## What changes were proposed in this pull request?
Currently we find the wider common type by comparing the two types from left to right, this can be a problem when you have two data types which don't have a common type but each can be promoted to StringType.
For instance, if you have a table with the schema:
[c1: date, c2: string, c3: int]
The following succeeds:
SELECT coalesce(c1, c2, c3) FROM table
While the following produces an exception:
SELECT coalesce(c1, c3, c2) FROM table
This is only a issue when the seq of dataTypes contains `StringType` and all the types can do string promotion.
close#19033
## How was this patch tested?
Add test in `TypeCoercionSuite`
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#21074 from jiangxb1987/typeCoercion.
## What changes were proposed in this pull request?
Easy fix in the documentation.
## How was this patch tested?
N/A
Closes#20948
Author: Daniel Sakuma <dsakuma@gmail.com>
Closes#20928 from dsakuma/fix_typo_configuration_docs.
## What changes were proposed in this pull request?
This PR is to finish https://github.com/apache/spark/pull/17272
This JIRA is a follow up work after SPARK-19583
As we discussed in that PR
The following DDL for a managed table with an existed default location should throw an exception:
CREATE TABLE ... (PARTITIONED BY ...) AS SELECT ...
CREATE TABLE ... (PARTITIONED BY ...)
Currently there are some situations which are not consist with above logic:
CREATE TABLE ... (PARTITIONED BY ...) succeed with an existed default location
situation: for both hive/datasource(with HiveExternalCatalog/InMemoryCatalog)
CREATE TABLE ... (PARTITIONED BY ...) AS SELECT ...
situation: hive table succeed with an existed default location
This PR is going to make above two situations consist with the logic that it should throw an exception
with an existed default location.
## How was this patch tested?
unit test added
Author: Gengliang Wang <gengliang.wang@databricks.com>
Closes#20886 from gengliangwang/pr-17272.
## What changes were proposed in this pull request?
This PR fixes an incorrect comparison in SQL between timestamp and date. This is because both of them are casted to `string` and then are compared lexicographically. This implementation shows `false` regarding this query `spark.sql("select cast('2017-03-01 00:00:00' as timestamp) between cast('2017-02-28' as date) and cast('2017-03-01' as date)").show`.
This PR shows `true` for this query by casting `date("2017-03-01")` to `timestamp("2017-03-01 00:00:00")`.
(Please fill in changes proposed in this fix)
## How was this patch tested?
Added new UTs to `TypeCoercionSuite`.
Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Closes#20774 from kiszk/SPARK-23549.
## What changes were proposed in this pull request?
Currently we allow writing data frames with empty schema into a file based datasource for certain file formats such as JSON, ORC etc. For formats such as Parquet and Text, we raise error at different times of execution. For text format, we return error from the driver early on in processing where as for format such as parquet, the error is raised from executor.
**Example**
spark.emptyDataFrame.write.format("parquet").mode("overwrite").save(path)
**Results in**
``` SQL
org.apache.parquet.schema.InvalidSchemaException: Cannot write a schema with an empty group: message spark_schema {
}
at org.apache.parquet.schema.TypeUtil$1.visit(TypeUtil.java:27)
at org.apache.parquet.schema.TypeUtil$1.visit(TypeUtil.java:37)
at org.apache.parquet.schema.MessageType.accept(MessageType.java:58)
at org.apache.parquet.schema.TypeUtil.checkValidWriteSchema(TypeUtil.java:23)
at org.apache.parquet.hadoop.ParquetFileWriter.<init>(ParquetFileWriter.java:225)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:342)
at org.apache.parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:302)
at org.apache.spark.sql.execution.datasources.parquet.ParquetOutputWriter.<init>(ParquetOutputWriter.scala:37)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$$anon$1.newInstance(ParquetFileFormat.scala:151)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$SingleDirectoryWriteTask.newOutputWriter(FileFormatWriter.scala:376)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$SingleDirectoryWriteTask.execute(FileFormatWriter.scala:387)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:278)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:276)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1411)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:281)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:206)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:205)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.
```
In this PR, we unify the error processing and raise error on attempt to write empty schema based dataframes into file based datasource (orc, parquet, text , csv, json etc) early on in the processing.
## How was this patch tested?
Unit tests added in FileBasedDatasourceSuite.
Author: Dilip Biswal <dbiswal@us.ibm.com>
Closes#20579 from dilipbiswal/spark-23372.
## What changes were proposed in this pull request?
To drop `exprId`s for `Alias` in user-facing info., this pr added an entry for `Alias` in `NonSQLExpression.sql`
## How was this patch tested?
Added tests in `UDFSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#20827 from maropu/SPARK-23666.
## What changes were proposed in this pull request?
In the PR https://github.com/apache/spark/pull/20671, I forgot to update the doc about this new support.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20789 from gatorsmile/docUpdate.
## What changes were proposed in this pull request?
Below are the two cases.
``` SQL
case 1
scala> List.empty[String].toDF().rdd.partitions.length
res18: Int = 1
```
When we write the above data frame as parquet, we create a parquet file containing
just the schema of the data frame.
Case 2
``` SQL
scala> val anySchema = StructType(StructField("anyName", StringType, nullable = false) :: Nil)
anySchema: org.apache.spark.sql.types.StructType = StructType(StructField(anyName,StringType,false))
scala> spark.read.schema(anySchema).csv("/tmp/empty_folder").rdd.partitions.length
res22: Int = 0
```
For the 2nd case, since number of partitions = 0, we don't call the write task (the task has logic to create the empty metadata only parquet file)
The fix is to create a dummy single partition RDD and set up the write task based on it to ensure
the metadata-only file.
## How was this patch tested?
A new test is added to DataframeReaderWriterSuite.
Author: Dilip Biswal <dbiswal@us.ibm.com>
Closes#20525 from dilipbiswal/spark-23271.
## What changes were proposed in this pull request?
This PR adds a configuration to control the fallback of Arrow optimization for `toPandas` and `createDataFrame` with Pandas DataFrame.
## How was this patch tested?
Manually tested and unit tests added.
You can test this by:
**`createDataFrame`**
```python
spark.conf.set("spark.sql.execution.arrow.enabled", False)
pdf = spark.createDataFrame([[{'a': 1}]]).toPandas()
spark.conf.set("spark.sql.execution.arrow.enabled", True)
spark.conf.set("spark.sql.execution.arrow.fallback.enabled", True)
spark.createDataFrame(pdf, "a: map<string, int>")
```
```python
spark.conf.set("spark.sql.execution.arrow.enabled", False)
pdf = spark.createDataFrame([[{'a': 1}]]).toPandas()
spark.conf.set("spark.sql.execution.arrow.enabled", True)
spark.conf.set("spark.sql.execution.arrow.fallback.enabled", False)
spark.createDataFrame(pdf, "a: map<string, int>")
```
**`toPandas`**
```python
spark.conf.set("spark.sql.execution.arrow.enabled", True)
spark.conf.set("spark.sql.execution.arrow.fallback.enabled", True)
spark.createDataFrame([[{'a': 1}]]).toPandas()
```
```python
spark.conf.set("spark.sql.execution.arrow.enabled", True)
spark.conf.set("spark.sql.execution.arrow.fallback.enabled", False)
spark.createDataFrame([[{'a': 1}]]).toPandas()
```
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20678 from HyukjinKwon/SPARK-23380-conf.
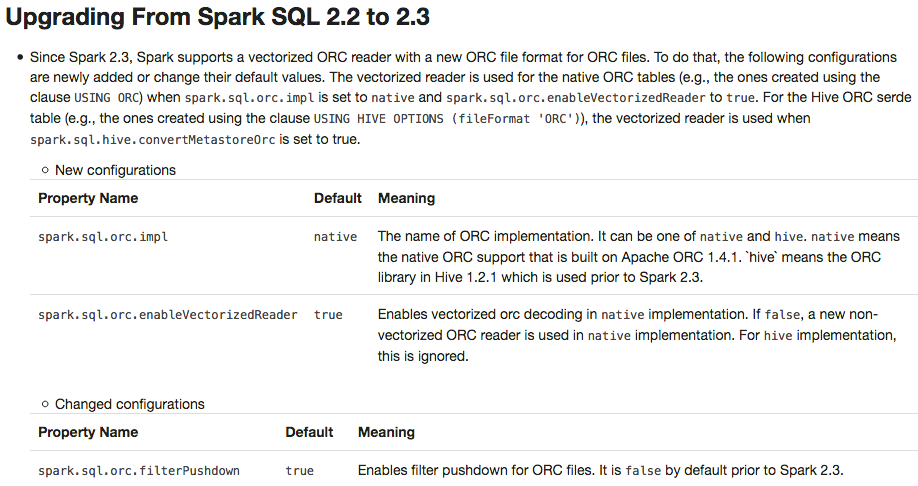
## What changes were proposed in this pull request?
Apache Spark 2.3 introduced `native` ORC supports with vectorization and many fixes. However, it's shipped as a not-default option. This PR enables `native` ORC implementation and predicate-pushdown by default for Apache Spark 2.4. We will improve and stabilize ORC data source before Apache Spark 2.4. And, eventually, Apache Spark will drop old Hive-based ORC code.
## How was this patch tested?
Pass the Jenkins with existing tests.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20634 from dongjoon-hyun/SPARK-23456.
## What changes were proposed in this pull request?
To prevent any regressions, this PR changes ORC implementation to `hive` by default like Spark 2.2.X.
Users can enable `native` ORC. Also, ORC PPD is also restored to `false` like Spark 2.2.X.

## How was this patch tested?
Pass all test cases.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20610 from dongjoon-hyun/SPARK-ORC-DISABLE.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/19579 introduces a behavior change. We need to document it in the migration guide.
## How was this patch tested?
Also update the HiveExternalCatalogVersionsSuite to verify it.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20606 from gatorsmile/addMigrationGuide.
## What changes were proposed in this pull request?
This PR targets to explicitly specify supported types in Pandas UDFs.
The main change here is to add a deduplicated and explicit type checking in `returnType` ahead with documenting this; however, it happened to fix multiple things.
1. Currently, we don't support `BinaryType` in Pandas UDFs, for example, see:
```python
from pyspark.sql.functions import pandas_udf
pudf = pandas_udf(lambda x: x, "binary")
df = spark.createDataFrame([[bytearray(1)]])
df.select(pudf("_1")).show()
```
```
...
TypeError: Unsupported type in conversion to Arrow: BinaryType
```
We can document this behaviour for its guide.
2. Also, the grouped aggregate Pandas UDF fails fast on `ArrayType` but seems we can support this case.
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
foo = pandas_udf(lambda v: v.mean(), 'array<double>', PandasUDFType.GROUPED_AGG)
df = spark.range(100).selectExpr("id", "array(id) as value")
df.groupBy("id").agg(foo("value")).show()
```
```
...
NotImplementedError: ArrayType, StructType and MapType are not supported with PandasUDFType.GROUPED_AGG
```
3. Since we can check the return type ahead, we can fail fast before actual execution.
```python
# we can fail fast at this stage because we know the schema ahead
pandas_udf(lambda x: x, BinaryType())
```
## How was this patch tested?
Manually tested and unit tests for `BinaryType` and `ArrayType(...)` were added.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20531 from HyukjinKwon/pudf-cleanup.
## What changes were proposed in this pull request?
This PR proposes to disallow default value None when 'to_replace' is not a dictionary.
It seems weird we set the default value of `value` to `None` and we ended up allowing the case as below:
```python
>>> df.show()
```
```
+----+------+-----+
| age|height| name|
+----+------+-----+
| 10| 80|Alice|
...
```
```python
>>> df.na.replace('Alice').show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
**After**
This PR targets to disallow the case above:
```python
>>> df.na.replace('Alice').show()
```
```
...
TypeError: value is required when to_replace is not a dictionary.
```
while we still allow when `to_replace` is a dictionary:
```python
>>> df.na.replace({'Alice': None}).show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
## How was this patch tested?
Manually tested, tests were added in `python/pyspark/sql/tests.py` and doctests were fixed.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20499 from HyukjinKwon/SPARK-19454-followup.
## What changes were proposed in this pull request?
Rename the public APIs and names of pandas udfs.
- `PANDAS SCALAR UDF` -> `SCALAR PANDAS UDF`
- `PANDAS GROUP MAP UDF` -> `GROUPED MAP PANDAS UDF`
- `PANDAS GROUP AGG UDF` -> `GROUPED AGG PANDAS UDF`
## How was this patch tested?
The existing tests
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20428 from gatorsmile/renamePandasUDFs.
## What changes were proposed in this pull request?
Adding user facing documentation for working with Arrow in Spark
Author: Bryan Cutler <cutlerb@gmail.com>
Author: Li Jin <ice.xelloss@gmail.com>
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#19575 from BryanCutler/arrow-user-docs-SPARK-2221.
## What changes were proposed in this pull request?
Fix spelling in quick-start doc.
## How was this patch tested?
Doc only.
Author: Shashwat Anand <me@shashwat.me>
Closes#20336 from ashashwat/SPARK-23165.
## What changes were proposed in this pull request?
When there is an operation between Decimals and the result is a number which is not representable exactly with the result's precision and scale, Spark is returning `NULL`. This was done to reflect Hive's behavior, but it is against SQL ANSI 2011, which states that "If the result cannot be represented exactly in the result type, then whether it is rounded or truncated is implementation-defined". Moreover, Hive now changed its behavior in order to respect the standard, thanks to HIVE-15331.
Therefore, the PR propose to:
- update the rules to determine the result precision and scale according to the new Hive's ones introduces in HIVE-15331;
- round the result of the operations, when it is not representable exactly with the result's precision and scale, instead of returning `NULL`
- introduce a new config `spark.sql.decimalOperations.allowPrecisionLoss` which default to `true` (ie. the new behavior) in order to allow users to switch back to the previous one.
Hive behavior reflects SQLServer's one. The only difference is that the precision and scale are adjusted for all the arithmetic operations in Hive, while SQL Server is said to do so only for multiplications and divisions in the documentation. This PR follows Hive's behavior.
A more detailed explanation is available here: https://mail-archives.apache.org/mod_mbox/spark-dev/201712.mbox/%3CCAEorWNAJ4TxJR9NBcgSFMD_VxTg8qVxusjP%2BAJP-x%2BJV9zH-yA%40mail.gmail.com%3E.
## How was this patch tested?
modified and added UTs. Comparisons with results of Hive and SQLServer.
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20023 from mgaido91/SPARK-22036.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/18164 introduces the behavior changes. We need to document it.
## How was this patch tested?
N/A
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20234 from gatorsmile/docBehaviorChange.
## What changes were proposed in this pull request?
doc update
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#20198 from felixcheung/rrefreshdoc.
[SPARK-21786][SQL] When acquiring 'compressionCodecClassName' in 'ParquetOptions', `parquet.compression` needs to be considered.
## What changes were proposed in this pull request?
Since Hive 1.1, Hive allows users to set parquet compression codec via table-level properties parquet.compression. See the JIRA: https://issues.apache.org/jira/browse/HIVE-7858 . We do support orc.compression for ORC. Thus, for external users, it is more straightforward to support both. See the stackflow question: https://stackoverflow.com/questions/36941122/spark-sql-ignores-parquet-compression-propertie-specified-in-tblproperties
In Spark side, our table-level compression conf compression was added by #11464 since Spark 2.0.
We need to support both table-level conf. Users might also use session-level conf spark.sql.parquet.compression.codec. The priority rule will be like
If other compression codec configuration was found through hive or parquet, the precedence would be compression, parquet.compression, spark.sql.parquet.compression.codec. Acceptable values include: none, uncompressed, snappy, gzip, lzo.
The rule for Parquet is consistent with the ORC after the change.
Changes:
1.Increased acquiring 'compressionCodecClassName' from `parquet.compression`,and the precedence order is `compression`,`parquet.compression`,`spark.sql.parquet.compression.codec`, just like what we do in `OrcOptions`.
2.Change `spark.sql.parquet.compression.codec` to support "none".Actually in `ParquetOptions`,we do support "none" as equivalent to "uncompressed", but it does not allowed to configured to "none".
3.Change `compressionCode` to `compressionCodecClassName`.
## How was this patch tested?
Add test.
Author: fjh100456 <fu.jinhua6@zte.com.cn>
Closes#20076 from fjh100456/ParquetOptionIssue.
## What changes were proposed in this pull request?
This pr modified `elt` to output binary for binary inputs.
`elt` in the current master always output data as a string. But, in some databases (e.g., MySQL), if all inputs are binary, `elt` also outputs binary (Also, this might be a small surprise).
This pr is related to #19977.
## How was this patch tested?
Added tests in `SQLQueryTestSuite` and `TypeCoercionSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#20135 from maropu/SPARK-22937.
## What changes were proposed in this pull request?
Currently, we do not guarantee an order evaluation of conjuncts in either Filter or Join operator. This is also true to the mainstream RDBMS vendors like DB2 and MS SQL Server. Thus, we should also push down the deterministic predicates that are after the first non-deterministic, if possible.
## How was this patch tested?
Updated the existing test cases.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20069 from gatorsmile/morePushDown.
## What changes were proposed in this pull request?
This pr modified `concat` to concat binary inputs into a single binary output.
`concat` in the current master always output data as a string. But, in some databases (e.g., PostgreSQL), if all inputs are binary, `concat` also outputs binary.
## How was this patch tested?
Added tests in `SQLQueryTestSuite` and `TypeCoercionSuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#19977 from maropu/SPARK-22771.
## What changes were proposed in this pull request?
Easy fix in the link.
## How was this patch tested?
Tested manually
Author: Mahmut CAVDAR <mahmutcvdr@gmail.com>
Closes#19996 from mcavdar/master.
## What changes were proposed in this pull request?
Update broadcast behavior changes in migration section.
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Closes#19858 from wangyum/SPARK-22489-migration.
## What changes were proposed in this pull request?
How to reproduce:
```scala
import org.apache.spark.sql.execution.joins.BroadcastHashJoinExec
spark.createDataFrame(Seq((1, "4"), (2, "2"))).toDF("key", "value").createTempView("table1")
spark.createDataFrame(Seq((1, "1"), (2, "2"))).toDF("key", "value").createTempView("table2")
val bl = sql("SELECT /*+ MAPJOIN(t1) */ * FROM table1 t1 JOIN table2 t2 ON t1.key = t2.key").queryExecution.executedPlan
println(bl.children.head.asInstanceOf[BroadcastHashJoinExec].buildSide)
```
The result is `BuildRight`, but should be `BuildLeft`. This PR fix this issue.
## How was this patch tested?
unit tests
Author: Yuming Wang <wgyumg@gmail.com>
Closes#19714 from wangyum/SPARK-22489.
## What changes were proposed in this pull request?
When converting Pandas DataFrame/Series from/to Spark DataFrame using `toPandas()` or pandas udfs, timestamp values behave to respect Python system timezone instead of session timezone.
For example, let's say we use `"America/Los_Angeles"` as session timezone and have a timestamp value `"1970-01-01 00:00:01"` in the timezone. Btw, I'm in Japan so Python timezone would be `"Asia/Tokyo"`.
The timestamp value from current `toPandas()` will be the following:
```
>>> spark.conf.set("spark.sql.session.timeZone", "America/Los_Angeles")
>>> df = spark.createDataFrame([28801], "long").selectExpr("timestamp(value) as ts")
>>> df.show()
+-------------------+
| ts|
+-------------------+
|1970-01-01 00:00:01|
+-------------------+
>>> df.toPandas()
ts
0 1970-01-01 17:00:01
```
As you can see, the value becomes `"1970-01-01 17:00:01"` because it respects Python timezone.
As we discussed in #18664, we consider this behavior is a bug and the value should be `"1970-01-01 00:00:01"`.
## How was this patch tested?
Added tests and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#19607 from ueshin/issues/SPARK-22395.
## What changes were proposed in this pull request?
Add incompatible Hive UDF describe to DOC.
## How was this patch tested?
N/A
Author: Yuming Wang <wgyumg@gmail.com>
Closes#18833 from wangyum/SPARK-21625.
## What changes were proposed in this pull request?
Easy fix in the documentation, which is reporting that only numeric types and string are supported in type inference for partition columns, while Date and Timestamp are supported too since 2.1.0, thanks to SPARK-17388.
## How was this patch tested?
n/a
Author: Marco Gaido <mgaido@hortonworks.com>
Closes#19628 from mgaido91/SPARK-22398.
## What changes were proposed in this pull request?
Added documentation for loading csv files into Dataframes
## How was this patch tested?
/dev/run-tests
Author: Jorge Machado <jorge.w.machado@hotmail.com>
Closes#19429 from jomach/master.
## What changes were proposed in this pull request?
The `percentile_approx` function previously accepted numeric type input and output double type results.
But since all numeric types, date and timestamp types are represented as numerics internally, `percentile_approx` can support them easily.
After this PR, it supports date type, timestamp type and numeric types as input types. The result type is also changed to be the same as the input type, which is more reasonable for percentiles.
This change is also required when we generate equi-height histograms for these types.
## How was this patch tested?
Added a new test and modified some existing tests.
Author: Zhenhua Wang <wangzhenhua@huawei.com>
Closes#19321 from wzhfy/approx_percentile_support_types.
## What changes were proposed in this pull request?
https://github.com/apache/spark/pull/18266 add a new feature to support read JDBC table use custom schema, but we must specify all the fields. For simplicity, this PR support specify partial fields.
## How was this patch tested?
unit tests
Author: Yuming Wang <wgyumg@gmail.com>
Closes#19231 from wangyum/SPARK-22002.
## What changes were proposed in this pull request?
Auto generated Oracle schema some times not we expect:
- `number(1)` auto mapped to BooleanType, some times it's not we expect, per [SPARK-20921](https://issues.apache.org/jira/browse/SPARK-20921).
- `number` auto mapped to Decimal(38,10), It can't read big data, per [SPARK-20427](https://issues.apache.org/jira/browse/SPARK-20427).
This PR fix this issue by custom schema as follows:
```scala
val props = new Properties()
props.put("customSchema", "ID decimal(38, 0), N1 int, N2 boolean")
val dfRead = spark.read.schema(schema).jdbc(jdbcUrl, "tableWithCustomSchema", props)
dfRead.show()
```
or
```sql
CREATE TEMPORARY VIEW tableWithCustomSchema
USING org.apache.spark.sql.jdbc
OPTIONS (url '$jdbcUrl', dbTable 'tableWithCustomSchema', customSchema'ID decimal(38, 0), N1 int, N2 boolean')
```
## How was this patch tested?
unit tests
Author: Yuming Wang <wgyumg@gmail.com>
Closes#18266 from wangyum/SPARK-20427.
## What changes were proposed in this pull request?
```
echo '{"field": 1}
{"field": 2}
{"field": "3"}' >/tmp/sample.json
```
```scala
import org.apache.spark.sql.types._
val schema = new StructType()
.add("field", ByteType)
.add("_corrupt_record", StringType)
val file = "/tmp/sample.json"
val dfFromFile = spark.read.schema(schema).json(file)
scala> dfFromFile.show(false)
+-----+---------------+
|field|_corrupt_record|
+-----+---------------+
|1 |null |
|2 |null |
|null |{"field": "3"} |
+-----+---------------+
scala> dfFromFile.filter($"_corrupt_record".isNotNull).count()
res1: Long = 0
scala> dfFromFile.filter($"_corrupt_record".isNull).count()
res2: Long = 3
```
When the `requiredSchema` only contains `_corrupt_record`, the derived `actualSchema` is empty and the `_corrupt_record` are all null for all rows. This PR captures above situation and raise an exception with a reasonable workaround messag so that users can know what happened and how to fix the query.
## How was this patch tested?
Added test case.
Author: Jen-Ming Chung <jenmingisme@gmail.com>
Closes#18865 from jmchung/SPARK-21610.
## What changes were proposed in this pull request?
Since [SPARK-15639](https://github.com/apache/spark/pull/13701), `spark.sql.parquet.cacheMetadata` and `PARQUET_CACHE_METADATA` is not used. This PR removes from SQLConf and docs.
## How was this patch tested?
Pass the existing Jenkins.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19129 from dongjoon-hyun/SPARK-13656.
## What changes were proposed in this pull request?
All built-in data sources support `Partition Discovery`. We had better update the document to give the users more benefit clearly.
**AFTER**
<img width="906" alt="1" src="https://user-images.githubusercontent.com/9700541/30083628-14278908-9244-11e7-98dc-9ad45fe233a9.png">
## How was this patch tested?
```
SKIP_API=1 jekyll serve --watch
```
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#19139 from dongjoon-hyun/partitiondiscovery.
Add an option to the JDBC data source to initialize the environment of the remote database session
## What changes were proposed in this pull request?
This proposes an option to the JDBC datasource, tentatively called " sessionInitStatement" to implement the functionality of session initialization present for example in the Sqoop connector for Oracle (see https://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html#_oraoop_oracle_session_initialization_statements ) . After each database session is opened to the remote DB, and before starting to read data, this option executes a custom SQL statement (or a PL/SQL block in the case of Oracle).
See also https://issues.apache.org/jira/browse/SPARK-21519
## How was this patch tested?
Manually tested using Spark SQL data source and Oracle JDBC
Author: LucaCanali <luca.canali@cern.ch>
Closes#18724 from LucaCanali/JDBC_datasource_sessionInitStatement.
## What changes were proposed in this pull request?
This commit adds a new argument for IllegalArgumentException message. This recent commit added the argument:
[dcac1d57f0)
## How was this patch tested?
Unit test have been passed
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Marcos P. Sanchez <mpenate@stratio.com>
Closes#18862 from mpenate/feature/exception-errorifexists.
## What changes were proposed in this pull request?
This pr added documents about unsupported functions in Hive UDF/UDTF/UDAF.
This pr relates to #18768 and #18527.
## How was this patch tested?
N/A
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes#18792 from maropu/HOTFIX-20170731.
## What changes were proposed in this pull request?
Few changes to the Structured Streaming documentation
- Clarify that the entire stream input table is not materialized
- Add information for Ganglia
- Add Kafka Sink to the main docs
- Removed a couple of leftover experimental tags
- Added more associated reading material and talk videos.
In addition, https://github.com/apache/spark/pull/16856 broke the link to the RDD programming guide in several places while renaming the page. This PR fixes those sameeragarwal cloud-fan.
- Added a redirection to avoid breaking internal and possible external links.
- Removed unnecessary redirection pages that were there since the separate scala, java, and python programming guides were merged together in 2013 or 2014.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#18485 from tdas/SPARK-21267.
## What changes were proposed in this pull request?
doc only change
## How was this patch tested?
manually
Author: Felix Cheung <felixcheung_m@hotmail.com>
Closes#18312 from felixcheung/sqljsonwholefiledoc.
## What changes were proposed in this pull request?
- Add Scala, Python and Java examples for `partitionBy`, `sortBy` and `bucketBy`.
- Add _Bucketing, Sorting and Partitioning_ section to SQL Programming Guide
- Remove bucketing from Unsupported Hive Functionalities.
## How was this patch tested?
Manual tests, docs build.
Author: zero323 <zero323@users.noreply.github.com>
Closes#17938 from zero323/DOCS-BUCKETING-AND-PARTITIONING.
(Link to Jira: https://issues.apache.org/jira/browse/SPARK-20888)
## What changes were proposed in this pull request?
Document change of default setting of spark.sql.hive.caseSensitiveInferenceMode configuration key from NEVER_INFO to INFER_AND_SAVE in the Spark SQL 2.1 to 2.2 migration notes.
Author: Michael Allman <michael@videoamp.com>
Closes#18112 from mallman/spark-20888-document_infer_and_save.
## What changes were proposed in this pull request?
Typos at a couple of place in the docs.
## How was this patch tested?
build including docs
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: ymahajan <ymahajan@snappydata.io>
Closes#17690 from ymahajan/master.
## What changes were proposed in this pull request?
This PR proposes corrections related to JSON APIs as below:
- Rendering links in Python documentation
- Replacing `RDD` to `Dataset` in programing guide
- Adding missing description about JSON Lines consistently in `DataFrameReader.json` in Python API
- De-duplicating little bit of `DataFrameReader.json` in Scala/Java API
## How was this patch tested?
Manually build the documentation via `jekyll build`. Corresponding snapstops will be left on the codes.
Note that currently there are Javadoc8 breaks in several places. These are proposed to be handled in https://github.com/apache/spark/pull/17477. So, this PR does not fix those.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#17602 from HyukjinKwon/minor-json-documentation.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}