fetching data by using blockTransferService, the shuffle client would connect relative executor's blockManager, so if the relative executor is dead, it would never fetch successfully.
When spark.shuffle.service.enabled is true and spark.dynamicAllocation.enabled is true, the executor will be removed while it has been idle for more than idleTimeout.
If a blockTransferService create connection to relative executor successfully, but the relative executor is removed when beginning to fetch broadcast block, it would retry (see RetryingBlockFetcher), which is Ineffective.
If the spark.shuffle.io.retryWait and spark.shuffle.io.maxRetries is big, such as 30s and 10 times, it would waste 5 minutes.
In this PR, we check whether relative executor is alive before retry.
## How was this patch tested?
Unit test.
Closes#24533 from turboFei/SPARK-27637.
Authored-by: hustfeiwang <wangfei3@corp.netease.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Kafka related Spark parameters has to start with `spark.kafka.` and not with `spark.sql.`. Because of this I've renamed `spark.sql.kafkaConsumerCache.capacity`.
Since Kafka consumer caching is not documented I've added this also.
## How was this patch tested?
Existing + added unit test.
```
cd docs
SKIP_API=1 jekyll build
```
and manual webpage check.
Closes#24590 from gaborgsomogyi/SPARK-27687.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
This feature allows proxy servers to identify the actual request user
using a request parameter, and performs access control checks against
that user instead of the authenticated user. Impersonation is only
allowed if the authenticated user is configured as an admin.
The request parameter used ("doAs") matches the one currently used by
Knox, but it should be easy to change / customize if different proxy
servers use a different way of identifying the original user.
Tested with updated unit tests and also with a live server behind Knox.
Closes#24582 from vanzin/SPARK-27678.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This replaces use of collection classes like `MutableList` and `ArrayStack` with workalikes that are available in 2.12, as they will be removed in 2.13. It also removes use of `.to[Collection]` as its uses was superfluous anyway. Removing `collection.breakOut` will have to wait until 2.13
## How was this patch tested?
Existing tests
Closes#24586 from srowen/SPARK-27682.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This removes usage of `Traversable`, which is removed in Scala 2.13. This is mostly an internal change, except for the change in the `SparkConf.setAll` method. See additional comments below.
## How was this patch tested?
Existing tests.
Closes#24584 from srowen/SPARK-27680.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
The Pull Request to add datatables to stage page SPARK-21809 got merged. The search functionality in those datatables being a great improvement for searching through a large number of tasks, also performs search over the raw data rather than the formatted data displayed in the tables. It would be great if the search can happen for the formatted data as well.
## What changes were proposed in this pull request?
Added code to enable searching over displayed data in tables e.g. searching on "165.7 MiB" or "0.3 ms" will now return the search results. Also, earlier we were missing search for two columns in the task table "Shuffle Read Bytes" as well as "Shuffle Remote Reads", which I have added here.
## How was this patch tested?
Manual Tests
Closes#24419 from pgandhi999/SPARK-25719.
Authored-by: pgandhi <pgandhi@verizonmedia.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Add in GPU and generic resource type allocation to the executors.
Note this is part of a bigger feature for gpu-aware scheduling and is just how the executor find the resources. The general flow :
- users ask for a certain set of resources, for instance number of gpus - each cluster manager has a specific way to do this.
- cluster manager allocates a container or set of resources (standalone mode)
- When spark launches the executor in that container, the executor either has to be told what resources it has or it has to auto discover them.
- Executor has to register with Driver and tell the driver the set of resources it has so the scheduler can use that to schedule tasks that requires a certain amount of each of those resources
In this pr I added configs and arguments to the executor to be able discover resources. The argument to the executor is intended to be used by standalone mode or other cluster managers that don't have isolation so that it can assign specific resources to specific executors in case there are multiple executors on a node. The argument is a file contains JSON Array of ResourceInformation objects.
The discovery script is meant to be used in an isolated environment where the executor only sees the resources it should use.
Note that there will be follow on PRs to add other parts like the scheduler part. See the epic high level jira: https://issues.apache.org/jira/browse/SPARK-24615
## How was this patch tested?
Added unit tests and manually tested.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24406 from tgravescs/gpu-sched-executor-clean.
Authored-by: Thomas Graves <tgraves@nvidia.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
For the below three thread configuration items applied to both driver and executor,
spark.rpc.io.serverThreads
spark.rpc.io.clientThreads
spark.rpc.netty.dispatcher.numThreads,
we separate them to driver specifics and executor specifics.
spark.driver.rpc.io.serverThreads < - > spark.executor.rpc.io.serverThreads
spark.driver.rpc.io.clientThreads < - > spark.executor.rpc.io.clientThreads
spark.driver.rpc.netty.dispatcher.numThreads < - > spark.executor.rpc.netty.dispatcher.numThreads
Spark reads these specifics first and fall back to the common configurations.
## How was this patch tested?
We ran the SimpleMap app without shuffle for benchmark purpose to test Spark's scalability in HPC with omini-path NIC which has higher bandwidth than normal ethernet NIC.
Spark's base version is 2.4.0.
Spark ran in the Standalone mode. Driver was in a standalone node.
After the separation, the performance is improved a lot in 256 nodes and 512 nodes. see below test results of SimpleMapTask before and after the enhancement. You can view the tables in the [JIRA](https://issues.apache.org/jira/browse/SPARK-26632) too.
ds: spark.driver.rpc.io.serverThreads
dc: spark.driver.rpc.io.clientThreads
dd: spark.driver.rpc.netty.dispatcher.numThreads
ed: spark.executor.rpc.netty.dispatcher.numThreads
time: Overall Time (s)
old time: Overall Time without Separation (s)
**Before:**
nodes | ds | dc | dd | ed | time
-- |-- | -- | -- | -- | --
128 nodes | 8 | 8 | 8 | 8 | 108
256 nodes | 8 | 8 | 8 | 8 | 196
512 nodes | 8 | 8 | 8 | 8 | 377
**After:**
nodes | ds | dc | dd | ed | time | improvement
-- | -- | -- | -- | -- | -- | --
128 nodes | 15 | 15 | 10 | 30 | 107 | 0.9%
256 nodes | 12 | 15 | 10 | 30 | 159 | 18.8%
512 nodes | 12 | 15 | 10 | 30 | 283 | 24.9%
Closes#23560 from zjf2012/thread_conf_separation.
Authored-by: jiafu.zhang@intel.com <jiafu.zhang@intel.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Python uses a prefetch approach to read the result from upstream and serve them in another thread, thus it's possible that if the children operator doesn't consume all the data then the Task cleanup may happen before Python side read process finishes, this in turn create a race condition that the block read locks are freed during Task cleanup and then the reader try to release the read lock it holds and find it has been released, in this case we shall hit a AssertionError.
We shall catch the AssertionError in PythonRunner and prevent this kill the Executor.
## How was this patch tested?
Hard to write a unit test case for this case, manually verified with failed job.
Closes#24542 from jiangxb1987/pyError.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This fixes an error when a PySpark local iterator, for both RDD and DataFrames, goes out of scope and the connection is closed before fully consuming the iterator. The error occurs on the JVM in the serving thread, when Python closes the local socket while the JVM is writing to it. This usually happens when there is enough data to fill the socket read buffer, causing the write call to block.
Additionally, this fixes a problem when an error occurs in the Python worker and the collect job is cancelled with an exception. Previously, the Python driver was never notified of the error so the user could get a partial result (iteration until the error) and the application will continue. With this change, an error in the worker is sent to the Python iterator and is then raised.
The change here introduces a protocol for PySpark local iterators that work as follows:
1) The local socket connection is made when the iterator is created
2) When iterating, Python first sends a request for partition data as a non-zero integer
3) While the JVM local iterator over partitions has next, it triggers a job to collect the next partition
4) The JVM sends a nonzero response to indicate it has the next partition to send
5) The next partition is sent to Python and read by the PySpark deserializer
6) After sending the entire partition, an `END_OF_DATA_SECTION` is sent to Python which stops the deserializer and allows to make another request
7) When the JVM gets a request from Python but has already consumed it's local iterator, it will send a zero response to Python and both will close the socket cleanly
8) If an error occurs in the worker, a negative response is sent to Python followed by the error message. Python will then raise a RuntimeError with the message, stopping iteration.
9) When the PySpark local iterator is garbage-collected, it will read any remaining data from the current partition (this is data that has already been collected) and send a request of zero to tell the JVM to stop collection jobs and close the connection.
Steps 1, 3, 5, 6 are the same as before. Step 8 was completely missing before because errors in the worker were never communicated back to Python. The other steps add synchronization to allow for a clean closing of the socket, with a small trade-off in performance for each partition. This is mainly because the JVM does not start collecting partition data until it receives a request to do so, where before it would eagerly write all data until the socket receive buffer is full.
## How was this patch tested?
Added new unit tests for DataFrame and RDD `toLocalIterator` and tested not fully consuming the iterator. Manual tests with Python 2.7 and 3.6.
Closes#24070 from BryanCutler/pyspark-toLocalIterator-clean-stop-SPARK-23961.
Authored-by: Bryan Cutler <cutlerb@gmail.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
## What changes were proposed in this pull request?
The actual implementation doesn't support multi-cluster Kafka connection with delegation token. In this PR I've added this functionality.
What this PR contains:
* New way of configuration
* Multiple delegation token obtain/store/use functionality
* Documentation
* The change works on DStreams also
## How was this patch tested?
Existing + additional unit tests.
Additionally tested on cluster.
Test scenario:
* 2 * 4 node clusters
* The 4-4 nodes are in different kerberos realms
* Cross-Realm trust between the 2 realms
* Yarn
* Kafka broker version 2.1.0
* security.protocol = SASL_SSL
* sasl.mechanism = SCRAM-SHA-512
* Artificial exceptions during processing
* Source reads from realm1 sink writes to realm2
Kafka broker settings:
* delegation.token.expiry.time.ms=600000 (10 min)
* delegation.token.max.lifetime.ms=1200000 (20 min)
* delegation.token.expiry.check.interval.ms=300000 (5 min)
Closes#24305 from gaborgsomogyi/SPARK-27294.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Fixed the `spark-<version>-yarn-shuffle.jar` artifact packaging to shade the native netty libraries:
- shade the `META-INF/native/libnetty_*` native libraries when packagin
the yarn shuffle service jar. This is required as netty library loader
derives that based on shaded package name.
- updated the `org/spark_project` shade package prefix to `org/sparkproject`
(i.e. removed underscore) as the former breaks the netty native lib loading.
This was causing the yarn external shuffle service to fail
when spark.shuffle.io.mode=EPOLL
## How was this patch tested?
Manual tests
Closes#24502 from amuraru/SPARK-27610_master.
Authored-by: Adi Muraru <amuraru@adobe.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/24375
When `TaskSetManager` skips a task because its corresponding partition is already completed by other `TaskSetManager`s, we should not consider the duration of the task that is finished by other `TaskSetManager`s to schedule the speculative tasks of this `TaskSetManager`.
## How was this patch tested?
updated test case
Closes#24485 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
In SPARK-27612, one correctness issue was reported. When protocol 4 is used to pickle Python objects, we found that unpickled objects were wrong. A temporary fix was proposed by not using highest protocol.
It was found that Opcodes.MEMOIZE was appeared in the opcodes in protocol 4. It is suspect to this issue.
A deeper dive found that Opcodes.MEMOIZE stores objects into internal map of Unpickler object. We use single Unpickler object to unpickle serialized Python bytes. Stored objects intervenes next round of unpickling, if the map is not cleared.
We has two options:
1. Continues to reuse Unpickler, but calls its close after each unpickling.
2. Not to reuse Unpickler and create new Unpickler object in each unpickling.
This patch takes option 1.
## How was this patch tested?
Passing the test added in SPARK-27612 (#24519).
Closes#24521 from viirya/SPARK-27629.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This is a long standing issue which I met before and I've seen other people got trouble with it:
[test cases stuck on "local-cluster mode" of ReplSuite?](http://apache-spark-developers-list.1001551.n3.nabble.com/test-cases-stuck-on-quot-local-cluster-mode-quot-of-ReplSuite-td3086.html)
[Spark tests hang on local machine due to "testGuavaOptional" in JavaAPISuite](http://apache-spark-developers-list.1001551.n3.nabble.com/Spark-tests-hang-on-local-machine-due-to-quot-testGuavaOptional-quot-in-JavaAPISuite-tc10999.html)
When running test under local-cluster mode with wrong SPARK_HOME(spark.test.home), test just get stuck and no response forever. After looking into SPARK_WORKER_DIR, I found there's endless executor directories under it. So, this explains what happens during test getting stuck.
The whole process looks like:
1. Driver submits an app to Master and asks for N executors
2. Master inits executor state with LAUNCHING and sends `LaunchExecutor` to Worker
3. Worker receives `LaunchExecutor`, launches ExecutorRunner asynchronously and sends `ExecutorStateChanged(state=RUNNING)` to Mater immediately
4. Master receives `ExecutorStateChanged(state=RUNNING)` and reset `_retyCount` to 0.
5. ExecutorRunner throws exception during executor launching, sends `ExecutorStateChanged(state=FAILED)` to Worker, Worker forwards the msg to Master
6. Master receives `ExecutorStateChanged(state=FAILED)`. Since Master always reset `_retyCount` when it receives RUNNING msg, so, event if a Worker fails to launch executor for continuous many times, ` _retryCount` would never exceed `maxExecutorRetries`. So, Master continue to launch executor and fall into the dead loop.
The problem exists in step 3. Worker sends `ExecutorStateChanged(state=RUNNING)` to Master immediately while executor is still launching. And, when Master receive that msg, it believes the executor has launched successfully, and reset `_retryCount` subsequently. However, that's not true.
This pr suggests to remove step 3 and requires Worker only send `ExecutorStateChanged(state=RUNNING)` after executor has really launched successfully.
## How was this patch tested?
Tested Manually.
Closes#24408 from Ngone51/fix-dead-loop.
Authored-by: wuyi <ngone_5451@163.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
## What changes were proposed in this pull request?
Update taskName in PythonRunner so it keeps align with that in Executor.
## How was this patch tested?
N/A
Closes#24510 from jiangxb1987/pylog.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
## What changes were proposed in this pull request?
This patch fixes a bug which YARN file-related configurations are being overwritten when there're some values to assign - e.g. if `--file` is specified as an argument, `spark.yarn.dist.files` is overwritten with the value of argument. After this patch the existing value and new value will be merged before assigning to the value of configuration.
## How was this patch tested?
Added UT, and manually tested with below command:
> ./bin/spark-submit --verbose --files /etc/spark2/conf/spark-defaults.conf.template --master yarn-cluster --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.0.jar 10
where the spark conf file has
`spark.yarn.dist.files=file:/etc/spark2/conf/atlas-application.properties.yarn#atlas-application.properties`
```
Spark config:
...
(spark.yarn.dist.files,file:/etc/spark2/conf/atlas-application.properties.yarn#atlas-application.properties,file:///etc/spark2/conf/spark-defaults.conf.template)
...
```
Closes#24465 from HeartSaVioR/SPARK-27575.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
There is a MemorySink v2 already so v1 can be removed. In this PR I've removed it completely.
What this PR contains:
* V1 memory sink removal
* V2 memory sink renamed to become the only implementation
* Since DSv2 sends exceptions in a chained format (linking them with cause field) I've made python side compliant
* Adapted all the tests
## How was this patch tested?
Existing unit tests.
Closes#24403 from gaborgsomogyi/SPARK-23014.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This PR avoids usage of reflective calls in Scala. It removes the import that suppresses the warnings and rewrites code in small ways to avoid accessing methods that aren't technically accessible.
## How was this patch tested?
Existing tests.
Closes#24463 from srowen/SPARK-27571.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
I want to get rid of as much use of `scala.language.existentials` as possible for 3.0. It's a complicated language feature that generates warnings unless this value is imported. It might even be on the way out of Scala: https://contributors.scala-lang.org/t/proposal-to-remove-existential-types-from-the-language/2785
For Spark, it comes up mostly where the code plays fast and loose with generic types, not the advanced situations you'll often see referenced where this feature is explained. For example, it comes up in cases where a function returns something like `(String, Class[_])`. Scala doesn't like matching this to any other instance of `(String, Class[_])` because doing so requires inferring the existence of some type that satisfies both. Seems obvious if the generic type is a wildcard, but, not technically something Scala likes to let you get away with.
This is a large PR, and it only gets rid of _most_ instances of `scala.language.existentials`. The change should be all compile-time and shouldn't affect APIs or logic.
Many of the changes simply touch up sloppiness about generic types, making the known correct value explicit in the code.
Some fixes involve being more explicit about the existence of generic types in methods. For instance, `def foo(arg: Class[_])` seems innocent enough but should really be declared `def foo[T](arg: Class[T])` to let Scala select and fix a single type when evaluating calls to `foo`.
For kind of surprising reasons, this comes up in places where code evaluates a tuple of things that involve a generic type, but is OK if the two parts of the tuple are evaluated separately.
One key change was altering `Utils.classForName(...): Class[_]` to the more correct `Utils.classForName[T](...): Class[T]`. This caused a number of small but positive changes to callers that otherwise had to cast the result.
In several tests, `Dataset[_]` was used where `DataFrame` seems to be the clear intent.
Finally, in a few cases in MLlib, the return type `this.type` was used where there are no subclasses of the class that uses it. This really isn't needed and causes issues for Scala reasoning about the return type. These are just changed to be concrete classes as return types.
After this change, we have only a few classes that still import `scala.language.existentials` (because modifying them would require extensive rewrites to fix) and no build warnings.
## How was this patch tested?
Existing tests.
Closes#24431 from srowen/SPARK-27536.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
https://issues.apache.org/jira/browse/SPARK-25250 reports a bug that, a task which is failed with `CommitDeniedException` gets retried many times.
This can happen when a stage has 2 task set managers, one is zombie, one is active. A task from the zombie TSM completes, and commits to a central coordinator(assuming it's a file writing task). Then the corresponding task from the active TSM will fail with `CommitDeniedException`. `CommitDeniedException.countTowardsTaskFailures` is false, so the active TSM will keep retrying this task, until the job finishes. This wastes resource a lot.
#21131 firstly implements that a previous successful completed task from zombie `TaskSetManager` could mark the task of the same partition completed in the active `TaskSetManager`. Later #23871 improves the implementation to cover a corner case that, an active `TaskSetManager` hasn't been created when a previous task succeed.
However, #23871 has a bug and was reverted in #24359. With hindsight, #23781 is fragile because we need to sync the states between `DAGScheduler` and `TaskScheduler`, about which partitions are completed.
This PR proposes a new fix:
1. When `DAGScheduler` gets a task success event from an earlier attempt, notify the `TaskSchedulerImpl` about it
2. When `TaskSchedulerImpl` knows a partition is already completed, ask the active `TaskSetManager` to mark the corresponding task as finished, if the task is not finished yet.
This fix covers the corner case, because:
1. If `DAGScheduler` gets the task completion event from zombie TSM before submitting the new stage attempt, then `DAGScheduler` knows that this partition is completed, and it will exclude this partition when creating task set for the new stage attempt. See `DAGScheduler.submitMissingTasks`
2. If `DAGScheduler` gets the task completion event from zombie TSM after submitting the new stage attempt, then the active TSM is already created.
Compared to the previous fix, the message loop becomes longer, so it's likely that, the active task set manager has already retried the task multiple times. But this failure window won't be too big, and we want to avoid the worse case that retries the task many times until the job finishes. So this solution is acceptable.
## How was this patch tested?
a new test case.
Closes#24375 from cloud-fan/fix2.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This patch makes several test flakiness fixes.
## How was this patch tested?
N/A
Closes#24434 from gatorsmile/fixFlakyTest.
Lead-authored-by: gatorsmile <gatorsmile@gmail.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Kind of related to https://github.com/gatorsmile/spark/pull/5 - let's update genjavadoc to see if it generates fewer spurious javadoc errors to begin with.
## How was this patch tested?
Existing docs build
Closes#24443 from srowen/genjavadoc013.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In some corner cases, `JobGenerator` thread (including some other EventLoop threads) may exit for some fatal error, like OOM, but Spark Streaming job keep running with no batch job generating. Currently, we only report any non-fatal error.
```
override def run(): Unit = {
try {
while (!stopped.get) {
val event = eventQueue.take()
try {
onReceive(event)
} catch {
case NonFatal(e) =>
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
} catch {
case ie: InterruptedException => // exit even if eventQueue is not empty
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
```
In this PR, we double check if event thread alive when post Event
## How was this patch tested?
existing unit tests
Closes#24400 from uncleGen/SPARK-27503.
Authored-by: uncleGen <hustyugm@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
When a fatal error (such as StackOverflowError) throws from "receiveAndReply", we should try our best to notify the sender. Otherwise, the sender will hang until timeout.
In addition, when a MessageLoop is dying unexpectedly, it should resubmit a new one so that Dispatcher is still working.
## How was this patch tested?
New unit tests.
Closes#24396 from zsxwing/SPARK-27496.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
We have disabled a test related to storage in the History server suite after SPARK-13845. But, after SPARK-22050, we can store the information about block updated events to eventLog, if we enable "spark.eventLog.logBlockUpdates.enabled=true".
So, we can enable the test, by adding an eventlog corresponding to the application, which has enabled the configuration, "spark.eventLog.logBlockUpdates.enabled=true"
## How was this patch tested?
Existing UTs
Closes#24390 from shahidki31/enableRddStorageTest.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Finish the rest work of https://github.com/apache/spark/pull/24317, https://github.com/apache/spark/pull/9030
a. Implement Kryo serialization for UnsafeArrayData
b. fix UnsafeMapData Java/Kryo Serialization issue when two machines have different Oops size
c. Move the duplicate code "getBytes()" to Utils.
## How was this patch tested?
According Units has been added & tested
Closes#24357 from pengbo/SPARK-27416_new.
Authored-by: pengbo <bo.peng1019@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Added Constant instead of referring the same String literal "spark.buffer.pageSize" from many places
## How was this patch tested?
Run the corresponding Unit Test Cases manually.
Closes#24368 from shivusondur/Constant.
Authored-by: shivusondur <shivusondur@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR supports `OpenJ9` in addition to `IBM JDK` and `OpenJDK` in Spark by handling `System.getProperty("java.vendor") = "Eclipse OpenJ9"`.
In `inferDefaultMemory()` and `getKrb5LoginModuleName()`, this PR uses non `IBM` way.
```
$ ~/jdk-11.0.2+9_openj9-0.12.1/bin/jshell
| Welcome to JShell -- Version 11.0.2
| For an introduction type: /help intro
jshell> System.out.println(System.getProperty("java.vendor"))
Eclipse OpenJ9
jshell> System.out.println(System.getProperty("java.vm.info"))
JRE 11 Linux amd64-64-Bit Compressed References 20190204_127 (JIT enabled, AOT enabled)
OpenJ9 - 90dd8cb40
OMR - d2f4534b
JCL - 289c70b6844 based on jdk-11.0.2+9
jshell> System.out.println(Class.forName("com.ibm.lang.management.OperatingSystemMXBean").getDeclaredMethod("getTotalPhysicalMemory"))
public abstract long com.ibm.lang.management.OperatingSystemMXBean.getTotalPhysicalMemory()
jshell> System.out.println(Class.forName("com.sun.management.OperatingSystemMXBean").getDeclaredMethod("getTotalPhysicalMemorySize"))
public abstract long com.sun.management.OperatingSystemMXBean.getTotalPhysicalMemorySize()
jshell> System.out.println(Class.forName("com.ibm.security.auth.module.Krb5LoginModule"))
| Exception java.lang.ClassNotFoundException: com.ibm.security.auth.module.Krb5LoginModule
| at Class.forNameImpl (Native Method)
| at Class.forName (Class.java:339)
| at (#1:1)
jshell> System.out.println(Class.forName("com.sun.security.auth.module.Krb5LoginModule"))
class com.sun.security.auth.module.Krb5LoginModule
```
## How was this patch tested?
Existing test suites
Manual testing with OpenJ9.
Closes#24308 from kiszk/SPARK-27397.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Our customer has a very complicated job. Sometimes it successes and sometimes it fails with
```
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: ShuffleMapStage 4 has failed the maximum allowable number of times: 4.
Most recent failure reason: org.apache.spark.shuffle.FetchFailedException
```
However, with the patch https://github.com/apache/spark/pull/23871 , the job hangs forever.
When I investigated it, I found that `DAGScheduler` and `TaskSchedulerImpl` define stage completion differently. `DAGScheduler` thinks a stage is completed if all its partitions are marked as completed ([result stage](https://github.com/apache/spark/blob/v2.4.1/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L1362-L1368) and [shuffle stage](https://github.com/apache/spark/blob/v2.4.1/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L1400)). `TaskSchedulerImpl` thinks a stage's task set is completed when all tasks finish (see the [code](https://github.com/apache/spark/blob/v2.4.1/core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala#L779-L784)).
Ideally this two definition should be consistent, but #23871 breaks it. In our customer's Spark log, I found that, a stage's task set completes, but the stage never completes. More specifically, `DAGScheduler` submits a task set for stage 4.1 with 1000 tasks, but the `TaskSetManager` skips to run the first 100 tasks. Later on, `TaskSetManager` finishes 900 tasks and marks the task set as completed. However, `DAGScheduler` doesn't agree with it and hangs forever, waiting for more task completion events of stage 4.1.
With hindsight, I think `TaskSchedulerIImpl.stageIdToFinishedPartitions` is fragile. We need to pay more effort to make sure this is consistent with `DAGScheduler`'s knowledge. When `DAGScheduler` marks some partitions from finished to unfinished, `TaskSchedulerIImpl.stageIdToFinishedPartitions` should be updated as well.
This PR reverts #23871, let's think of a more robust idea later.
## How was this patch tested?
N/A
Closes#24359 from cloud-fan/revert.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The RBackend and RBackendHandler create new conf objects that don't pick up conf values from the existing SparkSession and therefore always use the default conf values instead of values specified by the user.
In this fix we check to see if the spark env already exists, and get the conf from there. We fall back to creating a new conf. This follows the pattern used in other places including this: 3725b1324f/core/src/main/scala/org/apache/spark/api/r/BaseRRunner.scala (L261)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24353 from MrBago/r-backend-use-existing-conf.
Authored-by: Bago Amirbekian <bago@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Fix build warnings -- see some details below.
But mostly, remove use of postfix syntax where it causes warnings without the `scala.language.postfixOps` import. This is mostly in expressions like "120000 milliseconds". Which, I'd like to simplify to things like "2.minutes" anyway.
## How was this patch tested?
Existing tests.
Closes#24314 from srowen/SPARK-27404.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
I propose to disable (comment) result checking in `SorterSuite`.`java.lang.ArrayIndexOutOfBoundsException in TimSort` because:
1. The check is optional, and correctness of TimSort is checked by another tests. Purpose of the test is to check that TimSort doesn't fail with `ArrayIndexOutOfBoundsException`.
2. Significantly drops execution time of the test.
Here are timing of running the test locally:
```
Sort: 1.4 seconds
Result checking: 15.6 seconds
```
## How was this patch tested?
By `SorterSuite`.
Closes#24343 from MaxGekk/timsort-test-speedup.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR updates `AppStatusListener` to flush `LiveEntity` if necessary when receiving `SparkListenerExecutorMetricsUpdate`. This will ensure the staleness of Spark UI doesn't last more than the executor heartbeat interval.
## How was this patch tested?
The new unit test.
Closes#24303 from zsxwing/SPARK-27394.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
When you submit a stage on a large cluster, rack resolving takes a long time when initializing TaskSetManager because a script is invoked to resolve the rack of each host, one by one.
Based on current implementation, it takes 30~40 seconds to resolve the racks in our 5000 nodes' cluster. After applied the patch, it decreased to less than 15 seconds.
YARN-9332 has added an interface to handle multiple hosts in one invocation to save time. But before upgrading to the newest Hadoop, we could construct the same tool in Spark to resolve this issue.
## How was this patch tested?
UT and manually testing on a 5000 node cluster.
Closes#24245 from squito/SPARK-13704_update.
Lead-authored-by: LantaoJin <jinlantao@gmail.com>
Co-authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
check spark.task.cpus before creating TaskScheduler in SparkContext
## How was this patch tested?
UT
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24261 from liutang123/SPARK-27192.
Authored-by: liulijia <liutang123@yeah.net>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR aims to clean up package name mismatches.
## How was this patch tested?
Pass the Jenkins.
Closes#24300 from dongjoon-hyun/SPARK-27390.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Update jquery -> 1.12.4, datatables -> 1.10.18, mustache -> 2.3.12.
Add missing mustache license
## How was this patch tested?
I manually tested the UI locally with the javascript console open and didn't observe any problems or JS errors. The only 'risky' change seems to be mustache, but on reading its release notes, don't think the changes from 0.8.1 to 2.x would affect Spark's simple usage.
Closes#24288 from srowen/SPARK-27358.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/24265 breaks the lint check, because it has trailing space. (not sure why it passed jenkins). This PR fixes it.
## How was this patch tested?
N/A
Closes#24289 from cloud-fan/fix.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In `UnsafeExternalSorter.SpillableIterator#loadNext()` takes lock on the `UnsafeExternalSorter` and calls `freePage` once the `lastPage` is consumed which needs to take a lock on `TaskMemoryManager`. At the same time, there can be another MemoryConsumer using `UnsafeExternalSorter` as part of sorting can try to `allocatePage` needs to get lock on `TaskMemoryManager` which can cause spill to happen which requires lock on `UnsafeExternalSorter` again causing deadlock. This is a classic deadlock situation happening similar to the SPARK-26265.
To fix this, we can move the `freePage` call in `loadNext` outside of `Synchronized` block similar to the fix in SPARK-26265
## How was this patch tested?
Manual tests were being done and will also try to add a test.
Closes#24265 from venkata91/deadlock-sorter.
Authored-by: Venkata krishnan Sowrirajan <vsowrirajan@qubole.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
HighlyCompressedMapStatus uses RoaringBitmap to record the empty blocks. But RoaringBitmap couldn't be ser/deser with unsafe KryoSerializer.
It's a bug of RoaringBitmap-0.5.11 and fixed in latest version.
This is an update of #24157
## How was this patch tested?
Add a UT
Closes#24264 from LantaoJin/SPARK-27216.
Lead-authored-by: LantaoJin <jinlantao@gmail.com>
Co-authored-by: Lantao Jin <jinlantao@gmail.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
Use Single Abstract Method syntax where possible (and minor related cleanup). Comments below. No logic should change here.
## How was this patch tested?
Existing tests.
Closes#24241 from srowen/SPARK-27323.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Update thread audit whitelist to skip threads of the global broadcast exchange thread pool, process reaper and Hadoop FS statistics data reference cleaner thread.
## How was this patch tested?
Via existing UT using broadcast exchange via `sbt` i.e:
```
> project sql
> testOnly *.SessionStateSuite -- -z "fork new sessions and run query on inherited table"
```
Before (wrapped long line for manually to save horizontal scrolling for reviewers):
```
===== POSSIBLE THREAD LEAK IN SUITE o.a.s.sql.SessionStateSuite,
thread names: broadcast-exchange-6, broadcast-exchange-0,
broadcast-exchange-2, broadcast-exchange-5, broadcast-exchange-7,
broadcast-exchange-4, broadcast-exchange-1, process reaper, broadcast-exchange-3,
org.apache.hadoop.fs.FileSystem$Statistics$StatisticsDataReferenceCleaner =====
```
After this change no possible thread leak detected.
Closes#24244 from attilapiros/thread-audit-minor.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR is a FollowUp of https://github.com/apache/spark/pull/24196. It improves the test case by using the parameters that are being used in the actual scenarios.
## How was this patch tested?
N/A
Closes#24257 from gatorsmile/followupSPARK-27244.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Add AL2 license to metadata of all .md files.
This seemed to be the tidiest way as it will get ignored by .md renderers and other tools. Attempts to write them as markdown comments revealed that there is no such standard thing.
## How was this patch tested?
Doc build
Closes#24243 from srowen/SPARK-26918.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
spark.task.cpus should be less or equal than spark.executor.cores when use static executor allocation
## How was this patch tested?
manual
Closes#24131 from liutang123/SPARK-27192.
Authored-by: liulijia <liutang123@yeah.net>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
When logConf is set to true, config keys that contain password were printed in cleartext in driver log. This change uses the already present redact method in Utils, to redact all the passwords based on redact pattern in SparkConf and then print the conf to driver log thus ensuring that sensitive information like passwords is not printed in clear text.
## How was this patch tested?
This patch was tested through `SparkConfSuite` & then entire unit test through sbt
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24196 from ninadingole/SPARK-27244.
Authored-by: Ninad Ingole <robert.wallis@example.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
I was playing with the scheduler and found this weird thing. In `TaskSchedulerImpl` we import `scala.collection.Set` without any reason. This is bad in practice, as it silently changes the actual class when we simply type `Set`, which by default should point to the immutable set.
This change only affects one method: `getExecutorsAliveOnHost`. I checked all the caller side and none of them need a general `Set` type.
## How was this patch tested?
N/A
Closes#24231 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Raise the threshold size for serialized task size at which a warning is generated from 100KiB to 1000KiB.
As several people have noted, the original change for this JIRA highlighted that this threshold is low. Test output regularly shows:
```
- sorting on StringType with nullable=false, sortOrder=List('a DESC NULLS LAST)
22:47:53.320 WARN org.apache.spark.scheduler.TaskSetManager: Stage 80 contains a task of very large size (755 KiB). The maximum recommended task size is 100 KiB.
22:47:53.348 WARN org.apache.spark.scheduler.TaskSetManager: Stage 81 contains a task of very large size (755 KiB). The maximum recommended task size is 100 KiB.
22:47:53.417 WARN org.apache.spark.scheduler.TaskSetManager: Stage 83 contains a task of very large size (755 KiB). The maximum recommended task size is 100 KiB.
22:47:53.444 WARN org.apache.spark.scheduler.TaskSetManager: Stage 84 contains a task of very large size (755 KiB). The maximum recommended task size is 100 KiB.
...
- SPARK-20688: correctly check analysis for scalar sub-queries
22:49:10.314 WARN org.apache.spark.scheduler.DAGScheduler: Broadcasting large task binary with size 150.8 KiB
- SPARK-21835: Join in correlated subquery should be duplicateResolved: case 1
22:49:10.595 WARN org.apache.spark.scheduler.DAGScheduler: Broadcasting large task binary with size 150.7 KiB
22:49:10.744 WARN org.apache.spark.scheduler.DAGScheduler: Broadcasting large task binary with size 150.7 KiB
22:49:10.894 WARN org.apache.spark.scheduler.DAGScheduler: Broadcasting large task binary with size 150.7 KiB
- SPARK-21835: Join in correlated subquery should be duplicateResolved: case 2
- SPARK-21835: Join in correlated subquery should be duplicateResolved: case 3
- SPARK-23316: AnalysisException after max iteration reached for IN query
22:49:11.559 WARN org.apache.spark.scheduler.DAGScheduler: Broadcasting large task binary with size 154.2 KiB
```
It seems that a larger threshold of about 1MB is more suitable.
## How was this patch tested?
Existing tests.
Closes#24226 from srowen/SPARK-26660.2.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
## What changes were proposed in this pull request?
As per https://docs.oracle.com/javase/8/docs/api/java/lang/ClassLoader.html
``Class loaders that support concurrent loading of classes are known as parallel capable class loaders and are required to register themselves at their class initialization time by invoking the ClassLoader.registerAsParallelCapable method. Note that the ClassLoader class is registered as parallel capable by default. However, its subclasses still need to register themselves if they are parallel capable. ``
i.e we can have finer class loading locks by registering classloaders as parallel capable. (Refer to deadlock due to macro lock https://issues.apache.org/jira/browse/SPARK-26961).
All the classloaders we have are wrapper of URLClassLoader which by itself is parallel capable.
But this cannot be achieved by scala code due to static registration Refer https://github.com/scala/bug/issues/11429
## How was this patch tested?
All Existing UT must pass
Closes#24126 from ajithme/driverlock.
Authored-by: Ajith <ajith2489@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently, if we want to configure `spark.sql.files.maxPartitionBytes` to 256 megabytes, we must set `spark.sql.files.maxPartitionBytes=268435456`, which is very unfriendly to users.
And if we set it like this:`spark.sql.files.maxPartitionBytes=256M`, we will encounter this exception:
```
Exception in thread "main" java.lang.IllegalArgumentException:
spark.sql.files.maxPartitionBytes should be long, but was 256M
at org.apache.spark.internal.config.ConfigHelpers$.toNumber(ConfigBuilder.scala)
```
This PR use `bytesConf` to replace `longConf` or `intConf`, if the configuration is used to set the number of bytes.
Configuration change list:
`spark.files.maxPartitionBytes`
`spark.files.openCostInBytes`
`spark.shuffle.sort.initialBufferSize`
`spark.shuffle.spill.initialMemoryThreshold`
`spark.sql.autoBroadcastJoinThreshold`
`spark.sql.files.maxPartitionBytes`
`spark.sql.files.openCostInBytes`
`spark.sql.defaultSizeInBytes`
## How was this patch tested?
1.Existing unit tests
2.Manual testing
Closes#24187 from 10110346/bytesConf.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This applies some minor updates/cleaning following up SPARK-26928, notably renaming JVMCPU.scala to JVMCPUSource.scala.
## How was this patch tested?
Manually tested
Closes#24201 from LucaCanali/fixupSPARK-26928.
Authored-by: Luca Canali <luca.canali@cern.ch>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove Scala 2.11 support in build files and docs, and in various parts of code that accommodated 2.11. See some targeted comments below.
## How was this patch tested?
Existing tests.
Closes#23098 from srowen/SPARK-26132.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The hashSeed method allocates 64 bytes instead of 8. Other bytes are always zeros (thanks to default behavior of ByteBuffer). And they could be excluded from hash calculation because they don't differentiate inputs.
## How was this patch tested?
By running the existing tests - XORShiftRandomSuite
Closes#20793 from MaxGekk/hash-buff-size.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
For [SPARK-27184](https://issues.apache.org/jira/browse/SPARK-27184)
In the `org.apache.spark.internal.config`, we define the variables of `FILES` and `JARS`, we can use them instead of "spark.jars" and "spark.files".
```scala
private[spark] val JARS = ConfigBuilder("spark.jars")
.stringConf
.toSequence
.createWithDefault(Nil)
```
```scala
private[spark] val FILES = ConfigBuilder("spark.files")
.stringConf
.toSequence
.createWithDefault(Nil)
```
Other :
In the `org.apache.spark.internal.config`, we define the variables of `SUBMIT_PYTHON_FILES ` and `SUBMIT_DEPLOY_MODE `, we can use them instead of "spark.submit.pyFiles" and "spark.submit.deployMode".
```scala
private[spark] val SUBMIT_PYTHON_FILES = ConfigBuilder("spark.submit.pyFiles")
.stringConf
.toSequence
.createWithDefault(Nil)
```
```scala
private[spark] val SUBMIT_DEPLOY_MODE = ConfigBuilder("spark.submit.deployMode")
.stringConf
.createWithDefault("client")
```
Closes#24123 from hehuiyuan/hehuiyuan-patch-6.
Authored-by: hehuiyuan <hehuiyuan@ZBMAC-C02WD3K5H.local>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This patch fixes the issue that ClientEndpoint in standalone cluster doesn't recognize about driver options which are passed to SparkConf instead of system properties. When `Client` is executed via cli they should be provided as system properties, but with `spark-submit` they can be provided as SparkConf. (SpartSubmit will call `ClientApp.start` with SparkConf which would contain these options.)
## How was this patch tested?
Manually tested via following steps:
1) setup standalone cluster (launch master and worker via `./sbin/start-all.sh`)
2) submit one of example app with standalone cluster mode
```
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master "spark://localhost:7077" --conf "spark.driver.extraJavaOptions=-Dfoo=BAR" --deploy-mode "cluster" --num-executors 1 --driver-memory 512m --executor-memory 512m --executor-cores 1 examples/jars/spark-examples*.jar 10
```
3) check whether `foo=BAR` is provided in system properties in Spark UI
<img width="877" alt="Screen Shot 2019-03-21 at 8 18 04 AM" src="https://user-images.githubusercontent.com/1317309/54728501-97db1700-4bc1-11e9-89da-078445c71e9b.png">
Closes#24163 from HeartSaVioR/SPARK-26606.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This patch modifies Utils.classForName to have optional parameters - initialize, noSparkClassLoader - to let callers of Class.forName with thread context classloader to use it instead. This helps to reduce scalastyle off for Class.forName.
## How was this patch tested?
Existing UTs.
Closes#24148 from HeartSaVioR/MINOR-reduce-scalastyle-off-for-class-forname.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Refactored code in tests regarding the "withLogAppender()" pattern by creating a general helper method in SparkFunSuite.
## How was this patch tested?
Passed existing tests.
Closes#24172 from maryannxue/log-appender.
Authored-by: maryannxue <maryannxue@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
[SPARK-26977](https://issues.apache.org/jira/browse/SPARK-26977) introduced very strange bug which spark-shell is no longer able to load classes which are provided via `--packages`. TBH I don't know about the details why it is broken, but looks like initializing `object class` brings the weirdness (maybe due to static initialization done twice?).
This patch removes the logic to leave warning log when main class is scala.App, to not deal with such complexity for just leaving warning message.
## How was this patch tested?
Manual test: suppose we run spark-shell with `--packages` option like below:
```
./bin/spark-shell --verbose --master "local[*]" --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.0
```
Before this patch, importing class in transitive dependency fails:
```
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://localhost:4040
Spark context available as 'sc' (master = local[*], app id = local-1553005771597).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0-SNAPSHOT
/_/
Using Scala version 2.12.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_191)
Type in expressions to have them evaluated.
Type :help for more information.
scala> import org.apache.kafka
<console>:23: error: object kafka is not a member of package org.apache
import org.apache.kafka
```
After this patch, importing class in transitive dependency succeeds:
```
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://localhost:4040
Spark context available as 'sc' (master = local[*], app id = local-1553004095542).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0-SNAPSHOT
/_/
Using Scala version 2.12.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_191)
Type in expressions to have them evaluated.
Type :help for more information.
scala> import org.apache.kafka
import org.apache.kafka
```
Closes#24147 from HeartSaVioR/SPARK-27205.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
```scala
val KRYO_USE_UNSAFE = ConfigBuilder("spark.kyro.unsafe")
.booleanConf
.createWithDefault(false)
val KRYO_USE_POOL = ConfigBuilder("spark.kyro.pool")
.booleanConf
.createWithDefault(true)
```
**kyro should be kryo**
## How was this patch tested?
no need
Closes#24156 from LantaoJin/SPARK-27215.
Authored-by: Lantao Jin <jinlantao@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
Environment Page in SparkUI have all the configuration sorted by key. But this is not the case in History server case, to keep UX same, we can have it sorted in history server too
## What changes were proposed in this pull request?
On render of Env page the properties are sorted before creating page
## How was this patch tested?
Manually tested in UI
Closes#24143 from ajithme/historyenv.
Authored-by: Ajith <ajith2489@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
As we all know that spark on Yarn uses DB https://github.com/apache/spark/pull/7943 to record RegisteredExecutors information which can be reloaded and used again when the ExternalShuffleService is restarted .
The RegisteredExecutors information can't be recorded both in the mode of spark's standalone and spark on k8s , which will cause the RegisteredExecutors information to be lost ,when the ExternalShuffleService is restarted.
To solve the problem above, a method is proposed and is committed .
## How was this patch tested?
new unit tests
Closes#23393 from weixiuli/SPARK-26288.
Authored-by: weixiuli <weixiuli@jd.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
…when trying to kill executors either due to dynamic allocation or blacklisting
## What changes were proposed in this pull request?
There are two deadlocks as a result of the interplay between three different threads:
**task-result-getter thread**
**spark-dynamic-executor-allocation thread**
**dispatcher-event-loop thread(makeOffers())**
The fix ensures ordering synchronization constraint by acquiring lock on `TaskSchedulerImpl` before acquiring lock on `CoarseGrainedSchedulerBackend` in `makeOffers()` as well as killExecutors() method. This ensures resource ordering between the threads and thus, fixes the deadlocks.
## How was this patch tested?
Manual Tests
Closes#24072 from pgandhi999/SPARK-27112-2.
Authored-by: pgandhi <pgandhi@verizonmedia.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
When Result stage has zero tasks, the Job End event is never fired, hence the Job is always running in UI. Example: sc.emptyRDD[Int].countApprox(1000) never finishes even it has no tasks to launch
## How was this patch tested?
Added UT
Closes#24100 from ajithme/emptyRDD.
Authored-by: Ajith <ajith2489@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
This time tested against Scala 2.11 as well
Closes#24116 from fitermay/master.
Authored-by: fitermay <fiterman@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
When we run YarnSchedulerBackendSuite, the class path seems to be made from the classes folder(resource-managers/yarn/target/scala-2.12/classes) instead of jar (resource-managers/yarn/target/spark-yarn_2.12-3.0.0-SNAPSHOT.jar) . ui.getHandlers is in spark-core and its loaded from spark-core.jar which is shaded and hence refers to org.spark_project.jetty.servlet.ServletContextHandler
Here in org.apache.spark.scheduler.cluster.YarnSchedulerBackend, as its not shaded, it expects org.eclipse.jetty.servlet.ServletContextHandler
Refer discussion https://issues.apache.org/jira/browse/SPARK-27122?focusedCommentId=16792318&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-16792318
Hence as a fix, org.apache.spark.ui.WebUI must only return a wrapper class instance or references so that Jetty classes can be avoided in getters which are accessed outside spark-core
## How was this patch tested?
Existing UT can pass
Closes#24088 from ajithme/shadebug.
Authored-by: Ajith <ajith2489@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
this pr add check this spark.diskStore.subDirectories > 0.This value need to be checked before it can be used.
## How was this patch tested?
N/A
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24024 from lcqzte10192193/wid-lcq-190308.
Authored-by: lichaoqun <li.chaoqun@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently, when enabled streaming dynamic allocation for streaming applications, the maxNumExecutorFailures in ApplicationMaster is still computed with `spark.dynamicAllocation.maxExecutors`.
Actually, we should consider `spark.streaming.dynamicAllocation.maxExecutors` instead.
Related codes:
f87153a3ac/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala (L101)
## How was this patch tested?
NA
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23845 from liupc/Fix-incorrect-maxNumExecutorFailures-for-streaming.
Lead-authored-by: Liupengcheng <liupengcheng@xiaomi.com>
Co-authored-by: liupengcheng <liupengcheng@xiaomi.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Executor heartbeat interval is configurable by `"spark.executor.heartbeatInterval"`. But in a comment, heartbeat interval is presented as a constant `10s`. This pr tries to correct the description.
## How was this patch tested?
Existing unit tests.
Closes#24101 from SongYadong/heartbeat_interval_comment.
Authored-by: SongYadong <song.yadong1@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
When trying to coalesce a UnionRDD of two large FileScanRDDs
(each with a few million partitions) into around 8k partitions
the driver can stall for over an hour.
Profiler shows that over 90% of the time is spent in TimSort
which is invoked by `pickBin`. This patch replaces sorting with a more
efficient `min` for the purpose of finding the least occupied
PartitionGroup
Closes#23986 from fitermay/SPARK-27070.
Authored-by: fitermay <fiterman@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The race between org.apache.spark.deploy.DeployMessages.WorkDirCleanup event and org.apache.spark.deploy.worker.Worker#onStop. Here its possible that while the WorkDirCleanup event is being processed, org.apache.spark.deploy.worker.Worker#cleanupThreadExecutor was shutdown. hence any submission after ThreadPoolExecutor will result in java.util.concurrent.RejectedExecutionException
## How was this patch tested?
Manually
Closes#24056 from ajithme/workercleanup.
Authored-by: Ajith <ajith2489@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This patch changes the schema of url from http to https for bintray spark-packages repository. Looks like we already changed the schema of repository url for pom.xml but missed inside the code.
## How was this patch tested?
Manually ran the `--package` via `./bin/spark-shell --verbose --packages "RedisLabs:spark-redis:0.3.2"`
```
...
Ivy Default Cache set to: /Users/jlim/.ivy2/cache
The jars for the packages stored in: /Users/jlim/.ivy2/jars
:: loading settings :: url = jar:file:/Users/jlim/WorkArea/ScalaProjects/spark/dist/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
RedisLabs#spark-redis added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-2fee2e18-7832-4a4d-9e97-7b3d0fef766d;1.0
confs: [default]
found RedisLabs#spark-redis;0.3.2 in spark-packages
found redis.clients#jedis;2.7.2 in central
found org.apache.commons#commons-pool2;2.3 in central
downloading https://dl.bintray.com/spark-packages/maven/RedisLabs/spark-redis/0.3.2/spark-redis-0.3.2.jar ...
[SUCCESSFUL ] RedisLabs#spark-redis;0.3.2!spark-redis.jar (824ms)
downloading https://repo1.maven.org/maven2/redis/clients/jedis/2.7.2/jedis-2.7.2.jar ...
[SUCCESSFUL ] redis.clients#jedis;2.7.2!jedis.jar (576ms)
downloading https://repo1.maven.org/maven2/org/apache/commons/commons-pool2/2.3/commons-pool2-2.3.jar ...
[SUCCESSFUL ] org.apache.commons#commons-pool2;2.3!commons-pool2.jar (150ms)
:: resolution report :: resolve 4586ms :: artifacts dl 1555ms
:: modules in use:
RedisLabs#spark-redis;0.3.2 from spark-packages in [default]
org.apache.commons#commons-pool2;2.3 from central in [default]
redis.clients#jedis;2.7.2 from central in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 3 | 3 | 3 | 0 || 3 | 3 |
---------------------------------------------------------------------
```
Closes#24061 from HeartSaVioR/MINOR-use-https-to-bintray-repository.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}