## What changes were proposed in this pull request?
Added LogisticRegressionTrainingSummary for MultinomialLogisticRegression in Python API
## How was this patch tested?
Added unit test
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Ming Jiang <mjiang@fanatics.com>
Author: Ming Jiang <jmwdpk@gmail.com>
Author: jmwdpk <jmwdpk@gmail.com>
Closes#19185 from jmwdpk/SPARK-21854.
# What changes were proposed in this pull request?
Added tunable parallelism to the pyspark implementation of one vs. rest classification. Added a parallelism parameter to the Scala implementation of one vs. rest along with functionality for using the parameter to tune the level of parallelism.
I take this PR #18281 over because the original author is busy but we need merge this PR soon.
After this been merged, we can close#18281 .
## How was this patch tested?
Test suite added.
Author: Ajay Saini <ajays725@gmail.com>
Author: WeichenXu <weichen.xu@databricks.com>
Closes#19110 from WeichenXu123/spark-21027.
Probability and rawPrediction has been added to MultilayerPerceptronClassifier for Python
Add unit test.
Author: Chunsheng Ji <chunsheng.ji@gmail.com>
Closes#19172 from chunshengji/SPARK-21856.
https://issues.apache.org/jira/browse/SPARK-19866
## What changes were proposed in this pull request?
Add Python API for findSynonymsArray matching Scala API.
## How was this patch tested?
Manual test
`./python/run-tests --python-executables=python2.7 --modules=pyspark-ml`
Author: Xin Ren <iamshrek@126.com>
Author: Xin Ren <renxin.ubc@gmail.com>
Author: Xin Ren <keypointt@users.noreply.github.com>
Closes#17451 from keypointt/SPARK-19866.
## What changes were proposed in this pull request?
This PR proposes to support unicodes in Param methods in ML, other missed functions in DataFrame.
For example, this causes a `ValueError` in Python 2.x when param is a unicode string:
```python
>>> from pyspark.ml.classification import LogisticRegression
>>> lr = LogisticRegression()
>>> lr.hasParam("threshold")
True
>>> lr.hasParam(u"threshold")
Traceback (most recent call last):
...
raise TypeError("hasParam(): paramName must be a string")
TypeError: hasParam(): paramName must be a string
```
This PR is based on https://github.com/apache/spark/pull/13036
## How was this patch tested?
Unit tests in `python/pyspark/ml/tests.py` and `python/pyspark/sql/tests.py`.
Author: hyukjinkwon <gurwls223@gmail.com>
Author: sethah <seth.hendrickson16@gmail.com>
Closes#17096 from HyukjinKwon/SPARK-15243.
## What changes were proposed in this pull request?
Modify MLP model to inherit `ProbabilisticClassificationModel` and so that it can expose the probability column when transforming data.
## How was this patch tested?
Test added.
Author: WeichenXu <WeichenXu123@outlook.com>
Closes#17373 from WeichenXu123/expose_probability_in_mlp_model.
## What changes were proposed in this pull request?
Added call to copy values of Params from Estimator to Model after fit in PySpark ML. This will copy values for any params that are also defined in the Model. Since currently most Models do not define the same params from the Estimator, also added method to create new Params from looking at the Java object if they do not exist in the Python object. This is a temporary fix that can be removed once the PySpark models properly define the params themselves.
## How was this patch tested?
Refactored the `check_params` test to optionally check if the model params for Python and Java match and added this check to an existing fitted model that shares params between Estimator and Model.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#17849 from BryanCutler/pyspark-models-own-params-SPARK-10931.
Add Python API for `FeatureHasher` transformer.
## How was this patch tested?
New doc test.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#18970 from MLnick/SPARK-21468-pyspark-hasher.
## What changes were proposed in this pull request?
Implemented a Python-only persistence framework for pipelines containing stages that cannot be saved using Java.
## How was this patch tested?
Created a custom Python-only UnaryTransformer, included it in a Pipeline, and saved/loaded the pipeline. The loaded pipeline was compared against the original using _compare_pipelines() in tests.py.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18888 from ajaysaini725/PythonPipelines.
## What changes were proposed in this pull request?
Update breeze to 0.13.1 for an emergency bugfix in strong wolfe line search
https://github.com/scalanlp/breeze/pull/651
## How was this patch tested?
N/A
Author: WeichenXu <WeichenXu123@outlook.com>
Closes#18797 from WeichenXu123/update-breeze.
## What changes were proposed in this pull request?
PySpark GLR ```model.summary``` should return a printable representation by calling Scala ```toString```.
## How was this patch tested?
```
from pyspark.ml.regression import GeneralizedLinearRegression
dataset = spark.read.format("libsvm").load("data/mllib/sample_linear_regression_data.txt")
glr = GeneralizedLinearRegression(family="gaussian", link="identity", maxIter=10, regParam=0.3)
model = glr.fit(dataset)
model.summary
```
Before this PR:

After this PR:
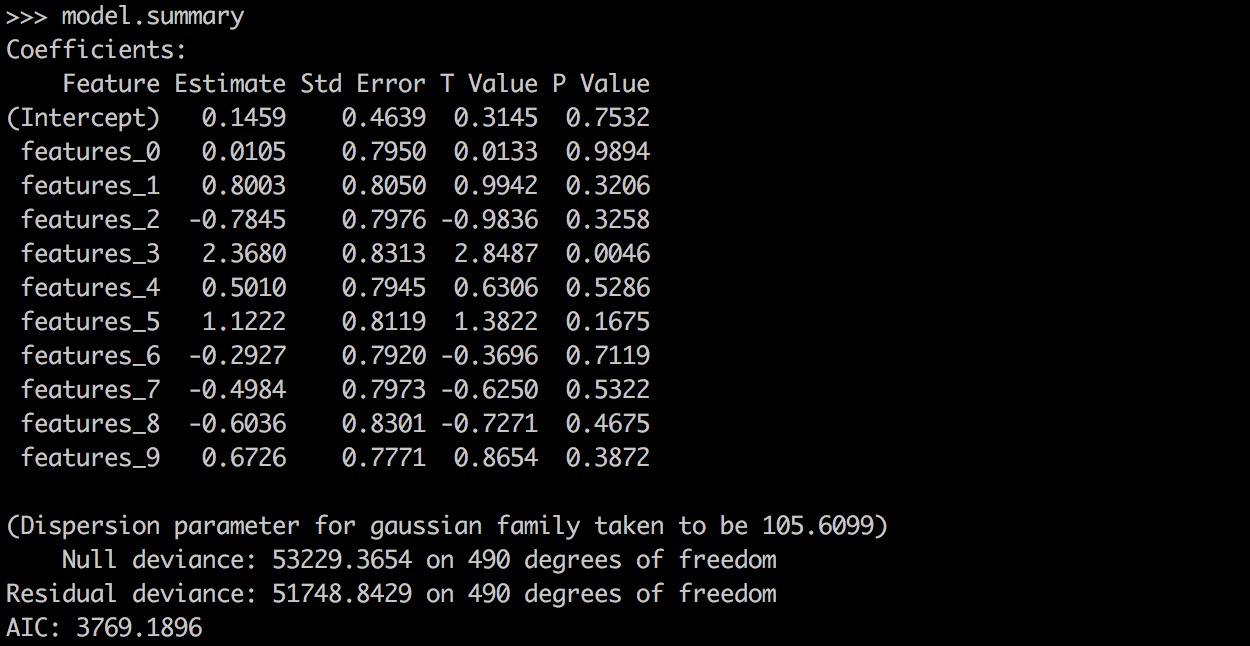
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18870 from yanboliang/spark-19270.
## What changes were proposed in this pull request?
Added DefaultParamsWriteable, DefaultParamsReadable, DefaultParamsWriter, and DefaultParamsReader to Python to support Python-only persistence of Json-serializable parameters.
## How was this patch tested?
Instantiated an estimator with Json-serializable parameters (ex. LogisticRegression), saved it using the added helper functions, and loaded it back, and compared it to the original instance to make sure it is the same. This test was both done in the Python REPL and implemented in the unit tests.
Note to reviewers: there are a few excess comments that I left in the code for clarity but will remove before the code is merged to master.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18742 from ajaysaini725/PythonPersistenceHelperFunctions.
## What changes were proposed in this pull request?
Implemented UnaryTransformer in Python.
## How was this patch tested?
This patch was tested by creating a MockUnaryTransformer class in the unit tests that extends UnaryTransformer and testing that the transform function produced correct output.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18746 from ajaysaini725/AddPythonUnaryTransformer.
## What changes were proposed in this pull request?
Python API for Constrained Logistic Regression based on #17922 , thanks for the original contribution from zero323 .
## How was this patch tested?
Unit tests.
Author: zero323 <zero323@users.noreply.github.com>
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18759 from yanboliang/SPARK-20601.
## What changes were proposed in this pull request?
GBTs inherit from HasStepSize & LInearSVC/Binarizer from HasThreshold
## How was this patch tested?
existing tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Author: Ruifeng Zheng <ruifengz@foxmail.com>
Closes#18612 from zhengruifeng/override_HasXXX.
## What changes were proposed in this pull request?
add `setWeightCol` method for OneVsRest.
`weightCol` is ignored if classifier doesn't inherit HasWeightCol trait.
## How was this patch tested?
+ [x] add an unit test.
Author: Yan Facai (颜发才) <facai.yan@gmail.com>
Closes#18554 from facaiy/BUG/oneVsRest_missing_weightCol.
## What changes were proposed in this pull request?
Added functionality for CrossValidator and TrainValidationSplit to persist nested estimators such as OneVsRest. Also added CrossValidator and TrainValidation split persistence to pyspark.
## How was this patch tested?
Performed both cross validation and train validation split with a one vs. rest estimator and tested read/write functionality of the estimator parameter maps required by these meta-algorithms.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18428 from ajaysaini725/MetaAlgorithmPersistNestedEstimators.
## What changes were proposed in this pull request?
```RFormula``` should handle invalid for both features and label column.
#18496 only handle invalid values in features column. This PR add handling invalid values for label column and test cases.
## How was this patch tested?
Add test cases.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18613 from yanboliang/spark-20307.
## What changes were proposed in this pull request?
1, HasHandleInvaild support override
2, Make QuantileDiscretizer/Bucketizer/StringIndexer/RFormula inherit from HasHandleInvalid
## How was this patch tested?
existing tests
[JIRA](https://issues.apache.org/jira/browse/SPARK-18619)
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#18582 from zhengruifeng/heritate_HasHandleInvalid.
## What changes were proposed in this pull request?
Add offset to PySpark in GLM as in #16699.
## How was this patch tested?
Python test
Author: actuaryzhang <actuaryzhang10@gmail.com>
Closes#18534 from actuaryzhang/pythonOffset.
## What changes were proposed in this pull request?
This PR is to maintain API parity with changes made in SPARK-17498 to support a new option
'keep' in StringIndexer to handle unseen labels or NULL values with PySpark.
Note: This is updated version of #17237 , the primary author of this PR is VinceShieh .
## How was this patch tested?
Unit tests.
Author: VinceShieh <vincent.xie@intel.com>
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18453 from yanboliang/spark-19852.
## What changes were proposed in this pull request?
1, make param support non-final with `finalFields` option
2, generate `HasSolver` with `finalFields = false`
3, override `solver` in LiR, GLR, and make MLPC inherit `HasSolver`
## How was this patch tested?
existing tests
Author: Ruifeng Zheng <ruifengz@foxmail.com>
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#16028 from zhengruifeng/param_non_final.
## What changes were proposed in this pull request?
LinearSVC should use its own threshold param, rather than the shared one, since it applies to rawPrediction instead of probability. This PR changes the param in the Scala, Python and R APIs.
## How was this patch tested?
New unit test to make sure the threshold can be set to any Double value.
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#18151 from jkbradley/ml-2.2-linearsvc-cleanup.
## What changes were proposed in this pull request?
PySpark supports stringIndexerOrderType in RFormula as in #17967.
## How was this patch tested?
docstring test
Author: actuaryzhang <actuaryzhang10@gmail.com>
Closes#18122 from actuaryzhang/PythonRFormula.
## What changes were proposed in this pull request?
Expose numPartitions (expert) param of PySpark FPGrowth.
## How was this patch tested?
+ [x] Pass all unit tests.
Author: Yan Facai (颜发才) <facai.yan@gmail.com>
Closes#18058 from facaiy/ENH/pyspark_fpg_add_num_partition.
## What changes were proposed in this pull request?
Follow-up for #17218, some minor fix for PySpark ```FPGrowth```.
## How was this patch tested?
Existing UT.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18089 from yanboliang/spark-19281.
## What changes were proposed in this pull request?
- Fix incorrect tests for `_check_thresholds`.
- Move test to `ParamTests`.
## How was this patch tested?
Unit tests.
Author: zero323 <zero323@users.noreply.github.com>
Closes#18085 from zero323/SPARK-20631-FOLLOW-UP.
## What changes were proposed in this pull request?
Add test cases for PR-18062
## How was this patch tested?
The existing UT
Author: Peng <peng.meng@intel.com>
Closes#18068 from mpjlu/moreTest.
Changes:
pyspark.ml Estimators can take either a list of param maps or a dict of params. This change allows the CrossValidator and TrainValidationSplit Estimators to pass through lists of param maps to the underlying estimators so that those estimators can handle parallelization when appropriate (eg distributed hyper parameter tuning).
Testing:
Existing unit tests.
Author: Bago Amirbekian <bago@databricks.com>
Closes#18077 from MrBago/delegate_params.
## What changes were proposed in this pull request?
SPARK-20097 exposed degreesOfFreedom in LinearRegressionSummary and numInstances in GeneralizedLinearRegressionSummary. Python API should be updated to reflect these changes.
## How was this patch tested?
The existing UT
Author: Peng <peng.meng@intel.com>
Closes#18062 from mpjlu/spark-20764.
## What changes were proposed in this pull request?
PySpark StringIndexer supports StringOrderType added in #17879.
Author: Wayne Zhang <actuaryzhang@uber.com>
Closes#17978 from actuaryzhang/PythonStringIndexer.
## What changes were proposed in this pull request?
Review new Scala APIs introduced in 2.2.
## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17934 from yanboliang/spark-20501.
## What changes were proposed in this pull request?
Before 2.2, MLlib keep to remove APIs deprecated in last feature/minor release. But from Spark 2.2, we decide to remove deprecated APIs in a major release, so we need to change corresponding annotations to tell users those will be removed in 3.0.
Meanwhile, this fixed bugs in ML documents. The original ML docs can't show deprecated annotations in ```MLWriter``` and ```MLReader``` related class, we correct it in this PR.
Before:

After:

## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17946 from yanboliang/spark-20707.
## What changes were proposed in this pull request?
- Replace `getParam` calls with `getOrDefault` calls.
- Fix exception message to avoid unintended `TypeError`.
- Add unit tests
## How was this patch tested?
New unit tests.
Author: zero323 <zero323@users.noreply.github.com>
Closes#17891 from zero323/SPARK-20631.
## What changes were proposed in this pull request?
Remove ML methods we deprecated in 2.1.
## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17867 from yanboliang/spark-20606.
Add Python API for `ALSModel` methods `recommendForAllUsers`, `recommendForAllItems`
## How was this patch tested?
New doc tests.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#17622 from MLnick/SPARK-20300-pyspark-recall.
## What changes were proposed in this pull request?
Some PySpark & SparkR tests run with tiny dataset and tiny ```maxIter```, which means they are not converged. I don’t think checking intermediate result during iteration make sense, and these intermediate result may vulnerable and not stable, so we should switch to check the converged result. We hit this issue at #17746 when we upgrade breeze to 0.13.1.
## How was this patch tested?
Existing tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17757 from yanboliang/flaky-test.
## What changes were proposed in this pull request?
Upgrade breeze version to 0.13.1, which fixed some critical bugs of L-BFGS-B.
## How was this patch tested?
Existing unit tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17746 from yanboliang/spark-20449.
## What changes were proposed in this pull request?
The Dataframes-based support for the correlation statistics is added in #17108. This patch adds the Python interface for it.
## How was this patch tested?
Python unit test.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#17494 from viirya/correlation-python-api.
## What changes were proposed in this pull request?
`_convert_to_vector` converts a scipy sparse matrix to csc matrix for initializing `SparseVector`. However, it doesn't guarantee the converted csc matrix has sorted indices and so a failure happens when you do something like that:
from scipy.sparse import lil_matrix
lil = lil_matrix((4, 1))
lil[1, 0] = 1
lil[3, 0] = 2
_convert_to_vector(lil.todok())
File "/home/jenkins/workspace/python/pyspark/mllib/linalg/__init__.py", line 78, in _convert_to_vector
return SparseVector(l.shape[0], csc.indices, csc.data)
File "/home/jenkins/workspace/python/pyspark/mllib/linalg/__init__.py", line 556, in __init__
% (self.indices[i], self.indices[i + 1]))
TypeError: Indices 3 and 1 are not strictly increasing
A simple test can confirm that `dok_matrix.tocsc()` won't guarantee sorted indices:
>>> from scipy.sparse import lil_matrix
>>> lil = lil_matrix((4, 1))
>>> lil[1, 0] = 1
>>> lil[3, 0] = 2
>>> dok = lil.todok()
>>> csc = dok.tocsc()
>>> csc.has_sorted_indices
0
>>> csc.indices
array([3, 1], dtype=int32)
I checked the source codes of scipy. The only way to guarantee it is `csc_matrix.tocsr()` and `csr_matrix.tocsc()`.
## How was this patch tested?
Existing tests.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#17532 from viirya/make-sure-sorted-indices.
## What changes were proposed in this pull request?
A pyspark wrapper for spark.ml.stat.ChiSquareTest
## How was this patch tested?
unit tests
doctests
Author: Bago Amirbekian <bago@databricks.com>
Closes#17421 from MrBago/chiSquareTestWrapper.
## What changes were proposed in this pull request?
- Add `HasSupport` and `HasConfidence` `Params`.
- Add new module `pyspark.ml.fpm`.
- Add `FPGrowth` / `FPGrowthModel` wrappers.
- Provide tests for new features.
## How was this patch tested?
Unit tests.
Author: zero323 <zero323@users.noreply.github.com>
Closes#17218 from zero323/SPARK-19281.
Add Python wrapper for `Imputer` feature transformer.
## How was this patch tested?
New doc tests and tweak to PySpark ML `tests.py`
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#17316 from MLnick/SPARK-15040-pyspark-imputer.
## What changes were proposed in this pull request?
PySpark ```GeneralizedLinearRegression``` supports tweedie distribution.
## How was this patch tested?
Add unit tests.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#17146 from yanboliang/spark-19806.
## What changes were proposed in this pull request?
The `keyword_only` decorator in PySpark is not thread-safe. It writes kwargs to a static class variable in the decorator, which is then retrieved later in the class method as `_input_kwargs`. If multiple threads are constructing the same class with different kwargs, it becomes a race condition to read from the static class variable before it's overwritten. See [SPARK-19348](https://issues.apache.org/jira/browse/SPARK-19348) for reproduction code.
This change will write the kwargs to a member variable so that multiple threads can operate on separate instances without the race condition. It does not protect against multiple threads operating on a single instance, but that is better left to the user to synchronize.
## How was this patch tested?
Added new unit tests for using the keyword_only decorator and a regression test that verifies `_input_kwargs` can be overwritten from different class instances.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#16782 from BryanCutler/pyspark-keyword_only-threadsafe-SPARK-19348.
## What changes were proposed in this pull request?
Updates the doc string to match up with the code
i.e. say dropLast instead of includeFirst
## How was this patch tested?
Not much, since it's a doc-like change. Will run unit tests via Jenkins job.
Author: Mark Grover <mark@apache.org>
Closes#17127 from markgrover/spark_19734.
## What changes were proposed in this pull request?
Remove `org.apache.spark.examples.` in
Add slash in one of the python doc.
## How was this patch tested?
Run examples using the commands in the comments.
Author: Yun Ni <yunn@uber.com>
Closes#17104 from Yunni/yunn_minor.
This PR adds a param to `ALS`/`ALSModel` to set the strategy used when encountering unknown users or items at prediction time in `transform`. This can occur in 2 scenarios: (a) production scoring, and (b) cross-validation & evaluation.
The current behavior returns `NaN` if a user/item is unknown. In scenario (b), this can easily occur when using `CrossValidator` or `TrainValidationSplit` since some users/items may only occur in the test set and not in the training set. In this case, the evaluator returns `NaN` for all metrics, making model selection impossible.
The new param, `coldStartStrategy`, defaults to `nan` (the current behavior). The other option supported initially is `drop`, which drops all rows with `NaN` predictions. This flag allows users to use `ALS` in cross-validation settings. It is made an `expertParam`. The param is made a string so that the set of strategies can be extended in future (some options are discussed in [SPARK-14489](https://issues.apache.org/jira/browse/SPARK-14489)).
## How was this patch tested?
New unit tests, and manual "before and after" tests for Scala & Python using MovieLens `ml-latest-small` as example data. Here, using `CrossValidator` or `TrainValidationSplit` with the default param setting results in metrics that are all `NaN`, while setting `coldStartStrategy` to `drop` results in valid metrics.
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#12896 from MLnick/SPARK-14489-als-nan.
## What changes were proposed in this pull request?
Fixed the PySpark Params.copy method to behave like the Scala implementation. The main issue was that it did not account for the _defaultParamMap and merged it into the explicitly created param map.
## How was this patch tested?
Added new unit test to verify the copy method behaves correctly for copying uid, explicitly created params, and default params.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#16772 from BryanCutler/pyspark-ml-param_copy-Scala_sync-SPARK-14772.
{kind=link}
{kind=link}
{kind=link}
{kind=link}