## What changes were proposed in this pull request?
In `UnsafeSorterSpillWriter.java`, when we write a record to a spill file wtih ` void write(Object baseObject, long baseOffset, int recordLength, long keyPrefix)`, `recordLength` and `keyPrefix` will be written the disk write buffer first, and these will take 12 bytes, so the disk write buffer size must be greater than 12.
If `diskWriteBufferSize` is 10, it will print this exception info:
_java.lang.ArrayIndexOutOfBoundsException: 10
at org.apache.spark.util.collection.unsafe.sort.UnsafeSorterSpillWriter.writeLongToBuffer (UnsafeSorterSpillWriter.java:91)
at org.apache.spark.util.collection.unsafe.sort.UnsafeSorterSpillWriter.write(UnsafeSorterSpillWriter.java:123)
at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.spillIterator(UnsafeExternalSorter.java:498)
at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.spill(UnsafeExternalSorter.java:222)
at org.apache.spark.memory.MemoryConsumer.spill(MemoryConsumer.java:65)_
## How was this patch tested?
Existing UT in `UnsafeExternalSorterSuite`
Closes#22754 from 10110346/diskWriteBufferSize.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
## What changes were proposed in this pull request?
Now we use only one `timer` (and thus a backing thread) in `BarrierTaskContext` companion object, and the objects can add `timerTasks` to that `timer`.
## How was this patch tested?
This was tested manually by generating logs and seeing that they look the same as ones before, namely, that is, a partition waiting on another partition for 5seconds generates 4-5 log messages when the frequency of logging is set to 1second.
Closes#22912 from yogeshg/thread.
Authored-by: Yogesh Garg <1059168+yogeshg@users.noreply.github.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
## What changes were proposed in this pull request?
'refreshInterval' is not used any where in the headerSparkPage method. So, we don't need to pass the parameter while calling the 'headerSparkPage' method.
## How was this patch tested?
Existing tests
Closes#22864 from shahidki31/unusedCode.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Avoid converting encrypted bocks to regular ByteBuffers, to ensure they can be sent over the network for replication & remote reads even when > 2GB.
Also updates some TODOs with links to a SPARK-25905 for improving the
handling here.
## How was this patch tested?
Tested on a cluster with encrypted data > 2GB (after SPARK-25904 was
applied as well).
Closes#22917 from squito/real_SPARK-25827.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
* Update `AppStatusListener` `cleanupStages` method to remove tasks for those stages in a single pass instead of 1 for each stage.
* This fixes an issue where the cleanupStages method would get backed up, causing a backup in the executor in ElementTrackingStore, resulting in stages and jobs not getting cleaned up properly.
Tasks seem most susceptible to this as there are a lot of them, however a similar issue could arise in other locations the `KVStore` `view` method is used. A broader fix might involve updates to `KVStoreView` and `InMemoryView` as it appears this interface and implementation can lead to multiple and inefficient traversals of the stored data.
## How was this patch tested?
Using existing tests in AppStatusListenerSuite
This is my original work and I license the work to the project under the project’s open source license.
Closes#22883 from patrickbrownsync/cleanup-stages-fix.
Authored-by: Patrick Brown <patrick.brown@blyncsy.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
I saw CoarseGrainedSchedulerBackendSuite failed in my PR and finally reproduced the following error on a very busy machine:
```
sbt.ForkMain$ForkError: org.scalatest.exceptions.TestFailedDueToTimeoutException: The code passed to eventually never returned normally. Attempted 400 times over 10.009828643999999 seconds. Last failure message: ArrayBuffer("2", "0", "3") had length 3 instead of expected length 4.
```
The logs in this test shows executor 1 was not up when the test failed.
```
18/10/30 11:34:03.563 dispatcher-event-loop-12 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.17.0.2:43656) with ID 2
18/10/30 11:34:03.593 dispatcher-event-loop-3 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.17.0.2:43658) with ID 3
18/10/30 11:34:03.629 dispatcher-event-loop-6 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.17.0.2:43654) with ID 0
18/10/30 11:34:03.885 pool-1-thread-1-ScalaTest-running-CoarseGrainedSchedulerBackendSuite INFO CoarseGrainedSchedulerBackendSuite:
===== FINISHED o.a.s.scheduler.CoarseGrainedSchedulerBackendSuite: 'compute max number of concurrent tasks can be launched' =====
```
And the following logs in executor 1 shows it was still doing the initialization when the timeout happened (at 18/10/30 11:34:03.885).
```
18/10/30 11:34:03.463 netty-rpc-connection-0 INFO TransportClientFactory: Successfully created connection to 54b6b6217301/172.17.0.2:33741 after 37 ms (0 ms spent in bootstraps)
18/10/30 11:34:03.959 main INFO DiskBlockManager: Created local directory at /home/jenkins/workspace/core/target/tmp/spark-383518bc-53bd-4d9c-885b-d881f03875bf/executor-61c406e4-178f-40a6-ac2c-7314ee6fb142/blockmgr-03fb84a1-eedc-4055-8743-682eb3ac5c67
18/10/30 11:34:03.993 main INFO MemoryStore: MemoryStore started with capacity 546.3 MB
```
Hence, I think our current 10 seconds is not enough on a slow Jenkins machine. This PR just increases the timeout from 10 seconds to 60 seconds to make the test more stable.
## How was this patch tested?
Jenkins
Closes#22910 from zsxwing/fix-flaky-test.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
This avoids having two classes to deal with tokens; now the above
class is a one-stop shop for dealing with delegation tokens. The
YARN backend extends that class instead of doing composition like
before, resulting in a bit less code there too.
The renewer functionality is basically the same code that used to
be in YARN's AMCredentialRenewer. That is also the reason why the
public API of HadoopDelegationTokenManager is a little bit odd;
the YARN AM has some odd requirements for how this all should be
initialized, and the weirdness is needed currently to support that.
Tested:
- YARN with stress app for DT renewal
- Mesos and K8S with basic kerberos tests (both tgt and keytab)
Closes#22624 from vanzin/SPARK-23781.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
This turns off hdfs erasure coding by default for event logs, regardless of filesystem defaults. Because this requires apis only available in hadoop 3, this uses reflection. EC isn't a very good choice for event logs, as hflush() is a no-op, and so updates to the file are not visible for a long time. This can still be configured by setting "spark.eventLog.allowErasureCoding=true", which will use filesystem defaults.
## How was this patch tested?
deployed a cluster with the changes with HDFS EC on. By default, event logs didn't use EC, but configuration still would allow EC. Also tried writing to the local fs (which doesn't support EC at all) and things worked fine.
Closes#22881 from squito/SPARK-25855.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Py4J 0.10.8.1 is released on October 21st and is the first release of Py4J to support Python 3.7 officially. We had better have this to get the official support. Also, there are some patches related to garbage collections.
https://www.py4j.org/changelog.html#py4j-0-10-8-and-py4j-0-10-8-1
## How was this patch tested?
Pass the Jenkins.
Closes#22901 from dongjoon-hyun/SPARK-25891.
Authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
When a job finishes, there may be some zombie tasks still running due to stage retry. Since a result stage will never be used by other jobs, running these tasks are just wasting the cluster resource. This PR just asks TaskScheduler to cancel the running tasks of a result stage when it's already finished. Credits go to srinathshankar who suggested this idea to me.
This PR also fixes two minor issues while I'm touching DAGScheduler:
- Invalid spark.job.interruptOnCancel should not crash DAGScheduler.
- Non fatal errors should not crash DAGScheduler.
## How was this patch tested?
The new unit tests.
Closes#22771 from zsxwing/SPARK-25773.
Lead-authored-by: Shixiong Zhu <zsxwing@gmail.com>
Co-authored-by: Shixiong Zhu <shixiong@databricks.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
MetricGetter should rename to ExecutorMetricType in comments.
## How was this patch tested?
Just comments, no need to test.
Closes#22884 from LantaoJin/SPARK-23429_FOLLOWUP.
Authored-by: LantaoJin <jinlantao@gmail.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
Set main args correctly in BenchmarkBase, to make it accessible for its subclass.
It will benefit:
- BuiltInDataSourceWriteBenchmark
- AvroWriteBenchmark
## How was this patch tested?
manual tests
Closes#22872 from yucai/main_args.
Authored-by: yucai <yyu1@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
There is a race condition when releasing a Python worker. If `ReaderIterator.handleEndOfDataSection` is not running in the task thread, when a task is early terminated (such as `take(N)`), the task completion listener may close the worker but "handleEndOfDataSection" can still put the worker into the worker pool to reuse.
0e07b483d2 is a patch to reproduce this issue.
I also found a user reported this in the mail list: http://mail-archives.apache.org/mod_mbox/spark-user/201610.mbox/%3CCAAUq=H+YLUEpd23nwvq13Ms5hOStkhX3ao4f4zQV6sgO5zM-xAmail.gmail.com%3E
This PR fixes the issue by using `compareAndSet` to make sure we will never return a closed worker to the work pool.
## How was this patch tested?
Jenkins.
Closes#22816 from zsxwing/fix-socket-closed.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
## What changes were proposed in this pull request?
`hsync` has been added as part of SPARK-19531 to get the latest data in the history sever ui, but that is causing the performance overhead and also leading to drop many history log events. `hsync` uses the force `FileChannel.force` to sync the data to the disk and happens for the data pipeline, it is costly operation and making the application to face overhead and drop the events.
I think getting the latest data in history server can be done in different way (no impact to application while writing events), there is an api `DFSInputStream.getFileLength()` which gives the file length including the `lastBlockBeingWrittenLength`(different from `FileStatus.getLen()`), this api can be used when the file status length and previously cached length are equal to verify whether any new data has been written or not, if there is any update in data length then the history server can update the in progress history log. And also I made this change as configurable with the default value false, and can be enabled for history server if users want to see the updated data in ui.
## How was this patch tested?
Added new test and verified manually, with the added conf `spark.history.fs.inProgressAbsoluteLengthCheck.enabled=true`, history server is reading the logs including the last block data which is being written and updating the Web UI with the latest data.
Closes#22752 from devaraj-kavali/SPARK-24787.
Authored-by: Devaraj K <devaraj@apache.org>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
In standalone cluster mode, one could launch driver with supervise mode
enabled. StandaloneRestServer class uses the host and port of current
master as the spark.master property while launching the driver
(even if you are running in HA mode). This class also ignores the
spark.master property passed as part of the request.
Due to the above problem, if the Spark masters switch due to some reason
and your driver is killed unexpectedly and relaunched, it will try to
connect to the master which is in the driver command specified as
-Dspark.master. But this master will be in STANDBY mode and after trying
multiple times, the SparkContext will kill itself (even though secondary
master was alive and healthy).
This change picks the spark.master property from request and uses it to
launch the driver process. Due to this, the driver process has both
masters in -Dspark.master property. Even if the masters switch, SparkContext
can still connect to the ALIVE master and work correctly.
## How was this patch tested?
This patch was manually tested on a standalone cluster running 2.2.1. It was rebased on current master and all tests were executed. I have added a unit test for this change (but since I am new I hope I have covered all).
Closes#21816 from bsikander/rest_driver_fix.
Authored-by: Behroz Sikander <behroz.sikander@sap.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Before the code changes, I tried to run it with 8G memory:
```
build/sbt -mem 8000 "core/testOnly org.apache.spark.serializer.KryoBenchmark"
```
Still I got got OOM.
This is because the lengths of the arrays are random
669ade3a8e/core/src/test/scala/org/apache/spark/serializer/KryoBenchmark.scala (L90-L91)
And the 2D array is usually large: `10000 * Random.nextInt(0, 10000)`
This PR is to fix it and refactor it to use main method.
The benchmark result is also reason compared to the original one.
## How was this patch tested?
Run with
```
bin/spark-submit --class org.apache.spark.serializer.KryoBenchmark core/target/scala-2.11/spark-core_2.11-3.0.0-SNAPSHOT-tests.jar
```
and
```
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "core/test:runMain org.apache.spark.serializer.KryoBenchmark"
Closes#22663 from gengliangwang/kyroBenchmark.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove JavaSparkContextVarargsWorkaround
## How was this patch tested?
Existing tests.
Closes#22729 from srowen/SPARK-25737.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove deprecated accumulator v1
## How was this patch tested?
Existing tests.
Closes#22730 from srowen/SPARK-16775.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Fix the following issues in PythonWorkerFactory
1. MonitorThread.run uses a wrong lock.
2. `createSimpleWorker` misses `synchronized` when updating `simpleWorkers`.
Other changes are just to improve the code style to make the thread-safe contract clear.
## How was this patch tested?
Jenkins
Closes#22770 from zsxwing/pwf.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
This is a follow up of #21601, `StreamFileInputFormat` and `WholeTextFileInputFormat` have the same problem.
`Minimum split size pernode 5123456 cannot be larger than maximum split size 4194304
java.io.IOException: Minimum split size pernode 5123456 cannot be larger than maximum split size 4194304
at org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat.getSplits(CombineFileInputFormat.java: 201)
at org.apache.spark.rdd.BinaryFileRDD.getPartitions(BinaryFileRDD.scala:52)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:254)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:252)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2138)`
## How was this patch tested?
Added a unit test
Closes#22725 from 10110346/maxSplitSize_node_rack.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
Currently in PagedTable.scala pageNavigation() method, if it is having only one page, they were not using the pagination.
Now it is made to use the pagination, even if it is having one page.
## How was this patch tested?
This tested with Spark webUI and History page in spark local setup.

Author: shivusondur <shivusondur@gmail.com>
Closes#22668 from shivusondur/pagination.
JVMs don't you allocate arrays of length exactly Int.MaxValue, so leave
a little extra room. This is necessary when reading blocks >2GB off
the network (for remote reads or for cache replication).
Unit tests via jenkins, ran a test with blocks over 2gb on a cluster
Closes#22705 from squito/SPARK-25704.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
When the first dropEvent occurs, LastReportTimestamp was printing in the log as
Wed Dec 31 16:00:00 PST 1969
(Dropped 1 events from eventLog since Wed Dec 31 16:00:00 PST 1969.)
The reason is that lastReportTimestamp initialized with 0.
Now log is updated to print "... since the application starts" if 'lastReportTimestamp' == 0.
this will happens first dropEvent occurs.
## How was this patch tested?
Manually verified.
Closes#22677 from shivusondur/AsyncEvent1.
Authored-by: shivusondur <shivusondur@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
The SQL execution listener framework was created from scratch(see https://github.com/apache/spark/pull/9078). It didn't leverage what we already have in the spark listener framework, and one major problem is, the listener runs on the spark execution thread, which means a bad listener can block spark's query processing.
This PR re-implements the SQL execution listener framework. Now `ExecutionListenerManager` is just a normal spark listener, which watches the `SparkListenerSQLExecutionEnd` events and post events to the
user-provided SQL execution listeners.
## How was this patch tested?
existing tests.
Closes#22674 from cloud-fan/listener.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
- Exposes several metrics regarding application status as a source, useful to scrape them via jmx instead of mining the metrics rest api. Example use case: prometheus + jmx exporter.
- Metrics are gathered when a job ends at the AppStatusListener side, could be more fine-grained but most metrics like tasks completed are also counted by executors. More metrics could be exposed in the future to avoid scraping executors in some scenarios.
- a config option `spark.app.status.metrics.enabled` is added to disable/enable these metrics, by default they are disabled.
This was manually tested with jmx source enabled and prometheus server on k8s:

In the next pic the job delay is shown for repeated pi calculation (Spark action).

Closes#22381 from skonto/add_app_status_metrics.
Authored-by: Stavros Kontopoulos <stavros.kontopoulos@lightbend.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Remove Kafka 0.8 integration
## How was this patch tested?
Existing tests, build scripts
Closes#22703 from srowen/SPARK-25705.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This is the work on setting up Secure HDFS interaction with Spark-on-K8S.
The architecture is discussed in this community-wide google [doc](https://docs.google.com/document/d/1RBnXD9jMDjGonOdKJ2bA1lN4AAV_1RwpU_ewFuCNWKg)
This initiative can be broken down into 4 Stages
**STAGE 1**
- [x] Detecting `HADOOP_CONF_DIR` environmental variable and using Config Maps to store all Hadoop config files locally, while also setting `HADOOP_CONF_DIR` locally in the driver / executors
**STAGE 2**
- [x] Grabbing `TGT` from `LTC` or using keytabs+principle and creating a `DT` that will be mounted as a secret or using a pre-populated secret
**STAGE 3**
- [x] Driver
**STAGE 4**
- [x] Executor
## How was this patch tested?
Locally tested on a single-noded, pseudo-distributed Kerberized Hadoop Cluster
- [x] E2E Integration tests https://github.com/apache/spark/pull/22608
- [ ] Unit tests
## Docs and Error Handling?
- [x] Docs
- [x] Error Handling
## Contribution Credit
kimoonkim skonto
Closes#21669 from ifilonenko/secure-hdfs.
Lead-authored-by: Ilan Filonenko <if56@cornell.edu>
Co-authored-by: Ilan Filonenko <ifilondz@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Update the next version of Spark from 2.5 to 3.0
## How was this patch tested?
N/A
Closes#22717 from gatorsmile/followupSPARK-25372.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Currently, if we try run
```
./start-history-server.sh -h
```
We will get such error
```
java.io.FileNotFoundException: File -h does not exist
```
1. This is not User-Friendly. For option `-h` or `--help`, it should be parsed correctly and show the usage of the class/script.
2. We can remove deprecated options for setting event log directory through command line options.
After fix, we can get following output:
```
Usage: ./sbin/start-history-server.sh [options]
Options:
--properties-file FILE Path to a custom Spark properties file.
Default is conf/spark-defaults.conf.
Configuration options can be set by setting the corresponding JVM system property.
History Server options are always available; additional options depend on the provider.
History Server options:
spark.history.ui.port Port where server will listen for connections
(default 18080)
spark.history.acls.enable Whether to enable view acls for all applications
(default false)
spark.history.provider Name of history provider class (defaults to
file system-based provider)
spark.history.retainedApplications Max number of application UIs to keep loaded in memory
(default 50)
FsHistoryProvider options:
spark.history.fs.logDirectory Directory where app logs are stored
(default: file:/tmp/spark-events)
spark.history.fs.updateInterval How often to reload log data from storage
(in seconds, default: 10)
```
## How was this patch tested?
Manual test
Closes#22699 from gengliangwang/refactorSHSUsage.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Fix old oversight in API: Java `flatMapValues` needs a `FlatMapFunction`
## How was this patch tested?
Existing tests.
Closes#22690 from srowen/SPARK-19287.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Refactor `JoinBenchmark` to use main method.
1. use `spark-submit`:
```console
bin/spark-submit --class org.apache.spark.sql.execution.benchmark.JoinBenchmark --jars ./core/target/spark-core_2.11-3.0.0-SNAPSHOT-tests.jar ./sql/catalyst/target/spark-sql_2.11-3.0.0-SNAPSHOT-tests.jar
```
2. Generate benchmark result:
```console
SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.JoinBenchmark"
```
## How was this patch tested?
manual tests
Closes#22661 from wangyum/SPARK-25664.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Yuming Wang <wgyumg@gmail.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
When we enable event log compression and compression codec as 'zstd', we are unable to open the webui of the running application from the history server page.
The reason is that, Replay listener was unable to read from the zstd compressed eventlog due to the zstd frame was not finished yet. This causes truncated error while reading the eventLog.
So, when we try to open the WebUI from the History server page, it throws "truncated error ", and we never able to open running application in the webui, when we enable zstd compression.
In this PR, when the IO excpetion happens, and if it is a running application, we log the error,
"Failed to read Spark event log: evetLogDirAppName.inprogress", instead of throwing exception.
## How was this patch tested?
Test steps:
1)spark.eventLog.compress = true
2)spark.io.compression.codec = zstd
3)restart history server
4) launch bin/spark-shell
5) run some queries
6) Open history server page
7) click on the application
**Before fix:**


**After fix:**


(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22689 from shahidki31/SPARK-25697.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently SQL tab in the WEBUI doesn't support pagination. Because of that following issues are happening.
1) For large number of executions, SQL page is throwing OOM exception (around 40,000)
2) For large number of executions, loading SQL page is taking time.
3) Difficult to analyse the execution table for large number of execution.
[Note: spark.sql.ui.retainedExecutions = 50000]
All the tabs, Jobs, Stages etc. supports pagination. So, to make it consistent with other tabs
SQL tab also should support pagination.
I have followed the similar flow of the pagination code in the Jobs and Stages page for SQL page.
Also, this patch doesn't make any behavior change for the SQL tab except the pagination support.
## How was this patch tested?
bin/spark-shell --conf spark.sql.ui.retainedExecutions=50000
Run 50,000 sql queries.
**Before this PR**
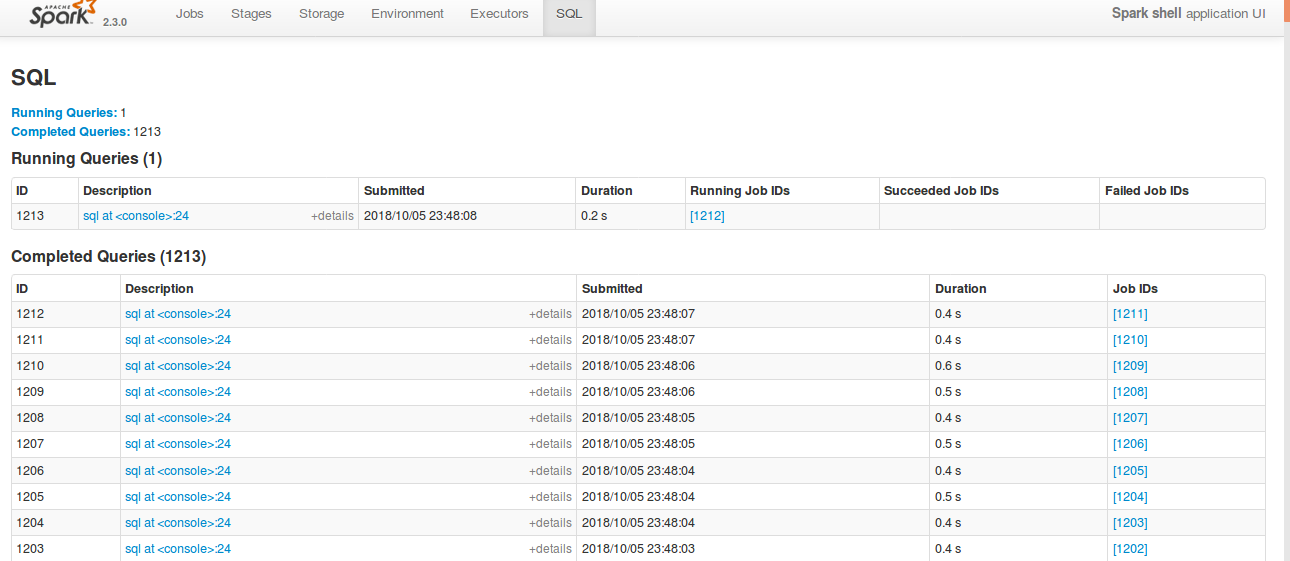
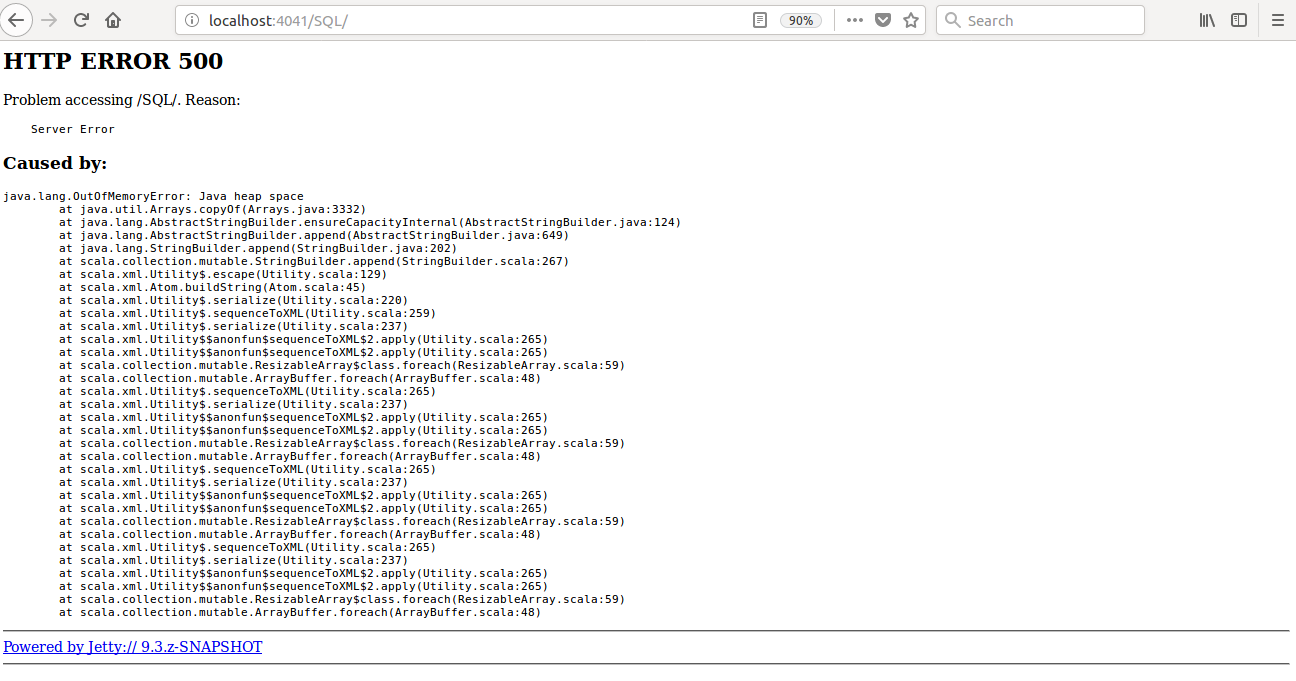
**After this PR**
Loading of the page is faster, and OOM issue doesn't happen.
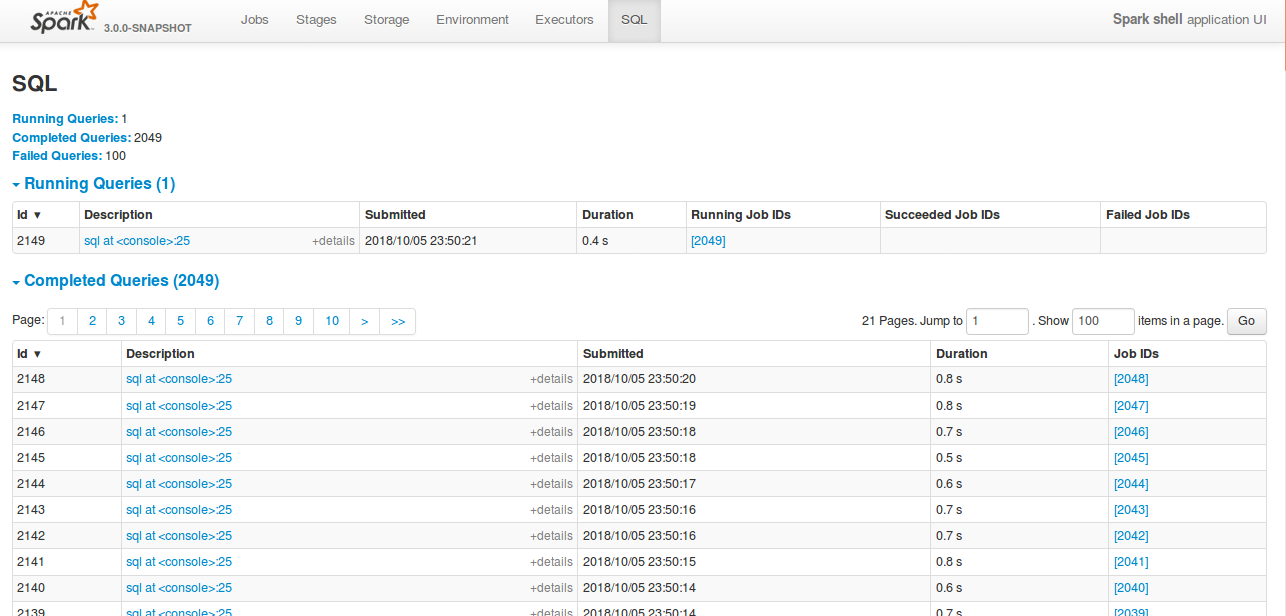
Closes#22645 from shahidki31/SPARK-25566.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove SnappyOutputStreamWrapper and other workaround now that new Snappy fixes these.
See also https://github.com/apache/spark/pull/21176 and comments it links to.
## How was this patch tested?
Existing tests
Closes#22691 from srowen/SPARK-24109.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Cause of the error is wrapped with SparkException, now finding the cause from the wrapped exception and throwing the cause instead of the wrapped exception.
## How was this patch tested?
Verified it manually by checking the cause of the error, it gives the error as shown below.
### Without the PR change
```
[apache-spark]$ ./bin/spark-submit --verbose --master spark://******
....
Error: Exception thrown in awaitResult:
Run with --help for usage help or --verbose for debug output
```
### With the PR change
```
[apache-spark]$ ./bin/spark-submit --verbose --master spark://******
....
Exception in thread "main" org.apache.spark.SparkException: Exception thrown in awaitResult:
at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:226)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:75)
....
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.io.IOException: Failed to connect to devaraj-pc1/10.3.66.65:7077
at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:245)
....
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: io.netty.channel.AbstractChannel$AnnotatedConnectException: Connection refused: devaraj-pc1/10.3.66.65:7077
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
....
at io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:138)
... 1 more
Caused by: java.net.ConnectException: Connection refused
... 11 more
```
Closes#22623 from devaraj-kavali/SPARK-25636.
Authored-by: Devaraj K <devaraj@apache.org>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
The commons-crypto library does some questionable error handling internally,
which can lead to JVM crashes if some call into native code fails and cleans
up state it should not.
While the library is not fixed, this change adds some workarounds in Spark code
so that when an error is detected in the commons-crypto side, Spark avoids
calling into the library further.
Tested with existing and added unit tests.
Closes#22557 from vanzin/SPARK-25535.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
It would be nice to have a field in Stage Page UI which would show mapping of the current stage id to the job id's to which that stage belongs to.
## What changes were proposed in this pull request?
Added a field in Stage UI to display the corresponding job id for that particular stage.
## How was this patch tested?
<img width="448" alt="screen shot 2018-07-25 at 1 33 07 pm" src="https://user-images.githubusercontent.com/22228190/43220447-a8e94f80-900f-11e8-8a20-a235bbd5a369.png">
Closes#21809 from pgandhi999/SPARK-24851.
Authored-by: pgandhi <pgandhi@oath.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
While working on another PR, I noticed that there is quite some legacy Java in there that can be beautified. For example the use of features from Java8, such as:
- Collection libraries
- Try-with-resource blocks
No logic has been changed. I think it is important to have a solid codebase with examples that will inspire next PR's to follow up on the best practices.
What are your thoughts on this?
This makes code easier to read, and using try-with-resource makes is less likely to forget to close something.
## What changes were proposed in this pull request?
No changes in the logic of Spark, but more in the aesthetics of the code.
## How was this patch tested?
Using the existing unit tests. Since no logic is changed, the existing unit tests should pass.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22637 from Fokko/SPARK-25408.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
After the PR, https://github.com/apache/spark/pull/22592, SQL tab supports collapsing table.
However, after refreshing the page, it doesn't store it previous state. This was due to a typo in the argument list in the collapseTablePageLoadCommand().
## How was this patch tested?
bin/spark-shell
```
sql("create table a (id int)")
for(i <- 1 to 100) sql(s"insert into a values ($i)")
```

Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22650 from shahidki31/SPARK-25575-followUp.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
Hi all,
Jackson is incompatible with upstream versions, therefore bump the Jackson version to a more recent one. I bumped into some issues with Azure CosmosDB that is using a more recent version of Jackson. This can be fixed by adding exclusions and then it works without any issues. So no breaking changes in the API's.
I would also consider bumping the version of Jackson in Spark. I would suggest to keep up to date with the dependencies, since in the future this issue will pop up more frequently.
## What changes were proposed in this pull request?
Bump Jackson to 2.9.6
## How was this patch tested?
Compiled and tested it locally to see if anything broke.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#21596 from Fokko/fd-bump-jackson.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
While working on another PR, I noticed that there is quite some legacy Java in there that can be beautified. For example the use og features from Java8, such as:
- Collection libraries
- Try-with-resource blocks
No code has been changed
What are your thoughts on this?
This makes code easier to read, and using try-with-resource makes is less likely to forget to close something.
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22399 from Fokko/SPARK-25408.
Authored-by: Fokko Driesprong <fokkodriesprong@godatadriven.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Cause: Recently test_glr_summary failed for PR of SPARK-25118, which enables
spark-shell to run with default log level. It failed because this logdebug was
called for GeneralizedLinearRegressionTrainingSummary which invoked its toString
method, which started a Spark Job and ended up running into an infinite loop.
Fix: Remove logDebug statement for outer objects as closures aren't implemented
with outerclasses in Scala 2.12 and this debug statement looses its purpose
## How was this patch tested?
Ran python pyspark-ml tests on top of PR for SPARK-25118 and ClosureCleaner unit
tests
Closes#22616 from ankuriitg/ankur/SPARK-25586.
Authored-by: ankurgupta <ankur.gupta@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Rename method `benchmark` in `BenchmarkBase` as `runBenchmarkSuite `. Also add comments.
Currently the method name `benchmark` is a bit confusing. Also the name is the same as instances of `Benchmark`:
f246813afb/sql/hive/src/test/scala/org/apache/spark/sql/hive/orc/OrcReadBenchmark.scala (L330-L339)
## How was this patch tested?
Unit test.
Closes#22599 from gengliangwang/renameBenchmarkSuite.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Currently, SQL tab in the WEBUI doesn't support hiding table. Other tabs in the web ui like, Jobs, stages etc supports hiding table (refer SPARK-23024 https://github.com/apache/spark/pull/20216).
In this PR, added the support for hide table in the sql tab also.
## How was this patch tested?
bin/spark-shell
```
sql("create table a (id int)")
for(i <- 1 to 100) sql(s"insert into a values ($i)")
```
Open SQL tab in the web UI
**Before fix:**
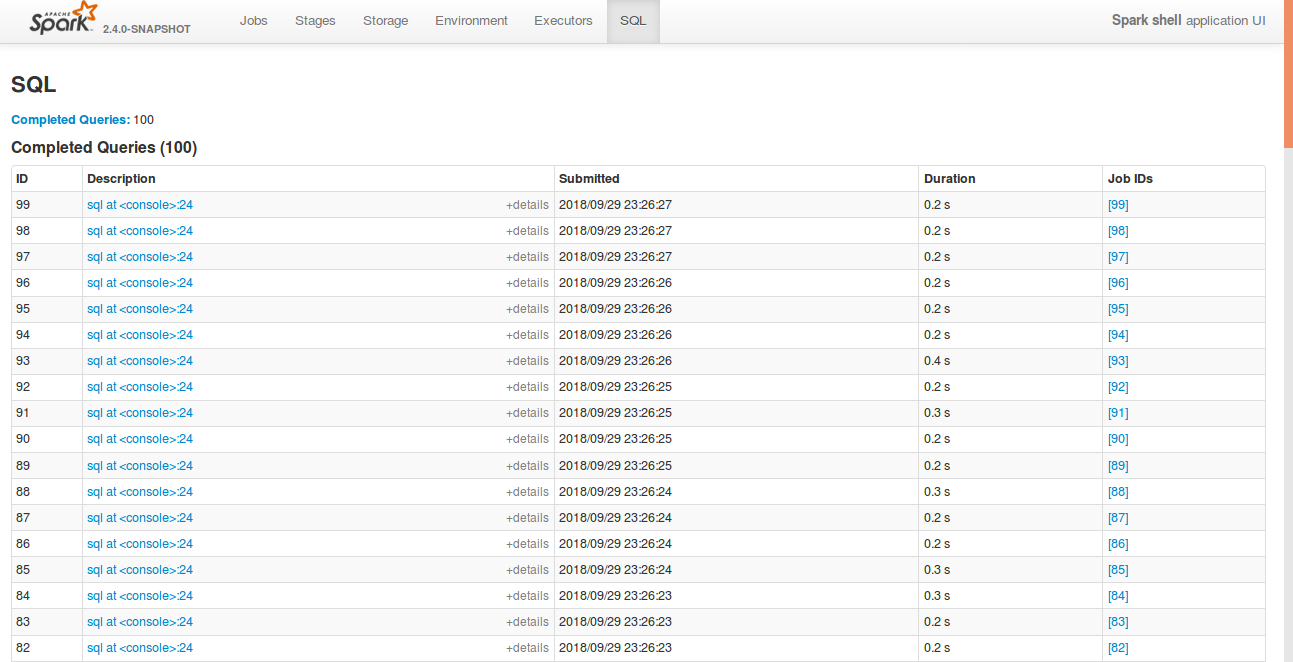
**After fix:** Consistent with the other tabs.

(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22592 from shahidki31/SPARK-25575.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Fix an obvious error.
## How was this patch tested?
Existing tests.
Closes#22577 from sadhen/minor_fix.
Authored-by: Darcy Shen <sadhen@zoho.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR adds a rule to force `.toLowerCase(Locale.ROOT)` or `toUpperCase(Locale.ROOT)`.
It produces an error as below:
```
[error] Are you sure that you want to use toUpperCase or toLowerCase without the root locale? In most cases, you
[error] should use toUpperCase(Locale.ROOT) or toLowerCase(Locale.ROOT) instead.
[error] If you must use toUpperCase or toLowerCase without the root locale, wrap the code block with
[error] // scalastyle:off caselocale
[error] .toUpperCase
[error] .toLowerCase
[error] // scalastyle:on caselocale
```
This PR excludes the cases above for SQL code path for external calls like table name, column name and etc.
For test suites, or when it's clear there's no locale problem like Turkish locale problem, it uses `Locale.ROOT`.
One minor problem is, `UTF8String` has both methods, `toLowerCase` and `toUpperCase`, and the new rule detects them as well. They are ignored.
## How was this patch tested?
Manually tested, and Jenkins tests.
Closes#22581 from HyukjinKwon/SPARK-25565.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Since we don't fail a job when `AccumulatorV2.merge` fails, we should try to update the remaining accumulators so that they can still report correct values.
## How was this patch tested?
The new unit test.
Closes#22586 from zsxwing/SPARK-25568.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Heartbeat shouldn't include accumulators for zero metrics.
Heartbeats sent from executors to the driver every 10 seconds contain metrics and are generally on the order of a few KBs. However, for large jobs with lots of tasks, heartbeats can be on the order of tens of MBs, causing tasks to die with heartbeat failures. We can mitigate this by not sending zero metrics to the driver.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22473 from mukulmurthy/25449-heartbeat.
Authored-by: Mukul Murthy <mukul.murthy@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
The specified test in OpenHashMapSuite to test large items is somehow flaky to throw OOM.
By considering the original work #6763 that added this test, the test can be against OpenHashSetSuite. And by doing this should be to save memory because OpenHashMap allocates two more arrays when growing the map/set.
## How was this patch tested?
Existing tests.
Closes#22569 from viirya/SPARK-25542.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
Caching the value of that config means different instances of SparkEnv
will always use whatever was the first value to be read. It also breaks
tests that use RDDInfo outside of the scope of a SparkContext.
Since this is not a performance sensitive area, there's no advantage
in caching the config value.
Closes#22558 from vanzin/SPARK-25546.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
Special case the situation where we know the partioner and the number of requested partions output is the same as the current partioner to avoid a shuffle and instead compute distinct inside of each partion.
## How was this patch tested?
New unit test that verifies partitioner does not change if the partitioner is known and distinct is called with the same target # of partition.
Closes#22010 from holdenk/SPARK-21436-take-advantage-of-known-partioner-for-distinct-on-rdds.
Authored-by: Holden Karau <holden@pigscanfly.ca>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
changed metric value of METRIC_OUTPUT_RECORDS_WRITTEN from 'task.metrics.inputMetrics.recordsRead' to 'task.metrics.outputMetrics.recordsWritten'.
This bug was introduced in SPARK-22190. https://github.com/apache/spark/pull/19426
## How was this patch tested?
Existing tests
Closes#22555 from shahidki31/SPARK-25536.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
SparkSubmit already logs in the user if a keytab is provided, the only issue is that it uses the existing configs which have "yarn" in their name. As such, the configs were changed to:
`spark.kerberos.keytab` and `spark.kerberos.principal`.
## How was this patch tested?
Will be tested with K8S tests, but needs to be tested with Yarn
- [x] K8S Secure HDFS tests
- [x] Yarn Secure HDFS tests vanzin
Closes#22362 from ifilonenko/SPARK-25372.
Authored-by: Ilan Filonenko <if56@cornell.edu>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Previously SPARK-24519 created a modifiable config SHUFFLE_MIN_NUM_PARTS_TO_HIGHLY_COMPRESS. However, the config is being parsed for every creation of MapStatus, which could be very expensive. Another problem with the previous approach is that it created the illusion that this can be changed dynamically at runtime, which was not true. This PR changes it so the config is computed only once.
## How was this patch tested?
Removed a test case that's no longer valid.
Closes#22521 from rxin/SPARK-24519.
Authored-by: Reynold Xin <rxin@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
SPARK-4105 provided a solution to block corruption issue by retrying the fetch or the stage. In that solution there is a step that wraps the input stream with compression and/or encryption. This step is prone to exceptions, but in the current code there is no exception handling for this step and this has caused confusion for the user. The confusion was that after SPARK-4105 the user expects to see either a fetchFailed exception or a warning about a corrupted block. However an exception during wrapping can fail the job without any of those. This change adds exception handling for the wrapping step and also adds a fetch retry if we experience a corruption during the wrapping step. The reason for adding the retry is that usually user won't experience the same failure after rerunning the job and so it seems reasonable try to fetch and wrap one more time instead of failing.
Closes#22325 from rezasafi/localcorruption.
Authored-by: Reza Safi <rezasafi@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
SHS V2 cannot enabled in Windows, because windows doesn't support POSIX permission.
## How was this patch tested?
test case fails in windows without this fix.
org.apache.spark.deploy.history.HistoryServerDiskManagerSuite test("leasing space")
SHS V2 cannot run successfully in Windows without this fix.
java.lang.UnsupportedOperationException: 'posix:permissions' not supported as initial attribute
at sun.nio.fs.WindowsSecurityDescriptor.fromAttribute(WindowsSecurityDescriptor.java:358)
Closes#22520 from jianjianjiao/FixWindowsPermssionsIssue.
Authored-by: Rong Tang <rotang@microsoft.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
After data has been streamed to disk, the buffers are inserted into the
memory store in some cases (eg., with broadcast blocks). But broadcast
code also disposes of those buffers when the data has been read, to
ensure that we don't leave mapped buffers using up memory, which then
leads to garbage data in the memory store.
## How was this patch tested?
Ran the old failing test in a loop. Full tests on jenkins
Closes#22546 from squito/SPARK-25422-master.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Test steps :
1) bin/spark-shell --conf spark.ui.retainedTasks=200
```
val rdd = sc.parallelize(1 to 1000, 1000)
rdd.count
```
Stage tab in the UI will display 10 pages with 100 tasks per page. But number of retained tasks is only 200. So, from the 3rd page onwards will display nothing.
We have to calculate total pages based on the number of tasks need display in the UI.
**Before fix:**

**After fix:**

## How was this patch tested?
Manually tested
Closes#22526 from shahidki31/SPARK-25502.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Currently there are two classes with the same naming BenchmarkBase:
1. `org.apache.spark.util.BenchmarkBase`
2. `org.apache.spark.sql.execution.benchmark.BenchmarkBase`
This is very confusing. And the benchmark object `org.apache.spark.sql.execution.benchmark.FilterPushdownBenchmark` is using the one in `org.apache.spark.util.BenchmarkBase`, while there is another class `BenchmarkBase` in the same package of it...
Here I propose:
1. the package `org.apache.spark.util.BenchmarkBase` should be in test package of core module. Move it to package `org.apache.spark.benchmark` .
2. Move `org.apache.spark.util.Benchmark` to test package of core module. Move it to package `org.apache.spark.benchmark` .
3. Rename the class `org.apache.spark.sql.execution.benchmark.BenchmarkBase` as `BenchmarkWithCodegen`
## How was this patch tested?
Unit test
Closes#22513 from gengliangwang/refactorBenchmarkBase.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
A continuation of squito's executor plugin task. By his request I took his code and added testing and moved the plugin initialization to a separate thread.
Executor plugins now run on one separate thread, so the executor does not wait on them. Added testing.
## How was this patch tested?
Added test cases that test using a sample plugin.
Closes#22192 from NiharS/executorPlugin.
Lead-authored-by: Nihar Sheth <niharrsheth@gmail.com>
Co-authored-by: NiharS <niharrsheth@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
This PR proposes to use add a helper in `PythonUtils` instead of direct accessing Scala package.
## How was this patch tested?
Jenkins tests.
Closes#22483 from HyukjinKwon/minor-refactoring.
Authored-by: hyukjinkwon <gurwls223@apache.org>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This goes to revert sequential PRs based on some discussion and comments at https://github.com/apache/spark/pull/16677#issuecomment-422650759.
#22344#22330#22239#16677
## How was this patch tested?
Existing tests.
Closes#22481 from viirya/revert-SPARK-19355-1.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Refactor `FilterPushdownBenchmark` use `main` method. we can use 3 ways to run this test now:
1. bin/spark-submit --class org.apache.spark.sql.execution.benchmark.FilterPushdownBenchmark spark-sql_2.11-2.5.0-SNAPSHOT-tests.jar
2. build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.FilterPushdownBenchmark"
3. SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.FilterPushdownBenchmark"
The method 2 and the method 3 do not need to compile the `spark-sql_*-tests.jar` package. So these two methods are mainly for developers to quickly do benchmark.
## How was this patch tested?
manual tests
Closes#22443 from wangyum/SPARK-25339.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
We've seen some flakiness in jenkins in SchedulerIntegrationSuite which looks like it just needs a
longer timeout.
Closes#22385 from squito/SPARK-25400.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR ensures to call `super.afterAll()` in `override afterAll()` method for test suites.
* Some suites did not call `super.afterAll()`
* Some suites may call `super.afterAll()` only under certain condition
* Others never call `super.afterAll()`.
This PR also ensures to call `super.beforeAll()` in `override beforeAll()` for test suites.
## How was this patch tested?
Existing UTs
Closes#22337 from kiszk/SPARK-25338.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
This is a rework of #21433 to address some concerns there.
Closes#22398 from michaelmior/long-callsite2.
Authored-by: Michael Mior <mmior@uwaterloo.ca>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Correct some comparisons between unrelated types to what they seem to… have been trying to do
## How was this patch tested?
Existing tests.
Closes#22384 from srowen/SPARK-25398.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
We will update block info coming from executors, at the timing like caching a RDD. However, when removing RDDs with unpersisting, we don't ask to update block info. So the block info is not updated.
We can fix this with few options:
1. Ask to update block info when unpersisting
This is simplest but changes driver-executor communication a bit.
2. Update block info when processing the event of unpersisting RDD
We send a `SparkListenerUnpersistRDD` event when unpersisting RDD. When processing this event, we can update block info of the RDD. This only changes event processing code so the risk seems to be lower.
Currently this patch takes option 2 for lower risk. If we agree first option has no risk, we can change to it.
## How was this patch tested?
Unit tests.
Closes#22341 from viirya/SPARK-24889.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Stop trimming values of properties loaded from a file
## How was this patch tested?
Added unit test demonstrating the issue hit in production.
Closes#22213 from gerashegalov/gera/SPARK-25221.
Authored-by: Gera Shegalov <gera@apache.org>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
When running TPC-DS benchmarks on 2.4 release, npoggi and winglungngai saw more than 10% performance regression on the following queries: q67, q24a and q24b. After we applying the PR https://github.com/apache/spark/pull/22338, the performance regression still exists. If we revert the changes in https://github.com/apache/spark/pull/19222, npoggi and winglungngai found the performance regression was resolved. Thus, this PR is to revert the related changes for unblocking the 2.4 release.
In the future release, we still can continue the investigation and find out the root cause of the regression.
## How was this patch tested?
The existing test cases
Closes#22361 from gatorsmile/revertMemoryBlock.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Add new executor level memory metrics (JVM used memory, on/off heap execution memory, on/off heap storage memory, on/off heap unified memory, direct memory, and mapped memory), and expose via the executors REST API. This information will help provide insight into how executor and driver JVM memory is used, and for the different memory regions. It can be used to help determine good values for spark.executor.memory, spark.driver.memory, spark.memory.fraction, and spark.memory.storageFraction.
## What changes were proposed in this pull request?
An ExecutorMetrics class is added, with jvmUsedHeapMemory, jvmUsedNonHeapMemory, onHeapExecutionMemory, offHeapExecutionMemory, onHeapStorageMemory, and offHeapStorageMemory, onHeapUnifiedMemory, offHeapUnifiedMemory, directMemory and mappedMemory. The new ExecutorMetrics is sent by executors to the driver as part of the Heartbeat. A heartbeat is added for the driver as well, to collect these metrics for the driver.
The EventLoggingListener store information about the peak values for each metric, per active stage and executor. When a StageCompleted event is seen, a StageExecutorsMetrics event will be logged for each executor, with peak values for the stage.
The AppStatusListener records the peak values for each memory metric.
The new memory metrics are added to the executors REST API.
## How was this patch tested?
New unit tests have been added. This was also tested on our cluster.
Author: Edwina Lu <edlu@linkedin.com>
Author: Imran Rashid <irashid@cloudera.com>
Author: edwinalu <edwina.lu@gmail.com>
Closes#21221 from edwinalu/SPARK-23429.2.
## What changes were proposed in this pull request?
This adds a test following https://github.com/apache/spark/pull/21638
## How was this patch tested?
Existing tests and new test.
Closes#22356 from srowen/SPARK-22357.2.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
This is not a perfect solution. It is designed to minimize complexity on the basis of solving problems.
It is effective for English, Chinese characters, Japanese, Korean and so on.
```scala
before:
+---+---------------------------+-------------+
|id |中国 |s2 |
+---+---------------------------+-------------+
|1 |ab |[a] |
|2 |null |[中国, abc] |
|3 |ab1 |[hello world]|
|4 |か行 きゃ(kya) きゅ(kyu) きょ(kyo) |[“中国] |
|5 |中国(你好)a |[“中(国), 312] |
|6 |中国山(东)服务区 |[“中(国)] |
|7 |中国山东服务区 |[中(国)] |
|8 | |[中国] |
+---+---------------------------+-------------+
after:
+---+-----------------------------------+----------------+
|id |中国 |s2 |
+---+-----------------------------------+----------------+
|1 |ab |[a] |
|2 |null |[中国, abc] |
|3 |ab1 |[hello world] |
|4 |か行 きゃ(kya) きゅ(kyu) きょ(kyo) |[“中国] |
|5 |中国(你好)a |[“中(国), 312]|
|6 |中国山(东)服务区 |[“中(国)] |
|7 |中国山东服务区 |[中(国)] |
|8 | |[中国] |
+---+-----------------------------------+----------------+
```
## What changes were proposed in this pull request?
When there are wide characters such as Chinese characters or Japanese characters in the data, the show method has a alignment problem.
Try to fix this problem.
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)

Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22048 from xuejianbest/master.
Authored-by: xuejianbest <384329882@qq.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Upgrade chill to 0.9.3, Kryo to 4.0.2, to get bug fixes and improvements.
The resolved tickets includes:
- SPARK-25258 Upgrade kryo package to version 4.0.2
- SPARK-23131 Kryo raises StackOverflow during serializing GLR model
- SPARK-25176 Kryo fails to serialize a parametrised type hierarchy
More details:
https://github.com/twitter/chill/releases/tag/v0.9.3cc3910d501
## How was this patch tested?
Existing tests.
Closes#22179 from wangyum/SPARK-23131.
Lead-authored-by: Yuming Wang <yumwang@ebay.com>
Co-authored-by: Dongjoon Hyun <dongjoon@apache.org>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
An alternative fix for https://github.com/apache/spark/pull/21698
When Spark rerun tasks for an RDD, there are 3 different behaviors:
1. determinate. Always return the same result with same order when rerun.
2. unordered. Returns same data set in random order when rerun.
3. indeterminate. Returns different result when rerun.
Normally Spark doesn't need to care about it. Spark runs stages one by one, when a task is failed, just rerun it. Although the rerun task may return a different result, users will not be surprised.
However, Spark may rerun a finished stage when seeing fetch failures. When this happens, Spark needs to rerun all the tasks of all the succeeding stages if the RDD output is indeterminate, because the input of the succeeding stages has been changed.
If the RDD output is determinate, we only need to rerun the failed tasks of the succeeding stages, because the input doesn't change.
If the RDD output is unordered, it's same as determinate, because shuffle partitioner is always deterministic(round-robin partitioner is not a shuffle partitioner that extends `org.apache.spark.Partitioner`), so the reducers will still get the same input data set.
This PR fixed the failure handling for `repartition`, to avoid correctness issues.
For `repartition`, it applies a stateful map function to generate a round-robin id, which is order sensitive and makes the RDD's output indeterminate. When the stage contains `repartition` reruns, we must also rerun all the tasks of all the succeeding stages.
**future improvement:**
1. Currently we can't rollback and rerun a shuffle map stage, and just fail. We should fix it later. https://issues.apache.org/jira/browse/SPARK-25341
2. Currently we can't rollback and rerun a result stage, and just fail. We should fix it later. https://issues.apache.org/jira/browse/SPARK-25342
3. We should provide public API to allow users to tag the random level of the RDD's computing function.
## How is this pull request tested?
a new test case
Closes#22112 from cloud-fan/repartition.
Lead-authored-by: Wenchen Fan <wenchen@databricks.com>
Co-authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
Running a large Spark job with speculation turned on was causing executor heartbeats to time out on the driver end after sometime and eventually, after hitting the max number of executor failures, the job would fail.
## What changes were proposed in this pull request?
The main reason for the heartbeat timeouts was that the heartbeat-receiver-event-loop-thread was blocked waiting on the TaskSchedulerImpl object which was being held by one of the dispatcher-event-loop threads executing the method dequeueSpeculativeTasks() in TaskSetManager.scala. On further analysis of the heartbeat receiver method executorHeartbeatReceived() in TaskSchedulerImpl class, we found out that instead of waiting to acquire the lock on the TaskSchedulerImpl object, we can remove that lock and make the operations to the global variables inside the code block to be atomic. The block of code in that method only uses one global HashMap taskIdToTaskSetManager. Making that map a ConcurrentHashMap, we are ensuring atomicity of operations and speeding up the heartbeat receiver thread operation.
## How was this patch tested?
Screenshots of the thread dump have been attached below:
**heartbeat-receiver-event-loop-thread:**
<img width="1409" alt="screen shot 2018-08-24 at 9 19 57 am" src="https://user-images.githubusercontent.com/22228190/44593413-e25df780-a788-11e8-9520-176a18401a59.png">
**dispatcher-event-loop-thread:**
<img width="1409" alt="screen shot 2018-08-24 at 9 21 56 am" src="https://user-images.githubusercontent.com/22228190/44593484-13d6c300-a789-11e8-8d88-34b1d51d4541.png">
Closes#22221 from pgandhi999/SPARK-25231.
Authored-by: pgandhi <pgandhi@oath.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
The problem occurs because stage object is removed from liveStages in
AppStatusListener onStageCompletion. Because of this any onTaskEnd event
received after onStageCompletion event do not update stage metrics.
The fix is to retain stage objects in liveStages until all tasks are complete.
1. Fixed the reproducible example posted in the JIRA
2. Added unit test
Closes#22209 from ankuriitg/ankurgupta/SPARK-24415.
Authored-by: ankurgupta <ankur.gupta@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Add a new metric to measure the executor's process (JVM) CPU time.
## How was this patch tested?
Manually tested on a Spark cluster (see SPARK-25228 for an example screenshot).
Closes#22218 from LucaCanali/AddExecutrCPUTimeMetric.
Authored-by: LucaCanali <luca.canali@cern.ch>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The configuration parameter "spark.shuffle.service.enabled" has defined in `package.scala`, and it is also used in many place, so we can replace it with `SHUFFLE_SERVICE_ENABLED`.
and unified this configuration parameter "spark.shuffle.service.port" together.
## How was this patch tested?
N/A
Closes#22306 from 10110346/unifiedserviceenable.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
I made one pass over barrier APIs added to Spark 2.4 and updates some scopes and docs. I will update Python docs once Scala doc was reviewed.
One major issue is that `BarrierTaskContext` implements `TaskContextImpl` that exposes some public methods. And internally there were several direct references to `TaskContextImpl` methods instead of `TaskContext`. This PR moved some methods from `TaskContextImpl` to `TaskContext`, remaining package private, and used delegate methods to avoid inheriting `TaskContextImp` and exposing unnecessary APIs.
TODOs:
- [x] scala doc
- [x] python doc (#22261 ).
Closes#22240 from mengxr/SPARK-25248.
Authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
`BytesToBytesMapOnHeapSuite`.`randomizedStressTest` caused `OutOfMemoryError` on several test runs. Seems better to reduce memory usage in this test.
## How was this patch tested?
Unit tests.
Closes#22297 from viirya/SPARK-25290.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
I propose to remove one of `parmap` methods which accepts an execution context as a parameter. The method should be removed to eliminate any deadlocks that can occur if `parmap` is called recursively on thread pools restricted by size.
Closes#22292 from MaxGekk/remove-overloaded-parmap.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Xiao Li <gatorsmile@gmail.com>
Spark scheduler can hang when fetch failures, executor lost, task running on lost executor, and multiple stage attempts. To fix this we change to always unregister the pending partition on task completion.
## What changes were proposed in this pull request?
this PR is actually reverting the change in SPARK-19263, so that it always does shuffleStage.pendingPartitions -= task.partitionId. The change in SPARK-23433, should fix the issue originally from SPARK-19263.
## How was this patch tested?
Unit tests. The condition happens on a race which I haven't reproduced on a real customer, just see it sometimes on customers jobs in a real cluster.
I am also working on adding spark scheduler integration tests.
Closes#21976 from tgravescs/SPARK-24909.
Authored-by: Thomas Graves <tgraves@unharmedunarmed.corp.ne1.yahoo.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
BarrierCoordinator uses Timer and TimerTask. `TimerTask#cancel()` is invoked in ContextBarrierState#cancelTimerTask but `Timer#purge()` is never invoked.
Once a TimerTask is scheduled, the reference to it is not released until `Timer#purge()` is invoked even though `TimerTask#cancel()` is invoked.
## How was this patch tested?
I checked the number of instances related to the TimerTask using jmap.
Closes#22258 from sarutak/fix-barrierexec-oom.
Authored-by: sarutak <sarutak@oss.nttdata.co.jp>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
This changes the calls of `toPandas()` and `createDataFrame()` to use the Arrow stream format, when Arrow is enabled. Previously, Arrow data was written to byte arrays where each chunk is an output of the Arrow file format. This was mainly due to constraints at the time, and caused some overhead by writing the schema/footer on each chunk of data and then having to read multiple Arrow file inputs and concat them together.
Using the Arrow stream format has improved these by increasing performance, lower memory overhead for the average case, and simplified the code. Here are the details of this change:
**toPandas()**
_Before:_
Spark internal rows are converted to Arrow file format, each group of records is a complete Arrow file which contains the schema and other metadata. Next a collect is done and an Array of Arrow files is the result. After that each Arrow file is sent to Python driver which then loads each file and concats them to a single Arrow DataFrame.
_After:_
Spark internal rows are converted to ArrowRecordBatches directly, which is the simplest Arrow component for IPC data transfers. The driver JVM then immediately starts serving data to Python as an Arrow stream, sending the schema first. It then starts a Spark job with a custom handler that sends Arrow RecordBatches to Python. Partitions arriving in order are sent immediately, and out-of-order partitions are buffered until the ones that precede it come in. This improves performance, simplifies memory usage on executors, and improves the average memory usage on the JVM driver. Since the order of partitions must be preserved, the worst case is that the first partition will be the last to arrive all data must be buffered in memory until then. This case is no worse that before when doing a full collect.
**createDataFrame()**
_Before:_
A Pandas DataFrame is split into parts and each part is made into an Arrow file. Then each file is prefixed by the buffer size and written to a temp file. The temp file is read and each Arrow file is parallelized as a byte array.
_After:_
A Pandas DataFrame is split into parts, then an Arrow stream is written to a temp file where each part is an ArrowRecordBatch. The temp file is read as a stream and the Arrow messages are examined. If the message is an ArrowRecordBatch, the data is saved as a byte array. After reading the file, each ArrowRecordBatch is parallelized as a byte array. This has slightly more processing than before because we must look each Arrow message to extract the record batches, but performance ends up a litle better. It is cleaner in the sense that IPC from Python to JVM is done over a single Arrow stream.
## How was this patch tested?
Added new unit tests for the additions to ArrowConverters in Scala, existing tests for Python.
## Performance Tests - toPandas
Tests run on a 4 node standalone cluster with 32 cores total, 14.04.1-Ubuntu and OpenJDK 8
measured wall clock time to execute `toPandas()` and took the average best time of 5 runs/5 loops each.
Test code
```python
df = spark.range(1 << 25, numPartitions=32).toDF("id").withColumn("x1", rand()).withColumn("x2", rand()).withColumn("x3", rand()).withColumn("x4", rand())
for i in range(5):
start = time.time()
_ = df.toPandas()
elapsed = time.time() - start
```
Current Master | This PR
---------------------|------------
5.803557 | 5.16207
5.409119 | 5.133671
5.493509 | 5.147513
5.433107 | 5.105243
5.488757 | 5.018685
Avg Master | Avg This PR
------------------|--------------
5.5256098 | 5.1134364
Speedup of **1.08060595**
## Performance Tests - createDataFrame
Tests run on a 4 node standalone cluster with 32 cores total, 14.04.1-Ubuntu and OpenJDK 8
measured wall clock time to execute `createDataFrame()` and get the first record. Took the average best time of 5 runs/5 loops each.
Test code
```python
def run():
pdf = pd.DataFrame(np.random.rand(10000000, 10))
spark.createDataFrame(pdf).first()
for i in range(6):
start = time.time()
run()
elapsed = time.time() - start
gc.collect()
print("Run %d: %f" % (i, elapsed))
```
Current Master | This PR
--------------------|----------
6.234608 | 5.665641
6.32144 | 5.3475
6.527859 | 5.370803
6.95089 | 5.479151
6.235046 | 5.529167
Avg Master | Avg This PR
---------------|----------------
6.4539686 | 5.4784524
Speedup of **1.178064192**
## Memory Improvements
**toPandas()**
The most significant improvement is reduction of the upper bound space complexity in the JVM driver. Before, the entire dataset was collected in the JVM first before sending it to Python. With this change, as soon as a partition is collected, the result handler immediately sends it to Python, so the upper bound is the size of the largest partition. Also, using the Arrow stream format is more efficient because the schema is written once per stream, followed by record batches. The schema is now only send from driver JVM to Python. Before, multiple Arrow file formats were used that each contained the schema. This duplicated schema was created in the executors, sent to the driver JVM, and then Python where all but the first one received are discarded.
I verified the upper bound limit by running a test that would collect data that would exceed the amount of driver JVM memory available. Using these settings on a standalone cluster:
```
spark.driver.memory 1g
spark.executor.memory 5g
spark.sql.execution.arrow.enabled true
spark.sql.execution.arrow.fallback.enabled false
spark.sql.execution.arrow.maxRecordsPerBatch 0
spark.driver.maxResultSize 2g
```
Test code:
```python
from pyspark.sql.functions import rand
df = spark.range(1 << 25, numPartitions=32).toDF("id").withColumn("x1", rand()).withColumn("x2", rand()).withColumn("x3", rand())
df.toPandas()
```
This makes total data size of 33554432×8×4 = 1073741824
With the current master, it fails with OOM but passes using this PR.
**createDataFrame()**
No significant change in memory except that using the stream format instead of separate file formats avoids duplicated the schema, similar to toPandas above. The process of reading the stream and parallelizing the batches does cause the record batch message metadata to be copied, but it's size is insignificant.
Closes#21546 from BryanCutler/arrow-toPandas-stream-SPARK-23030.
Authored-by: Bryan Cutler <cutlerb@gmail.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
This eliminates some duplication in the code to connect to a server on localhost to talk directly to the jvm. Also it gives consistent ipv6 and error handling. Two other incidental changes, that shouldn't matter:
1) python barrier tasks perform authentication immediately (rather than waiting for the BARRIER_FUNCTION indicator)
2) for `rdd._load_from_socket`, the timeout is only increased after authentication.
Closes#22247 from squito/py_connection_refactor.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Fix the issue that minPartitions was not used in the method. This is a simple fix and I am not trying to make it complicated. The purpose is to still allow user to control the defaultParallelism through the value of minPartitions, while also via sc.defaultParallelism parameters.
## How was this patch tested?
I have not provided the additional test since the fix is very straightforward.
Closes#21638 from bomeng/22357.
Lead-authored-by: Bo Meng <mengbo@hotmail.com>
Co-authored-by: Bo Meng <bo.meng@jd.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This adds `spark.executor.pyspark.memory` to configure Python's address space limit, [`resource.RLIMIT_AS`](https://docs.python.org/3/library/resource.html#resource.RLIMIT_AS). Limiting Python's address space allows Python to participate in memory management. In practice, we see fewer cases of Python taking too much memory because it doesn't know to run garbage collection. This results in YARN killing fewer containers. This also improves error messages so users know that Python is consuming too much memory:
```
File "build/bdist.linux-x86_64/egg/package/library.py", line 265, in fe_engineer
fe_eval_rec.update(f(src_rec_prep, mat_rec_prep))
File "build/bdist.linux-x86_64/egg/package/library.py", line 163, in fe_comp
comparisons = EvaluationUtils.leven_list_compare(src_rec_prep.get(item, []), mat_rec_prep.get(item, []))
File "build/bdist.linux-x86_64/egg/package/evaluationutils.py", line 25, in leven_list_compare
permutations = sorted(permutations, reverse=True)
MemoryError
```
The new pyspark memory setting is used to increase requested YARN container memory, instead of sharing overhead memory between python and off-heap JVM activity.
## How was this patch tested?
Tested memory limits in our YARN cluster and verified that MemoryError is thrown.
Author: Ryan Blue <blue@apache.org>
Closes#21977 from rdblue/SPARK-25004-add-python-memory-limit.
## What changes were proposed in this pull request?
Make sure TransportServer and SocketAuthHelper close the resources for all types of errors.
## How was this patch tested?
Jenkins
Closes#22210 from zsxwing/SPARK-25218.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
This PR adds a unit test for OpenHashMap , this can help developers to distinguish between the 0/0.0/0L and null
## How was this patch tested?
Closes#22241 from 10110346/openhashmap.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
[SPARK-25095](ad45299d04) introduced `ambiguous reference to overloaded definition`
```
[error] /Users/d_tsai/dev/apache-spark/core/src/main/scala/org/apache/spark/api/python/PythonRunner.scala:242: ambiguous reference to overloaded definition,
[error] both method addTaskCompletionListener in class TaskContext of type [U](f: org.apache.spark.TaskContext => U)org.apache.spark.TaskContext
[error] and method addTaskCompletionListener in class TaskContext of type (listener: org.apache.spark.util.TaskCompletionListener)org.apache.spark.TaskContext
[error] match argument types (org.apache.spark.TaskContext => Unit)
[error] context.addTaskCompletionListener(_ => server.close())
[error] ^
[error] one error found
[error] Compile failed at Aug 24, 2018 1:56:06 PM [31.582s]
```
which fails the Scala 2.12 branch build.
## How was this patch tested?
Existing tests
Closes#22229 from dbtsai/fix-2.12-build.
Authored-by: DB Tsai <d_tsai@apple.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
`ExternalAppendOnlyMapSuiteCheck` test is flaky.
We use a `SparkListener` to collect spill metrics of completed stages. `withListener` runs the code that does spill. Spill status was checked after the code finishes but it was still in `withListener`. At that time it was possibly not all events to the listener bus are processed.
We should check spill status after all events are processed.
## How was this patch tested?
Locally ran unit tests.
Closes#22181 from viirya/SPARK-25163.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
Limit Thread Pool size in BlockManager Master and Slave endpoints.
Currently, BlockManagerMasterEndpoint and BlockManagerSlaveEndpoint both have thread pools with nearly unbounded (Integer.MAX_VALUE) numbers of threads. In certain cases, this can lead to driver OOM errors. This change limits the thread pools to 100 threads; this should not break any existing behavior because any tasks beyond that number will get queued.
## How was this patch tested?
Manual testing
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#22176 from mukulmurthy/25181-threads.
Authored-by: Mukul Murthy <mukul.murthy@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
The PR moves the compilation of the regexp for code formatting outside the method which is called for each code block when splitting expressions, in order to avoid recompiling the regexp every time.
Credit should be given to Izek Greenfield.
## How was this patch tested?
existing UTs
Closes#22135 from mgaido91/SPARK-25093.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Add method `barrier()` and `getTaskInfos()` in python TaskContext, these two methods are only allowed for barrier tasks.
## How was this patch tested?
Add new tests in `tests.py`
Closes#22085 from jiangxb1987/python.barrier.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
When replicating large cached RDD blocks, it can be helpful to replicate
them as a stream, to avoid using large amounts of memory during the
transfer. This also allows blocks larger than 2GB to be replicated.
Added unit tests in DistributedSuite. Also ran tests on a cluster for
blocks > 2gb.
Closes#21451 from squito/clean_replication.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Fix several bugs in failure handling of barrier execution mode:
* Mark TaskSet for a barrier stage as zombie when a task attempt fails;
* Multiple barrier task failures from a single barrier stage should not trigger multiple stage retries;
* Barrier task failure from a previous failed stage attempt should not trigger stage retry;
* Fail the job when a task from a barrier ResultStage failed;
* RDD.isBarrier() should not rely on `ShuffleDependency`s.
## How was this patch tested?
Added corresponding test cases in `DAGSchedulerSuite` and `TaskSchedulerImplSuite`.
Closes#22158 from jiangxb1987/failure.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
Introducing R Bindings for Spark R on K8s
- [x] Running SparkR Job
## How was this patch tested?
This patch was tested with
- [x] Unit Tests
- [x] Integration Tests
## Example:
Commands to run example spark job:
1. `dev/make-distribution.sh --pip --r --tgz -Psparkr -Phadoop-2.7 -Pkubernetes`
2. `bin/docker-image-tool.sh -m -t testing build`
3.
```
bin/spark-submit \
--master k8s://https://192.168.64.33:8443 \
--deploy-mode cluster \
--name spark-r \
--conf spark.executor.instances=1 \
--conf spark.kubernetes.container.image=spark-r:testing \
local:///opt/spark/examples/src/main/r/dataframe.R
```
This above spark-submit command works given the distribution. (Will include this integration test in PR once PRB is ready).
Author: Ilan Filonenko <if56@cornell.edu>
Closes#21584 from ifilonenko/spark-r.
## What changes were proposed in this pull request?
We shall check whether the barrier stage requires more slots (to be able to launch all tasks in the barrier stage together) than the total number of active slots currently, and fail fast if trying to submit a barrier stage that requires more slots than current total number.
This PR proposes to add a new method `getNumSlots()` to try to get the total number of currently active slots in `SchedulerBackend`, support of this new method has been added to all the first-class scheduler backends except `MesosFineGrainedSchedulerBackend`.
## How was this patch tested?
Added new test cases in `BarrierStageOnSubmittedSuite`.
Closes#22001 from jiangxb1987/SPARK-24819.
Lead-authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Co-authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
(a) disabled rest submission server by default in standalone mode
(b) fails the standalone master if rest server enabled & authentication secret set
(c) fails the mesos cluster dispatcher if authentication secret set
(d) doc updates
(e) when submitting a standalone app, only try the rest submission first if spark.master.rest.enabled=true
otherwise you'd see a 10 second pause like
18/08/09 08:13:22 INFO RestSubmissionClient: Submitting a request to launch an application in spark://...
18/08/09 08:13:33 WARN RestSubmissionClient: Unable to connect to server spark://...
I also made sure the mesos cluster dispatcher failed with the secret enabled, though I had to do that on slightly different code as I don't have mesos native libs around.
## How was this patch tested?
I ran the tests in the mesos module & in core for org.apache.spark.deploy.*
I ran a test on a cluster with standalone master to make sure I could still start with the right configs, and would fail the right way too.
Closes#22071 from squito/rest_doc_updates.
Authored-by: Imran Rashid <irashid@cloudera.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR solves [SPARK-22713](https://issues.apache.org/jira/browse/SPARK-22713) which describes a memory leak that occurs when and ExternalAppendOnlyMap is spilled during iteration (opposed to insertion).
(Please fill in changes proposed in this fix)
ExternalAppendOnlyMap's iterator supports spilling but it kept a reference to the internal map (via an internal iterator) after spilling, it seems that the original code was actually supposed to 'get rid' of this reference on the next iteration but according to the elaborate investigation described in the JIRA this didn't happen.
the fix was simply replacing the internal iterator immediately after spilling.
## How was this patch tested?
I've introduced a new test to test suite ExternalAppendOnlyMapSuite, this test asserts that neither the external map itself nor its iterator hold any reference to the internal map after a spill.
These approach required some access relaxation of some members variables and nested classes of ExternalAppendOnlyMap, this members are now package provate and annotated with VisibleForTesting.
Closes#21369 from eyalfa/SPARK-22713__ExternalAppendOnlyMap_effective_spill.
Authored-by: Eyal Farago <eyal@nrgene.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Use ASM 6 APIs after we upgrading it to ASM6.
## How was this patch tested?
N/A
Closes#22082 from gatorsmile/asm6.
Authored-by: Xiao Li <gatorsmile@gmail.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
The class of UnsafeExternalSorter used UnsafeAlignedOffset to make the entire record of 8 byte Items aligned, but ShuffleExternalSorter not.
The SPARC platform requires this because using a 4 byte Int for record lengths causes the entire record of 8 byte Items to become misaligned by 4 bytes. Using a 8 byte long for record length keeps things 8 byte aligned.
## How was this patch tested?
Existing Test.
Closes#22053 from eatoncys/UnsafeAlignedOffset.
Authored-by: 10129659 <chen.yanshan@zte.com.cn>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Fixing typos is sometimes very hard. It's not so easy to visually review them. Recently, I discovered a very useful tool for it, [misspell](https://github.com/client9/misspell).
This pull request fixes minor typos detected by [misspell](https://github.com/client9/misspell) except for the false positives. If you would like me to work on other files as well, let me know.
## How was this patch tested?
### before
```
$ misspell . | grep -v '.js'
R/pkg/R/SQLContext.R:354:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:424:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:445:43: "definiton" is a misspelling of "definition"
R/pkg/R/SQLContext.R:495:43: "definiton" is a misspelling of "definition"
NOTICE-binary:454:16: "containd" is a misspelling of "contained"
R/pkg/R/context.R:46:43: "definiton" is a misspelling of "definition"
R/pkg/R/context.R:74:43: "definiton" is a misspelling of "definition"
R/pkg/R/DataFrame.R:591:48: "persistance" is a misspelling of "persistence"
R/pkg/R/streaming.R:166:44: "occured" is a misspelling of "occurred"
R/pkg/inst/worker/worker.R:65:22: "ouput" is a misspelling of "output"
R/pkg/tests/fulltests/test_utils.R:106:25: "environemnt" is a misspelling of "environment"
common/kvstore/src/test/java/org/apache/spark/util/kvstore/InMemoryStoreSuite.java:38:39: "existant" is a misspelling of "existent"
common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java:83:39: "existant" is a misspelling of "existent"
common/network-common/src/main/java/org/apache/spark/network/crypto/TransportCipher.java:243:46: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:234:19: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:238:63: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:244:46: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:276:39: "transfered" is a misspelling of "transferred"
common/network-common/src/main/java/org/apache/spark/network/util/AbstractFileRegion.java:27:20: "transfered" is a misspelling of "transferred"
common/unsafe/src/test/scala/org/apache/spark/unsafe/types/UTF8StringPropertyCheckSuite.scala:195:15: "orgin" is a misspelling of "origin"
core/src/main/scala/org/apache/spark/api/python/PythonRDD.scala:621:39: "gauranteed" is a misspelling of "guaranteed"
core/src/main/scala/org/apache/spark/status/storeTypes.scala:113:29: "ect" is a misspelling of "etc"
core/src/main/scala/org/apache/spark/storage/DiskStore.scala:282:18: "transfered" is a misspelling of "transferred"
core/src/main/scala/org/apache/spark/util/ListenerBus.scala:64:17: "overriden" is a misspelling of "overridden"
core/src/test/scala/org/apache/spark/ShuffleSuite.scala:211:7: "substracted" is a misspelling of "subtracted"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:1922:49: "agriculteur" is a misspelling of "agriculture"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:2468:84: "truely" is a misspelling of "truly"
core/src/test/scala/org/apache/spark/storage/FlatmapIteratorSuite.scala:25:18: "persistance" is a misspelling of "persistence"
core/src/test/scala/org/apache/spark/storage/FlatmapIteratorSuite.scala:26:69: "persistance" is a misspelling of "persistence"
data/streaming/AFINN-111.txt:1219:0: "humerous" is a misspelling of "humorous"
dev/run-pip-tests:55:28: "enviroments" is a misspelling of "environments"
dev/run-pip-tests:91:37: "virutal" is a misspelling of "virtual"
dev/merge_spark_pr.py:377:72: "accross" is a misspelling of "across"
dev/merge_spark_pr.py:378:66: "accross" is a misspelling of "across"
dev/run-pip-tests:126:25: "enviroments" is a misspelling of "environments"
docs/configuration.md:1830:82: "overriden" is a misspelling of "overridden"
docs/structured-streaming-programming-guide.md:525:45: "processs" is a misspelling of "processes"
docs/structured-streaming-programming-guide.md:1165:61: "BETWEN" is a misspelling of "BETWEEN"
docs/sql-programming-guide.md:1891:810: "behaivor" is a misspelling of "behavior"
examples/src/main/python/sql/arrow.py:98:8: "substract" is a misspelling of "subtract"
examples/src/main/python/sql/arrow.py:103:27: "substract" is a misspelling of "subtract"
licenses/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/hungarian.txt:170:0: "teh" is a misspelling of "the"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/portuguese.txt:53:0: "eles" is a misspelling of "eels"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:99:20: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:539:11: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/mllib/clustering/LDAOptimizer.scala:77:36: "Teh" is a misspelling of "The"
mllib/src/main/scala/org/apache/spark/mllib/clustering/StreamingKMeans.scala:230:24: "inital" is a misspelling of "initial"
mllib/src/main/scala/org/apache/spark/mllib/stat/MultivariateOnlineSummarizer.scala:276:9: "Euclidian" is a misspelling of "Euclidean"
mllib/src/test/scala/org/apache/spark/ml/clustering/KMeansSuite.scala:237:26: "descripiton" is a misspelling of "descriptions"
python/pyspark/find_spark_home.py:30:13: "enviroment" is a misspelling of "environment"
python/pyspark/context.py:937:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:938:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:939:12: "supress" is a misspelling of "suppress"
python/pyspark/context.py:940:12: "supress" is a misspelling of "suppress"
python/pyspark/heapq3.py:6:63: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:7:2: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:263:29: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:263:39: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:270:49: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:270:59: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:275:2: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:275:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:277:29: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:277:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:713:8: "probabilty" is a misspelling of "probability"
python/pyspark/ml/clustering.py:1038:8: "Currenlty" is a misspelling of "Currently"
python/pyspark/ml/stat.py:339:23: "Euclidian" is a misspelling of "Euclidean"
python/pyspark/ml/regression.py:1378:20: "paramter" is a misspelling of "parameter"
python/pyspark/mllib/stat/_statistics.py:262:8: "probabilty" is a misspelling of "probability"
python/pyspark/rdd.py:1363:32: "paramter" is a misspelling of "parameter"
python/pyspark/streaming/tests.py:825:42: "retuns" is a misspelling of "returns"
python/pyspark/sql/tests.py:768:29: "initalization" is a misspelling of "initialization"
python/pyspark/sql/tests.py:3616:31: "initalize" is a misspelling of "initialize"
resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosSchedulerBackendUtil.scala:120:39: "arbitary" is a misspelling of "arbitrary"
resource-managers/mesos/src/test/scala/org/apache/spark/deploy/mesos/MesosClusterDispatcherArgumentsSuite.scala:26:45: "sucessfully" is a misspelling of "successfully"
resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosSchedulerUtils.scala:358:27: "constaints" is a misspelling of "constraints"
resource-managers/yarn/src/test/scala/org/apache/spark/deploy/yarn/YarnClusterSuite.scala:111:24: "senstive" is a misspelling of "sensitive"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala:1063:5: "overwirte" is a misspelling of "overwrite"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala:1348:17: "compatability" is a misspelling of "compatibility"
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala:77:36: "paramter" is a misspelling of "parameter"
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:1374:22: "precendence" is a misspelling of "precedence"
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/AnalysisSuite.scala:238:27: "unnecassary" is a misspelling of "unnecessary"
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ConditionalExpressionSuite.scala:212:17: "whn" is a misspelling of "when"
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/StreamingSymmetricHashJoinHelper.scala:147:60: "timestmap" is a misspelling of "timestamp"
sql/core/src/test/scala/org/apache/spark/sql/TPCDSQuerySuite.scala:150:45: "precentage" is a misspelling of "percentage"
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVInferSchemaSuite.scala:135:29: "infered" is a misspelling of "inferred"
sql/hive/src/test/resources/golden/udf_instr-1-2e76f819563dbaba4beb51e3a130b922:1:52: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_instr-2-32da357fc754badd6e3898dcc8989182:1:52: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_locate-1-6e41693c9c6dceea4d7fab4c02884e4e:1:63: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_locate-2-d9b5934457931447874d6bb7c13de478:1:63: "occurance" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_translate-2-f7aa38a33ca0df73b7a1e6b6da4b7fe8:9:79: "occurence" is a misspelling of "occurrence"
sql/hive/src/test/resources/golden/udf_translate-2-f7aa38a33ca0df73b7a1e6b6da4b7fe8:13:110: "occurence" is a misspelling of "occurrence"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/annotate_stats_join.q:46:105: "distint" is a misspelling of "distinct"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/auto_sortmerge_join_11.q:29:3: "Currenly" is a misspelling of "Currently"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/avro_partitioned.q:72:15: "existant" is a misspelling of "existent"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/decimal_udf.q:25:3: "substraction" is a misspelling of "subtraction"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/groupby2_map_multi_distinct.q:16:51: "funtion" is a misspelling of "function"
sql/hive/src/test/resources/ql/src/test/queries/clientpositive/groupby_sort_8.q:15:30: "issueing" is a misspelling of "issuing"
sql/hive/src/test/scala/org/apache/spark/sql/sources/HadoopFsRelationTest.scala:669:52: "wiht" is a misspelling of "with"
sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java:474:9: "Refering" is a misspelling of "Referring"
```
### after
```
$ misspell . | grep -v '.js'
common/network-common/src/main/java/org/apache/spark/network/util/AbstractFileRegion.java:27:20: "transfered" is a misspelling of "transferred"
core/src/main/scala/org/apache/spark/status/storeTypes.scala:113:29: "ect" is a misspelling of "etc"
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala:1922:49: "agriculteur" is a misspelling of "agriculture"
data/streaming/AFINN-111.txt:1219:0: "humerous" is a misspelling of "humorous"
licenses/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:5:63: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:6:2: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:262:29: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:262:39: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:269:49: "Stichting" is a misspelling of "Stitching"
licenses-binary/LICENSE-heapq.txt:269:59: "Mathematisch" is a misspelling of "Mathematics"
licenses-binary/LICENSE-heapq.txt:274:2: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:274:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
licenses-binary/LICENSE-heapq.txt:276:29: "STICHTING" is a misspelling of "STITCHING"
licenses-binary/LICENSE-heapq.txt:276:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/hungarian.txt:170:0: "teh" is a misspelling of "the"
mllib/src/main/resources/org/apache/spark/ml/feature/stopwords/portuguese.txt:53:0: "eles" is a misspelling of "eels"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:99:20: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/ml/stat/Summarizer.scala:539:11: "Euclidian" is a misspelling of "Euclidean"
mllib/src/main/scala/org/apache/spark/mllib/clustering/LDAOptimizer.scala:77:36: "Teh" is a misspelling of "The"
mllib/src/main/scala/org/apache/spark/mllib/stat/MultivariateOnlineSummarizer.scala:276:9: "Euclidian" is a misspelling of "Euclidean"
python/pyspark/heapq3.py:6:63: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:7:2: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:263:29: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:263:39: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:270:49: "Stichting" is a misspelling of "Stitching"
python/pyspark/heapq3.py:270:59: "Mathematisch" is a misspelling of "Mathematics"
python/pyspark/heapq3.py:275:2: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:275:12: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/heapq3.py:277:29: "STICHTING" is a misspelling of "STITCHING"
python/pyspark/heapq3.py:277:39: "MATHEMATISCH" is a misspelling of "MATHEMATICS"
python/pyspark/ml/stat.py:339:23: "Euclidian" is a misspelling of "Euclidean"
```
Closes#22070 from seratch/fix-typo.
Authored-by: Kazuhiro Sera <seratch@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
## What changes were proposed in this pull request?
This PR add python support for barrier execution mode, thus enable launch a job containing barrier stage(s) from PySpark.
We just forked the existing `RDDBarrier` and `RDD.barrier()` in Python api.
## How was this patch tested?
Manually tested:
```
>>> rdd = sc.parallelize([1, 2, 3, 4])
>>> def f(iterator): yield sum(iterator)
...
>>> rdd.barrier().mapPartitions(f).isBarrier() == True
True
```
Unit tests will be added in a follow-up PR that implements BarrierTaskContext on python side.
Closes#22011 from jiangxb1987/python.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This issue is pretty similar to [SPARK-21907](https://issues.apache.org/jira/browse/SPARK-21907).
"allocateArray" in [ShuffleInMemorySorter.reset](9b8521e53e/core/src/main/java/org/apache/spark/shuffle/sort/ShuffleInMemorySorter.java (L99)) may trigger a spill and cause ShuffleInMemorySorter access the released `array`. Another task may get the same memory page from the pool. This will cause two tasks access the same memory page. When a task reads memory written by another task, many types of failures may happen. Here are some examples I have seen:
- JVM crash. (This is easy to reproduce in a unit test as we fill newly allocated and deallocated memory with 0xa5 and 0x5a bytes which usually points to an invalid memory address)
- java.lang.IllegalArgumentException: Comparison method violates its general contract!
- java.lang.NullPointerException at org.apache.spark.memory.TaskMemoryManager.getPage(TaskMemoryManager.java:384)
- java.lang.UnsupportedOperationException: Cannot grow BufferHolder by size -536870912 because the size after growing exceeds size limitation 2147483632
This PR resets states in `ShuffleInMemorySorter.reset` before calling `allocateArray` to fix the issue.
## How was this patch tested?
The new unit test will make JVM crash without the fix.
Closes#22062 from zsxwing/SPARK-25081.
Authored-by: Shixiong Zhu <zsxwing@gmail.com>
Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request?
A logical `Limit` is performed physically by two operations `LocalLimit` and `GlobalLimit`.
Most of time, we gather all data into a single partition in order to run `GlobalLimit`. If we use a very big limit number, shuffling data causes performance issue also reduces parallelism.
We can avoid shuffling into single partition if we don't care data ordering. This patch implements this idea by doing a map stage during global limit. It collects the info of row numbers at each partition. For each partition, we locally retrieves limited data without any shuffling to finish this global limit.
For example, we have three partitions with rows (100, 100, 50) respectively. In global limit of 100 rows, we may take (34, 33, 33) rows for each partition locally. After global limit we still have three partitions.
If the data partition has certain ordering, we can't distribute required rows evenly to each partitions because it could change data ordering. But we still can avoid shuffling.
## How was this patch tested?
Jenkins tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes#16677 from viirya/improve-global-limit-parallelism.
## What changes were proposed in this pull request?
This PR fixes typo regarding `auxiliary verb + verb[s]`. This is a follow-on of #21956.
## How was this patch tested?
N/A
Closes#22040 from kiszk/spellcheck1.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Signature of the function passed to `RDDBarrier.mapPartitions()` is different from that of `RDD.mapPartitions`. The later doesn’t take a `TaskContext`. We shall make the function signature the same to avoid confusion and misusage.
This PR proposes the following API changes:
- In `RDDBarrier`, migrate `mapPartitions` from
```
def mapPartitions[S: ClassTag](
f: (Iterator[T], BarrierTaskContext) => Iterator[S],
preservesPartitioning: Boolean = false): RDD[S]
}
```
to
```
def mapPartitions[S: ClassTag](
f: Iterator[T] => Iterator[S],
preservesPartitioning: Boolean = false): RDD[S]
}
```
- Add new static method to get a `BarrierTaskContext`:
```
object BarrierTaskContext {
def get(): BarrierTaskContext
}
```
## How was this patch tested?
Existing test cases.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#22026 from jiangxb1987/mapPartitions.
## What changes were proposed in this pull request?
Fixes for test issues that arose after Scala 2.12 support was added -- ones that only affect the 2.12 build.
## How was this patch tested?
Existing tests.
Closes#22004 from srowen/SPARK-25029.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
## What changes were proposed in this pull request?
In the PR, I propose to replace Scala parallel collections by new methods `parmap()`. The methods use futures to transform a sequential collection by applying a lambda function to each element in parallel. The result of `parmap` is another regular (sequential) collection.
The proposed `parmap` method aims to solve the problem of impossibility to interrupt parallel Scala collection. This possibility is needed for reliable task preemption.
## How was this patch tested?
A test was added to `ThreadUtilsSuite`
Closes#21913 from MaxGekk/par-map.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Implement BarrierTaskContext.barrier(), to support global sync between all the tasks in a barrier stage.
The function set a global barrier and waits until all tasks in this stage hit this barrier. Similar to MPI_Barrier function in MPI, the barrier() function call blocks until all tasks in the same stage have reached this routine. The global sync shall finish immediately once all tasks in the same barrier stage reaches the same barrier.
This PR implements BarrierTaskContext.barrier() based on netty-based RPC client, introduces new `BarrierCoordinator` and new `BarrierCoordinatorMessage`, and new config to handle timeout issue.
## How was this patch tested?
Add `BarrierTaskContextSuite` to test `BarrierTaskContext.barrier()`
Closes#21898 from jiangxb1987/taskcontext.barrier.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Fix a grammatical error in the comment of SortShuffleManager.
## How was this patch tested?
N/A
Closes#21956 from deshanxiao/master.
Authored-by: deshanxiao <42019462+deshanxiao@users.noreply.github.com>
Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In `SparkHadoopUtil. checkAccessPermission`, we consider only basic permissions in order to check wether a user can access a file or not. This is not a complete check, as it ignores ACLs and other policies a file system may apply in its internal. So this can result in returning wrongly that a user cannot access a file (despite he actually can).
The PR proposes to delegate to the filesystem the check whether a file is accessible or not, in order to return the right result. A caching layer is added for performance reasons.
## How was this patch tested?
modified UTs
Author: Marco Gaido <marcogaido91@gmail.com>
Closes#21895 from mgaido91/SPARK-24948.
**Description: [SPARK-24992](https://issues.apache.org/jira/browse/SPARK-24992)**
Utils.getLocalDir is used to get path of a temporary directory. However, it always returns the the same directory, which is the first element in the array localRootDirs. When running on YARN, this might causes the case that we always write to one disk, which makes it busy while other disks are free. We should randomize the selection to spread out the loads.
**What changes were proposed in this pull request?**
This PR randomized the selection of local directory inside the method Utils.getLocalDir. This change affects the Utils.fetchFile method since it based on the fact that Utils.getLocalDir always return the same directory to cache file. Therefore, a new variable cachedLocalDir is used to cache the first localDirectory that it gets from Utils.getLocalDir. Also, when getting the configured local directories (inside Utils. getConfiguredLocalDirs), in case we are in yarn mode, the array of directories are also randomized before return.
Author: Hieu Huynh <“Hieu.huynh@oath.com”>
Closes#21953 from hthuynh2/SPARK_24992.
**Description**
The issue is described in [SPARK-24981](https://issues.apache.org/jira/browse/SPARK-24981).
**How does this PR fix the issue?**
This PR catch the Exception that is thrown while the Sparkcontext.stop() is running (when it is called by the ShutdownHookManager).
**How was this patch tested?**
I manually tested it by adding delay (60s) inside the stop(). This make the shutdownHookManger interrupt the thread that is running stop(). The Interrupted Exception was catched and the job succeed.
Author: Hieu Huynh <“Hieu.huynh@oath.com”>
Author: Hieu Tri Huynh <hthieu96@gmail.com>
Closes#21936 from hthuynh2/SPARK_24981.
## What changes were proposed in this pull request?
There are many warnings in the current build (for instance see https://amplab.cs.berkeley.edu/jenkins/job/spark-master-test-sbt-hadoop-2.7/4734/console).
**common**:
```
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDB.java:237: warning: [rawtypes] found raw type: LevelDBIterator
[warn] void closeIterator(LevelDBIterator it) throws IOException {
[warn] ^
[warn] missing type arguments for generic class LevelDBIterator<T>
[warn] where T is a type-variable:
[warn] T extends Object declared in class LevelDBIterator
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/server/TransportServer.java:151: warning: [deprecation] group() in AbstractBootstrap has been deprecated
[warn] if (bootstrap != null && bootstrap.group() != null) {
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/server/TransportServer.java:152: warning: [deprecation] group() in AbstractBootstrap has been deprecated
[warn] bootstrap.group().shutdownGracefully();
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/server/TransportServer.java:154: warning: [deprecation] childGroup() in ServerBootstrap has been deprecated
[warn] if (bootstrap != null && bootstrap.childGroup() != null) {
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/server/TransportServer.java:155: warning: [deprecation] childGroup() in ServerBootstrap has been deprecated
[warn] bootstrap.childGroup().shutdownGracefully();
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/util/NettyUtils.java:112: warning: [deprecation] PooledByteBufAllocator(boolean,int,int,int,int,int,int,int) in PooledByteBufAllocator has been deprecated
[warn] return new PooledByteBufAllocator(
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/client/TransportClient.java:321: warning: [rawtypes] found raw type: Future
[warn] public void operationComplete(Future future) throws Exception {
[warn] ^
[warn] missing type arguments for generic class Future<V>
[warn] where V is a type-variable:
[warn] V extends Object declared in interface Future
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java:215: warning: [rawtypes] found raw type: StreamInterceptor
[warn] StreamInterceptor interceptor = new StreamInterceptor(this, resp.streamId, resp.byteCount,
[warn] ^
[warn] missing type arguments for generic class StreamInterceptor<T>
[warn] where T is a type-variable:
[warn] T extends Message declared in class StreamInterceptor
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java:215: warning: [rawtypes] found raw type: StreamInterceptor
[warn] StreamInterceptor interceptor = new StreamInterceptor(this, resp.streamId, resp.byteCount,
[warn] ^
[warn] missing type arguments for generic class StreamInterceptor<T>
[warn] where T is a type-variable:
[warn] T extends Message declared in class StreamInterceptor
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/client/TransportResponseHandler.java:215: warning: [unchecked] unchecked call to StreamInterceptor(MessageHandler<T>,String,long,StreamCallback) as a member of the raw type StreamInterceptor
[warn] StreamInterceptor interceptor = new StreamInterceptor(this, resp.streamId, resp.byteCount,
[warn] ^
[warn] where T is a type-variable:
[warn] T extends Message declared in class StreamInterceptor
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/server/TransportRequestHandler.java:255: warning: [rawtypes] found raw type: StreamInterceptor
[warn] StreamInterceptor interceptor = new StreamInterceptor(this, wrappedCallback.getID(),
[warn] ^
[warn] missing type arguments for generic class StreamInterceptor<T>
[warn] where T is a type-variable:
[warn] T extends Message declared in class StreamInterceptor
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/server/TransportRequestHandler.java:255: warning: [rawtypes] found raw type: StreamInterceptor
[warn] StreamInterceptor interceptor = new StreamInterceptor(this, wrappedCallback.getID(),
[warn] ^
[warn] missing type arguments for generic class StreamInterceptor<T>
[warn] where T is a type-variable:
[warn] T extends Message declared in class StreamInterceptor
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/server/TransportRequestHandler.java:255: warning: [unchecked] unchecked call to StreamInterceptor(MessageHandler<T>,String,long,StreamCallback) as a member of the raw type StreamInterceptor
[warn] StreamInterceptor interceptor = new StreamInterceptor(this, wrappedCallback.getID(),
[warn] ^
[warn] where T is a type-variable:
[warn] T extends Message declared in class StreamInterceptor
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/crypto/TransportCipher.java:270: warning: [deprecation] transfered() in FileRegion has been deprecated
[warn] region.transferTo(byteRawChannel, region.transfered());
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/main/java/org/apache/spark/network/sasl/SaslEncryption.java:304: warning: [deprecation] transfered() in FileRegion has been deprecated
[warn] region.transferTo(byteChannel, region.transfered());
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/test/java/org/apache/spark/network/ProtocolSuite.java:119: warning: [deprecation] transfered() in FileRegion has been deprecated
[warn] while (in.transfered() < in.count()) {
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/network-common/src/test/java/org/apache/spark/network/ProtocolSuite.java:120: warning: [deprecation] transfered() in FileRegion has been deprecated
[warn] in.transferTo(channel, in.transfered());
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/unsafe/src/test/java/org/apache/spark/unsafe/hash/Murmur3_x86_32Suite.java:80: warning: [static] static method should be qualified by type name, Murmur3_x86_32, instead of by an expression
[warn] Assert.assertEquals(-300363099, hasher.hashUnsafeWords(bytes, offset, 16, 42));
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/unsafe/src/test/java/org/apache/spark/unsafe/hash/Murmur3_x86_32Suite.java:84: warning: [static] static method should be qualified by type name, Murmur3_x86_32, instead of by an expression
[warn] Assert.assertEquals(-1210324667, hasher.hashUnsafeWords(bytes, offset, 16, 42));
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/common/unsafe/src/test/java/org/apache/spark/unsafe/hash/Murmur3_x86_32Suite.java:88: warning: [static] static method should be qualified by type name, Murmur3_x86_32, instead of by an expression
[warn] Assert.assertEquals(-634919701, hasher.hashUnsafeWords(bytes, offset, 16, 42));
[warn] ^
```
**launcher**:
```
[warn] Pruning sources from previous analysis, due to incompatible CompileSetup.
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/launcher/src/main/java/org/apache/spark/launcher/AbstractLauncher.java:31: warning: [rawtypes] found raw type: AbstractLauncher
[warn] public abstract class AbstractLauncher<T extends AbstractLauncher> {
[warn] ^
[warn] missing type arguments for generic class AbstractLauncher<T>
[warn] where T is a type-variable:
[warn] T extends AbstractLauncher declared in class AbstractLauncher
```
**core**:
```
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/main/scala/org/apache/spark/api/r/RBackend.scala:99: method group in class AbstractBootstrap is deprecated: see corresponding Javadoc for more information.
[warn] if (bootstrap != null && bootstrap.group() != null) {
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/main/scala/org/apache/spark/api/r/RBackend.scala💯 method group in class AbstractBootstrap is deprecated: see corresponding Javadoc for more information.
[warn] bootstrap.group().shutdownGracefully()
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/main/scala/org/apache/spark/api/r/RBackend.scala:102: method childGroup in class ServerBootstrap is deprecated: see corresponding Javadoc for more information.
[warn] if (bootstrap != null && bootstrap.childGroup() != null) {
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/main/scala/org/apache/spark/api/r/RBackend.scala:103: method childGroup in class ServerBootstrap is deprecated: see corresponding Javadoc for more information.
[warn] bootstrap.childGroup().shutdownGracefully()
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/util/ClosureCleanerSuite.scala:151: reflective access of structural type member method getData should be enabled
[warn] by making the implicit value scala.language.reflectiveCalls visible.
[warn] This can be achieved by adding the import clause 'import scala.language.reflectiveCalls'
[warn] or by setting the compiler option -language:reflectiveCalls.
[warn] See the Scaladoc for value scala.language.reflectiveCalls for a discussion
[warn] why the feature should be explicitly enabled.
[warn] val rdd = sc.parallelize(1 to 1).map(concreteObject.getData)
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/util/ClosureCleanerSuite.scala:175: reflective access of structural type member value innerObject2 should be enabled
[warn] by making the implicit value scala.language.reflectiveCalls visible.
[warn] val rdd = sc.parallelize(1 to 1).map(concreteObject.innerObject2.getData)
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/util/ClosureCleanerSuite.scala:175: reflective access of structural type member method getData should be enabled
[warn] by making the implicit value scala.language.reflectiveCalls visible.
[warn] val rdd = sc.parallelize(1 to 1).map(concreteObject.innerObject2.getData)
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/LocalSparkContext.scala:32: constructor Slf4JLoggerFactory in class Slf4JLoggerFactory is deprecated: see corresponding Javadoc for more information.
[warn] InternalLoggerFactory.setDefaultFactory(new Slf4JLoggerFactory())
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala:218: value attemptId in class StageInfo is deprecated: Use attemptNumber instead
[warn] assert(wrapper.stageAttemptId === stages.head.attemptId)
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala:261: value attemptId in class StageInfo is deprecated: Use attemptNumber instead
[warn] stageAttemptId = stages.head.attemptId))
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala:287: value attemptId in class StageInfo is deprecated: Use attemptNumber instead
[warn] stageAttemptId = stages.head.attemptId))
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala:471: value attemptId in class StageInfo is deprecated: Use attemptNumber instead
[warn] stageAttemptId = stages.last.attemptId))
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala:966: value attemptId in class StageInfo is deprecated: Use attemptNumber instead
[warn] listener.onTaskStart(SparkListenerTaskStart(dropped.stageId, dropped.attemptId, task))
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala:972: value attemptId in class StageInfo is deprecated: Use attemptNumber instead
[warn] listener.onTaskEnd(SparkListenerTaskEnd(dropped.stageId, dropped.attemptId,
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala:976: value attemptId in class StageInfo is deprecated: Use attemptNumber instead
[warn] .taskSummary(dropped.stageId, dropped.attemptId, Array(0.25d, 0.50d, 0.75d))
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala:1146: value attemptId in class StageInfo is deprecated: Use attemptNumber instead
[warn] SparkListenerTaskEnd(stage1.stageId, stage1.attemptId, "taskType", Success, tasks(1), null))
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala:1150: value attemptId in class StageInfo is deprecated: Use attemptNumber instead
[warn] SparkListenerTaskEnd(stage1.stageId, stage1.attemptId, "taskType", Success, tasks(0), null))
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/storage/DiskStoreSuite.scala:197: method transfered in trait FileRegion is deprecated: see corresponding Javadoc for more information.
[warn] while (region.transfered() < region.count()) {
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/core/src/test/scala/org/apache/spark/storage/DiskStoreSuite.scala:198: method transfered in trait FileRegion is deprecated: see corresponding Javadoc for more information.
[warn] region.transferTo(byteChannel, region.transfered())
[warn] ^
```
**sql**:
```
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/AnalysisSuite.scala:534: abstract type T is unchecked since it is eliminated by erasure
[warn] assert(partitioning.isInstanceOf[T])
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/AnalysisSuite.scala:534: abstract type T is unchecked since it is eliminated by erasure
[warn] assert(partitioning.isInstanceOf[T])
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ObjectExpressionsSuite.scala:323: inferred existential type Option[Class[_$1]]( forSome { type _$1 }), which cannot be expressed by wildcards, should be enabled
[warn] by making the implicit value scala.language.existentials visible.
[warn] This can be achieved by adding the import clause 'import scala.language.existentials'
[warn] or by setting the compiler option -language:existentials.
[warn] See the Scaladoc for value scala.language.existentials for a discussion
[warn] why the feature should be explicitly enabled.
[warn] val optClass = Option(collectionCls)
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java:226: warning: [deprecation] ParquetFileReader(Configuration,FileMetaData,Path,List<BlockMetaData>,List<ColumnDescriptor>) in ParquetFileReader has been deprecated
[warn] this.reader = new ParquetFileReader(
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java:178: warning: [deprecation] getType() in ColumnDescriptor has been deprecated
[warn] (descriptor.getType() == PrimitiveType.PrimitiveTypeName.INT32 ||
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java:179: warning: [deprecation] getType() in ColumnDescriptor has been deprecated
[warn] (descriptor.getType() == PrimitiveType.PrimitiveTypeName.INT64 &&
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java:181: warning: [deprecation] getType() in ColumnDescriptor has been deprecated
[warn] descriptor.getType() == PrimitiveType.PrimitiveTypeName.FLOAT ||
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java:182: warning: [deprecation] getType() in ColumnDescriptor has been deprecated
[warn] descriptor.getType() == PrimitiveType.PrimitiveTypeName.DOUBLE ||
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java:183: warning: [deprecation] getType() in ColumnDescriptor has been deprecated
[warn] descriptor.getType() == PrimitiveType.PrimitiveTypeName.BINARY))) {
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java:198: warning: [deprecation] getType() in ColumnDescriptor has been deprecated
[warn] switch (descriptor.getType()) {
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java:221: warning: [deprecation] getTypeLength() in ColumnDescriptor has been deprecated
[warn] readFixedLenByteArrayBatch(rowId, num, column, descriptor.getTypeLength());
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java:224: warning: [deprecation] getType() in ColumnDescriptor has been deprecated
[warn] throw new IOException("Unsupported type: " + descriptor.getType());
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java:246: warning: [deprecation] getType() in ColumnDescriptor has been deprecated
[warn] descriptor.getType().toString(),
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java:258: warning: [deprecation] getType() in ColumnDescriptor has been deprecated
[warn] switch (descriptor.getType()) {
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedColumnReader.java:384: warning: [deprecation] getType() in ColumnDescriptor has been deprecated
[warn] throw new UnsupportedOperationException("Unsupported type: " + descriptor.getType());
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/vectorized/ArrowColumnVector.java:458: warning: [static] static variable should be qualified by type name, BaseRepeatedValueVector, instead of by an expression
[warn] int index = rowId * accessor.OFFSET_WIDTH;
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/main/java/org/apache/spark/sql/vectorized/ArrowColumnVector.java:460: warning: [static] static variable should be qualified by type name, BaseRepeatedValueVector, instead of by an expression
[warn] int end = offsets.getInt(index + accessor.OFFSET_WIDTH);
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/test/scala/org/apache/spark/sql/BenchmarkQueryTest.scala:57: a pure expression does nothing in statement position; you may be omitting necessary parentheses
[warn] case s => s
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetInteroperabilitySuite.scala:182: inferred existential type org.apache.parquet.column.statistics.Statistics[?0]( forSome { type ?0 <: Comparable[?0] }), which cannot be expressed by wildcards, should be enabled
[warn] by making the implicit value scala.language.existentials visible.
[warn] This can be achieved by adding the import clause 'import scala.language.existentials'
[warn] or by setting the compiler option -language:existentials.
[warn] See the Scaladoc for value scala.language.existentials for a discussion
[warn] why the feature should be explicitly enabled.
[warn] val columnStats = oneBlockColumnMeta.getStatistics
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/test/scala/org/apache/spark/sql/execution/streaming/sources/ForeachBatchSinkSuite.scala:146: implicit conversion method conv should be enabled
[warn] by making the implicit value scala.language.implicitConversions visible.
[warn] This can be achieved by adding the import clause 'import scala.language.implicitConversions'
[warn] or by setting the compiler option -language:implicitConversions.
[warn] See the Scaladoc for value scala.language.implicitConversions for a discussion
[warn] why the feature should be explicitly enabled.
[warn] implicit def conv(x: (Int, Long)): KV = KV(x._1, x._2)
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/test/scala/org/apache/spark/sql/streaming/continuous/shuffle/ContinuousShuffleSuite.scala:48: implicit conversion method unsafeRow should be enabled
[warn] by making the implicit value scala.language.implicitConversions visible.
[warn] private implicit def unsafeRow(value: Int) = {
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetInteroperabilitySuite.scala:178: method getType in class ColumnDescriptor is deprecated: see corresponding Javadoc for more information.
[warn] assert(oneFooter.getFileMetaData.getSchema.getColumns.get(0).getType() ===
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetTest.scala:154: method readAllFootersInParallel in object ParquetFileReader is deprecated: see corresponding Javadoc for more information.
[warn] ParquetFileReader.readAllFootersInParallel(configuration, fs.getFileStatus(path)).asScala.toSeq
[warn] ^
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/sql/hive/src/test/java/org/apache/spark/sql/hive/test/Complex.java:679: warning: [cast] redundant cast to Complex
[warn] Complex typedOther = (Complex)other;
[warn] ^
```
**mllib**:
```
[warn] Pruning sources from previous analysis, due to incompatible CompileSetup.
[warn] /home/jenkins/workspace/spark-master-test-maven-hadoop-2.7/mllib/src/test/scala/org/apache/spark/ml/recommendation/ALSSuite.scala:597: match may not be exhaustive.
[warn] It would fail on the following inputs: None, Some((x: Tuple2[?, ?] forSome x not in (?, ?)))
[warn] val df = dfs.find {
[warn] ^
```
This PR does not target fix all of them since some look pretty tricky to fix and there look too many warnings including false positive (like deprecated API but it's used in its test, etc.)
## How was this patch tested?
Existing tests should cover this.
Author: hyukjinkwon <gurwls223@apache.org>
Closes#21975 from HyukjinKwon/remove-build-warnings.
## What changes were proposed in this pull request?
Netty could just ignore user-provided configurations. In particular, spark.driver.cores would be ignored when considering the number of cores available to netty (which would usually just default to Runtime.availableProcessors() ). In transport configurations, the number of threads are based directly on how many cores the system believes it has available, and in yarn cluster mode this would generally overshoot the user-preferred value.
## How was this patch tested?
As this is mostly a configuration change, tests were done manually by adding spark-submit confs and verifying the number of threads started by netty was what was expected.
Passes scalastyle checks from dev/run-tests
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Nihar Sheth <niharrsheth@gmail.com>
Closes#21885 from NiharS/usableCores.
## What changes were proposed in this pull request?
We don't support run a barrier stage with dynamic resource allocation enabled, it shall lead to some confusing behaviors (eg. with dynamic resource allocation enabled, it may happen that we acquire some executors (but not enough to launch all the tasks in a barrier stage) and later release them due to executor idle time expire, and then acquire again).
We perform the check on job submit and fail fast if running a barrier stage with dynamic resource allocation enabled.
## How was this patch tested?
Added new test suite `BarrierStageOnSubmittedSuite` to cover all the fail fast cases that submitted a job containing one or more barrier stages.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#21915 from jiangxb1987/SPARK-24954.
## What changes were proposed in this pull request?
It seems 'doRunMain()' has been removed accidentally by other PR and due to that the application submission is not happening, this PR adds back the 'doRunMain()' for standalone cluster submission.
## How was this patch tested?
I verified it manually by submitting application in standalone cluster mode, all the applications are submitting to the Master with the change.
Author: Devaraj K <devaraj@apache.org>
Closes#21979 from devaraj-kavali/SPARK-25009.
## What changes were proposed in this pull request?
According to https://github.com/apache/spark/pull/21758#discussion_r206746905 , current declaration of `BarrierTaskContext` didn't extend methods from `TaskContext`. Since `TaskContext` is an abstract class and we don't want to change it to a trait, we have to define class `BarrierTaskContext` directly.
## How was this patch tested?
Existing tests.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#21972 from jiangxb1987/BarrierTaskContext.
## What changes were proposed in this pull request?
Check on job submit to make sure we don't launch a barrier stage with unsupported RDD chain pattern. The following patterns are not supported:
- Ancestor RDDs that have different number of partitions from the resulting RDD (eg. union()/coalesce()/first()/PartitionPruningRDD);
- An RDD that depends on multiple barrier RDDs (eg. barrierRdd1.zip(barrierRdd2)).
## How was this patch tested?
Add test cases in `BarrierStageOnSubmittedSuite`.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#21927 from jiangxb1987/SPARK-24820.
## What changes were proposed in this pull request?
This PR addresses issues 2,3 in this [document](https://docs.google.com/document/d/1fbkjEL878witxVQpOCbjlvOvadHtVjYXeB-2mgzDTvk).
* We modified the closure cleaner to identify closures that are implemented via the LambdaMetaFactory mechanism (serializedLambdas) (issue2).
* We also fix the issue due to scala/bug#11016. There are two options for solving the Unit issue, either add () at the end of the closure or use the trick described in the doc. Otherwise overloading resolution does not work (we are not going to eliminate either of the methods) here. Compiler tries to adapt to Unit and makes these two methods candidates for overloading, when there is polymorphic overloading there is no ambiguity (that is the workaround implemented). This does not look that good but it serves its purpose as we need to support two different uses for method: `addTaskCompletionListener`. One that passes a TaskCompletionListener and one that passes a closure that is wrapped with a TaskCompletionListener later on (issue3).
Note: regarding issue 1 in the doc the plan is:
> Do Nothing. Don’t try to fix this as this is only a problem for Java users who would want to use 2.11 binaries. In that case they can cast to MapFunction to be able to utilize lambdas. In Spark 3.0.0 the API should be simplified so that this issue is removed.
## How was this patch tested?
This was manually tested:
```./dev/change-scala-version.sh 2.12
./build/mvn -DskipTests -Pscala-2.12 clean package
./build/mvn -Pscala-2.12 clean package -DwildcardSuites=org.apache.spark.serializer.ProactiveClosureSerializationSuite -Dtest=None
./build/mvn -Pscala-2.12 clean package -DwildcardSuites=org.apache.spark.util.ClosureCleanerSuite -Dtest=None
./build/mvn -Pscala-2.12 clean package -DwildcardSuites=org.apache.spark.streaming.DStreamClosureSuite -Dtest=None```
Author: Stavros Kontopoulos <stavros.kontopoulos@lightbend.com>
Closes#21930 from skonto/scala2.12-sup.
## What changes were proposed in this pull request?
Kill all running tasks when a task in a barrier stage fail in the middle. `TaskScheduler`.`cancelTasks()` will also fail the job, so we implemented a new method `killAllTaskAttempts()` to just kill all running tasks of a stage without cancel the stage/job.
## How was this patch tested?
Add new test cases in `TaskSchedulerImplSuite`.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#21943 from jiangxb1987/killAllTasks.
## What changes were proposed in this pull request?
The PR adds the SQL function `array_except`. The behavior of the function is based on Presto's one.
This function returns returns an array of the elements in array1 but not in array2.
Note: The order of elements in the result is not defined.
## How was this patch tested?
Added UTs.
Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Closes#21103 from kiszk/SPARK-23915.
There is a narrow race in this code that is caused when the code being
run in assertSpilled / assertNotSpilled runs more than a single job.
SpillListener assumed that only a single job was run, and so would only
block waiting for that single job to finish when `numSpilledStages` was
called. But some tests (like SQL tests that call `checkAnswer`) run more
than one job, and so that wait was basically a no-op.
This could cause the next test to install a listener to receive events
from the previous job. Which could cause test failures in certain cases.
The change fixes that race, and also uninstalls listeners after the
test runs, so they don't accumulate when the SparkContext is shared
among multiple tests.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#21639 from vanzin/SPARK-24653.
**Description**
Currently Speculative tasks that didn't commit can show up as success (depending on timing of commit). This is a bit confusing because that task didn't really succeed in the sense it didn't write anything.
I think these tasks should be marked as KILLED or something that is more obvious to the user exactly what happened. it is happened to hit the timing where it got a commit denied exception then it shows up as failed and counts against your task failures. It shouldn't count against task failures since that failure really doesn't matter.
MapReduce handles these situation so perhaps we can look there for a model.
<img width="1420" alt="unknown" src="https://user-images.githubusercontent.com/15680678/42013170-99db48c2-7a61-11e8-8c7b-ef94c84e36ea.png">
**How can this issue happen?**
When both attempts of a task finish before the driver sends command to kill one of them, both of them send the status update FINISHED to the driver. The driver calls TaskSchedulerImpl to handle one successful task at a time. When it handles the first successful task, it sends the command to kill the other copy of the task, however, because that task is already finished, the executor will ignore the command. After finishing handling the first attempt, it processes the second one, although all actions on the result of this task are skipped, this copy of the task is still marked as SUCCESS. As a result, even though this issue does not affect the result of the job, it might cause confusing to user because both of them appear to be successful.
**How does this PR fix the issue?**
The simple way to fix this issue is that when taskSetManager handles successful task, it checks if any other attempt succeeded. If this is the case, it will call handleFailedTask with state==KILLED and reason==TaskKilled(“another attempt succeeded”) to handle this task as begin killed.
**How was this patch tested?**
I tested this manually by running applications, that caused the issue before, a few times, and observed that the issue does not happen again. Also, I added a unit test in TaskSetManagerSuite to test that if we call handleSuccessfulTask to handle status update for 2 copies of a task, only the one that is handled first will be mark as SUCCESS
Author: Hieu Huynh <“Hieu.huynh@oath.com”>
Author: hthuynh2 <hthieu96@gmail.com>
Closes#21653 from hthuynh2/SPARK_13343.
In case there are any issues in converting FileSegmentManagedBuffer to
ChunkedByteBuffer, add a conf to go back to old code path.
Followup to 7e847646d1
Author: Imran Rashid <irashid@cloudera.com>
Closes#21867 from squito/SPARK-24307-p2.
## What changes were proposed in this pull request?
Propose new APIs and modify job/task scheduling to support barrier execution mode, which requires all tasks in a same barrier stage start at the same time, and retry all tasks in case some tasks fail in the middle. The barrier execution mode is useful for some ML/DL workloads.
The proposed API changes include:
- `RDDBarrier` that marks an RDD as barrier (Spark must launch all the tasks together for the current stage).
- `BarrierTaskContext` that support global sync of all tasks in a barrier stage, and provide extra `BarrierTaskInfo`s.
In DAGScheduler, we retry all tasks of a barrier stage in case some tasks fail in the middle, this is achieved by unregistering map outputs for a shuffleId (for ShuffleMapStage) or clear the finished partitions in an active job (for ResultStage).
## How was this patch tested?
Add `RDDBarrierSuite` to ensure we convert RDDs correctly;
Add new test cases in `DAGSchedulerSuite` to ensure we do task scheduling correctly;
Add new test cases in `SparkContextSuite` to ensure the barrier execution mode actually works (both under local mode and local cluster mode).
Add new test cases in `TaskSchedulerImplSuite` to ensure we schedule tasks for barrier taskSet together.
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes#21758 from jiangxb1987/barrier-execution-mode.
Fetch-to-mem is guaranteed to fail if the message is bigger than 2 GB,
so we might as well use fetch-to-disk in that case. The message includes
some metadata in addition to the block data itself (in particular
UploadBlock has a lot of metadata), so we leave a little room.
Author: Imran Rashid <irashid@cloudera.com>
Closes#21474 from squito/SPARK-24297.
## What changes were proposed in this pull request?
In Spark "local" scheme means resources are already on the driver/executor nodes, this pr ignore the files with "local" scheme in `SparkContext.addFile` for fixing potential bug.
## How was this patch tested?
Existing tests.
Author: Yuanjian Li <xyliyuanjian@gmail.com>
Closes#21533 from xuanyuanking/SPARK-24195.
(1) Netty's ByteBuf cannot support data > 2gb. So to transfer data from a
ChunkedByteBuffer over the network, we use a custom version of
FileRegion which is backed by the ChunkedByteBuffer.
(2) On the receiving end, we need to expose all the data in a
FileSegmentManagedBuffer as a ChunkedByteBuffer. We do that by memory
mapping the entire file in chunks.
Added unit tests. Ran the randomized test a couple of hundred times on my laptop. Tests cover the equivalent of SPARK-24107 for the ChunkedByteBufferFileRegion. Also tested on a cluster with remote cache reads >2gb (in memory and on disk).
Author: Imran Rashid <irashid@cloudera.com>
Closes#21440 from squito/chunked_bb_file_region.
**Description**
As described in [SPARK-24755](https://issues.apache.org/jira/browse/SPARK-24755), when speculation is enabled, there is scenario that executor loss can cause task to not be resubmitted.
This patch changes the variable killedByOtherAttempt to keeps track of the taskId of tasks that are killed by other attempt. By doing this, we can still prevent resubmitting task killed by other attempt while resubmit successful attempt when executor lost.
**How was this patch tested?**
A UT is added based on the UT written by xuanyuanking with modification to simulate the scenario described in SPARK-24755.
Author: Hieu Huynh <“Hieu.huynh@oath.com”>
Closes#21729 from hthuynh2/SPARK_24755.
## What changes were proposed in this pull request?
When speculation is enabled,
TaskSetManager#markPartitionCompleted should write successful task duration to MedianHeap,
not just increase tasksSuccessful.
Otherwise when TaskSetManager#checkSpeculatableTasks,tasksSuccessful non-zero, but MedianHeap is empty.
Then throw an exception successfulTaskDurations.median java.util.NoSuchElementException: MedianHeap is empty.
Finally led to stopping SparkContext.
## How was this patch tested?
TaskSetManagerSuite.scala
unit test:[SPARK-24677] MedianHeap should not be empty when speculation is enabled
Author: sychen <sychen@ctrip.com>
Closes#21656 from cxzl25/fix_MedianHeap_empty.
## What changes were proposed in this pull request?
While looking through the codebase, it appeared that the scala code for RDD.cartesian does not have any tests for correctness. This adds a couple basic tests to verify cartesian yields correct values. While the implementation for RDD.cartesian is pretty simple, it always helps to have a few tests!
## How was this patch tested?
The new test cases pass, and the scala style tests from running dev/run-tests all pass.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Nihar Sheth <niharrsheth@gmail.com>
Closes#21765 from NiharS/cartesianTests.
It is corrected as per the configuration.
## What changes were proposed in this pull request?
IdleTimeout info used to print in the logs is taken based on the cacheBlock. If it is cacheBlock then cachedExecutorIdleTimeoutS is considered else executorIdleTimeoutS
## How was this patch tested?
Manual Test
spark-sql> cache table sample;
2018-05-15 14:44:02 INFO DAGScheduler:54 - Submitting 3 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[8] at processCmd at CliDriver.java:376) (first 15 tasks are for partitions Vector(0, 1, 2))
2018-05-15 14:44:02 INFO YarnScheduler:54 - Adding task set 0.0 with 3 tasks
2018-05-15 14:44:03 INFO ExecutorAllocationManager:54 - Requesting 1 new executor because tasks are backlogged (new desired total will be 1)
...
...
2018-05-15 14:46:10 INFO YarnClientSchedulerBackend:54 - Actual list of executor(s) to be killed is 1
2018-05-15 14:46:10 INFO **ExecutorAllocationManager:54 - Removing executor 1 because it has been idle for 120 seconds (new desired total will be 0)**
2018-05-15 14:46:11 INFO YarnSchedulerBackend$YarnDriverEndpoint:54 - Disabling executor 1.
2018-05-15 14:46:11 INFO DAGScheduler:54 - Executor lost: 1 (epoch 1)
Author: sandeep-katta <sandeep.katta2007@gmail.com>
Closes#21565 from sandeep-katta/loginfoBug.
## What changes were proposed in this pull request?
In the PR, I propose to output an warning if the `addFile()` or `addJar()` methods are callled more than once for the same path. Currently, overwriting of already added files is not supported. New comments and warning are reflected the existing behaviour.
Author: Maxim Gekk <maxim.gekk@databricks.com>
Closes#21771 from MaxGekk/warning-on-adding-file.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}