## What changes were proposed in this pull request?
Docs changes:
- Adding a warning that the backend is experimental.
- Removing a defunct internal-only option from documentation
- Clarifying that node selectors can be used right away, and other minor cosmetic changes
## How was this patch tested?
Docs only change
Author: foxish <ramanathana@google.com>
Closes#20314 from foxish/ambiguous-docs.
## What changes were proposed in this pull request?
Several cleanups in `ColumnarBatch`
* remove `schema`. The `ColumnVector`s inside `ColumnarBatch` already have the data type information, we don't need this `schema`.
* remove `capacity`. `ColumnarBatch` is just a wrapper of `ColumnVector`s, not builders, it doesn't need a capacity property.
* remove `DEFAULT_BATCH_SIZE`. As a wrapper, `ColumnarBatch` can't decide the batch size, it should be decided by the reader, e.g. parquet reader, orc reader, cached table reader. The default batch size should also be defined by the reader.
## How was this patch tested?
existing tests.
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20316 from cloud-fan/columnar-batch.
## What changes were proposed in this pull request?
`ML.Vectors#sparse(size: Int, elements: Seq[(Int, Double)])` support zero-length
## How was this patch tested?
existing tests
Author: Zheng RuiFeng <ruifengz@foxmail.com>
Closes#20275 from zhengruifeng/SparseVector_size.
## What changes were proposed in this pull request?
After session cloning in `TestHive`, the conf of the singleton SparkContext for derby DB location is changed to a new directory. The new directory is created in `HiveUtils.newTemporaryConfiguration(useInMemoryDerby = false)`.
This PR is to keep the conf value of `ConfVars.METASTORECONNECTURLKEY.varname` unchanged during the session clone.
## How was this patch tested?
The issue can be reproduced by the command:
> build/sbt -Phive "hive/test-only org.apache.spark.sql.hive.HiveSessionStateSuite org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite"
Also added a test case.
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20328 from gatorsmile/fixTestFailure.
## What changes were proposed in this pull request?
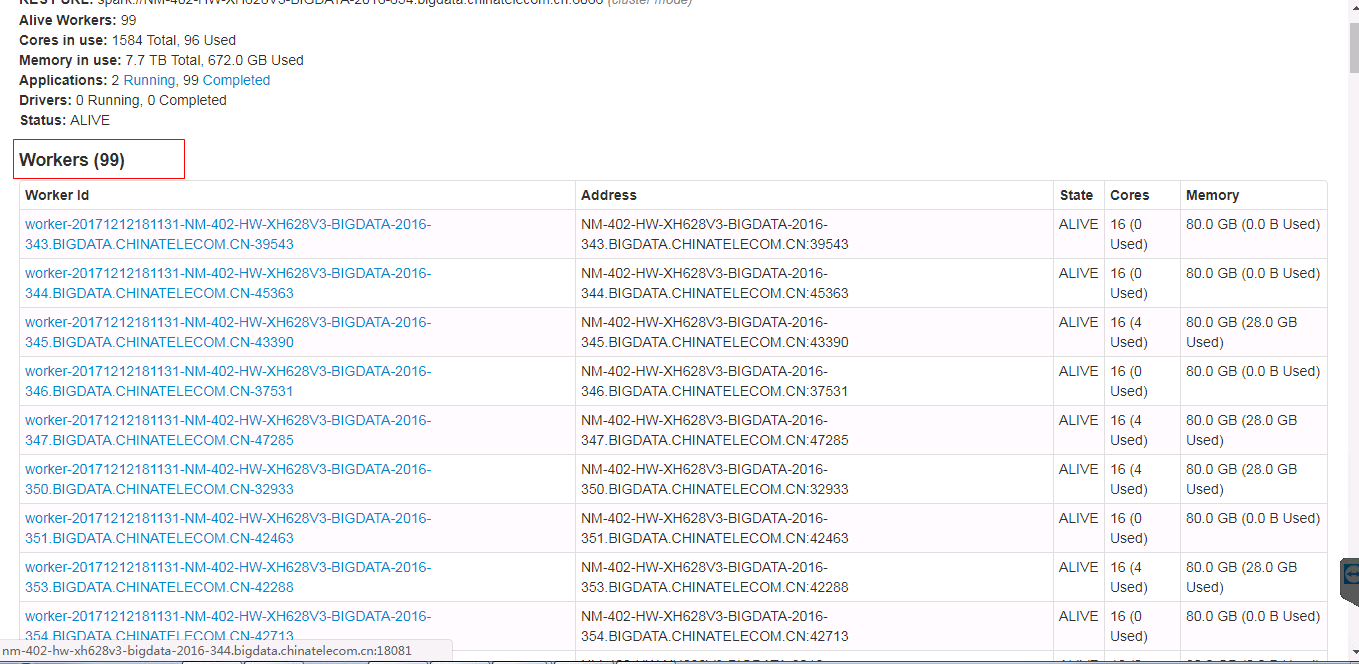
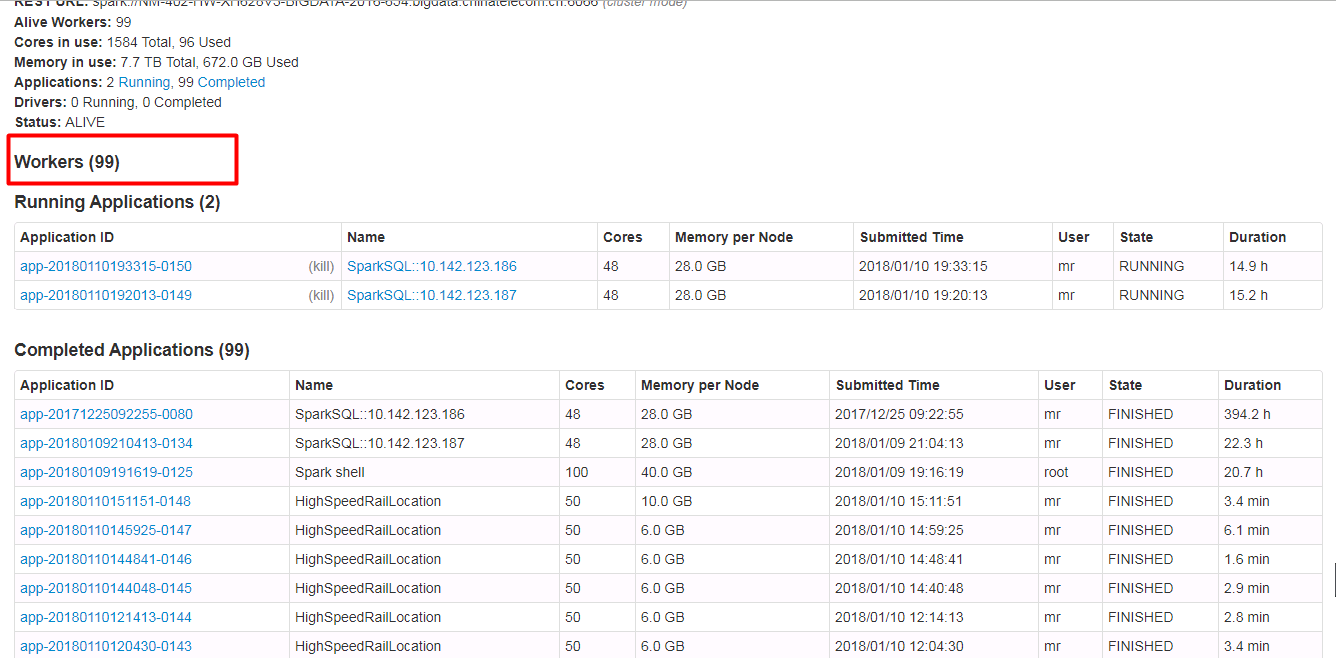
Spark ui about the contents of the form need to have hidden and show features, when the table records very much. Because sometimes you do not care about the record of the table, you just want to see the contents of the next table, but you have to scroll the scroll bar for a long time to see the contents of the next table.
Currently we have about 500 workers, but I just wanted to see the logs for the running applications table. I had to scroll through the scroll bars for a long time to see the logs for the running applications table.
In order to ensure functional consistency, I modified the Master Page, Worker Page, Job Page, Stage Page, Task Page, Configuration Page, Storage Page, Pool Page.
fix before:
fix after:
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: guoxiaolong <guo.xiaolong1@zte.com.cn>
Closes#20216 from guoxiaolongzte/SPARK-23024.
## What changes were proposed in this pull request?
When creating a session directory, Thrift should create the parent directory (i.e. /tmp/base_session_log_dir) if it is not present. It is common that many tools delete empty directories, so the directory may be deleted. This can cause the session log to be disabled.
This was fixed in HIVE-12262: this PR brings it in Spark too.
## How was this patch tested?
manual tests
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20281 from mgaido91/SPARK-23089.
## What changes were proposed in this pull request?
We have `OneHotEncoderEstimator` now and `OneHotEncoder` will be deprecated since 2.3.0. We should add `OneHotEncoderEstimator` into mllib document.
We also need to provide corresponding examples for `OneHotEncoderEstimator` which are used in the document too.
## How was this patch tested?
Existing tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#20257 from viirya/SPARK-23048.
Update user guide entry for `FeatureHasher` to match the Scala / Python doc, to describe the `categoricalCols` parameter.
## How was this patch tested?
Doc only
Author: Nick Pentreath <nickp@za.ibm.com>
Closes#20293 from MLnick/SPARK-23127-catCol-userguide.
## What changes were proposed in this pull request?
This patch fixes a few recently introduced java style check errors in master and release branch.
As an aside, given that [java linting currently fails](https://github.com/apache/spark/pull/10763
) on machines with a clean maven cache, it'd be great to find another workaround to [re-enable the java style checks](3a07eff5af/dev/run-tests.py (L577)) as part of Spark PRB.
/cc zsxwing JoshRosen srowen for any suggestions
## How was this patch tested?
Manual Check
Author: Sameer Agarwal <sameerag@apache.org>
Closes#20323 from sameeragarwal/java.
## What changes were proposed in this pull request?
This is a follow-up of #20246.
If a UDT in Python doesn't have its corresponding Scala UDT, cast to string will be the raw string of the internal value, e.g. `"org.apache.spark.sql.catalyst.expressions.UnsafeArrayDataxxxxxxxx"` if the internal type is `ArrayType`.
This pr fixes it by using its `sqlType` casting.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20306 from ueshin/issues/SPARK-23054/fup1.
## What changes were proposed in this pull request?
In latest structured-streaming-kafka-integration document, Java code example for Kafka integration is using `DataFrame<Row>`, shouldn't it be changed to `DataSet<Row>`?
## How was this patch tested?
manual test has been performed to test the updated example Java code in Spark 2.2.1 with Kafka 1.0
Author: brandonJY <brandonJY@users.noreply.github.com>
Closes#20312 from brandonJY/patch-2.
## What changes were proposed in this pull request?
In the Kubernetes mode, fails fast in the submission process if any submission client local dependencies are used as the use case is not supported yet.
## How was this patch tested?
Unit tests, integration tests, and manual tests.
vanzin foxish
Author: Yinan Li <liyinan926@gmail.com>
Closes#20320 from liyinan926/master.
## What changes were proposed in this pull request?
There were two related fixes regarding `from_json`, `get_json_object` and `json_tuple` ([Fix#1](c8803c0685),
[Fix#2](86174ea89b)), but they weren't comprehensive it seems. I wanted to extend those fixes to all the parsers, and add tests for each case.
## How was this patch tested?
Regression tests
Author: Burak Yavuz <brkyvz@gmail.com>
Closes#20302 from brkyvz/json-invfix.
Pass through spark java options to the executor in context of docker image.
Closes#20296
andrusha: Deployed two version of containers to local k8s, checked that java options were present in the updated image on the running executor.
Manual test
Author: Andrew Korzhuev <korzhuev@andrusha.me>
Closes#20322 from foxish/patch-1.
## What changes were proposed in this pull request?
Refactored ConsoleWriter into ConsoleMicrobatchWriter and ConsoleContinuousWriter.
## How was this patch tested?
new unit test
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20311 from tdas/SPARK-23144.
## What changes were proposed in this pull request?
Self-explanatory.
## How was this patch tested?
New python tests.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20309 from tdas/SPARK-23143.
## What changes were proposed in this pull request?
This PR completes the docs, specifying the default units assumed in configuration entries of type size.
This is crucial since unit-less values are accepted and the user might assume the base unit is bytes, which in most cases it is not, leading to hard-to-debug problems.
## How was this patch tested?
This patch updates only documentation only.
Author: Fernando Pereira <fernando.pereira@epfl.ch>
Closes#20269 from ferdonline/docs_units.
## What changes were proposed in this pull request?
Stage's task page table will throw an exception when there's no complete tasks. Furthermore, because the `dataSize` doesn't take running tasks into account, so sometimes UI cannot show the running tasks. Besides table will only be displayed when first task is finished according to the default sortColumn("index").
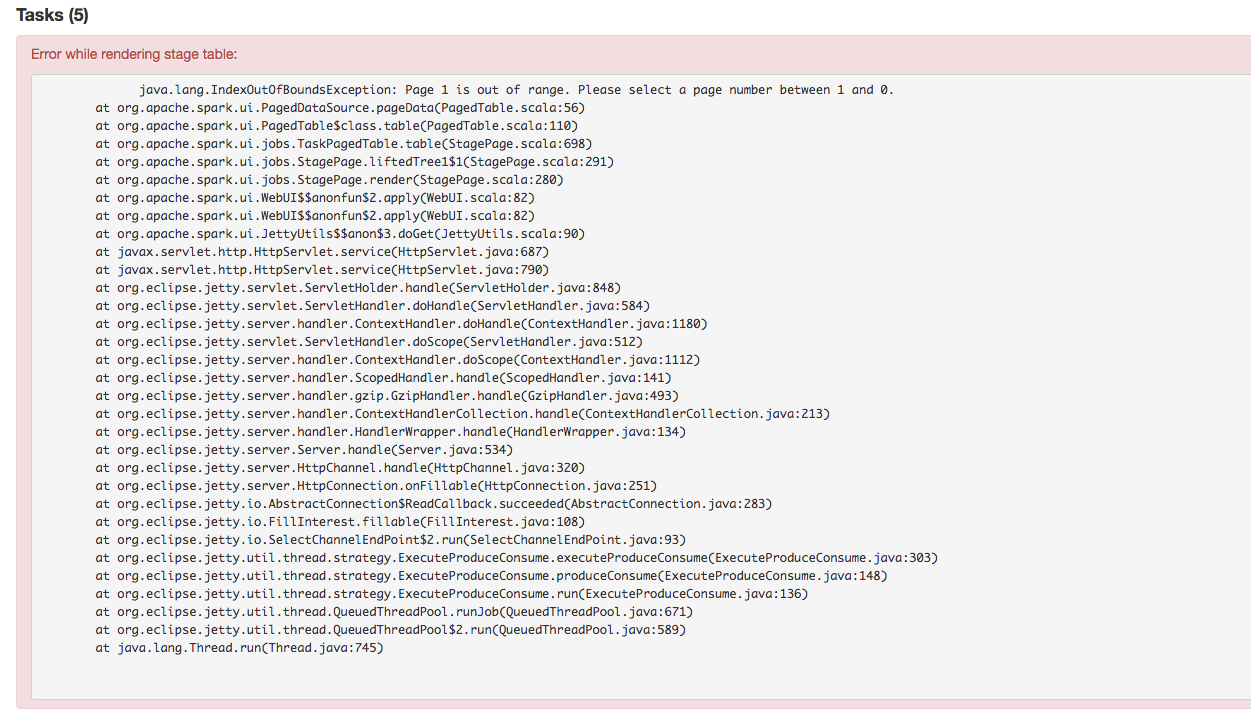
To reproduce this issue, user could try `sc.parallelize(1 to 20, 20).map { i => Thread.sleep(10000); i }.collect()` or `sc.parallelize(1 to 20, 20).map { i => Thread.sleep((20 - i) * 1000); i }.collect` to reproduce the above issue.
Here propose a solution to fix it. Not sure if it is a right fix, please help to review.
## How was this patch tested?
Manual test.
Author: jerryshao <sshao@hortonworks.com>
Closes#20315 from jerryshao/SPARK-23147.
## What changes were proposed in this pull request?
Currently `UDFRegistration.registerJavaFunction` doesn't support data type string as a `returnType` whereas `UDFRegistration.register`, `udf`, or `pandas_udf` does.
We can support it for `UDFRegistration.registerJavaFunction` as well.
## How was this patch tested?
Added a doctest and existing tests.
Author: Takuya UESHIN <ueshin@databricks.com>
Closes#20307 from ueshin/issues/SPARK-23141.
## What changes were proposed in this pull request?
When there is an operation between Decimals and the result is a number which is not representable exactly with the result's precision and scale, Spark is returning `NULL`. This was done to reflect Hive's behavior, but it is against SQL ANSI 2011, which states that "If the result cannot be represented exactly in the result type, then whether it is rounded or truncated is implementation-defined". Moreover, Hive now changed its behavior in order to respect the standard, thanks to HIVE-15331.
Therefore, the PR propose to:
- update the rules to determine the result precision and scale according to the new Hive's ones introduces in HIVE-15331;
- round the result of the operations, when it is not representable exactly with the result's precision and scale, instead of returning `NULL`
- introduce a new config `spark.sql.decimalOperations.allowPrecisionLoss` which default to `true` (ie. the new behavior) in order to allow users to switch back to the previous one.
Hive behavior reflects SQLServer's one. The only difference is that the precision and scale are adjusted for all the arithmetic operations in Hive, while SQL Server is said to do so only for multiplications and divisions in the documentation. This PR follows Hive's behavior.
A more detailed explanation is available here: https://mail-archives.apache.org/mod_mbox/spark-dev/201712.mbox/%3CCAEorWNAJ4TxJR9NBcgSFMD_VxTg8qVxusjP%2BAJP-x%2BJV9zH-yA%40mail.gmail.com%3E.
## How was this patch tested?
modified and added UTs. Comparisons with results of Hive and SQLServer.
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#20023 from mgaido91/SPARK-22036.
## What changes were proposed in this pull request?
`DataSourceV2Strategy` is missing in `HiveSessionStateBuilder`'s planner, which will throw exception as described in [SPARK-23140](https://issues.apache.org/jira/browse/SPARK-23140).
## How was this patch tested?
Manual test.
Author: jerryshao <sshao@hortonworks.com>
Closes#20305 from jerryshao/SPARK-23140.
## What changes were proposed in this pull request?
Migrate ConsoleSink to data source V2 api.
Note that this includes a missing piece in DataStreamWriter required to specify a data source V2 writer.
Note also that I've removed the "Rerun batch" part of the sink, because as far as I can tell this would never have actually happened. A MicroBatchExecution object will only commit each batch once for its lifetime, and a new MicroBatchExecution object would have a new ConsoleSink object which doesn't know it's retrying a batch. So I think this represents an anti-feature rather than a weakness in the V2 API.
## How was this patch tested?
new unit test
Author: Jose Torres <jose@databricks.com>
Closes#20243 from jose-torres/console-sink.
## What changes were proposed in this pull request?
This PR proposes to deprecate `register*` for UDFs in `SQLContext` and `Catalog` in Spark 2.3.0.
These are inconsistent with Scala / Java APIs and also these basically do the same things with `spark.udf.register*`.
Also, this PR moves the logcis from `[sqlContext|spark.catalog].register*` to `spark.udf.register*` and reuse the docstring.
This PR also handles minor doc corrections. It also includes https://github.com/apache/spark/pull/20158
## How was this patch tested?
Manually tested, manually checked the API documentation and tests added to check if deprecated APIs call the aliases correctly.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20288 from HyukjinKwon/deprecate-udf.
## What changes were proposed in this pull request?
Structured streaming is now able to read files with space in file name (previously it would skip the file and output a warning)
## How was this patch tested?
Added new unit test.
Author: Xiayun Sun <xiayunsun@gmail.com>
Closes#19247 from xysun/SPARK-21996.
## What changes were proposed in this pull request?
- Added `InterfaceStability.Evolving` annotations
- Improved docs.
## How was this patch tested?
Existing tests.
Author: Tathagata Das <tathagata.das1565@gmail.com>
Closes#20286 from tdas/SPARK-23119.
## What changes were proposed in this pull request?
Fixed some typos found in ML scaladocs
## How was this patch tested?
NA
Author: Bryan Cutler <cutlerb@gmail.com>
Closes#20300 from BryanCutler/ml-doc-typos-MINOR.
## What changes were proposed in this pull request?
This PR proposes to actually run the doctests in `ml/image.py`.
## How was this patch tested?
doctests in `python/pyspark/ml/image.py`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#20294 from HyukjinKwon/trigger-image.
## What changes were proposed in this pull request?
This PR changes usage of `MapVector` in Spark codebase to use `NullableMapVector`.
`MapVector` is an internal Arrow class that is not supposed to be used directly. We should use `NullableMapVector` instead.
## How was this patch tested?
Existing test.
Author: Li Jin <ice.xelloss@gmail.com>
Closes#20239 from icexelloss/arrow-map-vector.
## What changes were proposed in this pull request?
Keep the run ID static, using a different ID for the epoch coordinator to avoid cross-execution message contamination.
## How was this patch tested?
new and existing unit tests
Author: Jose Torres <jose@databricks.com>
Closes#20282 from jose-torres/fix-runid.
## What changes were proposed in this pull request?
Continuous processing tasks will fail on any attempt number greater than 0. ContinuousExecution will catch these failures and restart globally from the last recorded checkpoints.
## How was this patch tested?
unit test
Author: Jose Torres <jose@databricks.com>
Closes#20225 from jose-torres/no-retry.
## What changes were proposed in this pull request?
Temporarily ignoring flaky test `SparkLauncherSuite.testInProcessLauncher` to de-flake the builds. This should be re-enabled when SPARK-23020 is merged.
## How was this patch tested?
N/A (Test Only Change)
Author: Sameer Agarwal <sameerag@apache.org>
Closes#20291 from sameeragarwal/disable-test-2.
## What changes were proposed in this pull request?
Previously, PR #19201 fix the problem of non-converging constraints.
After that PR #19149 improve the loop and constraints is inferred only once.
So the problem of non-converging constraints is gone.
However, the case below will fail.
```
spark.range(5).write.saveAsTable("t")
val t = spark.read.table("t")
val left = t.withColumn("xid", $"id" + lit(1)).as("x")
val right = t.withColumnRenamed("id", "xid").as("y")
val df = left.join(right, "xid").filter("id = 3").toDF()
checkAnswer(df, Row(4, 3))
```
Because `aliasMap` replace all the aliased child. See the test case in PR for details.
This PR is to fix this bug by removing useless code for preventing non-converging constraints.
It can be also fixed with #20270, but this is much simpler and clean up the code.
## How was this patch tested?
Unit test
Author: Wang Gengliang <ltnwgl@gmail.com>
Closes#20278 from gengliangwang/FixConstraintSimple.
## What changes were proposed in this pull request?
ORC filter push-down is disabled by default from the beginning, [SPARK-2883](aa31e431fc (diff-41ef65b9ef5b518f77e2a03559893f4dR149)
).
Now, Apache Spark starts to depend on Apache ORC 1.4.1. For Apache Spark 2.3, this PR turns on ORC filter push-down by default like Parquet ([SPARK-9207](https://issues.apache.org/jira/browse/SPARK-21783)) as a part of [SPARK-20901](https://issues.apache.org/jira/browse/SPARK-20901), "Feature parity for ORC with Parquet".
## How was this patch tested?
Pass the existing tests.
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#20265 from dongjoon-hyun/SPARK-21783.
## What changes were proposed in this pull request?
Make the default behavior of EXCEPT (i.e. EXCEPT DISTINCT) more
explicit in the documentation, and call out the change in behavior
from 1.x.
Author: Henry Robinson <henry@cloudera.com>
Closes#20254 from henryr/spark-23062.
## What changes were proposed in this pull request?
The first commit added a new test, and the second refactored the class the test was in. The automatic merge put the test in the wrong place.
## How was this patch tested?
-
Author: Jose Torres <jose@databricks.com>
Closes#20289 from jose-torres/fix.
## What changes were proposed in this pull request?
The Kafka reader is now interruptible and can close itself.
## How was this patch tested?
I locally ran one of the ContinuousKafkaSourceSuite tests in a tight loop. Before the fix, my machine ran out of open file descriptors a few iterations in; now it works fine.
Author: Jose Torres <jose@databricks.com>
Closes#20253 from jose-torres/fix-data-reader.
## What changes were proposed in this pull request?
There are already quite a few integration tests using window frames, but the unit tests coverage is not ideal.
In this PR the already existing tests are reorganized, extended and where gaps found additional cases added.
## How was this patch tested?
Automated: Pass the Jenkins.
Author: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Closes#20019 from gaborgsomogyi/SPARK-22361.
## What changes were proposed in this pull request?
The following SQL involving scalar correlated query returns a map exception.
``` SQL
SELECT t1a
FROM t1
WHERE t1a = (SELECT count(*)
FROM t2
WHERE t2c = t1c
HAVING count(*) >= 1)
```
``` SQL
key not found: ExprId(278,786682bb-41f9-4bd5-a397-928272cc8e4e)
java.util.NoSuchElementException: key not found: ExprId(278,786682bb-41f9-4bd5-a397-928272cc8e4e)
at scala.collection.MapLike$class.default(MapLike.scala:228)
at scala.collection.AbstractMap.default(Map.scala:59)
at scala.collection.MapLike$class.apply(MapLike.scala:141)
at scala.collection.AbstractMap.apply(Map.scala:59)
at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$.org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$evalSubqueryOnZeroTups(subquery.scala:378)
at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$$anonfun$org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$constructLeftJoins$1.apply(subquery.scala:430)
at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$$anonfun$org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$constructLeftJoins$1.apply(subquery.scala:426)
```
In this case, after evaluating the HAVING clause "count(*) > 1" statically
against the binding of aggregtation result on empty input, we determine
that this query will not have a the count bug. We should simply return
the evalSubqueryOnZeroTups with empty value.
(Please fill in changes proposed in this fix)
## How was this patch tested?
A new test was added in the Subquery bucket.
Author: Dilip Biswal <dbiswal@us.ibm.com>
Closes#20283 from dilipbiswal/scalar-count-defect.
## What changes were proposed in this pull request?
* If there is any error while trying to assign the jira, prompt again
* Filter out the "Apache Spark" choice
* allow arbitrary user ids to be entered
## How was this patch tested?
Couldn't really test the error case, just some testing of similar-ish code in python shell. Haven't run a merge yet.
Author: Imran Rashid <irashid@cloudera.com>
Closes#20236 from squito/SPARK-23044.
## What changes were proposed in this pull request?
RFormula should use VectorSizeHint & OneHotEncoderEstimator in its pipeline to avoid using the deprecated OneHotEncoder & to ensure the model produced can be used in streaming.
## How was this patch tested?
Unit tests.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Bago Amirbekian <bago@databricks.com>
Closes#20229 from MrBago/rFormula.
## What changes were proposed in this pull request?
Lots of our tests don't properly shutdown everything they create, and end up leaking lots of threads. For example, `TaskSetManagerSuite` doesn't stop the extra `TaskScheduler` and `DAGScheduler` it creates. There are a couple more instances, eg. in `DAGSchedulerSuite`.
This PR adds the possibility to print out the not properly stopped thread list after a test suite executed. The format is the following:
```
===== FINISHED o.a.s.scheduler.DAGSchedulerSuite: 'task end event should have updated accumulators (SPARK-20342)' =====
...
===== Global thread whitelist loaded with name /thread_whitelist from classpath: rpc-client.*, rpc-server.*, shuffle-client.*, shuffle-server.*' =====
ScalaTest-run:
===== THREADS NOT STOPPED PROPERLY =====
ScalaTest-run: dag-scheduler-event-loop
ScalaTest-run: globalEventExecutor-2-5
ScalaTest-run:
===== END OF THREAD DUMP =====
ScalaTest-run:
===== EITHER PUT THREAD NAME INTO THE WHITELIST FILE OR SHUT IT DOWN PROPERLY =====
```
With the help of this leaking threads has been identified in TaskSetManagerSuite. My intention is to hunt down and fix such bugs in later PRs.
## How was this patch tested?
Manual: TaskSetManagerSuite test executed and found out where are the leaking threads.
Automated: Pass the Jenkins.
Author: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Closes#19893 from gaborgsomogyi/SPARK-16139.
## What changes were proposed in this pull request?
a new Data Source V2 interface to allow the data source to return `ColumnarBatch` during the scan.
## How was this patch tested?
new tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes#20153 from cloud-fan/columnar-reader.
## What changes were proposed in this pull request?
Register Vectorized UDFs for SQL Statement. For example,
```Python
>>> from pyspark.sql.functions import pandas_udf, PandasUDFType
>>> pandas_udf("integer", PandasUDFType.SCALAR)
... def add_one(x):
... return x + 1
...
>>> _ = spark.udf.register("add_one", add_one)
>>> spark.sql("SELECT add_one(id) FROM range(3)").collect()
[Row(add_one(id)=1), Row(add_one(id)=2), Row(add_one(id)=3)]
```
## How was this patch tested?
Added test cases
Author: gatorsmile <gatorsmile@gmail.com>
Closes#20171 from gatorsmile/supportVectorizedUDF.
The race in the code is because the handle might update
its state to the wrong state if the connection handling
thread is still processing incoming data; so the handle
needs to wait for the connection to finish up before
checking the final state.
The race in the test is because when waiting for a handle
to reach a final state, the waitFor() method needs to wait
until all handle state is updated (which also includes
waiting for the connection thread above to finish).
Otherwise, waitFor() may return too early, which would cause
a bunch of different races (like the listener not being yet
notified of the state change, or being in the middle of
being notified, or the handle not being properly disposed
and causing postChecks() to assert).
On top of that I found, by code inspection, a couple of
potential races that could make a handle end up in the
wrong state when being killed.
Tested by running the existing unit tests a lot (and not
seeing the errors I was seeing before).
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#20223 from vanzin/SPARK-23020.
## What changes were proposed in this pull request?
This problem reported by yanlin-Lynn ivoson and LiangchangZ. Thanks!
When we union 2 streams from kafka or other sources, while one of them have no continues data coming and in the same time task restart, this will cause an `IllegalStateException`. This mainly cause because the code in [MicroBatchExecution](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala#L190) , while one stream has no continues data, its comittedOffset same with availableOffset during `populateStartOffsets`, and `currentPartitionOffsets` not properly handled in KafkaSource. Also, maybe we should also consider this scenario in other Source.
## How was this patch tested?
Add a UT in KafkaSourceSuite.scala
Author: Yuanjian Li <xyliyuanjian@gmail.com>
Closes#20150 from xuanyuanking/SPARK-22956.
## What changes were proposed in this pull request?
In another attempt to fix DataSourceWithHiveMetastoreCatalogSuite, this patch uses qualified table names (`default.t`) in the individual tests.
## How was this patch tested?
N/A (Test Only Change)
Author: Sameer Agarwal <sameerag@apache.org>
Closes#20273 from sameeragarwal/flaky-test.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}