## What changes were proposed in this pull request?
The PR makes hardcoded `spark.test` and `spark.testing` configs to use `ConfigEntry` and put them in the config package.
## How was this patch tested?
existing UTs
Closes#23413 from mgaido91/SPARK-26491.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
This change modifies the behavior of the delegation token code when running
on YARN, so that the driver controls the renewal, in both client and cluster
mode. For that, a few different things were changed:
* The AM code only runs code that needs DTs when DTs are available.
In a way, this restores the AM behavior to what it was pre-SPARK-23361, but
keeping the fix added in that bug. Basically, all the AM code is run in a
"UGI.doAs()" block; but code that needs to talk to HDFS (basically the
distributed cache handling code) was delayed to the point where the driver
is up and running, and thus when valid delegation tokens are available.
* SparkSubmit / ApplicationMaster now handle user login, not the token manager.
The previous AM code was relying on the token manager to keep the user
logged in when keytabs are used. This required some odd APIs in the token
manager and the AM so that the right UGI was exposed and used in the right
places.
After this change, the logged in user is handled separately from the token
manager, so the API was cleaned up, and, as explained above, the whole AM
runs under the logged in user, which also helps with simplifying some more code.
* Distributed cache configs are sent separately to the AM.
Because of the delayed initialization of the cached resources in the AM, it
became easier to write the cache config to a separate properties file instead
of bundling it with the rest of the Spark config. This also avoids having
to modify the SparkConf to hide things from the UI.
* Finally, the AM doesn't manage the token manager anymore.
The above changes allow the token manager to be completely handled by the
driver's scheduler backend code also in YARN mode (whether client or cluster),
making it similar to other RMs. To maintain the fix added in SPARK-23361 also
in client mode, the AM now sends an extra message to the driver on initialization
to fetch delegation tokens; and although it might not really be needed, the
driver also keeps the running AM updated when new tokens are created.
Tested in a kerberized cluster with the same tests used to validate SPARK-23361,
in both client and cluster mode. Also tested with a non-kerberized cluster.
Closes#23338 from vanzin/SPARK-25689.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
When acquiring unroll memory from `StaticMemoryManager`, let it fail fast if required space exceeds memory limit, just like acquiring storage memory.
I think this may reduce some computation and memory evicting costs especially when required space(`numBytes`) is very big.
## How was this patch tested?
Existing unit tests.
Closes#23426 from SongYadong/acquireUnrollMemory_fail_fast.
Authored-by: SongYadong <song.yadong1@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR upgrades Mockito from 1.10.19 to 2.23.4. The following changes are required.
- Replace `org.mockito.Matchers` with `org.mockito.ArgumentMatchers`
- Replace `anyObject` with `any`
- Replace `getArgumentAt` with `getArgument` and add type annotation.
- Use `isNull` matcher in case of `null` is invoked.
```scala
saslHandler.channelInactive(null);
- verify(handler).channelInactive(any(TransportClient.class));
+ verify(handler).channelInactive(isNull());
```
- Make and use `doReturn` wrapper to avoid [SI-4775](https://issues.scala-lang.org/browse/SI-4775)
```scala
private def doReturn(value: Any) = org.mockito.Mockito.doReturn(value, Seq.empty: _*)
```
## How was this patch tested?
Pass the Jenkins with the existing tests.
Closes#23452 from dongjoon-hyun/SPARK-26536.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
The PR makes hardcoded spark.driver, spark.executor, and spark.cores.max configs to use `ConfigEntry`.
Note that some config keys are from `SparkLauncher` instead of defining in the config package object because the string is already defined in it and it does not depend on core module.
## How was this patch tested?
Existing tests.
Closes#23415 from ueshin/issues/SPARK-26445/hardcoded_driver_executor_configs.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The PR makes hardcoded configs below to use ConfigEntry.
* spark.pyspark
* spark.python
* spark.r
This patch doesn't change configs which are not relevant to SparkConf (e.g. system properties, python source code)
## How was this patch tested?
Existing tests.
Closes#23428 from HeartSaVioR/SPARK-26489.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
The overriden of SparkSubmit's exitFn at some previous tests in SparkSubmitSuite may cause the following tests pass even they failed when they were run separately. This PR is to fix this problem.
## How was this patch tested?
unittest
Closes#23404 from liupc/Fix-SparkSubmitSuite-exitFn.
Authored-by: Liupengcheng <liupengcheng@xiaomi.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This should make tests in core modules pass for Java 11.
## How was this patch tested?
Existing tests, with modifications.
Closes#23419 from srowen/Java11.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR addresses warning messages in Java files reported at [lgtm.com](https://lgtm.com).
[lgtm.com](https://lgtm.com) provides automated code review of Java/Python/JavaScript files for OSS projects. [Here](https://lgtm.com/projects/g/apache/spark/alerts/?mode=list&severity=warning) are warning messages regarding Apache Spark project.
This PR addresses the following warnings:
- Result of multiplication cast to wider type
- Implicit narrowing conversion in compound assignment
- Boxed variable is never null
- Useless null check
NOTE: `Potential input resource leak` looks false positive for now.
## How was this patch tested?
Existing UTs
Closes#23420 from kiszk/SPARK-26508.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
There's some inconsistency for log level while logging error messages in
delegation token providers. (DEBUG, INFO, WARNING)
Given that failing to obtain token would often crash the query, I guess
it would be nice to set higher log level for error log messages.
## How was this patch tested?
The patch just changed the log level.
Closes#23418 from HeartSaVioR/FIX-inconsistency-log-level-between-delegation-token-providers.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
The PR makes hardcoded `spark.eventLog` configs to use `ConfigEntry` and put them in the `config` package.
## How was this patch tested?
existing tests
Closes#23395 from mgaido91/SPARK-26470.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
In the method `taskList`(since https://github.com/apache/spark/pull/21688), the executor log value is queried in KV store for every task(method `constructTaskData`).
This PR propose to use a hashmap for reducing duplicated KV store lookups in the method.

## How was this patch tested?
Manual check
Closes#23310 from gengliangwang/removeExecutorLog.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This pr makes hardcoded "spark.history" configs to use `ConfigEntry` and put them in `History` config object.
## How was this patch tested?
Existing tests.
Closes#23384 from ueshin/issues/SPARK-26443/hardcoded_history_configs.
Authored-by: Takuya UESHIN <ueshin@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Add docs to describe how remove policy act while considering the property `spark.dynamicAllocation.cachedExecutorIdleTimeout` in ExecutorAllocationManager
## How was this patch tested?
comment-only PR.
Closes#23386 from TopGunViper/SPARK-26446.
Authored-by: wuqingxin <wuqingxin@baidu.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…leAccumulator
## What changes were proposed in this pull request?
This PR implements metric sources for LongAccumulator and DoubleAccumulator, such that a user can register these accumulators easily and have their values be reported by the driver's metric namespace.
## How was this patch tested?
Unit tests, and manual tests.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23242 from abellina/SPARK-26285_accumulator_source.
Lead-authored-by: Alessandro Bellina <abellina@yahoo-inc.com>
Co-authored-by: Alessandro Bellina <abellina@oath.com>
Co-authored-by: Alessandro Bellina <abellina@gmail.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
Recently, the ability to expose the metrics for YARN Shuffle Service was added as part of [SPARK-18364](https://github.com/apache/spark/pull/22485). We need to add some metrics to be able to determine the number of active connections as well as open connections to the external shuffle service to benchmark network and connection issues on large cluster environments.
Added two more shuffle server metrics for Spark Yarn shuffle service: numRegisteredConnections which indicate the number of registered connections to the shuffle service and numActiveConnections which indicate the number of active connections to the shuffle service at any given point in time.
If these metrics are outputted to a file, we get something like this:
1533674653489 default.shuffleService: Hostname=server1.abc.com, openBlockRequestLatencyMillis_count=729, openBlockRequestLatencyMillis_rate15=0.7110833548897356, openBlockRequestLatencyMillis_rate5=1.657808981793011, openBlockRequestLatencyMillis_rate1=2.2404486061620474, openBlockRequestLatencyMillis_rateMean=0.9242558551196706,
numRegisteredConnections=35,
blockTransferRateBytes_count=2635880512, blockTransferRateBytes_rate15=2578547.6094160094, blockTransferRateBytes_rate5=6048721.726302424, blockTransferRateBytes_rate1=8548922.518223226, blockTransferRateBytes_rateMean=3341878.633637769, registeredExecutorsSize=5, registerExecutorRequestLatencyMillis_count=5, registerExecutorRequestLatencyMillis_rate15=0.0027973949328659836, registerExecutorRequestLatencyMillis_rate5=0.0021278007987206426, registerExecutorRequestLatencyMillis_rate1=2.8270296777387467E-6, registerExecutorRequestLatencyMillis_rateMean=0.006339206380043053, numActiveConnections=35
Closes#22498 from pgandhi999/SPARK-18364.
Authored-by: pgandhi <pgandhi@oath.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
When NoClassDefFoundError thrown,it will cause job hang.
`Exception in thread "dag-scheduler-event-loop" java.lang.NoClassDefFoundError: Lcom/xxx/data/recommend/aggregator/queue/QueueName;
at java.lang.Class.getDeclaredFields0(Native Method)
at java.lang.Class.privateGetDeclaredFields(Class.java:2436)
at java.lang.Class.getDeclaredField(Class.java:1946)
at java.io.ObjectStreamClass.getDeclaredSUID(ObjectStreamClass.java:1659)
at java.io.ObjectStreamClass.access$700(ObjectStreamClass.java:72)
at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:480)
at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:468)
at java.security.AccessController.doPrivileged(Native Method)
at java.io.ObjectStreamClass.<init>(ObjectStreamClass.java:468)
at java.io.ObjectStreamClass.lookup(ObjectStreamClass.java:365)
at java.io.ObjectOutputStream.writeClass(ObjectOutputStream.java:1212)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1119)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.writeArray(ObjectOutputStream.java:1377)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1173)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
at java.io.ObjectOutputStream.writeArray(ObjectOutputStream.java:1377)`
It is caused by NoClassDefFoundError will not catch up during task seriazation.
`var taskBinary: Broadcast[Array[Byte]] = null
try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
val taskBinaryBytes: Array[Byte] = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort execution
return
case NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}`
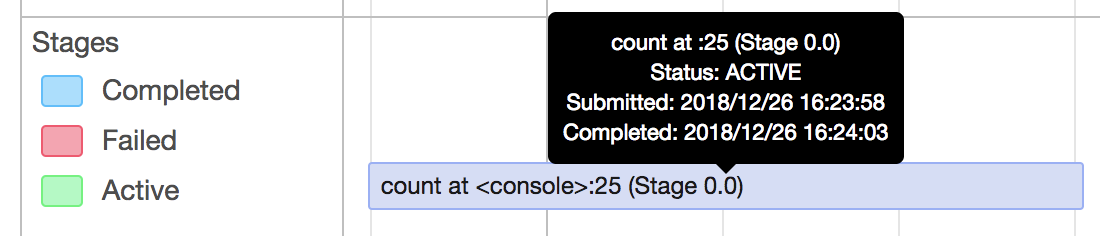
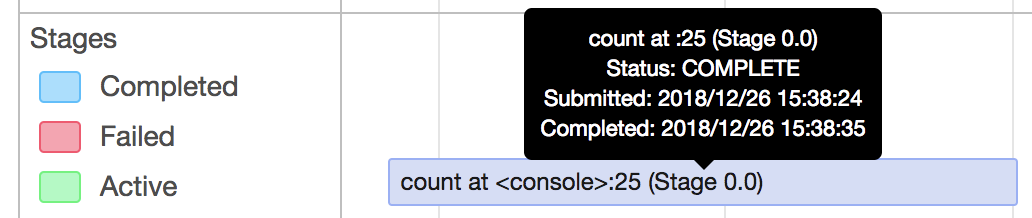
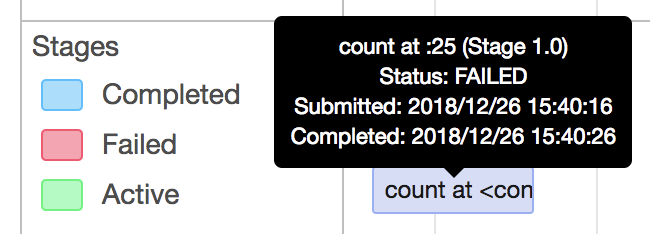
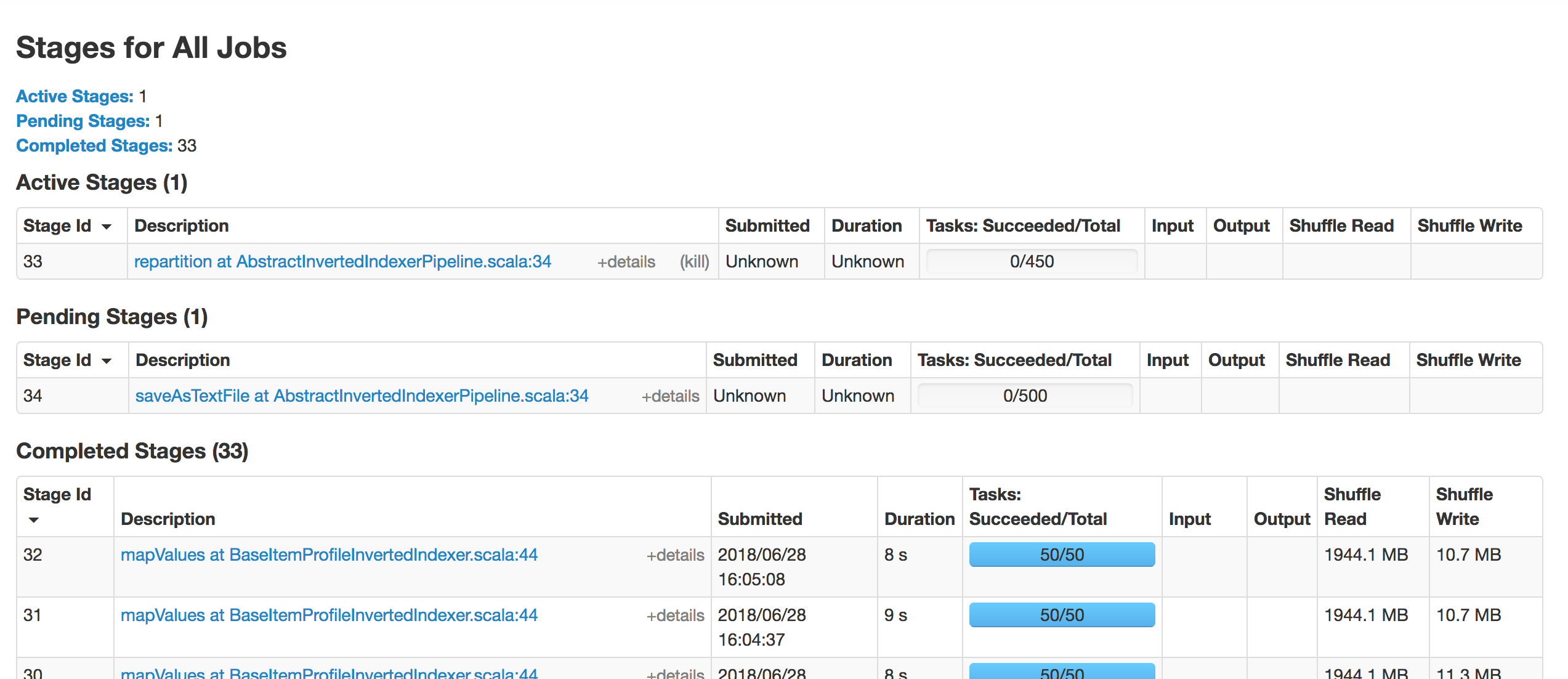
image below shows that stage 33 blocked and never be scheduled.
<img width="1273" alt="2018-06-28 4 28 42" src="https://user-images.githubusercontent.com/26762018/42621188-b87becca-85ef-11e8-9a0b-0ddf07504c96.png">
<img width="569" alt="2018-06-28 4 28 49" src="https://user-images.githubusercontent.com/26762018/42621191-b8b260e8-85ef-11e8-9d10-e97a5918baa6.png">
## How was this patch tested?
UT
Closes#21664 from caneGuy/zhoukang/fix-noclassdeferror.
Authored-by: zhoukang <zhoukang199191@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
This change hooks up the k8s backed to the updated HadoopDelegationTokenManager,
so that delegation tokens are also available in client mode, and keytab-based token
renewal is enabled.
The change re-works the k8s feature steps related to kerberos so
that the driver does all the credential management and provides all
the needed information to executors - so nothing needs to be added
to executor pods. This also makes cluster mode behave a lot more
similarly to client mode, since no driver-related config steps are run
in the latter case.
The main two things that don't need to happen in executors anymore are:
- adding the Hadoop config to the executor pods: this is not needed
since the Spark driver will serialize the Hadoop config and send
it to executors when running tasks.
- mounting the kerberos config file in the executor pods: this is
not needed once you remove the above. The Hadoop conf sent by
the driver with the tasks is already resolved (i.e. has all the
kerberos names properly defined), so executors do not need access
to the kerberos realm information anymore.
The change also avoids creating delegation tokens unnecessarily.
This means that they'll only be created if a secret with tokens
was not provided, and if a keytab is not provided. In either of
those cases, the driver code will handle delegation tokens: in
cluster mode by creating a secret and stashing them, in client
mode by using existing mechanisms to send DTs to executors.
One last feature: the change also allows defining a keytab with
a "local:" URI. This is supported in client mode (although that's
the same as not saying "local:"), and in k8s cluster mode. This
allows the keytab to be mounted onto the image from a pre-existing
secret, for example.
Finally, the new code always sets SPARK_USER in the driver and
executor pods. This is in line with how other resource managers
behave: the submitting user reflects which user will access
Hadoop services in the app. (With kerberos, that's overridden
by the logged in user.) That user is unrelated to the OS user
the app is running as inside the containers.
Tested:
- client and cluster mode with kinit
- cluster mode with keytab
- cluster mode with local: keytab
- YARN cluster with keytab (to make sure it isn't broken)
Closes#22911 from vanzin/SPARK-25815.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Change microseconds to milliseconds in annotation of Utils.timeStringAsMs.
Closes#23346 from stczwd/stczwd.
Authored-by: Jackey Lee <qcsd2011@163.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This is kind of a followup of https://github.com/apache/spark/pull/23239
The `UnsafeProject` will normalize special float/double values(NaN and -0.0), so the sorter doesn't have to handle it.
However, for consistency and future-proof, this PR proposes to normalize `-0.0` in the prefix comparator, so that it's same with the normal ordering. Note that prefix comparator handles NaN as well.
This is not a bug fix, but a safe guard.
## How was this patch tested?
existing tests
Closes#23334 from cloud-fan/sort.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Multiple SparkContexts are discouraged and it has been warning for last 4 years, see SPARK-4180. It could cause arbitrary and mysterious error cases, see SPARK-2243.
Honestly, I didn't even know Spark still allows it, which looks never officially supported, see SPARK-2243.
I believe It should be good timing now to remove this configuration.
## How was this patch tested?
Each doc was manually checked and manually tested:
```
$ ./bin/spark-shell --conf=spark.driver.allowMultipleContexts=true
...
scala> new SparkContext()
org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at:
org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:939)
...
org.apache.spark.SparkContext$.$anonfun$assertNoOtherContextIsRunning$2(SparkContext.scala:2435)
at scala.Option.foreach(Option.scala:274)
at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2432)
at org.apache.spark.SparkContext$.markPartiallyConstructed(SparkContext.scala:2509)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:80)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:112)
... 49 elided
```
Closes#23311 from HyukjinKwon/SPARK-26362.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Based on the [comment](https://github.com/apache/spark/pull/23272#discussion_r240735509), it seems to be better to put `freePage` into a `finally` block. This patch as a follow-up to do so.
## How was this patch tested?
Existing tests.
Closes#23294 from viirya/SPARK-26265-followup.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
Currently this check is only performed for dynamic allocation use case in
ExecutorAllocationManager.
## What changes were proposed in this pull request?
Checks that cpu per task is lower than number of cores per executor otherwise throw an exception
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23290 from ashangit/master.
Authored-by: n.fraison <n.fraison@criteo.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
These three condition descriptions should be updated, follow #23228 :
<li>no Ordering is specified,</li>
<li>no Aggregator is specified, and</li>
<li>the number of partitions is less than
<code>spark.shuffle.sort.bypassMergeThreshold</code>.
</li>
1、If the shuffle dependency specifies aggregation, but it only aggregates at the reduce-side, BypassMergeSortShuffle can still be used.
2、If the number of output partitions is spark.shuffle.sort.bypassMergeThreshold(eg.200), we can use BypassMergeSortShuffle.
## How was this patch tested?
N/A
Closes#23281 from lcqzte10192193/wid-lcq-1211.
Authored-by: lichaoqun <li.chaoqun@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
When Kafka delegation token obtained, SCRAM `sasl.mechanism` has to be configured for authentication. This can be configured on the related source/sink which is inconvenient from user perspective. Such granularity is not required and this configuration can be implemented with one central parameter.
In this PR `spark.kafka.sasl.token.mechanism` added to configure this centrally (default: `SCRAM-SHA-512`).
## How was this patch tested?
Existing unit tests + on cluster.
Closes#23274 from gaborgsomogyi/SPARK-26322.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
YARN applicationMaster metrics registration introduced in SPARK-24594 causes further registration of static metrics (Codegenerator and HiveExternalCatalog) and of JVM metrics, which I believe do not belong in this context.
This looks like an unintended side effect of using the start method of [[MetricsSystem]].
A possible solution proposed here, is to introduce startNoRegisterSources to avoid these additional registrations of static sources and of JVM sources in the case of YARN applicationMaster metrics (this could be useful for other metrics that may be added in the future).
## How was this patch tested?
Manually tested on a YARN cluster,
Closes#22279 from LucaCanali/YarnMetricsRemoveExtraSourceRegistration.
Lead-authored-by: Luca Canali <luca.canali@cern.ch>
Co-authored-by: LucaCanali <luca.canali@cern.ch>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Follow up pr for #23207, include following changes:
- Rename `SQLShuffleMetricsReporter` to `SQLShuffleReadMetricsReporter` to make it match with write side naming.
- Display text changes for read side for naming consistent.
- Rename function in `ShuffleWriteProcessor`.
- Delete `private[spark]` in execution package.
## How was this patch tested?
Existing tests.
Closes#23286 from xuanyuanking/SPARK-26193-follow.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
This proposes an alternative way to load secret keys into a Spark application that is running on Kubernetes. Instead of automatically generating the secret, the secret key can reside in a file that is shared between both the driver and executor containers.
Unit tests.
Closes#23252 from mccheah/auth-secret-with-file.
Authored-by: mcheah <mcheah@palantir.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
In `BytesToBytesMap.MapIterator.advanceToNextPage`, We will first lock this `MapIterator` and then `TaskMemoryManager` when going to free a memory page by calling `freePage`. At the same time, it is possibly that another memory consumer first locks `TaskMemoryManager` and then this `MapIterator` when it acquires memory and causes spilling on this `MapIterator`.
So it ends with the `MapIterator` object holds lock to the `MapIterator` object and waits for lock on `TaskMemoryManager`, and the other consumer holds lock to `TaskMemoryManager` and waits for lock on the `MapIterator` object.
To avoid deadlock here, this patch proposes to keep reference to the page to free and free it after releasing the lock of `MapIterator`.
## How was this patch tested?
Added test and manually test by running the test 100 times to make sure there is no deadlock.
Closes#23272 from viirya/SPARK-26265.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
… incorrect.
## What changes were proposed in this pull request?
In the reported heartbeat information, the unit of the memory data is bytes, which is converted by the formatBytes() function in the utils.js file before being displayed in the interface. The cardinality of the unit conversion in the formatBytes function is 1000, which should be 1024.
Change the cardinality of the unit conversion in the formatBytes function to 1024.
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22683 from httfighter/SPARK-25696.
Lead-authored-by: 韩田田00222924 <han.tiantian@zte.com.cn>
Co-authored-by: han.tiantian@zte.com.cn <han.tiantian@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
This adds the entire memory used by spark’s executor (as measured by procfs) to the executor metrics. The memory usage is collected from the entire process tree under the executor. The metrics are subdivided into memory used by java, by python, and by other processes, to aid users in diagnosing the source of high memory usage.
The additional metrics are sent to the driver in heartbeats, using the mechanism introduced by SPARK-23429. This also slightly extends that approach to allow one ExecutorMetricType to collect multiple metrics.
Added unit tests and also tested on a live cluster.
Closes#22612 from rezasafi/ptreememory2.
Authored-by: Reza Safi <rezasafi@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
`1. The shuffle dependency specifies no aggregation or output ordering.`
If the shuffle dependency specifies aggregation, but it only aggregates at the reduce-side, serialized shuffle can still be used.
`3. The shuffle produces fewer than 16777216 output partitions.`
If the number of output partitions is 16777216 , we can use serialized shuffle.
We can see this mothod: `canUseSerializedShuffle`
## How was this patch tested?
N/A
Closes#23228 from 10110346/SerializedShuffle_doc.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Add MAXIMUM_PAGE_SIZE_BYTES Exception test
## How was this patch tested?
Existing tests
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23226 from wangjiaochun/BytesToBytesMapSuite.
Authored-by: 10087686 <wang.jiaochun@zte.com.cn>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
If there are no records in memory, then we don't need to create an empty temp spill file.
## How was this patch tested?
Existing tests
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23225 from wangjiaochun/ShufflSorter.
Authored-by: 10087686 <wang.jiaochun@zte.com.cn>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Root cause: Prior to Spark2.4, When we enable zst for eventLog compression, for inprogress application, It always throws exception in the Application UI, when we open from the history server. But after 2.4 it will display the UI information based on the completed frames in the zstd compressed eventLog. But doesn't read incomplete frames for inprogress application.
In this PR, we have added 'setContinous(true)' for reading input stream from eventLog, so that it can read from open frames also. (By default 'isContinous=false' for zstd inputStream and when we try to read an open frame, it throws truncated error)
## How was this patch tested?
Test steps:
1) Add the configurations in the spark-defaults.conf
(i) spark.eventLog.compress true
(ii) spark.io.compression.codec zstd
2) Restart history server
3) bin/spark-shell
4) sc.parallelize(1 to 1000, 1000).count
5) Open app UI from the history server UI
**Before fix**

**After fix:**

Closes#23241 from shahidki31/zstdEventLog.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
1. Implement `SQLShuffleWriteMetricsReporter` on the SQL side as the customized `ShuffleWriteMetricsReporter`.
2. Add shuffle write metrics to `ShuffleExchangeExec`, and use these metrics to create corresponding `SQLShuffleWriteMetricsReporter` in shuffle dependency.
3. Rework on `ShuffleMapTask` to add new class named `ShuffleWriteProcessor` which control shuffle write process, we use sql shuffle write metrics by customizing a ShuffleWriteProcessor on SQL side.
## How was this patch tested?
Add UT in SQLMetricsSuite.
Manually test locally, update screen shot to document attached in JIRA.
Closes#23207 from xuanyuanking/SPARK-26193.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
spark.kafka.sasl.kerberos.service.name is an optional parameter but most of the time value `kafka` has to be set. As I've written in the jira the following reasoning is behind:
* Kafka's configuration guide suggest the same value: https://kafka.apache.org/documentation/#security_sasl_kerberos_brokerconfig
* It would be easier for spark users by providing less configuration
* Other streaming engines are doing the same
In this PR I've changed the parameter from optional to `WithDefault` and set `kafka` as default value.
## How was this patch tested?
Available unit tests + on cluster.
Closes#23254 from gaborgsomogyi/SPARK-26304.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Delete unnecessary If statement, because it Impossible execution when
records less than or equal to zero.it is only execution when records begin zero.
...................
if (inMemSorter == null || inMemSorter.numRecords() <= 0) {
return 0L;
}
....................
if (inMemSorter.numRecords() > 0) {
.....................
}
## How was this patch tested?
Existing tests
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#23247 from wangjiaochun/inMemSorter.
Authored-by: 10087686 <wang.jiaochun@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
Adds a new method to SparkAppHandle called getError which returns
the exception (if present) that caused the underlying Spark app to
fail.
New tests added to SparkLauncherSuite for the new method.
Closes#21849Closes#23221 from vanzin/SPARK-24243.
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
`enablePerfMetrics `was originally designed in `BytesToBytesMap `to control `getNumHashCollisions getTimeSpentResizingNs getAverageProbesPerLookup`.
However, as the Spark version gradual progress. this parameter is only used for `getAverageProbesPerLookup ` and always given to true when using `BytesToBytesMap`.
it is also dangerous to determine whether `getAverageProbesPerLookup `opens and throws an `IllegalStateException `exception.
So this pr will be remove `enablePerfMetrics `parameter from `BytesToBytesMap`. thanks.
## How was this patch tested?
the existed test cases.
Closes#23244 from heary-cao/enablePerfMetrics.
Authored-by: caoxuewen <cao.xuewen@zte.com.cn>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
This change modifies the logic in the SecurityManager to do two
things:
- generate unique app secrets also when k8s is being used
- only store the secret in the user's UGI on YARN
The latter is needed so that k8s won't unnecessarily create
k8s secrets for the UGI credentials when only the auth token
is stored there.
On the k8s side, the secret is propagated to executors using
an environment variable instead. This ensures it works in both
client and cluster mode.
Security doc was updated to mention the feature and clarify that
proper access control in k8s should be enabled for it to be secure.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#23174 from vanzin/SPARK-26194.
## What changes were proposed in this pull request?
We explicitly avoid files with hdfs erasure coding for the streaming WAL
and for event logs, as hdfs EC does not support all relevant apis.
However, the new builder api used has different semantics -- it does not
create parent dirs, and it does not resolve relative paths. This
updates createNonEcFile to have similar semantics to the old api.
## How was this patch tested?
Ran tests with the WAL pointed at a non-existent dir, which failed before this change. Manually tested the new function with a relative path as well.
Unit tests via jenkins.
Closes#23092 from squito/SPARK-26094.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
In my local setup, I set log4j root category as ERROR (https://stackoverflow.com/questions/27781187/how-to-stop-info-messages-displaying-on-spark-console , first item show up if we google search "set spark log level".) When I run such command
```
spark-submit --class foo bar.jar
```
Nothing shows up, and the script exits.
After quick investigation, I think the log level for ClassNotFoundException/NoClassDefFoundError in SparkSubmit should be ERROR instead of WARN. Since the whole process exit because of the exception/error.
Before https://github.com/apache/spark/pull/20925, the message is not controlled by `log4j.rootCategory`.
## How was this patch tested?
Manual check.
Closes#23189 from gengliangwang/changeLogLevel.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Correct some document description errors.
## How was this patch tested?
N/A
Closes#23162 from 10110346/docerror.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}