### What changes were proposed in this pull request?
This PR extends `ADD FILE/JAR/ARCHIVE` commands to be able to take multiple path arguments like Hive.
### Why are the changes needed?
To make those commands more useful.
### Does this PR introduce _any_ user-facing change?
Yes. In the current implementation, those commands can take a path which contains whitespaces without enclose it by neither `'` nor `"` but after this change, users need to enclose such paths.
I've note this incompatibility in the migration guide.
### How was this patch tested?
New tests.
Closes#32205 from sarutak/add-multiple-files.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
Add note in migration guide about DayTimeIntervalType/YearMonthIntervalType show different between Hive SerDe and row format delimited
### Why are the changes needed?
Add note
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32343 from AngersZhuuuu/SPARK-35220-FOLLOWUP.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Parse the year-month interval literals like `INTERVAL '1-1' YEAR TO MONTH` to values of `YearMonthIntervalType`, and day-time interval literals to `DayTimeIntervalType` values. Currently, Spark SQL supports:
- DAY TO HOUR
- DAY TO MINUTE
- DAY TO SECOND
- HOUR TO MINUTE
- HOUR TO SECOND
- MINUTE TO SECOND
All such interval literals are converted to `DayTimeIntervalType`, and `YEAR TO MONTH` to `YearMonthIntervalType` while loosing info about `from` and `to` units.
**Note**: new behavior is under the SQL config `spark.sql.legacy.interval.enabled` which is `false` by default. When the config is set to `true`, the interval literals are parsed to `CaledarIntervalType` values.
Closes#32176
### Why are the changes needed?
To conform the ANSI SQL standard which assumes conversions of interval literals to year-month or day-time interval but not to mixed interval type like Catalyst's `CalendarIntervalType`.
### Does this PR introduce _any_ user-facing change?
Yes.
Before:
```sql
spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND;
1 days 1 hours 2 minutes 3.123 seconds
spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND);
interval
```
After:
```sql
spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND;
1 01:02:03.123000000
spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND);
day-time interval
```
### How was this patch tested?
1. By running the affected test suites:
```
$ ./build/sbt "test:testOnly *.ExpressionParserSuite"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z create_view.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
```
2. PostgresSQL tests are executed with `spark.sql.legacy.interval.enabled` is set to `true` to keep compatibility with PostgreSQL output:
```sql
> SELECT interval '999' second;
0 years 0 mons 0 days 0 hours 16 mins 39.00 secs
```
Closes#32209 from MaxGekk/parse-ansi-interval-literals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Support no-serde mode script transform use ArrayType/MapType/StructStpe data.
### Why are the changes needed?
Make user can process array/map/struct data
### Does this PR introduce _any_ user-facing change?
Yes, user can process array/map/struct data in script transform `no-serde` mode
### How was this patch tested?
Added UT
Closes#30957 from AngersZhuuuu/SPARK-31937.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Normal function parameters should not support alias, hive not support too
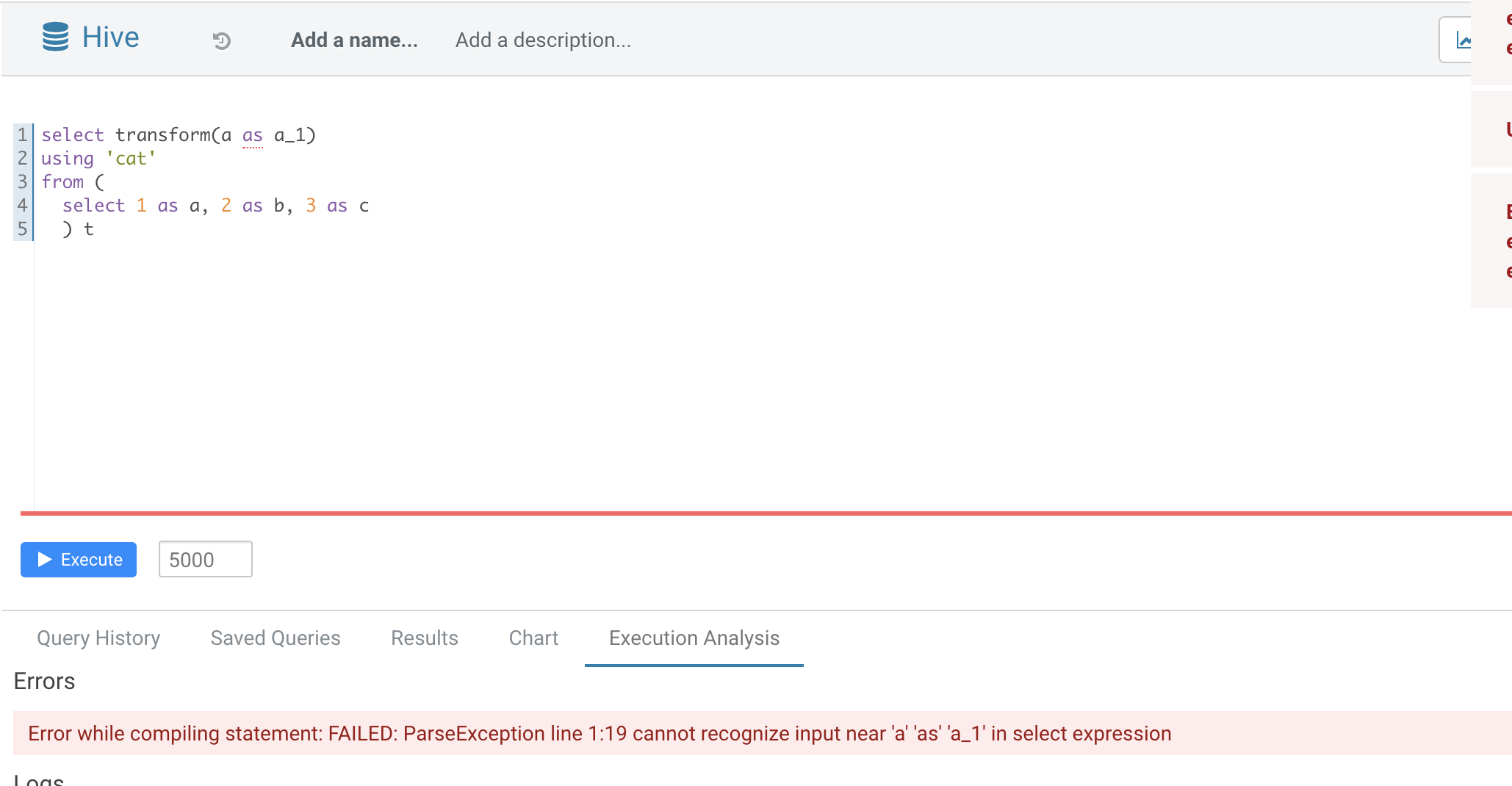
In this pr we forbid use alias in `TRANSFORM`'s inputs
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#32165 from AngersZhuuuu/SPARK-35070.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Add change of `DESC NAMESPACE`'s schema to migration guide
### Why are the changes needed?
Update doc
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#32155 from AngersZhuuuu/SPARK-34577-followup.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
CREATE TABLE LIKE should respect the reserved properties of tables and fail if specified, using `spark.sql.legacy.notReserveProperties` to restore.
### Why are the changes needed?
Make DDLs consistently treat reserved properties
### Does this PR introduce _any_ user-facing change?
YES, this is a breaking change as using `create table like` w/ reserved properties will fail.
### How was this patch tested?
new test
Closes#32025 from yaooqinn/SPARK-34935.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR removes the description that `||` and `&&` can be used as logical operators from the migration guide.
### Why are the changes needed?
At the `Compatibility with Apache Hive` section in the migration guide, it describes that `||` and `&&` can be used as logical operators.
But, in fact, they cannot be used as described.
AFAIK, Hive also doesn't support `&&` and `||` as logical operators.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
I confirmed that `&&` and `||` cannot be used as logical operators with both Hive's interactive shell and `spark-sql`.
I also built the modified document and confirmed that the modified document doesn't break layout.
Closes#32023 from sarutak/modify-hive-compatibility-doc.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Modify the `SubtractTimestamps` expression to return values of `DayTimeIntervalType` when `spark.sql.legacy.interval.enabled` is set to `false` (which is the default).
### Why are the changes needed?
To conform to the ANSI SQL standard which requires ANSI intervals as the result of timestamps subtraction, see
<img width="656" alt="Screenshot 2021-03-29 at 19 09 34" src="https://user-images.githubusercontent.com/1580697/112866455-7e2f0d00-90c2-11eb-96e6-3feb7eea7e09.png">
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateTimeUtilsSuite"
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
and some tests from `SQLQueryTestSuite`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#32016 from MaxGekk/subtract-timestamps-to-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
1. Add the SQL config `spark.sql.legacy.interval.enabled` which will control when Spark SQL should use `CalendarIntervalType` instead of ANSI intervals.
2. Modify the `SubtractDates` expression to return values of `DayTimeIntervalType` when `spark.sql.legacy.interval.enabled` is set to `false` (which is the default).
### Why are the changes needed?
To conform to the ANSI SQL standard which requires ANSI intervals as the result of dates subtraction, see
<img width="656" alt="Screenshot 2021-03-29 at 19 09 34" src="https://user-images.githubusercontent.com/1580697/112866455-7e2f0d00-90c2-11eb-96e6-3feb7eea7e09.png">
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running new tests:
```
$ build/sbt "test:testOnly *DateExpressionsSuite"
$ build/sbt "test:testOnly *ColumnExpressionSuite"
```
and some tests from `SQLQueryTestSuite`:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
```
Closes#31996 from MaxGekk/subtract-dates-to-intervals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request?
Use resolved attributes instead of data-frame fields for replacing values.
### Why are the changes needed?
dataframe.na.replace() does not work for column having a dot in the name
### Does this PR introduce _any_ user-facing change?
None
### How was this patch tested?
Added unit tests for the same
Closes#31769 from amandeep-sharma/master.
Authored-by: Amandeep Sharma <happyaman91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
1 add a sapce between words
2 unify the initials' case
### Why are the changes needed?
correct spelling issues for better user experience
### Does this PR introduce _any_ user-facing change?
yes.
### How was this patch tested?
manually
Closes#31748 from hopefulnick/doc_rectify.
Authored-by: nickhliu <nickhliu@tencent.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Hive support type constructed value as partition spec value, spark should support too.
### Why are the changes needed?
Support TypeConstructed partition spec value keep same with hive
### Does this PR introduce _any_ user-facing change?
Yes, user can use TypeConstruct value as partition spec value such as
```
CREATE TABLE t1(name STRING) PARTITIONED BY (part DATE)
INSERT INTO t1 PARTITION(part = date'2019-01-02') VALUES('a')
CREATE TABLE t2(name STRING) PARTITIONED BY (part TIMESTAMP)
INSERT INTO t2 PARTITION(part = timestamp'2019-01-02 11:11:11') VALUES('a')
CREATE TABLE t4(name STRING) PARTITIONED BY (part BINARY)
INSERT INTO t4 PARTITION(part = X'537061726B2053514C') VALUES('a')
```
### How was this patch tested?
Added UT
Closes#30421 from AngersZhuuuu/SPARK-33474.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
Add `table_identifier` in sql-migration-guide for SHOW CREATE TABLE.
### Why are the changes needed?
To make document more readable.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing test suites.
Closes#31608 from Karl-WangSK/sqldoc.
Lead-authored-by: Karl-WangSK <shikai.wang@linkflowtech.com>
Co-authored-by: ShiKai Wang <wskqing@gmail.com>
Signed-off-by: Yuming Wang <yumwang@ebay.com>
### What changes were proposed in this pull request?
This PR fix an issue that `java.sql.RowId` is mapped to `LongType` and prefer `StringType`.
In the current implementation, JDBC RowID type is mapped to `LongType` except for `OracleDialect`, but there is no guarantee to be able to convert RowID to long.
`java.sql.RowId` declares `toString` and the specification of `java.sql.RowId` says
> _all methods on the RowId interface must be fully implemented if the JDBC driver supports the data type_
(https://docs.oracle.com/javase/8/docs/api/java/sql/RowId.html)
So, we should prefer StringType to LongType.
### Why are the changes needed?
This seems to be a potential bug.
### Does this PR introduce _any_ user-facing change?
Yes. RowID is mapped to StringType rather than LongType.
### How was this patch tested?
New test and the existing test case `SPARK-32992: map Oracle's ROWID type to StringType` in `OracleIntegrationSuite` passes.
Closes#31491 from sarutak/rowid-type.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
This PR changes the type mapping for `money` and `money[]` types for PostgreSQL.
Currently, those types are tried to convert to `DoubleType` and `ArrayType` of `double` respectively.
But the JDBC driver seems not to be able to handle those types properly.
https://github.com/pgjdbc/pgjdbc/issues/100https://github.com/pgjdbc/pgjdbc/issues/1405
Due to these issue, we can get the error like as follows.
money type.
```
[info] org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0) (192.168.1.204 executor driver): org.postgresql.util.PSQLException: Bad value for type double : 1,000.00
[info] at org.postgresql.jdbc.PgResultSet.toDouble(PgResultSet.java:3104)
[info] at org.postgresql.jdbc.PgResultSet.getDouble(PgResultSet.java:2432)
[info] at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.$anonfun$makeGetter$5(JdbcUtils.scala:418)
```
money[] type.
```
[info] org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0) (192.168.1.204 executor driver): org.postgresql.util.PSQLException: Bad value for type double : $2,000.00
[info] at org.postgresql.jdbc.PgResultSet.toDouble(PgResultSet.java:3104)
[info] at org.postgresql.jdbc.ArrayDecoding$5.parseValue(ArrayDecoding.java:235)
[info] at org.postgresql.jdbc.ArrayDecoding$AbstractObjectStringArrayDecoder.populateFromString(ArrayDecoding.java:122)
[info] at org.postgresql.jdbc.ArrayDecoding.readStringArray(ArrayDecoding.java:764)
[info] at org.postgresql.jdbc.PgArray.buildArray(PgArray.java:310)
[info] at org.postgresql.jdbc.PgArray.getArrayImpl(PgArray.java:171)
[info] at org.postgresql.jdbc.PgArray.getArray(PgArray.java:111)
```
For money type, a known workaround is to treat it as string so this PR do it.
For money[], however, there is no reasonable workaround so this PR remove the support.
### Why are the changes needed?
This is a bug.
### Does this PR introduce _any_ user-facing change?
Yes. As of this PR merged, money type is mapped to `StringType` rather than `DoubleType` and the support for money[] is stopped.
For money type, if the value is less than one thousand, `$100.00` for instance, it works without this change so I also updated the migration guide because it's a behavior change for such small values.
On the other hand, money[] seems not to work with any value but mentioned in the migration guide just in case.
### How was this patch tested?
New test.
Closes#31442 from sarutak/fix-for-money-type.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
### What changes were proposed in this pull request?
Passing around the output attributes should have more benefits like keeping the exprID unchanged to avoid bugs when we apply more operators above the command output DataFrame.
This PR did 2 things :
1. After this pr, a `SHOW TBLPROPERTIES` clause's output shows `key` and `value` columns whether you specify the table property `key`. Before this pr, a `SHOW TBLPROPERTIES` clause's output only show a `value` column when you specify the table property `key`..
2. Keep `SHOW TBLPROPERTIES` command's output attribute exprId unchanged.
### Why are the changes needed?
1. Keep `SHOW TBLPROPERTIES`'s output schema consistence
2. Keep `SHOW TBLPROPERTIES` command's output attribute exprId unchanged.
### Does this PR introduce _any_ user-facing change?
After this pr, a `SHOW TBLPROPERTIES` clause's output shows `key` and `value` columns whether you specify the table property `key`. Before this pr, a `SHOW TBLPROPERTIES` clause's output only show a `value` column when you specify the table property `key`.
Before this PR:
```
sql > SHOW TBLPROPERTIES tabe_name('key')
value
value_of_key
```
After this PR
```
sql > SHOW TBLPROPERTIES tabe_name('key')
key value
key value_of_key
```
### How was this patch tested?
Added UT
Closes#31378 from AngersZhuuuu/SPARK-34240.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
The current implement of some DDL not unify the output and not pass the output properly to physical command.
Such as: The `ShowTables` output attributes `namespace`, but `ShowTablesCommand` output attributes `database`.
As the query plan, this PR pass the output attributes from `ShowTables` to `ShowTablesCommand`, `ShowTableExtended ` to `ShowTablesCommand`.
Take `show tables` and `show table extended like 'tbl'` as example.
The output before this PR:
`show tables`
|database|tableName|isTemporary|
-- | -- | --
| default| tbl| false|
If catalog is v2 session catalog, the output before this PR:
|namespace|tableName|
-- | --
| default| tbl
`show table extended like 'tbl'`
|database|tableName|isTemporary| information|
-- | -- | -- | --
| default| tbl| false|Database: default...|
The output after this PR:
`show tables`
|namespace|tableName|isTemporary|
-- | -- | --
| default| tbl| false|
`show table extended like 'tbl'`
|namespace|tableName|isTemporary| information|
-- | -- | -- | --
| default| tbl| false|Database: default...|
### Why are the changes needed?
This PR have benefits as follows:
First, Unify schema for the output of SHOW TABLES.
Second, pass the output attributes could keep the expr ID unchanged, so that avoid bugs when we apply more operators above the command output dataframe.
### Does this PR introduce _any_ user-facing change?
Yes.
The output schema of `SHOW TABLES` replace `database` by `namespace`.
### How was this patch tested?
Jenkins test.
Closes#31245 from beliefer/SPARK-34157.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: beliefer <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a followup of https://github.com/apache/spark/pull/26006
In #26006 , we merged the v1 and v2 SHOW DATABASES/NAMESPACES commands, but we missed a behavior change that the output schema of SHOW DATABASES becomes different.
This PR adds a legacy config to restore the old schema, with a migration guide item to mention this behavior change.
### Why are the changes needed?
Improve backward compatibility
### Does this PR introduce _any_ user-facing change?
No (the legacy config is false by default)
### How was this patch tested?
a new test
Closes#31474 from cloud-fan/command-schema.
Lead-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Co-authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Correct the version of SQL configuration `spark.sql.legacy.parseNullPartitionSpecAsStringLiteral` from 3.2.0 to 3.0.2.
Also, revise the documentation and test case.
### Why are the changes needed?
The release version in https://github.com/apache/spark/pull/31421 was wrong.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests
Closes#31434 from gengliangwang/reviseVersion.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In spark, the `count(table.*)` may cause very weird result, for example:
```
select count(*) from (select 1 as a, null as b) t;
output: 1
select count(t.*) from (select 1 as a, null as b) t;
output: 0
```
This is because spark expands `t.*` while converts `*` to count(1), this will confuse
users. After checking the ANSI standard, `count(*)` should always be `count(1)` while `count(t.*)`
is not allowed. What's more, this is also not allowed by common databases, e.g. MySQL, Oracle.
So, this PR proposes to block the ambiguous behavior and print a clear error message for users.
### Why are the changes needed?
to avoid ambiguous behavior and follow ANSI standard and other SQL engines
### Does this PR introduce _any_ user-facing change?
Yes, `count(table.*)` behavior will be blocked and output an error message.
### How was this patch tested?
newly added and existing tests
Closes#31286 from linhongliu-db/fix-table-star.
Authored-by: Linhong Liu <linhong.liu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a follow up for https://github.com/apache/spark/pull/30538.
It adds a legacy conf `spark.sql.legacy.parseNullPartitionSpecAsStringLiteral` in case users wants the legacy behavior.
It also adds document for the behavior change.
### Why are the changes needed?
In case users want the legacy behavior, they can set `spark.sql.legacy.parseNullPartitionSpecAsStringLiteral` as true.
### Does this PR introduce _any_ user-facing change?
Yes, adding a legacy configuration to restore the old behavior.
### How was this patch tested?
Unit test.
Closes#31421 from gengliangwang/legacyNullStringConstant.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Add document for the behavior change in SPARK-34052, in SQL migration guide.
### Why are the changes needed?
Document behavior change for Spark users.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
N/A
Closes#31351 from sunchao/SPARK-34052-followup.
Authored-by: Chao Sun <sunchao@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This is a follow up of the PRs https://github.com/apache/spark/pull/31066 and https://github.com/apache/spark/pull/31304 that changed behavior of some commands regarding to table cache refreshing. The PR updates the SQL migration guide, in particular, the item which describes new behavior.
### Why are the changes needed?
To inform users about command behavior changes.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
N/A
Closes#31309 from MaxGekk/refreshTable-sql-migration-guide.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR changes cache refreshing of v1 tables in v1 commands. In particular, v1 table dependents are not removed from the cache after this PR. Comparing to current implementation, we just clear cached data of all dependents and keep them in the cache. So, the next actions will fill in the cached data of the original v1 table and its dependents. In more details:
1. Modified the `CatalogImpl.refreshTable()` method to use `recacheByPlan()` instead of `lookupCachedData()`, `uncacheQuery()` and `cacheQuery()`. Users can call this method via public API like `spark.catalog.refreshTable()`.
2. Rewritten the part in `CatalogImpl.refreshTable()` which was responsible for table meta-data refreshing because this code stopped to work properly after removing of the second `sparkSession.table(tableIdent)`.
3. Added new private method `invalidateCachedTable()` to `SessionCatalog`. Comparing to the existing `SessionCatalog.refreshTable`, it invalidates the relation cache only. If we called `SessionCatalog.refreshTable` from `CatalogImpl.refreshTable()`, we would refresh temporary and global temporary views twice (that could lead to refreshing file index twice).
### Why are the changes needed?
1. This should improve user experience with table/view caching. For example, let's imagine that an user has cached v1 table and cached view based on the table. And the user passed the table to external library which drops/renames/adds partitions in the v1 table. Unfortunately, the user gets the view uncached after that even he/she hasn't uncached the view explicitly.
2. To improve code maintenance.
3. To reduce the amount of calls to Hive external catalog.
4. Also this should speed up table recaching.
5. To have the same behavior as for v2 tables supported by https://github.com/apache/spark/pull/31172
### Does this PR introduce _any_ user-facing change?
From the view of the correctness of query results, there are no behavior changes but the changes might influence on consuming memory and query execution time. For example:
Before:
```scala
scala> sql("CREATE TABLE tbl (c int)")
scala> sql("CACHE TABLE tbl")
scala> sql("CREATE VIEW v AS SELECT * FROM tbl")
scala> sql("CACHE TABLE v")
scala> spark.catalog.isCached("v")
res6: Boolean = true
scala> spark.catalog.refreshTable("tbl")
scala> spark.catalog.isCached("v")
res8: Boolean = false
```
After:
```scala
scala> spark.catalog.refreshTable("tbl")
scala> spark.catalog.isCached("v")
res8: Boolean = true
```
### How was this patch tested?
1. Added new unit tests that create a view, a temporary view and a global temporary view on top of v1/v2 tables, and refresh the base table via `ALTER TABLE .. ADD/DROP/RENAME PARTITION`.
2. By running the unified test suites:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableAddPartitionSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableDropPartitionSuite"
# build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *AlterTableRenamePartitionSuite"
```
Closes#31206 from MaxGekk/refreshTable-recache-by-plan.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Hive 2.3.8 changes:
HIVE-19662: Upgrade Avro to 1.8.2
HIVE-24324: Remove deprecated API usage from Avro
HIVE-23980: Shade Guava from hive-exec in Hive 2.3
HIVE-24436: Fix Avro NULL_DEFAULT_VALUE compatibility issue
HIVE-24512: Exclude calcite in packaging.
HIVE-22708: Fix for HttpTransport to replace String.equals
HIVE-24551: Hive should include transitive dependencies from calcite after shading it
HIVE-24553: Exclude calcite from test-jar dependency of hive-exec
### Why are the changes needed?
Upgrade Avro and Parquet to latest version.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing test add test try to upgrade Parquet to 1.11.1 and Avro to 1.10.1: https://github.com/apache/spark/pull/30517Closes#30657 from wangyum/SPARK-33696.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR aims to strip auto-generated cast. The main logic is:
1. Add tag if Cast is specified by user.
2. Wrap `PrettyAttribute` in usePrettyExpression.
### Why are the changes needed?
Make sql consistent with dsl. Here is an inconsistent example before this PR:
```
-- output field name: FLOOR(1)
spark.emptyDataFrame.select(floor(lit(1)))
-- output field name: FLOOR(CAST(1 AS DOUBLE))
spark.sql("select floor(1)")
```
Note that, we don't remove the `Cast` so the auto-generated `Cast` can still work. The only changed place is `usePrettyExpression`, we use `PrettyAttribute` replace `Cast` to give a better sql string.
### Does this PR introduce _any_ user-facing change?
Yes, the default field name may change.
### How was this patch tested?
Add test and pass exists test.
Closes#31034 from ulysses-you/SPARK-33989.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This is a followup PR for SPARK-33690 (#30647) .
In addition to the original PR, this PR intends to escape the following meta-characters in `Dataset#showString`.
* `\r` (carrige ret)
* `\f` (form feed)
* `\b` (backspace)
* `\u000B` (vertical tab)
* `\u0007` (bell)
### Why are the changes needed?
To avoid breaking the layout of `Dataset#showString`.
`\u0007` does not break the layout of `Dataset#showString` but it's noisy (beeps for each row) so it should be also escaped.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Modified the existing tests.
I also build the documents and check the generated html for `sql-migration-guide.md`.
Closes#31144 from sarutak/escape-metacharacters-in-getRows.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request?
Update migration guide according to https://github.com/apache/spark/pull/30942#issuecomment-755054562
### Why are the changes needed?
update migration guide.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes#31051 from AngersZhuuuu/SPARK-32685-FOLLOW-UP.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
For same SQL
```
SELECT TRANSFORM(a, b, c, null)
ROW FORMAT DELIMITED
USING 'cat'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '&'
FROM (select 1 as a, 2 as b, 3 as c) t
```
In hive:
```
hive> SELECT TRANSFORM(a, b, c, null)
> ROW FORMAT DELIMITED
> USING 'cat'
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '&'
> FROM (select 1 as a, 2 as b, 3 as c) t;
OK
123\N NULL
Time taken: 14.519 seconds, Fetched: 1 row(s)
hive> packet_write_wait: Connection to 10.191.58.100 port 32200: Broken pipe
```
In Spark
```
Spark master: local[*], Application Id: local-1609225830376
spark-sql> SELECT TRANSFORM(a, b, c, null)
> ROW FORMAT DELIMITED
> USING 'cat'
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '&'
> FROM (select 1 as a, 2 as b, 3 as c) t;
1 2 3 null NULL
Time taken: 4.297 seconds, Fetched 1 row(s)
spark-sql>
```
We should keep same. Change default ROW FORMAT FIELD DELIMIT to `\u0001`
In hive default value is '1' to char is '\u0001'
```
bucket_count -1
column.name.delimiter ,
columns
columns.comments
columns.types
file.inputformat org.apache.hadoop.hive.ql.io.NullRowsInputFormat
```
### Why are the changes needed?
Keep same behavior with hive
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes#30958 from AngersZhuuuu/SPARK-33930.
Authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Update the SQL migration guide about the changes made by:
- https://github.com/apache/spark/pull/30778
- https://github.com/apache/spark/pull/30711
- https://github.com/apache/spark/pull/30866
### Why are the changes needed?
To inform users about the recent changes in the upcoming releases.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
N/A
Closes#30925 from MaxGekk/sql-migr-guide-hiveclientimpl.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Addressed comments in PR #30567, including:
1. add test case for SPARK-33647 and SPARK-33142
2. add migration guide
3. add `getRawTempView` and `getRawGlobalTempView` to return the raw view info (i.e. TemporaryViewRelation)
4. other minor code clean
### Why are the changes needed?
Code clean and more test cases
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing and newly added test cases
Closes#30666 from linhongliu-db/SPARK-33142-followup.
Lead-authored-by: Linhong Liu <linhong.liu@databricks.com>
Co-authored-by: Linhong Liu <67896261+linhongliu-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR intends to escape meta-characters (e.g., \n and \t) in `Dataset.showString`.
Before this PR:
```
scala> Seq("aaa\nbbb\t\tccccc").toDF("value").show()
+--------------+
| value|
+--------------+
|aaa
bbb ccccc|
+--------------+
```
After this PR:
```
+-----------------+
| value|
+-----------------+
|aaa\nbbb\t\tccccc|
+-----------------+
```
### Why are the changes needed?
For better output.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added a unit test.
Closes#30647 from maropu/EscapeMetaInShow.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
Add migration guide for CHAR VARCHAR types
### Why are the changes needed?
for migration
### Does this PR introduce _any_ user-facing change?
doc change
### How was this patch tested?
passing ci
Closes#30654 from yaooqinn/SPARK-33641-F.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
This PR aims to enable `spark.sql.adaptive.enabled` by default for Apache Spark **3.2.0**.
### Why are the changes needed?
By switching the default for Apache Spark 3.2, the whole community can focus more on the stabilizing this feature in the various situation more seriously.
### Does this PR introduce _any_ user-facing change?
Yes, but this is an improvement and it's supposed to have no bugs.
### How was this patch tested?
Pass the CIs.
Closes#30628 from dongjoon-hyun/SPARK-33679.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request?
This PR intends to fix typos in the sub-modules:
* `bin`
* `core`
* `docs`
* `external`
* `mllib`
* `repl`
* `pom.xml`
Split per srowen https://github.com/apache/spark/pull/30323#issuecomment-728981618
NOTE: The misspellings have been reported at 706a726f87 (commitcomment-44064356)
### Why are the changes needed?
Misspelled words make it harder to read / understand content.
### Does this PR introduce _any_ user-facing change?
There are various fixes to documentation, etc...
### How was this patch tested?
No testing was performed
Closes#30530 from jsoref/spelling-bin-core-docs-external-mllib-repl.
Authored-by: Josh Soref <jsoref@users.noreply.github.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR makes CreateViewCommand/AlterViewAsCommand capturing runtime SQL configs and store them as view properties. These configs will be applied during the parsing and analysis phases of the view resolution. Users can set `spark.sql.legacy.useCurrentConfigsForView` to `true` to restore the behavior before.
### Why are the changes needed?
This PR is a sub-task of [SPARK-33138](https://issues.apache.org/jira/browse/SPARK-33138) that proposes to unify temp view and permanent view behaviors. This PR makes permanent views mimicking the temp view behavior that "fixes" view semantic by directly storing resolved LogicalPlan. For example, if a user uses spark 2.4 to create a view that contains null values from division-by-zero expressions, she may not want that other users' queries which reference her view throw exceptions when running on spark 3.x with ansi mode on.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
added UT + existing UTs (improved)
Closes#30289 from luluorta/SPARK-33141.
Authored-by: luluorta <luluorta@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In [SPARK-33139] we defined `setActionSession` and `clearActiveSession` as deprecated API, it turns out it is widely used, and after discussion, even if without this PR, it should work with unify view feature, it might only be a risk if user really abuse using these two API. So revert the PR is needed.
[SPARK-33139] has two commit, include a follow up. Revert them both.
### Why are the changes needed?
Revert.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing UT.
Closes#30367 from leanken/leanken-revert-SPARK-33139.
Authored-by: xuewei.linxuewei <xuewei.linxuewei@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Update SQL migration guide for SPARK-33290
### Why are the changes needed?
Make the change better documented.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
N/A
Closes#30256 from sunchao/SPARK-33290-2.
Authored-by: Chao Sun <sunchao@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add a configuration to control the legacy behavior of whether need to pad null value when value size less then schema size.
Since we can't decide whether it's a but and some use need it behavior same as Hive.
### Why are the changes needed?
Provides a compatible choice between historical behavior and Hive
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existed UT
Closes#30156 from AngersZhuuuu/SPARK-33284.
Lead-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Return schema in SQL format instead of Catalog string from the SchemaOfCsv expression.
### Why are the changes needed?
To unify output of the `schema_of_json()` and `schema_of_csv()`.
### Does this PR introduce _any_ user-facing change?
Yes, they can but `schema_of_csv()` is usually used in combination with `from_csv()`, so, the format of schema shouldn't be much matter.
Before:
```
> SELECT schema_of_csv('1,abc');
struct<_c0:int,_c1:string>
```
After:
```
> SELECT schema_of_csv('1,abc');
STRUCT<`_c0`: INT, `_c1`: STRING>
```
### How was this patch tested?
By existing test suites `CsvFunctionsSuite` and `CsvExpressionsSuite`.
Closes#30180 from MaxGekk/schema_of_csv-sql-schema.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Return schema in SQL format instead of Catalog string from the `SchemaOfJson` expression.
### Why are the changes needed?
In some cases, `from_json()` cannot parse schemas returned by `schema_of_json`, for instance, when JSON fields have spaces (gaps). Such fields will be quoted after the changes, and can be parsed by `from_json()`.
Here is the example:
```scala
val in = Seq("""{"a b": 1}""").toDS()
in.select(from_json('value, schema_of_json("""{"a b": 100}""")) as "parsed")
```
raises the exception:
```
== SQL ==
struct<a b:bigint>
------^^^
at org.apache.spark.sql.catalyst.parser.ParseException.withCommand(ParseDriver.scala:263)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parse(ParseDriver.scala:130)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parseTableSchema(ParseDriver.scala:76)
at org.apache.spark.sql.types.DataType$.fromDDL(DataType.scala:131)
at org.apache.spark.sql.catalyst.expressions.ExprUtils$.evalTypeExpr(ExprUtils.scala:33)
at org.apache.spark.sql.catalyst.expressions.JsonToStructs.<init>(jsonExpressions.scala:537)
at org.apache.spark.sql.functions$.from_json(functions.scala:4141)
```
### Does this PR introduce _any_ user-facing change?
Yes. For example, `schema_of_json` for the input `{"col":0}`.
Before: `struct<col:bigint>`
After: `STRUCT<`col`: BIGINT>`
### How was this patch tested?
By existing test suites `JsonFunctionsSuite` and `JsonExpressionsSuite`.
Closes#30172 from MaxGekk/schema_of_json-sql-schema.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
1. Set the default value for the SQL configs `spark.sql.legacy.parquet.int96RebaseModeInWrite` and `spark.sql.legacy.parquet.int96RebaseModeInRead` to `EXCEPTION`.
2. Update the SQL migration guide.
### Why are the changes needed?
Current default value `LEGACY` may lead to shifting timestamps in read or in write. We should leave the decision about rebasing to users.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
By existing test suites like `ParquetIOSuite`.
Closes#30121 from MaxGekk/int96-exception-by-default.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Address comments https://github.com/apache/spark/pull/29635#discussion_r507241899 to improve migration guide
### Why are the changes needed?
improve migration guide
### Does this PR introduce _any_ user-facing change?
NO,only doc update
### How was this patch tested?
passing GitHub action
Closes#30113 from yaooqinn/SPARK-32785-F.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request?
This PR is a sub-task of [SPARK-33138](https://issues.apache.org/jira/browse/SPARK-33138). In order to make SQLConf.get reliable and stable, we need to make sure user can't pollute the SQLConf and SparkSession Context via calling setActiveSession and clearActiveSession.
Change of the PR:
* add legacy config spark.sql.legacy.allowModifyActiveSession to fallback to old behavior if user do need to call these two API.
* by default, if user call these two API, it will throw exception
* add extra two internal and private API setActiveSessionInternal and clearActiveSessionInternal for current internal usage
* change all internal reference to new internal API except for SQLContext.setActive and SQLContext.clearActive
### Why are the changes needed?
Make SQLConf.get reliable and stable.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
* Add UT in SparkSessionBuilderSuite to test the legacy config
* Existing test
Closes#30042 from leanken/leanken-SPARK-33139.
Authored-by: xuewei.linxuewei <xuewei.linxuewei@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
As [SPARK-13860](https://issues.apache.org/jira/browse/SPARK-13860) stated, TPCDS Query 39 returns wrong results using SparkSQL. The root cause is that when stddev_samp is applied to a single element set, with TPCDS answer, it return null; as in SparkSQL, it return Double.NaN which caused the wrong result.
Add an extra legacy config to fallback into the NaN logical, and return null by default to align with TPCDS standard.
### Why are the changes needed?
SQL correctness issue.
### Does this PR introduce any user-facing change?
Yes. See sql-migration-guide
In Spark 3.1, statistical aggregation function includes `std`, `stddev`, `stddev_samp`, `variance`, `var_samp`, `skewness`, `kurtosis`, `covar_samp`, `corr` will return `NULL` instead of `Double.NaN` when `DivideByZero` occurs during expression evaluation, for example, when `stddev_samp` applied on a single element set. In Spark version 3.0 and earlier, it will return `Double.NaN` in such case. To restore the behavior before Spark 3.1, you can set `spark.sql.legacy.statisticalAggregate` to `true`.
### How was this patch tested?
Updated DataFrameAggregateSuite/DataFrameWindowFunctionsSuite to test both default and legacy behavior.
Adjust DataFrameWindowFunctionsSuite/SQLQueryTestSuite and some R case to update to the default return null behavior.
Closes#29983 from leanken/leanken-SPARK-13860.
Authored-by: xuewei.linxuewei <xuewei.linxuewei@alibaba-inc.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
As of today,
- SPARK-30034 Apache Spark 3.0.0 switched its default Hive execution engine from Hive 1.2 to Hive 2.3. This removes the direct dependency to the forked Hive 1.2.1 in maven repository.
- SPARK-32981 Apache Spark 3.1.0(`master` branch) removed Hive 1.2 related artifacts from Apache Spark binary distributions.
This PR(SPARK-20202) aims to remove the following usage of unofficial Apache Hive fork completely from Apache Spark master for Apache Spark 3.1.0.
```
<hive.group>org.spark-project.hive</hive.group>
<hive.version>1.2.1.spark2</hive.version>
```
For the forked Hive 1.2.1.spark2 users, Apache Spark 2.4(LTS) and 3.0 (~ 2021.12) will provide it.
### Why are the changes needed?
- First, Apache Spark community should not use the unofficial forked release of another Apache project.
- Second, Apache Hive 1.2.1 was released at 2015-06-26 and the forked Hive `1.2.1.spark2` exposed many unfixable bugs in Apache because the forked `1.2.1.spark2` is not maintained at all. Apache Hive 2.3.0 was released at 2017-07-19 and it has been used with less number of bugs compared with `1.2.1.spark2`. Many bugs still exist in `hive-1.2` profile and new Apache Spark unit tests are added with `HiveUtils.isHive23` condition so far.
### Does this PR introduce _any_ user-facing change?
No. This is a dev-only change. PRBuilder will not accept `[test-hive1.2]` on master and `branch-3.1`.
### How was this patch tested?
1. SBT/Hadoop 3.2/Hive 2.3 (https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129366)
2. SBT/Hadoop 2.7/Hive 2.3 (https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129382)
3. SBT/Hadoop 3.2/Hive 1.2 (This has not been supported already due to Hive 1.2 doesn't work with Hadoop 3.2.)
4. SBT/Hadoop 2.7/Hive 1.2 (https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129383, This is rejected)
Closes#29936 from dongjoon-hyun/SPARK-REMOVE-HIVE1.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
bugfix for incomplete interval values, e.g. interval '1', interval '1 day 2', currently these cases will result null, but actually we should fail them with IllegalArgumentsException
### Why are the changes needed?
correctness
### Does this PR introduce _any_ user-facing change?
yes, incomplete intervals will throw exception now
#### before
```
bin/spark-sql -S -e "select interval '1', interval '+', interval '1 day -'"
NULL NULL NULL
```
#### after
```
-- !query
select interval '1'
-- !query schema
struct<>
-- !query output
org.apache.spark.sql.catalyst.parser.ParseException
Cannot parse the INTERVAL value: 1(line 1, pos 7)
== SQL ==
select interval '1'
```
### How was this patch tested?
unit tests added
Closes#29635 from yaooqinn/SPARK-32785.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}