### What changes were proposed in this pull request?
Remove automatically generated param setters in _shared_params_code_gen.py
### Why are the changes needed?
To keep parity between scala and python
### Does this PR introduce any user-facing change?
Yes
Add some setters in Python ML XXXModels
### How was this patch tested?
unit tests
Closes#26232 from huaxingao/spark-29093.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
Add private _XXXParams classes for classification & regression
### Why are the changes needed?
To keep parity between scala and python
### Does this PR introduce any user-facing change?
Yes. Add gettters/setters for the following Model classes
```
LinearSVCModel:
get/setRegParam
get/setMaxIte
get/setFitIntercept
get/setTol
get/setStandardization
get/setWeightCol
get/setAggregationDepth
get/setThreshold
LogisticRegressionModel:
get/setRegParam
get/setElasticNetParam
get/setMaxIter
get/setFitIntercept
get/setTol
get/setStandardization
get/setWeightCol
get/setAggregationDepth
get/setThreshold
NaiveBayesModel:
get/setWeightCol
LinearRegressionModel:
get/setRegParam
get/setElasticNetParam
get/setMaxIter
get/setTol
get/setFitIntercept
get/setStandardization
get/setWeight
get/setSolver
get/setAggregationDepth
get/setLoss
GeneralizedLinearRegressionModel:
get/setFitIntercept
get/setMaxIter
get/setTol
get/setRegParam
get/setWeightCol
get/setSolver
```
### How was this patch tested?
Add a few doctest
Closes#26142 from huaxingao/spark-29381.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
- Move tree related classes to a separate file ```tree.py```
- add method ```predictLeaf``` in ```DecisionTreeModel```& ```TreeEnsembleModel```
### Why are the changes needed?
- keep parity between scala and python
- easy code maintenance
### Does this PR introduce any user-facing change?
Yes
add method ```predictLeaf``` in ```DecisionTreeModel```& ```TreeEnsembleModel```
add ```setMinWeightFractionPerNode``` in ```DecisionTreeClassifier``` and ```DecisionTreeRegressor```
### How was this patch tested?
add some doc tests
Closes#25929 from huaxingao/spark_29116.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
Adds
```python
class _IsotonicRegressionBase(HasFeaturesCol, HasLabelCol, HasPredictionCol, HasWeightCol): ...
```
with related `Params` and uses it to replace `JavaPredictor` and `HasWeightCol` in `IsotonicRegression` base classes and `JavaPredictionModel,` in `IsotonicRegressionModel` base classes.
### Why are the changes needed?
Previous work (#25776) on [SPARK-28985](https://issues.apache.org/jira/browse/SPARK-28985) replaced `JavaEstimator`, `HasFeaturesCol`, `HasLabelCol`, `HasPredictionCol` in `IsotonicRegression` and `JavaModel` in `IsotonicRegressionModel` with newly added `JavaPredictor`:
e97b55d322/python/pyspark/ml/wrapper.py (L377)
and `JavaPredictionModel`
e97b55d322/python/pyspark/ml/wrapper.py (L405)
respectively.
This however is inconsistent with Scala counterpart where both classes extend private `IsotonicRegressionBase`
3cb1b57809/mllib/src/main/scala/org/apache/spark/ml/regression/IsotonicRegression.scala (L42-L43)
This preserves some of the existing inconsistencies (`model` as defined in [the official example](https://github.com/apache/spark/blob/master/examples/src/main/python/ml/isotonic_regression_example.py)), i.e.
```python
from pyspark.ml.regression impor IsotonicRegressionMode
from pyspark.ml.param.shared import HasWeightCol
issubclass(IsotonicRegressionModel, HasWeightCol)
# False
hasattr(model, "weightCol")
# True
```
as well as introduces a bug, by adding unsupported `predict` method:
```python
import inspect
hasattr(model, "predict")
# True
inspect.getfullargspec(IsotonicRegressionModel.predict)
# FullArgSpec(args=['self', 'value'], varargs=None, varkw=None, defaults=None, kwonlyargs=[], kwonlydefaults=None, annotations={})
IsotonicRegressionModel.predict.__doc__
# Predict label for the given features.\n\n .. versionadded:: 3.0.0'
model.predict(dataset.first().features)
# Py4JError: An error occurred while calling o49.predict. Trace:
# py4j.Py4JException: Method predict([class org.apache.spark.ml.linalg.SparseVector]) does not exist
# ...
```
Furthermore existing implementation can cause further problems in the future, if `Predictor` / `PredictionModel` API changes.
### Does this PR introduce any user-facing change?
Yes. It:
- Removes invalid `IsotonicRegressionModel.predict` method.
- Adds `HasWeightColumn` to `IsotonicRegressionModel`.
however the faulty implementation hasn't been released yet, and proposed additions have negligible potential for breaking existing code (and none, compared to changes already made in #25776).
### How was this patch tested?
- Existing unit tests.
- Manual testing.
CC huaxingao, zhengruifeng
Closes#26023 from zero323/SPARK-28985-FOLLOW-UP-isotonic-regression.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Adds
```python
_AFTSurvivalRegressionParams(HasFeaturesCol, HasLabelCol, HasPredictionCol,
HasMaxIter, HasTol, HasFitIntercept,
HasAggregationDepth): ...
```
with related Params and uses it to replace `HasFitIntercept`, `HasMaxIter`, `HasTol` and `HasAggregationDepth` in `AFTSurvivalRegression` base classes and `JavaPredictionModel,` in `AFTSurvivalRegressionModel` base classes.
### Why are the changes needed?
Previous work (#25776) on [SPARK-28985](https://issues.apache.org/jira/browse/SPARK-28985) replaced `JavaEstimator`, `HasFeaturesCol`, `HasLabelCol`, `HasPredictionCol` in `AFTSurvivalRegression` and `JavaModel` in `AFTSurvivalRegressionModel` with newly added `JavaPredictor`:
e97b55d322/python/pyspark/ml/wrapper.py (L377)
and `JavaPredictionModel`
e97b55d322/python/pyspark/ml/wrapper.py (L405)
respectively.
This however is inconsistent with Scala counterpart where both classes extend private `AFTSurvivalRegressionBase`
eb037a8180/mllib/src/main/scala/org/apache/spark/ml/regression/AFTSurvivalRegression.scala (L48-L50)
This preserves some of the existing inconsistencies (variables as defined in [the official example](https://github.com/apache/spark/blob/master/examples/src/main/python/ml/aft_survival_regression.p))
```
from pyspark.ml.regression import AFTSurvivalRegression, AFTSurvivalRegressionModel
from pyspark.ml.param.shared import HasMaxIter, HasTol, HasFitIntercept, HasAggregationDepth
from pyspark.ml.param import Param
issubclass(AFTSurvivalRegressionModel, HasMaxIter)
# False
hasattr(model, "maxIter") and isinstance(model.maxIter, Param)
# True
issubclass(AFTSurvivalRegressionModel, HasTol)
# False
hasattr(model, "tol") and isinstance(model.tol, Param)
# True
```
and can cause problems in the future, if Predictor / PredictionModel API changes (unlike [`IsotonicRegression`](https://github.com/apache/spark/pull/26023), current implementation is technically speaking correct, though incomplete).
### Does this PR introduce any user-facing change?
Yes, it adds a number of base classes to `AFTSurvivalRegressionModel`. These change purely additive and have negligible potential for breaking existing code (and none, compared to changes already made in #25776). Additionally affected API hasn't been released in the current form yet.
### How was this patch tested?
- Existing unit tests.
- Manual testing.
CC huaxingao, zhengruifeng
Closes#26024 from zero323/SPARK-28985-FOLLOW-UP-aftsurival-regression.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Add some common classes in Python to make it have the same structure as Scala
1. Scala has ClassifierParams/Classifier/ClassificationModel:
```
trait ClassifierParams
extends PredictorParams with HasRawPredictionCol
abstract class Classifier
extends Predictor with ClassifierParams {
def setRawPredictionCol
}
abstract class ClassificationModel
extends PredictionModel with ClassifierParams {
def setRawPredictionCol
}
```
This PR makes Python has the following:
```
class JavaClassifierParams(HasRawPredictionCol, JavaPredictorParams):
pass
class JavaClassifier(JavaPredictor, JavaClassifierParams):
def setRawPredictionCol
class JavaClassificationModel(JavaPredictionModel, JavaClassifierParams):
def setRawPredictionCol
```
2. Scala has ProbabilisticClassifierParams/ProbabilisticClassifier/ProbabilisticClassificationModel:
```
trait ProbabilisticClassifierParams
extends ClassifierParams with HasProbabilityCol with HasThresholds
abstract class ProbabilisticClassifier
extends Classifier with ProbabilisticClassifierParams {
def setProbabilityCol
def setThresholds
}
abstract class ProbabilisticClassificationModel
extends ClassificationModel with ProbabilisticClassifierParams {
def setProbabilityCol
def setThresholds
}
```
This PR makes Python have the following:
```
class JavaProbabilisticClassifierParams(HasProbabilityCol, HasThresholds, JavaClassifierParams):
pass
class JavaProbabilisticClassifier(JavaClassifier, JavaProbabilisticClassifierParams):
def setProbabilityCol
def setThresholds
class JavaProbabilisticClassificationModel(JavaClassificationModel, JavaProbabilisticClassifierParams):
def setProbabilityCol
def setThresholds
```
3. Scala has PredictorParams/Predictor/PredictionModel:
```
trait PredictorParams extends Params
with HasLabelCol with HasFeaturesCol with HasPredictionCol
abstract class Predictor
extends Estimator with PredictorParams {
def setLabelCol
def setFeaturesCol
def setPredictionCol
}
abstract class PredictionModel
extends Model with PredictorParams {
def setFeaturesCol
def setPredictionCol
def numFeatures
def predict
}
```
This PR makes Python have the following:
```
class JavaPredictorParams(HasLabelCol, HasFeaturesCol, HasPredictionCol):
pass
class JavaPredictor(JavaEstimator, JavaPredictorParams):
def setLabelCol
def setFeaturesCol
def setPredictionCol
class JavaPredictionModel(JavaModel, JavaPredictorParams):
def setFeaturesCol
def setPredictionCol
def numFeatures
def predict
```
### Why are the changes needed?
Have parity between Python and Scala ML
### Does this PR introduce any user-facing change?
Yes. Add the following changes:
```
LinearSVCModel
- get/setFeatureCol
- get/setPredictionCol
- get/setLabelCol
- get/setRawPredictionCol
- predict
```
```
LogisticRegressionModel
DecisionTreeClassificationModel
RandomForestClassificationModel
GBTClassificationModel
NaiveBayesModel
MultilayerPerceptronClassificationModel
- get/setFeatureCol
- get/setPredictionCol
- get/setLabelCol
- get/setRawPredictionCol
- get/setProbabilityCol
- predict
```
```
LinearRegressionModel
IsotonicRegressionModel
DecisionTreeRegressionModel
RandomForestRegressionModel
GBTRegressionModel
AFTSurvivalRegressionModel
GeneralizedLinearRegressionModel
- get/setFeatureCol
- get/setPredictionCol
- get/setLabelCol
- predict
```
### How was this patch tested?
Add a few doc tests.
Closes#25776 from huaxingao/spark-28985.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
The Experimental and Evolving annotations are both (like Unstable) used to express that a an API may change. However there are many things in the code that have been marked that way since even Spark 1.x. Per the dev thread, anything introduced at or before Spark 2.3.0 is pretty much 'stable' in that it would not change without a deprecation cycle. Therefore I'd like to remove most of these annotations. And, remove the `:: Experimental ::` scaladoc tag too. And likewise for Python, R.
The changes below can be summarized as:
- Generally, anything introduced at or before Spark 2.3.0 has been unmarked as neither Evolving nor Experimental
- Obviously experimental items like DSv2, Barrier mode, ExperimentalMethods are untouched
- I _did_ unmark a few MLlib classes introduced in 2.4, as I am quite confident they're not going to change (e.g. KolmogorovSmirnovTest, PowerIterationClustering)
It's a big change to review, so I'd suggest scanning the list of _files_ changed to see if any area seems like it should remain partly experimental and examine those.
### Why are the changes needed?
Many of these annotations are incorrect; the APIs are de facto stable. Leaving them also makes legitimate usages of the annotations less meaningful.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#25558 from srowen/SPARK-28855.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
expose the newly added tree-based transformation in the py side
### Why are the changes needed?
function parity
### Does this PR introduce any user-facing change?
yes, add `setLeafCol` & `getLeafCol` in the py side
### How was this patch tested?
added tests & local tests
Closes#25566 from zhengruifeng/py_tree_path.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
## What changes were proposed in this pull request?
Leave ```shared.py``` untouched. Move Python ```DecisionTreeParams``` to ```regression.py```
## How was this patch tested?
Use existing tests
Closes#25406 from huaxingao/spark-28243.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove deprecated setFeatureSubsetStrategy and setSubsamplingRate from Python TreeEnsembleParams
## How was this patch tested?
Use existing tests.
Closes#25046 from huaxingao/spark-28243.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Add sample weights to decision trees
## How was this patch tested?
updated testsuites
Closes#23818 from zhengruifeng/py_tree_support_sample_weight.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Python version of https://github.com/apache/spark/pull/17654
## How was this patch tested?
Existing Python unit test
Closes#23676 from huaxingao/spark26754.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Misc code cleanup from lgtm.com analysis. See comments below for details.
## How was this patch tested?
Existing tests.
Closes#23571 from srowen/SPARK-26640.
Lead-authored-by: Sean Owen <sean.owen@databricks.com>
Co-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Co-authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Add validationIndicatorCol and validationTol to GBT Python.
## How was this patch tested?
Add test in doctest to test the new API.
Closes#21465 from huaxingao/spark-24333.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
(This change is a subset of the changes needed for the JIRA; see https://github.com/apache/spark/pull/22231)
## What changes were proposed in this pull request?
Use raw strings and simpler regex syntax consistently in Python, which also avoids warnings from pycodestyle about accidentally relying Python's non-escaping of non-reserved chars in normal strings. Also, fix a few long lines.
## How was this patch tested?
Existing tests, and some manual double-checking of the behavior of regexes in Python 2/3 to be sure.
Closes#22400 from srowen/SPARK-25238.2.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Fixing typos is sometimes very hard. It's not so easy to visually review them. Recently, I discovered a very useful tool for it, [misspell](https://github.com/client9/misspell).
This pull request fixes minor typos detected by [misspell](https://github.com/client9/misspell) except for the false positives. If you would like me to work on other files as well, let me know.
## How was this patch tested?
### before
```
$ misspell . | grep -v '.js'
R/pkg/R/SQLContext.R:354:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:424:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:445:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:495:43: "definiton" is a misspelling of "definition"
NOTICE-binary:454:16: "containd" is a misspelling of "contained"
R/pkg/R/context.R:46:43: "definiton" is a misspelling of "definition"
R/pkg/R/context.R:74:43: "definiton" is a misspelling of "definition"
R/pkg/R/DataFrame.R:591:48: "persistance" is a misspelling of "persistence"
R/pkg/R/streaming.R:166:44: "occured" is a misspelling of "occurred"
R/pkg/inst/worker/worker.R:65:22: "ouput" is a misspelling of "output"
R/pkg/tests/fulltests/test_utils.R:106:25: "environemnt" is a misspelling of "environment"
common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java:38:39: "existant" is a misspelling of "existent"
common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java:83:39: "existant" is a misspelling of "existent"
common/network-common/src/main/java/org/apache/spark/network/crypto/TransportCipher.java:243:46: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:234:19: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:238:63: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:244:46: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:276:39: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/util/AbstractFileRegion.java:27:20: "transfered" is a misspelling of "transferred"
common/unsafe/src/test/scala/org/apache/spark/unsafe/types/UTF8StringPropertyCheckSuite.scala:195:15: "orgin" is a misspelling of "origin"
core/src/main/scala/org/apache/spark/api/python/PythonRDD.scala:621:39: "gauranteed" is a misspelling of "guaranteed"
core/src/main/scala/org/apache/spark/status/storeTypes.scala:113:29: "ect" is a misspelling of "etc"
core/src/main/scala/org/apache/spark/storage/DiskStore.scala:282:18: "transfered" is a misspelling of "transferred"
core/src/main/scala/org/apache/spark/util/ListenerBus.scala:64:17: "overriden" is a misspelling of "overridden"
core/src/test/scala/org/apache/spark/ShuffleSuite.scala:211:7: "substracted" is a misspelling of "subtracted"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:1922:49: "agriculteur" is a misspelling of "agriculture"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:2468:84: "truely" is a misspelling of "truly"
core/src/test/scala/org/apache/spark/storage/FlatmapIteratorSuite.scala:25:18: "persistance" is a misspelling of "persistence"
core/src/test/scala/org/apache/spark/storage/FlatmapIteratorSuite.scala:26:69: "persistance" is a misspelling of "persistence"
data/streaming/AFINN-111.txt:1219:0: "humerous" is a misspelling of "humorous"
dev/run-pip-tests:55:28: "enviroments" is a misspelling of "environments"
dev/run-pip-tests:91:37: "virutal" is a misspelling of "virtual"
dev/merge_spark_pr.py:377:72: "accross" is a misspelling of "across"
dev/merge_spark_pr.py:378:66: "accross" is a misspelling of "across"
dev/run-pip-tests:126:25: "enviroments" is a misspelling of "environments"
docs/configuration.md:1830:82: "overriden" is a misspelling of "overridden"
docs/structured-streaming-programming-guide.md:525:45: "processs" is a misspelling of "processes"
docs/structured-streaming-programming-guide.md:1165:61: "BETWEN" is a misspelling of "BETWEEN"
docs/sql-programming-guide.md:1891:810: "behaivor" is a misspelling of "behavior"
examples/src/main/python/sql/arrow.py:98:8: "substract" is a misspelling of "subtract"
examples/src/main/python/sql/arrow.py:103:27: "substract" is a misspelling of "subtract"
licenses/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/hungarian.txt:170:0: "teh" is a misspelling of "the"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/portuguese.txt:53:0: "eles" is a misspelling of "eels"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:99:20: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:539:11: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/mllib/clustering/LDAOptimizer.scala:77:36: "Teh" is a misspelling of "The"
mllib/src/main/scala/org/apache/spark/mllib/clustering/StreamingKMeans.scala:230:24: "inital" is a misspelling of "initial"
mllib/src/main/scala/org/apache/spark/mllib/stat/MultivariateOnlineSummarizer.scala:276:9: "Euclidian" is a misspelling of "Euclidean"
mllib/src/test/scala/org/apache/spark/ml/clustering/KMeansSuite.scala:237:26: "descripiton" is a misspelling of "descriptions"
python/pyspark/find_spark_home.py:30:13: "enviroment" is a misspelling of "environment"
python/pyspark/context.py:937:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:938:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:939:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:940:12: "supress" is a misspelling of "suppress"
python/pyspark/heapq3.py:6:63: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:7:2: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:263:29: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:263:39: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:270:49: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:270:59: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:275:2: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:275:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:277:29: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:277:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:713:8: "probabilty" is a misspelling of "probability"
python/pyspark/ml/clustering.py:1038:8: "Currenlty" is a misspelling of "Currently"
python/pyspark/ml/stat.py:339:23: "Euclidian" is a misspelling of "Euclidean"
python/pyspark/ml/regression.py:1378:20: "paramter" is a misspelling of "parameter"
python/pyspark/mllib/stat/_statistics.py:262:8: "probabilty" is a misspelling of "probability"
python/pyspark/rdd.py:1363:32: "paramter" is a misspelling of "parameter"
python/pyspark/streaming/tests.py:825:42: "retuns" is a misspelling of "returns"
python/pyspark/sql/tests.py:768:29: "initalization" is a misspelling of "initialization"
python/pyspark/sql/tests.py:3616:31: "initalize" is a misspelling of "initialize"
resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosSchedulerBackendUtil.scala:120:39: "arbitary" is a misspelling of "arbitrary"
resource-managers/mesos/src/test/scala/org/apache/spark/deploy/mesos/MesosClusterDispatcherArgumentsSuite.scala:26:45: "sucessfully" is a misspelling of "successfully"
resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosSchedulerUtils.scala:358:27: "constaints" is a misspelling of "constraints"
resource-managers/yarn/src/test/scala/org/apache/spark/deploy/yarn/YarnClusterSuite.scala:111:24: "senstive" is a misspelling of "sensitive"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala:1063:5: "overwirte" is a misspelling of "overwrite"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala:1348:17: "compatability" is a misspelling of "compatibility"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala:77:36: "paramter" is a misspelling of "parameter"
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:1374:22: "precendence" is a misspelling of "precedence"
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/AnalysisSuite.scala:238:27: "unnecassary" is a misspelling of "unnecessary"
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ConditionalExpressionSuite.scala:212:17: "whn" is a misspelling of "when"
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamingSymmetricHashJoinHelper.scala:147:60: "timestmap" is a misspelling of "timestamp"
sql/core/src/test/scala/org/apache/spark/sql/TPCDSQuerySuite.scala:150:45: "precentage" is a misspelling of "percentage"
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVInferSchemaSuite.scala:135:29: "infered" is a misspelling of "inferred"
sql/hive/src/test/resources/golden/udf_instr-1-2e76f819563dbaba4beb51e3a130b922:1:52: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_instr-2-32da357fc754badd6e3898dcc8989182:1:52: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_locate-1-6e41693c9c6dceea4d7fab4c02884e4e:1:63: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_locate-2-d9b5934457931447874d6bb7c13de478:1:63: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_translate-2-f7aa38a33ca0df73b7a1e6b6da4b7fe8:9:79: "occurence" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_translate-2-f7aa38a33ca0df73b7a1e6b6da4b7fe8:13:110: "occurence" is a misspelling of "occurrence"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/annotate_stats_join.q:46:105: "distint" is a misspelling of "distinct"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/auto_sortmerge_join_11.q:29:3: "Currenly" is a misspelling of "Currently"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/avro_partitioned.q:72:15: "existant" is a misspelling of "existent"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/decimal_udf.q:25:3: "substraction" is a misspelling of "subtraction"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/groupby2_map_multi_distinct.q:16:51: "funtion" is a misspelling of "function"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/groupby_sort_8.q:15:30: "issueing" is a misspelling of "issuing"
sql/hive/src/test/scala/org/apache/spark/sql/sources/HadoopFsRelationTest.scala:669:52: "wiht" is a misspelling of "with"
sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java:474:9: "Refering" is a misspelling of "Referring"
```
### after
```
$ misspell . | grep -v '.js'
common/network-common/src/main/java/org/apache/spark/network/util/AbstractFileRegion.java:27:20: "transfered" is a misspelling of "transferred"
core/src/main/scala/org/apache/spark/status/storeTypes.scala:113:29: "ect" is a misspelling of "etc"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:1922:49: "agriculteur" is a misspelling of "agriculture"
data/streaming/AFINN-111.txt:1219:0: "humerous" is a misspelling of "humorous"
licenses/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/hungarian.txt:170:0: "teh" is a misspelling of "the"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/portuguese.txt:53:0: "eles" is a misspelling of "eels"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:99:20: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:539:11: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/mllib/clustering/LDAOptimizer.scala:77:36: "Teh" is a misspelling of "The"
mllib/src/main/scala/org/apache/spark/mllib/stat/MultivariateOnlineSummarizer.scala:276:9: "Euclidian" is a misspelling of "Euclidean"
python/pyspark/heapq3.py:6:63: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:7:2: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:263:29: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:263:39: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:270:49: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:270:59: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:275:2: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:275:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:277:29: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:277:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/ml/stat.py:339:23: "Euclidian" is a misspelling of "Euclidean"
```
Closes#22070 from seratch/fix-typo.
Authored-by: Kazuhiro Sera <seratch@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
## What changes were proposed in this pull request?
Adds basic PMML export support for Spark ML stages to PySpark as was previously done in Scala. Includes LinearRegressionModel as the first stage to implement.
## How was this patch tested?
Doctest, the main testing work for this is on the Scala side. (TODO holden add the unittest once I finish locally).
Author: Holden Karau <holden@pigscanfly.ca>
Closes#21172 from holdenk/SPARK-23120-add-pmml-export-support-to-pyspark.
## What changes were proposed in this pull request?
Add featureSubsetStrategy in GBTClassifier and GBTRegressor. Also make GBTClassificationModel inherit from JavaClassificationModel instead of prediction model so it will have numClasses.
## How was this patch tested?
Add tests in doctest
Author: Huaxin Gao <huaxing@us.ibm.com>
Closes#21413 from huaxingao/spark-23161.
## What changes were proposed in this pull request?
Add evaluateEachIteration for GBTClassification and GBTRegressionModel
## How was this patch tested?
doctest
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Lu WANG <lu.wang@databricks.com>
Closes#21335 from ludatabricks/SPARK-14682.
## What changes were proposed in this pull request?
Adding r2adj in LinearRegressionSummary for Python API.
## How was this patch tested?
Added unit tests to exercise the api calls for the summary classes in tests.py.
Author: Kevin Yu <qyu@us.ibm.com>
Closes#20842 from kevinyu98/spark-23162.
The exit() builtin is only for interactive use. applications should use sys.exit().
## What changes were proposed in this pull request?
All usage of the builtin `exit()` function is replaced by `sys.exit()`.
## How was this patch tested?
I ran `python/run-tests`.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Benjamin Peterson <benjamin@python.org>
Closes#20682 from benjaminp/sys-exit.
## What changes were proposed in this pull request?
Expose Python API for _LinearRegression_ with _huber_ loss.
## How was this patch tested?
Unit test.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#19994 from yanboliang/spark-22810.
## What changes were proposed in this pull request?
Update breeze to 0.13.1 for an emergency bugfix in strong wolfe line search
https://github.com/scalanlp/breeze/pull/651
## How was this patch tested?
N/A
Author: WeichenXu <WeichenXu123@outlook.com>
Closes#18797 from WeichenXu123/update-breeze.
## What changes were proposed in this pull request?
PySpark GLR ```model.summary``` should return a printable representation by calling Scala ```toString```.
## How was this patch tested?
```
from pyspark.ml.regression import GeneralizedLinearRegression
dataset = spark.read.format("libsvm").load("data/mllib/sample_linear_regression_data.txt")
glr = GeneralizedLinearRegression(family="gaussian", link="identity", maxIter=10, regParam=0.3)
model = glr.fit(dataset)
model.summary
```
Before this PR:

After this PR:
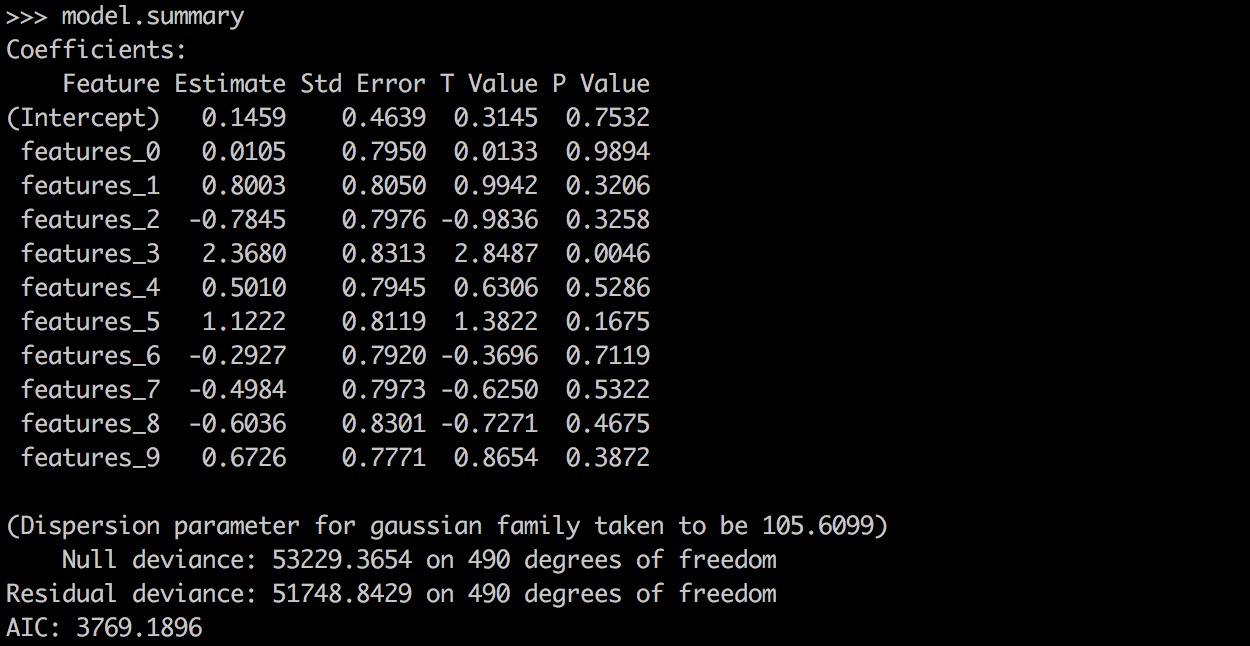
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18870 from yanboliang/spark-19270.
## What changes were proposed in this pull request?
GBTs inherit from HasStepSize & LInearSVC/Binarizer from HasThreshold
## How was this patch tested?
existing tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Author: Ruifeng Zheng <ruifengz@foxmail.com>
Closes#18612 from zhengruifeng/override_HasXXX.
## What changes were proposed in this pull request?
Add offset to PySpark in GLM as in #16699.
## How was this patch tested?
Python test
Author: actuaryzhang <actuaryzhang10@gmail.com>
Closes#18534 from actuaryzhang/pythonOffset.
## What changes were proposed in this pull request?
1, make param support non-final with `finalFields` option
2, generate `HasSolver` with `finalFields = false`
3, override `solver` in LiR, GLR, and make MLPC inherit `HasSolver`
## How was this patch tested?
existing tests
Author: Ruifeng Zheng <ruifengz@foxmail.com>
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#16028 from zhengruifeng/param_non_final.
## What changes were proposed in this pull request?
SPARK-20097 exposed degreesOfFreedom in LinearRegressionSummary and numInstances in GeneralizedLinearRegressionSummary. Python API should be updated to reflect these changes.
## How was this patch tested?
The existing UT
Author: Peng <peng.meng@intel.com>
Closes#18062 from mpjlu/spark-20764.
## What changes were proposed in this pull request?
PySpark ```GeneralizedLinearRegression``` supports tweedie distribution.
## How was this patch tested?
Add unit tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17146 from yanboliang/spark-19806.
## What changes were proposed in this pull request?
The `keyword_only` decorator in PySpark is not thread-safe. It writes kwargs to a static class variable in the decorator, which is then retrieved later in the class method as `_input_kwargs`. If multiple threads are constructing the same class with different kwargs, it becomes a race condition to read from the static class variable before it's overwritten. See [SPARK-19348](https://issues.apache.org/jira/browse/SPARK-19348) for reproduction code.
This change will write the kwargs to a member variable so that multiple threads can operate on separate instances without the race condition. It does not protect against multiple threads operating on a single instance, but that is better left to the user to synchronize.
## How was this patch tested?
Added new unit tests for using the keyword_only decorator and a regression test that verifies `_input_kwargs` can be overwritten from different class instances.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#16782 from BryanCutler/pyspark-keyword_only-threadsafe-SPARK-19348.
## What changes were proposed in this pull request?
Add model summary APIs for `GaussianMixtureModel` and `BisectingKMeansModel` in pyspark.
## How was this patch tested?
Unit tests.
Author: sethah <seth.hendrickson16@gmail.com>
Closes#15777 from sethah/pyspark_cluster_summaries.
## What changes were proposed in this pull request?
Gradient Boosted Tree in R.
With a few minor improvements to RandomForest in R.
Since this is relatively isolated I'd like to target this for branch-2.1
## How was this patch tested?
manual tests, unit tests
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#15746 from felixcheung/rgbt.
## What changes were proposed in this pull request?
Add subsmaplingRate to randomForestClassifier
Add varianceCol to randomForestRegressor
In Python
## How was this patch tested?
manual tests
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#15638 from felixcheung/pyrandomforest.
## What changes were proposed in this pull request?
Add treeAggregateDepth parameter for AFTSurvivalRegression to keep consistent with LiR/LoR.
## How was this patch tested?
Existing tests.
Author: WeichenXu <WeichenXu123@outlook.com>
Closes#14851 from WeichenXu123/add_treeAggregate_param_for_survival_regression.
## What changes were proposed in this pull request?
Add missing `numFeatures` and `numClasses` to the wrapped Java models in PySpark ML pipelines. Also tag `DecisionTreeClassificationModel` as Expiremental to match Scala doc.
## How was this patch tested?
Extended doctests
Author: Holden Karau <holden@us.ibm.com>
Closes#12889 from holdenk/SPARK-15113-add-missing-numFeatures-numClasses.
## What changes were proposed in this pull request?
Fix the typo of ```TreeEnsembleModels``` for PySpark, it should ```TreeEnsembleModel``` which will be consistent with Scala. What's more, it represents a tree ensemble model, so ```TreeEnsembleModel``` should be more reasonable. This should not be used public, so it will not involve breaking change.
## How was this patch tested?
No new tests, should pass existing ones.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#14454 from yanboliang/TreeEnsembleModel.
## What changes were proposed in this pull request?
General decisions to follow, except where noted:
* spark.mllib, pyspark.mllib: Remove all Experimental annotations. Leave DeveloperApi annotations alone.
* spark.ml, pyspark.ml
** Annotate Estimator-Model pairs of classes and companion objects the same way.
** For all algorithms marked Experimental with Since tag <= 1.6, remove Experimental annotation.
** For all algorithms marked Experimental with Since tag = 2.0, leave Experimental annotation.
* DeveloperApi annotations are left alone, except where noted.
* No changes to which types are sealed.
Exceptions where I am leaving items Experimental in spark.ml, pyspark.ml, mainly because the items are new:
* Model Summary classes
* MLWriter, MLReader, MLWritable, MLReadable
* Evaluator and subclasses: There is discussion of changes around evaluating multiple metrics at once for efficiency.
* RFormula: Its behavior may need to change slightly to match R in edge cases.
* AFTSurvivalRegression
* MultilayerPerceptronClassifier
DeveloperApi changes:
* ml.tree.Node, ml.tree.Split, and subclasses should no longer be DeveloperApi
## How was this patch tested?
N/A
Note to reviewers:
* spark.ml.clustering.LDA underwent significant changes (additional methods), so let me know if you want me to leave it Experimental.
* Be careful to check for cases where a class should no longer be Experimental but has an Experimental method, val, or other feature. I did not find such cases, but please verify.
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#14147 from jkbradley/experimental-audit.
[SPARK-14615](https://issues.apache.org/jira/browse/SPARK-14615) and #12627 changed `spark.ml` pipelines to use the new `ml.linalg` classes for `Vector`/`Matrix`. Some `Since` annotations for public methods/vals have not been updated accordingly to be `2.0.0`. This PR updates them.
## How was this patch tested?
Existing unit tests.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#13840 from MLnick/SPARK-16127-ml-linalg-since.
## What changes were proposed in this pull request?
Several places set the seed Param default value to None which will translate to a zero value on the Scala side. This is unnecessary because a default fixed value already exists and if a test depends on a zero valued seed, then it should explicitly set it to zero instead of relying on this translation. These cases can be safely removed except for the ALS doc test, which has been changed to set the seed value to zero.
## How was this patch tested?
Ran PySpark tests locally
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#13672 from BryanCutler/pyspark-cleanup-setDefault-seed-SPARK-15741.
## What changes were proposed in this pull request?
Fixed missing import for DecisionTreeRegressionModel used in GBTClassificationModel trees method.
## How was this patch tested?
Local tests
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#13787 from BryanCutler/pyspark-GBTClassificationModel-import-SPARK-16079.
## What changes were proposed in this pull request?
Now we have PySpark picklers for new and old vector/matrix, individually. However, they are all implemented under `PythonMLlibAPI`. To separate spark.mllib from spark.ml, we should implement the picklers of new vector/matrix under `spark.ml.python` instead.
## How was this patch tested?
Existing tests.
Author: Liang-Chi Hsieh <simonh@tw.ibm.com>
Closes#13219 from viirya/pyspark-pickler-ml.
## What changes were proposed in this pull request?
Add `toDebugString` and `totalNumNodes` to `TreeEnsembleModels` and add `toDebugString` to `DecisionTreeModel`
## How was this patch tested?
Extended doc tests.
Author: Holden Karau <holden@us.ibm.com>
Closes#12919 from holdenk/SPARK-15139-pyspark-treeEnsemble-missing-methods.
## What changes were proposed in this pull request?
PySpark: Add links to the predictors from the models in regression.py, improve linear and isotonic pydoc in minor ways.
User guide / R: Switch the installed package list to be enough to build the R docs on a "fresh" install on ubuntu and add sudo to match the rest of the commands.
User Guide: Add a note about using gem2.0 for systems with both 1.9 and 2.0 (e.g. some ubuntu but maybe more).
## How was this patch tested?
built pydocs locally, tested new user build instructions
Author: Holden Karau <holden@us.ibm.com>
Closes#13199 from holdenk/SPARK-15412-improve-linear-isotonic-regression-pydoc.
## What changes were proposed in this pull request?
Replace SQLContext and SparkContext with SparkSession using builder pattern in python test code.
## How was this patch tested?
Existing test.
Author: WeichenXu <WeichenXu123@outlook.com>
Closes#13242 from WeichenXu123/python_doctest_update_sparksession.
## What changes were proposed in this pull request?
Default value mismatch of param linkPredictionCol for GeneralizedLinearRegression between PySpark and Scala. That is because default value conflict between #13106 and #13129. This causes ml.tests failed.
## How was this patch tested?
Existing tests.
Author: Liang-Chi Hsieh <simonh@tw.ibm.com>
Closes#13220 from viirya/hotfix-regresstion.
## What changes were proposed in this pull request?
Add linkPredictionCol to GeneralizedLinearRegression and fix the PyDoc to generate the bullet list
## How was this patch tested?
doctests & built docs locally
Author: Holden Karau <holden@us.ibm.com>
Closes#13106 from holdenk/SPARK-15316-add-linkPredictionCol-toGeneralizedLinearRegression.
## What changes were proposed in this pull request?
Once SPARK-14487 and SPARK-14549 are merged, we will migrate to use the new vector and matrix type in the new ml pipeline based apis.
## How was this patch tested?
Unit tests
Author: DB Tsai <dbt@netflix.com>
Author: Liang-Chi Hsieh <simonh@tw.ibm.com>
Author: Xiangrui Meng <meng@databricks.com>
Closes#12627 from dbtsai/SPARK-14615-NewML.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}