### What changes were proposed in this pull request?
In the PR, I propose to add additional checks for ANSI interval types `YearMonthIntervalType` and `DayTimeIntervalType` to `LiteralExpressionSuite`.
Also, I replaced some long literal values by `CalendarInterval` to check `CalendarIntervalType` that the tests were supposed to check.
### Why are the changes needed?
To improve test coverage and have the same checks for ANSI types as for `CalendarIntervalType`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the modified test suite:
```
$ build/sbt "test:testOnly *LiteralExpressionSuite"
```
Closes#32213 from MaxGekk/interval-literal-tests.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
The precision of `java.time.Duration` is nanosecond, but when it is used as `DayTimeIntervalType` in Spark, it is microsecond.
At present, the `DayTimeIntervalType` data generated in the implementation of `RandomDataGenerator` is accurate to nanosecond, which will cause the `DayTimeIntervalType` to be converted to long, and then back to `DayTimeIntervalType` to lose the accuracy, which will cause the test to fail. For example: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137390/testReport/org.apache.spark.sql.hive.execution/HashAggregationQueryWithControlledFallbackSuite/udaf_with_all_data_types/
### Why are the changes needed?
Improve `RandomDataGenerator` so that the generated data fits the precision of DayTimeIntervalType in spark.
### Does this PR introduce _any_ user-facing change?
'No'. Just change the test class.
### How was this patch tested?
Jenkins test.
Closes#32212 from beliefer/SPARK-35116.
Authored-by: beliefer <beliefer@163.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
SPARK-10498 added the initial Jira client requirement with 1.0.3 five year ago (2016 January). As of today, it causes `dev/merge_spark_pr.py` failure with `Python 3.9.4` due to this old dependency. This PR aims to upgrade it to the latest version, 2.0.0. The latest version is also a little old (2018 July).
- https://pypi.org/project/jira/#history
### Why are the changes needed?
`Jira==2.0.0` works well with both Python 3.8/3.9 while `Jira==1.0.3` fails with Python 3.9.
**BEFORE**
```
$ pyenv global 3.9.4
$ pip freeze | grep jira
jira==1.0.3
$ dev/merge_spark_pr.py
Traceback (most recent call last):
File "/Users/dongjoon/APACHE/spark-merge/dev/merge_spark_pr.py", line 39, in <module>
import jira.client
File "/Users/dongjoon/.pyenv/versions/3.9.4/lib/python3.9/site-packages/jira/__init__.py", line 5, in <module>
from .config import get_jira
File "/Users/dongjoon/.pyenv/versions/3.9.4/lib/python3.9/site-packages/jira/config.py", line 17, in <module>
from .client import JIRA
File "/Users/dongjoon/.pyenv/versions/3.9.4/lib/python3.9/site-packages/jira/client.py", line 165
validate=False, get_server_info=True, async=False, logging=True, max_retries=3):
^
SyntaxError: invalid syntax
```
**AFTER**
```
$ pip install jira==2.0.0
$ dev/merge_spark_pr.py
git rev-parse --abbrev-ref HEAD
Which pull request would you like to merge? (e.g. 34):
```
### Does this PR introduce _any_ user-facing change?
No. This is a committer-only script.
### How was this patch tested?
Manually.
Closes#32215 from dongjoon-hyun/jira.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
TL;DR: now it shows green yellow read status of tests instead of relying on a comment in a PR, **see https://github.com/HyukjinKwon/spark/pull/41 for an example**.
This PR proposes the GitHub status checks instead of a comment that link to the build (from forked repository) in PRs.
This is how it works:
1. **forked repo**: "Build and test" workflow is triggered when you create a branch to create a PR which uses your resources in GitHub Actions.
1. **main repo**: "Notify test workflow" (previously created a comment) now creates a in-progress status (yellow status) as a GitHub Actions check to your current PR.
1. **main repo**: "Update build status workflow" regularly (every 15 mins) checks open PRs, and updates the status of GitHub Actions checks at PRs according to the status of workflows in the forked repositories (status sync).
**NOTE** that creating/updating statuses in the PRs is only allowed from the main repo. That's why the flow is as above.
### Why are the changes needed?
The GitHub status shows a green although the tests are running, which is confusing.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Manually tested at:
- https://github.com/HyukjinKwon/spark/pull/41
- HyukjinKwon#42
- HyukjinKwon#43
- https://github.com/HyukjinKwon/spark/pull/37
**queued**:
<img width="861" alt="Screen Shot 2021-04-16 at 10 56 03 AM" src="https://user-images.githubusercontent.com/6477701/114960831-c9a73080-9ea2-11eb-8442-ddf3f6008a45.png">
**in progress**:
<img width="871" alt="Screen Shot 2021-04-16 at 12 14 39 PM" src="https://user-images.githubusercontent.com/6477701/114966359-59ea7300-9ead-11eb-98cb-1e63323980ad.png">
**passed**:

**failure**:

Closes#32193 from HyukjinKwon/update-checks-pr-poc.
Lead-authored-by: HyukjinKwon <gurwls223@apache.org>
Co-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Co-authored-by: Yikun Jiang <yikunkero@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Make the attemptId in the log of historyServer to be more easily to read.
### Why are the changes needed?
Option variable in Spark historyServer log should be displayed as actual value instead of Some(XX)
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
manual test
Closes#32189 from kyoty/history-server-print-option-variable.
Authored-by: kyoty <echohlne@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Soften security warning and keep it in cluster management docs only, not in the main doc page, where it's not necessarily relevant.
### Why are the changes needed?
The statement is perhaps unnecessarily 'frightening' as the first section in the main docs page. It applies to clusters not local mode, anyhow.
### Does this PR introduce _any_ user-facing change?
Just a docs change.
### How was this patch tested?
N/A
Closes#32206 from srowen/SecurityStatement.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
There are some more changes in Koalas such as [databricks/koalas#2141](c8f803d6be), [databricks/koalas#2143](913d68868d) after the main code porting, this PR is to synchronize those changes with the `pyspark.pandas`.
### Why are the changes needed?
We should port the whole Koalas codes into PySpark and synchronize them.
### Does this PR introduce _any_ user-facing change?
Fixed some incompatible behavior with pandas 1.2.0 and added more to the `to_markdown` docstring.
### How was this patch tested?
Manually tested in local.
Closes#32197 from itholic/SPARK-34995-fix.
Authored-by: itholic <haejoon.lee@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This issue fixes an issue that indentation of multiple output JSON records in a single split file are broken except for the first record in the split when `pretty` option is `true`.
```
// Run in the Spark Shell.
// Set spark.sql.leafNodeDefaultParallelism to 1 for the current master.
// Or set spark.default.parallelism for the previous releases.
spark.conf.set("spark.sql.leafNodeDefaultParallelism", 1)
val df = Seq("a", "b", "c").toDF
df.write.option("pretty", "true").json("/path/to/output")
# Run in a Shell
$ cat /path/to/output/*.json
{
"value" : "a"
}
{
"value" : "b"
}
{
"value" : "c"
}
```
### Why are the changes needed?
It's not pretty even though `pretty` option is true.
### Does this PR introduce _any_ user-facing change?
I think "No". Indentation style is changed but JSON format is not changed.
### How was this patch tested?
New test.
Closes#32203 from sarutak/fix-ugly-indentation.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Use hadoop FileSystem instead of FileInputStream.
### Why are the changes needed?
Make `spark.scheduler.allocation.file` suport remote file. When using Spark as a server (e.g. SparkThriftServer), it's hard for user to specify a local path as the scheduler pool.
### Does this PR introduce _any_ user-facing change?
Yes, a minor feature.
### How was this patch tested?
Pass `core/src/test/scala/org/apache/spark/scheduler/PoolSuite.scala` and manul test
After add config `spark.scheduler.allocation.file=hdfs:///tmp/fairscheduler.xml`. We intrudoce the configed pool.

Closes#32184 from ulysses-you/SPARK-35083.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Handle `YearMonthIntervalType` and `DayTimeIntervalType` in the `sql()` and `toString()` method of `Literal`, and format the ANSI interval in the ANSI style.
### Why are the changes needed?
To improve readability and UX with Spark SQL. For example, a test output before the changes:
```
-- !query
select timestamp'2011-11-11 11:11:11' - interval '2' day
-- !query schema
struct<TIMESTAMP '2011-11-11 11:11:11' - 172800000000:timestamp>
-- !query output
2011-11-09 11:11:11
```
### Does this PR introduce _any_ user-facing change?
Should not since the new intervals haven't been released yet.
### How was this patch tested?
By running new tests:
```
$ ./build/sbt "test:testOnly *LiteralExpressionSuite"
```
Closes#32196 from MaxGekk/literal-ansi-interval-sql.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas Index unit tests to PySpark.
### Why are the changes needed?
Currently, the pandas-on-Spark modules are not tested fully. We should enable the Index unit tests.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Enable Index unit tests.
Closes#32139 from xinrong-databricks/port.indexes_tests.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR fixes a test failure in `OracleIntegrationSuite`.
After SPARK-34843 (#31965), the way to divide partitions is changed and `OracleIntegrationSuites` is affected.
```
[info] - SPARK-22814 support date/timestamp types in partitionColumn *** FAILED *** (230 milliseconds)
[info] Set(""D" < '2018-07-11' or "D" is null", ""D" >= '2018-07-11' AND "D" < '2018-07-15'", ""D" >= '2018-07-15'") did not equal Set(""D" < '2018-07-10' or "D" is null", ""D" >= '2018-07-10' AND "D" < '2018-07-14'", ""D" >= '2018-07-14'") (OracleIntegrationSuite.scala:448)
[info] Analysis:
[info] Set(missingInLeft: ["D" < '2018-07-10' or "D" is null, "D" >= '2018-07-10' AND "D" < '2018-07-14', "D" >= '2018-07-14'], missingInRight: ["D" < '2018-07-11' or "D" is null, "D" >= '2018-07-11' AND "D" < '2018-07-15', "D" >= '2018-07-15'])
```
### Why are the changes needed?
To follow the previous change.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
The modified test.
Closes#32186 from sarutak/fix-oracle-date-error.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
There are some more changes in Koalas such as [databricks/koalas#2141](c8f803d6be), [databricks/koalas#2143](913d68868d) after the main code porting, this PR is to synchronize those changes with the `pyspark.pandas`.
### Why are the changes needed?
We should port the whole Koalas codes into PySpark and synchronize them.
### Does this PR introduce _any_ user-facing change?
Fixed some incompatible behavior with pandas 1.2.0 and added more to the `to_markdown` docstring.
### How was this patch tested?
Manually tested in local.
Closes#32154 from itholic/SPARK-34995.
Authored-by: itholic <haejoon.lee@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
When counting the number of started fetch requests, we should exclude the deferred requests.
### Why are the changes needed?
Fix the wrong number in the log.
### Does this PR introduce _any_ user-facing change?
Yes, users see the correct number of started requests in logs.
### How was this patch tested?
Manually tested.
Closes#32180 from Ngone51/count-deferred-request.
Lead-authored-by: yi.wu <yi.wu@databricks.com>
Co-authored-by: wuyi <yi.wu@databricks.com>
Signed-off-by: attilapiros <piros.attila.zsolt@gmail.com>
### What changes were proposed in this pull request?
Normal function parameters should not support alias, hive not support too
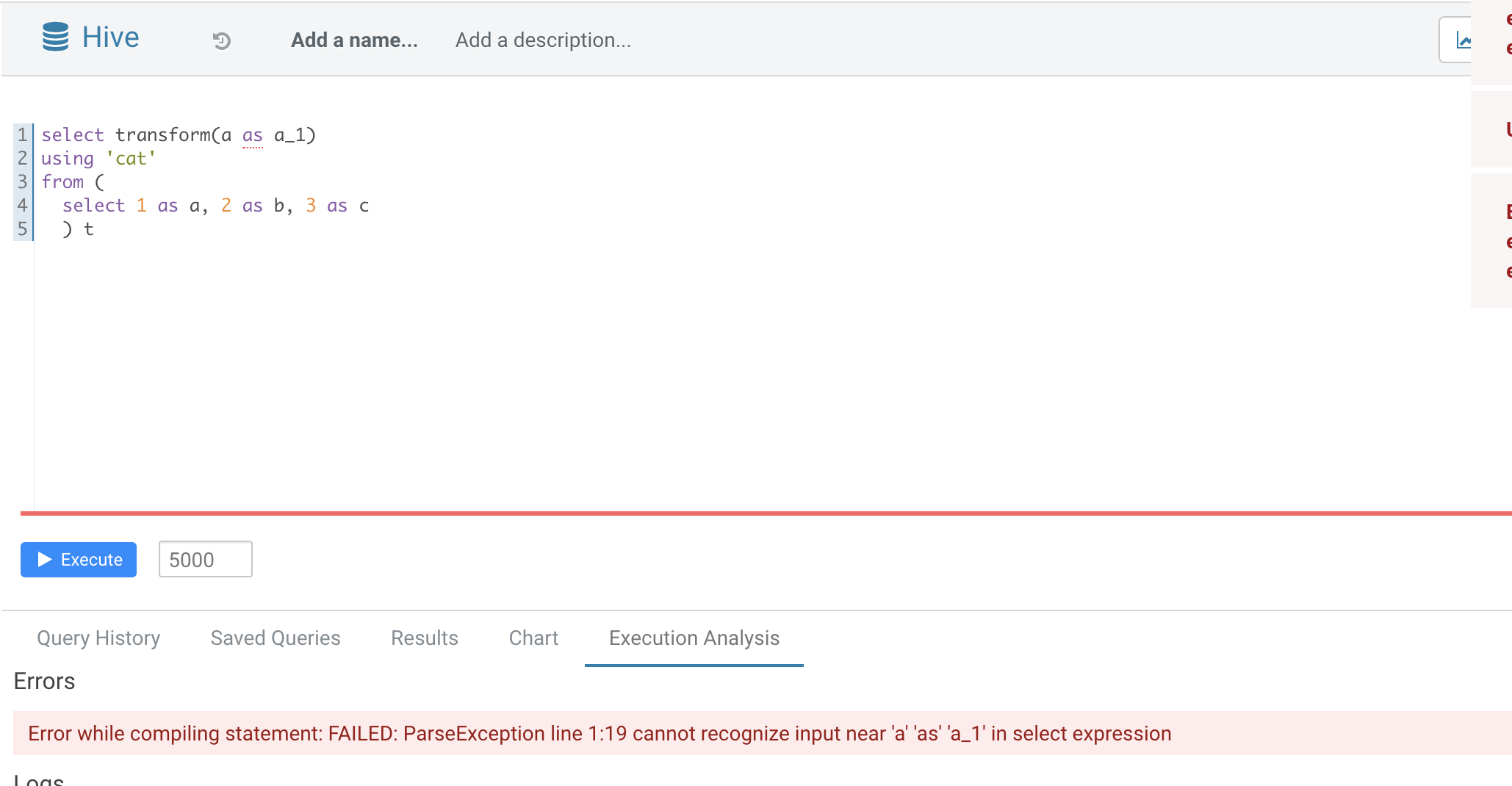
In this pr we forbid use alias in `TRANSFORM`'s inputs
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#32165 from AngersZhuuuu/SPARK-35070.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR proposes to replace Hadoop's `Path` with `Utils.resolveURI` to make the way to get URI simple in `SparkContext`.
### Why are the changes needed?
Keep the code simple.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#32164 from sarutak/followup-SPARK-34225.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
In current code, if we run spark sql with
```
./bin/spark-sql --verbose
```
It won't be passed to end SparkSQLCliDriver, then the SessionState won't call `setIsVerbose`
In the CLI option, it shows
```
CLI options:
-v,--verbose Verbose mode (echo executed SQL to the
console)
```
It's not consistent. This pr fix this issue
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
when user call `-v` when run spark sql, sql will be echoed to console.
### How was this patch tested?
Added UT
Closes#32163 from AngersZhuuuu/SPARK-35086.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
This PR refactors three parts of the comments in `HiveClientImpl.withHiveState`
One is about the following comment.
```
// The classloader in clientLoader could be changed after addJar, always use the latest
// classloader.
```
The comment was added in SPARK-10810 (#8909) because `IsolatedClientLoader.classLoader` was declared as `var`.
But the field is now `val` and cannot be changed after instanciation.
So, the comment can confuse developers.
One is about the following code and comment.
```
// classloader. We explicitly set the context class loader since "conf.setClassLoader" does
// not do that, and the Hive client libraries may need to load classes defined by the client's
// class loader.
Thread.currentThread().setContextClassLoader(clientLoader.classLoader)
```
It's not trivial why this part is necessary and it's difficult when we can remove this code in the future.
So, I revised the comment by adding the reference of the related JIRA.
And the last one is about the following code and comment.
```
// Replace conf in the thread local Hive with current conf
Hive.get(conf)
```
It's also not trivial why this part is necessary.
I revised the comment by adding the reference of the related discussion.
### Why are the changes needed?
To make code more readable.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
It's just a comment refactoring so I add no new test.
Closes#32162 from sarutak/refactor-HiveClientImpl.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Introducing a new test construct:
```
withHttpServer() { baseURL =>
...
}
```
Which starts and stops a Jetty server to serve files via HTTP.
Moreover this PR uses this new construct in the test `Run SparkRemoteFileTest using a remote data file`.
### Why are the changes needed?
Before this PR github URLs was used like "https://raw.githubusercontent.com/apache/spark/master/data/mllib/pagerank_data.txt".
This connects two Spark version in an unhealthy way like connecting the "master" branch which is moving part with the committed test code which is a non-moving (as it might be even released).
So this way a test running for an earlier version of Spark expects something (filename, content, path) from a the latter release and what is worse when the moving version is changed the earlier test will break.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing unit test.
Closes#31935 from attilapiros/SPARK-34789.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR proposes to rename Koalas to pandas-on-Spark in main codes
### Why are the changes needed?
To have the correct name in PySpark. NOTE that the official name in the main documentation will be pandas APIs on Spark to be extra clear. pandas-on-Spark is not the official term.
### Does this PR introduce _any_ user-facing change?
No, it's master-only change. It changes the docstring and class names.
### How was this patch tested?
Manually tested via:
```bash
./python/run-tests --python-executable=python3 --modules pyspark-pandas
```
Closes#32166 from HyukjinKwon/rename-koalas.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
There is an issue when syncing to the Apache master branch, see also https://github.com/apache/spark/pull/32168:
```
From https://github.com/yaooqinn/spark
* branch SPARK-35044 -> FETCH_HEAD
fatal: Not possible to fast-forward, aborting.
Error: Process completed with exit code 128.
```
This is because we use `--ff-only` option so it assumes that the fork is always based on the latest master branch.
We should make it less strict.
This PR proposes to use the same command when we merge PRs:
c8f56eb7bb/dev/merge_spark_pr.py (L127)
### Why are the changes needed?
To unblock PR testing broken.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Locally tested
Co-authored-by: Kent Yao <yaooqinnhotmail.com>
Closes#32168Closes#32182 from Yikun/SPARK-rm-fast-forward.
Lead-authored-by: Yikun Jiang <yikunkero@gmail.com>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas miscellaneous unit tests to PySpark.
### Why are the changes needed?
Currently, the pandas-on-Spark modules are not tested fully. We should enable miscellaneous unit tests.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Enable miscellaneous unit tests.
Closes#32152 from xinrong-databricks/port.misc_tests.
Lead-authored-by: xinrong-databricks <47337188+xinrong-databricks@users.noreply.github.com>
Co-authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This patch add `__version__` into pyspark.__init__.__all__ to make the `__version__` as exported explicitly, see more in https://github.com/apache/spark/pull/32110#issuecomment-817331896
### Why are the changes needed?
1. make the `__version__` as exported explicitly
2. cleanup `noqa: F401` on `__version`
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Python related CI passed
Closes#32125 from Yikun/SPARK-34629-Follow.
Authored-by: Yikun Jiang <yikunkero@gmail.com>
Signed-off-by: zero323 <mszymkiewicz@gmail.com>
### What changes were proposed in this pull request?
Currently, pure SQL users are short of ways to see the Hadoop configurations which may affect their jobs a lot, they are only able to get the Hadoop configs that exist in `SQLConf` while other defaults in `SharedState.hadoopConf` display wrongly and confusingly with `<undefined>`.
The pre-loaded ones from `core-site.xml, hive-site.xml` etc., will only stay in `sparkSession.sharedState.hadoopConf` or `sc._hadoopConfiguation` not `SQLConf`. Some of them that related the Hive Metastore connection(never change it spark runtime), e.g. `hive.metastore.uris`, are clearly global static and unchangeable but displayable I guess. Some of the ones that might be related to, for example, the output codec/compression, preset in Hadoop/hive config files like core-site.xml shall be still changeable from case to case, table to table, file to file, etc. It' meaningfully to show the defaults for users to change based on that.
In this PR, I propose to support get a Hadoop configuration by SET syntax, for example
```
SET mapreduce.map.output.compress.codec;
```
### Why are the changes needed?
better user experience for pure SQL users
### Does this PR introduce _any_ user-facing change?
yes, where retrieving a conf only existing in sessionState.hadoopConf, before is `undefined` and now you see it
### How was this patch tested?
new test
Closes#32144 from yaooqinn/SPARK-35044.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Kent Yao <yao@apache.org>
### What changes were proposed in this pull request?
There is a potential Netty memory leak in TransportResponseHandler.
### Why are the changes needed?
Fix a potential Netty memory leak in TransportResponseHandler.
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
NO
Closes#31942 from weixiuli/SPARK-34834.
Authored-by: weixiuli <weixiuli@jd.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
This patch introduces a VectorizedBLAS class which implements such hardware-accelerated BLAS operations. This feature is hidden behind the "vectorized" profile that you can enable by passing "-Pvectorized" to sbt or maven.
The Vector API has been introduced in JDK 16. Following discussion on the mailing list, this API is introduced transparently and needs to be enabled explicitely.
### Why are the changes needed?
Whenever a native BLAS implementation isn't available on the system, Spark automatically falls back onto a Java implementation. With the recent release of the Vector API in the OpenJDK [1], we can use hardware acceleration for such operations.
This change was also discussed on the mailing list. [2]
### Does this PR introduce _any_ user-facing change?
It introduces a build-time profile called `vectorized`. You can pass it to sbt and mvn with `-Pvectorized`. There is no change to the end-user of Spark and it should only impact Spark developpers. It is also disabled by default.
### How was this patch tested?
It passes `build/sbt mllib-local/test` with and without `-Pvectorized` with JDK 16. This patch also introduces benchmarks for BLAS.
The benchmark results are as follows:
```
[info] daxpy: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 37 37 0 271.5 3.7 1.0X
[info] vector 24 25 4 416.1 2.4 1.5X
[info]
[info] ddot: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 70 70 0 143.2 7.0 1.0X
[info] vector 35 35 2 288.7 3.5 2.0X
[info]
[info] sdot: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 50 51 1 199.8 5.0 1.0X
[info] vector 15 15 0 648.7 1.5 3.2X
[info]
[info] dscal: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 34 34 0 295.6 3.4 1.0X
[info] vector 19 19 0 531.2 1.9 1.8X
[info]
[info] sscal: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 25 25 1 399.0 2.5 1.0X
[info] vector 8 9 1 1177.3 0.8 3.0X
[info]
[info] dgemv[N]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 27 27 0 0.0 26651.5 1.0X
[info] vector 21 21 0 0.0 20646.3 1.3X
[info]
[info] dgemv[T]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 36 36 0 0.0 35501.4 1.0X
[info] vector 22 22 0 0.0 21930.3 1.6X
[info]
[info] sgemv[N]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 20 20 0 0.0 20283.3 1.0X
[info] vector 9 9 0 0.1 8657.7 2.3X
[info]
[info] sgemv[T]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 30 30 0 0.0 29845.8 1.0X
[info] vector 10 10 1 0.1 9695.4 3.1X
[info]
[info] dgemm[N,N]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 182 182 0 0.5 1820.0 1.0X
[info] vector 160 160 1 0.6 1597.6 1.1X
[info]
[info] dgemm[N,T]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 211 211 1 0.5 2106.2 1.0X
[info] vector 156 157 0 0.6 1564.4 1.3X
[info]
[info] dgemm[T,N]: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] f2j 276 276 0 0.4 2757.8 1.0X
[info] vector 137 137 0 0.7 1365.1 2.0X
```
/cc srowen xkrogen
[1] https://openjdk.java.net/jeps/338
[2] https://mail-archives.apache.org/mod_mbox/spark-dev/202012.mbox/%3cDM5PR2101MB11106162BB3AF32AD29C6C79B0C69DM5PR2101MB1110.namprd21.prod.outlook.com%3eCloses#30810 from luhenry/master.
Lead-authored-by: Ludovic Henry <luhenry@microsoft.com>
Co-authored-by: Ludovic Henry <git@ludovic.dev>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Support `date +/- day-time interval`. In the PR, I propose to update the binary arithmetic rules, and cast an input date to a timestamp at the session time zone, and then add a day-time interval to it.
### Why are the changes needed?
1. To conform the ANSI SQL standard which requires to support such operation over dates and intervals:
<img width="811" alt="Screenshot 2021-03-12 at 11 36 14" src="https://user-images.githubusercontent.com/1580697/111081674-865d4900-8515-11eb-86c8-3538ecaf4804.png">
2. To fix the regression comparing to the recent Spark release 3.1 with default settings.
Before the changes:
```sql
spark-sql> select date'now' + (timestamp'now' - timestamp'yesterday');
Error in query: cannot resolve 'DATE '2021-04-14' + subtracttimestamps(TIMESTAMP '2021-04-14 18:14:56.497', TIMESTAMP '2021-04-13 00:00:00')' due to data type mismatch: argument 1 requires timestamp type, however, 'DATE '2021-04-14'' is of date type.; line 1 pos 7;
'Project [unresolvedalias(cast(2021-04-14 + subtracttimestamps(2021-04-14 18:14:56.497, 2021-04-13 00:00:00, false, Some(Europe/Moscow)) as date), None)]
+- OneRowRelation
```
Spark 3.1:
```sql
spark-sql> select date'now' + (timestamp'now' - timestamp'yesterday');
2021-04-15
```
Hive:
```sql
0: jdbc:hive2://localhost:10000/default> select date'2021-04-14' + (timestamp'2020-04-14 18:15:30' - timestamp'2020-04-13 00:00:00');
+------------------------+
| _c0 |
+------------------------+
| 2021-04-15 18:15:30.0 |
+------------------------+
```
### Does this PR introduce _any_ user-facing change?
Should not since new intervals have not been released yet.
After the changes:
```sql
spark-sql> select date'now' + (timestamp'now' - timestamp'yesterday');
2021-04-15 18:13:16.555
```
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
Closes#32170 from MaxGekk/date-add-day-time-interval.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
This PR bumps up the version of pycodestyle from 2.6.0 to 2.7.0 released a month ago.
### Why are the changes needed?
2.7.0 includes three major fixes below (see https://readthedocs.org/projects/pycodestyle/downloads/pdf/latest/):
- Fix physical checks (such as W191) at end of file. PR #961.
- Add --indent-size option (defaulting to 4). PR #970.
- W605: fix escaped crlf false positive on windows. PR #976
The first and third ones could be useful for dev to detect the styles.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Manually tested locally.
Closes#32160 from HyukjinKwon/SPARK-35061.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
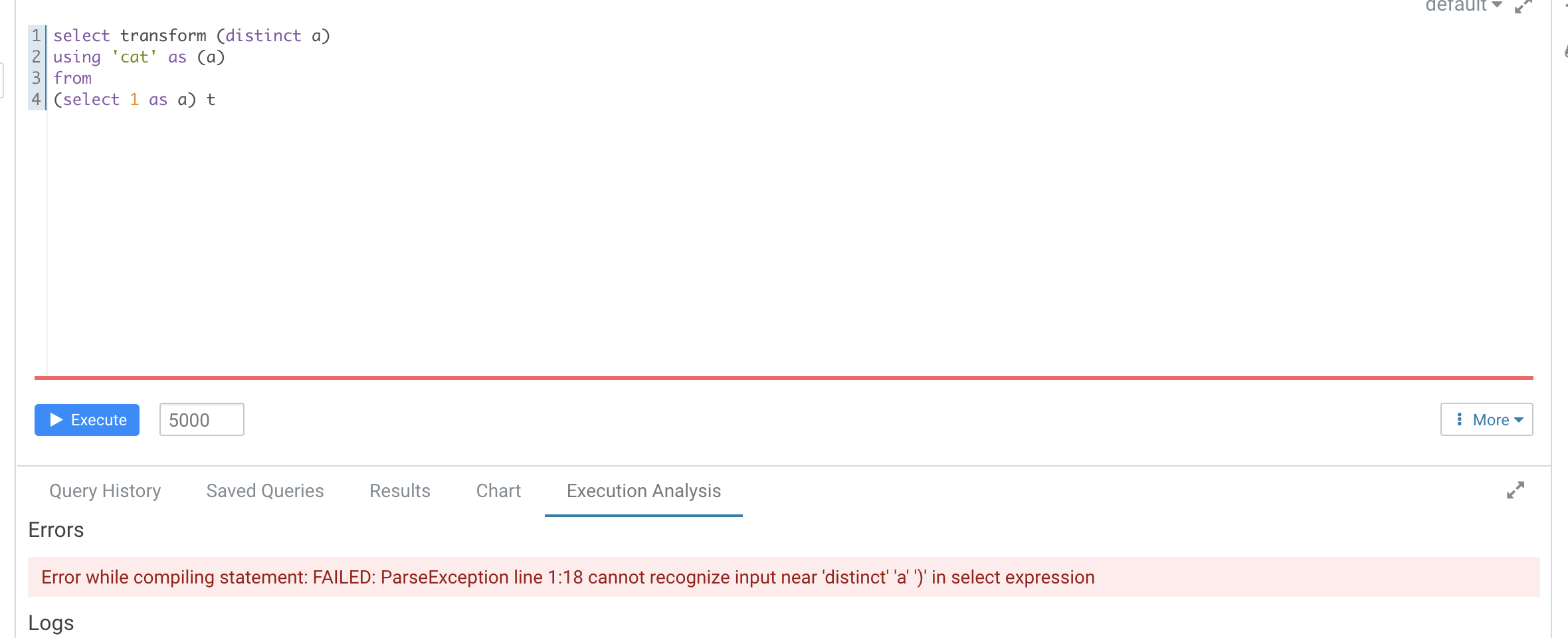
### What changes were proposed in this pull request?
According to https://github.com/apache/spark/pull/29087#discussion_r612267050, add UT in `transform.sql`
It seems that distinct is not recognized as a reserved word here
```
-- !query
explain extended SELECT TRANSFORM(distinct b, a, c)
USING 'cat' AS (a, b, c)
FROM script_trans
WHERE a <= 4
-- !query schema
struct<plan:string>
-- !query output
== Parsed Logical Plan ==
'ScriptTransformation [*], cat, [a#x, b#x, c#x], ScriptInputOutputSchema(List(),List(),None,None,List(),List(),None,None,false)
+- 'Project ['distinct AS b#x, 'a, 'c]
+- 'Filter ('a <= 4)
+- 'UnresolvedRelation [script_trans], [], false
== Analyzed Logical Plan ==
org.apache.spark.sql.AnalysisException: cannot resolve 'distinct' given input columns: [script_trans.a, script_trans.b, script_trans.c]; line 1 pos 34;
'ScriptTransformation [*], cat, [a#x, b#x, c#x], ScriptInputOutputSchema(List(),List(),None,None,List(),List(),None,None,false)
+- 'Project ['distinct AS b#x, a#x, c#x]
+- Filter (a#x <= 4)
+- SubqueryAlias script_trans
+- View (`script_trans`, [a#x,b#x,c#x])
+- Project [cast(a#x as int) AS a#x, cast(b#x as int) AS b#x, cast(c#x as int) AS c#x]
+- Project [a#x, b#x, c#x]
+- SubqueryAlias script_trans
+- LocalRelation [a#x, b#x, c#x]
```
Hive's error
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added Ut
Closes#32149 from AngersZhuuuu/SPARK-28227-new-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR fixes two tests below:
https://github.com/apache/spark/runs/2320161984
```
[info] YarnShuffleIntegrationSuite:
[info] org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite *** ABORTED *** (228 milliseconds)
[info] org.apache.hadoop.yarn.exceptions.YarnRuntimeException: org.apache.hadoop.yarn.webapp.WebAppException: Error starting http server
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster.startResourceManager(MiniYARNCluster.java:373)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster.access$300(MiniYARNCluster.java:128)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster$ResourceManagerWrapper.serviceStart(MiniYARNCluster.java:503)
[info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
[info] at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster.serviceStart(MiniYARNCluster.java:322)
[info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
[info] at org.apache.spark.deploy.yarn.BaseYarnClusterSuite.beforeAll(BaseYarnClusterSuite.scala:95)
...
[info] Cause: java.net.BindException: Port in use: fv-az186-831:0
[info] at org.apache.hadoop.http.HttpServer2.constructBindException(HttpServer2.java:1231)
[info] at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1253)
[info] at org.apache.hadoop.http.HttpServer2.openListeners(HttpServer2.java:1316)
[info] at org.apache.hadoop.http.HttpServer2.start(HttpServer2.java:1167)
[info] at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:449)
[info] at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.startWepApp(ResourceManager.java:1247)
[info] at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceStart(ResourceManager.java:1356)
[info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster.startResourceManager(MiniYARNCluster.java:365)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster.access$300(MiniYARNCluster.java:128)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster$ResourceManagerWrapper.serviceStart(MiniYARNCluster.java:503)
[info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
[info] at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121)
[info] at org.apache.hadoop.yarn.server.MiniYARNCluster.serviceStart(MiniYARNCluster.java:322)
[info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
[info] at org.apache.spark.deploy.yarn.BaseYarnClusterSuite.beforeAll(BaseYarnClusterSuite.scala:95)
[info] at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:212)
[info] at org.scalatest.BeforeAndAfterAll.run(BeforeAndAfterAll.scala:210)
[info] at org.scalatest.BeforeAndAfterAll.run$(BeforeAndAfterAll.scala:208)
[info] at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:61)
...
```
https://github.com/apache/spark/runs/2323342094
```
[info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret started
[error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret failed: java.lang.AssertionError: Connecting to /10.1.0.161:39895 timed out (120000 ms), took 120.081 sec
[error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret(ExternalShuffleSecuritySuite.java:85)
[error] ...
[info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId started
[error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId failed: java.lang.AssertionError: Connecting to /10.1.0.198:44633 timed out (120000 ms), took 120.08 sec
[error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId(ExternalShuffleSecuritySuite.java:76)
[error] ...
[info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid started
[error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid failed: java.io.IOException: Connecting to /10.1.0.119:43575 timed out (120000 ms), took 120.089 sec
[error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:285)
[error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:218)
[error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:230)
[error] at org.apache.spark.network.shuffle.ExternalBlockStoreClient.registerWithShuffleServer(ExternalBlockStoreClient.java:211)
[error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.validate(ExternalShuffleSecuritySuite.java:108)
[error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid(ExternalShuffleSecuritySuite.java:68)
[error] ...
[info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption started
[error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption failed: java.io.IOException: Connecting to /10.1.0.248:35271 timed out (120000 ms), took 120.014 sec
[error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:285)
[error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:218)
[error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:230)
[error] at org.apache.spark.network.shuffle.ExternalBlockStoreClient.registerWithShuffleServer(ExternalBlockStoreClient.java:211)
[error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.validate(ExternalShuffleSecuritySuite.java:108)
[error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption(ExternalShu
```
For Yarn cluster suites, its difficult to fix. This PR makes it skipped if it fails to bind.
For shuffle related suites, it uses local host
### Why are the changes needed?
To make the tests stable
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Its tested in GitHub Actions: https://github.com/HyukjinKwon/spark/runs/2340210765Closes#32126 from HyukjinKwon/SPARK-35002-followup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
This PR proposes to introduce the `AnalysisOnlyCommand` trait such that a command that extends this trait can have its children only analyzed, but not optimized. There is a corresponding analysis rule `HandleAnalysisOnlyCommand` that marks the command as analyzed after all other analysis rules are run.
This can be useful if a logical plan has children where they need to be only analyzed, but not optimized - e.g., `CREATE VIEW` or `CACHE TABLE AS`. This also addresses the issue found in #31933.
This PR also updates `CreateViewCommand`, `CacheTableAsSelect`, and `AlterViewAsCommand` to use the new trait / rule such that their children are only analyzed.
### Why are the changes needed?
To address the issue where the plan is unnecessarily re-analyzed in `CreateViewCommand`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests should cover the changes.
Closes#32032 from imback82/skip_transform.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Adds the duplicated common columns as hidden columns to the Projection used to rewrite NATURAL/USING JOINs.
### Why are the changes needed?
Allows users to resolve either side of the NATURAL/USING JOIN's common keys.
Previously, the user could only resolve the following columns:
| Join type | Left key columns | Right key columns |
| --- | --- | --- |
| Inner | Yes | No |
| Left | Yes | No |
| Right | No | Yes |
| Outer | No | No |
### Does this PR introduce _any_ user-facing change?
Yes. The user can now symmetrically resolve the common columns from a NATURAL/USING JOIN.
### How was this patch tested?
SQL-side tests. The behavior matches PostgreSQL and MySQL.
Closes#31666 from karenfeng/spark-34527.
Authored-by: Karen Feng <karen.feng@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add change of `DESC NAMESPACE`'s schema to migration guide
### Why are the changes needed?
Update doc
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32155 from AngersZhuuuu/SPARK-34577-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Removes PySpark version dependent codes from `pyspark.pandas` main codes.
### Why are the changes needed?
There are several places to check the PySpark version and switch the logic, but now those are not necessary.
We should remove them.
We will do the same thing after we finish porting tests.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#32138 from ueshin/issues/SPARK-35039/pyspark_version.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas internal implementation unit tests to PySpark.
### Why are the changes needed?
Currently, the pandas-on-Spark modules are not tested fully. We should enable the internal implementation unit tests.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Enable internal implementation unit tests.
Closes#32137 from xinrong-databricks/port.test_internal_impl.
Lead-authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Co-authored-by: xinrong-databricks <47337188+xinrong-databricks@users.noreply.github.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR proposes to leverage the GitHub Actions resources from the forked repositories instead of using the resources in ASF organisation at GitHub.
This is how it works:
1. "Build and test" (`build_and_test.yml`) triggers a build on any commit on any branch (except `branch-*.*`), which roughly means:
- The original repository will trigger the build on any commits in `master` branch
- The forked repository will trigger the build on any commit in any branch.
2. The build triggered in the forked repository will checkout the original repository's `master` branch locally, and merge the branch from the forked repository into the original repository's `master` branch locally.
Therefore, the tests in the forked repository will run after being sync'ed with the original repository's `master` branch.
3. In the original repository, it triggers a workflow that detects the workflow triggered in the forked repository, and add a comment, to the PR, pointing out the workflow in forked repository.
In short, please see this example HyukjinKwon#34
1. You create a PR and your repository triggers the workflow. Your PR uses the resources allocated to you for testing.
2. Apache Spark repository finds your workflow, and links it in a comment in your PR
**NOTE** that we will still run the tests in the original repository for each commit pushed to `master` branch. This distributes the workflows only in PRs.
### Why are the changes needed?
ASF shares the resources across all the ASF projects, which makes the development slow down.
Please see also:
- Discussion in the buildsa.o mailing list: https://lists.apache.org/x/thread.html/r48d079eeff292254db22705c8ef8618f87ff7adc68d56c4e5d0b4105%3Cbuilds.apache.org%3E
- Infra ticket: https://issues.apache.org/jira/browse/INFRA-21646
By distributing the workflows to use author's resources, we can get around this issue.
### Does this PR introduce _any_ user-facing change?
No, this is a dev-only change.
### How was this patch tested?
Manually tested at https://github.com/HyukjinKwon/spark/pull/34 and https://github.com/HyukjinKwon/spark/pull/33.
Closes#32092 from HyukjinKwon/poc-fork-resources.
Lead-authored-by: HyukjinKwon <gurwls223@apache.org>
Co-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas plot unit tests to PySpark.
### Why are the changes needed?
Currently, the pandas-on-Spark modules are not tested fully. We should enable the plot unit tests.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Enable plot unit tests.
Closes#32151 from xinrong-databricks/port.plot_tests.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Deprecate Apache Mesos support for Spark 3.2.0 by adding documentation to this effect.
### Why are the changes needed?
Apache Mesos is ceasing development (https://lists.apache.org/thread.html/rab2a820507f7c846e54a847398ab20f47698ec5bce0c8e182bfe51ba%40%3Cdev.mesos.apache.org%3E) ; at some point we'll want to drop support, so, deprecate it now.
This doesn't mean it'll go away in 3.3.0.
### Does this PR introduce _any_ user-facing change?
No, docs only.
### How was this patch tested?
N/A
Closes#32150 from srowen/SPARK-35050.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add a new line to the `lineSep` parameter so that the doc renders correctly.
### Why are the changes needed?
> <img width="608" alt="image" src="https://user-images.githubusercontent.com/8269566/114631408-5c608900-9c71-11eb-8ded-ae1e21ae48b2.png">
The first line of the description is part of the signature and is **bolded**.
### Does this PR introduce _any_ user-facing change?
Yes, it changes how the docs for `pyspark.sql.DataFrameWriter.json` are rendered.
### How was this patch tested?
I didn't test it; I don't have the doc rendering tool chain on my machine, but the change is obvious.
Closes#32153 from AlexMooney/patch-1.
Authored-by: Alex Mooney <alexmooney@fastmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR fixes an issue that `LIST FILES/JARS/ARCHIVES path1 path2 ...` cannot list all paths if at least one path is quoted.
An example here.
```
ADD FILE /tmp/test1;
ADD FILE /tmp/test2;
LIST FILES /tmp/test1 /tmp/test2;
file:/tmp/test1
file:/tmp/test2
LIST FILES /tmp/test1 "/tmp/test2";
file:/tmp/test2
```
In this example, the second `LIST FILES` doesn't show `file:/tmp/test1`.
To resolve this issue, I modified the syntax rule to be able to handle this case.
I also changed `SparkSQLParser` to be able to handle paths which contains white spaces.
### Why are the changes needed?
This is a bug.
I also have a plan which extends `ADD FILE/JAR/ARCHIVE` to take multiple paths like Hive and the syntax rule change is necessary for that.
### Does this PR introduce _any_ user-facing change?
Yes. Users can pass quoted paths when using `ADD FILE/JAR/ARCHIVE`.
### How was this patch tested?
New test.
Closes#32074 from sarutak/fix-list-files-bug.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas DataFrame-related unit tests to PySpark.
### Why are the changes needed?
Currently, the pandas-on-Spark modules are not fully tested. We should enable the DataFrame-related unit tests first.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Enable DataFrame-related unit tests.
Closes#32131 from xinrong-databricks/port.test_dataframe_related.
Lead-authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Co-authored-by: xinrong-databricks <47337188+xinrong-databricks@users.noreply.github.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
### What changes were proposed in this pull request?
Remove unused MapOutputTracker in BlockStoreShuffleReader
### Why are the changes needed?
Remove unused MapOutputTracker in BlockStoreShuffleReader
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32148 from AngersZhuuuu/SPARK-35049.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com>
### What changes were proposed in this pull request?
This PR group exception messages in `/core/src/main/scala/org/apache/spark/sql/execution`.
### Why are the changes needed?
It will largely help with standardization of error messages and its maintenance.
### Does this PR introduce _any_ user-facing change?
No. Error messages remain unchanged.
### How was this patch tested?
No new tests - pass all original tests to make sure it doesn't break any existing behavior.
Closes#31920 from beliefer/SPARK-33604.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Populate table catalog and identifier from `DataStreamWriter` to `WriteToMicroBatchDataSource` so that we can invalidate cache for tables that are updated by a streaming write.
This is somewhat related [SPARK-27484](https://issues.apache.org/jira/browse/SPARK-27484) and [SPARK-34183](https://issues.apache.org/jira/browse/SPARK-34183) (#31700), as ideally we may want to replace `WriteToMicroBatchDataSource` and `WriteToDataSourceV2` with logical write nodes and feed them to analyzer. That will potentially change the code path involved in this PR.
### Why are the changes needed?
Currently `WriteToDataSourceV2` doesn't have cache invalidation logic, and therefore, when the target table for a micro batch streaming job is cached, the cache entry won't be removed when the table is updated.
### Does this PR introduce _any_ user-facing change?
Yes now when a DSv2 table which supports streaming write is updated by a streaming job, its cache will also be invalidated.
### How was this patch tested?
Added a new UT.
Closes#32039 from sunchao/streaming-cache.
Authored-by: Chao Sun <sunchao@apple.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Remove duplicate code in `TreeNode.treePatternBits`
### Why are the changes needed?
Code clean up. Make it easier for maintainence.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests.
Closes#32143 from gengliangwang/getBits.
Authored-by: Gengliang Wang <ltnwgl@gmail.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
This PR makes the input buffer configurable (as an internal option). This is mainly to work around uniVocity/univocity-parsers#449.
### Why are the changes needed?
To work around uniVocity/univocity-parsers#449.
### Does this PR introduce _any_ user-facing change?
No, it's only internal option.
### How was this patch tested?
Manually tested by modifying the unittest added in https://github.com/apache/spark/pull/31858 as below:
```diff
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
index fd25a79619d..b58f0bd3661 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
-2460,6 +2460,7 abstract class CSVSuite
Seq(line).toDF.write.text(path.getAbsolutePath)
assert(spark.read.format("csv")
.option("delimiter", "|")
+ .option("inputBufferSize", "128")
.option("ignoreTrailingWhiteSpace", "true").load(path.getAbsolutePath).count() == 1)
}
}
```
Closes#32145 from HyukjinKwon/SPARK-35045.
Lead-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Fix PhysicalAggregation to not transform a foldable expression.
### Why are the changes needed?
It can potentially break certain queries like the added unit test shows.
### Does this PR introduce _any_ user-facing change?
Yes, it fixes undesirable errors caused by a returned TypeCheckFailure from places like RegExpReplace.checkInputDataTypes.
Closes#32113 from sigmod/foldable.
Authored-by: Yingyi Bu <yingyi.bu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR contains:
- AnalysisHelper changes to allow the resolve function family to stop earlier without traversing the entire tree;
- Example changes in a few rules to support such pruning, e.g., ResolveRandomSeed, ResolveWindowFrame, ResolveWindowOrder, and ResolveNaturalAndUsingJoin.
### Why are the changes needed?
It's a framework-level change for reducing the query compilation time.
In particular, if we update existing analysis rules' call sites as per the examples in this PR, the analysis time can be reduced as described in the [doc](https://docs.google.com/document/d/1SEUhkbo8X-0cYAJFYFDQhxUnKJBz4lLn3u4xR2qfWqk).
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
It is tested by existing tests.
Closes#32135 from sigmod/resolver.
Authored-by: Yingyi Bu <yingyi.bu@databricks.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
### What changes were proposed in this pull request?
Add overflow check before do `new byte[]`.
### Why are the changes needed?
Avoid overflow in extreme case.
### Does this PR introduce _any_ user-facing change?
Maybe yes, the error msg changed if overflow.
### How was this patch tested?
Pass CI.
Closes#32142 from ulysses-you/SPARK-35041.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}