### What changes were proposed in this pull request?
Use `Utils.getSimpleName` to avoid hitting `Malformed class name` error in `TreeNode`.
### Why are the changes needed?
On older JDK versions (e.g. JDK8u), nested Scala classes may trigger `java.lang.Class.getSimpleName` to throw an `java.lang.InternalError: Malformed class name` error.
Similar to https://github.com/apache/spark/pull/29050, we should use Spark's `Utils.getSimpleName` utility function in place of `Class.getSimpleName` to avoid hitting the issue.
### Does this PR introduce _any_ user-facing change?
Fixes a bug that throws an error when invoking `TreeNode.nodeName`, otherwise no changes.
### How was this patch tested?
Added new unit test case in `TreeNodeSuite`. Note that the test case assumes the test code can trigger the expected error, otherwise it'll skip the test safely, for compatibility with newer JDKs.
Manually tested on JDK8u and JDK11u and observed expected behavior:
- JDK8u: the test case triggers the "Malformed class name" issue and the fix works;
- JDK11u: the test case does not trigger the "Malformed class name" issue, and the test case is safely skipped.
Closes#29875 from rednaxelafx/spark-32999-getsimplename.
Authored-by: Kris Mok <kris.mok@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Unevaluable expressions are not foldable because we don't have an eval for it. This PR is to clean up the code and enforce it.
### Why are the changes needed?
Ensure that we will not hit the weird cases that trigger ConstantFolding.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
The existing tests.
Closes#29798 from gatorsmile/refactorUneval.
Lead-authored-by: gatorsmile <gatorsmile@gmail.com>
Co-authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This pr aims to add a new `table` API in DataStreamReader, which is similar to the table API in DataFrameReader.
### Why are the changes needed?
Users can directly use this API to get a Streaming DataFrame on a table. Below is a simple example:
Application 1 for initializing and starting the streaming job:
```
val path = "/home/yuanjian.li/runtime/to_be_deleted"
val tblName = "my_table"
// Write some data to `my_table`
spark.range(3).write.format("parquet").option("path", path).saveAsTable(tblName)
// Read the table as a streaming source, write result to destination directory
val table = spark.readStream.table(tblName)
table.writeStream.format("parquet").option("checkpointLocation", "/home/yuanjian.li/runtime/to_be_deleted_ck").start("/home/yuanjian.li/runtime/to_be_deleted_2")
```
Application 2 for appending new data:
```
// Append new data into the path
spark.range(5).write.format("parquet").option("path", "/home/yuanjian.li/runtime/to_be_deleted").mode("append").save()
```
Check result:
```
// The desitination directory should contains all written data
spark.read.parquet("/home/yuanjian.li/runtime/to_be_deleted_2").show()
```
### Does this PR introduce _any_ user-facing change?
Yes, a new API added.
### How was this patch tested?
New UT added and integrated testing.
Closes#29756 from xuanyuanking/SPARK-32885.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add test to cover Hive UDF whose input contains complex decimal type.
Add comment to explain why we can't make `HiveSimpleUDF` extend `ImplicitTypeCasts`.
### Why are the changes needed?
For better test coverage with Hive which we compatible or not.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Add test.
Closes#29863 from ulysses-you/SPARK-32877-test.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR proposes to migrate `REFRESH TABLE` to use `UnresolvedTableOrView` to resolve the table/view identifier. This allows consistent resolution rules (temp view first, etc.) to be applied for both v1/v2 commands. More info about the consistent resolution rule proposal can be found in [JIRA](https://issues.apache.org/jira/browse/SPARK-29900) or [proposal doc](https://docs.google.com/document/d/1hvLjGA8y_W_hhilpngXVub1Ebv8RsMap986nENCFnrg/edit?usp=sharing).
### Why are the changes needed?
The current behavior is not consistent between v1 and v2 commands when resolving a temp view.
In v2, the `t` in the following example is resolved to a table:
```scala
sql("CREATE TABLE testcat.ns.t (id bigint) USING foo")
sql("CREATE TEMPORARY VIEW t AS SELECT 2")
sql("USE testcat.ns")
sql("REFRESH TABLE t") // 't' is resolved to testcat.ns.t
```
whereas in v1, the `t` is resolved to a temp view:
```scala
sql("CREATE DATABASE test")
sql("CREATE TABLE spark_catalog.test.t (id bigint) USING csv")
sql("CREATE TEMPORARY VIEW t AS SELECT 2")
sql("USE spark_catalog.test")
sql("REFRESH TABLE t") // 't' is resolved to a temp view
```
### Does this PR introduce _any_ user-facing change?
After this PR, `REFRESH TABLE t` is resolved to a temp view `t` instead of `testcat.ns.t`.
### How was this patch tested?
Added a new test
Closes#29866 from imback82/refresh_table_consistent.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
<!--
Thanks for sending a pull request! Here are some tips for you:
1. If this is your first time, please read our contributor guidelines: https://spark.apache.org/contributing.html
2. Ensure you have added or run the appropriate tests for your PR: https://spark.apache.org/developer-tools.html
3. If the PR is unfinished, add '[WIP]' in your PR title, e.g., '[WIP][SPARK-XXXX] Your PR title ...'.
4. Be sure to keep the PR description updated to reflect all changes.
5. Please write your PR title to summarize what this PR proposes.
6. If possible, provide a concise example to reproduce the issue for a faster review.
7. If you want to add a new configuration, please read the guideline first for naming configurations in
'core/src/main/scala/org/apache/spark/internal/config/ConfigEntry.scala'.
-->
### What changes were proposed in this pull request?
<!--
Please clarify what changes you are proposing. The purpose of this section is to outline the changes and how this PR fixes the issue.
If possible, please consider writing useful notes for better and faster reviews in your PR. See the examples below.
1. If you refactor some codes with changing classes, showing the class hierarchy will help reviewers.
2. If you fix some SQL features, you can provide some references of other DBMSes.
3. If there is design documentation, please add the link.
4. If there is a discussion in the mailing list, please add the link.
-->
This moves and refactors the parallel listing utilities from `InMemoryFileIndex` to Spark core so it can be reused by modules beside SQL. Along the process this also did some cleanups/refactorings:
- Created a `HadoopFSUtils` class under core
- Moved `InMemoryFileIndex.bulkListLeafFiles` into `HadoopFSUtils.parallelListLeafFiles`. It now depends on a `SparkContext` instead of `SparkSession` in SQL. Also added a few parameters which used to be read from `SparkSession.conf`: `ignoreMissingFiles`, `ignoreLocality`, `parallelismThreshold`, `parallelismMax ` and `filterFun` (for additional filtering support but we may be able to merge this with `filter` parameter in future).
- Moved `InMemoryFileIndex.listLeafFiles` into `HadoopFSUtils.listLeafFiles` with similar changes above.
### Why are the changes needed?
<!--
Please clarify why the changes are needed. For instance,
1. If you propose a new API, clarify the use case for a new API.
2. If you fix a bug, you can clarify why it is a bug.
-->
Currently the locality-aware parallel listing mechanism only applies to `InMemoryFileIndex`. By moving this to core, we can potentially reuse the same mechanism for other code paths as well.
### Does this PR introduce _any_ user-facing change?
<!--
Note that it means *any* user-facing change including all aspects such as the documentation fix.
If yes, please clarify the previous behavior and the change this PR proposes - provide the console output, description and/or an example to show the behavior difference if possible.
If possible, please also clarify if this is a user-facing change compared to the released Spark versions or within the unreleased branches such as master.
If no, write 'No'.
-->
No.
### How was this patch tested?
<!--
If tests were added, say they were added here. Please make sure to add some test cases that check the changes thoroughly including negative and positive cases if possible.
If it was tested in a way different from regular unit tests, please clarify how you tested step by step, ideally copy and paste-able, so that other reviewers can test and check, and descendants can verify in the future.
If tests were not added, please describe why they were not added and/or why it was difficult to add.
-->
Since this is mostly a refactoring, it relies on existing unit tests such as those for `InMemoryFileIndex`.
Closes#29471 from sunchao/SPARK-32381.
Lead-authored-by: Chao Sun <sunchao@apache.org>
Co-authored-by: Holden Karau <hkarau@apple.com>
Co-authored-by: Chao Sun <sunchao@uber.com>
Signed-off-by: Holden Karau <hkarau@apple.com>
### What changes were proposed in this pull request?
The default is always ErrorsOnExist regardless of DataSource version. Fixing the JavaDoc to reflect this.
### Why are the changes needed?
To fix documentation
### Does this PR introduce _any_ user-facing change?
Doc change.
### How was this patch tested?
Manual.
Closes#29853 from RussellSpitzer/SPARK-32977.
Authored-by: Russell Spitzer <russell.spitzer@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Remove unnecessary code.
### Why are the changes needed?
General housekeeping. Might be a slight performance improvement, especially on big-endian systems.
There is no need for separate code paths for big- and little-endian
platforms in putDoubles and putFloats anymore (since PR #24861). On
all platforms values are encoded in native byte order and can just
be copied directly.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#29815 from mundaym/clean-putfloats.
Authored-by: Michael Munday <mike.munday@ibm.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
MurmurHash3 and xxHash64 interpret sequences of bytes as integers
encoded in little-endian byte order. This requires a byte reversal
on big endian platforms.
I've left the hashInt and hashLong functions as-is for now. My
interpretation of these functions is that they perform the hash on
the integer value as if it were serialized in little-endian byte
order. Therefore no byte reversal is necessary.
### What changes were proposed in this pull request?
Modify hash functions to produce correct results on big-endian platforms.
### Why are the changes needed?
Hash functions produce incorrect results on big-endian platforms which, amongst other potential issues, causes test failures.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests run on the IBM Z (s390x) platform which uses a big-endian byte order.
Closes#29762 from mundaym/fix-hashes.
Authored-by: Michael Munday <mike.munday@ibm.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR addresses two issues related to the `Relation: view text` test in `DataSourceV2SQLSuite`.
1. The test has the following block:
```scala
withView("view1") { v1: String =>
sql(...)
}
```
Since `withView`'s signature is `withView(v: String*)(f: => Unit): Unit`, the `f` that will be executed is ` v1: String => sql(..)`, which is just defining the anonymous function, and _not_ executing it.
2. Once the test is fixed to run, it actually fails. The reason is that the v2 session catalog implementation used in tests does not correctly handle `V1Table` for views in `loadTable`. And this results in views resolved to `ResolvedTable` instead of `ResolvedView`, causing the test failure: f1dc479d39/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala (L1007-L1011)
### Why are the changes needed?
Fixing a bug in test.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing test.
Closes#29811 from imback82/fix_minor_test.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In the PR, I propose to replace current examples for `percentile_approx()` with **only one** input value by example **with multiple values** in the input column.
### Why are the changes needed?
Current examples are pretty trivial, and don't demonstrate function's behaviour on a sequence of values.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- by running `ExpressionInfoSuite`
- `./dev/scalastyle`
Closes#29841 from MaxGekk/example-percentile_approx.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
More precise description of the result of the `percentile_approx()` function and its synonym `approx_percentile()`. The proposed sentence clarifies that the function returns **one of elements** (or array of elements) from the input column.
### Why are the changes needed?
To improve Spark docs and avoid misunderstanding of the function behavior.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
`./dev/scalastyle`
Closes#29835 from MaxGekk/doc-percentile_approx.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request?
This is a minor followup of https://github.com/apache/spark/pull/29601 , to preserve the attribute name in `SubqueryBroadcastExec.output`.
### Why are the changes needed?
During explain, it's better to see the origin column name instead of always "key".
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
existing tests.
Closes#29839 from cloud-fan/followup2.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/29475.
This PR updates the code to broadcast the Array instead of Set, which was the behavior before #29475
### Why are the changes needed?
The size of Set can be much bigger than Array. It's safer to keep the behavior the same as before and build the set at the executor side.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing tests
Closes#29838 from cloud-fan/followup.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR adds foldable propagation from `Aggregate` as per: https://github.com/apache/spark/pull/29771#discussion_r490412031
### Why are the changes needed?
This is an improvement as `Aggregate`'s `aggregateExpressions` can contain foldables that can be propagated up.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New UT.
Closes#29816 from peter-toth/SPARK-32951-foldable-propagation-from-aggregate.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In current mode, when explain a SQL plan with HiveTableRelation, it will show so many info about HiveTableRelation's prunedPartition, this make plan hard to read, this pr make this information simpler.
Before:

For UT
```
test("Make HiveTableScanExec message simple") {
withSQLConf("hive.exec.dynamic.partition.mode" -> "nonstrict") {
withTable("df") {
spark.range(30)
.select(col("id"), col("id").as("k"))
.write
.partitionBy("k")
.format("hive")
.mode("overwrite")
.saveAsTable("df")
val df = sql("SELECT df.id, df.k FROM df WHERE df.k < 2")
df.explain(true)
}
}
}
```
After this pr will show
```
== Parsed Logical Plan ==
'Project ['df.id, 'df.k]
+- 'Filter ('df.k < 2)
+- 'UnresolvedRelation [df], []
== Analyzed Logical Plan ==
id: bigint, k: bigint
Project [id#11L, k#12L]
+- Filter (k#12L < cast(2 as bigint))
+- SubqueryAlias spark_catalog.default.df
+- HiveTableRelation [`default`.`df`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [id#11L], Partition Cols: [k#12L]]
== Optimized Logical Plan ==
Filter (isnotnull(k#12L) AND (k#12L < 2))
+- HiveTableRelation [`default`.`df`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [id#11L], Partition Cols: [k#12L], Pruned Partitions: [(k=0), (k=1)]]
== Physical Plan ==
Scan hive default.df [id#11L, k#12L], HiveTableRelation [`default`.`df`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [id#11L], Partition Cols: [k#12L], Pruned Partitions: [(k=0), (k=1)]], [isnotnull(k#12L), (k#12L < 2)]
```
In my pr, I will construct `HiveTableRelation`'s `simpleString` method to avoid show too much unnecessary info in explain plan. compared to what we had before,I decrease the detail metadata of each partition and only retain the partSpec to show each partition was pruned. Since for detail information, we always don't see this in Plan but to use DESC EXTENDED statement.
### Why are the changes needed?
Make plan about HiveTableRelation more readable
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
No
Closes#29739 from AngersZhuuuu/HiveTableScan-meta-location-info.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add optional `allowMissingColumns` argument to SparkR `unionByName`.
### Why are the changes needed?
Feature parity.
### Does this PR introduce _any_ user-facing change?
`unionByName` supports `allowMissingColumns`.
### How was this patch tested?
Existing unit tests. New unit tests targeting this feature.
Closes#29813 from zero323/SPARK-32799.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This is a follow-up PR to https://github.com/apache/spark/pull/29771 and just adds a new test case.
### Why are the changes needed?
To have better test coverage.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New UT.
Closes#29802 from peter-toth/SPARK-32635-fix-foldable-propagation-followup.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
After https://github.com/apache/spark/pull/29660 and https://github.com/apache/spark/pull/29689 there are 13 remaining failed cases of sql core module with Scala 2.13.
The reason for the remaining failed cases is the optimization result of `CostBasedJoinReorder` maybe different with same input in Scala 2.12 and Scala 2.13 if there are more than one same cost candidate plans.
In this pr give a way to make the optimization result deterministic as much as possible to pass all remaining failed cases of `sql/core` module in Scala 2.13, the main change of this pr as follow:
- Change to use `LinkedHashMap` instead of `Map` to store `foundPlans` in `JoinReorderDP.search` method to ensure same iteration order with same insert order because iteration order of `Map` behave differently under Scala 2.12 and 2.13
- Fixed `StarJoinCostBasedReorderSuite` affected by the above change
- Regenerate golden files affected by the above change.
### Why are the changes needed?
We need to support a Scala 2.13 build.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Scala 2.12: Pass the Jenkins or GitHub Action
- Scala 2.13: All tests passed.
Do the following:
```
dev/change-scala-version.sh 2.13
mvn clean install -DskipTests -pl sql/core -Pscala-2.13 -am
mvn test -pl sql/core -Pscala-2.13
```
**Before**
```
Tests: succeeded 8485, failed 13, canceled 1, ignored 52, pending 0
*** 13 TESTS FAILED ***
```
**After**
```
Tests: succeeded 8498, failed 0, canceled 1, ignored 52, pending 0
All tests passed.
```
Closes#29711 from LuciferYang/SPARK-32808-3.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Found via discussion https://github.com/apache/spark/pull/29746#issuecomment-694726504
and the root cause it that hive-1.2 does not recognize NULL
```scala
sbt.ForkMain$ForkError: java.sql.SQLException: Unrecognized column type: NULL
at org.apache.hive.jdbc.JdbcColumn.typeStringToHiveType(JdbcColumn.java:160)
at org.apache.hive.jdbc.HiveResultSetMetaData.getHiveType(HiveResultSetMetaData.java:48)
at org.apache.hive.jdbc.HiveResultSetMetaData.getPrecision(HiveResultSetMetaData.java:86)
at org.apache.spark.sql.hive.thriftserver.SparkThriftServerProtocolVersionsSuite.$anonfun$new$35(SparkThriftServerProtocolVersionsSuite.scala:358)
at org.apache.spark.sql.hive.thriftserver.SparkThriftServerProtocolVersionsSuite.$anonfun$new$35$adapted(SparkThriftServerProtocolVersionsSuite.scala:351)
at org.apache.spark.sql.hive.thriftserver.SparkThriftServerProtocolVersionsSuite.testExecuteStatementWithProtocolVersion(SparkThriftServerProtocolVersionsSuite.scala:66)
at org.apache.spark.sql.hive.thriftserver.SparkThriftServerProtocolVersionsSuite.$anonfun$new$34(SparkThriftServerProtocolVersionsSuite.scala:351)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85)
at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83)
at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104)
at org.scalatest.Transformer.apply(Transformer.scala:22)
at org.scalatest.Transformer.apply(Transformer.scala:20)
at org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:189)
at org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:176)
at org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:187)
at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:199)
at org.scalatest.SuperEngine.runTestImpl(Engine.scala:306)
at org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:199)
at org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:181)
at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:61)
at org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:234)
at org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:227)
at org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:61)
at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTests$1(AnyFunSuiteLike.scala:232)
at org.scalatest.SuperEngine.$anonfun$runTestsInBranch$1(Engine.scala:413)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.scalatest.SuperEngine.traverseSubNodes$1(Engine.scala:401)
at org.scalatest.SuperEngine.runTestsInBranch(Engine.scala:396)
at org.scalatest.SuperEngine.runTestsImpl(Engine.scala:475)
at org.scalatest.funsuite.AnyFunSuiteLike.runTests(AnyFunSuiteLike.scala:232)
at org.scalatest.funsuite.AnyFunSuiteLike.runTests$(AnyFunSuiteLike.scala:231)
at org.scalatest.funsuite.AnyFunSuite.runTests(AnyFunSuite.scala:1562)
at org.scalatest.Suite.run(Suite.scala:1112)
at org.scalatest.Suite.run$(Suite.scala:1094)
at org.scalatest.funsuite.AnyFunSuite.org$scalatest$funsuite$AnyFunSuiteLike$$super$run(AnyFunSuite.scala:1562)
at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$run$1(AnyFunSuiteLike.scala:236)
at org.scalatest.SuperEngine.runImpl(Engine.scala:535)
at org.scalatest.funsuite.AnyFunSuiteLike.run(AnyFunSuiteLike.scala:236)
at org.scalatest.funsuite.AnyFunSuiteLike.run$(AnyFunSuiteLike.scala:235)
at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterAll$$super$run(SparkFunSuite.scala:61)
at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:213)
at org.scalatest.BeforeAndAfterAll.run(BeforeAndAfterAll.scala:210)
at org.scalatest.BeforeAndAfterAll.run$(BeforeAndAfterAll.scala:208)
at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:61)
at org.scalatest.tools.Framework.org$scalatest$tools$Framework$$runSuite(Framework.scala:318)
at org.scalatest.tools.Framework$ScalaTestTask.execute(Framework.scala:513)
at sbt.ForkMain$Run$2.call(ForkMain.java:296)
at sbt.ForkMain$Run$2.call(ForkMain.java:286)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
In this PR, we simply ignore these checks for hive 1.2
### Why are the changes needed?
fix jenkins
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
test itself.
Closes#29803 from yaooqinn/SPARK-32874-F.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to replace deprecated `isFile` and `isDirectory` methods.
```diff
- fs.isDirectory(hadoopPath)
+ fs.getFileStatus(hadoopPath).isDirectory
```
```diff
- fs.isFile(new Path(inProgressLog))
+ fs.getFileStatus(new Path(inProgressLog)).isFile
```
### Why are the changes needed?
It shows deprecation warnings.
- https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-3.2-hive-2.3/1244/consoleFull
```
[warn] /home/jenkins/workspace/spark-master-test-sbt-hadoop-3.2-hive-2.3/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala:815: method isFile in class FileSystem is deprecated: see corresponding Javadoc for more information.
[warn] if (!fs.isFile(new Path(inProgressLog))) {
```
```
[warn] /home/jenkins/workspace/spark-master-test-sbt-hadoop-3.2-hive-2.3/core/src/main/scala/org/apache/spark/SparkContext.scala:1884: method isDirectory in class FileSystem is deprecated: see corresponding Javadoc for more information.
[warn] if (fs.isDirectory(hadoopPath)) {
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the Jenkins.
Closes#29796 from williamhyun/filesystem.
Authored-by: William Hyun <williamhyun3@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Change the target error calculation according to the paper [Space-Efficient Online Computation of Quantile Summaries](http://infolab.stanford.edu/~datar/courses/cs361a/papers/quantiles.pdf). It says that the error `e = max(gi, deltai)/2` (see the page 59). Also this has clear explanation [ε-approximate quantiles](http://www.mathcs.emory.edu/~cheung/Courses/584/Syllabus/08-Quantile/Greenwald.html#proofprop1).
2. Added a test to check different accuracies.
3. Added an input CSV file `percentile_approx-input.csv.bz2` to the resource folder `sql/catalyst/src/main/resources` for the test.
### Why are the changes needed?
To fix incorrect percentile calculation, see an example in SPARK-32908.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
- By running existing tests in `QuantileSummariesSuite` and in `ApproximatePercentileQuerySuite`.
- Added new test `SPARK-32908: maximum target error in percentile_approx` to `ApproximatePercentileQuerySuite`.
Closes#29784 from MaxGekk/fix-percentile_approx-2.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Recently, we added code to log plan changes in the preparation phase in `QueryExecution` for execution (https://github.com/apache/spark/pull/29544). This PR intends to apply the same fix for logging plan changes in AQE.
### Why are the changes needed?
Easy debugging for AQE plans
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added unit tests.
Closes#29774 from maropu/PlanChangeLogForAQE.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR rewrites `FoldablePropagation` rule to replace attribute references in a node with foldables coming only from the node's children.
Before this PR in the case of this example (with setting`spark.sql.optimizer.excludedRules=org.apache.spark.sql.catalyst.optimizer.ConvertToLocalRelation`):
```scala
val a = Seq("1").toDF("col1").withColumn("col2", lit("1"))
val b = Seq("2").toDF("col1").withColumn("col2", lit("2"))
val aub = a.union(b)
val c = aub.filter($"col1" === "2").cache()
val d = Seq("2").toDF( "col4")
val r = d.join(aub, $"col2" === $"col4").select("col4")
val l = c.select("col2")
val df = l.join(r, $"col2" === $"col4", "LeftOuter")
df.show()
```
foldable propagation happens incorrectly:
```
Join LeftOuter, (col2#6 = col4#34) Join LeftOuter, (col2#6 = col4#34)
!:- Project [col2#6] :- Project [1 AS col2#6]
: +- InMemoryRelation [col1#4, col2#6], StorageLevel(disk, memory, deserialized, 1 replicas) : +- InMemoryRelation [col1#4, col2#6], StorageLevel(disk, memory, deserialized, 1 replicas)
: +- Union : +- Union
: :- *(1) Project [value#1 AS col1#4, 1 AS col2#6] : :- *(1) Project [value#1 AS col1#4, 1 AS col2#6]
: : +- *(1) Filter (isnotnull(value#1) AND (value#1 = 2)) : : +- *(1) Filter (isnotnull(value#1) AND (value#1 = 2))
: : +- *(1) LocalTableScan [value#1] : : +- *(1) LocalTableScan [value#1]
: +- *(2) Project [value#10 AS col1#13, 2 AS col2#15] : +- *(2) Project [value#10 AS col1#13, 2 AS col2#15]
: +- *(2) Filter (isnotnull(value#10) AND (value#10 = 2)) : +- *(2) Filter (isnotnull(value#10) AND (value#10 = 2))
: +- *(2) LocalTableScan [value#10] : +- *(2) LocalTableScan [value#10]
+- Project [col4#34] +- Project [col4#34]
+- Join Inner, (col2#6 = col4#34) +- Join Inner, (col2#6 = col4#34)
:- Project [value#31 AS col4#34] :- Project [value#31 AS col4#34]
: +- LocalRelation [value#31] : +- LocalRelation [value#31]
+- Project [col2#6] +- Project [col2#6]
+- Union false, false +- Union false, false
:- Project [1 AS col2#6] :- Project [1 AS col2#6]
: +- LocalRelation [value#1] : +- LocalRelation [value#1]
+- Project [2 AS col2#15] +- Project [2 AS col2#15]
+- LocalRelation [value#10] +- LocalRelation [value#10]
```
and so the result is wrong:
```
+----+----+
|col2|col4|
+----+----+
| 1|null|
+----+----+
```
After this PR foldable propagation will not happen incorrectly and the result is correct:
```
+----+----+
|col2|col4|
+----+----+
| 2| 2|
+----+----+
```
### Why are the changes needed?
To fix a correctness issue.
### Does this PR introduce _any_ user-facing change?
Yes, fixes a correctness issue.
### How was this patch tested?
Existing and new UTs.
Closes#29771 from peter-toth/SPARK-32635-fix-foldable-propagation.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
make orc table column name support special characters like `$`
### Why are the changes needed?
Special characters like `$` are allowed in orc table column name by Hive.
But it's error when execute command "CREATE TABLE tbl(`$` INT, b INT) using orc" in spark. it's not compatible with Hive.
`Column name "$" contains invalid character(s). Please use alias to rename it.;Column name "$" contains invalid character(s). Please use alias to rename it.;org.apache.spark.sql.AnalysisException: Column name "$" contains invalid character(s). Please use alias to rename it.;
at org.apache.spark.sql.execution.datasources.orc.OrcFileFormat$.checkFieldName(OrcFileFormat.scala:51)
at org.apache.spark.sql.execution.datasources.orc.OrcFileFormat$.$anonfun$checkFieldNames$1(OrcFileFormat.scala:59)
at org.apache.spark.sql.execution.datasources.orc.OrcFileFormat$.$anonfun$checkFieldNames$1$adapted(OrcFileFormat.scala:59)
at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.WrappedArray.foreach(WrappedArray.scala:38) `
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Add unit test
Closes#29761 from jzc928/orcColSpecialChar.
Authored-by: jzc <jzc@jzcMacBookPro.local>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This pr fix failed and aborted cases in sql hive-thriftserver module in Scala 2.13, the main change of this pr as follow:
- Use `s.c.Seq` instead of `Seq` in `HiveResult` because the input type maybe `mutable.ArraySeq`, but `Seq` represent `immutable.Seq` in Scala 2.13.
- Reset classLoader after `HiveMetastoreLazyInitializationSuite` completed because context class loader is `NonClosableMutableURLClassLoader` in `HiveMetastoreLazyInitializationSuite` running process, and it propagate to `HiveThriftServer2ListenerSuite` trigger following problems in Scala 2.13:
```
HiveThriftServer2ListenerSuite:
*** RUN ABORTED ***
java.lang.LinkageError: loader constraint violation: loader (instance of net/bytebuddy/dynamic/loading/MultipleParentClassLoader) previously initiated loading for a different type with name "org/apache/hive/service/ServiceStateChangeListener"
at org.mockito.codegen.HiveThriftServer2$MockitoMock$1850222569.<clinit>(Unknown Source)
at sun.reflect.GeneratedSerializationConstructorAccessor530.newInstance(Unknown Source)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.objenesis.instantiator.sun.SunReflectionFactoryInstantiator.newInstance(SunReflectionFactoryInstantiator.java:48)
at org.objenesis.ObjenesisBase.newInstance(ObjenesisBase.java:73)
at org.mockito.internal.creation.instance.ObjenesisInstantiator.newInstance(ObjenesisInstantiator.java:19)
at org.mockito.internal.creation.bytebuddy.SubclassByteBuddyMockMaker.createMock(SubclassByteBuddyMockMaker.java:47)
at org.mockito.internal.creation.bytebuddy.ByteBuddyMockMaker.createMock(ByteBuddyMockMaker.java:25)
at org.mockito.internal.util.MockUtil.createMock(MockUtil.java:35)
at org.mockito.internal.MockitoCore.mock(MockitoCore.java:63)
...
```
After this pr `HiveThriftServer2Suites` and `HiveThriftServer2ListenerSuite` was fixed and all 461 test passed
### Why are the changes needed?
We need to support a Scala 2.13 build.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Scala 2.12: Pass the Jenkins or GitHub Action
- Scala 2.13: All tests passed.
Do the following:
```
dev/change-scala-version.sh 2.13
mvn clean install -DskipTests -pl sql/hive-thriftserver -am -Phive-thriftserver -Pscala-2.13
mvn test -pl sql/hive-thriftserver -Phive -Phive-thriftserver -Pscala-2.13
```
**Before**
```
HiveThriftServer2ListenerSuite:
*** RUN ABORTED ***
```
**After**
```
Tests: succeeded 461, failed 0, canceled 0, ignored 17, pending 0
All tests passed.
```
Closes#29783 from LuciferYang/sql-thriftserver-tests.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a follow-up on #29565, and addresses a few issues in the last PR:
- style issue pointed by [this comment](https://github.com/apache/spark/pull/29565#discussion_r487646749)
- skip optimization when `fromExp` is foldable (by [this comment](https://github.com/apache/spark/pull/29565#discussion_r487646973)) as there could be more efficient rule to apply for this case.
- pass timezone info to the generated cast on the literal value
- a bunch of cleanups and test improvements
Originally I plan to handle this when implementing [SPARK-32858](https://issues.apache.org/jira/browse/SPARK-32858) but now think it's better to isolate these changes from that.
### Why are the changes needed?
To fix a few left over issues in the above PR.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added a test for the foldable case. Otherwise relying on existing tests.
Closes#29775 from sunchao/SPARK-24994-followup.
Authored-by: Chao Sun <sunchao@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Write to static partition, check in advance that the partition field is empty.
### Why are the changes needed?
When writing to the current static partition, the partition field is empty, and an error will be reported when all tasks are completed.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
add ut
Closes#29316 from cxzl25/SPARK-32508.
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This patch proposes to make GeneratePredicate eliminate common sub-expressions.
### Why are the changes needed?
Both GenerateMutableProjection and GenerateUnsafeProjection, such codegen objects can eliminate common sub-expressions. But GeneratePredicate currently doesn't do it.
We encounter a customer issue that a Filter pushed down through a Project causes performance issue, compared with not pushed down case. The issue is one expression used in Filter predicates are run many times. Due to the complex schema, the query nodes are not wholestage codegen, so it runs Filter.doExecute and then call GeneratePredicate. The common expression was run many time and became performance bottleneck. GeneratePredicate should be able to eliminate common sub-expressions for such case.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests.
Closes#29776 from viirya/filter-pushdown.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Credits to tdas who reported and described the fix to [SPARK-26425](https://issues.apache.org/jira/browse/SPARK-26425). I just followed the description of the issue.
This patch adds more checks on commit log as well as file streaming source so that multiple concurrent runs of streaming query don't mess up the status of query/checkpoint. This patch addresses two different spots which are having a bit different issues:
1. FileStreamSource.fetchMaxOffset()
In structured streaming, we don't allow multiple streaming queries to run with same checkpoint (including concurrent runs of same query), so query should fail if it fails to write the metadata of specific batch ID due to same batch ID being written by others.
2. commit log
As described in JIRA issue, assertion is already applied to the `offsetLog` for the same reason.
8167714cab/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala (L394-L402)
This patch applied the same for commit log.
### Why are the changes needed?
This prevents the inconsistent behavior on streaming query and lets query fail instead.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
N/A, as the change is simple and obvious, and it's really hard to artificially reproduce the issue.
Closes#25965 from HeartSaVioR/SPARK-26425.
Lead-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Co-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
### What changes were proposed in this pull request?
This pr fix failed cases in sql hive module in Scala 2.13 as follow:
- HiveSchemaInferenceSuite (1 FAILED -> PASS)
- HiveSparkSubmitSuite (1 FAILED-> PASS)
- StatisticsSuite (1 FAILED-> PASS)
- HiveDDLSuite (1 FAILED-> PASS)
After this patch all test passed in sql hive module in Scala 2.13.
### Why are the changes needed?
We need to support a Scala 2.13 build.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Scala 2.12: Pass the Jenkins or GitHub Action
- Scala 2.13: All tests passed.
Do the following:
```
dev/change-scala-version.sh 2.13
mvn clean install -DskipTests -pl sql/hive -am -Pscala-2.13 -Phive
mvn clean test -pl sql/hive -Pscala-2.13 -Phive
```
**Before**
```
Tests: succeeded 3662, failed 4, canceled 0, ignored 601, pending 0
*** 4 TESTS FAILED ***
```
**After**
```
Tests: succeeded 3666, failed 0, canceled 0, ignored 601, pending 0
All tests passed.
```
Closes#29760 from LuciferYang/sql-hive-test.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This PR fixes a conflict between `RewriteDistinctAggregates` and `DecimalAggregates`.
In some cases, `DecimalAggregates` will wrap the decimal column to `UnscaledValue` using
different rules for different aggregates.
This means, same distinct column with different aggregates will change to different distinct columns
after `DecimalAggregates`. For example:
`avg(distinct decimal_col), sum(distinct decimal_col)` may change to
`avg(distinct UnscaledValue(decimal_col)), sum(distinct decimal_col)`
We assume after `RewriteDistinctAggregates`, there will be at most one distinct column in aggregates,
but `DecimalAggregates` breaks this assumption. To fix this, we have to switch the order of these two
rules.
### Why are the changes needed?
bug fix
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
added test cases
Closes#29673 from linhongliu-db/SPARK-32816.
Authored-by: Linhong Liu <linhong.liu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This pr makes cast string type to decimal decimal type fast fail if precision larger that 38.
### Why are the changes needed?
It is very slow if precision very large.
Benchmark and benchmark result:
```scala
import org.apache.spark.benchmark.Benchmark
val bd1 = new java.math.BigDecimal("6.0790316E+25569151")
val bd2 = new java.math.BigDecimal("6.0790316E+25");
val benchmark = new Benchmark("Benchmark string to decimal", 1, minNumIters = 2)
benchmark.addCase(bd1.toString) { _ =>
println(Decimal(bd1).precision)
}
benchmark.addCase(bd2.toString) { _ =>
println(Decimal(bd2).precision)
}
benchmark.run()
```
```
Java HotSpot(TM) 64-Bit Server VM 1.8.0_251-b08 on Mac OS X 10.15.6
Intel(R) Core(TM) i9-9980HK CPU 2.40GHz
Benchmark string to decimal: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
6.0790316E+25569151 9340 9381 57 0.0 9340094625.0 1.0X
6.0790316E+25 0 0 0 0.5 2150.0 4344230.1X
```
Stacktrace:
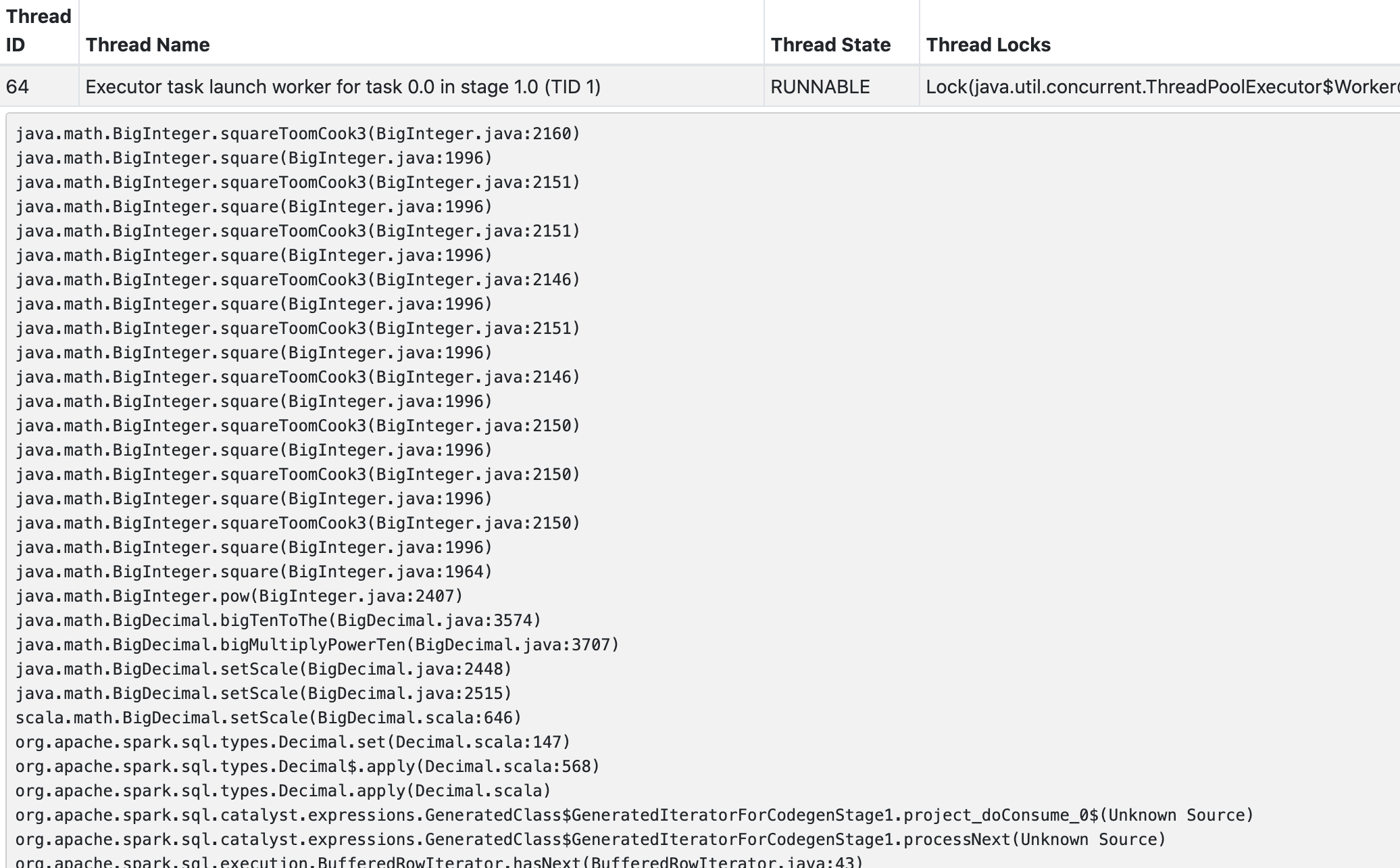
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test and benchmark test:
Dataset | Before this pr (Seconds) | After this pr (Seconds)
-- | -- | --
https://issues.apache.org/jira/secure/attachment/13011406/part-00000.parquet | 2640 | 2
Closes#29731 from wangyum/SPARK-32706.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This proposes to enhance user document of the API for loading a Dataset of strings storing CSV rows. If the header option is set to true, the API will remove all lines same with the header.
### Why are the changes needed?
This behavior can confuse users. We should explicitly document it.
### Does this PR introduce _any_ user-facing change?
No. Only doc change.
### How was this patch tested?
Only doc change.
Closes#29765 from viirya/SPARK-32888.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR updates the `RemoveRedundantProjects` rule to make `GenerateExec` require column ordering.
### Why are the changes needed?
`GenerateExec` was originally considered as a node that does not require column ordering. However, `GenerateExec` binds its input rows directly with its `requiredChildOutput` without using the child's output schema.
In `doExecute()`:
```scala
val proj = UnsafeProjection.create(output, output)
```
In `doConsume()`:
```scala
val values = if (requiredChildOutput.nonEmpty) {
input
} else {
Seq.empty
}
```
In this case, changing input column ordering will result in `GenerateExec` binding the wrong schema to the input columns. For example, if we do not require child columns to be ordered, the `requiredChildOutput` [a, b, c] will directly bind to the schema of the input columns [c, b, a], which is incorrect:
```
GenerateExec explode(array(a, b, c)), [a, b, c], false, [d]
HashAggregate(keys=[a, b, c], functions=[], output=[c, b, a])
...
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes#29734 from allisonwang-db/generator.
Authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The `LiteralGenerator` for float and double datatypes was supposed to yield special values (NaN, +-inf) among others, but the `Gen.chooseNum` method does not yield values that are outside the defined range. The `Gen.chooseNum` for a wide range of floats and doubles does not yield values in the "everyday" range as stated in https://github.com/typelevel/scalacheck/issues/113 .
There is an similar class `RandomDataGenerator` that is used in some other tests. Added `-0.0` and `-0.0f` as special values to there too.
These changes revealed an inconsistency with the equality check between `-0.0` and `0.0`.
### Why are the changes needed?
The `LiteralGenerator` is mostly used in the `checkConsistencyBetweenInterpretedAndCodegen` method in `MathExpressionsSuite`. This change would have caught the bug fixed in #29495 .
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Locally reverted #29495 and verified that the existing test cases caught the bug.
Closes#29515 from tanelk/SPARK-32688.
Authored-by: Tanel Kiis <tanel.kiis@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR only checks if there's any physical rule runs instead of a specific rule. This is rather just a trivial fix to make the tests more robust.
In fact, I faced a test failure from a in-house fork that applies a different physical rule that makes `CollapseCodegenStages` ineffective.
### Why are the changes needed?
To make the test more robust by unrelated changes.
### Does this PR introduce _any_ user-facing change?
No, test-only
### How was this patch tested?
Manually tested. Jenkins tests should pass.
Closes#29766 from HyukjinKwon/SPARK-32704.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR skips the test if trash directory cannot be created. It is possible that the trash directory cannot be created, for example, by permission. And the test fails below:
```
- SPARK-32481 Move data to trash on truncate table if enabled *** FAILED *** (154 milliseconds)
fs.exists(trashPath) was false (DDLSuite.scala:3184)
org.scalatest.exceptions.TestFailedException:
at org.scalatest.Assertions.newAssertionFailedException(Assertions.scala:530)
at org.scalatest.Assertions.newAssertionFailedException$(Assertions.scala:529)
at org.scalatest.FunSuite.newAssertionFailedException(FunSuite.scala:1560)
at org.scalatest.Assertions$AssertionsHelper.macroAssert(Assertions.scala:503)
```
### Why are the changes needed?
To make the tests pass independently.
### Does this PR introduce _any_ user-facing change?
No, test-only.
### How was this patch tested?
Manually tested.
Closes#29759 from HyukjinKwon/SPARK-32481.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add a new config `spark.sql.maxMetadataStringLength`. This config aims to limit metadata value length, e.g. file location.
### Why are the changes needed?
Some metadata have been abbreviated by `...` when I tried to add some test in `SQLQueryTestSuite`. We need to replace such value to `notIncludedMsg`. That caused we can't replace that like location value by `className` since the `className` has been abbreviated.
Here is a case:
```
CREATE table explain_temp1 (key int, val int) USING PARQUET;
EXPLAIN EXTENDED SELECT sum(distinct val) FROM explain_temp1;
-- ignore parsed,analyzed,optimized
-- The output like
== Physical Plan ==
*HashAggregate(keys=[], functions=[sum(distinct cast(val#x as bigint)#xL)], output=[sum(DISTINCT val)#xL])
+- Exchange SinglePartition, true, [id=#x]
+- *HashAggregate(keys=[], functions=[partial_sum(distinct cast(val#x as bigint)#xL)], output=[sum#xL])
+- *HashAggregate(keys=[cast(val#x as bigint)#xL], functions=[], output=[cast(val#x as bigint)#xL])
+- Exchange hashpartitioning(cast(val#x as bigint)#xL, 4), true, [id=#x]
+- *HashAggregate(keys=[cast(val#x as bigint) AS cast(val#x as bigint)#xL], functions=[], output=[cast(val#x as bigint)#xL])
+- *ColumnarToRow
+- FileScan parquet default.explain_temp1[val#x] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/home/runner/work/spark/spark/sql/core/spark-warehouse/org.apache.spark.sq...], PartitionFilters: ...
```
### Does this PR introduce _any_ user-facing change?
No, a new config.
### How was this patch tested?
new test.
Closes#29688 from ulysses-you/SPARK-32827.
Authored-by: ulysses <youxiduo@weidian.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR adds test cases for the result set metadata checking for Spark's `ExecuteStatementOperation` to make the JDBC API more future-proofing because any server-side change may affect the client compatibility.
### Why are the changes needed?
add test to prevent potential silent behavior change for JDBC users.
### Does this PR introduce _any_ user-facing change?
NO, test only
### How was this patch tested?
add new test
Closes#29746 from yaooqinn/SPARK-32874.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR refactors the way we propagate the options from the `SparkSession.Builder` to the` SessionState`. This currently done via a mutable map inside the SparkSession. These setting settings are then applied **after** the Session. This is a bit confusing when you expect something to be set when constructing the `SessionState`. This PR passes the options as a constructor parameter to the `SessionStateBuilder` and this will set the options when the configuration is created.
### Why are the changes needed?
It makes it easier to reason about the configurations set in a SessionState than before. We recently had an incident where someone was using `SparkSessionExtensions` to create a planner rule that relied on a conf to be set. While this is in itself probably incorrect usage, it still illustrated this somewhat funky behavior.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests.
Closes#29752 from hvanhovell/SPARK-32879.
Authored-by: herman <herman@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to mark the following suite as `ExtendedSQLTest` to reduce GitHub Action test time.
- TPCDSQuerySuite
- TPCDSQueryANSISuite
- TPCDSQueryWithStatsSuite
### Why are the changes needed?
Currently, the longest GitHub Action task is `Build and test / Build modules: sql - other tests` with `1h 57m 10s` while `Build and test / Build modules: sql - slow tests` takes `42m 20s`. With this PR, we can move the workload from `other tests` to `slow tests` task and reduce the total waiting time about 7 ~ 8 minutes.
### Does this PR introduce _any_ user-facing change?
No. This is a test-only change.
### How was this patch tested?
Pass the GitHub Action with the reduced running time.
Closes#29755 from dongjoon-hyun/SPARK-SLOWTEST.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR appends `toMap` to `Map` instances with `filterKeys` if such maps is to be concatenated with another maps.
### Why are the changes needed?
As of Scala 2.13, Map#filterKeys return a MapView, not the original Map type.
This can cause compile error.
```
/sql/DataFrameReader.scala:279: type mismatch;
[error] found : Iterable[(String, String)]
[error] required: java.util.Map[String,String]
[error] Error occurred in an application involving default arguments.
[error] val dsOptions = new CaseInsensitiveStringMap(finalOptions.asJava)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Compile passed with the following command.
`build/mvn -Pscala-2.13 -Phive -Phive-thriftserver -Pyarn -Pkubernetes -DskipTests test-compile`
Closes#29742 from sarutak/fix-filterKeys-issue.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
The Jenkins job fails to get the versions. This was fixed by adding temporary fallbacks at https://github.com/apache/spark/pull/28536.
This still doesn't work without the temporary fallbacks. See https://github.com/apache/spark/pull/29694
This PR adds new fallbacks since 2.3 is EOL and Spark 3.0.1 and 2.4.7 are released.
### Why are the changes needed?
To test correctly in Jenkins.
### Does this PR introduce _any_ user-facing change?
No, dev-only
### How was this patch tested?
Jenkins and GitHub Actions builds should test.
Closes#29748 from HyukjinKwon/SPARK-32876.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Mark `BitAggregate` as order irrelevant in `EliminateSorts`.
### Why are the changes needed?
Performance improvements in some queries
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Generalized an existing UT
Closes#29740 from tanelk/SPARK-32868.
Authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Make `DataFrameReader.table` take the specified options for datasource v1.
### Why are the changes needed?
Keep the same behavior of v1/v2 datasource, the v2 fix has been done in SPARK-32592.
### Does this PR introduce _any_ user-facing change?
Yes. The DataFrameReader.table will take the specified options. Also, if there are the same key and value exists in specified options and table properties, an exception will be thrown.
### How was this patch tested?
New UT added.
Closes#29712 from xuanyuanking/SPARK-32844.
Authored-by: Yuanjian Li <yuanjian.li@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}