## What changes were proposed in this pull request?
Currently `df.na.replace("*", Map[String, String]("NULL" -> null))` will produce exception.
This PR enables passing null/None as value in the replacement map in DataFrame.replace().
Note that the replacement map keys and values should still be the same type, while the values can have a mix of null/None and that type.
This PR enables following operations for example:
`df.na.replace("*", Map[String, String]("NULL" -> null))`(scala)
`df.na.replace("*", Map[Any, Any](60 -> null, 70 -> 80))`(scala)
`df.na.replace('Alice', None)`(python)
`df.na.replace([10, 20])`(python, replacing with None is by default)
One use case could be: I want to replace all the empty strings with null/None because they were incorrectly generated and then drop all null/None data
`df.na.replace("*", Map("" -> null)).na.drop()`(scala)
`df.replace(u'', None).dropna()`(python)
## How was this patch tested?
Scala unit test.
Python doctest and unit test.
Author: bravo-zhang <mzhang1230@gmail.com>
Closes#18820 from bravo-zhang/spark-14932.
## What changes were proposed in this pull request?
This modification increases the timeout for `serveIterator` (which is not dynamically configurable). This fixes timeout issues in pyspark when using `collect` and similar functions, in cases where Python may take more than a couple seconds to connect.
See https://issues.apache.org/jira/browse/SPARK-21551
## How was this patch tested?
Ran the tests.
cc rxin
Author: peay <peay@protonmail.com>
Closes#18752 from peay/spark-21551.
## What changes were proposed in this pull request?
Update breeze to 0.13.1 for an emergency bugfix in strong wolfe line search
https://github.com/scalanlp/breeze/pull/651
## How was this patch tested?
N/A
Author: WeichenXu <WeichenXu123@outlook.com>
Closes#18797 from WeichenXu123/update-breeze.
## What changes were proposed in this pull request?
PySpark GLR ```model.summary``` should return a printable representation by calling Scala ```toString```.
## How was this patch tested?
```
from pyspark.ml.regression import GeneralizedLinearRegression
dataset = spark.read.format("libsvm").load("data/mllib/sample_linear_regression_data.txt")
glr = GeneralizedLinearRegression(family="gaussian", link="identity", maxIter=10, regParam=0.3)
model = glr.fit(dataset)
model.summary
```
Before this PR:

After this PR:
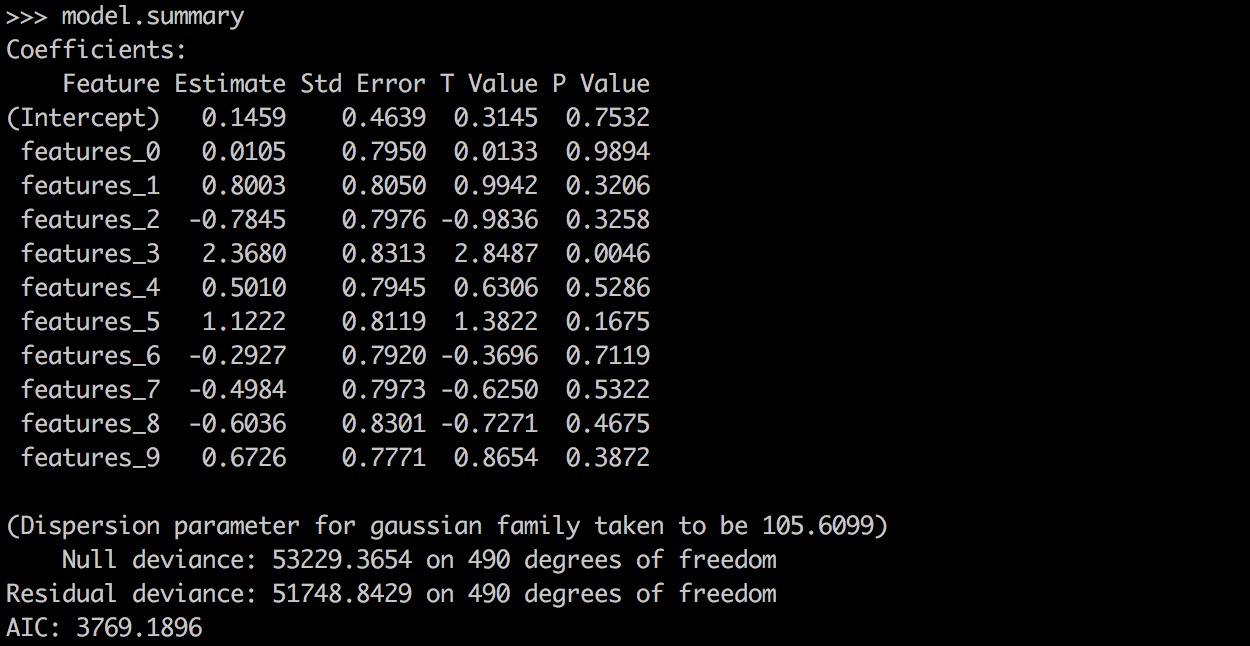
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18870 from yanboliang/spark-19270.
## What changes were proposed in this pull request?
Added DefaultParamsWriteable, DefaultParamsReadable, DefaultParamsWriter, and DefaultParamsReader to Python to support Python-only persistence of Json-serializable parameters.
## How was this patch tested?
Instantiated an estimator with Json-serializable parameters (ex. LogisticRegression), saved it using the added helper functions, and loaded it back, and compared it to the original instance to make sure it is the same. This test was both done in the Python REPL and implemented in the unit tests.
Note to reviewers: there are a few excess comments that I left in the code for clarity but will remove before the code is merged to master.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18742 from ajaysaini725/PythonPersistenceHelperFunctions.
## What changes were proposed in this pull request?
Enhanced some existing documentation
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Mac <maclockard@gmail.com>
Closes#18710 from maclockard/maclockard-patch-1.
## What changes were proposed in this pull request?
Implemented UnaryTransformer in Python.
## How was this patch tested?
This patch was tested by creating a MockUnaryTransformer class in the unit tests that extends UnaryTransformer and testing that the transform function produced correct output.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18746 from ajaysaini725/AddPythonUnaryTransformer.
## What changes were proposed in this pull request?
Python API for Constrained Logistic Regression based on #17922 , thanks for the original contribution from zero323 .
## How was this patch tested?
Unit tests.
Author: zero323 <zero323@users.noreply.github.com>
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18759 from yanboliang/SPARK-20601.
## What changes were proposed in this pull request?
When using PySpark broadcast variables in a multi-threaded environment, `SparkContext._pickled_broadcast_vars` becomes a shared resource. A race condition can occur when broadcast variables that are pickled from one thread get added to the shared ` _pickled_broadcast_vars` and become part of the python command from another thread. This PR introduces a thread-safe pickled registry using thread local storage so that when python command is pickled (causing the broadcast variable to be pickled and added to the registry) each thread will have their own view of the pickle registry to retrieve and clear the broadcast variables used.
## How was this patch tested?
Added a unit test that causes this race condition using another thread.
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#18695 from BryanCutler/pyspark-bcast-threadsafe-SPARK-12717.
## What changes were proposed in this pull request?
GBTs inherit from HasStepSize & LInearSVC/Binarizer from HasThreshold
## How was this patch tested?
existing tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Author: Ruifeng Zheng <ruifengz@foxmail.com>
Closes#18612 from zhengruifeng/override_HasXXX.
## What changes were proposed in this pull request?
This PR proposes `StructType.fieldNames` that returns a copy of a field name list rather than a (undocumented) `StructType.names`.
There are two points here:
- API consistency with Scala/Java
- Provide a safe way to get the field names. Manipulating these might cause unexpected behaviour as below:
```python
from pyspark.sql.types import *
struct = StructType([StructField("f1", StringType(), True)])
names = struct.names
del names[0]
spark.createDataFrame([{"f1": 1}], struct).show()
```
```
...
java.lang.IllegalStateException: Input row doesn't have expected number of values required by the schema. 1 fields are required while 0 values are provided.
at org.apache.spark.sql.execution.python.EvaluatePython$.fromJava(EvaluatePython.scala:138)
at org.apache.spark.sql.SparkSession$$anonfun$6.apply(SparkSession.scala:741)
at org.apache.spark.sql.SparkSession$$anonfun$6.apply(SparkSession.scala:741)
...
```
## How was this patch tested?
Added tests in `python/pyspark/sql/tests.py`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18618 from HyukjinKwon/SPARK-20090.
## What changes were proposed in this pull request?
add `setWeightCol` method for OneVsRest.
`weightCol` is ignored if classifier doesn't inherit HasWeightCol trait.
## How was this patch tested?
+ [x] add an unit test.
Author: Yan Facai (颜发才) <facai.yan@gmail.com>
Closes#18554 from facaiy/BUG/oneVsRest_missing_weightCol.
## What changes were proposed in this pull request?
This is a refactoring of `ArrowConverters` and related classes.
1. Refactor `ColumnWriter` as `ArrowWriter`.
2. Add `ArrayType` and `StructType` support.
3. Refactor `ArrowConverters` to skip intermediate `ArrowRecordBatch` creation.
## How was this patch tested?
Added some tests and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#18655 from ueshin/issues/SPARK-21440.
### What changes were proposed in this pull request?
Like [Hive UDFType](https://hive.apache.org/javadocs/r2.0.1/api/org/apache/hadoop/hive/ql/udf/UDFType.html), we should allow users to add the extra flags for ScalaUDF and JavaUDF too. _stateful_/_impliesOrder_ are not applicable to our Scala UDF. Thus, we only add the following two flags.
- deterministic: Certain optimizations should not be applied if UDF is not deterministic. Deterministic UDF returns same result each time it is invoked with a particular input. This determinism just needs to hold within the context of a query.
When the deterministic flag is not correctly set, the results could be wrong.
For ScalaUDF in Dataset APIs, users can call the following extra APIs for `UserDefinedFunction` to make the corresponding changes.
- `nonDeterministic`: Updates UserDefinedFunction to non-deterministic.
Also fixed the Java UDF name loss issue.
Will submit a separate PR for `distinctLike` for UDAF
### How was this patch tested?
Added test cases for both ScalaUDF
Author: gatorsmile <gatorsmile@gmail.com>
Author: Wenchen Fan <cloud0fan@gmail.com>
Closes#17848 from gatorsmile/udfRegister.
## What changes were proposed in this pull request?
After SPARK-12661, I guess we officially dropped Python 2.6 support. It looks there are few places missing this notes.
I grepped "Python 2.6" and "python 2.6" and the results were below:
```
./core/src/main/scala/org/apache/spark/api/python/SerDeUtil.scala: // Unpickle array.array generated by Python 2.6
./docs/index.md:Note that support for Java 7, Python 2.6 and old Hadoop versions before 2.6.5 were removed as of Spark 2.2.0.
./docs/rdd-programming-guide.md:Spark {{site.SPARK_VERSION}} works with Python 2.6+ or Python 3.4+. It can use the standard CPython interpreter,
./docs/rdd-programming-guide.md:Note that support for Python 2.6 is deprecated as of Spark 2.0.0, and may be removed in Spark 2.2.0.
./python/pyspark/context.py: warnings.warn("Support for Python 2.6 is deprecated as of Spark 2.0.0")
./python/pyspark/ml/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/mllib/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/serializers.py: # On Python 2.6, we can't write bytearrays to streams, so we need to convert them
./python/pyspark/sql/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/streaming/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier')
./python/pyspark/tests.py: # NOTE: dict is used instead of collections.Counter for Python 2.6
./python/pyspark/tests.py: # NOTE: dict is used instead of collections.Counter for Python 2.6
```
This PR only proposes to change visible changes as below:
```
./docs/rdd-programming-guide.md:Spark {{site.SPARK_VERSION}} works with Python 2.6+ or Python 3.4+. It can use the standard CPython interpreter,
./docs/rdd-programming-guide.md:Note that support for Python 2.6 is deprecated as of Spark 2.0.0, and may be removed in Spark 2.2.0.
./python/pyspark/context.py: warnings.warn("Support for Python 2.6 is deprecated as of Spark 2.0.0")
```
This one is already correct:
```
./docs/index.md:Note that support for Java 7, Python 2.6 and old Hadoop versions before 2.6.5 were removed as of Spark 2.2.0.
```
## How was this patch tested?
```bash
grep -r "Python 2.6" .
grep -r "python 2.6" .
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18682 from HyukjinKwon/minor-python.26.
## What changes were proposed in this pull request?
This is the reopen of https://github.com/apache/spark/pull/14198, with merge conflicts resolved.
ueshin Could you please take a look at my code?
Fix bugs about types that result an array of null when creating DataFrame using python.
Python's array.array have richer type than python itself, e.g. we can have `array('f',[1,2,3])` and `array('d',[1,2,3])`. Codes in spark-sql and pyspark didn't take this into consideration which might cause a problem that you get an array of null values when you have `array('f')` in your rows.
A simple code to reproduce this bug is:
```
from pyspark import SparkContext
from pyspark.sql import SQLContext,Row,DataFrame
from array import array
sc = SparkContext()
sqlContext = SQLContext(sc)
row1 = Row(floatarray=array('f',[1,2,3]), doublearray=array('d',[1,2,3]))
rows = sc.parallelize([ row1 ])
df = sqlContext.createDataFrame(rows)
df.show()
```
which have output
```
+---------------+------------------+
| doublearray| floatarray|
+---------------+------------------+
|[1.0, 2.0, 3.0]|[null, null, null]|
+---------------+------------------+
```
## How was this patch tested?
New test case added
Author: Xiang Gao <qasdfgtyuiop@gmail.com>
Author: Gao, Xiang <qasdfgtyuiop@gmail.com>
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#18444 from zasdfgbnm/fix_array_infer.
## What changes were proposed in this pull request?
Added functionality for CrossValidator and TrainValidationSplit to persist nested estimators such as OneVsRest. Also added CrossValidator and TrainValidation split persistence to pyspark.
## How was this patch tested?
Performed both cross validation and train validation split with a one vs. rest estimator and tested read/write functionality of the estimator parameter maps required by these meta-algorithms.
Author: Ajay Saini <ajays725@gmail.com>
Closes#18428 from ajaysaini725/MetaAlgorithmPersistNestedEstimators.
## What changes were proposed in this pull request?
This PR proposes to avoid `__name__` in the tuple naming the attributes assigned directly from the wrapped function to the wrapper function, and use `self._name` (`func.__name__` or `obj.__class__.name__`).
After SPARK-19161, we happened to break callable objects as UDFs in Python as below:
```python
from pyspark.sql import functions
class F(object):
def __call__(self, x):
return x
foo = F()
udf = functions.udf(foo)
```
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../spark/python/pyspark/sql/functions.py", line 2142, in udf
return _udf(f=f, returnType=returnType)
File ".../spark/python/pyspark/sql/functions.py", line 2133, in _udf
return udf_obj._wrapped()
File ".../spark/python/pyspark/sql/functions.py", line 2090, in _wrapped
functools.wraps(self.func)
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/functools.py", line 33, in update_wrapper
setattr(wrapper, attr, getattr(wrapped, attr))
AttributeError: F instance has no attribute '__name__'
```
This worked in Spark 2.1:
```python
from pyspark.sql import functions
class F(object):
def __call__(self, x):
return x
foo = F()
udf = functions.udf(foo)
spark.range(1).select(udf("id")).show()
```
```
+-----+
|F(id)|
+-----+
| 0|
+-----+
```
**After**
```python
from pyspark.sql import functions
class F(object):
def __call__(self, x):
return x
foo = F()
udf = functions.udf(foo)
spark.range(1).select(udf("id")).show()
```
```
+-----+
|F(id)|
+-----+
| 0|
+-----+
```
_In addition, we also happened to break partial functions as below_:
```python
from pyspark.sql import functions
from functools import partial
partial_func = partial(lambda x: x, x=1)
udf = functions.udf(partial_func)
```
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../spark/python/pyspark/sql/functions.py", line 2154, in udf
return _udf(f=f, returnType=returnType)
File ".../spark/python/pyspark/sql/functions.py", line 2145, in _udf
return udf_obj._wrapped()
File ".../spark/python/pyspark/sql/functions.py", line 2099, in _wrapped
functools.wraps(self.func, assigned=assignments)
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/functools.py", line 33, in update_wrapper
setattr(wrapper, attr, getattr(wrapped, attr))
AttributeError: 'functools.partial' object has no attribute '__module__'
```
This worked in Spark 2.1:
```python
from pyspark.sql import functions
from functools import partial
partial_func = partial(lambda x: x, x=1)
udf = functions.udf(partial_func)
spark.range(1).select(udf()).show()
```
```
+---------+
|partial()|
+---------+
| 1|
+---------+
```
**After**
```python
from pyspark.sql import functions
from functools import partial
partial_func = partial(lambda x: x, x=1)
udf = functions.udf(partial_func)
spark.range(1).select(udf()).show()
```
```
+---------+
|partial()|
+---------+
| 1|
+---------+
```
## How was this patch tested?
Unit tests in `python/pyspark/sql/tests.py` and manual tests.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18615 from HyukjinKwon/callable-object.
## What changes were proposed in this pull request?
```RFormula``` should handle invalid for both features and label column.
#18496 only handle invalid values in features column. This PR add handling invalid values for label column and test cases.
## How was this patch tested?
Add test cases.
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18613 from yanboliang/spark-20307.
## What changes were proposed in this pull request?
1, HasHandleInvaild support override
2, Make QuantileDiscretizer/Bucketizer/StringIndexer/RFormula inherit from HasHandleInvalid
## How was this patch tested?
existing tests
[JIRA](https://issues.apache.org/jira/browse/SPARK-18619)
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#18582 from zhengruifeng/heritate_HasHandleInvalid.
## What changes were proposed in this pull request?
This PR deals with four points as below:
- Reuse existing DDL parser APIs rather than reimplementing within PySpark
- Support DDL formatted string, `field type, field type`.
- Support case-insensitivity for parsing.
- Support nested data types as below:
**Before**
```
>>> spark.createDataFrame([[[1]]], "struct<a: struct<b: int>>").show()
...
ValueError: The strcut field string format is: 'field_name:field_type', but got: a: struct<b: int>
```
```
>>> spark.createDataFrame([[[1]]], "a: struct<b: int>").show()
...
ValueError: The strcut field string format is: 'field_name:field_type', but got: a: struct<b: int>
```
```
>>> spark.createDataFrame([[1]], "a int").show()
...
ValueError: Could not parse datatype: a int
```
**After**
```
>>> spark.createDataFrame([[[1]]], "struct<a: struct<b: int>>").show()
+---+
| a|
+---+
|[1]|
+---+
```
```
>>> spark.createDataFrame([[[1]]], "a: struct<b: int>").show()
+---+
| a|
+---+
|[1]|
+---+
```
```
>>> spark.createDataFrame([[1]], "a int").show()
+---+
| a|
+---+
| 1|
+---+
```
## How was this patch tested?
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18590 from HyukjinKwon/deduplicate-python-ddl.
## What changes were proposed in this pull request?
This PR proposes to simply ignore the results in examples that are timezone-dependent in `unix_timestamp` and `from_unixtime`.
```
Failed example:
time_df.select(unix_timestamp('dt', 'yyyy-MM-dd').alias('unix_time')).collect()
Expected:
[Row(unix_time=1428476400)]
Got:unix_timestamp
[Row(unix_time=1428418800)]
```
```
Failed example:
time_df.select(from_unixtime('unix_time').alias('ts')).collect()
Expected:
[Row(ts=u'2015-04-08 00:00:00')]
Got:
[Row(ts=u'2015-04-08 16:00:00')]
```
## How was this patch tested?
Manually tested and `./run-tests --modules pyspark-sql`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18597 from HyukjinKwon/SPARK-20456.
## What changes were proposed in this pull request?
At example of repartitionAndSortWithinPartitions at rdd.py, third argument should be True or False.
I proposed fix of example code.
## How was this patch tested?
* I rename test_repartitionAndSortWithinPartitions to test_repartitionAndSortWIthinPartitions_asc to specify boolean argument.
* I added test_repartitionAndSortWithinPartitions_desc to test False pattern at third argument.
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: chie8842 <chie8842@gmail.com>
Closes#18586 from chie8842/SPARK-21358.
## What changes were proposed in this pull request?
Integrate Apache Arrow with Spark to increase performance of `DataFrame.toPandas`. This has been done by using Arrow to convert data partitions on the executor JVM to Arrow payload byte arrays where they are then served to the Python process. The Python DataFrame can then collect the Arrow payloads where they are combined and converted to a Pandas DataFrame. Data types except complex, date, timestamp, and decimal are currently supported, otherwise an `UnsupportedOperation` exception is thrown.
Additions to Spark include a Scala package private method `Dataset.toArrowPayload` that will convert data partitions in the executor JVM to `ArrowPayload`s as byte arrays so they can be easily served. A package private class/object `ArrowConverters` that provide data type mappings and conversion routines. In Python, a private method `DataFrame._collectAsArrow` is added to collect Arrow payloads and a SQLConf "spark.sql.execution.arrow.enable" can be used in `toPandas()` to enable using Arrow (uses the old conversion by default).
## How was this patch tested?
Added a new test suite `ArrowConvertersSuite` that will run tests on conversion of Datasets to Arrow payloads for supported types. The suite will generate a Dataset and matching Arrow JSON data, then the dataset is converted to an Arrow payload and finally validated against the JSON data. This will ensure that the schema and data has been converted correctly.
Added PySpark tests to verify the `toPandas` method is producing equal DataFrames with and without pyarrow. A roundtrip test to ensure the pandas DataFrame produced by pyspark is equal to a one made directly with pandas.
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Li Jin <ice.xelloss@gmail.com>
Author: Li Jin <li.jin@twosigma.com>
Author: Wes McKinney <wes.mckinney@twosigma.com>
Closes#18459 from BryanCutler/toPandas_with_arrow-SPARK-13534.
## What changes were proposed in this pull request?
This PR supports schema in a DDL formatted string for `from_json` in R/Python and `dapply` and `gapply` in R, which are commonly used and/or consistent with Scala APIs.
Additionally, this PR exposes `structType` in R to allow working around in other possible corner cases.
**Python**
`from_json`
```python
from pyspark.sql.functions import from_json
data = [(1, '''{"a": 1}''')]
df = spark.createDataFrame(data, ("key", "value"))
df.select(from_json(df.value, "a INT").alias("json")).show()
```
**R**
`from_json`
```R
df <- sql("SELECT named_struct('name', 'Bob') as people")
df <- mutate(df, people_json = to_json(df$people))
head(select(df, from_json(df$people_json, "name STRING")))
```
`structType.character`
```R
structType("a STRING, b INT")
```
`dapply`
```R
dapply(createDataFrame(list(list(1.0)), "a"), function(x) {x}, "a DOUBLE")
```
`gapply`
```R
gapply(createDataFrame(list(list(1.0)), "a"), "a", function(key, x) { x }, "a DOUBLE")
```
## How was this patch tested?
Doc tests for `from_json` in Python and unit tests `test_sparkSQL.R` in R.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18498 from HyukjinKwon/SPARK-21266.
## What changes were proposed in this pull request?
This adds documentation to many functions in pyspark.sql.functions.py:
`upper`, `lower`, `reverse`, `unix_timestamp`, `from_unixtime`, `rand`, `randn`, `collect_list`, `collect_set`, `lit`
Add units to the trigonometry functions.
Renames columns in datetime examples to be more informative.
Adds links between some functions.
## How was this patch tested?
`./dev/lint-python`
`python python/pyspark/sql/functions.py`
`./python/run-tests.py --module pyspark-sql`
Author: Michael Patterson <map222@gmail.com>
Closes#17865 from map222/spark-20456.
## What changes were proposed in this pull request?
Currently `ArrayConstructor` handles an array of typecode `'l'` as `int` when converting Python object in Python 2 into Java object, so if the value is larger than `Integer.MAX_VALUE` or smaller than `Integer.MIN_VALUE` then the overflow occurs.
```python
import array
data = [Row(longarray=array.array('l', [-9223372036854775808, 0, 9223372036854775807]))]
df = spark.createDataFrame(data)
df.show(truncate=False)
```
```
+----------+
|longarray |
+----------+
|[0, 0, -1]|
+----------+
```
This should be:
```
+----------------------------------------------+
|longarray |
+----------------------------------------------+
|[-9223372036854775808, 0, 9223372036854775807]|
+----------------------------------------------+
```
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#18553 from ueshin/issues/SPARK-21327.
## What changes were proposed in this pull request?
Support register Java UDAFs in PySpark so that user can use Java UDAF in PySpark. Besides that I also add api in `UDFRegistration`
## How was this patch tested?
Unit test is added
Author: Jeff Zhang <zjffdu@apache.org>
Closes#17222 from zjffdu/SPARK-19439.
## What changes were proposed in this pull request?
Add offset to PySpark in GLM as in #16699.
## How was this patch tested?
Python test
Author: actuaryzhang <actuaryzhang10@gmail.com>
Closes#18534 from actuaryzhang/pythonOffset.
## What changes were proposed in this pull request?
**Context**
While reviewing https://github.com/apache/spark/pull/17227, I realised here we type-dispatch per record. The PR itself is fine in terms of performance as is but this prints a prefix, `"obj"` in exception message as below:
```
from pyspark.sql.types import *
schema = StructType([StructField('s', IntegerType(), nullable=False)])
spark.createDataFrame([["1"]], schema)
...
TypeError: obj.s: IntegerType can not accept object '1' in type <type 'str'>
```
I suggested to get rid of this but during investigating this, I realised my approach might bring a performance regression as it is a hot path.
Only for SPARK-19507 and https://github.com/apache/spark/pull/17227, It needs more changes to cleanly get rid of the prefix and I rather decided to fix both issues together.
**Propersal**
This PR tried to
- get rid of per-record type dispatch as we do in many code paths in Scala so that it improves the performance (roughly ~25% improvement) - SPARK-21296
This was tested with a simple code `spark.createDataFrame(range(1000000), "int")`. However, I am quite sure the actual improvement in practice is larger than this, in particular, when the schema is complicated.
- improve error message in exception describing field information as prose - SPARK-19507
## How was this patch tested?
Manually tested and unit tests were added in `python/pyspark/sql/tests.py`.
Benchmark - codes: https://gist.github.com/HyukjinKwon/c3397469c56cb26c2d7dd521ed0bc5a3
Error message - codes: https://gist.github.com/HyukjinKwon/b1b2c7f65865444c4a8836435100e398
**Before**
Benchmark:
- Results: https://gist.github.com/HyukjinKwon/4a291dab45542106301a0c1abcdca924
Error message
- Results: https://gist.github.com/HyukjinKwon/57b1916395794ce924faa32b14a3fe19
**After**
Benchmark
- Results: https://gist.github.com/HyukjinKwon/21496feecc4a920e50c4e455f836266e
Error message
- Results: https://gist.github.com/HyukjinKwon/7a494e4557fe32a652ce1236e504a395Closes#17227
Author: hyukjinkwon <gurwls223@gmail.com>
Author: David Gingrich <david@textio.com>
Closes#18521 from HyukjinKwon/python-type-dispatch.
## What changes were proposed in this pull request?
Currently, it throws a NPE when missing columns but join type is speicified in join at PySpark as below:
```python
spark.conf.set("spark.sql.crossJoin.enabled", "false")
spark.range(1).join(spark.range(1), how="inner").show()
```
```
Traceback (most recent call last):
...
py4j.protocol.Py4JJavaError: An error occurred while calling o66.join.
: java.lang.NullPointerException
at org.apache.spark.sql.Dataset.join(Dataset.scala:931)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
...
```
```python
spark.conf.set("spark.sql.crossJoin.enabled", "true")
spark.range(1).join(spark.range(1), how="inner").show()
```
```
...
py4j.protocol.Py4JJavaError: An error occurred while calling o84.join.
: java.lang.NullPointerException
at org.apache.spark.sql.Dataset.join(Dataset.scala:931)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
...
```
This PR suggests to follow Scala's one as below:
```scala
scala> spark.conf.set("spark.sql.crossJoin.enabled", "false")
scala> spark.range(1).join(spark.range(1), Seq.empty[String], "inner").show()
```
```
org.apache.spark.sql.AnalysisException: Detected cartesian product for INNER join between logical plans
Range (0, 1, step=1, splits=Some(8))
and
Range (0, 1, step=1, splits=Some(8))
Join condition is missing or trivial.
Use the CROSS JOIN syntax to allow cartesian products between these relations.;
...
```
```scala
scala> spark.conf.set("spark.sql.crossJoin.enabled", "true")
scala> spark.range(1).join(spark.range(1), Seq.empty[String], "inner").show()
```
```
+---+---+
| id| id|
+---+---+
| 0| 0|
+---+---+
```
**After**
```python
spark.conf.set("spark.sql.crossJoin.enabled", "false")
spark.range(1).join(spark.range(1), how="inner").show()
```
```
Traceback (most recent call last):
...
pyspark.sql.utils.AnalysisException: u'Detected cartesian product for INNER join between logical plans\nRange (0, 1, step=1, splits=Some(8))\nand\nRange (0, 1, step=1, splits=Some(8))\nJoin condition is missing or trivial.\nUse the CROSS JOIN syntax to allow cartesian products between these relations.;'
```
```python
spark.conf.set("spark.sql.crossJoin.enabled", "true")
spark.range(1).join(spark.range(1), how="inner").show()
```
```
+---+---+
| id| id|
+---+---+
| 0| 0|
+---+---+
```
## How was this patch tested?
Added tests in `python/pyspark/sql/tests.py`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18484 from HyukjinKwon/SPARK-21264.
## What changes were proposed in this pull request?
This PR is to maintain API parity with changes made in SPARK-17498 to support a new option
'keep' in StringIndexer to handle unseen labels or NULL values with PySpark.
Note: This is updated version of #17237 , the primary author of this PR is VinceShieh .
## How was this patch tested?
Unit tests.
Author: VinceShieh <vincent.xie@intel.com>
Author: Yanbo Liang <ybliang8@gmail.com>
Closes#18453 from yanboliang/spark-19852.
## What changes were proposed in this pull request?
1, make param support non-final with `finalFields` option
2, generate `HasSolver` with `finalFields = false`
3, override `solver` in LiR, GLR, and make MLPC inherit `HasSolver`
## How was this patch tested?
existing tests
Author: Ruifeng Zheng <ruifengz@foxmail.com>
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#16028 from zhengruifeng/param_non_final.
## What changes were proposed in this pull request?
This pr supported a DDL-formatted string in `DataStreamReader.schema`.
This fix could make users easily define a schema without importing the type classes.
For example,
```scala
scala> spark.readStream.schema("col0 INT, col1 DOUBLE").load("/tmp/abc").printSchema()
root
|-- col0: integer (nullable = true)
|-- col1: double (nullable = true)
```
## How was this patch tested?
Added tests in `DataStreamReaderWriterSuite`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#18373 from HyukjinKwon/SPARK-20431.
## What changes were proposed in this pull request?
Integrate Apache Arrow with Spark to increase performance of `DataFrame.toPandas`. This has been done by using Arrow to convert data partitions on the executor JVM to Arrow payload byte arrays where they are then served to the Python process. The Python DataFrame can then collect the Arrow payloads where they are combined and converted to a Pandas DataFrame. All non-complex data types are currently supported, otherwise an `UnsupportedOperation` exception is thrown.
Additions to Spark include a Scala package private method `Dataset.toArrowPayloadBytes` that will convert data partitions in the executor JVM to `ArrowPayload`s as byte arrays so they can be easily served. A package private class/object `ArrowConverters` that provide data type mappings and conversion routines. In Python, a public method `DataFrame.collectAsArrow` is added to collect Arrow payloads and an optional flag in `toPandas(useArrow=False)` to enable using Arrow (uses the old conversion by default).
## How was this patch tested?
Added a new test suite `ArrowConvertersSuite` that will run tests on conversion of Datasets to Arrow payloads for supported types. The suite will generate a Dataset and matching Arrow JSON data, then the dataset is converted to an Arrow payload and finally validated against the JSON data. This will ensure that the schema and data has been converted correctly.
Added PySpark tests to verify the `toPandas` method is producing equal DataFrames with and without pyarrow. A roundtrip test to ensure the pandas DataFrame produced by pyspark is equal to a one made directly with pandas.
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Li Jin <ice.xelloss@gmail.com>
Author: Li Jin <li.jin@twosigma.com>
Author: Wes McKinney <wes.mckinney@twosigma.com>
Closes#15821 from BryanCutler/wip-toPandas_with_arrow-SPARK-13534.
## What changes were proposed in this pull request?
Currently we convert a spark DataFrame to Pandas Dataframe by `pd.DataFrame.from_records`. It infers the data type from the data and doesn't respect the spark DataFrame Schema. This PR fixes it.
## How was this patch tested?
a new regression test
Author: hyukjinkwon <gurwls223@gmail.com>
Author: Wenchen Fan <wenchen@databricks.com>
Author: Wenchen Fan <cloud0fan@gmail.com>
Closes#18378 from cloud-fan/to_pandas.
## What changes were proposed in this pull request?
Add Python wrappers for `o.a.s.sql.functions.explode_outer` and `o.a.s.sql.functions.posexplode_outer`.
## How was this patch tested?
Unit tests, doctests.
Author: zero323 <zero323@users.noreply.github.com>
Closes#18049 from zero323/SPARK-20830.
## What changes were proposed in this pull request?
Extend setJobDescription to PySpark and JavaSpark APIs
SPARK-21125
## How was this patch tested?
Testing was done by running a local Spark shell on the built UI. I originally had added a unit test but the PySpark context cannot easily access the Scala Spark Context's private variable with the Job Description key so I omitted the test, due to the simplicity of this addition.
Also ran the existing tests.
# Misc
This contribution is my original work and that I license the work to the project under the project's open source license.
Author: sjarvie <sjarvie@uber.com>
Closes#18332 from sjarvie/add_python_set_job_description.
## What changes were proposed in this pull request?
LinearSVC should use its own threshold param, rather than the shared one, since it applies to rawPrediction instead of probability. This PR changes the param in the Scala, Python and R APIs.
## How was this patch tested?
New unit test to make sure the threshold can be set to any Double value.
Author: Joseph K. Bradley <joseph@databricks.com>
Closes#18151 from jkbradley/ml-2.2-linearsvc-cleanup.
## What changes were proposed in this pull request?
Fix some typo of the document.
## How was this patch tested?
Existing tests.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Xianyang Liu <xianyang.liu@intel.com>
Closes#18350 from ConeyLiu/fixtypo.
## What changes were proposed in this pull request?
This fix tries to address the issue in SPARK-19975 where we
have `map_keys` and `map_values` functions in SQL yet there
is no Python equivalent functions.
This fix adds `map_keys` and `map_values` functions to Python.
## How was this patch tested?
This fix is tested manually (See Python docs for examples).
Author: Yong Tang <yong.tang.github@outlook.com>
Closes#17328 from yongtang/SPARK-19975.
### What changes were proposed in this pull request?
The current option name `wholeFile` is misleading for CSV users. Currently, it is not representing a record per file. Actually, one file could have multiple records. Thus, we should rename it. Now, the proposal is `multiLine`.
### How was this patch tested?
N/A
Author: Xiao Li <gatorsmile@gmail.com>
Closes#18202 from gatorsmile/renameCVSOption.
## What changes were proposed in this pull request?
Document Dataset.union is resolution by position, not by name, since this has been a confusing point for a lot of users.
## How was this patch tested?
N/A - doc only change.
Author: Reynold Xin <rxin@databricks.com>
Closes#18256 from rxin/SPARK-21042.
## What changes were proposed in this pull request?
Allow fill/replace of NAs with booleans, both in Python and Scala
## How was this patch tested?
Unit tests, doctests
This PR is original work from me and I license this work to the Spark project
Author: Ruben Berenguel Montoro <ruben@mostlymaths.net>
Author: Ruben Berenguel <ruben@mostlymaths.net>
Closes#18164 from rberenguel/SPARK-19732-fillna-bools.
### What changes were proposed in this pull request?
This PR does the following tasks:
- Added since
- Added the Python API
- Added test cases
### How was this patch tested?
Added test cases to both Scala and Python
Author: gatorsmile <gatorsmile@gmail.com>
Closes#18147 from gatorsmile/createOrReplaceGlobalTempView.
## What changes were proposed in this pull request?
PySpark supports stringIndexerOrderType in RFormula as in #17967.
## How was this patch tested?
docstring test
Author: actuaryzhang <actuaryzhang10@gmail.com>
Closes#18122 from actuaryzhang/PythonRFormula.
Now that Structured Streaming has been out for several Spark release and has large production use cases, the `Experimental` label is no longer appropriate. I've left `InterfaceStability.Evolving` however, as I think we may make a few changes to the pluggable Source & Sink API in Spark 2.3.
Author: Michael Armbrust <michael@databricks.com>
Closes#18065 from marmbrus/streamingGA.
## What changes were proposed in this pull request?
Expose numPartitions (expert) param of PySpark FPGrowth.
## How was this patch tested?
+ [x] Pass all unit tests.
Author: Yan Facai (颜发才) <facai.yan@gmail.com>
Closes#18058 from facaiy/ENH/pyspark_fpg_add_num_partition.
{kind=link}
{kind=link}