## What changes were proposed in this pull request?
The SQL execution listener framework was created from scratch(see https://github.com/apache/spark/pull/9078). It didn't leverage what we already have in the spark listener framework, and one major problem is, the listener runs on the spark execution thread, which means a bad listener can block spark's query processing.
This PR re-implements the SQL execution listener framework. Now `ExecutionListenerManager` is just a normal spark listener, which watches the `SparkListenerSQLExecutionEnd` events and post events to the
user-provided SQL execution listeners.
## How was this patch tested?
existing tests.
Closes#22674 from cloud-fan/listener.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
`Literal.value` should have a value a value corresponding to `dataType`. This pr added code to verify it and fixed the existing tests to do so.
## How was this patch tested?
Modified the existing tests.
Closes#22724 from maropu/SPARK-25734.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The PR adds new function `from_csv()` similar to `from_json()` to parse columns with CSV strings. I added the following methods:
```Scala
def from_csv(e: Column, schema: StructType, options: Map[String, String]): Column
```
and this signature to call it from Python, R and Java:
```Scala
def from_csv(e: Column, schema: String, options: java.util.Map[String, String]): Column
```
## How was this patch tested?
Added new test suites `CsvExpressionsSuite`, `CsvFunctionsSuite` and sql tests.
Closes#22379 from MaxGekk/from_csv.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Co-authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
AFAIK multi-column count is not widely supported by the mainstream databases(postgres doesn't support), and the SQL standard doesn't define it clearly, as near as I can tell.
Since Spark supports it, we should clearly document the current behavior and add tests to verify it.
## How was this patch tested?
N/A
Closes#22728 from cloud-fan/doc.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Only test these 4 cases is enough:
be2238fb50/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetWriteSupport.scala (L269-L279)
## How was this patch tested?
Manual tests on my local machine.
before:
```
- filter pushdown - decimal (13 seconds, 683 milliseconds)
```
after:
```
- filter pushdown - decimal (9 seconds, 713 milliseconds)
```
Closes#22636 from wangyum/SPARK-25629.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
LOAD DATA INPATH didn't work if the defaultFS included a port for hdfs.
Handling this just requires a small change to use the correct URI
constructor.
## How was this patch tested?
Added a unit test, ran all tests via jenkins
Closes#22733 from squito/SPARK-25738.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This PR is a follow-up of https://github.com/apache/spark/pull/22594 . This alternative can avoid the unneeded computation in the hot code path.
- For row-based scan, we keep the original way.
- For the columnar scan, we just need to update the stats after each batch.
## How was this patch tested?
N/A
Closes#22731 from gatorsmile/udpateStatsFileScanRDD.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The PR addresses [the comment](https://github.com/apache/spark/pull/22715#discussion_r225024084) in the previous one. `outputOrdering` becomes a field of `InMemoryRelation`.
## How was this patch tested?
existing UTs
Closes#22726 from mgaido91/SPARK-25727_followup.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Add `outputOrdering ` to `otherCopyArgs` in InMemoryRelation so that this field will be copied when we doing the tree transformation.
```
val data = Seq(100).toDF("count").cache()
data.queryExecution.optimizedPlan.toJSON
```
The above code can generate the following error:
```
assertion failed: InMemoryRelation fields: output, cacheBuilder, statsOfPlanToCache, outputOrdering, values: List(count#178), CachedRDDBuilder(true,10000,StorageLevel(disk, memory, deserialized, 1 replicas),*(1) Project [value#176 AS count#178]
+- LocalTableScan [value#176]
,None), Statistics(sizeInBytes=12.0 B, hints=none)
java.lang.AssertionError: assertion failed: InMemoryRelation fields: output, cacheBuilder, statsOfPlanToCache, outputOrdering, values: List(count#178), CachedRDDBuilder(true,10000,StorageLevel(disk, memory, deserialized, 1 replicas),*(1) Project [value#176 AS count#178]
+- LocalTableScan [value#176]
,None), Statistics(sizeInBytes=12.0 B, hints=none)
at scala.Predef$.assert(Predef.scala:170)
at org.apache.spark.sql.catalyst.trees.TreeNode.jsonFields(TreeNode.scala:611)
at org.apache.spark.sql.catalyst.trees.TreeNode.org$apache$spark$sql$catalyst$trees$TreeNode$$collectJsonValue$1(TreeNode.scala:599)
at org.apache.spark.sql.catalyst.trees.TreeNode.jsonValue(TreeNode.scala:604)
at org.apache.spark.sql.catalyst.trees.TreeNode.toJSON(TreeNode.scala:590)
```
## How was this patch tested?
Added a test
Closes#22715 from gatorsmile/copyArgs1.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
[SPARK-22479](https://github.com/apache/spark/pull/19708/files#diff-5c22ac5160d3c9d81225c5dd86265d27R31) adds a test case which sometimes fails because the used password string `123` matches `41230802`. This PR aims to fix the flakiness.
- https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97343/consoleFull
```scala
SaveIntoDataSourceCommandSuite:
- simpleString is redacted *** FAILED ***
"SaveIntoDataSourceCommand .org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider41230802, Map(password -> *********(redacted), url -> *********(redacted), driver -> mydriver), ErrorIfExists
+- Range (0, 1, step=1, splits=Some(2))
" contained "123" (SaveIntoDataSourceCommandSuite.scala:42)
```
## How was this patch tested?
Pass the Jenkins with the updated test case
Closes#22716 from dongjoon-hyun/SPARK-25726.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Currently `Range` reports metrics in batch granularity. This is acceptable, but it's better if we can make it row granularity without performance penalty.
Before this PR, the metrics are updated when preparing the batch, which is before we actually consume data. In this PR, the metrics are updated after the data are consumed. There are 2 different cases:
1. The data processing loop has a stop check. The metrics are updated when we need to stop.
2. no stop check. The metrics are updated after the loop.
## How was this patch tested?
existing tests and a new benchmark
Closes#22698 from cloud-fan/range.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
```Scala
val df1 = Seq(("abc", 1), (null, 3)).toDF("col1", "col2")
df1.write.mode(SaveMode.Overwrite).parquet("/tmp/test1")
val df2 = spark.read.parquet("/tmp/test1")
df2.filter("col1 = 'abc' OR (col1 != 'abc' AND col2 == 3)").show()
```
Before the PR, it returns both rows. After the fix, it returns `Row ("abc", 1))`. This is to fix the bug in NULL handling in BooleanSimplification. This is a bug introduced in Spark 1.6 release.
## How was this patch tested?
Added test cases
Closes#22702 from gatorsmile/fixBooleanSimplify2.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Refactor `JoinBenchmark` to use main method.
1. use `spark-submit`:
```console
bin/spark-submit --class org.apache.spark.sql.execution.benchmark.JoinBenchmark --jars ./core/target/spark-core_2.11-3.0.0-SNAPSHOT-tests.jar ./sql/catalyst/target/spark-sql_2.11-3.0.0-SNAPSHOT-tests.jar
```
2. Generate benchmark result:
```console
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.JoinBenchmark"
```
## How was this patch tested?
manual tests
Closes#22661 from wangyum/SPARK-25664.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Yuming Wang <wgyumg@gmail.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
The PR addresses the exception raised on accessing chars out of delimiter string. In particular, the backward slash `\` as the CSV fields delimiter causes the following exception on reading `abc\1`:
```Scala
String index out of range: 1
java.lang.StringIndexOutOfBoundsException: String index out of range: 1
at java.lang.String.charAt(String.java:658)
```
because `str.charAt(1)` tries to access a char out of `str` in `CSVUtils.toChar`
## How was this patch tested?
Added tests for empty string and string containing the backward slash to `CSVUtilsSuite`. Besides of that I added an end-to-end test to check how the backward slash is handled in reading CSV string with it.
Closes#22654 from MaxGekk/csv-slash-delim.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Currently SQL tab in the WEBUI doesn't support pagination. Because of that following issues are happening.
1) For large number of executions, SQL page is throwing OOM exception (around 40,000)
2) For large number of executions, loading SQL page is taking time.
3) Difficult to analyse the execution table for large number of execution.
[Note: spark.sql.ui.retainedExecutions = 50000]
All the tabs, Jobs, Stages etc. supports pagination. So, to make it consistent with other tabs
SQL tab also should support pagination.
I have followed the similar flow of the pagination code in the Jobs and Stages page for SQL page.
Also, this patch doesn't make any behavior change for the SQL tab except the pagination support.
## How was this patch tested?
bin/spark-shell --conf spark.sql.ui.retainedExecutions=50000
Run 50,000 sql queries.
**Before this PR**
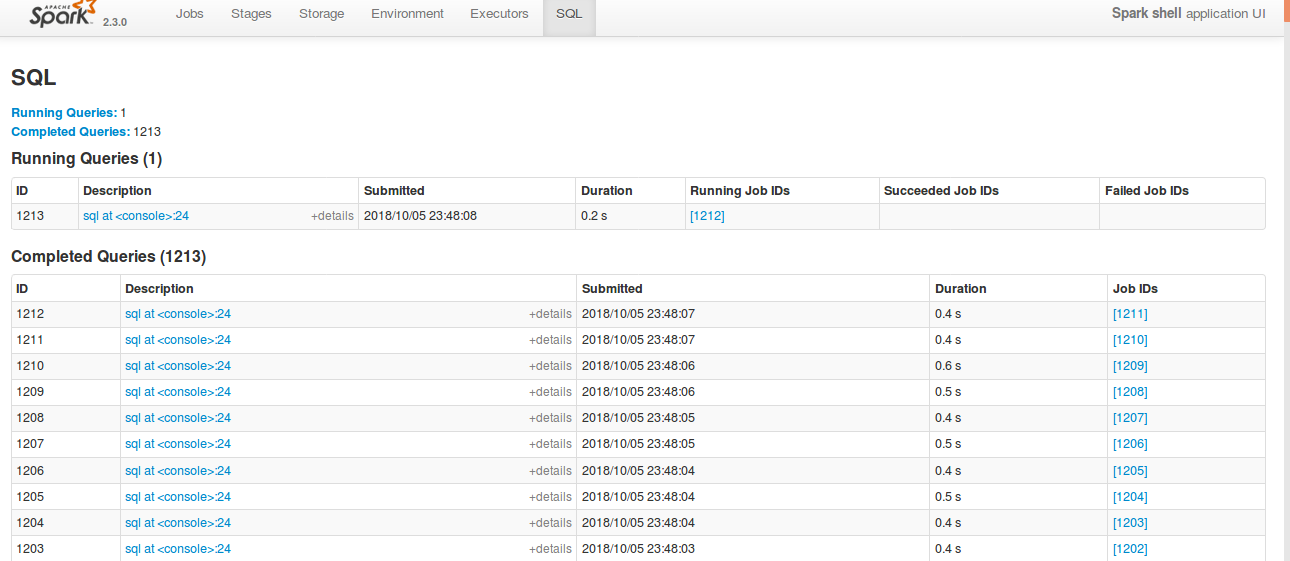
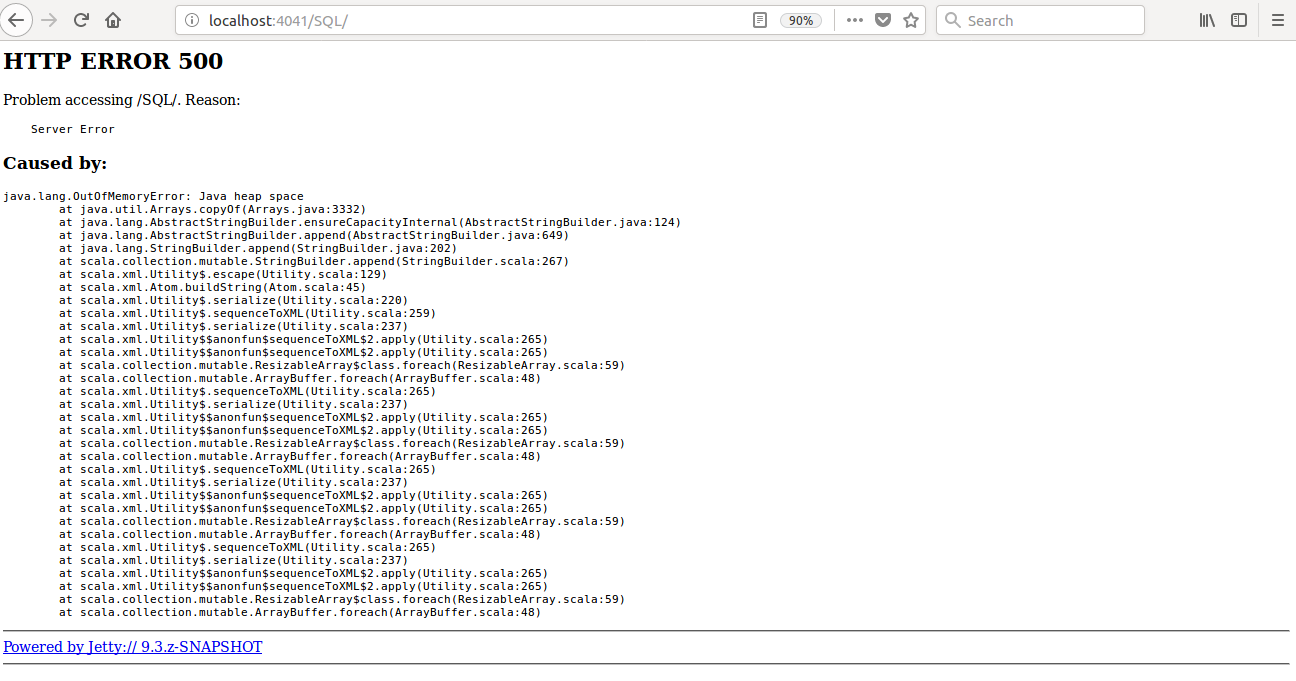
**After this PR**
Loading of the page is faster, and OOM issue doesn't happen.
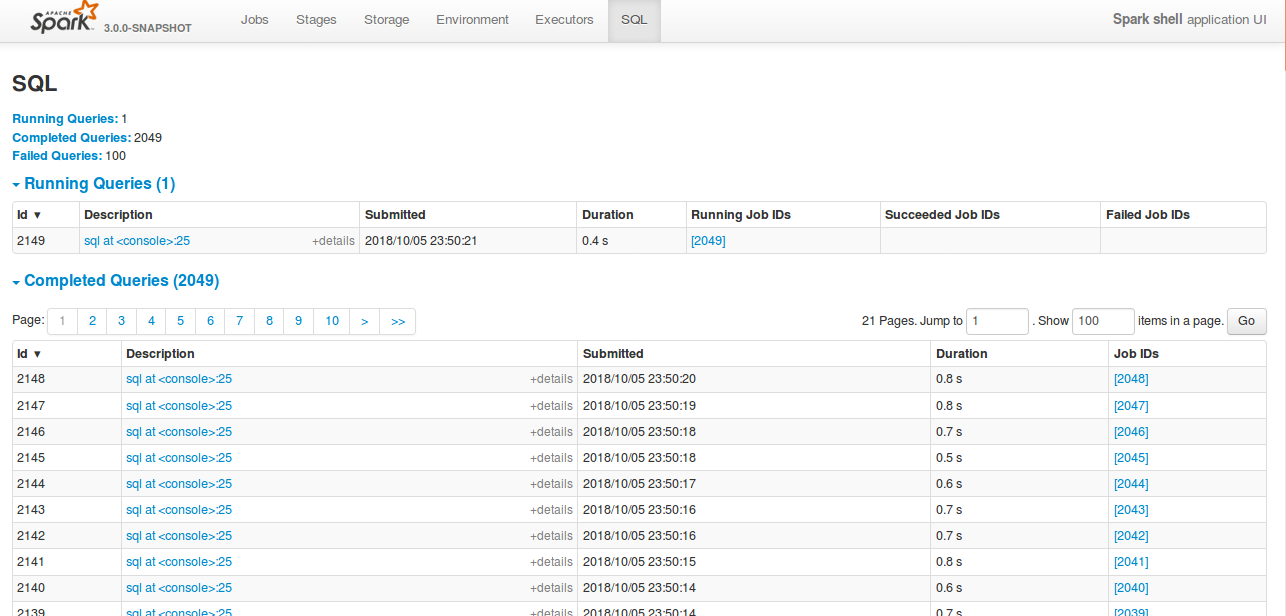
Closes#22645 from shahidki31/SPARK-25566.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
According to the SQL standard, when a query contains `HAVING`, it indicates an aggregate operator. For more details please refer to https://blog.jooq.org/2014/12/04/do-you-really-understand-sqls-group-by-and-having-clauses/
However, in Spark SQL parser, we treat HAVING as a normal filter when there is no GROUP BY, which breaks SQL semantic and lead to wrong result. This PR fixes the parser.
## How was this patch tested?
new test
Closes#22696 from cloud-fan/having.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
1. Move `CSVDataSource.makeSafeHeader` to `CSVUtils.makeSafeHeader` (as is).
- Historically and at the first place of refactoring (which I did), I intended to put all CSV specific handling (like options), filtering, extracting header, etc.
- See `JsonDataSource`. Now `CSVDataSource` is quite consistent with `JsonDataSource`. Since CSV's code path is quite complicated, we might better match them as possible as we can.
2. Create `CSVHeaderChecker` and put `enforceSchema` logics into that.
- The checking header and column pruning stuff were added (per https://github.com/apache/spark/pull/20894 and https://github.com/apache/spark/pull/21296) but some of codes such as https://github.com/apache/spark/pull/22123 are duplicated
- Also, checking header code is basically here and there. We better put them in a single place, which was quite error-prone. See (https://github.com/apache/spark/pull/22656).
3. Move `CSVDataSource.checkHeaderColumnNames` to `CSVHeaderChecker.checkHeaderColumnNames` (as is).
- Similar reasons above with 1.
## How was this patch tested?
Existing tests should cover this.
Closes#22676 from HyukjinKwon/refactoring-csv.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
If the records are incremented by more than 1 at a time,the number of bytes might rarely ever get updated,because it might skip over the count that is an exact multiple of UPDATE_INPUT_METRICS_INTERVAL_RECORDS.
This PR just checks whether the increment causes the value to exceed a higher multiple of UPDATE_INPUT_METRICS_INTERVAL_RECORDS.
## How was this patch tested?
existed unit tests
Closes#22594 from 10110346/inputMetrics.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
remove Redundant semicolons in SortMergeJoinExec, thanks.
## How was this patch tested?
N/A
Closes#22695 from heary-cao/RedundantSemicolons.
Authored-by: caoxuewen <cao.xuewen@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
1. Refactor DataSourceReadBenchmark
## How was this patch tested?
Manually tested and regenerated results.
```
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.DataSourceReadBenchmark"
```
Closes#22664 from peter-toth/SPARK-25662.
Lead-authored-by: Peter Toth <peter.toth@gmail.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
Inspired by https://github.com/apache/spark/pull/22574 .
We can partially push down top level conjunctive predicates to Orc.
This PR improves Orc predicate push down in both SQL and Hive module.
## How was this patch tested?
New unit test.
Closes#22684 from gengliangwang/pushOrcFilters.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
This is a follow up of https://github.com/apache/spark/pull/22574. Renamed the parameter and added comments.
## How was this patch tested?
N/A
Closes#22679 from gatorsmile/followupSPARK-25559.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
This PR is inspired by https://github.com/apache/spark/pull/22524, but proposes a safer fix.
The current limit whole stage codegen has 2 problems:
1. It's only applied to `InputAdapter`, many leaf nodes can't stop earlier w.r.t. limit.
2. It needs to override a method, which will break if we have more than one limit in the whole-stage.
The first problem is easy to fix, just figure out which nodes can stop earlier w.r.t. limit, and update them. This PR updates `RangeExec`, `ColumnarBatchScan`, `SortExec`, `HashAggregateExec`.
The second problem is hard to fix. This PR proposes to propagate the limit counter variable name upstream, so that the upstream leaf/blocking nodes can check the limit counter and quit the loop earlier.
For better performance, the implementation here follows `CodegenSupport.needStopCheck`, so that we only codegen the check only if there is limit in the query. For columnar node like range, we check the limit counter per-batch instead of per-row, to make the inner loop tight and fast.
Why this is safer?
1. the leaf/blocking nodes don't have to check the limit counter and stop earlier. It's only for performance. (this is same as before)
2. The blocking operators can stop propagating the limit counter name, because the counter of limit after blocking operators will never increase, before blocking operators consume all the data from upstream operators. So the upstream operators don't care about limit after blocking operators. This is also for performance only, it's OK if we forget to do it for some new blocking operators.
## How was this patch tested?
a new test
Closes#22630 from cloud-fan/limit.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
## What changes were proposed in this pull request?
Currently the first row of dataset of CSV strings is compared to field names of user specified or inferred schema independently of presence of CSV header. It causes false-positive error messages. For example, parsing `"1,2"` outputs the error:
```java
java.lang.IllegalArgumentException: CSV header does not conform to the schema.
Header: 1, 2
Schema: _c0, _c1
Expected: _c0 but found: 1
```
In the PR, I propose:
- Checking CSV header only when it exists
- Filter header from the input dataset only if it exists
## How was this patch tested?
Added a test to `CSVSuite` which reproduces the issue.
Closes#22656 from MaxGekk/inferred-header-check.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
`InMemoryFileIndex` contains a cache of `LocatedFileStatus` objects. Each `LocatedFileStatus` object can contain several `BlockLocation`s or some subclass of it. Filling up this cache by listing files happens recursively either on the driver or on the executors, depending on the parallel discovery threshold (`spark.sql.sources.parallelPartitionDiscovery.threshold`). If the listing happens on the executors block location objects are converted to simple `BlockLocation` objects to ensure serialization requirements. If it happens on the driver then there is no conversion and depending on the file system a `BlockLocation` object can be a subclass like `HdfsBlockLocation` and consume more memory. This PR adds the conversion to the latter case and decreases memory consumption.
## How was this patch tested?
Added unit test.
Closes#22603 from peter-toth/SPARK-25062.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This PR fixes the Scala-2.12 build error due to ambiguity in `foreachBatch` test cases.
- https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7-ubuntu-scala-2.12/428/console
```scala
[error] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7-ubuntu-scala-2.12/sql/core/src/test/scala/org/apache/spark/sql/execution/streaming/sources/ForeachBatchSinkSuite.scala:102: ambiguous reference to overloaded definition,
[error] both method foreachBatch in class DataStreamWriter of type (function: org.apache.spark.api.java.function.VoidFunction2[org.apache.spark.sql.Dataset[Int],Long])org.apache.spark.sql.streaming.DataStreamWriter[Int]
[error] and method foreachBatch in class DataStreamWriter of type (function: (org.apache.spark.sql.Dataset[Int], Long) => Unit)org.apache.spark.sql.streaming.DataStreamWriter[Int]
[error] match argument types ((org.apache.spark.sql.Dataset[Int], Any) => Unit)
[error] ds.writeStream.foreachBatch((_, _) => {}).trigger(Trigger.Continuous("1 second")).start()
[error] ^
[error] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7-ubuntu-scala-2.12/sql/core/src/test/scala/org/apache/spark/sql/execution/streaming/sources/ForeachBatchSinkSuite.scala:106: ambiguous reference to overloaded definition,
[error] both method foreachBatch in class DataStreamWriter of type (function: org.apache.spark.api.java.function.VoidFunction2[org.apache.spark.sql.Dataset[Int],Long])org.apache.spark.sql.streaming.DataStreamWriter[Int]
[error] and method foreachBatch in class DataStreamWriter of type (function: (org.apache.spark.sql.Dataset[Int], Long) => Unit)org.apache.spark.sql.streaming.DataStreamWriter[Int]
[error] match argument types ((org.apache.spark.sql.Dataset[Int], Any) => Unit)
[error] ds.writeStream.foreachBatch((_, _) => {}).partitionBy("value").start()
[error] ^
```
## How was this patch tested?
Manual.
Since this failure occurs in Scala-2.12 profile and test cases, Jenkins will not test this. We need to build with Scala-2.12 and run the tests.
Closes#22649 from dongjoon-hyun/SPARK-SCALA212.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Refactor `MiscBenchmark ` to use main method.
Generate benchmark result:
```sh
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.MiscBenchmark"
```
## How was this patch tested?
manual tests
Closes#22500 from wangyum/SPARK-25488.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Yuming Wang <wgyumg@gmail.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
By replacing loops with random possible value.
- `read partitioning bucketed tables with bucket pruning filters` reduce from 55s to 7s
- `read partitioning bucketed tables having composite filters` reduce from 54s to 8s
- total time: reduce from 288s to 192s
## How was this patch tested?
Unit test
Closes#22640 from gengliangwang/fastenBucketedReadSuite.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Current the CSV's infer schema code inlines `TypeCoercion.findTightestCommonType`. This is a minor refactor to make use of the common type coercion code when applicable. This way we can take advantage of any improvement to the base method.
Thanks to MaxGekk for finding this while reviewing another PR.
## How was this patch tested?
This is a minor refactor. Existing tests are used to verify the change.
Closes#22619 from dilipbiswal/csv_minor.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Adds support for the setting limit in the sql split function
## How was this patch tested?
1. Updated unit tests
2. Tested using Scala spark shell
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22227 from phegstrom/master.
Authored-by: Parker Hegstrom <phegstrom@palantir.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In this test case, we are verifying that the result of an UDF is cached when the underlying data frame is cached and that the udf is not evaluated again when the cached data frame is used.
To reduce the runtime we do :
1) Use a single partition dataframe, so the total execution time of UDF is more deterministic.
2) Cut down the size of the dataframe from 10 to 2.
3) Reduce the sleep time in the UDF from 5secs to 2secs.
4) Reduce the failafter condition from 3 to 2.
With the above change, it takes about 4 secs to cache the first dataframe. And subsequent check takes a few hundred milliseconds.
The new runtime for 5 consecutive runs of this test is as follows :
```
[info] - cache UDF result correctly (4 seconds, 906 milliseconds)
[info] - cache UDF result correctly (4 seconds, 281 milliseconds)
[info] - cache UDF result correctly (4 seconds, 288 milliseconds)
[info] - cache UDF result correctly (4 seconds, 355 milliseconds)
[info] - cache UDF result correctly (4 seconds, 280 milliseconds)
```
## How was this patch tested?
This is s test fix.
Closes#22638 from dilipbiswal/SPARK-25610.
Authored-by: Dilip Biswal <dbiswal@us.ibm.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Before ORC 1.5.3, `orc.dictionary.key.threshold` and `hive.exec.orc.dictionary.key.size.threshold` are applied for all columns. This has been a big huddle to enable dictionary encoding. From ORC 1.5.3, `orc.column.encoding.direct` is added to enforce direct encoding selectively in a column-wise manner. This PR aims to add that feature by upgrading ORC from 1.5.2 to 1.5.3.
The followings are the patches in ORC 1.5.3 and this feature is the only one related to Spark directly.
```
ORC-406: ORC: Char(n) and Varchar(n) writers truncate to n bytes & corrupts multi-byte data (gopalv)
ORC-403: [C++] Add checks to avoid invalid offsets in InputStream
ORC-405: Remove calcite as a dependency from the benchmarks.
ORC-375: Fix libhdfs on gcc7 by adding #include <functional> two places.
ORC-383: Parallel builds fails with ConcurrentModificationException
ORC-382: Apache rat exclusions + add rat check to travis
ORC-401: Fix incorrect quoting in specification.
ORC-385: Change RecordReader to extend Closeable.
ORC-384: [C++] fix memory leak when loading non-ORC files
ORC-391: [c++] parseType does not accept underscore in the field name
ORC-397: Allow selective disabling of dictionary encoding. Original patch was by Mithun Radhakrishnan.
ORC-389: Add ability to not decode Acid metadata columns
```
## How was this patch tested?
Pass the Jenkins with newly added test cases.
Closes#22622 from dongjoon-hyun/SPARK-25635.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
The java `foreachBatch` API in `DataStreamWriter` should accept `java.lang.Long` rather `scala.Long`.
## How was this patch tested?
New java test.
Closes#22633 from zsxwing/fix-java-foreachbatch.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
When constructing a DataFrame from a Java bean, using nested beans throws an error despite [documentation](http://spark.apache.org/docs/latest/sql-programming-guide.html#inferring-the-schema-using-reflection) stating otherwise. This PR aims to add that support.
This PR does not yet add nested beans support in array or List fields. This can be added later or in another PR.
## How was this patch tested?
Nested bean was added to the appropriate unit test.
Also manually tested in Spark shell on code emulating the referenced JIRA:
```
scala> import scala.beans.BeanProperty
import scala.beans.BeanProperty
scala> class SubCategory(BeanProperty var id: String, BeanProperty var name: String) extends Serializable
defined class SubCategory
scala> class Category(BeanProperty var id: String, BeanProperty var subCategory: SubCategory) extends Serializable
defined class Category
scala> import scala.collection.JavaConverters._
import scala.collection.JavaConverters._
scala> spark.createDataFrame(Seq(new Category("s-111", new SubCategory("sc-111", "Sub-1"))).asJava, classOf[Category])
java.lang.IllegalArgumentException: The value (SubCategory65130cf2) of the type (SubCategory) cannot be converted to struct<id:string,name:string>
at org.apache.spark.sql.catalyst.CatalystTypeConverters$StructConverter.toCatalystImpl(CatalystTypeConverters.scala:262)
at org.apache.spark.sql.catalyst.CatalystTypeConverters$StructConverter.toCatalystImpl(CatalystTypeConverters.scala:238)
at org.apache.spark.sql.catalyst.CatalystTypeConverters$CatalystTypeConverter.toCatalyst(CatalystTypeConverters.scala:103)
at org.apache.spark.sql.catalyst.CatalystTypeConverters$$anonfun$createToCatalystConverter$2.apply(CatalystTypeConverters.scala:396)
at org.apache.spark.sql.SQLContext$$anonfun$beansToRows$1$$anonfun$apply$1.apply(SQLContext.scala:1108)
at org.apache.spark.sql.SQLContext$$anonfun$beansToRows$1$$anonfun$apply$1.apply(SQLContext.scala:1108)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:186)
at org.apache.spark.sql.SQLContext$$anonfun$beansToRows$1.apply(SQLContext.scala:1108)
at org.apache.spark.sql.SQLContext$$anonfun$beansToRows$1.apply(SQLContext.scala:1106)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$class.toStream(Iterator.scala:1320)
at scala.collection.AbstractIterator.toStream(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.toSeq(TraversableOnce.scala:298)
at scala.collection.AbstractIterator.toSeq(Iterator.scala:1334)
at org.apache.spark.sql.SparkSession.createDataFrame(SparkSession.scala:423)
... 51 elided
```
New behavior:
```
scala> spark.createDataFrame(Seq(new Category("s-111", new SubCategory("sc-111", "Sub-1"))).asJava, classOf[Category])
res0: org.apache.spark.sql.DataFrame = [id: string, subCategory: struct<id: string, name: string>]
scala> res0.show()
+-----+---------------+
| id| subCategory|
+-----+---------------+
|s-111|[sc-111, Sub-1]|
+-----+---------------+
```
Closes#22527 from michalsenkyr/SPARK-17952.
Authored-by: Michal Senkyr <mike.senkyr@gmail.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
Hi all,
Jackson is incompatible with upstream versions, therefore bump the Jackson version to a more recent one. I bumped into some issues with Azure CosmosDB that is using a more recent version of Jackson. This can be fixed by adding exclusions and then it works without any issues. So no breaking changes in the API's.
I would also consider bumping the version of Jackson in Spark. I would suggest to keep up to date with the dependencies, since in the future this issue will pop up more frequently.
## What changes were proposed in this pull request?
Bump Jackson to 2.9.6
## How was this patch tested?
Compiled and tested it locally to see if anything broke.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#21596 from Fokko/fd-bump-jackson.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
``As part of insert command in FileFormatWriter, a job context is created for handling the write operation , While initializing the job context using setupJob() API
in HadoopMapReduceCommitProtocol , we set the jobid in the Jobcontext configuration.In FileFormatWriter since we are directly getting the jobId from the map reduce JobContext the job id will come as null while adding the log. As a solution we shall get the jobID from the configuration of the map reduce Jobcontext.``
## How was this patch tested?
Manually, verified the logs after the changes.

Closes#22572 from sujith71955/master_log_issue.
Authored-by: s71955 <sujithchacko.2010@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The PR changes the test introduced for SPARK-22226, so that we don't run analysis and optimization on the plan. The scope of the test is code generation and running the above mentioned operation is expensive and useless for the test.
The UT was also moved to the `CodeGenerationSuite` which is a better place given the scope of the test.
## How was this patch tested?
running the UT before SPARK-22226 fails, after it passes. The execution time is about 50% the original one. On my laptop this means that the test now runs in about 23 seconds (instead of 50 seconds).
Closes#22629 from mgaido91/SPARK-25609.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Refactor `DatasetBenchmark` to use main method.
Generate benchmark result:
```sh
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.DatasetBenchmark"
```
## How was this patch tested?
manual tests
Closes#22488 from wangyum/SPARK-25479.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In `SparkPlan.getByteArrayRdd`, we should only call `it.hasNext` when the limit is not hit, as `iter.hasNext` may produce one row and buffer it, and cause wrong metrics.
## How was this patch tested?
new tests
Closes#22621 from cloud-fan/range.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Refactor `UnsafeArrayDataBenchmark` to use main method.
Generate benchmark result:
```sh
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.UnsafeArrayDataBenchmark"
```
## How was this patch tested?
manual tests
Closes#22491 from wangyum/SPARK-25483.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This PR aims to add `BloomFilterBenchmark`. For ORC data source, Apache Spark has been supporting for a long time. For Parquet data source, it's expected to be added with next Parquet release update.
## How was this patch tested?
Manual.
```scala
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.BloomFilterBenchmark"
```
Closes#22605 from dongjoon-hyun/SPARK-25589.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Rename method `benchmark` in `BenchmarkBase` as `runBenchmarkSuite `. Also add comments.
Currently the method name `benchmark` is a bit confusing. Also the name is the same as instances of `Benchmark`:
f246813afb/sql/hive/src/test/scala/org/apache/spark/sql/hive/orc/OrcReadBenchmark.scala (L330-L339)
## How was this patch tested?
Unit test.
Closes#22599 from gengliangwang/renameBenchmarkSuite.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This patch is to bump the master branch version to 3.0.0-SNAPSHOT.
## How was this patch tested?
N/A
Closes#22606 from gatorsmile/bump3.0.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Currently, SQL tab in the WEBUI doesn't support hiding table. Other tabs in the web ui like, Jobs, stages etc supports hiding table (refer SPARK-23024 https://github.com/apache/spark/pull/20216).
In this PR, added the support for hide table in the sql tab also.
## How was this patch tested?
bin/spark-shell
```
sql("create table a (id int)")
for(i <- 1 to 100) sql(s"insert into a values ($i)")
```
Open SQL tab in the web UI
**Before fix:**
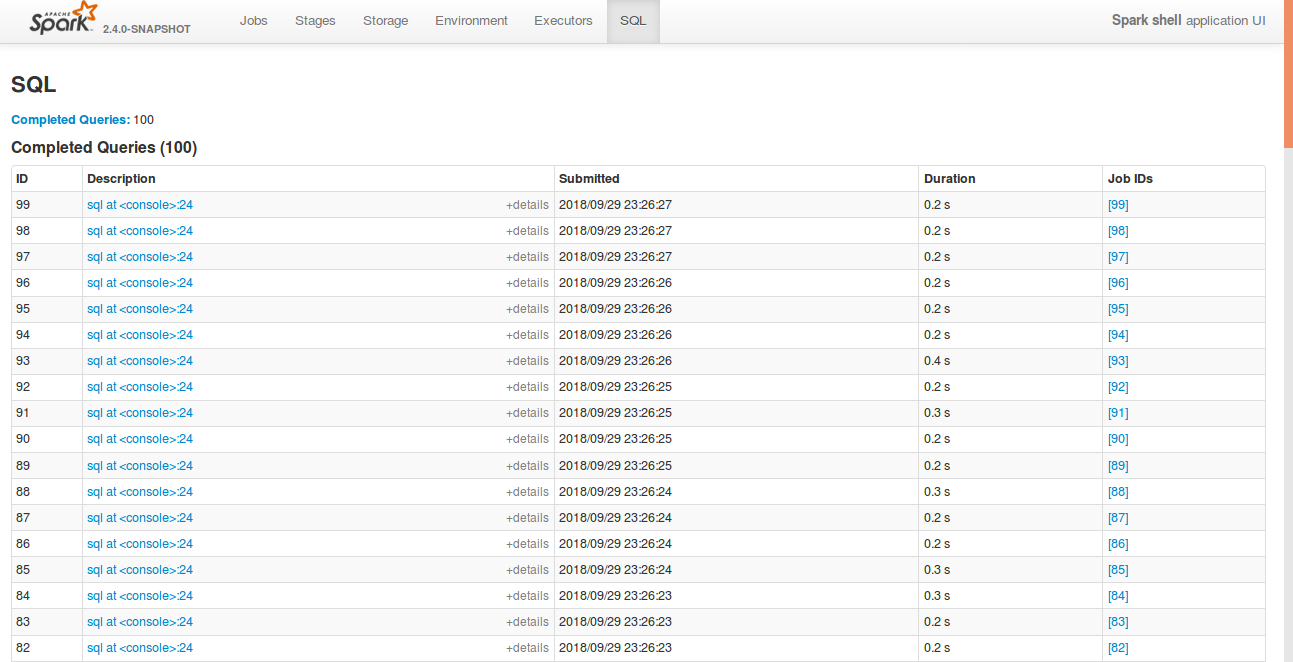
**After fix:** Consistent with the other tabs.

(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22592 from shahidki31/SPARK-25575.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR does 2 things:
1. Add a new trait(`SqlBasedBenchmark`) to better support Dataset and DataFrame API.
2. Refactor `AggregateBenchmark` to use main method. Generate benchmark result:
```
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.AggregateBenchmark"
```
## How was this patch tested?
manual tests
Closes#22484 from wangyum/SPARK-25476.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
#22519 introduced a bug when the attributes in the pivot clause are cosmetically different from the output ones (eg. different case). In particular, the problem is that the PR used a `Set[Attribute]` instead of an `AttributeSet`.
## How was this patch tested?
added UT
Closes#22582 from mgaido91/SPARK-25505_followup.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This PR adds a rule to force `.toLowerCase(Locale.ROOT)` or `toUpperCase(Locale.ROOT)`.
It produces an error as below:
```
[error] Are you sure that you want to use toUpperCase or toLowerCase without the root locale? In most cases, you
[error] should use toUpperCase(Locale.ROOT) or toLowerCase(Locale.ROOT) instead.
[error] If you must use toUpperCase or toLowerCase without the root locale, wrap the code block with
[error] // scalastyle:off caselocale
[error] .toUpperCase
[error] .toLowerCase
[error] // scalastyle:on caselocale
```
This PR excludes the cases above for SQL code path for external calls like table name, column name and etc.
For test suites, or when it's clear there's no locale problem like Turkish locale problem, it uses `Locale.ROOT`.
One minor problem is, `UTF8String` has both methods, `toLowerCase` and `toUpperCase`, and the new rule detects them as well. They are ignored.
## How was this patch tested?
Manually tested, and Jenkins tests.
Closes#22581 from HyukjinKwon/SPARK-25565.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}