## What changes were proposed in this pull request?
This PR change `CalendarIntervalType`'s readable string representation from `calendarinterval` to `interval`.
## How was this patch tested?
Existing UT
Closes#25225 from wangyum/SPARK-28469.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Fix CSV datasource to throw `com.univocity.parsers.common.TextParsingException` with large size message, which will make log output consume large disk space.
This issue is troublesome when sometimes we need parse CSV with large size column.
This PR proposes to set CSV parser/writer settings by `setErrorContentLength(1000)` to limit the error message length.
## How was this patch tested?
Manually.
```
val s = "a" * 40 * 1000000
Seq(s).toDF.write.mode("overwrite").csv("/tmp/bogdan/es4196.csv")
spark.read .option("maxCharsPerColumn", 30000000) .csv("/tmp/bogdan/es4196.csv").count
```
**Before:**
The thrown message will include error content of about 30MB size (The column size exceed the max value 30MB, so the error content include the whole parsed content, so it is 30MB).
**After:**
The thrown message will include error content like "...aaa...aa" (the number of 'a' is 1024), i.e. limit the content size to be 1024.
Closes#25184 from WeichenXu123/limit_csv_exception_size.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
New function `make_date()` takes 3 columns `year`, `month` and `day`, and makes new column of the `DATE` type. If values in the input columns are `null` or out of valid ranges, the function returns `null`. Valid ranges are:
- `year` - `[1, 9999]`
- `month` - `[1, 12]`
- `day` - `[1, 31]`
Also constructed date must be valid otherwise `make_date` returns `null`.
The function is implemented similarly to `make_date` in PostgreSQL: https://www.postgresql.org/docs/11/functions-datetime.html to maintain feature parity with it.
Here is an example:
```sql
select make_date(2013, 7, 15);
2013-07-15
```
## How was this patch tested?
Added new tests to `DateExpressionsSuite`.
Closes#25210 from MaxGekk/make_date-timestamp.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds some tests converted from `group-by.sql` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
<details><summary>Diff comparing to 'group-by.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/udf/udf-group-by.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-group-by.sql.out
index 3a5df254f2..0118c05b1d 100644
--- a/sql/core/src/test/resources/sql-tests/results/udf/udf-group-by.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-group-by.sql.out
-13,26 +13,26 struct<>
-- !query 1
-SELECT a, COUNT(b) FROM testData
+SELECT udf(a), udf(COUNT(b)) FROM testData
-- !query 1 schema
struct<>
-- !query 1 output
org.apache.spark.sql.AnalysisException
-grouping expressions sequence is empty, and 'testdata.`a`' is not an aggregate function. Wrap '(count(testdata.`b`) AS `count(b)`)' in windowing function(s) or wrap 'testdata.`a`' in first() (or first_value) if you don't care which value you get.;
+grouping expressions sequence is empty, and 'testdata.`a`' is not an aggregate function. Wrap '(CAST(udf(cast(count(b) as string)) AS BIGINT) AS `CAST(udf(cast(count(b) as string)) AS BIGINT)`)' in windowing function(s) or wrap 'testdata.`a`' in first() (or first_value) if you don't care which value you get.;
-- !query 2
-SELECT COUNT(a), COUNT(b) FROM testData
+SELECT COUNT(udf(a)), udf(COUNT(b)) FROM testData
-- !query 2 schema
-struct<count(a):bigint,count(b):bigint>
+struct<count(CAST(udf(cast(a as string)) AS INT)):bigint,CAST(udf(cast(count(b) as string)) AS BIGINT):bigint>
-- !query 2 output
7 7
-- !query 3
-SELECT a, COUNT(b) FROM testData GROUP BY a
+SELECT udf(a), COUNT(udf(b)) FROM testData GROUP BY a
-- !query 3 schema
-struct<a:int,count(b):bigint>
+struct<CAST(udf(cast(a as string)) AS INT):int,count(CAST(udf(cast(b as string)) AS INT)):bigint>
-- !query 3 output
1 2
2 2
-41,7 +41,7 NULL 1
-- !query 4
-SELECT a, COUNT(b) FROM testData GROUP BY b
+SELECT udf(a), udf(COUNT(udf(b))) FROM testData GROUP BY b
-- !query 4 schema
struct<>
-- !query 4 output
-50,9 +50,9 expression 'testdata.`a`' is neither present in the group by, nor is it an aggre
-- !query 5
-SELECT COUNT(a), COUNT(b) FROM testData GROUP BY a
+SELECT COUNT(udf(a)), COUNT(udf(b)) FROM testData GROUP BY udf(a)
-- !query 5 schema
-struct<count(a):bigint,count(b):bigint>
+struct<count(CAST(udf(cast(a as string)) AS INT)):bigint,count(CAST(udf(cast(b as string)) AS INT)):bigint>
-- !query 5 output
0 1
2 2
-61,15 +61,15 struct<count(a):bigint,count(b):bigint>
-- !query 6
-SELECT 'foo', COUNT(a) FROM testData GROUP BY 1
+SELECT 'foo', COUNT(udf(a)) FROM testData GROUP BY 1
-- !query 6 schema
-struct<foo:string,count(a):bigint>
+struct<foo:string,count(CAST(udf(cast(a as string)) AS INT)):bigint>
-- !query 6 output
foo 7
-- !query 7
-SELECT 'foo' FROM testData WHERE a = 0 GROUP BY 1
+SELECT 'foo' FROM testData WHERE a = 0 GROUP BY udf(1)
-- !query 7 schema
struct<foo:string>
-- !query 7 output
-77,25 +77,25 struct<foo:string>
-- !query 8
-SELECT 'foo', APPROX_COUNT_DISTINCT(a) FROM testData WHERE a = 0 GROUP BY 1
+SELECT 'foo', udf(APPROX_COUNT_DISTINCT(udf(a))) FROM testData WHERE a = 0 GROUP BY 1
-- !query 8 schema
-struct<foo:string,approx_count_distinct(a):bigint>
+struct<foo:string,CAST(udf(cast(approx_count_distinct(cast(udf(cast(a as string)) as int), 0.05, 0, 0) as string)) AS BIGINT):bigint>
-- !query 8 output
-- !query 9
-SELECT 'foo', MAX(STRUCT(a)) FROM testData WHERE a = 0 GROUP BY 1
+SELECT 'foo', MAX(STRUCT(udf(a))) FROM testData WHERE a = 0 GROUP BY 1
-- !query 9 schema
-struct<foo:string,max(named_struct(a, a)):struct<a:int>>
+struct<foo:string,max(named_struct(col1, CAST(udf(cast(a as string)) AS INT))):struct<col1:int>>
-- !query 9 output
-- !query 10
-SELECT a + b, COUNT(b) FROM testData GROUP BY a + b
+SELECT udf(a + b), udf(COUNT(b)) FROM testData GROUP BY a + b
-- !query 10 schema
-struct<(a + b):int,count(b):bigint>
+struct<CAST(udf(cast((a + b) as string)) AS INT):int,CAST(udf(cast(count(b) as string)) AS BIGINT):bigint>
-- !query 10 output
2 1
3 2
-105,7 +105,7 NULL 1
-- !query 11
-SELECT a + 2, COUNT(b) FROM testData GROUP BY a + 1
+SELECT udf(a + 2), udf(COUNT(b)) FROM testData GROUP BY a + 1
-- !query 11 schema
struct<>
-- !query 11 output
-114,37 +114,35 expression 'testdata.`a`' is neither present in the group by, nor is it an aggre
-- !query 12
-SELECT a + 1 + 1, COUNT(b) FROM testData GROUP BY a + 1
+SELECT udf(a + 1 + 1), udf(COUNT(b)) FROM testData GROUP BY udf(a + 1)
-- !query 12 schema
-struct<((a + 1) + 1):int,count(b):bigint>
+struct<>
-- !query 12 output
-3 2
-4 2
-5 2
-NULL 1
+org.apache.spark.sql.AnalysisException
+expression 'testdata.`a`' is neither present in the group by, nor is it an aggregate function. Add to group by or wrap in first() (or first_value) if you don't care which value you get.;
-- !query 13
-SELECT SKEWNESS(a), KURTOSIS(a), MIN(a), MAX(a), AVG(a), VARIANCE(a), STDDEV(a), SUM(a), COUNT(a)
+SELECT SKEWNESS(udf(a)), udf(KURTOSIS(a)), udf(MIN(a)), MAX(udf(a)), udf(AVG(udf(a))), udf(VARIANCE(a)), STDDEV(udf(a)), udf(SUM(a)), udf(COUNT(a))
FROM testData
-- !query 13 schema
-struct<skewness(CAST(a AS DOUBLE)):double,kurtosis(CAST(a AS DOUBLE)):double,min(a):int,max(a):int,avg(a):double,var_samp(CAST(a AS DOUBLE)):double,stddev_samp(CAST(a AS DOUBLE)):double,sum(a):bigint,count(a):bigint>
+struct<skewness(CAST(CAST(udf(cast(a as string)) AS INT) AS DOUBLE)):double,CAST(udf(cast(kurtosis(cast(a as double)) as string)) AS DOUBLE):double,CAST(udf(cast(min(a) as string)) AS INT):int,max(CAST(udf(cast(a as string)) AS INT)):int,CAST(udf(cast(avg(cast(cast(udf(cast(a as string)) as int) as bigint)) as string)) AS DOUBLE):double,CAST(udf(cast(var_samp(cast(a as double)) as string)) AS DOUBLE):double,stddev_samp(CAST(CAST(udf(cast(a as string)) AS INT) AS DOUBLE)):double,CAST(udf(cast(sum(cast(a as bigint)) as string)) AS BIGINT):bigint,CAST(udf(cast(count(a) as string)) AS BIGINT):bigint>
-- !query 13 output
-0.2723801058145729 -1.5069204152249134 1 3 2.142857142857143 0.8095238095238094 0.8997354108424372 15 7
-- !query 14
-SELECT COUNT(DISTINCT b), COUNT(DISTINCT b, c) FROM (SELECT 1 AS a, 2 AS b, 3 AS c) GROUP BY a
+SELECT COUNT(DISTINCT udf(b)), udf(COUNT(DISTINCT b, c)) FROM (SELECT 1 AS a, 2 AS b, 3 AS c) GROUP BY a
-- !query 14 schema
-struct<count(DISTINCT b):bigint,count(DISTINCT b, c):bigint>
+struct<count(DISTINCT CAST(udf(cast(b as string)) AS INT)):bigint,CAST(udf(cast(count(distinct b, c) as string)) AS BIGINT):bigint>
-- !query 14 output
1 1
-- !query 15
-SELECT a AS k, COUNT(b) FROM testData GROUP BY k
+SELECT a AS k, COUNT(udf(b)) FROM testData GROUP BY k
-- !query 15 schema
-struct<k:int,count(b):bigint>
+struct<k:int,count(CAST(udf(cast(b as string)) AS INT)):bigint>
-- !query 15 output
1 2
2 2
-153,21 +151,21 NULL 1
-- !query 16
-SELECT a AS k, COUNT(b) FROM testData GROUP BY k HAVING k > 1
+SELECT a AS k, udf(COUNT(b)) FROM testData GROUP BY k HAVING k > 1
-- !query 16 schema
-struct<k:int,count(b):bigint>
+struct<k:int,CAST(udf(cast(count(b) as string)) AS BIGINT):bigint>
-- !query 16 output
2 2
3 2
-- !query 17
-SELECT COUNT(b) AS k FROM testData GROUP BY k
+SELECT udf(COUNT(b)) AS k FROM testData GROUP BY k
-- !query 17 schema
struct<>
-- !query 17 output
org.apache.spark.sql.AnalysisException
-aggregate functions are not allowed in GROUP BY, but found count(testdata.`b`);
+aggregate functions are not allowed in GROUP BY, but found CAST(udf(cast(count(b) as string)) AS BIGINT);
-- !query 18
-180,7 +178,7 struct<>
-- !query 19
-SELECT k AS a, COUNT(v) FROM testDataHasSameNameWithAlias GROUP BY a
+SELECT k AS a, udf(COUNT(udf(v))) FROM testDataHasSameNameWithAlias GROUP BY a
-- !query 19 schema
struct<>
-- !query 19 output
-197,32 +195,32 spark.sql.groupByAliases false
-- !query 21
-SELECT a AS k, COUNT(b) FROM testData GROUP BY k
+SELECT a AS k, udf(COUNT(udf(b))) FROM testData GROUP BY k
-- !query 21 schema
struct<>
-- !query 21 output
org.apache.spark.sql.AnalysisException
-cannot resolve '`k`' given input columns: [testdata.a, testdata.b]; line 1 pos 47
+cannot resolve '`k`' given input columns: [testdata.a, testdata.b]; line 1 pos 57
-- !query 22
-SELECT a, COUNT(1) FROM testData WHERE false GROUP BY a
+SELECT a, COUNT(udf(1)) FROM testData WHERE false GROUP BY a
-- !query 22 schema
-struct<a:int,count(1):bigint>
+struct<a:int,count(CAST(udf(cast(1 as string)) AS INT)):bigint>
-- !query 22 output
-- !query 23
-SELECT COUNT(1) FROM testData WHERE false
+SELECT udf(COUNT(1)) FROM testData WHERE false
-- !query 23 schema
-struct<count(1):bigint>
+struct<CAST(udf(cast(count(1) as string)) AS BIGINT):bigint>
-- !query 23 output
0
-- !query 24
-SELECT 1 FROM (SELECT COUNT(1) FROM testData WHERE false) t
+SELECT 1 FROM (SELECT udf(COUNT(1)) FROM testData WHERE false) t
-- !query 24 schema
struct<1:int>
-- !query 24 output
-232,7 +230,7 struct<1:int>
-- !query 25
SELECT 1 from (
SELECT 1 AS z,
- MIN(a.x)
+ udf(MIN(a.x))
FROM (select 1 as x) a
WHERE false
) b
-244,32 +242,32 struct<1:int>
-- !query 26
-SELECT corr(DISTINCT x, y), corr(DISTINCT y, x), count(*)
+SELECT corr(DISTINCT x, y), udf(corr(DISTINCT y, x)), count(*)
FROM (VALUES (1, 1), (2, 2), (2, 2)) t(x, y)
-- !query 26 schema
-struct<corr(DISTINCT CAST(x AS DOUBLE), CAST(y AS DOUBLE)):double,corr(DISTINCT CAST(y AS DOUBLE), CAST(x AS DOUBLE)):double,count(1):bigint>
+struct<corr(DISTINCT CAST(x AS DOUBLE), CAST(y AS DOUBLE)):double,CAST(udf(cast(corr(distinct cast(y as double), cast(x as double)) as string)) AS DOUBLE):double,count(1):bigint>
-- !query 26 output
1.0 1.0 3
-- !query 27
-SELECT 1 FROM range(10) HAVING true
+SELECT udf(1) FROM range(10) HAVING true
-- !query 27 schema
-struct<1:int>
+struct<CAST(udf(cast(1 as string)) AS INT):int>
-- !query 27 output
1
-- !query 28
-SELECT 1 FROM range(10) HAVING MAX(id) > 0
+SELECT udf(udf(1)) FROM range(10) HAVING MAX(id) > 0
-- !query 28 schema
-struct<1:int>
+struct<CAST(udf(cast(cast(udf(cast(1 as string)) as int) as string)) AS INT):int>
-- !query 28 output
1
-- !query 29
-SELECT id FROM range(10) HAVING id > 0
+SELECT udf(id) FROM range(10) HAVING id > 0
-- !query 29 schema
struct<>
-- !query 29 output
-291,33 +289,33 struct<>
-- !query 31
-SELECT every(v), some(v), any(v) FROM test_agg WHERE 1 = 0
+SELECT udf(every(v)), udf(some(v)), any(v) FROM test_agg WHERE 1 = 0
-- !query 31 schema
-struct<every(v):boolean,some(v):boolean,any(v):boolean>
+struct<CAST(udf(cast(every(v) as string)) AS BOOLEAN):boolean,CAST(udf(cast(some(v) as string)) AS BOOLEAN):boolean,any(v):boolean>
-- !query 31 output
NULL NULL NULL
-- !query 32
-SELECT every(v), some(v), any(v) FROM test_agg WHERE k = 4
+SELECT udf(every(udf(v))), some(v), any(v) FROM test_agg WHERE k = 4
-- !query 32 schema
-struct<every(v):boolean,some(v):boolean,any(v):boolean>
+struct<CAST(udf(cast(every(cast(udf(cast(v as string)) as boolean)) as string)) AS BOOLEAN):boolean,some(v):boolean,any(v):boolean>
-- !query 32 output
NULL NULL NULL
-- !query 33
-SELECT every(v), some(v), any(v) FROM test_agg WHERE k = 5
+SELECT every(v), udf(some(v)), any(v) FROM test_agg WHERE k = 5
-- !query 33 schema
-struct<every(v):boolean,some(v):boolean,any(v):boolean>
+struct<every(v):boolean,CAST(udf(cast(some(v) as string)) AS BOOLEAN):boolean,any(v):boolean>
-- !query 33 output
false true true
-- !query 34
-SELECT k, every(v), some(v), any(v) FROM test_agg GROUP BY k
+SELECT k, every(v), udf(some(v)), any(v) FROM test_agg GROUP BY k
-- !query 34 schema
-struct<k:int,every(v):boolean,some(v):boolean,any(v):boolean>
+struct<k:int,every(v):boolean,CAST(udf(cast(some(v) as string)) AS BOOLEAN):boolean,any(v):boolean>
-- !query 34 output
1 false true true
2 true true true
-327,9 +325,9 struct<k:int,every(v):boolean,some(v):boolean,any(v):boolean>
-- !query 35
-SELECT k, every(v) FROM test_agg GROUP BY k HAVING every(v) = false
+SELECT udf(k), every(v) FROM test_agg GROUP BY k HAVING every(v) = false
-- !query 35 schema
-struct<k:int,every(v):boolean>
+struct<CAST(udf(cast(k as string)) AS INT):int,every(v):boolean>
-- !query 35 output
1 false
3 false
-337,16 +335,16 struct<k:int,every(v):boolean>
-- !query 36
-SELECT k, every(v) FROM test_agg GROUP BY k HAVING every(v) IS NULL
+SELECT k, udf(every(v)) FROM test_agg GROUP BY k HAVING every(v) IS NULL
-- !query 36 schema
-struct<k:int,every(v):boolean>
+struct<k:int,CAST(udf(cast(every(v) as string)) AS BOOLEAN):boolean>
-- !query 36 output
4 NULL
-- !query 37
SELECT k,
- Every(v) AS every
+ udf(Every(v)) AS every
FROM test_agg
WHERE k = 2
AND v IN (SELECT Any(v)
-360,7 +358,7 struct<k:int,every:boolean>
-- !query 38
-SELECT k,
+SELECT udf(udf(k)),
Every(v) AS every
FROM test_agg
WHERE k = 2
-369,45 +367,45 WHERE k = 2
WHERE k = 1)
GROUP BY k
-- !query 38 schema
-struct<k:int,every:boolean>
+struct<CAST(udf(cast(cast(udf(cast(k as string)) as int) as string)) AS INT):int,every:boolean>
-- !query 38 output
-- !query 39
-SELECT every(1)
+SELECT every(udf(1))
-- !query 39 schema
struct<>
-- !query 39 output
org.apache.spark.sql.AnalysisException
-cannot resolve 'every(1)' due to data type mismatch: Input to function 'every' should have been boolean, but it's [int].; line 1 pos 7
+cannot resolve 'every(CAST(udf(cast(1 as string)) AS INT))' due to data type mismatch: Input to function 'every' should have been boolean, but it's [int].; line 1 pos 7
-- !query 40
-SELECT some(1S)
+SELECT some(udf(1S))
-- !query 40 schema
struct<>
-- !query 40 output
org.apache.spark.sql.AnalysisException
-cannot resolve 'some(1S)' due to data type mismatch: Input to function 'some' should have been boolean, but it's [smallint].; line 1 pos 7
+cannot resolve 'some(CAST(udf(cast(1 as string)) AS SMALLINT))' due to data type mismatch: Input to function 'some' should have been boolean, but it's [smallint].; line 1 pos 7
-- !query 41
-SELECT any(1L)
+SELECT any(udf(1L))
-- !query 41 schema
struct<>
-- !query 41 output
org.apache.spark.sql.AnalysisException
-cannot resolve 'any(1L)' due to data type mismatch: Input to function 'any' should have been boolean, but it's [bigint].; line 1 pos 7
+cannot resolve 'any(CAST(udf(cast(1 as string)) AS BIGINT))' due to data type mismatch: Input to function 'any' should have been boolean, but it's [bigint].; line 1 pos 7
-- !query 42
-SELECT every("true")
+SELECT udf(every("true"))
-- !query 42 schema
struct<>
-- !query 42 output
org.apache.spark.sql.AnalysisException
-cannot resolve 'every('true')' due to data type mismatch: Input to function 'every' should have been boolean, but it's [string].; line 1 pos 7
+cannot resolve 'every('true')' due to data type mismatch: Input to function 'every' should have been boolean, but it's [string].; line 1 pos 11
-- !query 43
-428,9 +426,9 struct<k:int,v:boolean,every(v) OVER (PARTITION BY k ORDER BY v ASC NULLS FIRST
-- !query 44
-SELECT k, v, some(v) OVER (PARTITION BY k ORDER BY v) FROM test_agg
+SELECT k, udf(udf(v)), some(v) OVER (PARTITION BY k ORDER BY v) FROM test_agg
-- !query 44 schema
-struct<k:int,v:boolean,some(v) OVER (PARTITION BY k ORDER BY v ASC NULLS FIRST RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW):boolean>
+struct<k:int,CAST(udf(cast(cast(udf(cast(v as string)) as boolean) as string)) AS BOOLEAN):boolean,some(v) OVER (PARTITION BY k ORDER BY v ASC NULLS FIRST RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW):boolean>
-- !query 44 output
1 false false
1 true true
-445,9 +443,9 struct<k:int,v:boolean,some(v) OVER (PARTITION BY k ORDER BY v ASC NULLS FIRST R
-- !query 45
-SELECT k, v, any(v) OVER (PARTITION BY k ORDER BY v) FROM test_agg
+SELECT udf(udf(k)), v, any(v) OVER (PARTITION BY k ORDER BY v) FROM test_agg
-- !query 45 schema
-struct<k:int,v:boolean,any(v) OVER (PARTITION BY k ORDER BY v ASC NULLS FIRST RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW):boolean>
+struct<CAST(udf(cast(cast(udf(cast(k as string)) as int) as string)) AS INT):int,v:boolean,any(v) OVER (PARTITION BY k ORDER BY v ASC NULLS FIRST RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW):boolean>
-- !query 45 output
1 false false
1 true true
-462,17 +460,17 struct<k:int,v:boolean,any(v) OVER (PARTITION BY k ORDER BY v ASC NULLS FIRST RA
-- !query 46
-SELECT count(*) FROM test_agg HAVING count(*) > 1L
+SELECT udf(count(*)) FROM test_agg HAVING count(*) > 1L
-- !query 46 schema
-struct<count(1):bigint>
+struct<CAST(udf(cast(count(1) as string)) AS BIGINT):bigint>
-- !query 46 output
10
-- !query 47
-SELECT k, max(v) FROM test_agg GROUP BY k HAVING max(v) = true
+SELECT k, udf(max(v)) FROM test_agg GROUP BY k HAVING max(v) = true
-- !query 47 schema
-struct<k:int,max(v):boolean>
+struct<k:int,CAST(udf(cast(max(v) as string)) AS BOOLEAN):boolean>
-- !query 47 output
1 true
2 true
-480,7 +478,7 struct<k:int,max(v):boolean>
-- !query 48
-SELECT * FROM (SELECT COUNT(*) AS cnt FROM test_agg) WHERE cnt > 1L
+SELECT * FROM (SELECT udf(COUNT(*)) AS cnt FROM test_agg) WHERE cnt > 1L
-- !query 48 schema
struct<cnt:bigint>
-- !query 48 output
-488,7 +486,7 struct<cnt:bigint>
-- !query 49
-SELECT count(*) FROM test_agg WHERE count(*) > 1L
+SELECT udf(count(*)) FROM test_agg WHERE count(*) > 1L
-- !query 49 schema
struct<>
-- !query 49 output
-500,7 +498,7 Invalid expressions: [count(1)];
-- !query 50
-SELECT count(*) FROM test_agg WHERE count(*) + 1L > 1L
+SELECT udf(count(*)) FROM test_agg WHERE count(*) + 1L > 1L
-- !query 50 schema
struct<>
-- !query 50 output
-512,7 +510,7 Invalid expressions: [count(1)];
-- !query 51
-SELECT count(*) FROM test_agg WHERE k = 1 or k = 2 or count(*) + 1L > 1L or max(k) > 1
+SELECT udf(count(*)) FROM test_agg WHERE k = 1 or k = 2 or count(*) + 1L > 1L or max(k) > 1
-- !query 51 schema
struct<>
-- !query 51 output
```
</p>
</details>
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Verified pandas & pyarrow versions:
```$python3
Python 3.6.8 (default, Jan 14 2019, 11:02:34)
[GCC 8.0.1 20180414 (experimental) [trunk revision 259383]] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas
>>> import pyarrow
>>> pyarrow.__version__
'0.14.0'
>>> pandas.__version__
'0.24.2'
```
From the sql output it seems that sql statements are evaluated correctly given that udf returns a string and may change results as Null will be returned as None and will be counted in returned values.
Closes#25098 from skonto/group-by.sql.
Authored-by: Stavros Kontopoulos <st.kontopoulos@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Because `Encoder` is not thread safe, the user cannot reuse an `Encoder` in multiple `Dataset`s. However, creating an `Encoder` for a complicated class is slow due to Scala Reflection. To eliminate the cost of Scala Reflection, right now I usually use the private API `ExpressionEncoder.copy` as follows:
```scala
object FooEncoder {
private lazy val _encoder: ExpressionEncoder[Foo] = ExpressionEncoder[Foo]()
implicit def encoder: ExpressionEncoder[Foo] = _encoder.copy()
}
```
This PR proposes a new method `makeCopy` in `Encoder` so that the above codes can be rewritten using public APIs.
```scala
object FooEncoder {
private lazy val _encoder: Encoder[Foo] = Encoders.product[Foo]()
implicit def encoder: Encoder[Foo] = _encoder.makeCopy
}
```
The method name is consistent with `TreeNode.makeCopy`.
## How was this patch tested?
Jenkins
Closes#25209 from zsxwing/encoder-copy.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Implements the `REPLACE TABLE` and `REPLACE TABLE AS SELECT` logical plans. `REPLACE TABLE` is now a valid operation in spark-sql provided that the tables being modified are managed by V2 catalogs.
This also introduces an atomic mix-in that table catalogs can choose to implement. Table catalogs can now implement `TransactionalTableCatalog`. The semantics of this API are that table creation and replacement can be "staged" and then "committed".
On the execution of `REPLACE TABLE AS SELECT`, `REPLACE TABLE`, and `CREATE TABLE AS SELECT`, if the catalog implements transactional operations, the physical plan will use said functionality. Otherwise, these operations fall back on non-atomic variants. For `REPLACE TABLE` in particular, the usage of non-atomic operations can unfortunately lead to inconsistent state.
## How was this patch tested?
Unit tests - multiple additions to `DataSourceV2SQLSuite`.
Closes#24798 from mccheah/spark-27724.
Authored-by: mcheah <mcheah@palantir.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
When a `ScalaUDF` returns a value which overflows, currently it returns null regardless of the value of the config `spark.sql.decimalOperations.nullOnOverflow`.
The PR makes it respect the above-mentioned config and behave accordingly.
## How was this patch tested?
added UT
Closes#25144 from mgaido91/SPARK-28369.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This pr proposes to add a prefix '*' to non-nullable attribute names in PlanTestBase.comparePlans failures. In the current master, nullability mismatches might generate the same error message for left/right logical plans like this;
```
// This failure message was extracted from #24765
- constraints should be inferred from aliased literals *** FAILED ***
== FAIL: Plans do not match ===
!'Join Inner, (two#0 = a#0) 'Join Inner, (two#0 = a#0)
:- Filter (isnotnull(a#0) AND (2 <=> a#0)) :- Filter (isnotnull(a#0) AND (2 <=> a#0))
: +- LocalRelation <empty>, [a#0, b#0, c#0] : +- LocalRelation <empty>, [a#0, b#0, c#0]
+- Project [2 AS two#0] +- Project [2 AS two#0]
+- LocalRelation <empty>, [a#0, b#0, c#0] +- LocalRelation <empty>, [a#0, b#0, c#0] (PlanTest.scala:145)
```
With this pr, this error message is changed to one below;
```
- constraints should be inferred from aliased literals *** FAILED ***
== FAIL: Plans do not match ===
!'Join Inner, (*two#0 = a#0) 'Join Inner, (*two#0 = *a#0)
:- Filter (isnotnull(a#0) AND (2 <=> a#0)) :- Filter (isnotnull(a#0) AND (2 <=> a#0))
: +- LocalRelation <empty>, [a#0, b#0, c#0] : +- LocalRelation <empty>, [a#0, b#0, c#0]
+- Project [2 AS two#0] +- Project [2 AS two#0]
+- LocalRelation <empty>, [a#0, b#0, c#0] +- LocalRelation <empty>, [a#0, b#0, c#0] (PlanTest.scala:145)
```
## How was this patch tested?
N/A
Closes#25213 from maropu/MarkForNullability.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr is to remove the unnecessary test in DataFrameSuite.
## How was this patch tested?
N/A
Closes#25216 from maropu/SPARK-28189-FOLLOWUP.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
The optimize rule `PushDownPredicate` has been combined into `PushDownPredicates`, update the comment that references the old rule.
## How was this patch tested?
N/A
Closes#25207 from jiangxb1987/comment.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from `inline-table.sql` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
<details><summary>Diff comparing to 'inline-table.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/inline-table.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-inline-table.sql.out
index 4e80f0bda5..2cf24e50c8 100644
--- a/sql/core/src/test/resources/sql-tests/results/inline-table.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-inline-table.sql.out
-3,33 +3,33
-- !query 0
-select * from values ("one", 1)
+select udf(col1), udf(col2) from values ("one", 1)
-- !query 0 schema
-struct<col1:string,col2:int>
+struct<CAST(udf(cast(col1 as string)) AS STRING):string,CAST(udf(cast(col2 as string)) AS INT):int>
-- !query 0 output
one 1
-- !query 1
-select * from values ("one", 1) as data
+select udf(col1), udf(udf(col2)) from values ("one", 1) as data
-- !query 1 schema
-struct<col1:string,col2:int>
+struct<CAST(udf(cast(col1 as string)) AS STRING):string,CAST(udf(cast(cast(udf(cast(col2 as string)) as int) as string)) AS INT):int>
-- !query 1 output
one 1
-- !query 2
-select * from values ("one", 1) as data(a, b)
+select udf(a), b from values ("one", 1) as data(a, b)
-- !query 2 schema
-struct<a:string,b:int>
+struct<CAST(udf(cast(a as string)) AS STRING):string,b:int>
-- !query 2 output
one 1
-- !query 3
-select * from values 1, 2, 3 as data(a)
+select udf(a) from values 1, 2, 3 as data(a)
-- !query 3 schema
-struct<a:int>
+struct<CAST(udf(cast(a as string)) AS INT):int>
-- !query 3 output
1
2
-37,9 +37,9 struct<a:int>
-- !query 4
-select * from values ("one", 1), ("two", 2), ("three", null) as data(a, b)
+select udf(a), b from values ("one", 1), ("two", 2), ("three", null) as data(a, b)
-- !query 4 schema
-struct<a:string,b:int>
+struct<CAST(udf(cast(a as string)) AS STRING):string,b:int>
-- !query 4 output
one 1
three NULL
-47,107 +47,107 two 2
-- !query 5
-select * from values ("one", null), ("two", null) as data(a, b)
+select udf(a), b from values ("one", null), ("two", null) as data(a, b)
-- !query 5 schema
-struct<a:string,b:null>
+struct<CAST(udf(cast(a as string)) AS STRING):string,b:null>
-- !query 5 output
one NULL
two NULL
-- !query 6
-select * from values ("one", 1), ("two", 2L) as data(a, b)
+select udf(a), b from values ("one", 1), ("two", 2L) as data(a, b)
-- !query 6 schema
-struct<a:string,b:bigint>
+struct<CAST(udf(cast(a as string)) AS STRING):string,b:bigint>
-- !query 6 output
one 1
two 2
-- !query 7
-select * from values ("one", 1 + 0), ("two", 1 + 3L) as data(a, b)
+select udf(udf(a)), udf(b) from values ("one", 1 + 0), ("two", 1 + 3L) as data(a, b)
-- !query 7 schema
-struct<a:string,b:bigint>
+struct<CAST(udf(cast(cast(udf(cast(a as string)) as string) as string)) AS STRING):string,CAST(udf(cast(b as string)) AS BIGINT):bigint>
-- !query 7 output
one 1
two 4
-- !query 8
-select * from values ("one", array(0, 1)), ("two", array(2, 3)) as data(a, b)
+select udf(a), b from values ("one", array(0, 1)), ("two", array(2, 3)) as data(a, b)
-- !query 8 schema
-struct<a:string,b:array<int>>
+struct<CAST(udf(cast(a as string)) AS STRING):string,b:array<int>>
-- !query 8 output
one [0,1]
two [2,3]
-- !query 9
-select * from values ("one", 2.0), ("two", 3.0D) as data(a, b)
+select udf(a), b from values ("one", 2.0), ("two", 3.0D) as data(a, b)
-- !query 9 schema
-struct<a:string,b:double>
+struct<CAST(udf(cast(a as string)) AS STRING):string,b:double>
-- !query 9 output
one 2.0
two 3.0
-- !query 10
-select * from values ("one", rand(5)), ("two", 3.0D) as data(a, b)
+select udf(a), b from values ("one", rand(5)), ("two", 3.0D) as data(a, b)
-- !query 10 schema
struct<>
-- !query 10 output
org.apache.spark.sql.AnalysisException
-cannot evaluate expression rand(5) in inline table definition; line 1 pos 29
+cannot evaluate expression rand(5) in inline table definition; line 1 pos 37
-- !query 11
-select * from values ("one", 2.0), ("two") as data(a, b)
+select udf(a), udf(b) from values ("one", 2.0), ("two") as data(a, b)
-- !query 11 schema
struct<>
-- !query 11 output
org.apache.spark.sql.AnalysisException
-expected 2 columns but found 1 columns in row 1; line 1 pos 14
+expected 2 columns but found 1 columns in row 1; line 1 pos 27
-- !query 12
-select * from values ("one", array(0, 1)), ("two", struct(1, 2)) as data(a, b)
+select udf(a), udf(b) from values ("one", array(0, 1)), ("two", struct(1, 2)) as data(a, b)
-- !query 12 schema
struct<>
-- !query 12 output
org.apache.spark.sql.AnalysisException
-incompatible types found in column b for inline table; line 1 pos 14
+incompatible types found in column b for inline table; line 1 pos 27
-- !query 13
-select * from values ("one"), ("two") as data(a, b)
+select udf(a), udf(b) from values ("one"), ("two") as data(a, b)
-- !query 13 schema
struct<>
-- !query 13 output
org.apache.spark.sql.AnalysisException
-expected 2 columns but found 1 columns in row 0; line 1 pos 14
+expected 2 columns but found 1 columns in row 0; line 1 pos 27
-- !query 14
-select * from values ("one", random_not_exist_func(1)), ("two", 2) as data(a, b)
+select udf(a), udf(b) from values ("one", random_not_exist_func(1)), ("two", 2) as data(a, b)
-- !query 14 schema
struct<>
-- !query 14 output
org.apache.spark.sql.AnalysisException
-Undefined function: 'random_not_exist_func'. This function is neither a registered temporary function nor a permanent function registered in the database 'default'.; line 1 pos 29
+Undefined function: 'random_not_exist_func'. This function is neither a registered temporary function nor a permanent function registered in the database 'default'.; line 1 pos 42
-- !query 15
-select * from values ("one", count(1)), ("two", 2) as data(a, b)
+select udf(a), udf(b) from values ("one", count(1)), ("two", 2) as data(a, b)
-- !query 15 schema
struct<>
-- !query 15 output
org.apache.spark.sql.AnalysisException
-cannot evaluate expression count(1) in inline table definition; line 1 pos 29
+cannot evaluate expression count(1) in inline table definition; line 1 pos 42
-- !query 16
-select * from values (timestamp('1991-12-06 00:00:00.0'), array(timestamp('1991-12-06 01:00:00.0'), timestamp('1991-12-06 12:00:00.0'))) as data(a, b)
+select udf(a), b from values (timestamp('1991-12-06 00:00:00.0'), array(timestamp('1991-12-06 01:00:00.0'), timestamp('1991-12-06 12:00:00.0'))) as data(a, b)
-- !query 16 schema
-struct<a:timestamp,b:array<timestamp>>
+struct<CAST(udf(cast(a as string)) AS TIMESTAMP):timestamp,b:array<timestamp>>
-- !query 16 output
1991-12-06 00:00:00 [1991-12-06 01:00:00.0,1991-12-06 12:00:00.0]
```
</p>
</details>
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25124 from imback82/inline-table-sql.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from group-analytics.sql to test UDFs. Please see contribution guide of this umbrella ticket - SPARK-27921.
<details><summary>Diff comparing to 'group-analytics.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/udf/udf-group-analytics.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-group-analytics.sql.out
index 31e9e08e2c..3439a05727 100644
--- a/sql/core/src/test/resources/sql-tests/results/udf/udf-group-analytics.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-group-analytics.sql.out
-13,9 +13,9 struct<>
-- !query 1
-SELECT a + b, b, udf(SUM(a - b)) FROM testData GROUP BY a + b, b WITH CUBE
+SELECT a + b, b, SUM(a - b) FROM testData GROUP BY a + b, b WITH CUBE
-- !query 1 schema
-struct<(a + b):int,b:int,CAST(udf(cast(sum(cast((a - b) as bigint)) as string)) AS BIGINT):bigint>
+struct<(a + b):int,b:int,sum((a - b)):bigint>
-- !query 1 output
2 1 0
2 NULL 0
-33,9 +33,9 NULL NULL 3
-- !query 2
-SELECT a, udf(b), SUM(b) FROM testData GROUP BY a, b WITH CUBE
+SELECT a, b, SUM(b) FROM testData GROUP BY a, b WITH CUBE
-- !query 2 schema
-struct<a:int,CAST(udf(cast(b as string)) AS INT):int,sum(b):bigint>
+struct<a:int,b:int,sum(b):bigint>
-- !query 2 output
1 1 1
1 2 2
-52,9 +52,9 NULL NULL 9
-- !query 3
-SELECT udf(a + b), b, SUM(a - b) FROM testData GROUP BY a + b, b WITH ROLLUP
+SELECT a + b, b, SUM(a - b) FROM testData GROUP BY a + b, b WITH ROLLUP
-- !query 3 schema
-struct<CAST(udf(cast((a + b) as string)) AS INT):int,b:int,sum((a - b)):bigint>
+struct<(a + b):int,b:int,sum((a - b)):bigint>
-- !query 3 output
2 1 0
2 NULL 0
-70,9 +70,9 NULL NULL 3
-- !query 4
-SELECT a, b, udf(SUM(b)) FROM testData GROUP BY a, b WITH ROLLUP
+SELECT a, b, SUM(b) FROM testData GROUP BY a, b WITH ROLLUP
-- !query 4 schema
-struct<a:int,b:int,CAST(udf(cast(sum(cast(b as bigint)) as string)) AS BIGINT):bigint>
+struct<a:int,b:int,sum(b):bigint>
-- !query 4 output
1 1 1
1 2 2
-97,7 +97,7 struct<>
-- !query 6
-SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP(course, year) ORDER BY udf(course), year
+SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP(course, year) ORDER BY course, year
-- !query 6 schema
struct<course:string,year:int,sum(earnings):bigint>
-- !query 6 output
-111,7 +111,7 dotNET 2013 48000
-- !query 7
-SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE(course, year) ORDER BY course, udf(year)
+SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE(course, year) ORDER BY course, year
-- !query 7 schema
struct<course:string,year:int,sum(earnings):bigint>
-- !query 7 output
-127,9 +127,9 dotNET 2013 48000
-- !query 8
-SELECT course, udf(year), SUM(earnings) FROM courseSales GROUP BY course, year GROUPING SETS(course, year)
+SELECT course, year, SUM(earnings) FROM courseSales GROUP BY course, year GROUPING SETS(course, year)
-- !query 8 schema
-struct<course:string,CAST(udf(cast(year as string)) AS INT):int,sum(earnings):bigint>
+struct<course:string,year:int,sum(earnings):bigint>
-- !query 8 output
Java NULL 50000
NULL 2012 35000
-138,26 +138,26 dotNET NULL 63000
-- !query 9
-SELECT course, year, udf(SUM(earnings)) FROM courseSales GROUP BY course, year GROUPING SETS(course)
+SELECT course, year, SUM(earnings) FROM courseSales GROUP BY course, year GROUPING SETS(course)
-- !query 9 schema
-struct<course:string,year:int,CAST(udf(cast(sum(cast(earnings as bigint)) as string)) AS BIGINT):bigint>
+struct<course:string,year:int,sum(earnings):bigint>
-- !query 9 output
Java NULL 50000
dotNET NULL 63000
-- !query 10
-SELECT udf(course), year, SUM(earnings) FROM courseSales GROUP BY course, year GROUPING SETS(year)
+SELECT course, year, SUM(earnings) FROM courseSales GROUP BY course, year GROUPING SETS(year)
-- !query 10 schema
-struct<CAST(udf(cast(course as string)) AS STRING):string,year:int,sum(earnings):bigint>
+struct<course:string,year:int,sum(earnings):bigint>
-- !query 10 output
NULL 2012 35000
NULL 2013 78000
-- !query 11
-SELECT course, udf(SUM(earnings)) AS sum FROM courseSales
-GROUP BY course, earnings GROUPING SETS((), (course), (course, earnings)) ORDER BY course, udf(sum)
+SELECT course, SUM(earnings) AS sum FROM courseSales
+GROUP BY course, earnings GROUPING SETS((), (course), (course, earnings)) ORDER BY course, sum
-- !query 11 schema
struct<course:string,sum:bigint>
-- !query 11 output
-173,7 +173,7 dotNET 63000
-- !query 12
SELECT course, SUM(earnings) AS sum, GROUPING_ID(course, earnings) FROM courseSales
-GROUP BY course, earnings GROUPING SETS((), (course), (course, earnings)) ORDER BY udf(course), sum
+GROUP BY course, earnings GROUPING SETS((), (course), (course, earnings)) ORDER BY course, sum
-- !query 12 schema
struct<course:string,sum:bigint,grouping_id(course, earnings):int>
-- !query 12 output
-188,10 +188,10 dotNET 63000 1
-- !query 13
-SELECT udf(course), udf(year), GROUPING(course), GROUPING(year), GROUPING_ID(course, year) FROM courseSales
+SELECT course, year, GROUPING(course), GROUPING(year), GROUPING_ID(course, year) FROM courseSales
GROUP BY CUBE(course, year)
-- !query 13 schema
-struct<CAST(udf(cast(course as string)) AS STRING):string,CAST(udf(cast(year as string)) AS INT):int,grouping(course):tinyint,grouping(year):tinyint,grouping_id(course, year):int>
+struct<course:string,year:int,grouping(course):tinyint,grouping(year):tinyint,grouping_id(course, year):int>
-- !query 13 output
Java 2012 0 0 0
Java 2013 0 0 0
-205,7 +205,7 dotNET NULL 0 1 1
-- !query 14
-SELECT course, udf(year), GROUPING(course) FROM courseSales GROUP BY course, year
+SELECT course, year, GROUPING(course) FROM courseSales GROUP BY course, year
-- !query 14 schema
struct<>
-- !query 14 output
-214,7 +214,7 grouping() can only be used with GroupingSets/Cube/Rollup;
-- !query 15
-SELECT course, udf(year), GROUPING_ID(course, year) FROM courseSales GROUP BY course, year
+SELECT course, year, GROUPING_ID(course, year) FROM courseSales GROUP BY course, year
-- !query 15 schema
struct<>
-- !query 15 output
-223,7 +223,7 grouping_id() can only be used with GroupingSets/Cube/Rollup;
-- !query 16
-SELECT course, year, grouping__id FROM courseSales GROUP BY CUBE(course, year) ORDER BY grouping__id, course, udf(year)
+SELECT course, year, grouping__id FROM courseSales GROUP BY CUBE(course, year) ORDER BY grouping__id, course, year
-- !query 16 schema
struct<course:string,year:int,grouping__id:int>
-- !query 16 output
-240,7 +240,7 NULL NULL 3
-- !query 17
SELECT course, year FROM courseSales GROUP BY CUBE(course, year)
-HAVING GROUPING(year) = 1 AND GROUPING_ID(course, year) > 0 ORDER BY course, udf(year)
+HAVING GROUPING(year) = 1 AND GROUPING_ID(course, year) > 0 ORDER BY course, year
-- !query 17 schema
struct<course:string,year:int>
-- !query 17 output
-250,7 +250,7 dotNET NULL
-- !query 18
-SELECT course, udf(year) FROM courseSales GROUP BY course, year HAVING GROUPING(course) > 0
+SELECT course, year FROM courseSales GROUP BY course, year HAVING GROUPING(course) > 0
-- !query 18 schema
struct<>
-- !query 18 output
-259,7 +259,7 grouping()/grouping_id() can only be used with GroupingSets/Cube/Rollup;
-- !query 19
-SELECT course, udf(udf(year)) FROM courseSales GROUP BY course, year HAVING GROUPING_ID(course) > 0
+SELECT course, year FROM courseSales GROUP BY course, year HAVING GROUPING_ID(course) > 0
-- !query 19 schema
struct<>
-- !query 19 output
-268,9 +268,9 grouping()/grouping_id() can only be used with GroupingSets/Cube/Rollup;
-- !query 20
-SELECT udf(course), year FROM courseSales GROUP BY CUBE(course, year) HAVING grouping__id > 0
+SELECT course, year FROM courseSales GROUP BY CUBE(course, year) HAVING grouping__id > 0
-- !query 20 schema
-struct<CAST(udf(cast(course as string)) AS STRING):string,year:int>
+struct<course:string,year:int>
-- !query 20 output
Java NULL
NULL 2012
-281,7 +281,7 dotNET NULL
-- !query 21
SELECT course, year, GROUPING(course), GROUPING(year) FROM courseSales GROUP BY CUBE(course, year)
-ORDER BY GROUPING(course), GROUPING(year), course, udf(year)
+ORDER BY GROUPING(course), GROUPING(year), course, year
-- !query 21 schema
struct<course:string,year:int,grouping(course):tinyint,grouping(year):tinyint>
-- !query 21 output
-298,7 +298,7 NULL NULL 1 1
-- !query 22
SELECT course, year, GROUPING_ID(course, year) FROM courseSales GROUP BY CUBE(course, year)
-ORDER BY GROUPING(course), GROUPING(year), course, udf(year)
+ORDER BY GROUPING(course), GROUPING(year), course, year
-- !query 22 schema
struct<course:string,year:int,grouping_id(course, year):int>
-- !query 22 output
-314,7 +314,7 NULL NULL 3
-- !query 23
-SELECT course, udf(year) FROM courseSales GROUP BY course, udf(year) ORDER BY GROUPING(course)
+SELECT course, year FROM courseSales GROUP BY course, year ORDER BY GROUPING(course)
-- !query 23 schema
struct<>
-- !query 23 output
-323,7 +323,7 grouping()/grouping_id() can only be used with GroupingSets/Cube/Rollup;
-- !query 24
-SELECT course, udf(year) FROM courseSales GROUP BY course, udf(year) ORDER BY GROUPING_ID(course)
+SELECT course, year FROM courseSales GROUP BY course, year ORDER BY GROUPING_ID(course)
-- !query 24 schema
struct<>
-- !query 24 output
-332,7 +332,7 grouping()/grouping_id() can only be used with GroupingSets/Cube/Rollup;
-- !query 25
-SELECT course, year FROM courseSales GROUP BY CUBE(course, year) ORDER BY grouping__id, udf(course), year
+SELECT course, year FROM courseSales GROUP BY CUBE(course, year) ORDER BY grouping__id, course, year
-- !query 25 schema
struct<course:string,year:int>
-- !query 25 output
-348,7 +348,7 NULL NULL
-- !query 26
-SELECT udf(a + b) AS k1, udf(b) AS k2, SUM(a - b) FROM testData GROUP BY CUBE(k1, k2)
+SELECT a + b AS k1, b AS k2, SUM(a - b) FROM testData GROUP BY CUBE(k1, k2)
-- !query 26 schema
struct<k1:int,k2:int,sum((a - b)):bigint>
-- !query 26 output
-368,7 +368,7 NULL NULL 3
-- !query 27
-SELECT udf(udf(a + b)) AS k, b, SUM(a - b) FROM testData GROUP BY ROLLUP(k, b)
+SELECT a + b AS k, b, SUM(a - b) FROM testData GROUP BY ROLLUP(k, b)
-- !query 27 schema
struct<k:int,b:int,sum((a - b)):bigint>
-- !query 27 output
-386,9 +386,9 NULL NULL 3
-- !query 28
-SELECT udf(a + b), udf(udf(b)) AS k, SUM(a - b) FROM testData GROUP BY a + b, k GROUPING SETS(k)
+SELECT a + b, b AS k, SUM(a - b) FROM testData GROUP BY a + b, k GROUPING SETS(k)
-- !query 28 schema
-struct<CAST(udf(cast((a + b) as string)) AS INT):int,k:int,sum((a - b)):bigint>
+struct<(a + b):int,k:int,sum((a - b)):bigint>
-- !query 28 output
NULL 1 3
NULL 2 0
```
</p>
</details>
## How was this patch tested?
Tested as guided in SPARK-27921.
Verified pandas & pyarrow versions:
```$python3
Python 3.6.8 (default, Jan 14 2019, 11:02:34)
[GCC 8.0.1 20180414 (experimental) [trunk revision 259383]] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas
>>> import pyarrow
>>> pyarrow.__version__
'0.14.0'
>>> pandas.__version__
'0.24.2'
```
From the sql output it seems that sql statements are evaluated correctly given that udf returns a string and may change results as Null will be returned as None and will be counted in returned values.
Closes#25196 from skonto/group-analytics.sql.
Authored-by: Stavros Kontopoulos <st.kontopoulos@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR removes a few hardware-dependent assertions which can cause a failure in `aarch64`.
**x86_64**
```
rootdonotdel-openlab-allinone-l00242678:/home/ubuntu# uname -a
Linux donotdel-openlab-allinone-l00242678 4.4.0-154-generic #181-Ubuntu SMP Tue Jun 25 05:29:03 UTC
2019 x86_64 x86_64 x86_64 GNU/Linux
scala> import java.lang.Float.floatToRawIntBits
import java.lang.Float.floatToRawIntBits
scala> floatToRawIntBits(0.0f/0.0f)
res0: Int = -4194304
scala> floatToRawIntBits(Float.NaN)
res1: Int = 2143289344
```
**aarch64**
```
[rootarm-huangtianhua spark]# uname -a
Linux arm-huangtianhua 4.14.0-49.el7a.aarch64 #1 SMP Tue Apr 10 17:22:26 UTC 2018 aarch64 aarch64 aarch64 GNU/Linux
scala> import java.lang.Float.floatToRawIntBits
import java.lang.Float.floatToRawIntBits
scala> floatToRawIntBits(0.0f/0.0f)
res1: Int = 2143289344
scala> floatToRawIntBits(Float.NaN)
res2: Int = 2143289344
```
## How was this patch tested?
Pass the Jenkins (This removes the test coverage).
Closes#25186 from huangtianhua/special-test-case-for-aarch64.
Authored-by: huangtianhua <huangtianhua@huawei.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
SPARK-28199 (#24996) hid implementations of Triggers into `private[sql]` and encourage end users to use `Trigger.xxx` methods instead.
As I got some post review comment on 7548a8826d (r34366934) we could remove annotations which are meant to be used with public API.
## How was this patch tested?
N/A
Closes#25200 from HeartSaVioR/SPARK-28199-FOLLOWUP.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds some tests converted from `join-empty-relation.sql` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
<details><summary>Diff comparing to 'join-empty-relation.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/join-empty-relation.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-join-empty-relation.sql.out
index 857073a827..e79d01fb14 100644
--- a/sql/core/src/test/resources/sql-tests/results/join-empty-relation.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-join-empty-relation.sql.out
-27,111 +27,111 struct<>
-- !query 3
-SELECT * FROM t1 INNER JOIN empty_table
+SELECT udf(t1.a), udf(empty_table.a) FROM t1 INNER JOIN empty_table ON (udf(t1.a) = udf(udf(empty_table.a)))
-- !query 3 schema
-struct<a:int,a:int>
+struct<CAST(udf(cast(a as string)) AS INT):int,CAST(udf(cast(a as string)) AS INT):int>
-- !query 3 output
-- !query 4
-SELECT * FROM t1 CROSS JOIN empty_table
+SELECT udf(t1.a), udf(udf(empty_table.a)) FROM t1 CROSS JOIN empty_table ON (udf(udf(t1.a)) = udf(empty_table.a))
-- !query 4 schema
-struct<a:int,a:int>
+struct<CAST(udf(cast(a as string)) AS INT):int,CAST(udf(cast(cast(udf(cast(a as string)) as int) as string)) AS INT):int>
-- !query 4 output
-- !query 5
-SELECT * FROM t1 LEFT OUTER JOIN empty_table
+SELECT udf(udf(t1.a)), empty_table.a FROM t1 LEFT OUTER JOIN empty_table ON (udf(t1.a) = udf(empty_table.a))
-- !query 5 schema
-struct<a:int,a:int>
+struct<CAST(udf(cast(cast(udf(cast(a as string)) as int) as string)) AS INT):int,a:int>
-- !query 5 output
1 NULL
-- !query 6
-SELECT * FROM t1 RIGHT OUTER JOIN empty_table
+SELECT udf(t1.a), udf(empty_table.a) FROM t1 RIGHT OUTER JOIN empty_table ON (udf(t1.a) = udf(empty_table.a))
-- !query 6 schema
-struct<a:int,a:int>
+struct<CAST(udf(cast(a as string)) AS INT):int,CAST(udf(cast(a as string)) AS INT):int>
-- !query 6 output
-- !query 7
-SELECT * FROM t1 FULL OUTER JOIN empty_table
+SELECT udf(t1.a), empty_table.a FROM t1 FULL OUTER JOIN empty_table ON (udf(t1.a) = udf(empty_table.a))
-- !query 7 schema
-struct<a:int,a:int>
+struct<CAST(udf(cast(a as string)) AS INT):int,a:int>
-- !query 7 output
1 NULL
-- !query 8
-SELECT * FROM t1 LEFT SEMI JOIN empty_table
+SELECT udf(udf(t1.a)) FROM t1 LEFT SEMI JOIN empty_table ON (udf(t1.a) = udf(udf(empty_table.a)))
-- !query 8 schema
-struct<a:int>
+struct<CAST(udf(cast(cast(udf(cast(a as string)) as int) as string)) AS INT):int>
-- !query 8 output
-- !query 9
-SELECT * FROM t1 LEFT ANTI JOIN empty_table
+SELECT udf(t1.a) FROM t1 LEFT ANTI JOIN empty_table ON (udf(t1.a) = udf(empty_table.a))
-- !query 9 schema
-struct<a:int>
+struct<CAST(udf(cast(a as string)) AS INT):int>
-- !query 9 output
1
-- !query 10
-SELECT * FROM empty_table INNER JOIN t1
+SELECT udf(empty_table.a), udf(t1.a) FROM empty_table INNER JOIN t1 ON (udf(udf(empty_table.a)) = udf(t1.a))
-- !query 10 schema
-struct<a:int,a:int>
+struct<CAST(udf(cast(a as string)) AS INT):int,CAST(udf(cast(a as string)) AS INT):int>
-- !query 10 output
-- !query 11
-SELECT * FROM empty_table CROSS JOIN t1
+SELECT udf(empty_table.a), udf(udf(t1.a)) FROM empty_table CROSS JOIN t1 ON (udf(empty_table.a) = udf(udf(t1.a)))
-- !query 11 schema
-struct<a:int,a:int>
+struct<CAST(udf(cast(a as string)) AS INT):int,CAST(udf(cast(cast(udf(cast(a as string)) as int) as string)) AS INT):int>
-- !query 11 output
-- !query 12
-SELECT * FROM empty_table LEFT OUTER JOIN t1
+SELECT udf(udf(empty_table.a)), udf(t1.a) FROM empty_table LEFT OUTER JOIN t1 ON (udf(empty_table.a) = udf(t1.a))
-- !query 12 schema
-struct<a:int,a:int>
+struct<CAST(udf(cast(cast(udf(cast(a as string)) as int) as string)) AS INT):int,CAST(udf(cast(a as string)) AS INT):int>
-- !query 12 output
-- !query 13
-SELECT * FROM empty_table RIGHT OUTER JOIN t1
+SELECT empty_table.a, udf(t1.a) FROM empty_table RIGHT OUTER JOIN t1 ON (udf(empty_table.a) = udf(t1.a))
-- !query 13 schema
-struct<a:int,a:int>
+struct<a:int,CAST(udf(cast(a as string)) AS INT):int>
-- !query 13 output
NULL 1
-- !query 14
-SELECT * FROM empty_table FULL OUTER JOIN t1
+SELECT empty_table.a, udf(udf(t1.a)) FROM empty_table FULL OUTER JOIN t1 ON (udf(empty_table.a) = udf(t1.a))
-- !query 14 schema
-struct<a:int,a:int>
+struct<a:int,CAST(udf(cast(cast(udf(cast(a as string)) as int) as string)) AS INT):int>
-- !query 14 output
NULL 1
-- !query 15
-SELECT * FROM empty_table LEFT SEMI JOIN t1
+SELECT udf(udf(empty_table.a)) FROM empty_table LEFT SEMI JOIN t1 ON (udf(empty_table.a) = udf(udf(t1.a)))
-- !query 15 schema
-struct<a:int>
+struct<CAST(udf(cast(cast(udf(cast(a as string)) as int) as string)) AS INT):int>
-- !query 15 output
-- !query 16
-SELECT * FROM empty_table LEFT ANTI JOIN t1
+SELECT empty_table.a FROM empty_table LEFT ANTI JOIN t1 ON (udf(empty_table.a) = udf(t1.a))
-- !query 16 schema
struct<a:int>
-- !query 16 output
-139,56 +139,56 struct<a:int>
-- !query 17
-SELECT * FROM empty_table INNER JOIN empty_table
+SELECT udf(empty_table.a) FROM empty_table INNER JOIN empty_table AS empty_table2 ON (udf(empty_table.a) = udf(udf(empty_table2.a)))
-- !query 17 schema
-struct<a:int,a:int>
+struct<CAST(udf(cast(a as string)) AS INT):int>
-- !query 17 output
-- !query 18
-SELECT * FROM empty_table CROSS JOIN empty_table
+SELECT udf(udf(empty_table.a)) FROM empty_table CROSS JOIN empty_table AS empty_table2 ON (udf(udf(empty_table.a)) = udf(empty_table2.a))
-- !query 18 schema
-struct<a:int,a:int>
+struct<CAST(udf(cast(cast(udf(cast(a as string)) as int) as string)) AS INT):int>
-- !query 18 output
-- !query 19
-SELECT * FROM empty_table LEFT OUTER JOIN empty_table
+SELECT udf(empty_table.a) FROM empty_table LEFT OUTER JOIN empty_table AS empty_table2 ON (udf(empty_table.a) = udf(empty_table2.a))
-- !query 19 schema
-struct<a:int,a:int>
+struct<CAST(udf(cast(a as string)) AS INT):int>
-- !query 19 output
-- !query 20
-SELECT * FROM empty_table RIGHT OUTER JOIN empty_table
+SELECT udf(udf(empty_table.a)) FROM empty_table RIGHT OUTER JOIN empty_table AS empty_table2 ON (udf(empty_table.a) = udf(udf(empty_table2.a)))
-- !query 20 schema
-struct<a:int,a:int>
+struct<CAST(udf(cast(cast(udf(cast(a as string)) as int) as string)) AS INT):int>
-- !query 20 output
-- !query 21
-SELECT * FROM empty_table FULL OUTER JOIN empty_table
+SELECT udf(empty_table.a) FROM empty_table FULL OUTER JOIN empty_table AS empty_table2 ON (udf(empty_table.a) = udf(empty_table2.a))
-- !query 21 schema
-struct<a:int,a:int>
+struct<CAST(udf(cast(a as string)) AS INT):int>
-- !query 21 output
-- !query 22
-SELECT * FROM empty_table LEFT SEMI JOIN empty_table
+SELECT udf(udf(empty_table.a)) FROM empty_table LEFT SEMI JOIN empty_table AS empty_table2 ON (udf(empty_table.a) = udf(empty_table2.a))
-- !query 22 schema
-struct<a:int>
+struct<CAST(udf(cast(cast(udf(cast(a as string)) as int) as string)) AS INT):int>
-- !query 22 output
-- !query 23
-SELECT * FROM empty_table LEFT ANTI JOIN empty_table
+SELECT udf(empty_table.a) FROM empty_table LEFT ANTI JOIN empty_table AS empty_table2 ON (udf(empty_table.a) = udf(empty_table2.a))
-- !query 23 schema
-struct<a:int>
+struct<CAST(udf(cast(a as string)) AS INT):int>
-- !query 23 output
```
</p>
</details>
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25127 from imback82/join-empty-relation-sql.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Performance issue using explode was found when a complex field contains huge array is to get duplicated as the number of exploded array elements. Given example:
```scala
val df = spark.sparkContext.parallelize(Seq(("1",
Array.fill(M)({
val i = math.random
(i.toString, (i + 1).toString, (i + 2).toString, (i + 3).toString)
})))).toDF("col", "arr")
.selectExpr("col", "struct(col, arr) as st")
.selectExpr("col", "st.col as col1", "explode(st.arr) as arr_col")
```
The explode causes `st` to be duplicated as many as the exploded elements.
Benchmarks it:
```
[info] Java HotSpot(TM) 64-Bit Server VM 1.8.0_202-b08 on Mac OS X 10.14.4
[info] Intel(R) Core(TM) i7-8750H CPU 2.20GHz
[info] generate big nested struct array: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] generate big nested struct array wholestage off 52668 53162 699 0.0 877803.4 1.0X
[info] generate big nested struct array wholestage on 47261 49093 1125 0.0 787690.2 1.1X
[info]
```
The query plan:
```
== Physical Plan ==
Project [col#508, st#512.col AS col1#515, arr_col#519]
+- Generate explode(st#512.arr), [col#508, st#512], false, [arr_col#519]
+- Project [_1#503 AS col#508, named_struct(col, _1#503, arr, _2#504) AS st#512]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, scala.Tuple2, true]))._1, true, false) AS _1#503, mapobjects(MapObjects_loopValue84, MapObjects_loopIsNull84, ObjectType(class scala.Tuple4), if (isnull(lambdavariable(MapObjects_loopValue84, MapObjects_loopIsNull84, ObjectType(class scala.Tuple4), true))) null else named_struct(_1, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue84, MapObjects_loopIsNull84, ObjectType(class scala.Tuple4), true))._1, true, false), _2, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue84, MapObjects_loopIsNull84, ObjectType(class scala.Tuple4), true))._2, true, false), _3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue84, MapObjects_loopIsNull84, ObjectType(class scala.Tuple4), true))._3, true, false), _4, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue84, MapObjects_loopIsNull84, ObjectType(class scala.Tuple4), true))._4, true, false)), knownnotnull(assertnotnull(input[0, scala.Tuple2, true]))._2, None) AS _2#504]
+- Scan[obj#534]
```
This patch takes nested column pruning approach to prune unnecessary nested fields. It adds a projection of the needed nested fields as aliases on the child of `Generate`, and substitutes them by alias attributes on the projection on top of `Generate`.
Benchmarks it after the change:
```
[info] Java HotSpot(TM) 64-Bit Server VM 1.8.0_202-b08 on Mac OS X 10.14.4
[info] Intel(R) Core(TM) i7-8750H CPU 2.20GHz
[info] generate big nested struct array: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] generate big nested struct array wholestage off 311 331 28 0.2 5188.6 1.0X
[info] generate big nested struct array wholestage on 297 312 15 0.2 4947.3 1.0X
[info]
```
The query plan:
```
== Physical Plan ==
Project [col#592, _gen_alias_608#608 AS col1#599, arr_col#603]
+- Generate explode(st#596.arr), [col#592, _gen_alias_608#608], false, [arr_col#603]
+- Project [_1#587 AS col#592, named_struct(col, _1#587, arr, _2#588) AS st#596, _1#587 AS _gen_alias_608#608]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(in
put[0, scala.Tuple2, true]))._1, true, false) AS _1#587, mapobjects(MapObjects_loopValue102, MapObjects_loopIsNull102, ObjectType(class scala.Tuple4),
if (isnull(lambdavariable(MapObjects_loopValue102, MapObjects_loopIsNull102, ObjectType(class scala.Tuple4), true))) null else named_struct(_1, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue102, MapObjects_loopIsNull102, ObjectType(class scala.Tuple4), true))._1, true, false), _2, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue102, MapObjects_loopIsNull102, ObjectType(class scala.Tuple4), true))._2, true, false), _3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue102, MapObjects_loopIsNull102, ObjectType(class scala.Tuple4), true))._3, true, false), _4, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(lambdavariable(MapObjects_loopValue102, MapObjects_loopIsNull102, ObjectType(class scala.Tuple4), true))._4, true, false)), knownnotnull(assertnotnull(input[0, scala.Tuple2, true]))._2, None) AS _2#588]
+- Scan[obj#586]
```
This behavior is controlled by a SQL config `spark.sql.optimizer.expression.nestedPruning.enabled`.
## How was this patch tested?
Added benchmark.
Closes#24637 from viirya/SPARK-27707.
Lead-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds some tests converted from ```except.sql``` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
<details><summary>Diff comparing to 'except.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/except.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-except.sql.out
index c9b712d4d2..27ca7ea226 100644
--- a/sql/core/src/test/resources/sql-tests/results/except.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-except.sql.out
-30,16 +30,16 struct<>
-- !query 2
-SELECT * FROM t1 EXCEPT SELECT * FROM t2
+SELECT udf(k), udf(v) FROM t1 EXCEPT SELECT udf(k), udf(v) FROM t2
-- !query 2 schema
-struct<k:string,v:int>
+struct<CAST(udf(cast(k as string)) AS STRING):string,CAST(udf(cast(v as string)) AS INT):int>
-- !query 2 output
three 3
two 2
-- !query 3
-SELECT * FROM t1 EXCEPT SELECT * FROM t1 where v <> 1 and v <> 2
+SELECT * FROM t1 EXCEPT SELECT * FROM t1 where udf(v) <> 1 and v <> udf(2)
-- !query 3 schema
struct<k:string,v:int>
-- !query 3 output
-49,7 +49,7 two 2
-- !query 4
-SELECT * FROM t1 where v <> 1 and v <> 22 EXCEPT SELECT * FROM t1 where v <> 2 and v >= 3
+SELECT * FROM t1 where udf(v) <> 1 and v <> udf(22) EXCEPT SELECT * FROM t1 where udf(v) <> 2 and v >= udf(3)
-- !query 4 schema
struct<k:string,v:int>
-- !query 4 output
-59,7 +59,7 two 2
-- !query 5
SELECT t1.* FROM t1, t2 where t1.k = t2.k
EXCEPT
-SELECT t1.* FROM t1, t2 where t1.k = t2.k and t1.k != 'one'
+SELECT t1.* FROM t1, t2 where t1.k = t2.k and t1.k != udf('one')
-- !query 5 schema
struct<k:string,v:int>
-- !query 5 output
-68,7 +68,7 one NULL
-- !query 6
-SELECT * FROM t2 where v >= 1 and v <> 22 EXCEPT SELECT * FROM t1
+SELECT * FROM t2 where v >= udf(1) and udf(v) <> 22 EXCEPT SELECT * FROM t1
-- !query 6 schema
struct<k:string,v:int>
-- !query 6 output
-77,9 +77,9 one 5
-- !query 7
-SELECT (SELECT min(k) FROM t2 WHERE t2.k = t1.k) min_t2 FROM t1
+SELECT (SELECT min(udf(k)) FROM t2 WHERE t2.k = t1.k) min_t2 FROM t1
MINUS
-SELECT (SELECT min(k) FROM t2) abs_min_t2 FROM t1 WHERE t1.k = 'one'
+SELECT (SELECT udf(min(k)) FROM t2) abs_min_t2 FROM t1 WHERE t1.k = udf('one')
-- !query 7 schema
struct<min_t2:string>
-- !query 7 output
-90,16 +90,17 two
-- !query 8
SELECT t1.k
FROM t1
-WHERE t1.v <= (SELECT max(t2.v)
+WHERE t1.v <= (SELECT udf(max(udf(t2.v)))
FROM t2
- WHERE t2.k = t1.k)
+ WHERE udf(t2.k) = udf(t1.k))
MINUS
SELECT t1.k
FROM t1
-WHERE t1.v >= (SELECT min(t2.v)
+WHERE udf(t1.v) >= (SELECT min(udf(t2.v))
FROM t2
WHERE t2.k = t1.k)
-- !query 8 schema
-struct<k:string>
+struct<>
-- !query 8 output
-two
+java.lang.UnsupportedOperationException
+Cannot evaluate expression: udf(cast(null as string))
```
</p>
</details>
## How was this patch tested?
Tested as guided in [SPARK-27921.](https://issues.apache.org/jira/browse/SPARK-27921)
Closes#25101 from huaxingao/spark-28277.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from ```outer-join.sql``` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
<details><summary>Diff comparing to 'outer-join.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/outer-join.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-outer-join.sql.out
index 5db3bae5d0..819f786070 100644
--- a/sql/core/src/test/resources/sql-tests/results/outer-join.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-outer-join.sql.out
-24,17 +24,17 struct<>
-- !query 2
SELECT
- (SUM(COALESCE(t1.int_col1, t2.int_col0))),
- ((COALESCE(t1.int_col1, t2.int_col0)) * 2)
+ (udf(SUM(udf(COALESCE(t1.int_col1, t2.int_col0))))),
+ (udf(COALESCE(t1.int_col1, t2.int_col0)) * 2)
FROM t1
RIGHT JOIN t2
- ON (t2.int_col0) = (t1.int_col1)
-GROUP BY GREATEST(COALESCE(t2.int_col1, 109), COALESCE(t1.int_col1, -449)),
+ ON udf(t2.int_col0) = udf(t1.int_col1)
+GROUP BY udf(GREATEST(COALESCE(udf(t2.int_col1), 109), COALESCE(t1.int_col1, udf(-449)))),
COALESCE(t1.int_col1, t2.int_col0)
-HAVING (SUM(COALESCE(t1.int_col1, t2.int_col0)))
- > ((COALESCE(t1.int_col1, t2.int_col0)) * 2)
+HAVING (udf(SUM(COALESCE(udf(t1.int_col1), udf(t2.int_col0)))))
+ > (udf(COALESCE(t1.int_col1, t2.int_col0)) * 2)
-- !query 2 schema
-struct<sum(coalesce(int_col1, int_col0)):bigint,(coalesce(int_col1, int_col0) * 2):int>
+struct<CAST(udf(cast(sum(cast(cast(udf(cast(coalesce(int_col1, int_col0) as string)) as int) as bigint)) as string)) AS BIGINT):bigint,(CAST(udf(cast(coalesce(int_col1, int_col0) as string)) AS INT) * 2):int>
-- !query 2 output
-367 -734
-507 -1014
-70,10 +70,10 spark.sql.crossJoin.enabled true
SELECT *
FROM (
SELECT
- COALESCE(t2.int_col1, t1.int_col1) AS int_col
+ udf(COALESCE(udf(t2.int_col1), udf(t1.int_col1))) AS int_col
FROM t1
LEFT JOIN t2 ON false
-) t where (t.int_col) is not null
+) t where (udf(t.int_col)) is not null
-- !query 6 schema
struct<int_col:int>
-- !query 6 output
```
</p>
</details>
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25103 from huaxingao/spark-28285.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from 'udaf.sql' to test UDFs
<details><summary>Diff comparing to 'udaf.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/udaf.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-udaf.sql.out
index f4455bb717..e1747f4667 100644
--- a/sql/core/src/test/resources/sql-tests/results/udaf.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-udaf.sql.out
-3,6 +3,8
-- !query 0
+-- This test file was converted from udaf.sql.
+
CREATE OR REPLACE TEMPORARY VIEW t1 AS SELECT * FROM VALUES
(1), (2), (3), (4)
as t1(int_col1)
-21,15 +23,15 struct<>
-- !query 2
-SELECT default.myDoubleAvg(int_col1) as my_avg from t1
+SELECT default.myDoubleAvg(udf(int_col1)) as my_avg, udf(default.myDoubleAvg(udf(int_col1))) as my_avg2, udf(default.myDoubleAvg(int_col1)) as my_avg3 from t1
-- !query 2 schema
-struct<my_avg:double>
+struct<my_avg:double,my_avg2:double,my_avg3:double>
-- !query 2 output
-102.5
+102.5 102.5 102.5
-- !query 3
-SELECT default.myDoubleAvg(int_col1, 3) as my_avg from t1
+SELECT default.myDoubleAvg(udf(int_col1), udf(3)) as my_avg from t1
-- !query 3 schema
struct<>
-- !query 3 output
-46,12 +48,12 struct<>
-- !query 5
-SELECT default.udaf1(int_col1) as udaf1 from t1
+SELECT default.udaf1(udf(int_col1)) as udaf1, udf(default.udaf1(udf(int_col1))) as udaf2, udf(default.udaf1(int_col1)) as udaf3 from t1
-- !query 5 schema
struct<>
-- !query 5 output
org.apache.spark.sql.AnalysisException
-Can not load class 'test.non.existent.udaf' when registering the function 'default.udaf1', please make sure it is on the classpath; line 1 pos 7
+Can not load class 'test.non.existent.udaf' when registering the function 'default.udaf1', please make sure it is on the classpath; line 1 pos 94
-- !query 6
```
</p>
</details>
## How was this patch tested?
Tested as guided in SPARK-27921.
Closes#25194 from vinodkc/br_Fix_SPARK-27921_3.
Authored-by: Vinod KC <vinod.kc.in@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The `DateTimeUtils.timestampAddInterval` method was rewritten by using Java 8 time API. To add months and microseconds, I used the `plusMonths()` and `plus()` methods of `ZonedDateTime`. Also the signature of `timestampAddInterval()` was changed to accept an `ZoneId` instance instead of `TimeZone`. Using `ZoneId` allows to avoid the conversion `TimeZone` -> `ZoneId` on every invoke of `timestampAddInterval()`.
## How was this patch tested?
By existing test suites `DateExpressionsSuite`, `TypeCoercionSuite` and `CollectionExpressionsSuite`.
Closes#25173 from MaxGekk/timestamp-add-interval.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR adds some tests converted from pivot.sql to test UDFs following the combination guide in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
<details><summary>Diff comparing to 'pivot.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/pivot.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-pivot.sql.out
index 9a8f783da4..cb9e4d736c 100644
--- a/sql/core/src/test/resources/sql-tests/results/pivot.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-pivot.sql.out
-1,5 +1,5
-- Automatically generated by SQLQueryTestSuite
--- Number of queries: 32
+-- Number of queries: 30
-- !query 0
-40,14 +40,14 struct<>
-- !query 3
SELECT * FROM (
- SELECT year, course, earnings FROM courseSales
+ SELECT udf(year), course, earnings FROM courseSales
)
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR course IN ('dotNET', 'Java')
)
-- !query 3 schema
-struct<year:int,dotNET:bigint,Java:bigint>
+struct<CAST(udf(cast(year as string)) AS INT):int,dotNET:bigint,Java:bigint>
-- !query 3 output
2012 15000 20000
2013 48000 30000
-56,7 +56,7 struct<year:int,dotNET:bigint,Java:bigint>
-- !query 4
SELECT * FROM courseSales
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR year IN (2012, 2013)
)
-- !query 4 schema
-71,11 +71,11 SELECT * FROM (
SELECT year, course, earnings FROM courseSales
)
PIVOT (
- sum(earnings), avg(earnings)
+ udf(sum(earnings)), udf(avg(earnings))
FOR course IN ('dotNET', 'Java')
)
-- !query 5 schema
-struct<year:int,dotNET_sum(CAST(earnings AS BIGINT)):bigint,dotNET_avg(CAST(earnings AS BIGINT)):double,Java_sum(CAST(earnings AS BIGINT)):bigint,Java_avg(CAST(earnings AS BIGINT)):double>
+struct<year:int,dotNET_CAST(udf(cast(sum(cast(earnings as bigint)) as string)) AS BIGINT):bigint,dotNET_CAST(udf(cast(avg(cast(earnings as bigint)) as string)) AS DOUBLE):double,Java_CAST(udf(cast(sum(cast(earnings as bigint)) as string)) AS BIGINT):bigint,Java_CAST(udf(cast(avg(cast(earnings as bigint)) as string)) AS DOUBLE):double>
-- !query 5 output
2012 15000 7500.0 20000 20000.0
2013 48000 48000.0 30000 30000.0
-83,10 +83,10 struct<year:int,dotNET_sum(CAST(earnings AS BIGINT)):bigint,dotNET_avg(CAST(earn
-- !query 6
SELECT * FROM (
- SELECT course, earnings FROM courseSales
+ SELECT udf(course) as course, earnings FROM courseSales
)
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR course IN ('dotNET', 'Java')
)
-- !query 6 schema
-100,23 +100,23 SELECT * FROM (
SELECT year, course, earnings FROM courseSales
)
PIVOT (
- sum(earnings), min(year)
+ udf(sum(udf(earnings))), udf(min(year))
FOR course IN ('dotNET', 'Java')
)
-- !query 7 schema
-struct<dotNET_sum(CAST(earnings AS BIGINT)):bigint,dotNET_min(year):int,Java_sum(CAST(earnings AS BIGINT)):bigint,Java_min(year):int>
+struct<dotNET_CAST(udf(cast(sum(cast(cast(udf(cast(earnings as string)) as int) as bigint)) as string)) AS BIGINT):bigint,dotNET_CAST(udf(cast(min(year) as string)) AS INT):int,Java_CAST(udf(cast(sum(cast(cast(udf(cast(earnings as string)) as int) as bigint)) as string)) AS BIGINT):bigint,Java_CAST(udf(cast(min(year) as string)) AS INT):int>
-- !query 7 output
63000 2012 50000 2012
-- !query 8
SELECT * FROM (
- SELECT course, year, earnings, s
+ SELECT course, year, earnings, udf(s) as s
FROM courseSales
JOIN years ON year = y
)
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR s IN (1, 2)
)
-- !query 8 schema
-135,11 +135,11 SELECT * FROM (
JOIN years ON year = y
)
PIVOT (
- sum(earnings), min(s)
+ udf(sum(earnings)), udf(min(s))
FOR course IN ('dotNET', 'Java')
)
-- !query 9 schema
-struct<year:int,dotNET_sum(CAST(earnings AS BIGINT)):bigint,dotNET_min(s):int,Java_sum(CAST(earnings AS BIGINT)):bigint,Java_min(s):int>
+struct<year:int,dotNET_CAST(udf(cast(sum(cast(earnings as bigint)) as string)) AS BIGINT):bigint,dotNET_CAST(udf(cast(min(s) as string)) AS INT):int,Java_CAST(udf(cast(sum(cast(earnings as bigint)) as string)) AS BIGINT):bigint,Java_CAST(udf(cast(min(s) as string)) AS INT):int>
-- !query 9 output
2012 15000 1 20000 1
2013 48000 2 30000 2
-152,7 +152,7 SELECT * FROM (
JOIN years ON year = y
)
PIVOT (
- sum(earnings * s)
+ udf(sum(earnings * s))
FOR course IN ('dotNET', 'Java')
)
-- !query 10 schema
-167,7 +167,7 SELECT 2012_s, 2013_s, 2012_a, 2013_a, c FROM (
SELECT year y, course c, earnings e FROM courseSales
)
PIVOT (
- sum(e) s, avg(e) a
+ udf(sum(e)) s, udf(avg(e)) a
FOR y IN (2012, 2013)
)
-- !query 11 schema
-182,7 +182,7 SELECT firstYear_s, secondYear_s, firstYear_a, secondYear_a, c FROM (
SELECT year y, course c, earnings e FROM courseSales
)
PIVOT (
- sum(e) s, avg(e) a
+ udf(sum(e)) s, udf(avg(e)) a
FOR y IN (2012 as firstYear, 2013 secondYear)
)
-- !query 12 schema
-195,7 +195,7 struct<firstYear_s:bigint,secondYear_s:bigint,firstYear_a:double,secondYear_a:do
-- !query 13
SELECT * FROM courseSales
PIVOT (
- abs(earnings)
+ udf(abs(earnings))
FOR year IN (2012, 2013)
)
-- !query 13 schema
-210,7 +210,7 SELECT * FROM (
SELECT year, course, earnings FROM courseSales
)
PIVOT (
- sum(earnings), year
+ udf(sum(earnings)), year
FOR course IN ('dotNET', 'Java')
)
-- !query 14 schema
-225,7 +225,7 SELECT * FROM (
SELECT course, earnings FROM courseSales
)
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR year IN (2012, 2013)
)
-- !query 15 schema
-240,11 +240,11 SELECT * FROM (
SELECT year, course, earnings FROM courseSales
)
PIVOT (
- ceil(sum(earnings)), avg(earnings) + 1 as a1
+ udf(ceil(udf(sum(earnings)))), avg(earnings) + 1 as a1
FOR course IN ('dotNET', 'Java')
)
-- !query 16 schema
-struct<year:int,dotNET_CEIL(sum(CAST(earnings AS BIGINT))):bigint,dotNET_a1:double,Java_CEIL(sum(CAST(earnings AS BIGINT))):bigint,Java_a1:double>
+struct<year:int,dotNET_CAST(udf(cast(CEIL(cast(udf(cast(sum(cast(earnings as bigint)) as string)) as bigint)) as string)) AS BIGINT):bigint,dotNET_a1:double,Java_CAST(udf(cast(CEIL(cast(udf(cast(sum(cast(earnings as bigint)) as string)) as bigint)) as string)) AS BIGINT):bigint,Java_a1:double>
-- !query 16 output
2012 15000 7501.0 20000 20001.0
2013 48000 48001.0 30000 30001.0
-255,7 +255,7 SELECT * FROM (
SELECT year, course, earnings FROM courseSales
)
PIVOT (
- sum(avg(earnings))
+ sum(udf(avg(earnings)))
FOR course IN ('dotNET', 'Java')
)
-- !query 17 schema
-272,7 +272,7 SELECT * FROM (
JOIN years ON year = y
)
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR (course, year) IN (('dotNET', 2012), ('Java', 2013))
)
-- !query 18 schema
-289,7 +289,7 SELECT * FROM (
JOIN years ON year = y
)
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR (course, s) IN (('dotNET', 2) as c1, ('Java', 1) as c2)
)
-- !query 19 schema
-306,7 +306,7 SELECT * FROM (
JOIN years ON year = y
)
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR (course, year) IN ('dotNET', 'Java')
)
-- !query 20 schema
-319,7 +319,7 Invalid pivot value 'dotNET': value data type string does not match pivot column
-- !query 21
SELECT * FROM courseSales
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR year IN (s, 2013)
)
-- !query 21 schema
-332,7 +332,7 cannot resolve '`s`' given input columns: [coursesales.course, coursesales.earni
-- !query 22
SELECT * FROM courseSales
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR year IN (course, 2013)
)
-- !query 22 schema
-343,151 +343,118 Literal expressions required for pivot values, found 'course#x';
-- !query 23
-SELECT * FROM (
- SELECT course, year, a
- FROM courseSales
- JOIN yearsWithComplexTypes ON year = y
-)
-PIVOT (
- min(a)
- FOR course IN ('dotNET', 'Java')
-)
--- !query 23 schema
-struct<year:int,dotNET:array<int>,Java:array<int>>
--- !query 23 output
-2012 [1,1] [1,1]
-2013 [2,2] [2,2]
-
-
--- !query 24
-SELECT * FROM (
- SELECT course, year, y, a
- FROM courseSales
- JOIN yearsWithComplexTypes ON year = y
-)
-PIVOT (
- max(a)
- FOR (y, course) IN ((2012, 'dotNET'), (2013, 'Java'))
-)
--- !query 24 schema
-struct<year:int,[2012, dotNET]:array<int>,[2013, Java]:array<int>>
--- !query 24 output
-2012 [1,1] NULL
-2013 NULL [2,2]
-
-
--- !query 25
SELECT * FROM (
SELECT earnings, year, a
FROM courseSales
JOIN yearsWithComplexTypes ON year = y
)
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR a IN (array(1, 1), array(2, 2))
)
--- !query 25 schema
+-- !query 23 schema
struct<year:int,[1, 1]:bigint,[2, 2]:bigint>
--- !query 25 output
+-- !query 23 output
2012 35000 NULL
2013 NULL 78000
--- !query 26
+-- !query 24
SELECT * FROM (
- SELECT course, earnings, year, a
+ SELECT course, earnings, udf(year) as year, a
FROM courseSales
JOIN yearsWithComplexTypes ON year = y
)
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR (course, a) IN (('dotNET', array(1, 1)), ('Java', array(2, 2)))
)
--- !query 26 schema
+-- !query 24 schema
struct<year:int,[dotNET, [1, 1]]:bigint,[Java, [2, 2]]:bigint>
--- !query 26 output
+-- !query 24 output
2012 15000 NULL
2013 NULL 30000
--- !query 27
+-- !query 25
SELECT * FROM (
SELECT earnings, year, s
FROM courseSales
JOIN yearsWithComplexTypes ON year = y
)
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR s IN ((1, 'a'), (2, 'b'))
)
--- !query 27 schema
+-- !query 25 schema
struct<year:int,[1, a]:bigint,[2, b]:bigint>
--- !query 27 output
+-- !query 25 output
2012 35000 NULL
2013 NULL 78000
--- !query 28
+-- !query 26
SELECT * FROM (
SELECT course, earnings, year, s
FROM courseSales
JOIN yearsWithComplexTypes ON year = y
)
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR (course, s) IN (('dotNET', (1, 'a')), ('Java', (2, 'b')))
)
--- !query 28 schema
+-- !query 26 schema
struct<year:int,[dotNET, [1, a]]:bigint,[Java, [2, b]]:bigint>
--- !query 28 output
+-- !query 26 output
2012 15000 NULL
2013 NULL 30000
--- !query 29
+-- !query 27
SELECT * FROM (
SELECT earnings, year, m
FROM courseSales
JOIN yearsWithComplexTypes ON year = y
)
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR m IN (map('1', 1), map('2', 2))
)
--- !query 29 schema
+-- !query 27 schema
struct<>
--- !query 29 output
+-- !query 27 output
org.apache.spark.sql.AnalysisException
Invalid pivot column 'm#x'. Pivot columns must be comparable.;
--- !query 30
+-- !query 28
SELECT * FROM (
SELECT course, earnings, year, m
FROM courseSales
JOIN yearsWithComplexTypes ON year = y
)
PIVOT (
- sum(earnings)
+ udf(sum(earnings))
FOR (course, m) IN (('dotNET', map('1', 1)), ('Java', map('2', 2)))
)
--- !query 30 schema
+-- !query 28 schema
struct<>
--- !query 30 output
+-- !query 28 output
org.apache.spark.sql.AnalysisException
Invalid pivot column 'named_struct(course, course#x, m, m#x)'. Pivot columns must be comparable.;
--- !query 31
+-- !query 29
SELECT * FROM (
- SELECT course, earnings, "a" as a, "z" as z, "b" as b, "y" as y, "c" as c, "x" as x, "d" as d, "w" as w
+ SELECT course, earnings, udf("a") as a, udf("z") as z, udf("b") as b, udf("y") as y,
+ udf("c") as c, udf("x") as x, udf("d") as d, udf("w") as w
FROM courseSales
)
PIVOT (
- sum(Earnings)
+ udf(sum(Earnings))
FOR Course IN ('dotNET', 'Java')
)
--- !query 31 schema
+-- !query 29 schema
struct<a:string,z:string,b:string,y:string,c:string,x:string,d:string,w:string,dotNET:bigint,Java:bigint>
--- !query 31 output
+-- !query 29 output
a z b y c x d w 63000 50000
```
</p>
</details>
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25122 from chitralverma/SPARK-28286.
Authored-by: chitralverma <chitralverma@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from `except-all.sql` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
<details><summary>Diff comparing to 'except-all.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/except-all.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-except-all.sql.out
index 01091a2f75..b7bfad0e53 100644
--- a/sql/core/src/test/resources/sql-tests/results/except-all.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-except-all.sql.out
-49,11 +49,11 struct<>
-- !query 4
-SELECT * FROM tab1
+SELECT udf(c1) FROM tab1
EXCEPT ALL
-SELECT * FROM tab2
+SELECT udf(c1) FROM tab2
-- !query 4 schema
-struct<c1:int>
+struct<CAST(udf(cast(c1 as string)) AS INT):int>
-- !query 4 output
0
2
-62,11 +62,11 NULL
-- !query 5
-SELECT * FROM tab1
+SELECT udf(c1) FROM tab1
MINUS ALL
-SELECT * FROM tab2
+SELECT udf(c1) FROM tab2
-- !query 5 schema
-struct<c1:int>
+struct<CAST(udf(cast(c1 as string)) AS INT):int>
-- !query 5 output
0
2
-75,11 +75,11 NULL
-- !query 6
-SELECT * FROM tab1
+SELECT udf(c1) FROM tab1
EXCEPT ALL
-SELECT * FROM tab2 WHERE c1 IS NOT NULL
+SELECT udf(c1) FROM tab2 WHERE udf(c1) IS NOT NULL
-- !query 6 schema
-struct<c1:int>
+struct<CAST(udf(cast(c1 as string)) AS INT):int>
-- !query 6 output
0
2
-89,21 +89,21 NULL
-- !query 7
-SELECT * FROM tab1 WHERE c1 > 5
+SELECT udf(c1) FROM tab1 WHERE udf(c1) > 5
EXCEPT ALL
-SELECT * FROM tab2
+SELECT udf(c1) FROM tab2
-- !query 7 schema
-struct<c1:int>
+struct<CAST(udf(cast(c1 as string)) AS INT):int>
-- !query 7 output
-- !query 8
-SELECT * FROM tab1
+SELECT udf(c1) FROM tab1
EXCEPT ALL
-SELECT * FROM tab2 WHERE c1 > 6
+SELECT udf(c1) FROM tab2 WHERE udf(c1 > udf(6))
-- !query 8 schema
-struct<c1:int>
+struct<CAST(udf(cast(c1 as string)) AS INT):int>
-- !query 8 output
0
1
-117,11 +117,11 NULL
-- !query 9
-SELECT * FROM tab1
+SELECT udf(c1) FROM tab1
EXCEPT ALL
-SELECT CAST(1 AS BIGINT)
+SELECT CAST(udf(1) AS BIGINT)
-- !query 9 schema
-struct<c1:bigint>
+struct<CAST(udf(cast(c1 as string)) AS INT):bigint>
-- !query 9 output
0
2
-134,7 +134,7 NULL
-- !query 10
-SELECT * FROM tab1
+SELECT udf(c1) FROM tab1
EXCEPT ALL
SELECT array(1)
-- !query 10 schema
-145,62 +145,62 ExceptAll can only be performed on tables with the compatible column types. arra
-- !query 11
-SELECT * FROM tab3
+SELECT udf(k), v FROM tab3
EXCEPT ALL
-SELECT * FROM tab4
+SELECT k, udf(v) FROM tab4
-- !query 11 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,v:int>
-- !query 11 output
1 2
1 3
-- !query 12
-SELECT * FROM tab4
+SELECT k, udf(v) FROM tab4
EXCEPT ALL
-SELECT * FROM tab3
+SELECT udf(k), v FROM tab3
-- !query 12 schema
-struct<k:int,v:int>
+struct<k:int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 12 output
2 2
2 20
-- !query 13
-SELECT * FROM tab4
+SELECT udf(k), udf(v) FROM tab4
EXCEPT ALL
-SELECT * FROM tab3
+SELECT udf(k), udf(v) FROM tab3
INTERSECT DISTINCT
-SELECT * FROM tab4
+SELECT udf(k), udf(v) FROM tab4
-- !query 13 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 13 output
2 2
2 20
-- !query 14
-SELECT * FROM tab4
+SELECT udf(k), v FROM tab4
EXCEPT ALL
-SELECT * FROM tab3
+SELECT k, udf(v) FROM tab3
EXCEPT DISTINCT
-SELECT * FROM tab4
+SELECT udf(k), udf(v) FROM tab4
-- !query 14 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,v:int>
-- !query 14 output
-- !query 15
-SELECT * FROM tab3
+SELECT k, udf(v) FROM tab3
EXCEPT ALL
-SELECT * FROM tab4
+SELECT udf(k), udf(v) FROM tab4
UNION ALL
-SELECT * FROM tab3
+SELECT udf(k), v FROM tab3
EXCEPT DISTINCT
-SELECT * FROM tab4
+SELECT k, udf(v) FROM tab4
-- !query 15 schema
-struct<k:int,v:int>
+struct<k:int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 15 output
1 3
-217,83 +217,83 ExceptAll can only be performed on tables with the same number of columns, but t
-- !query 17
-SELECT * FROM tab3
+SELECT udf(k), udf(v) FROM tab3
EXCEPT ALL
-SELECT * FROM tab4
+SELECT udf(k), udf(v) FROM tab4
UNION
-SELECT * FROM tab3
+SELECT udf(k), udf(v) FROM tab3
EXCEPT DISTINCT
-SELECT * FROM tab4
+SELECT udf(k), udf(v) FROM tab4
-- !query 17 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 17 output
1 3
-- !query 18
-SELECT * FROM tab3
+SELECT udf(k), udf(v) FROM tab3
MINUS ALL
-SELECT * FROM tab4
+SELECT k, udf(v) FROM tab4
UNION
-SELECT * FROM tab3
+SELECT udf(k), udf(v) FROM tab3
MINUS DISTINCT
-SELECT * FROM tab4
+SELECT k, udf(v) FROM tab4
-- !query 18 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 18 output
1 3
-- !query 19
-SELECT * FROM tab3
+SELECT k, udf(v) FROM tab3
EXCEPT ALL
-SELECT * FROM tab4
+SELECT udf(k), v FROM tab4
EXCEPT DISTINCT
-SELECT * FROM tab3
+SELECT k, udf(v) FROM tab3
EXCEPT DISTINCT
-SELECT * FROM tab4
+SELECT udf(k), v FROM tab4
-- !query 19 schema
-struct<k:int,v:int>
+struct<k:int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 19 output
-- !query 20
SELECT *
-FROM (SELECT tab3.k,
- tab4.v
+FROM (SELECT tab3.k,
+ udf(tab4.v)
FROM tab3
JOIN tab4
- ON tab3.k = tab4.k)
+ ON udf(tab3.k) = tab4.k)
EXCEPT ALL
SELECT *
-FROM (SELECT tab3.k,
- tab4.v
+FROM (SELECT udf(tab3.k),
+ tab4.v
FROM tab3
JOIN tab4
- ON tab3.k = tab4.k)
+ ON tab3.k = udf(tab4.k))
-- !query 20 schema
-struct<k:int,v:int>
+struct<k:int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 20 output
-- !query 21
SELECT *
-FROM (SELECT tab3.k,
- tab4.v
+FROM (SELECT udf(udf(tab3.k)),
+ udf(tab4.v)
FROM tab3
JOIN tab4
- ON tab3.k = tab4.k)
+ ON udf(udf(tab3.k)) = udf(tab4.k))
EXCEPT ALL
SELECT *
-FROM (SELECT tab4.v AS k,
- tab3.k AS v
+FROM (SELECT udf(tab4.v) AS k,
+ udf(udf(tab3.k)) AS v
FROM tab3
JOIN tab4
- ON tab3.k = tab4.k)
+ ON udf(tab3.k) = udf(tab4.k))
-- !query 21 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(cast(udf(cast(k as string)) as int) as string)) AS INT):int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 21 output
1 2
1 2
-305,11 +305,11 struct<k:int,v:int>
-- !query 22
-SELECT v FROM tab3 GROUP BY v
+SELECT udf(v) FROM tab3 GROUP BY v
EXCEPT ALL
-SELECT k FROM tab4 GROUP BY k
+SELECT udf(k) FROM tab4 GROUP BY k
-- !query 22 schema
-struct<v:int>
+struct<CAST(udf(cast(v as string)) AS INT):int>
-- !query 22 output
3
```
</p>
</details>
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25090 from imback82/except-all.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from `intersect-all.sql` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
<details><summary>Diff comparing to 'intersect-all.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/intersect-all.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-intersect-all.sql.out
index 63dd56ce46..0cb82be2da 100644
--- a/sql/core/src/test/resources/sql-tests/results/intersect-all.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-intersect-all.sql.out
-34,11 +34,11 struct<>
-- !query 2
-SELECT * FROM tab1
+SELECT udf(k), v FROM tab1
INTERSECT ALL
-SELECT * FROM tab2
+SELECT k, udf(v) FROM tab2
-- !query 2 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,v:int>
-- !query 2 output
1 2
1 2
-48,11 +48,11 NULL NULL
-- !query 3
-SELECT * FROM tab1
+SELECT k, udf(v) FROM tab1
INTERSECT ALL
-SELECT * FROM tab1 WHERE k = 1
+SELECT udf(k), v FROM tab1 WHERE udf(k) = 1
-- !query 3 schema
-struct<k:int,v:int>
+struct<k:int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 3 output
1 2
1 2
-61,39 +61,39 struct<k:int,v:int>
-- !query 4
-SELECT * FROM tab1 WHERE k > 2
+SELECT udf(k), udf(v) FROM tab1 WHERE k > udf(2)
INTERSECT ALL
-SELECT * FROM tab2
+SELECT udf(k), udf(v) FROM tab2
-- !query 4 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 4 output
-- !query 5
-SELECT * FROM tab1
+SELECT udf(k), v FROM tab1
INTERSECT ALL
-SELECT * FROM tab2 WHERE k > 3
+SELECT udf(k), v FROM tab2 WHERE udf(udf(k)) > 3
-- !query 5 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,v:int>
-- !query 5 output
-- !query 6
-SELECT * FROM tab1
+SELECT udf(k), v FROM tab1
INTERSECT ALL
-SELECT CAST(1 AS BIGINT), CAST(2 AS BIGINT)
+SELECT CAST(udf(1) AS BIGINT), CAST(udf(2) AS BIGINT)
-- !query 6 schema
-struct<k:bigint,v:bigint>
+struct<CAST(udf(cast(k as string)) AS INT):bigint,v:bigint>
-- !query 6 output
1 2
-- !query 7
-SELECT * FROM tab1
+SELECT k, udf(v) FROM tab1
INTERSECT ALL
-SELECT array(1), 2
+SELECT array(1), udf(2)
-- !query 7 schema
struct<>
-- !query 7 output
-102,9 +102,9 IntersectAll can only be performed on tables with the compatible column types. a
-- !query 8
-SELECT k FROM tab1
+SELECT udf(k) FROM tab1
INTERSECT ALL
-SELECT k, v FROM tab2
+SELECT udf(k), udf(v) FROM tab2
-- !query 8 schema
struct<>
-- !query 8 output
-113,13 +113,13 IntersectAll can only be performed on tables with the same number of columns, bu
-- !query 9
-SELECT * FROM tab2
+SELECT udf(k), v FROM tab2
INTERSECT ALL
-SELECT * FROM tab1
+SELECT k, udf(v) FROM tab1
INTERSECT ALL
-SELECT * FROM tab2
+SELECT udf(k), udf(v) FROM tab2
-- !query 9 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,v:int>
-- !query 9 output
1 2
1 2
-129,15 +129,15 NULL NULL
-- !query 10
-SELECT * FROM tab1
+SELECT udf(k), v FROM tab1
EXCEPT
-SELECT * FROM tab2
+SELECT k, udf(v) FROM tab2
UNION ALL
-SELECT * FROM tab1
+SELECT k, udf(udf(v)) FROM tab1
INTERSECT ALL
-SELECT * FROM tab2
+SELECT udf(k), v FROM tab2
-- !query 10 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,v:int>
-- !query 10 output
1 2
1 2
-148,15 +148,15 NULL NULL
-- !query 11
-SELECT * FROM tab1
+SELECT udf(k), udf(v) FROM tab1
EXCEPT
-SELECT * FROM tab2
+SELECT udf(k), v FROM tab2
EXCEPT
-SELECT * FROM tab1
+SELECT k, udf(v) FROM tab1
INTERSECT ALL
-SELECT * FROM tab2
+SELECT udf(k), udf(udf(v)) FROM tab2
-- !query 11 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 11 output
1 3
-165,38 +165,38 struct<k:int,v:int>
(
(
(
- SELECT * FROM tab1
+ SELECT udf(k), v FROM tab1
EXCEPT
- SELECT * FROM tab2
+ SELECT k, udf(v) FROM tab2
)
EXCEPT
- SELECT * FROM tab1
+ SELECT udf(k), udf(v) FROM tab1
)
INTERSECT ALL
- SELECT * FROM tab2
+ SELECT udf(k), udf(v) FROM tab2
)
-- !query 12 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,v:int>
-- !query 12 output
-- !query 13
SELECT *
-FROM (SELECT tab1.k,
- tab2.v
+FROM (SELECT udf(tab1.k),
+ udf(tab2.v)
FROM tab1
JOIN tab2
- ON tab1.k = tab2.k)
+ ON udf(udf(tab1.k)) = tab2.k)
INTERSECT ALL
SELECT *
-FROM (SELECT tab1.k,
- tab2.v
+FROM (SELECT udf(tab1.k),
+ udf(tab2.v)
FROM tab1
JOIN tab2
- ON tab1.k = tab2.k)
+ ON udf(tab1.k) = udf(udf(tab2.k)))
-- !query 13 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 13 output
1 2
1 2
-211,30 +211,30 struct<k:int,v:int>
-- !query 14
SELECT *
-FROM (SELECT tab1.k,
- tab2.v
+FROM (SELECT udf(tab1.k),
+ udf(tab2.v)
FROM tab1
JOIN tab2
- ON tab1.k = tab2.k)
+ ON udf(tab1.k) = udf(tab2.k))
INTERSECT ALL
SELECT *
-FROM (SELECT tab2.v AS k,
- tab1.k AS v
+FROM (SELECT udf(tab2.v) AS k,
+ udf(tab1.k) AS v
FROM tab1
JOIN tab2
- ON tab1.k = tab2.k)
+ ON tab1.k = udf(tab2.k))
-- !query 14 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 14 output
-- !query 15
-SELECT v FROM tab1 GROUP BY v
+SELECT udf(v) FROM tab1 GROUP BY v
INTERSECT ALL
-SELECT k FROM tab2 GROUP BY k
+SELECT udf(udf(k)) FROM tab2 GROUP BY k
-- !query 15 schema
-struct<v:int>
+struct<CAST(udf(cast(v as string)) AS INT):int>
-- !query 15 output
2
3
-250,15 +250,15 spark.sql.legacy.setopsPrecedence.enabled true
-- !query 17
-SELECT * FROM tab1
+SELECT udf(k), v FROM tab1
EXCEPT
-SELECT * FROM tab2
+SELECT k, udf(v) FROM tab2
UNION ALL
-SELECT * FROM tab1
+SELECT udf(k), udf(v) FROM tab1
INTERSECT ALL
-SELECT * FROM tab2
+SELECT udf(udf(k)), udf(v) FROM tab2
-- !query 17 schema
-struct<k:int,v:int>
+struct<CAST(udf(cast(k as string)) AS INT):int,v:int>
-- !query 17 output
1 2
1 2
-268,15 +268,15 NULL NULL
-- !query 18
-SELECT * FROM tab1
+SELECT k, udf(v) FROM tab1
EXCEPT
-SELECT * FROM tab2
+SELECT udf(k), v FROM tab2
UNION ALL
-SELECT * FROM tab1
+SELECT udf(k), udf(v) FROM tab1
INTERSECT
-SELECT * FROM tab2
+SELECT udf(k), udf(udf(v)) FROM tab2
-- !query 18 schema
-struct<k:int,v:int>
+struct<k:int,CAST(udf(cast(v as string)) AS INT):int>
-- !query 18 output
1 2
2 3
```
</p>
</details>
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25119 from imback82/intersect-all-sql.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from `cross-join.sql'` to test UDFs.
<details><summary>Diff comparing to 'cross-join.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/cross-join.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-cross-join.sql.out
index 3833c42bdf..11c1e01d54 100644
--- a/sql/core/src/test/resources/sql-tests/results/cross-join.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-cross-join.sql.out
-43,7 +43,7 two 2 two 22
-- !query 3
-SELECT * FROM nt1 cross join nt2 where nt1.k = nt2.k
+SELECT * FROM nt1 cross join nt2 where udf(nt1.k) = udf(nt2.k)
-- !query 3 schema
struct<k:string,v1:int,k:string,v2:int>
-- !query 3 output
-53,7 +53,7 two 2 two 22
-- !query 4
-SELECT * FROM nt1 cross join nt2 on (nt1.k = nt2.k)
+SELECT * FROM nt1 cross join nt2 on (udf(nt1.k) = udf(nt2.k))
-- !query 4 schema
struct<k:string,v1:int,k:string,v2:int>
-- !query 4 output
-63,7 +63,7 two 2 two 22
-- !query 5
-SELECT * FROM nt1 cross join nt2 where nt1.v1 = 1 and nt2.v2 = 22
+SELECT * FROM nt1 cross join nt2 where udf(nt1.v1) = "1" and udf(nt2.v2) = "22"
-- !query 5 schema
struct<k:string,v1:int,k:string,v2:int>
-- !query 5 output
-71,12 +71,12 one 1 two 22
-- !query 6
-SELECT a.key, b.key FROM
-(SELECT k key FROM nt1 WHERE v1 < 2) a
+SELECT udf(a.key), udf(b.key) FROM
+(SELECT udf(k) key FROM nt1 WHERE v1 < 2) a
CROSS JOIN
-(SELECT k key FROM nt2 WHERE v2 = 22) b
+(SELECT udf(k) key FROM nt2 WHERE v2 = 22) b
-- !query 6 schema
-struct<key:string,key:string>
+struct<udf(key):string,udf(key):string>
-- !query 6 output
one two
-114,23 +114,29 struct<>
-- !query 11
-select * from ((A join B on (a = b)) cross join C) join D on (a = d)
+select * from ((A join B on (udf(a) = udf(b))) cross join C) join D on (udf(a) = udf(d))
-- !query 11 schema
-struct<a:string,va:int,b:string,vb:int,c:string,vc:int,d:string,vd:int>
+struct<>
-- !query 11 output
-one 1 one 1 one 1 one 1
-one 1 one 1 three 3 one 1
-one 1 one 1 two 2 one 1
-three 3 three 3 one 1 three 3
-three 3 three 3 three 3 three 3
-three 3 three 3 two 2 three 3
-two 2 two 2 one 1 two 2
-two 2 two 2 three 3 two 2
-two 2 two 2 two 2 two 2
+org.apache.spark.sql.AnalysisException
+Detected implicit cartesian product for INNER join between logical plans
+Filter (udf(a#x) = udf(b#x))
++- Join Inner
+ :- Project [k#x AS a#x, v1#x AS va#x]
+ : +- LocalRelation [k#x, v1#x]
+ +- Project [k#x AS b#x, v1#x AS vb#x]
+ +- LocalRelation [k#x, v1#x]
+and
+Project [k#x AS d#x, v1#x AS vd#x]
++- LocalRelation [k#x, v1#x]
+Join condition is missing or trivial.
+Either: use the CROSS JOIN syntax to allow cartesian products between these
+relations, or: enable implicit cartesian products by setting the configuration
+variable spark.sql.crossJoin.enabled=true;
-- !query 12
-SELECT * FROM nt1 CROSS JOIN nt2 ON (nt1.k > nt2.k)
+SELECT * FROM nt1 CROSS JOIN nt2 ON (udf(nt1.k) > udf(nt2.k))
-- !query 12 schema
struct<k:string,v1:int,k:string,v2:int>
-- !query 12 output
```
</p>
</details>
## How was this patch tested?
Added test.
Closes#25168 from viirya/SPARK-28276.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
PostgreSQL doesn't have `TINYINT`, which would map directly, but `SMALLINT`s are sufficient for uni-directional translation.
A side-effect of this fix is that `AggregatedDialect` is now usable with multiple dialects targeting `jdbc:postgresql`, as `PostgresDialect.getJDBCType` no longer throws (for which reason backporting this fix would be lovely):
1217996f15/sql/core/src/main/scala/org/apache/spark/sql/jdbc/AggregatedDialect.scala (L42)
`dialects.flatMap` currently throws on the first attempt to get a JDBC type preventing subsequent dialects in the chain from providing an alternative.
## How was this patch tested?
Unit tests.
Closes#24845 from mojodna/postgres-byte-type-mapping.
Authored-by: Seth Fitzsimmons <seth@mojodna.net>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Current UDFs available in `IntegratedUDFTestUtils` are not exactly no-op. It converts input column to strings and outputs to strings.
It causes some issues when we convert and port the tests at SPARK-27921. Integrated UDF test cases share one output file and it should outputs the same. However,
1. Special values are converted into strings differently:
| Scala | Python |
| ---------- | ------ |
| `null` | `None` |
| `Infinity` | `inf` |
| `-Infinity`| `-inf` |
| `NaN` | `nan` |
2. Due to float limitation at Python (see https://docs.python.org/3/tutorial/floatingpoint.html), if float is passed into Python and sent back to JVM, the values are potentially not exactly correct. See https://github.com/apache/spark/pull/25128 and https://github.com/apache/spark/pull/25110
To work around this, this PR targets to change the current UDF to be wrapped by cast. So, Input column is casted into string, UDF returns strings as are, and then output column is casted back to the input column.
Roughly:
**Before:**
```
JVM (col1) -> (cast to string within Python) Python (string) -> (string) JVM
```
**After:**
```
JVM (cast col1 to string) -> (string) Python (string) -> (cast back to col1's type) JVM
```
In this way, UDF is virtually no-op although there might be some subtleties due to roundtrip in string cast. I believe this is good enough.
Python native functions and Scala native functions will take strings and output strings as are. So, there will be no potential test failures due to differences of conversion between Python and Scala.
After this fix, for instance, `udf-aggregates_part1.sql` outputs exactly same as `aggregates_part1.sql`:
<details><summary>Diff comparing to 'pgSQL/aggregates_part1.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/pgSQL/aggregates_part1.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-aggregates_part1.sql.out
index 51ca1d55869..801735781c7 100644
--- a/sql/core/src/test/resources/sql-tests/results/pgSQL/aggregates_part1.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-aggregates_part1.sql.out
-3,7 +3,7
-- !query 0
-SELECT avg(four) AS avg_1 FROM onek
+SELECT avg(udf(four)) AS avg_1 FROM onek
-- !query 0 schema
struct<avg_1:double>
-- !query 0 output
-11,7 +11,7 struct<avg_1:double>
-- !query 1
-SELECT avg(a) AS avg_32 FROM aggtest WHERE a < 100
+SELECT udf(avg(a)) AS avg_32 FROM aggtest WHERE a < 100
-- !query 1 schema
struct<avg_32:double>
-- !query 1 output
-19,7 +19,7 struct<avg_32:double>
-- !query 2
-select CAST(avg(b) AS Decimal(10,3)) AS avg_107_943 FROM aggtest
+select CAST(avg(udf(b)) AS Decimal(10,3)) AS avg_107_943 FROM aggtest
-- !query 2 schema
struct<avg_107_943:decimal(10,3)>
-- !query 2 output
-27,7 +27,7 struct<avg_107_943:decimal(10,3)>
-- !query 3
-SELECT sum(four) AS sum_1500 FROM onek
+SELECT sum(udf(four)) AS sum_1500 FROM onek
-- !query 3 schema
struct<sum_1500:bigint>
-- !query 3 output
-35,7 +35,7 struct<sum_1500:bigint>
-- !query 4
-SELECT sum(a) AS sum_198 FROM aggtest
+SELECT udf(sum(a)) AS sum_198 FROM aggtest
-- !query 4 schema
struct<sum_198:bigint>
-- !query 4 output
-43,7 +43,7 struct<sum_198:bigint>
-- !query 5
-SELECT sum(b) AS avg_431_773 FROM aggtest
+SELECT udf(udf(sum(b))) AS avg_431_773 FROM aggtest
-- !query 5 schema
struct<avg_431_773:double>
-- !query 5 output
-51,7 +51,7 struct<avg_431_773:double>
-- !query 6
-SELECT max(four) AS max_3 FROM onek
+SELECT udf(max(four)) AS max_3 FROM onek
-- !query 6 schema
struct<max_3:int>
-- !query 6 output
-59,7 +59,7 struct<max_3:int>
-- !query 7
-SELECT max(a) AS max_100 FROM aggtest
+SELECT max(udf(a)) AS max_100 FROM aggtest
-- !query 7 schema
struct<max_100:int>
-- !query 7 output
-67,7 +67,7 struct<max_100:int>
-- !query 8
-SELECT max(aggtest.b) AS max_324_78 FROM aggtest
+SELECT udf(udf(max(aggtest.b))) AS max_324_78 FROM aggtest
-- !query 8 schema
struct<max_324_78:float>
-- !query 8 output
-75,237 +75,238 struct<max_324_78:float>
-- !query 9
-SELECT stddev_pop(b) FROM aggtest
+SELECT stddev_pop(udf(b)) FROM aggtest
-- !query 9 schema
-struct<stddev_pop(CAST(b AS DOUBLE)):double>
+struct<stddev_pop(CAST(CAST(udf(cast(b as string)) AS FLOAT) AS DOUBLE)):double>
-- !query 9 output
131.10703231895047
-- !query 10
-SELECT stddev_samp(b) FROM aggtest
+SELECT udf(stddev_samp(b)) FROM aggtest
-- !query 10 schema
-struct<stddev_samp(CAST(b AS DOUBLE)):double>
+struct<CAST(udf(cast(stddev_samp(cast(b as double)) as string)) AS DOUBLE):double>
-- !query 10 output
151.38936080399804
-- !query 11
-SELECT var_pop(b) FROM aggtest
+SELECT var_pop(udf(b)) FROM aggtest
-- !query 11 schema
-struct<var_pop(CAST(b AS DOUBLE)):double>
+struct<var_pop(CAST(CAST(udf(cast(b as string)) AS FLOAT) AS DOUBLE)):double>
-- !query 11 output
17189.053923482323
-- !query 12
-SELECT var_samp(b) FROM aggtest
+SELECT udf(var_samp(b)) FROM aggtest
-- !query 12 schema
-struct<var_samp(CAST(b AS DOUBLE)):double>
+struct<CAST(udf(cast(var_samp(cast(b as double)) as string)) AS DOUBLE):double>
-- !query 12 output
22918.738564643096
-- !query 13
-SELECT stddev_pop(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT udf(stddev_pop(CAST(b AS Decimal(38,0)))) FROM aggtest
-- !query 13 schema
-struct<stddev_pop(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<CAST(udf(cast(stddev_pop(cast(cast(b as decimal(38,0)) as double)) as string)) AS DOUBLE):double>
-- !query 13 output
131.18117242958306
-- !query 14
-SELECT stddev_samp(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT stddev_samp(CAST(udf(b) AS Decimal(38,0))) FROM aggtest
-- !query 14 schema
-struct<stddev_samp(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<stddev_samp(CAST(CAST(CAST(udf(cast(b as string)) AS FLOAT) AS DECIMAL(38,0)) AS DOUBLE)):double>
-- !query 14 output
151.47497042966097
-- !query 15
-SELECT var_pop(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT udf(var_pop(CAST(b AS Decimal(38,0)))) FROM aggtest
-- !query 15 schema
-struct<var_pop(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<CAST(udf(cast(var_pop(cast(cast(b as decimal(38,0)) as double)) as string)) AS DOUBLE):double>
-- !query 15 output
17208.5
-- !query 16
-SELECT var_samp(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT var_samp(udf(CAST(b AS Decimal(38,0)))) FROM aggtest
-- !query 16 schema
-struct<var_samp(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<var_samp(CAST(CAST(udf(cast(cast(b as decimal(38,0)) as string)) AS DECIMAL(38,0)) AS DOUBLE)):double>
-- !query 16 output
22944.666666666668
-- !query 17
-SELECT var_pop(1.0), var_samp(2.0)
+SELECT udf(var_pop(1.0)), var_samp(udf(2.0))
-- !query 17 schema
-struct<var_pop(CAST(1.0 AS DOUBLE)):double,var_samp(CAST(2.0 AS DOUBLE)):double>
+struct<CAST(udf(cast(var_pop(cast(1.0 as double)) as string)) AS DOUBLE):double,var_samp(CAST(CAST(udf(cast(2.0 as string)) AS DECIMAL(2,1)) AS DOUBLE)):double>
-- !query 17 output
0.0 NaN
-- !query 18
-SELECT stddev_pop(CAST(3.0 AS Decimal(38,0))), stddev_samp(CAST(4.0 AS Decimal(38,0)))
+SELECT stddev_pop(udf(CAST(3.0 AS Decimal(38,0)))), stddev_samp(CAST(udf(4.0) AS Decimal(38,0)))
-- !query 18 schema
-struct<stddev_pop(CAST(CAST(3.0 AS DECIMAL(38,0)) AS DOUBLE)):double,stddev_samp(CAST(CAST(4.0 AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<stddev_pop(CAST(CAST(udf(cast(cast(3.0 as decimal(38,0)) as string)) AS DECIMAL(38,0)) AS DOUBLE)):double,stddev_samp(CAST(CAST(CAST(udf(cast(4.0 as string)) AS DECIMAL(2,1)) AS DECIMAL(38,0)) AS DOUBLE)):double>
-- !query 18 output
0.0 NaN
-- !query 19
-select sum(CAST(null AS int)) from range(1,4)
+select sum(udf(CAST(null AS int))) from range(1,4)
-- !query 19 schema
-struct<sum(CAST(NULL AS INT)):bigint>
+struct<sum(CAST(udf(cast(cast(null as int) as string)) AS INT)):bigint>
-- !query 19 output
NULL
-- !query 20
-select sum(CAST(null AS long)) from range(1,4)
+select sum(udf(CAST(null AS long))) from range(1,4)
-- !query 20 schema
-struct<sum(CAST(NULL AS BIGINT)):bigint>
+struct<sum(CAST(udf(cast(cast(null as bigint) as string)) AS BIGINT)):bigint>
-- !query 20 output
NULL
-- !query 21
-select sum(CAST(null AS Decimal(38,0))) from range(1,4)
+select sum(udf(CAST(null AS Decimal(38,0)))) from range(1,4)
-- !query 21 schema
-struct<sum(CAST(NULL AS DECIMAL(38,0))):decimal(38,0)>
+struct<sum(CAST(udf(cast(cast(null as decimal(38,0)) as string)) AS DECIMAL(38,0))):decimal(38,0)>
-- !query 21 output
NULL
-- !query 22
-select sum(CAST(null AS DOUBLE)) from range(1,4)
+select sum(udf(CAST(null AS DOUBLE))) from range(1,4)
-- !query 22 schema
-struct<sum(CAST(NULL AS DOUBLE)):double>
+struct<sum(CAST(udf(cast(cast(null as double) as string)) AS DOUBLE)):double>
-- !query 22 output
NULL
-- !query 23
-select avg(CAST(null AS int)) from range(1,4)
+select avg(udf(CAST(null AS int))) from range(1,4)
-- !query 23 schema
-struct<avg(CAST(NULL AS INT)):double>
+struct<avg(CAST(udf(cast(cast(null as int) as string)) AS INT)):double>
-- !query 23 output
NULL
-- !query 24
-select avg(CAST(null AS long)) from range(1,4)
+select avg(udf(CAST(null AS long))) from range(1,4)
-- !query 24 schema
-struct<avg(CAST(NULL AS BIGINT)):double>
+struct<avg(CAST(udf(cast(cast(null as bigint) as string)) AS BIGINT)):double>
-- !query 24 output
NULL
-- !query 25
-select avg(CAST(null AS Decimal(38,0))) from range(1,4)
+select avg(udf(CAST(null AS Decimal(38,0)))) from range(1,4)
-- !query 25 schema
-struct<avg(CAST(NULL AS DECIMAL(38,0))):decimal(38,4)>
+struct<avg(CAST(udf(cast(cast(null as decimal(38,0)) as string)) AS DECIMAL(38,0))):decimal(38,4)>
-- !query 25 output
NULL
-- !query 26
-select avg(CAST(null AS DOUBLE)) from range(1,4)
+select avg(udf(CAST(null AS DOUBLE))) from range(1,4)
-- !query 26 schema
-struct<avg(CAST(NULL AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(cast(null as double) as string)) AS DOUBLE)):double>
-- !query 26 output
NULL
-- !query 27
-select sum(CAST('NaN' AS DOUBLE)) from range(1,4)
+select sum(CAST(udf('NaN') AS DOUBLE)) from range(1,4)
-- !query 27 schema
-struct<sum(CAST(NaN AS DOUBLE)):double>
+struct<sum(CAST(CAST(udf(cast(NaN as string)) AS STRING) AS DOUBLE)):double>
-- !query 27 output
NaN
-- !query 28
-select avg(CAST('NaN' AS DOUBLE)) from range(1,4)
+select avg(CAST(udf('NaN') AS DOUBLE)) from range(1,4)
-- !query 28 schema
-struct<avg(CAST(NaN AS DOUBLE)):double>
+struct<avg(CAST(CAST(udf(cast(NaN as string)) AS STRING) AS DOUBLE)):double>
-- !query 28 output
NaN
-- !query 30
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('Infinity'), ('1')) v(x)
-- !query 30 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(CAST(udf(cast(x as string)) AS STRING) AS DOUBLE)):double,var_pop(CAST(CAST(udf(cast(x as string)) AS STRING) AS DOUBLE)):double>
-- !query 30 output
Infinity NaN
-- !query 31
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('Infinity'), ('Infinity')) v(x)
-- !query 31 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(CAST(udf(cast(x as string)) AS STRING) AS DOUBLE)):double,var_pop(CAST(CAST(udf(cast(x as string)) AS STRING) AS DOUBLE)):double>
-- !query 31 output
Infinity NaN
-- !query 32
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('-Infinity'), ('Infinity')) v(x)
-- !query 32 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(CAST(udf(cast(x as string)) AS STRING) AS DOUBLE)):double,var_pop(CAST(CAST(udf(cast(x as string)) AS STRING) AS DOUBLE)):double>
-- !query 32 output
NaN NaN
-- !query 33
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(udf(CAST(x AS DOUBLE))), udf(var_pop(CAST(x AS DOUBLE)))
FROM (VALUES (100000003), (100000004), (100000006), (100000007)) v(x)
-- !query 33 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(cast(x as double) as string)) AS DOUBLE)):double,CAST(udf(cast(var_pop(cast(x as double)) as string)) AS DOUBLE):double>
-- !query 33 output
1.00000005E8 2.5
-- !query 34
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(udf(CAST(x AS DOUBLE))), udf(var_pop(CAST(x AS DOUBLE)))
FROM (VALUES (7000000000005), (7000000000007)) v(x)
-- !query 34 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(cast(x as double) as string)) AS DOUBLE)):double,CAST(udf(cast(var_pop(cast(x as double)) as string)) AS DOUBLE):double>
-- !query 34 output
7.000000000006E12 1.0
-- !query 35
-SELECT covar_pop(b, a), covar_samp(b, a) FROM aggtest
+SELECT udf(covar_pop(b, udf(a))), covar_samp(udf(b), a) FROM aggtest
-- !query 35 schema
-struct<covar_pop(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double,covar_samp(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double>
+struct<CAST(udf(cast(covar_pop(cast(b as double), cast(cast(udf(cast(a as string)) as int) as double)) as string)) AS DOUBLE):double,covar_samp(CAST(CAST(udf(cast(b as string)) AS FLOAT) AS DOUBLE), CAST(a AS DOUBLE)):double>
-- !query 35 output
653.6289553875104 871.5052738500139
-- !query 36
-SELECT corr(b, a) FROM aggtest
+SELECT corr(b, udf(a)) FROM aggtest
-- !query 36 schema
-struct<corr(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double>
+struct<corr(CAST(b AS DOUBLE), CAST(CAST(udf(cast(a as string)) AS INT) AS DOUBLE)):double>
-- !query 36 output
0.1396345165178734
-- !query 37
-SELECT count(four) AS cnt_1000 FROM onek
+SELECT count(udf(four)) AS cnt_1000 FROM onek
-- !query 37 schema
struct<cnt_1000:bigint>
-- !query 37 output
-313,7 +314,7 struct<cnt_1000:bigint>
-- !query 38
-SELECT count(DISTINCT four) AS cnt_4 FROM onek
+SELECT udf(count(DISTINCT four)) AS cnt_4 FROM onek
-- !query 38 schema
struct<cnt_4:bigint>
-- !query 38 output
-321,10 +322,10 struct<cnt_4:bigint>
-- !query 39
-select ten, count(*), sum(four) from onek
+select ten, udf(count(*)), sum(udf(four)) from onek
group by ten order by ten
-- !query 39 schema
-struct<ten:int,count(1):bigint,sum(four):bigint>
+struct<ten:int,CAST(udf(cast(count(1) as string)) AS BIGINT):bigint,sum(CAST(udf(cast(four as string)) AS INT)):bigint>
-- !query 39 output
0 100 100
1 100 200
-339,10 +340,10 struct<ten:int,count(1):bigint,sum(four):bigint>
-- !query 40
-select ten, count(four), sum(DISTINCT four) from onek
+select ten, count(udf(four)), udf(sum(DISTINCT four)) from onek
group by ten order by ten
-- !query 40 schema
-struct<ten:int,count(four):bigint,sum(DISTINCT four):bigint>
+struct<ten:int,count(CAST(udf(cast(four as string)) AS INT)):bigint,CAST(udf(cast(sum(distinct cast(four as bigint)) as string)) AS BIGINT):bigint>
-- !query 40 output
0 100 2
1 100 4
-357,11 +358,11 struct<ten:int,count(four):bigint,sum(DISTINCT four):bigint>
-- !query 41
-select ten, sum(distinct four) from onek a
+select ten, udf(sum(distinct four)) from onek a
group by ten
-having exists (select 1 from onek b where sum(distinct a.four) = b.four)
+having exists (select 1 from onek b where udf(sum(distinct a.four)) = b.four)
-- !query 41 schema
-struct<ten:int,sum(DISTINCT four):bigint>
+struct<ten:int,CAST(udf(cast(sum(distinct cast(four as bigint)) as string)) AS BIGINT):bigint>
-- !query 41 output
0 2
2 2
-374,23 +375,23 struct<ten:int,sum(DISTINCT four):bigint>
select ten, sum(distinct four) from onek a
group by ten
having exists (select 1 from onek b
- where sum(distinct a.four + b.four) = b.four)
+ where sum(distinct a.four + b.four) = udf(b.four))
-- !query 42 schema
struct<>
-- !query 42 output
org.apache.spark.sql.AnalysisException
Aggregate/Window/Generate expressions are not valid in where clause of the query.
-Expression in where clause: [(sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT)) = CAST(b.`four` AS BIGINT))]
+Expression in where clause: [(sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT)) = CAST(CAST(udf(cast(four as string)) AS INT) AS BIGINT))]
Invalid expressions: [sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT))];
-- !query 43
select
- (select max((select i.unique2 from tenk1 i where i.unique1 = o.unique1)))
+ (select udf(max((select i.unique2 from tenk1 i where i.unique1 = o.unique1))))
from tenk1 o
-- !query 43 schema
struct<>
-- !query 43 output
org.apache.spark.sql.AnalysisException
-cannot resolve '`o.unique1`' given input columns: [i.even, i.fivethous, i.four, i.hundred, i.odd, i.string4, i.stringu1, i.stringu2, i.ten, i.tenthous, i.thousand, i.twenty, i.two, i.twothousand, i.unique1, i.unique2]; line 2 pos 63
+cannot resolve '`o.unique1`' given input columns: [i.even, i.fivethous, i.four, i.hundred, i.odd, i.string4, i.stringu1, i.stringu2, i.ten, i.tenthous, i.thousand, i.twenty, i.two, i.twothousand, i.unique1, i.unique2]; line 2 pos 67
```
</p>
</details>
## How was this patch tested?
Manually tested.
Closes#25130 from HyukjinKwon/SPARK-28359.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Add 4 additional agg to KeyValueGroupedDataset
## How was this patch tested?
New test in DatasetSuite for typed aggregation
Closes#24993 from nooberfsh/sqlagg.
Authored-by: nooberfsh <nooberfsh@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR enables `spark.sql.function.preferIntegralDivision` for PostgreSQL testing.
## How was this patch tested?
N/A
Closes#25170 from wangyum/SPARK-28343-2.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
PR builder failed with the following error:
```
[error] /home/jenkins/workspace/SparkPullRequestBuilder/sql/core/src/test/scala/org/apache/spark/sql/execution/PlannerSuite.scala:714: wrong number of arguments for pattern org.apache.spark.sql.execution.exchange.ShuffleExchangeExec(outputPartitioning: org.apache.spark.sql.catalyst.plans.physical.Partitioning,child: org.apache.spark.sql.execution.SparkPlan,canChangeNumPartitions: Boolean)
[error] ShuffleExchangeExec(HashPartitioning(leftPartitioningExpressions, _), _), _),
[error] ^
[error] /home/jenkins/workspace/SparkPullRequestBuilder/sql/core/src/test/scala/org/apache/spark/sql/execution/PlannerSuite.scala:716: wrong number of arguments for pattern org.apache.spark.sql.execution.exchange.ShuffleExchangeExec(outputPartitioning: org.apache.spark.sql.catalyst.plans.physical.Partitioning,child: org.apache.spark.sql.execution.SparkPlan,canChangeNumPartitions: Boolean)
[error] ShuffleExchangeExec(HashPartitioning(rightPartitioningExpressions, _), _), _)) =>
[error] ^
```
## How was this patch tested?
Existing unit test.
Closes#25171 from gaborgsomogyi/SPARK-27485.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: herman <herman@databricks.com>
## What changes were proposed in this pull request?
Adaptive execution reduces the number of post-shuffle partitions at runtime, even for shuffles caused by repartition. However, the user likely wants to get the desired number of partition when he calls repartition even in adaptive execution. This PR adds an internal config to control this and by default adaptive execution will not change the number of post-shuffle partition for repartition.
## How was this patch tested?
New tests added.
Closes#25121 from carsonwang/AE_repartition.
Authored-by: Carson Wang <carson.wang@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
When reordering joins EnsureRequirements only checks if all the join keys are present in the partitioning expression seq. This is problematic when the joins keys and and partitioning expressions both contain duplicates but not the same number of duplicates for each expression, e.g. `Seq(a, a, b)` vs `Seq(a, b, b)`. This fails with an index lookup failure in the `reorder` function.
This PR fixes this removing the equality checking logic from the `reorderJoinKeys` function, and by doing the multiset equality in the `reorder` function while building the reordered key sequences.
## How was this patch tested?
Added a unit test to the `PlannerSuite` and added an integration test to `JoinSuite`
Closes#25167 from hvanhovell/SPARK-27485.
Authored-by: herman <herman@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
A `Filter` predicate using `PythonUDF` can't be push down into join condition, currently. A predicate like that should be able to push down to join condition. For `PythonUDF`s that can't be evaluated in join condition, `PullOutPythonUDFInJoinCondition` will pull them out later.
An example like:
```scala
val pythonTestUDF = TestPythonUDF(name = "udf")
val left = Seq((1, 2), (2, 3)).toDF("a", "b")
val right = Seq((1, 2), (3, 4)).toDF("c", "d")
val df = left.crossJoin(right).where(pythonTestUDF($"a") === pythonTestUDF($"c"))
```
Query plan before the PR:
```
== Physical Plan ==
*(3) Project [a#2121, b#2122, c#2132, d#2133]
+- *(3) Filter (pythonUDF0#2142 = pythonUDF1#2143)
+- BatchEvalPython [udf(a#2121), udf(c#2132)], [pythonUDF0#2142, pythonUDF1#2143]
+- BroadcastNestedLoopJoin BuildRight, Cross
:- *(1) Project [_1#2116 AS a#2121, _2#2117 AS b#2122]
: +- LocalTableScan [_1#2116, _2#2117]
+- BroadcastExchange IdentityBroadcastMode
+- *(2) Project [_1#2127 AS c#2132, _2#2128 AS d#2133]
+- LocalTableScan [_1#2127, _2#2128]
```
Query plan after the PR:
```
== Physical Plan ==
*(3) Project [a#2121, b#2122, c#2132, d#2133]
+- *(3) BroadcastHashJoin [pythonUDF0#2142], [pythonUDF0#2143], Cross, BuildRight
:- BatchEvalPython [udf(a#2121)], [pythonUDF0#2142]
: +- *(1) Project [_1#2116 AS a#2121, _2#2117 AS b#2122]
: +- LocalTableScan [_1#2116, _2#2117]
+- BroadcastExchange HashedRelationBroadcastMode(List(input[2, string, true]))
+- BatchEvalPython [udf(c#2132)], [pythonUDF0#2143]
+- *(2) Project [_1#2127 AS c#2132, _2#2128 AS d#2133]
+- LocalTableScan [_1#2127, _2#2128]
```
After this PR, the join can use `BroadcastHashJoin`, instead of `BroadcastNestedLoopJoin`.
## How was this patch tested?
Added tests.
Closes#25106 from viirya/pythonudf-join-condition.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Existing random generators in tests produce wide ranges of values that can be out of supported ranges for:
- `DateType`, the valid range is `[0001-01-01, 9999-12-31]`
- `TimestampType` supports values in `[0001-01-01T00:00:00.000000Z, 9999-12-31T23:59:59.999999Z]`
- `CalendarIntervalType` should define intervals for the ranges above.
Dates and timestamps produced by random literal generators are usually out of valid ranges for those types. And tests just check invalid values or values caused by arithmetic overflow.
In the PR, I propose to restrict tested pseudo-random values by valid ranges of `DateType`, `TimestampType` and `CalendarIntervalType`. This should allow to check valid values in test, and avoid wasting time on a priori invalid inputs.
## How was this patch tested?
The changes were checked by `DateExpressionsSuite` and modified `DateTimeUtils.dateAddMonths`:
```Scala
def dateAddMonths(days: SQLDate, months: Int): SQLDate = {
localDateToDays(LocalDate.ofEpochDay(days).plusMonths(months))
}
```
Closes#25166 from MaxGekk/datetime-lit-random-gen.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR aims to correct mappings in `MsSqlServerDialect`. `ShortType` is mapped to `SMALLINT` and `FloatType` is mapped to `REAL` per [JBDC mapping]( https://docs.microsoft.com/en-us/sql/connect/jdbc/using-basic-data-types?view=sql-server-2017) respectively.
ShortType and FloatTypes are not correctly mapped to right JDBC types when using JDBC connector. This results in tables and spark data frame being created with unintended types. The issue was observed when validating against SQLServer.
Refer [JBDC mapping]( https://docs.microsoft.com/en-us/sql/connect/jdbc/using-basic-data-types?view=sql-server-2017 ) for guidance on mappings between SQLServer, JDBC and Java. Note that java "Short" type should be mapped to JDBC "SMALLINT" and java Float should be mapped to JDBC "REAL".
Some example issue that can happen because of wrong mappings
- Write from df with column type results in a SQL table of with column type as INTEGER as opposed to SMALLINT.Thus a larger table that expected.
- Read results in a dataframe with type INTEGER as opposed to ShortType
- ShortType has a problem in both the the write and read path
- FloatTypes only have an issue with read path. In the write path Spark data type 'FloatType' is correctly mapped to JDBC equivalent data type 'Real'. But in the read path when JDBC data types need to be converted to Catalyst data types ( getCatalystType) 'Real' gets incorrectly gets mapped to 'DoubleType' rather than 'FloatType'.
Refer #28151 which contained this fix as one part of a larger PR. Following PR #28151 discussion it was decided to file seperate PRs for each of the fixes.
## How was this patch tested?
UnitTest added in JDBCSuite.scala and these were tested.
Integration test updated and passed in MsSqlServerDialect.scala
E2E test done with SQLServer
Closes#25146 from shivsood/float_short_type_fix.
Authored-by: shivsood <shivsood@microsoft.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
`System.currentTimeMillis` read two times in a loop in `RateStreamContinuousPartitionReader`. If the test machine is slow enough and it spends quite some time between the `while` condition check and the `Thread.sleep` then the timeout value is negative and throws `IllegalArgumentException`.
In this PR I've fixed this issue.
## How was this patch tested?
Existing unit tests.
Closes#25162 from gaborgsomogyi/SPARK-28404.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
Idempotence of the `NormalizeFloatingNumbers` rule was broken due to the implementation of `ExtractEquiJoinKeys`. There is no reason that we don't remove `EqualNullSafe` join keys from an equi-join's `otherPredicates`.
## How was this patch tested?
A new UT.
Closes#25126 from yeshengm/spark-28306.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
For Thrift server, It's downward compatible. Such as if a PROTOCOL_VERSION_V7 client connect to a PROTOCOL_VERSION_V8 server, when OpenSession, server will change his response's protocol version to min of (client and server).
`TProtocolVersion protocol = getMinVersion(CLIService.SERVER_VERSION,`
` req.getClient_protocol());`
then set it to OpenSession's response.
But if OpenSession failed , it won't execute behavior of reset response's protocol_version.
Then it will return server's origin protocol version.
Finally client will get en error as below:
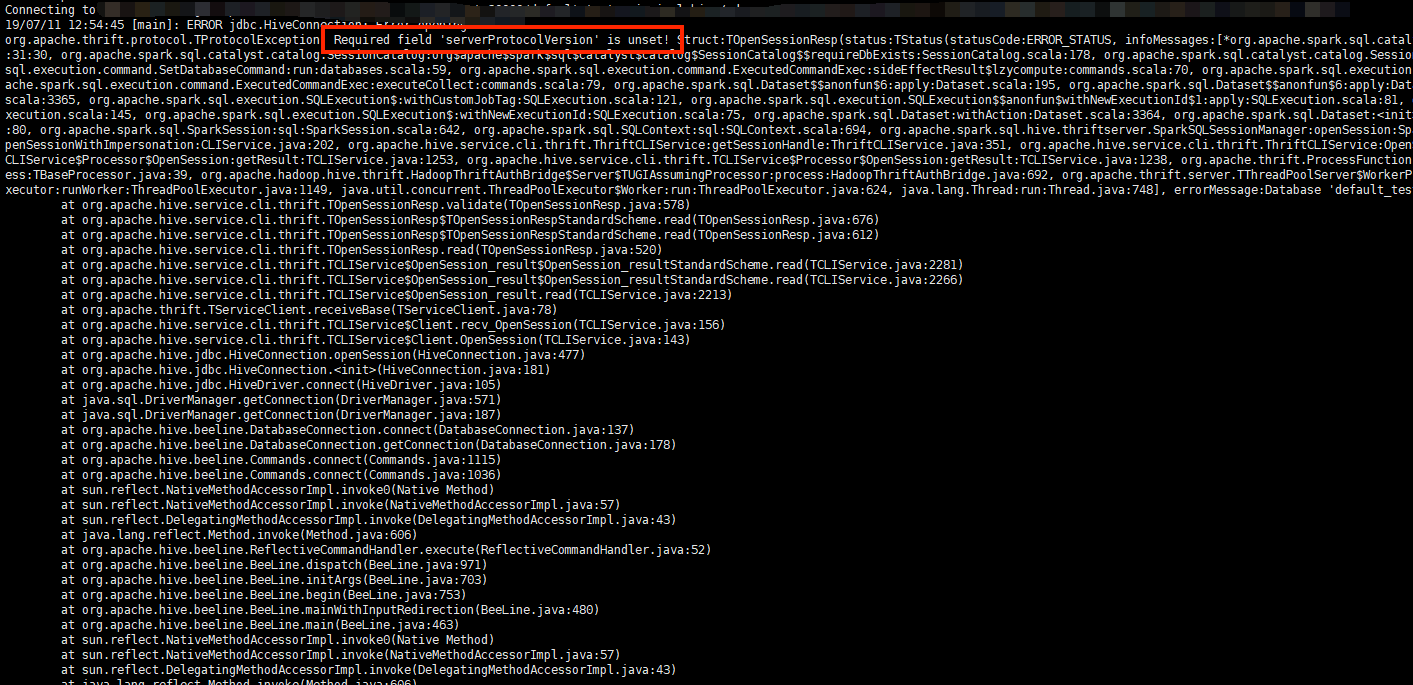
Since we write a wrong database,, OpenSession failed, right protocol version haven't been rest.
## How was this patch tested?
Since I really don't know how to write unit test about this, so I build a jar with this PR,and retry the error above, then it will return a reasonable Error of DB not found :

Closes#25083 from AngersZhuuuu/SPARK-28311.
Authored-by: 朱夷 <zhuyi01@corp.netease.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In the PR, I propose to use the `plusMonths()` method of `LocalDate` to add months to a date. This method adds the specified amount to the months field of `LocalDate` in three steps:
1. Add the input months to the month-of-year field
2. Check if the resulting date would be invalid
3. Adjust the day-of-month to the last valid day if necessary
The difference between current behavior and propose one is in handling the last day of month in the original date. For example, adding 1 month to `2019-02-28` will produce `2019-03-28` comparing to the current implementation where the result is `2019-03-31`.
The proposed behavior is implemented in MySQL and PostgreSQL.
## How was this patch tested?
By existing test suites `DateExpressionsSuite`, `DateFunctionsSuite` and `DateTimeUtilsSuite`.
Closes#25153 from MaxGekk/add-months.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR adds some traits so that we can deduplicate initialization stuff for each type of test case. For instance, see [SPARK-28343](https://issues.apache.org/jira/browse/SPARK-28343).
It's a little bit overkill but I think it will make adding test cases easier and cause less confusions.
This PR adds both:
```
private trait PgSQLTest
private trait UDFTest
```
To indicate and share the logics related to each combination of test types.
## How was this patch tested?
Manually tested.
Closes#25155 from HyukjinKwon/SPARK-28392.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Adding support to hyperbolic functions like asinh\acosh\atanh in spark SQL.
Feature parity: https://www.postgresql.org/docs/12/functions-math.html#FUNCTIONS-MATH-HYP-TABLE
The followings are the diffence from PostgreSQL.
```
spark-sql> SELECT acosh(0); (PostgreSQL returns `ERROR: input is out of range`)
NaN
spark-sql> SELECT atanh(2); (PostgreSQL returns `ERROR: input is out of range`)
NaN
```
Teradata has similar behavior as PostgreSQL with out of range input float values - It outputs **Invalid Input: numeric value within range only.**
These newly added asinh/acosh/atanh handles special input(NaN, +-Infinity) in the same way as existing cos/sin/tan/acos/asin/atan in spark. For which input value range is not (-∞, ∞)):
out of range float values: Spark returns NaN and PostgreSQL shows input is out of range
NaN: Spark returns NaN, PostgreSQL also returns NaN
Infinity: Spark return NaN, PostgreSQL shows input is out of range
## How was this patch tested?
```
spark.sql("select asinh(xx)")
spark.sql("select acosh(xx)")
spark.sql("select atanh(xx)")
./build/sbt "testOnly org.apache.spark.sql.MathFunctionsSuite"
./build/sbt "testOnly org.apache.spark.sql.catalyst.expressions.MathExpressionsSuite"
```
Closes#25041 from Tonix517/SPARK-28133.
Authored-by: Tony Zhang <tony.zhang@uber.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This upgraded to a newer version of Pyrolite. Most updates [1] in the newer version are for dotnot. For java, it includes a bug fix to Unpickler regarding cleaning up Unpickler memo, and support of protocol 5.
After upgrading, we can remove the fix at SPARK-27629 for the bug in Unpickler.
[1] https://github.com/irmen/Pyrolite/compare/pyrolite-4.23...master
## How was this patch tested?
Manually tested on Python 3.6 in local on existing tests.
Closes#25143 from viirya/upgrade-pyrolite.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This patch proposes moving all Trigger implementations to `Triggers.scala`, to avoid exposing these implementations to the end users and let end users only deal with `Trigger.xxx` static methods. This fits the intention of deprecation of `ProcessingTIme`, and we agree to move others without deprecation as this patch will be shipped in major version (Spark 3.0.0).
## How was this patch tested?
UTs modified to work with newly introduced class.
Closes#24996 from HeartSaVioR/SPARK-28199.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This pr enables `spark.sql.crossJoin.enabled` and `spark.sql.parser.ansi.enabled` for PostgreSQL test.
## How was this patch tested?
manual tests:
Run `test.sql` in [pgSQL](https://github.com/apache/spark/tree/master/sql/core/src/test/resources/sql-tests/inputs/pgSQL) directory and in [inputs](https://github.com/apache/spark/tree/master/sql/core/src/test/resources/sql-tests/inputs) directory:
```sql
cat <<EOF > test.sql
create or replace temporary view t1 as
select * from (values(1), (2)) as v (val);
create or replace temporary view t2 as
select * from (values(2), (1)) as v (val);
select t1.*, t2.* from t1 join t2;
EOF
```
Closes#25109 from wangyum/SPARK-28343.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
Parquet may call the filter with a null value to check whether nulls are
accepted. While it seems Spark avoids that path in Parquet with 1.10, in
1.11 that causes Spark unit tests to fail.
Tested with Parquet 1.11 (and new unit test).
Closes#25140 from vanzin/SPARK-28371.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This patch fixes the flaky test "query without test harness" on ContinuousSuite, via adding some more gaps on waiting query to commit the epoch which writes output rows.
The observation of this issue is below (injected some debug logs to get them):
```
reader creation time 1562225320210
epoch 1 launched 1562225320593 (+380ms from reader creation time)
epoch 13 launched 1562225321702 (+1.5s from reader creation time)
partition reader creation time 1562225321715 (+1.5s from reader creation time)
next read time for first next call 1562225321210 (+1s from reader creation time)
first next called in partition reader 1562225321746 (immediately after creation of partition reader)
wait finished in next called in partition reader 1562225321746 (no wait)
second next called in partition reader 1562225321747 (immediately after first next())
epoch 0 commit started 1562225321861
writing rows (0, 1) (belong to epoch 13) 1562225321866 (+100ms after first next())
wait start in waitForRateSourceTriggers(2) 1562225322059
next read time for second next call 1562225322210 (+1s from previous "next read time")
wait finished in next called in partition reader 1562225322211 (+450ms wait)
writing rows (2, 3) (belong to epoch 13) 1562225322211 (immediately after next())
epoch 14 launched 1562225322246
desired wait time in waitForRateSourceTriggers(2) 1562225322510 (+2.3s from reader creation time)
epoch 12 committed 1562225323034
```
These rows were written within desired wait time, but the epoch 13 couldn't be committed within it. Interestingly, epoch 12 was lucky to be committed within a gap between finished waiting in waitForRateSourceTriggers and query.stop() - but even suppose the rows were written in epoch 12, it would be just in luck and epoch should be committed within desired wait time.
This patch modifies Rate continuous stream to track the highest committed value, so that test can wait until desired value is reported to the stream as committed.
This patch also modifies Rate continuous stream to track the timestamp at stream gets the first committed offset, and let `waitForRateSourceTriggers` use the timestamp. This also relies on waiting for specific period, but safer approach compared to current based on the observation above. Based on the change, this patch saves couple of seconds in test time.
## How was this patch tested?
10 sequential test runs succeeded locally.
Closes#25048 from HeartSaVioR/SPARK-28247.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
A code gen test in WholeStageCodeGenSuite was flaky because it used the codegen metrics class to test if the generated code for equivalent plans was identical under a particular flag. This patch switches the test to compare the generated code directly.
N/A
Closes#25131 from gatorsmile/WholeStageCodegenSuite.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds compatibility of handling a `WITH` clause within another `WITH` cause. Before this PR these queries retuned `1` while after this PR they return `2` as PostgreSQL does:
```
WITH
t AS (SELECT 1),
t2 AS (
WITH t AS (SELECT 2)
SELECT * FROM t
)
SELECT * FROM t2
```
```
WITH t AS (SELECT 1)
SELECT (
WITH t AS (SELECT 2)
SELECT * FROM t
)
```
As this is an incompatible change, the PR introduces the `spark.sql.legacy.cte.substitution.enabled` flag as an option to restore old behaviour.
## How was this patch tested?
Added new UTs.
Closes#25029 from peter-toth/SPARK-28228.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
There are some hardcoded configs, using config entry to replace them.
## How was this patch tested?
Existing UT
Closes#25059 from WangGuangxin/ConfigEntry.
Authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
0-args Java UDF alone calls the function even before making it as an expression.
It causes that the function always returns the same value and the function is called at driver side.
Seems like a mistake.
## How was this patch tested?
Unit test was added
Closes#25108 from HyukjinKwon/SPARK-28321.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Implement `ALTER TABLE` for v2 tables:
* Add `AlterTable` logical plan and `AlterTableExec` physical plan
* Convert `ALTER TABLE` parsed plans to `AlterTable` when a v2 catalog is responsible for an identifier
* Validate that columns to alter exist in analyzer checks
* Fix nested type handling in `CatalogV2Util`
## How was this patch tested?
* Add extensive tests in `DataSourceV2SQLSuite`
Closes#24937 from rdblue/SPARK-28139-add-v2-alter-table.
Lead-authored-by: Ryan Blue <blue@apache.org>
Co-authored-by: Ryan Blue <rdblue@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Cleaned up (removed) code duplication in `ObjectProducerExec` operators so they use the trait's methods.
## How was this patch tested?
Local build. Waiting for Jenkins.
Closes#25065 from jaceklaskowski/ObjectProducerExec-operators-cleanup.
Authored-by: Jacek Laskowski <jacek@japila.pl>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This is a second part of the https://issues.apache.org/jira/browse/SPARK-27396 and a follow on to #24795
## How was this patch tested?
I did some manual tests and ran/updated the automated tests
I did some simple performance tests on a single node to try to verify that there is no performance impact, and I was not able to measure anything beyond noise.
Closes#25008 from revans2/columnar-remove-batch-scan.
Authored-by: Robert (Bobby) Evans <bobby@apache.org>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
The tests added at https://github.com/apache/spark/pull/25069 seem flaky in some environments. See https://github.com/apache/spark/pull/25069#issuecomment-510338469
Python's string representation of floats can make the tests flaky. See https://docs.python.org/3/tutorial/floatingpoint.html.
I think it's just better to explicitly cast everywhere udf returns a float (or a double) to stay safe. (note that we're not targeting the Python <> Scala value conversions - there are inevitable differences between Python and Scala; therefore, other languages' UDFs cannot guarantee the same results between Python and Scala).
This PR proposes to cast cases to long, integer and decimal explicitly to make the test cases robust.
<details><summary>Diff comparing to 'pgSQL/aggregates_part1.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/pgSQL/aggregates_part1.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-aggregates_part1.sql.out
index 51ca1d55869..734634b7388 100644
--- a/sql/core/src/test/resources/sql-tests/results/pgSQL/aggregates_part1.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-aggregates_part1.sql.out
-3,23 +3,23
-- !query 0
-SELECT avg(four) AS avg_1 FROM onek
+SELECT CAST(avg(udf(four)) AS decimal(10,3)) AS avg_1 FROM onek
-- !query 0 schema
-struct<avg_1:double>
+struct<avg_1:decimal(10,3)>
-- !query 0 output
1.5
-- !query 1
-SELECT avg(a) AS avg_32 FROM aggtest WHERE a < 100
+SELECT CAST(udf(avg(a)) AS decimal(10,3)) AS avg_32 FROM aggtest WHERE a < 100
-- !query 1 schema
-struct<avg_32:double>
+struct<avg_32:decimal(10,3)>
-- !query 1 output
-32.666666666666664
+32.667
-- !query 2
-select CAST(avg(b) AS Decimal(10,3)) AS avg_107_943 FROM aggtest
+select CAST(avg(udf(b)) AS Decimal(10,3)) AS avg_107_943 FROM aggtest
-- !query 2 schema
struct<avg_107_943:decimal(10,3)>
-- !query 2 output
-27,39 +27,39 struct<avg_107_943:decimal(10,3)>
-- !query 3
-SELECT sum(four) AS sum_1500 FROM onek
+SELECT CAST(sum(udf(four)) AS int) AS sum_1500 FROM onek
-- !query 3 schema
-struct<sum_1500:bigint>
+struct<sum_1500:int>
-- !query 3 output
1500
-- !query 4
-SELECT sum(a) AS sum_198 FROM aggtest
+SELECT udf(sum(a)) AS sum_198 FROM aggtest
-- !query 4 schema
-struct<sum_198:bigint>
+struct<sum_198:string>
-- !query 4 output
198
-- !query 5
-SELECT sum(b) AS avg_431_773 FROM aggtest
+SELECT CAST(udf(udf(sum(b))) AS decimal(10,3)) AS avg_431_773 FROM aggtest
-- !query 5 schema
-struct<avg_431_773:double>
+struct<avg_431_773:decimal(10,3)>
-- !query 5 output
-431.77260909229517
+431.773
-- !query 6
-SELECT max(four) AS max_3 FROM onek
+SELECT udf(max(four)) AS max_3 FROM onek
-- !query 6 schema
-struct<max_3:int>
+struct<max_3:string>
-- !query 6 output
3
-- !query 7
-SELECT max(a) AS max_100 FROM aggtest
+SELECT max(CAST(udf(a) AS int)) AS max_100 FROM aggtest
-- !query 7 schema
struct<max_100:int>
-- !query 7 output
-67,245 +67,246 struct<max_100:int>
-- !query 8
-SELECT max(aggtest.b) AS max_324_78 FROM aggtest
+SELECT CAST(udf(udf(max(aggtest.b))) AS decimal(10,3)) AS max_324_78 FROM aggtest
-- !query 8 schema
-struct<max_324_78:float>
+struct<max_324_78:decimal(10,3)>
-- !query 8 output
324.78
-- !query 9
-SELECT stddev_pop(b) FROM aggtest
+SELECT CAST(stddev_pop(udf(b)) AS decimal(10,3)) FROM aggtest
-- !query 9 schema
-struct<stddev_pop(CAST(b AS DOUBLE)):double>
+struct<CAST(stddev_pop(CAST(udf(b) AS DOUBLE)) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 9 output
-131.10703231895047
+131.107
-- !query 10
-SELECT stddev_samp(b) FROM aggtest
+SELECT CAST(udf(stddev_samp(b)) AS decimal(10,3)) FROM aggtest
-- !query 10 schema
-struct<stddev_samp(CAST(b AS DOUBLE)):double>
+struct<CAST(udf(stddev_samp(cast(b as double))) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 10 output
-151.38936080399804
+151.389
-- !query 11
-SELECT var_pop(b) FROM aggtest
+SELECT CAST(var_pop(udf(b)) AS decimal(10,3)) FROM aggtest
-- !query 11 schema
-struct<var_pop(CAST(b AS DOUBLE)):double>
+struct<CAST(var_pop(CAST(udf(b) AS DOUBLE)) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 11 output
-17189.053923482323
+17189.054
-- !query 12
-SELECT var_samp(b) FROM aggtest
+SELECT CAST(udf(var_samp(b)) AS decimal(10,3)) FROM aggtest
-- !query 12 schema
-struct<var_samp(CAST(b AS DOUBLE)):double>
+struct<CAST(udf(var_samp(cast(b as double))) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 12 output
-22918.738564643096
+22918.739
-- !query 13
-SELECT stddev_pop(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT CAST(udf(stddev_pop(CAST(b AS Decimal(38,0)))) AS decimal(10,3)) FROM aggtest
-- !query 13 schema
-struct<stddev_pop(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<CAST(udf(stddev_pop(cast(cast(b as decimal(38,0)) as double))) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 13 output
-131.18117242958306
+131.181
-- !query 14
-SELECT stddev_samp(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT CAST(stddev_samp(CAST(udf(b) AS Decimal(38,0))) AS decimal(10,3)) FROM aggtest
-- !query 14 schema
-struct<stddev_samp(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<CAST(stddev_samp(CAST(CAST(udf(b) AS DECIMAL(38,0)) AS DOUBLE)) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 14 output
-151.47497042966097
+151.475
-- !query 15
-SELECT var_pop(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT CAST(udf(var_pop(CAST(b AS Decimal(38,0)))) AS decimal(10,3)) FROM aggtest
-- !query 15 schema
-struct<var_pop(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<CAST(udf(var_pop(cast(cast(b as decimal(38,0)) as double))) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 15 output
17208.5
-- !query 16
-SELECT var_samp(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT CAST(var_samp(udf(CAST(b AS Decimal(38,0)))) AS decimal(10,3)) FROM aggtest
-- !query 16 schema
-struct<var_samp(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<CAST(var_samp(CAST(udf(cast(b as decimal(38,0))) AS DOUBLE)) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 16 output
-22944.666666666668
+22944.667
-- !query 17
-SELECT var_pop(1.0), var_samp(2.0)
+SELECT CAST(udf(var_pop(1.0)) AS int), var_samp(udf(2.0))
-- !query 17 schema
-struct<var_pop(CAST(1.0 AS DOUBLE)):double,var_samp(CAST(2.0 AS DOUBLE)):double>
+struct<CAST(udf(var_pop(cast(1.0 as double))) AS INT):int,var_samp(CAST(udf(2.0) AS DOUBLE)):double>
-- !query 17 output
-0.0 NaN
+0 NaN
-- !query 18
-SELECT stddev_pop(CAST(3.0 AS Decimal(38,0))), stddev_samp(CAST(4.0 AS Decimal(38,0)))
+SELECT CAST(stddev_pop(udf(CAST(3.0 AS Decimal(38,0)))) AS int), stddev_samp(CAST(udf(4.0) AS Decimal(38,0)))
-- !query 18 schema
-struct<stddev_pop(CAST(CAST(3.0 AS DECIMAL(38,0)) AS DOUBLE)):double,stddev_samp(CAST(CAST(4.0 AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<CAST(stddev_pop(CAST(udf(cast(3.0 as decimal(38,0))) AS DOUBLE)) AS INT):int,stddev_samp(CAST(CAST(udf(4.0) AS DECIMAL(38,0)) AS DOUBLE)):double>
-- !query 18 output
-0.0 NaN
+0 NaN
-- !query 19
-select sum(CAST(null AS int)) from range(1,4)
+select sum(udf(CAST(null AS int))) from range(1,4)
-- !query 19 schema
-struct<sum(CAST(NULL AS INT)):bigint>
+struct<sum(CAST(udf(cast(null as int)) AS DOUBLE)):double>
-- !query 19 output
NULL
-- !query 20
-select sum(CAST(null AS long)) from range(1,4)
+select sum(udf(CAST(null AS long))) from range(1,4)
-- !query 20 schema
-struct<sum(CAST(NULL AS BIGINT)):bigint>
+struct<sum(CAST(udf(cast(null as bigint)) AS DOUBLE)):double>
-- !query 20 output
NULL
-- !query 21
-select sum(CAST(null AS Decimal(38,0))) from range(1,4)
+select sum(udf(CAST(null AS Decimal(38,0)))) from range(1,4)
-- !query 21 schema
-struct<sum(CAST(NULL AS DECIMAL(38,0))):decimal(38,0)>
+struct<sum(CAST(udf(cast(null as decimal(38,0))) AS DOUBLE)):double>
-- !query 21 output
NULL
-- !query 22
-select sum(CAST(null AS DOUBLE)) from range(1,4)
+select sum(udf(CAST(null AS DOUBLE))) from range(1,4)
-- !query 22 schema
-struct<sum(CAST(NULL AS DOUBLE)):double>
+struct<sum(CAST(udf(cast(null as double)) AS DOUBLE)):double>
-- !query 22 output
NULL
-- !query 23
-select avg(CAST(null AS int)) from range(1,4)
+select avg(udf(CAST(null AS int))) from range(1,4)
-- !query 23 schema
-struct<avg(CAST(NULL AS INT)):double>
+struct<avg(CAST(udf(cast(null as int)) AS DOUBLE)):double>
-- !query 23 output
NULL
-- !query 24
-select avg(CAST(null AS long)) from range(1,4)
+select avg(udf(CAST(null AS long))) from range(1,4)
-- !query 24 schema
-struct<avg(CAST(NULL AS BIGINT)):double>
+struct<avg(CAST(udf(cast(null as bigint)) AS DOUBLE)):double>
-- !query 24 output
NULL
-- !query 25
-select avg(CAST(null AS Decimal(38,0))) from range(1,4)
+select avg(udf(CAST(null AS Decimal(38,0)))) from range(1,4)
-- !query 25 schema
-struct<avg(CAST(NULL AS DECIMAL(38,0))):decimal(38,4)>
+struct<avg(CAST(udf(cast(null as decimal(38,0))) AS DOUBLE)):double>
-- !query 25 output
NULL
-- !query 26
-select avg(CAST(null AS DOUBLE)) from range(1,4)
+select avg(udf(CAST(null AS DOUBLE))) from range(1,4)
-- !query 26 schema
-struct<avg(CAST(NULL AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(null as double)) AS DOUBLE)):double>
-- !query 26 output
NULL
-- !query 27
-select sum(CAST('NaN' AS DOUBLE)) from range(1,4)
+select sum(CAST(udf('NaN') AS DOUBLE)) from range(1,4)
-- !query 27 schema
-struct<sum(CAST(NaN AS DOUBLE)):double>
+struct<sum(CAST(udf(NaN) AS DOUBLE)):double>
-- !query 27 output
NaN
-- !query 28
-select avg(CAST('NaN' AS DOUBLE)) from range(1,4)
+select avg(CAST(udf('NaN') AS DOUBLE)) from range(1,4)
-- !query 28 schema
-struct<avg(CAST(NaN AS DOUBLE)):double>
+struct<avg(CAST(udf(NaN) AS DOUBLE)):double>
-- !query 28 output
NaN
-- !query 30
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('Infinity'), ('1')) v(x)
-- !query 30 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 30 output
Infinity NaN
-- !query 31
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('Infinity'), ('Infinity')) v(x)
-- !query 31 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 31 output
Infinity NaN
-- !query 32
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('-Infinity'), ('Infinity')) v(x)
-- !query 32 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 32 output
NaN NaN
-- !query 33
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT CAST(avg(udf(CAST(x AS DOUBLE))) AS int), CAST(udf(var_pop(CAST(x AS DOUBLE))) AS decimal(10,3))
FROM (VALUES (100000003), (100000004), (100000006), (100000007)) v(x)
-- !query 33 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<CAST(avg(CAST(udf(cast(x as double)) AS DOUBLE)) AS INT):int,CAST(udf(var_pop(cast(x as double))) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 33 output
-1.00000005E8 2.5
+100000005 2.5
-- !query 34
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT CAST(avg(udf(CAST(x AS DOUBLE))) AS long), CAST(udf(var_pop(CAST(x AS DOUBLE))) AS decimal(10,3))
FROM (VALUES (7000000000005), (7000000000007)) v(x)
-- !query 34 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<CAST(avg(CAST(udf(cast(x as double)) AS DOUBLE)) AS BIGINT):bigint,CAST(udf(var_pop(cast(x as double))) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 34 output
-7.000000000006E12 1.0
+7000000000006 1
-- !query 35
-SELECT covar_pop(b, a), covar_samp(b, a) FROM aggtest
+SELECT CAST(udf(covar_pop(b, udf(a))) AS decimal(10,3)), CAST(covar_samp(udf(b), a) as decimal(10,3)) FROM aggtest
-- !query 35 schema
-struct<covar_pop(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double,covar_samp(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double>
+struct<CAST(udf(covar_pop(cast(b as double), cast(udf(a) as double))) AS DECIMAL(10,3)):decimal(10,3),CAST(covar_samp(CAST(udf(b) AS DOUBLE), CAST(a AS DOUBLE)) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 35 output
-653.6289553875104 871.5052738500139
+653.629 871.505
-- !query 36
-SELECT corr(b, a) FROM aggtest
+SELECT CAST(corr(b, udf(a)) AS decimal(10,3)) FROM aggtest
-- !query 36 schema
-struct<corr(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double>
+struct<CAST(corr(CAST(b AS DOUBLE), CAST(udf(a) AS DOUBLE)) AS DECIMAL(10,3)):decimal(10,3)>
-- !query 36 output
-0.1396345165178734
+0.14
-- !query 37
-SELECT count(four) AS cnt_1000 FROM onek
+SELECT count(udf(four)) AS cnt_1000 FROM onek
-- !query 37 schema
struct<cnt_1000:bigint>
-- !query 37 output
-313,18 +314,18 struct<cnt_1000:bigint>
-- !query 38
-SELECT count(DISTINCT four) AS cnt_4 FROM onek
+SELECT udf(count(DISTINCT four)) AS cnt_4 FROM onek
-- !query 38 schema
-struct<cnt_4:bigint>
+struct<cnt_4:string>
-- !query 38 output
4
-- !query 39
-select ten, count(*), sum(four) from onek
+select ten, udf(count(*)), CAST(sum(udf(four)) AS int) from onek
group by ten order by ten
-- !query 39 schema
-struct<ten:int,count(1):bigint,sum(four):bigint>
+struct<ten:int,udf(count(1)):string,CAST(sum(CAST(udf(four) AS DOUBLE)) AS INT):int>
-- !query 39 output
0 100 100
1 100 200
-339,10 +340,10 struct<ten:int,count(1):bigint,sum(four):bigint>
-- !query 40
-select ten, count(four), sum(DISTINCT four) from onek
+select ten, count(udf(four)), udf(sum(DISTINCT four)) from onek
group by ten order by ten
-- !query 40 schema
-struct<ten:int,count(four):bigint,sum(DISTINCT four):bigint>
+struct<ten:int,count(udf(four)):bigint,udf(sum(distinct cast(four as bigint))):string>
-- !query 40 output
0 100 2
1 100 4
-357,11 +358,11 struct<ten:int,count(four):bigint,sum(DISTINCT four):bigint>
-- !query 41
-select ten, sum(distinct four) from onek a
+select ten, udf(sum(distinct four)) from onek a
group by ten
-having exists (select 1 from onek b where sum(distinct a.four) = b.four)
+having exists (select 1 from onek b where udf(sum(distinct a.four)) = b.four)
-- !query 41 schema
-struct<ten:int,sum(DISTINCT four):bigint>
+struct<ten:int,udf(sum(distinct cast(four as bigint))):string>
-- !query 41 output
0 2
2 2
-374,23 +375,23 struct<ten:int,sum(DISTINCT four):bigint>
select ten, sum(distinct four) from onek a
group by ten
having exists (select 1 from onek b
- where sum(distinct a.four + b.four) = b.four)
+ where sum(distinct a.four + b.four) = udf(b.four))
-- !query 42 schema
struct<>
-- !query 42 output
org.apache.spark.sql.AnalysisException
Aggregate/Window/Generate expressions are not valid in where clause of the query.
-Expression in where clause: [(sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT)) = CAST(b.`four` AS BIGINT))]
+Expression in where clause: [(sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT)) = CAST(udf(four) AS BIGINT))]
Invalid expressions: [sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT))];
-- !query 43
select
- (select max((select i.unique2 from tenk1 i where i.unique1 = o.unique1)))
+ (select udf(max((select i.unique2 from tenk1 i where i.unique1 = o.unique1))))
from tenk1 o
-- !query 43 schema
struct<>
-- !query 43 output
org.apache.spark.sql.AnalysisException
-cannot resolve '`o.unique1`' given input columns: [i.even, i.fivethous, i.four, i.hundred, i.odd, i.string4, i.stringu1, i.stringu2, i.ten, i.tenthous, i.thousand, i.twenty, i.two, i.twothousand, i.unique1, i.unique2]; line 2 pos 63
+cannot resolve '`o.unique1`' given input columns: [i.even, i.fivethous, i.four, i.hundred, i.odd, i.string4, i.stringu1, i.stringu2, i.ten, i.tenthous, i.thousand, i.twenty, i.two, i.twothousand, i.unique1, i.unique2]; line 2 pos 67
```
</p>
</details>
## How was this patch tested?
Manually tested in local.
Also, with JDK 11:
```
Using /.../jdk-11.0.3.jdk/Contents/Home as default JAVA_HOME.
Note, this will be overridden by -java-home if it is set.
[info] Loading project definition from /.../spark/project
[info] Updating {file:/.../spark/project/}spark-build...
...
[info] SQLQueryTestSuite:
...
[info] - udf/pgSQL/udf-aggregates_part1.sql - Scala UDF (17 seconds, 228 milliseconds)
[info] - udf/pgSQL/udf-aggregates_part1.sql - Regular Python UDF (36 seconds, 170 milliseconds)
[info] - udf/pgSQL/udf-aggregates_part1.sql - Scalar Pandas UDF (41 seconds, 132 milliseconds)
...
```
Closes#25110 from HyukjinKwon/SPARK-28270-1.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The optimizer rule `NormalizeFloatingNumbers` is not idempotent. It will generate multiple `NormalizeNaNAndZero` and `ArrayTransform` expression nodes for multiple runs. This patch fixed this non-idempotence by adding a marking tag above normalized expressions. It also adds missing UTs for `NormalizeFloatingNumbers`.
## How was this patch tested?
New UTs.
Closes#25080 from yeshengm/spark-28306.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to replace `REL_12_BETA1` to `REL_12_BETA2` which is latest.
## How was this patch tested?
Manually checked each link and checked via `git grep -r REL_12_BETA1` as well.
Closes#25105 from HyukjinKwon/SPARK-28342.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
The new adaptive execution framework introduced configuration `spark.sql.runtime.reoptimization.enabled`. We now rename it back to `spark.sql.adaptive.enabled` as the umbrella configuration for adaptive execution.
## How was this patch tested?
Existing tests.
Closes#25102 from carsonwang/renameAE.
Authored-by: Carson Wang <carson.wang@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR adds some tests converted from `pgSQL/aggregates_part1.sql'` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
This PR also contains two minor fixes:
1. Change name of Scala UDF from `UDF:name(...)` to `name(...)` to be consistent with Python'
2. Fix Scala UDF at `IntegratedUDFTestUtils.scala ` to handle `null` in strings.
<details><summary>Diff comparing to 'pgSQL/aggregates_part1.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/pgSQL/aggregates_part1.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-aggregates_part1.sql.out
index 51ca1d55869..124fdd6416e 100644
--- a/sql/core/src/test/resources/sql-tests/results/pgSQL/aggregates_part1.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-aggregates_part1.sql.out
-3,7 +3,7
-- !query 0
-SELECT avg(four) AS avg_1 FROM onek
+SELECT avg(udf(four)) AS avg_1 FROM onek
-- !query 0 schema
struct<avg_1:double>
-- !query 0 output
-11,15 +11,15 struct<avg_1:double>
-- !query 1
-SELECT avg(a) AS avg_32 FROM aggtest WHERE a < 100
+SELECT udf(avg(a)) AS avg_32 FROM aggtest WHERE a < 100
-- !query 1 schema
-struct<avg_32:double>
+struct<avg_32:string>
-- !query 1 output
32.666666666666664
-- !query 2
-select CAST(avg(b) AS Decimal(10,3)) AS avg_107_943 FROM aggtest
+select CAST(avg(udf(b)) AS Decimal(10,3)) AS avg_107_943 FROM aggtest
-- !query 2 schema
struct<avg_107_943:decimal(10,3)>
-- !query 2 output
-27,285 +27,286 struct<avg_107_943:decimal(10,3)>
-- !query 3
-SELECT sum(four) AS sum_1500 FROM onek
+SELECT sum(udf(four)) AS sum_1500 FROM onek
-- !query 3 schema
-struct<sum_1500:bigint>
+struct<sum_1500:double>
-- !query 3 output
-1500
+1500.0
-- !query 4
-SELECT sum(a) AS sum_198 FROM aggtest
+SELECT udf(sum(a)) AS sum_198 FROM aggtest
-- !query 4 schema
-struct<sum_198:bigint>
+struct<sum_198:string>
-- !query 4 output
198
-- !query 5
-SELECT sum(b) AS avg_431_773 FROM aggtest
+SELECT udf(udf(sum(b))) AS avg_431_773 FROM aggtest
-- !query 5 schema
-struct<avg_431_773:double>
+struct<avg_431_773:string>
-- !query 5 output
431.77260909229517
-- !query 6
-SELECT max(four) AS max_3 FROM onek
+SELECT udf(max(four)) AS max_3 FROM onek
-- !query 6 schema
-struct<max_3:int>
+struct<max_3:string>
-- !query 6 output
3
-- !query 7
-SELECT max(a) AS max_100 FROM aggtest
+SELECT max(udf(a)) AS max_100 FROM aggtest
-- !query 7 schema
-struct<max_100:int>
+struct<max_100:string>
-- !query 7 output
-100
+56
-- !query 8
-SELECT max(aggtest.b) AS max_324_78 FROM aggtest
+SELECT CAST(udf(udf(max(aggtest.b))) AS int) AS max_324_78 FROM aggtest
-- !query 8 schema
-struct<max_324_78:float>
+struct<max_324_78:int>
-- !query 8 output
-324.78
+324
-- !query 9
-SELECT stddev_pop(b) FROM aggtest
+SELECT CAST(stddev_pop(udf(b)) AS int) FROM aggtest
-- !query 9 schema
-struct<stddev_pop(CAST(b AS DOUBLE)):double>
+struct<CAST(stddev_pop(CAST(udf(b) AS DOUBLE)) AS INT):int>
-- !query 9 output
-131.10703231895047
+131
-- !query 10
-SELECT stddev_samp(b) FROM aggtest
+SELECT udf(stddev_samp(b)) FROM aggtest
-- !query 10 schema
-struct<stddev_samp(CAST(b AS DOUBLE)):double>
+struct<udf(stddev_samp(cast(b as double))):string>
-- !query 10 output
151.38936080399804
-- !query 11
-SELECT var_pop(b) FROM aggtest
+SELECT CAST(var_pop(udf(b)) as int) FROM aggtest
-- !query 11 schema
-struct<var_pop(CAST(b AS DOUBLE)):double>
+struct<CAST(var_pop(CAST(udf(b) AS DOUBLE)) AS INT):int>
-- !query 11 output
-17189.053923482323
+17189
-- !query 12
-SELECT var_samp(b) FROM aggtest
+SELECT udf(var_samp(b)) FROM aggtest
-- !query 12 schema
-struct<var_samp(CAST(b AS DOUBLE)):double>
+struct<udf(var_samp(cast(b as double))):string>
-- !query 12 output
22918.738564643096
-- !query 13
-SELECT stddev_pop(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT udf(stddev_pop(CAST(b AS Decimal(38,0)))) FROM aggtest
-- !query 13 schema
-struct<stddev_pop(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<udf(stddev_pop(cast(cast(b as decimal(38,0)) as double))):string>
-- !query 13 output
131.18117242958306
-- !query 14
-SELECT stddev_samp(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT stddev_samp(CAST(udf(b) AS Decimal(38,0))) FROM aggtest
-- !query 14 schema
-struct<stddev_samp(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<stddev_samp(CAST(CAST(udf(b) AS DECIMAL(38,0)) AS DOUBLE)):double>
-- !query 14 output
151.47497042966097
-- !query 15
-SELECT var_pop(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT udf(var_pop(CAST(b AS Decimal(38,0)))) FROM aggtest
-- !query 15 schema
-struct<var_pop(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<udf(var_pop(cast(cast(b as decimal(38,0)) as double))):string>
-- !query 15 output
17208.5
-- !query 16
-SELECT var_samp(CAST(b AS Decimal(38,0))) FROM aggtest
+SELECT var_samp(udf(CAST(b AS Decimal(38,0)))) FROM aggtest
-- !query 16 schema
-struct<var_samp(CAST(CAST(b AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<var_samp(CAST(udf(cast(b as decimal(38,0))) AS DOUBLE)):double>
-- !query 16 output
22944.666666666668
-- !query 17
-SELECT var_pop(1.0), var_samp(2.0)
+SELECT udf(var_pop(1.0)), var_samp(udf(2.0))
-- !query 17 schema
-struct<var_pop(CAST(1.0 AS DOUBLE)):double,var_samp(CAST(2.0 AS DOUBLE)):double>
+struct<udf(var_pop(cast(1.0 as double))):string,var_samp(CAST(udf(2.0) AS DOUBLE)):double>
-- !query 17 output
0.0 NaN
-- !query 18
-SELECT stddev_pop(CAST(3.0 AS Decimal(38,0))), stddev_samp(CAST(4.0 AS Decimal(38,0)))
+SELECT stddev_pop(udf(CAST(3.0 AS Decimal(38,0)))), stddev_samp(CAST(udf(4.0) AS Decimal(38,0)))
-- !query 18 schema
-struct<stddev_pop(CAST(CAST(3.0 AS DECIMAL(38,0)) AS DOUBLE)):double,stddev_samp(CAST(CAST(4.0 AS DECIMAL(38,0)) AS DOUBLE)):double>
+struct<stddev_pop(CAST(udf(cast(3.0 as decimal(38,0))) AS DOUBLE)):double,stddev_samp(CAST(CAST(udf(4.0) AS DECIMAL(38,0)) AS DOUBLE)):double>
-- !query 18 output
0.0 NaN
-- !query 19
-select sum(CAST(null AS int)) from range(1,4)
+select sum(udf(CAST(null AS int))) from range(1,4)
-- !query 19 schema
-struct<sum(CAST(NULL AS INT)):bigint>
+struct<sum(CAST(udf(cast(null as int)) AS DOUBLE)):double>
-- !query 19 output
NULL
-- !query 20
-select sum(CAST(null AS long)) from range(1,4)
+select sum(udf(CAST(null AS long))) from range(1,4)
-- !query 20 schema
-struct<sum(CAST(NULL AS BIGINT)):bigint>
+struct<sum(CAST(udf(cast(null as bigint)) AS DOUBLE)):double>
-- !query 20 output
NULL
-- !query 21
-select sum(CAST(null AS Decimal(38,0))) from range(1,4)
+select sum(udf(CAST(null AS Decimal(38,0)))) from range(1,4)
-- !query 21 schema
-struct<sum(CAST(NULL AS DECIMAL(38,0))):decimal(38,0)>
+struct<sum(CAST(udf(cast(null as decimal(38,0))) AS DOUBLE)):double>
-- !query 21 output
NULL
-- !query 22
-select sum(CAST(null AS DOUBLE)) from range(1,4)
+select sum(udf(CAST(null AS DOUBLE))) from range(1,4)
-- !query 22 schema
-struct<sum(CAST(NULL AS DOUBLE)):double>
+struct<sum(CAST(udf(cast(null as double)) AS DOUBLE)):double>
-- !query 22 output
NULL
-- !query 23
-select avg(CAST(null AS int)) from range(1,4)
+select avg(udf(CAST(null AS int))) from range(1,4)
-- !query 23 schema
-struct<avg(CAST(NULL AS INT)):double>
+struct<avg(CAST(udf(cast(null as int)) AS DOUBLE)):double>
-- !query 23 output
NULL
-- !query 24
-select avg(CAST(null AS long)) from range(1,4)
+select avg(udf(CAST(null AS long))) from range(1,4)
-- !query 24 schema
-struct<avg(CAST(NULL AS BIGINT)):double>
+struct<avg(CAST(udf(cast(null as bigint)) AS DOUBLE)):double>
-- !query 24 output
NULL
-- !query 25
-select avg(CAST(null AS Decimal(38,0))) from range(1,4)
+select avg(udf(CAST(null AS Decimal(38,0)))) from range(1,4)
-- !query 25 schema
-struct<avg(CAST(NULL AS DECIMAL(38,0))):decimal(38,4)>
+struct<avg(CAST(udf(cast(null as decimal(38,0))) AS DOUBLE)):double>
-- !query 25 output
NULL
-- !query 26
-select avg(CAST(null AS DOUBLE)) from range(1,4)
+select avg(udf(CAST(null AS DOUBLE))) from range(1,4)
-- !query 26 schema
-struct<avg(CAST(NULL AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(null as double)) AS DOUBLE)):double>
-- !query 26 output
NULL
-- !query 27
-select sum(CAST('NaN' AS DOUBLE)) from range(1,4)
+select sum(CAST(udf('NaN') AS DOUBLE)) from range(1,4)
-- !query 27 schema
-struct<sum(CAST(NaN AS DOUBLE)):double>
+struct<sum(CAST(udf(NaN) AS DOUBLE)):double>
-- !query 27 output
NaN
-- !query 28
-select avg(CAST('NaN' AS DOUBLE)) from range(1,4)
+select avg(CAST(udf('NaN') AS DOUBLE)) from range(1,4)
-- !query 28 schema
-struct<avg(CAST(NaN AS DOUBLE)):double>
+struct<avg(CAST(udf(NaN) AS DOUBLE)):double>
-- !query 28 output
NaN
-- !query 29
SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
-FROM (VALUES (CAST('1' AS DOUBLE)), (CAST('Infinity' AS DOUBLE))) v(x)
+FROM (VALUES (CAST(udf('1') AS DOUBLE)), (CAST(udf('Infinity') AS DOUBLE))) v(x)
-- !query 29 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<>
-- !query 29 output
-Infinity NaN
+org.apache.spark.sql.AnalysisException
+cannot evaluate expression CAST(udf(1) AS DOUBLE) in inline table definition; line 2 pos 14
-- !query 30
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('Infinity'), ('1')) v(x)
-- !query 30 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 30 output
Infinity NaN
-- !query 31
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('Infinity'), ('Infinity')) v(x)
-- !query 31 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 31 output
Infinity NaN
-- !query 32
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(CAST(udf(x) AS DOUBLE)), var_pop(CAST(udf(x) AS DOUBLE))
FROM (VALUES ('-Infinity'), ('Infinity')) v(x)
-- !query 32 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(x) AS DOUBLE)):double,var_pop(CAST(udf(x) AS DOUBLE)):double>
-- !query 32 output
NaN NaN
-- !query 33
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(udf(CAST(x AS DOUBLE))), udf(var_pop(CAST(x AS DOUBLE)))
FROM (VALUES (100000003), (100000004), (100000006), (100000007)) v(x)
-- !query 33 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(x as double)) AS DOUBLE)):double,udf(var_pop(cast(x as double))):string>
-- !query 33 output
1.00000005E8 2.5
-- !query 34
-SELECT avg(CAST(x AS DOUBLE)), var_pop(CAST(x AS DOUBLE))
+SELECT avg(udf(CAST(x AS DOUBLE))), udf(var_pop(CAST(x AS DOUBLE)))
FROM (VALUES (7000000000005), (7000000000007)) v(x)
-- !query 34 schema
-struct<avg(CAST(x AS DOUBLE)):double,var_pop(CAST(x AS DOUBLE)):double>
+struct<avg(CAST(udf(cast(x as double)) AS DOUBLE)):double,udf(var_pop(cast(x as double))):string>
-- !query 34 output
7.000000000006E12 1.0
-- !query 35
-SELECT covar_pop(b, a), covar_samp(b, a) FROM aggtest
+SELECT CAST(udf(covar_pop(b, udf(a))) AS int), CAST(covar_samp(udf(b), a) as int) FROM aggtest
-- !query 35 schema
-struct<covar_pop(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double,covar_samp(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double>
+struct<CAST(udf(covar_pop(cast(b as double), cast(udf(a) as double))) AS INT):int,CAST(covar_samp(CAST(udf(b) AS DOUBLE), CAST(a AS DOUBLE)) AS INT):int>
-- !query 35 output
-653.6289553875104 871.5052738500139
+653 871
-- !query 36
-SELECT corr(b, a) FROM aggtest
+SELECT corr(b, udf(a)) FROM aggtest
-- !query 36 schema
-struct<corr(CAST(b AS DOUBLE), CAST(a AS DOUBLE)):double>
+struct<corr(CAST(b AS DOUBLE), CAST(udf(a) AS DOUBLE)):double>
-- !query 36 output
0.1396345165178734
-- !query 37
-SELECT count(four) AS cnt_1000 FROM onek
+SELECT count(udf(four)) AS cnt_1000 FROM onek
-- !query 37 schema
struct<cnt_1000:bigint>
-- !query 37 output
-313,36 +314,36 struct<cnt_1000:bigint>
-- !query 38
-SELECT count(DISTINCT four) AS cnt_4 FROM onek
+SELECT udf(count(DISTINCT four)) AS cnt_4 FROM onek
-- !query 38 schema
-struct<cnt_4:bigint>
+struct<cnt_4:string>
-- !query 38 output
4
-- !query 39
-select ten, count(*), sum(four) from onek
+select ten, udf(count(*)), sum(udf(four)) from onek
group by ten order by ten
-- !query 39 schema
-struct<ten:int,count(1):bigint,sum(four):bigint>
+struct<ten:int,udf(count(1)):string,sum(CAST(udf(four) AS DOUBLE)):double>
-- !query 39 output
-0 100 100
-1 100 200
-2 100 100
-3 100 200
-4 100 100
-5 100 200
-6 100 100
-7 100 200
-8 100 100
-9 100 200
+0 100 100.0
+1 100 200.0
+2 100 100.0
+3 100 200.0
+4 100 100.0
+5 100 200.0
+6 100 100.0
+7 100 200.0
+8 100 100.0
+9 100 200.0
-- !query 40
-select ten, count(four), sum(DISTINCT four) from onek
+select ten, count(udf(four)), udf(sum(DISTINCT four)) from onek
group by ten order by ten
-- !query 40 schema
-struct<ten:int,count(four):bigint,sum(DISTINCT four):bigint>
+struct<ten:int,count(udf(four)):bigint,udf(sum(distinct cast(four as bigint))):string>
-- !query 40 output
0 100 2
1 100 4
-357,11 +358,11 struct<ten:int,count(four):bigint,sum(DISTINCT four):bigint>
-- !query 41
-select ten, sum(distinct four) from onek a
+select ten, udf(sum(distinct four)) from onek a
group by ten
-having exists (select 1 from onek b where sum(distinct a.four) = b.four)
+having exists (select 1 from onek b where udf(sum(distinct a.four)) = b.four)
-- !query 41 schema
-struct<ten:int,sum(DISTINCT four):bigint>
+struct<ten:int,udf(sum(distinct cast(four as bigint))):string>
-- !query 41 output
0 2
2 2
-374,23 +375,23 struct<ten:int,sum(DISTINCT four):bigint>
select ten, sum(distinct four) from onek a
group by ten
having exists (select 1 from onek b
- where sum(distinct a.four + b.four) = b.four)
+ where sum(distinct a.four + b.four) = udf(b.four))
-- !query 42 schema
struct<>
-- !query 42 output
org.apache.spark.sql.AnalysisException
Aggregate/Window/Generate expressions are not valid in where clause of the query.
-Expression in where clause: [(sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT)) = CAST(b.`four` AS BIGINT))]
+Expression in where clause: [(sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT)) = CAST(udf(four) AS BIGINT))]
Invalid expressions: [sum(DISTINCT CAST((outer() + b.`four`) AS BIGINT))];
-- !query 43
select
- (select max((select i.unique2 from tenk1 i where i.unique1 = o.unique1)))
+ (select udf(max((select i.unique2 from tenk1 i where i.unique1 = o.unique1))))
from tenk1 o
-- !query 43 schema
struct<>
-- !query 43 output
org.apache.spark.sql.AnalysisException
-cannot resolve '`o.unique1`' given input columns: [i.even, i.fivethous, i.four, i.hundred, i.odd, i.string4, i.stringu1, i.stringu2, i.ten, i.tenthous, i.thousand, i.twenty, i.two, i.twothousand, i.unique1, i.unique2]; line 2 pos 63
+cannot resolve '`o.unique1`' given input columns: [i.even, i.fivethous, i.four, i.hundred, i.odd, i.string4, i.stringu1, i.stringu2, i.ten, i.tenthous, i.thousand, i.twenty, i.two, i.twothousand, i.unique1, i.unique2]; line 2 pos 67
```
</p>
</details>
Note that, currently, `IntegratedUDFTestUtils.scala`'s UDFs only return strings. There are some differences between those UDFs (Scala, Pandas and Python):
- Python's string representation of floats can make the tests flaky. (See https://docs.python.org/3/tutorial/floatingpoint.html). To work around this, I had to `CAST(... as int)`.
- There are string representation differences between `Inf` `-Inf` <> `Infinity` `-Infinity` and `nan` <> `NaN`
- Maybe we should add other type versions of UDFs if this makes adding tests difficult.
Note that one issue found - [SPARK-28291](https://issues.apache.org/jira/browse/SPARK-28291). The test was commented for now.
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25069 from HyukjinKwon/SPARK-28270.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Fix `stringToDate()` for the formats `yyyy` and `yyyy-[m]m` that assumes there are no additional chars after the last components `yyyy` and `[m]m`. In the PR, I propose to check that entire input was consumed for the formats.
After the fix, the input `1999 08 01` will be invalid because it matches to the pattern `yyyy` but the strings contains additional chars ` 08 01`.
Since Spark 1.6.3 ~ 2.4.3, the behavior is the same.
```
spark-sql> SELECT CAST('1999 08 01' AS DATE);
1999-01-01
```
This PR makes it return NULL like Hive.
```
spark-sql> SELECT CAST('1999 08 01' AS DATE);
NULL
```
## How was this patch tested?
Added new checks to `DateTimeUtilsSuite` for the `1999 08 01` and `1999 08` inputs.
Closes#25097 from MaxGekk/spark-28015-invalid-date-format.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This fixes a problem where it is possible to create a v2 table using the default catalog that cannot be loaded with the session catalog. A session catalog should be used when the v1 catalog is responsible for tables with no catalog in the table identifier.
* Adds a v2 catalog implementation that delegates to the analyzer's SessionCatalog
* Uses the v2 session catalog for CTAS and CreateTable when the provider is a v2 provider and no v2 catalog is in the table identifier
* Updates catalog lookup to always provide the default if it is set for consistent behavior
## How was this patch tested?
* Adds a new test suite for the v2 session catalog that validates the TableCatalog API
* Adds test cases in PlanResolutionSuite to validate the v2 session catalog is used
* Adds test suite for LookupCatalog with a default catalog
Closes#24768 from rdblue/SPARK-27919-add-v2-session-catalog.
Authored-by: Ryan Blue <blue@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The interval conversion behavior is same with the PostgreSQL.
https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/interval.sql#L180-L203
## How was this patch tested?
UT.
Closes#25000 from lipzhu/SPARK-28107.
Lead-authored-by: Zhu, Lipeng <lipzhu@ebay.com>
Co-authored-by: Dongjoon Hyun <dhyun@apple.com>
Co-authored-by: Lipeng Zhu <lipzhu@icloud.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds some tests converted from having.sql to test UDFs following the combination guide in [SPARK-27921](url)
<details><summary>Diff comparing to 'having.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/having.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-having.sql.out
index d87ee52216..7cea2e5128 100644
--- a/sql/core/src/test/resources/sql-tests/results/having.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-having.sql.out
-16,34 +16,34 struct<>
-- !query 1
-SELECT k, sum(v) FROM hav GROUP BY k HAVING sum(v) > 2
+SELECT udf(k) AS k, udf(sum(v)) FROM hav GROUP BY k HAVING udf(sum(v)) > 2
-- !query 1 schema
-struct<k:string,sum(v):bigint>
+struct<k:string,udf(sum(cast(v as bigint))):string>
-- !query 1 output
one 6
three 3
-- !query 2
-SELECT count(k) FROM hav GROUP BY v + 1 HAVING v + 1 = 2
+SELECT udf(count(udf(k))) FROM hav GROUP BY v + 1 HAVING v + 1 = udf(2)
-- !query 2 schema
-struct<count(k):bigint>
+struct<udf(count(udf(k))):string>
-- !query 2 output
1
-- !query 3
-SELECT MIN(t.v) FROM (SELECT * FROM hav WHERE v > 0) t HAVING(COUNT(1) > 0)
+SELECT udf(MIN(t.v)) FROM (SELECT * FROM hav WHERE v > 0) t HAVING(udf(COUNT(udf(1))) > 0)
-- !query 3 schema
-struct<min(v):int>
+struct<udf(min(v)):string>
-- !query 3 output
1
-- !query 4
-SELECT a + b FROM VALUES (1L, 2), (3L, 4) AS T(a, b) GROUP BY a + b HAVING a + b > 1
+SELECT udf(a + b) FROM VALUES (1L, 2), (3L, 4) AS T(a, b) GROUP BY a + b HAVING a + b > udf(1)
-- !query 4 schema
-struct<(a + CAST(b AS BIGINT)):bigint>
+struct<udf((a + cast(b as bigint))):string>
-- !query 4 output
3
7
```
</p>
</details>
## How was this patch tested?
Tested as guided in SPARK-27921.
Closes#25093 from huaxingao/spark-28281.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from `natural-join.sql` to test UDFs following the combination guide in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
<details><summary>Diff results comparing to `natural-join.sql`</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.
sql.out
index 43f2f9a..53ef177 100644
--- a/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out
-27,7 +27,7 struct<>
-- !query 2
-SELECT * FROM nt1 natural join nt2 where k = "one"
+SELECT * FROM nt1 natural join nt2 where udf(k) = "one"
-- !query 2 schema
struct<k:string,v1:int,v2:int>
-- !query 2 output
-36,7 +36,7 one 1 5
-- !query 3
-SELECT * FROM nt1 natural left join nt2 order by v1, v2
+SELECT * FROM nt1 natural left join nt2 where k <> udf("") order by v1, v2
-- !query 3 schema
diff --git a/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.
sql.out
index 43f2f9a..53ef177 100644
--- a/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/udf-natural-join.sql.out
-27,7 +27,7 struct<>
-- !query 2
-SELECT * FROM nt1 natural join nt2 where k = "one"
+SELECT * FROM nt1 natural join nt2 where udf(k) = "one"
-- !query 2 schema
struct<k:string,v1:int,v2:int>
-- !query 2 output
-36,7 +36,7 one 1 5
-- !query 3
-SELECT * FROM nt1 natural left join nt2 order by v1, v2
+SELECT * FROM nt1 natural left join nt2 where k <> udf("") order by v1, v2
-- !query 3 schema
struct<k:string,v1:int,v2:int>
```
</p>
</details>
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25088 from manuzhang/SPARK-27922.
Authored-by: manu.zhang <manu.zhang@vipshop.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
There is a bug in `ExtractPythonUDFs` that produces wrong result attributes. It causes a failure when using `PythonUDF`s among multiple child plans, e.g., join. An example is using `PythonUDF`s in join condition.
```python
>>> left = spark.createDataFrame([Row(a=1, a1=1, a2=1), Row(a=2, a1=2, a2=2)])
>>> right = spark.createDataFrame([Row(b=1, b1=1, b2=1), Row(b=1, b1=3, b2=1)])
>>> f = udf(lambda a: a, IntegerType())
>>> df = left.join(right, [f("a") == f("b"), left.a1 == right.b1])
>>> df.collect()
19/07/10 12:20:49 ERROR Executor: Exception in task 5.0 in stage 0.0 (TID 5)
java.lang.ArrayIndexOutOfBoundsException: 1
at org.apache.spark.sql.catalyst.expressions.GenericInternalRow.genericGet(rows.scala:201)
at org.apache.spark.sql.catalyst.expressions.BaseGenericInternalRow.getAs(rows.scala:35)
at org.apache.spark.sql.catalyst.expressions.BaseGenericInternalRow.isNullAt(rows.scala:36)
at org.apache.spark.sql.catalyst.expressions.BaseGenericInternalRow.isNullAt$(rows.scala:36)
at org.apache.spark.sql.catalyst.expressions.GenericInternalRow.isNullAt(rows.scala:195)
at org.apache.spark.sql.catalyst.expressions.JoinedRow.isNullAt(JoinedRow.scala:70)
...
```
## How was this patch tested?
Added test.
Closes#25091 from viirya/SPARK-28323.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
## What changes were proposed in this pull request?
`SslContextFactory` is deprecated at Jetty 9.4 and we are using `9.4.18.v20190429`. This PR aims to replace it with `SslContextFactory.Server`.
- https://www.eclipse.org/jetty/javadoc/9.4.19.v20190610/org/eclipse/jetty/util/ssl/SslContextFactory.html
- https://www.eclipse.org/jetty/javadoc/9.3.24.v20180605/org/eclipse/jetty/util/ssl/SslContextFactory.html
```
[WARNING] /Users/dhyun/APACHE/spark/core/src/main/scala/org/apache/spark/SSLOptions.scala:71:
constructor SslContextFactory in class SslContextFactory is deprecated:
see corresponding Javadoc for more information.
[WARNING] val sslContextFactory = new SslContextFactory()
[WARNING] ^
```
## How was this patch tested?
Pass the Jenkins with the existing tests.
Closes#25067 from dongjoon-hyun/SPARK-28290.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This is a followup of the discussion in https://github.com/apache/spark/pull/24675#discussion_r286786053
`QueryPlan#references` is an important property. The `ColumnPrunning` rule relies on it.
Some query plan nodes have `Seq[Attribute]` parameter, which is used as its output attributes. For example, leaf nodes, `Generate`, `MapPartitionsInPandas`, etc. These nodes override `producedAttributes` to make `missingInputs` correct.
However, these nodes also need to override `references` to make column pruning work. This PR proposes to exclude `producedAttributes` from the default implementation of `QueryPlan#references`, so that we don't need to override `references` in all these nodes.
Note that, technically we can remove `producedAttributes` and always ask query plan nodes to override `references`. But I do find the code can be simpler with `producedAttributes` in some places, where there is a base class for some specific query plan nodes.
## How was this patch tested?
existing tests
Closes#25052 from cloud-fan/minor.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR adds some tests converted from `pgSQL/case.sql'` to test UDFs. Please see contribution guide of this umbrella ticket - [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
This PR also contains two minor fixes:
1. Change name of Scala UDF from `UDF:name(...)` to `name(...)` to be consistent with Python'
2. Fix Scala UDF at `IntegratedUDFTestUtils.scala ` to handle `null` in strings.
<details><summary>Diff comparing to 'pgSQL/case.sql'</summary>
<p>
```diff
diff --git a/sql/core/src/test/resources/sql-tests/results/pgSQL/case.sql.out b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-case.sql.out
index fa078d16d6d..55bef64338f 100644
--- a/sql/core/src/test/resources/sql-tests/results/pgSQL/case.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/udf/pgSQL/udf-case.sql.out
-115,7 +115,7 struct<>
-- !query 13
SELECT '3' AS `One`,
CASE
- WHEN 1 < 2 THEN 3
+ WHEN CAST(udf(1 < 2) AS boolean) THEN 3
END AS `Simple WHEN`
-- !query 13 schema
struct<One:string,Simple WHEN:int>
-126,10 +126,10 struct<One:string,Simple WHEN:int>
-- !query 14
SELECT '<NULL>' AS `One`,
CASE
- WHEN 1 > 2 THEN 3
+ WHEN 1 > 2 THEN udf(3)
END AS `Simple default`
-- !query 14 schema
-struct<One:string,Simple default:int>
+struct<One:string,Simple default:string>
-- !query 14 output
<NULL> NULL
-137,17 +137,17 struct<One:string,Simple default:int>
-- !query 15
SELECT '3' AS `One`,
CASE
- WHEN 1 < 2 THEN 3
- ELSE 4
+ WHEN udf(1) < 2 THEN udf(3)
+ ELSE udf(4)
END AS `Simple ELSE`
-- !query 15 schema
-struct<One:string,Simple ELSE:int>
+struct<One:string,Simple ELSE:string>
-- !query 15 output
3 3
-- !query 16
-SELECT '4' AS `One`,
+SELECT udf('4') AS `One`,
CASE
WHEN 1 > 2 THEN 3
ELSE 4
-159,10 +159,10 struct<One:string,ELSE default:int>
-- !query 17
-SELECT '6' AS `One`,
+SELECT udf('6') AS `One`,
CASE
- WHEN 1 > 2 THEN 3
- WHEN 4 < 5 THEN 6
+ WHEN CAST(udf(1 > 2) AS boolean) THEN 3
+ WHEN udf(4) < 5 THEN 6
ELSE 7
END AS `Two WHEN with default`
-- !query 17 schema
-173,7 +173,7 struct<One:string,Two WHEN with default:int>
-- !query 18
SELECT '7' AS `None`,
- CASE WHEN rand() < 0 THEN 1
+ CASE WHEN rand() < udf(0) THEN 1
END AS `NULL on no matches`
-- !query 18 schema
struct<None:string,NULL on no matches:int>
-182,36 +182,36 struct<None:string,NULL on no matches:int>
-- !query 19
-SELECT CASE WHEN 1=0 THEN 1/0 WHEN 1=1 THEN 1 ELSE 2/0 END
+SELECT CASE WHEN CAST(udf(1=0) AS boolean) THEN 1/0 WHEN 1=1 THEN 1 ELSE 2/0 END
-- !query 19 schema
-struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
+struct<CASE WHEN CAST(udf((1 = 0)) AS BOOLEAN) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
-- !query 19 output
1.0
-- !query 20
-SELECT CASE 1 WHEN 0 THEN 1/0 WHEN 1 THEN 1 ELSE 2/0 END
+SELECT CASE 1 WHEN 0 THEN 1/udf(0) WHEN 1 THEN 1 ELSE 2/0 END
-- !query 20 schema
-struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
+struct<CASE WHEN (1 = 0) THEN (CAST(1 AS DOUBLE) / CAST(CAST(udf(0) AS DOUBLE) AS DOUBLE)) WHEN (1 = 1) THEN CAST(1 AS DOUBLE) ELSE (CAST(2 AS DOUBLE) / CAST(0 AS DOUBLE)) END:double>
-- !query 20 output
1.0
-- !query 21
-SELECT CASE WHEN i > 100 THEN 1/0 ELSE 0 END FROM case_tbl
+SELECT CASE WHEN i > 100 THEN udf(1/0) ELSE udf(0) END FROM case_tbl
-- !query 21 schema
-struct<CASE WHEN (i > 100) THEN (CAST(1 AS DOUBLE) / CAST(0 AS DOUBLE)) ELSE CAST(0 AS DOUBLE) END:double>
+struct<CASE WHEN (i > 100) THEN udf((cast(1 as double) / cast(0 as double))) ELSE udf(0) END:string>
-- !query 21 output
-0.0
-0.0
-0.0
-0.0
+0
+0
+0
+0
-- !query 22
-SELECT CASE 'a' WHEN 'a' THEN 1 ELSE 2 END
+SELECT CASE 'a' WHEN 'a' THEN udf(1) ELSE udf(2) END
-- !query 22 schema
-struct<CASE WHEN (a = a) THEN 1 ELSE 2 END:int>
+struct<CASE WHEN (a = a) THEN udf(1) ELSE udf(2) END:string>
-- !query 22 output
1
-283,7 +283,7 big
-- !query 27
-SELECT * FROM CASE_TBL WHERE COALESCE(f,i) = 4
+SELECT * FROM CASE_TBL WHERE udf(COALESCE(f,i)) = 4
-- !query 27 schema
struct<i:int,f:double>
-- !query 27 output
-291,7 +291,7 struct<i:int,f:double>
-- !query 28
-SELECT * FROM CASE_TBL WHERE NULLIF(f,i) = 2
+SELECT * FROM CASE_TBL WHERE udf(NULLIF(f,i)) = 2
-- !query 28 schema
struct<i:int,f:double>
-- !query 28 output
-299,10 +299,10 struct<i:int,f:double>
-- !query 29
-SELECT COALESCE(a.f, b.i, b.j)
+SELECT udf(COALESCE(a.f, b.i, b.j))
FROM CASE_TBL a, CASE2_TBL b
-- !query 29 schema
-struct<coalesce(f, CAST(i AS DOUBLE), CAST(j AS DOUBLE)):double>
+struct<udf(coalesce(f, cast(i as double), cast(j as double))):string>
-- !query 29 output
-30.3
-30.3
-332,8 +332,8 struct<coalesce(f, CAST(i AS DOUBLE), CAST(j AS DOUBLE)):double>
-- !query 30
SELECT *
- FROM CASE_TBL a, CASE2_TBL b
- WHERE COALESCE(a.f, b.i, b.j) = 2
+ FROM CASE_TBL a, CASE2_TBL b
+ WHERE udf(COALESCE(a.f, b.i, b.j)) = 2
-- !query 30 schema
struct<i:int,f:double,i:int,j:int>
-- !query 30 output
-342,7 +342,7 struct<i:int,f:double,i:int,j:int>
-- !query 31
-SELECT '' AS Five, NULLIF(a.i,b.i) AS `NULLIF(a.i,b.i)`,
+SELECT udf('') AS Five, NULLIF(a.i,b.i) AS `NULLIF(a.i,b.i)`,
NULLIF(b.i, 4) AS `NULLIF(b.i,4)`
FROM CASE_TBL a, CASE2_TBL b
-- !query 31 schema
-377,7 +377,7 struct<Five:string,NULLIF(a.i,b.i):int,NULLIF(b.i,4):int>
-- !query 32
SELECT '' AS `Two`, *
FROM CASE_TBL a, CASE2_TBL b
- WHERE COALESCE(f,b.i) = 2
+ WHERE CAST(udf(COALESCE(f,b.i) = 2) AS boolean)
-- !query 32 schema
struct<Two:string,i:int,f:double,i:int,j:int>
-- !query 32 output
-388,15 +388,15 struct<Two:string,i:int,f:double,i:int,j:int>
-- !query 33
SELECT CASE
(CASE vol('bar')
- WHEN 'foo' THEN 'it was foo!'
- WHEN vol(null) THEN 'null input'
+ WHEN udf('foo') THEN 'it was foo!'
+ WHEN udf(vol(null)) THEN 'null input'
WHEN 'bar' THEN 'it was bar!' END
)
- WHEN 'it was foo!' THEN 'foo recognized'
- WHEN 'it was bar!' THEN 'bar recognized'
- ELSE 'unrecognized' END
+ WHEN udf('it was foo!') THEN 'foo recognized'
+ WHEN 'it was bar!' THEN udf('bar recognized')
+ ELSE 'unrecognized' END AS col
-- !query 33 schema
-struct<CASE WHEN (CASE WHEN (UDF:vol(bar) = foo) THEN it was foo! WHEN (UDF:vol(bar) = UDF:vol(null)) THEN null input WHEN (UDF:vol(bar) = bar) THEN it was bar! END = it was foo!) THEN foo recognized WHEN (CASE WHEN (UDF:vol(bar) = foo) THEN it was foo! WHEN (UDF:vol(bar) = UDF:vol(null)) THEN null input WHEN (UDF:vol(bar) = bar) THEN it was bar! END = it was bar!) THEN bar recognized ELSE unrecognized END:string>
+struct<col:string>
-- !query 33 output
bar recognized
```
</p>
</details>
https://github.com/apache/spark/pull/25069 contains the same minor fixes as it's required to write the tests.
## How was this patch tested?
Tested as guided in [SPARK-27921](https://issues.apache.org/jira/browse/SPARK-27921).
Closes#25070 from HyukjinKwon/SPARK-28273.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The sub-second part of the interval should be padded before parsing. Currently, Spark gives a correct value only when there is 9 digits below `.`.
```
spark-sql> select interval '0 0:0:0.123456789' day to second;
interval 123 milliseconds 456 microseconds
spark-sql> select interval '0 0:0:0.12345678' day to second;
interval 12 milliseconds 345 microseconds
spark-sql> select interval '0 0:0:0.1234' day to second;
interval 1 microseconds
```
## How was this patch tested?
Pass the Jenkins with the fixed test cases.
Closes#25079 from dongjoon-hyun/SPARK-28308.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
In Dataset drop(col: Column) method, the `equals` comparison method was used instead of `semanticEquals`, which caused the problem of abnormal case-sensitivity behavior. When attributes of LogicalPlan are checked for equality, `semanticEquals` should be used instead.
A similar PR I referred to: https://github.com/apache/spark/pull/22713 created by mgaido91
## How was this patch tested?
- Added new unit test case in DataFrameSuite
- ./build/sbt "testOnly org.apache.spark.sql.*"
- The python code from ticket reporter at https://issues.apache.org/jira/browse/SPARK-28189Closes#25055 from Tonix517/SPARK-28189.
Authored-by: Tony Zhang <tony.zhang@uber.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
We changed our non-standard syntax for `trim` function in #24902 from `TRIM(trimStr, str)` to `TRIM(str, trimStr)` to be compatible with other databases. This pr update the migration guide.
I checked various databases(PostgreSQL, Teradata, Vertica, Oracle, DB2, SQL Server 2019, MySQL, Hive, Presto) and it seems that only PostgreSQL and Presto support this non-standard syntax.
**PostgreSQL**:
```sql
postgres=# select substr(version(), 0, 16), trim('yxTomxx', 'x');
substr | btrim
-----------------+-------
PostgreSQL 11.3 | yxTom
(1 row)
```
**Presto**:
```sql
presto> select trim('yxTomxx', 'x');
_col0
-------
yxTom
(1 row)
```
## How was this patch tested?
manual tests
Closes#24948 from wangyum/SPARK-28093-FOLLOW-UP-DOCS.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds some more WITH test cases as a follow-up to https://github.com/apache/spark/pull/24842
## How was this patch tested?
Add new UTs.
Closes#24949 from peter-toth/SPARK-28002-follow-up.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
- Currently, `ExpressionEncoder` does not handle bigdecimal overflow. Round-tripping overflowing java/scala BigDecimal/BigInteger returns null.
- The serializer encode java/scala BigDecimal to to sql Decimal, which still has the underlying data to the former.
- When writing out to UnsafeRow, `changePrecision` will be false and row has null value.
24e1e41648/sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/codegen/UnsafeRowWriter.java (L202-L206)
- In [SPARK-23179](https://github.com/apache/spark/pull/20350), an option to throw exception on decimal overflow was introduced.
- This PR adds the option in `ExpressionEncoder` to throw when detecting overflowing BigDecimal/BigInteger before its corresponding Decimal gets written to Row. This gives a consistent behavior between decimal arithmetic on sql expression (DecimalPrecision), and getting decimal from dataframe (RowEncoder)
Thanks to mgaido91 for the very first PR `SPARK-23179` and follow-up discussion on this change.
Thanks to JoshRosen for working with me on this.
## How was this patch tested?
added unit tests
Closes#25016 from mickjermsurawong-stripe/SPARK-28200.
Authored-by: Mick Jermsurawong <mickjermsurawong@stripe.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to rename `mapPartitionsInPandas` to `mapInPandas` with a separate evaluation type .
Had an offline discussion with rxin, mengxr and cloud-fan
The reason is basically:
1. `SCALAR_ITER` doesn't make sense with `mapPartitionsInPandas`.
2. It cannot share the same Pandas UDF, for instance, at `select` and `mapPartitionsInPandas` unlike `GROUPED_AGG` because iterator's return type is different.
3. `mapPartitionsInPandas` -> `mapInPandas` - see https://github.com/apache/spark/pull/25044#issuecomment-508298552 and https://github.com/apache/spark/pull/25044#issuecomment-508299764
Renaming `SCALAR_ITER` as `MAP_ITER` is abandoned due to 2. reason.
For `XXX_ITER`, it might have to have a different interface in the future if we happen to add other versions of them. But this is an orthogonal topic with `mapPartitionsInPandas`.
## How was this patch tested?
Existing tests should cover.
Closes#25044 from HyukjinKwon/SPARK-28198.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Before this PR inserting into a non-existing table returned a weird error message:
```
sql("INSERT INTO test VALUES (1)").show
org.apache.spark.sql.AnalysisException: unresolved operator 'InsertIntoTable 'UnresolvedRelation [test], false, false;;
'InsertIntoTable 'UnresolvedRelation [test], false, false
+- LocalRelation [col1#4]
```
after this PR the error message becomes:
```
org.apache.spark.sql.AnalysisException: Table not found: test;;
'InsertIntoTable 'UnresolvedRelation [test], false, false
+- LocalRelation [col1#0]
```
## How was this patch tested?
Added a new UT.
Closes#25054 from peter-toth/SPARK-28251.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR adds support of `WITH` clause within a subquery so this query becomes valid:
```
SELECT max(c) FROM (
WITH t AS (SELECT 1 AS c)
SELECT * FROM t
)
```
## How was this patch tested?
Added new UTs.
Closes#24831 from peter-toth/SPARK-19799-2.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This is to implement a ReduceNumShufflePartitions rule in the new adaptive execution framework introduced in #24706. This rule is used to adjust the post shuffle partitions based on the map output statistics.
## How was this patch tested?
Added ReduceNumShufflePartitionsSuite
Closes#24978 from carsonwang/reduceNumShufflePartitions.
Authored-by: Carson Wang <carson.wang@intel.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This pr add calculate local directory size to `SQLTestUtils`.
We can avoid these changes after this pr:
## How was this patch tested?
Existing test
Closes#25014 from wangyum/SPARK-28216.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR makes the predicate pushdown logic in catalyst optimizer more efficient by unifying two existing rules `PushdownPredicates` and `PushPredicateThroughJoin`. Previously pushing down a predicate for queries such as `Filter(Join(Join(Join)))` requires n steps. This patch essentially reduces this to a single pass.
To make this actually work, we need to unify a few rules such as `CombineFilters`, `PushDownPredicate` and `PushDownPrdicateThroughJoin`. Otherwise cases such as `Filter(Join(Filter(Join)))` still requires several passes to fully push down predicates. This unification is done by composing several partial functions, which makes a minimal code change and can reuse existing UTs.
Results show that this optimization can improve the catalyst optimization time by 16.5%. For queries with more joins, the performance is even better. E.g., for TPC-DS q64, the performance boost is 49.2%.
## How was this patch tested?
Existing UTs + new a UT for the new rule.
Closes#24956 from yeshengm/fixed-point-opt.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This pr add `PLACING` to `ansiNonReserved` and add `overlay` and `placing` to `TableIdentifierParserSuite`.
## How was this patch tested?
N/A
Closes#25013 from wangyum/SPARK-28077.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr add support show global temporary view and local temporary view in database tool.
TODO: Database tools should support show temporary views because it's schema is null.
## How was this patch tested?
unit tests and manual tests:
Closes#24972 from wangyum/SPARK-28167.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}