### What changes were proposed in this pull request?
Removed unnecessary persist.
### Why are the changes needed?
Persist in `PythonMLLibAPI.scala` is unnecessary because later in `run()` of `gmmAlg` is caching the data.
710ddab39e/mllib/src/main/scala/org/apache/spark/mllib/clustering/GaussianMixture.scala (L167-L171)
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manually
Closes#26758 from amanomer/improperPersist.
Authored-by: Aman Omer <amanomer1996@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Where it generates a deprecation warning in Scala 2.13, replace Symbol shorthand syntax `'foo` with an equivalent.
### Why are the changes needed?
Symbol syntax `'foo` is deprecated in Scala 2.13. The lines changed below otherwise generate about 440 warnings when building for 2.13.
The previous PR directly replaced many usages with `Symbol("foo")`. But it's also used to specify Columns via implicit conversion (`.select('foo)`) or even where simple Strings are used (`.as('foo)`), as it's kind of an abstraction for interned Strings.
While I find this syntax confusing and would like to deprecate it, here I just replaced it where it generates a build warning (not sure why all occurrences don't): `$"foo"` or just `"foo"`.
### Does this PR introduce any user-facing change?
Should not change behavior.
### How was this patch tested?
Existing tests.
Closes#26748 from srowen/SPARK-29392.2.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
1, `predictionCol` in `ml.classification` & `ml.clustering` add `NominalAttribute`
2, `rawPredictionCol` in `ml.classification` add `AttributeGroup` containing vectorsize=`numClasses`
3, `probabilityCol` in `ml.classification` & `ml.clustering` add `AttributeGroup` containing vectorsize=`numClasses`/`k`
4, `leafCol` in GBT/RF add `AttributeGroup` containing vectorsize=`numTrees`
5, `leafCol` in DecisionTree add `NominalAttribute`
6, `outputCol` in models in `ml.feature` add `AttributeGroup` containing vectorsize
7, `outputCol` in `UnaryTransformer`s in `ml.feature` add `AttributeGroup` containing vectorsize
### Why are the changes needed?
Appened metadata can be used in downstream ops, like `Classifier.getNumClasses`
There are many impls (like `Binarizer`/`Bucketizer`/`VectorAssembler`/`OneHotEncoder`/`FeatureHasher`/`HashingTF`/`VectorSlicer`/...) in `.ml` that append appropriate metadata in `transform`/`transformSchema` method.
However there are also many impls return no metadata in transformation, even some metadata like `vector.size`/`numAttrs`/`attrs` can be ealily inferred.
### Does this PR introduce any user-facing change?
Yes, add some metadatas in transformed dataset.
### How was this patch tested?
existing testsuites and added testsuites
Closes#26547 from zhengruifeng/add_output_vecSize.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
When PCA was first impled in [SPARK-5521](https://issues.apache.org/jira/browse/SPARK-5521), at that time Matrix.multiply(BLAS.gemv internally) did not support sparse vector. So worked around it by applying a sparse matrix multiplication.
Since [SPARK-7681](https://issues.apache.org/jira/browse/SPARK-7681), BLAS.gemv supported sparse vector. So we can directly use Matrix.multiply now.
### Why are the changes needed?
for simplity
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
existing testsuites
Closes#26745 from zhengruifeng/pca_mul.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
MNB/CNB/BNB use empty sigma matrix instead of null
### Why are the changes needed?
1,Using empty sigma matrix will simplify the impl
2,I am reviewing FM impl these days, FMModels have optional bias and linear part. It seems more reasonable to set optional part an empty vector/matrix or zero value than `null`
### Does this PR introduce any user-facing change?
yes, sigma from `null` to empty matrix
### How was this patch tested?
updated testsuites
Closes#26679 from zhengruifeng/nb_use_empty_sigma.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
Summarizer support more metrics: sum, std
### Why are the changes needed?
Those metrics are widely used, it will be convenient to directly obtain them other than a conversion.
in `NaiveBayes`: we want the sum of vectors, mean & weightSum need to computed then multiplied
in `StandardScaler`,`AFTSurvivalRegression`,`LinearRegression`,`LinearSVC`,`LogisticRegression`: we need to obtain `variance` and then sqrt it to get std
### Does this PR introduce any user-facing change?
yes, new metrics are exposed to end users
### How was this patch tested?
added testsuites
Closes#26596 from zhengruifeng/summarizer_add_metrics.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
MulticlassClassificationEvaluator support hammingLoss
### Why are the changes needed?
1, it is an easy to compute hammingLoss based on confusion matrix
2, scikit-learn supports it
### Does this PR introduce any user-facing change?
yes
### How was this patch tested?
added testsuites
Closes#26597 from zhengruifeng/multi_class_hamming_loss.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
Impl Complement Naive Bayes Classifier as a `modelType` option in `NaiveBayes`
### Why are the changes needed?
1, it is a better choice for text classification: it is said in [scikit-learn](https://scikit-learn.org/stable/modules/naive_bayes.html#complement-naive-bayes) that 'CNB regularly outperforms MNB (often by a considerable margin) on text classification tasks.'
2, CNB is highly similar to existing MNB, only a small part of existing MNB need to be changed, so it is a easy win to support CNB.
### Does this PR introduce any user-facing change?
yes, a new `modelType` is supported
### How was this patch tested?
added testsuites
Closes#26575 from zhengruifeng/cnb.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
A follow-up to rm useless test in VectorUDTSuite
### Why are the changes needed?
rm useless test, which is already covered.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
no
Closes#26620 from yaooqinn/SPARK-29961-f.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add typeof function for Spark to get the underlying type of value.
```sql
-- !query 0
select typeof(1)
-- !query 0 schema
struct<typeof(1):string>
-- !query 0 output
int
-- !query 1
select typeof(1.2)
-- !query 1 schema
struct<typeof(1.2):string>
-- !query 1 output
decimal(2,1)
-- !query 2
select typeof(array(1, 2))
-- !query 2 schema
struct<typeof(array(1, 2)):string>
-- !query 2 output
array<int>
-- !query 3
select typeof(a) from (values (1), (2), (3.1)) t(a)
-- !query 3 schema
struct<typeof(a):string>
-- !query 3 output
decimal(11,1)
decimal(11,1)
decimal(11,1)
```
##### presto
```sql
presto> select typeof(array[1]);
_col0
----------------
array(integer)
(1 row)
```
##### PostgreSQL
```sql
postgres=# select pg_typeof(a) from (values (1), (2), (3.0)) t(a);
pg_typeof
-----------
numeric
numeric
numeric
(3 rows)
```
##### impala
https://issues.apache.org/jira/browse/IMPALA-1597
### Why are the changes needed?
a function which is better we have to help us debug, test, develop ...
### Does this PR introduce any user-facing change?
add a new function
### How was this patch tested?
add ut and example
Closes#26599 from yaooqinn/SPARK-29961.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
Use JUnit assertions in tests uniformly, not JVM assert() statements.
### Why are the changes needed?
assert() statements do not produce as useful errors when they fail, and, if they were somehow disabled, would fail to test anything.
### Does this PR introduce any user-facing change?
No. The assertion logic should be identical.
### How was this patch tested?
Existing tests.
Closes#26581 from srowen/assertToJUnit.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
```LSHModel.approxNearestNeighbors``` sorts the full dataset on the hashDistance in order to find a threshold. This PR uses approxQuantile instead.
### Why are the changes needed?
To improve performance.
### Does this PR introduce any user-facing change?
Yes.
Changed ```LSH``` to make it extend ```HasRelativeError```
```LSH``` and ```LSHModel``` have new APIs ```setRelativeError/getRelativeError```
### How was this patch tested?
Existing tests. Also added a couple doc test in python to test newly added ```getRelativeError```
Closes#26415 from huaxingao/spark-18409.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
support `modelType` `gaussian`
### Why are the changes needed?
current modelTypes do not support continuous data
### Does this PR introduce any user-facing change?
yes, add a `modelType` option
### How was this patch tested?
existing testsuites and added ones
Closes#26413 from zhengruifeng/gnb.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
Add multi-cols support in StopWordsRemover
### Why are the changes needed?
As a basic Transformer, StopWordsRemover should support multi-cols.
Param stopWords can be applied across all columns.
### Does this PR introduce any user-facing change?
```StopWordsRemover.setInputCols```
```StopWordsRemover.setOutputCols```
### How was this patch tested?
Unit tests
Closes#26480 from huaxingao/spark-29808.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Adjust RDD to persist.
### Why are the changes needed?
To handle the improper persist strategy.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manually
Closes#26483 from amanomer/SPARK-29823.
Authored-by: Aman Omer <amanomer1996@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Adjust improper unpersist timing on RDD.
### Why are the changes needed?
Improper unpersist timing will result in memory waste
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manually
Closes#26469 from Icysandwich/SPARK-29844.
Authored-by: DongWang <cqwd123@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
1,ML models should extend toString method to expose basic information.
Current some algs (GBT/RF/LoR) had done this, while others not yet.
2,add `val numFeatures` in `BisectingKMeansModel`/`GaussianMixtureModel`/`KMeansModel`/`AFTSurvivalRegressionModel`/`IsotonicRegressionModel`
### Why are the changes needed?
ML models should extend toString method to expose basic information.
### Does this PR introduce any user-facing change?
yes
### How was this patch tested?
existing testsuites
Closes#26439 from zhengruifeng/models_toString.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
1,unpersist intermediate rdd `wordCounts`
2,if the `dataset` is already persisted, we do not need to persist rdd `input`
3,if both `minDF`&`maxDF` are gteq or lt than 1, we can compare & check them af first.
### Why are the changes needed?
we should unpersit unused rdd ASAP
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing testsuites
Closes#26398 from zhengruifeng/CountVectorizer_unpersist_wordCounts.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
use `ml.Summarizer` instead of `mllib.MultivariateOnlineSummarizer`
### Why are the changes needed?
1, I found that using `ml.Summarizer` is faster than current impl;
2, `mllib.MultivariateOnlineSummarizer` maintain all arrays, while `ml.Summarizer` only maintain necessary arrays
3, using `ml.Summarizer` will avoid vector conversions to `mlllib.Vector`
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
existing testsuites
Closes#26393 from zhengruifeng/maxabs_opt.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This PR implements ```validateInput``` in ```ElementwiseProduct```, ```Normalizer``` and ```PolynomialExpansion```.
### Why are the changes needed?
```UnaryTransformer``` has abstract method ```validateInputType``` and call it in ```transformSchema```, but this method is not implemented in ```ElementwiseProduct```, ```Normalizer``` and ```PolynomialExpansion```.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing tests
Closes#26388 from huaxingao/spark-29746.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
1, change the scope of `ml.SummarizerBuffer` and add a method `createSummarizerBuffer` for it, so it can be used as an aggregator like `MultivariateOnlineSummarizer`;
2, In LoR/AFT/LiR/SVC, use Summarizer instead of MultivariateOnlineSummarizer
### Why are the changes needed?
The computation of summary before learning iterations is a bottleneck in high-dimension cases, since `MultivariateOnlineSummarizer` compute much more than needed.
In the [ticket](https://issues.apache.org/jira/browse/SPARK-29754) is an example, with `--driver-memory=4G` LoR will always fail on KDDA dataset. If we swith to `ml.Summarizer`, then `--driver-memory=3G` is enough to train a model.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
existing testsuites & manual test in REPL
Closes#26396 from zhengruifeng/using_SummarizerBuffer.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
expose expert param `aggregationDepth` in algs: GMM/GLR
### Why are the changes needed?
SVC/LoR/LiR/AFT had exposed expert param aggregationDepth to end users. It should be nice to expose it in similar algs.
### Does this PR introduce any user-facing change?
yes, expose new param
### How was this patch tested?
added pytext tests
Closes#26322 from zhengruifeng/agg_opt.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
The `assertEquals` method of JUnit Assert requires the first parameter to be the expected value. In this PR, I propose to change the order of parameters when the expected value is passed as the second parameter.
### Why are the changes needed?
Wrong order of assert parameters confuses when the assert fails and the parameters have special string representation. For example:
```java
assertEquals(input1.add(input2), new CalendarInterval(5, 5, 367200000000L));
```
```
java.lang.AssertionError:
Expected :interval 5 months 5 days 101 hours
Actual :interval 5 months 5 days 102 hours
```
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
By existing tests.
Closes#26377 from MaxGekk/fix-order-in-assert-equals.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
persist the input if needed
### Why are the changes needed?
training with non-cached dataset will hurt performance
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
existing tests
Closes#26344 from zhengruifeng/linear_svc_cache.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
1, add shared param `relativeError`
2, `Imputer`/`RobusterScaler`/`QuantileDiscretizer` extend `HasRelativeError`
### Why are the changes needed?
It makes sense to expose RelativeError to end users, since it controls both the precision and memory overhead.
`QuantileDiscretizer` had already added this param, while other algs not yet.
### Does this PR introduce any user-facing change?
yes, new param is added in `Imputer`/`RobusterScaler`
### How was this patch tested?
existing testsutes
Closes#26305 from zhengruifeng/add_relative_err.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
To push the built jars to maven release repository, we need to remove the 'SNAPSHOT' tag from the version name.
Made the following changes in this PR:
* Update all the `3.0.0-SNAPSHOT` version name to `3.0.0-preview`
* Update the sparkR version number check logic to allow jvm version like `3.0.0-preview`
**Please note those changes were generated by the release script in the past, but this time since we manually add tags on master branch, we need to manually apply those changes too.**
We shall revert the changes after 3.0.0-preview release passed.
### Why are the changes needed?
To make the maven release repository to accept the built jars.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
### What changes were proposed in this pull request?
add single-column input/ouput support in OneHotEncoder
### Why are the changes needed?
Currently, OneHotEncoder only has multi columns support. It makes sense to support single column as well.
### Does this PR introduce any user-facing change?
Yes
```OneHotEncoder.setInputCol```
```OneHotEncoder.setOutputCol```
### How was this patch tested?
Unit test
Closes#26265 from huaxingao/spark-29565.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Liang-Chi Hsieh <liangchi@uber.com>
### What changes were proposed in this pull request?
To push the built jars to maven release repository, we need to remove the 'SNAPSHOT' tag from the version name.
Made the following changes in this PR:
* Update all the `3.0.0-SNAPSHOT` version name to `3.0.0-preview`
* Update the PySpark version from `3.0.0.dev0` to `3.0.0`
**Please note those changes were generated by the release script in the past, but this time since we manually add tags on master branch, we need to manually apply those changes too.**
We shall revert the changes after 3.0.0-preview release passed.
### Why are the changes needed?
To make the maven release repository to accept the built jars.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
N/A
Closes#26243 from jiangxb1987/3.0.0-preview-prepare.
Lead-authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
### What changes were proposed in this pull request?
add single-column input/output support in Imputer
### Why are the changes needed?
Currently, Imputer only has multi-column support. This PR adds single-column input/output support.
### Does this PR introduce any user-facing change?
Yes. add single-column input/output support in Imputer
```Imputer.setInputCol```
```Imputer.setOutputCol```
### How was this patch tested?
add unit tests
Closes#26247 from huaxingao/spark-29566.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
Remove automatically generated param setters in _shared_params_code_gen.py
### Why are the changes needed?
To keep parity between scala and python
### Does this PR introduce any user-facing change?
Yes
Add some setters in Python ML XXXModels
### How was this patch tested?
unit tests
Closes#26232 from huaxingao/spark-29093.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
add weight support for GBTs by sampling data before passing it to trees and then passing weights to trees
in summary:
1, add setters of `minWeightFractionPerNode` & `weightCol`
2, update input types in private methods from `RDD[LabeledPoint]` to `RDD[Instance]`:
`DecisionTreeRegressor.train`, `GradientBoostedTrees.run`, `GradientBoostedTrees.runWithValidation`, `GradientBoostedTrees.computeInitialPredictionAndError`, `GradientBoostedTrees.computeError`,
`GradientBoostedTrees.evaluateEachIteration`, `GradientBoostedTrees.boost`, `GradientBoostedTrees.updatePredictionError`
3, add new private method `GradientBoostedTrees.computeError(data, predError)` to compute average error, since original `predError.values.mean()` do not take weights into account.
4, add new tests
### Why are the changes needed?
GBTs should support sample weights like other algs
### Does this PR introduce any user-facing change?
yes, new setters are added
### How was this patch tested?
existing & added testsuites
Closes#25926 from zhengruifeng/gbt_add_weight.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
The trees (Array[```DecisionTreeRegressionModel```]) in ```RandomForestRegressionModel``` only contains the default parameter value. Need to update the parameter maps for these trees.
Same issues in ```RandomForestClassifier```, ```GBTClassifier``` and ```GBTRegressor```
### Why are the changes needed?
User wants to access each individual tree and build the trees back up for the random forest estimator. This doesn't work because trees don't have the correct parameter values
### Does this PR introduce any user-facing change?
Yes. Now the trees in ```RandomForestRegressionModel```, ```RandomForestClassifier```, ```GBTClassifier``` and ```GBTRegressor``` have the correct parameter values.
### How was this patch tested?
Add tests
Closes#26154 from huaxingao/spark-29232.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
`ml.MulticlassClassificationEvaluator` & `mllib.MulticlassMetrics` support log-loss
### Why are the changes needed?
log-loss is an important classification metric and is widely used in practice
### Does this PR introduce any user-facing change?
Yes, add new option ("logloss") and a related param `eps`
### How was this patch tested?
added testsuites & local tests refering to sklearn
Closes#26135 from zhengruifeng/logloss.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
Binarizer support multi-column by extending `HasInputCols`/`HasOutputCols`/`HasThreshold`/`HasThresholds`
### Why are the changes needed?
similar algs in `ml.feature` already support multi-column, like `Bucketizer`/`StringIndexer`/`QuantileDiscretizer`
### Does this PR introduce any user-facing change?
yes, add setter/getter of `thresholds`/`inputCols`/`outputCols`
### How was this patch tested?
added suites
Closes#26064 from zhengruifeng/binarizer_multicols.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
get the first row lazily, and reuse it for each vector column.
### Why are the changes needed?
avoid unnecssary `first` jobs
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing testsuites & local tests in repl
Closes#26052 from zhengruifeng/rformula_lazy_row.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
Use `.sameElements` to compare (non-nested) arrays, as `Arrays.deep` is removed in 2.13 and wasn't the best way to do this in the first place.
### Why are the changes needed?
To compile with 2.13.
### Does this PR introduce any user-facing change?
None.
### How was this patch tested?
Existing tests.
Closes#26073 from srowen/SPARK-29416.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Replace `Unit` with equivalent `()` where code refers to the `Unit` companion object.
### Why are the changes needed?
It doesn't compile otherwise in Scala 2.13.
- https://github.com/scala/scala/blob/v2.13.0/src/library/scala/Unit.scala#L30
### Does this PR introduce any user-facing change?
Should be no behavior change at all.
### How was this patch tested?
Existing tests.
Closes#26070 from srowen/SPARK-29411.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Invocations like `sc.parallelize(Array((1,2)))` cause a compile error in 2.13, like:
```
[ERROR] [Error] /Users/seanowen/Documents/spark_2.13/core/src/test/scala/org/apache/spark/ShuffleSuite.scala:47: overloaded method value apply with alternatives:
(x: Unit,xs: Unit*)Array[Unit] <and>
(x: Double,xs: Double*)Array[Double] <and>
(x: Float,xs: Float*)Array[Float] <and>
(x: Long,xs: Long*)Array[Long] <and>
(x: Int,xs: Int*)Array[Int] <and>
(x: Char,xs: Char*)Array[Char] <and>
(x: Short,xs: Short*)Array[Short] <and>
(x: Byte,xs: Byte*)Array[Byte] <and>
(x: Boolean,xs: Boolean*)Array[Boolean]
cannot be applied to ((Int, Int), (Int, Int), (Int, Int), (Int, Int))
```
Using a `Seq` instead appears to resolve it, and is effectively equivalent.
### Why are the changes needed?
To better cross-build for 2.13.
### Does this PR introduce any user-facing change?
None.
### How was this patch tested?
Existing tests.
Closes#26062 from srowen/SPARK-29401.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Add getters/setters in Pyspark ALSModel.
### Why are the changes needed?
To keep parity between python and scala.
### Does this PR introduce any user-facing change?
Yes.
add the following getters/setters to ALSModel
```
get/setUserCol
get/setItemCol
get/setColdStartStrategy
get/setPredictionCol
```
### How was this patch tested?
add doctest
Closes#25947 from huaxingao/spark-29269.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
- Removal of `private[ml]` modifier from `Regressor`.
- Marking `Regressor` as `DeveloperApi`.
### Why are the changes needed?
Consistency with the rest of ML API as described in [the corresponding JIRA ticket](https://issues.apache.org/jira/browse/SPARK-29363).
### Does this PR introduce any user-facing change?
Yes, as described above.
### How was this patch tested?
Existing tests.
Closes#26033 from zero323/SPARK-29363.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR aims to remove `scalatest` deprecation warnings with the following changes.
- `org.scalatest.mockito.MockitoSugar` -> `org.scalatestplus.mockito.MockitoSugar`
- `org.scalatest.selenium.WebBrowser` -> `org.scalatestplus.selenium.WebBrowser`
- `org.scalatest.prop.Checkers` -> `org.scalatestplus.scalacheck.Checkers`
- `org.scalatest.prop.GeneratorDrivenPropertyChecks` -> `org.scalatestplus.scalacheck.ScalaCheckDrivenPropertyChecks`
### Why are the changes needed?
According to the Jenkins logs, there are 118 warnings about this.
```
grep "is deprecated" ~/consoleText | grep scalatest | wc -l
118
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
After Jenkins passes, we need to check the Jenkins log.
Closes#25982 from dongjoon-hyun/SPARK-29307.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
Scala 2.13 emits a deprecation warning for procedure-like declarations:
```
def foo() {
...
```
This is equivalent to the following, so should be changed to avoid a warning:
```
def foo(): Unit = {
...
```
### Why are the changes needed?
It will avoid about a thousand compiler warnings when we start to support Scala 2.13. I wanted to make the change in 3.0 as there are less likely to be back-ports from 3.0 to 2.4 than 3.1 to 3.0, for example, minimizing that downside to touching so many files.
Unfortunately, that makes this quite a big change.
### Does this PR introduce any user-facing change?
No behavior change at all.
### How was this patch tested?
Existing tests.
Closes#25968 from srowen/SPARK-29291.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR regenerate the benchmark results in `core` and `mllib` module in order to compare JDK8/JDK11 result.
### Why are the changes needed?
According to the result, For `PropertiesCloneBenchmark` and `UDTSerializationBenchmark`, JDK11 is slightly faster. In general, there is no regression in JDK11.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
This is a test-only PR. Manually run the benchmark.
Closes#25969 from dongjoon-hyun/SPARK-29297.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
1, expose `BinaryClassificationMetrics.numBins` in `BinaryClassificationEvaluator`
2, expose `RegressionMetrics.throughOrigin` in `RegressionEvaluator`
3, add metric `explainedVariance` in `RegressionEvaluator`
### Why are the changes needed?
existing function in mllib.metrics should also be exposed in ml
### Does this PR introduce any user-facing change?
yes, this PR add two expert params and one metric option
### How was this patch tested?
existing and added tests
Closes#25940 from zhengruifeng/evaluator_add_param.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
common methods support extract weights
### Why are the changes needed?
today more and more ML algs support weighting, add this method will make impls simple
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing testsuites
Closes#25802 from zhengruifeng/add_extractInstances.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Support for dot product with:
- `ml.linalg.Vector`
- `ml.linalg.Vectors`
- `mllib.linalg.Vector`
- `mllib.linalg.Vectors`
### Why are the changes needed?
Dot product is useful for feature engineering and scoring. BLAS routines are already there, just a wrapper is needed.
### Does this PR introduce any user-facing change?
No user facing changes, just some new functionality.
### How was this patch tested?
Tests were written and added to the appropriate `VectorSuites` classes. They can be quickly run with:
```
sbt "mllib-local/testOnly org.apache.spark.ml.linalg.VectorsSuite"
sbt "mllib/testOnly org.apache.spark.mllib.linalg.VectorsSuite"
```
Closes#25818 from phpisciuneri/SPARK-29121.
Authored-by: Patrick Pisciuneri <phpisciuneri@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Update breeze dependency to 1.0.
### Why are the changes needed?
Breeze 1.0 supports Scala 2.13 and has a few bug fixes.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#25874 from srowen/SPARK-28772.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
if threshold<0, convert implict 0 to 1, althought this will break sparsity
### Why are the changes needed?
if `threshold<0`, current impl deal with sparse vector incorrectly.
See JIRA [SPARK-29144](https://issues.apache.org/jira/browse/SPARK-29144) and [Scikit-Learn's Binarizer](https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.Binarizer.html) ('Threshold may not be less than 0 for operations on sparse matrices.') for details.
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
added testsuite
Closes#25829 from zhengruifeng/binarizer_throw_exception_sparse_vector.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
1,GMM: obtaining the prediction (double) from its probabilty prediction(vector)
2,GLR: obtaining the prediction (double) from its link prediction(double)
### Why are the changes needed?
it avoid predict twice
### Does this PR introduce any user-facing change?
no
### How was this patch tested?
existing tests
Closes#25815 from zhengruifeng/gmm_transform_opt.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Fitting ALS model can be failed due to nondeterministic input data. Currently the failure is thrown by an ArrayIndexOutOfBoundsException which is not explainable for end users what is wrong in fitting.
This patch catches this exception and rethrows a more explainable one, when the input data is nondeterministic.
Because we may not exactly know the output deterministic level of RDDs produced by user code, this patch also adds a note to Scala/Python/R ALS document about the training data deterministic level.
### Why are the changes needed?
ArrayIndexOutOfBoundsException was observed during fitting ALS model. It was caused by mismatching between in/out user/item blocks during computing ratings.
If the training RDD output is nondeterministic, when fetch failure is happened, rerun part of training RDD can produce inconsistent user/item blocks.
This patch is needed to notify users ALS fitting on nondeterministic input.
### Does this PR introduce any user-facing change?
Yes. When fitting ALS model on nondeterministic input data, previously if rerun happens, users would see ArrayIndexOutOfBoundsException caused by mismatch between In/Out user/item blocks.
After this patch, a SparkException with more clear message will be thrown, and original ArrayIndexOutOfBoundsException is wrapped.
### How was this patch tested?
Tested on development cluster.
Closes#25789 from viirya/als-indeterminate-input.
Lead-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Co-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
This removes the duplicated dependency which is added by [SPARK-29007](b62ef8f793/mllib/pom.xml (L58-L64)).
### Why are the changes needed?
Maven complains this kind of duplications. We had better be safe in the future Maven versions.
```
$ cd mllib
$ mvn clean package -DskipTests
[INFO] Scanning for projects...
[WARNING]
[WARNING] Some problems were encountered while building the effective model for org.apache.spark:spark-mllib_2.12🫙3.0.0-SNAPSHOT
[WARNING] 'dependencies.dependency.(groupId:artifactId:type:classifier)' must be unique: org.apache.spark:spark-streaming_${scala.binary.version}:test-jar -> duplicate declaration of version ${project.version} line 119, column 17
[WARNING]
[WARNING] It is highly recommended to fix these problems because they threaten the stability of your build.
[WARNING]
[WARNING] For this reason, future Maven versions might no longer support building such malformed projects.
[WARNING]
...
```
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Manual check since this is a warning.
```
$ cd mllib
$ mvn clean package -DskipTests
```
Closes#25783 from dongjoon-hyun/SPARK-29007.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This patch enforces tests to prevent leaking newly created SparkContext while is created via initializing StreamingContext. Leaking SparkContext in test would make most of following tests being failed as well, so this patch applies defensive programming, trying its best to ensure SparkContext is cleaned up.
### Why are the changes needed?
We got some case in CI build where SparkContext is being leaked and other tests are affected by leaked SparkContext. Ideally we should isolate the environment among tests if possible.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Modified UTs.
Closes#25709 from HeartSaVioR/SPARK-29007.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
SPARK-22799 added more comprehensive error logic for Bucketizer. This PR is to update QuantileDiscretizer match the new error logic in Bucketizer.
## How was this patch tested?
Add new unit test.
Closes#20442 from huaxingao/spark-23265.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Liang-Chi Hsieh <liangchi@uber.com>
### What changes were proposed in this pull request?
- Remove SQLContext.createExternalTable and Catalog.createExternalTable, deprecated in favor of createTable since 2.2.0, plus tests of deprecated methods
- Remove HiveContext, deprecated in 2.0.0, in favor of `SparkSession.builder.enableHiveSupport`
- Remove deprecated KinesisUtils.createStream methods, plus tests of deprecated methods, deprecate in 2.2.0
- Remove deprecated MLlib (not Spark ML) linear method support, mostly utility constructors and 'train' methods, and associated docs. This includes methods in LinearRegression, LogisticRegression, Lasso, RidgeRegression. These have been deprecated since 2.0.0
- Remove deprecated Pyspark MLlib linear method support, including LogisticRegressionWithSGD, LinearRegressionWithSGD, LassoWithSGD
- Remove 'runs' argument in KMeans.train() method, which has been a no-op since 2.0.0
- Remove deprecated ChiSqSelector isSorted protected method
- Remove deprecated 'yarn-cluster' and 'yarn-client' master argument in favor of 'yarn' and deploy mode 'cluster', etc
Notes:
- I was not able to remove deprecated DataFrameReader.json(RDD) in favor of DataFrameReader.json(Dataset); the former was deprecated in 2.2.0, but, it is still needed to support Pyspark's .json() method, which can't use a Dataset.
- Looks like SQLContext.createExternalTable was not actually deprecated in Pyspark, but, almost certainly was meant to be? Catalog.createExternalTable was.
- I afterwards noted that the toDegrees, toRadians functions were almost removed fully in SPARK-25908, but Felix suggested keeping just the R version as they hadn't been technically deprecated. I'd like to revisit that. Do we really want the inconsistency? I'm not against reverting it again, but then that implies leaving SQLContext.createExternalTable just in Pyspark too, which seems weird.
- I *kept* LogisticRegressionWithSGD, LinearRegressionWithSGD, LassoWithSGD, RidgeRegressionWithSGD in Pyspark, though deprecated, as it is hard to remove them (still used by StreamingLogisticRegressionWithSGD?) and they are not fully removed in Scala. Maybe should not have been deprecated.
### Why are the changes needed?
Deprecated items are easiest to remove in a major release, so we should do so as much as possible for Spark 3. This does not target items deprecated 'recently' as of Spark 2.3, which is still 18 months old.
### Does this PR introduce any user-facing change?
Yes, in that deprecated items are removed from some public APIs.
### How was this patch tested?
Existing tests.
Closes#25684 from srowen/SPARK-28980.
Lead-authored-by: Sean Owen <sean.owen@databricks.com>
Co-authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Add HasNumFeatures in the scala side, with `1<<18` as the default value
### Why are the changes needed?
HasNumFeatures is already added in the py side, it is reasonable to keep them in sync.
I don't find other similar place.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Existing testsuites
Closes#25671 from zhengruifeng/add_HasNumFeatures.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: zhengruifeng <ruifengz@foxmail.com>
### What changes were proposed in this pull request?
When Initializing factors in ALS, we should use `mapPartitions` instead of current `map`, so we can preserve existing partition of the RDD of `InBlock`. The RDD of `InBlock` is already partitioned by src block id. We don't change the partition when initializing factors.
### Why are the changes needed?
This patch can reduce unnecessary shuffle after initializing factors.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
It should not change existing tests. It should pass added test that verifies shuffle dependency of factor RDDs.
Closes#25639 from viirya/fix-als-partition.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <liangchi@uber.com>
### What changes were proposed in this pull request?
The Experimental and Evolving annotations are both (like Unstable) used to express that a an API may change. However there are many things in the code that have been marked that way since even Spark 1.x. Per the dev thread, anything introduced at or before Spark 2.3.0 is pretty much 'stable' in that it would not change without a deprecation cycle. Therefore I'd like to remove most of these annotations. And, remove the `:: Experimental ::` scaladoc tag too. And likewise for Python, R.
The changes below can be summarized as:
- Generally, anything introduced at or before Spark 2.3.0 has been unmarked as neither Evolving nor Experimental
- Obviously experimental items like DSv2, Barrier mode, ExperimentalMethods are untouched
- I _did_ unmark a few MLlib classes introduced in 2.4, as I am quite confident they're not going to change (e.g. KolmogorovSmirnovTest, PowerIterationClustering)
It's a big change to review, so I'd suggest scanning the list of _files_ changed to see if any area seems like it should remain partly experimental and examine those.
### Why are the changes needed?
Many of these annotations are incorrect; the APIs are de facto stable. Leaving them also makes legitimate usages of the annotations less meaningful.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes#25558 from srowen/SPARK-28855.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
In ALS ML implementation, for non-implicit case, we checkpoint the RDD of item factors, between intervals. Before checkpointing (.checkpoint()) and materializing (.count()) RDD, this RDD was not persisted. It causes recomputation. In an experiment, there is performance difference between persisting and no persisting before checkpointing the RDD.
The performance difference is not big, but this change is not big too. The actual performance difference varies depending the interval of checkpoint, training dataset, etc.
### Why are the changes needed?
Persisting the RDD before checkpointing the RDD of item factors can avoid recomputation.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manual check RDD recomputation or not.
Taking 30% MovieLens 20M Dataset as training dataset. Setting checkpoint dir for SparkContext. Fitting an ALS model like:
```scala
val als = new ALS()
.setMaxIter(100)
.setCheckpointInterval(5)
.setRegParam(0.01)
.setUserCol("userId")
.setItemCol("movieId")
.setRatingCol("rating")
val t0 = System.currentTimeMillis()
val model = als.fit(training)
val t1 = System.currentTimeMillis()
```
Before this patch: 65.386 s
After this patch: 61.022 s
Closes#25576 from viirya/persist-item-factors.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
since method `labels` is already deprecated, we should update the examples and suites to turn off warings when compiling spark:
```
[warn] /Users/zrf/Dev/OpenSource/spark/examples/src/main/scala/org/apache/spark/examples/ml/DecisionTreeClassificationExample.scala:65: method labels in class StringIndexerModel is deprecated (since 3.0.0): `labels` is deprecated and will be removed in 3.1.0. Use `labelsArray` instead.
[warn] .setLabels(labelIndexer.labels)
[warn] ^
[warn] /Users/zrf/Dev/OpenSource/spark/examples/src/main/scala/org/apache/spark/examples/ml/GradientBoostedTreeClassifierExample.scala:68: method labels in class StringIndexerModel is deprecated (since 3.0.0): `labels` is deprecated and will be removed in 3.1.0. Use `labelsArray` instead.
[warn] .setLabels(labelIndexer.labels)
[warn] ^
```
## How was this patch tested?
existing suites
Closes#25428 from zhengruifeng/del_stringindexer_labels_usage.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Tree-based feature transformation is a widely used feature and already implemented in many famous libraries, like sklearn/xgboost/lightgbm/catboost. But is still missing in ML.
The previous discussions and design doc can be found in [SPARK-13677](https://issues.apache.org/jira/browse/SPARK-13677), which is the only left subtask in 'GBT improvement umbrella' [SPARK-14047](https://issues.apache.org/jira/browse/SPARK-14047).
This pr is to add tree-based feature transformation.
## How was this patch tested?
existing and added suites
Closes#25383 from zhengruifeng/tree_path.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
<!--
Thanks for sending a pull request! Here are some tips for you:
1. If this is your first time, please read our contributor guidelines: https://spark.apache.org/contributing.html
2. Ensure you have added or run the appropriate tests for your PR: https://spark.apache.org/developer-tools.html
3. If the PR is unfinished, add '[WIP]' in your PR title, e.g., '[WIP][SPARK-XXXX] Your PR title ...'.
4. Be sure to keep the PR description updated to reflect all changes.
5. Please write your PR title to summarize what this PR proposes.
6. If possible, provide a concise example to reproduce the issue for a faster review.
-->
### What changes were proposed in this pull request?
SparkML writer gets hadoop conf from session state, instead of the spark context.
<!--
Please clarify what changes you are proposing. The purpose of this section is to outline the changes and how this PR fixes the issue.
If possible, please consider writing useful notes for better and faster reviews in your PR. See the examples below.
1. If you refactor some codes with changing classes, showing the class hierarchy will help reviewers.
2. If you fix some SQL features, you can provide some references of other DBMSes.
3. If there is design documentation, please add the link.
4. If there is a discussion in the mailing list, please add the link.
-->
### Why are the changes needed?
Allow for multiple sessions in the same context that have different hadoop configurations.
<!--
Please clarify why the changes are needed. For instance,
1. If you propose a new API, clarify the use case for a new API.
2. If you fix a bug, you can clarify why it is a bug.
-->
### Does this PR introduce any user-facing change?
<!--
If yes, please clarify the previous behavior and the change this PR proposes - provide the console output, description and/or an example to show the behavior difference if possible.
If no, write 'No'.
-->
No
### How was this patch tested?
<!--
If tests were added, say they were added here. Please make sure to add some test cases that check the changes thoroughly including negative and positive cases if possible.
If it was tested in a way different from regular unit tests, please clarify how you tested step by step, ideally copy and paste-able, so that other reviewers can test and check, and descendants can verify in the future.
If tests were not added, please describe why they were not added and/or why it was difficult to add.
-->
Tested in pyspark.ml.tests.test_persistence.PersistenceTest test_default_read_write
Closes#25505 from helenyugithub/SPARK-28776.
Authored-by: heleny <heleny@palantir.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Delete the incorrect method `def setWeightCol(value: Double): this.type = set(threshold, value)` in `LinearSVCModel`
### Why are the changes needed?
`LinearSVCModel` should not provide this setter, moreover, this method is wrongly defined.
### Does this PR introduce any user-facing change?
yes, a public method is removed
### How was this patch tested?
existing suites
Closes#25510 from zhengruifeng/linearsvc_model_set_weightcol.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
### What changes were proposed in this pull request?
Fix dummy tree created in decision tree tests to have actually consistent stats, so that it can be compared in tests more completely. The current one has values for, say, impurity that don't even match internally.
With this, the tests can assert more about stats staying correct after load.
### Why are the changes needed?
Fixes a TODO and improves the test slightly.
### Does this PR introduce any user-facing change?
None
### How was this patch tested?
Existing tests.
Closes#25485 from srowen/SPARK-28434.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The `fit` method in `StringIndexer` sorts given labels in a sequential approach, if there are multiple input columns. When the number of input column increases, the time of label sorting dramatically increases too so it is hard to use in practice if dealing with hundreds of input columns.
This patch tries to make the label sorting parallel.
This runs benchmark like:
```scala
import org.apache.spark.ml.feature.StringIndexer
val numCol = 300
val data = (0 to 100).map { i =>
(i, 100 * i)
}
var df = data.toDF("id", "label0")
(1 to numCol).foreach { idx =>
df = df.withColumn(s"label$idx", col("label0") + 1)
}
val inputCols = (0 to numCol).map(i => s"label$i").toArray
val outputCols = (0 to numCol).map(i => s"labelIndex$i").toArray
val t0 = System.nanoTime()
val indexer = new StringIndexer().setInputCols(inputCols).setOutputCols(outputCols).setStringOrderType("alphabetDesc").fit(df)
val t1 = System.nanoTime()
println("Elapsed time: " + (t1 - t0) / 1000000000.0 + "s")
```
| numCol | 20 | 50 | 100 | 200 | 300 |
|--:|---|---|---|---|---|
| Before | 9.85 | 28.62 | 64.35 | 167.17 | 431.60 |
| After | 2.44 | 2.71 | 3.34 | 4.83 | 6.90 |
Unit: second
## How was this patch tested?
Passed existing tests. Manually test for performance.
Closes#25442 from viirya/improve_stringindexer2.
Authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR fixed typos in comments and replace the explicit type with '<>' for Java 8+.
## How was this patch tested?
Manually tested.
Closes#25338 from younggyuchun/younggyu.
Authored-by: younggyu chun <younggyuchun@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
some cleanup and tiny optimization
1, since the `transformImpl` method in the .mllib side is no longer used in the .ml side, the scope should be limited;
2, in the `hashUDF`, val `numOfFeatures` is never used;
3, in the udf, it is inefficient to involve param getter (`$(numFeatures)`/`$(binary)`) directly or via method `indexOf` ((`$(numFeatures)`) . instead, the getter should be called outside of the udf;
## How was this patch tested?
existing suites
Closes#25324 from zhengruifeng/hashingtf_cleanup.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove the redundant and confusing transformImpl method in RF & GBT;
1, In `GBTClassifier` & `RandomForestClassifier`, the real `transform` methods inherit from `ProbabilisticClassificationModel` which can deal with multi output columns.
The `transformImpl` method, which deals with only one column - `predictionCol`, completely does nothing. This is quite confusing.
2, In `GBTRegressor` & `RandomForestRegressor`, the `transformImpl` do exactly what the superclass `PredictionModel` does (except model broadcasting), so can be removed.
## How was this patch tested?
existing suites
Closes#25256 from zhengruifeng/del_ensamble_transformImpl.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Use `log1p(x)` over `log(1+x)` and `expm1(x)` over `exp(x)-1` for accuracy, where possible. This should improve accuracy a tiny bit in ML-related calculations, and shouldn't hurt in any event.
## How was this patch tested?
Existing tests.
Closes#25337 from srowen/SPARK-28604.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Imputer currently requires input column to be Double or Float, but the logic should work on any numeric data types. Many practical problems have integer data types, and it could get very tedious to manually cast them into Double before calling imputer. This transformer could be extended to handle all numeric types.
## How was this patch tested?
new test
Closes#17864 from actuaryzhang/imputer.
Lead-authored-by: actuaryzhang <actuaryzhang10@gmail.com>
Co-authored-by: Wayne Zhang <actuaryzhang@uber.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Update HashingTF to use new implementation of MurmurHash3
Make HashingTF use the old MurmurHash3 when a model from pre 3.0 is loaded
## How was this patch tested?
Change existing unit tests. Also add one unit test to make sure HashingTF use the old MurmurHash3 when a model from pre 3.0 is loaded
Closes#25303 from huaxingao/spark-23469.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
avoid `.ml.vector => .breeze.vector` conversion in `MaxAbsScaler`,
and reuse the transformation method in `StandardScalerModel`, which can deal with dense & sparse vector separately.
## How was this patch tested?
existing suites
Closes#25311 from zhengruifeng/maxabs_opt.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
I remove the deprecate `ImageSchema.readImages`.
Move some useful methods from class `ImageSchema` into class `ImageFileFormat`.
In pyspark, I rename `ImageSchema` class to be `ImageUtils`, and keep some useful python methods in it.
## How was this patch tested?
UT.
Please review https://spark.apache.org/contributing.html before opening a pull request.
Closes#25245 from WeichenXu123/remove_image_schema.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Implement `RobustScaler`
Since the transformation is quite similar to `StandardScaler`, I refactor the transform function so that it can be reused in both scalers.
## How was this patch tested?
existing and added tests
Closes#25160 from zhengruifeng/robust_scaler.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Add indexOf method for ml.feature.HashingTF.
## How was this patch tested?
Add Unit test.
Closes#25250 from huaxingao/spark-21481.
Authored-by: Huaxin Gao <huaxing@us.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
1, avoid calling param getter in udf;
2, for constant dims, precompute the transformed result;
3, for usual dims, precompute `scale / originalRange(i)` to skip a division;
## How was this patch tested?
existing suites
Closes#25244 from zhengruifeng/minmax_opt.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Because the local default locale isn't in available locales at `Locale`, when I did some tests locally with python code, `StopWordsRemover` related python test hits some errors, like:
```
Traceback (most recent call last):
File "/spark-1/python/pyspark/ml/tests/test_feature.py", line 87, in test_stopwordsremover
stopWordRemover = StopWordsRemover(inputCol="input", outputCol="output")
File "/spark-1/python/pyspark/__init__.py", line 111, in wrapper
return func(self, **kwargs)
File "/spark-1/python/pyspark/ml/feature.py", line 2646, in __init__
self.uid)
File "/spark-1/python/pyspark/ml/wrapper.py", line 67, in _new_java_obj
return java_obj(*java_args)
File /spark-1/python/lib/py4j-0.10.8.1-src.zip/py4j/java_gateway.py", line 1554, in __call__
answer, self._gateway_client, None, self._fqn)
File "/spark-1/python/pyspark/sql/utils.py", line 93, in deco
raise converted
pyspark.sql.utils.IllegalArgumentException: 'StopWordsRemover_4598673ee802 parameter locale given invalid value en_TW.'
```
As per HyukjinKwon's advice, instead of setting up locale to pass test, it is better to have a workable locale if system default locale can't be found in available locales in JVM. Otherwise, users have to manually change system locale or accessing a private property _jvm in PySpark.
## How was this patch tested?
Added test and manual test.
```
scala> val remover = new StopWordsRemover().setInputCol("raw").setOutputCol("filtered")
19/07/14 19:20:03 WARN StopWordsRemover: Default locale set was [en_TW]; however, it was not found in available locales in JVM, falling back to en_US locale. Set param `locale` in order to respect another locale.
```
Closes#25133 from viirya/pytest-default-locale.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
optimize the `SparseVector.apply` by avoiding internal conversion
Since the speed up is significant (2.5X ~ 5X), and this method is widely used in ml, I suggest back porting.
| size| nnz | apply(old) | apply2(new impl) | apply3(new impl with extra range check)|
|------|----------|------------|----------|----------|
|10000000|100|75294|12208|18682|
|10000000|10000|75616|23132|32932|
|10000000|1000000|92949|42529|48821|
## How was this patch tested?
existing tests
using following code to test performance (here the new impl is named `apply2`, and another impl with extra range check is named `apply3`):
```
import scala.util.Random
import org.apache.spark.ml.linalg._
val size = 10000000
for (nnz <- Seq(100, 10000, 1000000)) {
val rng = new Random(123)
val indices = Array.fill(nnz + nnz)(rng.nextInt.abs % size).distinct.take(nnz).sorted
val values = Array.fill(nnz)(rng.nextDouble)
val vec = Vectors.sparse(size, indices, values).toSparse
val tic1 = System.currentTimeMillis;
(0 until 100).foreach{ round => var i = 0; var sum = 0.0; while(i < size) {sum+=vec(i); i+=1} };
val toc1 = System.currentTimeMillis;
val tic2 = System.currentTimeMillis;
(0 until 100).foreach{ round => var i = 0; var sum = 0.0; while(i < size) {sum+=vec.apply2(i); i+=1} };
val toc2 = System.currentTimeMillis;
val tic3 = System.currentTimeMillis;
(0 until 100).foreach{ round => var i = 0; var sum = 0.0; while(i < size) {sum+=vec.apply3(i); i+=1} };
val toc3 = System.currentTimeMillis;
println((size, nnz, toc1 - tic1, toc2 - tic2, toc3 - tic3))
}
```
Closes#25178 from zhengruifeng/sparse_vec_apply.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Use `org.apache.spark.mllib.util.TestingUtils` object across `MLLIB` component to compare floating point values in tests.
## How was this patch tested?
`build/mvn test` - existing tests against updated code.
Closes#25191 from eugen-prokhorenko/mllib-testingutils-double-comparison.
Authored-by: Ievgen Prokhorenko <eugen.prokhorenko@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
In regression/clustering/ovr/als, if an output column name is empty, igore it. And if all names are empty, log a warning msg, then do nothing.
## How was this patch tested?
existing tests
Closes#24793 from zhengruifeng/aft_iso_check_empty_outputCol.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This upgraded to a newer version of Pyrolite. Most updates [1] in the newer version are for dotnot. For java, it includes a bug fix to Unpickler regarding cleaning up Unpickler memo, and support of protocol 5.
After upgrading, we can remove the fix at SPARK-27629 for the bug in Unpickler.
[1] https://github.com/irmen/Pyrolite/compare/pyrolite-4.23...master
## How was this patch tested?
Manually tested on Python 3.6 in local on existing tests.
Closes#25143 from viirya/upgrade-pyrolite.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
fix typo in spark-28159
`transfromWithMean` -> `transformWithMean`
## How was this patch tested?
existing test
Closes#25129 from zhengruifeng/to_ml_vec_cleanup.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
In both cases, the input `DataFrame` schema must contain only the information that's required for the matrix object, so a vector column in the case of `RowMatrix` and long and vector columns for `IndexedRowMatrix`.
## How was this patch tested?
Unit tests that verify:
- `RowMatrix` and `IndexedRowMatrix` can be created from `DataFrame`s
- If the schema does not match expectations, we throw an `IllegalArgumentException`
Please review https://spark.apache.org/contributing.html before opening a pull request.
Closes#24953 from henrydavidge/row-matrix-df.
Authored-by: Henry D <henrydavidge@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Make the transform natively in ml framework to avoid extra conversion.
There are many TODOs in current ml module, like `// TODO: Make the transformer natively in ml framework to avoid extra conversion.` in ChiSqSelector.
This PR is to make ml algs no longer need to convert ml-vector to mllib-vector in transforms.
Including: LDA/ChiSqSelector/ElementwiseProduct/HashingTF/IDF/Normalizer/PCA/StandardScaler.
## How was this patch tested?
existing testsuites
Closes#24963 from zhengruifeng/to_ml_vector.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
if the input dataset is alreadly cached, then we do not need to cache the internal rdd (like kmeans)
## How was this patch tested?
existing test
Closes#24919 from zhengruifeng/gmm_fix_double_caching.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
cache dataset in BisectingKMeans
cache dataset in LDA if Online solver is chosen.
## How was this patch tested?
existing test
Closes#24920 from zhengruifeng/bikm_cache.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
add missing RankingEvaluator
## How was this patch tested?
added testsuites
Closes#24869 from zhengruifeng/ranking_eval.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Provide a way to recursively load data from datasource.
I add a "recursiveFileLookup" option.
When "recursiveFileLookup" option turn on, then partition inferring is turned off and all files from the directory will be loaded recursively.
If some datasource explicitly specify the partitionSpec, then if user turn on "recursive" option, then exception will be thrown.
## How was this patch tested?
Unit tests.
Please review https://spark.apache.org/contributing.html before opening a pull request.
Closes#24830 from WeichenXu123/recursive_ds.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Modifies the HuberAggregator class so that a copy of the coefficients vector isn't created every time that an instance is added. Follows the approach of LeastSquaresAggregator and uses transient lazy class variable to store the reused quantities. (See https://github.com/apache/spark/pull/14109 for explanation of the use of transient lazy variables)
On the test case in the linked JIRA, this change gives an order of magnitude performance improvement reducing the time taken to fit the model from 540 to 47 seconds.
## How was this patch tested?
Existing unit tests.
See https://issues.apache.org/jira/browse/SPARK-28062 for results from running a benchmark script.
Closes#24880 from Andrew-Crosby/spark-28062.
Authored-by: Andrew-Crosby <andrew.crosby@autotrader.co.uk>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
expose more metrics in evaluator: weightedTruePositiveRate/weightedFalsePositiveRate/weightedFMeasure/truePositiveRateByLabel/falsePositiveRateByLabel/precisionByLabel/recallByLabel/fMeasureByLabel
## How was this patch tested?
existing cases and add cases
Closes#24868 from zhengruifeng/multi_class_support_bylabel.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The word2vec logic fails if a corpora has a word with count > 1e9. We should be able to handle very large counts generally better here by using longs to count.
This takes over https://github.com/apache/spark/pull/24814
## How was this patch tested?
Existing tests.
Closes#24893 from srowen/SPARK-28081.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
add MultilabelClassificationEvaluator
## How was this patch tested?
added testsuites
Closes#24777 from zhengruifeng/multi_label_eval.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Added support for `*` and `^` operators, along with expressions within parentheses. New operators just expand to already supported terms, such as;
- y ~ a * b = y ~ a + b + a : b
- y ~ (a+b+c)^3 = y ~ a + b + c + a : b + a : c + a :b : c
## How was this patch tested?
Added new unit tests to RFormulaParserSuite
mengxr yanboliang
Closes#24764 from ozancicek/rformula.
Authored-by: ozan <ozancancicekci@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
add missing since annotation of meanAveragePrecision
## How was this patch tested?
existing tests
Closes#24778 from zhengruifeng/ranking_missing_since.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
compute all metrics with only one pass
## How was this patch tested?
existing tests
Closes#24717 from zhengruifeng/multi_label_opt.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Single-point clusters should have silhouette score of 0, according to the original paper and scikit implementation.
## How was this patch tested?
Existing test suite + new test case.
Closes#24756 from srowen/SPARK-27896.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This pr wrap all `PrintWriter` with `Utils.tryWithResource` to prevent resource leak.
## How was this patch tested?
Existing test
Closes#24739 from wangyum/SPARK-27875.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…lure
## What changes were proposed in this pull request?
The failure log format is fixed according to the jdk implementation.
## How was this patch tested?
Manual tests have been done. The new failure log format would be like:
java.lang.RuntimeException: Failed to finish the task
at com.xxx.Test.test(Test.java:106)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.testng.internal.MethodInvocationHelper.invokeMethod(MethodInvocationHelper.java:124)
at org.testng.internal.Invoker.invokeMethod(Invoker.java:571)
at org.testng.internal.Invoker.invokeTestMethod(Invoker.java:707)
at org.testng.internal.Invoker.invokeTestMethods(Invoker.java:979)
at org.testng.internal.TestMethodWorker.invokeTestMethods(TestMethodWorker.java:125)
at org.testng.internal.TestMethodWorker.run(TestMethodWorker.java:109)
at org.testng.TestRunner.privateRun(TestRunner.java:648)
at org.testng.TestRunner.run(TestRunner.java:505)
at org.testng.SuiteRunner.runTest(SuiteRunner.java:455)
at org.testng.SuiteRunner.runSequentially(SuiteRunner.java:450)
at org.testng.SuiteRunner.privateRun(SuiteRunner.java:415)
at org.testng.SuiteRunner.run(SuiteRunner.java:364)
at org.testng.SuiteRunnerWorker.runSuite(SuiteRunnerWorker.java:52)
at org.testng.SuiteRunnerWorker.run(SuiteRunnerWorker.java:84)
at org.testng.TestNG.runSuitesSequentially(TestNG.java:1187)
at org.testng.TestNG.runSuitesLocally(TestNG.java:1116)
at org.testng.TestNG.runSuites(TestNG.java:1028)
at org.testng.TestNG.run(TestNG.java:996)
at org.testng.IDEARemoteTestNG.run(IDEARemoteTestNG.java:72)
at org.testng.RemoteTestNGStarter.main(RemoteTestNGStarter.java:123)
Caused by: java.io.FileNotFoundException: File is not found
at com.xxx.Test.test(Test.java:105)
... 24 more
Closes#24684 from breakdawn/master.
Authored-by: MJ Tang <mingjtang@ebay.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
compute AUC on one pass
## How was this patch tested?
existing tests
performance tests:
```
import org.apache.spark.mllib.evaluation._
val scoreAndLabels = sc.parallelize(Array.range(0, 100000).map{ i => (i.toDouble / 100000, (i % 2).toDouble) }, 4)
scoreAndLabels.persist()
scoreAndLabels.count()
val tic = System.currentTimeMillis
(0 until 100).foreach{i => val metrics = new BinaryClassificationMetrics(scoreAndLabels, 0); val auc = metrics.areaUnderROC; metrics.unpersist}
val toc = System.currentTimeMillis
toc - tic
```
|New| Existing|
|------|----------|
|87532|103644|
One-pass AUC saves about 16% computation time.
Closes#24648 from zhengruifeng/auc_opt.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Eliminate uncessary job to compute SSreg
Compute SSreg based on the summary of predictions
## How was this patch tested?
existing tests
Closes#24656 from zhengruifeng/RegressionMetrics_opt.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
avoid hardcoded configs in `SparkConf` and `SparkSubmit` and test
## How was this patch tested?
N/A
Closes#24631 from wenxuanguan/minor-fix.
Authored-by: wenxuanguan <choose_home@126.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This replaces use of collection classes like `MutableList` and `ArrayStack` with workalikes that are available in 2.12, as they will be removed in 2.13. It also removes use of `.to[Collection]` as its uses was superfluous anyway. Removing `collection.breakOut` will have to wait until 2.13
## How was this patch tested?
Existing tests
Closes#24586 from srowen/SPARK-27682.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Test steps to reproduce:
1) bin/spark-shell
```
val dataset = spark.createDataFrame(Seq(
(0L, 1L, 1.0),
(1L,2L,1.0),
(3L, 4L,1.0),
(4L,0L,0.1))).toDF("src", "dst", "weight")
val model = new PowerIterationClustering().
setMaxIter(10).
setInitMode("degree").
setWeightCol("weight")
val prediction = model.assignClusters(dataset).select("id", "cluster")
```
2) Open storage tab of the UI. We can see many RDD block cached, even after running the PIC.
In this PR, basically materializes the new graph before unpersisting the old ones.
## How was this patch tested?
Manually tested and existing UTs.
Before patch:

After patch:

Closes#24531 from shahidki31/SPARK-27636.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Added method 'meanAveragePrecisionAt' k to RankingMetrics.
This branch is rebased with squashed commits from https://github.com/apache/spark/pull/24458
## How was this patch tested?
Added code in the existing test RankingMetricsSuite.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24543 from qb-tarushg/SPARK-27540-REBASE.
Authored-by: qb-tarushg <tarush.grover@quantumblack.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Fixed the `spark-<version>-yarn-shuffle.jar` artifact packaging to shade the native netty libraries:
- shade the `META-INF/native/libnetty_*` native libraries when packagin
the yarn shuffle service jar. This is required as netty library loader
derives that based on shaded package name.
- updated the `org/spark_project` shade package prefix to `org/sparkproject`
(i.e. removed underscore) as the former breaks the netty native lib loading.
This was causing the yarn external shuffle service to fail
when spark.shuffle.io.mode=EPOLL
## How was this patch tested?
Manual tests
Closes#24502 from amuraru/SPARK-27610_master.
Authored-by: Adi Muraru <amuraru@adobe.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
Choose the last record in chunks when calculating metrics with downsampling in `BinaryClassificationMetrics`.
## How was this patch tested?
A new unit test is added to verify thresholds from downsampled records.
Closes#24470 from shishaochen/spark-mllib-binary-metrics.
Authored-by: Shaochen Shi <shishaochen@bytedance.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In SPARK-27612, one correctness issue was reported. When protocol 4 is used to pickle Python objects, we found that unpickled objects were wrong. A temporary fix was proposed by not using highest protocol.
It was found that Opcodes.MEMOIZE was appeared in the opcodes in protocol 4. It is suspect to this issue.
A deeper dive found that Opcodes.MEMOIZE stores objects into internal map of Unpickler object. We use single Unpickler object to unpickle serialized Python bytes. Stored objects intervenes next round of unpickling, if the map is not cleared.
We has two options:
1. Continues to reuse Unpickler, but calls its close after each unpickling.
2. Not to reuse Unpickler and create new Unpickler object in each unpickling.
This patch takes option 1.
## How was this patch tested?
Passing the test added in SPARK-27612 (#24519).
Closes#24521 from viirya/SPARK-27629.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
When transform(...) method is called on a LinearRegressionModel created directly with the coefficients and intercepts, the following exception is encountered.
```
java.util.NoSuchElementException: Failed to find a default value for loss
at org.apache.spark.ml.param.Params$$anonfun$getOrDefault$2.apply(params.scala:780)
at org.apache.spark.ml.param.Params$$anonfun$getOrDefault$2.apply(params.scala:780)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.ml.param.Params$class.getOrDefault(params.scala:779)
at org.apache.spark.ml.PipelineStage.getOrDefault(Pipeline.scala:42)
at org.apache.spark.ml.param.Params$class.$(params.scala:786)
at org.apache.spark.ml.PipelineStage.$(Pipeline.scala:42)
at org.apache.spark.ml.regression.LinearRegressionParams$class.validateAndTransformSchema(LinearRegression.scala:111)
at org.apache.spark.ml.regression.LinearRegressionModel.validateAndTransformSchema(LinearRegression.scala:637)
at org.apache.spark.ml.PredictionModel.transformSchema(Predictor.scala:192)
at org.apache.spark.ml.PipelineModel$$anonfun$transformSchema$5.apply(Pipeline.scala:311)
at org.apache.spark.ml.PipelineModel$$anonfun$transformSchema$5.apply(Pipeline.scala:311)
at scala.collection.IndexedSeqOptimized$class.foldl(IndexedSeqOptimized.scala:57)
at scala.collection.IndexedSeqOptimized$class.foldLeft(IndexedSeqOptimized.scala:66)
at scala.collection.mutable.ArrayOps$ofRef.foldLeft(ArrayOps.scala:186)
at org.apache.spark.ml.PipelineModel.transformSchema(Pipeline.scala:311)
at org.apache.spark.ml.PipelineStage.transformSchema(Pipeline.scala:74)
at org.apache.spark.ml.PipelineModel.transform(Pipeline.scala:305)
```
This is because validateAndTransformSchema() is called both during training and scoring phases, but the checks against the training related params like loss should really be performed during training phase only, I think, please correct me if I'm missing anything :)
This issue was first reported for mleap (https://github.com/combust/mleap/issues/455) because basically when we serialize the Spark transformers for mleap, we only serialize the params that are relevant for scoring. We do have the option to de-serialize the serialized transformers back into Spark for scoring again, but in that case, we no longer have all the training params.
## How was this patch tested?
Added a unit test to check this scenario.
Please let me know if there's anything additional required, this is the first PR that I've raised in this project.
Closes#24509 from ancasarb/linear_regression_params_fix.
Authored-by: asarb <asarb@expedia.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
There is a MemorySink v2 already so v1 can be removed. In this PR I've removed it completely.
What this PR contains:
* V1 memory sink removal
* V2 memory sink renamed to become the only implementation
* Since DSv2 sends exceptions in a chained format (linking them with cause field) I've made python side compliant
* Adapted all the tests
## How was this patch tested?
Existing unit tests.
Closes#24403 from gaborgsomogyi/SPARK-23014.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
I want to get rid of as much use of `scala.language.existentials` as possible for 3.0. It's a complicated language feature that generates warnings unless this value is imported. It might even be on the way out of Scala: https://contributors.scala-lang.org/t/proposal-to-remove-existential-types-from-the-language/2785
For Spark, it comes up mostly where the code plays fast and loose with generic types, not the advanced situations you'll often see referenced where this feature is explained. For example, it comes up in cases where a function returns something like `(String, Class[_])`. Scala doesn't like matching this to any other instance of `(String, Class[_])` because doing so requires inferring the existence of some type that satisfies both. Seems obvious if the generic type is a wildcard, but, not technically something Scala likes to let you get away with.
This is a large PR, and it only gets rid of _most_ instances of `scala.language.existentials`. The change should be all compile-time and shouldn't affect APIs or logic.
Many of the changes simply touch up sloppiness about generic types, making the known correct value explicit in the code.
Some fixes involve being more explicit about the existence of generic types in methods. For instance, `def foo(arg: Class[_])` seems innocent enough but should really be declared `def foo[T](arg: Class[T])` to let Scala select and fix a single type when evaluating calls to `foo`.
For kind of surprising reasons, this comes up in places where code evaluates a tuple of things that involve a generic type, but is OK if the two parts of the tuple are evaluated separately.
One key change was altering `Utils.classForName(...): Class[_]` to the more correct `Utils.classForName[T](...): Class[T]`. This caused a number of small but positive changes to callers that otherwise had to cast the result.
In several tests, `Dataset[_]` was used where `DataFrame` seems to be the clear intent.
Finally, in a few cases in MLlib, the return type `this.type` was used where there are no subclasses of the class that uses it. This really isn't needed and causes issues for Scala reasoning about the return type. These are just changed to be concrete classes as return types.
After this change, we have only a few classes that still import `scala.language.existentials` (because modifying them would require extensive rewrites to fix) and no build warnings.
## How was this patch tested?
Existing tests.
Closes#24431 from srowen/SPARK-27536.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Kind of related to https://github.com/gatorsmile/spark/pull/5 - let's update genjavadoc to see if it generates fewer spurious javadoc errors to begin with.
## How was this patch tested?
Existing docs build
Closes#24443 from srowen/genjavadoc013.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Otherwise, tests that use tables from multiple sessions will run into issues if they access the same table. The correct location is in shared state.
A couple other minor test improvements.
cc gatorsmile srinathshankar
## How was this patch tested?
Existing unit tests.
Closes#24302 from ericl/test-conflicts.
Lead-authored-by: Eric Liang <ekl@databricks.com>
Co-authored-by: Eric Liang <ekhliang@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Fix in Spark image datasource fail when encounter some illegal images.
This related to bugs inside `ImageIO.read` so in spark code I add exception handling for it.
## How was this patch tested?
N/A
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24362 from WeichenXu123/fix_image_ds_bug.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
## What changes were proposed in this pull request?
This should reduce the total runtime of these tests from about 2 minutes to about 25 seconds.
## How was this patch tested?
Existing tests
Closes#24360 from srowen/SpeedQDS.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Loosen some tolerances in the ML regression-related tests, as they seem to account for some of the top slow tests in https://spark-tests.appspot.com/slow-tests
These changes are good for about a 25 second speedup on my laptop.
## How was this patch tested?
Existing tests
Closes#24351 from srowen/SpeedReg.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Fix build warnings -- see some details below.
But mostly, remove use of postfix syntax where it causes warnings without the `scala.language.postfixOps` import. This is mostly in expressions like "120000 milliseconds". Which, I'd like to simplify to things like "2.minutes" anyway.
## How was this patch tested?
Existing tests.
Closes#24314 from srowen/SPARK-27404.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Remove deprecated / no-op mllib.KMeans getRuns, setRuns
mllib.KMeans has getRuns, setRuns methods which haven't done anything since Spark 2.1. They're deprecated, and no-ops, and should be removed for Spark 3.
## How was this patch tested?
Existing tests.
Closes#24320 from srowen/SPARK-27410.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
Changes proposed:
- Adding method to compute treeAggregate depth required to avoid exceeding driver max result size (first commit)
- Using it in the computation of grammian of RowMatrix (second commit)
Tests:
- Unit Test wise, one unit test checking the behavior of the depth computation method
- Tested at scale on hadoop cluster by doing PCA on a large dataset (needed depth 3 to succeed)
Debatable choice:
I'm not sure if RDD API is the right place to put the depth computation method. The advantage of it is that it allows to access driver max result size, and rdd number of partitions, to set default arguments for the method. Semantically, such a method might belong to something like org.apache.spark.util.Utils though.
Closes#23983 from gagafunctor/Heuristic_for_treeAggregate_depth.
Authored-by: Rafael Renaudin <renaudin.rafael@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Followup to PR https://github.com/apache/spark/pull/17085
This PR adds the weight column to the pyspark side, which was already added to the scala API.
The PR also undoes a name change in the scala side corresponding to a change in another similar PR as noted here:
https://github.com/apache/spark/pull/17084#discussion_r259648639
## How was this patch tested?
This patch adds python tests for the changes to the pyspark API.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#24197 from imatiach-msft/ilmat/regressor-eval-python.
Authored-by: Ilya Matiach <ilmat@microsoft.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The hashSeed method allocates 64 bytes instead of 8. Other bytes are always zeros (thanks to default behavior of ByteBuffer). And they could be excluded from hash calculation because they don't differentiate inputs.
## How was this patch tested?
By running the existing tests - XORShiftRandomSuite
Closes#20793 from MaxGekk/hash-buff-size.
Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Co-authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
`Saveable` interface introduces `formatVersion` which is protected and it is used nowhere. So the PR proposes to remove it.
## How was this patch tested?
existing tests
Closes#22830 from mgaido91/SPARK-25838.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Add 'Recall_at_k' metric to RankingMetrics
## How was this patch tested?
Add test to RankingMetricsSuite.
Closes#23881 from masa3141/SPARK-26981.
Authored-by: masa3141 <masahiro@kazama.tv>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Redundant `get` when getting a value from `Map` given a key.
## How was this patch tested?
N/A
Closes#23901 from 10110346/removegetfrommap.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Add sample weights to decision trees
## How was this patch tested?
updated testsuites
Closes#23818 from zhengruifeng/py_tree_support_sample_weight.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Comparing whether Boolean expression is equal to true is redundant
For example:
The datatype of `a` is boolean.
Before:
if (a == true)
After:
if (a)
## How was this patch tested?
N/A
Closes#23884 from 10110346/simplifyboolean.
Authored-by: liuxian <liu.xian3@zte.com.cn>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Add reference JAXB impl for Java 9+ from Glassfish. Right now it's only apparently necessary in MLlib but can be expanded later.
## How was this patch tested?
Existing tests particularly PMML-related ones, which use JAXB.
This works on Java 11.
Closes#23890 from srowen/SPARK-26986.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The evaluators BinaryClassificationEvaluator, RegressionEvaluator, and MulticlassClassificationEvaluator and the corresponding metrics classes BinaryClassificationMetrics, RegressionMetrics and MulticlassMetrics should use sample weight data.
I've closed the PR: https://github.com/apache/spark/pull/16557
as recommended in favor of creating three pull requests, one for each of the evaluators (binary/regression/multiclass) to make it easier to review/update.
## How was this patch tested?
I added tests to the metrics and evaluators classes.
Closes#17084 from imatiach-msft/ilmat/binary-evalute.
Authored-by: Ilya Matiach <ilmat@microsoft.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
JPMML apparently only supports Java 9 in 1.4.2+. We are seeing text failures from JPMML relating to JAXB when running on Java 11. It's shaded and not a big change, so should be safe.
## How was this patch tested?
Existing tests.
Closes#23868 from srowen/SPARK-26966.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
expose method `predict` in KMeans/BiKMeans/GMM
## How was this patch tested?
added testsuites
Closes#22087 from zhengruifeng/clu_pre_instance.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This patch aims to address flakiness I've observed in MLEventsSuite in these tests:
* test("pipeline read/write events")
* test("pipeline model read/write events")
The issue is in the "read/write events" tests, which work as follows:
* write
* wait until we see at least 1 write-related SparkListenerEvent
* read
* wait until we see at least 1 read-related SparkListenerEvent
The problem is that the last step does NOT allow any write-related SparkListenerEvents, but some of those events may be delayed enough that they are seen in this last step. We should ideally add logic before "read" to wait until the listener events are cleared/complete. Looking into other SparkListener tests, we need to use `sc.listenerBus.waitUntilEmpty(TIMEOUT)`.
This patch adds the waitUntilEmpty() call.
## How was this patch tested?
It's a test!
Closes#23863 from jkbradley/SPARK-26960.
Authored-by: Joseph K. Bradley <joseph@databricks.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Our feature importance calculation is taken from sklearn's one, which has been recently fixed (in https://github.com/scikit-learn/scikit-learn/pull/11176). Citing the description of that PR:
> Because the feature importances are (currently, by default) normalized and then averaged, feature importances from later stages are overweighted.
The PR performs a fix similar to sklearn's one. The per-tree normalization of the feature importance is skipped and GBT.
Credits for pointing out clearly the issue and the sklearn's PR to Daniel Jumper.
## How was this patch tested?
modified UT, checked that the computed `featureImportance` in that test is similar to sklearn's one (ti can't be the same, because the trees may be slightly different)
Closes#23773 from mgaido91/SPARK-26721.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
In the PR, I propose to use `System.nanoTime()` instead of `System.currentTimeMillis()` in measurements of time intervals.
`System.currentTimeMillis()` returns current wallclock time and will follow changes to the system clock. Thus, negative wallclock adjustments can cause timeouts to "hang" for a long time (until wallclock time has caught up to its previous value again). This can happen when ntpd does a "step" after the network has been disconnected for some time. The most canonical example is during system bootup when DHCP takes longer than usual. This can lead to failures that are really hard to understand/reproduce. `System.nanoTime()` is guaranteed to be monotonically increasing irrespective of wallclock changes.
## How was this patch tested?
By existing test suites.
Closes#23727 from MaxGekk/system-nanotime.
Lead-authored-by: Maxim Gekk <max.gekk@gmail.com>
Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Make .unpersist(), .destroy() non-blocking by default and adjust callers to request blocking only where important.
This also adds an optional blocking argument to Pyspark's RDD.unpersist(), which never had one.
## How was this patch tested?
Existing tests.
Closes#23685 from srowen/SPARK-26771.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
Error message falsely states standardization=True is causing a problem, even when standardization=False. The real issue is standardizeLabels=True, which is set automatically in LinearRegression and not currently available in the Public API.
## What changes were proposed in this pull request?
A simple change to an error message. More details here: https://jira.apache.org/jira/browse/SPARK-26787
## How was this patch tested?
This does not change any functionality.
Closes#23705 from bscan/bscan-errormsg-1.
Authored-by: bscan <brianjscannell@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
This is a follow-up to PR:
https://github.com/apache/spark/pull/21632
## What changes were proposed in this pull request?
This PR tunes the tolerance used for deciding whether to add zero feature values to a value-count map (where the key is the feature value and the value is the weighted count of those feature values).
In the previous PR the tolerance scaled by the square of the unweighted number of samples, which is too aggressive for a large number of unweighted samples. Unfortunately using just "Utils.EPSILON * unweightedNumSamples" is not enough either, so I multiplied that by a factor tuned by the testing procedure below.
## How was this patch tested?
This involved manually running the sample weight tests for decision tree regressor to see whether the tolerance was large enough to exclude zero feature values.
Eg in SBT:
```
./build/sbt
> project mllib
> testOnly *DecisionTreeRegressorSuite -- -z "training with sample weights"
```
For validation, I added a print inside the if in the code below and validated that the tolerance was large enough so that we would not include zero features (which don't exist in that test):
```
val valueCountMap = if (weightedNumSamples - partNumSamples > tolerance) {
print("should not print this")
partValueCountMap + (0.0 -> (weightedNumSamples - partNumSamples))
} else {
partValueCountMap
}
```
Closes#23682 from imatiach-msft/ilmat/sample-weights-tol.
Authored-by: Ilya Matiach <ilmat@microsoft.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This takes over #19621 to add multi-column support to StringIndexer:
1. Supports encoding multiple columns.
2. Previously, when specifying `frequencyDesc` or `frequencyAsc` as `stringOrderType` param in `StringIndexer`, in case of equal frequency, the order of strings is undefined. After this change, the strings with equal frequency are further sorted alphabetically.
## How was this patch tested?
Added tests.
Closes#20146 from viirya/SPARK-11215.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This PR proposes to add ML events to Instrumentation, and use it in Pipeline so that other developers can track and add some actions for them.
## Introduction
ML events (like SQL events) can be quite useful when people want to track and make some actions for corresponding ML operations. For instance, I have been working on integrating
Apache Spark with [Apache Atlas](https://atlas.apache.org/QuickStart.html). With some custom changes with this PR, I can visualise ML pipeline as below:

Another good thing that might have to be considered is, that we can interact this with other SQL/Streaming events. For instance, where the input `Dataset` is originated. For instance, with current Apache Spark, I can visualise SQL operations as below:

I think we can combine those existing lineages together to easily understand where the data comes and goes. Currently, ML side is a hole so the lineages can't be connected for the current Apache Spark ..
To add up, I think it's not to mention how useful it is to track the SQL/Streaming operations. Likewise, I would like to propose ML events as well (as lowest stability `Unstable` APIs for now - no guarantee about stability).
## Implementation Details
### Sends event (but not expose ML specific listener)
**`mllib/src/main/scala/org/apache/spark/ml/events.scala`**
```scala
Unstable
case class ...StartEvent(caller, input)
Unstable
case class ...EndEvent(caller, output)
trait MLEvents {
// Wrappers to send events:
// def with...Event(body) = {
// body()
// SparkContext.getOrCreate().listenerBus.post(event)
// }
}
```
This trait is used by `Instrumentation`.
```scala
class Instrumentation ... with MLEvents {
```
and used as below:
```scala
instrumented { instr =>
instr.with...Event(...) {
...
}
}
```
This way mimics both:
**1. Catalog events (see `org/apache/spark/sql/catalyst/catalog/events.scala`)**
- This allows a Catalog specific listener to be added `ExternalCatalogEventListener`
- It's implemented in a way of wrapping whole `ExternalCatalog` named `ExternalCatalogWithListener`
which delegates the operations to `ExternalCatalog`
This is not quite possible in this case because most of instances (like `Pipeline`) will be directly created in most of cases. We might be able to do that via extending `ListenerBus` for all possible instances but IMHO it's too invasive. Also, exposing another ML specific listener sounds a bit too much at this stage. Therefore, I simply borrowed file name and structures here
**2. SQL execution events (see `org/apache/spark/sql/execution/SQLExecution.scala`)**
- Add an object that wraps a body to send events
Current apporach is rather close to this. It has a `with...` wrapper to send events. I borrowed this approach to be consistent.
## Usage
It needs a custom implementation for a query listener. For instance,
with the custom listener below:
```scala
class CustomMLListener extends SparkListener
def onOtherEvents(e) = e match {
case e: MLEvent => // do something
case _ => // pass
}
}
```
There are two (existing) ways to use this.
```scala
spark.sparkContext.addSparkListener(new CustomMLListener)
```
```bash
spark-submit ...\
--conf spark.extraListeners=CustomMLListener\
...
```
It's also similar with other existing implementation in SQL side.
## Target users
1. I think someone in general would likely utilise this feature like other event listeners. At least, I can see some interests going on outside.
- SQL Listener
- https://stackoverflow.com/questions/46409339/spark-listener-to-an-sql-query
- http://apache-spark-user-list.1001560.n3.nabble.com/spark-sql-Custom-Query-Execution-listener-via-conf-properties-td30979.html
- Streaming Query Listener
- https://jhui.github.io/2017/01/15/Apache-Spark-Streaming/
- http://apache-spark-developers-list.1001551.n3.nabble.com/Structured-Streaming-with-Watermark-td25413.html#a25416
2. Someone would likely run this via Atlas. The plugin mirror intentionally is exposed at [spark-atlas-connector](https://github.com/hortonworks-spark/spark-atlas-connector) so that anyone could do something about lineage and governance in Atlas. I'm trying to show integrated lineages in Apache Spark but this is a missing hole.
## How was this patch tested?
Manually tested and unit tests were added.
Closes#23263 from HyukjinKwon/SPARK-23674-1.
Authored-by: Hyukjin Kwon <gurwls223@apache.org>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
This is updated PR https://github.com/apache/spark/pull/16722 to latest master
## What changes were proposed in this pull request?
This patch adds support for sample weights to DecisionTreeRegressor and DecisionTreeClassifier.
Note: This patch does not add support for sample weights to RandomForest. As discussed in the JIRA, we would like to add sample weights into the bagging process. This patch is large enough as is, and there are some additional considerations to be made for random forests. Since the machinery introduced here needs to be present regardless, I have opted to leave random forests for a follow up pr.
## How was this patch tested?
The algorithms are tested to ensure that:
1. Arbitrary scaling of constant weights has no effect
2. Outliers with small weights do not affect the learned model
3. Oversampling and weighting are equivalent
Unit tests are also added to test other smaller components.
## Summary of changes
- Impurity aggregators now store weighted sufficient statistics. They also store a raw count, however, since this is needed to use minInstancesPerNode.
- Impurity aggregators now also hold the raw count.
- This patch maintains the meaning of minInstancesPerNode, in that the parameter still corresponds to raw, unweighted counts. It also adds a new parameter minWeightFractionPerNode which requires that nodes must contain at least minWeightFractionPerNode * weightedNumExamples total weight.
- This patch modifies findSplitsForContinuousFeatures to use weighted sums. Unit tests are added.
- TreePoint is modified to hold a sample weight
- BaggedPoint is modified from:
``` Scala
private[spark] class BaggedPoint[Datum](val datum: Datum, val subsampleWeights: Array[Double]) extends Serializable
```
to
``` Scala
private[spark] class BaggedPoint[Datum](
val datum: Datum,
val subsampleCounts: Array[Int],
val sampleWeight: Double) extends Serializable
```
We do not simply multiply the counts by the weight and store that because we need the raw counts and the weight in order to use both minInstancesPerNode and minWeightPerNode
**Note**: many of the changed files are due simply to using Instance instead of LabeledPoint
Closes#21632 from imatiach-msft/ilmat/sample-weights.
Authored-by: Ilya Matiach <ilmat@microsoft.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Avoid memory problems in closure cleaning when handling large Gramians (>= 16K rows/cols) by using null as zeroValue
## How was this patch tested?
Existing tests.
Note that it's hard to test the case that triggers this issue as it would require a large amount of memory and run a while. I confirmed locally that a 16K x 16K Gramian failed with tons of driver memory before, and didn't fail upfront after this change.
Closes#23600 from srowen/SPARK-26228.
Authored-by: Sean Owen <sean.owen@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The PR makes hardcoded `spark.dynamicAllocation`, `spark.scheduler`, `spark.rpc`, `spark.task`, `spark.speculation`, and `spark.cleaner` configs to use `ConfigEntry`.
## How was this patch tested?
Existing tests
Closes#23416 from kiszk/SPARK-26463.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This change exposes the `df` (document frequency) as a public val along with the number of documents (`m`) as part of the IDF model.
* The document frequency is returned as an `Array[Long]`
* If the minimum document frequency is set, this is considered in the df calculation. If the count is less than minDocFreq, the df is 0 for such terms
* numDocs is not very required. But it can be useful, if we plan to provide a provision in future for user to give their own idf function, instead of using a default (log((1+m)/(1+df))). In such cases, the user can provide a function taking input of `m` and `df` and returning the idf value
* Pyspark changes
## How was this patch tested?
The existing test case was edited to also check for the document frequency values.
I am not very good with python or pyspark. I have committed and run tests based on my understanding. Kindly let me know if I have missed anything
Reviewer request: mengxr zjffdu yinxusen
Closes#23549 from purijatin/master.
Authored-by: Jatin Puri <purijatin@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Currently, there are some minor inconsistencies in doc compared to the code. In this PR, I am correcting those inconsistencies.
1) Links related to the evaluation metrics in the docs are not working
2) Minor correction in the evaluation metrics formulas in docs.
## How was this patch tested?
NA
Closes#23589 from shahidki31/docCorrection.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The PR makes hardcoded `spark.unsafe` configs to use ConfigEntry and put them in the `config` package.
## How was this patch tested?
Existing UTs
Closes#23412 from kiszk/SPARK-26477.
Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
## What changes were proposed in this pull request?
The PR makes hardcoded configs below to use `ConfigEntry`.
* spark.kryo
* spark.kryoserializer
* spark.serializer
* spark.jars
* spark.files
* spark.submit
* spark.deploy
* spark.worker
This patch doesn't change configs which are not relevant to SparkConf (e.g. system properties).
## How was this patch tested?
Existing tests.
Closes#23532 from HeartSaVioR/SPARK-26466-v2.
Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
If users set equivalent values to spark.network.timeout and spark.executor.heartbeatInterval, they get the following message:
```
java.lang.IllegalArgumentException: requirement failed: The value of spark.network.timeout=120s must be no less than the value of spark.executor.heartbeatInterval=120s.
```
But it's misleading since it can be read as they could be equal. So this PR replaces "no less than" with "greater than". Also, it fixes similar inconsistencies found in MLlib and SQL components.
## How was this patch tested?
Ran Spark with equivalent values for them manually and confirmed that the revised message was displayed.
Closes#23488 from sekikn/SPARK-26564.
Authored-by: Kengo Seki <sekikn@apache.org>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The test case will result the following failure. currently in ml.PIC, there is no check for the data type of weight column.
```
test("invalid input types for weight") {
val invalidWeightData = spark.createDataFrame(Seq(
(0L, 1L, "a"),
(2L, 3L, "b")
)).toDF("src", "dst", "weight")
val pic = new PowerIterationClustering()
.setWeightCol("weight")
val result = pic.assignClusters(invalidWeightData)
}
```
```
Job aborted due to stage failure: Task 0 in stage 8077.0 failed 1 times, most recent failure: Lost task 0.0 in stage 8077.0 (TID 882, localhost, executor driver): scala.MatchError: [0,1,null] (of class org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema)
at org.apache.spark.ml.clustering.PowerIterationClustering$$anonfun$3.apply(PowerIterationClustering.scala:178)
at org.apache.spark.ml.clustering.PowerIterationClustering$$anonfun$3.apply(PowerIterationClustering.scala:178)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:409)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:434)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:440)
at scala.collection.Iterator$class.foreach(Iterator.scala:893)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1336)
at org.apache.spark.graphx.EdgeRDD$$anonfun$1.apply(EdgeRDD.scala:107)
at org.apache.spark.graphx.EdgeRDD$$anonfun$1.apply(EdgeRDD.scala:105)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1$$anonfun$apply$26.apply(RDD.scala:847)
```
In this PR, added check types for weight column.
## How was this patch tested?
UT added
Please review http://spark.apache.org/contributing.html before opening a pull request.
Closes#21509 from shahidki31/testCasePic.
Authored-by: Shahid <shahidki31@gmail.com>
Signed-off-by: Holden Karau <holden@pigscanfly.ca>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
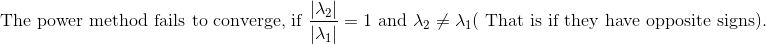{kind=link}
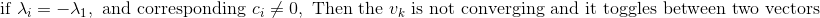{kind=link}
{kind=link}
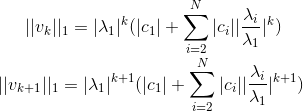{kind=link}
{kind=link}
{kind=link}
{kind=link}
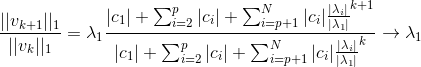{kind=link}
{kind=link}
{kind=link}
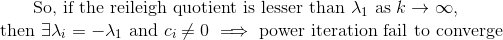{kind=link}
{kind=link}