These options were used to configure the built-in JRE SSL libraries
when downloading files from HTTPS servers. But because they were also
used to set up the now (long) removed internal HTTPS file server,
their default configuration chose convenience over security by having
overly lenient settings.
This change removes the configuration options that affect the JRE SSL
libraries. The JRE trust store can still be configured via system
properties (or globally in the JRE security config). The only lost
functionality is not being able to disable the default hostname
verifier when using spark-submit, which should be fine since Spark
itself is not using https for any internal functionality anymore.
I also removed the HTTP-related code from the REPL class loader, since
we haven't had a HTTP server for REPL-generated classes for a while.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20723 from vanzin/SPARK-23538.
## What changes were proposed in this pull request?
If spark is run with "spark.authenticate=true", then it will fail to start in local mode.
This PR generates secret in local mode when authentication on.
## How was this patch tested?
Modified existing unit test.
Manually started spark-shell.
Author: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Closes#20652 from gaborgsomogyi/SPARK-23476.
## What changes were proposed in this pull request?
- Added clear information about triggers
- Made the semantics guarantees of watermarks more clear for streaming aggregations and stream-stream joins.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20631 from tdas/SPARK-23454.
## What changes were proposed in this pull request?
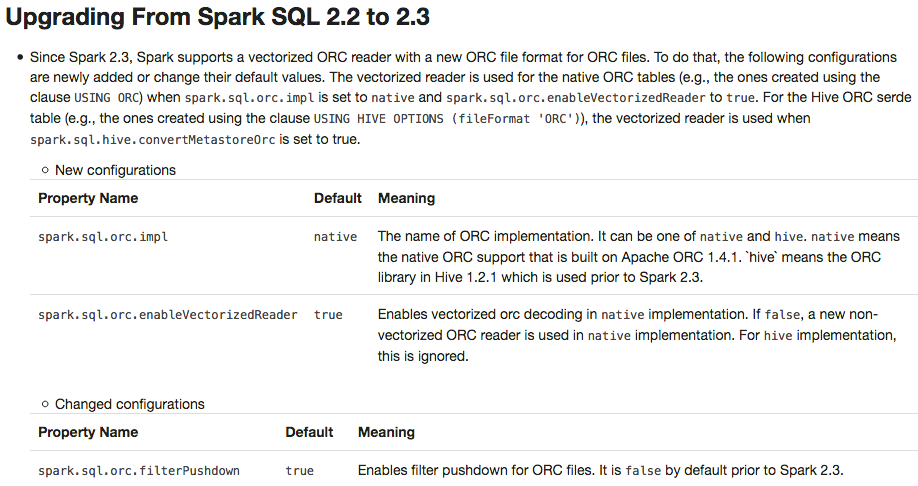
Apache Spark 2.3 introduced `native` ORC supports with vectorization and many fixes. However, it's shipped as a not-default option. This PR enables `native` ORC implementation and predicate-pushdown by default for Apache Spark 2.4. We will improve and stabilize ORC data source before Apache Spark 2.4. And, eventually, Apache Spark will drop old Hive-based ORC code.
## How was this patch tested?
Pass the Jenkins with existing tests.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20634 from dongjoon-hyun/SPARK-23456.
## What changes were proposed in this pull request?
To prevent any regressions, this PR changes ORC implementation to `hive` by default like Spark 2.2.X.
Users can enable `native` ORC. Also, ORC PPD is also restored to `false` like Spark 2.2.X.

## How was this patch tested?
Pass all test cases.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20610 from dongjoon-hyun/SPARK-ORC-DISABLE.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/19579 introduces a behavior change. We need to document it in the migration guide.
## How was this patch tested?
Also update the HiveExternalCatalogVersionsSuite to verify it.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20606 from gatorsmile/addMigrationGuide.
## What changes were proposed in this pull request?
Added documentation about what MLlib guarantees in terms of loading ML models and Pipelines from old Spark versions. Discussed & confirmed on linked JIRA.
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#20592 from jkbradley/SPARK-23154-backwards-compat-doc.
## What changes were proposed in this pull request?
This PR targets to explicitly specify supported types in Pandas UDFs.
The main change here is to add a deduplicated and explicit type checking in `returnType` ahead with documenting this; however, it happened to fix multiple things.
1. Currently, we don't support `BinaryType` in Pandas UDFs, for example, see:
```python
from pyspark.sql.functions import pandas_udf
pudf = pandas_udf(lambda x: x, "binary")
df = spark.createDataFrame([[bytearray(1)]])
df.select(pudf("_1")).show()
```
```
...
TypeError: Unsupported type in conversion to Arrow: BinaryType
```
We can document this behaviour for its guide.
2. Also, the grouped aggregate Pandas UDF fails fast on `ArrayType` but seems we can support this case.
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
foo = pandas_udf(lambda v: v.mean(), 'array<double>', PandasUDFType.GROUPED_AGG)
df = spark.range(100).selectExpr("id", "array(id) as value")
df.groupBy("id").agg(foo("value")).show()
```
```
...
NotImplementedError: ArrayType, StructType and MapType are not supported with PandasUDFType.GROUPED_AGG
```
3. Since we can check the return type ahead, we can fail fast before actual execution.
```python
# we can fail fast at this stage because we know the schema ahead
pandas_udf(lambda x: x, BinaryType())
```
## How was this patch tested?
Manually tested and unit tests for `BinaryType` and `ArrayType(...)` were added.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20531 from HyukjinKwon/pudf-cleanup.
This commit modifies the Mesos submission client to allow the principal
and secret to be provided indirectly via files. The path to these files
can be specified either via Spark configuration or via environment
variable.
Assuming these files are appropriately protected by FS/OS permissions
this means we don't ever leak the actual values in process info like ps
Environment variable specification is useful because it allows you to
interpolate the location of this file when using per-user Mesos
credentials.
For some background as to why we have taken this approach I will briefly describe our set up. On our systems we provide each authorised user account with their own Mesos credentials to provide certain security and audit guarantees to our customers. These credentials are managed by a central Secret management service. In our `spark-env.sh` we determine the appropriate secret and principal files to use depending on the user who is invoking Spark hence the need to inject these via environment variables as well as by configuration properties. So we set these environment variables appropriately and our Spark read in the contents of those files to authenticate itself with Mesos.
This is functionality we have been using it in production across multiple customer sites for some time. This has been in the field for around 18 months with no reported issues. These changes have been sufficient to meet our customer security and audit requirements.
We have been building and deploying custom builds of Apache Spark with various minor tweaks like this which we are now looking to contribute back into the community in order that we can rely upon stock Apache Spark builds and stop maintaining our own internal fork.
Author: Rob Vesse <rvesse@dotnetrdf.org>
Closes#20167 from rvesse/SPARK-16501.
## What changes were proposed in this pull request?
This PR proposes to disallow default value None when 'to_replace' is not a dictionary.
It seems weird we set the default value of `value` to `None` and we ended up allowing the case as below:
```python
>>> df.show()
```
```
+----+------+-----+
| age|height| name|
+----+------+-----+
| 10| 80|Alice|
...
```
```python
>>> df.na.replace('Alice').show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
**After**
This PR targets to disallow the case above:
```python
>>> df.na.replace('Alice').show()
```
```
...
TypeError: value is required when to_replace is not a dictionary.
```
while we still allow when `to_replace` is a dictionary:
```python
>>> df.na.replace({'Alice': None}).show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
## How was this patch tested?
Manually tested, tests were added in `python/pyspark/sql/tests.py` and doctests were fixed.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20499 from HyukjinKwon/SPARK-19454-followup.
## What changes were proposed in this pull request?
Further clarification of caveats in using stream-stream outer joins.
## How was this patch tested?
N/A
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20494 from tdas/SPARK-23064-2.
Add breaking changes, as well as update behavior changes, to `2.3` ML migration guide.
## How was this patch tested?
Doc only
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#20421 from MLnick/SPARK-23112-ml-guide.
## What changes were proposed in this pull request?
Rename the public APIs and names of pandas udfs.
- `PANDAS SCALAR UDF` -> `SCALAR PANDAS UDF`
- `PANDAS GROUP MAP UDF` -> `GROUPED MAP PANDAS UDF`
- `PANDAS GROUP AGG UDF` -> `GROUPED AGG PANDAS UDF`
## How was this patch tested?
The existing tests
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20428 from gatorsmile/renamePandasUDFs.
## What changes were proposed in this pull request?
User guide and examples are updated to reflect multiclass logistic regression summary which was added in [SPARK-17139](https://issues.apache.org/jira/browse/SPARK-17139).
I did not make a separate summary example, but added the summary code to the multiclass example that already existed. I don't see the need for a separate example for the summary.
## How was this patch tested?
Docs and examples only. Ran all examples locally using spark-submit.
Author: sethah <shendrickson@cloudera.com>
Closes#20332 from sethah/multiclass_summary_example.
## What changes were proposed in this pull request?
Adding user facing documentation for working with Arrow in Spark
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Li Jin <ice.xelloss@gmail.com>
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19575 from BryanCutler/arrow-user-docs-SPARK-2221.
Update ML user guide with highlights and migration guide for `2.3`.
## How was this patch tested?
Doc only.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#20363 from MLnick/SPARK-23112-ml-guide.
## What changes were proposed in this pull request?
Added documentation for new transformer.
Author: Bago Amirbekian <bago@databricks.com>
Closes#20285 from MrBago/sizeHintDocs.
## What changes were proposed in this pull request?
The example jar file is now in ./examples/jars directory of Spark distribution.
Author: Arseniy Tashoyan <tashoyan@users.noreply.github.com>
Closes#20349 from tashoyan/patch-1.
## What changes were proposed in this pull request?
streaming programming guide changes
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#20340 from felixcheung/rstreamdoc.
## What changes were proposed in this pull request?
Fix spelling in quick-start doc.
## How was this patch tested?
Doc only.
Author: Shashwat Anand <me@shashwat.me>
Closes#20336 from ashashwat/SPARK-23165.
## What changes were proposed in this pull request?
Docs changes:
- Adding a warning that the backend is experimental.
- Removing a defunct internal-only option from documentation
- Clarifying that node selectors can be used right away, and other minor cosmetic changes
## How was this patch tested?
Docs only change
Author: foxish <ramanathana@google.com>
Closes#20314 from foxish/ambiguous-docs.
## What changes were proposed in this pull request?
We have `OneHotEncoderEstimator` now and `OneHotEncoder` will be deprecated since 2.3.0. We should add `OneHotEncoderEstimator` into mllib document.
We also need to provide corresponding examples for `OneHotEncoderEstimator` which are used in the document too.
## How was this patch tested?
Existing tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20257 from viirya/SPARK-23048.
Update user guide entry for `FeatureHasher` to match the Scala / Python doc, to describe the `categoricalCols` parameter.
## How was this patch tested?
Doc only
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#20293 from MLnick/SPARK-23127-catCol-userguide.
## What changes were proposed in this pull request?
In latest structured-streaming-kafka-integration document, Java code example for Kafka integration is using `DataFrame<Row>`, shouldn't it be changed to `DataSet<Row>`?
## How was this patch tested?
manual test has been performed to test the updated example Java code in Spark 2.2.1 with Kafka 1.0
Author: brandonJY <brandonJY@users.noreply.github.com>
Closes#20312 from brandonJY/patch-2.
## What changes were proposed in this pull request?
In the Kubernetes mode, fails fast in the submission process if any submission client local dependencies are used as the use case is not supported yet.
## How was this patch tested?
Unit tests, integration tests, and manual tests.
vanzin foxish
Author: Yinan Li <liyinan926@gmail.com>
Closes#20320 from liyinan926/master.
## What changes were proposed in this pull request?
This PR completes the docs, specifying the default units assumed in configuration entries of type size.
This is crucial since unit-less values are accepted and the user might assume the base unit is bytes, which in most cases it is not, leading to hard-to-debug problems.
## How was this patch tested?
This patch updates only documentation only.
Author: Fernando Pereira <fernando.pereira@epfl.ch>
Closes#20269 from ferdonline/docs_units.
## What changes were proposed in this pull request?
When there is an operation between Decimals and the result is a number which is not representable exactly with the result's precision and scale, Spark is returning `NULL`. This was done to reflect Hive's behavior, but it is against SQL ANSI 2011, which states that "If the result cannot be represented exactly in the result type, then whether it is rounded or truncated is implementation-defined". Moreover, Hive now changed its behavior in order to respect the standard, thanks to HIVE-15331.
Therefore, the PR propose to:
- update the rules to determine the result precision and scale according to the new Hive's ones introduces in HIVE-15331;
- round the result of the operations, when it is not representable exactly with the result's precision and scale, instead of returning `NULL`
- introduce a new config `spark.sql.decimalOperations.allowPrecisionLoss` which default to `true` (ie. the new behavior) in order to allow users to switch back to the previous one.
Hive behavior reflects SQLServer's one. The only difference is that the precision and scale are adjusted for all the arithmetic operations in Hive, while SQL Server is said to do so only for multiplications and divisions in the documentation. This PR follows Hive's behavior.
A more detailed explanation is available here: https://mail-archives.apache.org/mod_mbox/spark-dev/201712.mbox/%3CCAEorWNAJ4TxJR9NBcgSFMD_VxTg8qVxusjP%2BAJP-x%2BJV9zH-yA%40mail.gmail.com%3E.
## How was this patch tested?
modified and added UTs. Comparisons with results of Hive and SQLServer.
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20023 from mgaido91/SPARK-22036.
## What changes were proposed in this pull request?
This patch bumps the master branch version to `2.4.0-SNAPSHOT`.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20222 from gatorsmile/bump24.
## What changes were proposed in this pull request?
Small typing correction - double word
## How was this patch tested?
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Matthias Beaupère <matthias.beaupere@gmail.com>
Closes#20212 from matthiasbe/patch-1.
This change allows a user to submit a Spark application on kubernetes
having to provide a single image, instead of one image for each type
of container. The image's entry point now takes an extra argument that
identifies the process that is being started.
The configuration still allows the user to provide different images
for each container type if they so desire.
On top of that, the entry point was simplified a bit to share more
code; mainly, the same env variable is used to propagate the user-defined
classpath to the different containers.
Aside from being modified to match the new behavior, the
'build-push-docker-images.sh' script was renamed to 'docker-image-tool.sh'
to more closely match its purpose; the old name was a little awkward
and now also not entirely correct, since there is a single image. It
was also moved to 'bin' since it's not necessarily an admin tool.
Docs have been updated to match the new behavior.
Tested locally with minikube.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20192 from vanzin/SPARK-22994.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/18164 introduces the behavior changes. We need to document it.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20234 from gatorsmile/docBehaviorChange.
## What changes were proposed in this pull request?
doc update
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#20198 from felixcheung/rrefreshdoc.
[SPARK-21786][SQL] When acquiring 'compressionCodecClassName' in 'ParquetOptions', `parquet.compression` needs to be considered.
## What changes were proposed in this pull request?
Since Hive 1.1, Hive allows users to set parquet compression codec via table-level properties parquet.compression. See the JIRA: https://issues.apache.org/jira/browse/HIVE-7858 . We do support orc.compression for ORC. Thus, for external users, it is more straightforward to support both. See the stackflow question: https://stackoverflow.com/questions/36941122/spark-sql-ignores-parquet-compression-propertie-specified-in-tblproperties
In Spark side, our table-level compression conf compression was added by #11464 since Spark 2.0.
We need to support both table-level conf. Users might also use session-level conf spark.sql.parquet.compression.codec. The priority rule will be like
If other compression codec configuration was found through hive or parquet, the precedence would be compression, parquet.compression, spark.sql.parquet.compression.codec. Acceptable values include: none, uncompressed, snappy, gzip, lzo.
The rule for Parquet is consistent with the ORC after the change.
Changes:
1.Increased acquiring 'compressionCodecClassName' from `parquet.compression`,and the precedence order is `compression`,`parquet.compression`,`spark.sql.parquet.compression.codec`, just like what we do in `OrcOptions`.
2.Change `spark.sql.parquet.compression.codec` to support "none".Actually in `ParquetOptions`,we do support "none" as equivalent to "uncompressed", but it does not allowed to configured to "none".
3.Change `compressionCode` to `compressionCodecClassName`.
## How was this patch tested?
Add test.
Author: fjh100456 <fu.jinhua6@zte.com.cn>
Closes#20076 from fjh100456/ParquetOptionIssue.
## What changes were proposed in this pull request?
This pr modified `elt` to output binary for binary inputs.
`elt` in the current master always output data as a string. But, in some databases (e.g., MySQL), if all inputs are binary, `elt` also outputs binary (Also, this might be a small surprise).
This pr is related to #19977.
## How was this patch tested?
Added tests in `SQLQueryTestSuite` and `TypeCoercionSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#20135 from maropu/SPARK-22937.
- Make it possible to build images from a git clone.
- Make it easy to use minikube to test things.
Also fixed what seemed like a bug: the base image wasn't getting the tag
provided in the command line. Adding the tag allows users to use multiple
Spark builds in the same kubernetes cluster.
Tested by deploying images on minikube and running spark-submit from a dev
environment; also by building the images with different tags and verifying
"docker images" in minikube.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20154 from vanzin/SPARK-22960.
## What changes were proposed in this pull request?
update R migration guide and vignettes
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#20106 from felixcheung/rreleasenote23.
## What changes were proposed in this pull request?
Fixing three small typos in the docs, in particular:
It take a `RDD` -> It takes an `RDD` (twice)
It take an `JavaRDD` -> It takes a `JavaRDD`
I didn't create any Jira issue for this minor thing, I hope it's ok.
## How was this patch tested?
visually by clicking on 'preview'
Author: Jirka Kremser <jkremser@redhat.com>
Closes#20108 from Jiri-Kremser/docs-typo.
## What changes were proposed in this pull request?
Currently, we do not guarantee an order evaluation of conjuncts in either Filter or Join operator. This is also true to the mainstream RDBMS vendors like DB2 and MS SQL Server. Thus, we should also push down the deterministic predicates that are after the first non-deterministic, if possible.
## How was this patch tested?
Updated the existing test cases.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20069 from gatorsmile/morePushDown.
## What changes were proposed in this pull request?
This pr modified `concat` to concat binary inputs into a single binary output.
`concat` in the current master always output data as a string. But, in some databases (e.g., PostgreSQL), if all inputs are binary, `concat` also outputs binary.
## How was this patch tested?
Added tests in `SQLQueryTestSuite` and `TypeCoercionSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#19977 from maropu/SPARK-22771.
## What changes were proposed in this pull request?
This PR updates the Kubernetes documentation corresponding to the following features/changes in #19954.
* Ability to use remote dependencies through the init-container.
* Ability to mount user-specified secrets into the driver and executor pods.
vanzin jiangxb1987 foxish
Author: Yinan Li <liyinan926@gmail.com>
Closes#20059 from liyinan926/doc-update.
What changes were proposed in this pull request?
This PR contains documentation on the usage of Kubernetes scheduler in Spark 2.3, and a shell script to make it easier to build docker images required to use the integration. The changes detailed here are covered by https://github.com/apache/spark/pull/19717 and https://github.com/apache/spark/pull/19468 which have merged already.
How was this patch tested?
The script has been in use for releases on our fork. Rest is documentation.
cc rxin mateiz (shepherd)
k8s-big-data SIG members & contributors: foxish ash211 mccheah liyinan926 erikerlandson ssuchter varunkatta kimoonkim tnachen ifilonenko
reviewers: vanzin felixcheung jiangxb1987 mridulm
TODO:
- [x] Add dockerfiles directory to built distribution. (https://github.com/apache/spark/pull/20007)
- [x] Change references to docker to instead say "container" (https://github.com/apache/spark/pull/19995)
- [x] Update configuration table.
- [x] Modify spark.kubernetes.allocation.batch.delay to take time instead of int (#20032)
Author: foxish <ramanathana@google.com>
Closes#19946 from foxish/update-k8s-docs.
## What changes were proposed in this pull request?
Like `Parquet`, users can use `ORC` with Apache Spark structured streaming. This PR adds `orc()` to `DataStreamReader`(Scala/Python) in order to support creating streaming dataset with ORC file format more easily like the other file formats. Also, this adds a test coverage for ORC data source and updates the document.
**BEFORE**
```scala
scala> spark.readStream.schema("a int").orc("/tmp/orc_ss").writeStream.format("console").start()
<console>:24: error: value orc is not a member of org.apache.spark.sql.streaming.DataStreamReader
spark.readStream.schema("a int").orc("/tmp/orc_ss").writeStream.format("console").start()
```
**AFTER**
```scala
scala> spark.readStream.schema("a int").orc("/tmp/orc_ss").writeStream.format("console").start()
res0: org.apache.spark.sql.streaming.StreamingQuery = org.apache.spark.sql.execution.streaming.StreamingQueryWrapper678b3746
scala>
-------------------------------------------
Batch: 0
-------------------------------------------
+---+
| a|
+---+
| 1|
+---+
```
## How was this patch tested?
Pass the newly added test cases.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19975 from dongjoon-hyun/SPARK-22781.
## What changes were proposed in this pull request?
Easy fix in the link.
## How was this patch tested?
Tested manually
Author: Mahmut CAVDAR <mahmutcvdr@gmail.com>
Closes#19996 from mcavdar/master.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}