## What changes were proposed in this pull request?
tl;dr: Add a class, `MesosHadoopDelegationTokenManager` that updates delegation tokens on a schedule on the behalf of Spark Drivers. Broadcast renewed credentials to the executors.
## The problem
We recently added Kerberos support to Mesos-based Spark jobs as well as Secrets support to the Mesos Dispatcher (SPARK-16742, SPARK-20812, respectively). However the delegation tokens have a defined expiration. This poses a problem for long running Spark jobs (e.g. Spark Streaming applications). YARN has a solution for this where a thread is scheduled to renew the tokens they reach 75% of their way to expiration. It then writes the tokens to HDFS for the executors to find (uses a monotonically increasing suffix).
## This solution
We replace the current method in `CoarseGrainedSchedulerBackend` which used to discard the token renewal time with a protected method `fetchHadoopDelegationTokens`. Now the individual cluster backends are responsible for overriding this method to fetch and manage token renewal. The delegation tokens themselves, are still part of the `CoarseGrainedSchedulerBackend` as before.
In the case of Mesos renewed Credentials are broadcasted to the executors. This maintains all transfer of Credentials within Spark (as opposed to Spark-to-HDFS). It also does not require any writing of Credentials to disk. It also does not require any GC of old files.
## How was this patch tested?
Manually against a Kerberized HDFS cluster.
Thank you for the reviews.
Author: ArtRand <arand@soe.ucsc.edu>
Closes#19272 from ArtRand/spark-21842-450-kerberos-ticket-renewal.
## What changes were proposed in this pull request?
A discussed in SPARK-19606, the addition of a new config property named "spark.mesos.constraints.driver" for constraining drivers running on a Mesos cluster
## How was this patch tested?
Corresponding unit test added also tested locally on a Mesos cluster
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Paul Mackles <pmackles@adobe.com>
Closes#19543 from pmackles/SPARK-19606.
## Background
In #18837 , ArtRand added Mesos secrets support to the dispatcher. **This PR is to add the same secrets support to the drivers.** This means if the secret configs are set, the driver will launch executors that have access to either env or file-based secrets.
One use case for this is to support TLS in the driver <=> executor communication.
## What changes were proposed in this pull request?
Most of the changes are a refactor of the dispatcher secrets support (#18837) - moving it to a common place that can be used by both the dispatcher and drivers. The same goes for the unit tests.
## How was this patch tested?
There are four config combinations: [env or file-based] x [value or reference secret]. For each combination:
- Added a unit test.
- Tested in DC/OS.
Author: Susan X. Huynh <xhuynh@mesosphere.com>
Closes#19437 from susanxhuynh/sh-mesos-driver-secret.
## What changes were proposed in this pull request?
Added Launcher support for monitoring Mesos apps in Client mode. SPARK-11033 can handle the support for Mesos/Cluster mode since the Standalone/Cluster and Mesos/Cluster modes use the same code at client side.
## How was this patch tested?
I verified it manually by running launcher application, able to launch, stop and kill the mesos applications and also can invoke other launcher API's.
Author: Devaraj K <devaraj@apache.org>
Closes#19385 from devaraj-kavali/SPARK-11034.
## What changes were proposed in this pull request?
Improve the Spark-Mesos coarse-grained scheduler to consider the preferred locations when dynamic allocation is enabled.
## How was this patch tested?
Added a unittest, and performed manual testing on AWS.
Author: Gene Pang <gene.pang@gmail.com>
Closes#18098 from gpang/mesos_data_locality.
## What changes were proposed in this pull request?
Fix a trivial bug with how metrics are registered in the mesos dispatcher. Bug resulted in creating a new registry each time the metricRegistry() method was called.
## How was this patch tested?
Verified manually on local mesos setup
Author: Paul Mackles <pmackles@adobe.com>
Closes#19358 from pmackles/SPARK-22135.
…build; fix some things that will be warnings or errors in 2.12; restore Scala 2.12 profile infrastructure
## What changes were proposed in this pull request?
This change adds back the infrastructure for a Scala 2.12 build, but does not enable it in the release or Python test scripts.
In order to make that meaningful, it also resolves compile errors that the code hits in 2.12 only, in a way that still works with 2.11.
It also updates dependencies to the earliest minor release of dependencies whose current version does not yet support Scala 2.12. This is in a sense covered by other JIRAs under the main umbrella, but implemented here. The versions below still work with 2.11, and are the _latest_ maintenance release in the _earliest_ viable minor release.
- Scalatest 2.x -> 3.0.3
- Chill 0.8.0 -> 0.8.4
- Clapper 1.0.x -> 1.1.2
- json4s 3.2.x -> 3.4.2
- Jackson 2.6.x -> 2.7.9 (required by json4s)
This change does _not_ fully enable a Scala 2.12 build:
- It will also require dropping support for Kafka before 0.10. Easy enough, just didn't do it yet here
- It will require recreating `SparkILoop` and `Main` for REPL 2.12, which is SPARK-14650. Possible to do here too.
What it does do is make changes that resolve much of the remaining gap without affecting the current 2.11 build.
## How was this patch tested?
Existing tests and build. Manually tested with `./dev/change-scala-version.sh 2.12` to verify it compiles, modulo the exceptions above.
Author: Sean Owen <sowen@cloudera.com>
Closes#18645 from srowen/SPARK-14280.
Mesos has secrets primitives for environment and file-based secrets, this PR adds that functionality to the Spark dispatcher and the appropriate configuration flags.
Unit tested and manually tested against a DC/OS cluster with Mesos 1.4.
Author: ArtRand <arand@soe.ucsc.edu>
Closes#18837 from ArtRand/spark-20812-dispatcher-secrets-and-labels.
JIRA ticket: https://issues.apache.org/jira/browse/SPARK-21694
## What changes were proposed in this pull request?
Spark already supports launching containers attached to a given CNI network by specifying it via the config `spark.mesos.network.name`.
This PR adds support to pass in network labels to CNI plugins via a new config option `spark.mesos.network.labels`. These network labels are key-value pairs that are set in the `NetworkInfo` of both the driver and executor tasks. More details in the related Mesos documentation: http://mesos.apache.org/documentation/latest/cni/#mesos-meta-data-to-cni-plugins
## How was this patch tested?
Unit tests, for both driver and executor tasks.
Manual integration test to submit a job with the `spark.mesos.network.labels` option, hit the mesos/state.json endpoint, and check that the labels are set in the driver and executor tasks.
ArtRand skonto
Author: Susan X. Huynh <xhuynh@mesosphere.com>
Closes#18910 from susanxhuynh/sh-mesos-cni-labels.
## What changes were proposed in this pull request?
Add Kerberos Support to Mesos. This includes kinit and --keytab support, but does not include delegation token renewal.
## How was this patch tested?
Manually against a Secure DC/OS Apache HDFS cluster.
Author: ArtRand <arand@soe.ucsc.edu>
Author: Michael Gummelt <mgummelt@mesosphere.io>
Closes#18519 from mgummelt/SPARK-16742-kerberos.
This version fixes a few issues in the import order checker; it provides
better error messages, and detects more improper ordering (thus the need
to change a lot of files in this patch). The main fix is that it correctly
complains about the order of packages vs. classes.
As part of the above, I moved some "SparkSession" import in ML examples
inside the "$example on$" blocks; that didn't seem consistent across
different source files to start with, and avoids having to add more on/off blocks
around specific imports.
The new scalastyle also seems to have a better header detector, so a few
license headers had to be updated to match the expected indentation.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18943 from vanzin/SPARK-21731.
## What changes were proposed in this pull request?
Adds a sandbox link per driver in the dispatcher ui with minimal changes after a bug was fixed here:
https://issues.apache.org/jira/browse/MESOS-4992
The sandbox uri has the following format:
http://<proxy_uri>/#/slaves/\<agent-id\>/ frameworks/ \<scheduler-id\>/executors/\<driver-id\>/browse
For dc/os the proxy uri is <dc/os uri>/mesos. For the dc/os deployment scenario and to make things easier I introduced a new config property named `spark.mesos.proxy.baseURL` which should be passed to the dispatcher when launched using --conf. If no such configuration is detected then no sandbox uri is depicted, and there is an empty column with a header (this can be changed so nothing is shown).
Within dc/os the base url must be a property for the dispatcher that we should add in the future here:
9e7c909c3b/repo/packages/S/spark/26/config.json
It is not easy to detect in different environments what is that uri so user should pass it.
## How was this patch tested?
Tested with the mesos test suite here: https://github.com/typesafehub/mesos-spark-integration-tests.
Attached image shows the ui modification where the sandbox header is added.
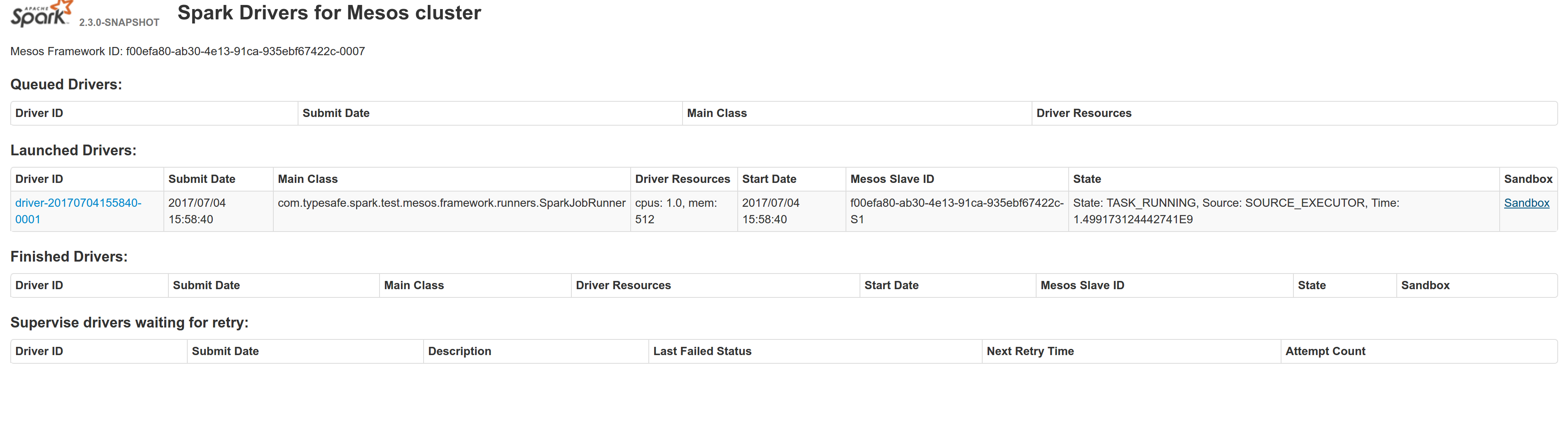
Tested the uri redirection the way it was suggested here:
https://issues.apache.org/jira/browse/MESOS-4992
Built mesos 1.4 from the master branch and started the mesos dispatcher with the command:
`./sbin/start-mesos-dispatcher.sh --conf spark.mesos.proxy.baseURL=http://localhost:5050 -m mesos://127.0.0.1:5050`
Run a spark example:
`./bin/spark-submit --class org.apache.spark.examples.SparkPi --master mesos://10.10.1.79:7078 --deploy-mode cluster --executor-memory 2G --total-executor-cores 2 http://<path>/spark-examples_2.11-2.1.1.jar 10`
Sandbox uri is shown at the bottom of the page:
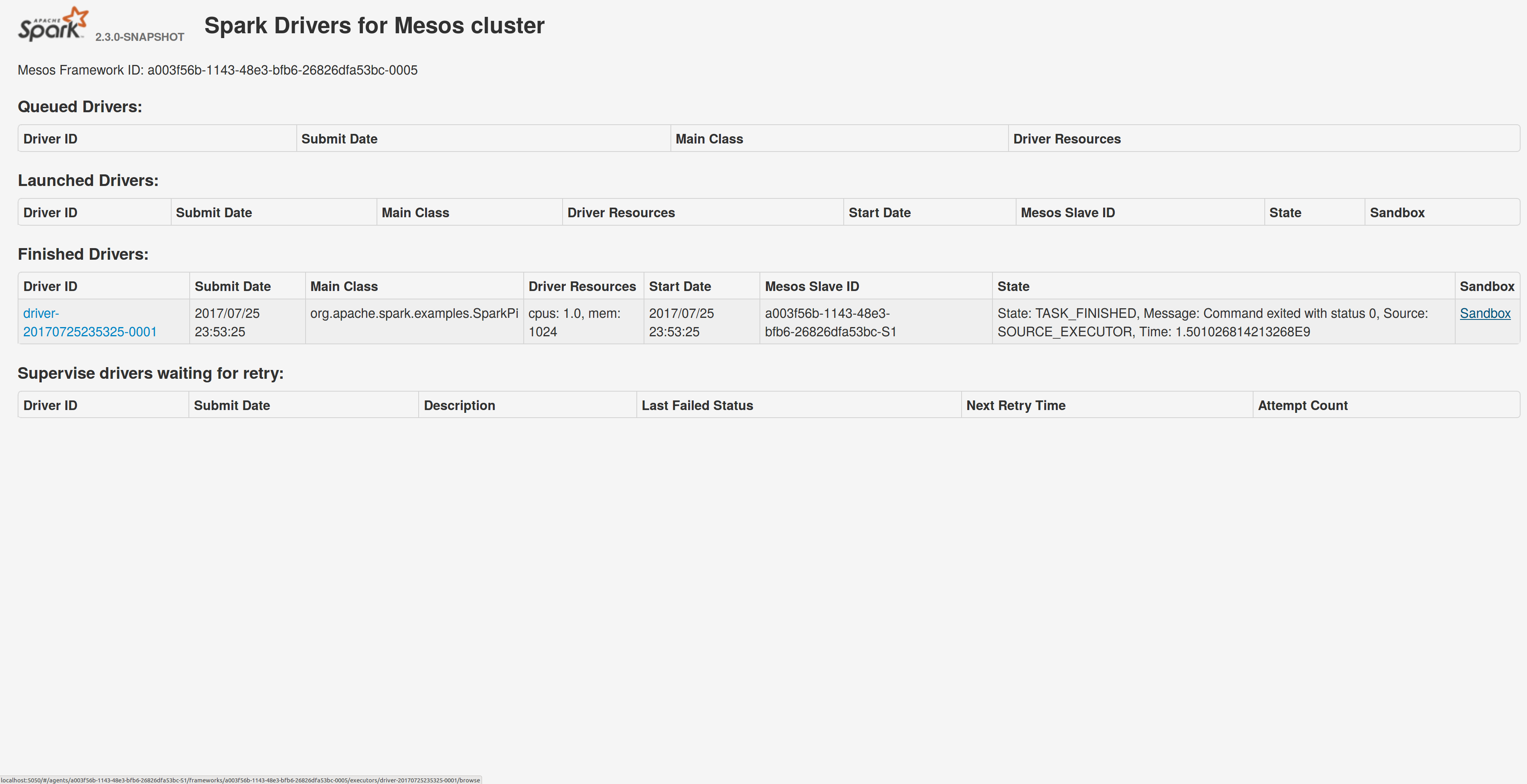
Redirection works as expected:
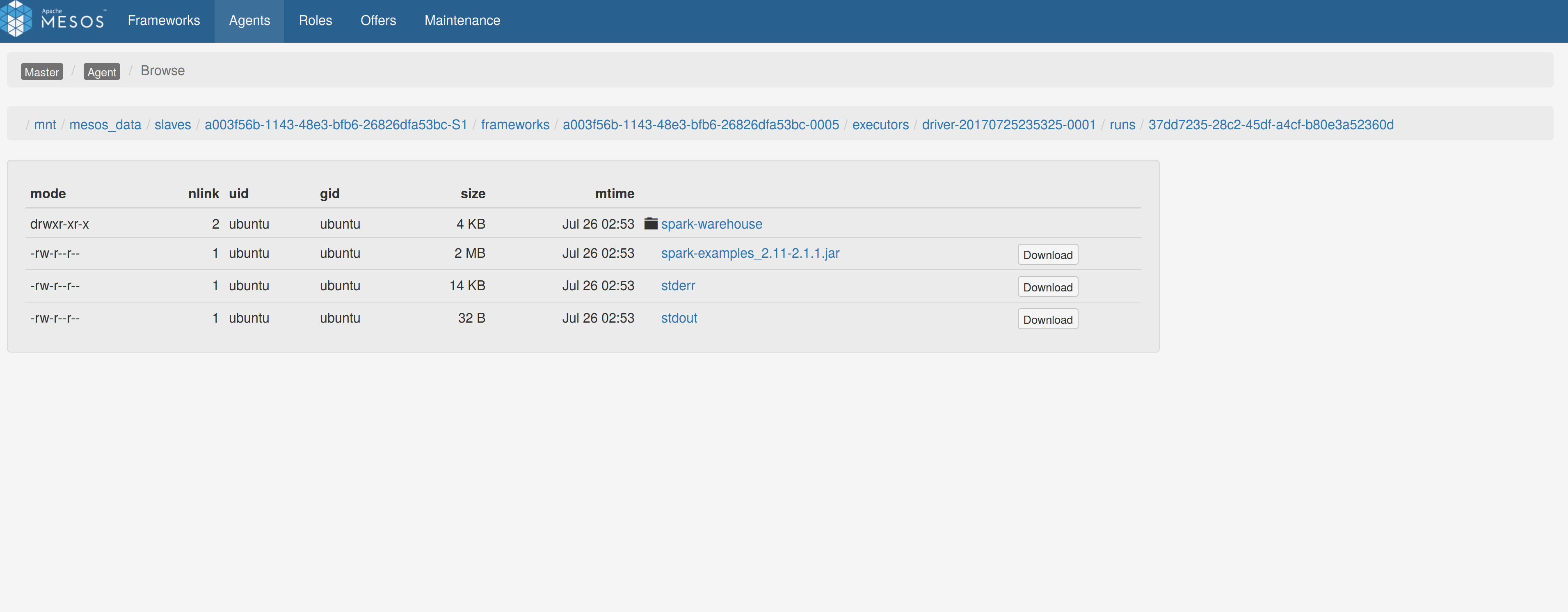
Author: Stavros Kontopoulos <st.kontopoulos@gmail.com>
Closes#18528 from skonto/adds_the_sandbox_uri.
## What changes were proposed in this pull request?
With supervise enabled for a driver, re-launching it was failing because the driver had the same framework Id. This patch creates a new driver framework id every time we re-launch a driver, but we keep the driver submission id the same since that is the same with the task id the driver was launched with on mesos and retry state and other info within Dispatcher's data structures uses that as a key.
We append a "-retry-%4d" string as a suffix to the framework id passed by the dispatcher to the driver and the same value to the app_id created by each driver, except the first time where we dont need the retry suffix.
The previous format for the frameworkId was 'DispactherFId-DriverSubmissionId'.
We also detect the case where we have multiple spark contexts started from within the same driver and we do set proper names to their corresponding app-ids. The old practice was to unset the framework id passed from the dispatcher after the driver framework was started for the first time and let mesos decide the framework ID for subsequent spark contexts. The decided fId was passed as an appID.
This patch affects heavily the history server. Btw we dont have the issues of the standalone case where driver id must be different since the dispatcher will re-launch a driver(mesos task) only if it gets an update that it is dead and this is verified by mesos implicitly. We also dont fix the fine grained mode which is deprecated and of no use.
## How was this patch tested?
This task was manually tested on dc/os. Launched a driver, stoped its container and verified the expected behavior.
Initial retry of the driver, driver in pending state:

Driver re-launched:
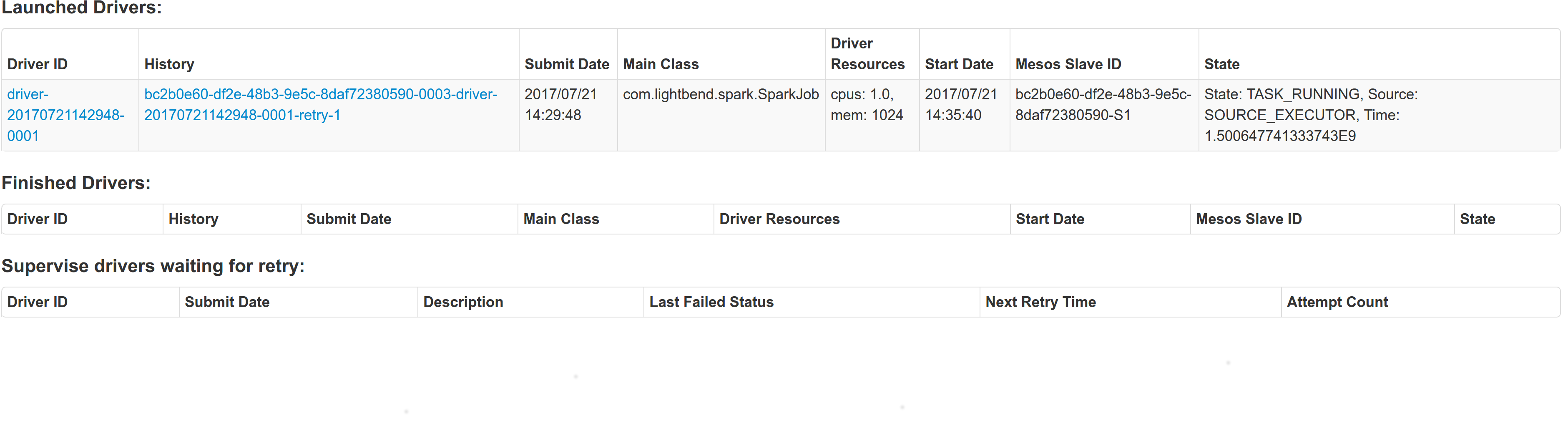
Another re-try:

The resulted entries in history server at the bottom:
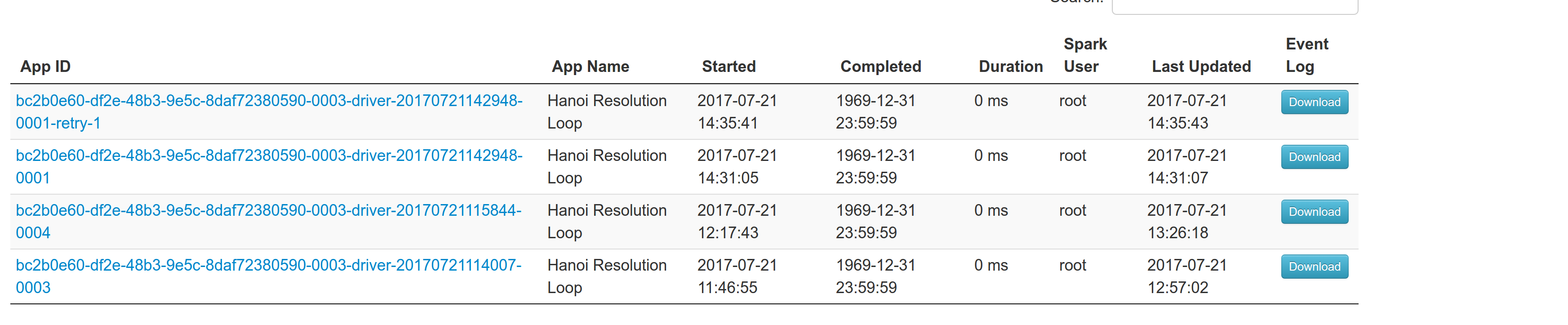
Regarding multiple spark contexts here is the end result regarding the spark history server, for the second spark context we add an increasing number as a suffix:

Author: Stavros Kontopoulos <st.kontopoulos@gmail.com>
Closes#18705 from skonto/fix_supervise_flag.
## What changes were proposed in this pull request?
Current behavior: in Mesos cluster mode, the driver failover_timeout is set to zero. If the driver temporarily loses connectivity with the Mesos master, the framework will be torn down and all executors killed.
Proposed change: make the failover_timeout configurable via a new option, spark.mesos.driver.failoverTimeout. The default value is still zero.
Note: with non-zero failover_timeout, an explicit teardown is needed in some cases. This is captured in https://issues.apache.org/jira/browse/SPARK-21458
## How was this patch tested?
Added a unit test to make sure the config option is set while creating the scheduler driver.
Ran an integration test with mesosphere/spark showing that with a non-zero failover_timeout the Spark job finishes after a driver is disconnected from the master.
Author: Susan X. Huynh <xhuynh@mesosphere.com>
Closes#18674 from susanxhuynh/sh-mesos-failover-timeout.
## What changes were proposed in this pull request?
Address scapegoat warnings for:
- BigDecimal double constructor
- Catching NPE
- Finalizer without super
- List.size is O(n)
- Prefer Seq.empty
- Prefer Set.empty
- reverse.map instead of reverseMap
- Type shadowing
- Unnecessary if condition.
- Use .log1p
- Var could be val
In some instances like Seq.empty, I avoided making the change even where valid in test code to keep the scope of the change smaller. Those issues are concerned with performance and it won't matter for tests.
## How was this patch tested?
Existing tests
Author: Sean Owen <sowen@cloudera.com>
Closes#18635 from srowen/Scapegoat1.
## What changes were proposed in this pull request?
Adding the default UncaughtExceptionHandler to the Worker.
## How was this patch tested?
I verified it manually, when any of the worker thread gets uncaught exceptions then the default UncaughtExceptionHandler will handle those exceptions.
Author: Devaraj K <devaraj@apache.org>
Closes#18357 from devaraj-kavali/SPARK-21146.
## What changes were proposed in this pull request?
Currently the shuffle service registration timeout and retry has been hardcoded. This works well for small workloads but under heavy workload when the shuffle service is busy transferring large amount of data we see significant delay in responding to the registration request, as a result we often see the executors fail to register with the shuffle service, eventually failing the job. We need to make these two parameters configurable.
## How was this patch tested?
* Updated `BlockManagerSuite` to test registration timeout and max attempts configuration actually works.
cc sitalkedia
Author: Li Yichao <lyc@zhihu.com>
Closes#18092 from liyichao/SPARK-20640.
## What changes were proposed in this pull request?
Add Mesos labels support to the Spark Dispatcher
## How was this patch tested?
unit tests
Author: Michael Gummelt <mgummelt@mesosphere.io>
Closes#18220 from mgummelt/SPARK-21000-dispatcher-labels.
Restore code that was removed as part of SPARK-17979, but instead of
using the deprecated env variable name to propagate the class path, use
a new one.
Verified by running "./bin/spark-class o.a.s.executor.CoarseGrainedExecutorBackend"
manually.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#18037 from vanzin/SPARK-20814.
## What changes were proposed in this pull request?
Add stripXSS and stripXSSMap to Spark Core's UIUtils. Calling these functions at any point that getParameter is called against a HttpServletRequest.
## How was this patch tested?
Unit tests, IBM Security AppScan Standard no longer showing vulnerabilities, manual verification of WebUI pages.
Author: NICHOLAS T. MARION <nmarion@us.ibm.com>
Closes#17686 from n-marion/xss-fix.
## What changes were proposed in this pull request?
After SPARK-10997, client mode Netty RpcEnv doesn't require to start server, so port configurations are not used any more, here propose to remove these two configurations: "spark.executor.port" and "spark.am.port".
## How was this patch tested?
Existing UTs.
Author: jerryshao <sshao@hortonworks.com>
Closes#17866 from jerryshao/SPARK-20605.
Signed-off-by: liuxian <liu.xian3zte.com.cn>
## What changes were proposed in this pull request?
When the input parameter is null, may be a runtime exception occurs
## How was this patch tested?
Existing unit tests
Author: liuxian <liu.xian3@zte.com.cn>
Closes#17796 from 10110346/wip_lx_0428.
## What changes were proposed in this pull request?
Add test case for scenarios where executor.cores is set as a
(non)divisor of spark.cores.max
This tests the change in
#17786
## How was this patch tested?
Ran the existing test suite with the new tests
dbtsai
Author: Davis Shepherd <dshepherd@netflix.com>
Closes#17788 from dgshep/add_mesos_test.
## What changes were proposed in this pull request?
Set maxCores to be a multiple of the smallest executor that can be launched. This ensures that we correctly detect the condition where no more executors will be launched when spark.cores.max is not a multiple of spark.executor.cores
## How was this patch tested?
This was manually tested with other sample frameworks measuring their incoming offers to determine if starvation would occur.
dbtsai mgummelt
Author: Davis Shepherd <dshepherd@netflix.com>
Closes#17786 from dgshep/fix_mesos_max_cores.
## What changes were proposed in this pull request?
Submitted Time' field, the date format **needs to be formatted**, in running Drivers table or Completed Drivers table in master web ui.
Before fix this problem e.g.
Completed Drivers
Submission ID **Submitted Time** Worker State Cores Memory Main Class
driver-20170419145755-0005 **Wed Apr 19 14:57:55 CST 2017** worker-20170419145250-zdh120-40412 FAILED 1 1024.0 MB cn.zte.HdfsTest
please see the attachment:https://issues.apache.org/jira/secure/attachment/12863977/before_fix.png
After fix this problem e.g.
Completed Drivers
Submission ID **Submitted Time** Worker State Cores Memory Main Class
driver-20170419145755-0006 **2017/04/19 16:01:25** worker-20170419145250-zdh120-40412 FAILED 1 1024.0 MB cn.zte.HdfsTest
please see the attachment:https://issues.apache.org/jira/secure/attachment/12863976/after_fix.png
'Submitted Time' field, the date format **has been formatted**, in running Applications table or Completed Applicationstable in master web ui, **it is correct.**
e.g.
Running Applications
Application ID Name Cores Memory per Executor **Submitted Time** User State Duration
app-20170419160910-0000 (kill) SparkSQL::10.43.183.120 1 5.0 GB **2017/04/19 16:09:10** root RUNNING 53 s
**Format after the time easier to observe, and consistent with the applications table,so I think it's worth fixing.**
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: 郭小龙 10207633 <guo.xiaolong1@zte.com.cn>
Author: guoxiaolong <guo.xiaolong1@zte.com.cn>
Author: guoxiaolongzte <guo.xiaolong1@zte.com.cn>
Closes#17682 from guoxiaolongzte/SPARK-20385.
## What changes were proposed in this pull request?
Allow passing in arbitrary parameters into docker when launching spark executors on mesos with docker containerizer tnachen
## How was this patch tested?
Manually built and tested with passed in parameter
Author: Ji Yan <jiyan@Jis-MacBook-Air.local>
Closes#17109 from yanji84/ji/allow_set_docker_user.
## What changes were proposed in this pull request?
This PR proposes to run Spark unidoc to test Javadoc 8 build as Javadoc 8 is easily re-breakable.
There are several problems with it:
- It introduces little extra bit of time to run the tests. In my case, it took 1.5 mins more (`Elapsed :[94.8746569157]`). How it was tested is described in "How was this patch tested?".
- > One problem that I noticed was that Unidoc appeared to be processing test sources: if we can find a way to exclude those from being processed in the first place then that might significantly speed things up.
(see joshrosen's [comment](https://issues.apache.org/jira/browse/SPARK-18692?focusedCommentId=15947627&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel#comment-15947627))
To complete this automated build, It also suggests to fix existing Javadoc breaks / ones introduced by test codes as described above.
There fixes are similar instances that previously fixed. Please refer https://github.com/apache/spark/pull/15999 and https://github.com/apache/spark/pull/16013
Note that this only fixes **errors** not **warnings**. Please see my observation https://github.com/apache/spark/pull/17389#issuecomment-288438704 for spurious errors by warnings.
## How was this patch tested?
Manually via `jekyll build` for building tests. Also, tested via running `./dev/run-tests`.
This was tested via manually adding `time.time()` as below:
```diff
profiles_and_goals = build_profiles + sbt_goals
print("[info] Building Spark unidoc (w/Hive 1.2.1) using SBT with these arguments: ",
" ".join(profiles_and_goals))
+ import time
+ st = time.time()
exec_sbt(profiles_and_goals)
+ print("Elapsed :[%s]" % str(time.time() - st))
```
produces
```
...
========================================================================
Building Unidoc API Documentation
========================================================================
...
[info] Main Java API documentation successful.
...
Elapsed :[94.8746569157]
...
Author: hyukjinkwon <gurwls223@gmail.com>
Closes#17477 from HyukjinKwon/SPARK-18692.
## What changes were proposed in this pull request?
Add spark.mesos.task.labels configuration option to add mesos key:value labels to the executor.
"k1:v1,k2:v2" as the format, colons separating key-value and commas to list out more than one.
Discussion of labels with mgummelt at #17404
## How was this patch tested?
Added unit tests to verify labels were added correctly, with incorrect labels being ignored and added a test to test the name of the executor.
Tested with: `./build/sbt -Pmesos mesos/test`
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Kalvin Chau <kalvin.chau@viasat.com>
Closes#17413 from kalvinnchau/mesos-labels.
## What changes were proposed in this pull request?
Adding configurable mesos executor names and labels using `spark.mesos.task.name` and `spark.mesos.task.labels`.
Labels were defined as `k1:v1,k2:v2`.
mgummelt
## How was this patch tested?
Added unit tests to verify labels were added correctly, with incorrect labels being ignored and added a test to test the name of the executor.
Tested with: `./build/sbt -Pmesos mesos/test`
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Kalvin Chau <kalvin.chau@viasat.com>
Closes#17404 from kalvinnchau/mesos-config.
This commit adds a killTaskAttempt method to SparkContext, to allow users to
kill tasks so that they can be re-scheduled elsewhere.
This also refactors the task kill path to allow specifying a reason for the task kill. The reason is propagated opaquely through events, and will show up in the UI automatically as `(N killed: $reason)` and `TaskKilled: $reason`. Without this change, there is no way to provide the user feedback through the UI.
Currently used reasons are "stage cancelled", "another attempt succeeded", and "killed via SparkContext.killTask". The user can also specify a custom reason through `SparkContext.killTask`.
cc rxin
In the stage overview UI the reasons are summarized:

Within the stage UI you can see individual task kill reasons:

Existing tests, tried killing some stages in the UI and verified the messages are as expected.
Author: Eric Liang <ekl@databricks.com>
Author: Eric Liang <ekl@google.com>
Closes#17166 from ericl/kill-reason.
## What changes were proposed in this pull request?
Fixup typo in comment.
## How was this patch tested?
Don't need.
Author: Ye Yin <eyniy@qq.com>
Closes#17396 from hustcat/fix.
## What changes were proposed in this pull request?
Increase default refuse_seconds timeout, and make it configurable. See JIRA for details on how this reduces the risk of starvation.
## How was this patch tested?
Unit tests, Manual testing, and Mesos/Spark integration test suite
cc susanxhuynh skonto jmlvanre
Author: Michael Gummelt <mgummelt@mesosphere.io>
Closes#17031 from mgummelt/SPARK-19702-suppress-revive.
## What changes were proposed in this pull request?
See JIRA
## How was this patch tested?
Unit tests, Mesos/Spark integration tests
cc skonto susanxhuynh
Author: Michael Gummelt <mgummelt@mesosphere.io>
Closes#17045 from mgummelt/SPARK-19373-registered-resources.
## What changes were proposed in this pull request?
Adding the default UncaughtExceptionHandler to the MesosClusterDispatcher.
## How was this patch tested?
I verified it manually, when any of the dispatcher thread gets uncaught exceptions then the default UncaughtExceptionHandler will handle those exceptions.
Author: Devaraj K <devaraj@apache.org>
Closes#13072 from devaraj-kavali/SPARK-15288.
## What changes were proposed in this pull request?
`askSync` is already added in `RpcEndpointRef` (see SPARK-19347 and https://github.com/apache/spark/pull/16690#issuecomment-276850068) and `askWithRetry` is marked as deprecated.
As mentioned SPARK-18113(https://github.com/apache/spark/pull/16503#event-927953218):
>askWithRetry is basically an unneeded API, and a leftover from the akka days that doesn't make sense anymore. It's prone to cause deadlocks (exactly because it's blocking), it imposes restrictions on the caller (e.g. idempotency) and other things that people generally don't pay that much attention to when using it.
Since `askWithRetry` is just used inside spark and not in user logic. It might make sense to replace all of them with `askSync`.
## How was this patch tested?
This PR doesn't change code logic, existing unit test can cover.
Author: jinxing <jinxing@meituan.com>
Closes#16790 from jinxing64/SPARK-19450.
## What changes were proposed in this pull request?
Now handling the spark exception which gets thrown for invalid job configuration, marking that job as failed and continuing to launch the other drivers instead of throwing the exception.
## How was this patch tested?
I verified manually, now the misconfigured jobs move to Finished Drivers section in UI and continue to launch the other jobs.
Author: Devaraj K <devaraj@apache.org>
Closes#13077 from devaraj-kavali/SPARK-10748.
## What changes were proposed in this pull request?
After using Apache Parquet 1.8.2, `ParquetAvroCompatibilitySuite` fails on **Maven** test. It is because `org.apache.parquet.avro.AvroParquetWriter` in the test code used new `avro 1.8.0` specific class, `LogicalType`. This PR aims to fix the test dependency of `sql/core` module to use avro 1.8.0.
https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7/2530/consoleFull
```
ParquetAvroCompatibilitySuite:
*** RUN ABORTED ***
java.lang.NoClassDefFoundError: org/apache/avro/LogicalType
at org.apache.parquet.avro.AvroParquetWriter.writeSupport(AvroParquetWriter.java:144)
```
## How was this patch tested?
Pass the existing test with **Maven**.
```
$ build/mvn -Pyarn -Phadoop-2.7 -Pkinesis-asl -Phive -Phive-thriftserver test
...
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 02:07 h
[INFO] Finished at: 2017-02-04T05:41:43+00:00
[INFO] Final Memory: 77M/987M
[INFO] ------------------------------------------------------------------------
```
Author: Dongjoon Hyun <dongjoon@apache.org>
Closes#16795 from dongjoon-hyun/SPARK-19409-2.
This change introduces a new auth mechanism to the transport library,
to be used when users enable strong encryption. This auth mechanism
has better security than the currently used DIGEST-MD5.
The new protocol uses symmetric key encryption to mutually authenticate
the endpoints, and is very loosely based on ISO/IEC 9798.
The new protocol falls back to SASL when it thinks the remote end is old.
Because SASL does not support asking the server for multiple auth protocols,
which would mean we could re-use the existing SASL code by just adding a
new SASL provider, the protocol is implemented outside of the SASL API
to avoid the boilerplate of adding a new provider.
Details of the auth protocol are discussed in the included README.md
file.
This change partly undos the changes added in SPARK-13331; AES encryption
is now decoupled from SASL authentication. The encryption code itself,
though, has been re-used as part of this change.
## How was this patch tested?
- Unit tests
- Tested Spark 2.2 against Spark 1.6 shuffle service with SASL enabled
- Tested Spark 2.2 against Spark 2.2 shuffle service with SASL fallback disabled
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes#16521 from vanzin/SPARK-19139.
In the existing code, there are three layers of serialization
involved in sending a task from the scheduler to an executor:
- A Task object is serialized
- The Task object is copied to a byte buffer that also
contains serialized information about any additional JARs,
files, and Properties needed for the task to execute. This
byte buffer is stored as the member variable serializedTask
in the TaskDescription class.
- The TaskDescription is serialized (in addition to the serialized
task + JARs, the TaskDescription class contains the task ID and
other metadata) and sent in a LaunchTask message.
While it *is* necessary to have two layers of serialization, so that
the JAR, file, and Property info can be deserialized prior to
deserializing the Task object, the third layer of deserialization is
unnecessary. This commit eliminates a layer of serialization by moving
the JARs, files, and Properties into the TaskDescription class.
This commit also serializes the Properties manually (by traversing the map),
as is done with the JARs and files, which reduces the final serialized size.
Unit tests
This is a simpler alternative to the approach proposed in #15505.
shivaram and I did some benchmarking of this and #15505 on a 20-machine m2.4xlarge EC2 machines (160 cores). We ran ~30 trials of code [1] (a very simple job with 10K tasks per stage) and measured the average time per stage:
Before this change: 2490ms
With this change: 2345 ms (so ~6% improvement over the baseline)
With witgo's approach in #15505: 2046 ms (~18% improvement over baseline)
The reason that #15505 has a more significant improvement is that it also moves the serialization from the TaskSchedulerImpl thread to the CoarseGrainedSchedulerBackend thread. I added that functionality on top of this change, and got almost the same improvement [1] as #15505 (average of 2103ms). I think we should decouple these two changes, both so we have some record of the improvement form each individual improvement, and because this change is more about simplifying the code base (the improvement is negligible) while the other is about performance improvement. The plan, currently, is to merge this PR and then merge the remaining part of #15505 that moves serialization.
[1] The reason the improvement wasn't quite as good as with #15505 when we ran the benchmarks is almost certainly because, at the point when we ran the benchmarks, I hadn't updated the code to manually serialize the Properties (instead the code was using Java's default serialization for the Properties object, whereas #15505 manually serialized the Properties). This PR has since been updated to manually serialize the Properties, just like the other maps.
Author: Kay Ousterhout <kayousterhout@gmail.com>
Closes#16053 from kayousterhout/SPARK-17931.
## What changes were proposed in this pull request?
Not adding the Killed applications for retry.
## How was this patch tested?
I have verified manually in the Mesos cluster, with the changes the killed applications move to Finished Drivers section and will not retry.
Author: Devaraj K <devaraj@apache.org>
Closes#13323 from devaraj-kavali/SPARK-15555.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}