## What changes were proposed in this pull request?
MetricGetter should rename to ExecutorMetricType in comments.
## How was this patch tested?
Just comments, no need to test.
Closes#22884 from LantaoJin/SPARK-23429_FOLLOWUP.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
Set main args correctly in BenchmarkBase, to make it accessible for its subclass.
It will benefit:
- BuiltInDataSourceWriteBenchmark
- AvroWriteBenchmark
## How was this patch tested?
manual tests
Closes#22872 from yucai/main_args.
Authored-by: yucai <yyu1@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
There is a race condition when releasing a Python worker. If `ReaderIterator.handleEndOfDataSection` is not running in the task thread, when a task is early terminated (such as `take(N)`), the task completion listener may close the worker but "handleEndOfDataSection" can still put the worker into the worker pool to reuse.
0e07b483d2 is a patch to reproduce this issue.
I also found a user reported this in the mail list: http://mail-archives.apache.org/mod_mbox/spark-user/201610.mbox/%3CCAAUq=H+YLUEpd23nwvq13Ms5hOStkhX3ao4f4zQV6sgO5zM-xAmail.gmail.com%3E
This PR fixes the issue by using `compareAndSet` to make sure we will never return a closed worker to the work pool.
## How was this patch tested?
Jenkins.
Closes#22816 from zsxwing/fix-socket-closed.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
## What changes were proposed in this pull request?
`hsync` has been added as part of SPARK-19531 to get the latest data in the history sever ui, but that is causing the performance overhead and also leading to drop many history log events. `hsync` uses the force `FileChannel.force` to sync the data to the disk and happens for the data pipeline, it is costly operation and making the application to face overhead and drop the events.
I think getting the latest data in history server can be done in different way (no impact to application while writing events), there is an api `DFSInputStream.getFileLength()` which gives the file length including the `lastBlockBeingWrittenLength`(different from `FileStatus.getLen()`), this api can be used when the file status length and previously cached length are equal to verify whether any new data has been written or not, if there is any update in data length then the history server can update the in progress history log. And also I made this change as configurable with the default value false, and can be enabled for history server if users want to see the updated data in ui.
## How was this patch tested?
Added new test and verified manually, with the added conf `spark.history.fs.inProgressAbsoluteLengthCheck.enabled=true`, history server is reading the logs including the last block data which is being written and updating the Web UI with the latest data.
Closes#22752 from devaraj-kavali/SPARK-24787.
Authored-by: Devaraj K <devaraj@apache.org>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
In standalone cluster mode, one could launch driver with supervise mode
enabled. StandaloneRestServer class uses the host and port of current
master as the spark.master property while launching the driver
(even if you are running in HA mode). This class also ignores the
spark.master property passed as part of the request.
Due to the above problem, if the Spark masters switch due to some reason
and your driver is killed unexpectedly and relaunched, it will try to
connect to the master which is in the driver command specified as
-Dspark.master. But this master will be in STANDBY mode and after trying
multiple times, the SparkContext will kill itself (even though secondary
master was alive and healthy).
This change picks the spark.master property from request and uses it to
launch the driver process. Due to this, the driver process has both
masters in -Dspark.master property. Even if the masters switch, SparkContext
can still connect to the ALIVE master and work correctly.
## How was this patch tested?
This patch was manually tested on a standalone cluster running 2.2.1. It was rebased on current master and all tests were executed. I have added a unit test for this change (but since I am new I hope I have covered all).
Closes#21816 from bsikander/rest_driver_fix.
Authored-by: Behroz Sikander <behroz.sikander@sap.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Before the code changes, I tried to run it with 8G memory:
```
build/sbt -mem 8000 "core/testOnly org.apache.spark.serializer.KryoBenchmark"
```
Still I got got OOM.
This is because the lengths of the arrays are random
669ade3a8e/core/src/test/scala/org/apache/spark/serializer/KryoBenchmark.scala (L90-L91)
And the 2D array is usually large: `10000 * Random.nextInt(0, 10000)`
This PR is to fix it and refactor it to use main method.
The benchmark result is also reason compared to the original one.
## How was this patch tested?
Run with
```
bin/spark-submit --class org.apache.spark.serializer.KryoBenchmark core/target/scala-2.11/spark-core_2.11-3.0.0-SNAPSHOT-tests.jar
```
and
```
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "core/test:runMain org.apache.spark.serializer.KryoBenchmark"
Closes#22663 from gengliangwang/kyroBenchmark.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove JavaSparkContextVarargsWorkaround
## How was this patch tested?
Existing tests.
Closes#22729 from srowen/SPARK-25737.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove deprecated accumulator v1
## How was this patch tested?
Existing tests.
Closes#22730 from srowen/SPARK-16775.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Fix the following issues in PythonWorkerFactory
1. MonitorThread.run uses a wrong lock.
2. `createSimpleWorker` misses `synchronized` when updating `simpleWorkers`.
Other changes are just to improve the code style to make the thread-safe contract clear.
## How was this patch tested?
Jenkins
Closes#22770 from zsxwing/pwf.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
This is a follow up of #21601, `StreamFileInputFormat` and `WholeTextFileInputFormat` have the same problem.
`Minimum split size pernode 5123456 cannot be larger than maximum split size 4194304
java.io.IOException: Minimum split size pernode 5123456 cannot be larger than maximum split size 4194304
at org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat.getSplits(CombineFileInputFormat.java: 201)
at org.apache.spark.rdd.BinaryFileRDD.getPartitions(BinaryFileRDD.scala:52)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:254)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:252)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2138)`
## How was this patch tested?
Added a unit test
Closes#22725 from 10110346/maxSplitSize_node_rack.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
Currently in PagedTable.scala pageNavigation() method, if it is having only one page, they were not using the pagination.
Now it is made to use the pagination, even if it is having one page.
## How was this patch tested?
This tested with Spark webUI and History page in spark local setup.

Author: shivusondur <shivusondur@gmail.com>
Closes#22668 from shivusondur/pagination.
JVMs don't you allocate arrays of length exactly Int.MaxValue, so leave
a little extra room. This is necessary when reading blocks >2GB off
the network (for remote reads or for cache replication).
Unit tests via jenkins, ran a test with blocks over 2gb on a cluster
Closes#22705 from squito/SPARK-25704.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
When the first dropEvent occurs, LastReportTimestamp was printing in the log as
Wed Dec 31 16:00:00 PST 1969
(Dropped 1 events from eventLog since Wed Dec 31 16:00:00 PST 1969.)
The reason is that lastReportTimestamp initialized with 0.
Now log is updated to print "... since the application starts" if 'lastReportTimestamp' == 0.
this will happens first dropEvent occurs.
## How was this patch tested?
Manually verified.
Closes#22677 from shivusondur/AsyncEvent1.
Authored-by: shivusondur <shivusondur@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
The SQL execution listener framework was created from scratch(see https://github.com/apache/spark/pull/9078). It didn't leverage what we already have in the spark listener framework, and one major problem is, the listener runs on the spark execution thread, which means a bad listener can block spark's query processing.
This PR re-implements the SQL execution listener framework. Now `ExecutionListenerManager` is just a normal spark listener, which watches the `SparkListenerSQLExecutionEnd` events and post events to the
user-provided SQL execution listeners.
## How was this patch tested?
existing tests.
Closes#22674 from cloud-fan/listener.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
- Exposes several metrics regarding application status as a source, useful to scrape them via jmx instead of mining the metrics rest api. Example use case: prometheus + jmx exporter.
- Metrics are gathered when a job ends at the AppStatusListener side, could be more fine-grained but most metrics like tasks completed are also counted by executors. More metrics could be exposed in the future to avoid scraping executors in some scenarios.
- a config option `spark.app.status.metrics.enabled` is added to disable/enable these metrics, by default they are disabled.
This was manually tested with jmx source enabled and prometheus server on k8s:

In the next pic the job delay is shown for repeated pi calculation (Spark action).

Closes#22381 from skonto/add_app_status_metrics.
Authored-by: Stavros Kontopoulos <stavros.kontopoulos@lightbend.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Remove Kafka 0.8 integration
## How was this patch tested?
Existing tests, build scripts
Closes#22703 from srowen/SPARK-25705.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This is the work on setting up Secure HDFS interaction with Spark-on-K8S.
The architecture is discussed in this community-wide google [doc](https://docs.google.com/document/d/1RBnXD9jMDjGonOdKJ2bA1lN4AAV_1RwpU_ewFuCNWKg)
This initiative can be broken down into 4 Stages
**STAGE 1**
- [x] Detecting `HADOOP_CONF_DIR` environmental variable and using Config Maps to store all Hadoop config files locally, while also setting `HADOOP_CONF_DIR` locally in the driver / executors
**STAGE 2**
- [x] Grabbing `TGT` from `LTC` or using keytabs+principle and creating a `DT` that will be mounted as a secret or using a pre-populated secret
**STAGE 3**
- [x] Driver
**STAGE 4**
- [x] Executor
## How was this patch tested?
Locally tested on a single-noded, pseudo-distributed Kerberized Hadoop Cluster
- [x] E2E Integration tests https://github.com/apache/spark/pull/22608
- [ ] Unit tests
## Docs and Error Handling?
- [x] Docs
- [x] Error Handling
## Contribution Credit
kimoonkim skonto
Closes#21669 from ifilonenko/secure-hdfs.
Lead-authored-by: Ilan Filonenko <if56@cornell.edu>
Co-authored-by: Ilan Filonenko <ifilondz@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Update the next version of Spark from 2.5 to 3.0
## How was this patch tested?
N/A
Closes#22717 from gatorsmile/followupSPARK-25372.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Currently, if we try run
```
./start-history-server.sh -h
```
We will get such error
```
java.io.FileNotFoundException: File -h does not exist
```
1. This is not User-Friendly. For option `-h` or `--help`, it should be parsed correctly and show the usage of the class/script.
2. We can remove deprecated options for setting event log directory through command line options.
After fix, we can get following output:
```
Usage: ./sbin/start-history-server.sh [options]
Options:
--properties-file FILE Path to a custom Spark properties file.
Default is conf/spark-defaults.conf.
Configuration options can be set by setting the corresponding JVM system property.
History Server options are always available; additional options depend on the provider.
History Server options:
spark.history.ui.port Port where server will listen for connections
(default 18080)
spark.history.acls.enable Whether to enable view acls for all applications
(default false)
spark.history.provider Name of history provider class (defaults to
file system-based provider)
spark.history.retainedApplications Max number of application UIs to keep loaded in memory
(default 50)
FsHistoryProvider options:
spark.history.fs.logDirectory Directory where app logs are stored
(default: file:/tmp/spark-events)
spark.history.fs.updateInterval How often to reload log data from storage
(in seconds, default: 10)
```
## How was this patch tested?
Manual test
Closes#22699 from gengliangwang/refactorSHSUsage.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Fix old oversight in API: Java `flatMapValues` needs a `FlatMapFunction`
## How was this patch tested?
Existing tests.
Closes#22690 from srowen/SPARK-19287.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Refactor `JoinBenchmark` to use main method.
1. use `spark-submit`:
```console
bin/spark-submit --class org.apache.spark.sql.execution.benchmark.JoinBenchmark --jars ./core/target/spark-core_2.11-3.0.0-SNAPSHOT-tests.jar ./sql/catalyst/target/spark-sql_2.11-3.0.0-SNAPSHOT-tests.jar
```
2. Generate benchmark result:
```console
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.JoinBenchmark"
```
## How was this patch tested?
manual tests
Closes#22661 from wangyum/SPARK-25664.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Yuming Wang <wgyumg@gmail.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
When we enable event log compression and compression codec as 'zstd', we are unable to open the webui of the running application from the history server page.
The reason is that, Replay listener was unable to read from the zstd compressed eventlog due to the zstd frame was not finished yet. This causes truncated error while reading the eventLog.
So, when we try to open the WebUI from the History server page, it throws "truncated error ", and we never able to open running application in the webui, when we enable zstd compression.
In this PR, when the IO excpetion happens, and if it is a running application, we log the error,
"Failed to read Spark event log: evetLogDirAppName.inprogress", instead of throwing exception.
## How was this patch tested?
Test steps:
1)spark.eventLog.compress = true
2)spark.io.compression.codec = zstd
3)restart history server
4) launch bin/spark-shell
5) run some queries
6) Open history server page
7) click on the application
**Before fix:**


**After fix:**


(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22689 from shahidki31/SPARK-25697.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently SQL tab in the WEBUI doesn't support pagination. Because of that following issues are happening.
1) For large number of executions, SQL page is throwing OOM exception (around 40,000)
2) For large number of executions, loading SQL page is taking time.
3) Difficult to analyse the execution table for large number of execution.
[Note: spark.sql.ui.retainedExecutions = 50000]
All the tabs, Jobs, Stages etc. supports pagination. So, to make it consistent with other tabs
SQL tab also should support pagination.
I have followed the similar flow of the pagination code in the Jobs and Stages page for SQL page.
Also, this patch doesn't make any behavior change for the SQL tab except the pagination support.
## How was this patch tested?
bin/spark-shell --conf spark.sql.ui.retainedExecutions=50000
Run 50,000 sql queries.
**Before this PR**
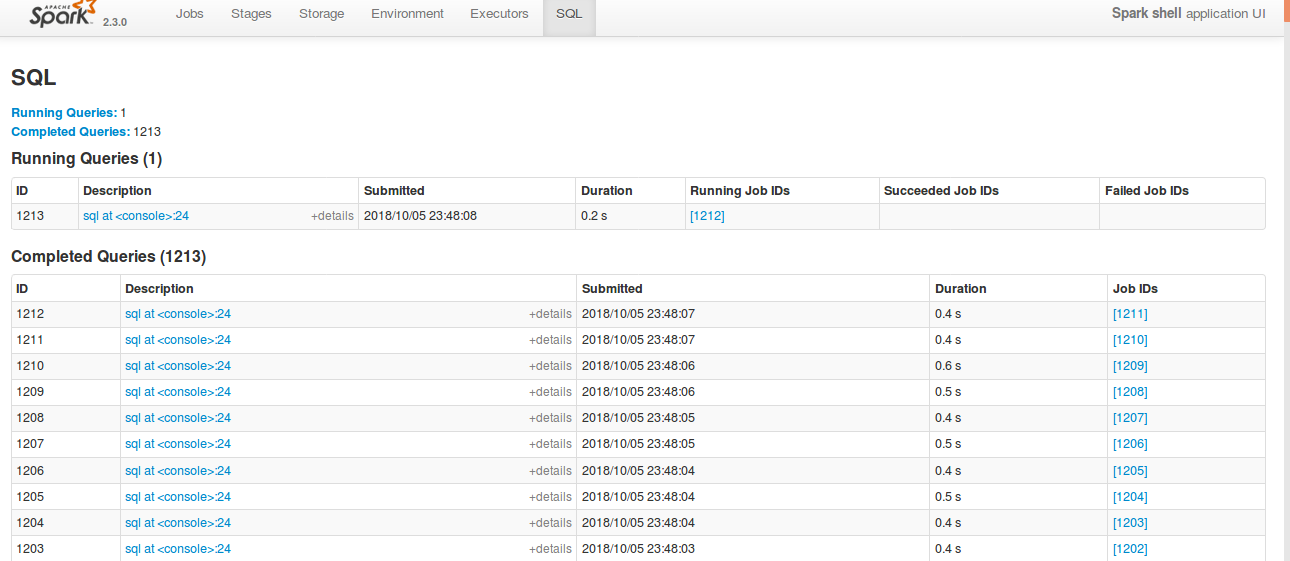
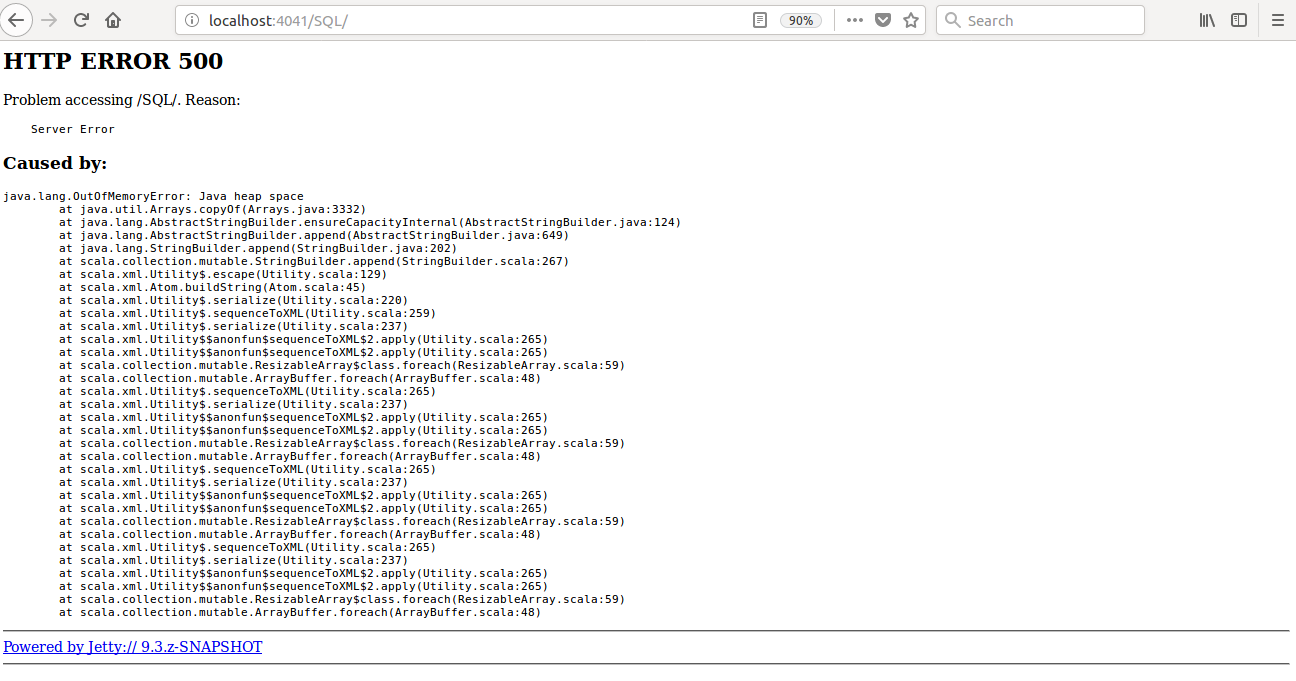
**After this PR**
Loading of the page is faster, and OOM issue doesn't happen.
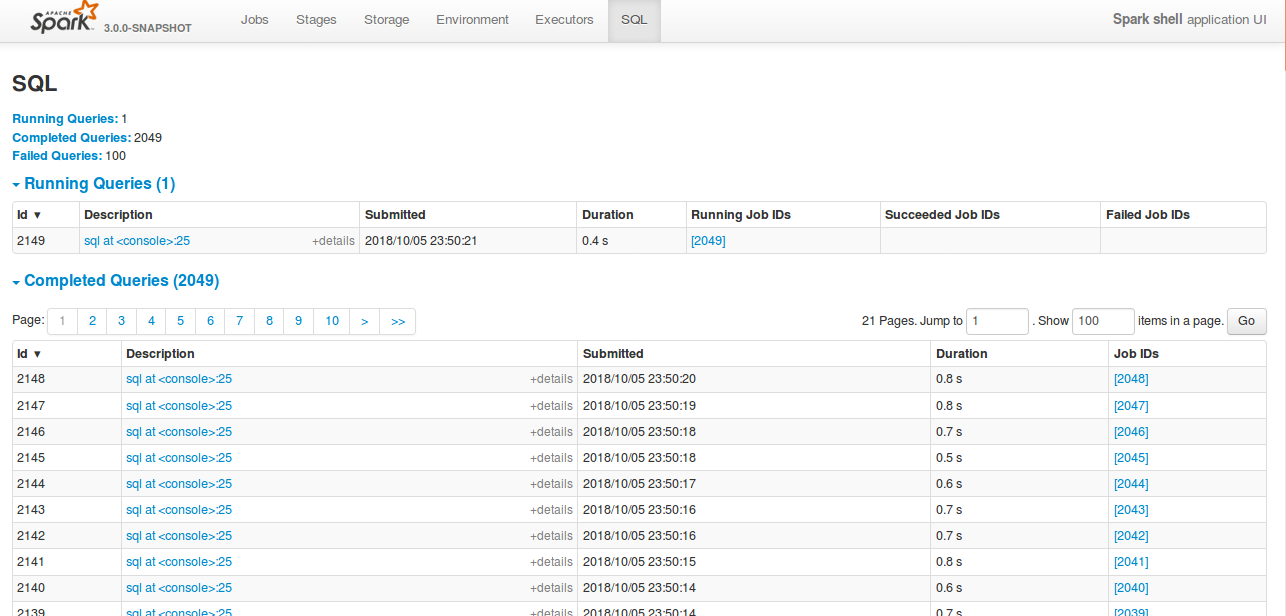
Closes#22645 from shahidki31/SPARK-25566.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove SnappyOutputStreamWrapper and other workaround now that new Snappy fixes these.
See also https://github.com/apache/spark/pull/21176 and comments it links to.
## How was this patch tested?
Existing tests
Closes#22691 from srowen/SPARK-24109.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Cause of the error is wrapped with SparkException, now finding the cause from the wrapped exception and throwing the cause instead of the wrapped exception.
## How was this patch tested?
Verified it manually by checking the cause of the error, it gives the error as shown below.
### Without the PR change
```
[apache-spark]$ ./bin/spark-submit --verbose --master spark://******
....
Error: Exception thrown in awaitResult:
Run with --help for usage help or --verbose for debug output
```
### With the PR change
```
[apache-spark]$ ./bin/spark-submit --verbose --master spark://******
....
Exception in thread "main" org.apache.spark.SparkException: Exception thrown in awaitResult:
at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:226)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:75)
....
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.io.IOException: Failed to connect to devaraj-pc1/10.3.66.65:7077
at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:245)
....
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: io.netty.channel.AbstractChannel$AnnotatedConnectException: Connection refused: devaraj-pc1/10.3.66.65:7077
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
....
at io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:138)
... 1 more
Caused by: java.net.ConnectException: Connection refused
... 11 more
```
Closes#22623 from devaraj-kavali/SPARK-25636.
Authored-by: Devaraj K <devaraj@apache.org>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
The commons-crypto library does some questionable error handling internally,
which can lead to JVM crashes if some call into native code fails and cleans
up state it should not.
While the library is not fixed, this change adds some workarounds in Spark code
so that when an error is detected in the commons-crypto side, Spark avoids
calling into the library further.
Tested with existing and added unit tests.
Closes#22557 from vanzin/SPARK-25535.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
It would be nice to have a field in Stage Page UI which would show mapping of the current stage id to the job id's to which that stage belongs to.
## What changes were proposed in this pull request?
Added a field in Stage UI to display the corresponding job id for that particular stage.
## How was this patch tested?
<img width="448" alt="screen shot 2018-07-25 at 1 33 07 pm" src="https://user-images.githubusercontent.com/22228190/43220447-a8e94f80-900f-11e8-8a20-a235bbd5a369.png">
Closes#21809 from pgandhi999/SPARK-24851.
Authored-by: pgandhi <pgandhi@oath.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
While working on another PR, I noticed that there is quite some legacy Java in there that can be beautified. For example the use of features from Java8, such as:
- Collection libraries
- Try-with-resource blocks
No logic has been changed. I think it is important to have a solid codebase with examples that will inspire next PR's to follow up on the best practices.
What are your thoughts on this?
This makes code easier to read, and using try-with-resource makes is less likely to forget to close something.
## What changes were proposed in this pull request?
No changes in the logic of Spark, but more in the aesthetics of the code.
## How was this patch tested?
Using the existing unit tests. Since no logic is changed, the existing unit tests should pass.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22637 from Fokko/SPARK-25408.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
After the PR, https://github.com/apache/spark/pull/22592, SQL tab supports collapsing table.
However, after refreshing the page, it doesn't store it previous state. This was due to a typo in the argument list in the collapseTablePageLoadCommand().
## How was this patch tested?
bin/spark-shell
```
sql("create table a (id int)")
for(i <- 1 to 100) sql(s"insert into a values ($i)")
```

Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22650 from shahidki31/SPARK-25575-followUp.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
Hi all,
Jackson is incompatible with upstream versions, therefore bump the Jackson version to a more recent one. I bumped into some issues with Azure CosmosDB that is using a more recent version of Jackson. This can be fixed by adding exclusions and then it works without any issues. So no breaking changes in the API's.
I would also consider bumping the version of Jackson in Spark. I would suggest to keep up to date with the dependencies, since in the future this issue will pop up more frequently.
## What changes were proposed in this pull request?
Bump Jackson to 2.9.6
## How was this patch tested?
Compiled and tested it locally to see if anything broke.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#21596 from Fokko/fd-bump-jackson.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
While working on another PR, I noticed that there is quite some legacy Java in there that can be beautified. For example the use og features from Java8, such as:
- Collection libraries
- Try-with-resource blocks
No code has been changed
What are your thoughts on this?
This makes code easier to read, and using try-with-resource makes is less likely to forget to close something.
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22399 from Fokko/SPARK-25408.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Cause: Recently test_glr_summary failed for PR of SPARK-25118, which enables
spark-shell to run with default log level. It failed because this logdebug was
called for GeneralizedLinearRegressionTrainingSummary which invoked its toString
method, which started a Spark Job and ended up running into an infinite loop.
Fix: Remove logDebug statement for outer objects as closures aren't implemented
with outerclasses in Scala 2.12 and this debug statement looses its purpose
## How was this patch tested?
Ran python pyspark-ml tests on top of PR for SPARK-25118 and ClosureCleaner unit
tests
Closes#22616 from ankuriitg/ankur/SPARK-25586.
Authored-by: ankurgupta <ankur.gupta@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Rename method `benchmark` in `BenchmarkBase` as `runBenchmarkSuite `. Also add comments.
Currently the method name `benchmark` is a bit confusing. Also the name is the same as instances of `Benchmark`:
f246813afb/sql/hive/src/test/scala/org/apache/spark/sql/hive/orc/OrcReadBenchmark.scala (L330-L339)
## How was this patch tested?
Unit test.
Closes#22599 from gengliangwang/renameBenchmarkSuite.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
This patch is to bump the master branch version to 3.0.0-SNAPSHOT.
## How was this patch tested?
N/A
Closes#22606 from gatorsmile/bump3.0.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Currently, SQL tab in the WEBUI doesn't support hiding table. Other tabs in the web ui like, Jobs, stages etc supports hiding table (refer SPARK-23024 https://github.com/apache/spark/pull/20216).
In this PR, added the support for hide table in the sql tab also.
## How was this patch tested?
bin/spark-shell
```
sql("create table a (id int)")
for(i <- 1 to 100) sql(s"insert into a values ($i)")
```
Open SQL tab in the web UI
**Before fix:**
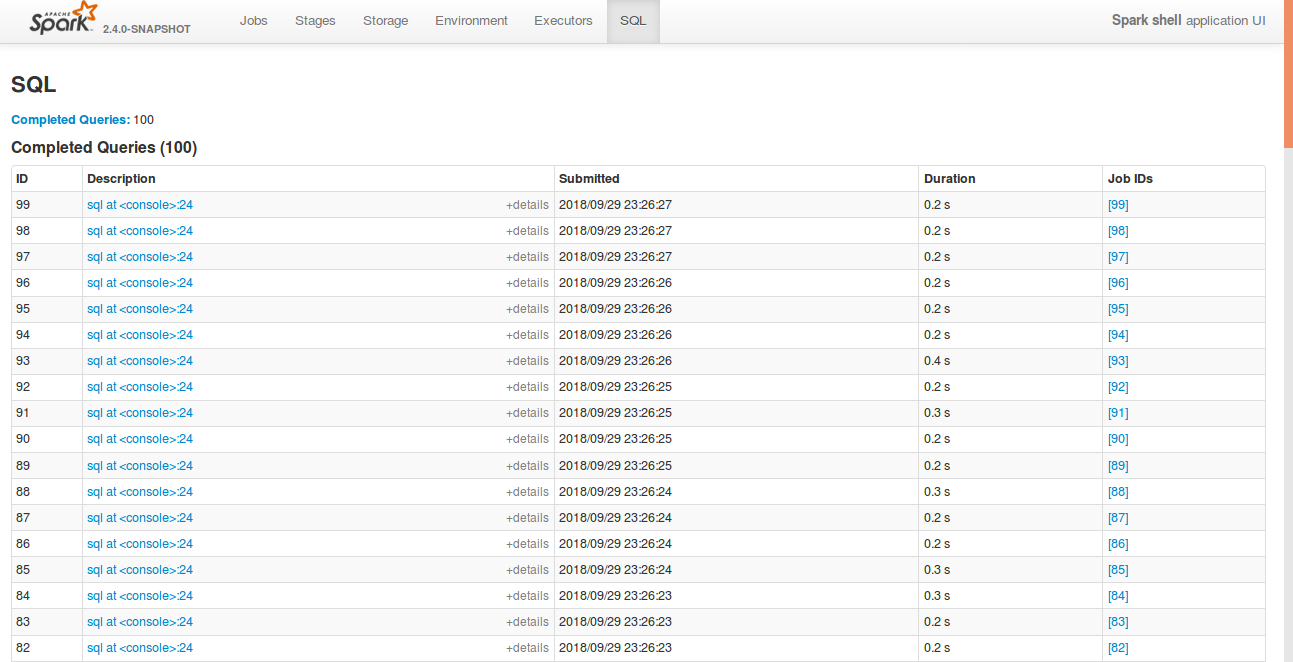
**After fix:** Consistent with the other tabs.

(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22592 from shahidki31/SPARK-25575.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Fix an obvious error.
## How was this patch tested?
Existing tests.
Closes#22577 from sadhen/minor_fix.
Authored-by: Darcy Shen <sadhen@zoho.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR adds a rule to force `.toLowerCase(Locale.ROOT)` or `toUpperCase(Locale.ROOT)`.
It produces an error as below:
```
[error] Are you sure that you want to use toUpperCase or toLowerCase without the root locale? In most cases, you
[error] should use toUpperCase(Locale.ROOT) or toLowerCase(Locale.ROOT) instead.
[error] If you must use toUpperCase or toLowerCase without the root locale, wrap the code block with
[error] // scalastyle:off caselocale
[error] .toUpperCase
[error] .toLowerCase
[error] // scalastyle:on caselocale
```
This PR excludes the cases above for SQL code path for external calls like table name, column name and etc.
For test suites, or when it's clear there's no locale problem like Turkish locale problem, it uses `Locale.ROOT`.
One minor problem is, `UTF8String` has both methods, `toLowerCase` and `toUpperCase`, and the new rule detects them as well. They are ignored.
## How was this patch tested?
Manually tested, and Jenkins tests.
Closes#22581 from HyukjinKwon/SPARK-25565.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Since we don't fail a job when `AccumulatorV2.merge` fails, we should try to update the remaining accumulators so that they can still report correct values.
## How was this patch tested?
The new unit test.
Closes#22586 from zsxwing/SPARK-25568.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Heartbeat shouldn't include accumulators for zero metrics.
Heartbeats sent from executors to the driver every 10 seconds contain metrics and are generally on the order of a few KBs. However, for large jobs with lots of tasks, heartbeats can be on the order of tens of MBs, causing tasks to die with heartbeat failures. We can mitigate this by not sending zero metrics to the driver.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22473 from mukulmurthy/25449-heartbeat.
Authored-by: Mukul Murthy <mukul.murthy@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
The specified test in OpenHashMapSuite to test large items is somehow flaky to throw OOM.
By considering the original work #6763 that added this test, the test can be against OpenHashSetSuite. And by doing this should be to save memory because OpenHashMap allocates two more arrays when growing the map/set.
## How was this patch tested?
Existing tests.
Closes#22569 from viirya/SPARK-25542.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
Caching the value of that config means different instances of SparkEnv
will always use whatever was the first value to be read. It also breaks
tests that use RDDInfo outside of the scope of a SparkContext.
Since this is not a performance sensitive area, there's no advantage
in caching the config value.
Closes#22558 from vanzin/SPARK-25546.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Special case the situation where we know the partioner and the number of requested partions output is the same as the current partioner to avoid a shuffle and instead compute distinct inside of each partion.
## How was this patch tested?
New unit test that verifies partitioner does not change if the partitioner is known and distinct is called with the same target # of partition.
Closes#22010 from holdenk/SPARK-21436-take-advantage-of-known-partioner-for-distinct-on-rdds.
Authored-by: Holden Karau <holden@pigscanfly.ca>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
changed metric value of METRIC_OUTPUT_RECORDS_WRITTEN from 'task.metrics.inputMetrics.recordsRead' to 'task.metrics.outputMetrics.recordsWritten'.
This bug was introduced in SPARK-22190. https://github.com/apache/spark/pull/19426
## How was this patch tested?
Existing tests
Closes#22555 from shahidki31/SPARK-25536.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
SparkSubmit already logs in the user if a keytab is provided, the only issue is that it uses the existing configs which have "yarn" in their name. As such, the configs were changed to:
`spark.kerberos.keytab` and `spark.kerberos.principal`.
## How was this patch tested?
Will be tested with K8S tests, but needs to be tested with Yarn
- [x] K8S Secure HDFS tests
- [x] Yarn Secure HDFS tests vanzin
Closes#22362 from ifilonenko/SPARK-25372.
Authored-by: Ilan Filonenko <if56@cornell.edu>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Previously SPARK-24519 created a modifiable config SHUFFLE_MIN_NUM_PARTS_TO_HIGHLY_COMPRESS. However, the config is being parsed for every creation of MapStatus, which could be very expensive. Another problem with the previous approach is that it created the illusion that this can be changed dynamically at runtime, which was not true. This PR changes it so the config is computed only once.
## How was this patch tested?
Removed a test case that's no longer valid.
Closes#22521 from rxin/SPARK-24519.
Authored-by: Reynold Xin <rxin@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}