## What changes were proposed in this pull request?
`requestHeaderSize` is added in https://github.com/apache/spark/pull/23090 and applies to Spark + History server UI as well. Without debug log it's hard to find out on which side what configuration is used.
In this PR I've added a log message which prints out the value.
## How was this patch tested?
Manually checked log files.
Closes#25045 from gaborgsomogyi/SPARK-26118.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
This PR makes the predicate pushdown logic in catalyst optimizer more efficient by unifying two existing rules `PushdownPredicates` and `PushPredicateThroughJoin`. Previously pushing down a predicate for queries such as `Filter(Join(Join(Join)))` requires n steps. This patch essentially reduces this to a single pass.
To make this actually work, we need to unify a few rules such as `CombineFilters`, `PushDownPredicate` and `PushDownPrdicateThroughJoin`. Otherwise cases such as `Filter(Join(Filter(Join)))` still requires several passes to fully push down predicates. This unification is done by composing several partial functions, which makes a minimal code change and can reuse existing UTs.
Results show that this optimization can improve the catalyst optimization time by 16.5%. For queries with more joins, the performance is even better. E.g., for TPC-DS q64, the performance boost is 49.2%.
## How was this patch tested?
Existing UTs + new a UT for the new rule.
Closes#24956 from yeshengm/fixed-point-opt.
Authored-by: Yesheng Ma <kimi.ysma@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This pr add `PLACING` to `ansiNonReserved` and add `overlay` and `placing` to `TableIdentifierParserSuite`.
## How was this patch tested?
N/A
Closes#25013 from wangyum/SPARK-28077.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request?
In Python 2.7 with latest PyArrow and Pandas, the error message seems a bit different with Python 3. This PR simply fixes the test.
```
======================================================================
FAIL: test_createDataFrame_with_incorrect_schema (pyspark.sql.tests.test_arrow.ArrowTests)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/.../spark/python/pyspark/sql/tests/test_arrow.py", line 275, in test_createDataFrame_with_incorrect_schema
self.spark.createDataFrame(pdf, schema=wrong_schema)
AssertionError: "integer.*required.*got.*str" does not match "('Exception thrown when converting pandas.Series (object) to Arrow Array (int32). It can be caused by overflows or other unsafe conversions warned by Arrow. Arrow safe type check can be disabled by using SQL config `spark.sql.execution.pandas.arrowSafeTypeConversion`.', ArrowTypeError('an integer is required',))"
======================================================================
FAIL: test_createDataFrame_with_incorrect_schema (pyspark.sql.tests.test_arrow.EncryptionArrowTests)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/.../spark/python/pyspark/sql/tests/test_arrow.py", line 275, in test_createDataFrame_with_incorrect_schema
self.spark.createDataFrame(pdf, schema=wrong_schema)
AssertionError: "integer.*required.*got.*str" does not match "('Exception thrown when converting pandas.Series (object) to Arrow Array (int32). It can be caused by overflows or other unsafe conversions warned by Arrow. Arrow safe type check can be disabled by using SQL config `spark.sql.execution.pandas.arrowSafeTypeConversion`.', ArrowTypeError('an integer is required',))"
```
## How was this patch tested?
Manually tested.
```
cd python
./run-tests --python-executables=python --modules pyspark-sql
```
Closes#25042 from HyukjinKwon/SPARK-28240.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This pr add support show global temporary view and local temporary view in database tool.
TODO: Database tools should support show temporary views because it's schema is null.
## How was this patch tested?
unit tests and manual tests:
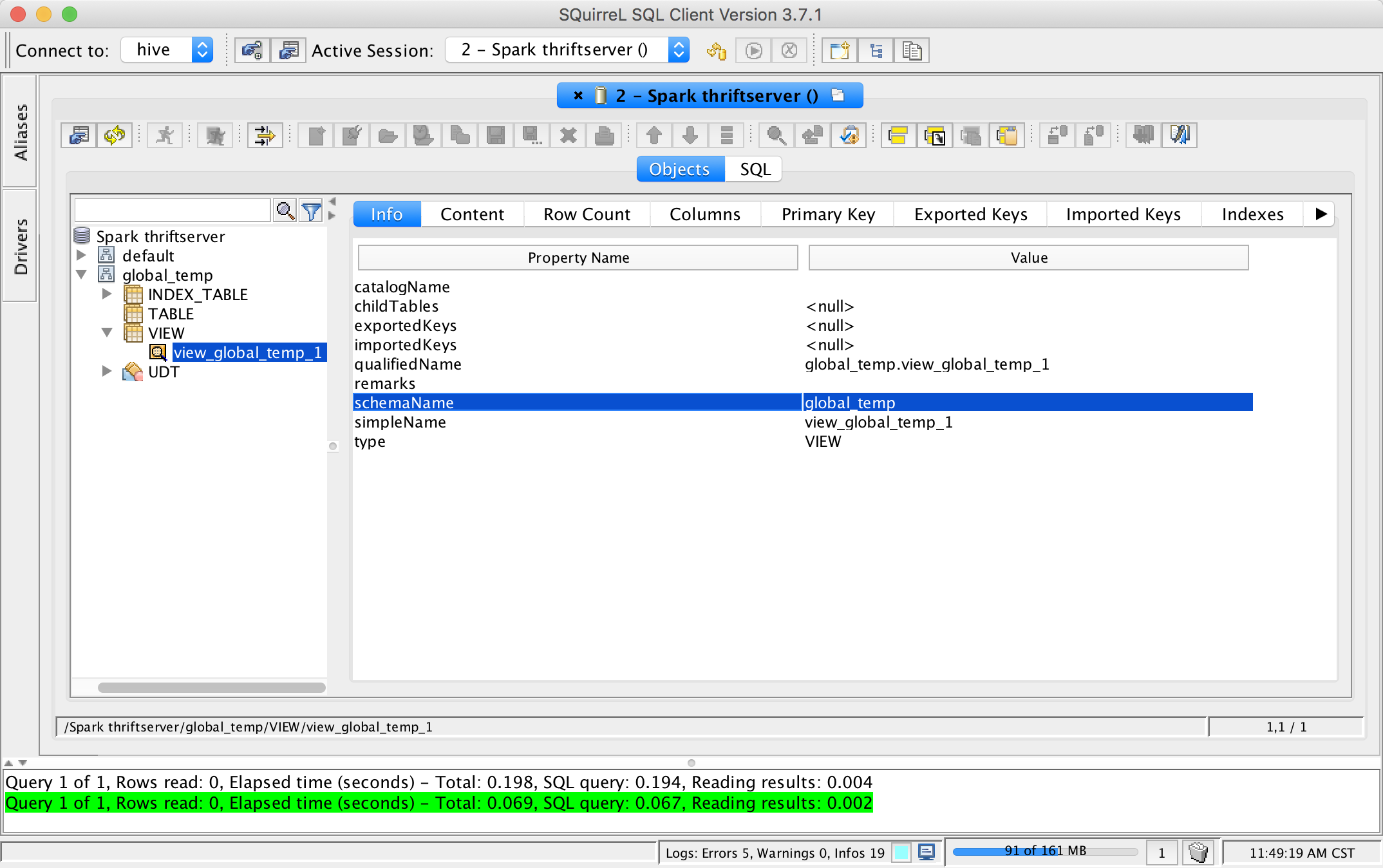
Closes#24972 from wangyum/SPARK-28167.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
link doc & example of Interaction
## How was this patch tested?
existing tests
Closes#25027 from zhengruifeng/py_doc_interaction.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Right now they fail only for inner joins, because we implemented the check when that was the only supported type.
## How was this patch tested?
new unit test
Closes#25023 from jose-torres/changevalidation.
Authored-by: Jose Torres <torres.joseph.f+github@gmail.com>
Signed-off-by: Jose Torres <torres.joseph.f+github@gmail.com>
## What changes were proposed in this pull request?
In some cases, executeTake in SparkPlan could decode more than necessary.
For example, in case of below odd/even number partitioning, total row's count from partitions will be 100, although it is limited with 51. And 'executeTake' in SparkPlan decodes all of them, "49" rows of which are unnecessarily decoded.
```scala
spark.sparkContext.parallelize((0 until 100).map(i => (i, 1))).toDF()
.repartitionByRange(2, $"_1" % 2).limit(51).collect()
```
By using a iterator of the scalar collection, we can make ensure that at most n rows are decoded.
## How was this patch tested?
Existing unit tests that call limit function of DataFrame.
testOnly *SQLQuerySuite
testOnly *DataFrameSuite
Closes#22347 from Dooyoung-Hwang/refactor_execute_take.
Authored-by: Dooyoung Hwang <dooyoung.hwang@sk.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
According to the documentation `groupIdPrefix` should be available for `streaming and batch`.
It is not the case because the batch part is missing.
In this PR I've added:
* Structured Streaming test for v1 and v2 to cover `groupIdPrefix`
* Batch test for v1 and v2 to cover `groupIdPrefix`
* Added `groupIdPrefix` usage in batch
## How was this patch tested?
Additional + existing unit tests.
Closes#25030 from gaborgsomogyi/SPARK-28232.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This is a small follow-up for SPARK-28054 to fix wrong indent and use `withSQLConf` as suggested by gatorsmile.
## How was this patch tested?
Existing tests.
Closes#24971 from viirya/SPARK-28054-followup.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
When SPARK_HOME of env is set and contains a specific `spark-defaults,conf`, `org.apache.spark.util.loadDefaultSparkProperties` method may noise `system props`. So when runs `core/test` module, it is possible to fail to run `SparkConfSuite` .
It's easy to repair by setting `loadDefaults` in `SparkConf` to be false.
```
[info] - deprecated configs *** FAILED *** (79 milliseconds)
[info] 7 did not equal 4 (SparkConfSuite.scala:266)
[info] org.scalatest.exceptions.TestFailedException:
[info] at org.scalatest.Assertions.newAssertionFailedException(Assertions.scala:528)
[info] at org.scalatest.Assertions.newAssertionFailedException$(Assertions.scala:527)
[info] at org.scalatest.FunSuite.newAssertionFailedException(FunSuite.scala:1560)
[info] at org.scalatest.Assertions$AssertionsHelper.macroAssert(Assertions.scala:501)
[info] at org.apache.spark.SparkConfSuite.$anonfun$new$26(SparkConfSuite.scala:266)
[info] at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85)
[info] at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83)
[info] at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104)
[info] at org.scalatest.Transformer.apply(Transformer.scala:22)
[info] at org.scalatest.Transformer.apply(Transformer.scala:20)
[info] at org.scalatest.FunSuiteLike$$anon$1.apply(FunSuiteLike.scala:186)
[info] at org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:149)
[info] at org.scalatest.FunSuiteLike.invokeWithFixture$1(FunSuiteLike.scala:184)
[info] at org.scalatest.FunSuiteLike.$anonfun$runTest$1(FunSuiteLike.scala:196)
[info] at org.scalatest.SuperEngine.runTestImpl(Engine.scala:289)
```
Closes#24998 from LiShuMing/SPARK-28202.
Authored-by: ShuMingLi <ming.moriarty@gmail.com>
Signed-off-by: jerryshao <jerryshao@tencent.com>
## What changes were proposed in this pull request?
This PR proposes to add `mapPartitionsInPandas` API to DataFrame by using existing `SCALAR_ITER` as below:
1. Filtering via setting the column
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
df = spark.createDataFrame([(1, 21), (2, 30)], ("id", "age"))
pandas_udf(df.schema, PandasUDFType.SCALAR_ITER)
def filter_func(iterator):
for pdf in iterator:
yield pdf[pdf.id == 1]
df.mapPartitionsInPandas(filter_func).show()
```
```
+---+---+
| id|age|
+---+---+
| 1| 21|
+---+---+
```
2. `DataFrame.loc`
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
import pandas as pd
df = spark.createDataFrame([['aa'], ['bb'], ['cc'], ['aa'], ['aa'], ['aa']], ["value"])
pandas_udf(df.schema, PandasUDFType.SCALAR_ITER)
def filter_func(iterator):
for pdf in iterator:
yield pdf.loc[pdf.value.str.contains('^a'), :]
df.mapPartitionsInPandas(filter_func).show()
```
```
+-----+
|value|
+-----+
| aa|
| aa|
| aa|
| aa|
+-----+
```
3. `pandas.melt`
```python
from pyspark.sql.functions import pandas_udf, PandasUDFType
import pandas as pd
df = spark.createDataFrame(
pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}}))
pandas_udf("A string, variable string, value long", PandasUDFType.SCALAR_ITER)
def filter_func(iterator):
for pdf in iterator:
import pandas as pd
yield pd.melt(pdf, id_vars=['A'], value_vars=['B', 'C'])
df.mapPartitionsInPandas(filter_func).show()
```
```
+---+--------+-----+
| A|variable|value|
+---+--------+-----+
| a| B| 1|
| a| C| 2|
| b| B| 3|
| b| C| 4|
| c| B| 5|
| c| C| 6|
+---+--------+-----+
```
The current limitation of `SCALAR_ITER` is that it doesn't allow different length of result, which is pretty critical in practice - for instance, we cannot simply filter by using Pandas APIs but we merely just map N to N. This PR allows map N to M like flatMap.
This API mimics the way of `mapPartitions` but keeps API shape of `SCALAR_ITER` by allowing different results.
### How does this PR implement?
This PR adds mimics both `dapply` with Arrow optimization and Grouped Map Pandas UDF. At Python execution side, it reuses existing `SCALAR_ITER` code path.
Therefore, externally, we don't introduce any new type of Pandas UDF but internally we use another evaluation type code `205` (`SQL_MAP_PANDAS_ITER_UDF`).
This approach is similar with Pandas' Windows function implementation with Grouped Aggregation Pandas UDF functions - internally we have `203` (`SQL_WINDOW_AGG_PANDAS_UDF`) but externally we just share the same `GROUPED_AGG`.
## How was this patch tested?
Manually tested and unittests were added.
Closes#24997 from HyukjinKwon/scalar-udf-iter.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Kafka batch data source is using v1 at the moment. In the PR I've migrated to v2. Majority of the change is moving code.
What this PR contains:
* useV1Sources usage fixed in `DataFrameReader` and `DataFrameWriter`
* `KafkaBatch` added to handle DSv2 batch reading
* `KafkaBatchWrite` added to handle DSv2 batch writing
* `KafkaBatchPartitionReader` extracted to share between batch and microbatch
* `KafkaDataWriter` extracted to share between batch, microbatch and continuous
* Batch related source/sink tests are now executing on v1 and v2 connectors
* Couple of classes hidden now, functions moved + couple of minor fixes
## How was this patch tested?
Existing + added unit tests.
Closes#24738 from gaborgsomogyi/SPARK-23098.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
In the migration PR of Kafka V2: ac16c9a9ef (r298470645)
We find that the useV1SourceList configuration(spark.sql.sources.read.useV1SourceList and spark.sql.sources.write.useV1SourceList) should be for all data sources, instead of file source V2 only.
This PR is to fix it in DataFrameWriter/DataFrameReader.
## How was this patch tested?
Unit test
Closes#25004 from gengliangwang/reviseUseV1List.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
New R api of Arrow has removed `as_tibble` as of 2ef96c8623. Arrow optimization for DataFrame in R doesn't work due to the change.
This can be tested as below, after installing latest Arrow:
```
./bin/sparkR --conf spark.sql.execution.arrow.sparkr.enabled=true
```
```
> collect(createDataFrame(mtcars))
```
Before this PR:
```
> collect(createDataFrame(mtcars))
Error in get("as_tibble", envir = asNamespace("arrow")) :
object 'as_tibble' not found
```
After:
```
> collect(createDataFrame(mtcars))
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
...
```
## How was this patch tested?
Manual test.
Closes#25012 from viirya/SPARK-28215.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
In SPARK-23179, it has been introduced a flag to control the behavior in case of overflow on decimals. The behavior is: returning `null` when `spark.sql.decimalOperations.nullOnOverflow` (default and traditional Spark behavior); throwing an `ArithmeticException` if that conf is false (according to SQL standards, other DBs behavior).
`MakeDecimal` so far had an ambiguous behavior. In case of codegen mode, it returned `null` as the other operators, but in interpreted mode, it was throwing an `IllegalArgumentException`.
The PR aligns `MakeDecimal`'s behavior with the one of other operators as defined in SPARK-23179. So now both modes return `null` or throw `ArithmeticException` according to `spark.sql.decimalOperations.nullOnOverflow`'s value.
Credits for this PR to mickjermsurawong-stripe who pointed out the wrong behavior in #20350.
## How was this patch tested?
improved UTs
Closes#25010 from mgaido91/SPARK-28201.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
The documentation in `linalg.py` is not consistent. This PR uniforms the documentation.
## How was this patch tested?
NA
Closes#25011 from mgaido91/SPARK-28170.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This is very like #23590 .
`ByteBuffer.allocate` may throw `OutOfMemoryError` when the response is large but no enough memory is available. However, when this happens, `TransportClient.sendRpcSync` will just hang forever if the timeout set to unlimited.
This PR catches `Throwable` and uses the error to complete `SettableFuture`.
## How was this patch tested?
I tested in my IDE by setting the value of size to -1 to verify the result. Without this patch, it won't be finished until timeout (May hang forever if timeout set to MAX_INT), or the expected `IllegalArgumentException` will be caught.
```java
Override
public void onSuccess(ByteBuffer response) {
try {
int size = response.remaining();
ByteBuffer copy = ByteBuffer.allocate(size); // set size to -1 in runtime when debug
copy.put(response);
// flip "copy" to make it readable
copy.flip();
result.set(copy);
} catch (Throwable t) {
result.setException(t);
}
}
```
Closes#24964 from LantaoJin/SPARK-28160.
Lead-authored-by: LantaoJin <jinlantao@gmail.com>
Co-authored-by: lajin <lajin@ebay.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
This pr add two API for [SessionCatalog](df4cb471c9/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala):
```scala
def listTables(db: String, pattern: String, includeLocalTempViews: Boolean): Seq[TableIdentifier]
def listLocalTempViews(pattern: String): Seq[TableIdentifier]
```
Because in some cases `listTables` does not need local temporary view and sometimes only need list local temporary view.
## How was this patch tested?
unit tests
Closes#24995 from wangyum/SPARK-28196.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
To make the #24972 change smaller. This pr improves `SparkMetadataOperationSuite` to avoid creating new sessions when getSchemas/getTables/getColumns.
## How was this patch tested?
N/A
Closes#24985 from wangyum/SPARK-28184.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
Currently, ORC's `inferSchema` is implemented as randomly choosing one ORC file and reading its schema.
This PR follows the behavior of Parquet, it implements merge schemas logic by reading all ORC files in parallel through a spark job.
Users can enable merge schema by `spark.read.orc("xxx").option("mergeSchema", "true")` or by setting `spark.sql.orc.mergeSchema` to `true`, the prior one has higher priority.
## How was this patch tested?
tested by UT OrcUtilsSuite.scala
Closes#24043 from WangGuangxin/SPARK-11412.
Lead-authored-by: wangguangxin.cn <wangguangxin.cn@gmail.com>
Co-authored-by: wangguangxin.cn <wangguangxin.cn@bytedance.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
SPARK-27534 missed to address my own comments at https://github.com/WeichenXu123/spark/pull/8
It's better to push this in since the codes are already cleaned up.
## How was this patch tested?
Unittests fixed
Closes#25003 from HyukjinKwon/SPARK-27534.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Add docstring/doctest for `SCALAR_ITER` Pandas UDF. I explicitly mentioned that per-partition execution is an implementation detail, not guaranteed. I will submit another PR to add the same to user guide, just to keep this PR minimal.
I didn't add "doctest: +SKIP" in the first commit so it is easy to test locally.
cc: HyukjinKwon gatorsmile icexelloss BryanCutler WeichenXu123


## How was this patch tested?
doctest
Closes#25005 from mengxr/SPARK-28056.2.
Authored-by: Xiangrui Meng <meng@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
This is the first part of [SPARK-27396](https://issues.apache.org/jira/browse/SPARK-27396). This is the minimum set of changes necessary to support a pluggable back end for columnar processing. Follow on JIRAs would cover removing some of the duplication between functionality in this patch and functionality currently covered by things like ColumnarBatchScan.
## How was this patch tested?
I added in a new unit test to cover new code not really covered in other places.
I also did manual testing by implementing two plugins/extensions that take advantage of the new APIs to allow for columnar processing for some simple queries. One version runs on the [CPU](https://gist.github.com/revans2/c3cad77075c4fa5d9d271308ee2f1b1d). The other version run on a GPU, but because it has unreleased dependencies I will not include a link to it yet.
The CPU version I would expect to add in as an example with other documentation in a follow on JIRA
This is contributed on behalf of NVIDIA Corporation.
Closes#24795 from revans2/columnar-basic.
Authored-by: Robert (Bobby) Evans <bobby@apache.org>
Signed-off-by: Thomas Graves <tgraves@apache.org>
## What changes were proposed in this pull request?
Add error handling to `ExecutorPodsPollingSnapshotSource`
Closes#24952 from onursatici/os/polling-source.
Authored-by: Onur Satici <onursatici@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
The `OVERLAY` function is a `ANSI` `SQL`.
For example:
```
SELECT OVERLAY('abcdef' PLACING '45' FROM 4);
SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5);
SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5 FOR 0);
SELECT OVERLAY('babosa' PLACING 'ubb' FROM 2 FOR 4);
```
The results of the above four `SQL` are:
```
abc45f
yabadaba
yabadabadoo
bubba
```
Note: If the input string is null, then the result is null too.
There are some mainstream database support the syntax.
**PostgreSQL:**
https://www.postgresql.org/docs/11/functions-string.html
**Vertica:** https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/Functions/String/OVERLAY.htm?zoom_highlight=overlay
**Oracle:**
https://docs.oracle.com/en/database/oracle/oracle-database/19/arpls/UTL_RAW.html#GUID-342E37E7-FE43-4CE1-A0E9-7DAABD000369
**DB2:**
https://www.ibm.com/support/knowledgecenter/SSGMCP_5.3.0/com.ibm.cics.rexx.doc/rexx/overlay.html
There are some show of the PR on my production environment.
```
spark-sql> SELECT OVERLAY('abcdef' PLACING '45' FROM 4);
abc45f
Time taken: 6.385 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5);
yabadaba
Time taken: 0.191 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('yabadoo' PLACING 'daba' FROM 5 FOR 0);
yabadabadoo
Time taken: 0.186 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY('babosa' PLACING 'ubb' FROM 2 FOR 4);
bubba
Time taken: 0.151 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING '45' FROM 4);
NULL
Time taken: 0.22 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'daba' FROM 5);
NULL
Time taken: 0.157 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'daba' FROM 5 FOR 0);
NULL
Time taken: 0.254 seconds, Fetched 1 row(s)
spark-sql> SELECT OVERLAY(null PLACING 'ubb' FROM 2 FOR 4);
NULL
Time taken: 0.159 seconds, Fetched 1 row(s)
```
## How was this patch tested?
Exists UT and new UT.
Closes#24918 from beliefer/ansi-sql-overlay.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
## What changes were proposed in this pull request?
Closes the generator when Python UDFs stop early.
### Manually verification on pandas iterator UDF and mapPartitions
```python
from pyspark.sql import SparkSession
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.functions import col, udf
from pyspark.taskcontext import TaskContext
import time
import os
spark.conf.set('spark.sql.execution.arrow.maxRecordsPerBatch', '1')
spark.conf.set('spark.sql.pandas.udf.buffer.size', '4')
pandas_udf("int", PandasUDFType.SCALAR_ITER)
def fi1(it):
try:
for batch in it:
yield batch + 100
time.sleep(1.0)
except BaseException as be:
print("Debug: exception raised: " + str(type(be)))
raise be
finally:
open("/tmp/000001.tmp", "a").close()
df1 = spark.range(10).select(col('id').alias('a')).repartition(1)
# will see log Debug: exception raised: <class 'GeneratorExit'>
# and file "/tmp/000001.tmp" generated.
df1.select(col('a'), fi1('a')).limit(2).collect()
def mapper(it):
try:
for batch in it:
yield batch
except BaseException as be:
print("Debug: exception raised: " + str(type(be)))
raise be
finally:
open("/tmp/000002.tmp", "a").close()
df2 = spark.range(10000000).repartition(1)
# will see log Debug: exception raised: <class 'GeneratorExit'>
# and file "/tmp/000002.tmp" generated.
df2.rdd.mapPartitions(mapper).take(2)
```
## How was this patch tested?
Unit test added.
Please review https://spark.apache.org/contributing.html before opening a pull request.
Closes#24986 from WeichenXu123/pandas_iter_udf_limit.
Authored-by: WeichenXu <weichen.xu@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Avoid hard-coded config: `spark.sql.globalTempDatabase`.
## How was this patch tested?
N/A
Closes#24979 from wangyum/SPARK-28179.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
This ensures that tokens are always created with an empty UGI, which
allows multiple contexts to be (sequentially) started from the same JVM.
Tested with code attached to the bug, and also usual kerberos tests.
Closes#24955 from vanzin/SPARK-28150.
Authored-by: Marcelo Vanzin <vanzin@cloudera.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request?
For simplicity, all `LambdaVariable`s are globally unique, to avoid any potential conflicts. However, this causes a perf problem: we can never hit codegen cache for encoder expressions that deal with collections (which means they contain `LambdaVariable`).
To overcome this problem, `LambdaVariable` should have per-query unique IDs. This PR does 2 things:
1. refactor `LambdaVariable` to carry an ID, so that it's easier to change the ID.
2. add an optimizer rule to reassign `LambdaVariable` IDs, which are per-query unique.
## How was this patch tested?
new tests
Closes#24735 from cloud-fan/dataset.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
SQL ANSI 2011 states that in case of overflow during arithmetic operations, an exception should be thrown. This is what most of the SQL DBs do (eg. SQLServer, DB2). Hive currently returns NULL (as Spark does) but HIVE-18291 is open to be SQL compliant.
The PR introduce an option to decide which behavior Spark should follow, ie. returning NULL on overflow or throwing an exception.
## How was this patch tested?
added UTs
Closes#20350 from mgaido91/SPARK-23179.
Authored-by: Marco Gaido <marcogaido91@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
To support GPU-aware scheduling in Standalone (cluster mode), Worker should have ability to setup resources(e.g. GPU/FPGA) when it starts up.
Similar as driver/executor do, Worker has two ways(resourceFile & resourceDiscoveryScript) to setup resources when it starts up. User could use `SPARK_WORKER_OPTS` to apply resource configs on Worker in the form of "-Dx=y". For example,
```
SPARK_WORKER_OPTS="-Dspark.worker.resource.gpu.amount=2 \
-Dspark.worker.resource.fpga.amount=1 \
-Dspark.worker.resource.fpga.discoveryScript=/Users/wuyi/tmp/getFPGAResources.sh \
-Dspark.worker.resourcesFile=/Users/wuyi/tmp/worker-resource-file"
```
## How was this patch tested?
Tested manually in Standalone locally:
- Worker could start up normally when no resources are configured
- Worker should fail to start up when exception threw during setup resources(e.g. unknown directory, parse fail)
- Worker could setup resources from resource file
- Worker could setup resources from discovery scripts
- Worker should setup resources from resource file & discovery scripts when both are configure.
Closes#24841 from Ngone51/dev-worker-resources-setup.
Authored-by: wuyi <ngone_5451@163.com>
Signed-off-by: Xingbo Jiang <xingbo.jiang@databricks.com>
## What changes were proposed in this pull request?
Currently with `toLocalIterator()` and `toPandas()` with Arrow enabled, if the Spark job being run in the background serving thread errors, it will be caught and sent to Python through the PySpark serializer.
This is not the ideal solution because it is only catch a SparkException, it won't handle an error that occurs in the serializer, and each method has to have it's own special handling to propagate the error.
This PR instead returns the Python Server object along with the serving port and authentication info, so that it allows the Python caller to join with the serving thread. During the call to join, the serving thread Future is completed either successfully or with an exception. In the latter case, the exception will be propagated to Python through the Py4j call.
## How was this patch tested?
Existing tests
Closes#24834 from BryanCutler/pyspark-propagate-server-error-SPARK-27992.
Authored-by: Bryan Cutler <cutlerb@gmail.com>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
## What changes were proposed in this pull request?
At Spark 2.4.0/2.3.2/2.2.3, [SPARK-24948](https://issues.apache.org/jira/browse/SPARK-24948) delegated access permission checks to the file system, and maintains a blacklist for all event log files failed once at reading. The blacklisted log files are released back after `CLEAN_INTERVAL_S` seconds.
However, the released files whose sizes don't changes are ignored forever due to `info.fileSize < entry.getLen()` condition (previously [here](3c96937c7b (diff-a7befb99e7bd7e3ab5c46c2568aa5b3eR454)) and now at [shouldReloadLog](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L571)) which returns `false` always when the size is the same with the existing value in `KVStore`. This is recovered only via SHS restart.
This PR aims to remove the existing entry from `KVStore` when it goes to the blacklist.
## How was this patch tested?
Pass the Jenkins with the updated test case.
Closes#24966 from dongjoon-hyun/SPARK-28157.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request?
updated the usage message in sbin/start-slave.sh.
<masterURL> argument moved to first
## How was this patch tested?
tested locally with
Starting master
starting slave with (./start-slave.sh spark://<IP>:<PORT> -c 1
and opening spark shell with ./spark-shell --master spark://<IP>:<PORT>
Closes#24974 from shivusondur/jira28164.
Authored-by: shivusondur <shivusondur@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
SparkRackResolver generates an INFO message every time is called with 0 arguments.
In this PR I've deleted it because it's too verbose.
## How was this patch tested?
Existing unit tests + spark-shell.
Closes#24935 from gaborgsomogyi/SPARK-28005.
Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
Spark's `InMemoryFileIndex` contains two places where `FileNotFound` exceptions are caught and logged as warnings (during [directory listing](bcd3b61c4b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InMemoryFileIndex.scala (L274)) and [block location lookup](bcd3b61c4b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InMemoryFileIndex.scala (L333))). This logic was added in #15153 and #21408.
I think that this is a dangerous default behavior because it can mask bugs caused by race conditions (e.g. overwriting a table while it's being read) or S3 consistency issues (there's more discussion on this in the [JIRA ticket](https://issues.apache.org/jira/browse/SPARK-27676)). Failing fast when we detect missing files is not sufficient to make concurrent table reads/writes or S3 listing safe (there are other classes of eventual consistency issues to worry about), but I think it's still beneficial to throw exceptions and fail-fast on the subset of inconsistencies / races that we _can_ detect because that increases the likelihood that an end user will notice the problem and investigate further.
There may be some cases where users _do_ want to ignore missing files, but I think that should be an opt-in behavior via the existing `spark.sql.files.ignoreMissingFiles` flag (the current behavior is itself race-prone because a file might be be deleted between catalog listing and query execution time, triggering FileNotFoundExceptions on executors (which are handled in a way that _does_ respect `ignoreMissingFIles`)).
This PR updates `InMemoryFileIndex` to guard the log-and-ignore-FileNotFoundException behind the existing `spark.sql.files.ignoreMissingFiles` flag.
**Note**: this is a change of default behavior, so I think it needs to be mentioned in release notes.
## How was this patch tested?
New unit tests to simulate file-deletion race conditions, tested with both values of the `ignoreMissingFIles` flag.
Closes#24668 from JoshRosen/SPARK-27676.
Lead-authored-by: Josh Rosen <rosenville@gmail.com>
Co-authored-by: Josh Rosen <joshrosen@stripe.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
Track tasks separately for each stage attempt (instead of tracking by stage), and do NOT reset the numRunningTasks to 0 on StageCompleted.
In the case of stage retry, the `taskEnd` event from the zombie stage sometimes makes the number of `totalRunningTasks` negative, which will causes the job to get stuck.
Similar problem also exists with `stageIdToTaskIndices` & `stageIdToSpeculativeTaskIndices`.
If it is a failed `taskEnd` event of the zombie stage, this will cause `stageIdToTaskIndices` or `stageIdToSpeculativeTaskIndices` to remove the task index of the active stage, and the number of `totalPendingTasks` will increase unexpectedly.
## How was this patch tested?
unit test properly handle task end events from completed stages
Closes#24497 from cxzl25/fix_stuck_job_follow_up.
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Imran Rashid <irashid@cloudera.com>
## What changes were proposed in this pull request?
Before this PR during fetching a disk persisted RDD block the network was always used to get the requested block content even when both the source and fetcher executor was running on the same host.
The idea to access another executor local disk files by directly reading the disk comes from the external shuffle service where the local dirs are stored for each executor (block manager).
To make this possible the following changes are done:
- `RegisterBlockManager` message is extended with the `localDirs` which is stored by the block manager master for each block manager as a new property of the `BlockManagerInfo`
- `GetLocationsAndStatus` is extended with the requester host
- `BlockLocationsAndStatus` (the reply for `GetLocationsAndStatus` message) is extended with the an option of local directories, which is filled with a local directories of a same host executor (if there is any, otherwise None is used). This is where the block content can be read from.
Shuffle blocks are out of scope of this PR: there will be a separate PR opened for that (for another Jira issue).
## How was this patch tested?
With a new unit test in `BlockManagerSuite`. See the the test prefixed by "SPARK-27622: avoid the network when block requested from same host".
Closes#24554 from attilapiros/SPARK-27622.
Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com>
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
continuation to https://github.com/apache/spark/pull/24788
## What changes were proposed in this pull request?
Changes are related to BIG ENDIAN system
This changes are done to
identify s390x platform.
use byteorder to BIG_ENDIAN for big endian systems
changes for 2 are done in access functions putFloats() and putDouble()
## How was this patch tested?
Changes have been tested to build successfully on s390x as well x86 platform to make sure build is successful.
Closes#24861 from ketank-new/ketan_latest_v2.3.2.
Authored-by: ketank-new <ketan22584@gmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
if the input dataset is alreadly cached, then we do not need to cache the internal rdd (like kmeans)
## How was this patch tested?
existing test
Closes#24919 from zhengruifeng/gmm_fix_double_caching.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
cache dataset in BisectingKMeans
cache dataset in LDA if Online solver is chosen.
## How was this patch tested?
existing test
Closes#24920 from zhengruifeng/bikm_cache.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
add missing RankingEvaluator
## How was this patch tested?
added testsuites
Closes#24869 from zhengruifeng/ranking_eval.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request?
Update doc of config `spark.driver.resourcesFile`
## How was this patch tested?
N/A
Closes#24954 from jiangxb1987/ResourceAllocation.
Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
After this PR, we can test Pandas and Python UDF as below **in Scala side**:
```scala
import IntegratedUDFTestUtils._
val pandasTestUDF = TestScalarPandasUDF("udf")
spark.range(10).select(pandasTestUDF($"id")).show()
```
## How was this patch tested?
Manually tested.
Closes#24945 from HyukjinKwon/SPARK-27893-followup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
This PR proposes to remove cloned `pyspark-coverage-site` repo.
it doesn't looks a problem in PR builder but somehow it's problematic in `spark-master-test-sbt-hadoop-2.7`.
## How was this patch tested?
Jenkins.
Closes#23729 from HyukjinKwon/followup-coverage.
Lead-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Co-authored-by: shane knapp <incomplete@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
{kind=link}
{kind=link}
{kind=link}